分布式之日志系统平台ELK
ELK解决了什么问题
我们开发完成后发布到线上的项目出现问题时(中小型公司),我们可能需要获取服务器中的日志文件进行定位分析问题。但在规模较大或者更加复杂的分布式场景下就显得力不从心。因此急需通过集中化的日志管理,将所有服务器上的日志进行收集汇总。所以ELK应运而生,它通过一系列开源框架提供了一整套解决方案,将所有节点上的日志统一收集、存储、分析、可视化等。
- 注意:ELK不仅仅适用于日志分析,它还可以支持其它任何数据分析(比如我们之前项目开发中通过ES实现了用户在不同周期内访问系统的活跃度)和收集的场景,日志分析和收集只是更具有代表性而并非唯一性
概念
ELK是Elasticsearch(存储、检索数据)、Logstash(收集、转换、筛选数据)、Kibana(可视化数据) 三大开源框架的首字母大写简称,目前通常也被称为Elastic Stack(在 ELK的基础上增加了 Beats)

Elasticsearch(ES,Port:9200)
- 开源分布式搜索引擎,提供搜集、分析、存储数据功能
- ES是面向文档document存储,它可以存储整个对象或文档(document)。同时也可以对文档进行索引、搜索、排序、过滤。这种理解数据的方式与传统的关系型数据库完全不同,因此这也是ES能够执行复杂的全文搜索的原因之一,document可以类比为RDMS中的行
- ES使用JSON作为文档序列化格式,统一将document数据转换为json格式进行存储,JSON已经成为NoSQL领域的标准格式
- ES是基于Lucene实现的全文检索,底层是基于倒排的索引方法,用来存储在全文检索下某个单词在一个/组文档中的存储位置[倒排索引是ES具有高检索性能的本质原因]
-
ES-head插件(Port:9100)
- 查看我们导入的数据是否正常生成索引
-
数据删除操作
-
数据浏览
-
Index: Index是文档的容器,在ES的早期版本中的index(类似于RDMS中的库)中还包含有type(类似于RDMS中的表)的概念。但在后续版本中,type被逐渐取消而index同时具有数据库和表的概念
-
查询DSL: 使用JSON格式并基于RESTful API进行通信,提供了全文搜索、范围查询、布尔查询、聚合查询等不同的搜索需求
Logstash(Port:5044)

