深度学习500问——Chapter12:网络搭建及训练(1)
文章目录
12.1 TensorFlow
12.1.1 TensorFlow 是什么
12.1.2 TensorFlow的设计理念是什么
12.1.3 TensorFlow特点有哪些
12.1.4 TensorFlow的系统架构是怎样的
12.1.5 TensorFlow编程模型是怎样的
12.1.6 如何基于TensorFlow搭建VGG16
12.1 TensorFlow
12.1.1 TensorFlow 是什么
TensorFlow支持各种异构平台,支持多CPU/GPU、服务器、移动设备,具有良好的跨平台的特性;TensorFlow架构灵活,能够支持各种网络模型,具有良好的通用性;此外,TensorFlow架构i具有良好的可扩展性,对OP的扩展支持,Kernel特化方面表现出众。
TensorFlow最初由Google大脑的研究员和工程师开发出来,用于机器学习和神经网络方面的研究,于2015.10宣布开源,在众多深度学习框架中脱颖而出,在Github上获得了最多的Star量。
12.1.2 TensorFlow的设计理念是什么
TensorFlow的设计理念主要体现在两个方面:
(1)将图定义和图运算完全分开。TensorFlow 被认为是一个“符号主义”的库。我们知道,编程模式通常分为命令式编程(imperative style programming)和符号式编程(symbolic style 皮肉gramming)。命令式编程就是编写我们理解的通常意义上的程序,很容易理解和调试,按照原有逻辑执行。符号式编程涉及很多的嵌入和优化,不容易理解和调试,但运行速度相对有所提升。现有的深度学习框架中,Torch是典型的命令式的,Caffe、MXNet采用了两种编程模式混合的方法,而TensorFlow完全采用符号式编程。
符号式计算一般是先定义各种变量,然后建立一个数据流图,在数据流图中规定各个变量间的计算关系,最后需要对数据流图进行编译,但此时的数据流图还是一个空壳,里面没有任何实际数据,只有把需要运算的输入放进去后,才能在整个模型中形成数据流,从而形成输出值。
例如:
t = 8 + 9
print(t)在传统的程序操作中,定义了 t 的运算,在运行时就执行了,并输出 17。而在 TensorFlow中,数据流图中的节点,实际上对应的是 TensorFlow API 中的一个操作,并没有真正去运行:
import tensorflow as tf
t = tf.add(8,9)
print(t)#输出 Tensor{"Add_1:0",shape={},dtype=int32}(2)TensorFlow 中涉及的运算都要放在图中,而图的运行只发生在会话(session)中。开启会话后,就可以用数据去填充节点,进行运算;关闭会话后,就不能进行计算了。因此,会话提供了操作运行和 Tensor 求值的环境。
例如:
import tensorflow as tf
#创建图
a = tf.constant([4.0,5.0])
b = tf.constant([6.0,7.0])
c = a * b
#创建会话
sess = tf.Session()
#计算c
print(sess.run(c)) #进行矩阵乘法,输出[24.,35.]
sess.close()
12.1.3 TensorFlow特点有哪些
1. 高度的灵活性
TensorFlow并不仅仅是一个深度学习库,只要可以把你的计算过程表示成一个数据流图的过程,我们就可以使用TensorFlow来进行计算。TensorFlow允许我们用计算图的方式建立计算网络,同时又可以很方便的对网络进行操作。用户可以基于TensorFlow的基础上用Python编写自己的上层结构和库,如果TensorFlow没有提供我们需要的API的,我们也可以自己编写底层的C++代码,通过自定义操作将新编写的功能添加到TensorFlow中。
2. 真正的移植性
TensorFlow 可以在 CPU 和 GPU 上运行,可以在台式机、服务器、移动设备上运行。你想在你的笔记本上跑一下深度学习的训练,或者又不想修改代码,想把你的模型在多个CPU上运行, 亦或想将训练好的模型放到移动设备上跑一下,这些TensorFlow都可以帮你做到。
3. 多语言支持
TensorFlow采用非常易用的python来构建和执行我们的计算图,同时也支持 C++ 的语言。我们可以直接写python和C++的程序来执行TensorFlow,也可以采用交互式的ipython来方便的尝试我们的想法。当然,这只是一个开始,后续会支持更多流行的语言,比如Lua,JavaScript 或者R语言。
4. 丰富的算法库
TensorFlow提供了所有开源的深度学习框架里,最全的算法库,并且在不断的添加新的算法库。这些算法库基本上已经满足了大部分的需求,对于普通的应用,基本上不用自己再去自定义实现基本的算法库了。
5. 完善的文档
TensorFlow的官方网站,提供了非常详细的文档介绍,内容包括各种API的使用介绍和各种基础应用的使用例子,也包括一部分深度学习的基础理论。
自从宣布开源以来,大量人员对TensorFlow做出贡献,其中包括Google员工,外部研究人员和独立程序员,全球各地的工程师对TensorFlow的完善,已经让TensorFlow社区变成了Github上最活跃的深度学习框架。
12.1.4 TensorFlow的系统架构是怎样的
整个系统从底层到上层可分为七层:
设备层:硬件计算资源,支持CPU、GPU
网络层:支持两种通信协议
数值计算层:提供最基础的计算,有线性计算、卷积计算
