计算机组成原理(Wrong Question)
目录
一、计算机系统概述
*1.1 计算机发展历程
1.2 计算机系统层次结构
1.3 计算机的性能指标
二、 数据的表示和运算
2.1 数制和编码
2.2 运算方法和运算电路
2.3 浮点数的表示与运算
三、存储系统
3.1 存储器概述
3.2 主存储器
3.3 主存储器与CPU的连接
3.4 外部存储器
3.5 高速缓冲存储器
3.6 虚拟存储器
四、指令系统
4.1 指令系统
4.2 指令的寻址方式
4.3 程序的机器级代码表示
4.4 CISC和RISC的基本概念
五、中央处理器
5.1 CPU的功能和基本结构
5.2 指令执行过程
5.3 数据通路的功能和基本结构
5.4 控制器的功能和工作原理
5.5 异常和中断机制
5.6 指令流水线
5.7 多处理器的基本概念
六、总线
6.1 总线的概述
6.2 总线事务和定时
七、输入/输出系统
*7.1 I/O系统基本概念
7.2 I/O接口
7.3 I/O方式
一、计算机系统概述
*1.1 计算机发展历程
已经不考咯
1.2 计算机系统层次结构
Blunder:7/24

A
注:其实就是文字在前期很唬人看不懂。
-
控制流驱动方式: 控制流驱动方式是指计算机的执行流程由控制单元(Control Unit, CU)来驱动。控制单元根据程序计数器(Program Counter, PC)的值,从指令存储器中取出指令,并根据指令的类型和操作码来生成相应的控制信号,以驱动数据路径执行相应的操作。这种方式强调指令的顺序执行,每条指令的执行都依赖于前一条指令的完成。
-
多指令多数据流方式(MIMD, Multiple Instruction Multiple Data): MIMD是指计算机系统中有多个处理器,每个处理器可以独立地执行不同的指令流,同时处理不同的数据。这种方式允许高度的并行处理能力,常见于多处理器系统或多核处理器中。
-
微程序控制方式: 微程序控制方式是一种使用微指令(Micro-operations)来实现指令集的控制方式。在这种方式中,每条机器指令被分解成一系列更小的、更简单的微指令,这些微指令被存储在微指令存储器中。控制单元通过执行这些微指令来实现复杂指令的功能。微程序控制方式允许更灵活的指令集设计和更简单的硬件实现。
-
数据流驱动方式: 数据流驱动方式是一种以数据为中心的计算模型,其中计算的执行不是由指令的顺序控制,而是由数据的可用性来驱动。当所需的输入数据准备好时,相应的操作就会自动执行,而不需要等待指令的顺序执行。这种方式可以提高计算效率,因为它减少了等待时间,并允许更自然的并行处理。
那其实这些方式在后续章节的学习中我们都能有所了解。冯·诺依曼机的工作方式主要是控制流驱动方式,并且具有顺序执行的特点。

C
咱就是有图有真相。(CPU的基本结构如下)
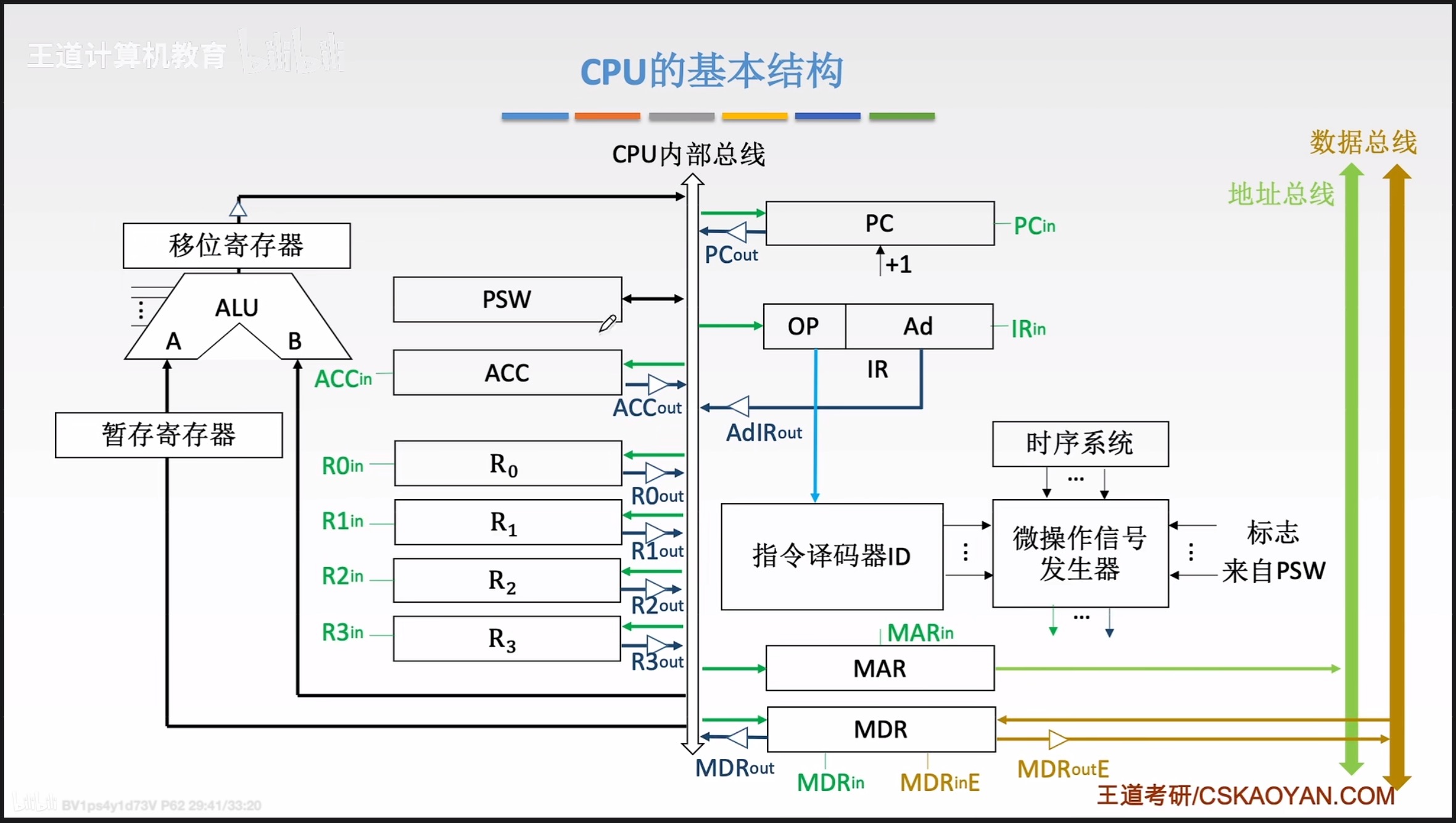
注:地址译码器是主存储器的构成部分,不属于CPU。地址寄存器虽然一般属于主存储器,但现代计算机中绝大多数CPU内集成了地址寄存器。

D

注:首先,运算器的核心是ALU,毋庸置疑的对吧。然后,PSW自然也是运算器中的重中之重。那地址寄存器虽然是位于CPU中,但并未集成到运算器和控制器上。最后这个数据总线为毛是对的,书里没有给确切的答案,我是这样理解的——在计算机体系结构中,运算器(ALU)是执行算术和逻辑操作的硬件部件。它通常不包含数据总线本身,但数据总线是连接运算器和其他系统组件(如CPU、内存、输入/输出设备等)的物理通道。但是要是硬要说包含一捏捏应该也没错吧。
再写个可能值得记忆的点,这里的地址寄存器可和CU中的MAR不是一个东西,切勿搞混咯。

D
注:大意了,没有闪。在不同的设备中,汇编语言对应着不同的机器语言指令集,通过汇编程序转换成机器指令。特定的汇编语言与特定的机器语言指令是一一对应的,不同的平台之间不可直接移植。

C
注:要想全面代表计算机的性能,那应该是实际应用程序的运行情况蛤。剩下两个就很好理解。

C
注:这个貌似很爱考,大家也很容易搞混。先上图。

搞清楚概念之后,这题应该就迎刃而解了。这里补充一下书里面没有提到(或者是我没有看到)
链接程序(Linker):是计算机软件编译过程中的一个重要工具,它的作用是将编译器生成的目标文件(Object Files)或库文件(Libraries)组合起来,生成一个单一的可执行文件(Executable File)或库文件。

C

注:指令确实是按地址访问,但是除了立即数寻址之外,数据其实都存放在存储器中。

A
注:这个可以直接背蛤,将高级语言源程序转换成可执行目标文件的主要过程其实就是 预处理->编译->汇编->链接。那其实根据上头那个22题所补充的知识点,也很容易能够想到(平时我们所编写的C语言程序是不是最后执行完都会在桌面生成一个exe文件,故链接应该是放在最后一步)
1.3 计算机的性能指标
Blunder:7/31

