Word2Vec基本实践
系列文章目录
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第一章 Python 机器学习入门之pandas的使用
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 系列文章目录
- 前言
- 一、使用SkipGram 模型
- 1. 构建实验语料库
- 2. 生成Skip-Gram训练数据
- 3. 对Skip-Gram数据进行One-Hot编码
- 4. 定义Skip-Gram模型
- 5. 训练Skip-Gram模型
- 6. 输出Skip-Gram词向量
- 二、使用CBOW 模型
- 1. 构建实验语料库
- 2. 生成CBOW训练数据
- 3. CBOW数据进行One-Hot编码
- 4. 定义CBOW模型
- 5. 训练CBOW模型
- 6. 输出CBOW词向量
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、使用SkipGram 模型
1. 构建实验语料库
# 定义一个句子列表,后面会用这些句子来训练CBOW和Skip-Gram模型
sentences = ["Kage is Teacher", "Mazong is Boss", "Niuzong is Boss","Xiaobing is Student", "Xiaoxue is Student",]
# 将所有句子连接在一起,然后用空格分隔成词汇
words = ' '.join(sentences).split()
# 构建词汇表,去除重复的词
word_list = list(set(words))
# 创建一个字典,将每个词汇映射到一个唯一的索引
word_to_idx = {word: idx for idx, word in enumerate(word_list)}
# 创建一个字典,将每个索引映射到对应的词汇
idx_to_word = {idx: word for idx, word in enumerate(word_list)}
voc_size = len(word_list) # 计算词汇表的大小
print("词汇表:", word_list) # 输出词汇表
print("词汇到索引的字典:", word_to_idx) # 输出词汇到索引的字典
print("索引到词汇的字典:", idx_to_word) # 输出索引到词汇的字典
print("词汇表大小:", voc_size) # 输出词汇表大小
2. 生成Skip-Gram训练数据
# 生成Skip-Gram训练数据
def create_skipgram_dataset(sentences, window_size=2):data = []for sentence in sentences:sentence = sentence.split() # 将句子分割成单词列表for idx, word in enumerate(sentence): # 遍历单词及其索引# 获取相邻的单词,将当前单词前后各N个单词作为相邻单词for neighbor in sentence[max(idx - window_size, 0): min(idx + window_size + 1, len(sentence))]:if neighbor != word: # 排除当前单词本身# 将相邻单词与当前单词作为一组训练数据data.append((neighbor, word))return data
# 使用函数创建Skip-Gram训练数据
skipgram_data = create_skipgram_dataset(sentences)
# 打印未编码的Skip-Gram数据样例
print("Skip-Gram数据样例(未编码):", skipgram_data)
3. 对Skip-Gram数据进行One-Hot编码
# 定义One-Hot编码函数
import torch # 导入torch库
def one_hot_encoding(word, word_to_idx):# 创建一个全为0的张量,长度与词汇表大小相同tensor = torch.zeros(len(word_to_idx)) tensor[word_to_idx[word]] = 1 # 将对应词汇的索引位置置为1return tensor # 返回生成的One-Hot向量# 展示One-Hot编码前后的数据
word_example = "Teacher"