高维计算层:数据的计算都是以数组的形式参与计算
计算图层:用来设计神经网络的结构
工作流层:提供轻量级的框架调用
构造层:最后构造的深度学习网络可以通过TensorBoard服务端可视化
12.1.5 TensorFlow编程模型是怎样的
TensorFlow 的编程模型:让向量数据在计算图里流动。那么在编程时至少有这几个过程:1、构建图;2、启动图;3、给图输入数据并获取结果。
1. 构建图
TensorFlow 的图的类型是 tf.FGraph,它包含着计算节点和tensor的集合。
这里引用了两个新概念:tensor和计算节点。我们先介绍tensor,一开始我们就介绍了,我们需要把数据输入给启动的图才能获取计算结果。那么问题来了,在构建图时用什么表示中间计算结果?这个时候tensor的概念就需要引入了。类型是 tf.Tensor,代表某个计算节点的输出,一定要看清楚是“代表”。它主要有两个作用:
(1)构建不同计算节点直接的数据流
(2)在启动图时,可以设置某些tensor的值,然后获取指定tensor的值。这样就完成了计算的输入输出功能。
如下代码所示:
inImage = tf.placeholder(tf.float32,[32,32,3],"inputImage")
processedImage = tf.image.per_image_standardization(inImage,"processedImage")这里inImage和processedImage都是tensor类型。它们代表着计算节点输出的数据,数据的值具体是多少在启动图的时候才知道。上面两个方法调用都传递了一个字符串,它是计算节点的名字,最好给节点命名,这样我们可以在图上调用get_tensor_by_name(name)获取对应的tensor对象,十分方便。(tensor名字为“<计算节点名字>:<tensor索引>”)
创建tensor时,需要指定类型和shape。对不同tensor进行计算时要求类型相同,可以使用 tf.cast 进行类型转换。同时也要求 shape (向量维度)满足运算的条件,我们可以使用 tf.reshape 改变shape。
现在了解计算节点的概念,其功能是对tensor进行计算、创建tensor或进行其他操作,类型是tf.Operation。获取节点对象的方法为get_operation_by_name(name)。
构建图,如下代码:
g=tf.Graph()with g.as_default():input_data=tf.placeholder(tf.float32,[None,2],"input_data")input_label=tf.placeholder(tf.float32,[None,2],"input_label")W1=tf.Variable(tf.truncated_normal([2,2]),name="W1")B1=tf.Variable(tf.zeros([2]),name="B1")output=tf.add(tf.matmul(input_data,W1),B1,name="output")cross_entropy=tf.nn.softmax_cross_entropy_with_logits(logits=output,labels=input_label)train_step=tf.train.AdamOptimizer().minimize(cross_entropy,name="train_step")initer=tf.global_variables_initializer()上面的代码中我们创建了一个图,并在上面添加了很多节点。我们可以通过调用get_default_graph()获取默认的图。
Input_data,input_label,W1,B1,output,cross_entropy都是tensor类型,train_step,initer,是节点类型。
有几类tensor或节点比较重要,下面介绍一下:
(1)placeholder
Tensorflow,顾名思义, tensor代表张量数据,flow代表流,其最初的设计理念就是构建一张静态的数据流图。图是有各个计算节点连接而成,计算节点之间流动的便是中间的张量数据。要想让张量数据在我们构建的静态计算图中流动起来,就必须有最初的输入数据流。而placeholder,翻译过来叫做占位符,顾名思义,是给我们的输入数据提供一个接口,也就是说我们的一切输入数据,例如训练样本数据,超参数数据等都可以通过占位符接口输送到数据流图之中。使用实例如下代码:
import tensorflow as tf
x = tf.placeholder(dtype=tf.float32,shape=[],name='x')
y = tf.placeholder(dtpe=tf.float32,shape=[],nmae='y')
z = x*y
with tf.Session() as sess:prod = sess.run(z,feed_dict={x:1.,y:5.2})print(prod)
[out]:5.2(2)variable
无论是传统的机器学习算法,例如线性支持向量机(Support Vector Machine, SVM),其数学模型为y = <w,x> + b,还是更先进的深度学习算法,例如卷积神经网络(Convolutional Neural Network, CNN)单个神经元输出的模型y = w*x + b。可以看到,w和b就是我们要求的模型,模型的求解是通过优化算法(对于SVM,使用 SMO[1]算法,对于CNN,一般基于梯度下降法)来一步一步更新w和b的值直到满足停止条件。因此,大多数机器学习的模型中的w和b实际上是以变量的形式出现在代码中的,这就要求我们在代码中定义模型变量。