B
注:这也是个很高平出现的考点了,对于用户来说就是MAR、MDR、IR还有一个暂存寄存器是完全透明的。

A
注:相信应该有人和我想的一样A一定有关,这就恰恰中了人家的陷进其实。先看一下CPI的定义(CPI是指执行一条指令平均需要的时钟周期数。这个数值取决于指令的复杂性、CPU的微架构设计、流水线的效率以及指令的类型等因素。)是执行一条指令平均的时钟周期数,与时钟频率其实是无关的(也就是这俩根本就不是一个维度的)

B
注:其余三个都只能间接的影响CPI,这并不算是综合性能的体现。而吞吐量指的是系统在单位时间内处理请求的数量,这其实就是很重要的一个评估计算机系统性能好坏的综合参数。

D
注:纯纯就是和13题连带的错误,其余三个所带来的提升都太有限了。而采用并行处理技术的话,则可以大大提高计算机的性能表现。

D
注:唯一一个要注意的点就是IPC(Instructions Per Clock,是CPI的倒数,表示每时钟周期内可以完成的指令数。)那自然和CPI就是等同的地位了。
字长其实就是指数据总线一次性能处理的二进制位数(数据总线的宽度)

这题很鸡贼啊。
B
注:首先先看机器字长的定义(计算机能直接处理的二进制数据的位数,机器字长一般等于内部寄存器的大小,它决定了计算机的运算精度。)那答案里头还有个不一样的说法,机器字长是指CPU内部用于整数运算的数据通路的宽度。然后数据通路又是指数据在指令执行的过程中所经过的路径及路径上的部件,主要是CPU内部进行数据运算、存储和传送的部件,这些部件的宽度基本上要一致才能相互匹配。因此,机器字长等于ALU位数和通用寄存器宽度。

D
注:直接开始背我们的口诀买高铁票Easy(MGTPEZ)那我们的P应该是6+3+3+3=15,那再加1就是16,那就是亿亿。
二、 数据的表示和运算
2.1 数制和编码
Blunder:8/34
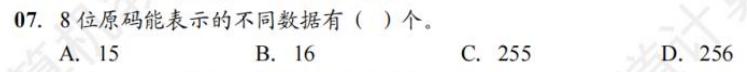 C
C
注:坑就挖在0这个地方,很自然2^8=256,but在原码and反码中“0”是由两种表示的(区分正负)那就要在原基础能表示的数中扣除1,就得出255了。

B
注:A和D显然正确,那我们看B和C。eg:机器字长4位,[0]补=0000,[0]移=2^3+0=1000,表示不相同,但是在补码和移码中一个数字的表示形式是唯一的。

C
注:当然也可以直接用特值法(选择题还是推荐特值法,毕竟比较快)

 B
B
注:纯计算写错,我真的是笨蛋了。

D
注:有一个小坑,这里暗示了寄存器长度为8(00000000)[-128]移=2^7+(-10000000)=00000000

B
注:低位向高位扩时,填的是符号位。(又是看走眼了www)

B
注:始终记住一条负数补码规则(补码数值越小, 原码负得越多),那再看题目要小,那第一位肯定是1了,再根据规则很容易写出一个数10000011。还原一下就是11111101=-125

A
注:三个考点:1、无符号数转有符号数;2、unsigned short和short各占2字节;3、计算机中的数通常都用补码表示。
2.2 运算方法和运算电路
Blunder:3/32

B
注:相当阴险的一道题目呀,如果你按手算的方法会选成D。其实就是没搞懂计算机内到底是怎么实现减法这个操作的。首先只要是减法运算,都会转换称为被减数加上减数的负数的补码来实现。那如何实现呢?简单来说,最关键的点就在于那个加1。在计算机中减法时会有个Sub控制端,其实就是只要是减法它的值就为1,而它也同样是那个低位进位。流程都明白但是就是没有掌握加法电路的原理。

C

注:x右移移出了0,没有溢出或者精度损失;y为负数左移之后符号位未发生改变,没有溢出;看回结果,我们知道只有同号相加、异号相减才有可能发生溢出,显然没有。

B
注:ALU生成标志位时只负责计算,而不管运算对象是有符号数还是无符号数,CF=1表示当作无符号数运算时溢出,OF表示当作有符号数运算时溢出。
2.3 浮点数的表示与运算
Blunder:7/50

B
注:就是想当然的认为计算机中通通都是用补码表示结果就错了。原码的话,正数应该是0.1,负数应该是1.1;补码的话,正数应该是0.1,负数应该是1.0.其实就是要保证尾数的绝对值是小等于1和大等于1/2的。(基数为2的情况下)

D

注:选择题的话,是不是我们连小数点后面是什么都不用计算了。

A

注:E是阶码,M是尾数。 死记硬背也行,不过还是推荐理解一下。

C
注:很容易选到A啊(个人是这样),理一下概念。舍入呢,是浮点数特有的概念,定点数是没有的。浮点数需要舍入的情况有两种啊,一、对阶;二、右规格化;那这题就只有C选项符合了。
 A
A
注:对IEEE754单精度格式的基本考察,过程不再赘述了。
FR1中的内容应该是:1;1000 0010;000 0100 0000 0000 0000 0000=C1040000H

D
注:
- 对阶是较小的阶码向较大的阶码对齐,故对阶后的阶码其实就是先前较大的那个阶码不会引起溢出。
- 也只有对阶和右规时会需要舍入,但是要区分开(如1)。只有右归和尾数舍入时会引起阶码上溢(加1)同理,自然左规时就有可能引起阶码下溢。
- 尾数溢出要分成两种呀,一种是阶码已经兜不住的情况下确实是溢出的;另一种则是只会产生误差。

A
注:8020 0000H=1;0000 0000;010 0000 0000 0000 0000
E=0,M!=0。首先知道这个数是非规格化的数,那其真值应该为-2^-126*(0.01)=-2^-128
三、存储系统
3.1 存储器概述
Blunder:1/14

C
注:概念题都是纸老虎。
- 存取时间Ta是指从存储器读出或写入一次信息所需要的平均时间;
- 存取周期Tm是指连续两次访问存储器之间所必需的最短时间间隔。对Tm一般有Tm=Ta+Tr,其中为Tr复原时间;
- 对SRAM指存取信息的稳定时间,对DRAM指刷新的又一次存取时间。
- D指的是存取时间。
3.2 主存储器
Blunder:6/34

A
注:MM=ROM(BIOS)+RAM,故随机存储器和只读存储器是可以统一编址的。

A
注:64K×1位的DRAM芯片由一个256×256的位平面组成。构成存储器的所有芯片同时按行刷,每个芯片有256行,故存储器所有单元刷新一遍至少需要256次刷新操作。若采用异步刷新方式,则相邻两次刷新信息的时间间隔为2ms/256约等于7.8us。若采用集中刷新方式,则整个存储器刷新一遍最少需256个读/写周期,在刷新过程中,存储器不能进行读/写操作。
-
集中刷新(集中式刷新): 集中刷新是一种在特定时间间隔内对所有存储器行或页进行刷新的方法。在这种模式下,存储器控制器会暂停正常的数据访问操作,集中时间对所有DRAM行进行刷新。这种方式简单,但可能会导致较长的刷新暂停时间,影响性能。
-
异步刷新: 异步刷新指的是刷新操作与CPU或内存控制器的时钟周期不同步进行。在这种模式下,刷新请求可以独立于主时钟周期发生,允许存储器在进行数据访问的同时进行刷新。这样可以减少刷新操作对系统性能的影响,但需要更复杂的控制逻辑来协调刷新和数据访问。
-
分散刷新(分布式刷新): 分散刷新是一种将刷新操作分散到不同时间点进行的方法,以减少对系统性能的影响。在这种模式下,存储器控制器会根据需要对单个存储器行或小批次的行进行刷新,而不是同时刷新所有行。分散刷新可以更好地平衡性能和刷新需求,但需要更高级的刷新调度算法。

C
注:擦亮小眼睛or大眼睛是SDRAM哦。
SDRAM是一种快速的内存技术。也同样是DRAM这句话的意思就是,故也需要定期刷新。
- 与系统的时钟同步工作,提高数据传输效率。
- 能够在每个时钟周期的上升沿和下降沿传输数据,实现双倍的数据传输速率。
- 广泛应用于个人电脑和服务器,因其高速性能而受到青睐。
- 随着技术发展,SDRAM已经演进为更快的版本,如DDR、DDR2、DDR3和DDR4。