- ELK的数据流引擎,从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过滤后输出到ES
- Filebeat是一个轻量级的日志收集处理工具(Agent),占用资源少,可在各服务器上搜集信息后传输给Logastash(官方推荐)
- logback+rabbitmq整合日志模式下,我们在logstash.conf配置input从rabbitmq绑定的队列读取日志->filter解析和处理(可选)->output输出日志到目标ES
Kibana(Port:5601)
- 分析和可视化数据:利用工具分析 es中的数据,编制图表仪表板,利用仪表、地图和其他可视化显示发现的内容
- 搜索、观察和保护数据:向应用和网站添加搜索框,分析日志和指标,并发现安全漏洞
- 管理、监控和保护 Elastic Stack:监控和管理 es集群、kibana等 elastic stack的运行状况,并控制用户访问特征和数据
- 常用核心功能
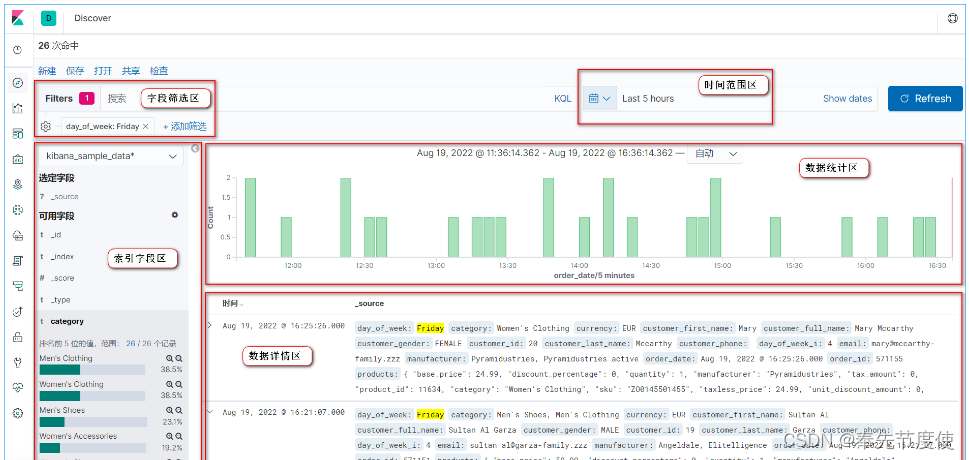
- Discover: 浏览ES索引中的数据,还可以添加筛选条件进而查看感兴趣的数据
-
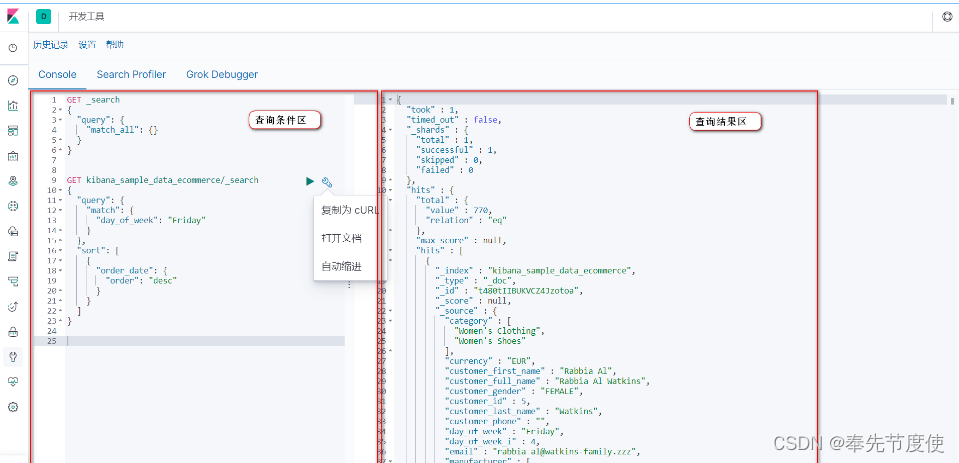
- Dev_Tool: 用ES支持的语法编写查询条件查询,也可用于测试代码中的查询条件
-
- 管理:索引管理和索引模式
- 索引管理:查看索引的运行状况、状态、主分片和副本分片等信息
- 索引模式:用于匹配命名符合一定规律的单个或多个索引,便于在 discover界面查看和分析目标索引的数据
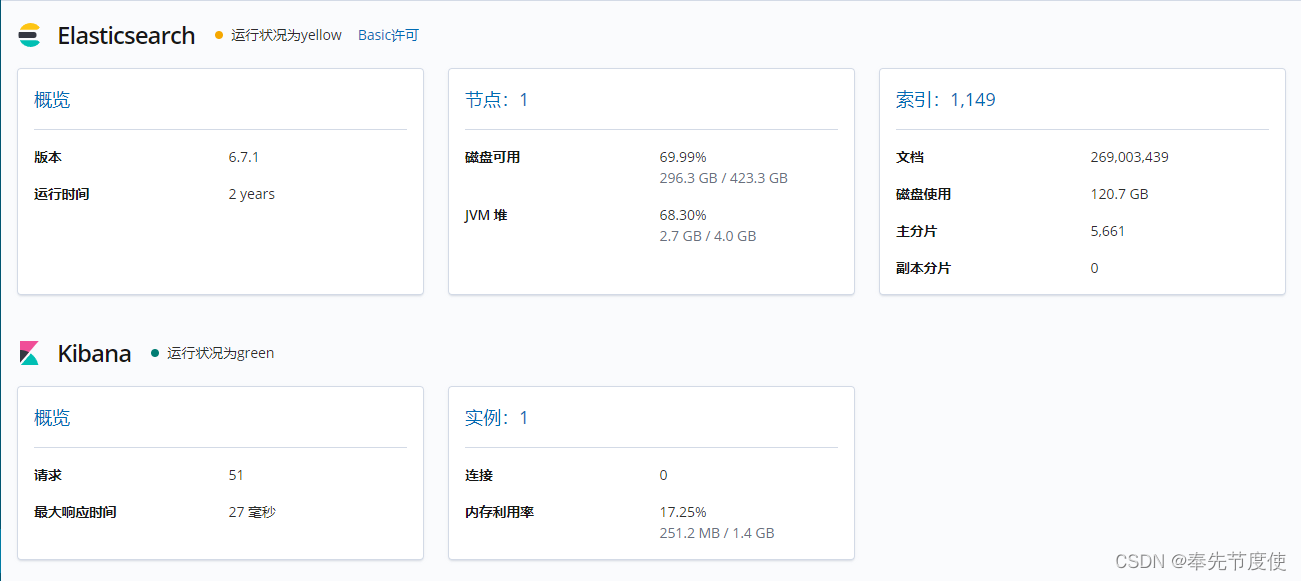
- Monitoring: 查看ES集群版本、运行时间、节点状态情况和索引情况
- 管理:索引管理和索引模式
-
- 可视化: 根据需求可创建条形图、饼图、云图(词云图)进行个性化定制
项目实战
在公司项目实际开发中我们基于logback -> rabbitmq -> elk 工作模式进行日志收集,实现了日志的集中管理。在此基础上通过ES搜索建立系统可视化看板来显示用户在不同周期内访问系统的活跃度
注意:logback是日志框架(log4j也是一种日志框架),而slf4j是日志门面接口
具体相关核心实现流程
- Maven导入Logback、ElasticSearch依赖
<dependency><groupId>net.logstash.logback</groupId><artifactId>logstash-logback-encoder</artifactId><version>5.1</version> </dependency> <dependency><groupId>net.logstash.log4j</groupId><artifactId>jsonevent-layout</artifactId><version>1.7</version> </dependency><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>6.3.1</version> </dependency> <dependency><groupId>org.elasticsearch.client</groupId><artifactId>transport</artifactId><version>6.3.1</version> </dependency> <dependency><groupId>org.elasticsearch.plugin</groupId><artifactId>transport-netty4-client</artifactId><version>6.3.1</version> </dependency> - 定义logback-prod.xml配置文件
# 首先需要在application.yml文件配置log日志相关属性配置 logging:config: classpath:logback-prod.xml #配置logback文件,本地开发不需要配置file: logs/${logback.log.file} #存储日志的文件#我们logback采用Rabbitmq方式收集日志时消息服务配置信息 logback:log:path: "./logs/"file: logback_amqp.logamqp:host: 10.225.225.225port: 5672username: adminpassword: admin<?xml version="1.0" encoding="UTF-8"?> <configuration scan="true" scanPeriod="60 seconds" debug="false"><include resource="org/springframework/boot/logging/logback/base.xml" /><contextName>logback</contextName><!-- 日志输出路径: source对应的值取自application.yml文件--><springProperty scope="context" name="log.path" source="logback.log.path" /><springProperty scope="context" name="log.file" source="logback.log.file" /><springProperty scope="context" name="logback.amqp.host" source="logback.amqp.host"/><springProperty scope="context" name="logback.amqp.port" source="logback.amqp.port"/><springProperty scope="context" name="logback.amqp.username" source="logback.amqp.username"/><springProperty scope="context" name="logback.amqp.password" source="logback.amqp.password"/><!-- 输出到logstash的appender--><appender name="stash-amqp" class="org.springframework.amqp.rabbit.logback.AmqpAppender"> <!--日志收集模式:logback -> rabbitmq -> elk 工作模式,因此我们需要使用net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder实现--><encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder"><providers><pattern><!-- 其中"application": "application"中的值必须为小写,否则elk创建index报错(elk创建index基本规则为:字母必须都为小写) --><pattern>{"time": "%date{ISO8601}", "thread": "%thread", "level": "%level", "class": "%logger{60}", "message": "%message", "application": "application" }</pattern></pattern></providers></encoder><host>${logback.amqp.host}</host> <port>${logback.amqp.port}</port> <username>${logback.amqp.username}</username> <password>${logback.amqp.password}</password><declareExchange>true</declareExchange> <exchangeType>fanout</exchangeType> <exchangeName>ex_common_application_Log</exchangeName> <!-- 需在rabbitmq页面手动配置交换机与队列--><generateId>true</generateId> <charset>UTF-8</charset> <durable>true</durable> <deliveryMode>PERSISTENT</deliveryMode> </appender> <!--输出到控制台--><appender name="console" class="ch.qos.logback.core.ConsoleAppender"><encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"><!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符--><pattern>%d{HH:mm:ss.SSS} %contextName [%thread] %-5level %logger{36} - %msg%n</pattern></encoder></appender><!--输出到文件--><!-- 按照每天生成日志文件 --><appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>${log.path}/${log.file}</file><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><!