import tensorflow as tf
a = tf.Variable(2.)
b = tf.Variable(3.)
with tf.Session() as sess:sess.run(tf.global_variables_initializer()) #变量初始化print(sess.run(a*b))
[out]:6.[1] Platt, John. "Sequential minimal optimization: A fast algorithm for training support vector machines." (1998).
(3)initializer
由于tensorflow构建的是静态的计算流图,在开启会话之前,所有的操作都不会被执行。因此为了执行在计算图中所构建的赋值初始化计算节点,需要在开启会话之后,在会话环境下运行初始化。如果计算图中定义了变量,而会话环境下为执行初始化命令,则程序报错,代码如下:
import tensorflow as tf
a = tf.Variable(2.)
b = tf.Variable(3.)
with tf.Session() as sess:#sess.run(tf.global_variables_initializer()) #注释掉初始化命令print(sess.run(a*b))
[Error]: Attempting to use uninitialized value Variable2. 启动图
先了解session的概念,然后才能更好的理解图的启动。 图的每个运行实例都必须在一个session里,session为图的运行提供环境。Session的类型是tf.Session,在实例化session对象时我们需要给它传递一个图对象,如果不显示给出将使用默认的图。Session有一个graph属性,我们可以通过它获取session对应的图。
代码如下:
numOfBatch=5
datas=np.zeros([numOfBatch,2],np.float32)
labels=np.zeros([numOfBatch,2],np.float32)sess=tf.Session(graph=g)
graph=sess.graph
sess.run([graph.get_operation_by_name("initer")])dataHolder=graph.get_tensor_by_name("input_data:0")
labelHolder=graph.get_tensor_by_name("input_label:0")
train=graph.get_operation_by_name("train_step")
out=graph.get_tensor_by_name("output:0")for i inrange(200):result=sess.run([out,train],feed_dict={dataHolder:datas,labelHolder:labels})if i%100==0:saver.save(sess,"./moules")sess.close()代码都比较简单,就不介绍了。不过要注意2点:1.别忘记运行初始化节点,2.别忘记close掉session对象以释放资源。
3. 给图输入数据并获取结果
代码:
for i inrange(200):result=sess.run([out,train],feed_dict={dataHolder:datas,labelHolder:labels})这里主要用到了session对象的run方法,它用来运行某个节点或tensor并获取对应的值。我们一般会一次传递一小部分数据进行mini-batch梯度下降来优化模型。
我们需要把我们需要运行的节点或tensor放入一个列表,然后作为第一个参数(不考虑self)传递给run方法,run方法会返回一个计算结果的列表,与我们传递的参数一一对应。
如果我们运行的节点依赖某个placeholder,那我们必须给这个placeholder指定值,怎么指定代码里面很清楚,给关键字参数feed_dict传递一个字典即可,字典里的元素的key是placeholder对象,value是我们指定的值。值的数据的类型必须和placeholder一致,包括shape。值本身的类型是numpy数组。
这里再解释一个细节,在定义placeholder时代码如下:
input_data=tf.placeholder(tf.float32,[None,2],"input_data")
input_label=tf.placeholder(tf.float32,[None,2],"input_label")
shape为[None,2],说明数据第一个维度是不确定的,然后TensorFlow会根据我们传递的数据动态推断第一个维度,这样我们就可以在运行时改变batch的大小。比如一个数据是2维,一次传递10个数据对应的tensor的shape就是[10,2]。可不可以把多个维度指定为None?理论上不可以!
12.1.6 如何基于TensorFlow搭建VGG16
介绍完关于tensorflow的基础知识,是时候来一波网络搭建实战了。虽然网上有很多相关教程,但我想从最标准的tensorflow代码和语法出发(而不是调用更高级的API,失去了原来的味道),向大家展示如何搭建其标准的VGG16网络架构。话不多说,上代码:
import numpy as np
import tensorflow as tfdef get_weight_variable(shape):return tf.get_variable('weight', shape=shape, initializer=tf.truncated_normal_initializer(stddev=0.1))def get_bias_variable(shape):return tf.get_variable('bias', shape=shape, initializer=tf.constant_initializer(0))def conv2d(x, w, padding = 'SAME', s=1):x = tf.nn.conv2d(x, w, strides=[1, s, s, 1], padding = padding)return xdef maxPoolLayer(x):return tf.nn.max_pool(x, ksize = [1, 2, 2, 1],strides = [1, 2, 2, 1], padding = 'SAME')def conv2d_layer(x,in_chs, out_chs, ksize, layer_name):with tf.variable_scope(layer_name):w = get_weight_variable([ksize, ksize, in_chs, out_chs])b = get_bias_variable([out_chs])y = tf.nn.relu(tf.bias_add(conv2d(x,w,padding = 'SAME', s=1), b))return ydef fc_layer(x,in_kernels, out_kernels, layer_name):with tf.variable_scope(layer_name):w = get_weight_variable([in_kernels,out_kernels])b = get_bias_variable([out_kernels])y = tf.nn.relu(tf.bias_add(tf.matmul(x,w),b))return ydef VGG16(x):conv1_1 = conv2d_layer(x,tf.get_shape(x).as_list()[-1], 64, 3, 'conv1_1')conv1_2 = conv2d_layer(conv1_1,64, 64, 3, 'conv1_2')pool_1 = maxPoolLayer(conv1_2)conv2_1 = conv2d_layer(pool1,64, 128, 3, 'conv2_1')conv2_2 = conv2d_layer(conv2_1,128, 128, 3, 'conv2_2')pool2 = maxPoolLayer(conv2_2)conv3_1 = conv2d_layer(pool2,128, 256, 3, 'conv3_1')conv3_2 = conv2d_layer(conv3_1,256, 256, 3, 'conv3_2')conv3_3 = conv2d_layer(conv3_2,256, 256, 3, 'conv3_3')pool3 = maxPoolLayer(conv3_3)conv4_1 = conv2d_layer(pool3,256, 512, 3, 'conv4_1')conv4_2 = conv2d_layer(conv4_1,512, 512, 3, 'conv4_2')conv4_3 = conv2d_layer(conv4_2,512, 512, 3, 'conv4_3')pool4 = maxPoolLayer(conv4_3)conv5_1 = conv2d_layer(pool4,512, 512, 3, 'conv5_1')conv5_2 = conv2d_layer(conv5_1,512, 512, 3, 'conv5_2')conv5_3 = conv2d_layer(conv5_1,512, 512, 3, 'conv5_3')pool5 = maxPoolLayer(conv5_3)pool5_flatten_dims = int(np.prod(pool5.get_shape().as_list()[1:]))pool5_flatten = tf.reshape(pool5,[-1,pool5_flatten_dims])fc_6 = fc_layer(pool5_flatten, pool5_flatten_dims, 4096, 'fc6')fc_7 = fc_layer(fc_6, 4096, 4096, 'fc7')fc_8 = fc_layer(fc_7, 4096, 10, 'fc8')return fc_8相关文章:
)
深度学习500问——Chapter12:网络搭建及训练(1)
文章目录 12.1 TensorFlow 12.1.1 TensorFlow 是什么 12.1.2 TensorFlow的设计理念是什么 12.1.3 TensorFlow特点有哪些 12.1.4 TensorFlow的系统架构是怎样的 12.1.5 TensorFlow编程模型是怎样的 12.1.6 如何基于TensorFlow搭建VGG16 12.1 TensorFlow 12.1.1 TensorFlow 是什…...

