架构师指南:现代 Datalake 参考架构

这篇文章的缩写版本于 2024 年 3 月 26 日出现在 The New Stack 上。
旨在最大化其数据资产的企业正在采用可扩展、灵活和统一的数据存储和分析方法。这一趋势是由企业架构师推动的,他们的任务是制定符合不断变化的业务需求的基础设施。现代数据湖体系结构通过将数据湖的可伸缩性和灵活性与数据仓库的结构和性能优化集成来满足这一需求。这篇文章是理解和实施现代数据湖架构的指南。
什么是现代数据湖?
现代数据湖是一半数据仓库和一半数据湖,对所有事情都使用对象存储。这听起来像是一种营销技巧 - 将两个产品放在一个包中并称之为新产品 - 但本文中将介绍的数据仓库比传统的数据仓库更好 - 它使用对象存储 - 因此,它在可伸缩性和性能方面提供了对象存储的所有好处。采用这种方法的组织只需为他们需要的东西付费(通过对象存储的可扩展性促进),如果需要极快的速度,他们可以为其底层对象存储配备通过高端网络连接的 NVMe 驱动器。
以这种方式使用对象存储的原因是 Apache Iceberg、Apache Hudi 和 Delta Lake 等开放表格式 (OTF) 的兴起,这些规范一旦实施,就可以无缝地将对象存储用作数据仓库的底层存储解决方案。这些规范还提供了传统数据仓库中可能不存在的功能,例如快照(也称为时间旅行)、架构演变、分区、分区演变和零拷贝分支。
但是,如上所述,现代数据湖不仅仅是一个花哨的数据仓库,它还包含一个用于非结构化数据的数据湖。OTF 还提供与数据湖中外部数据的集成。如果需要,这种集成允许将外部数据用作 SQL 表,或者可以使用高速处理引擎和熟悉的 SQL 命令转换外部数据并将其路由到数据仓库。
因此,新式数据湖不仅仅是一个数据仓库和一个数据湖,它位于一个具有不同名称的包中。总的来说,它们提供了比传统数据仓库或独立数据湖更多的价值。
概念架构
分层是呈现现代数据湖所需的所有组件和服务的便捷方式。分层提供了一种清晰的方式来对提供类似功能的服务进行分组。它还允许建立层次结构,消费者位于顶部,数据源(及其原始数据)位于底部。现代数据湖的层从上到下依次为:
-
消耗层 - 包含高级用户用于分析数据的工具。还包含将以编程方式访问现代数据湖的应用程序和 AI/ML 工作负载。
-
语义层 - 用于数据发现和治理的可选元数据层。
-
处理层 - 此层包含查询新式 Datalake 所需的计算群集。它还包含用于分布式模型训练的计算集群。通过利用存储层在数据湖和数据仓库之间的集成,可以在处理层中进行复杂的转换。
-
存储层 - 对象存储是现代数据湖的主要存储服务;但是,MLOP 工具可能需要其他存储服务,例如关系数据库。如果你正在追求生成式人工智能,你将需要一个向量数据库。
