Mybatis Plus 详解 IService、BaseMapper、自动填充、分页查询功能
结构直接看目录
前言
MyBatis-Plus 是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
愿景
我们的愿景是成为 MyBatis 最好的搭档,就像 魂斗罗 中的 1P、2P,基友搭配,效率翻倍。

特性:
- 无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
- 损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
- 强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
- 支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错
- 支持主键自动生成:支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题
- 支持 ActiveRecord 模式:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作
- 支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )
- 内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用
- 内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
- 分页插件支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等多种数据库
- 内置性能分析插件:可输出 SQL 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询
- 内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作
SpringBoot使用
将以下内容引入pom.xml
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.4.2</version></dependency>
以下内容可自选
spring:#配置数据源信息datasource:type: com.zaxxer.hikari.HikariDataSource#配置数据库连接信息driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhostusername: rootpassword: root#mybatisplus添加日志功能
mybatis-plus:configuration:log-impl: org.apache.ibatis.logging.stdout.stdOutImpl
global-config:db-config:#配置Mybatis-plus操作表的默认前缀table-prefix: t_#配置Mybatis-plus的主键策略id-type: auto配置文件注意事项
驱动类driver-class-name
spring boot 2.0(内置jdbc5驱动),驱动类使用:driver-class-name: com.mysql.jdbc.Driver
spring boot 2.1及以上(内置jdbc8驱动),驱动类使用:
driver-class-name: com.mysql.cj.jdbc.Driver
否则运行测试用例的时候会有 WARN 信息
连接地址url
MySQL5.7版本的url:
jdbc:mysql://localhost:3306/?characterEncoding=utf-8&useSSL=false
MySQL8.0版本的url:
jdbc:mysql://localhost:3306/?
serverTimezone=GMT%2B8&characterEncoding=utf-8&useSSL=false
注意事项
// 这个属性用于指定 MyBatis Mapper XML 文件的位置,例如:mybatis-plus: mapper-locations: classpath*:/mapper/*Mapper.xml
mybatis-plus.mapper-locations
// 这个属性用于设置是否显示 MyBatis-Plus 的启动 banner。在示例中,该属性被设置为 false,表示禁用启动 banner
mybatis-plus.global-config.banner
// 这个属性用于设置主键 ID 的生成策略。在示例中,auto 表示使用数据库自动生成的主键 ID
mybatis-plus.global-config.db-config.id-type:auto
// 这些属性用于设置全局的 SQL 过滤策略。在示例中,not_empty 表示只在参数值非空时才会生成对应的 SQL 条件
mybatis-plus.global-config.db-config.where-strategy:not_empty
mybatis-plus.global-config.db-config.insert-strategy:not_empty
mybatis-plus.global-config.db-config.update-strategy:not_null
// 这个属性用于设置在 SQL 中处理空值时使用的 JDBC 类型。在示例中,'null' 表示使用 NULL 类型
mybatis-plus.configuration.jdbc-type-for-null:'null'
// 这个属性用于设置是否在设置属性为 NULL 时调用对应的 setter 方法。在示例中,该属性被设置为 true,表示在设置属性为 NULL 时会调用 setter 方法
mybatis-plus.configuration.call-setters-on-nulls:true
引导类中添加 @MapperScan 注解,扫描 Mapper 文件夹
@SpringBootApplication
@MapperScan("com.baomidou.mybatisplus.samples.quickstart.mapper")
public class MPApplication {public static void main(String[] args) {SpringApplication.run(Application.class, args);}}
建立实体类
自行建立一个实体,可以是最简单的 学生,姓名,班级,学号
建立Mapper层
继承BaseMapper,后面的实体写自己的实体
@Mapper
public interface UserMapper extends BaseMapper<UserEntity>{}
建立Service层
建立Service接口
public interface UserService extends IService<UserEntity> {}建立Service接口实现类ServiceImpl
@Slf4j@Servicepublic class UserServiceImpl extends ServiceImpl<UserMapper, UserEntity> implements UserService {}Service Interface接口内容说明
插入功能save
// 插入一条记录(选择字段,策略插入)
boolean save(T entity);
// 插入(批量)
boolean saveBatch(Collection<T> entityList);
// 插入(批量)
boolean saveBatch(Collection<T> entityList, int batchSize);功能描述:插入记录,根据实体对象的字段进行策略性插入。
返回值: boolean,表示插入操作是否成功。
参数说明:
| 类型 | 参数名 | 描述 |
|---|---|---|
| T | entity | 实体对象 |
| Collection<T> | entityList | 实体对象集合 |
| int | batchSize | 插入批次数量 |
示例
// 假设有一个 User 实体对象
User user = new User();
user.setName("John Doe");
user.setEmail("john.doe@example.com");
boolean result = userService.save(user); // 调用 save 方法
if (result) {System.out.println("User saved successfully.");
} else {System.out.println("Failed to save user.");
}生成的 SQL:
INSERT INTO user (name, email) VALUES ('John Doe', 'john.doe@example.com')如果存在就更新不存在就新增 saveOrUpdate
