【机器学习】基于Softmax松弛技术的离散数据采样
1.引言
1.1.离散数据采样的意义
离散数据采样在深度学习中起着至关重要的作用,它直接影响到模型的性能、泛化能力、训练效率、鲁棒性和解释性。
首先,采样方法能够有效地平衡数据集中不同类别的样本数量,使得模型在训练时能够更均衡地学习各个类别的特征,从而避免因数据不平衡导致的偏差。
其次,合理的采样策略可以确保模型在训练过程中能够接触到足够多的样本,避免过拟合和欠拟合问题,提高模型的泛化能力。
此外,通过随机选择部分样本来减少训练数据的规模,可以提高训练效率,使得深度学习模型在处理大规模数据集时更加高效。同时,离散数据采样还能增加数据集的多样性,使得模型在训练过程中能够接触到更多不同类型的样本,从而提高模型的鲁棒性,使其能够更好地适应各种实际应用场景。
最后,通过控制训练数据的分布来影响模型的决策过程,离散数据采样可以为深度学习模型提供一定的解释性,使得模型的决策过程更加可理解和可信任。
在实际应用中,选择合适的离散数据采样策略对于提高深度学习模型的性能和可解释性至关重要。
1.2.主要内容
本文探讨了如何从非结构化的向量数据中有效地采样出离散变量,并将这些变量转化为具有特定结构的实体,例如集合、序列或网络图等形式,进而将它们嵌入到可微分的模型框架中。
文章的核心在于应用连续的松弛技术来处理离散随机变量,尤其是二元和分类类型的变量。在第一部分中,我们详细介绍了利用Gumbel-Softmax技巧来实现从离散概率分布中进行采样。通过这种方法,我们成功地训练了一个变分自编码器模型,该模型具备了分类型的潜在变量。这种技巧为处理离散性和结构化数据提供了一种新颖的途径,并使得模型能够通过标准的反向传播算法进行训练和优化。
2.离散数据采样理论和实践
2.1.使用Gumbel-Argmax进行分类采样
Gumbel-Argmax,也称为Gumbel-Softmax trick,是一种在深度学习中处理离散变量的技巧,特别是在变分推断和生成模型中。这种方法允许我们从离散分布中进行可微分的采样,从而使得梯度下降算法可以应用于包含离散选择的模型。
2.1.1.基本原理
Gumbel-Argmax方法基于Gumbel分布,一种极端值分布,它可以被用来将离散的随机变量转换成连续的形式,从而便于梯度的传播。Gumbel-Argmax方法,也称为Gumbel-Softmax trick,在深度学习中是一种处理离散变量的技巧,尤其是在需要不同iable的随机采样时。这种方法利用Gumbel分布的特性,允许模型通过softmax函数进行梯度的反向传播。
Gumbel分布是一种极端值分布,常用于模拟独立随机变量的最大值或最小值。它的概率密度函数(PDF)和累积分布函数(CDF)具有以下形式:
-
PDF:
f ( z ; μ , β ) = 1 β exp ( − z − μ β ) exp ( − exp ( − z − μ β ) ) f(z; \mu, \beta) = \frac{1}{\beta} \exp\left(-\frac{z - \mu}{\beta}\right) \exp\left(-\exp\left(-\frac{z - \mu}{\beta}\right)\right) f(z;μ,β)=β1exp(−βz−μ)exp(−exp(−βz−μ))
其中 μ \mu μ是位置参数, b e t a beta beta是尺度参数。 -
CDF:
F ( z ; μ , β ) = exp ( − exp ( − z − μ β ) ) F(z; \mu, \beta) = \exp\left(-\exp\left(-\frac{z - \mu}{\beta}\right)\right) F(z;μ,β)=exp(−exp(−βz−μ))
在Gumbel-Argmax技巧中,通常将尺度参数 β \beta β设为1,以简化计算。
2.1.2.Gumbel-Argmax的工作原理
-
Gumbel噪声的添加:对于每个离散选择的对数几率 x k x_k xk,我们添加一个独立的Gumbel噪声 g k g_k gk,得到 x k + g k x_k + g_k xk+gk。
-
Softmax归一化:将添加了噪声的对数几率通过softmax函数进行归一化,得到概率分布 π k \pi_k πk。
-
Argmax采样:在前向传播中,使用softmax得到的概率分布进行argmax操作,得到最可能的选择。在反向传播中,使用softmax的梯度进行传播。
2.1.3.梯度传播的实现
Gumbel-Argmax方法的关键优势在于它允许梯度通过离散采样过程进行传播。在反向传播时,尽管argmax操作本身不可微,但是可以通过Gumbel噪声的连续性来实现梯度的传播。这就是所谓的“直通估计器”(Straight-Through Estimator, STE)。
2.1.4.采样步骤
-
Gumbel噪声采样:对于每个离散选择,我们首先从Gumbel分布中采样一个噪声项。Gumbel分布是一种以0为位置参数,1为尺度参数的分布。
-
对数几率调整:将Gumbel噪声加到原始的对数几率(logits)上,使得每个选择的值变为
logits + Gumbel噪声。 -
Softmax归一化:应用softmax函数对调整后的值进行归一化,得到一个概率分布。
-
Argmax转换:在前向传播中,使用softmax得到的分布进行argmax操作,得到最可能的选择;在反向传播中,使用softmax的梯度进行传播。
2.1.5.采样数学模型
假设我们有一个具有 C C C个可能值的分类分布,每个值的权重为 w i ∈ ( 0 , ∞ ) w_i \in (0,\infty) wi∈(0,∞),我们的目标是从此分布中抽取一个样本,类别 c i c_i ci的概率由softmax分布决定,公式如下:
p i = exp ( log ( w i ) ) ∑ j exp ( log ( w j ) ) p_i = \frac{\exp(\log(w_i))}{\sum_{j} \exp(\log(w_j))} pi=∑jexp(log(wj))exp(log(wi))
Gumbel-Argmax采样方法的步骤是:
- 从均匀分布 U n i f o r m ( 0 , 1 ) Uniform(0,1) Uniform(0,1)中独立同分布地采样 U k U_k Uk,然后计算 r k = log ( w i ) − log ( − log U k ) r_k = \log(w_i) - \log(-\log U_k) rk=log(wi)−log(−logUk)。
- 选择使得 r k r_k rk最大的索引 i i i(即执行argmax操作),并返回一个1-hot编码的向量,其中第 i i i位为1,其余位置为0。
添加到 r k r_k rk中的噪声项 − l o g ( − log U k ) -log(-\log U_k) −log(−logUk)遵循Gumbel分布,这也是该方法名称的由来。Gumbel分布(位置参数为0,尺度参数为1)的累积分布函数定义为:
F ( z ) = exp ( − exp ( − z ) ) F(z) = \exp(-\exp(-z)) F(z)=exp(−exp(−z))
备注:有关这种方法确实能从softmax分布中采样的证明,如下:
在神经网络、广义线性模型、主题模型以及许多其他概率模型中,人们常常希望用一个无约束的向量来参数化一个离散分布,即一个不受单纯形限制、可以是负数等的向量。解决这个问题的一个非常常见的方法是使用“softmax”变换:
π k = exp { x k } ∑ k ′ = 1 K exp { x k ′ } \pi_k = \frac{\exp\{x_k\}}{\sum_{k'=1}^K\exp\{x_{k'}\}} πk=∑k′=1Kexp{xk′}exp{xk}其中 x k x_k xk 在 R \mathbb{R} R 中是无约束的,但是 π k \pi_k πk 位于单纯形上,即 π k ≥ 0 \pi_k \geq 0 πk≥0 且 ∑ k π k = 1 \sum_{k}\pi_k=1 ∑kπk=1。 x k x_k xk 参数化了一个离散分布(不是唯一的),我们可以通过执行softmax变换然后进行通常的抽样来生成数据。有趣的是,实际上存在一种替代方法来获得这样的离散样本,而不需要构建离散分布。
这种方法是softmax-离散过程的等价物:向每个 x k x_k xk 添加Gumbel噪声,然后取argmax。也就是说,向每个 x k x_k xk 添加独立的噪声,然后进行最大值操作。这并没有改变算法的渐近复杂度,但是为一些有趣的实现可能性打开了大门。这是如何工作的呢?具有单位尺度和位置参数 μ \mu μ 的Gumbel分布具有以下概率密度函数(PDF):
f ( z ; μ ) = exp { − ( z − μ ) − exp { − ( z − μ ) } } . f(z\,;\,\mu) = \exp\{-(z-\mu) - \exp\{-(z-\mu)\}\}. f(z;μ)=exp{−(z−μ)−exp{−(z−μ)}}.Gumbel的累积分布函数(CDF)是
F ( z ; μ ) = exp { − exp { − ( z − μ ) } } . F(z\,;\,\mu) = \exp\{-\exp\{-(z-\mu)\}\}. F(z;μ)=exp{−exp{−(z−μ)}}.现在,假设我们的第 k k k 个Gumbel,位置参数为 x k x_k xk,结果为 z k z_k zk。所有其他的 z k ′ ≠ k z_{k'\neq k} zk′=k 小于这个值的概率是
Pr ( z k is largest ∣ z k , { x k ′ } k ′ = 1 K ) = ∏ k ′ ≠ k exp { − exp { − ( z k − x k ′ ) } } . \Pr(z_k \text{ is largest}\,|\, z_k, \{x_{k'}\}^K_{k'=1}) = \prod_{k'\neq k}\exp\{-\exp\{-(z_k-x_{k'})\}\}. Pr(zk is largest∣zk,{xk′}k′=1K)=k′=k∏exp{−exp{−(zk−xk′)}}.我们知道 z k z_k zk 的边缘分布,我们需要积分它来找到整体概率:
Pr ( k is largest ∣ { x k ′ } ) = ∫ exp { − ( z k − x k ) − exp { − ( z k − x k ) } } × ∏ k ′ ≠ k exp { − exp { − ( z k − x k ′ ) } } d z k . \Pr(\text{$k$ is largest}\,|\,\{x_{k'}\}) = \\ \int \exp\{-(z_k-x_k)-\exp\{-(z_k-x_k)\}\}\times\\ \prod_{k'\neq k}\exp\{-\exp\{-(z_k-x_{k'})\}\} \,\mathrm{d}z_k. Pr(k is largest∣{xk′})=∫exp{−(zk−xk)−exp{−(zk−xk)}}×k′=k∏exp{−exp{−(zk−xk′)}}dzk.通过一些代数运算,我们得到:
Pr ( k is largest ∣ { x k ′ } ) = exp { x k } ∑ k ′ = 1 K exp { x k ′ } . \Pr(\text{$k$ is largest}\,|\,\{x_{k'}\}) = \frac{\exp\{x_k\}}{\sum_{k'=1}^K\exp\{x_{k'}\}}. Pr(k is largest∣{xk′})=∑k′=1Kexp{xk′}exp{xk}.我们可以看到,这正是softmax概率.
简而言之,使用Gumbel重新参数化技巧对分类变量进行采样的步骤如下:
- 给定权重 w i w_i wi,计算 r i = w i + g i r_i = w_i + g_i ri=wi+gi,其中 g i g_i gi是从Gumbel分布中独立同分布采样得到的。
- 执行Argmax操作:返回最大的 r i r_i ri对应的索引,作为1-hot向量。
3.Softmax松弛技术
在深度学习中,当我们需要从一个分布中选取一个类别时,通常会使用softmax函数来得到每个类别的概率分布,然后使用argmax来选取概率最大的类别。然而,由于argmax操作在大多数深度学习框架中是不可导的,这就使得在训练过程中无法使用基于梯度的优化算法。
为了解决这个问题,我们采用softmax函数来近似argmax,因为它本身是连续且可导的。但是,原始的softmax输出是一个概率分布,而argmax输出的是一个离散值(即类别的索引)。为了控制softmax输出与1-hot向量的接近程度,我们引入了温度参数 τ \tau τ(希腊字母tau)。
引入温度参数 τ \tau τ后的softmax函数可以写作:
p i = exp ( r i / τ ) ∑ j exp ( r j / τ ) p_i = \frac{\exp(r_i / \tau)}{\sum_j \exp(r_j / \tau)} pi=∑jexp(rj/τ)exp(ri/τ)
其中, p i p_i pi是第 i i i个类别的概率, r i r_i ri是该类别的原始得分(在深度学习模型中通常是模型的输出层的线性变换结果), τ \tau τ是温度参数。
当温度参数 τ \tau τ较小时,softmax的输出会更加接近一个1-hot向量,即最大概率的类别概率接近1,而其他类别的概率接近0。这使得softmax的输出更接近于argmax的结果。
相反,当温度参数 τ \tau τ较大时,softmax的输出会更加平滑,即所有类别的概率都会相对均匀,没有哪一个类别的概率特别突出。这有助于在训练初期鼓励模型探索不同的类别,避免过早地陷入局部最优解。
因此,通过调整温度参数 τ \tau τ,我们可以控制softmax输出与1-hot向量的距离,从而实现对argmax操作的可导近似。在训练过程中, τ \tau τ可以是一个固定的值,也可以是一个可学习的参数,根据具体的任务和数据集进行调整。
温度参数对分布和样本的影响可以通过下图(图引用自论文:CATEGORICAL REPARAMETERIZATION WITH GUMBEL-SOFTMAX)观察到。

在训练过程中,可以通过调整 τ \tau τ来控制模型的“柔软度”。开始时,可以使用较大的 τ \tau τ值来帮助模型在类别之间进行探索,随着训练的进行,逐渐减小 τ \tau τ值以鼓励模型做出更确定的预测。
然而,如果你提到的是Gumbel-Softmax采样,这是一种用于离散潜变量(如分类变量)的可导近似方法。Gumbel-Softmax允许你通过softmax函数从离散分布中采样,同时保持整个过程的可导性。这种方法通过添加Gumbel噪声到原始logits(未归一化的概率)上,然后使用softmax进行归一化,并通过一个温度参数来控制分布的离散程度。
