爬虫 pandas Linux Flume Pig填空题
目录
试卷:Python网络数据处理
答案
试卷:Pandas基础操作
答案
试卷:Linux基础指令
答案
试卷:Apache Flume基础指令
答案
试卷:Apache Pig基础指令
答案:
Hadoop题
答案
试卷:Python网络数据处理
一、填空题
-
requests库用于发送HTTP请求和接收_____。 -
response.status_code可以获取HTTP响应的_____。 -
使用
requests.get(url)发送GET请求时,响应内容可以通过_____属性获取。 -
JSON(JavaScript Object Notation)是一种_____数据交换格式。
-
JSON对象由__和__组成。
-
使用
response.json()方法可以将响应内容解析为_____格式。 -
在
requests.post(url, json=data)中,json=data用于发送_____数据。 -
HTML解析常用的库是_____。
-
BeautifulSoup的解析器通常使用_____。 -
soup.find_all('a')用于找到HTML中所有_____标签。 -
response.cookies用于获取_____。 -
在
requests.get(url, headers=headers)中,headers=headers用于发送_____。 -
在POST请求中,传统表单数据通过_____参数发送。
-
通过
response.url可以获取_____。 -
requests.exceptions.Timeout是requests库中的_____异常。 -
使用
requests.get(url, params=params)可以发送GET请求并附带_____。 -
response.history包含了_____的响应历史。 -
使用
response.text可以获得HTTP响应的_____。 -
response.content返回的是HTTP响应的_____形式。 -
soup.find('div', class_='content')可以找到HTML中class为_____的<div>标签。 -
response.headers返回的是HTTP响应的_____。 -
在响应的JSON数据中,
null表示_____。 -
response.encoding用于获取HTTP响应的_____。 -
requests.get(url, timeout=5)中,timeout=5表示设置超时时间为_____秒。 -
response.raise_for_status()用于在请求发生_____时抛出异常。 -
使用
requests.get(url, cookies=cookies)可以发送GET请求并附带_____。 -
使用
response.ok可以判断HTTP响应是否_____。 -
在HTML解析中,
soup.title用于获取HTML文档的_____标签。 -
使用
requests.put(url, data=data)可以发送_____请求。 -
response.elapsed.total_seconds()返回的是请求的_____时间(秒)。
答案
一、填空题
-
requests库用于发送HTTP请求和接收HTTP响应。 -
response.status_code可以获取HTTP响应的状态码。 -
使用
requests.get(url)发送GET请求时,响应内容可以通过response.text属性获取。 -
JSON(JavaScript Object Notation)是一种数据交换格式。
-
JSON对象由键和值组成。
-
使用
response.json()方法可以将响应内容解析为JSON格式。 -
在
requests.post(url, json=data)中,json=data用于发送JSON格式数据。 -
HTML解析常用的库是BeautifulSoup。
-
BeautifulSoup的解析器通常使用html.parser。 -
soup.find_all('a')用于找到HTML中所有<a>标签。 -
response.cookies用于获取响应中的Cookies。 -
在
requests.get(url, headers=headers)中,headers=headers用于发送自定义的请求头。 -
在POST请求中,传统表单数据通过data参数发送。
-
通过
response.url可以获取最终的URL。 -
requests.exceptions.Timeout是requests库中的超时异常。 -
使用
requests.get(url, params=params)可以发送GET请求并附带查询参数。 -
response.history包含了重定向的响应历史。 -
使用
response.text可以获得HTTP响应的文本内容。 -
response.content返回的是HTTP响应的字节形式。 -
soup.find('div', class_='content')可以找到HTML中class为'content'的<div>标签。 -
response.headers返回的是HTTP响应的头部信息。 -
在响应的JSON数据中,
null表示空值。 -
response.encoding用于获取HTTP响应的编码。 -
requests.get(url, timeout=5)中,timeout=5表示设置超时时间为5秒。 -
response.raise_for_status()用于在请求发生错误时抛出异常。 -
使用
requests.get(url, cookies=cookies)可以发送GET请求并附带Cookies。 -
使用
response.ok可以判断HTTP响应是否成功。 -
在HTML解析中,
soup.title用于获取HTML文档的<title>标签。 -
使用
requests.put(url, data=data)可以发送PUT请求。 -
response.elapsed.total_seconds()返回的是请求的响应时间(秒)。
试卷:Pandas基础操作
一、填空题
-
导入Pandas库的标准语句是
import pandas as __。 -
使用
pd.Series(data)创建一个Pandas的_____对象。 -
从CSV文件中读取数据可以使用
pd.read_csv('file.csv'),返回的数据结构是_____。 -
查看DataFrame的前几行数据可以使用_____方法。
-
查看DataFrame的列名可以使用_____属性。
-
获取DataFrame的行数和列数可以使用_____属性。
-
在DataFrame中选取一列数据可以使用
df['column_name']或df.column_name的_____方法。 -
在DataFrame中选取多列数据可以使用
df[['col1', 'col2']]的_____语法。 -
使用
df.head(10)可以查看DataFrame的_____行数据。 -
使用
df.tail(5)可以查看DataFrame的_____行数据。 -
创建一个新的列可以使用
df['new_column'] = values的_____方法。 -
使用
df.info()可以查看DataFrame的_____信息。 -
使用
df.describe()可以获取DataFrame的_____统计信息。 -
使用
df.dropna()可以删除包含_____值的行。 -
使用
df.fillna(value)可以将DataFrame中的_____值替换为指定值。 -
使用
df.groupby('column').mean()可以按_____分组计算均值。 -
使用
df['new_col'] = df.apply(lambda row: func(row['col']), axis=1)可以在DataFrame中应用_____函数。 -
使用
pd.concat([df1, df2], axis=0)可以沿着_____方向连接两个DataFrame。 -
使用
pd.merge(df1, df2, on='key')可以根据_____列合并两个DataFrame。 -
使用
df.pivot_table(values='value', index='index_col', columns='col')可以创建一个_____表格。 -
使用
df.sort_values('column', ascending=False)可以按_____排序DataFrame。 -
使用
df.drop_duplicates()可以删除DataFrame中的_____行。 -
使用
df.set_index('column')可以将DataFrame的_____设置为指定列。 -