功能描述: 根据实体对象的主键 ID 进行判断,存在则更新记录,否则插入记录。
返回值: boolean,表示插入或更新操作是否成功。
参数说明:
| 类型 | 参数名 | 描述 |
|---|---|---|
| T | entity | 实体对象 |
| Wrapper<T> | updateWrapper | 实体对象封装操作类 UpdateWrapper |
| Collection<T> | entityList | 实体对象集合 |
| int | batchSize | 插入批次数量 |
// TableId 注解属性值存在则更新记录,否插入一条记录
boolean saveOrUpdate(T entity);
// 根据updateWrapper尝试更新,否继续执行saveOrUpdate(T)方法
boolean saveOrUpdate(T entity, Wrapper<T> updateWrapper);
// 批量修改插入
boolean saveOrUpdateBatch(Collection<T> entityList);
// 批量修改插入
boolean saveOrUpdateBatch(Collection<T> entityList, int batchSize);示例
// 假设有一个 User 实体对象,其中 id 是 TableId 注解的属性
User user = new User();
user.setId(1);
user.setName("John Doe");
user.setEmail("john.doe@example.com");
boolean result = userService.saveOrUpdate(user); // 调用 saveOrUpdate 方法
if (result) {System.out.println("User updated or saved successfully.");
} else {System.out.println("Failed to update or save user.");
}生成的 SQL(假设 id 为 1 的记录已存在):
UPDATE user SET name = 'John Doe', email = 'john.doe@example.com' WHERE id = 1生成的 SQL(假设 id 为 1 的记录不存在):
INSERT INTO user (id, name, email) VALUES (1, 'John Doe', 'john.doe@example.com')
删除功能remove
// 根据 queryWrapper 设置的条件,删除记录
boolean remove(Wrapper<T> queryWrapper);
// 根据 ID 删除
boolean removeById(Serializable id);
// 根据 columnMap 条件,删除记录
boolean removeByMap(Map<String, Object> columnMap);
// 删除(根据ID 批量删除)
boolean removeByIds(Collection<? extends Serializable> idList);功能描述: 通过指定条件删除符合条件的记录。
返回值: boolean,表示删除操作是否成功。
参数说明:
| 类型 | 参数名 | 描述 |
|---|---|---|
| Wrapper<T> | queryWrapper | 实体包装类 QueryWrapper |
| Serializable | id | 主键 ID |
| Map<String, Object> | columnMap | 表字段 map 对象 |
| Collection<? extends Serializable> | idList | 主键 ID 列表 |
示例:
删除
// 假设有一个 QueryWrapper 对象,设置删除条件为 name = 'John Doe'
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("name", "John Doe");
boolean result = userService.remove(queryWrapper); // 调用 remove 方法
if (result) {System.out.println("Record deleted successfully.");
} else {System.out.println("Failed to delete record.");
}生成的 SQL:
DELETE FROM user WHERE name = 'John Doe'根据ID删除
// 假设要删除 ID 为 1 的用户
boolean result = userService.removeById(1); // 调用 removeById 方法
if (result) {System.out.println("User deleted successfully.");
} else {System.out.println("Failed to delete user.");
}生成的 SQL:
DELETE FROM user WHERE id = 1批量删除
// 假设有一组 ID 列表,批量删除用户
List<Integer> ids = Arrays.asList(1, 2, 3);
boolean result = userService.removeByIds(ids); // 调用 removeByIds 方法
if (result) {System.out.println("Users deleted successfully.");
} else {System.out.println("Failed to delete users.");
}生成的 SQL:
DELETE FROM user WHERE id IN (1, 2, 3)更新功能update
// 根据 UpdateWrapper 条件,更新记录 需要设置sqlset
boolean update(Wrapper<T> updateWrapper);
// 根据 whereWrapper 条件,更新记录
boolean update(T updateEntity, Wrapper<T> whereWrapper);
// 根据 ID 选择修改
boolean updateById(T entity);
// 根据ID 批量更新
boolean updateBatchById(Collection<T> entityList);
// 根据ID 批量更新
boolean updateBatchById(Collection<T> entityList, int batchSize);功能描述: 通过指定条件更新符合条件的记录。
返回值: boolean,表示更新操作是否成功。
参数说明:
| 类型 | 参数名 | 描述 |
|---|---|---|
| Wrapper<T> | updateWrapper | 实体对象封装操作类 UpdateWrapper |
| T | entity | 实体对象 |
| Collection<T> | entityList | 实体对象集合 |
| int | batchSize | 更新批次数量 |
根据元素进行更新
// 假设有一个 UpdateWrapper 对象,设置更新条件为 name = 'John Doe',更新字段为 email
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
updateWrapper.eq("name", "John Doe").set("email", "john.doe@newdomain.com");
boolean result = userService.update(updateWrapper); // 调用 update 方法
if (result) {System.out.println("Record updated successfully.");
} else {System.out.println("Failed to update record.");
}生成的 SQL:
UPDATE user SET email = 'john.doe@newdomain.com' WHERE name = 'John Doe'根据ID进行更新
// 假设有一个 User 实体对象,设置更新字段为 email,根据 ID 更新
User updateEntity = new User();
updateEntity.setId(1);
updateEntity.setEmail("updated.email@example.com");
boolean result = userService.updateById(updateEntity); // 调用 updateById 方法
if (result) {System.out.println("Record updated successfully.");
