【Ruby爬虫01】某吃瓜网站图片数据采集
介绍
由于最近在学习Ruby,写一个爬虫锻炼一下。涉及xml解析、多线程、xpath语法等基础知识。
实现代码
使用说明
使用前请先安装如下gem
gem install nokogiri http openssl# nokogiri:一个解析xml和html的库,支持css、xpath语法
# http:一个发送http请求的库
源代码
require 'nokogiri'
require 'openssl'
require 'time'
require 'http'
require 'thread' # 由于网站涉不良内容,网站已编码,自行研究解码方式
BASE_URL = 'l5VKR[9`aI10.P;m*LzIh,]@P17&0^F' # AES-128-CBC解密 ,网站图片有加密,需要解密
def aes_128_cbc_decrypt(encrypted_data, key = 'f5d965df75336270', iv = '97b60394abc2fbe1') aes = OpenSSL::Cipher.new('aes-128-cbc') aes.decrypt aes.key = key aes.iv = iv aes.padding = 0 # 禁用填充 aes.update(encrypted_data) + aes.final
end # 获取页面
def get_page_doc(page_url) begin # 使用HTTP.follow自动跟随重定向 resp = HTTP.follow.get(page_url) # 转换为doc doc = Nokogiri::HTML(resp.body.to_s) rescue Exception => e puts e.message end doc
end # 获取列表页面
def fetch_list_urls(doc) page_list = [] urls = [] infos = [] # 获取页面链接地址 doc.xpath('//*[@id="archive"]/article/a/@href').each do |link| # 添加 urls << BASE_URL + link end # 匹配标题及发布时间 doc.xpath('//*[@class="post-card"]/div[2]/div').each do |title| info = {} if title.content.gsub(/\s+/,'')!='' # 获取标题 t = title.xpath('h2[@class="post-card-title"]/text()')[0].content # 获取发布时间 time_str = title.xpath('div[@class="post-card-info"]/span[2]/@content')[0].content publish_time = Time.parse(time_str).strftime('%Y/%m/%d') info['title'] , info['publish_time']= t ,publish_time infos << info else # 内容为空的都为广告 info['title'], info['publish_time'] = '','' infos << info end end # 转换hash对象 urls.each_with_index do |url, i| page= {'url' => url,'title'=>infos[i]['title'],'publish_time'=> infos[i]['publish_time']} page_list << page end # 返回page_list page_list
end # 获取某一页的图片
def fetch_page(title,page_url) doc = get_page_doc(page_url) # 去除特殊字符,不然创建目录会失败,windows环境 title = title.gsub(/[“”:、\-*<>?\|\/?!!\s]*/,'') # filename = "images/#{title}" filename = File.join(File.dirname($0), "images/#{title}") unless doc.nil? # 创建目录 Dir.mkdir(filename) unless Dir.exist?(filename) # 匹配页面中的图片 urls = doc.xpath('//*[@itemprop="articleBody"]/p/img/@data-xkrkllgl') # 将url添加进队列 work_queue = Queue.new urls.each { |img_url| work_queue << img_url } workers = (1..urls.size).map do |i| Thread.new(i) do begin while (img_url = work_queue.pop(true)) begin p "下载图片:#{img_url.content}" # 读取图片数据,设置超时时间为3s raw_data = HTTP.timeout(3).get(img_url.content).body.to_s sleep 0.1 # 解密保存 raw_data = aes_128_cbc_decrypt(raw_data) File.binwrite("#{filename}/image#{i}.jpg", raw_data) rescue Exception => e p e.message next end end rescue ThreadError end end end workers.map(&:join) end
end def start_crawl page_index = 1 loop do begin url = "#{BASE_URL}category/wpcz/#{page_index}/" # 今日吃瓜页面 p "正在抓取#{page_index}页,地址:#{url}" doc = get_page_doc(url) fetch_list_urls(doc).each do |page| fetch_page(page['title'],page['url']) end # 匹配下一页按钮 next_page_xpath = '//*[@class="page-navigator"]/ol/li[@class="btn btn-primary next"]/a/text()' # 退出抓取的条件 break if doc.xpath(next_page_xpath)[0].content != "下一页" # 抓取下一页 page_index += 1 sleep 0.1 rescue Exception => e p e.message page_index += 1 next end endend # 执行抓取方法
if __FILE__==$0 start_crawl
end
本文由【产品经理不是经理】gzh 同步发布,欢迎关注
相关文章:

【Ruby爬虫01】某吃瓜网站图片数据采集
介绍 由于最近在学习Ruby,写一个爬虫锻炼一下。涉及xml解析、多线程、xpath语法等基础知识。 实现代码 使用说明 使用前请先安装如下gem gem install nokogiri http openssl# nokogiri:一个解析xml和html的库,支持css、xpath语法 # htt…...

