数据分析:微生物组差异丰度方法汇总
欢迎大家关注全网生信学习者系列:
- WX公zhong号:生信学习者
- Xiao hong书:生信学习者
- 知hu:生信学习者
- CDSN:生信学习者2
介绍
微生物数据具有一下的特点,这使得在做差异分析的时候需要考虑到更多的问题,
-
Sparsity
-
Compositional
-
Overdispersion
现在 **Nearing, Douglas et al. Nature Comm. Microbiome differential abundance methods produce different results across 38 datasets.**文章对常用的差异分析方法做了基准测试,本文讲把不同方法的核心计算代码记录下来。
作者这项工作的目标是比较一系列常见的差异分析(DA)方法在16S rRNA基因数据集上的表现。因此,在这项工作的大部分中,作者并不确切知道正确答案是什么:作者主要只能说哪些工具在性能上更相似于其他工具。然而,还包含了几项分析,以帮助评估这些工具在不同环境下来自同一数据集的假阳性率和一致性。
简单地说,该工作试图评估不同的微生物组差异丰度分析方法在多个数据集上的表现,并比较它们之间的相似性和一致性,同时尝试评估这些工具在不同数据集上产生假阳性结果的频率。
Sparsity
即使在同一环境中,不同样本的微生物出现概率或者丰度都是不一样的,大部分微生物丰度极低。又因为在测序仪的检测极限下,微生物丰度(相对或绝对丰度)为0的概率又极大增加了。除此之外,比对所使用的数据库大小也即是覆盖物种率也会对最终的微生物丰度表达谱有较大的影响。最后我们所获得的微生物丰度谱必然含有大量的零值,它有两种情况,一种是真实的零值,另一种是误差导致的零值。很多算法会针对这两个特性构建不同的处理零值策略。
零值数量的大小构成了微生物丰度谱稀疏性。在某次16s数据的OTU水平中,零值比例高达80%以上。Sparsity属性导致常用的数据分析方法如t-test/wilcox-test假设检验方法均不适合。为了解决sparsity对分析的影响,很多R包的方法如ANCOM的Zero划分,metagenomeSeq的ZIP/ZILN对Zero进行处理,处理后的矩阵再做如CLR等变换,CLR变换又是为了处理微生物数据另一个特点compositional (下一部分讲)。最后转换后的数据会服从常见的分布,也即是可以使用常见的如Wilcox/t-test之类(两分组)的方法做假设检验,需要说明的是ANCOM还会根据物种在样本内的显著性的差异比例区分差异物种,这也是为何ANCOM的稳健性的原因。
Compositional
Compositional的数据特性是服从simplex空间,简而言之是指:某个样本内所有微生物的加和是一个常数(可以是1也可以是10,100)。符合该属性的数据内部元素之间存在着相关关系,即某个元素的比例发生波动,必然引起其他元素比例的波动,但在实际的微生物环境中,这种关联关系可能是不存在的。为了解决compositional的问题,有人提出了使用各种normalization方法(比如上文提到的CLR: X i = l o g ( x i G e a m e t r i c M e a n ( X ) ) X_{i}=log(\frac{x_{i}}{GeametricMean(X)}) Xi=log(GeametricMean(X)xi),我暂时只熟悉这个方法)。
Compositional数据不服从欧式空间分布,在使用log-ratio transformation后,数据可以一一对应到真实的多维变量的空间,方便后续应用标准分析方法。
Overdispersion
Overdispersion的条件是 Variance >> mean,也就是说数据的方差要远远大于均值。常用的适合count matrix的Poisson分布是无法处理这样的数据的,因此现在很多方法都是用负二项分布去拟合数据。
总结
使用一张自己讲过的PPT总结一下。