print("One-Hot编码前的单词:", word_example)
print("One-Hot编码后的向量:", one_hot_encoding(word_example, word_to_idx))# 展示编码后的Skip-Gram数据样例
print("Skip-Gram数据样例(已编码):", [(one_hot_encoding(context, word_to_idx), word_to_idx[target]) for context, target in skipgram_data[:3]])
4. 定义Skip-Gram模型
# 定义Skip-Gram模型
import torch.nn as nn # 导入neural network
class SkipGram(nn.Module):def __init__(self, voc_size, embedding_size):super(SkipGram, self).__init__()# 从词汇表大小到嵌入大小的线性层(权重矩阵)self.input_to_hidden = nn.Linear(voc_size, embedding_size, bias=False) # 从嵌入大小到词汇表大小的线性层(权重矩阵)self.hidden_to_output = nn.Linear(embedding_size, voc_size, bias=False) def forward(self, X): # X : [batch_size, voc_size] # 生成隐藏层:[batch_size, embedding_size]hidden_layer = self.input_to_hidden(X) # 生成输出层:[batch_size, voc_size]output_layer = self.hidden_to_output(hidden_layer) return output_layerembedding_size = 2 # 设定嵌入层的大小,这里选择2是为了方便展示
skipgram_model = SkipGram(voc_size,embedding_size) # 实例化SkipGram模型
print("Skip-Gram模型:", skipgram_model)##建立skipgram模型--使用nn.embedding层替代线性层import torch.nn as nn
class SkipGram(nn.Module):def __init__(self,voc_size,embeding_size):super(SkipGram,self).__init__()self.input_to_hidden=nn.Embedding(voc_size,embeding_size)self.hidden_to_output=nn.Linear(embeding_size,voc_size,bias=False)def forward(self,X):hidden_layer=self.input_to_hidden(X)output_layer=self.hidden_to_output(hidden_layer)return output_layervoc_size=len(words_list)
skipgram_model=SkipGram(voc_size,embeding_size=2)
5. 训练Skip-Gram模型
# 训练Skip-Gram模型
learning_rate = 0.001 # 设置学习速率
epochs = 1000 # 设置训练轮次
criterion = nn.CrossEntropyLoss() # 定义交叉熵损失函数
import torch.optim as optim # 导入随机梯度下降优化器
optimizer = optim.SGD(skipgram_model.parameters(), lr=learning_rate) # 开始训练循环
loss_values = [] # 用于存储每轮的平均损失值
