Pytorch构建vgg16模型
VGG-16
1. 导入工具包
import torch.optim as optim
import torch
import torch.nn as nn
import torch.utils.data
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from torch.utils.data import DataLoader
import torch.optim.lr_scheduler as lr_scheduler
import os
注:
torch: 这是PyTorch框架的基础库,提供了自动求导机制和丰富的张量运算支持,是构建和训练神经网络的基础。
torch.nn: PyTorch的神经网络库,包含多种构建神经网络所需的层结构(如卷积层、全连接层)和激活函数等
torch.utils.data: 提供了数据加载和处理的工具,是加载数据集并进行批处理的重要模块
torchvision.transforms: PyTorch的视觉库中的一个模块,提供了一系列图像处理的变换操作,用于数据增强和预处理
torchvision.datasets: 提供了常见的数据集和相关的数据加载方法,如MNIST、CIFAR-10、ImageNet等
DataLoader: torch.utils.data中的一个类,用于构建可迭代的数据加载器,可以方便地在训练循环中按批次加载数据
torch.optim.lr_scheduler: 提供了学习率调整策略,如学习率衰减,有助于训练过程中改善模型性能和减少过拟合
os: Python的标准库之一,提供了与操作系统交互的功能,如文件创建、路径操作等
2. 判断环境是CPU运行还是GPU
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
注:通过这行代码,程序可以根据当前环境自动选择最佳的计算设备,以提高计算效率和性能。在GPU上运行可以显著加速深度学习模型的训练和推理过程。
3. 数据预处理
# 定义数据预处理
transform = {'train': transforms.Compose([transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),transforms.RandomRotation(degrees=15),transforms.RandomHorizontalFlip(),transforms.CenterCrop(size=224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])]),'val': transforms.Compose([transforms.Resize(size=256),transforms.CenterCrop(size=224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])])
}
注:
训练数据预处理 (transform[‘train’])
transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)): 随机裁剪图像,裁剪后的图像大小为256x256像素。裁剪区域的大小是原始图像尺寸的0.8到1.0倍之间随机选择
transforms.RandomRotation(degrees=15): 随机旋转图像,旋转角度在-15度到15度之间随机选择
transforms.RandomHorizontalFlip(): 随机水平翻转图像,即有一半的概率会翻转,一半的概率不翻
transforms.CenterCrop(size=224): 从图像中心裁剪出224x224像素的区域
transforms.ToTensor(): 将图像转换为PyTorch张量,并且将像素值从[0, 255]范围缩放到[0, 1]范围
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]): 对图像进行标准化处理。这里使用的是ImageNet数据集的均值和标准差,这些值分别用于每个颜色通道的减均值和除以标准差操作
验证数据预处理 (transform[‘val’])
transforms.Resize(size=256): 将图像大小调整为256x256像素,这里没有使用随机裁剪,而是直接调整大小
transforms.CenterCrop(size=224): 从图像中心裁剪出224x224像素的区域
transforms.ToTensor(): 将图像转换为PyTorch张量,并且将像素值从[0, 255]范围缩放到[0, 1]范围
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]): 对图像进行标准化处理,使用的是ImageNet数据集的均值和标准差
4. 读取数据
dataset = './dataset'
train_directory = os.path.join(dataset, 'train')
valid_directory = os.path.join(dataset, 'val')
注:
valid_directory = os.path.join(dataset, ‘val’):同样地,这行代码将dataset目录和字符串’val’连接起来,创建验证数据集的路径。valid_directory将包含数据集根目录下的验证数据子目录的完整路径。这两行代码通常用于准备深度学习实验的数据集路径,以便在后续的数据加载和模型训练过程中引用这些路径。
5. 设置超参数
batch_size = 32
num_classes = 2 # 修改为您的分类数
注:batch_size = 32:这行代码设置了批量大小(batch size)为32。批量大小是指在一次梯度更新中使用的样本数量。在训练神经网络时,通常会一次性处理一小批数据样本,而不是整个数据集。批量大小的大小会影响模型的训练速度和稳定性。较小的批量大小可能会导致训练过程波动较大,而较大的批量大小可能会提高训练的稳定性但需要更多的内存。
num_classes = 2:这行代码设置了分类数(number of classes)为2,这意味着模型是一个二分类模型,用于区分两个不同的类别。如果您的任务需要识别更多的类别,比如多分类问题,您需要将这个值修改为实际类别的数量。例如,对于一个包含10个类别的数据集,您需要将 num_classes 设置为10。
6. 创建训练(train)和验证(val)数据集的数据加载器
data = {'train': datasets.ImageFolder(root=train_directory, transform=transform['train']),'val': datasets.ImageFolder(root=valid_directory, transform=transform['val'])
}
train_loader = DataLoader(data['train'], batch_size=batch_size, shuffle=True, num_workers=8)
test_loader = DataLoader(data['val'], batch_size=batch_size, shuffle=False, num_workers=8)