差异分析方法
不同的差异分析方法识别到差异微生物可能会存在较大的区别,这是因为这些方法的原理是不一样的,但从微生物的数据特点而言,方法需要符合微生物数据特性。
数据
文章提供了38个16S数据集,大家通过以下链接下载数据:
- 百度网盘链接:https://pan.baidu.com/s/1tIMcqm6rs1EEbhJzH-Z4mg
- 提取码: 请关注WX公zhong号_生信学习者_后台发送 微生物差异方法 获取提取码
ALDEx2
ALDEx2(ANOVA-Like Differential Expression 2)是一种用于微生物组数据差异分析的方法,它特别适用于处理组成数据(compositional data),这类数据的特点是在每个样本中各部分的总和为一个固定值,例如微生物群落中各物种的相对丰度之和为1。ALDEx2方法的核心原理包括以下几个步骤:
- 生成后验概率分布:首先,ALDEx2使用Dirichlet分布来模拟每个分类单元(如OTU或ASV)的读数计数的后验概率分布。这一步是基于微生物群落数据的组成特性,即数据点在高维空间中位于一个低维的简单形(simplex)上。
- 中心对数比变换(CLR):ALDEx2对原始计数数据进行中心对数比(Centered Log-Ratio)变换,这是一种适合组成数据的变换方法,可以消除数据的组成特性带来的影响,使得数据更适合常规的统计分析方法。
- 单变量统计检验:变换后的数据将用于单变量统计检验,如Welch’s t检验或秩和检验,以确定不同组之间各分类单元的丰度是否存在显著差异。
- 效应量估计:ALDEx2还计算效应量大小,这是衡量组间差异相对于组内变异的一个重要指标,有助于评估差异的生物学意义。
- 多重检验校正:在识别出显著差异的分类单元后,ALDEx2使用Benjamini-Hochberg方法进行多重检验校正,以控制假阳性率。
#### Script to Run ALDEX2 differential abundancedeps = c("ALDEx2")
for (dep in deps){if (dep %in% installed.packages()[,"Package"] == FALSE){if (!requireNamespace("BiocManager", quietly = TRUE))install.packages("BiocManager")BiocManager::install("ALDEx2")}library(dep, character.only = TRUE)
}library(ALDEx2)args <- commandArgs(trailingOnly = TRUE)#test if there is an argument supply
if (length(args) <= 2) {stop("At least three arguments must be supplied", call.=FALSE)
}con <- file(args[1])
file_1_line1 <- readLines(con,n=1)
close(con)if(grepl("Constructed from biom file", file_1_line1)){ASV_table <- read.table(args[1], sep="\t", skip=1, header=T, row.names = 1, comment.char = "", quote="", check.names = F)
}else{ASV_table <- read.table(args[1], sep="\t", header=T, row.names = 1, comment.char = "", quote="", check.names = F)
}groupings <- read.table(args[2], sep="\t", row.names = 1, header=T, comment.char = "", quote="", check.names = F)#number of samples
sample_num <- length(colnames(ASV_table))
grouping_num <- length(rownames(groupings))#check if the same number of samples are being input.
if(sample_num != grouping_num){message("The number of samples in the ASV table and the groupings table are unequal")message("Will remove any samples that are not found in either the ASV table or the groupings table")
}#check if order of samples match up.
if(identical(colnames(ASV_table), rownames(groupings))==T){message("Groupings and ASV table are in the same order")
}else{rows_to_keep <- intersect(colnames(ASV_table), rownames(groupings))groupings <- groupings[rows_to_keep,,drop=F]ASV_table <- ASV_table[,rows_to_keep]if(identical(colnames(ASV_table), rownames(groupings))==T){message("Groupings table was re-arrange to be in the same order as the ASV table")message("A total of ", sample_num-length(colnames(ASV_table)), " from the ASV_table")message("A total of ", grouping_num-length(rownames(groupings)), " from the groupings table")}else{stop("Unable to match samples between the ASV table and groupings table")}
}results <- aldex(reads = ASV_table,conditions = groupings[, 1],mc.samples = 128,test = "t",effect = TRUE,include.sample.summary = FALSE,verbose = T, denom = "all")write.table(results, file=args[3], quote=FALSE, sep='\t', col.names = NA)message("Results table saved to ", args[3])
ANCOM-II
ANCOM(Analysis of Composition of Microbiomes)是一种用于分析微生物组数据的统计方法,专门设计来识别和比较不同样本或处理组之间的微生物组成差异。其核心原理包括以下几个步骤:
- 数据聚合:首先,对数据进行预处理,去除低丰度的微生物分类单元(OTU/ASV),并对数据进行标准化或转换操作,将绝对丰度转换为相对丰度。
- 添加伪计数:由于ANCOM分析过程中需要使用对数变换,而相对丰度为0的分类群无法进行对数变换,因此需要添加一个小的正数作为伪计数,以解决这个问题。
- 计算特征差异:ANCOM使用W统计量来检测不同组之间的特征是否存在显著差异。W统计量的计算包括以下步骤:
- 对每个特征在所有样本中的相对丰度进行排序。
- 将样本分为目标组和参考组,通常情况下,目标组是研究者感兴趣的组别,而参考组是其他组别的合并。
- 计算目标组和参考组中每个特征的累积相对丰度,即从最低相对丰度的特征开始,逐渐累积到当前特征的相对丰度之和。
- 计算目标组和参考组中每个特征的平均累积相对丰度。
- 计算目标组和参考组之间的差异值,即目标组的平均累积相对丰度减去参考组的均累积相对丰度。
- 计算每个特征的W统计量,即将差异值除以其标准差。W统计量的绝对值大于1.96通常被认为是显著差异的特征。
- 结果解读:ANCOM的结果通常包括火山图和统计表格,火山图展示了W统计量与中心对数比例(CLR)变换后的数据,而统计表格列出了差异显著的特征及其相关信息。
ANCOM的优点包括能够处理稀疏数据、保持较低的误报率以及对异常值具有鲁棒性。然而,它也存在一些限制,例如对数据的分布假设敏感,对样本数目和特征维度的要求较高
- Anchor_v2.1.R脚本
### This script was downloaded May 11 2020 from FrederickHuangLin/Ancom repo on github
## This script will be used to test ancom2 resultslibrary(exactRankTests)
library(nlme)
library(dplyr)
library(ggplot2)
library(compositions)# OTU table should be a matrix/data.frame with each feature in rows and sample in columns.
# Metadata should be a matrix/data.frame containing the sample identifier. # Data Pre-Processing
feature_table_pre_process = function(feature_table, meta_data, sample_var, group_var = NULL, out_cut = 0.05, zero_cut = 0.90, lib_cut, neg_lb){feature_table = data.frame(feature_table, check.names = FALSE)meta_data = data.frame(meta_data, check.names = FALSE)# Drop unused levelsmeta_data[] = lapply(meta_data, function(x) if(is.factor(x)) factor(x) else x)# Match sample IDs between metadata and feature tablesample_ID = intersect(meta_data[, sample_var], colnames(feature_table))feature_table = feature_table[, sample_ID]meta_data = meta_data[match(sample_ID, meta_data[, sample_var]), ]# 1. Identify outliers within each taxonif (!is.null(group_var)) {group = meta_data[, group_var]z = feature_table + 1 # Add pseudo-count (1) f = log(z); f[f == 0] = NA; f = colMeans(f, na.rm = T)f_fit = lm(f ~ group)e = rep(0, length(f)); e[!is.na(group)] = residuals(f_fit)y = t(t(z) - e)outlier_check = function(x){# Fitting the mixture model using the algorithm of Peddada, S. Das, and JT Gene Hwang (2002)mu1 = quantile(x, 0.25, na.rm = T); mu2 = quantile(x, 0.75, na.rm = T)sigma1 = quantile(x, 0.75, na.rm = T) - quantile(x, 0.25, na.rm = T); sigma2 = sigma1pi = 0.75n = length(x)epsilon = 100tol = 1e-5score = pi*dnorm(x, mean = mu1, sd = sigma1)/((1 - pi)*dnorm(x, mean = mu2, sd = sigma2))while (epsilon > tol) {grp1_ind = (score >= 1)mu1_new = mean(x[grp1_ind]); mu2_new = mean(x[!grp1_ind])sigma1_new = sd(x[grp1_ind]); if(is.na(sigma1_new)) sigma1_new = 0sigma2_new = sd(x[!grp1_ind]); if(is.na(sigma2_new)) sigma2_new = 0pi_new = sum(grp1_ind)/npara = c(mu1_new, mu2_new, sigma1_new, sigma2_new, pi_new)if(any(is.na(para))) breakscore = pi_new * dnorm(x, mean = mu1_new, sd = sigma1_new)/((1-pi_new) * dnorm(x, mean = mu2_new, sd = sigma2_new))epsilon = sqrt((mu1 - mu1_new)^2 + (mu2 - mu2_new)^2 + (sigma1 - sigma1_new)^2 + (sigma2 - sigma2_new)^2 + (pi - pi_new)^2)mu1 = mu1_new; mu2 = mu2_new; sigma1 = sigma1_new; sigma2 = sigma2_new; pi = pi_new}if(mu1 + 1.96 * sigma1 < mu2 - 1.96 * sigma2){if(pi < out_cut){out_ind = grp1_ind}else if(pi > 1 - out_cut){out_ind = (!grp1_ind)}else{out_ind = rep(FALSE, n)}}else{out_ind = rep(FALSE, n)}return(out_ind)}out_ind = matrix(FALSE, nrow = nrow(feature_table), ncol = ncol(feature_table))out_ind[, !is.na(group)] = t(apply(y, 1, function(i) unlist(tapply(i, group, function(j) outlier_check(j)))))feature_table[out_ind] = NA}# 2. Discard taxa with zeros >= zero_cutzero_prop = apply(feature_table, 1, function(x) sum(x == 0, na.rm = T)/length(x[!is.na(x)]))taxa_del = which(zero_prop >= zero_cut)if(length(taxa_del) > 0){feature_table = feature_table[- taxa_del, ]}# 3. Discard samples with library size < lib_cutlib_size = colSums(feature_table, na.rm = T)if(any(lib_size < lib_cut)){subj_del = which(lib_size < lib_cut)feature_table = feature_table[, - subj_del]meta_data = meta_data[- subj_del, ]}# 4. Identify taxa with structure zerosif (!is.null(group_var)) {group = factor(meta_data[, group_var])present_table = as.matrix(feature_table)present_table[is.na(present_table)] = 0present_table[present_table != 0] = 1p_hat = t(apply(present_table, 1, function(x)unlist(tapply(x, group, function(y) mean(y, na.rm = T)))))samp_size = t(apply(feature_table, 1, function(x)unlist(tapply(x, group, function(y) length(y[!is.na(y)])))))p_hat_lo = p_hat - 1.96 * sqrt(p_hat * (1 - p_hat)/samp_size)struc_zero = (p_hat == 0) * 1# Whether we need to classify a taxon into structural zero by its negative lower bound?if(neg_lb) struc_zero[p_hat_lo <= 0] = 1# Entries considered to be structural zeros are set to be 0sstruc_ind = struc_zero[, group]feature_table = feature_table * (1 - struc_ind)colnames(struc_zero) = paste0("structural_zero (", colnames(struc_zero), ")")}else{struc_zero = NULL}# 5. Return resultsres = list(feature_table = feature_table, meta_data = meta_data, structure_zeros = struc_zero)return(res)
}# ANCOM main function
ANCOM = function(feature_table, meta_data, struc_zero = NULL, main_var, p_adj_method = "BH", alpha = 0.05, adj_formula = NULL, rand_formula = NULL, ...){# OTU table transformation: # (1) Discard taxa with structural zeros (if any); (2) Add pseudocount (1) and take logarithm.if (!is.null(struc_zero)) {num_struc_zero = apply(struc_zero, 1, sum)comp_table = feature_table[num_struc_zero == 0, ]}else{comp_table = feature_table}comp_table = log(as.matrix(comp_table) + 1)n_taxa = dim(comp_table)[1]taxa_id = rownames(comp_table)n_samp = dim(comp_table)[2]# Determine the type of statistical test and its formula.if (is.null(rand_formula) & is.null(adj_formula)) {# Basic model# Whether the main variable of interest has two levels or more?if (length(unique(meta_data%>%pull(main_var))) == 2) {# Two levels: Wilcoxon rank-sum testtfun = exactRankTests::wilcox.exact} else{# More than two levels: Kruskal-Wallis testtfun = stats::kruskal.test}# Formulatformula = formula(paste("x ~", main_var, sep = " "))}else if (is.null(rand_formula) & !is.null(adj_formula)) {# Model: ANOVAtfun = stats::aov# Formulatformula = formula(paste("x ~", main_var, "+", adj_formula, sep = " "))}else if (!is.null(rand_formula)) {# Model: Mixed-effects modeltfun = nlme::lme# Formulaif (is.null(adj_formula)) {# Random intercept modeltformula = formula(paste("x ~", main_var))}else {# Random coefficients/slope modeltformula = formula(paste("x ~", main_var, "+", adj_formula))}}# Calculate the p-value for each pairwise comparison of taxa.p_data = matrix(NA, nrow = n_taxa, ncol = n_taxa)colnames(p_data) = taxa_idrownames(p_data) = taxa_idfor (i in 1:(n_taxa - 1)) {# Loop through each taxon.# For each taxon i, additive log ratio (alr) transform the OTU table using taxon i as the reference.# e.g. the first alr matrix will be the log abundance data (comp_table) recursively subtracted # by the log abundance of 1st taxon (1st column) column-wisely, and remove the first i columns since:# the first (i - 1) columns were calculated by previous iterations, and# the i^th column contains all zeros.alr_data = apply(comp_table, 1, function(x) x - comp_table[i, ]) # apply(...) allows crossing the data in a number of ways and avoid explicit use of loop constructs.# Here, we basically want to iteratively subtract each column of the comp_table by its i^th column.alr_data = alr_data[, - (1:i), drop = FALSE]n_lr = dim(alr_data)[2] # number of log-ratios (lr)alr_data = cbind(alr_data, meta_data) # merge with the metadata# P-valuesif (is.null(rand_formula) & is.null(adj_formula)) {p_data[-(1:i), i] = apply(alr_data[, 1:n_lr, drop = FALSE], 2, function(x){tfun(tformula, data = data.frame(x, alr_data, check.names = FALSE))$p.value}) }else if (is.null(rand_formula) & !is.null(adj_formula)) {p_data[-(1:i), i] = apply(alr_data[, 1:n_lr, drop = FALSE], 2, function(x){fit = tfun(tformula, data = data.frame(x, alr_data, check.names = FALSE), na.action = na.omit)summary(fit)[[1]][main_var, "Pr(>F)"]})}else if (!is.null(rand_formula)) {p_data[-(1:i), i] = apply(alr_data[, 1:n_lr, drop = FALSE], 2, function(x){fit = tfun(fixed = tformula, data = data.frame(x, alr_data, check.names = FALSE),random = formula(rand_formula),na.action = na.omit, ...)anova(fit)[main_var, "p-value"]}) }}# Complete the p-value matrix.