for epoch in range(epochs):loss_sum = 0 # 初始化损失值for context, target in skipgram_data: X = one_hot_encoding(target, word_to_idx).float().unsqueeze(0) # 将中心词转换为One-Hot向量 y_true = torch.tensor([word_to_idx[context]], dtype=torch.long) # 将周围词转换为索引值 y_pred = skipgram_model(X) # 计算预测值loss = criterion(y_pred, y_true) # 计算损失loss_sum += loss.item() # 累积损失optimizer.zero_grad() # 清空梯度loss.backward() # 反向传播optimizer.step() # 更新参数if (epoch+1) % 100 == 0: # 输出每100轮的损失,并记录损失print(f"Epoch: {epoch+1}, Loss: {loss_sum/len(skipgram_data)}") loss_values.append(loss_sum / len(skipgram_data))# 绘制训练损失曲线
import matplotlib.pyplot as plt # 导入matplotlib
plt.plot(range(1, epochs//100 + 1), loss_values) # 绘图
plt.title('Training Loss') # 图题
plt.xlabel('Epochs') # X轴Label
plt.ylabel('Loss') # Y轴Label
plt.show() # 显示图
6. 输出Skip-Gram词向量
# 输出Skip-Gram习得的词嵌入
print("\nSkip-Gram词嵌入:")
for word, idx in word_to_idx.items(): # 输出每个单词的嵌入向量print(f"{word}: \{skipgram_model.input_to_hidden.weight[:, idx].detach().numpy()}") plt.rcParams["font.family"]=['SimHei'] # 用来设定字体样式
plt.rcParams['font.sans-serif']=['SimHei'] # 用来设定无衬线字体样式
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
# 绘制二维词向量图
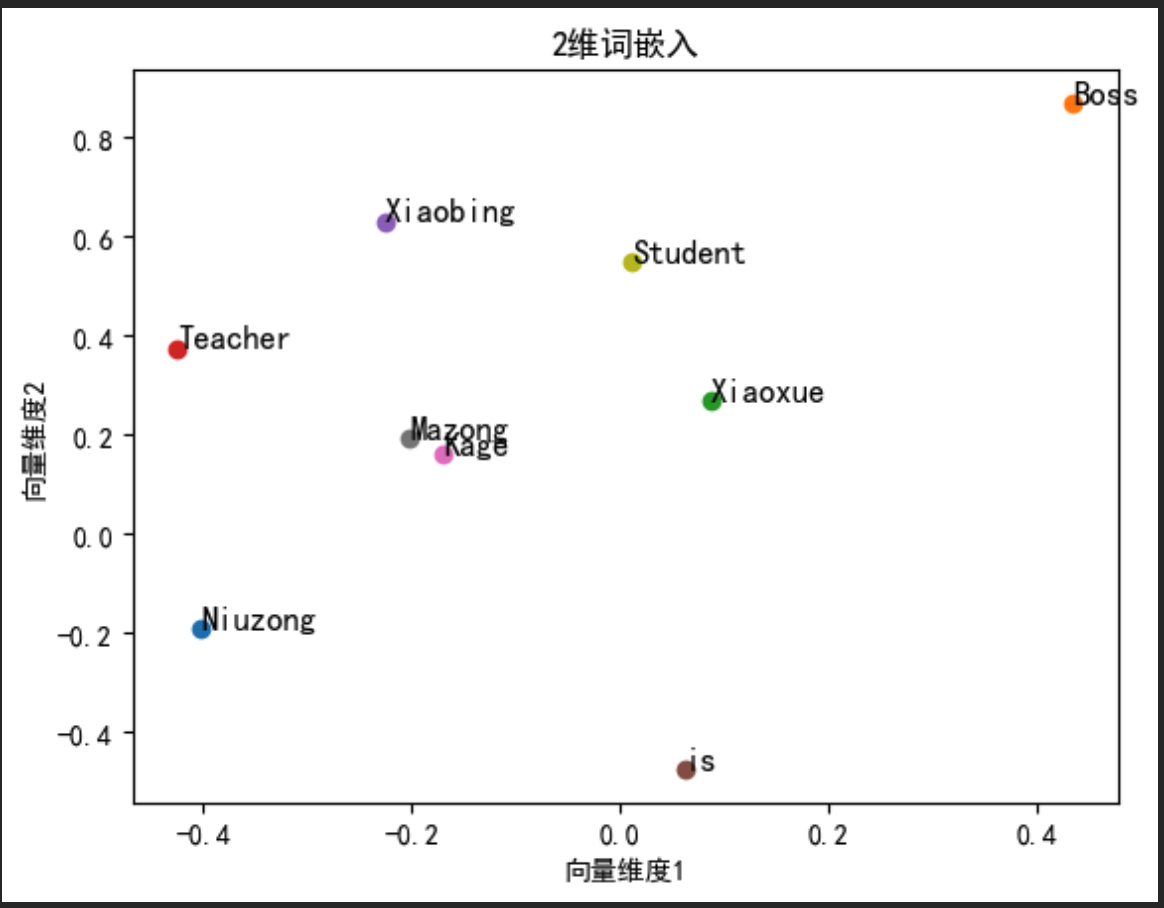
fig, ax = plt.subplots()
for word, idx in word_to_idx.items():vec = skipgram_model.input_to_hidden.weight[:, \idx].detach().numpy() # 获取每个单词的嵌入向量ax.scatter(vec[0], vec[1]) # 在图中绘制嵌入向量的点ax.annotate(word, (vec[0], vec[1]), fontsize=12) # 点旁添加单词标签
plt.title('2维词嵌入') # 图题
plt.xlabel('向量维度1') # X轴Label
plt.ylabel('向量维度2') # Y轴Label
plt.show() # 显示图
二、使用CBOW 模型
1. 构建实验语料库
# 定义一个句子列表,后面会用这些句子来训练CBOW和CBOW模型
sentences = ["Kage is Teacher", "Mazong is Boss", "Niuzong is Boss","Xiaobing is Student", "Xiaoxue is Student",]
# 将所有句子连接在一起,然后用空格分隔成词汇
words = ' '.join(sentences).split()
# 构建词汇表,去除重复的词
word_list = list(set(words))
# 创建一个字典,将每个词汇映射到一个唯一的索引
word_to_idx = {word: idx for idx, word in enumerate(word_list)}
# 创建一个字典,将每个索引映射到对应的词汇
idx_to_word = {idx: word for idx, word in enumerate(word_list)}
voc_size = len(word_list) # 计算词汇表的大小
print("词汇表:", word_list) # 输出词汇表
print("词汇到索引的字典:", word_to_idx) # 输出词汇到索引的字典
print("索引到词汇的字典:", idx_to_word) # 输出索引到词汇的字典
print("词汇表大小:", voc_size) # 输出词汇表大小2. 生成CBOW训练数据