--日志文件输出的文件名,如果文件名为.zip结尾,则归档时支持自动压缩--><fileNamePattern>${log.path}/%d{yyyy/MM}/${log.file}.%i.zip</fileNamePattern><!--日志文件保留天数--><MaxHistory>30</MaxHistory><!-- 最多存储5GB日志 --><totalSizeCap>5GB</totalSizeCap><!-- 每个文件最大500MB --><maxFileSize>300MB</maxFileSize></rollingPolicy><encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"><!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符--><pattern>%d{HH:mm:ss.SSS} %contextName [%thread] %-5level %logger{36} - %msg%n</pattern></encoder></appender><!-- 总开关 --><!-- 日志输出级别 --><root level="info"><!-- <appender-ref ref="console" /> --><appender-ref ref="file" /><appender-ref ref="stash-amqp" /></root> </configuration> - SpringBoot集成Elasticsearch
# 所属应用的yml文件配置elasticsearch信息 elasticsearch:protocol: httphostList: 10.225.225.225:9200 # elasticsearch集群-单节点connectTimeout: 5000socketTimeout: 5000connectionRequestTimeout: 5000maxConnectNum: 10maxConnectPerRoute: 10username: # 帐号为空password: # 密码为空Elasticsearch配置类
package com.bierce;import java.io.IOException; import java.util.concurrent.TimeUnit; import org.apache.commons.lang3.StringUtils; import org.apache.http.HttpHost; import org.apache.http.auth.AuthScope; import org.apache.http.auth.UsernamePasswordCredentials; import org.apache.http.client.CredentialsProvider; import org.apache.http.client.config.RequestConfig.Builder; import org.apache.http.impl.client.BasicCredentialsProvider; import org.apache.http.impl.nio.client.HttpAsyncClientBuilder; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestClientBuilder; import org.elasticsearch.client.RestClientBuilder.HttpClientConfigCallback; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.client.sniff.ElasticsearchHostsSniffer; import org.elasticsearch.client.sniff.HostsSniffer; import org.elasticsearch.client.sniff.SniffOnFailureListener; import org.elasticsearch.client.sniff.Sniffer; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration;/*** * @ClassName: ElasticSearchConfiguration* @Description: ES配置类*/ @Configuration public class ElasticSearchConfiguration {@Value("${elasticsearch.protocol}") // 基于Http协议private String protocol;@Value("${elasticsearch.hostlist}") // 集群地址,如果有多个用“,”隔开private String hostList;@Value("${elasticsearch.connectTimeout}") // 连接超时时间private int connectTimeout;@Value("${elasticsearch.socketTimeout}") // Socket 连接超时时间private int socketTimeout;@Value("${elasticsearch.connectionRequestTimeout}") // 获取请求连接的超时时间private int connectionRequestTimeout;@Value("${elasticsearch.maxConnectNum}") // 最大连接数private int maxConnectNum;@Value("${elasticsearch.maxConnectPerRoute}") // 最大路由连接数private int maxConnectPerRoute;@Value("${elasticsearch.username:}")private String username;@Value("${elasticsearch.password:}")private String password;// 配置restHighLevelClient,// 当Spring容器关闭时,应该调用RestHighLevelClient类的close方法来执行清理工作@Bean(destroyMethod="close")public RestHighLevelClient restHighLevelClient() { String[] split = hostList.split(",");HttpHost[] httphostArray = new HttpHost[split.length];SniffOnFailureListener sniffOnFailureListener = new SniffOnFailureListener();//获取集群地址进行ip和端口后放入数组for(int i=0; i<split.length; i++) {String hostName = split[i];httphostArray[i] = new HttpHost(hostName.split(":")[0], Integer.parseInt(hostName.split(":")[1]), protocol);}// 构建连接对象// 为RestClient 实例设置故障监听器RestClientBuilder builder = RestClient.builder(httphostArray).setFailureListener(sniffOnFailureListener);// 异步连接延时配置builder.setRequestConfigCallback(new RestClientBuilder.RequestConfigCallback() {@Overridepublic Builder customizeRequestConfig(Builder requestConfigBuilder) {requestConfigBuilder.setConnectTimeout(connectTimeout);requestConfigBuilder.setSocketTimeout(socketTimeout);requestConfigBuilder.setConnectionRequestTimeout(connectionRequestTimeout);return requestConfigBuilder;}});// 连接认证CredentialsProvider credentialsProvider = new BasicCredentialsProvider();if( StringUtils.isNotBlank( username ) && StringUtils.isNotBlank(password )) {credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, password));}// 异步连接数配置builder.setHttpClientConfigCallback(new HttpClientConfigCallback() {@Overridepublic HttpAsyncClientBuilder customizeHttpClient(HttpAsyncClientBuilder httpClientBuilder) {httpClientBuilder.setMaxConnTotal(maxConnectNum);httpClientBuilder.setMaxConnPerRoute(maxConnectPerRoute);// 设置帐号密码if(credentialsProvider != null && StringUtils.isNotBlank( username ) && StringUtils.isNotBlank(password )) {httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);}return httpClientBuilder;}});RestHighLevelClient restHighLevelClient = new RestHighLevelClient(builder);RestClient restClient = restHighLevelClient.getLowLevelClient();HostsSniffer hostsSniffer = new ElasticsearchHostsSniffer(restClient,ElasticsearchHostsSniffer.DEFAULT_SNIFF_REQUEST_TIMEOUT,ElasticsearchHostsSniffer.Scheme.HTTP);try {/* 故障后嗅探,不仅意味着每次故障后会更新节点,也会添加普通计划外的嗅探行为,* 默认情况是故障之后1分钟后,假设节点将恢复正常,那么我们希望尽可能快的获知。