Gumbel-Softmax采样的基本步骤如下:
- 对于每个logits x i x_i xi,从其对应的Gumbel分布中抽取一个样本 g i g_i gi。
- 计算 r i = x i + g i r_i = x_i + g_i ri=xi+gi。
- 应用带有温度参数 τ \tau τ的softmax函数,得到 softmax τ ( r ) \text{softmax}_\tau(r) softmaxτ(r)。
- 最后,通常使用softmax输出的概率作为权重,从类别中进行采样(在训练时通常使用softmax输出本身作为近似,而在测试时可能使用argmax或采样)。
注意,在训练过程中,Gumbel-Softmax通常用于反向传播梯度,因为它是可导的。然而,在评估或测试模型时,你可能想要一个离散的输出,这时可以使用argmax或基于softmax输出的采样方法。
4.分类变分自编码器(Categorical VAE)
我们编写了一个Gumbel-Softmax技巧应用的案例,呈现了一个变分自编码器(VAE),它专门设计用于处理MNIST数据集,并拥有一个由分类变量构成的潜在空间。这个潜在空间由多个分类变量组成,每个变量都能够取有限个可能的类别。
具体来说,在这个例子中,我们的潜在空间由30个独立的分类变量组成,每个变量都限定在10个可能的类别中。鉴于VAE模型的工作原理,我们需要为这些潜在变量定义一个先验分布,这里我们选择了一个均匀的分类分布作为先验,意味着在潜在空间中每个类别的出现概率是相同的。
通过这种方式,我们能够利用Gumbel-Softmax分布来实现对潜在变量的可微分采样,从而允许模型通过标准的反向传播算法进行训练。这种采样方法不仅提供了一种灵活的方式来处理离散数据,而且还保持了模型在概率建模上的理论完整性。
4.1.设置
我们从所需的导入和超参数定义开始。
import numpy as np # 导入NumPy库,用于数学运算import torch # 导入PyTorch库,用于构建和训练神经网络
import torch.nn.functional as F # 导入PyTorch的功能性模块,包含一些神经网络中常用的函数
from torch import nn, optim # 从PyTorch中导入神经网络模块(nn)和优化器模块(optim)
from torch.nn import functional as F # 导入PyTorch神经网络的功能性方法,F是函数库的别名
from torchvision import datasets, transforms # 从torchvision库中导入数据集和转换模块,用于加载和预处理数据
from torchvision.utils import save_image # 从torchvision.utils中导入保存图像的函数
from torch.distributions.one_hot_categorical import OneHotCategorical # 从PyTorch的分布库中导入OneHotCategorical分布import matplotlib # 导入matplotlib库,用于绘图
import matplotlib.pyplot as plt # 导入matplotlib的pyplot模块,用于创建图表
%matplotlib inline # 使得matplotlib的图表可以在Jupyter笔记本中直接显示cuda=True # 设置是否使用CUDA(GPU加速),如果设置为True且GPU可用,代码将使用GPU进行加速
batch_size = 100 # 设置每个批次的样本数量为100
epochs = 10 # 设置训练的轮数(epoch)为10
latent_dim = 30 # 设置潜在空间的维度为30
categorical_dim = 10 # 设置分类潜在变量的类别数量为10
temp = 1.0 # 设置Gumbel-Softmax采样中的温度参数为1.0,控制采样的随机性
4.2.Gumbel采样
我们现在转向实现Gumbel-Softmax采样的过程,这是一种在深度学习中处理离散变量的策略,允许模型利用梯度下降算法进行训练。以下是三个关键函数的定义,它们共同构成了Gumbel-Softmax采样方法:
-
sample_gumbel函数:
这个函数用于生成Gumbel分布的样本。它首先从均匀分布 U ( 0 , 1 ) U(0,1) U(0,1) 中抽取随机数,然后通过计算 − log ( − log ( U ( 0 , 1 ) ) ) -\log(-\log(U(0,1))) −log(−log(U(0,1))) 来得到Gumbel分布的样本。这些样本是按照尺度为0、位置参数为1的Gumbel分布生成的。 -
gumbel_softmax_sample函数:
该函数负责将Gumbel噪声添加到未经归一化的对数概率(即logits)上,然后通过设置一个温度参数来控制softmax函数的平滑程度,最终应用softmax函数来获取概率分布。 -
gumbel_softmax函数:
这个函数结合了上述的采样和softmax操作,并增加了评估模式下的行为。在评估模式下,它直接从由logits定义的分类分布中采样,而不会进行Gumbel-Softmax松弛。这允许我们在模型评估时获得确定性的样本。
这些函数的实现为深度学习模型中离散变量的处理提供了一种有效的方法,使模型能够通过连续的放松来优化通常不可微的离散采样步骤。通过这种方式,我们可以训练通常难以优化的模型,并且能够处理更广泛的数据类型和结构。
def sample_gumbel(shape, eps=1e-20):# 函数用于生成Gumbel分布的样本U = torch.rand(shape) # 生成与shape相同形状的[0,1)之间的均匀分布随机数if cuda:U = U.cuda() # 如果cuda为True,将数据转移到GPU上return -torch.log(-torch.log(U + eps) + eps) # 通过变换得到Gumbel分布的样本,eps用于避免对数为负无穷def gumbel_softmax_sample(logits, temperature):# 函数用于在给定的对数几率(logits)和温度参数下,通过Gumbel-Softmax技巧采样y = logits + sample_gumbel(logits.size()) # 将Gumbel分布的样本加到logits上return F.softmax(y / temperature, dim=-1) # 应用softmax函数,并除以温度参数,得到概率分布def gumbel_softmax(logits, temperature, evaluate=False):# 函数用于在评估模式下进行Gumbel-Softmax采样或者进行训练if evaluate:# 如果是在评估模式下,直接从分类分布中采样d = OneHotCategorical(logits=logits.view(-1, latent_dim, categorical_dim)) # 创建OneHotCategorical分布return d.sample().view(-1, latent_dim * categorical_dim) # 采样并重塑形状# 如果不是评估模式,使用Gumbel-Softmax技巧进行采样y = gumbel_softmax_sample(logits, temperature) # 调用上面定义的采样函数return y.view(-1, latent_dim * categorical_dim) # 重塑采样结果的形状