-
引入层 - 包含接收数据所需的服务。高级摄取层将能够根据计划检索数据。现代数据湖应支持各种协议。它还应该支持以流和批处理形式到达的数据。简单和复杂的数据转换可以在引入层中发生。
-
数据源 - 从技术上讲,数据源层不是现代数据湖解决方案的一部分,但它包含在这篇文章中,因为构建良好的现代数据湖必须支持具有不同数据发送功能的各种数据源。
下图直观地描述了上述所有层以及实现这些层可能需要的所有功能。这是一个端到端架构,平台的核心是现代数据湖。此体系结构不仅关注处理层和存储层,还展示了引入、转换、发现、治理和使用数据所需的组件。还包括支持依赖于现代数据湖的重要用例所需的工具,例如 MLOps 存储、向量数据库和机器学习群集。
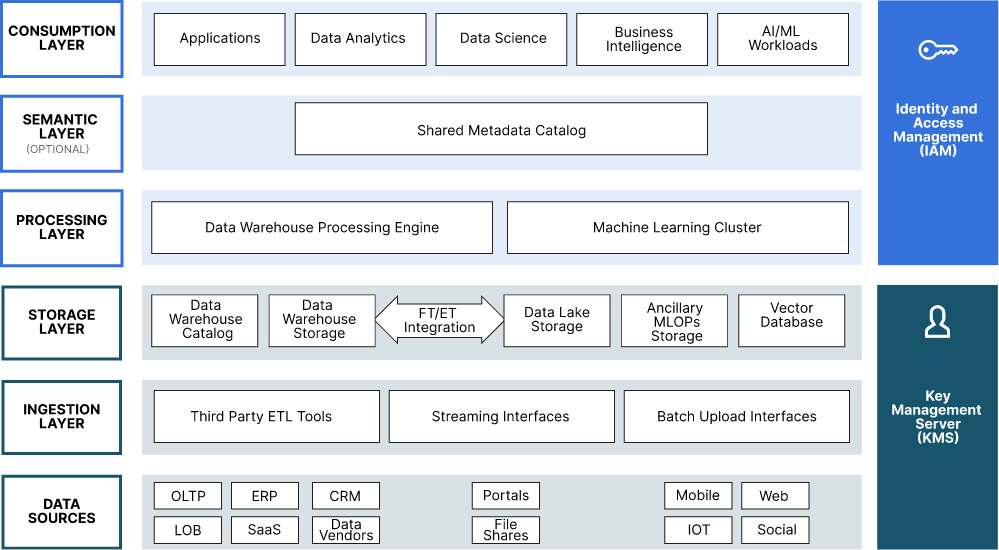
本文中使用的方法的概念性质很重要。如果上图使用了产品名称,那么意义就会丢失。选择产品名称很少是为了意义,而是为了品牌知名度和记忆力而选择的。为此,我们的概念架构使用简单的名词,其中提供的功能是直观的。下一节将为熟悉当今市场上更流行的大数据项目和产品的读者提供具体实现的示例。但是,鼓励读者在为他们的组织做出决策时参考概念图。
最后,没有箭头。箭头通常描述数据流和依赖关系。显示所有可能的数据流和依赖关系会不必要地使关系图复杂化。更好的方法是在用例的上下文中查看数据流和依赖关系。一旦在用例的上下文中隔离了几个组件,就可以更清楚地说明数据流和依赖关系。
混凝土建筑
本节的目的是通过具体的开源示例来为我们的参考架构设计奠定基础。对于渴望潜入并开始建造的建筑师来说,下面显示的项目和产品可以在概念验证中免费使用。当您的 POC 毕业到一个有朝一日将在生产中运行的资助项目时,请务必检查 POC 中使用的所有软件的开源许可证和使用条款。
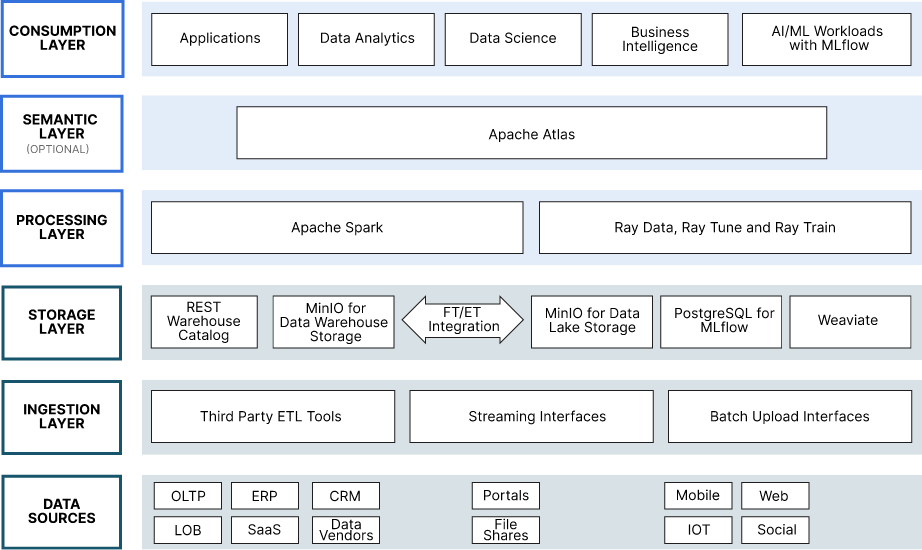
关于数据源的几句话
为您的现代 Datalake 提供数据的应用程序、设备和供应商有多种形式,其数据也是如此。本地现代应用程序可能能够使用 AVRO 和 Parquet 等格式实时流式传输结构良好的数据。另一方面,较旧的遗留应用程序可能只能批量发送简单文件,例如 XML、JSON 和 CSV。 数据供应商可能根本不发送数据 - 期望他们的客户检索数据。
移动应用、网站、IOT 设备和社交媒体应用通常会将应用程序日志和其他遥测数据(使用情况统计信息)发送到引入层。日志分析是新式数据湖的常用用例。此外,它们可能会发送图像和音频文件以在 AI/ML 工作负载中使用。
最后,希望利用生成式 AI 的组织需要将文件共享和门户(如 SharePoint Portal Server 和 Confluence)中的文档存储在数据湖中。
