spark学习总结
系列文章目录
第1天总结:spark基础学习
- 1- Spark基本介绍(了解)
- 2- Spark入门案例(掌握)
- 3- 常见面试题(掌握)
文章目录
- 系列文章目录
- 前言
- 一、Spark基本介绍
- 1、Spark是什么
- 1.1 定义
- 1.2 Spark与MapReduce对比(面试题)
- 2、Spark特点
- 3、Spark框架模块
- 二、Spark入门案例(掌握)
- 1、需求描述
- 2、需求分析
- 3、代码编写
- 代码:
- 绑定指定的Python解释器
- 创建main函数
- 总结
- 常见面试题
- 1.spark和mr的区别
- Spark和MR(通常指的是Hadoop MapReduce)在多个方面存在显著的区别。
- 计算速度与迭代计算:
- 并行度与任务调度:
- 编程模型与灵活性:
- 资源申请与释放:
- 2.Spark的四大特性:
- Speed(高速性):
- Ease of Use(易用性):
- Generality(通用性):
- Runs Everywhere(随处运行):
- 3.spark为什么执行快
- Spark执行速度快的原因:
- 内存计算:
- DAG执行引擎:
- 弹性分布式数据集(RDD):
- 任务调度优化:
- 容错性:
- 分布式计算:
- 4.Spark词频统计的步骤以及每步涉及到的算子作用:
- 步骤一:基于文本文件创建RDD
- 步骤二:按空格拆分作扁平化映射
- 步骤三:将单词数组映射成二元组数组
- 步骤四:将二元组数组按键归约
- 步骤六(可选):收集并输出结果
- 案例总结:
前言
本文就介绍了spark学习的基础内容
以及详细介绍了词频统计案例。
一、Spark基本介绍
1、Spark是什么
1.1 定义
Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。
1.2 Spark与MapReduce对比(面试题)
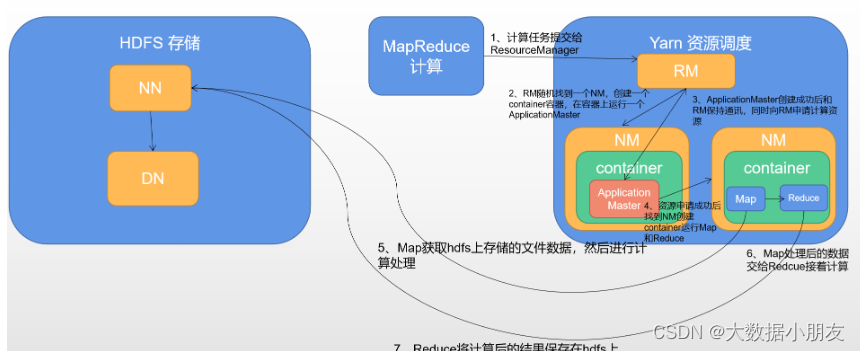
MapReduce架构回顾
-
MapReduce的主要缺点:
- 1- MapReduce是基于进程进行数据处理,进程相对线程来说,在创建和销毁的过程比较消耗资源,并且速度比较慢
- 2- MapReduce运行的时候,中间有大量的磁盘IO过程。也就是磁盘数据到内存,内存到磁盘反复的读写过程
- 3- MapReduce只提供了非常低级(底层)的编程API,如果想要开发比较复杂的程序,那么就需要编写大量的代码。
-
Spark相对MapReduce的优点:
- 1- Spark底层是基于线程来执行任务
- 2- 引入了新的数据结构——RDD(弹性分布式数据集),能够让Spark程序主要基于内存进行运行。内存的读写数据相对磁盘来说,要快很多
- 3- Spark提供了更加丰富的(顶层)编程API,能够非常轻松的实现功能开发
2、Spark特点
快速记忆: speed, easy use , general , runs everywhere
-
高效性
- 计算速度快
- 提供了一个全新的数据结构RDD(弹性分布式数据集)。整个计算操作,基于内存计算。当内存不足的时候,可以放置到磁盘上。整个流程是基于DAG(有向无环图)执行方案。
- Task线程完成计算任务执行
- 计算速度快
-
易用性
- 支持多种语言开发 (Python,SQL,Java,Scala,R),降低了学习难度
-
通用性
- 在 Spark 的基础上,Spark 还提供了包括Spark SQL、Spark Streaming、MLlib 及GraphX在内的多个工具库(模块),我们可以在一个应用中无缝地使用这些工具库。
-
兼容性(任何地方运行)
-
支持三方工具接入
- 存储工具
- hdfs
- kafka
- hbase
- 资源调度
- yarn
- Kubernetes(K8s容器)
- standalone(spark自带的)
- 高可用
- zookeeper
- 存储工具
-
支持多种操作系统
- Linux
- windows
- Mac
-
3、Spark框架模块