这些函数中使用了一些PyTorch的函数和类,例如torch.rand生成均匀分布的随机数,F.softmax应用softmax函数,以及OneHotCategorical分布用于从分类变量中采样。cuda变量用于判断是否使用GPU加速运算。logits是分类概率的对数,temperature参数控制了采样的随机性,evaluate参数用于判断当前是在训练模式还是评估模式。在评估模式下,直接采样并返回离散的样本;在训练模式下,使用Gumbel-Softmax技巧进行梯度估计和优化。
4.3.VAE模型
我们现在转向构建一个变分自编码器(VAE)模型,该模型采用了Gumbel-Softmax技巧来处理潜在空间中的离散变量:
-
模型定义:
我们创建了一个名为VAE_gumbel的类,它基于PyTorch的nn.Module构建。这个类实现了一个VAE模型,其中潜在变量通过Gumbel-Softmax分布进行采样,从而允许梯度下降算法的应用。 -
初始化 (
__init__方法):
在类的构造函数中,我们初始化了模型所需的网络层,包括线性层、ReLU激活函数和Sigmoid激活函数。这些层构成了模型的编码器和解码器部分。 -
编码过程 (
encode方法):
encode方法负责将输入数据x转换成潜在变量的对数几率。这一过程涉及多个线性层和非线性激活函数,最终输出潜在变量的未归一化对数概率。 -
解码过程 (
decode方法):
decode方法接收潜在变量作为输入,并通过一个由线性层和激活函数组成的网络结构来重建输入数据。最终,该方法输出重构数据的概率分布。 -
前向传播 (
forward方法):
forward方法实现了模型的前向传播。它首先通过编码器获取潜在变量的对数几率,然后根据提供的temp温度参数和evaluate标志,使用Gumbel-Softmax技巧或确定性采样来生成潜在变量。最后,解码器将潜在变量转换为重构数据。 -
温度参数和评估标志:
temp参数控制Gumbel-Softmax采样的随机性。较低的温度值使得采样更接近确定性选择,而较高的温度值则增加随机性。evaluate标志用于确定是否在评估模式下运行模型。在评估模式下,模型使用确定性采样来直接从潜在变量的分布中获取样本,以便进行模型的评估和测试。
通过这种方式,VAE_gumbel 类提供了一种灵活的方法来训练和评估VAE模型,同时处理潜在空间中的离散性质。这种模型特别适用于那些需要学习离散潜在表示的任务,例如处理分类数据或进行结构化数据建模。
class VAE_gumbel(nn.Module):def __init__(self, temp):super(VAE_gumbel, self).__init__() # 调用基类的初始化方法# 定义模型的层self.fc1 = nn.Linear(784, 512) # 定义一个线性层,输入维度784,输出维度512self.fc2 = nn.Linear(512, 256) # 定义一个线性层,输入维度512,输出维度256self.fc3 = nn.Linear(256, latent_dim * categorical_dim) # 定义一个线性层,输出维度为潜在维度乘以分类维度self.fc4 = nn.Linear(latent_dim * categorical_dim, 256) # 定义一个线性层,输入维度为潜在维度乘以分类维度self.fc5 = nn.Linear(256, 512) # 定义一个线性层,输入维度256,输出维度512self.fc6 = nn.Linear(512, 784) # 定义一个线性层,输出维度784# 定义激活函数self.relu = nn.ReLU() # ReLU激活函数self.sigmoid = nn.Sigmoid() # Sigmoid激活函数def encode(self, x):# 定义编码器h1 = self.relu(self.fc1(x)) # 通过线性层和ReLU激活函数h2 = self.relu(self.fc2(h1)) # 通过第二个线性层和ReLU激活函数return self.relu(self.fc3(h2)) # 通过第三个线性层和ReLU激活函数得到潜在变量的对数几率def decode(self, z):# 定义解码器h4 = self.relu(self.fc4(z)) # 通过线性层和ReLU激活函数h5 = self.relu(self.fc5(h4)) # 通过第二个线性层和ReLU激活函数return self.sigmoid(self.fc6(h5)) # 通过第三个线性层和Sigmoid激活函数得到重构图像的概率def forward(self, x, temp, evaluate=False):# 定义前向传播过程q = self.encode(x.view(-1, 784)) # 对输入x进行编码,得到潜在变量的对数几率q_y = q.view(q.size(0), latent_dim, categorical_dim) # 重塑编码后的形状z = gumbel_softmax(q_y, temp, evaluate) # 使用Gumbel-Softmax技巧进行采样return self.decode(z), F.softmax(q_y, dim=-1).reshape(*q.size()) # 解码并返回重构图像和潜在变量的概率分布
4.2.计算KL散度
在变分自编码器(VAE)的训练过程中,除了重建输入数据,模型还需要确保潜在变量的分布与先验分布保持一致。这通常通过最小化潜在分布与均匀先验分布之间的Kullback-Leibler (KL) 散度来实现。
-
KL散度的计算:
VAE模型中的KL散度衡量了潜在变量的概率分布 $ q(x) $ 与均匀先验分布 $ p(x) = \frac{1}{C} $ 之间的差异。对于离散的潜在变量,KL散度可以表示为:
KLD ( q ∣ ∣ p ) = ∑ i = 1 C q ( x i ) log ( C ⋅ q ( x i ) 1 ) \text{KLD}(q||p) = \sum_{i=1}^{C} q(x_i) \log \left(\frac{C \cdot q(x_i)}{1}\right) KLD(q∣∣p)=i=1∑Cq(xi)log(1C⋅q(xi))
其中, C C C 是潜在变量可能取值的总数, q ( x i ) q(x_i) q(xi) 是潜在变量取第 i i i 个值的概率。 -
重构损失:
除了KL散度,VAE的损失函数还包括重构损失,它通常采用二元交叉熵(Binary Cross-Entropy, BCE)来衡量模型重构的图像 recon _ x \text{recon}\_x recon_x 与原始输入图像 x x x 之间的差异。 -
VAE损失的组成:
VAE的总损失是重构损失和KL散度的结合,可以表示为:
VAE Loss = BCE ( recon x , x ) + KLD ( q ∣ ∣ p ) \text{VAE Loss} = \text{BCE}(\text{recon}_x, x) + \text{KLD}(q||p) VAE Loss=BCE(reconx,x)+KLD(q∣∣p)