HuggingFace CLI 命令全面指南
文章目录 安装与认证1.1 安装 HuggingFace Hub 库使用 pip 安装使用 conda 安装验证安装 1.2 认证与登录生成访问令牌使用访问令牌登录环境变量认证验证认证 下载文件2.1 下载单个文件安装 huggingface_hub 库认证与登录下载单个文件 2.2 下载特定版本的文件下载特定版本的文件…...
FreeRTOS源码分析
目录 1、FreeRTOS目录结构 2、核心文件 3、移植时涉及的文件 4、头文件相关 4.1 头文件目录 4.2 头文件 5、内存管理 6、入口函数 7、数据类型和编程规范 7.1 数据类型 7.2 变量名 7.3 函数名 7.4 宏的名 1、FreeRTOS目录结构 使用 STM32CubeMX 创建的 FreeRTOS 工…...

python实战:将视频内容上传到社交媒体平台
在Python中,上传视频到不同的平台可能需要使用不同的API和库。以下是一些常见的平台以及如何使用Python进行上传的示例: YouTube: 使用Google提供的YouTube Data API。 首先,你需要从Google Cloud控制台获取API密钥,并安装google-…...
【深度学习】sdwebui A1111 加速方案对比,xformers vs Flash Attention 2
文章目录 资料支撑资料结论sdwebui A1111 速度对比测试sdxlxformers 用contorlnet sdxlsdpa(--opt-sdp-no-mem-attention) 用contorlnet sdxlsdpa(--opt-sdp-attention) 用contorlnet sdxl不用xformers或者sdpa ,用contorlnet sdxl不用xformers或者sdpa …...