- Spark Core API:实现了 Spark 的基本功能。包含RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块。数据结构RDD。–重点学习
- Spark SQL:我们可以使用 SQL处理结构化数据。数据结构:Dataset/DataFrame = RDD + Schema。–重点学习
- Structured Streaming:基于Spark SQL进行流式/实时的处理组件,主要处理结构化数据。–部分学习
- Streaming(Spark Streaming):提供的对实时数据进行流式计算的组件,底层依然是离线计算,只不过时间粒度很小,攒批。–了解
- MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等。–了解
- GraphX:Spark中用于图计算的API,性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。–了解
二、Spark入门案例(掌握)
1、需求描述
读取文本文件,文件内容是一行一行的文本,每行文本含有多个单词,单词间使用空格分隔。统计文本中每个单词出现的总次数。WordCount词频统计。
文本内容如下:
hello hello spark
hello heima spark
2、需求分析
Python编程思维的实现过程:

PySpark实现过程:
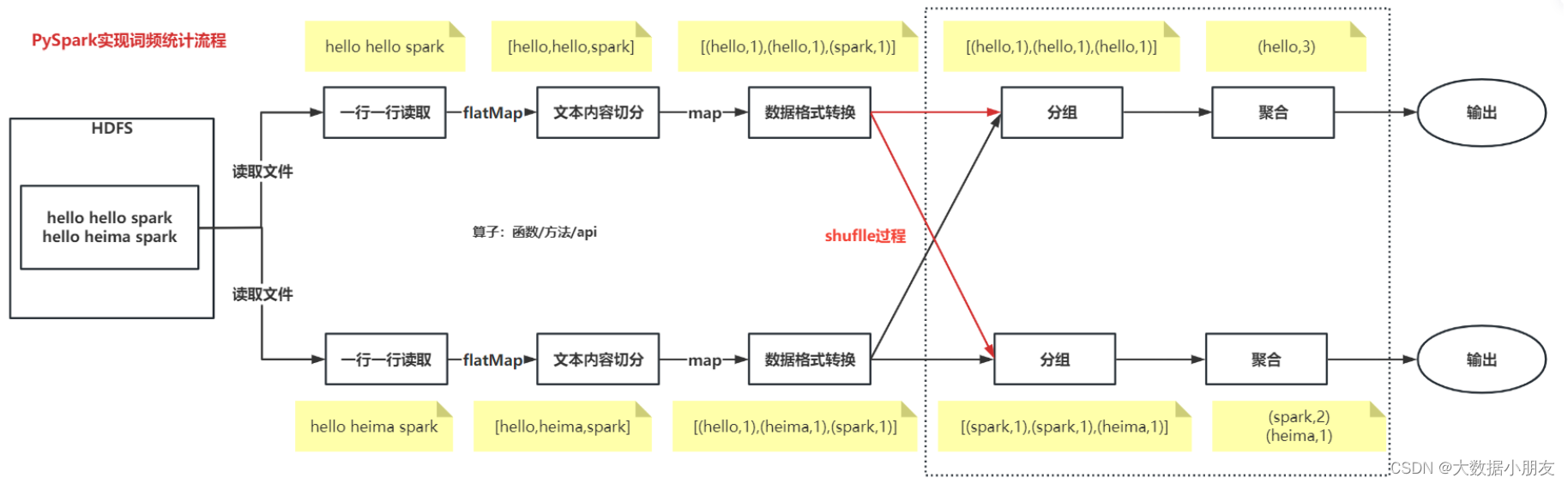
编程过程总结:
-
1.创建SparkContext对象
-
2.数据输入
-
3.数据处理
- 3.1文本内容切分
- 3.2数据格式转换
- 3.3分组和聚合
-
4.数据输出
-
5.释放资源
3、代码编写
可能出现的错误:
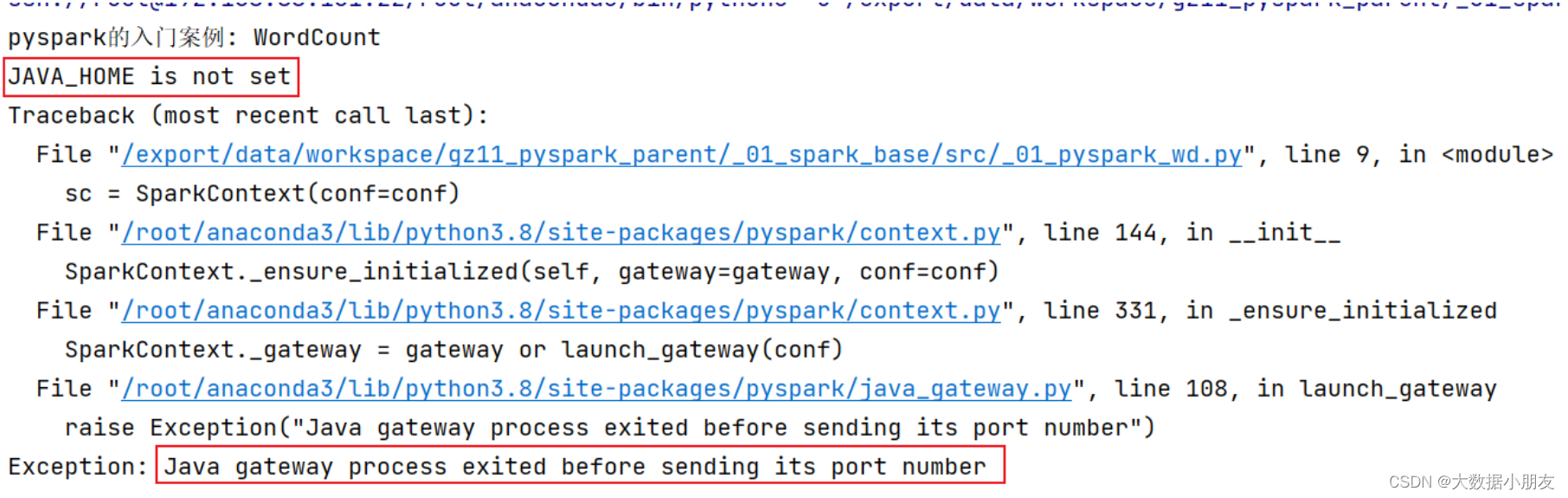
结果: 可能会报错: JAVA_HOME is not set
原因: 找不到JAVA_HOME环境
解决方案: 需要在代码中指定远端的环境地址 以及 在node1环境中初始化JAVA_HOME地址
第一步:在node1的 /root/.bashrc 中配置初始化环境的配置
vim /root/.bashrc
export JAVA_HOME=/export/server/jdk1.8.0_241
第二步: 在main函数上面添加以下内容os.environ['SPARK_HOME'] = '/export/server/spark'os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
注意: jdk路径配置到node1的 /root/.bashrc 文件的第三行,示例如下:

代码:
from pyspark import SparkConf, SparkContext
import os
绑定指定的Python解释器
os.environ[‘SPARK_HOME’] = ‘/export/server/spark’
os.environ[‘PYSPARK_PYTHON’] = ‘/root/anaconda3/bin/python3’
os.environ[‘PYSPARK_DRIVER_PYTHON’] = ‘/root/anaconda3/bin/python3’
创建main函数
if name == ‘main’:
print(“Spark入门案例: WordCount词频统计”)
# 1- 创建SparkContext对象
"""setAppName:设置PySpark程序运行时的名称setMaster:设置PySpark程序运行时的集群模式
"""
conf = SparkConf()\.setAppName('spark_wordcount_demo')\.setMaster('local[*]')
sc = SparkContext(conf=conf)# 2- 数据输入
"""textFile:支持读取HDFS文件系统和linux本地文件系统HDFS文件系统:hdfs://node1:8020/文件路径linux本地文件系统:file:///文件路径
"""
init_rdd = sc.textFile("file:///export/data/gz16_pyspark/01_spark_core/data/content.txt")# 3- 数据处理
# 文本内容切分
"""flatMap运行结果:输入数据:['hello hello spark', 'hello heima spark']输出数据:['hello', 'hello', 'spark', 'hello', 'heima', 'spark']map运行结果:输入数据:['hello hello spark', 'hello heima spark']输出数据:[['hello', 'hello', 'spark'], ['hello', 'heima', 'spark']]
"""
# flatmap_rdd = init_rdd.map(lambda line: line.split(" "))
flatmap_rdd = init_rdd.flatMap(lambda line: line.split(" "))# 数据格式转换
"""输入数据:['hello', 'hello', 'spark', 'hello', 'heima', 'spark']输出数据:[('hello', 1), ('hello', 1), ('spark', 1), ('hello', 1), ('heima', 1), ('spark', 1)]
"""
map_rdd = flatmap_rdd.map(lambda word: (word,1))# 分组和聚合
"""输入数据:[('hello', 1), ('hello', 1), ('spark', 1), ('hello', 1), ('heima', 1), ('spark', 1)]输出数据:[('hello', 3), ('spark', 2), ('heima', 1)]reduceByKey底层运行过程分析:1- 该算子同时具备分组和聚合的功能。而且是先对数据按照key进行分组,对相同key的value会形成得到List列表。再对分组后的value列表进行聚合。2- 分组和聚合功能不能分割,也就是一个整体结合案例进行详细分析:1- 分组输入数据:[('hello', 1), ('hello', 1), ('spark', 1), ('hello', 1), ('heima', 1), ('spark', 1)]分组后的结果: key value列表hello [1,1,1] spark [1,1]heima [1]2- 聚合(以hello为例)lambda agg,curr: agg+curr -> agg表示中间临时value聚合结果,默认取列表中的第一个元素;curr表示当前遍历到的value元素,默认取列表中的第二个元素最后发现已经遍历到value列表的最后一个元素,因此聚合过程结果。最终的hello的次数,就是3
"""
result = map_rdd.reduceByKey(lambda agg,curr: agg+curr)# 4- 数据输出
"""collect():用来收集数据,返回值类型是List列表
"""
print(result.collect())# 5- 释放资源
sc.stop()
###运行结果:

总结
常见面试题
1.spark和mr的区别
Spark和MR(通常指的是Hadoop MapReduce)在多个方面存在显著的区别。
Spark在计算速度、并行度、资源利用率、编程灵活性和资源申请与释放等方面,相较于Hadoop MapReduce具有显著的优势。这使得Spark在处理大规模数据集和分析任务时,成为了一个更加高效和灵活的选择。
以下是它们之间的主要差异:
计算速度与迭代计算:
Spark:除了需要shuffle的计算外,Spark将结果/中间结果持久化到内存中,因此避免了频繁的磁盘I/O操作。这使得Spark在处理需要频繁读写中间结果的迭代计算时,比MR具有更高的效率。
MR:所有的中间结果都需要写入磁盘,并在下一个阶段从磁盘中读取,这导致了较高的磁盘I/O开销和较低的计算速度。
并行度与任务调度:
Spark:将不同的计算环节抽象为Stage,允许多个Stage既可以串行执行,又可以并行执行。这种基于DAG(有向无环图)的任务调度执行机制,提高了任务的并行度和整体执行效率。
MR:任务之间的衔接涉及I/O开销,且下个任务的执行依赖于上个任务的结果,这限制了其并行度和处理复杂、多阶段计算任务的能力。
资源模型:
Spark:基于线程,采用多进程多线程模型。在同一个节点上,多个任务可以共享内存和资源,提高了数据和资源的利用率。
MR:基于进程,采用多进程单线程模型。每个任务都是独立的进程,申请资源和数据都是独立进行的,这导致了较高的资源申请和释放开销。
编程模型与灵活性:
Spark:提供了多种数据集操作类型,包括转换算子、行动算子和持久化算子,使得编程模型比Hadoop MapReduce更灵活。同时,Spark支持使用Scala、Java、Python和R语言进行编程,具有更好的易用性。
MR:只有map和reduce两个类,相当于Spark中的两个算子,其编程模型相对较为简单和固定。
资源申请与释放:
Spark:多个task运行在同一个进程中,这个进程会伴随Spark应用程序的整个生命周期。即使在没有作业进行时,进程也是存在的,这避免了频繁的进程创建和销毁开销。
MR:每个task都是一个独立的进程,当task完成时,进程也会结束。这导致了较高的进程创建和销毁开销。
综上所述,
2.Spark的四大特性:
Speed(高速性):
Spark是一个基于内存计算的分布式计算框架,能够在内存中直接处理数据,减少了磁盘I/O的开销,从而显著提高了计算速度。
官方数据表明,如果数据从内存中读取,Spark的速度可以高达Hadoop MapReduce的100多倍;即使数据从磁盘读取,Spark的速度也是Hadoop MapReduce的10倍以上。
Spark通过DAG(有向无环图)执行引擎支持无环数据流,使得数据处理更加高效。
Ease of Use(易用性):
Spark提供了丰富的API,支持多种编程语言,如Scala、Java、Python和R,使得用户可以轻松地开发复杂的分布式应用程序。
Spark的易用性还体现在其支持的高级功能上,如SQL查询、机器学习和图计算等,这些功能都通过简洁的代码接口提供。
Generality(通用性):
Spark生态圈即BDAS(伯克利数据分析栈)包含了多个组件,如Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等,这些组件能够无缝集成并提供一站式解决平台。
Spark Core提供内存计算框架,Spark SQL支持即席查询,Spark Streaming处理实时数据流,MLlib和MLbase支持机器学习,GraphX则专注于图处理。
Runs Everywhere(随处运行):
Spark具有很强的适应性,能够读取多种数据源,如HDFS、Cassandra、HBase、S3和Techyon等。
Spark支持多种部署模式,包括Hadoop YARN、Apache Mesos、Standalone(独立部署)以及云环境(如Kubernetes)等,使得用户可以根据自身需求选择合适的部署方式。
综上所述,Spark的四大特性包括高速性、易用性、通用性和随处运行,这些特性使得Spark在处理大规模数据集和分析任务时表现出色,成为大数据处理领域的重要工具。
3.spark为什么执行快
Spark执行速度快的原因:
Spark通过内存计算、DAG执行引擎、RDD、任务调度优化、容错性和分布式计算等特性,实现了高性能的数据处理能力,从而能够在处理大规模数据集和分析任务时表现出色。