这种损失函数的设计旨在使模型在保持数据重构精度的同时,也让潜在变量的分布接近于先验分布。 -
损失函数的作用:
通过最小化这个损失函数,VAE模型学习到如何将输入数据有效地编码到潜在空间,并且在这个空间中探索数据的分布。KL散度正则化确保了潜在变量的分布不会偏离均匀分布太远,这有助于模型学习到更加泛化的特征表示。 -
实现考虑:
在实际实现中,为了数值稳定性和计算效率,我们通常会对KL散度进行一些调整,例如通过减去一个常数项或使用log-trick来避免数值下溢。
通过这种方式,VAE模型不仅能够学习到数据的重构,还能够学习到数据的潜在结构,使其能够在生成任务或特征学习中发挥重要作用。
def loss_function(recon_x, x, qy):# 定义VAE的损失函数,包括重构损失和KL散度BCE = F.binary_cross_entropy( # 计算重构损失recon_x, # 模型重构的图像x.view(-1, 784), # 原始图像,调整为匹配重构图像的形状size_average=False # 不使用大小平均,直接使用所有样本的总损失) / x.shape[0] # 将损失平均到每个样本log_ratio = torch.log(qy * categorical_dim + 1e-20) # 计算潜在变量分布的对数比率,1e-20用于数值稳定性KLD = torch.sum( # 计算KL散度,即潜在变量分布与先验分布之间的差异qy * log_ratio, # 每个潜在维度上的KL散度贡献dim=-1 # 沿着最后一个维度(潜在变量的类别维度)求和).mean() # 计算所有样本的平均KL散度return BCE + KLD # 返回总损失,即重构损失和KL散度的和
4.3.建立并训练模型
为了构建一个变分自编码器(VAE)并进行训练,我们需要定义模型结构、损失函数、优化器,以及数据加载器。
4.3.1.训练准备
在本阶段,我们的主要任务是设置变分自编码器(VAE)模型的训练环境,并准备相应的数据加载器。
-
模型初始化:
我们首先实例化VAE模型,这是执行数据学习和重构的核心组件。 -
数据加载器的准备:
利用PyTorch的DataLoader工具,我们能够高效地加载训练和测试数据。DataLoader的优势在于它支持批量数据处理、多线程加载,以及自动的数据随机化,这些都是训练过程中的重要特性。 -
GPU加速:
通过检查CUDA的可用性,我们有条件地将模型和数据迁移到GPU,这样做可以显著提升计算速度,尤其是在处理大规模数据集或复杂模型时。 -
优化器配置:
我们选择了Adam优化器,这是深度学习中一个非常流行的选择,因为它自适应地调整学习率,通常能够更快地收敛。通过optim.Adam,我们初始化了优化器,并设置了一个初始学习率0.001。 -
损失目标的计算:
在训练过程中,我们不仅计算放松目标,也评估未放松目标。虽然未放松目标不直接用于训练,但它提供了一个基准,帮助我们理解当前模型的状态,并指导我们如何调整模型参数,特别是温度参数,以平衡训练性能和目标的接近度。 -
训练与评估的平衡:
通过评估放松目标与实际目标之间的差异,我们可以调整模型的温度参数,确保在训练过程中,模型既能有效学习数据的分布,又能保持潜在空间的离散性。
通过这些步骤,我们建立了一个完整的训练框架,它不仅包括模型的构建和数据的准备,还包括了训练过程中的监控和调整机制,确保模型能够在学习数据的同时,保持良好的泛化能力和生成能力。
model = VAE_gumbel(temp) # 创建VAE模型实例,temp是温度参数
if cuda:model.cuda() # 如果cuda为True,将模型转移到GPU上
optimizer = optim.Adam(model.parameters(), lr=1e-3) # 创建Adam优化器,用于模型参数的优化,学习率为0.001# 设置数据加载器的参数,如果使用GPU,则使用多线程和锁定内存
kwargs = {'num_workers': 1, 'pin_memory': True} if cuda else {}# 创建训练数据加载器,使用MNIST数据集
train_loader = torch.utils.data.DataLoader(datasets.MNIST('./data/MNIST', train=True, download=True, # MNIST训练数据集路径和下载选项transform=transforms.ToTensor()), # 将图像转换为Tensorbatch_size=batch_size, # 每个批次的样本数量shuffle=True, # 在每个epoch开始时打乱数据**kwargs # 根据是否使用GPU设置多线程和锁定内存的参数
)# 创建测试数据加载器,使用MNIST数据集
test_loader = torch.utils.data.DataLoader(datasets.MNIST('./data/MNIST', train=False, # MNIST测试数据集路径transform=transforms.ToTensor()),batch_size=batch_size, # 每个批次的样本数量shuffle=True, # 在每个epoch开始时打乱数据**kwargs # 根据是否使用GPU设置多线程和锁定内存的参数
)
4.3.2.训练模型
在训练阶段,我们通过编写两个关键函数train和test来对变分自编码器(VAE)模型进行训练和评估。
-
训练过程 (
train函数):- 每个epoch期间,模型遍历整个训练数据集。
- 损失函数计算当前批次的重构误差和潜在变量分布的KL散度。
- 执行反向传播来计算损失相对于模型参数的梯度。
- 更新模型参数以最小化损失。
-
评估过程 (
test函数):- 在评估模式下运行模型,此时模型不会进行梯度更新。
- 计算并输出模型在测试集上的性能,通常是通过测试损失来衡量。
-
GPU加速:
- 使用
cuda变量检查GPU是否可用,以决定是否将模型和数据迁移到GPU上,从而加速训练。
- 使用
-
梯度管理:
- 在每次迭代前,
optimizer.zero_grad()确保梯度被清零,避免累积。 loss.backward()根据当前损失计算参数梯度。optimizer.step()根据计算出的梯度更新模型参数。
- 在每次迭代前,
-
评估模式:
evaluate=True参数指示模型在评估模式下运行,此时Gumbel-Softmax采样是确定性的,直接从潜在变量的分布中采样。
-
温度参数的影响:
- 训练时,可以尝试不同的温度值来观察其对放松目标与真实目标之间关系的影响,以及如何求解最接近的值。
通过这些步骤,我们能够系统地训练VAE模型,并通过调整温度参数来平衡模型的训练性能和目标接近度。这种方法不仅有助于提高模型的重构能力,还能够确保模型在潜在空间中学习到有意义的分布。