注:train_loader = DataLoader(…):这行代码创建了一个用于训练的数据加载器。DataLoader会遍历data[‘train’]中的数据,每次返回一个包含batch_size个样本的小批量。shuffle=True表示在每个epoch开始时,数据加载器会随机打乱数据顺序。num_workers=8表示使用8个子进程来同时加载数据,这可以在数据读取时提高效率。这些数据加载器在训练深度学习模型时非常重要,因为它们可以高效地加载和批量处理数据,同时还能够提供数据的随机化,这对于模型的泛化能力至关重要。
7. 定义VGG16模型
class VGG16(nn.Module):def __init__(self, num_classes=1000):super(VGG16, self).__init__()self.features = nn.Sequential(# Block 1nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(64, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# Block 2nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(128, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# Block 3nn.Conv2d(128, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# Block 4nn.Conv2d(256, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# Block 5nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),)self.classifier = nn.Sequential(nn.Linear(512 * 7 * 7, 4096),nn.ReLU(True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(True),nn.Dropout(),nn.Linear(4096, num_classes) # 修改这里,默认为1000个类别)def forward(self, x):x = self.features(x)x = torch.flatten(x, 1) # 展开特征图x = self.classifier(x)return x
注:这段代码定义了一个继承自nn.Module的类VGG16,它是一个用于图像分类的卷积神经网络模型。
class VGG16(nn.Module):定义了一个名为VGG16的类,它继承自nn.Module,这是PyTorch中定义神经网络模型的基础类。
def init(self, num_classes=1000):这是类的构造函数,它接受一个可选参数num_classes,默认值为1000。这个参数决定了模型的输出层有多少个神经元,对应于分类任务中的类别数。
super(VGG16, self).init():调用父类nn.Module的构造函数。
self.features = nn.Sequential(…):创建了一个序列模块self.features,它包含了一系列的卷积层、ReLU激活函数和最大池化层。这些层组成了VGG-16的卷积部分。
self.classifier = nn.Sequential(…):创建了一个序列模块self.classifier,它包含了一系列的全连接层、ReLU激活函数和dropout层。这些层组成了VGG-16的全连接部分。
nn.Linear(512 * 7 * 7, 4096):第一个全连接层有512个输入神经元,对应于卷积部分最后一个池化层后的特征图大小(512个特征图,每个特征图7x7像素),输出4096个神经元。
nn.Linear(4096, 4096):第二个全连接层有4096个输入神经元,对应于第一个全连接层的输出,输出4096个神经元。
nn.Linear(4096, num_classes):输出层有num_classes个输入神经元,对应于分类任务的类别数,输出num_classes个神经元。
def forward(self, x):定义了模型的前向传播函数。这个函数定义了当输入一个张量x时,模型如何计算输出。
x = self.features(x):通过self.features模块处理输入的图像x,得到一系列的卷积特征。
x = torch.flatten(x, 1):将特征图x展平为一个一维张量,以便输入到全连接层。
x = self.classifier(x):通过self.classifier模块处理展平的特征,得到最终的分类结果。
return x:返回模型的输出,通常是一个包含每个类别概率的向量。
8. 初始化VGG-16模型
vgg16 = VGG16(num_classes=2)
vgg16 = vgg16.to(DEVICE)
注:
vgg16 = VGG16(num_classes=2): 这行代码创建了一个VGG-16模型的实例,并将输出类别数设置为2。这意味着模型的最后一层全连接层将有2个输出节点,对应于两个类别
vgg16 = vgg16.to(DEVICE): 这行代码将创建的VGG-16模型移动到指定的设备上。这里的DEVICE应该是一个之前定义的变量,表示您希望模型运行的设备。例如,如果DEVICE是torch.device(‘cuda’),则模型将被移动到GPU上;如果DEVICE是torch.device(‘cpu’),则模型将在CPU上运行
9. 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(vgg16.parameters(), lr=0.001, momentum=0.9)
注:
optimizer = optim.SGD(vgg16.parameters(), lr=0.001, momentum=0.9):这里创建了一个SGD优化器的实例,它是随机梯度下降(Stochastic Gradient Descent)的缩写。SGD优化器用于更新模型的参数,以最小化损失函数。vgg16.parameters()表示要优化的参数集合,包括所有的卷积层、全连接层等。lr=0.001表示学习率,即每次迭代时参数更新的步长。momentum=0.9表示动量,这是一种加速SGD收敛的技术,它利用了之前的梯度信息来调整当前梯度。
10. 定义学习率调整策略
scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
注:
scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1):这里创建了一个StepLR调度器的实例。StepLR是一种简单的学习率调度策略,它在训练过程中按照预定的步长step_size来调整学习率。每个步长结束后,学习率会按照gamma的比例进行缩减。optimizer是需要调度的优化器,而step_size=7表示每7个epoch学习率会调整一次,gamma=0.1表示每次调整时学习率会减少10%。