内存计算:
Spark采用了内存计算的方式,将数据和中间计算结果存储在内存中,而不是传统的硬盘中。
由于内存的速度远快于硬盘,因此Spark能够避免频繁的磁盘I/O操作,从而显著提高了数据处理的速度。
官方数据表明,如果数据从内存中读取,Spark的速度可以高达Hadoop MapReduce的100多倍;即使数据从磁盘读取,Spark的速度也是Hadoop MapReduce的10倍以上。
DAG执行引擎:
Spark采用了基于有向无环图(DAG)的执行引擎,将作业转化为一系列的有向无环图进行计算。
DAG执行引擎可以优化任务调度和计算,使得多个任务能够并行执行,进一步提高了计算效率。
弹性分布式数据集(RDD):
RDD是Spark的核心数据模型,提供了对数据集的高效分布式处理。
RDD具有不可变性,但可以通过一系列的转换操作生成新的RDD,并支持在内存中缓存RDD,从而提高计算性能。
任务调度优化:
Spark将用户的代码转化为一系列的任务,并以有向无环图(DAG)的形式进行调度执行。
Spark的任务调度器可以根据数据的依赖关系来优化任务的执行顺序,将多个相关的任务合并在一起执行,减少了任务调度的开销。
容错性:
Spark通过将数据划分成多个分区,并在集群中复制多份数据来实现容错性。
当某个计算节点发生故障时,Spark可以自动将计算任务转移到其他节点上,并重新执行失败的任务,确保了计算的完整性和准确性。
分布式计算:
Spark支持分布式计算,能够将数据分成多个分区,并分布到不同的计算节点上进行并行处理。
这种分布式计算的方式能够充分利用集群资源,提高计算效率。
4.Spark词频统计的步骤以及每步涉及到的算子作用:
步骤一:基于文本文件创建RDD
使用sc.textFile(“/path/to/file.txt”)读取文本文件,并创建一个RDD(弹性分布式数据集)。
涉及到的算子:无。这是数据输入步骤,不涉及Spark的转换或行动算子。
步骤二:按空格拆分作扁平化映射
使用flatMap(_.split(" "))将RDD中的每一行文本按空格拆分成单词,并将所有单词合并成一个新的RDD。
涉及到的算子:flatMap。这是一个转换算子(Transformation),它会对RDD中的每个元素应用一个函数,并返回一个新的RDD,其中包含所有函数输出的元素。
步骤三:将单词数组映射成二元组数组
使用map((_, 1))将每个单词映射为一个二元组(单词,1),表示该单词出现了一次。
涉及到的算子:map。这也是一个转换算子,它将RDD中的每个元素转换成一个新的元素。
步骤四:将二元组数组按键归约
使用reduceByKey(_ + _)对二元组RDD进行归约操作,将具有相同键(即单词)的二元组合并,并将它们的值(即计数)相加。
涉及到的算子:reduceByKey。这是一个转换算子,它会对具有相同键的元素进行归约操作,并返回一个新的RDD。
步骤五:将词频统计结果按次数降序排列
使用sortBy(_._2, false)对词频统计结果进行排序,按照单词出现的次数从高到低排序。
涉及到的算子:sortBy。这是一个转换算子,它会对RDD中的元素进行排序,并返回一个新的RDD。
步骤六(可选):收集并输出结果
使用collect将排序后的词频统计结果收集到驱动程序节点,并使用foreach(println)输出结果。
涉及到的算子:collect和foreach。collect是一个行动算子(Action),它会触发Spark作业的执行,并将RDD中的所有元素收集到驱动程序节点。foreach是一个行动算子,它会对RDD中的每个元素应用一个函数,但该函数不返回任何值。
案例总结:
在上述步骤中,flatMap、map、reduceByKey和sortBy是转换算子,它们用于创建和转换RDD;而collect和foreach是行动算子,它们会触发Spark作业的执行,并返回结果或进行其他操作。这些算子的组合使用,使得Spark能够高效地进行词频统计任务。
相关文章:
spark学习总结
系列文章目录 第1天总结:spark基础学习 1- Spark基本介绍(了解)2- Spark入门案例(掌握)3- 常见面试题(掌握) 文章目录 系列文章目录前言一、Spark基本介绍1、Spark是什么1.1 定义1.2 Spark与M…...