* 如上所述,周期可以通过 `setSniffAfterFailureDelayMillis` * 方法在创建 Sniffer 实例时进行自定义设置。需要注意的是,当没有启用故障监听时,* 这最后一个配置参数不会生效 */Sniffer sniffer = Sniffer.builder(restClient).setSniffAfterFailureDelayMillis(30000).setHostsSniffer(hostsSniffer).build();// 将嗅探器关联到嗅探故障监听器上sniffOnFailureListener.setSniffer(sniffer); sniffer.close();} catch (IOException e) {e.printStackTrace();}return restHighLevelClient;} } - 通过ES提供的API搜索相关数据
package com.bierce;/*** * @ClassName: UserVisitInfo* @Description: 用戶访问系统相关信息类**/ public class UserVisitInfo {private String dayOfWeek; // 星期几private Long docCount; //访问次数public UserVisitInfo() {}public UserVisitInfo(String dayOfWeek, Long docCount) {super();this.dayOfWeek = dayOfWeek;this.docCount = docCount;}public String getDayOfWeek() {return dayOfWeek;}public void setDayOfWeek(String dayOfWeek) {this.dayOfWeek = dayOfWeek;}public Long getDocCount() {return docCount;}public void setDocCount(Long docCount) {this.docCount = docCount;}@Overridepublic String toString() {return "UserVisitInfo [dayOfWeek=" + dayOfWeek + ", docCount=" + docCount + "]";} }package com.bierce;import java.util.ArrayList; import java.util.List; import com.bierce.UserVisitInfo; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.index.query.QueryBuilder; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.script.Script; import org.elasticsearch.search.aggregations.AggregationBuilders; import org.elasticsearch.search.aggregations.Aggregations; import org.elasticsearch.search.aggregations.bucket.histogram.Histogram; import org.elasticsearch.search.aggregations.bucket.histogram.HistogramAggregationBuilder; import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service;/*** * @ClassName: VisitUserCountSearchTemplate* @Description: 获取用户不同周期内活跃度**/ @Service public class VisitUserCountSearchTemplate {private static final String INDEX_PREFIX = "user-visit-";@Autowiredprivate RestHighLevelClient restHighLevelClient;/*** * @Title: getUserActivityInfo* @Description: 获取用户访问系统活跃度* @param startDate* @param endDate* @return*/public List<UserVisitInfo> getUserActivityInfo(String startDate, String endDate) {SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.size(0);searchSourceBuilder.query(QueryBuilders.matchAllQuery());// 设置聚合查询相关參數String aggregationName = "timeslice";String rangeField = "@timestamp";String termField = "keyword";Script script = new Script("doc['@timestamp'].value.dayOfWeek");String[] igonredAppCode = {"AMQP", "Test"}; QueryBuilder timeQueryBuilder = QueryBuilders.boolQuery().must(QueryBuilders.rangeQuery(rangeField).gte(startDate).lte(endDate)).mustNot(QueryBuilders.termsQuery(termField, igonredAppCode)).filter(QueryBuilders.existsQuery(termField));// 按照星期几搜索对应数据HistogramAggregationBuilder dayOfWeekAggregationBuilder = AggregationBuilders.histogram(aggregationName).script(script).interval(1).extendedBounds(1, 7);searchSourceBuilder.query(timeQueryBuilder);searchSourceBuilder.aggregation(dayOfWeekAggregationBuilder); SearchResponse searchResponse = ElasticsearchUtils.buildSearchSource(INDEX_PREFIX + "*", searchSourceBuilder, client); List<UserVisitInfo> userActivityInfoList = new ArrayList<>();Aggregations aggregations = searchResponse.getAggregations();Histogram dayOfWeekHistogram = aggregations.get(aggregationName);List<? extends Histogram.Bucket> buckets = dayOfWeekHistogram.getBuckets();for(Histogram.Bucket bucket: buckets) {String dayOfWeek = bucket.getKeyAsString();long docCount = bucket.getDocCount();UserVisitInfo item = new UserVisitInfo(dayOfWeek, docCount);userActivityInfoList.add(item);}return userActivityInfoList;} } - 将数据返回给前台进行页面渲染,最终实现的效果
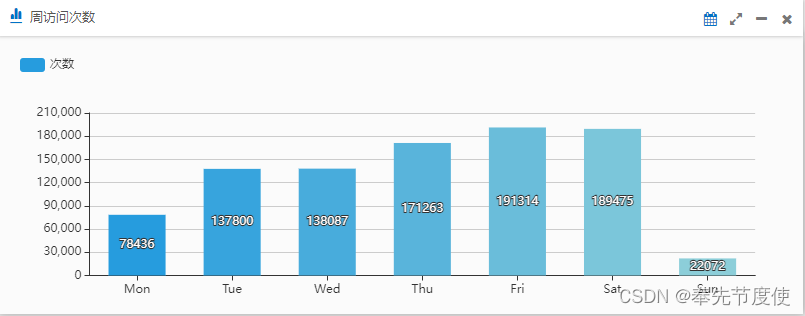
相关文章:
分布式之日志系统平台ELK
ELK解决了什么问题 我们开发完成后发布到线上的项目出现问题时(中小型公司),我们可能需要获取服务器中的日志文件进行定位分析问题。但在规模较大或者更加复杂的分布式场景下就显得力不从心。因此急需通过集中化的日志管理,将所有服务器上的日志进行收集汇总。所以ELK应运而生…...