C
注:以为很简单秒选A对不对!那你就中了命题老师的陷阱了,考研题!!!宇哥真传一眼对的答案要再思考一遍。
在DRAM芯片中,采用地址线复用技术,行地址和列地址分时复用,故每增加一个地址线,行地址和列地址都会增加一位。所以容量至少提高到原来的4倍。

C
注:感觉王道书里面讲的很详细。注意看这条注。

3.3 主存储器与CPU的连接
Blunder:1/17
 C
C
注:首先,这个RAM区有400000H=2^22个地址。又是按字编址(题目中给了数据是32位,故字长为4B)因此RAM区的大小就是2^22*32bit。故所需要的芯片数一除就出来了。
3.4 外部存储器
Blunder:2/12

D
注: 磁盘存储器以成批(组)方式进行数据读/写,CPU中没有那么多通用存储器用于存放交换的数据,且磁盘与通用存储器的速度相差过大,因此磁盘存储器通常直接和主存交换信息。
- 磁盘存储器的批量数据传输:磁盘存储器确实以批量(通常是扇区或块)的方式进行数据读写,因为磁盘的物理特性决定了它不适合进行频繁的单字节读写操作。
- CPU与通用存储器:CPU通常直接与主存(RAM)交互,因为主存的速度接近CPU的处理速度。通用存储器通常指的是RAM,它是非易失性的,可以快速读写。
- 速度差异:磁盘存储器(特别是机械硬盘)的速度远低于RAM,这种速度差异可能导致CPU等待磁盘操作完成,从而影响整体性能。
- 直接与主存交换信息:由于磁盘与主存之间的速度差异,操作系统通常会使用缓冲区(Buffer)或高速缓存(Cache)来减少这种差异带来的影响。数据会先从磁盘读到缓冲区,然后再从缓冲区传输到RAM;写操作则相反。
- 缓冲区的作用:缓冲区可以暂存从磁盘读取的数据或待写入磁盘的数据。这样可以减少磁盘I/O操作的频率,因为操作系统可以收集多个小的读写请求,然后一次性地与磁盘交换较大的数据块。
- DMA(Direct Memory Access):为了进一步提高效率,许多系统使用DMA,允许数据在不经过CPU的情况下直接在内存和I/O设备之间传输。
- 虚拟内存:操作系统还使用虚拟内存技术,将一些不常用的数据从RAM移动到磁盘上,从而为更频繁访问的数据腾出空间。
- 磁盘调度算法:操作系统使用磁盘调度算法来优化磁盘访问的顺序,减少磁头移动的距离和时间,提高数据传输效率。

B
注:
- RAID(Redundant Array of Independent Disks,独立磁盘冗余阵列)是一种将多个磁盘驱动器组合成一个逻辑单元的数据存储虚拟化技术。它主要用于提高数据的可靠性、增加存储容量、提高数据访问速度或同时实现这些目标。
- RAID0方案是无冗余和无校验的磁盘阵列,而RAID1~RAID5方案均是加入了冗余(镜像)或校验的磁盘阵列。
- 条带化是指一种将数据分片,分别存储至不同的磁盘,提高读/写速度的技术。
3.5 高速缓冲存储器
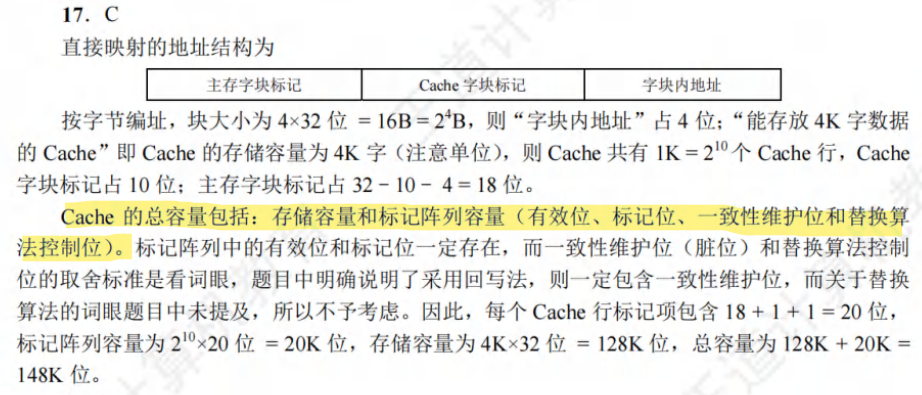
Blunder:9/33

C
注:这就是一个很简单的列方程计算问题蛤,也不知道为什么算对答案了,还会选错。
3ns = 2ns * h + (1 - h) * 40ns 这个解出来就是答案咯,大概是0.9736巴拉巴拉,就大概是C。

C
注:就只要搞清楚一个概念,那就是局部性原理中的时间局部性和空间局部性各自是什么?
- 时间局部性(Temporal Locality):
- 时间局部性是指程序在未来某个时刻很可能再次访问最近访问过的数据。
- 这种局部性原理使得缓存(Cache)等技术非常有效,因为缓存可以暂存最近访问的数据,以便快速响应可能的再次访问。
- 空间局部性(Spatial Locality):
- 空间局部性是指程序倾向于访问一块连续的内存区域或靠近最近访问的数据的内存位置。
- 这种局部性原理支持了诸如循环展开(Loop Unrolling)、数据结构的内存对齐和数据访问模式优化等技术,以提高数据访问效率。

D
注:指令缓存(Instruction Cache)和数据缓存(Data Cache)是两种不同类型的缓存,它们在现代计算机体系结构中用于提高性能:
- 指令缓存(Instruction Cache):
- 指令缓存用于存储最近或可能即将执行的指令。
- 它允许CPU快速访问和执行指令,而不必每次都从慢速的主存中获取指令。
- 指令缓存通常与程序计数器(Program Counter)紧密相关,程序计数器指向下一条要执行的指令。
- 数据缓存(Data Cache):
- 数据缓存用于存储最近或可能即将访问的数据,包括变量和常量等。
- 它允许CPU快速读取和写入数据,而不必每次都访问主存,从而提高数据操作的速度。
- 数据缓存通常与CPU执行指令时所需的操作数和结果相关。
这两种缓存的共同目标是减少CPU访问主存的次数,因为主存相对于CPU的速度较慢。通过在缓存中存储指令和数据,计算机系统可以利用时间局部性和空间局部性原理,提高整体性能。
此外,现代CPU可能还具有其他类型的缓存,如:
- 二级缓存(L2 Cache):通常比L1缓存大,但访问速度稍慢。
- 三级缓存(L3 Cache):在多核处理器中,L3缓存可以被所有核心共享,提供更大的缓存空间和一致性。
指令缓存和数据缓存可以是分开的,也可以是合并的,这取决于具体的CPU设计。合并缓存(Unified Cache)同时存储指令和数据,而分离缓存(Separate Caches)则将它们分开存储,有时可以提供更好的性能和更有效的缓存空间利用。

B


A

B
注:直接映射和其余两个不一样的点就是这题的一个小考点,当发生冲突时,无条件换出,故无需考虑替换算法。而先进先出表面上好像是无需记录替换信息,但实际上需要有一个时间戳来记录何时装入了一个新MM块。

C
注:我感觉这题没有什么研究的必要,因为应该这个和大多数人教材上的所学习的并不一样。
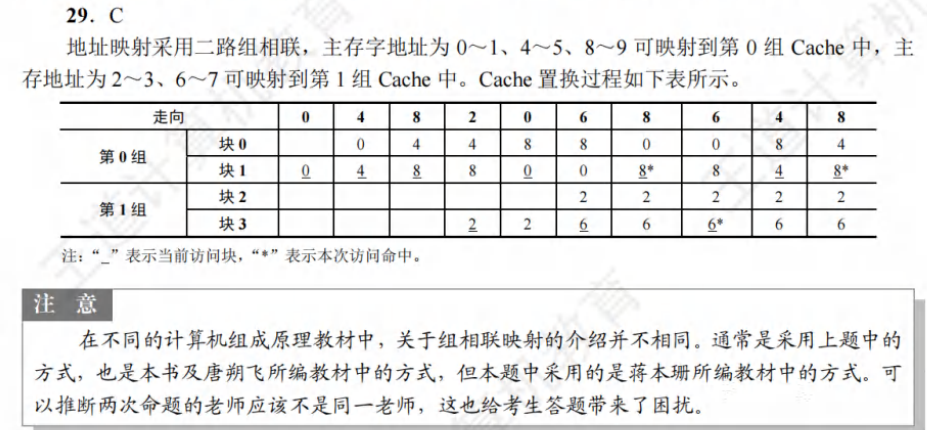

