信息检索(43):SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking
SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking
- 摘要
- 1 引言
- 2 相关工作
- 3 方法
- 3.1 SparTerm
- 3.2 SPLADE:稀疏词汇和扩展模型
- 4 实验
- 5 结论
发布时间(2021)
标题:稀疏词汇 + 扩展模型
摘要
稀疏的优点:
1)术语精确匹配
2)倒排索引效率
两部分:
1、显式稀疏正则化:explicit sparsity regularization
2、术语权重的对数饱和效应:explicit sparsity regularization
在神经信息检索中,正在进行的研究旨在改进排名管道中的第一个检索器。学习密集嵌入以使用有效的近似最近邻方法进行检索已被证明效果很好。同时,人们对学习文档和查询的稀疏表示的兴趣日益浓厚,这些表示可以继承词袋模型的理想属性,例如术语的精确匹配和倒排索引的效率。在这项工作中,我们提出了一种新的第一阶段排名器,该排名器基于显式稀疏正则化和对术语权重的对数饱和效应,从而产生高度稀疏的表示和与最先进的密集和稀疏方法相比具有竞争力的结果。我们的方法很简单,在一个阶段进行端到端训练。我们还通过控制稀疏正则化的贡献来探索有效性和效率之间的权衡。
1 引言
BERT [7] 等大型预训练语言模型的发布震撼了自然语言处理和信息检索领域。这些模型表现出通过简单微调就能适应各种任务的强大能力。2019 年初,Nogueira 和 Cho [17] 在 MS MARCO 段落重排序任务中取得了领先优势,为基于 LM 的神经排序模型铺平了道路。由于严格的效率要求,这些模型最初被用作两阶段排序流程中的重排序器,其中第一阶段检索(或候选生成)是使用依赖于倒排索引的词袋模型(例如 BM25)进行的。
尽管 BOW 模型仍然是强大的基线 [27],但它们受到长期存在的词汇不匹配问题的困扰,即相关文档可能不包含查询中出现的术语。因此,有人尝试用学习的(神经)排序器替代标准 BOW 方法。 设计这样的模型在效率和可扩展性方面带来了一些挑战:因此需要一种可以离线完成大部分计算并且在线推理速度快的方法。使用近似最近邻搜索的密集检索已显示出令人印象深刻的结果 [8, 15, 26],但由于无法明确模拟术语匹配,因此仍然与 BOW 模型相结合。因此,最近人们对学习查询和文档的稀疏表示的兴趣日益浓厚 [1, 4, 19, 28, 29]。 通过这样做,模型可以继承 BOW 模型的理想属性,例如(可能潜在的)术语的精确匹配、倒排索引的效率和可解释性。此外,通过对隐式或显式(潜在的、语境化的)扩展机制进行建模(类似于 IR 中的标准扩展模型),这些模型可以减少词汇不匹配。
本文的贡献有三点:(1)我们在 SparTerm [1] 的基础上进行了改进,并表明对超参数进行轻微调整可以带来远超原始论文中报告结果的改进;(2)我们提出了基于对数激活和稀疏正则化的 SParse 词汇和数据扩展 (SPLADE) 模型。SPLADE 可执行有效的文档扩展 [1, 16],与 ANCE [26] 等密集模型的复杂训练流程相比,其结果具有竞争力;(3)最后,我们展示了如何控制稀疏正则化来影响效率(就浮点运算次数而言)和有效性之间的权衡。
2 相关工作
基于 BERT Siamese 模型 [22] 的密集检索已成为问答和 IR 中候选生成的标准方法 [8, 10, 12, 15, 25]。虽然这些模型的主干保持不变,但最近的研究强调了训练策略的关键方面,以获得最先进的结果,从改进的负采样 [8, 25] 到蒸馏 [11, 15]。 ColBERT [13] 更进一步:推迟的 token 级交互允许有效地将模型应用于第一阶段检索,受益于建模细粒度交互的有效性,但代价是存储每个(子)术语的嵌入 - 引发了人们对该方法对于大型集合的实际可扩展性的担忧。据我们所知,很少有研究讨论使用近似最近邻 (ANN) 搜索对 IR 指标的影响 [2, 23]。由于 MS MARCO 集合的规模适中,结果通常通过精确的强力搜索来报告,因此无法表明有效计算成本
密集索引的替代方案是基于术语的索引。在标准 BOW 模型的基础上,Zamani 等人首次引入了 SNRM [28]:该模型通过对表示进行 ℓ1 正则化,将文档和查询嵌入到稀疏的高维潜在空间中。然而,SNRM 的有效性仍然有限,其效率也受到了质疑 [20]。最近,有人尝试将知识从预训练的 LM 转移到稀疏方法。 基于 BERT,DeepCT [4–6] 专注于在完整词汇空间中学习语境化术语权重——类似于 BOW 术语权重。然而,由于与文档相关的词汇保持不变,这种方法无法解决词汇不匹配的问题,正如使用查询扩展进行检索所承认的那样 [4]。这个问题的第一个解决方案是使用生成方法(如 doc2query [19] 和 docTTTTTquery [18])扩展文档,以预测文档的扩展词。 文档扩展会向文档中添加新术语(从而解决词汇不匹配问题),并重复现有术语,通过提升重要术语来隐式地重新加权。