# 生成CBOW训练数据
def create_cbow_dataset(sentences, window_size=2):data = []for sentence in sentences:sentence = sentence.split() # 将句子分割成单词列表for idx, word in enumerate(sentence): # 遍历单词及其索引# 获取上下文词汇,将当前单词前后各window_size个单词作为上下文词汇context_words = sentence[max(idx - window_size, 0):idx] \+ sentence[idx + 1:min(idx + window_size + 1, len(sentence))]# 将当前单词与上下文词汇作为一组训练数据data.append((word, context_words))return data# 使用函数创建CBOW训练数据
cbow_data = create_cbow_dataset(sentences)
# 打印未编码的CBOW数据样例(前三个)
print("CBOW数据样例(未编码):", cbow_data[:3])3. CBOW数据进行One-Hot编码
# 定义One-Hot编码函数
import torch # 导入torch库
def one_hot_encoding(word, word_to_idx):# 创建一个全为0的张量,长度与词汇表大小相同tensor = torch.zeros(len(word_to_idx)) tensor[word_to_idx[word]] = 1 # 将对应词汇的索引位置置为1return tensor # 返回生成的One-Hot向量# 展示One-Hot编码前后的数据
word_example = "Teacher"
print("One-Hot编码前的单词:", word_example)
print("One-Hot编码后的向量:", one_hot_encoding(word_example, word_to_idx))# 展示编码后的CBOW数据样例
# 展示编码后的CBOW数据样例
print("CBOW数据样例(已编码):", [(one_hot_encoding(target, word_to_idx), [one_hot_encoding(context, word_to_idx) for context in context_words]) for target, context_words in cbow_data[:3]])4. 定义CBOW模型
# 定义CBOW模型
import torch.nn as nn # 导入neural network# 定义CBOW模型
class CBOW(nn.Module):def __init__(self, voc_size, embedding_size):super(CBOW, self).__init__()# 从词汇表大小到嵌入大小的线性层(权重矩阵)self.input_to_hidden = nn.Linear(voc_size, embedding_size, bias=False) # 从嵌入大小到词汇表大小的线性层(权重矩阵)self.hidden_to_output = nn.Linear(embedding_size, voc_size, bias=False) def forward(self, X): # X: [num_context_words, voc_size]# 生成嵌入:[num_context_words, embedding_size]embeddings = self.input_to_hidden(X) # 计算隐藏层,求嵌入的均值:[embedding_size]hidden_layer = torch.mean(embeddings, dim=0) # 生成输出层:[1, voc_size]output_layer = self.hidden_to_output(hidden_layer.unsqueeze(0)) return output_layerembedding_size = 2 # 设定嵌入层的大小,这里选择2是为了方便展示
cbow_model = CBOW(voc_size,embedding_size) # 实例化cbow模型
print("CBOW模型:", cbow_model)5. 训练CBOW模型
# 训练CBOW模型
learning_rate = 0.001 # 设置学习速率