eNSP学习——帧中继基本配置
目录 主要命令 基本原理 实验目的 实验内容 实验拓扑 实验编址 实验步骤 1、基本配置 2、静态与动态映射的配置 3、子接口配置和静态路由 主要命令 [R1]int s1/0/0 [R1-Serial1/0/0]link-protocol fr //配置链路层协议为FR Warning: The encapsulation protocol…...
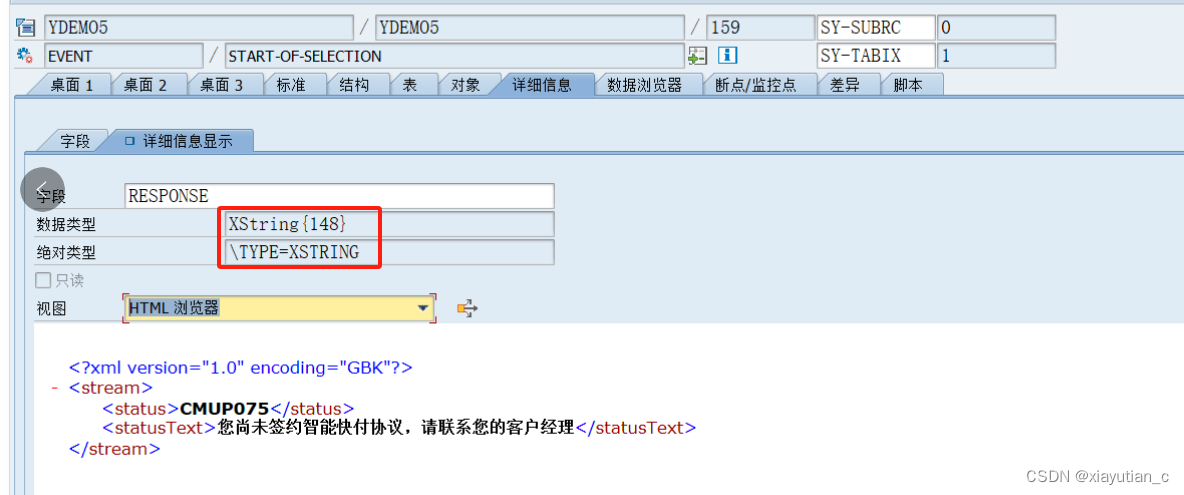
XML Encoding = ‘GBK‘ after STRANS,中文乱码
最近帮同事处理了一个中信银行银企直连接口的一个问题,同事反馈,使用STRANS转换XML后,encoding始终是’utf-16’,就算指定了GBK也不行。尝试了很多办法始终不行,发到银行的数据中,中文始终是乱码。 Debug使用HTML视图…...