git常见错误
refusing to merge unrelated histories 如果git merge合并的时候出现refusing to merge unrelated histories的错误,原因是两个仓库不同而导致的,需要在后面加上--allow-unrelated-histories进行允许合并,即可解决问题。 git push origin …...

构建稳定高效的消息传递中间件:消息队列系统的设计与实现
✨✨谢谢大家捧场,祝屏幕前的小伙伴们每天都有好运相伴左右,一定要天天开心哦!✨✨ 🎈🎈作者主页: 喔的嘛呀🎈🎈 目录 一、引言 二、设计目标 2.1、高可用性 1. 集群搭建 1.1 …...
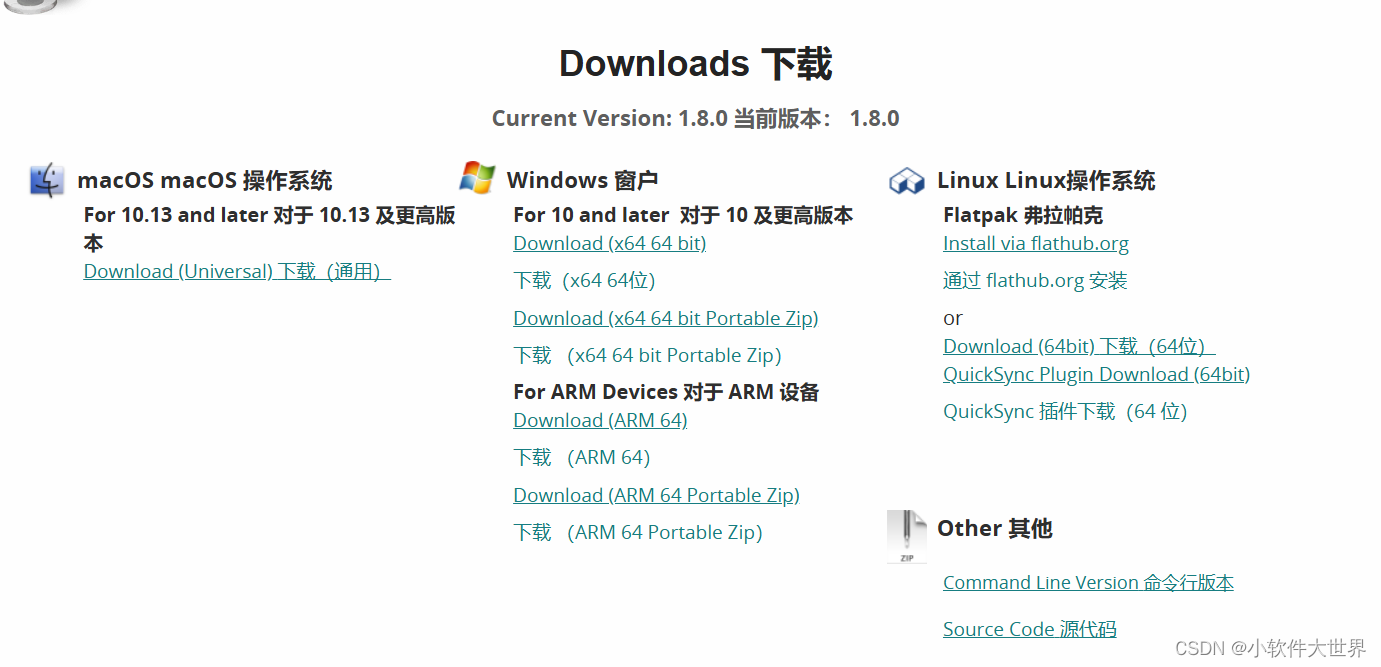
支持 MKV、MP4、AVI、MPG 等格式视频转码器
一、简介 1、一款开源的视频转码器,适用于 Linux、Mac 和 Windows。它是一个免费的工具,由志愿者们开发,可以将几乎所有格式的视频转换为现代、广泛支持的编码格式。你可以在官网上下载该应用或源代码。该软件支持 MKV、MP4、AVI、MPG 等格式…...