epochs = 1000 # 设置训练轮次
criterion = nn.CrossEntropyLoss() # 定义交叉熵损失函数
import torch.optim as optim # 导入随机梯度下降优化器
optimizer = optim.SGD(cbow_model.parameters(), lr=learning_rate) # 开始训练循环
loss_values = [] # 用于存储每轮的平均损失值
for epoch in range(epochs):loss_sum = 0for target, context_words in cbow_data:# 将上下文词转换为One-hot向量并堆叠X = torch.stack([one_hot_encoding(word, word_to_idx) for word in context_words]).float() y_true = torch.tensor([word_to_idx[target]], dtype=torch.long) # 将目标词转换为索引值y_pred = cbow_model(X) # 计算预测值loss = criterion(y_pred, y_true) # 计算损失loss_sum += loss.item()optimizer.zero_grad() # 清空梯度loss.backward() # 反向传播optimizer.step() # 更新参数if (epoch+1) % 100 == 0: # 输出每100轮的损失,并记录损失print(f"Epoch: {epoch+1}, Loss: {loss_sum/len(cbow_data)}") loss_values.append(loss_sum / len(cbow_data))
# 绘制训练损失曲线
import matplotlib.pyplot as plt # 导入matplotlib
plt.plot(range(1, epochs//100 + 1), loss_values) # 绘图
plt.title('Training Loss') # 图题
plt.xlabel('Epochs') # X轴Label
plt.ylabel('Loss') # Y轴Label
plt.show() # 显示图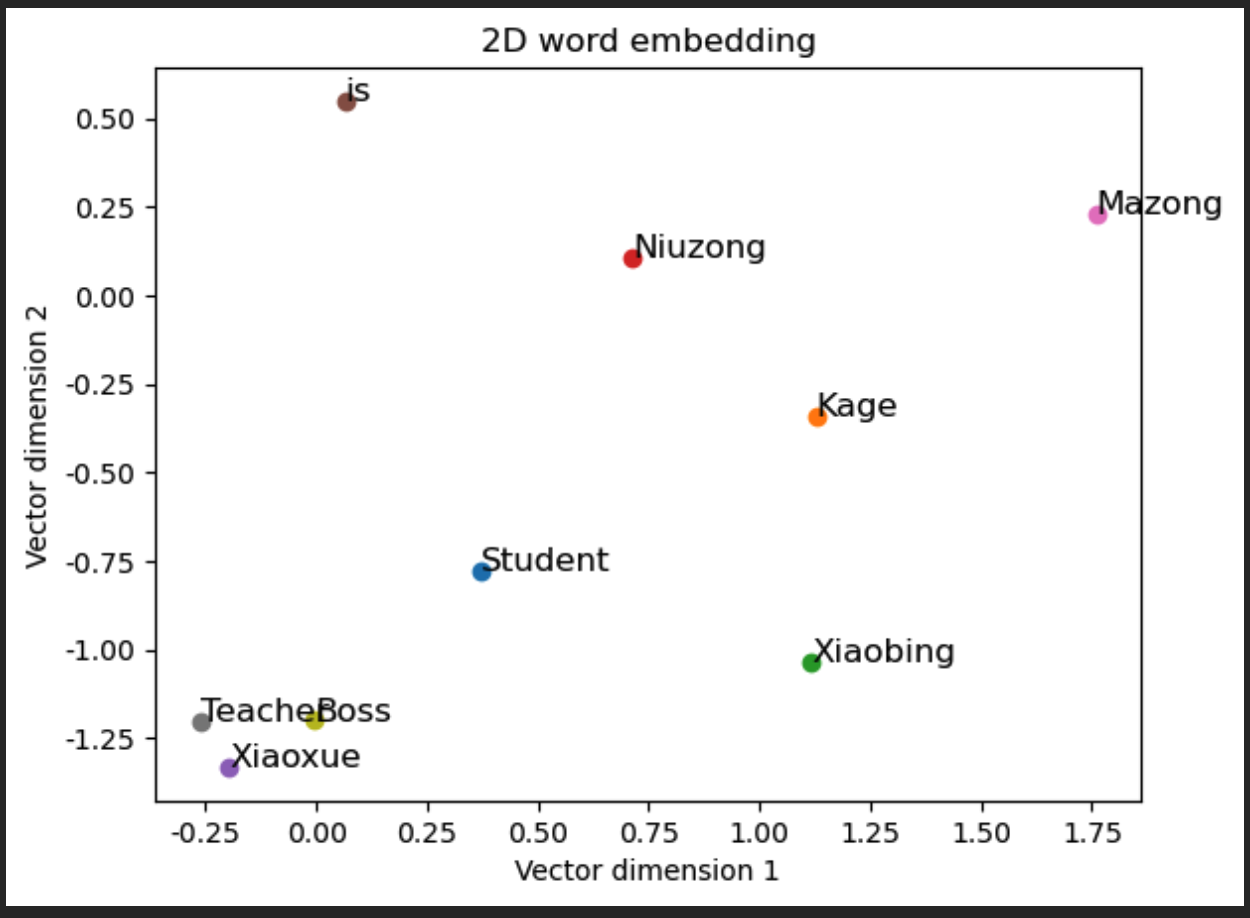
6. 输出CBOW词向量
# 输出CBOW习得的词嵌入
print("\nCBOW词嵌入:")
for word, idx in word_to_idx.items(): # 输出每个单词的嵌入向量print(f"{word}: \{cbow_model.input_to_hidden.weight[:, idx].detach().numpy()}")
plt.rcParams["font.family"]=['SimHei'] # 用来设定字体样式
plt.rcParams['font.sans-serif']=['SimHei'] # 用来设定无衬线字体样式
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
# 绘制二维词向量图
fig, ax = plt.subplots()
for word, idx in word_to_idx.items():vec = cbow_model.input_to_hidden.weight[:, \idx].detach().numpy() # 获取每个单词的嵌入向量ax.scatter(vec[0], vec[1]) # 在图中绘制嵌入向量的点ax.annotate(word, (vec[0], vec[1]), fontsize=12) # 点旁添加单词标签
plt.title('2维词嵌入') # 图题
plt.xlabel('向量维度1') # X轴Label
plt.ylabel('向量维度2') # Y轴Label
plt.show() # 显示图
相关文章:
Word2Vec基本实践
系列文章目录 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 例如:第一章 Python 机器学习入门之pandas的使用 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目…...
IIS配置網站登錄驗證,禁止匿名登陸
需要維護一個以前的舊系統,這個系統在內網運行,需要抓取電腦的登陸賬號,作為權限管理的一部分因此需要在IIS配置一下...