然而,这些方法受到训练方式(预测查询)的限制,这种方式本质上是间接的,限制了它们的进展。最近的研究(如 [1, 16, 29])选择了解决这个问题的第二种方法,即估计文档每个术语所隐含的词汇表每个术语的重要性,即计算文档或查询标记与词汇表中所有标记之间的交互矩阵。 接下来是一个聚合机制(对于 SparTerm [1] 大致是 sum,对于 EPIC [16] 和 SPARTA [29] 是 max),它允许计算词汇表每个术语、完整文档或查询的重要性权重。然而,EPIC 和 SPARTA(文档)表示在构造上不够稀疏——除非诉诸 top-𝑘 池化——与 SparTerm 相反,因此可以实现快速检索。此外,后者不包括(像 SNRM)显式稀疏正则化,这会阻碍其性能。我们的 SPLADE 模型依赖于这种正则化以及其他关键变化,从而提高了此类模型的效率和有效性。
3 方法
SparTerm:
1)对于词汇表中的每个词的权重都与query/doc进行运算
2)通过门控获得稀疏向量:门控有两种方式
a)手动设置参数
b)参数可学习
在本节中,我们首先详细描述 SparTerm 模型 [1],然后介绍我们的模型 SPLADE。
3.1 SparTerm
SparTerm 根据 Masked Language Model (MLM) 层的 logits 预测 BERT WordPiece 词汇表 (|𝑉 | = 30522) 中的术语重要性。更准确地说,让我们考虑一个输入查询或文档序列(WordPiece 标记化之后)𝑡 = (𝑡1, 𝑡2, …, 𝑡𝑁 ),以及其对应的 BERT 嵌入 (ℎ1, ℎ2, …, ℎ𝑁 )。 我们考虑标记 𝑗 (词汇表) 对于标记 𝑖 (输入序列) 的重要性 𝑤𝑖𝑗:
其中 𝑔𝑗 是后面描述的二进制掩码(门控)。上面的等式可以看作是查询/文档扩展的一种形式,如 [1, 16] 中所示,因为对于词汇表的每个标记,模型都会预测一个新的权重 𝑤𝑗 。SparTerm [1] 引入了两种稀疏化方案,可以关闭查询和文档表示中的大量维度,从而可以有效地从倒排索引中检索:
仅词汇是 BOW 掩蔽,即如果标记 𝑗 出现在 𝑡 中,则 𝑔𝑗 = 1,否则为 0;
损失函数:对比损失
局限性。
1)SparTerm 扩展感知门控有些复杂,
2)并且模型无法进行端到端训练:门控机制是事先学习的,并在使用 L𝑟𝑎𝑛𝑘 微调匹配模型时进行固定,
因此阻止模型学习排名任务的最佳稀疏化策略。此外,词汇和扩展感知两种策略的表现几乎一样好,这让人对扩展的实际好处产生质疑。
3.2 SPLADE:稀疏词汇和扩展模型
下面,我们建议对 SparTerm 模型进行细微但必要的改动,以大幅提高其性能。
模型。我们对公式 2 中的重要性估计进行了微小的改动,引入了对数饱和效应,这可以防止某些项占主导地位,并自然地确保表示中的稀疏性:
虽然直观地看,使用对数饱和可以防止某些项占主导地位——与 IR 和 log(tf) 模型中的公理方法相似 [9]——但隐含的稀疏性乍一看可能令人惊讶,但根据我们的实验,它获得了更好的实验结果,并且已经允许在没有任何正则化的情况下获得稀疏解。
排名损失。给定一个批次中的查询 𝑞𝑖、一个正文档 𝑑 + 𝑖、一个(硬)负文档 𝑑 − 𝑖(例如来自 BM25 采样)以及批次中的一组负文档(来自其他查询的正文档){𝑑 − 𝑖,𝑗 }𝑗,我们考虑来自 [8] 的排名损失,它可以解释为最大化文档 𝑑 + 𝑖 在文档 𝑑 + 𝑖 、𝑑− 𝑖 和 {𝑑 − 𝑖,𝑗 } 中相关的概率:
4 实验
我们在完整排名设置下,使用 MS MARCO 段落排名数据集 1 训练并评估了我们的模型。该数据集包含约 880 万段段落,以及数十万个带有浅层注释的训练查询(平均每个查询约 1.1 个相关段落)。开发集包含 6980 个带有相似标签的查询,而 TREC DL 2019 评估集为 43 个查询提供了来自人工评估员的细粒度注释 [3]。
5 结论
最近,基于 BERT 的密集检索已证明其在第一阶段检索中的优势,从而对传统稀疏模型的竞争力提出了质疑。在这项工作中,我们提出了 SPLADE,这是一种重新审视查询/文档扩展的稀疏模型。我们的方法依赖于批内负样本、对数激活和 FLOPS 正则化来学习有效且高效的稀疏表示。 SPLADE 是初始检索的一个有吸引力的候选者:它可以与最新的最先进的密集检索模型相媲美,其训练过程简单明了,其稀疏性/FLOPS 可以通过正则化明确控制,并且可以对倒排索引进行操作。 由于其简单性,SPLADE 为进一步改进这一研究领域奠定了坚实的基础。
相关文章:
:SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking)
信息检索(43):SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking
SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking 摘要1 引言2 相关工作3 方法3.1 SparTerm3.2 SPLADE:稀疏词汇和扩展模型 4 实验5 结论 发布时间(2021) 标题:稀疏词汇 扩展模型 摘要 稀疏的优点…...