yum
文章目录 本地源配置本地yum源仓库yum常用的操作命令 网络源阿里云当yum 安装源代码软件包需要编译安装,需要安装支持c和c程序语言的编译器,如gcc、gcc-c、make 如果使用rpm方式安装,则需要先安装多个依赖包,这样会很繁琐。可以使…...
【单片机毕业设计选题24016】-基于STM32和阿里云的采空区环境监测系统设计
系统功能: 系统分为主机端和从机端,主机端主动向从机端发送信息和命令,从机端 收到主机端的信息后回复温度,甲烷,一氧化碳,氧气和系统状态等信息。 同时主机端将这些信息上传至阿里云服务器。 主要功能模块原理图: 电源时钟烧…...
Leetcode3179. K 秒后第 N 个元素的值
Every day a Leetcode 题目来源:3179. K 秒后第 N 个元素的值 解法1:模拟 模拟 k 轮,数组保存上一次结果,然后计算当前轮次的结果。 代码: /** lc appleetcode.cn id3179 langcpp** [3179] K 秒后第 N 个元素的值…...

vue3第二阶段的开发文档
1 2.1 案例——学习计划表 2.1.1 准备工作 在开发“学习计划表”案例之前,需要先完成一些准备工作,具体步骤如下。 ① 打开命令提示符,切换到 D:\vue\chapter02 目录,在该目录下执行如下命令,创建 项目。 np…...
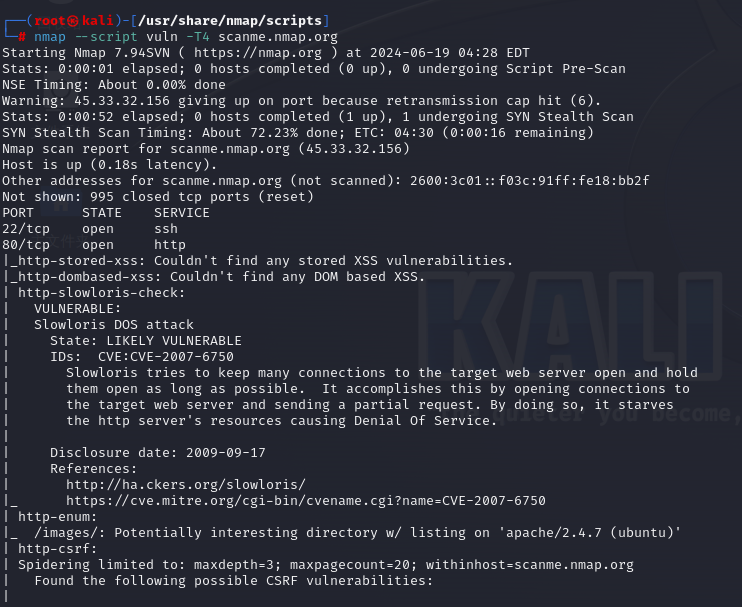
【网络安全学习】漏洞扫描:- 02- nmap漏洞扫描
1.nmap的介绍 Nmap是一款功能强大的网络探测和安全扫描工具,可以对目标进行端口扫描、服务探测、操作系统指纹识别等操作。 Nmap自带了许多内置的NSE脚本,它们可以根据不同的目标和场景来执行不同的功能。这些脚本存放在Nmap安装目录**/usr/share/nmap…...