C
注:首先,a[k]=a[k]+32(4B) 也就是说在执行这条语句的时候要访问a[k]两遍,这题也就是难在这里了。那我们看题目一个int型数据占4B,一个块大小为16B。是不是就表明了每一个块可以存放四个int型数据,那就是说每4次会有一次缺失是吧。但是但是我们需要访问a[k]两遍,故而这个缺失率还应该再除以2才是我们真正的缺失率。

A
注:Cache采用组相联映射,主存地址结构应分为Tag标记、组号、块内地址三个部分。
然后补充一下比较器的基本概念及主要的功能。
在计算机体系结构中,Cache中的比较器(Comparator)是用于确定主存中的访问地址是否已经在缓存中的关键组件。以下是比较器在缓存操作中的几个主要功能:
- 地址匹配:当CPU发起一个内存访问请求时,比较器会检查请求的地址是否与缓存中的任何条目(缓存行或缓存块)的标签(Tag)相匹配。
- 缓存命中检测:如果地址匹配,比较器会确定这次访问是缓存命中(Cache Hit)还是缓存未命中(Cache Miss)。缓存命中意味着请求的数据已经在缓存中,可以直接从缓存中读取,而不需要访问主存。
- 多路比较:在具有多个缓存行的缓存中,比较器能够同时比较多个地址,以快速确定是否存在缓存命中。
- 替换策略:当发生缓存未命中且需要将新数据加载到缓存中时,比较器可以参与决定哪个缓存行被替换,这通常基于特定的替换算法(如最近最少使用LRU)。
- 写操作:在执行写操作时,比较器同样会检查数据是否在缓存中。如果是写命中,数据将直接更新在缓存中;如果是写未命中,数据可能需要先加载到缓存,然后再更新。
- 一致性维护:在多级缓存或多处理器系统中,比较器还参与维护缓存一致性,确保所有缓存中的数据都是最新的。
比较器是缓存系统中不可或缺的部分,它的效率直接影响缓存的性能。高效的比较器设计可以快速完成地址匹配,减少访问延迟,提高系统的整体性能。
其实个数就会等于Cache的行数。而位数其实就是等于Tag标志位的位数。

3.6 虚拟存储器
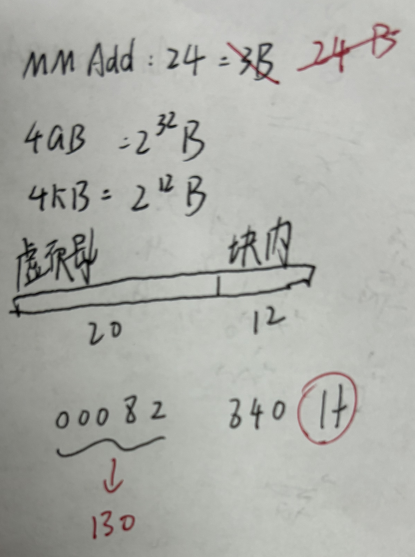
Blunder:7/20
 A
A
注:B、C、Dare just part of the right principle.

D
注:就看你是否真的理解蛤,页式毫无疑问就是用页为单位进行交换。而段页式存储则是先按逻辑分段,然后分页,以页为单位和主存交互。就是本质上在最后还是分页,所以还是采用“页”为单位来交换信息。

A
注:就只需要明白一个点系统程序员是操作系统的设计者,ta如果看不见了还做毛线系统。而应用程序员写的程序所使用的是逻辑地址(虚地址),因此对其是透明的。

B
注:就是没搞清楚虚拟存储器的本质是什么?就是让程序员可以在一个比主存地址大得多得虚拟地址空间中编程,先让逻辑地址空间比主存地址空间要大,不然设计者不是白忙活了吗?其余三项就没有什么好说的,显然正确(虽然我这个笨蛋还是没有选对)

D
注:错了一遍就不能再错咯,还是没有消化好本质上的知识。


注:hin重要!!

C
注:很隐蔽的陷阱,请擦亮眼睛。
四、指令系统
4.1 指令系统
Blunder:3.5/17

A
注:送分题蛤,我也不知道自己为什么会错。PC存放当前欲执行指令的地址,而指令的地址字段则保存操作数地址。

B
注:有些东西没有必然的联系其实,就比如指令的地址个数与指令的长度,即使是单地址指令,也可能由于单地址的寻址方式不同而导致指令长度不同。

D
注:感觉易错点就是不理解先定义长的之后再定义短的该如何处理,(2^8-250)*2^12。

B

4.2 指令的寻址方式
Blunder:4/35

B
注:顾名思义啦,隐含在ACC中,自然简化了地址结构。

B
注:小端存储是相反,大端存储是原序。


注:最最最最最容易出现纰漏的点就是PC自动加"1"。

 D
D
注:补码拓展是拓符号位,知道这个就好了。
4.3 程序的机器级代码表示
Blunder:2/12
![]()

D
注:j是小等于i的,所以说是会执行跳转指令的,那我们看到了题目中告诉了我们偏移量了,那直接加就好了,值得注意的是首先pc会自动加“1”。所以应该是804846c+2+0d=804847bH

D
注:为了能保证从被调用过程返回到调用过程继续执行,必须确定并保存返回地址,这个地址是调用指令随后的指令的地址,返回地址只能由调用指令来计算并保存,因为执行调用指令后就跳转到了被调用过程,因为无法获取返回地址。为了保证嵌套调用时能返回到调用过程,必须将返回地址压栈,若不压栈而保存在特定寄存器中,则后面执行的调用指令会将前面调用指令保存的返回地址覆盖掉。调用指令执行时将无条件的转移到目标地址处,这个目标地址就是被调用过程中第一条指令的地址,它一定在调用指令中明显给出。
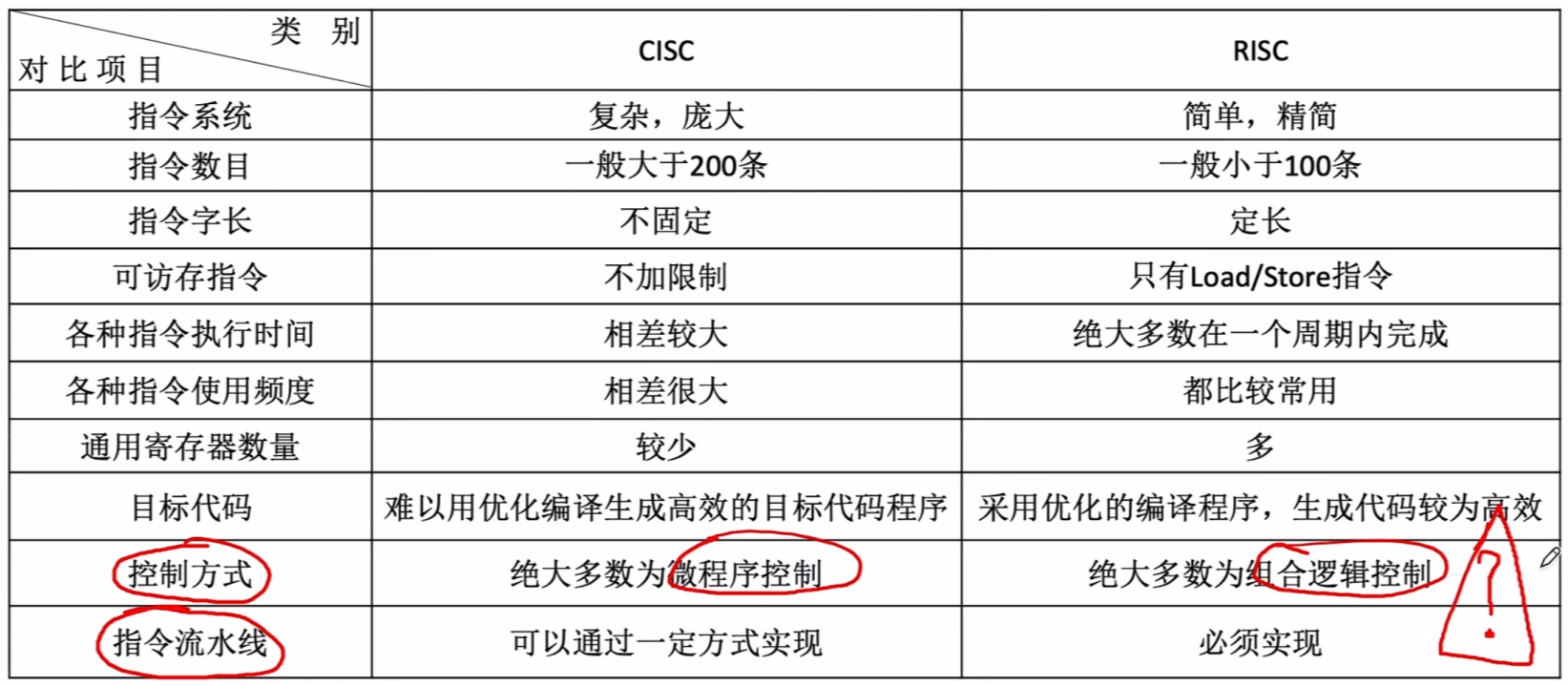
4.4 CISC和RISC的基本概念
Blunder:1/5