DockerHub 镜像加速
Docker Hub 作为目前全球最大的容器镜像仓库,为开发者提供了丰富的资源。Docker Hub 是目前最大的容器镜像社区,DokcerHub的不能使用,导致在docker下pull镜像无法下载,安装kubernetes镜像也受到影响,下面请看解决方式。 1.加速原理 Docker下载加速的原理…...

Oracle 迁移 Mysql
-- Oracle->MySQL -- 使用时改一下where条件的owner和table_name -- 字段数据类型映射时会将Oracle中的浮点NUMBER转换为decimal(65,8)定点数 -- 可以识别主键约束、非空约束,但无法识别外键约束、唯一约束、自定义check -- 对于Oracle字符串长度为4000的&#x…...

vue3父子组件通信
一,父传子——defineProps 方法: 在父组件的模板中使用子组件标签,并且给标签自定义属性和属性名,即通过v-bind绑定数值,而后传给子组件;子组件则通过defineProps接收使用。 父组件: <tem…...

CSS中使用应用在伪元素中的计数器属性counter-increment
在CSS中,counter-increment 是一个用于递增计数器值的属性。它通常与 counter-reset 和 content 属性一起使用,以在文档中的特定位置(如列表项、标题等)插入自动生成的数字或符号。 counter-increment 基本用法: 使…...

【SkiaSharp绘图08】SKPaint方法:自动换行、是否乱码、字符偏移、边界、截距、文本轮廓、测量文本
文章目录 SKPaint方法BreakText 计算指定宽度内可绘制的字符个数ContainsGlyphs字体是否包含文本字符(是否会乱码)GetGlyphOffsets 字符偏移量GetGlyphPositions 偏移坐标GetGlyphWidths 每个字符的宽度与边界GetHorizontalTextIntercepts 轮廓截距GetPositionedTextIntercepts…...

深入理解Servlet Filter及其限流实践
引言 在Java Servlet技术中,Filter是一个拦截器,它允许开发者在请求到达目标资源之前或响应发送给客户端之后,对请求或响应进行拦截和处理。这种机制为实现诸如身份验证、日志记录、请求修改等功能提供了极大的灵活性。 Filter基础 Filter…...

使用cv2对视频指定区域进行去噪
视频去噪其实和图象一样,只是需要现将视频截成图片,在对图片进行去噪,将去噪的图片在合成视频就行。可以利用cv2.imread()、imwrite()等轻松实现。 去噪步骤 1、视频逐帧读成图片 2、图片指定区域批量去噪 2、去噪后的图片写入视频 1、视频逐…...

AI在创造还是毁掉音乐?
AI对音乐产业的影响是复杂而多维的,既有创造性的贡献也存在潜在的挑战。我们可以从以下几个角度来分析这个问题: ### 创造性贡献 1. **音乐创作**:AI可以帮助音乐家创作新的旋律和和声,甚至生成完整的音乐作品。例如,…...