可以免费领取tokens的大模型服务
本文更新时间:2024年6月20日 豆包大模型 “亲爱的客户,模型提供方将在5月15日至8月30日期间,为您提供一次独特的机会,即高达5亿tokens的免费权益。这是我们对您长期支持的感谢,也是对未来合作的期待。” 在8月30日之…...
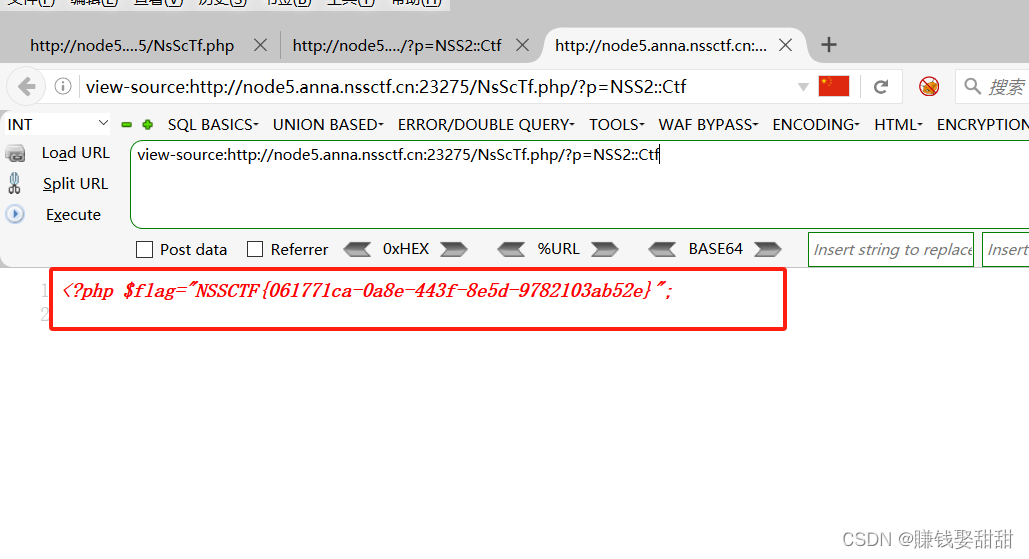
NSSCTF-Web题目11
目录 [鹤城杯 2021]EasyP 1、题目 2、知识点 3、思路 [SWPUCTF 2022 新生赛]numgame 1、题目 2、知识点 3、思路 [鹤城杯 2021]EasyP 1、题目 2、知识点 php代码审计 3、思路 打开题目,出现一段代码,我们对代码进行审计 这里出现了很多不懂的…...
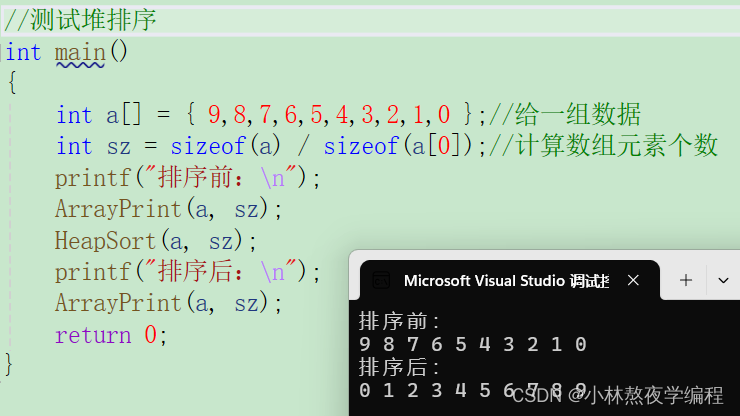
【数据结构】第十八弹---C语言实现堆排序
✨个人主页: 熬夜学编程的小林 💗系列专栏: 【C语言详解】 【数据结构详解】【C详解】 目录 1、堆排序 1.1、基本思想 1.2、初步代码实现 1.3、代码优化 1.4、代码测试 总结 1、堆排序 在博主数据结构第十二弹---堆的应用有详细讲解堆…...