学习率调度器在训练过程中是非常有用的,尤其是在使用较大的学习率时,它可以帮助模型在训练的早期阶段快速收敛,然后在后期阶段更加稳定地优化模型。这样可以防止模型在训练早期过拟合,并在后期仍然保持较好的性能。
11. 定义训练过程
def train(model, device, train_loader, optimizer, criterion, epoch):model.train()running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 修正缩进optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()running_loss += loss.item()_, predicted = torch.max(output.data, 1)total += target.size(0)correct += (predicted == target).sum().item()if batch_idx % 10 == 0: # 每10个批次打印一次print(f'Epoch {epoch}, Batch {batch_idx}, Loss: {loss.item()}')print(f'Epoch {epoch}, Loss: {running_loss / len(train_loader)}, Accuracy: {100 * correct / total}%')
注:
model.train():将模型设置为训练模式,这会启用如批标准化(Batch Normalization)和dropout等训练时的特定功能。
running_loss = 0.0:初始化一个变量来记录当前epoch的损失总和。
correct = 0 和 total = 0:初始化两个变量来记录当前epoch的预测正确的数量和总数量。
for batch_idx, (data, target) in enumerate(train_loader):循环遍历训练数据加载器的每个批次。batch_idx是当前批次的索引,(data, target)是当前批次的数据和目标标签。
data, target = data.to(device), target.to(device):将数据和标签移动到指定的设备上。如果device是’cuda’,则数据会被复制到GPU上;如果是’cpu’,则数据会保留在CPU上。
optimizer.zero_grad():清空所有参数的梯度,以便在新的批数据上重新计算。
output = model(data):通过模型计算输出。
loss = criterion(output, target):计算损失,使用output和target。
loss.backward():反向传播计算损失的梯度。
optimizer.step():使用计算出的梯度来更新模型的参数。
running_loss += loss.item():累加损失值。
_, predicted = torch.max(output.data, 1):预测输出中的最大值所在的索引,这代表了模型对每个样本的预测类别。
11.定义验证过程
# 定义验证过程
def val(model, device, test_loader, criterion):model.eval()running_loss = 0.0correct = 0total = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)loss = criterion(output, target)running_loss += loss.item()_, predicted = torch.max(output.data, 1)total += target.size(0)correct += (predicted == target).sum().item()print(f'Validation, Loss: {running_loss / len(test_loader)}, Accuracy: {100 * correct / total}%')
注:
model.eval(): 这行代码将模型设置为评估模式。在某些模型中,训练模式和评估模式(例如BatchNorm和Dropout)的行为是不同的
running_loss = 0.0: 初始化运行损失为0,用于累加每个批次的损失
correct = 0: 初始化正确分类的样本数为0
total = 0: 初始化总样本数为0
with torch.no_grad(): 这个上下文管理器用于告诉PyTorch在接下来的代码块中不要计算梯度。因为在验证过程中我们不需要更新模型参数,所以不需要计算梯度
for data, target in test_loader: 这行代码开始一个循环,遍历验证数据加载器test_loader中的每个批次。data是当前批次的数据,target是当前批次的目标标签
data, target = data.to(device), target.to(device): 这行代码将数据和目标标签移动到之前定义的设备上,如果设备是GPU,这将使数据能够在GPU上进行计算
12.训练模型
EPOCHS = 10
for epoch in range(1, EPOCHS + 1):train(vgg16, DEVICE, train_loader, optimizer, criterion, epoch)val(vgg16, DEVICE, test_loader, criterion)scheduler.step() # 调整学习率
注:
EPOCHS = 10:定义了一个变量EPOCHS,其值为10,表示模型将进行10个epoch的训练。
for epoch in range(1, EPOCHS + 1):开始一个循环,循环的起始值为1,结束值为EPOCHS + 1。每个epoch代表模型在训练数据上的一个完整遍历。
train(vgg16, DEVICE, train_loader, optimizer, criterion, epoch):调用train函数,传入模型vgg16、设备DEVICE、训练数据加载器train_loader、优化器optimizer、损失函数criterion和当前的epoch。train函数负责训练模型,即执行前向传播、计算损失、反向传播和更新参数。
val(vgg16, DEVICE, test_loader, criterion):调用val函数,传入模型vgg16、设备DEVICE、测试数据加载器test_loader和损失函数criterion。val函数负责评估模型的性能,即在测试数据上执行前向传播并计算损失。
scheduler.step():在每个epoch结束后,调用学习率调度器scheduler的step方法,根据预定的策略调整学习率。这有助于模型在训练过程中适应不同的学习速率,以达到更好的性能。
通过这个循环,模型将在训练数据上进行10个epoch的训练,并在每个epoch结束后在测试数据上评估其性能,并调整学习率。这样可以逐渐优化模型的性能,使其在测试数据上达到较好的准确率。
13.保存模型的状态字典
torch.save(vgg16.state_dict(), 'vgg16_model_weights.pth')