【2023年全国青少年信息素养大赛智能算法挑战赛复赛真题卷】
目录 2023全国青少年信息素养大赛智能算法挑战赛初中组复赛真题 2023全国⻘少年信息素养⼤赛智能算法挑战复赛⼩学组真题 2023全国青少年信息素养大赛智能算法挑战赛初中组复赛真题 1. 修复机器人的对话词库错误 【题目描述】 基于人工智能技术的智能陪伴机器人的语言词库被…...

Android系统揭秘(一)-Activity启动流程(上)
public ActivityResult execStartActivity( Context who, IBinder contextThread, IBinder token, Activity target, Intent intent, int requestCode, Bundle options) { IApplicationThread whoThread (IApplicationThread) contextThread; … try { … int result …...

使用Java实现哈夫曼编码
前言 哈夫曼编码是一种经典的无损数据压缩算法,它通过赋予出现频率较高的字符较短的编码,出现频率较低的字符较长的编码,从而实现压缩效果。这篇博客将详细讲解如何使用Java实现哈夫曼编码,包括哈夫曼编码的原理、具体实现步骤以…...
IDEA、PyCharm等基于IntelliJ平台的IDE汉化方式
PyCharm 或者 IDEA 等编辑器是比较常用的,默认是英文界面,有些同学用着不方便,想要汉化版本的,但官方没有这个设置项,不过可以通过插件的方式进行设置。 方式1:插件安装 1、打开设置 File->Settings&a…...
visual studio 创建c++项目
目录 环境准备:安装 visual studiovisual studio 创建c项目Tips:新建cpp文件注释与取消注释代码 其他初学者使用Visual Studio开发C和C时常遇到的3个坑 环境准备:安装 visual studio 官网:https://visualstudio.microsoft.com/zh…...

MGV电源维修KUKA机器人电源模块PH2003-4840
MGV电源维修 库卡电源模块维修 机器人电源模块维修 库卡控制器维修 KUKA电源维修 库卡机器人KUKA主机维修 KUKA驱动器模块维修 机械行业维修:西门子系统、法那克系统、沙迪克、FIDIA、天田、阿玛达、友嘉、大宇系统;数控冲床、剪板机、折弯机等品牌数控…...
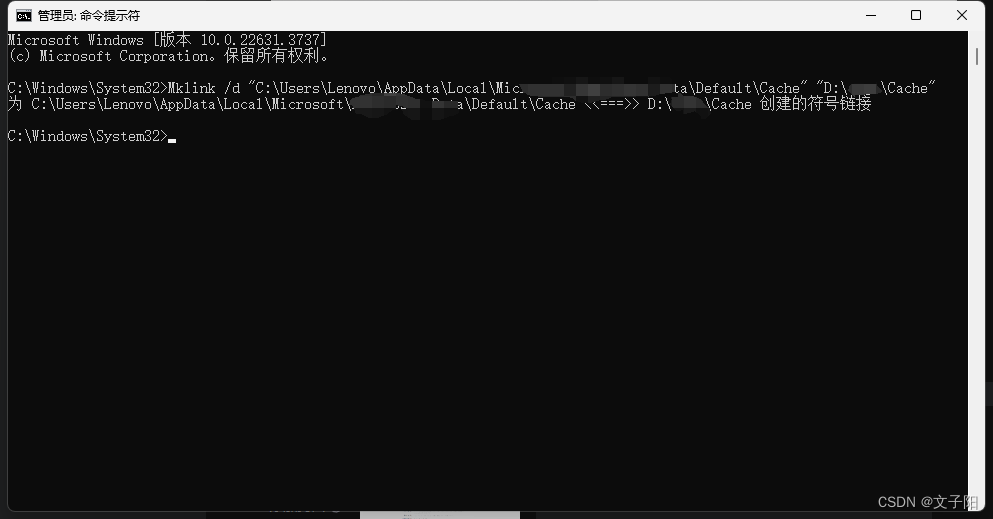
设置浏览器互不干扰
目录 一、查看浏览器文件路径 二、 其他盘新建文件夹Cache 三、以管理员运行CMD 四、执行命令 一、查看浏览器文件路径 chrome://version/ 二、 其他盘新建文件夹Cache D:\chrome\Cache 三、以管理员运行CMD 四、执行命令 Mklink /d "C:\Users\Lenovo\AppData\Loca…...

kafka操作命令详解
目录 1、集群运维命令 1.1、集群启停命令 1.3、集群迁移命令 1.4、权限管理命令 1.4.1、权限参数介绍 1.4.2、增加权限命令 1.4.3、移出权限命令 1.4.4、查看所有topic权限命令 1.4.5、查看某个topic权限命令 2、生产者命令 2.1、创建topic命令 2.2、删除topic命令 …...
graalvm jdk和openjdk
下载地址:https://github.com/graalvm/graalvm-ce-builds/releases 官网: https://www.graalvm.org...

docker基础使用教程
1.准备工作 例子:工程在docker_test 生成requirements.txt文件命令:(使用参考链接2) pip list --formatfreeze > requirements.txt 参考链接1: 安装pipreqs可能比较困难 python 项目自动生成环境配置文件require…...