使用
df.reset_index()可以重置DataFrame的_____索引。 -
使用
df['column'].value_counts()可以统计某一列中各个值的_____。 -
使用
df['new_col'] = pd.to_datetime(df['date_col'])可以将_____转换为日期时间格式。 -
使用
df.to_csv('file.csv', index=False)可以将DataFrame保存为_____文件。 -
使用
df.plot()可以绘制_____图形。 -
使用
df.corr()可以计算DataFrame中各列之间的_____系数。 -
使用
df.isnull().sum()可以统计DataFrame中每列的_____值数量。
答案
-
导入Pandas库的标准语句是
import pandas as pd。 -
使用
pd.Series(data)创建一个Pandas的 Series 对象。 -
从CSV文件中读取数据可以使用
pd.read_csv('file.csv'),返回的数据结构是 DataFrame。 -
查看DataFrame的前几行数据可以使用 head() 方法。
-
查看DataFrame的列名可以使用 columns 属性。
-
获取DataFrame的行数和列数可以使用 shape 属性。
-
在DataFrame中选取一列数据可以使用
df['column_name']或df.column_name的 索引 方法。 -
在DataFrame中选取多列数据可以使用
df[['col1', 'col2']]的 列表 语法。 -
使用
df.head(10)可以查看DataFrame的 前 10 行数据。 -
使用
df.tail(5)可以查看DataFrame的 后 5 行数据。 -
创建一个新的列可以使用
df['new_column'] = values的 赋值 方法。 -
使用
df.info()可以查看DataFrame的 信息。 -
使用
df.describe()可以获取DataFrame的 描述性 统计信息。 -
使用
df.dropna()可以删除包含 缺失值 的行。 -
使用
df.fillna(value)可以将DataFrame中的 缺失值 替换为指定值。 -
使用
df.groupby('column').mean()可以按 分组 计算均值。 -
使用
df['new_col'] = df.apply(lambda row: func(row['col']), axis=1)可以在DataFrame中应用 自定义函数。 -
使用
pd.concat([df1, df2], axis=0)可以沿着 行 方向连接两个DataFrame。 -
使用
pd.merge(df1, df2, on='key')可以根据 键 列合并两个DataFrame。 -
使用
df.pivot_table(values='value', index='index_col', columns='col')可以创建一个 透视 表格。 -
使用
df.sort_values('column', ascending=False)可以按 降序 排序DataFrame。 -
使用
df.drop_duplicates()可以删除DataFrame中的 重复 行。 -
使用
df.set_index('column')可以将DataFrame的 索引 设置为指定列。 -
使用
df.reset_index()可以重置DataFrame的 索引。 -
使用
df['column'].value_counts()可以统计某一列中各个值的 出现 次数。 -
使用
df['new_col'] = pd.to_datetime(df['date_col'])可以将 日期 列转换为日期时间格式。 -
使用
df.to_csv('file.csv', index=False)可以将DataFrame保存为 CSV 文件。 -
使用
df.plot()可以绘制 折线 图形。 -
使用
df.corr()可以计算DataFrame中各列之间的 相关 系数。 -
使用
df.isnull().sum()可以统计DataFrame中每列的 缺失 值数量。
试卷:Linux基础指令
一、填空题
-
查看当前所在目录的命令是
_________。 -
显示当前用户的用户名的命令是
_________。 -
创建一个名为
test.txt的空文件的命令是_________。 -
切换到根目录的命令是
_________。 -
切换到用户
user1的命令是_________。 -
查看文件或目录的详细信息的命令是
_________。 -
列出当前目录下的所有文件和子目录的命令是
_________。 -
创建一个名为
new_dir的新目录的命令是_________。 -
删除名为
file1.txt的文件的命令是_________。 -
删除名为
old_dir的空目录的命令是_________。 -
复制文件
source.txt到目录dest的命令是_________。 -
将
file1.txt重命名为file2.txt的命令是_________。 -
查看文件内容的命令是
_________。 -
将
file1.txt的内容输出到屏幕的命令是_________。 -
在终端中连续按两次
Tab键可以进行_____。 -
将
file1.txt的内容追加到file2.txt的命令是_________。 -
将
source_dir目录及其内容压缩成source_dir.tar.gz的命令是_________。 -
解压名为
archive.tar.gz的压缩文件的命令是_________。 -
在Linux中,
*通配符代表_____。 -
显示系统当前时间的命令是
_________。 -
列出当前所有正在运行的进程的命令是
_________。 -
结束进程号为
1234的进程的命令是_________。 -
在后台运行命令
command的命令是_________。 -
查看系统中使用的磁盘空间的命令是
_________。 -
显示当前用户使用的磁盘配额的命令是
_________。 -
将
file1.txt从本地上传到远程主机的命令是_________。 -
从远程主机下载名为
file1.txt的文件到本地的命令是_________。 -
在Linux中,
>符号用于_____。 -
在Linux中,
|符号用于_____。 -
在Linux中,
sudo命令用于以_____权限执行命令。
答案
一、填空题
-
查看当前所在目录的命令是
pwd。 -
显示当前用户的用户名的命令是
whoami。 -
创建一个名为
test.txt的空文件的命令是touch test.txt。 -
切换到根目录的命令是
cd /。 -
切换到用户
user1的命令是su user1或sudo -u user1 -i。 -
查看文件或目录的详细信息的命令是
ls -l或ls -lh。 -
列出当前目录下的所有文件和子目录的命令是
ls。 -
创建一个名为
new_dir的新目录的命令是mkdir new_dir。 -
删除名为
file1.txt的文件的命令是rm file1.txt。 -
删除名为
old_dir的空目录的命令是rmdir old_dir。 -
复制文件
source.txt到目录dest的命令是cp source.txt dest/。 -
将
file1.txt重命名为file2.txt的命令是mv file1.txt file2.txt。 -
查看文件内容的命令是
cat filename或less filename。 -
将
file1.txt的内容输出到屏幕的命令是cat file1.txt。 -
在终端中连续按两次
Tab键可以进行 文件名自动补全。 -
将
file1.txt的内容追加到file2.txt的命令是cat file1.txt >> file2.txt。 -
将
source_dir目录及其内容压缩成source_dir.tar.gz的命令是tar -czvf source_dir.tar.gz source_dir/。 -
解压名为
archive.tar.gz的压缩文件的命令是tar -xzvf archive.tar.gz。 -
在Linux中,
*通配符代表 匹配任意字符。 -
显示系统当前时间的命令是
date。 -
列出当前所有正在运行的进程的命令是
ps aux或top。 -
结束进程号为
1234的进程的命令是kill 1234或kill -9 1234。 -
在后台运行命令
command的命令是command &。 -
查看系统中使用的磁盘空间的命令是
df -h。 -
显示当前用户使用的磁盘配额的命令是
quota -v。 -
将