# What we got from above iterations is a lower triangle matrix of p-values.p_data[upper.tri(p_data)] = t(p_data)[upper.tri(p_data)]diag(p_data) = 1 # let p-values on diagonal equal to 1# Multiple comparisons correction.q_data = apply(p_data, 2, function(x) p.adjust(x, method = p_adj_method))# Calculate the W statistic of ANCOM.# For each taxon, count the number of q-values < alpha.W = apply(q_data, 2, function(x) sum(x < alpha))# Organize outputsout_comp = data.frame(taxa_id, W, row.names = NULL, check.names = FALSE)# Declare a taxon to be differentially abundant based on the quantile of W statistic.# We perform (n_taxa - 1) hypothesis testings on each taxon, so the maximum number of rejections is (n_taxa - 1).out_comp = out_comp%>%mutate(detected_0.9 = ifelse(W > 0.9 * (n_taxa -1), TRUE, FALSE),detected_0.8 = ifelse(W > 0.8 * (n_taxa -1), TRUE, FALSE),detected_0.7 = ifelse(W > 0.7 * (n_taxa -1), TRUE, FALSE),detected_0.6 = ifelse(W > 0.6 * (n_taxa -1), TRUE, FALSE))# Taxa with structural zeros are automatically declared to be differentially abundantif (!is.null(struc_zero)){out = data.frame(taxa_id = rownames(struc_zero), W = Inf, detected_0.9 = TRUE, detected_0.8 = TRUE, detected_0.7 = TRUE, detected_0.6 = TRUE, row.names = NULL, check.names = FALSE)out[match(taxa_id, out$taxa_id), ] = out_comp}else{out = out_comp}# Draw volcano plot# Calculate clrclr_table = apply(feature_table, 2, clr)# Calculate clr mean differenceeff_size = apply(clr_table, 1, function(y) lm(y ~ x, data = data.frame(y = y, x = meta_data %>% pull(main_var),check.names = FALSE))$coef[-1])if (is.matrix(eff_size)){# Data frame for the figuredat_fig = data.frame(taxa_id = out$taxa_id, t(eff_size), y = out$W, check.names = FALSE) %>% mutate(zero_ind = factor(ifelse(is.infinite(y), "Yes", "No"), levels = c("Yes", "No"))) %>%gather(key = group, value = x, rownames(eff_size))# Replcace "x" to the name of covariatedat_fig$group = sapply(dat_fig$group, function(x) gsub("x", paste0(main_var, " = "), x))# Replace Inf by (n_taxa - 1) for structural zerosdat_fig$y = replace(dat_fig$y, is.infinite(dat_fig$y), n_taxa - 1)fig = ggplot(data = dat_fig) + aes(x = x, y = y) + geom_point(aes(color = zero_ind)) + facet_wrap(~ group) +labs(x = "CLR mean difference", y = "W statistic") +scale_color_discrete(name = "Structural zero", drop = FALSE) + theme_bw() +theme(plot.title = element_text(hjust = 0.5), legend.position = "top",strip.background = element_rect(fill = "white"))fig } else{# Data frame for the figuredat_fig = data.frame(taxa_id = out$taxa_id, x = eff_size, y = out$W) %>% mutate(zero_ind = factor(ifelse(is.infinite(y), "Yes", "No"), levels = c("Yes", "No")))# Replace Inf by (n_taxa - 1) for structural zerosdat_fig$y = replace(dat_fig$y, is.infinite(dat_fig$y), n_taxa - 1)fig = ggplot(data = dat_fig) + aes(x = x, y = y) + geom_point(aes(color = zero_ind)) + labs(x = "CLR mean difference", y = "W statistic") +scale_color_discrete(name = "Structural zero", drop = FALSE) + theme_bw() +theme(plot.title = element_text(hjust = 0.5), legend.position = "top")fig}res = list(out = out, fig = fig)return(res)
}
- 运行
deps = c("exactRankTests", "nlme", "dplyr", "ggplot2", "compositions")
for (dep in deps){if (dep %in% installed.packages()[,"Package"] == FALSE){install.packages(dep)}library(dep, character.only = TRUE)
}#args[4] will contain path for the ancom codeargs <- commandArgs(trailingOnly = TRUE)if (length(args) <= 3) {stop("At least three arguments must be supplied", call.=FALSE)
}source(args[[4]])con <- file(args[1])
file_1_line1 <- readLines(con,n=1)
close(con)if(grepl("Constructed from biom file", file_1_line1)){ASV_table <- read.table(args[1], sep="\t", skip=1, header=T, row.names = 1, comment.char = "", quote="", check.names = F)
}else{ASV_table <- read.table(args[1], sep="\t", header=T, row.names = 1, comment.char = "", quote="", check.names = F)
}groupings <- read.table(args[2], sep="\t", row.names = 1, header=T, comment.char = "", quote="", check.names = F)#number of samples
sample_num <- length(colnames(ASV_table))
grouping_num <- length(rownames(groupings))if(sample_num != grouping_num){message("The number of samples in the ASV table and the groupings table are unequal")message("Will remove any samples that are not found in either the ASV table or the groupings table")
}if(identical(colnames(ASV_table), rownames(groupings))==T){message("Groupings and ASV table are in the same order")
}else{rows_to_keep <- intersect(colnames(ASV_table), rownames(groupings))groupings <- groupings[rows_to_keep,,drop=F]ASV_table <- ASV_table[,rows_to_keep]if(identical(colnames(ASV_table), rownames(groupings))==T){message("Groupings table was re-arrange to be in the same order as the ASV table")message("A total of ", sample_num-length(colnames(ASV_table)), " from the ASV_table")message("A total of ", grouping_num-length(rownames(groupings)), " from the groupings table")}else{stop("Unable to match samples between the ASV table and groupings table")}
}groupings$Sample <- rownames(groupings)prepro <- feature_table_pre_process(feature_table = ASV_table, meta_data = groupings, sample_var = 'Sample', group_var = NULL, out_cut = 0.05, zero_cut = 0.90,lib_cut = 1000, neg_lb=FALSE)feature_table <- prepro$feature_table
metadata <- prepro$meta_data
struc_zero <- prepro$structure_zeros#run ancom
main_var <- colnames(groupings)[1]
p_adj_method = "BH"
alpha=0.05
adj_formula=NULL
rand_formula=NULL
res <- ANCOM(feature_table = feature_table, meta_data = metadata, struc_zero = struc_zero, main_var = main_var, p_adj_method = p_adj_method,alpha=alpha, adj_formula = adj_formula, rand_formula = rand_formula)write.table(res$out, file=args[3], quote=FALSE, sep="\t", col.names = NA)Corncob
Corncob 是一种用于微生物组数据分析的R包,它专门用于对微生物相对丰度进行建模并测试协变量对相对丰度的影响。其核心原理包括以下几个方面:
- 相对丰度建模:Corncob 通过统计模型来分析微生物的相对丰度数据,考虑到数据的组成性特征,即样本中各微生物的相对丰度总和为1。
- β-二项式分布:Corncob 假设微生物的计数数据遵循β-二项式分布,这种分布可以更好地描述微生物组数据中的离散性和过度离散现象。
- 协变量效应测试:Corncob 允许研究者测试一个或多个协变量对微生物相对丰度的影响,这可以通过Wald检验等统计方法来实现。
- 多重假设检验校正:在分析过程中,Corncob 会对多重比较问题进行校正,以控制第一类错误率,常用的校正方法包括Benjamini-Hochberg (BH) 方法。
- 模型拟合与假设检验:Corncob 进行模型拟合并对模型参数进行估计,然后通过假设检验确定特定微生物分类群的相对丰度是否存在显著差异。
- 稀疏性和零膨胀数据处理:Corncob 还考虑到了微生物组数据的稀疏性,即许多微生物在多数样本中可能未被检测到,以及零膨胀问题,即存在大量零计数的情况。
#### Run Corncoblibrary(corncob)
library(phyloseq)#install corncob if its not installed.
deps = c("corncob")
for (dep in deps){if (dep %in% installed.packages()[,"Package"] == FALSE){if(dep=="corncob"){devtools::install_github("bryandmartin/corncob")}elseif (!requireNamespace("BiocManager", quietly = TRUE))install.packages("BiocManager")BiocManager::install("phyloseq")}library(dep, character.only = TRUE)
}args <- commandArgs(trailingOnly = TRUE)if (length(args) <= 2) {stop("At least three arguments must be supplied", call.=FALSE)
}con <- file(args[1])
file_1_line1 <- readLines(con,n=1)
close(con)if(grepl("Constructed from biom file", file_1_line1)){ASV_table <- read.table(args[1], sep="\t", skip=1, header=T, row.names = 1, comment.char = "", quote="", check.names = F)
}else{ASV_table <- read.table(args[1], sep="\t", header=T, row.names = 1, comment.char = "", quote="", check.names = F)
}groupings <- read.table(args[2], sep="\t", row.names = 1, header=T, comment.char = "", quote="", check.names = F)#number of samples
sample_num <- length(colnames(ASV_table))
grouping_num <- length(rownames(groupings))#check if the same number of samples are being input.
if(sample_num != grouping_num){message("The number of samples in the ASV table and the groupings table are unequal")message("Will remove any samples that are not found in either the ASV table or the groupings table")
}#check if order of samples match up.
if(identical(colnames(ASV_table), rownames(groupings))==T){message("Groupings and ASV table are in the same order")
}else{rows_to_keep <- intersect(colnames(ASV_table), rownames(groupings))groupings <- groupings[rows_to_keep,,drop=F]ASV_table <- ASV_table[,rows_to_keep]if(identical(colnames(ASV_table), rownames(groupings))==T){message("Groupings table was re-arrange to be in the same order as the ASV table")message("A total of ", sample_num-length(colnames(ASV_table)), " from the ASV_table")message("A total of ", grouping_num-length(rownames(groupings)), " from the groupings table")}else{stop("Unable to match samples between the ASV table and groupings table")}
}#run corncob
#put data into phyloseq object.
colnames(groupings)
colnames(groupings)[1] <- "places"OTU <- phyloseq::otu_table(ASV_table, taxa_are_rows = T)
sampledata <- phyloseq::sample_data(groupings, errorIfNULL = T)
phylo <- phyloseq::merge_phyloseq(OTU, sampledata)my_formula <- as.formula(paste("~","places",sep=" ", collapse = ""))
my_formula
results <- corncob::differentialTest(formula= my_formula,phi.formula = my_formula,phi.formula_null = my_formula,formula_null = ~ 1,test="Wald", data=phylo,boot=F,fdr_cutoff = 0.05)write.table(results$p_fdr, file=args[[3]], sep="\t", col.names = NA, quote=F)
write.table(results$p, file=paste0(args[[3]], "_uncor", sep=""), sep="\t", col.names = NA, quote=F)DESeq2
DESeq2是一种用于微生物组数据差异分析的统计方法,特别适用于处理计数数据,如RNA-seq数据或微生物组的OTU(操作分类单元)计数。DESeq2的核心原理包括以下几个关键步骤:
- 数据标准化:DESeq2首先对原始的计数数据进行标准化,以校正样本间的测序深度差异。这是通过计算大小因子(size factors)实现的,每个样本的大小因子乘以其总计数,以调整测序深度。
- 离散度估计:DESeq2估计每个特征(如OTU或基因)的离散度,即数据的变异程度。离散度是负二项分布的一个参数,用于描述数据的过度离散现象。
- 经验贝叶斯收缩:DESeq2使用经验贝叶斯方法对离散度进行收缩,即利用所有特征的离散度估计来改进个别特征的离散度估计,这有助于提高统计估计的稳定性。
- 负二项分布建模:DESeq2假设计数数据遵循负二项分布,该分布是处理计数数据的常用分布,特别适用于处理微生物组数据中的零膨胀现象。
- 设计公式:DESeq2通过设计公式来考虑实验设计,包括处理效应、批次效应和其他协变量,从而允许研究者评估特定条件下的微生物差异丰度。
- 假设检验:DESeq2使用统计检验来确定不同样本组之间特定微生物的丰度是否存在显著差异。这通常涉及比较零假设(两组间无差异)和备择假设(两组间有差异)。
- 多重检验校正:由于微生物组数据涉及大量多重比较,DESeq2使用Benjamini-Hochberg方法进行多重检验校正,以控制假发现率(FDR)。
- 结果解释:DESeq2提供了丰富的结果输出,包括P值、校正后的P值、对数倍数变化(log2 fold change)等,这些结果可以帮助研究者识别和解释数据中的生物学意义。
#Run_DeSeq2deps = c("DESeq2")
for (dep in deps){if (dep %in% installed.packages()[,"Package"] == FALSE){if (!requireNamespace("BiocManager", quietly = TRUE))install.packages("BiocManager")BiocManager::install("DESeq2")}library(dep, character.only = TRUE)
}library(DESeq2)args <- commandArgs(trailingOnly = TRUE)
#test if there is an argument supply
if (length(args) <= 2) {stop("At least three arguments must be supplied", call.=FALSE)
}con <- file(args[1])
file_1_line1 <- readLines(con,n=1)
close(con)if(grepl("Constructed from biom file", file_1_line1)){ASV_table <- read.table(args[1], sep="\t", skip=1, header=T, row.names = 1,comment.char = "", quote="", check.names = F)
}else{ASV_table <- read.table(args[1], sep="\t", header=T, row.names = 1,comment.char = "", quote="", check.names = F)
}groupings <- read.table(args[2], sep="\t", row.names = 1, header=T, comment.char = "", quote="", check.names = F)#number of samples
sample_num <- length(colnames(ASV_table))
grouping_num <- length(rownames(groupings))#check if the same number of samples are being input.
if(sample_num != grouping_num){message("The number of samples in the ASV table and the groupings table are unequal")message("Will remove any samples that are not found in either the ASV table or the groupings table")
