基于bash通过cdo批处理数据
***####################################
- ubuntu中编写shell脚本文件
第一步:用vim创建一个以.sh结尾的文件,此时这个文件是暂时性的文件,当编写好文件并保存时才能看到文件;
第二步:要首先按一下“i”键才能进行插入(编写)模式,文件开头要写一段特殊符号,“#!/bin/bash” ,这个是开头文件的要求;
第三步:可以开始写里面的内容了,其中可以使用 # 作为单行注释的符号,用 “:<<! !”,作为多行注释的符号;
第四步:编写完语句之后按一下esc键,然后再按冒号键进入最后一行,然后在按“wq”键进行保存,在运行前要使用 “chmod”进行修改权限,具体的指令为“chmod 777 a.sh”;
最后一步:进行运行,使用" ./ "+文件名来运行这个脚本文件。
vi filename :打开或新建文件,并将光标置于第一行首
vi +n filename :打开文件,并将光标置于第n行首
vi + filename :打开文件,并将光标置于最后一行首
2.bash+cdo批量处理
#tree 命令查看文件夹下的所有文件
如果没有tree,需要重新打开ubuntu终端通过# sudo apt-get install tree 安装tree
A.输出文件的路径(以当前路径./为起始路径)到filelist.txt
find ./ | xargs ls -d >filelist.txt
B. 由于filelist.txt此时包含单独的目录,这里仅保留末尾为nc文件的行,去掉另外那些行:
sed -i ‘/nc/!d’ filelist.txt
#当一个文件夹中有多个变量,但只需要对某一个变量进行数据操作时,需要借助.sh脚本。如
我的文件夹下面有多个变量,其中每个变量都需要进行合并时,编辑的.sh脚本如下所示:
#!/bin/bash
varname=(clt od550aer rsds sfcWind tas)for var in "${varname[@]}"; domergetime "${var}"*.nc "${var}"_historical.nc
done#当对数据重采样以后又想合并数据又想提取区域时:
#!/bin/bash# Define the variable names and experiments
varnames=("clt" "od550aer" "rsds" "sfcWind" "tas")
experiments=("historical" "ssp126" "ssp245" "ssp585")# Create the output directory