现代数据湖需要能够高效可靠地与所有这些数据源进行交互,从而将数据传输到 Data Lake Storage 或 Data Warehouse Storage。载入数据是我们体系结构的引入层的主要用途。这要求引入层支持能够接收流数据和批处理数据的各种协议。接下来,让我们研究一下这一层的组件。
引入层
引入层是通往新式 Datalake 的入口。它负责将数据摄取到数据存储层中。来自为新式数据湖的数据仓库端设计源的源的结构化数据可以绕过数据湖,并将其数据直接发送到数据仓库。另一方面,没有以这种方式设计源的源将需要将其数据发送到数据湖,在将其引入数据仓库之前可以对其进行转换。
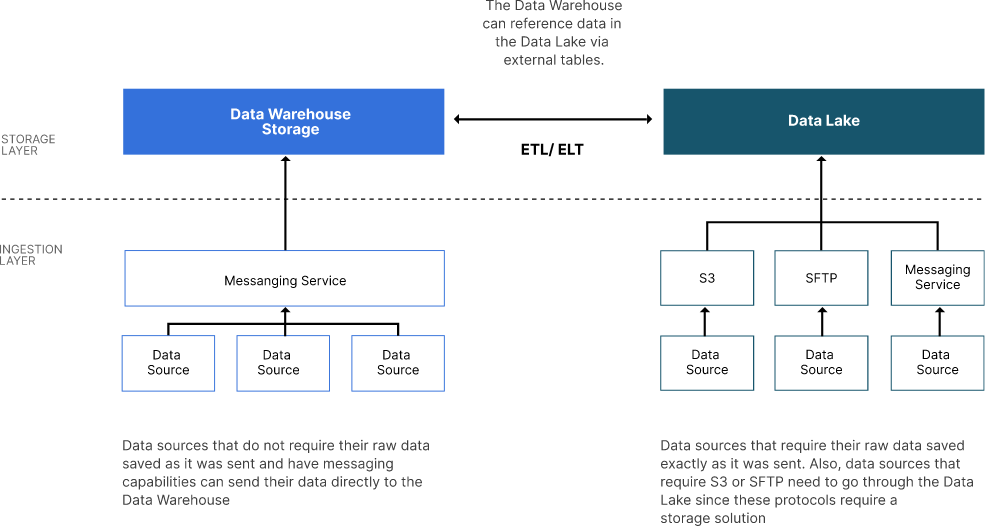
引入层应该能够接收和检索数据。内部业务线 (LOB) 应用程序可能已被授予通过流式处理或批处理发送其数据的授权。对于这些应用程序,引入层需要提供用于接收数据的终结点。但是,数据供应商和其他外部数据源可能不太愿意提供数据。引入层还应提供计划的检索功能。例如,数据供应商可能会在每个月的第一天提供新的数据集。计划的检索功能将允许引入层在正确的时间连接和下载数据。
流式处理是将数据传输到现代数据湖或任何目标的最佳方式。Steaming 意味着使用消息传递服务,使其具有弹性、可用性和高性能。消息传递服务通常提供一种排队机制,该机制仅在成功存储消息时才确认收到消息。然后,该服务向下游服务提供“恰好一次”的传递,该服务负责将消息中的数据保存到数据仓库或数据湖。(注意:某些邮件服务提供“至少一次”传递,要求下游服务对数据源实现幂等更新。请务必检查您最终使用的服务的细则。这种引入方式的特别好处是,如果下游服务失败并且不确认消息的成功处理,则该消息将重新出现在队列中,以供将来引入。消息传递服务还为反复失败的消息提供“死信队列”。
流式引入很棒,但在许多情况下,不需要实时见解。在这些情况下,批处理或小批量处理工作正常,并且实现起来要简单得多。对于批量上传,S3 API 是您的最佳选择。MinIO 符合 S3 标准,当前向 S3 终端节点发送批处理数据的任何数据源都将“按原样”工作,只需切换到 MinIO 数据湖后进行连接更改。但是,许多组织可能仍然更喜欢 FTP/SFTP,因为它的简单性和在高度受限的环境中运行的能力。MinIO 还支持 FTP 和 SFTP。此接口允许数据源将数据发送到 MinIO,就像将数据发送到 FTP 服务器一样。从应用程序或用户的角度来看,使用 SFTP 将数据移动到 MinIO 是无缝的,因为从策略、安全性等角度来看,一切都基本相同。
数据存储层