file1.txt从本地上传到远程主机的命令是scp file1.txt user@remote_host:/path/to/destination/。 -
从远程主机下载名为
file1.txt的文件到本地的命令是scp user@remote_host:/path/to/file1.txt /local/path/。 -
在Linux中,
>符号用于 重定向输出到文件。 -
在Linux中,
|符号用于 管道,将一个命令的输出作为另一个命令的输入。 -
在Linux中,
sudo命令用于以 超级用户 权限执行命令。
试卷:Apache Flume基础指令
一、填空题
-
启动Flume代理服务的命令是
flume-ng __。 -
指定Flume配置文件启动代理的参数是
-c __。 -
使用哪个参数指定Flume配置文件的路径?
-f __。 -
在Flume配置文件中,用来定义source的关键字是
__。 -
在Flume配置文件中,用来定义channel的关键字是
__。 -
在Flume配置文件中,用来定义sink的关键字是
__。 -
在Flume中,
avro是一种常见的 __类型。 -
Flume中用来将数据从source传输到sink的组件是 __。
-
Flume中用来存储数据的缓冲区是 __。
-
指定Flume agent名称的参数是
-n __。 -
使用Flume收集的数据一般存储在 __中。
-
在Flume中,将数据从一个source传输到多个sink的组件是 __。
-
Flume的日志输出级别可以通过参数
-D__=进行设置。 -
在Flume配置文件中,指定source类型的参数是
type = __。 -
Flume中用来管理数据流的组件是 __。
-
Flume中用来确保数据不会丢失的channel类型是 __。
-
使用Flume将日志数据传输到HDFS时,sink类型是 __。
-
Flume中用来连接source和sink的关键字是 __。
-
在Flume配置文件中,可以使用
agent.sources.sourceName.channels = channelName来连接 __ 和 __。 -
Flume中用来启动多个agent的工具是 __。
-
在Flume配置文件中,指定channel类型的参数是
type = __。 -
Flume中用来监控和管理agent的工具是 __。
-
在Flume中,使用哪个参数指定自定义的Flume插件路径?
-cp __。 -
Flume中用来设置source的绑定端口的参数是
port = __。 -
Flume中用来设置sink的目标地址的参数是
hostname = __。 -
Flume中用来设置sink的目标端口的参数是
port = __。 -
Flume中用来设置sink的HDFS写入路径的参数是
hdfs.path = __。 -
Flume中用来设置sink的batch大小的参数是
batchSize = __。 -
Flume中用来设置channel的容量大小的参数是
capacity = __。 -
Flume中用来设置channel的事务容量大小的参数是
transactionCapacity = __。
答案
一、填空题
-
启动Flume代理服务的命令是
flume-ng agent。 -
指定Flume配置文件启动代理的参数是
-c。 -
使用哪个参数指定Flume配置文件的路径?
-f。 -
在Flume配置文件中,用来定义source的关键字是
source。 -
在Flume配置文件中,用来定义channel的关键字是
channel。 -
在Flume配置文件中,用来定义sink的关键字是
sink。 -
在Flume中,
avro是一种常见的 source 类型。 -
Flume中用来将数据从source传输到sink的组件是 channel。
-
Flume中用来存储数据的缓冲区是 channel。
-
指定Flume agent名称的参数是
-n。 -
使用Flume收集的数据一般存储在 HDFS 中。
-
在Flume中,将数据从一个source传输到多个sink的组件是 interceptor。
-
Flume的日志输出级别可以通过参数
-Dflume.root.logger进行设置。 -
在Flume配置文件中,指定source类型的参数是
type =。 -
Flume中用来管理数据流的组件是 agent。
-
Flume中用来确保数据不会丢失的channel类型是 file。
-
使用Flume将日志数据传输到HDFS时,sink类型是 hdfs。
-
Flume中用来连接source和sink的关键字是
agent.sources.sourceName.channels = channelName。 -
在Flume配置文件中,可以使用
agent.sources.sourceName.channels = channelName来连接 source 和 channel。 -
Flume中用来启动多个agent的工具是 flume-ng multi。
-
在Flume配置文件中,指定channel类型的参数是
type =。 -
Flume中用来监控和管理agent的工具是 Flume NG Manager。
-
在Flume中,使用哪个参数指定自定义的Flume插件路径?
-cp。 -
Flume中用来设置source的绑定端口的参数是
port =。 -
Flume中用来设置sink的目标地址的参数是
hostname =。 -
Flume中用来设置sink的目标端口的参数是
port =。 -
Flume中用来设置sink的HDFS写入路径的参数是
hdfs.path =。 -
Flume中用来设置sink的batch大小的参数是
batchSize =。 -
Flume中用来设置channel的容量大小的参数是
capacity =。 -
Flume中用来设置channel的事务容量大小的参数是
transactionCapacity =。
试卷:Apache Pig基础指令
一、填空题
-
使用Pig Latin语言加载数据的命令是 _____。
-
在Pig Latin中,用来创建关系型数据的命令是 _____
-
在Pig Latin中,用来过滤数据的命令是 _____
-
在Pig Latin中,用来选择特定列的命令是 _____
-
在Pig Latin中,用来对数据分组的命令是 _____
-
在Pig Latin中,用来对数据排序的命令是 ` _____
-
在Pig Latin中,用来计算数据统计信息的命令是 _____
-
在Pig Latin中,用来将数据存储到文件系统中的命令是 _____
-
在Pig Latin中,用来清除已定义关系的命令是 _____
-
在Pig Latin中,用来连接两个或多个关系的命令是 _____
-
在Pig Latin中,用来计算关系的最大值的命令是 _____
-
在Pig Latin中,用来计算关系的最小值的命令是 _____
-
在Pig Latin中,用来计算关系的唯一值的命令是 _____
-
在Pig Latin中,用来将字符串转换为小写的函数是 _____
-
在Pig Latin中,用来将字符串转换为大写的函数是 _____
-
在Pig Latin中,用来截取字符串的函数是 _____
-
在Pig Latin中,用来连接字符串的函数是 _____
-
在Pig Latin中,用来判断字符串是否匹配某种模式的函数是 _____
-
在Pig Latin中,用来计算字符串长度的函数是 _____
-
在Pig Latin中,用来转换字符串为整数的函数是 _____。
-
在Pig Latin中,用来转换字符串为浮点数的函数是 _____
-
在Pig Latin中,用来获取当前日期的函数是 _____
-
在Pig Latin中,用来获取当前时间的函数是 _____
-
在Pig Latin中,用来获取当前日期和时间的函数是 _____
-
在Pig Latin中,用来获取指定关系的字段数目的函数是 _____
-
在Pig Latin中,用来获取指定关系的数据类型的函数是 _____
答案:
一、填空题
-
使用Pig Latin语言加载数据的命令是
LOADINTO...。 -
在Pig Latin中,用来创建关系型数据的命令是
DEFINE。 -
在Pig Latin中,用来过滤数据的命令是
FILTERBY。 -
在Pig Latin中,用来选择特定列的命令是
FOREACHGENERATE。 -
在Pig Latin中,用来对数据分组的命令是
GROUPBY。 -
在Pig Latin中,用来对数据排序的命令是
ORDERBY。 -
在Pig Latin中,用来计算数据统计信息的命令是
DESCRIBE。 -
在Pig Latin中,用来将数据存储到文件系统中的命令是
STOREINTO。 -