mkdir -p post# Loop over the variables and experiments
for varname in "${varnames[@]}"; dofor experiment in "${experiments[@]}"; do# Merge the files for the current variable and experimentcdo mergetime "${varname}"*"${experiment}"*.nc "post/${varname}.${experiment}.nc"done
done#!/bin/bash# Define input and output directories
indir="input"
outdir="output"# Define input and output region
region="-180,180,-90,90"
outregion="-100,20,0,60"# Loop through input files and extract region
for infile in ${indir}/*.nc; dooutfile="${outdir}/$(basename ${infile})"cdo sellonlatbox,${region} ${infile} ${outfile}
done# Merge all output files
cdo mergetime ${outdir}/*.nc ${outdir}/merged.nc# Re-grid merged file to output region
cdo remapbil,${outregion} ${outdir}/merged.nc ${outdir}/merged_regrid.nc相关文章:
基于bash通过cdo批处理数据
***#################################### ubuntu中编写shell脚本文件 第一步:用vim创建一个以.sh结尾的文件,此时这个文件是暂时性的文件,当编写好文件并保存时才能看到文件; 第二步:要首先按一下“i”键才能进行插入…...
Map和Set总结
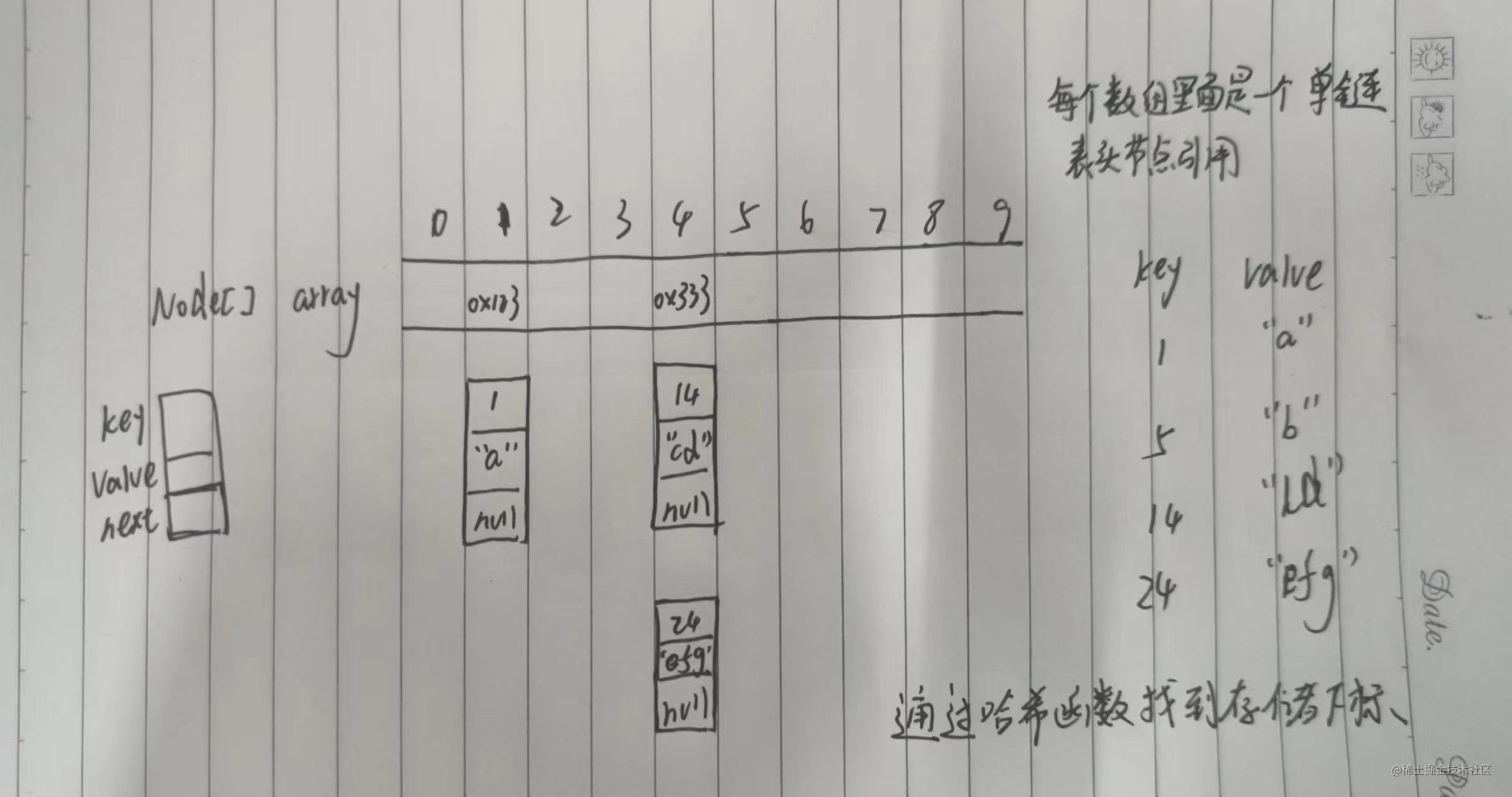
Map和Set Map和Set是专门用来进行搜索的数据结构,适合动态查找 模型 搜索的数据称为关键字(key),关键字对应的叫值(value),key-value键值对 key模型key-value模型 Map存储的就是key-value模型,Set只存储了key Map Map是接口类…...