}#check if order of samples match up.
if(identical(colnames(ASV_table), rownames(groupings))==T){message("Groupings and ASV table are in the same order")
}else{rows_to_keep <- intersect(colnames(ASV_table), rownames(groupings))groupings <- groupings[rows_to_keep,,drop=F]ASV_table <- ASV_table[,rows_to_keep]if(identical(colnames(ASV_table), rownames(groupings))==T){message("Groupings table was re-arrange to be in the same order as the ASV table")message("A total of ", sample_num-length(colnames(ASV_table)), " from the ASV_table")message("A total of ", grouping_num-length(rownames(groupings)), " from the groupings table")}else{stop("Unable to match samples between the ASV table and groupings table")}
}colnames(groupings)[1] <- "Groupings"
#Run Deseq2dds <- DESeq2::DESeqDataSetFromMatrix(countData = ASV_table,colData=groupings,design = ~ Groupings)
dds_res <- DESeq2::DESeq(dds, sfType = "poscounts")res <- results(dds_res, tidy=T, format="DataFrame")rownames(res) <- res$row
res <- res[,-1]write.table(res, file=args[3], quote=FALSE, sep="\t", col.names = NA)message("Results written to ", args[3])edgeR
EdgeR(Empirical Analysis of Digital Gene Expression in R)是一种用于分析计数数据的统计方法,特别适用于微生物组学、转录组学和其他高通量测序技术产生的数据。EdgeR的核心原理包括以下几个关键步骤:
- 数据标准化:EdgeR通过计算标准化因子(Normalization Factors)来调整不同样本的测序深度或库大小,确保比较的公平性。
- 离散度估计:EdgeR估计每个基因或OTU的离散度(Dispersion),这是衡量数据变异程度的一个参数,对于后续的统计检验至关重要。
- 负二项分布建模:EdgeR假设数据遵循负二项分布,这是一种常用于计数数据的分布模型,可以处理数据的过度离散现象。
- 经验贝叶斯收缩:EdgeR使用经验贝叶斯方法对离散度进行收缩(Shrinkage),通过借用全局信息来提高对每个基因或OTU离散度估计的准确性。
- 设计矩阵:EdgeR通过设计矩阵(Design Matrix)来表示实验设计,包括处理效应、时间效应、批次效应等,允许研究者评估不同条件下的基因或OTU表达差异。
- 统计检验:EdgeR进行似然比检验(Likelihood Ratio Test, LRT)或精确检验(Exact Test),以确定不同样本组之间特定基因或OTU的表达是否存在显著差异。
- 多重检验校正:EdgeR使用多种方法进行多重检验校正,如Benjamini-Hochberg(BH)方法,以控制假发现率(FDR)。
- 结果解释:EdgeR提供了丰富的结果输出,包括P值、校正后的P值、对数倍数变化(Log Fold Change, LFC)等,帮助研究者识别和解释数据中的生物学变化。
deps = c("edgeR", "phyloseq")
for (dep in deps){if (dep %in% installed.packages()[,"Package"] == FALSE){if (!requireNamespace("BiocManager", quietly = TRUE))install.packages("BiocManager")BiocManager::install(deps)}library(dep, character.only = TRUE)
}### Taken from phyloseq authors at: https://joey711.github.io/phyloseq-extensions/edgeR.html
phyloseq_to_edgeR = function(physeq, group, method="RLE", ...){require("edgeR")require("phyloseq")# Enforce orientation.if( !taxa_are_rows(physeq) ){ physeq <- t(physeq) }x = as(otu_table(physeq), "matrix")# Add one to protect against overflow, log(0) issues.x = x + 1# Check `group` argumentif( identical(all.equal(length(group), 1), TRUE) & nsamples(physeq) > 1 ){# Assume that group was a sample variable name (must be categorical)group = get_variable(physeq, group)}# Define gene annotations (`genes`) as tax_tabletaxonomy = tax_table(physeq, errorIfNULL=FALSE)if( !is.null(taxonomy) ){taxonomy = data.frame(as(taxonomy, "matrix"))} # Now turn into a DGEListy = DGEList(counts=x, group=group, genes=taxonomy, remove.zeros = TRUE, ...)# Calculate the normalization factorsz = calcNormFactors(y, method=method)# Check for division by zero inside `calcNormFactors`if( !all(is.finite(z$samples$norm.factors)) ){stop("Something wrong with edgeR::calcNormFactors on this data,non-finite $norm.factors, consider changing `method` argument")}# Estimate dispersionsreturn(estimateTagwiseDisp(estimateCommonDisp(z)))
}args <- commandArgs(trailingOnly = TRUE)
#test if there is an argument supply
if (length(args) <= 2) { stop("At least three arguments must be supplied", call.=FALSE)
}con <- file(args[1])
file_1_line1 <- readLines(con,n=1)
close(con)if(grepl("Constructed from biom file", file_1_line1)){ASV_table <- read.table(args[1], sep="\t", skip=1, header=T, row.names = 1, comment.char = "", quote="", check.names = F)
}else{ASV_table <- read.table(args[1], sep="\t", header=T, row.names = 1, comment.char = "", quote="", check.names = F)
}groupings <- read.table(args[2], sep="\t", row.names = 1, header=T, comment.char = "", quote="", check.names = F)#number of samples
sample_num <- length(colnames(ASV_table))
grouping_num <- length(rownames(groupings))#check if the same number of samples are being input.
if(sample_num != grouping_num){message("The number of samples in the ASV table and the groupings table are unequal")message("Will remove any samples that are not found in either the ASV table or the groupings table")
}#check if order of samples match up.
if(identical(colnames(ASV_table), rownames(groupings))==T){message("Groupings and ASV table are in the same order")
}else{rows_to_keep <- intersect(colnames(ASV_table), rownames(groupings))groupings <- groupings[rows_to_keep,,drop=F]ASV_table <- ASV_table[,rows_to_keep]if(identical(colnames(ASV_table), rownames(groupings))==T){message("Groupings table was re-arrange to be in the same order as the ASV table")message("A total of ", sample_num-length(colnames(ASV_table)), " from the ASV_table")message("A total of ", grouping_num-length(rownames(groupings)), " from the groupings table")}else{stop("Unable to match samples between the ASV table and groupings table")}
}OTU <- phyloseq::otu_table(ASV_table, taxa_are_rows = T)
sampledata <- phyloseq::sample_data(groupings, errorIfNULL = T)
phylo <- phyloseq::merge_phyloseq(OTU, sampledata)test <- phyloseq_to_edgeR(physeq = phylo, group=colnames(groupings)[1])et = exactTest(test)tt = topTags(et, n=nrow(test$table), adjust.method="fdr", sort.by="PValue")
res <- tt@.Data[[1]]write.table(res, file=args[3], quote=F, sep="\t", col.names = NA)Limma-Voom-TMM
Limma-Voom-TMM(Trimmed Mean of M-values)是一种用于微生物组数据差异分析的方法,它结合了limma、voom和TMM(Trimmed Mean of M-values)技术的优势,以处理和分析来自高通量测序技术(如RNA-seq)的数据。下面是Limma-Voom-TMM方法的基本原理:
- 数据预处理:首先,使用limma包中的预处理功能对原始的测序数据进行质量控制和标准化处理。
- TMM标准化:TMM是一种用于RNA-seq数据的标准化方法,它通过计算所有基因的几何平均表达值,然后对每个基因的表达值进行缩放,以校正样本间的测序深度差异。
- voom转换:voom是一种用于将计数数据转换为适合线性模型分析的格式的方法。它通过对数据进行对数变换和中心化处理,将原始的计数数据转换为相对于某个参照样本的比例,从而减少数据的离散性。
- 线性模型:Limma-Voom方法使用线性模型来分析数据,这种模型可以包括多个协变量和批次效应,以评估不同样本组之间的基因表达差异。
- 经验贝叶斯估计:Limma-Voom方法使用经验贝叶斯统计来估计基因表达的离散度,这有助于提高对基因表达变化的检测灵敏度。
- 统计检验:在模型拟合之后,Limma-Voom进行统计检验来确定基因表达是否存在显著差异。这通常涉及到似然比检验(LRT)或t检验。
- 多重检验校正:由于同时测试多个基因,Limma-Voom使用多重检验校正方法(如Benjamini-Hochberg方法)来控制假发现率(FDR)。
- 结果解释:最终,Limma-Voom提供了一系列结果,包括P值、校正后的P值、对数倍数变化(Log Fold Change, LFC)等,这些结果可以帮助研究者识别差异表达的基因或微生物类群。
deps = c("edgeR")
for (dep in deps){if (dep %in% installed.packages()[,"Package"] == FALSE){if (!requireNamespace("BiocManager", quietly = TRUE))install.packages("BiocManager")BiocManager::install(deps)}library(dep, character.only = TRUE)
}args <- commandArgs(trailingOnly = TRUE)
#test if there is an argument supply
if (length(args) <= 2) {stop("At least three arguments must be supplied", call.=FALSE)
}con <- file(args[1])
file_1_line1 <- readLines(con,n=1)
close(con)if(grepl("Constructed from biom file", file_1_line1)){ASV_table <- read.table(args[1], sep="\t", skip=1, header=T, row.names = 1,comment.char = "", quote="", check.names = F)
}else{ASV_table <- read.table(args[1], sep="\t", header=T, row.names = 1,comment.char = "", quote="", check.names = F)
}groupings <- read.table(args[2], sep="\t", row.names = 1, header=T, comment.char = "", quote="", check.names = F)#number of samples
sample_num <- length(colnames(ASV_table))
grouping_num <- length(rownames(groupings))#check if the same number of samples are being input.
if(sample_num != grouping_num){message("The number of samples in the ASV table and the groupings table are unequal")message("Will remove any samples that are not found in either the ASV table or the groupings table")
}#check if order of samples match up.
if(identical(colnames(ASV_table), rownames(groupings))==T){message("Groupings and ASV table are in the same order")
}else{rows_to_keep <- intersect(colnames(ASV_table), rownames(groupings))groupings <- groupings[rows_to_keep,,drop=F]ASV_table <- ASV_table[,rows_to_keep]if(identical(colnames(ASV_table), rownames(groupings))==T){message("Groupings table was re-arrange to be in the same order as the ASV table")message("A total of ", sample_num-length(colnames(ASV_table)), " from the ASV_table")message("A total of ", grouping_num-length(rownames(groupings)), " from the groupings table")}else{stop("Unable to match samples between the ASV table and groupings table")}
}DGE_LIST <- DGEList(ASV_table)
### do normalization
### Reference sample will be the sample with the highest read depth### check if upper quartile method works for selecting reference
Upper_Quartile_norm_test <- calcNormFactors(DGE_LIST, method="upperquartile")summary_upper_quartile <- summary(Upper_Quartile_norm_test$samples$norm.factors)[3]
if(is.na(summary_upper_quartile) | is.infinite(summary_upper_quartile)){message("Upper Quartile reference selection failed will use find sample with largest sqrt(read_depth) to use as reference")Ref_col <- which.max(colSums(sqrt(ASV_table)))DGE_LIST_Norm <- calcNormFactors(DGE_LIST, method = "TMM", refColumn = Ref_col)fileConn<-file(args[[4]])writeLines(c("Used max square root read depth to determine reference sample"), fileConn)close(fileConn)}else{DGE_LIST_Norm <- calcNormFactors(DGE_LIST, method="TMM")
}## make matrix for testing
colnames(groupings) <- c("comparison")
mm <- model.matrix(~comparison, groupings)voomvoom <- voom(DGE_LIST_Norm, mm, plot=F)fit <- lmFit(voomvoom,mm)
fit <- eBayes(fit)
res <- topTable(fit, coef=2, n=nrow(DGE_LIST_Norm), sort.by="none")
write.table(res, file=args[3], quote=F, sep="\t", col.names = NA)Limma-Voom-TMMwsp
Limma-Voom-TMMwsp(Trimmed Mean of M-values with Singleton Pairing)是一种用于处理和分析微生物组数据的差异分析方法,它结合了几种不同的统计技术来提高分析的准确性和可靠性。下面是Limma-Voom-TMMwsp方法的基本原理:
- 数据预处理:首先,对原始的测序数据进行质量控制和预处理操作,包括去除低质量的读段、过滤掉可能的污染物等。
- TMMwsp标准化:TMMwsp是一种标准化方法,用于校正不同样本之间的测序深度差异。它通过对每个样本的计数数据应用TMM方法,并在计算中考虑单例配对(singleton pairing),以减少由于样本间测序深度不同带来的偏差。
- voom转换:voom是一种转换方法,用于将原始的计数数据转换为适合线性模型分析的格式。voom通过对数据进行对数变换,并根据样本之间的差异来估计每个基因或OTU的准确差异度量。
- 线性模型:Limma-Voom方法使用线性模型来分析数据,这种模型可以包括多个协变量和批次效应,以评估不同样本组之间的基因或OTU表达差异。
- 经验贝叶斯估计:Limma-Voom方法使用经验贝叶斯统计来估计基因或OTU表达的离散度,这有助于提高对基因或OTU表达变化的检测灵敏度。
- 统计检验:在模型拟合之后,Limma-Voom进行统计检验来确定基因或OTU表达是否存在显著差异。这通常涉及到似然比检验(LRT)或t检验。
- 多重检验校正:由于同时测试多个基因或OTU,Limma-Voom使用多重检验校正方法(如Benjamini-Hochberg方法)来控制假发现率(FDR)。
- 结果解释:最终,Limma-Voom提供了一系列结果,包括P值、校正后的P值、对数倍数变化(Log Fold Change, LFC)等,这些结果可以帮助研究者识别差异表达的基因或微生物类群。
deps = c("edgeR")
for (dep in deps){if (dep %in% installed.packages()[,"Package"] == FALSE){if (!requireNamespace("BiocManager", quietly = TRUE))install.packages("BiocManager")BiocManager::install(deps)}library(dep, character.only = TRUE)
}args <- commandArgs(trailingOnly = TRUE)
#test if there is an argument supply
if (length(args) <= 2) {stop("At least three arguments must be supplied", call.=FALSE)
}con <- file(args[1])
file_1_line1 <- readLines(con,n=1)
close(con)if(grepl("Constructed from biom file", file_1_line1)){ASV_table <- read.table(args[1], sep="\t", skip=1, header=T, row.names = 1,comment.char = "", quote="", check.names = F)
}else{ASV_table <- read.table(args[1], sep="\t", header=T, row.names = 1,comment.char = "", quote="", check.names = F)
}groupings <- read.table(args[2], sep="\t", row.names = 1, header=T, comment.char = "", quote="", check.names = F)#number of samples
sample_num <- length(colnames(ASV_table))