} else {System.out.println("Failed to update record.");
}生成的 SQL:
UPDATE user SET email = 'updated.email@example.com' WHERE id = 1查询功能get
// 根据 ID 查询
T getById(Serializable id);
// 根据 Wrapper,查询一条记录。结果集,如果是多个会抛出异常,随机取一条加上限制条件 wrapper.last("LIMIT 1")
T getOne(Wrapper<T> queryWrapper);
// 根据 Wrapper,查询一条记录
T getOne(Wrapper<T> queryWrapper, boolean throwEx);
// 根据 Wrapper,查询一条记录
Map<String, Object> getMap(Wrapper<T> queryWrapper);
// 根据 Wrapper,查询一条记录
<V> V getObj(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);功能描述: 根据指定条件查询符合条件的记录。
返回值: 查询结果,可能是实体对象、Map 对象或其他类型。
参数说明:
| 类型 | 参数名 | 描述 |
|---|---|---|
| Serializable | id | 主键 ID |
| Wrapper<T> | queryWrapper | 实体对象封装操作类 QueryWrapper |
| boolean | throwEx | 有多个 result 是否抛出异常 |
| T | entity | 实体对象 |
| Function<? super Object, V> | mapper | 转换函数 |
根据id进行查询
// 假设要查询 ID 为 1 的用户
User user = userService.getById(1); // 调用 getById 方法
if (user != null) {System.out.println("User found: " + user);
} else {System.out.println("User not found.");
}生成的 SQL:
SELECT * FROM user WHERE id = 1根据对象进行查询
// 假设有一个 QueryWrapper 对象,设置查询条件为 name = 'John Doe'
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("name", "John Doe");
User user = userService.getOne(queryWrapper); // 调用 getOne 方法
if (user != null) {System.out.println("User found: " + user);
} else {System.out.println("User not found.");
}生成的SQL:
SELECT * FROM user WHERE name = 'John Doe' LIMIT 1查询记录功能list
// 查询所有
List<T> list();
// 查询列表
List<T> list(Wrapper<T> queryWrapper);
// 查询(根据ID 批量查询)
Collection<T> listByIds(Collection<? extends Serializable> idList);
// 查询(根据 columnMap 条件)
Collection<T> listByMap(Map<String, Object> columnMap);
// 查询所有列表
List<Map<String, Object>> listMaps();
// 查询列表
List<Map<String, Object>> listMaps(Wrapper<T> queryWrapper);
// 查询全部记录
List<Object> listObjs();
// 查询全部记录
<V> List<V> listObjs(Function<? super Object, V> mapper);
// 根据 Wrapper 条件,查询全部记录
List<Object> listObjs(Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录
<V> List<V> listObjs(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);功能描述: 查询符合条件的记录。
返回值: 查询结果,可能是实体对象、Map 对象或其他类型。
参数说明:
| 类型 | 参数名 | 描述 |
|---|---|---|
| Wrapper<T> | queryWrapper | 实体对象封装操作类 QueryWrapper |
| Collection<? extends Serializable> | idList | 主键 ID 列表 |
| Map<String, Object> | columnMap | 表字段 map 对象 |
| Function<? super Object, V> | mapper | 转换函数 |
示例:
查询全部
// 查询所有用户
List<User> users = userService.list(); // 调用 list 方法
for (User user : users) {System.out.println("User: " + user);
}生成的SQL:
SELECT * FROM user根据实体进行查询
// 假设有一个 QueryWrapper 对象,设置查询条件为 age > 25
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.gt("age", 25);
List<User> users = userService.list(queryWrapper); // 调用 list 方法
for (User user : users) {System.out.println("User: " + user);
}生成的SQL:
SELECT * FROM user WHERE age > 25批量查询用户
// 假设有一组 ID 列表,批量查询用户
List<Integer> ids = Arrays.asList(1, 2, 3);
Collection<User> users = userService.listByIds(ids); // 调用 listByIds 方法
for (User user : users) {System.out.println("User: " + user);
}生成的SQL:
SELECT * FROM user WHERE id IN (1, 2, 3)分页查询
// 无条件分页查询
IPage<T> page(IPage<T> page);
// 条件分页查询
IPage<T> page(IPage<T> page, Wrapper<T> queryWrapper);
// 无条件分页查询
IPage<Map<String, Object>> pageMaps(IPage<T> page);
// 条件分页查询
IPage<Map<String, Object>> pageMaps(IPage<T> page, Wrapper<T> queryWrapper);功能描述: 分页查询符合条件的记录。
返回值: 分页查询结果,包含记录列表和总记录数。
参数说明:
| 类型 | 参数名 | 描述 |
|---|---|---|
| IPage<T> | page | 翻页对象 |
| Wrapper<T> | queryWrapper | 实体对象封装操作类 QueryWrapper |
示例
分页查询
// 假设要进行无条件的分页查询,每页显示10条记录,查询第1页
IPage<User> page = new Page<>(1, 10);
IPage<User> userPage = userService.page(page); // 调用 page 方法
List<User> userList = userPage.getRecords();
long total = userPage.getTotal();
System.out.println("Total users: " + total);
for (User user : userList) {System.out.println("User: " + user);
}生成的SQL:
SELECT * FROM user LIMIT 10 OFFSET 0相关文章:
Mybatis Plus 详解 IService、BaseMapper、自动填充、分页查询功能
结构直接看目录 前言 MyBatis-Plus 是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。 愿景 我们的愿景是成为 MyBatis 最好的搭档,就像 魂斗罗 中的 1P、2P,基友搭配,效…...