注:
torch.save(vgg16.state_dict(), ‘vgg16_model_weights.pth’):这里使用torch.save函数将模型vgg16的权重(state_dict)保存到文件中。vgg16.state_dict()会返回一个包含模型所有参数的字典,每个键值对代表模型的一个参数及其值。
‘vgg16_model_weights.pth’:这是保存文件的名字,.pth是PyTorch保存文件常用的扩展名。这个文件通常包含了模型的权重,可以用于模型的复现或进一步的训练。
通过这行代码,你可以将训练好的模型权重保存到文件中,以便在后续的实验中使用。这有助于避免每次训练都从头开始,也可以方便地将模型分享给其他研究者或团队成员。
相关文章:
Pytorch构建vgg16模型
VGG-16 1. 导入工具包 import torch.optim as optim import torch import torch.nn as nn import torch.utils.data import torchvision.transforms as transforms import torchvision.datasets as datasets from torch.utils.data import DataLoader import torch.optim.lr_…...
分支结构相关
1.if 语句 结构: if 条件语句: 代码块 小练习: 使用random.randint()函数随机生成一个1~100之间的整数,判断是否是偶数 import random n random.randint(1,100) print(n) if n % 2 0:print(str(n) "是偶数") 2.else语…...

flutter开发实战-RichText富文本居中对齐
flutter开发实战-RichText富文本居中对齐 在开发过程中,经常会使用到RichText,当使用RichText时候,不同文本字体大小默认没有居中对齐。这里记录一下设置过程。 一、使用RichText 我这里使用RichText设置不同字体大小的文本 Container(de…...
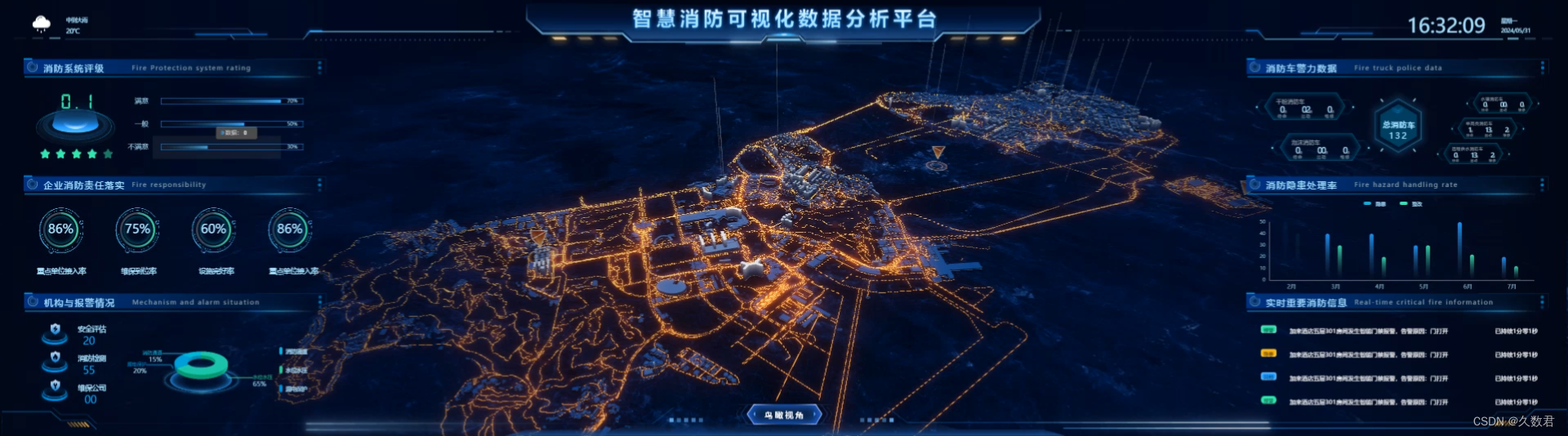
智慧消防新篇章:可视化数据分析平台引领未来
一、什么是智慧消防可视化数据分析平台? 智慧消防可视化数据分析平台,运用大数据、云计算、物联网等先进技术,将消防信息以直观、易懂的图形化方式展示出来。它不仅能够实时监控消防设备的运行状态,还能对火灾风险进行预测和评估…...