Web开发技能树-HTML-class/id/name/tag
1 需求 需求1:CSS查找HTML元素 *tagclassid派生选择器 需求2:JavaScript查找HTML元素 通过id找到HTML元素:document.getElementById()通过标签名找到HTML元素:getElementsByTagName()通过类名找到HTML元素:document.getElemen…...
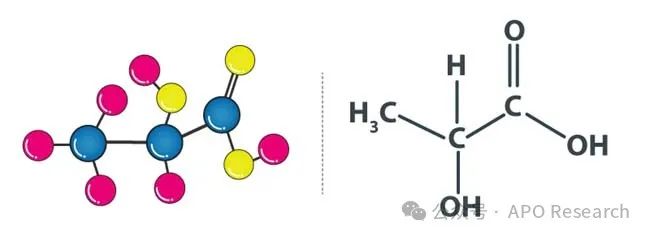
据APO Research(阿谱尔)统计,2023年全球乳酸企业产能约119.3万吨
乳酸又称 2-羟基丙酸,一种天然有机酸,分子式是 C3H6O3。是自然界中最为广泛存在的羟基酸,于 1780 年被瑞典科学家 Scheele 首次发现。乳酸是自然界最小的手性分子,以两种立体异构体的形式存在于自然界中,即左旋型 L-乳…...

百度文心智能体平台(想象即现实):轻松上手,开启智能新时代!创建属于自己的智能体应用。
目录 1.1、文心智能体平台 1.2、创建智能体 1.3、智能体报名入口 1.4、古诗词小助手 1.5、访问我的智能体 在这个全新的时代里,人工智能技术正以前所未有的速度发展,渗透到我们生活的方方面面。无论是智能家居、自动驾驶,还是医疗诊断、…...

Linux中ls -lsa 和ls -lst区别
在Linux中,ls 命令用于列出目录内容。当与不同的选项组合时,它可以以不同的方式显示文件和目录的详细信息。 对于 ls -lsa 和 ls -lst,它们的主要区别在于显示的列和排序方式: ls -lsa: -l: 使用长格式显示文件和目录的详细信息。…...

TDengine 签约上海晶澳太阳能,助力储能业务平台搭建
在全球能源结构转型和碳中和目标的大背景下,太阳能作为清洁能源的重要组成部分,正逐渐成为新能源发展的关键。作为一个领先的数据处理平台,TDengine 最近与太阳能行业的领头羊晶澳太阳能科技股份有限公司开展了深度合作。这项合作旨在利用 TD…...

【数据结构】选择题
在数据结构中,从逻辑上可以把数据结构分为(线性结构和非线性结构) 当输入规模为n时,下列算法渐进复杂性中最低的是() 时间复杂度 某线性表采用顺序存储结构,每个元素占4个存储单元…...

数据库 |试卷八试卷九试卷十
1.基数是指元组的个数 2.游标机制 3.触发器自动调用 4.count(*)统计所有行,不忽略空值null,但不但要全局扫描,也要对表的每个字段进行扫描; 5.eacherNO INT NOT NULL UNIQUE,为什么不能断定TeacherNO是主码ÿ…...