C
五、中央处理器
5.1 CPU的功能和基本结构
Blunder:7/26

A
注:一定时指令寄存器保存的是当前正在执行的指令

A
注:CPU是根据程序计数器PC中的内容从主存储器中存取指令。

B
注:程序计数器(PC)用于指出下一条指令在主存储器中的地址。可以用字节地址表示指令地址,此时PC的位数与存储器地址的位数相等,而存储器地址的位数取决于存储器的容量;也可以用字地址表示指令地址,这种情况下指令必须采用按边界对齐的方式存放,此时PC的位数=存储器地址的位数—log2(指令字长的字节数)。可知,PC的位数取决于存储器的容量和指令字长。

B
注:此加1非彼加“1”(一条指令的长度)

C
注:通用存储器用于存放操作数和各种地址信息等,其位数与机器字长相等,因此便于操作控制。

B
注:其实想想为什么要有指令寄存器就知道啦,那么多聪明的前辈都没有在大框架中扣掉它的存在,自然它是有它的独特性的。通用寄存器供用户自由编程,可以存放数据和地址。

B
注:B、C是不是超级容易混。但是只要想想间址周期是干嘛的(取操作数的有效地址),其实就不会被迷惑了。
5.2 指令执行过程
Blunder:2/17

D
注:指令周期、时钟周期、机器周期和存取周期的区别。
-
时钟周期(Clock Cycle):时钟周期是计算机操作的基础时间单位,也称为振荡周期或CPU周期。它是CPU时钟频率的倒数,定义了电子信号在电路中传输的最小时间间隔。
-
指令周期(Instruction Cycle):指令周期是执行一条指令所需的全部时间,包括取指、译码、执行等步骤。一个指令周期可能由多个时钟周期组成,具体取决于指令的复杂性和CPU的设计。
-
机器周期(Machine Cycle):机器周期通常指的是完成一个基本操作所需的时间,如数据传输、算术运算等。一个机器周期可能包含多个时钟周期,并且可能涉及多个指令周期的一部分。
-
存取周期(Memory Access Cycle):存取周期是读写存储器中数据所需的时间。它包括从内存中读取数据到CPU寄存器或从寄存器写入数据到内存的完整过程。存取周期的长度取决于内存的速度和CPU与内存之间的接口。
具体区别如下:
- 时间长度:时钟周期是最基本的时间单位,而指令周期、机器周期和存取周期都比时钟周期长,它们的长度取决于具体操作的复杂性。
- 功能:指令周期关注于指令的完整执行过程;机器周期关注于完成特定硬件操作的步骤;存取周期专注于内存与CPU之间的数据交换。
- 组成:一个指令周期可能包含多个机器周期,而一个机器周期可能包含多个时钟周期。
- 依赖性:存取周期通常依赖于内存的速度,而机器周期和指令周期则更多地依赖于CPU的性能。
 A
A
注:其实这题可以用排除法来做。
指令字长一般都取存储字长的整数倍,若指令字长等于存储字长的2倍,则需要两次访存,取指周期等于机器周期的2倍;若指令字长等于存储字长,则取指周期等于机器周期,因此I错。根据I的分析可知,I正确。指令字长取决于操作码的长度、操作数地址的长度和操作数地址的个数,与机器字长没有必然的联系。但为了硬件设计方便,指令字长一般取字节或存储字长的整数倍,因此II正确。根据II的分析可知,指令字长一般取字节或存储字长的整数倍,而不一定都和存储字长一样大,因此IV错误。综上所述,I、II正确。
5.3 数据通路的功能和基本结构
Blunder:5/11

C
注:
- 多周期CPU中的指令通常需要多个时钟周期才能完成,CPI>1;单周期CPU的每条指令在一个时钟周期内完成,CPI=1。
- 单周期CPU的时钟周期取决于最复杂指令的执行时间,通常比多周期CPU的时钟周期长。
- 在一条指令的执行过程中,单周期CPU的每个控制信号保持不变,每个部件只能使用一次;多周期CPU的控制信号可能会发生改变,同一个部件可使用多次。

D
注:
- 采用CPU内部总线方式的数据通路的特点:结构简单,实现容易,性能较低,存在较多的冲突现象;
- 不采用CPU内部总线方式的数据通路的特点:结构复杂,硬件量大,不易实现,性能高,基本不存在数据冲突现象。

D
注:显然A、B、C都正确。

A
注:
- 单周期处理器中所有指令的指令周期为一个时钟周期,D正确。
- 因为每条指令的CPI为1,要考虑比较慢的指令,所以处理器的时钟频率较低,B正确。
- 单总线数据通路将所有寄存器的输入输出端都连接在一条公共通路上,一个时钟内只允许一次操作,无法完成指令的所有操作,A错误。
- 控制信号是CU根据指令操作码发出的信号,对于单周期处理器来说,每条指令的执行只有一个时钟周期,而在一个时钟周期内控制信号并不会变化;若是多周期处理器,则指令的执行需要多个时钟周期,在每个时钟周期控制器会发出不同信号,C正确。

B
注:组合逻辑元件(操作元件)不含存储信号的记忆单元,任何时刻产生的输出仅取决于当前的输入,加法器、算术逻辑单元(ALU)、译码器、多路选择器、三态门等都属于操作元件。时序逻辑元件(状态元件)包含存储信号的记忆单元,各类寄存器和存储器,如通用寄存器组、程序计数器、状态/移位/暂存/锁存寄存器等,都属于状态元件。
5.4 控制器的功能和工作原理
Blunder:4/26
 B
B
注:


C
注:执行公用的取指微程序从主存中取出机器指令后,由机器指令的操作码字段指出各个微程序的入口地址(初始微地址)
不要想当然的以为是地址码哦。

D
注:在微程序控制中,控制存储器中存放有微指令,在执行时需要从中读出相应的微指令,从而增加了时间消耗。

B
注:看清楚了哦,是取数及执行过程。指令译码器在指令的译码阶段最为关键,但在取值、执行和中断等阶段也可能间接参与到指令的处理过程中。译码器确保CPU正确理解每条指令,并生成适当的控制信号来驱动后续操作。
5.5 异常和中断机制
Blunder:1/13

D
注:
在硬件层,CPU中有检测异常和中断事件并将控制转移到操作系统内核执行的机制;
在操作系统层,内核能通过进程的上下文切换将一个进程的执行转移到另一个进程的执行,它们都会产生异常控制流。响应异常/中断请求后,CPU执行的是异常/中断服务程序,是操作系统的内核程序。进程上下文切换由操作系统的内核程序实现,而异常中断的响应则由硬件实现。
补充知识:CPU所执行指令的地址序列称为CPU的控制流。在程序正常执行时,通过顺序执行指令或转移指令得到的控制流称为正常控制流。在正常执行过程中,因遇到异常或中断事件而引起用户程序的正常执行被打断所形成的意外控制流,称为异常控制流
5.6 指令流水线
Blunder:10/31

A
注:在某个时钟周期内,不同的流水段受到不同指令的控制信号控制,执行不同指令的不同功能,在指令译码阶段由控制器产生指令各流水段的所有控制信号,并通过流水段寄存器传递到下一个流水段。不同流水段存放的信息不同,因此流水段寄存器位数不一定相同,流水段寄存器对用户程序是透明的,用户程序不能通过指令指定访问哪个流水段寄存器。

D
注:这四个选项都显然正确。

A
注:若ALU运算指令的某个操作数是分支指令转移后的执行结果,就会产生数据冒险。


D
注:

D
注:
- 无条件转移指令的转移目标地址在执行阶段才确定,所以是会发生控制冒险的。
- 插入空操作可使条件转移指令的结果在取下一条有效指令之前确定,从而避免控制冒险。
- 流水段的数量与控制冒险引发的开销有关。流水段的数量越多,意味着在转移结果确定之前,可能取出更多的时间和资源来处理这些错误指令。

D
 其实这就是一种空分复用技术,又是套娃,在原有的基础上再进行细分,超标量流水线不仅指运算操作并行,还包括取指、译码、访存、写回等其他操作。
其实这就是一种空分复用技术,又是套娃,在原有的基础上再进行细分,超标量流水线不仅指运算操作并行,还包括取指、译码、访存、写回等其他操作。

B
注:用超标量流水线并不能缩短流水线功能段的处理时间。

A
注:数据通路由控制部件控制,控制部件根据每条指令功能的不同生成对数据通路的控制信号。因此不包括控制部件。

B
注:可以用排除法的思想来做蛤,首先多周期CPU的CPI肯定不是1,所以有2先错排除A、C。紧接着我们又知道单周期CPU的CPI是1。故我们直接敢选答案就是B。