pytorch网络模型构建中的注意点
记录使用pytorch构建网络模型过程遇到的点 1. 网络模型构建中的问题 1.1 输入变量是Tensor张量 各个模块和网络模型的输入, 一定要是tensor 张量; 可以用一个列表存放多个张量。 如果是张量维度不够,需要升维度, 可以先使用 …...

面试时候这样介绍redis,redis经典面试题
为什么要用redis做缓存 使用Redis缓存有以下几个优点: 1. 提高系统性能:缓存可以将数据存储在内存中,加快数据的访问速度,减少对数据库的读写次数,从而提高系统的性能。 2. 减轻后端压力:使用缓存可以减…...

机械学习 - scikit-learn - 数据预处理 - 2
目录关于 scikit-learn 实现规范化的方法详解一、fit_transform 方法1. 最大最小归一化手动化与自动化代码对比演示 1:2. 均值归一化手动化代码演示:3. 小数定标归一化手动化代码演示:4. 零-均值标准化(均值移除)手动与自动化代码演示&#x…...
| 机考必刷)
华为OD机试题 - 最长连续交替方波信号(JavaScript)| 机考必刷
更多题库,搜索引擎搜 梦想橡皮擦华为OD 👑👑👑 更多华为OD题库,搜 梦想橡皮擦 华为OD 👑👑👑 更多华为机考题库,搜 梦想橡皮擦华为OD 👑👑👑 华为OD机试题 最近更新的博客使用说明本篇题解:最长连续交替方波信号题目输入输出示例一输入输出Code解题思路版…...
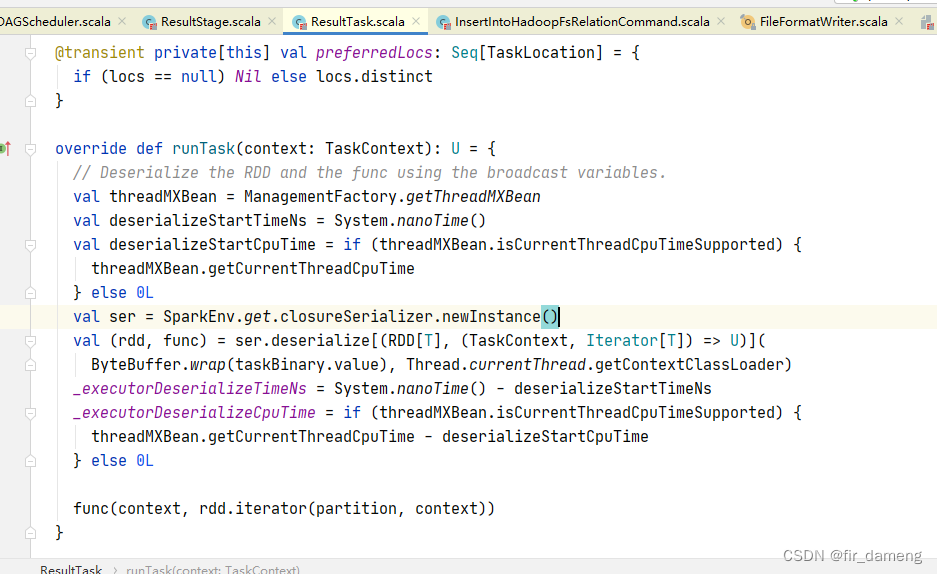
executor行为相关Spark sql参数源码分析
0、前言 参数名和默认值spark.default.parallelismDefault number of partitions in RDDsspark.executor.cores1 in YARN mode 一般默认值spark.files.maxPartitionBytes134217728(128M)spark.files.openCostInBytes4194304 (4 MiB)spark.hadoop.mapreduce.fileoutputcommitte…...
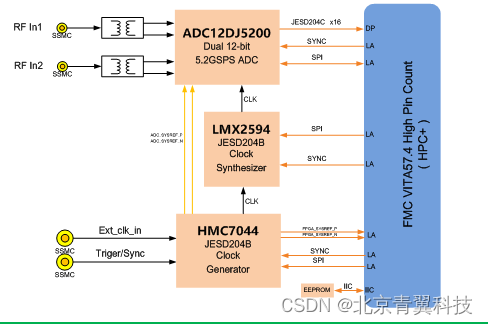
双通道5.2GSPS(或单通道10.4GSPS)射频采样FMC+模块
概述 FMC140是一款具有缓冲模拟输入的低功耗、12位、双通道(5.2GSPS/通道)、单通道10.4GSPS、射频采样ADC模块,该板卡为FMC标准,符合VITA57.1规范,该模块可以作为一个理想的IO单元耦合至FPGA前端,8通道的JE…...