在Pig Latin中,用来清除已定义关系的命令是
CLEAR。 -
在Pig Latin中,用来连接两个或多个关系的命令是
JOINBY,BY。 -
在Pig Latin中,用来处理NULL值的命令是
COGROUPBY。 -
在Pig Latin中,用来计算关系的行数的命令是
COUNT()。 -
在Pig Latin中,用来计算关系的聚合函数SUM的命令是
SUM()。 -
在Pig Latin中,用来计算关系的平均值的命令是
AVG()。 -
在Pig Latin中,用来计算关系的最大值的命令是
MAX()。 -
在Pig Latin中,用来计算关系的最小值的命令是
MIN()。 -
在Pig Latin中,用来计算关系的唯一值的命令是
DISTINCT()。 -
在Pig Latin中,用来将字符串转换为小写的函数是
LOWER()。 -
在Pig Latin中,用来将字符串转换为大写的函数是
UPPER()。 -
在Pig Latin中,用来截取字符串的函数是
SUBSTRING()。 -
在Pig Latin中,用来连接字符串的函数是
CONCAT()。 -
在Pig Latin中,用来判断字符串是否匹配某种模式的函数是
MATCHES()。 -
在Pig Latin中,用来计算字符串长度的函数是
SIZE()。 -
在Pig Latin中,用来转换字符串为整数的函数是
INT()。 -
在Pig Latin中,用来转换字符串为浮点数的函数是
DOUBLE()。 -
在Pig Latin中,用来获取当前日期的函数是
CURRENT_DATE()。 -
在Pig Latin中,用来获取当前时间的函数是
CURRENT_TIME()。 -
在Pig Latin中,用来获取当前日期和时间的函数是
CURRENT_TIMESTAMP()。 -
在Pig Latin中,用来获取指定关系的字段数目的函数是
SIZE()。 -
在Pig Latin中,用来获取指定关系的数据类型的函数是
TYPEOF()。
Hadoop题
一、填空题
-
查看Hadoop集群中文件系统状态的命令是
hadoop fs ___。 -
在Hadoop集群中创建一个新目录的命令是
hadoop fs ___。 -
将本地文件上传到Hadoop集群中的命令是
hadoop fs ___ ___。 -
从Hadoop集群中下载文件到本地的命令是
hadoop fs ___ ___。 -
在Hadoop集群中删除一个文件的命令是
hadoop fs ___。 -
在Hadoop集群中递归删除一个目录的命令是
hadoop fs ___。 -
查看Hadoop集群中指定路径下的文件列表的命令是
hadoop fs ___。 -
查看Hadoop集群中文件的详细信息的命令是
hadoop fs ___。 -
查看Hadoop集群中文件的块信息的命令是
hadoop fs -___。 -
在Hadoop集群中复制文件的命令是
hadoop fs ___ ___。 -
将Hadoop集群中的文件合并到一个本地文件的命令是
hadoop fs ___ ___。 -
在Hadoop集群中更改文件或目录的权限的命令是
hadoop fs ___ ___。 -
在Hadoop集群中更改文件或目录的所有者的命令是
hadoop fs ___ ___。 -
在Hadoop集群中查看文件或目录的ACL信息的命令是
hadoop fs ___。 -
在Hadoop集群中设置文件或目录的ACL信息的命令是
hadoop fs ___ ___。 -
在Hadoop集群中列出当前运行的作业的命令是 ___`。
-
查看Hadoop集群中运行作业的详细信息的命令是 ___`。
-
杀死正在运行的Hadoop作业的命令是 b ___`。
-
查看Hadoop集群中的节点信息的命令是 ___`。
-
在Hadoop集群中格式化文件系统的命令是 ___`。
-
启动Hadoop集群中的所有守护进程的命令是 ___`。
-
停止Hadoop集群中的所有守护进程的命令是 ___`。
-
在Hadoop集群中查看HDFS容量使用情况的命令是 ___`。
-
在Hadoop集群中设置MapReduce作业的参数的命令是 ___`。
-
在Hadoop集群中运行一个已打包的MapReduce作业的命令是 ___`。
-
在Hadoop集群中查看MapReduce作业日志的命令是 ___`。
-
在Hadoop集群中查看HDFS文件系统中文件块的位置的命令是 ___`。
-
在Hadoop集群中复制文件到HDFS的命令是 ___`。
-
在Hadoop集群中从HDFS复制文件到本地的命令是 ___`。
-
在Hadoop集群中查看当前所有运行的MapReduce作业的命令是 ___`。
答案
一、填空题
-
查看Hadoop集群中文件系统状态的命令是
hadoop fs -stat。 -
在Hadoop集群中创建一个新目录的命令是
hadoop fs -mkdir。 -
将本地文件上传到Hadoop集群中的命令是
hadoop fs -put <local-path> <hdfs-path>。 -
从Hadoop集群中下载文件到本地的命令是
hadoop fs -get <hdfs-path> <local-path>。 -
在Hadoop集群中删除一个文件的命令是
hadoop fs -rm <hdfs-path>。 -
在Hadoop集群中递归删除一个目录的命令是
hadoop fs -rm -r <hdfs-path>。 -
查看Hadoop集群中指定路径下的文件列表的命令是
hadoop fs -ls <hdfs-path>。 -
查看Hadoop集群中文件的详细信息的命令是
hadoop fs -stat <hdfs-path>。 -
查看Hadoop集群中文件的块信息的命令是
hadoop fs -du -h <hdfs-path>。 -
在Hadoop集群中复制文件的命令是
hadoop fs -cp <src> <dest>。 -
将Hadoop集群中的文件合并到一个本地文件的命令是
hadoop fs -getmerge <src> <local-path>。 -
在Hadoop集群中更改文件或目录的权限的命令是
hadoop fs -chmod <permission> <hdfs-path>。 -
在Hadoop集群中更改文件或目录的所有者的命令是
hadoop fs -chown <owner> <hdfs-path>。 -
在Hadoop集群中查看文件或目录的ACL信息的命令是
hadoop fs -getfacl <hdfs-path>。 -
在Hadoop集群中设置文件或目录的ACL信息的命令是
hadoop fs -setfacl -m <acl-spec> <hdfs-path>。 -
在Hadoop集群中列出当前运行的作业的命令是
hadoop job -list。 -
查看Hadoop集群中运行作业的详细信息的命令是
hadoop job -status <job-id>。 -
杀死正在运行的Hadoop作业的命令是
hadoop job -kill <job-id>。 -
查看Hadoop集群中的节点信息的命令是
hadoop dfsadmin -report。 -
在Hadoop集群中格式化文件系统的命令是
hadoop namenode -format。 -
启动Hadoop集群中的所有守护进程的命令是
start-all.sh。 -
停止Hadoop集群中的所有守护进程的命令是
stop-all.sh。 -
在Hadoop集群中查看HDFS容量使用情况的命令是
hadoop fs -df -h。 -
在Hadoop集群中设置MapReduce作业的参数的命令是
hadoop jar <jar-file> <main-class> -D<property>=<value>。 -
在Hadoop集群中运行一个已打包的MapReduce作业的命令是
hadoop jar <jar-file> <main-class>。 -
在Hadoop集群中查看MapReduce作业日志的命令是
yarn logs -applicationId <application-id>。 -
在Hadoop集群中查看HDFS文件系统中文件块的位置的命令是
hadoop fsck <hdfs-path> -files -blocks -locations。 -
在Hadoop集群中复制文件到HDFS的命令是
hadoop fs -copyFromLocal <local-src> <hdfs-dest>。 -
在Hadoop集群中从HDFS复制文件到本地的命令是
hadoop fs -copyToLocal <hdfs-src> <local-dest>。 -
在Hadoop集群中查看当前所有运行的MapReduce作业的命令是
hadoop job -list-active.
相关文章:

爬虫 pandas Linux Flume Pig填空题
目录 试卷:Python网络数据处理 答案 试卷:Pandas基础操作 答案 试卷:Linux基础指令 答案 试卷:Apache Flume基础指令 答案 试卷:Apache Pig基础指令 答案: Hadoop题 答案 试卷:Pyth…...

Spring框架中哪些地方使用了反射
Spring框架中哪些地方使用了反射? 1. 依赖注入:Spring 使用反射机制获取对象并进行属性注入,从而实现依赖注入。 2. AOP:Spring AOP 使用 JDK 动态代理或者 CGLIB 字节码增强技术来实现 AOP 的切面逻辑,这其中就包含…...

难辨真假的Midjourney案例(附提示词):适合练手
人物 时尚女孩 Street style fashion photo, full-body shot of a young Chinese woman with long curly black hair, walking confidently with a crowd of people down a sidewalk in Hong Kong, wearing a emerald green Gucci maxi dress & gold jewelry, sunset lig…...

数据库讲解---(数据库保护)【上】
一.事务 1.1事务的概念【重要】 事务:“将一组数据库操作打包起来形成一个逻辑独立的单元,这个工作单元不可分割,其中包含的数据要么全部都发生,要么全部都不发生”。 在SQL中,界定事务的语句有三条: B…...

【Android】【Compose】Compose的简单介绍
前言 Jetpack Compose 是谷歌推出的用于构建现代化 Android 应用界面的工具包。它采用了声明式的方式来定义用户界面,与传统的 XML 布局和视图层次结构相比,Compose 提供了更直观、更简洁的方式来创建和管理界面组件。 需求配置 Android 版本要求 An…...
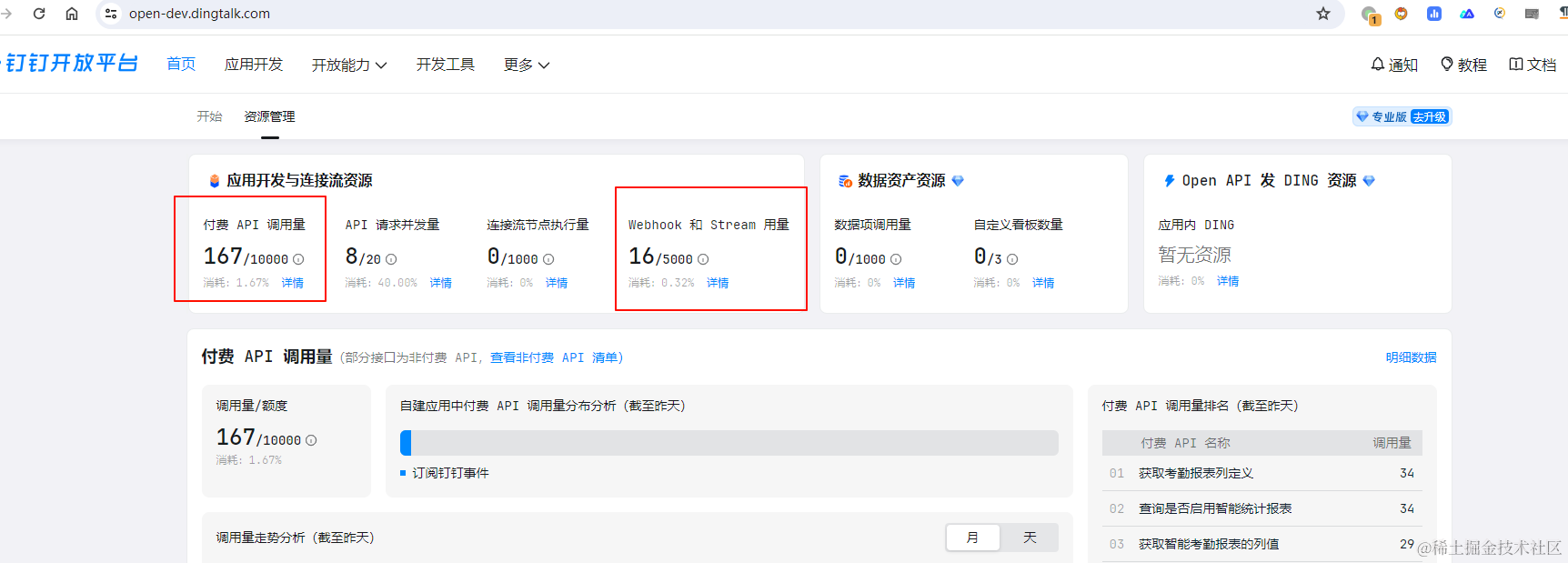
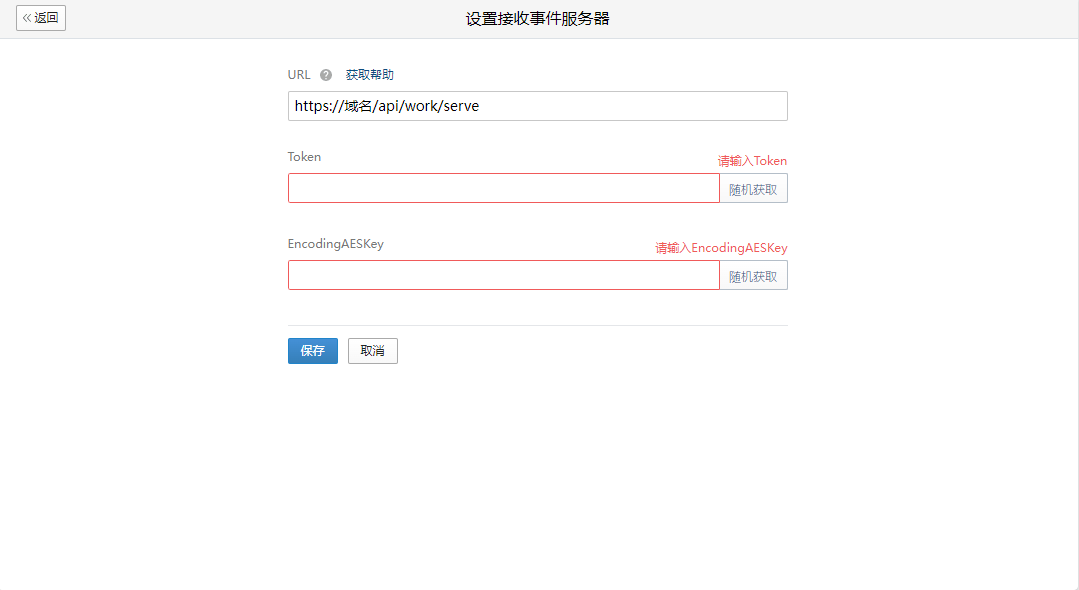
对接钉钉Stream模式考勤打卡相关事件的指南
钉钉之前的accessToken是公司级别的,现在的accessToken是基于应用的,接口的权限也是基于应用的。所以第一步是在钉钉开放平台(https://open-dev.dingtalk.com/)创建一个应用。 创建好应用之后,因为我们后续还需要调用钉…...
CRMEB PRO企业微信通讯录配置
企业微信通讯录配置 登录企业微信管理后台 企业微信 1、点击【管理工具】找到【通讯录同步】点击进入 2、点击【开启API接口同步】 进入设置【通讯录同步】页面后,权限一栏,勾选【API编辑通讯录】勾选【开启手动编辑】; 3、点击下图箭头所…...