grouping_num <- length(rownames(groupings))#check if the same number of samples are being input.
if(sample_num != grouping_num){message("The number of samples in the ASV table and the groupings table are unequal")message("Will remove any samples that are not found in either the ASV table or the groupings table")
}#check if order of samples match up.
if(identical(colnames(ASV_table), rownames(groupings))==T){message("Groupings and ASV table are in the same order")
}else{rows_to_keep <- intersect(colnames(ASV_table), rownames(groupings))groupings <- groupings[rows_to_keep,,drop=F]ASV_table <- ASV_table[,rows_to_keep]if(identical(colnames(ASV_table), rownames(groupings))==T){message("Groupings table was re-arrange to be in the same order as the ASV table")message("A total of ", sample_num-length(colnames(ASV_table)), " from the ASV_table")message("A total of ", grouping_num-length(rownames(groupings)), " from the groupings table")}else{stop("Unable to match samples between the ASV table and groupings table")}
}DGE_LIST <- DGEList(ASV_table)
### do normalization
### Reference sample will be the sample with the highest read depth### check if upper quartile method works for selecting reference
Upper_Quartile_norm_test <- calcNormFactors(DGE_LIST, method="upperquartile")summary_upper_quartile <- summary(Upper_Quartile_norm_test$samples$norm.factors)[3]
if(is.na(summary_upper_quartile) | is.infinite(summary_upper_quartile)){message("Upper Quartile reference selection failed will use find sample with largest sqrt(read_depth) to use as reference")Ref_col <- which.max(colSums(sqrt(ASV_table)))DGE_LIST_Norm <- calcNormFactors(DGE_LIST, method = "TMMwsp", refColumn = Ref_col)fileConn<-file(args[[4]])writeLines(c("Used max square root read depth to determine reference sample"), fileConn)close(fileConn)
}else{DGE_LIST_Norm <- calcNormFactors(DGE_LIST, method="TMMwsp")
}## make matrix for testing
colnames(groupings) <- c("comparison")
mm <- model.matrix(~comparison, groupings)voomvoom <- voom(DGE_LIST_Norm, mm, plot=F)fit <- lmFit(voomvoom,mm)
fit <- eBayes(fit)
res <- topTable(fit, coef=2, n=nrow(DGE_LIST_Norm), sort.by="none")
write.table(res, file=args[3], quote=F, sep="\t", col.names = NA)Maaslin2
MaAsLin2是一种用于微生物组数据差异分析的统计方法,它专门设计用来处理微生物组数据的复杂性,包括噪声、稀疏性(零膨胀)、高维度、极端非正态分布以及通常以计数或组成性测量的形式出现的数据。以下是MaAsLin2方法的基本原理:
- 多变量统计框架:MaAsLin2(Microbiome Multivariable Associations with Linear Models)使用广义线性和混合模型来适应各种现代流行病学研究设计,包括横截面和纵向研究。
- 数据预处理:MaAsLin2提供了预处理模块,用于处理元数据和微生物特征中的缺失值、未知数据值和异常值。
- 归一化和转换:MaAsLin2可以对微生物测量结果进行归一化和转换,以解决样本中可变的覆盖深度。
- 特征标准化:可选择执行特征标准化,并使用元数据的子集或完整补充来模拟生成的质量控制微生物特征。
- 多变量模型:MaAsLin2使用各种可能的多变量模型之一为每个特征的每个元数据关联定义p值。
- 重复测量的处理:在存在重复测量的情况下,MaAsLin2通过在混合模型范式中适当地模拟对象内(或环境)相关来识别协变量相关的微生物特征,同时还通过指定对象间随机效应来解释个体变异在模型中。
- 统计检验:MaAsLin2可以识别每个单独特征与元数据对之间的关联,促进特征方面的协变量调整,并提高转化和基本生物学应用的可解释性。
- 结果校正:MaAsLin2还提供多重检验校正功能,以控制第一类错误率。
if(!requireNamespace("BiocManager", quietly = TRUE))install.packages("BiocManager")
#BiocManager::install("Maaslin2")args <- commandArgs(trailingOnly = TRUE)if (length(args) <= 2) {stop("At least three arguments must be supplied", call.=FALSE)
}con <- file(args[1])
file_1_line1 <- readLines(con,n=1)
close(con)if(grepl("Constructed from biom file", file_1_line1)){ASV_table <- read.table(args[1], sep="\t", skip=1, header=T, row.names = 1, comment.char = "", quote="", check.names = F)
}else{ASV_table <- read.table(args[1], sep="\t", header=T, row.names = 1, comment.char = "", quote="", check.names = F)
}
groupings <- read.table(args[2], sep="\t", row.names = 1, header=T, comment.char = "", quote="", check.names = F)#number of samples
sample_num <- length(colnames(ASV_table))
grouping_num <- length(rownames(groupings))if(sample_num != grouping_num){message("The number of samples in the ASV table and the groupings table are unequal")message("Will remove any samples that are not found in either the ASV table or the groupings table")
}if(identical(colnames(ASV_table), rownames(groupings))==T){message("Groupings and ASV table are in the same order")
}else{rows_to_keep <- intersect(colnames(ASV_table), rownames(groupings))groupings <- groupings[rows_to_keep,,drop=F]ASV_table <- ASV_table[,rows_to_keep]if(identical(colnames(ASV_table), rownames(groupings))==T){message("Groupings table was re-arrange to be in the same order as the ASV table")message("A total of ", sample_num-length(colnames(ASV_table)), " from the ASV_table")message("A total of ", grouping_num-length(rownames(groupings)), " from the groupings table")}else{stop("Unable to match samples between the ASV table and groupings table")}
}library(Maaslin2)ASV_table <- data.frame(t(ASV_table), check.rows = F, check.names = F, stringsAsFactors = F)fit_data <- Maaslin2(ASV_table, groupings,args[3], transform = "AST",fixed_effects = c(colnames(groupings[1])),standardize = FALSE, plot_heatmap = F, plot_scatter = F)metagenomeSeq
metagenomeSeq是一种用于分析微生物组测序数据的统计学方法,它可以帮助研究人员发现不同条件下微生物组的差异丰度。以下是metagenomeSeq方法的基本原理:
- 数据预处理:metagenomeSeq首先对原始的测序数据进行质量控制和预处理,以确保数据的准确性和可靠性。
- 归一化:对测序数据进行归一化处理,以校正样本间的测序深度差异,确保不同样本间的比较是公平的。
- 统计模型:metagenomeSeq使用统计模型来分析数据,尤其是针对组成性数据的模型,比如零膨胀模型或负二项分布模型,这些模型可以处理微生物组数据的离散性和零膨胀问题。
- 差异丰度分析:metagenomeSeq确定在两个或多个组之间具有差异丰度的特征(如OTU、物种等),通过比较它们的相对丰度来识别差异。
- 多重检验校正:由于同时测试多个特征,metagenomeSeq使用多重检验校正方法(如Benjamini-Hochberg方法)来控制假发现率(FDR)。
- 结果解释:metagenomeSeq提供了丰富的结果输出,包括P值、校正后的P值、对数倍数变化(Log Fold Change, LFC)等,这些结果可以帮助研究者识别和解释数据中的生物学意义。
deps = c("metagenomeSeq")
for (dep in deps){if (dep %in% installed.packages()[,"Package"] == FALSE){if (!requireNamespace("BiocManager", quietly = TRUE))install.packages("BiocManager")BiocManager::install(deps)}library(dep, character.only = TRUE)
}args <- commandArgs(trailingOnly = TRUE)
#test if there is an argument supply
if (length(args) <= 2) {stop("At least three arguments must be supplied", call.=FALSE)
}con <- file(args[1])
file_1_line1 <- readLines(con,n=1)
close(con)if(grepl("Constructed from biom file", file_1_line1)){ASV_table <- read.table(args[1], sep="\t", skip=1, header=T, row.names = 1, comment.char = "", quote="", check.names = F)
}else{ASV_table <- read.table(args[1], sep="\t", header=T, row.names = 1, comment.char = "", quote="", check.names = F)
}groupings <- read.table(args[2], sep="\t", row.names = 1, header=T, comment.char = "", quote="", check.names = F)#number of samples
sample_num <- length(colnames(ASV_table))
grouping_num <- length(rownames(groupings))#check if the same number of samples are being input.
if(sample_num != grouping_num){message("The number of samples in the ASV table and the groupings table are unequal")message("Will remove any samples that are not found in either the ASV table or the groupings table")
}#check if order of samples match up.
if(identical(colnames(ASV_table), rownames(groupings))==T){message("Groupings and ASV table are in the same order")
}else{rows_to_keep <- intersect(colnames(ASV_table), rownames(groupings))groupings <- groupings[rows_to_keep,,drop=F]ASV_table <- ASV_table[,rows_to_keep]if(identical(colnames(ASV_table), rownames(groupings))==T){message("Groupings table was re-arrange to be in the same order as the ASV table")message("A total of ", sample_num-length(colnames(ASV_table)), " from the ASV_table")message("A total of ", grouping_num-length(rownames(groupings)), " from the groupings table")}else{stop("Unable to match samples between the ASV table and groupings table")}
}data_list <- list()
data_list[["counts"]] <- ASV_table
data_list[["taxa"]] <- rownames(ASV_table)pheno <- AnnotatedDataFrame(groupings)
pheno
counts <- AnnotatedDataFrame(ASV_table)
feature_data <- data.frame("ASV"=rownames(ASV_table),"ASV2"=rownames(ASV_table))
feature_data <- AnnotatedDataFrame(feature_data)
rownames(feature_data) <- feature_data@data$ASVtest_obj <- newMRexperiment(counts = data_list$counts, phenoData = pheno, featureData = feature_data)p <- cumNormStat(test_obj, pFlag = T)
ptest_obj_norm <- cumNorm(test_obj, p=p)fromula <- as.formula(paste(~1, colnames(groupings)[1], sep=" + "))
pd <- pData(test_obj_norm)
mod <- model.matrix(fromula, data=pd)
regres <- fitFeatureModel(test_obj_norm, mod)res_table <- MRfulltable(regres, number = length(rownames(ASV_table)))write.table(res_table, file=args[3], quote=F, sep="\t", col.names = NA)T-test-rare
T-test-rarefaction是一种用于微生物组数据分析的统计方法,它结合了两种不同的技术:t检验和稀释抽样(rarefaction)。这种方法特别适用于处理微生物群落的计数数据,尤其是在样本数量有限或样本之间测序深度不均一的情况下。以下是T-test-rarefaction方法的基本原理:
- 稀释抽样(Rarefaction):在微生物组数据中,不同的样本可能具有不同的测序深度,即不同的读段总数。为了在比较之前使样本之间具有可比性,可以使用稀释抽样技术,即随机选择每个样本中相同数量的读段进行分析,从而模拟所有样本具有相同的测序深度。
- 数据标准化:在稀释抽样之后,数据通常需要进行标准化处理,以确保不同样本间的比较是公平的。这可以通过将读段计数转换为相对丰度来实现。
- t检验:在数据经过稀释抽样和标准化之后,使用t检验来比较两组样本中特定微生物分类单元(如OTU或物种)的丰度是否存在显著差异。t检验是一种常用的统计方法,用于确定两组独立样本均值是否存在显著差异。
- 重复稀释抽样:为了评估t检验结果的稳健性,可以多次进行稀释抽样,每次抽样后都进行t检验,然后计算显著性结果的一致性。
- 效应量计算:T-test-rarefaction方法还会计算效应量,如Cohen’s d,来衡量两组样本均值差异的实际重要性。
- 多重检验校正:由于同时对多个分类单元进行t检验,T-test-rarefaction使用多重检验校正方法(如Benjamini-Hochberg方法)来控制假发现率(FDR)。
- 结果解释:T-test-rarefaction提供了P值、校正后的P值、效应量等结果,帮助研究者识别和解释数据中的生物学意义。
### Run T Test on rarifiedargs <- commandArgs(trailingOnly = TRUE)if (length(args) <= 2) {stop("At least three arguments must be supplied", call.=FALSE)
}con <- file(args[1])
file_1_line1 <- readLines(con,n=1)
close(con)if(grepl("Constructed from biom file", file_1_line1)){ASV_table <- read.table(args[1], sep="\t", skip=1, header=T, row.names = 1, comment.char = "", quote="", check.names = F)
}else{ASV_table <- read.table(args[1], sep="\t", header=T, row.names = 1, comment.char = "", quote="", check.names = F)
}groupings <- read.table(args[2], sep="\t", row.names = 1, header=T, comment.char = "", quote="", check.names = F)#number of samples
sample_num <- length(colnames(ASV_table))
grouping_num <- length(rownames(groupings))if(sample_num != grouping_num){message("The number of samples in the ASV table and the groupings table are unequal")message("Will remove any samples that are not found in either the ASV table or the groupings table")
}if(identical(colnames(ASV_table), rownames(groupings))==T){message("Groupings and ASV table are in the same order")
}else{rows_to_keep <- intersect(colnames(ASV_table), rownames(groupings))groupings <- groupings[rows_to_keep,,drop=F]ASV_table <- ASV_table[,rows_to_keep]if(identical(colnames(ASV_table), rownames(groupings))==T){message("Groupings table was re-arrange to be in the same order as the ASV table")message("A total of ", sample_num-length(colnames(ASV_table)), " from the ASV_table")message("A total of ", grouping_num-length(rownames(groupings)), " from the groupings table")}else{stop("Unable to match samples between the ASV table and groupings table")}
}colnames(groupings)
colnames(groupings)[1] <- "places"#apply wilcox test to rarified table
pvals <- apply(ASV_table, 1, function(x) t.test(x ~ groupings[,1], exact=F)$p.value)write.table(pvals, file=args[[3]], sep="\t", col.names = NA, quote=F)
更多内容请前往:识别差异微生物的方法汇总
总结
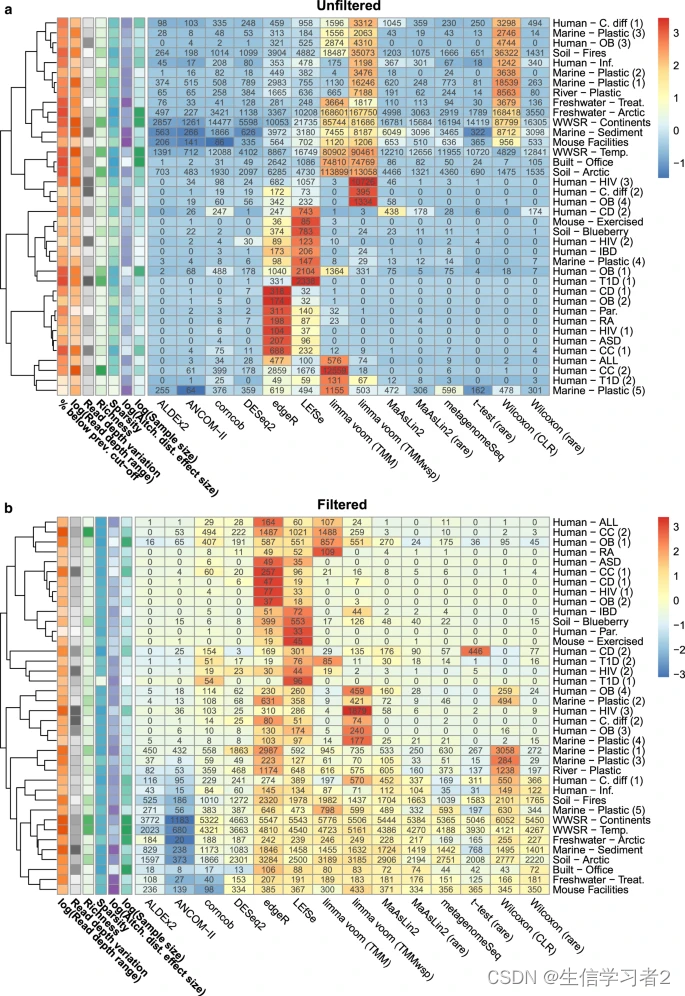
该研究证实,上述不同差异分析方法识别出了截然不同的数量和显著ASV(扩增序列变体)集合,结果依赖于数据预处理。对于许多方法来说,识别出的特征数量与数据的某些方面相关,如样本大小、测序深度以及群落差异的效应大小。ALDEx2和ANCOM-II在不同研究中产生最一致的结果,并且与不同方法结果交集的一致性最好。
相关文章:
数据分析:微生物组差异丰度方法汇总
欢迎大家关注全网生信学习者系列: WX公zhong号:生信学习者Xiao hong书:生信学习者知hu:生信学习者CDSN:生信学习者2 介绍 微生物数据具有一下的特点,这使得在做差异分析的时候需要考虑到更多的问题&…...