理解java反射
是什么Java反射是Java编程语言的一个功能,它允许程序在运行时(而不是编译时)检查、访问和修改类、对象和方法的属性和行为。使用反射创建对象相比直接创建对象有什么优点使用反射创建对象相比直接创建对象的主要优点是灵活性和可扩展性。当我…...

EasyRcovery16免费的电脑照片数据恢复软件
电脑作为一种重要的数据储存设备,其中保存着大量的文档,邮件,视频,音频和照片。那么,如果电脑照片被删除了怎么办?今天小编给大家介绍,误删除的照片从哪里可以找回来,误删除的照片如…...
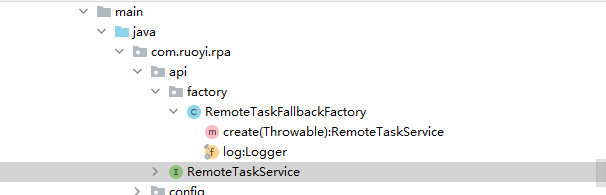
若依微服务版在定时任务里面跨模块调用服务
第一步 在被调用的模块中添加代理 RemoteTaskFallbackFactory.java: package com.ruoyi.rpa.api.factory;import com.ruoyi.common.core.domain.R; import com.ruoyi.rpa.api.RemoteTaskService; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springf…...

SpringMVC简单配置
1、pom.xml配置 <dependencies><dependency><groupId>org.springframework</groupId><artifactId>spring-webmvc</artifactId><version>5.1.12.RELEASE</version></dependency></dependencies><build><…...

xcat快速入门工作流程指南
目录一、快速入门指南一、先决条件二、准备管理节点xcatmn.mydomain.com三、第1阶段:添加你的第一个节点并且用带外BMC接口控制它四、第 2 阶段 预配节点并使用并行 shell 对其进行管理二:工作流程指南1. 查找 xCAT 管理节点的服务器2. 在所选服务器上安…...

C++回顾(十九)—— 容器string
19.1 string概述 1、string是STL的字符串类型,通常用来表示字符串。而在使用string之前,字符串通常是 用char * 表示的。string 与char * 都可以用来表示字符串,那么二者有什么区别呢。 2、string和 char * 的比较 (1)…...

Hadoop入门
数据分析与企业数据分析方向 数据是什么 数据是指对可观事件进行记录并可以鉴别的符号,是对客观事物的性质、状态以及相互关系等进行记载的物理符号或这些物理符号的组合,它是可以识别的、抽象的符号。 他不仅指狭义上的数字,还可以是具有一…...

高校如何通过校企合作/实验室建设来提高大数据人工智能学生就业质量
高校人才培养应该如何结合市场需求进行相关专业设置和就业引导,一直是高校就业工作的讨论热点。亘古不变的原则是,高校设置不能脱离市场需求太远,最佳的结合方式是,高校具有前瞻性,能领先市场一步,培养未来…...

提升学习 Prompt 总结
NLP现有的四个阶段: 完全有监督机器学习完全有监督深度学习预训练:预训练 -> 微调 -> 预测提示学习:预训练 -> 提示 -> 预测 阶段1,word的本质是特征,即特征的选取、衍生、侧重上的针对性工程。 阶段2&…...
)
JavaScript学习笔记(2.0)
BOM--(browser object model) 获取浏览器窗口尺寸 获取可视窗口高度:window.innerWidth 获取可视窗口高度:window.innerHeight 浏览器弹出层 提示框:window.alert(提示信息) 询问框:window.confirm(提示信息) 输…...

直击2023云南移动生态合作伙伴大会,聚焦云南移动的“价值裂变”
作者 | 曾响铃 文 | 响铃说 2023年3月2日下午,云南移动生态合作伙伴大会在昆明召开。云南移动党委书记,总经理葛松海在大会上提到“2023年,云南移动将重点在‘做大平台及生态级新产品,做优渠道转型新动能,做强合作新…...