抖音矩阵系统搭建,AI剪辑短视频,一键管理矩阵账号
目录 前言: 一、抖音矩阵系统有哪些功能? 1.AI智能文案 2.多平台账号授权 3.多种剪辑模式 4. 矩阵一键发布,智能发布 5.抖音爆店码功能 6.私信实时互动 7.去水印及外链 二、抖音矩阵系统可以解决哪些问题? 总结ÿ…...

山东大学软件学院创新项目实训开发日志——收尾篇
山东大学软件学院创新项目实训开发日志——收尾篇 项目名称:ModuFusion Visionary:实现跨模态文本与视觉的相关推荐 -------项目目标: 本项目旨在开发一款跨模态交互式应用,用户可以上传图片或视频,并使用文本、点、…...

vue2.7支持组合式API,但是对应的vue-router3并不支持useRoute、useRouter。
最近在做一个项目,因为目标用户浏览器版本并不确定,可能会有较旧版本,于是采用vue2.7而不是vue3,最近一年多使用vue3开发的项目都碰到了很多chrome 63-73版本,而对应UI 库 element plus又问题很多。 为了不碰到这些问…...
摊位纠纷演变肢体冲突,倒赔了500:残疾夫妇与摊主谁之过?
在一个小商贩密集的街区,一起由摊位纠纷引发的肢体冲突事件在当地社区和网络上引起了热议。涉事双方为一名摊主和一对残疾夫妇,他们的争执源自对一个摊位的使用权。本是口头上的争吵,却由于双方情绪激动,迅速升级为肢体冲突&#…...
深入理解和实现Windows进程间通信(消息队列)
常见的进程间通信方法 常见的进程间通信方法有: 管道(Pipe)消息队列共享内存信号量套接字 下面,我们将详细介绍消息队列的原理以及具体实现。 什么是消息队列? Windows操作系统使用消息机制来促进应用程序与操作系…...