鸿蒙开发组件:【FA模型的Context】
FA模型的Context FA模型下只有一个Context。Context中的所有功能都是通过方法来提供的,它提供了一些featureAbility中不存在的方法,相当于featureAbility的一个扩展和补全。 接口说明 FA模型下使用Context,需要通过featureAbility下的接口…...
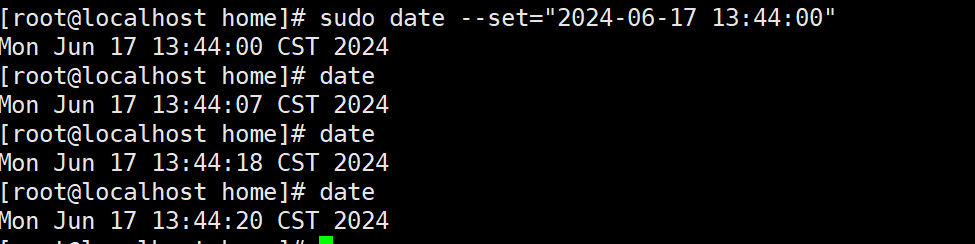
Linux下手动修改服务器时间(没网环境下)
在客户服务器上更新程序时,发现服务器时间不对,现在应该是下午13:44:00,但服务器却显示为:21:40:53,所有是不对的。 date解决办法: 1、由于服务器是没有网的,只能手动设置时间,输入…...