直播新篇章 | 金仓数据库“零距离”探索与知识挑战双重奏
KING大咖成就计划 全新进阶!!!携手知识竞答挑战赛震撼来袭~为您带来一场别开生面的金仓数据库探索之旅与知识竞答盛宴! 直 播 活 动 01 大咖引领,KING BASE产品“零距离”体验 您是否对金仓数据库充满好奇🧐…...

List的介绍
1. 什么是List List是一个接口,继承自Collection。 Collection也是一个接口,该接口中规范了后序容器中常用的一些方法。 Iterable也是一个接口,表示实现该接口的类是可以逐个元素进行遍历。 2. 常见接口介绍 List中提供了好的方法&#x…...
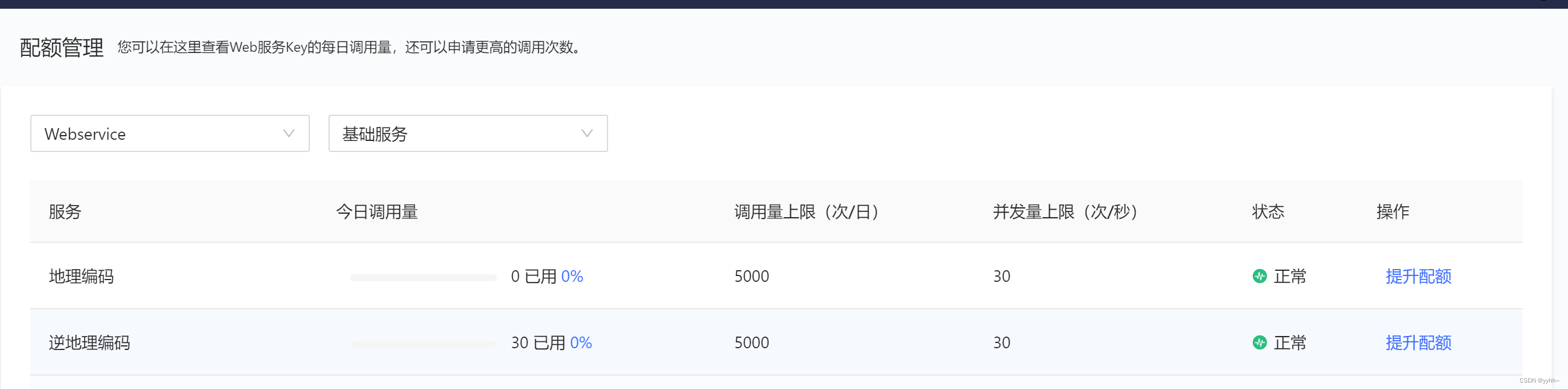
Uniapp获取具体地理位置
使用uniapp自带uni.getLocation获取当前定位经纬度 再调用高德逆地理编码API,查到具体位置信息 https://restapi.amap.com/v3/geocode/regeo?location${longitude},${latitude}&key${key}&extensionsall 但是个人申请的key,有配额限制 最多每…...

Kafka基础教程
Kafka基础教程 资料来源:Apache Kafka - Introduction (tutorialspoint.com) Apache Kafka起源于LinkedIn,后来在2011年成为一个开源Apache项目,然后在2012年成为一流的Apache项目。Kafka是用Scala和Java编写的。Apache Kafka是基于发布-订…...
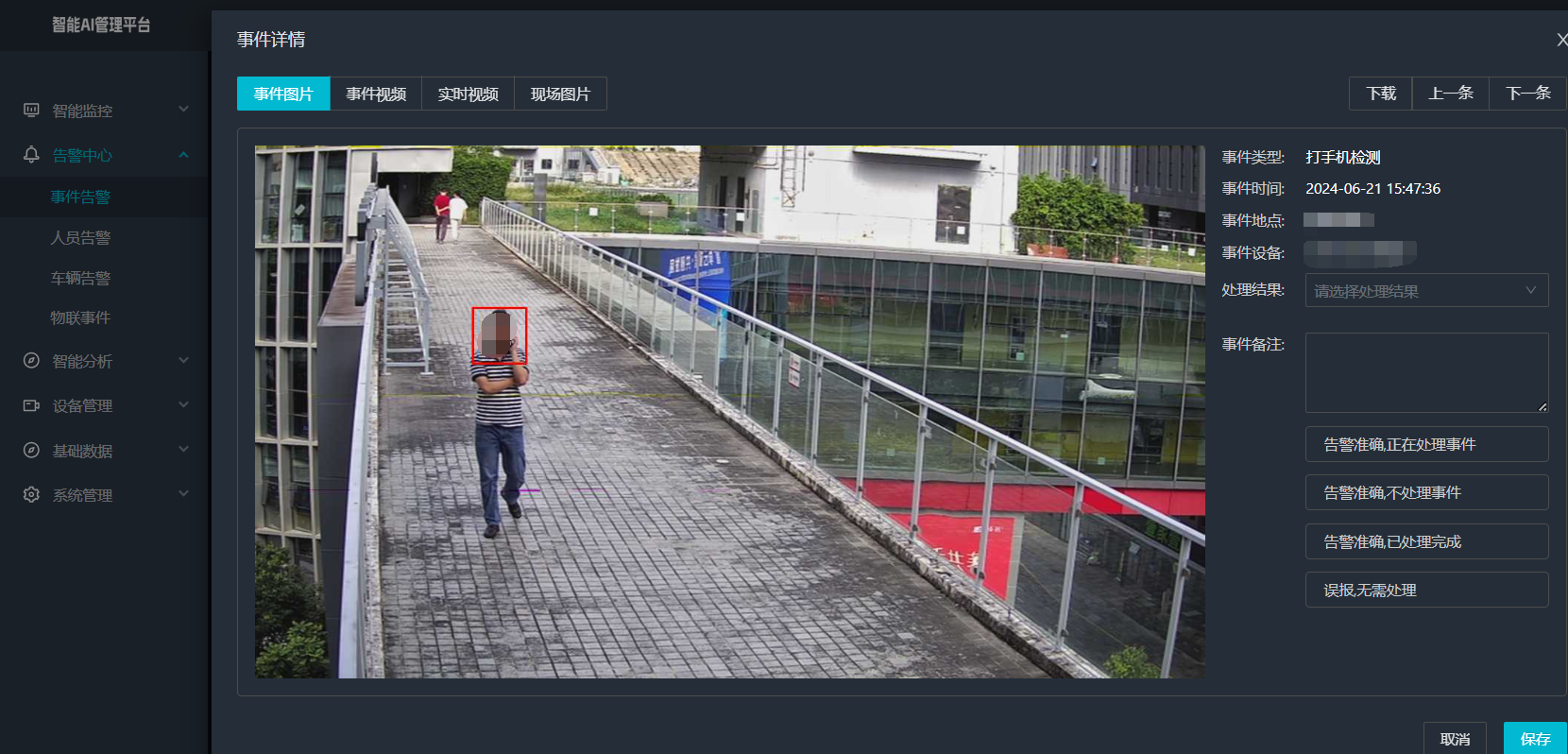
视频智能分析平台智能边缘分析一体机安防监控平台打手机检测算法工作原理介绍
智能边缘分析一体机的打手机检测算法是一种集成了计算机视觉和人工智能技术的先进算法,专门用于实时监测和识别监控画面中的打手机行为。以下是关于该算法的详细介绍: 工作原理 1、视频流获取: 智能边缘分析一体机首先通过连接的视频监控设…...