[面试题]Kafka
[面试题]Java【基础】[面试题]Java【虚拟机】[面试题]Java【并发】[面试题]Java【集合】[面试题]MySQL[面试题]Maven[面试题]Spring Boot[面试题]Spring Cloud[面试题]Spring MVC[面试题]Spring[面试题]MyBatis[面试题]Nginx[面试题]缓存[面试题]Redis[面试题]消息队列[面试题]…...
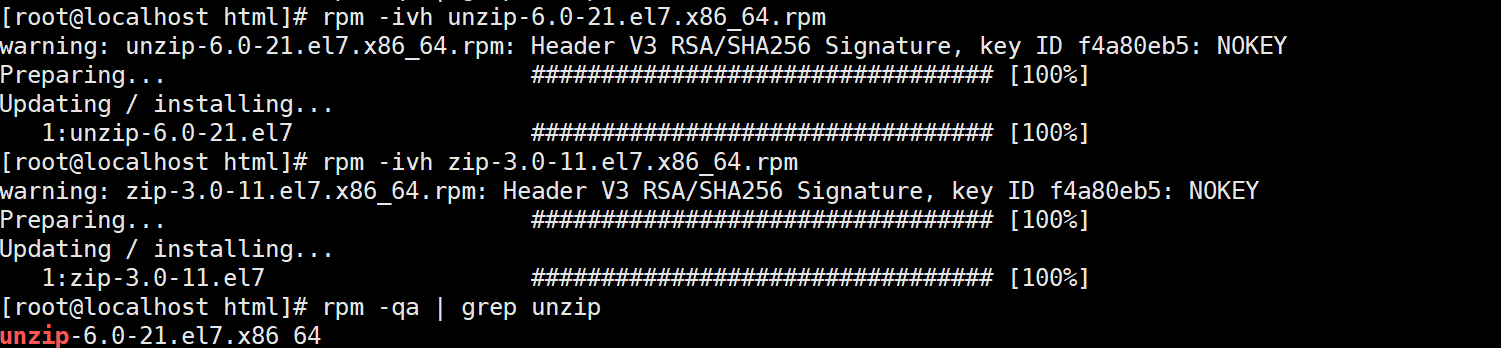
centos7 离线安装zip和unzip
解压的时候发现不能解压,报-bash: unzip: command not found 1、访问https://www.rpmfind.net/linux/rpm2html/search.php?queryzip&submitSearch…&systemcentos&arch#/ 2、输入zip和centos搜索,选择el7下载 3、输入unzip和centos搜索&am…...

Linux下lsof命令使用
目录 lsof 命令使用指南基本语法常用选项使用示例 lsof vs netstatlsofnetstat区别示例对比 lsof 命令使用指南 lsof (List Open Files) 是一个用于列出当前系统中打开文件的命令,适用于 Unix 和类 Unix 操作系统。它不仅可以列出常规文件,还可以列出打…...

基于ChatGPT的大型语言模型试用心得
近年来,ChatGPT这样的大型语言模型,它如同一颗冉冉升起的新星,迅速在商业、教育、娱乐等多个领域照亮了创新的天空,极大地革新了我们的工作与日常生活。 最近我发现一些国内用户也能自由访问的中文ChatGPT APP。这个平台不仅提供…...
)
Python 列表添加多个值(四种方法)
Python 列表添加多个值有多种方法,以下是其中几种实现方法: 一、使用extend()方法 Python 中列表对象有一个 extend() 方法,它可以一次性添加另一个列表中的所有元素到当前列表中。 例1: a = [1, 2, 3] b = [4, 5, 6] a.extend(b)...
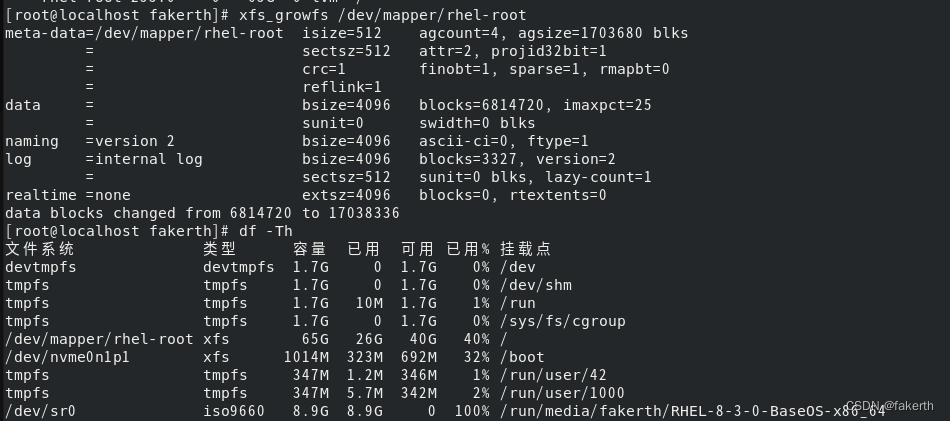
VMware RedHat虚拟机磁盘扩容(添加磁盘和扩展磁盘)
前言 自己的电脑上配一个虚拟机还是很有必要的,用起来比双系统方便一点,之前搞了100g的ubuntu没用到,后面重装redhat觉得随便搞个20g就够用了,后面用到之后就遇到磁盘不够用的情况,只能说情况允许的话,磁盘…...