C
5.7 多处理器的基本概念
Blunder:1/12

C
注:超线程技术(模拟实体双核)是一项硬件创新,允许在每个内核上运行多个线程。更多的线程意味着可以并行完成更多的工作。在一个CPU中,提供两套线程处理单元,让单个处理器实现线程级并行。虽然采用超线程技术能够同时执行两个线程,但是当两个线程同时需要某个资源时,其中一个线程必须暂时挂起,直到这些资源空闲后才能继续运行。因此超线程的性能并不等于两个CPU的性能。而且超线程技术的CPU需要芯片组、操作系统和应用软件的支持,才能发挥该项技术的优势。
六、总线
6.1 总线的概述
Blunder:5/25

D
注:真的很容易就能比对出答案,mygod真的不知道我怎么想的。

B
注:answer = 4 / ( 2 * 1/10)
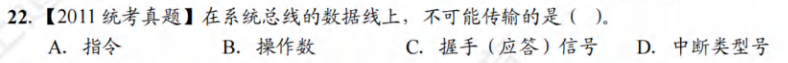
C
注:握手信号是一种控制信号,用于在设备之间进行通信同步,它们通常不会通过数据总线传输,而是可能通过其他专门的控制线路或协议来处理。数据总线主要用于传输数据和地址信息。
选项A、B和D中的内容(指令、操作数、中断类型号)都可能在数据总线上传输,因为它们都是数据的一部分,或与数据紧密相关。

C
注:66(MHz) * 4(B) * 2 = 528MB/s

B
注:算法与上一题相似。
6.2 总线事务和定时
Blunder:8/20

C
注:这个题就很坏,其实是都可以用对吧,只是同步不能发挥出快速设备的高速性能。

D
注:异步就是没有统一的时钟,完全依靠握手来实现定时控制,所以应该是按需分配时间。

A
注:这就考察那两个设备之间的速度差异较大。我们选三个中差距最大的即是答案。

C
注:同步同步就是因为时钟信号是一致的,所以才称为同步。

D
注:
- 多总线结构用速率高的总线连接高速设备,用速率低的总线连接低速设备。一般来说,CPU
- 是计算机的核心,是计算机中速度最快的设备之一,A正确。
- 突发传送方式把多个数据单元作为一个独立传输处理,从而最大化设备的吞吐量。现实中一般用支持突发传送方式的总线来提高存储器的读/写效率,B正确。
- 各总线通过桥接器相连,后者起流量交换作用。
- PCI-Express总线都采用串行数据包传输数据。

B
注:总线数据传输速率 = 总线工作频率 ×(总线宽度 / 8),所以I和Ⅱ会影响总线数据传输速率。采用突发(猝发)传输方式,可在一个总线周期内传输存储地址连续的多个数据字,因此能提高传输效率。采用地址/数据线复用只是减少了线的数量,节省了成本,并不能提高传输速率。
![]()

C
注:
- 总线是在两个或多个设备之间进行通信的传输介质,A正确。
- 同步总线是指总线通信的双方采用同一个时钟信号,但是一次总线事务不一定在一个时钟周期内完成,即时钟频率不一定等于工作频率,B正确。
- 异步总线采用握手的方式进行通信,每次握手的过程完成一次通信,但是一次通信往往会交换多位而非一位数据,C错误。
- 突发传送总线事务是指发送方在传输完地址后,连续进行若干次数据的发送,D正确。

D
注:每次传输需经过传输地址、准备数据和传输数据三个过程,分别需要1s(时钟频率为1GHz,因此时钟周期为1ns)、6ns和1ns,共8ns。总线宽度为64位,所以每次传输的数据为64位,主存块大小为32B,所以读取一个主存块需要传输4次,即8s×4=32ns。
七、输入/输出系统
*7.1 I/O系统基本概念
7.2 I/O接口
Blunder:6/18

D
注:在统一编址方式下,指令靠地址码区分内存和/O设备,若随意在地址的任何地方编址,将给编程造成极大的混乱,D错误。选项A、B、C的做法都是可取的。

A

B
注:CPU和主存通过I/O总线和I/O接口连接,I/O接口通过通信总线和外设相连。

A
注:I/O接口中主机侧通过I/O总线与主机相连,设备侧通过通信总线(电缆)与外设相连。显然,I/O总线中的数据线宽度和连接设备的电缆中的数据线宽度不一定相同。

D
注:I/O总线分为三类:数据线、控制线和地址线。
- 数据缓冲寄存器和命令状态寄存器的内容都是通过数据线来传送的;
- 地址线用以传送与CPU交换数据的端口地址;
- 而控制线用于给I/O端口发送读/写信号,仅用于对端口进行读/写控制。
中断类型号用于指出中断向量的地址,CPU响应某一外部中断后,就从数据总线上获取该中断源的中断类型号,然后据此计算对应中断向量在中断向量表(存放在内存中)的位置。因此1、2和3均正确。

D
注:I/O端口是指I/O接口中用于缓冲信息的寄存器,由于主机和/O设备的工作方式和工作速度有很大差异,I/O端口应运而生。在执行一条指令时,CPU使用地址总线选择所请求的I/O端口,使用数据总线在CPU寄存器和端口之间传输数据。
7.3 I/O方式
Blunder:13/55

C
注:就是套娃概念容易搞混。
- 中断服务程序是处理器处理的紧急事件,可理解为一种服务,是事先编好的某些特定的程序,一般属于操作系统的模块,以供调用执行,A正确。
- 中断向量由向量地址形成部件,即由硬件产生,并且不同的中断源对应不同的中断服务程序,因此通过该方法,可以较快速地识别中断源,B正确。
- 中断向量是中断服务程序的入口地址,中断向量地址是内存中存放中断向量的地址,即中断服务程序入口地址的地址,C错误。
- 重叠处理中断的现象称为中断嵌套,D正确。

![]()
D
注:
- 外部事件如按Esc键以退出运行的程序等,属于外中断,I正确。
- Cache完全是由硬件实现的,不会涉及中断层面,Ⅱ错误。
- 虚拟存储器失效如缺页等,会发出缺页中断,属于内中断,Ⅲ正确。
- 浮点数运算下溢,直接当作机器零处理,而不会引发中断,IV错误。
- 浮点数上溢,表示超过了浮点数的表示范围,属于内中断,V正确。

D
注:中断隐指令并不是一条由程序员安排的真正的指令,因此不可能把它预先编入程序中,只能在响应中断时由硬件直接控制执行。中断隐指令不在指令系统中,因此不属于程序控制指令。

C
 B
B
注:允许中断触发器置0表示关中断,在中断响应周期由硬件自动完成,即中断隐指令完成。虽然关中断指令也能实现关中断的功能,但在中断响应周期,关中断是由中断隐指令完成的。在恢复现场和屏蔽字的时候,也需要关中断的操作,此时是由关中断指令来完成的。

D
注 :中断优先级包括响应优先级和处理优先级,中断屏蔽标志改变的是处理优先级。中断响应优先级是由中断查询程序或中断判优电路决定的,它反映的是多个中断同时请求时哪个先被响应,即中断服务程序开始执行的顺序。在多重中断系统中,中断处理优先级决定了本中断是否能打断正在执行的中断服务程序,决定了多个中断服务程序执行完的次序。

C
注:按启动查询方式的不同,程序查询方式可分为定时查询方式和独占查询方式。在程序查询方式中,由CPU负责数据的传送。每完成一次数据传送后,将主存地址加1,计数值减1。

B
注:
- DMA方式的数据传送不经过CPU,但需要经过DMA控制器中的数据缓冲寄存器。输入时,数据由外设(如磁盘)先送往DMA的数据缓冲寄存器,再通过数据总线送到主存。反之,输出时,数据由主存通过数据总线送到DMA的数据缓冲寄存器,然后送到外设。
- DMAC 是 Direct Memory Access Controller(直接内存访问控制器)的缩写。它是一种硬件设备,用于在计算机系统中提供直接内存访问(DMA)功能。

B

C
注:周期挪用法由DMA控制器挪用一个或几个主存周期来访问主存,传送完一个数据字后立即释放总线,是一种单字传送方式,每个字传送完后CPU可以访问主存,C错误。停止CPU访存法则是指在整个数据块的传送过程中,使CPU脱离总线,停止访问主存。

A
注:
- 中断服务程序在内核态下执行,若只能在用户态下检测和响应中断,则显然无法实现多重中断(中断嵌套),A错误。
- 在多重中断中,CPU只有在检测到中断请求信号后(中断处理优先级更低的中断请求信号是检测不到的),才会进入中断响应周期。进入中断响应周期时,说明此时CPU一定处于中断允许状态,否则无法响应该中断。若所有中断源都被屏蔽(说明该中断的处理优先级最高),则CPU不会检测到任何中断请求信号。
![]()