辅助构造函数相关学习以及php实现
https://mp.weixin.qq.com/s/J9hgLTxYi7ZJdFVG2VszQg 对这个文章进行摘要生成 ### 总体概要 文章阐述了在对象创建过程中,辅助构造函数(或称为“多个”构造函数)的重要性,它们为代码增加了功能性逻辑,并允许根据需求调…...
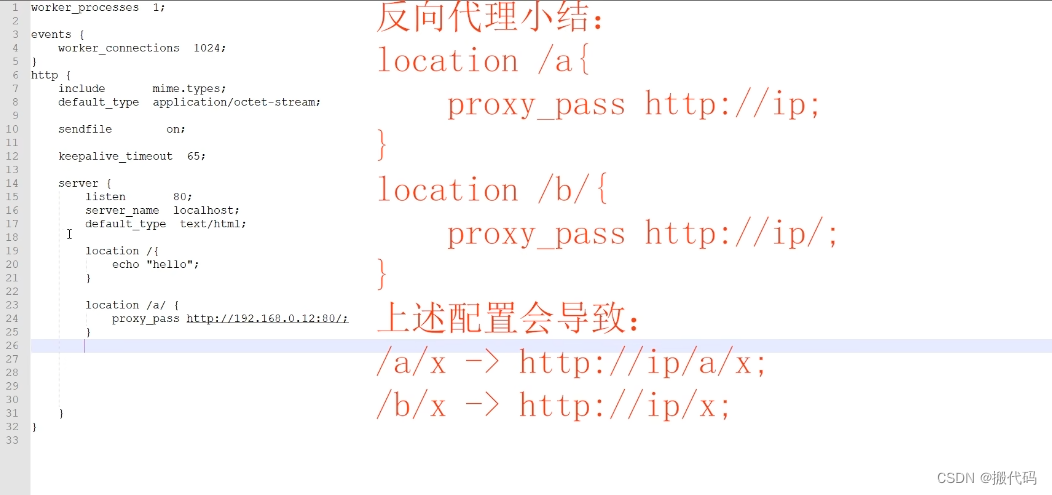
Linux中nginx.conf如何配置【搬代码】
Nginx 是一个独立的软件。 它是一款高性能的 Web 服务器、反向代理服务器和负载均衡器等,具有强大的功能和广泛的应用场景。它通常需要单独进行安装和配置来发挥其作用。 下载网址:http://nginx.org/en/download.html nginx.conf写法: #配置…...

Django REST framework序列化器详解:普通序列化器与模型序列化器的选择与运用
系列文章目录 Django入门全攻略:从零搭建你的第一个Web项目Django ORM入门指南:从概念到实践,掌握模型创建、迁移与视图操作Django ORM实战:模型字段与元选项配置,以及链式过滤与QF查询详解Django ORM深度游ÿ…...

红队内网攻防渗透:内网渗透之内网对抗:隧道技术篇防火墙组策略ICMPDNSSMB协议出网判断C2上线解决方案
红队内网攻防渗透 1. 内网隧道技术1.1 学隧道前先搞清楚的知识1.2 常用的隧道技术1.3 判断协议出网的命令1.4 C2上线-开防火墙入站只80&出站只放ICMP1.4.1 icmp隧道上线CS后门1.4.1 icmp隧道上线MSF后门1.5 C2上线-开防火墙入站只80&出站只放DNS1.5.1 DNS隧道上线CS后门…...