最近,GPT-4o横空出世。对GPT-4o这一人工智能技术进行评价,包括版本间的对比分析、GPT-4o的技术能力以及个人整体感受等
GPT-4o是一款引人瞩目的人工智能技术,它在之前版本的基础上取得了长足的进步。本文将对GPT-4o进行评价,包括版本间的对比分析、GPT-4o的技术能力以及个人整体感受等。 首先,我们来进行GPT-4o与之前版本的对比分析。GPT-4o相较于GPT-3和GPT-2…...

C#面:C#支持多重继承么?
C#不支持多重继承。在C#中,一个类只能直接继承自一个基类。这是由于C#的设计目标之一是避免多重继承可能带来的复杂性和潜在的问题。 然而,C#提供了接口(interface)的概念来实现类似多重继承的功能。一个类可以实现多个接口&…...
细说MCU修改回调函数调用模式的方法
目录 1、硬件及工程 2、实现方法 (1)修改while(1)中的代码: (2)修改2 (3)修改3 (4)修改4 (5)修改5 3、下载并运行 在本文作者的文章中&a…...
Java共享台球室无人系统支持微信小程序+微信公众号
共享台球室无人系统 🎱 创新台球体验 近年来,共享经济如火如荼,从共享单车到共享汽车,无一不改变着我们的生活方式。而如今,这一模式已经渗透到了更多领域,共享台球室便是其中之一。不同于传统的台球室&a…...

如何开发一个海外仓系统?难度在哪,怎么选择高性价解决方案
作为海外仓管理的重要工具,海外仓系统的实际应用价值还是非常高的。为了让大家能更好的理解wms海外仓系统,今天会介绍海外仓系统开发的逻辑架构,以及作为海外仓企业要怎么确定高性价比的数字化管理解决方案。 1、开发海外仓系统要考虑的功能…...

计算机组成原理(Wrong Question)
目录 一、计算机系统概述 *1.1 计算机发展历程 1.2 计算机系统层次结构 1.3 计算机的性能指标 二、 数据的表示和运算 2.1 数制和编码 2.2 运算方法和运算电路 2.3 浮点数的表示与运算 三、存储系统 3.1 存储器概述 3.2 主存储器 3.3 主存储器与CPU的连接 3.4 外部…...

ACL2024 | AI的时空穿越记:大型语言模型共时推理的奇幻之旅!
作者:苏肇辰 标题:Living in the Moment: Can Large Language Models Grasp Co-Temporal Reasoning? 录取:ACL2024 Main 论文链接:https://arxiv.org/abs/2406.09072 代码链接:https://github.com/zhaochen0110/Cotem…...
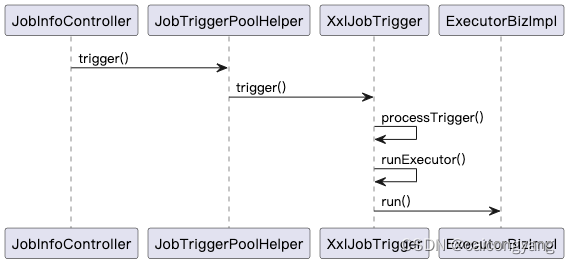
从xxl-job源码中学习Netty的使用
1. 启动与Spring实例化 com.xxl.job.core.executor.impl.XxlJobSpringExecutor.java类 继承SmartInitializingSingleton 类,在afterSingletonsInstantiated 实例化后方法中 调用initJobHandlerMethodRepository 把所有的xxljob任务管理起来; private…...

人工智能发展历程了解和Tensorflow基础开发环境构建
目录 人工智能的三次浪潮 开发环境介绍 Anaconda Anaconda的下载和安装 下载说明 安装指导 模块介绍 使用Anaconda Navigator Home界面介绍 Environment界面介绍 使用Jupter Notebook 打开Jupter Notebook 配置默认目录 新建文件 两种输入模式 Conda 虚拟环境 添…...

makefile追加warning日志
在Makefile中,你不能直接“追加”warning日志到构建过程中,但你可以通过几种方式在构建时产生额外的警告或消息。以下是一些常用的方法: 使用echo或printf命令: 在Makefile的规则中,你可以使用echo或printf命令来输出警…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

YSYX学习记录(八)
C语言,练习0: 先创建一个文件夹,我用的是物理机: 安装build-essential 练习1: 我注释掉了 #include <stdio.h> 出现下面错误 在你的文本编辑器中打开ex1文件,随机修改或删除一部分,之后…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...
相比,优缺点是什么?适用于哪些场景?)
Redis的发布订阅模式与专业的 MQ(如 Kafka, RabbitMQ)相比,优缺点是什么?适用于哪些场景?
Redis 的发布订阅(Pub/Sub)模式与专业的 MQ(Message Queue)如 Kafka、RabbitMQ 进行比较,核心的权衡点在于:简单与速度 vs. 可靠与功能。 下面我们详细展开对比。 Redis Pub/Sub 的核心特点 它是一个发后…...