数据存储层是所有其他层所依赖的基石。其目的是可靠地存储数据并有效地提供数据。新式数据湖的数据湖端将有一个对象存储服务,数据仓库将有一个对象存储服务。

如果需要,可以使用存储桶将数据仓库存储与 Data Lake Storage 分开,从而将这两个对象存储服务组合到对象存储的一个物理实例中。但是,如果处理层将把不同的工作负载放在这两个存储服务上,请考虑将它们分开并安装在不同的硬件上。例如,一个常见的数据流是让所有新数据都进入数据湖。进入数据湖后,可以将其转换并引入数据仓库,在那里它可以被其他应用程序使用,并用于数据科学、商业智能和数据分析。如果这是数据流,则新式数据湖将给数据仓库带来更多负载,并且您需要确保它在高端硬件(存储设备、存储集群和网络)上运行。
外部表功能允许数据仓库和处理引擎读取数据湖中的对象,就好像它们是 SQL 表一样。如果将 Data Lake 用作原始数据的登陆区域,则此功能以及 Data Warehouse SQL 功能可用于在将原始数据插入数据仓库之前对其进行转换。或者,外部表可以“按原样”使用,并与数据仓库中的其他表和资源联接,而无需离开 Data Lake。此模式有助于节省迁移成本,并且可以通过将数据保存在一个位置,同时使其可供外部服务使用来克服一些数据安全问题。
大多数 MLOP 工具使用对象存储和关系数据库的组合来支持 MLOps。例如,MLOP 工具应存储训练指标、超参数、模型检查点和数据集版本。模型和数据集应存储在数据湖中,而指标和超参数将更有效地存储在关系数据库中。
如果您正在追求生成式 AI,则需要为您的组织构建自定义语料库。它应该包含其他人没有的知识的文件,并且只应使用真实和准确的文件。此外,您的自定义语料库应使用向量数据库构建。矢量数据库为文档及其矢量嵌入(文档的数值表示)编制索引、存储并提供对文档的访问。向量数据库有助于语义搜索,这是检索增强生成所必需的,生成式 AI 利用这种技术将自定义语料库中的信息与经过训练的LLMs参数存储器相结合。
处理层
处理层包含现代 Datalake 支持的所有工作负载所需的计算。在较高级别上,计算有两种类型:数据仓库的处理引擎和分布式机器学习的集群。