Linux驱动开发(二)--字符设备驱动开发提升 LED驱动开发实验
1、地址映射 在编写驱动之前,需要知道MMU,也就是内存管理单元,在老版本的 Linux 中要求处理器必须有 MMU,但是现在Linux 内核已经支持无 MMU 的处理器了。 MMU的功能如下: 完成虚拟空间到物理空间的映射 内存保护&…...
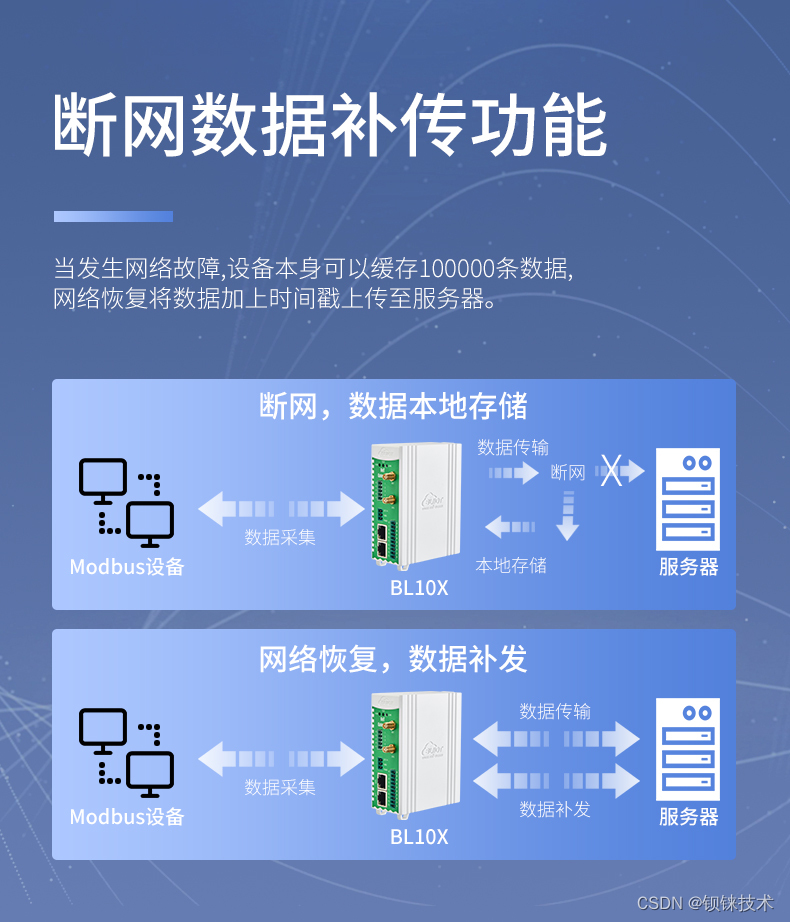
钡铼BL101网关助力智慧城市路灯远程智能管控
在迈向智慧城市的征途中,基础设施的智能化改造是关键一环,而路灯作为城市脉络的照明灯塔,其智能化升级对于节能减排、提升城市管理效率具有重要意义。钡铼BL101网关,作为Modbus转MQTT的专业桥梁,正以其卓越的性能和广泛…...
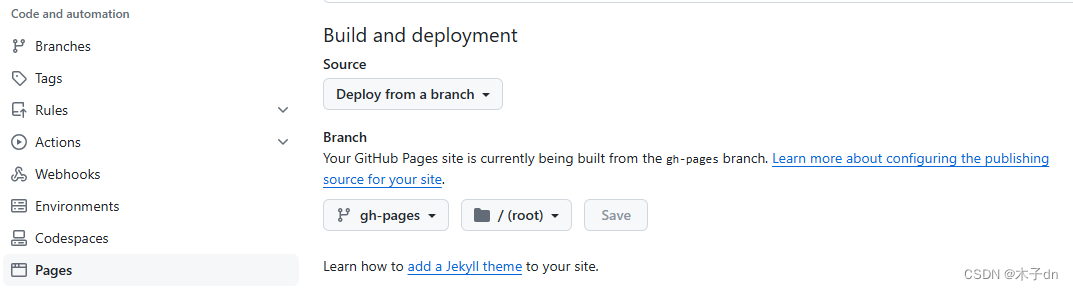
如何优雅的使用Github Action服务来将Hexo部署到Github Pages
文章目录 参考文章前提条件1. 初始化Hexo2. 初始化仓库3. 创建Token4. 修改_config.yml5. 配置Github Action工作流6. 推送验证7. 配置Github Pages8. 修改Hexo主题样式10. 添加文章遇到了一些问题和方案1. 网站没有样式问题2. 图片不显示 参考文章 Bilibili视频教程-9分钟零成…...