C 语言通用MySQL 功能增删查改功能.
前提条件:Ubuntu 22.04.4 LTS、MSQL 8数据库 并且已经安装MySQL 8 开发库。如果没有安装,可以查考:C 语言连接MySQL数据库 项目要求: 1、完成MySQL数据库增删改查通用功能封装 2、编辑makefile 文件实现项目动态更新和快速编译 项目结构…...

Java学习 - MySQL表 增减删查
建表 按照DDL练习,先创建student表和home表 插入【增】 向student表中同时插入三个新的字段【1,Alice,f,15353535353】【2,Bob,m,13646464646】【3,Jack,m,13745908686】 INSERT INTO student(id,name,gender,phone) VALUES(1,Alice,f,15353535353),(2,Bob,m,1364…...
力扣SQL50 有趣的电影 简单查询
Problem: 620. 有趣的电影 Code select * from cinema where id % 2 1 and description ! boring order by rating desc;...

01. Java并发编程简介
1. 前言 大家好,本节我们来一起学习 Java 并发编程的核心原理。 作为本专题的第一个小节,我们先来了解下什么是并发编程,以及学习并发编程的必要性,及学习过程应该注意的事项。 下面,我们先了解一下 Java 并发编程。…...

使用Node.js+Express开发简单接口
Node.js 和 Express 是非常流行的组合,用于开发快速、高效的 web 服务器和 API。下面是一个基础教程,介绍如何使用 Node.js 和 Express 开发一个简单的 API。 1. 安装 Node.js 和 npm 首先,确保您已经安装了 Node.js 和 npm(Nod…...
【Python】使用OpenCV特征匹配检测图像中的【特定水印】
如果没有方向 往哪里走都是前方 做自己的光 不需要多亮 曾受过的伤 会长出翅膀 大雨冲刷过的天空会更加明亮 流过泪的眼睛也一样 做自己的光 悄悄的发亮 逆风的方向 更容易飞翔 世界怎样在于你凝视它的目光 那未曾谋面过的远方 或许就在身旁 🎵…...

基于 Clang和LLVM 的 C++ 代码静态分析工具开发教程
基于 Clang和LLVM 的 C 代码静态分析工具开发教程 简介 静态代码分析是一种在不实际运行程序的情况下对源代码进行分析的技术。它可以帮助开发者在编译之前发现潜在的错误、安全漏洞、性能问题等。 在 C 开发中,有几种常用的静态代码分析工具,它们可以…...
Mathtype与word字号对照+Mathtype与word字号对照
字体大小对照表如下 初号44pt 小初36pt 一号26pt 小一24pt 二号22pt 小二18pt 三号16pt 小三15pt 四号14pt 小四12pt 五号10.5pt 小五9pt 六号7.5pt 小六6.5pt 七号5.5pt 八号5pt 1 保存12pt文件 首选选择第一个公式,将其大小改为12pt 然后依次选择 “预置”—…...