def train(epoch):# 定义训练循环model.train() # 设置模型为训练模式train_loss = 0 # 初始化训练损失为0train_loss_unrelaxed = 0 # 初始化未放松训练目标的损失为0for batch_idx, (data, _) in enumerate(train_loader): # 遍历训练数据加载器if cuda:data = data.cuda() # 如果使用GPU,将数据转移到GPU上optimizer.zero_grad() # 清除之前的梯度recon_batch, qy = model(data, temp) # 通过模型得到重构图像和潜在变量的分布loss = loss_function(recon_batch, data, qy) # 计算损失loss.backward() # 反向传播,计算梯度train_loss += loss.item() * len(data) # 累加损失optimizer.step() # 更新模型参数# 评估未放松训练目标(不用于训练,仅用于比较)recon_batch_eval, qy_eval = model(data, temp, evaluate=True)loss_eval = loss_function(recon_batch_eval, data, qy_eval)train_loss_unrelaxed += loss_eval.item() * len(data)print('Epoch: {} Average loss relaxed: {:.4f} Unrelaxed: {:.4f}'.format(epoch, train_loss / len(train_loader.dataset), # 打印平均放松损失train_loss_unrelaxed / len(train_loader.dataset))) # 打印平均未放松损失def test(epoch):# 定义评估循环model.eval() # 设置模型为评估模式test_loss = 0 # 初始化测试损失为0for i, (data, _) in enumerate(test_loader): # 遍历测试数据加载器if cuda:data = data.cuda() # 如果使用GPU,将数据转移到GPU上recon_batch, qy = model(data, temp, evaluate=True) # 通过模型得到重构图像和潜在变量的分布(评估模式)test_loss += loss_function(recon_batch, data, qy).item() * len(data) # 累加损失test_loss /= len(test_loader.dataset) # 计算平均测试损失print('Eval loss: {:.4f}'.format(test_loss)) # 打印平均测试损失
4.3.3.评估模型
本节定义了一个名为 run 的函数,它负责驱动VAE模型的训练和评估周期。
- 训练周期 (
epoch):epoch是指模型完整地在训练集上学习一次的周期。 - 训练轮数指定:使用
range(1, epochs + 1)来确定训练过程需要进行的总周期数。 - 执行训练 (
train(epoch)):在每个周期内,调用train函数来执行训练任务。此函数通过反向传播算法更新模型参数,目的是减少训练损失。 - 执行评估 (
test(epoch)): 每个周期训练结束后,调用test函数对模型进行评估。此函数计算模型在测试集上的损失表现,并输出结果,但不会对模型参数进行更新。
通过连续的训练和评估循环,我们可以监测模型性能的变化。理想情况下,我们期望训练损失逐渐降低,测试损失也应保持稳定或降低,这显示了模型正在有效地学习数据特征,同时避免了对训练集的过拟合。
def run():# 定义run函数来运行整个训练和评估过程for epoch in range(1, epochs + 1): # 从第1个epoch到epochs变量指定的epoch数train(epoch) # 调用train函数进行训练test(epoch) # 调用test函数对模型在测试集上进行评估run() # 调用run函数开始训练和评估过程
4.3.4.生成样本
现在,我们将从训练完成的解码器中生成图像样本。这一过程涉及从先验分布中采样均匀分类变量,并将这些变量输入解码器。我们定义了两个函数:generate_samples用于从VAE模型生成样本,而show_gray_image_grid则用于展示这些生成的图像。
generate_samples函数:
model.eval():设置模型为评估模式,确保在生成样本时不应用如Dropout或Batch Normalization等只在训练时使用的层。- 创建一个形状为
[64, latent_dim, categorical_dim]的张量,填充为1,然后每个元素乘以1/categorical_dim,得到均匀的概率分布。这里的64代表生成样本的数量。 - 使用
OneHotCategorical分布根据概率probs采样,并通过.cuda()将概率张量转移到GPU(如果使用CUDA)。 model.decode(cat_samples):将one-hot编码的潜在变量通过解码器转换回图像数据。output.view(-1,28,28).detach().cpu().numpy():将解码器的输出调整为28x28像素的图像尺寸,从PyTorch张量分离出来,并转换为NumPy数组,以便于展示和处理。
show_gray_image_grid函数:
plt.subplots(x, y, figsize=size):根据提供的行数x、列数y和图像大小size创建一个图像网格。axs.flatten():将二维轴数组展平为一维,以便于迭代。ax.imshow(np.squeeze(img), cmap='gray'):在每个轴上展示图像,使用灰度色彩映射,np.squeeze(img)用于去除不必要的单维度。ax.set_axis_off():关闭坐标轴显示,以便更清晰地展示图像。- 如果提供了
path参数,plt.savefig(path)会将图像保存到文件;否则,plt.show()会直接展示图像。
最后,通过调用 show_gray_image_grid(samples, 8,8),我们以8行8列的格式展示生成的样本图像。这允许我们直观地评估模型生成图像的质量和多样性。
def generate_samples():# 生成样本的函数model.eval() # 设置模型为评估模式probs = torch.ones([64, latent_dim, categorical_dim])*(1/categorical_dim) # 创建一个均匀概率向量cat_samples = OneHotCategorical(probs=probs.cuda()).sample().view(-1, latent_dim*categorical_dim) # 从均匀分布采样得到分类样本output = model.decode(cat_samples) # 使用模型的解码器部分生成图像return output.view(-1,28,28).detach().cpu().numpy() # 将输出转换为numpy数组并返回samples = generate_samples() # 调用函数生成样本def show_gray_image_grid(imgs, x=2, y=5, size=(8,8), path=None, save=False):# 展示灰度图像网格的函数fig, axs = plt.subplots(x, y, figsize=size) # 创建图像展示的网格axs = axs.flatten() # 将轴对象扁平化为一维数组for img, ax in zip(imgs, axs): # 遍历每个图像和对应的轴对象ax.imshow(np.squeeze(img), cmap='gray') # 在轴上展示图像,使用灰度色彩映射ax.set_axis_off() # 不展示坐标轴if save: # 如果指定了保存路径plt.savefig(path) # 保存图像到文件else:plt.show() # 直接展示图像show_gray_image_grid(samples, 8,8) # 展示生成的样本图像,8行8列的网格布局