数据仓库处理引擎支持对数据仓库存储中的数据分布式执行 SQL 命令。作为引入过程一部分的转换可能还需要处理层中的计算能力。例如,某些数据仓库可能希望使用奖章架构,而其他数据仓库可能选择带有维度表的星型架构。这些设计通常需要在引入过程中对原始数据进行大量 ETL。
新式数据湖中使用的数据仓库将计算与存储进行分解。因此,如果需要,单个 Data Warehouse 数据存储可以存在多个处理引擎。(这与传统的关系数据库不同,在传统的关系数据库中,计算和存储是紧密耦合的,每个存储设备都有一个计算资源。处理层的一种可能设计是为消费层中的每个实体设置一个处理引擎。例如,一个用于商业智能的处理集群,一个用于数据分析的单独集群,以及另一个用于数据科学的集群。每个处理引擎都会查询相同的数据仓库存储服务,但是,由于每个团队都有自己的专用集群,因此它们不会相互竞争计算。如果商业智能团队正在运行计算密集型月末报表,则他们不会干扰可能运行每日报表的另一个团队。
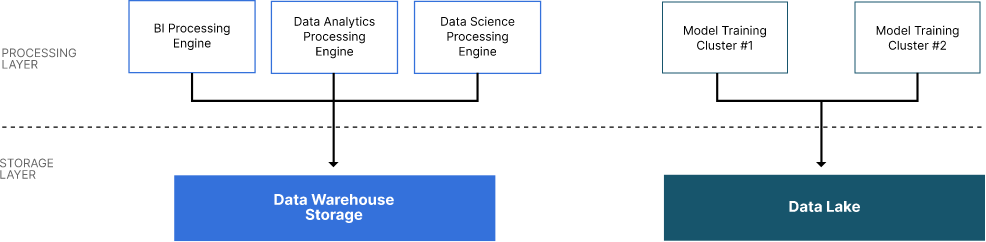
如果以分布式方式进行训练,则机器学习模型(尤其是大型语言模型)可以更快地进行训练。机器学习群集支持分布式训练。分布式训练应与 MLOP 工具集成,用于实验跟踪和检查点。
可选语义层
语义层可帮助企业理解其数据。语义层位于处理层和消费层之间,前者提供来自存储层的数据,后者包含查找数据的工具和应用程序。它就像一个翻译器,弥合了业务语言和用于描述数据的技术术语之间的差距。它还可以帮助数据专业人员和业务用户查找相关数据,以便为最终用户报告或为 AI/ML 创建数据集。
在最简单的形式中,语义层可以是数据目录或有组织的数据清单。数据目录通常包括原始数据源位置(世系)、架构、简短说明和详细描述。更强大的语义层可以通过合并策略、控制和数据质量规则来提供安全性、隐私和治理。
此图层是可选的。数据源很少且结构良好的源的组织可能不需要语义层。结构良好的源是包含直观的字段名称和准确的字段描述的源,可以很容易地从数据源中提取并加载到数据仓库中。结构良好的源还应在源头实施数据质量检查,以便仅将质量数据传输到现代数据湖。
但是,如果大型组织具有许多数据源,在设计架构和源时,元数据是事后才想到的,则应考虑实现语义层。此图层中可以使用的许多产品都提供了帮助组织填充元数据目录的功能。此外,在复杂行业中运营的组织应考虑语义层。例如,金融服务、医疗保健和法律等行业大量使用非日常用语的术语。当这些特定于域的术语用作表名和字段名时,数据的基本含义可能难以确定。
消费层
让我们通过查看在最顶层(消耗层)中运行的工作负载,并讨论下面的层如何支持其特定用例来结束对现代 Datalake 层的介绍。下面的许多工作负载通常可以互换使用或同义使用 - 这很不幸,因为在调查它们的需求时,最好有精确的定义。在下面的讨论中,我将精确描述每个功能,然后将其与现代数据湖的功能保持一致。
应用程序 - 自定义应用程序可以通过编程方式将 SQL 查询发送到新式 Datalake,以便为最终用户提供自定义视图。这些应用程序可能与将原始数据作为关系图底部的数据源提交的应用程序相同。现代数据湖应该支持的一个用例是允许应用程序提交原始数据、清理数据、将其与其他数据合并,并最终快速提供数据。应用程序可以使用使用来自现代数据湖的数据训练的模型。这是现代 Datalake 应该支持的另一个用例。应用程序应该能够将原始数据发送到 Modern Datalake,对其进行处理,然后发送到模型训练管道 - 从那里,模型可用于在应用程序内进行预测。
数据科学是对数据的研究。数据科学家设计数据集,并可能设计将训练和用于推理的模型。数据科学家还使用数学和统计学中的技术进行特征工程。特征工程是一种用于改进用于训练模型的数据集的技术。Modern Datalakes 拥有的一个非常巧妙的功能是零拷贝分支,它允许数据分支,就像代码在 Git 存储库中分支一样。顾名思义,此功能不会创建数据的副本,而是利用用于实现数据仓库的开放表格式的元数据层来创建数据唯一副本的外观。数据科学家可以使用分支进行实验 - 如果他们的实验成功,那么他们可以将他们的分支合并回主分支,供其他数据科学家使用。