After Effects 2024 mac/win版:创意视效,梦想起航
After Effects 2024是一款引领视效革命的专业软件,汇聚了创意与技术的精华。作为Adobe推出的全新版本,它以其强大的视频处理和动画创作能力,成为从事设计和视频特技的机构,如电视台、动画制作公司、个人后期制作工作室以及多媒体工…...

信息打点web篇----web后端源码专项收集
前言 欢迎来到我的博客 个人主页:北岭敲键盘的荒漠猫-CSDN博客 专栏描述:因为第一遍过信息收集的时候,没怎么把收集做回事 导致后来在实战中,遭遇资产获取少,可渗透点少的痛苦,如今决定 从头来过,全面全方位…...

ArcGIS批量投影转换的妙用(地理坐标系转换为平面坐标系)
点击下方全系列课程学习 点击学习—>ArcGIS全系列实战视频教程——9个单一课程组合系列直播回放 这次文章我们来介绍一下,如何巧妙用要素数据集来实现要素的批量投影。不需要ArcGIS的模型构建器与解决。 例如,有多个要素要将CGCS_2000地理坐标系投…...

YOLOv10训练自己的数据集(图像目标检测)
目录 1、下载代码 2、环境配置 3、准备数据集 4、yolov10训练 可能会出现报错: 1、下载代码 源码地址:https://github.com/THU-MIG/yolov10 2、环境配置 打开源代码,在Terminal中,使用conda 创建虚拟环境配置 命令如下&a…...

解决不能拉取 docker 镜像
# 编辑镜像仓库文件 sudo vi /etc/docker/daemon.json { "registry-mirrors": ["https://registry.docker-cn.com","https://s3d6l2fh.mirror.aliyuncs.com"] }# 重启docker sudo systemctl restart docker参考 https://blog.csdn.net/u01019733…...
44、基于深度学习的癌症检测(matlab)
1、基于深度学习的癌症检测原理及流程 基于深度学习的癌症检测是利用深度学习算法对医学影像数据进行分析和诊断,以帮助医生准确地检测癌症病变。其原理和流程主要包括以下几个步骤: 数据采集:首先需要收集包括X光片、CT扫描、MRI等医学影像…...

Vue3 【仿 react 的 hook】封装 useTitle
效果预览 页码加载时,自动获取网页标题通过input输入框,可以实时改变网页标题 代码实现 index.vue <template><h1>网页的标题为: {{ titleRef }}</h1><p>通过input输入框实时改变网页的标题 <input v-model"…...

CSS 计数器
CSS 计数器 CSS 计数器是 CSS 中一个强大但经常被忽视的功能。它们允许开发者创建和管理计数器,这些计数器可以在文档中自动递增,非常适合用于编号章节、列表项或其他文档元素。在本文中,我们将深入探讨 CSS 计数器的使用方法、优势和实际应用场景。 CSS 计数器的基本概念…...

磁力搜索器,解读新一代的搜索引擎方式,磁力王、磁力猫等引擎的异同及原理
最近国内几年,不依赖追踪服务器的磁力搜索开始流行,成为新的资源搜索的方式。 我们平常所说的磁力王(jigecili.com)、磁力猫(yinghuacili.com)、bt磁力(btcili.cn)、磁力狗最新版(cilizhai.net)、磁力兔子、磁力宝、人…...

Apache Doris 全新分区策略 Auto Partition 应用场景与功能详解 | Deep Dive系列
编辑:SelectDB 技术团队 在当今数据驱动的时代,如何高效、有序地管理数据库中的海量数据成为挑战。为了处理庞大的数据集,分布式数据库引入了类似分区和分桶策略,通过将数据按特定规则划分成较小的单位并分布到不同节点上&#x…...

【Linux】关于在华为云中开放了端口后仍然无法访问的问题
已在安全组中添加规则: 通过指令: netstat -nltp | head -2 && netstat -nltp | grep 8080 运行结果: 可以看到服务器确实处于监听状态了. 通过指令 telnet 公网ip port 也提示: "正在连接xxx.xx.xx.xxx...无法打开到主机的连接。 在端口 8080: 连接失败"…...
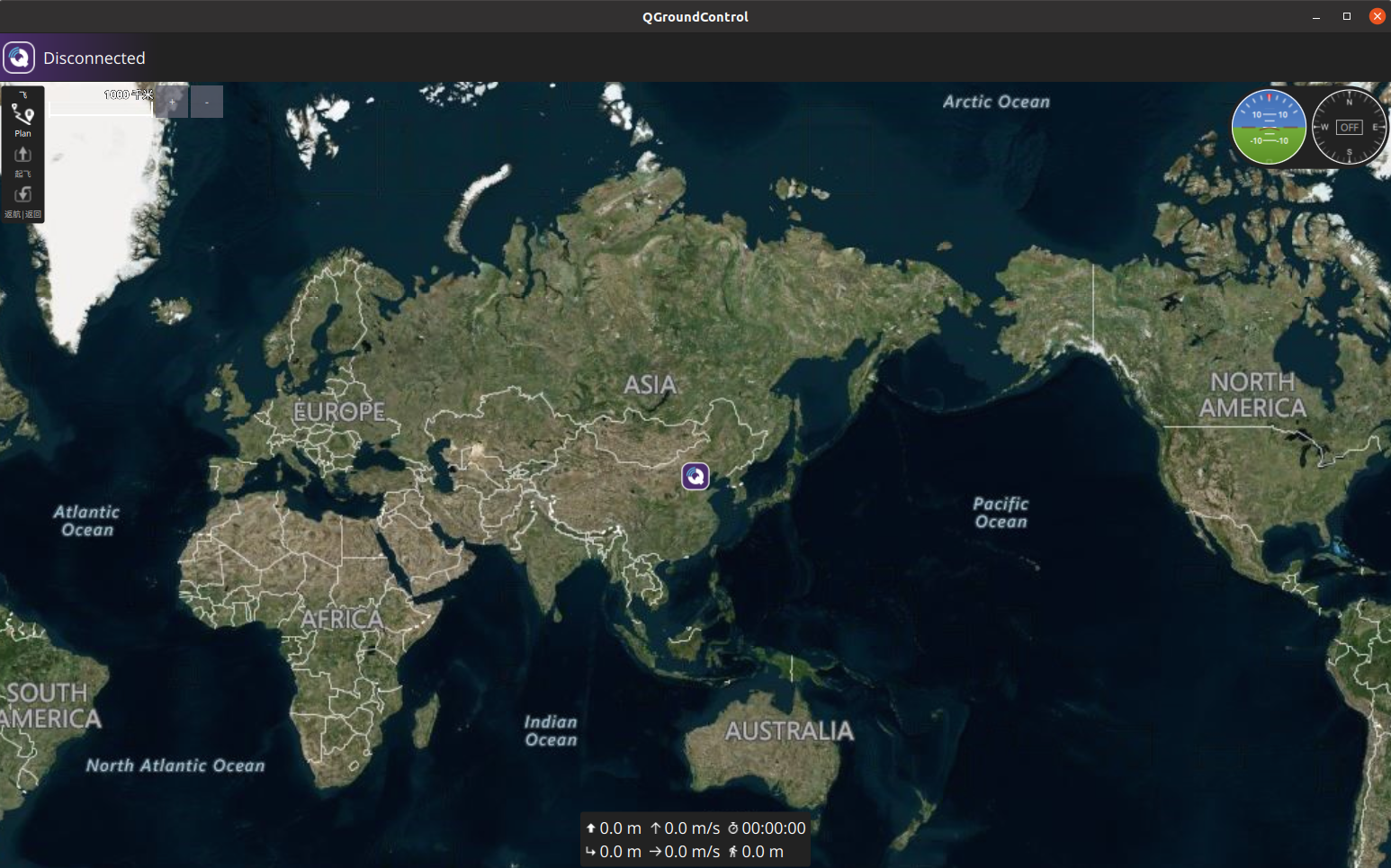
Linux系统ubuntu20.04 无人机PX4 开发环境搭建(失败率很低)
Linux系统ubuntu20.04 无人机PX4 开发环境搭建 PX4固件下载开发环境搭建MAVROS安装安装地面站QGC PX4固件下载 PX4的源码处于GitHub,因为众所周知的原因git clone经常失败,此处从Gitee获取PX4源码和依赖模块。 git clone https://gitee.com/voima/PX4-…...
)
中间件(express)
中间件(express) 在Express.js中,中间件(Middleware)是一个重要的组成部分,用于处理HTTP请求和响应。中间件函数具有特定的签名,并可以接受请求对象(req)、响应对象&…...

【代码随想录算法训练Day44】LeetCode 322.零钱兑换、LeetCode 279.完全平方数、LeetCode139.单词拆分
Day44 动态规划第六天 LeetCode 322.零钱兑换 dp数组的含义:装满容量为j的背包需要的最少物品数为dp[j] 递推公式:dp[j]min(dp[j-coins[i]]1,dp[j]) 初始化:dp[0]0,dp[j]INT_MAX 遍历顺序:个数问题与遍历顺序无关,都…...

ChatGLM2-6B 部署
本文主要对 ChatGLM2-6B 模型的部署和推理过程进行介绍。 一、部署环境 在阿里云服务器上部署,具体环境如下: modelscope:1.9.5 pytorch 2.0.1 tensorflow 2.13.0 python 3.8 cuda 118 ubuntu 20.04 CPU 8 core 内存 30 GiB GPU NVIDIA A10 2…...
武汉工程大学24计算机考研数据,有学硕招收调剂,而专硕不招收调剂!
武汉工程大学是一所以工为主,覆盖工、理、管、经、文、法、艺术、医学、教育学等九大学科门类的多科性教学研究型大学,是湖北省重点建设高校、湖北省国内一流学科建设高校,入选卓越工程师教育培养计划、中西部高校基础能力建设工程、“新工科…...

对WWDC 2025 Keynote 内容的预测
借助我们以往对苹果公司发展路径的深入研究经验,以及大语言模型的分析能力,我们系统梳理了多年来苹果 WWDC 主题演讲的规律。在 WWDC 2025 即将揭幕之际,我们让 ChatGPT 对今年的 Keynote 内容进行了一个初步预测,聊作存档。等到明…...