【Autoware】Autoware.universe安装过程与问题记录
😏★,:.☆( ̄▽ ̄)/$:.★ 😏 这篇文章主要介绍Autoware.universe安装过程与问题记录。 无专精则不能成,无涉猎则不能通。——梁启超 欢迎来到我的博客,一起学习,共同进步。 喜欢的朋友可以关注一下…...
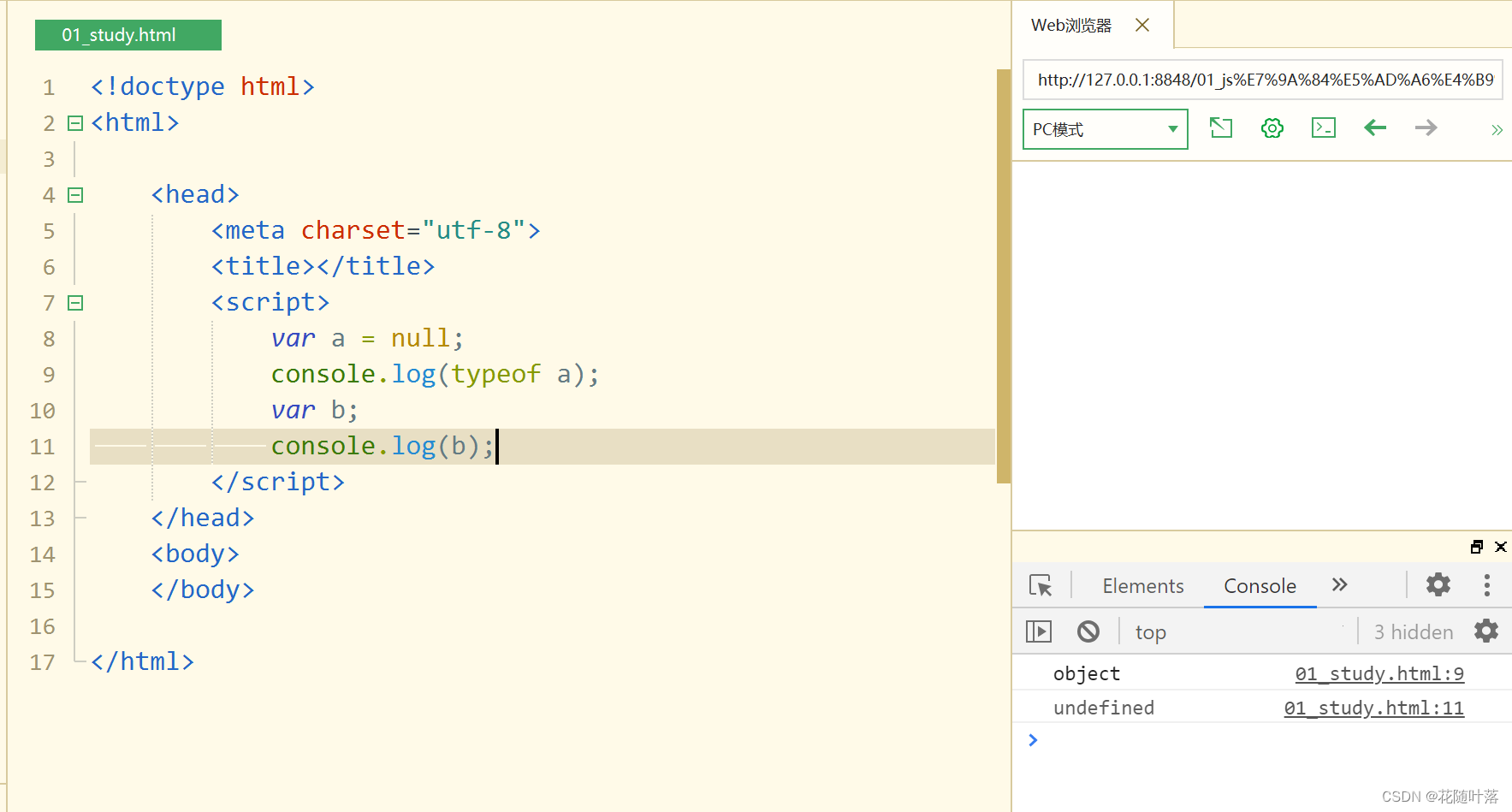
JavaScript的学习之旅之基本数据类型
目录 一、字面量(常量)和变量 二、标识符 三、数据类型 1.String类型 2.Number类型 四、布尔值类型 五、Null和Undefined类型 一、字面量(常量)和变量 字面量:不可变的数据,一般位于等式的右边 变量&…...
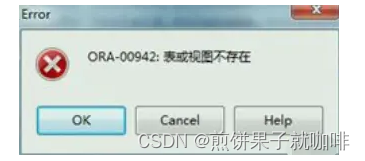
oracle开放某些视图给特定用户,查询报视图不存在问题
以sysdba身份登录到Oracle数据库。 创建新用户。例如,创建一个名为new_user的用户,密码为password: CREATE USER new_user IDENTIFIED BY password;为新用户分配表空间和临时表空间。例如,将表空间users和临时表空间temp分配给新…...

es 更新索引mapping和setting
1.关闭索引 curl -X POST "localhost:9200/your_index_name/_close"2.修改setting 配置 无法更新一些默认数据,按照需求构建,我这边是构建增加了分词器 "settings": {"index": {"creation_date": "1718850346547…...

ScriptCat脚本猫:重新定义浏览器脚本管理的全能工具
ScriptCat脚本猫:重新定义浏览器脚本管理的全能工具 【免费下载链接】scriptcat 脚本猫,一个可以执行用户脚本的浏览器扩展 项目地址: https://gitcode.com/gh_mirrors/sc/scriptcat 在信息爆炸的今天,浏览器已成为我们工作与生活的核…...

Xycom XVME-560模拟输入模块
Xycom XVME-560 模拟输入模块产品特点Xycom XVME-560 是一款面向工业自动化与过程控制领域的高性能模拟输入模块,适用于复杂环境下的精确数据采集与监测任务,具备稳定性强、精度高、扩展性好的特点。主要产品特点:高精度数据采集能力支持多通…...
与损失计算)
【重温YOLOV5】第四章 检测头(Head)与损失计算
目录 第四章 检测头(Head)与损失计算 4.1 YOLOv5 Head 结构剖析 解耦头的雏形:11卷积的分类/定位分支 三个检测层的Anchor分配策略 输出张量解析 4.2 Anchor 机制与AutoAnchor 预设Anchor的尺寸设计逻辑 AutoAnchor算法:K…...

阿里大动作
3月16日晚,阿里一则内部通知,在科技圈里掀起了不小的波澜——正式成立Alibaba Token Hub(ATH)事业群,由CEO吴泳铭亲自挂帅。如果你只把它当成一次普通的组织架构调整,那就有点低估这件事的分量了。更准确地…...

Qwen-Image定制镜像实战案例:在RTX4090D上高效加载Qwen-VL大模型
Qwen-Image定制镜像实战案例:在RTX4090D上高效加载Qwen-VL大模型 1. 为什么需要定制镜像 在部署大模型时,环境配置往往是最耗时的环节之一。特别是对于Qwen-VL这样的视觉语言大模型,需要精确匹配的CUDA版本、GPU驱动以及各种依赖库。传统部…...

跨平台实战:Windows QGC与Linux JMAVSim模拟器局域网联调指南
1. 环境准备与基础概念 在开始跨平台联调之前,我们需要先理解几个关键组件。QGroundControl(QGC)是无人机领域最流行的开源地面站软件,相当于飞行器的"指挥中心";而JMAVSim是PX4生态中的轻量级仿真器&#x…...

StructBERT情感分类镜像实战教程:钉钉群机器人情感预警自动推送
StructBERT情感分类镜像实战教程:钉钉群机器人情感预警自动推送 1. 引言:当AI情感分析遇上钉钉机器人 想象一下这样的场景:你的电商平台每天收到成千上万条用户评论,客服团队需要及时处理负面反馈,但人工筛查效率低下…...

SAM3部署实战:在CUDA 11.8环境下绕过官方高版本限制
1. 为什么要在CUDA 11.8环境下部署SAM3? 最近很多开发者都在尝试部署最新的SAM3模型,但官方文档明确要求CUDA版本必须≥12.6。这给很多还在使用老版本CUDA环境的团队带来了困扰。我最近就在一台配备3090显卡(CUDA 11.8)的服务器上…...
)
Python+SimpleITK实战:5步搞定DICOM剂量叠加CT的可视化(附避坑指南)
PythonSimpleITK实战:5步搞定DICOM剂量叠加CT的可视化(附避坑指南) 在放射治疗计划评估中,将剂量分布数据与CT解剖图像精准叠加是临床决策的关键环节。传统商业软件往往存在操作繁琐、定制化程度低的问题,而PythonSimp…...

为什么你的input在iOS上无法自动聚焦?深入解析Safari的限制与应对策略
为什么iOS Safari拒绝自动聚焦?揭秘移动端输入框的交互困局与实战方案 每次在iOS设备上测试网页表单时,开发者总会遇到那个熟悉又恼人的问题——明明设置了autofocus属性的输入框,在Safari中就像被施了定身术。这背后远不止是一个简单的兼容性…...