商业智能通常是回顾性的,提供对过去事件的见解。它涉及使用报告工具、仪表板和关键绩效指标 (KPI) 来提供业务绩效视图。BI 所需的大部分数据都是聚合,可能需要大量计算才能创建。
数据分析涉及对数据的分析,以提取见解、识别趋势并做出预测。它更具前瞻性,旨在了解某些事件发生的原因以及未来可能发生的事情。数据分析与数据科学重叠,因为它结合了统计分析和机器学习技术。
机器学习 - 机器学习工作负载是 ML 团队运行实验和 MLOP 团队测试模型并将其推广到生产环境的地方。使用机器学习进行研究和原型设计的团队与定期将模型投入生产的团队的需求之间通常存在相当大的差异。只做研究和实验工作的团队通常可以使用最少的 ML-Ops 工具,而那些将模型投入生产的团队则需要更严格的工具和流程。
安全
现代数据湖必须为用户和服务提供身份验证和授权。它还应该为静态数据和动态数据提供加密。本节将探讨安全性的这些方面。
Data Lake 和 Data Warehouse 都必须支持有助于身份验证和授权的身份和访问管理 (IAM) 解决方案。新式数据湖的两半都应使用相同的目录服务来跟踪用户和组,允许用户在登录到 Data Lake 和 Data Warehouse 的用户界面时出示其公司凭据。对于编程访问,由于每个产品需要不同的连接类型,因此需要为身份验证提供的凭据将有所不同。同样,由于基础资源和操作不同,用于授权的策略也会有所不同。Data Lake 需要对存储桶和对象以及存储桶和对象操作进行授权。另一方面,数据仓库需要对表和与表相关的操作进行授权。
数据湖身份验证 - 与数据湖的每个连接都需要验证身份,并且数据湖应与组织的标识提供者集成。由于数据湖是符合 S3 的对象存储,因此应使用 AWS 签名版本 4 协议。对于编程访问,这意味着希望访问管理 API 或 S3 API 的每个服务(如 PUT、GET 和 DELETE 操作)都必须提供有效的访问密钥和私有密钥。
Data Lake 授权 - 授权是限制经过身份验证的客户端可以在 Data Lake 上执行的操作和资源的行为。符合 S3 标准的对象存储应使用基于策略的访问控制 (PBAC),其中每个策略都描述一个或多个规则,这些规则概述了用户或用户组的权限。在创建策略时,数据湖应支持特定于 S3 的操作和条件。默认情况下,MinIO 拒绝访问用户分配或继承的策略中未明确引用的操作或资源。
数据仓库身份验证 - 与数据湖类似,与数据仓库的每个连接都必须经过身份验证,并且数据仓库应与组织的标识提供者集成,以便对用户进行身份验证。数据仓库可以提供以下编程访问选项:ODBC 连接、JDBC 连接或 REST 会话。每个都需要一个访问令牌。
数据仓库授权 - 数据仓库应支持对数据仓库中的表、视图和其他对象进行用户、组和角色级别的访问控制。这允许根据用户的 ID、组或角色配置对单个对象的访问。
密钥管理服务器 - 为了确保静态和传输中的安全性,新式数据湖使用密钥管理服务器 (KMS)。KMS 是一种服务,负责生成、分发和管理用于加密和解密的加密密钥。
总结
这就是现代数据湖从数据源到消费的五个层。本文探讨了现代数据湖的概念参考架构。目标是为组织提供战略蓝图,以构建一个平台,有效地管理和从其庞大而多样化的数据集中提取价值。现代数据湖结合了传统数据仓库和灵活数据湖的优势,为存储、处理和分析数据提供了统一且可扩展的解决方案。
相关文章:
架构师指南:现代 Datalake 参考架构
这篇文章的缩写版本于 2024 年 3 月 26 日出现在 The New Stack 上。 旨在最大化其数据资产的企业正在采用可扩展、灵活和统一的数据存储和分析方法。这一趋势是由企业架构师推动的,他们的任务是制定符合不断变化的业务需求的基础设施。现代数据湖体系结构通过将数…...