【华为HCIA数通网络工程师真题-构建互联互通的IP网络】
文章目录 一、选择题 一、选择题 1、缺省情况下,广播网络上OSPF协议RouterDeadInterval是? 40s (ospf 的 RouterDeadInterval 为四倍 hello time 时间,hello time 周期默认为10s,所以 RouterDeadInterval 默认为 40s …...
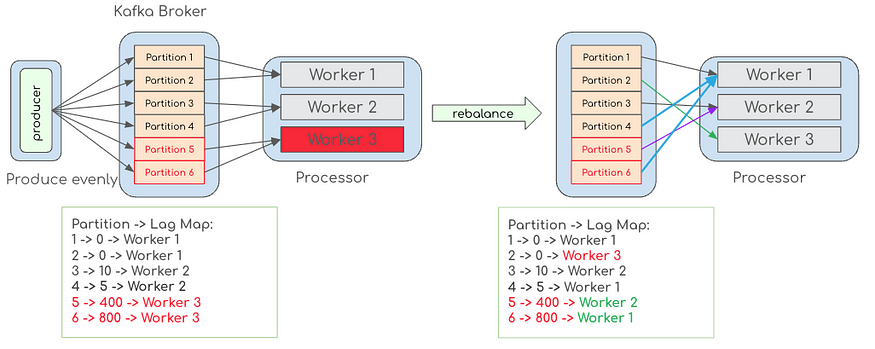
Kafka 负载均衡挑战及解决思路
本文转载自 Agoda Engineering,介绍了在实际应用中,如何应对 Kafka 负载均衡所遇到的各种挑战,并提出相应的解决思路。本文简要阐述了 Kafka 的并行性机制、常用的分区策略以及在实际操作中遇到的异构硬件、不均匀工作负载等问题。通过深入分…...
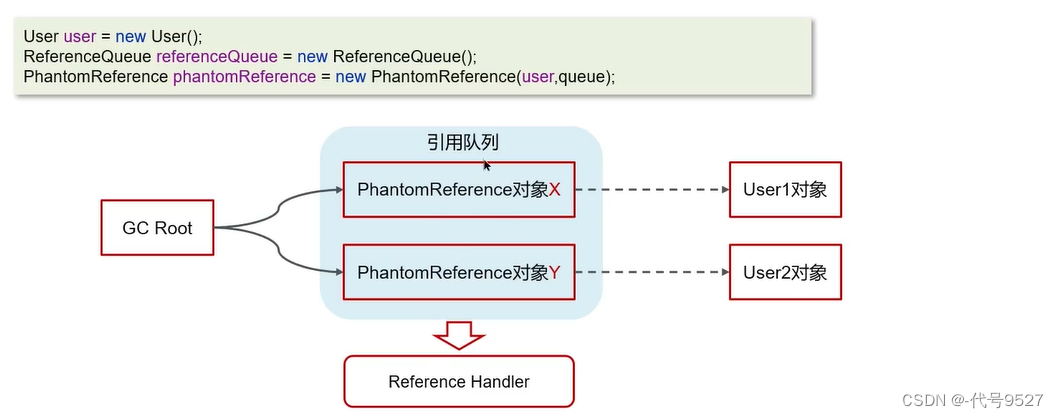
【Java面试】二十一、JVM篇(中):垃圾回收相关
文章目录 1、类加载器1.1 什么是类加载器1.2 什么是双亲委派机制 2、类装载的执行过程(类的生命周期)3、对象什么时候可以被垃圾回收器处理4、JVM垃圾回收算法4.1 标记清除算法4.2 标记整理算法4.3 复制算法 5、分代收集算法5.1 MinorGC、Mixed GC、Full…...
深入理解预处理
1.预定义符号 C语言设置了⼀些预定义符号,可以直接使用,预定义符号也是在预处理期间处理的。 __FILE__ //进⾏编译的源⽂件 __LINE__ //⽂件当前的⾏号 __DATE__ //⽂件被编译的⽇期 __TIME__ //⽂件被编译的时间 __STDC__ //如果编译器遵循ANSI C&…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

拉力测试cuda pytorch 把 4070显卡拉满
import torch import timedef stress_test_gpu(matrix_size16384, duration300):"""对GPU进行压力测试,通过持续的矩阵乘法来最大化GPU利用率参数:matrix_size: 矩阵维度大小,增大可提高计算复杂度duration: 测试持续时间(秒&…...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...

Python Ovito统计金刚石结构数量
大家好,我是小马老师。 本文介绍python ovito方法统计金刚石结构的方法。 Ovito Identify diamond structure命令可以识别和统计金刚石结构,但是无法直接输出结构的变化情况。 本文使用python调用ovito包的方法,可以持续统计各步的金刚石结构,具体代码如下: from ovito…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...

Matlab实现任意伪彩色图像可视化显示
Matlab实现任意伪彩色图像可视化显示 1、灰度原始图像2、RGB彩色原始图像 在科研研究中,如何展示好看的实验结果图像非常重要!!! 1、灰度原始图像 灰度图像每个像素点只有一个数值,代表该点的亮度(或…...

小智AI+MCP
什么是小智AI和MCP 如果还不清楚的先看往期文章 手搓小智AI聊天机器人 MCP 深度解析:AI 的USB接口 如何使用小智MCP 1.刷支持mcp的小智固件 2.下载官方MCP的示例代码 Github:https://github.com/78/mcp-calculator 安这个步骤执行 其中MCP_ENDPOI…...

【java】【服务器】线程上下文丢失 是指什么
目录 ■前言 ■正文开始 线程上下文的核心组成部分 为什么会出现上下文丢失? 直观示例说明 为什么上下文如此重要? 解决上下文丢失的关键 总结 ■如果我想在servlet中使用线程,代码应该如何实现 推荐方案:使用 ManagedE…...