u8g2 使用IIC驱动uc1617 lcd有时候某些像素显示不正确
折腾了很久,本来lcd是挂载到已经存在的iic总线上的,总线原来是工作正常的,挂载之后lcd也能显示,但是有时候显示不正确,有时候全白的时候有黑色的杂点。 解决方案: 1.最开始以为是IIC总线速度快࿰…...

使用opencv合并两个图像
本节的目的 linear blending(线性混合)使用**addWeighted()**来添加两个图像 原理 (其实我也没太懂,留个坑,感觉本科的时候线代没学好。不对,我本科就没学线代。) 源码分析 源码链接 #include "opencv2/imgc…...
k8s学习笔记(一)
configMap 一般用来存储配置信息 创建configMap 从文件中获取信息创建:kubectl create configmap my-config --from-file/tmp/k8s/user.txt 直接指定信息: kubectl create configmap my-config01 --from-literalkey1config1 --from-literalkey2confi…...

自学前端——JavaScript篇
JavaScript 什么是JavsScript JavaScript是一种轻量级、解释型、面向对象的脚本语言。它主要被设计用于在网页上实现动态效果,增加用户与网页的交互性。 作为一种客户端语言,JavaScript可以直接嵌入HTML,并在浏览器中执行。 与HTML和CSS不…...

高考毕业季--浅谈自己感想
随着2024年高考落幕,数百万高三学生又将面临人生中的重要抉择:选择大学专业。在这个关键节点,计算机相关专业是否仍是“万金油”的选择?在过去很长一段时间里,计算机科学与技术、人工智能、网络安全、软件工程等专业一…...
遥感图像地物覆盖分类,数据集制作-分类模型对比-分类保姆级教程
遥感图像地物覆盖分类,数据集制作-分类模型对比-分类保姆级教程 在遥感影像上人工制作分类数据集采用python+gdal库制作数据集挑选分类模型(RF、KNN、SVM、逻辑回归)选择随机森林模型建模分类遥感图像预测在遥感影像上人工制作分类数据集 1.新建shp文件 地理坐标系保持和影像…...

【Android面试八股文】Kotlin内置标准函数let的原理是什么?
确实,let 函数在 Kotlin 中被广泛使用,特别是在处理可空类型或者需要在对象上执行一系列操作后返回结果的场景中非常有用。 let 函数的源代码 /*** Calls the specified function [block] with `this` value as its argument and returns its result.** For detailed usage i…...

网工面试总结1
网工还是要基本会ACL、ISIS、OSPF、MPLS、QOS、GVRP、VRRP、FW、BGP、STP、IV4\6、WLAN、路由策略、策略路由、LACP等都或多或少要知道,常见的哪怕没有实战,要在ensp、cisco中练过! OSPF邻居故障,你认为是哪些原因?或者…...
[stm32]密码锁
[stm32]密码锁 需要资料的请在文章末尾获取~ 01描述 使用原件:stm32f103c8t6最小系统板x1,0.96寸OLED显示屏四角x1,4x4矩阵按键x1; 键位对应图: 1, 2, 3, 4------------- 1 2 3 4 5&am…...