5分钟了解单元测试
🍅 视频学习:文末有免费的配套视频可观看 🍅 点击文末小卡片 ,免费获取软件测试全套资料,资料在手,涨薪更快 一、什么是单元测试? 单元测试是指,对软件中的最小可测试单元在与程序其…...
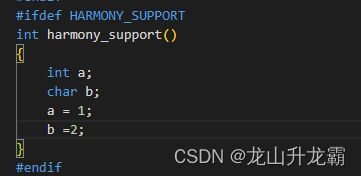
VSCode之C/C++插件之宏定义导致颜色变暗
这是因为该宏没有定义或者定义在makefile文件中导致无法被插件识别到,导致误判了 索性将该机制去了,显示也会好看些,如下将C_Cpp下的Dim Inactive Regions勾去了 显示效果会好很多。...

自然语言处理概述
目录 1.概述 2.背景 3.作用 4.优缺点 4.1.优点 4.2.缺点 5.应用场景 5.1.十个应用场景 5.2.文本分类 5.2.1.一般流程 5.2.2.示例 6.使用示例 7.总结 1.概述 自然语言处理(NLP)是计算机科学、人工智能和语言学的交叉领域,旨在实…...

用Rust和Pingora轻松构建超越Nginx的高效负载均衡器
目录 什么是Pingora?实现过程 初始化项目编写负载均衡器代码代码解析部署 总结 1. 什么是Pingora? Pingora 是一个高性能的 Rust 库,用于构建可负载均衡器的代理服务器,它的诞生是为了弥补 Nginx 存在的缺陷。 Pingora 提供了…...
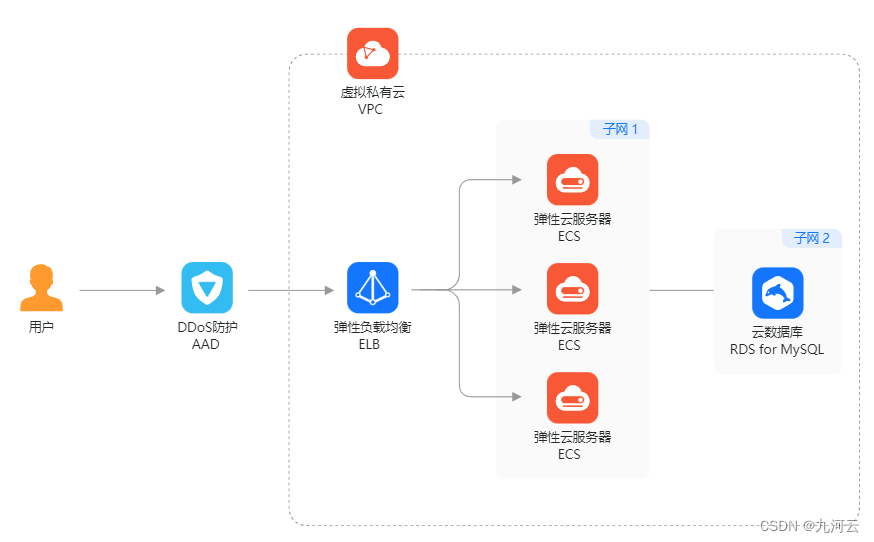
华为云与AWS负载均衡服务深度对比:性能、成本与可用性
随着云计算的迅速发展,企业对于云服务提供商的选择变得越来越关键。在选择云服务提供商时,负载均衡服务是企业关注的重点之一。我们九河云将深入比较两大知名云服务提供商华为云和AWS的负载均衡服务,从性能、成本和可用性等方面进行对比。 AW…...
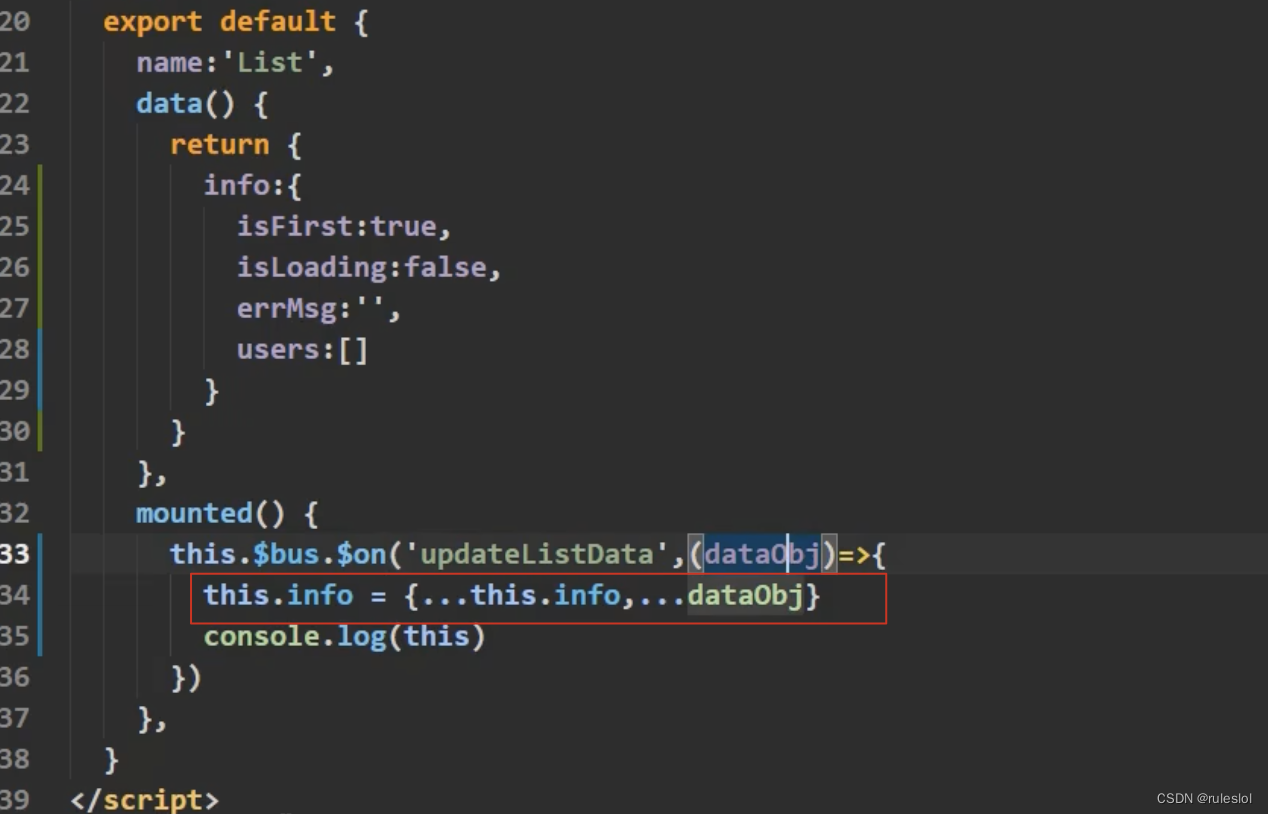
Vue65-组件之间的传值
1、收数据 2、传数据 3、批量的数据替换 若是info里面有四个数据,传过来的dataObj里面有三个数据,则info里面也只有三个数据了 解决方式: 该写法还有一个优势:传参的时候,顺序可以随意!...