4.4.Gumbel直通(Gumbel Straight-Through)
在深度学习中,我们经常遇到需要训练包含离散变量的模型的情况。然而,这些离散变量的放松值可能不适合作为模型输入,或者我们可能需要在优化过程中使用分类/离散输入。为了解决这个问题,我们可以使用一种称为直通估计器(Straight-Through Estimator, STE)的启发式方法。
4.4.1.直通估计器(STE)的概念:
-
预激活与采样:
给定预激活值 y y y,我们首先通过非可微的采样操作(例如,从分类或伯努利分布中采样)来计算样本 z z z。 -
下游函数计算:
使用得到的硬样本 z z z来计算下游函数 f f f。 -
直通梯度:
在反向传播过程中,我们采用直通梯度,忽略非可微的采样步骤,直接将相对于 z z z的梯度 ∂ z f \partial_z f ∂zf作为相对于 y y y的梯度 ∂ y f \partial_y f ∂yf传递回去。∂ y f : = ∂ z f \partial_y f := \partial_z f ∂yf:=∂zf
4.4.2.Gumbel-Softmax与直通估计器的结合:
-
Gumbel-Softmax松弛:
我们使用Gumbel-Softmax技巧来生成放松的离散样本,这些样本在训练过程中是连续的,但在前向传递中可以被视为硬离散值。 -
硬采样与直通梯度结合:
给定硬向量 y hard y_{\text{hard}} yhard和软向量 y y y,我们使用以下技巧来结合直通梯度:y = ( y hard − y ) .detach() + y y = (y_{\text{hard}} - y) \text{.detach()} + y y=(yhard−y).detach()+y
这样,在前向传递中使用 y hard y_{\text{hard}} yhard,在反向传递中则使用 y y y的梯度。
-
gumbel_softmax函数的变体:
我们定义了一个名为gumbel_softmax的函数,它是Gumbel-Softmax技巧的一个变体,允许在评估模式下进行硬采样,或者在训练模式下使用直通梯度进行优化。
通过这种方法,我们可以有效地训练包含离散变量的模型,即使这些变量在模型的某些部分需要以确定性的方式进行处理。直通估计器提供了一种在反向传播中处理非可微操作的有效手段,使得模型能够学习到离散变量的分布,同时保持梯度的流动。这种技巧在处理强化学习策略、序列生成模型以及其他需要离散决策的领域中非常有用。
def gumbel_softmax(logits, temperature, evaluate=False, hard=False):# logits: 分类概率的对数几率# temperature: 控制采样随机性的温度参数# evaluate: 是否处于评估模式,如果是,则直接采样# hard: 是否执行直通梯度估计,如果是,则返回硬采样(one-hot编码)if evaluate:# 如果处于评估模式,直接从潜在变量的分布中采样d = OneHotCategorical(logits=logits.view(-1, latent_dim, categorical_dim))return d.sample().view(-1, latent_dim * categorical_dim)y = gumbel_softmax_sample(logits, temperature) # 应用Gumbel-Softmax采样if hard:# 如果需要硬采样,执行直通梯度估计# 取得每个样本最大值的索引,并将其转换为one-hot向量shape = logits.size()_, k = y.max(-1) # 取得最大值的索引y_hard = torch.zeros_like(logits) # 创建一个和logits形状相同的零张量y_hard = y_hard.zero_().scatter_(-1, k.view(shape[:-1] + (1,)), 1.0) # 在最大值索引位置插入1# 直通梯度技巧:在前向传播中使用硬采样值,在反向传播中使用放松梯度y = (y_hard - y).detach() + y # 将y的梯度固定,只传递y_hard的梯度return y.view(-1, latent_dim * categorical_dim) # 返回重塑为(N, latent_dim * categorical_dim)形状的张量
在这个函数中:
logits是指每个潜在类别的对数几率。temperature是控制Gumbel-Softmax分布随机性的超参数。evaluate标志指示是否处于评估模式,在评估模式下,模型会直接从潜在变量的分布中采样,而不是使用Gumbel-Softmax技巧。hard标志指示是否执行直通梯度估计,在这种情况下,函数会返回一个硬采样的one-hot向量,但在反向传播时使用Gumbel-Softmax采样的梯度。
直通梯度技巧允许我们在前向传播中使用硬采样的离散值,而在反向传播中使用放松的连续梯度,这有助于训练包含离散选择的模型。当然,你也可以使用上述函数在模型定义中使用Gumbel-Straight-Through来训练上述VAE模型,并将hard设置为True。
5.总结和展望
5.1.总结
Gumbel-Softmax提供了一种强大的方法,用于在深度学习模型中引入离散性和结构化变量。通过使用这种技巧,我们可以训练通常难以优化的模型,并且能够处理更广泛的数据类型和结构。随着深度学习领域的不断发展,Gumbel-Softmax和其他相关技术将继续在开发新的模型和算法中发挥关键作用。
5.2.未来方向
未来的研究可能会探索如何将Gumbel-Softmax与其他类型的梯度估计技术结合使用,以进一步提高模型的性能和稳定性。此外,研究者可能会探索如何将这些技术应用于强化学习、序列建模和其他需要离散决策的领域。
最后,随着对Gumbel-Softmax和其他相关技术的深入理解,我们可能会发现新的应用场景,这些场景以前由于计算和优化的限制而无法实现。这将为开发更智能、更灵活的AI系统开辟新的可能性。
相关文章:
【机器学习】基于Softmax松弛技术的离散数据采样
1.引言 1.1.离散数据采样的意义 离散数据采样在深度学习中起着至关重要的作用,它直接影响到模型的性能、泛化能力、训练效率、鲁棒性和解释性。 首先,采样方法能够有效地平衡数据集中不同类别的样本数量,使得模型在训练时能够更均衡地学习…...
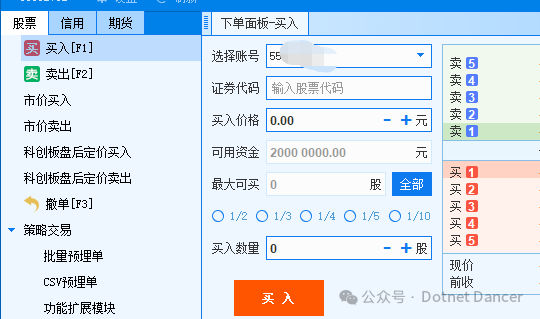
.NET+Python量化【1】——环境部署和个人资金账户信息查询
前言:量化资料很少,.NET更少。那我就来开个先河吧~ 以下是使用QMT进行量化开发的环境部署和基础信息获取有关操作。 1、首先自己申请券商的QMT权限,此步骤省略。 2、登陆QMT,选择极简模式,或者独立交易模式之类的。会进…...