优化yarn在任务执行时核数把控不准确的问题
核数不准这个事情是个概率问题,如果你碰见了,只能说你有点非欧,本质上是因为集群配置问题,默认时yarn不会去精准把控任务的核数,因为默认的资源计算方式是用实际内存去估算核数,这就导致如果大家配置任务时…...

2024年,收付通申请开通流程
大家好,今天咱们来聊聊关于APP场景中开通微信收付通的一些实用小窍门。在如今的移动互联网时代,很多商家都选择通过APP来提供服务和产品,因此如何在APP中顺利集成微信收付通功能,让用户能够轻松完成支付,就显得尤为重要…...

Django使用django-apscheduler实现定时任务
定时任务可以在后台定时执行指定的代码,避免了很多人为操作。下面是在Django项目中如何使用定时任务的具体操作流程。 我在这里使用的 django-apscheduler库来实现定时任务。 一、安装 django-apscheduler pip install django-apscheduler二、在项目的setting.py…...

python数据分析:修改数据
在 Python 中进行数据分析时,通常使用 pandas 库来处理和修改数据。以下是一个完整的示例,展示如何使用 pandas 库读取数据、修改数据并保存结果。 1. 安装并导入必要的库 首先,确保你已经安装了 pandas 库。如果没有安装,可以使…...

【免费API推荐】:解锁无限创意,让您的应用更具竞争力(8)
热门高效的免费实用类API是当今开发者们追逐的宝藏。这些API提供了各种热门功能和服务,能够帮助开发者轻松地为应用程序增添实用性和吸引力。无论是人脸识别、自然语言处理、机器学习还是图像处理,这些热门高效的免费API提供了强大的功能和高效的性能&am…...

日语 11 12
11. 若者の意識 わかもの いしき 新作 新作 新作 新作 新作 しんさく 公開 公開 公開 公開 公開 こうかい 映像 映像 映像 映像 映像 えいぞう 人気 人気 人気 人気 人気 にんき 来週 来週 来週 来週 来週 らいしゅう 外国 外国 外国 外国 外…...

STM32程序启动过程
(1)首先对栈和堆的大小进行定义,并在代码区的起始处建立中断向量表,其第一个表项是栈顶地址(32位),第二个表项是复位中断服务入口地址; (2)然后执行复位中断&…...
结构体的进阶应用)
基于算法竞赛的c++编程(28)结构体的进阶应用
结构体的嵌套与复杂数据组织 在C中,结构体可以嵌套使用,形成更复杂的数据结构。例如,可以通过嵌套结构体描述多层级数据关系: struct Address {string city;string street;int zipCode; };struct Employee {string name;int id;…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

生成 Git SSH 证书
🔑 1. 生成 SSH 密钥对 在终端(Windows 使用 Git Bash,Mac/Linux 使用 Terminal)执行命令: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 参数说明: -t rsa&#x…...

【OSG学习笔记】Day 16: 骨骼动画与蒙皮(osgAnimation)
骨骼动画基础 骨骼动画是 3D 计算机图形中常用的技术,它通过以下两个主要组件实现角色动画。 骨骼系统 (Skeleton):由层级结构的骨头组成,类似于人体骨骼蒙皮 (Mesh Skinning):将模型网格顶点绑定到骨骼上,使骨骼移动…...

基于PHP的连锁酒店管理系统
有需要请加文章底部Q哦 可远程调试 基于PHP的连锁酒店管理系统 一 介绍 连锁酒店管理系统基于原生PHP开发,数据库mysql,前端bootstrap。系统角色分为用户和管理员。 技术栈 phpmysqlbootstrapphpstudyvscode 二 功能 用户 1 注册/登录/注销 2 个人中…...

论文阅读笔记——Muffin: Testing Deep Learning Libraries via Neural Architecture Fuzzing
Muffin 论文 现有方法 CRADLE 和 LEMON,依赖模型推理阶段输出进行差分测试,但在训练阶段是不可行的,因为训练阶段直到最后才有固定输出,中间过程是不断变化的。API 库覆盖低,因为各个 API 都是在各种具体场景下使用。…...

前端中slice和splic的区别
1. slice slice 用于从数组中提取一部分元素,返回一个新的数组。 特点: 不修改原数组:slice 不会改变原数组,而是返回一个新的数组。提取数组的部分:slice 会根据指定的开始索引和结束索引提取数组的一部分。不包含…...