嵌入式系统软件开发环境_3.主要功能和典型产品
1.嵌入式系统软件开发环境的主要功能 由于嵌入式系统的软件开发通常采用的是交叉开发方式,因此其开发环境中的工具应支持这种交叉开发的特点。嵌入式系统软件开发环境的功能应覆盖嵌入式软件开发过程,即编码过程、编译过程、构建过程、下载过程、调式过程…...

使用Python保护或加密Excel文件的7种方法
目录 安装Python Excel库 Python 使用文档打开密码保护 Excel 文件 Python 使用文档修改密码保护 Excel 文件 Python 将 Excel 文件标记为最终版本 Python 保护 Excel 工作表 Python 在保护 Excel 工作表的同时允许编辑某些单元格 Python 锁定 Excel 工作表中的特定单元…...
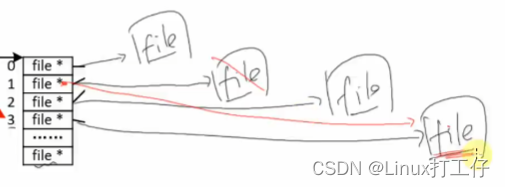
【嵌入式Linux】<总览> 文件IO(更新中)
文章目录 前言 一、常用函数 1. open函数 2. close函数 3. write函数 4. read函数 5. dup函数 6. dup2函数 二、文件读写细节 1. 换行符 2. 文件描述符 3. errno和perror 前言 在Linux系统中,一切皆文件。因此,掌握Linux下文件IO常用的函数…...

【无线传感网】分簇路由算法介绍
目录 1、LEACH路由算法 2、PEGASIS 算法 3、TEEN 算法 5、APTEEN 5、LEACH-C 算法 无线传感网中的路由协议就是寻找一条路径让网络中节点沿着这条路径将数据信息传输出去。路由协议的两大关键要点就是路径的优化和数据的分组,在传统计算机网络中,是将网络的拓扑…...

java 利用poi读取wps嵌入式图片,自测
代码 主要工具类 需要引入依赖: package com.chenkang.demo.util;import cn.wps.officeDocument.x2017.etCustomData.CellImagesDocument; import org.apache.poi.openxml4j.opc.OPCPackage; import org.apache.poi.openxml4j.opc.PackagePart; import org.apache.…...

git 常用操作指令
文章目录 git clonegit configgit addgit commitgit rmgit branch/checkoutgit pull/pushgit rebash/merge git clone git clone 可以将一个远程 Git 仓库拷贝到本地,让自己能够查看该项目,或者进行修改。 拷贝项目命令格式如下:git clone [u…...

达梦导入导出
针对导出数据库表结构通常有 3 种方法: 使用 DTS 导出 打开 DTS 迁移工具,选择【DM-->SQL】并链接到数据库中,如下图所示: 添加定义脚本,并选择【迁移范围】(仅迁移对象定义),如…...
超级数据查看器 教程pdf 1-31集 百度网盘
百度网盘链接 提取码1234https://pan.baidu.com/s/1s_2lbwZ2_Su83vDElv76ag?pwd1234 通过百度网盘分享的文件:超级数据查看器 … 链接:https://pan.baidu.com/s/1s_2lbwZ2_Su83vDElv76ag?pwd1234 提取码:1234 复制这段内容打开「百度网盘APP 即可获取」...
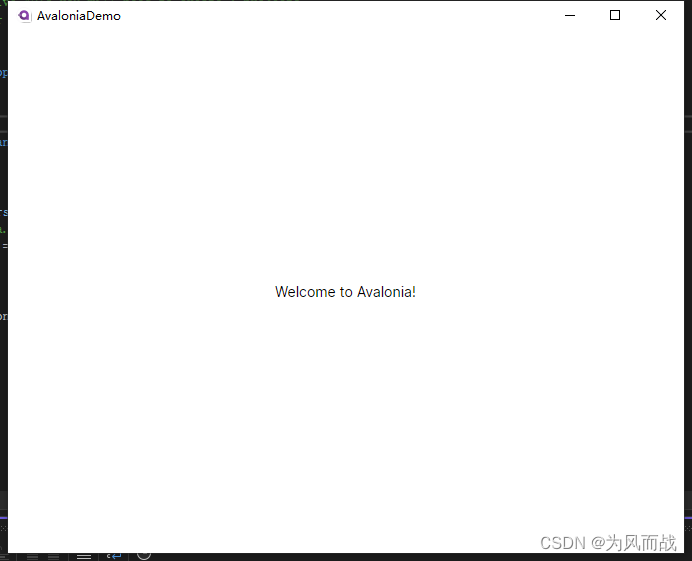
一、开发环境安装 Avalonia
1、概述 官网中是这么介绍Avalonia的,Avalonia是一个强大的框架,使开发人员能够使用.NET创建跨平台应用程序。它使用自己的渲染引擎绘制UI控件,确保在Windows、macOS、Linux、Android、iOS和WebAssembly等不同平台上具有一致的外观和行为。这…...