【论文笔记】若干矿井粉尘检测算法概述
总的来说,传统机器学习、传统机器学习与深度学习的结合、LSTM等算法所需要的数据集来源于矿井传感器测量的粉尘浓度,通过建立回归模型来预测未来矿井的粉尘浓度。传统机器学习算法性能易受数据中极端值的影响。YOLO等计算机视觉算法所需要的数据集来源于…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

LabVIEW双光子成像系统技术
双光子成像技术的核心特性 双光子成像通过双低能量光子协同激发机制,展现出显著的技术优势: 深层组织穿透能力:适用于活体组织深度成像 高分辨率观测性能:满足微观结构的精细研究需求 低光毒性特点:减少对样本的损伤…...
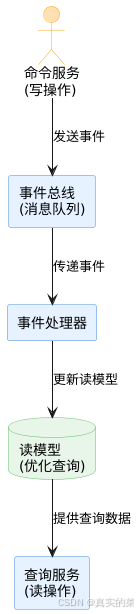
消息队列系统设计与实践全解析
文章目录 🚀 消息队列系统设计与实践全解析🔍 一、消息队列选型1.1 业务场景匹配矩阵1.2 吞吐量/延迟/可靠性权衡💡 权衡决策框架 1.3 运维复杂度评估🔧 运维成本降低策略 🏗️ 二、典型架构设计2.1 分布式事务最终一致…...

WebRTC调研
WebRTC是什么,为什么,如何使用 WebRTC有什么优势 WebRTC Architecture Amazon KVS WebRTC 其它厂商WebRTC 海康门禁WebRTC 海康门禁其他界面整理 威视通WebRTC 局域网 Google浏览器 Microsoft Edge 公网 RTSP RTMP NVR ONVIF SIP SRT WebRTC协…...
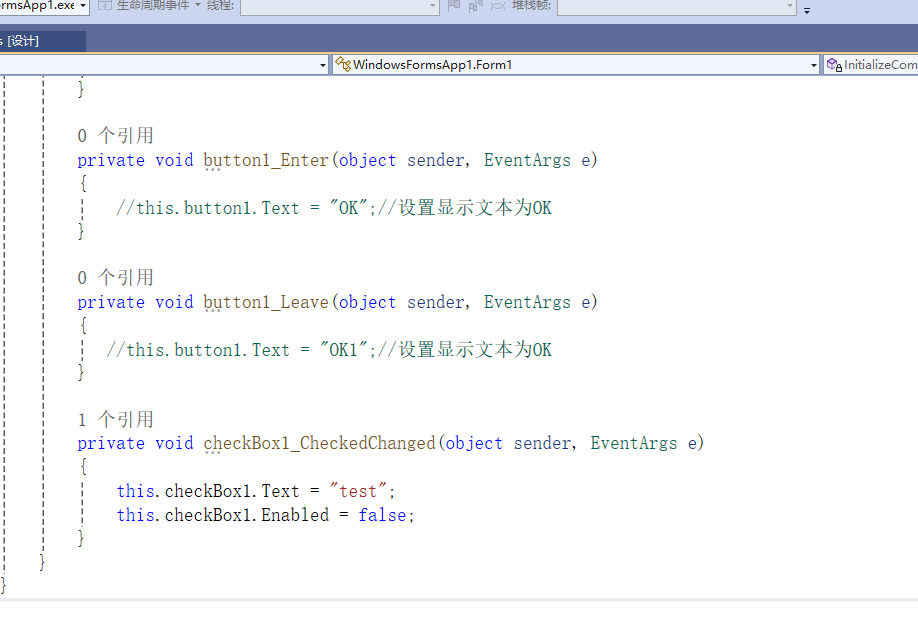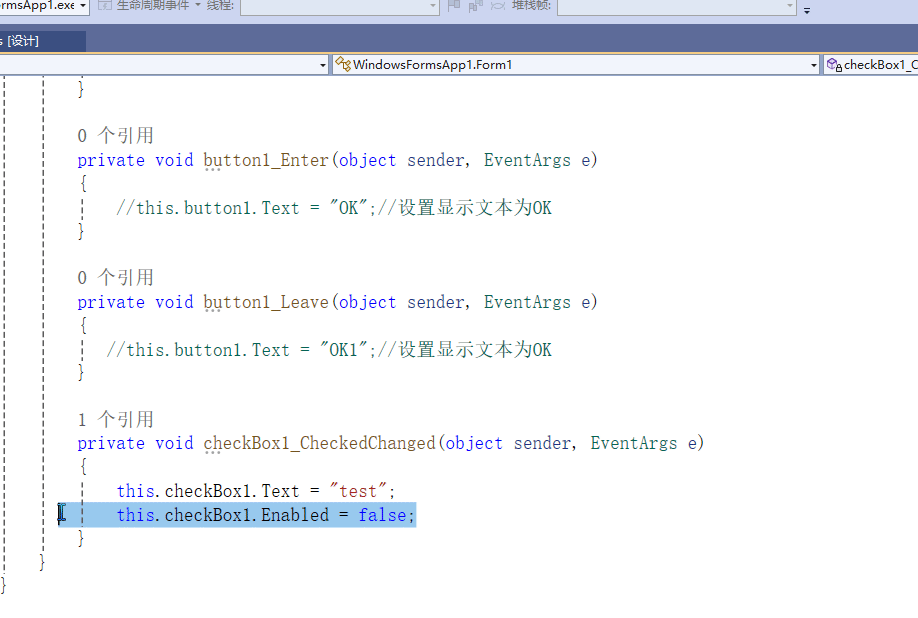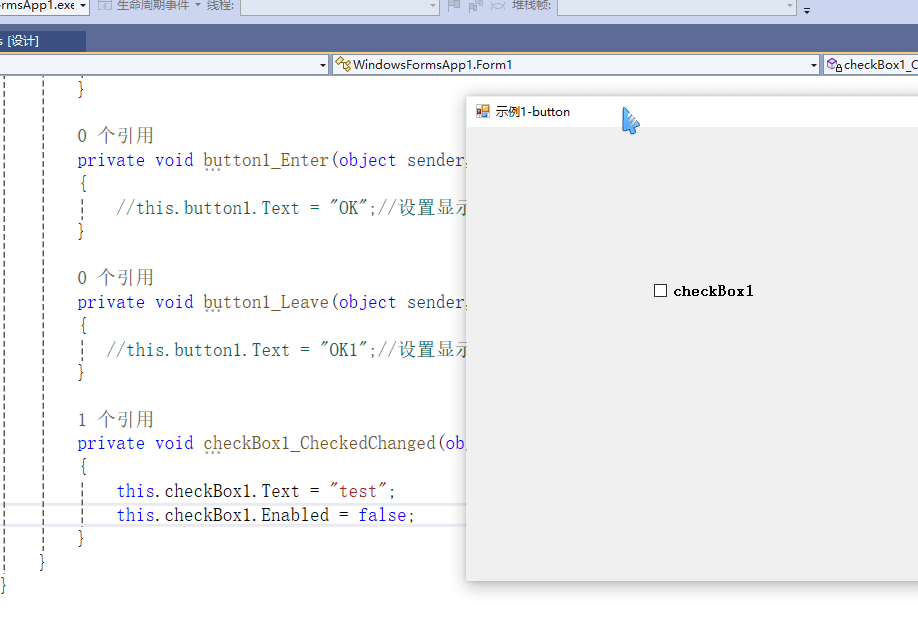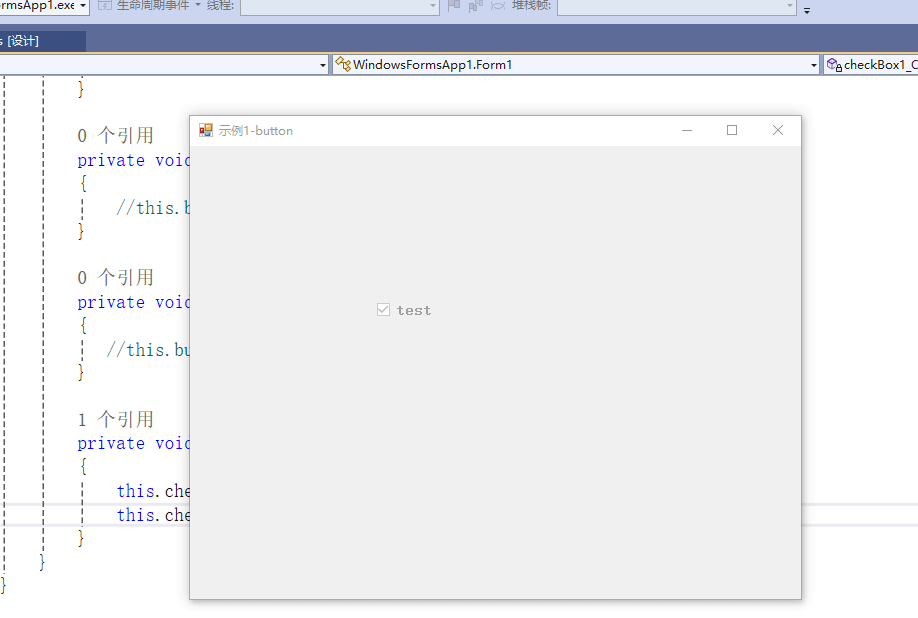
C# winform教程(二)----checkbox
一、作用 提供一个用户选择或者不选的状态,这是一个可以多选的控件。 二、属性 其实功能大差不差,除了特殊的几个外,与button基本相同,所有说几个独有的 checkbox属性 名称内容含义appearance控件外观可以变成按钮形状checkali…...
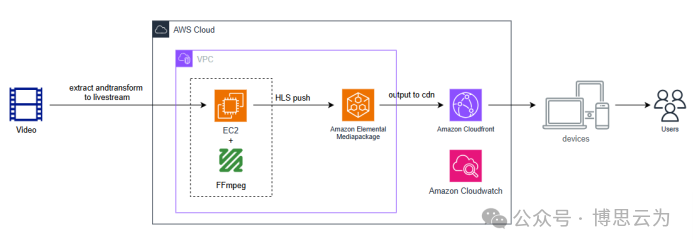
客户案例 | 短视频点播企业海外视频加速与成本优化:MediaPackage+Cloudfront 技术重构实践
01技术背景与业务挑战 某短视频点播企业深耕国内用户市场,但其后台应用系统部署于东南亚印尼 IDC 机房。 随着业务规模扩大,传统架构已较难满足当前企业发展的需求,企业面临着三重挑战: ① 业务:国内用户访问海外服…...

WEB3全栈开发——面试专业技能点P4数据库
一、mysql2 原生驱动及其连接机制 概念介绍 mysql2 是 Node.js 环境中广泛使用的 MySQL 客户端库,基于 mysql 库改进而来,具有更好的性能、Promise 支持、流式查询、二进制数据处理能力等。 主要特点: 支持 Promise / async-await…...

算法—栈系列
一:删除字符串中的所有相邻重复项 class Solution { public:string removeDuplicates(string s) {stack<char> st;for(int i 0; i < s.size(); i){char target s[i];if(!st.empty() && target st.top())st.pop();elsest.push(s[i]);}string ret…...