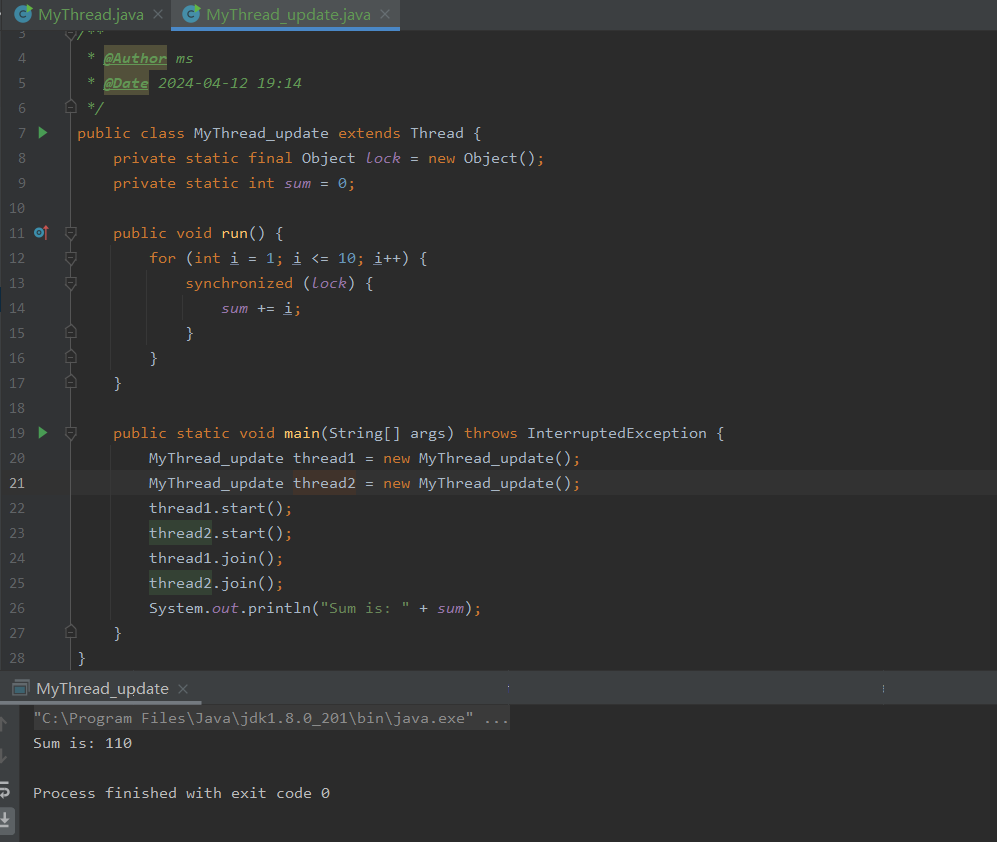
Java零基础之多线程篇:线程生命周期
哈喽,各位小伙伴们,你们好呀,我是喵手。运营社区:C站/掘金/腾讯云;欢迎大家常来逛逛 今天我要给大家分享一些自己日常学习到的一些知识点,并以文字的形式跟大家一起交流,互相学习,一…...
技术差异,应用场景;虚拟机可以当作云服务器吗
虚拟机和云服务器是现在市面上常见的两种计算资源提供方式,很多人把这两者看成可以相互转换或者替代的物品,实则不然,这两种资源提供方式有许多相似之处,但是也有不少区别,一篇文章教你识别两者的技术差异,…...
Qt Quick 教程(一)
文章目录 1.Qt Quick2.QML3.Day01 案例main.qml退出按钮,基于上面代码添加 4.使用Qt Design StudioQt Design Studio简介Qt Design Studio工具使用版本信息 1.Qt Quick Qt Quick 是一种现代的用户界面技术,将声明性用户界面设计和命令性编程逻辑分开。 …...
)
react钩子函数用法(useCallback、useMemo)
useMemo import { useMemo } from react; function MyComponent({ a, b }) { const memoizedValue useMemo(() > { // 进行一些昂贵的计算 return a b; }, [a, b]); // 当 a 或 b 发生变化时,memoizedValue 将被重新计算 return <div>{memoizedVa…...
linux配置Vnc Server给Windows连接
1. linux 安装必要vnc server和桌面组件 sudo apt -y install tightvncserversudo apt install xfce4 xfce4-goodies2. linux 配置vncserver密码 #bash vncserver参考: https://cn.linux-console.net/?p21846#google_vignette 3. 将启动桌面命令写入.vnc/xstartup # .vnc/x…...