通讯协议大全(UART,RS485,SPI,IIC)
参考自: 常见的通讯协议总结(USART、IIC、SPI、485、CAN)-CSDN博客 UART那么好用,为什么单片机还需要I2C和SPI?_哔哩哔哩_bilibili 5分钟看懂!串口RS232 RS485最本质的区别!_哔哩哔哩_bilibili 喜欢几位…...

基于EXCEL数据表格创建省份专题地图
1 数据源 随着西藏于5月1日发布2022年一季度经济运行情况,31省份一季度GDP数据已全部出炉。 总量方面,粤苏鲁稳居前三;增速方面,23省份高于“全国线”,新疆表现最佳,增速达到7.0%。 表格表现数据不够直观…...

基于java+springboot+vue实现的电商应用系统(文末源码+Lw)241
摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本电商应用系统就是在这样的大环境下诞生,其可以帮助管理者在短时间内处理完毕庞大的数据信息&a…...

好文!12个策略解决 Kafka 数据丢失问题
哥们儿!有遇到Kafka数据丢失问题的问题吗,你是如何解决的?今天的文章,V哥来详细解释一下,整理了12种解决策略,希望可以帮助你解决项目中的问题:以下是一些常见的解决方案和最佳实践。 生产者确认…...

Android 第三方框架:网络:OkHttp:源码分析:拦截器
文章目录 涉及到的设计模式 责任链模式:ArrayList策略模式:Interceptor和XXXInterceptor源码分析API总结涉及到的设计模式 责任链模式:ArrayList ArrayList 用ArrayList作为保存顺序的数据结构 把系统提供的各种Interceptor和自定义的Interceptor放入ArrayList中 RealI…...

FlowUs AI的使用教程和使用体验
FlowUs AI 使用教程 FlowUs AI特点使其成为提升个人和团队生产力的有力工具,无论是在学术研究、内容创作、技术开发还是日常办公中都能发挥重要作用。现在来看看如何使用FlowUs AI吧! 注册与登录:首先,确保您已经注册并登录FlowU…...

SwiftUI 6.0(iOS 18)ScrollView 全新的滚动位置(ScrollPosition)揭秘
概览 在只有方寸之间大小的手持设备上要想体面的向用户展示海量信息,滚动视图(ScrollView)无疑是绝佳的“东牀之选”。 在 SwiftUI 历史的长河中,总觉得苹果对于 ScrollView 视图功能的升级是在“挤牙膏”。这不,在本…...
阿贝云免费虚拟主机和免费云服务器评测
阿贝云是一家提供免费虚拟主机和免费云服务器的服务商,为用户提供了一个便捷的搭建网站和应用的平台。他们的服务受到了很多用户的好评。用户可以轻松地在阿贝云上创建自己的网站,并享受免费的虚拟主机和云服务器。通过阿贝云的服务,用户可以…...

不懂就问,开通小程序地理位置接口有那么难吗?
小程序地理位置接口有什么功能? 若提审后被驳回,理由是“当前提审小程序代码包中地理位置相关接口( chooseAddress、getLocation )暂未开通,建议完成接口开通后或移除接口相关内容后再进行后续版本提审”,那么遇到这种情况&#x…...
)
Python 全栈系列256 异步任务与队列消息控制(填坑)
说明 每个创新都会伴随着一系列的改变。 在使用celery进行异步任务后,产生的一个问题恰好也是因为异步产生的。 内容 1 问题描述 我有一个队列 stream1, 对应的worker1需要周期性的获取数据,对输入的数据进行模式识别后分流。worker1我设施为10秒运行…...
从零开始的Ollama指南:部署私域大模型
大模型相关目录 大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容 从0起步,扬帆起航。 大模型应用向开发路径:AI代理工作流大模型应用开发实用开源项目汇总大模…...

C++类和对象总结
目录 总结 一、引言 二、类的定义 三、对象的创建与初始化 四、访问控制 五、封装 六、继承 七、多态 八、其他特性 九、总结 C类的定义 C对象的创建和初始化 C类的访问控制 总结 一、引言 C是一种面向对象的编程语言,其核心概念是类和对象。类是对现…...
基于PHP的民宿管理系统
有需要请加文章底部Q哦 可远程调试 基于PHP的民宿管理系统 一 介绍 此民宿管理系统基于原生PHP开发,数据库mysql,前端jquery.js和echarts.js。系统角色分为用户和管理员。用户可以在线浏览和预订民宿,管理员登录后台进行相关管理等。(在系统…...