Web网页前端教程免费:引领您踏入编程的奇幻世界
Web网页前端教程免费:引领您踏入编程的奇幻世界 在当今数字化时代,Web前端技术已成为互联网发展的重要驱动力。想要踏入这一领域,掌握相关技能,却苦于找不到合适的教程?别担心,本文将为您带来一份免费的We…...

北斗短报文终端在应急消防通信场景中的应用
在应对自然灾害和紧急情况时,北斗三号短报文终端以其全球覆盖、实时通信和精准定位的能力,成为应急消防通信的得力助手。它不仅能够在地面通信中断的极端条件下保障信息传递的畅通,还能提供精准的位置信息,为救援行动提供有力支持…...

Java跳动爱心代码
1.计算爱心曲线上的点的公式 计算爱心曲线上的点的公式通常基于参数方程。以下是两种常见的参数方程表示方法,用于绘制爱心曲线: 1.1基于 (x, y) 坐标的参数方程 x a * (2 * cos(θ) - sin(θ))^3 y a * (2 * sin(θ) - cos(θ))^3 其中ÿ…...
)
Swift Combine — Operators(常用Filtering类操作符介绍)
目录 filter(_: )tryFilter(_: )compactMap(_: )tryCompactMap(_: )removeDuplicates()first(where:)last(where:) Combine中对 Publisher的值进行操作的方法称为 Operator(操作符)。 Combine中的 Operator通常会生成一个 Publisher,该 …...

Windows11+CUDA12.0+RTX4090如何配置安装Tensorflow2-GPU环境?
1 引言 电脑配置 Windows 11 cuda 12.0 RTX4090 由于tensorflow2官网已经不支持cuda11以上的版本了,配置cuda和tensorflow可以通过以下步骤配置实现。 2 步骤 (1)创建conda环境并安装cuda和cudnn,以及安装tensorflow2.10 con…...

韩顺平0基础学Java——第27天
p548-568 明天开始坦克大战 Entry 昨天没搞明白的Map、Entry、EntrySet://GPT教的 Map 和 Entry 的关系 1.Map 接口:它定义了一些方法来操作键值对集合。常用的实现类有 HashMap、TreeMap 等。 2. Entry接口:Entry 是 Map 接口的一个嵌…...

YesPMP探索Python在生活中的应用,助力提升开发效率
Python是一种简单易学、高效强大的编程语言,正变成越来越多人选择的热门技能。学习Python不仅可以提供更多就业机会,还能让自己在职场更加有竞争力,那可以去哪里拓展自己的技能呢? YesPMP平台 为熟练掌握Python语言的程序员提供了…...

TikTok账号运营:静态住宅IP为什么可以防封?
静态住宅IP代理服务是一种提供稳定、静态IP地址并可隐藏用户真实IP地址的网络代理服务。此类代理服务通常使用高速光纤网络来提供稳定、高速的互联网体验。与动态IP代理相比,静态住宅IP代理的IP地址更稳定,被封的可能性更小,因此更受用户欢迎…...
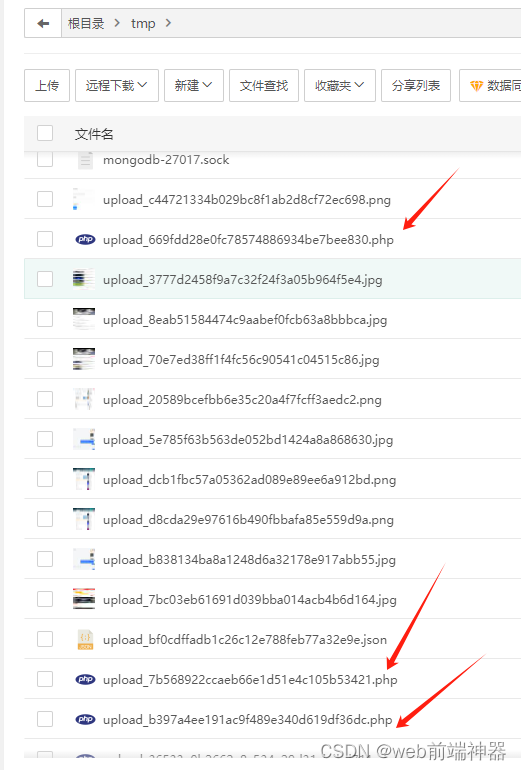
linux系统宝塔服务器temp文件夹里总是被上传病毒php脚本
目录 简介 上传过程 修复上传漏洞 tmp文件夹总是被上传病毒文件如下图: 简介 服务器时不时的会发送短信说你服务器有病毒, 找到了这个tmp文件, 删除了之后又有了。 确实是有很多人就这么无聊, 每天都攻击你的服务器。 找了很久的原因, 网上也提供了一大堆方法,…...