融资A轮B轮是什么意思?
环境: 融资 问题描述: 融资A轮B轮是什么意思 解决方案: 在A轮融资之前,通常有以下几轮融资阶段: 种子轮(Seed Round):这是企业生命周期中最早的融资阶段,通常发生在…...

开发一个python工具,pdf转图片,并且截成单个图片,然后修整没用的白边
今天推荐一键款本人开发的pdf转单张图片并截取没有用的白边工具 一、开发背景: 业务需要将一个pdf文件展示在前端显示,但是基于各种原因,放弃了h5使用插件展示 原因有多个,文件资源太大加载太慢、pdf展示兼容性问题、pdf展示效果…...

手机网络卡顿,试试飞行模式
当你遇到某个网页刷新慢或者打不开,而通过切换飞行模式就能解决这个问题,可能的原因有以下几种: 1. 网络连接重置 切换飞行模式会导致你的手机断开当前的网络连接(包括Wi-Fi和移动数据),然后重新建立连接…...

【退役之重学 AI】Ubuntu 安装 Anaconda
一. 下载 安装文件 https://www.anaconda.com/download/success 二. 安装 bash anaconda****.bash 一路 enter,yes 最后一个问你 要不要 conda init,这里得输入yes(默认是no,所以不要直接 enter),否则你…...

flutter 命令
1.查看依赖树 flutter pub deps 2.清理Flutter缓存 flutter clean 3.清理Gradle缓存 ./gradlew cleanBuildCache 4.清理Pub缓存: flutter pub cache repair 5.获取依赖项: flutter pub get 6.更新依赖项: flutter pub upgrade 7.…...

商超仓库管理系统
摘要 随着全球经济和互联网技术的快速发展,依靠互联网技术的各种管理系统逐渐应用到社会的方方面面。各行业的有识之士都逐渐开始意识到过去传统的人工管理模式已经逐渐成为企业发展的绊脚石,不再适应现代企业的发展需要。企业想要得到更好的发展&#…...

校园疫情防控健康打卡系统
摘 要 自疫情出现以来,全世界人民的生命安全和健康都面临着严重威胁。高校是我国培养人才的重要基地,其安全和稳定影响着社会的发展和进步。因此,各高校高度重视疫情防控工作,并在校园疫情防控中引入了健康打卡系统。本论文主要研…...

关于阿里云效流水线自动部署项目教程
1、登录阿里云效:阿里云登录 - 欢迎登录阿里云,安全稳定的云计算服务平台 2、点击左侧流水线: 3、在流水线界面,新建流水线 4、我的是php代码,因此选择php模版 5、创建之后添加流程线源,如下图 6、选择相应的源头。比…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...
)
rknn优化教程(二)
文章目录 1. 前述2. 三方库的封装2.1 xrepo中的库2.2 xrepo之外的库2.2.1 opencv2.2.2 rknnrt2.2.3 spdlog 3. rknn_engine库 1. 前述 OK,开始写第二篇的内容了。这篇博客主要能写一下: 如何给一些三方库按照xmake方式进行封装,供调用如何按…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...

Java编程之桥接模式
定义 桥接模式(Bridge Pattern)属于结构型设计模式,它的核心意图是将抽象部分与实现部分分离,使它们可以独立地变化。这种模式通过组合关系来替代继承关系,从而降低了抽象和实现这两个可变维度之间的耦合度。 用例子…...

CRMEB 中 PHP 短信扩展开发:涵盖一号通、阿里云、腾讯云、创蓝
目前已有一号通短信、阿里云短信、腾讯云短信扩展 扩展入口文件 文件目录 crmeb\services\sms\Sms.php 默认驱动类型为:一号通 namespace crmeb\services\sms;use crmeb\basic\BaseManager; use crmeb\services\AccessTokenServeService; use crmeb\services\sms\…...