Android中的KeyEvent详解
介绍 在Android中,KeyEvent 是用来表示按键事件的类,可根据对应的事件来处理按键输入,具体包含了关于按键事件的信息,例如按键的代码、动作(按下或释放)以及事件的时间戳,KeyEvent 对象通常在用…...

移植案例与原理 - HDF驱动框架-驱动配置(2)
1.2.7 节点复制 节点复制可以实现在节点定义时从另一个节点先复制内容,用于定义内容相似的节点。语法如下,表示在定义"node"节点时将另一个节点"source_node"的属性复制过来。 node : source_node示例如下,编译后bar节点…...

年终奖发放没几天,提离职领导指责我不厚道,我该怎么办?
“年终奖都发了,你还跳槽?太不厚道了吧!” “拿完年终奖就走人,这不是典型的‘骑驴找马’吗?” 每到岁末年初,关于“拿到年终奖后是否应该立即辞职”的话题总会引发热议。支持者认为,这是个人…...

多处理系统结构
目录 统一内存访问(UMA)多处理器系统结构 优点 缺点 应用场景 UMA 结构的架构示例 解决方案和改进 非统一内存访问(NUMA)多处理系统结构 概述 NUMA的优点 NUMA的缺点 NUMA系统的工作原理 NUMA优化策略 结论 现代计算…...

TrackWeight:将MacBook触控板转化为精准称重工具的创新解决方案
TrackWeight:将MacBook触控板转化为精准称重工具的创新解决方案 【免费下载链接】TrackWeight Use your Mac trackpad as a weighing scale 项目地址: https://gitcode.com/gh_mirrors/tr/TrackWeight TrackWeight是一款基于macOS平台的开源工具,…...

开箱即用环境+保姆级教程:深度学习项目训练环境助你快速入门AI
开箱即用环境保姆级教程:深度学习项目训练环境助你快速入门AI 1. 镜像环境概述 深度学习项目训练环境镜像是一个预装了完整深度学习开发环境的解决方案,专为快速启动AI项目而设计。这个镜像基于深度学习项目改进与实战专栏,集成了训练、推理…...

OpenClaw调试技巧:百川2-13B模型任务执行过程的实时日志分析
OpenClaw调试技巧:百川2-13B模型任务执行过程的实时日志分析 1. 为什么需要关注OpenClaw的实时日志? 上周我在用OpenClaw自动处理一批Markdown文档时,遇到了一个奇怪的现象:任务执行到一半就卡住了,既没有报错也没有…...

如何通过手机号快速找回QQ账号:3分钟完成的终极指南
如何通过手机号快速找回QQ账号:3分钟完成的终极指南 【免费下载链接】phone2qq 项目地址: https://gitcode.com/gh_mirrors/ph/phone2qq 还在为忘记QQ账号而烦恼吗?每次需要验证好友身份时都要翻遍通讯录?现在,通过phone2…...

在 Windows 11 家庭版安装 Docker Desktop解决虚拟化问题
目录 前言 环境说明 架构原理 第一步:启用 Windows 虚拟化功能 第二步:修复 Hypervisor 启动配置 第三步:安装 WSL 2 与 Ubuntu 第四步:启动 Docker Desktop 第五步:验证安装 常见问题 总结 前言 Docker 是目…...
)
Elsevier投稿遇Publishing Options卡死?别慌,试试这3个亲测有效的急救方案(附Edge浏览器操作)
Elsevier投稿遇Publishing Options卡死?3个急救方案与Edge浏览器实战指南 凌晨三点,实验室的灯光依然亮着。张教授盯着屏幕上那个纹丝不动的"Publishing Options"页面,手指无意识地敲击着桌面。距离返修截止只剩不到12小时…...

Rivets.js实际项目案例:构建电商应用的数据绑定架构
Rivets.js实际项目案例:构建电商应用的数据绑定架构 【免费下载链接】rivets Lightweight and powerful data binding. 项目地址: https://gitcode.com/gh_mirrors/ri/rivets Rivets.js是一个轻量级且功能强大的数据绑定库,它能帮助你快速构建响应…...

如何使用Aimeos构建高效产品目录:从基础商品到复杂配置型产品的完整指南
如何使用Aimeos构建高效产品目录:从基础商品到复杂配置型产品的完整指南 【免费下载链接】aimeos Integrated online shop based on Laravel 10 and the Aimeos e-commerce framework for ultra-fast online shops, scalable marketplaces, complex B2B application…...

Qwen3-1.7B效果实测:轻量级模型也能写出高质量文案和代码
Qwen3-1.7B效果实测:轻量级模型也能写出高质量文案和代码 1. 开篇:小身材,大能量 你可能听过很多关于大模型的讨论,动辄几百亿、上千亿参数,听起来很厉害,但部署起来也让人头疼——需要昂贵的显卡&#x…...

easy-connect-gr-peach:GR-PEACH多网络连接抽象库详解
1. easy-connect-gr-peach 项目概述 easy-connect-gr-peach 是专为 Renesas GR-PEACH 开发板设计的轻量级网络连接抽象库,属于 mbed OS 生态中 easy-connect 系统在特定硬件平台上的适配实现。其核心目标并非提供底层驱动,而是构建一套 统一、可配置…...