C
注:
- 中断/O方式适用于字符型设备,此类设备的特点是数据传输速率慢,以字符或字为单位进行传输,A正确。
- 若采用中断I/O方式,当外设准备好数据后,向CPU发出中断请求,CPU暂时中止现行程序,转去运行中断服务程序,由中断服务程序完成数据传送,B正确。
- 若外设准备数据的时间小于中断处理时间,则可能导致数据丢失,以输入设备为例,设备为进程准备的数据会先写入设备控制器的缓冲区(缓冲区大小有限),缓冲区每写满一次,就向CPU发出一次中断请求,CPU响应并处理中断的过程,就是将缓冲区中的数据“取走”的过程,因此若外设准备数据的时间小于中断处理时间,则可能导致外设往缓冲区写入数据的速度快于CPU从缓冲区取走数据的速度,从而导致缓冲区的数据被覆盖,进而导致数据丢失,C错误。
- 若采用中断/O方式,则外设为某进程准备数据时,可令该进程阻塞,CPU运行其他进程,D正确。

D
注:A和B显然正确。开中断时,CPU在执行完一条指令时检测中断请求信号,若检测到中断请求信号,就立即响应;即便是多重中断,CPU正在处理某个中断的过程中,由于中断屏蔽字的存在,因此CU检测不到处理优先级更低的中断请求信号,若检测到中断请求信号,则说明其处理优先级更高,同样也立即响应,C正确。外设通过中断控制器向CPU发中断请求信号,CPU响应中断请求后开始执行中断服务程序,中断服务程序执行结束后CPU自行返回(中断服务程序的最后一条指令是返回指令),无须外设发中断结束信号,D错误。

C
注:DMA在预处理和后处理阶段需要CPU来处理,而数据传输阶段由DMA控制器完成。
相关文章:
计算机组成原理(Wrong Question)
目录 一、计算机系统概述 *1.1 计算机发展历程 1.2 计算机系统层次结构 1.3 计算机的性能指标 二、 数据的表示和运算 2.1 数制和编码 2.2 运算方法和运算电路 2.3 浮点数的表示与运算 三、存储系统 3.1 存储器概述 3.2 主存储器 3.3 主存储器与CPU的连接 3.4 外部…...

ACL2024 | AI的时空穿越记:大型语言模型共时推理的奇幻之旅!
作者:苏肇辰 标题:Living in the Moment: Can Large Language Models Grasp Co-Temporal Reasoning? 录取:ACL2024 Main 论文链接:https://arxiv.org/abs/2406.09072 代码链接:https://github.com/zhaochen0110/Cotem…...
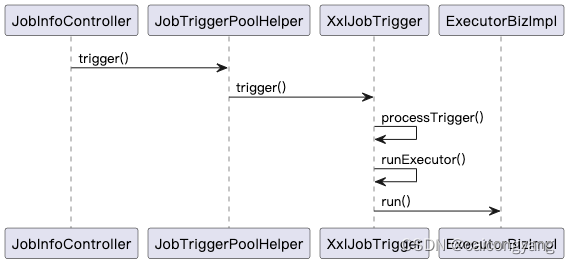
从xxl-job源码中学习Netty的使用
1. 启动与Spring实例化 com.xxl.job.core.executor.impl.XxlJobSpringExecutor.java类 继承SmartInitializingSingleton 类,在afterSingletonsInstantiated 实例化后方法中 调用initJobHandlerMethodRepository 把所有的xxljob任务管理起来; private…...

人工智能发展历程了解和Tensorflow基础开发环境构建
目录 人工智能的三次浪潮 开发环境介绍 Anaconda Anaconda的下载和安装 下载说明 安装指导 模块介绍 使用Anaconda Navigator Home界面介绍 Environment界面介绍 使用Jupter Notebook 打开Jupter Notebook 配置默认目录 新建文件 两种输入模式 Conda 虚拟环境 添…...

makefile追加warning日志
在Makefile中,你不能直接“追加”warning日志到构建过程中,但你可以通过几种方式在构建时产生额外的警告或消息。以下是一些常用的方法: 使用echo或printf命令: 在Makefile的规则中,你可以使用echo或printf命令来输出警…...

不要直接使用unidefined 而使用void 0
为什么不要使用unidefined 而使用void 0? 在JavaScript中,undefined 和 void 0 都可以用来表示未定义的值,但它们在使用和上下文中有一些微妙的差异,这也是为什么有时可能会推荐使用 void 0 而不是直接使用 undefined。 全局污染ÿ…...

注解详解系列 - @Scope:Bean作用域管理
注解简介 在今天的注解详解系列中,我们将探讨Scope注解。Scope是Spring框架中的一个重要注解,用于定义Spring bean的作用域。通过指定bean的作用域,我们可以控制bean的生命周期和创建方式。 注解定义 Scope注解用于指定Spring bean的作用域…...

数学建模基础:数学建模概述
目录 前言 一、数学建模的步骤 二、模型的分类 三、模型评价指标 四、常见的数学建模方法 实际案例:线性回归建模 步骤 1:导入数据 步骤 2:数据预处理 步骤 3:建立线性回归模型 步骤 4:模型验证 步骤 5&…...
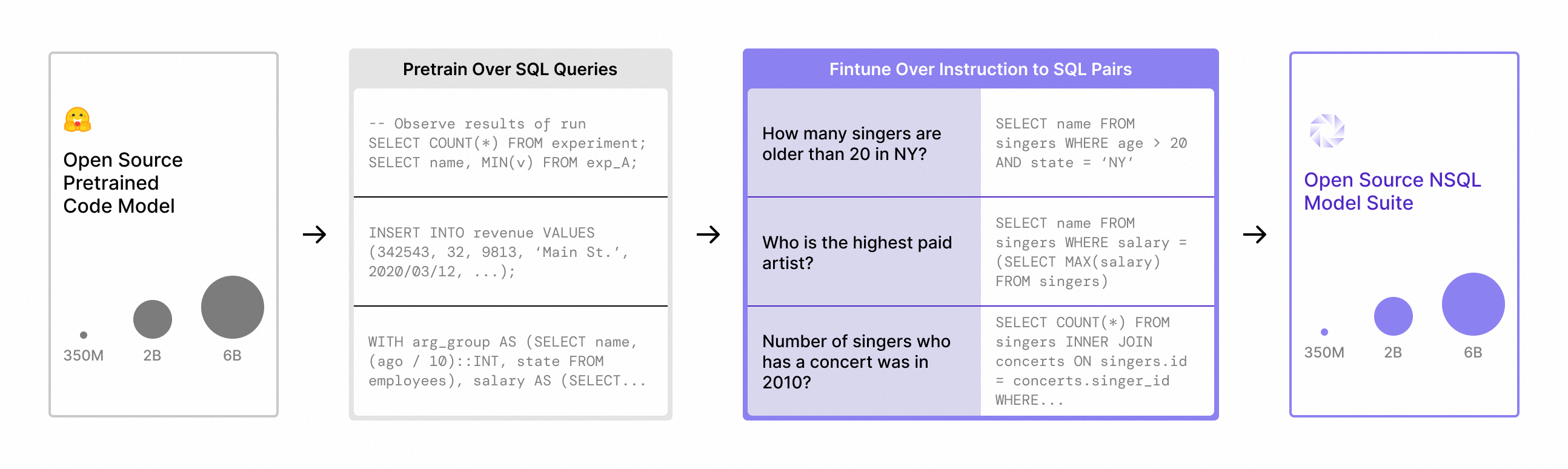
人工智能大模型之开源大语言模型汇总(国内外开源项目模型汇总)
开源大语言模型完整列表 Large Language Model (LLM) 即大规模语言模型,是一种基于深度学习的自然语言处理模型,它能够学习到自然语言的语法和语义,从而可以生成人类可读的文本。 所谓"语言模型",就是只用来处理语言文…...