计算机网络 交换机的安全配置
一、理论知识 1.交换机端口安全功能介绍 交换机端口安全功能是针对交换机端口进行安全属性的配置,以控制用户的安全接入。主要包括以下两种配置项: ①限制交换机端口的最大连接数:控制交换机端口连接的主机数量;防止用户进行恶…...

Source Han Serif CN:企业级开源字体终极实战指南
Source Han Serif CN:企业级开源字体终极实战指南 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 在当今数字化时代,企业面临字体选择的两难困境:商…...

3DS游戏格式转换神器:5分钟让.3ds文件变身为可安装的CIA
3DS游戏格式转换神器:5分钟让.3ds文件变身为可安装的CIA 【免费下载链接】3dsconv Python script to convert Nintendo 3DS CCI (".cci", ".3ds") files to the CIA format 项目地址: https://gitcode.com/gh_mirrors/3d/3dsconv 还在为…...
)
别再死记硬背公式了!用Python+NumPy手把手带你仿真RLC串联谐振(附代码)
用PythonNumPy动态仿真RLC串联谐振:告别枯燥公式,直观理解电路本质 当你第一次翻开电路分析教材,看到那些密密麻麻的公式推导和抽象的频率响应曲线时,是否感到一阵眩晕?RLC串联谐振作为电路分析的核心概念,…...

iOS越狱终极指南:解锁iPhone隐藏功能的3个关键步骤
iOS越狱终极指南:解锁iPhone隐藏功能的3个关键步骤 【免费下载链接】Jailbreak iOS 26.4 - 26, 17 - 17.7.5 & iOS 18 - 18.7.3 Jailbreak Tools, Cydia/Sileo/Zebra Tweaks & Jailbreak News Updates || AI Jailbreak Finder 👇 项目地址: ht…...

NVIDIA Profile Inspector完整指南:200+隐藏设置解锁显卡极致性能
NVIDIA Profile Inspector完整指南:200隐藏设置解锁显卡极致性能 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 还在为游戏画面撕裂、输入延迟过高而烦恼吗?想要彻底掌控NVIDIA…...

芯片老化座的工作温度范围?
在芯片测试领域,老化座(Burn-in Socket)是保障半导体器件长期可靠性的关键设备。它不仅要在极端温度下稳定工作,还要确保测试数据的精准度。今天,我们以HMILU(深圳市鸿怡电子有限公司)为例&…...

Kubernetes自动化更新利器Keel:实现容器镜像的持续部署
1. 项目概述:为什么我们需要一个“自动化的应用更新管家”? 如果你和我一样,负责维护着几个、十几个,甚至几十个运行在Kubernetes或Docker环境中的应用,那你一定对“更新”这件事又爱又恨。爱的是,新版本意…...

开源办公套件自动化部署与集成实战:基于OpenOffice的服务化解决方案
1. 项目概述:为什么我们需要一个“开源”的办公套件?如果你在GitHub上搜索过办公软件相关的仓库,大概率会看到过longyangxi/OpenOffice这个项目。乍一看,你可能会以为这是一个Apache OpenOffice的镜像或者某个分支。但点进去仔细研…...

Redis高效开发工具集:从SCAN迭代到数据迁移的Python实践
1. 项目概述:一个Redis开发者的“瑞士军刀”如果你和我一样,日常开发中重度依赖Redis,那你一定遇到过这些场景:想快速查看某个大Key的内存占用,得写脚本遍历;想分析某个Pattern下的所有键,得手动…...
如何构建鲁棒的点云局部描述符)
从理论到实践:三维形状上下文(3DSC)如何构建鲁棒的点云局部描述符
1. 为什么我们需要三维形状上下文(3DSC) 想象一下你正在玩一个拼图游戏,但所有碎片都被随机撒上了胡椒粉,有些碎片还被书本盖住了一角。这就是计算机处理含噪声、遮挡的点云数据时的真实处境。在机器人导航、自动驾驶或者工业质检中,我们经常…...