HTML+CSS+PHP实现网页留言板功能(需要创建数据库)
话说前头,我这方面很菜滴。这是我网页作业的一部分。 1.body部分效果展示(不包括footer) 2、代码 2.1 leaving.php(看到的网页) <!DOCTYPE html> <html lang"en"> <head> <met…...

【谷歌】实用的搜索技巧
1、使用正确的谷歌网址 我们知道https://www.google.com是谷歌的网址。但根据国家,用户可能会被重定向到 google.fr(法国)或google.co.in(印度)。 最主要的URL——google.com是为美国用户准备的(或是针对全世界所有用户的唯一URL))。当你在谷歌上搜索时,了解这一点是相…...
打造完美启动页:关键策略与设计技巧
启动页(Splash Screen)设计是指在应用程序启动时,首先展示给用户的界面设计。这个界面通常在应用加载或初始化期间显示,其主要目的是为用户提供一个视觉缓冲,展示品牌标识,并减少用户在等待过程中的焦虑感。…...

电子书(chm)-加载JS--CS上线
免责声明: 本文仅做技术交流与学习... 目录 cs--web投递 html(js)代码 html生成chm工具--EasyCHM 1-选择powershell 模式 生成 2-选择bitsadmin模式生成 chm反编译成html cs--web投递 cs配置监听器--->攻击---->web投递---> 端口选择没占用的, URL路径到时候会在…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

【HTTP三个基础问题】
面试官您好!HTTP是超文本传输协议,是互联网上客户端和服务器之间传输超文本数据(比如文字、图片、音频、视频等)的核心协议,当前互联网应用最广泛的版本是HTTP1.1,它基于经典的C/S模型,也就是客…...

HarmonyOS运动开发:如何用mpchart绘制运动配速图表
##鸿蒙核心技术##运动开发##Sensor Service Kit(传感器服务)# 前言 在运动类应用中,运动数据的可视化是提升用户体验的重要环节。通过直观的图表展示运动过程中的关键数据,如配速、距离、卡路里消耗等,用户可以更清晰…...
宇树科技,改名了!
提到国内具身智能和机器人领域的代表企业,那宇树科技(Unitree)必须名列其榜。 最近,宇树科技的一项新变动消息在业界引发了不少关注和讨论,即: 宇树向其合作伙伴发布了一封公司名称变更函称,因…...

计算机基础知识解析:从应用到架构的全面拆解
目录 前言 1、 计算机的应用领域:无处不在的数字助手 2、 计算机的进化史:从算盘到量子计算 3、计算机的分类:不止 “台式机和笔记本” 4、计算机的组件:硬件与软件的协同 4.1 硬件:五大核心部件 4.2 软件&#…...

Caliper 配置文件解析:fisco-bcos.json
config.yaml 文件 config.yaml 是 Caliper 的主配置文件,通常包含以下内容: test:name: fisco-bcos-test # 测试名称description: Performance test of FISCO-BCOS # 测试描述workers:type: local # 工作进程类型number: 5 # 工作进程数量monitor:type: - docker- pro…...