数据结构之B树
引言 在计算机科学中,数据结构是用于组织和存储数据的关键工具。其中,B树(B-tree)作为一种自平衡的树形数据结构,被广泛应用于数据库和文件系统中,以提高查找、插入、删除和范围查询的效率。本文将深入探讨…...
,——森林机器学习、时间序列)
双色球预测算法(Java),——森林机器学习、时间序列
最近AI很火,老想着利用AI的什么算法,干点什么有意义的事情。其中之一便想到了双色球,然后让AI给我预测,结果基本都是简单使用随机算法列出了几个数字。 额,,,,咋说呢,双…...
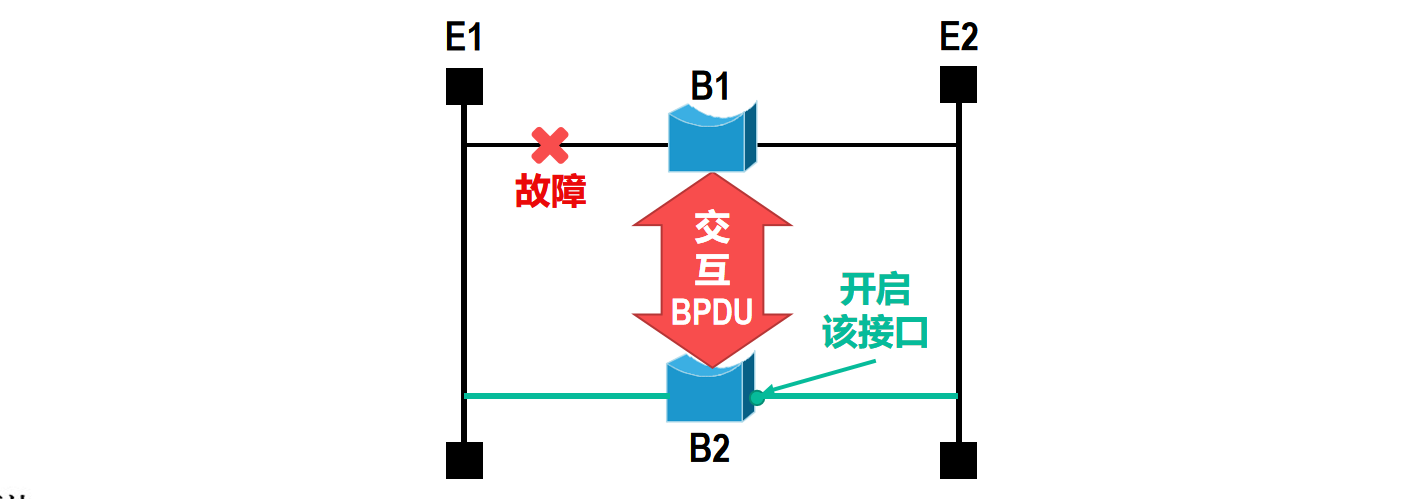
【计算机网络篇】数据链路层(11)在数据链路层扩展以太网
文章目录 🍔使用网桥在数据链路层扩展以太网🥚网桥的主要结构和基本工作原理🎈网桥的主要结构🔎网桥转发帧的例子🔎网桥丢弃帧的例子🔎网桥转发广播帧的例子 🥚透明网桥🔎透明网桥的…...

Ubuntu20.04 使用scrapy-splash爬取动态网页
我们要先安装splash服务,使用dock安装,如果dock没有安装,请参考我的上一篇博文: 按照官方文档:https://splash.readthedocs.io/en/stable/install.html 1.下载splash sudo docker pull scrapinghub/splash2.安装scrapy…...

Function:控制继电器上下电,上电后adb登录,copy配置文件
import serial import time import datetime import subprocess import osdef append_to_txt(file_path, content):if os.path.exists(file_path):with open(file_path, a) as file: # 使用 a 模式打开文件进行追加file.write(content \n) # 追加内容,并换行else…...

香港电讯高可用网络助力企业变革金融计算
客户背景 客户是一家金融行业知名的量化私募对冲基金公司,专注于股票、期权、期货、债券等主要投资市场,在量化私募管理深耕多年,目前资管规模已达数百亿级,在国内多个城市均设有办公地点。 客户需求 由于客户业务倚重量化技术…...
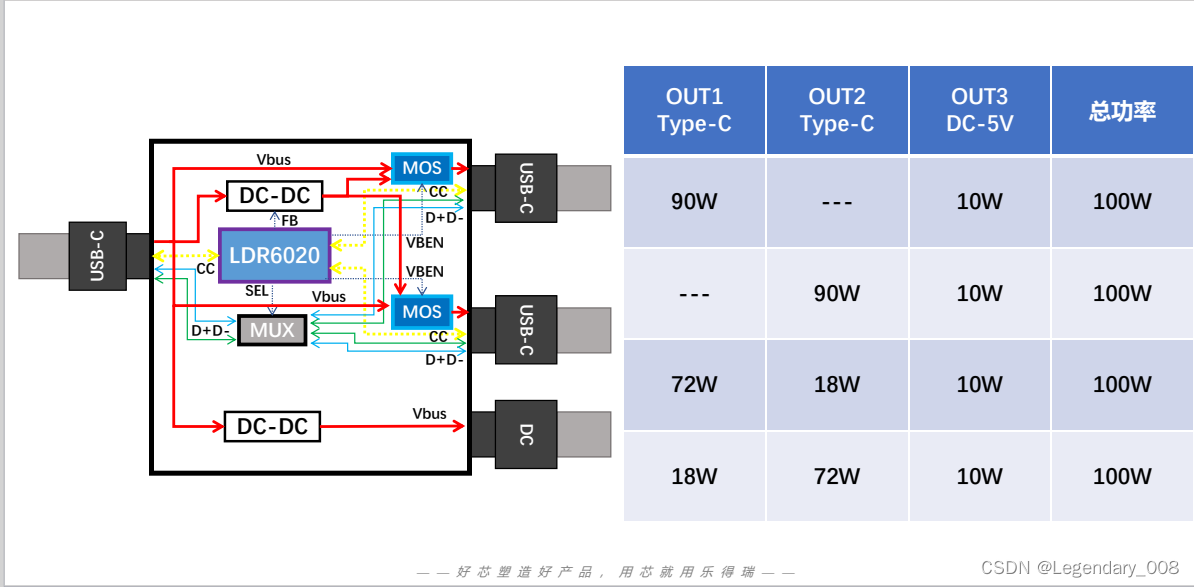
LDR6020一拖二快充线:多设备充电新选择
随着科技的快速发展,我们的日常生活中越来越多地依赖于智能设备。然而,每当手机、平板或其他移动设备电量告急时,我们总是需要寻找合适的充电线进行充电。为了解决这一痛点,市场上出现了一款备受瞩目的新产品——LDR6020一拖二快充…...

电脑ffmpeg.dll丢失原因解析,找不到ffmpeg.dll的5种解决方法
在数字化时代,多媒体文件的处理已经成为我们日常生活和工作中不可或缺的一部分。在计算机使用过程中,丢失ffmpeg.dll文件是一个特定但常见的问题,尤其是对于那些经常处理视频编解码任务的用户来说。下面小编讲全面分析ffmpeg.dll丢失原因以及…...
手机网站制作软件是哪些
手机网站制作软件是一种用于设计、开发和创建适用于移动设备的网站的软件工具。随着移动互联网时代的到来,越来越多的用户开始使用手机浏览网页和进行在线交流,因此,手机网站制作软件也逐渐成为了市场上的热门工具。 1. Adobe Dreamweaver&am…...
【Kubernetes项目部署】k8s集群+高可用、负载均衡+防火墙
项目架构图 (1)部署 kubernetes 集群 详见:http://t.csdnimg.cn/RLveS (2) 在 Kubernetes 环境中,通过yaml文件的方式,创建2个Nginx Pod分别放置在两个不同的节点上; Pod使用hostP…...

IPC工业电脑的现状、发展未来与破局策略
文章目录 全球工业电脑市场概况1.1 市场规模与增长1.2 区域分布与主要市场 工业电脑的技术发展与应用2.1 技术趋势与创新2.2 应用领域扩展2.3 工业自动化与智能化 竞争格局与市场参与者3.1 主要企业与市场竞争3.2 国内外竞争对比3.3 市场集中度与竞争策略 未来发展趋势与市场预…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

React19源码系列之 事件插件系统
事件类别 事件类型 定义 文档 Event Event 接口表示在 EventTarget 上出现的事件。 Event - Web API | MDN UIEvent UIEvent 接口表示简单的用户界面事件。 UIEvent - Web API | MDN KeyboardEvent KeyboardEvent 对象描述了用户与键盘的交互。 KeyboardEvent - Web…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...

#Uniapp篇:chrome调试unapp适配
chrome调试设备----使用Android模拟机开发调试移动端页面 Chrome://inspect/#devices MuMu模拟器Edge浏览器:Android原生APP嵌入的H5页面元素定位 chrome://inspect/#devices uniapp单位适配 根路径下 postcss.config.js 需要装这些插件 “postcss”: “^8.5.…...

推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材)
推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材) 这个项目能干嘛? 使用 gemini 2.0 的 api 和 google 其他的 api 来做衍生处理 简化和优化了文生图和图生图的行为(我的最主要) 并且有一些目标检测和切割(我用不到) 视频和 imagefx 因为没 a…...