ROS中C++、Python完整的目录结构
文章目录 在ROS中,一个典型的C软件包目录结构通常包括以下几个主要目录: include:该目录包含C头文件(.hpp或者.h文件),用于声明类、函数、变量等。通常,这些头文件定义了ROS节点、消息类型、服务…...
Boosting原理代码实现
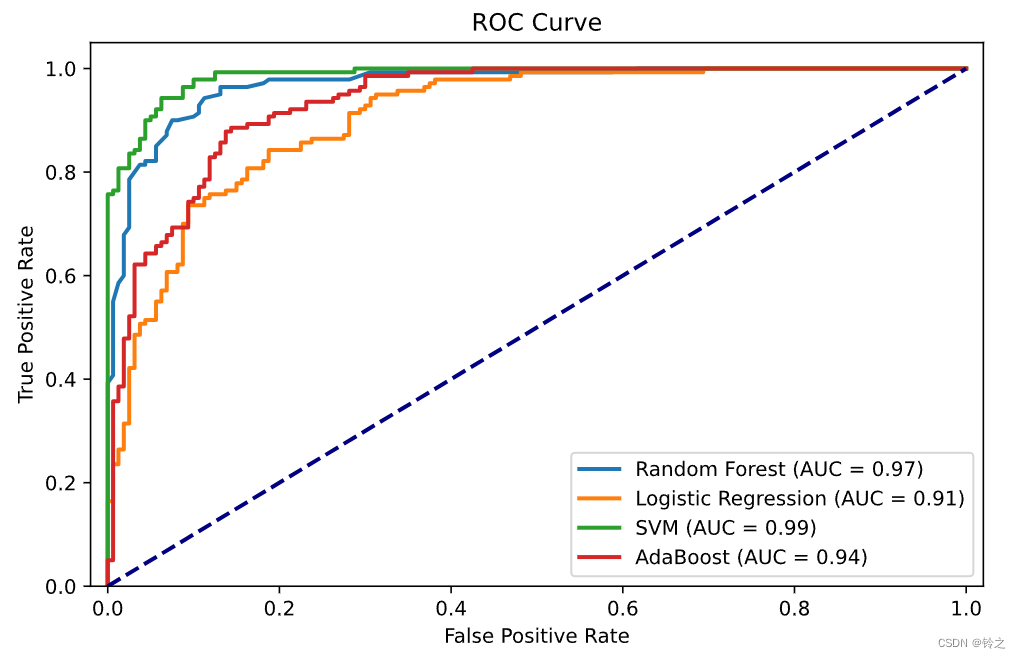
1.提升方法是将弱学习算法提升为强学习算法的统计学习方法。在分类学习中,提升方法通过反复修改训练数据的权值分布,构建一系列基本分类器(弱分类器),并将这些基本分类器线性组合,构成一个强分类…...

【Qt基础教程】事件
文章目录 前言事件简介事件示例总结 前言 在开发复杂的图形用户界面(GUI)应用程序时,理解和掌握事件处理是至关重要的。Qt,作为一个强大的跨平台应用程序开发框架,提供了一套完整的事件处理系统。本教程旨在介绍Qt事件处理的基础知识&#x…...

外星人Alienware m15R7 原厂Windows11系统
装后恢复到您开箱的体验界面,包括所有原机所有驱动AWCC、Mydell、office、mcafee等所有预装软件。 最适合您电脑的系统,经厂家手调试最佳状态,性能与功耗直接拉满,体验最原汁原味的系统。 原厂系统下载网址:http://w…...

stata17中java installation not found或java not recognozed的问题
此问题在于stata不知道去哪里找java,因此需要手动的告诉他 方法1: 1.你得保证已经安装并配置好java环境 2.在stata中输入以下内容并重启stata即可 set java_home "D:\Develope\JDk17" 其中java_home后面的""里面的内容是你的jdk安装路径 我的…...

Harbor本地仓库搭建003_Harbor常见错误解决_以及各功能使用介绍_镜像推送和拉取---分布式云原生部署架构搭建003
首先我们去登录一下harbor,但是可以看到,用户名密码没有错,但是登录不上去 是因为,我们用了负债均衡,nginx会把,负载均衡进行,随机分配,访问的 是harbora,还是harborb机器. loadbalancer中 解决方案,去loadbalance那个机器中,然后 这里就是25机器,我们登录25机器 然后去配置…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

多模态商品数据接口:融合图像、语音与文字的下一代商品详情体验
一、多模态商品数据接口的技术架构 (一)多模态数据融合引擎 跨模态语义对齐 通过Transformer架构实现图像、语音、文字的语义关联。例如,当用户上传一张“蓝色连衣裙”的图片时,接口可自动提取图像中的颜色(RGB值&…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...
)
postgresql|数据库|只读用户的创建和删除(备忘)
CREATE USER read_only WITH PASSWORD 密码 -- 连接到xxx数据库 \c xxx -- 授予对xxx数据库的只读权限 GRANT CONNECT ON DATABASE xxx TO read_only; GRANT USAGE ON SCHEMA public TO read_only; GRANT SELECT ON ALL TABLES IN SCHEMA public TO read_only; GRANT EXECUTE O…...

工业自动化时代的精准装配革新:迁移科技3D视觉系统如何重塑机器人定位装配
AI3D视觉的工业赋能者 迁移科技成立于2017年,作为行业领先的3D工业相机及视觉系统供应商,累计完成数亿元融资。其核心技术覆盖硬件设计、算法优化及软件集成,通过稳定、易用、高回报的AI3D视觉系统,为汽车、新能源、金属制造等行…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...