STM32F1开发实例-振动传感器(机械)
振动(敲击)传感器 振动无处不在,有声音就有振动,哒哒的脚步是匆匆的过客,沙沙的夜雨是暗夜的忧伤。那你知道理科工程男是如何理解振动的吗?今天我们就来讲一讲本节的主角:最简单的机械式振动传感器。 下图即为振动传…...

010 Editor破解指南:从安装到激活的完整步骤
1. 010 Editor简介与破解前的准备 010 Editor是一款功能强大的十六进制编辑器,广泛应用于逆向工程、文件分析和数据恢复等领域。它的二进制编辑能力和模板解析功能深受安全研究人员和开发者的喜爱。不过正版软件价格较高,个人用户可能会考虑寻找替代方案…...
)
基于IMS轴承数据的实战:5步搭建你的第一个LSTM故障预警模型(TensorFlow/PyTorch)
基于IMS轴承数据的实战:5步搭建你的第一个LSTM故障预警模型(TensorFlow/PyTorch) 轴承作为工业设备的核心部件,其健康状态直接影响生产线的稳定运行。传统的人工巡检和定期维护方式已无法满足现代工业对效率和成本的要求。预测性维…...

5 种简单方法,将联系人从电脑/苹果电脑传输至三星手机
如果你刚入手最新款三星 S25,首要任务大概率是把联系人导入新手机。由于在电脑和三星设备间传输联系人的操作稍显繁琐,本文将为你详细讲解如何轻松把联系人从 Windows 电脑或苹果电脑传输到三星盖乐世手机。方法一:通过谷歌账户将电脑联系人传…...

2026届最火的六大降AI率神器横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 维普平台已正式引进AIGC检测模块,可借之识别学术论文里由人工智能生成的内容&…...

GHCJS与Emscripten集成:构建高性能Web应用的最佳实践
GHCJS与Emscripten集成:构建高性能Web应用的最佳实践 【免费下载链接】ghcjs Haskell to JavaScript compiler, based on GHC 项目地址: https://gitcode.com/gh_mirrors/gh/ghcjs GHCJS是一个强大的Haskell到JavaScript编译器,它基于GHC…...

Vivado时序报错排查与跨时钟域处理实战指南
1. Vivado时序报错排查基础 遇到Vivado时序报错时,很多开发者第一反应是直接修改约束文件,这其实是个误区。我建议先从代码层面入手排查,因为大多数时序问题根源都在RTL设计上。打开Vivado的时序报告,你会看到类似"Setup/Hol…...

YOLOE官版镜像效果展示:YOLOE-v8s模型在低光照场景下的鲁棒分割效果
YOLOE官版镜像效果展示:YOLOE-v8s模型在低光照场景下的鲁棒分割效果 想象一下,深夜的街道监控画面,或者光线昏暗的仓库内部,传统的视觉模型往往“看不清”或“认不准”,导致关键目标漏检或误判。这正是许多实际应用场…...

Ostrakon-VL像素特工部署实战:Python入门者的3步环境搭建指南
Ostrakon-VL像素特工部署实战:Python入门者的3步环境搭建指南 1. 为什么选择Ostrakon-VL 如果你刚接触Python又想尝试AI图像处理,Ostrakon-VL是个不错的起点。这个模型特别适合处理图像扫描和基础视觉任务,对硬件要求不高,部署过…...

都是微软亲儿子,WPF凭啥干不掉WinForm?这3个场景说明白了
大家好,我是码农刚子。 前两天有个刚入行的兄弟问我:“现在学桌面开发,是学WinForm还是WPF?我看网上也有人问都是基于.NET平台,WPF能取代Winform吗?” 我听完笑了笑。这个问题吧,就跟“C#能不能取代Java”一…...
)
Latex写论文必看:如何从谷歌学术获取完整的BibTeX引用信息(含Springer/Elsevier/IEEE案例)
LaTeX论文写作进阶:精准获取BibTeX引用数据的全流程指南 作为科研工作者,我们都经历过这样的场景:深夜赶论文时,发现从谷歌学术导出的BibTeX条目缺少关键字段,特别是那些期刊要求的卷号(number)、页码或DOI信息。这种…...