PHP 8.4有哪些新功能值得关注
属性钩子(Property Hooks) 允许开发者为每个属性定义自己的get和set钩子,以在属性访问前后添加自定义逻辑。属性钩子通过__get()和__set()方法实现,类似于其他编程语言(如Kotlin、C#和Swift)中的属性访问器…...

PyCharm新手入门
前言 在之前《Python集成开发工具的选择》一文中介绍了python初学者可以使用Jupyter Notebook,Jupyter Notebook简单易用,可以用来练习代码编写,但是实际生产开发环境使用这个工具是远远不够用的,因为实际软件开发中需要软件调试…...
[Linux] 系统管理
全局配置文件 用户个性化配置 配置文件的种类 alias命令和unalias命令 进程管理 进程表...
Xcode无法使用设备:Failed to prepare the device for development
问题: Xcode无法使用设备开发,失败报错如下: Failed to prepare the device for development. This operation can fail if the version of the OS on the device is incompatible with the installed version of Xcode. You may also need…...

AWS无服务器 应用程序开发—第十二章 AWS Step Functions
AWS Step Functions 是一种服务,用于协调和管理分布式应用程序中的多个 AWS 服务和 Lambda 函数。它通过创建有状态的工作流来简化和自动化应用程序的各种工作流程,使得复杂的业务逻辑可以以可管理和可调试的方式实现。 主要功能和特点: 状态机定义: 使用 JSON 或 Amazo…...

Linux tcpdump详解
目录 前言:BPF伯克利包过滤器介绍1.BPF语法(tcpdump语法)2.逻辑运算符3.常用的原子条件1. 协议相关的原子条件2. 地址相关的原子条件3. 端口相关的原子条件4. 网络层和链路层(mac地址)原子条件5. 广播和多播6. VLAN 相关的原子条件…...

vue2实现打印功能(vue-print-nb的实现)
实现效果: 引入插件 npm install vue-print-nb --save import Print from vue-print-nb Vue.use(Print) <div ref"printTest" id"printTest"><div style"text-align: center; page-break-after: always"><div style…...

某全国增值税发票查验平台 接口JS逆向
注意,本文只提供学习的思路,严禁违反法律以及破坏信息系统等行为,本文只提供思路 本文的验证码网址如下,使用base64解码获得 aHR0cHM6Ly9pbnYtdmVyaS5jaGluYXRheC5nb3YuY24v 这个平台功能没什么好说的,就是发票查验&am…...

前端练习小项目——视觉冲击卡片
前言: 前言:在学习完HTML和CSS之后,我们就可以开始做一些小项目了,本篇文章所讲的小项目为——视觉冲击卡片 ✨✨✨这里是秋刀鱼不做梦的BLOG ✨✨✨想要了解更多内容可以访问我的主页秋刀鱼不做梦-CSDN博客 先让我们看一下效果&a…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

Spring Boot面试题精选汇总
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Spring Boot面试题精选汇总⚙️ **一、核心概…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...

人工智能(大型语言模型 LLMs)对不同学科的影响以及由此产生的新学习方式
今天是关于AI如何在教学中增强学生的学习体验,我把重要信息标红了。人文学科的价值被低估了 ⬇️ 转型与必要性 人工智能正在深刻地改变教育,这并非炒作,而是已经发生的巨大变革。教育机构和教育者不能忽视它,试图简单地禁止学生使…...

Unity UGUI Button事件流程
场景结构 测试代码 public class TestBtn : MonoBehaviour {void Start(){var btn GetComponent<Button>();btn.onClick.AddListener(OnClick);}private void OnClick(){Debug.Log("666");}}当添加事件时 // 实例化一个ButtonClickedEvent的事件 [Formerl…...