洛谷 P10584 [蓝桥杯 2024 国 A] 数学题(整除分块+杜教筛)
题目 思路来源 登录 - Luogu Spilopelia 题解 参考了两篇洛谷题解,第一篇能得出这个式子,第二篇有比较严格的复杂度分析 结合去年蓝桥杯洛谷P9238,基本就能得出这题的正确做法 代码 #include<bits/stdc.h> #include<iostream&g…...
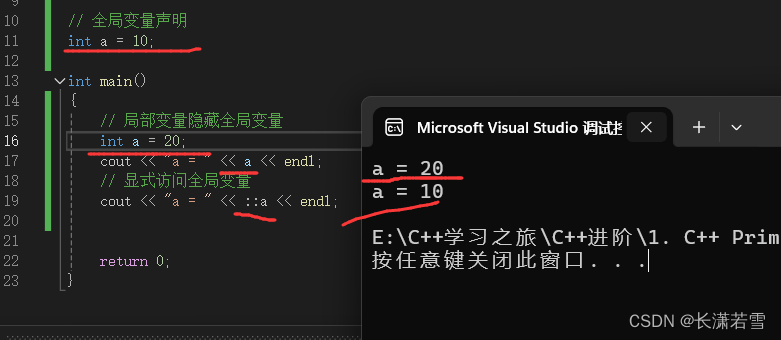
深入讲解C++基础知识(一)
目录 一、基本内置类型1. 类型的作用2. 分类3. 整型3.1 内存描述及查询3.2 布尔类型 —— bool3.3 字符类型 —— char3.4 其他整型 4. 有符号类型和无符号类型5. 浮点型6. 如何选择类型7. 类型转换7.1 自动类型转换7.2 强制类型转换7.3 类型转换总结 8. 类型溢出8.1 注意事项 …...

Python爬虫实战:批量下载网站图片
1.获取图片的url链接 首先,打开百度图片首页,注意下图url中的index 接着,把页面切换成传统翻页版(flip),因为这样有利于我们爬取图片! 对比了几个url发现,pn参数是请求到的数量。…...

使用 JavaScript 获取电池状态
在现代的移动设备和笔记本电脑上,了解电池状态是一项非常有用的功能。使用 JavaScript 可以轻松地获取电池的充电状态、电量百分比等信息。本文将介绍如何使用 JavaScript 访问这些信息,并将其显示在网页上。 1. HTML 结构 首先,我们需要一…...
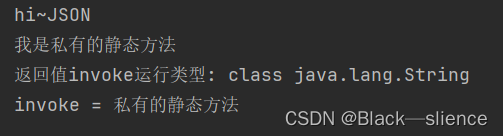
java—类反射机制
简述 反射机制允许程序在执行期间借助于Reflection API取得任何类的内部信息(如成员变量,构造器,成员方法等),并能操作对象的属性及方法。反射机制在设计模式和框架底层都能用到。 类一旦加载,在堆中会产生…...

浏览器-服务器架构 (BS架构) 详解
目录 前言1. BS架构概述1.1 BS架构的定义1.2 BS架构的基本原理 2. BS架构的优势2.1 客户端简化2.2 易于更新和维护2.3 跨平台性强2.4 扩展性高 3. BS架构的劣势3.1 网络依赖性强3.2 安全性问题3.3 用户体验局限 4. BS架构的典型应用场景4.1 企业内部应用4.2 电子商务平台4.3 在…...

微型操作系统内核源码详解系列五(四):cm3下svc启动任务
系列一:微型操作系统内核源码详解系列一:rtos内核源码概论篇(以freertos为例)-CSDN博客 系列二:微型操作系统内核源码详解系列二:数据结构和对象篇(以freertos为例)-CSDN博客 系列…...
)
筛质数(暴力法、埃氏筛、欧拉筛)
筛质数(暴力法、埃氏筛、欧拉筛) 暴力法 思路分析: 直接双for循环来求解质数 如果不设置标记只是简单地执行了break会导致内部循环(由j控制)而不是立即打印i或者跳过它。如果打印语句写到内部循环中,也会导致每个 非素数也被打…...

使用USI作为主SPI接口
代码; lcd_drive.c //***************************************************************************** // // File........: LCD_driver.c // // Author(s)...: ATMEL Norway // // Target(s)...: ATmega169 // // Compiler....: AVR-GCC 3.3.1; avr-libc 1.0 // // D…...

AI播客下载:Eye on AI(AI深度洞察)
"Eye on A.I." 是一档双周播客节目,由长期担任《纽约时报》记者的 Craig S. Smith 主持。在每一集中,Craig 都会与在人工智能领域产生影响的人们交谈。该播客的目的是将渐进的进步置于更广阔的背景中,并考虑发展中的技术的全球影响…...

Flink 窗口触发器
参考: NoteWarehouse/05_BigData/09_Flink(1).md at main FGL12321/NoteWarehouse GitHub Flink系列 9. 介绍 Flink 窗口触发器、移除器和延迟数据等 | hnbian https://github.com/kinoxyz1/bigdata-learning-notes/blob/master/note/flink/Window%26%E6%97%B6…...

Java面试题:解释线程间如何通过wait、notify和notifyAll方法进行通信
在 Java 中,线程间的通信可以通过 wait()、notify() 和 notifyAll() 这三个方法实现。这些方法是 Java 线程 Thread 类的一部分,它们与 synchronized 关键字一起使用,以实现线程间的协调。 基本概念 wait():当一个线程执行到 wa…...
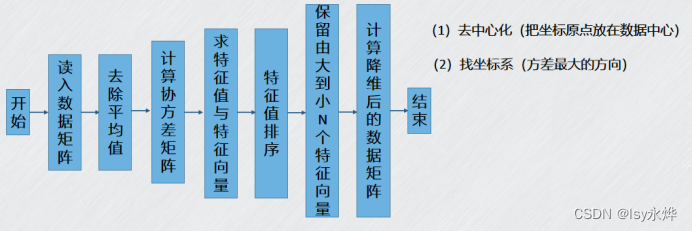
【机器学习 复习】第9章 降维算法——PCA降维
一、概念 1.PCA (1)主成分分析(Principal ComponentAnalysis,PCA)一种经典的线性降维分析算法。 (2)原理,这里以二维转一维为例,原来的平面变成了一条直线 这是三维变二…...

Ubuntu系统docker gpu环境搭建
Ubuntu系统dockergpu环境搭建 安装步骤前置安装安装指定版本的依赖包用docker官方脚本安装Docker-ce添加稳定仓库和GPG秘钥更新源 安装docker安装nvidia-docker2重启docker服务阿里云镜像加速 相关命令网络 docker常用命令镜像容器 docker相关问题解决方案使用wsl时docker的容器…...
网络安全-如何设计一个安全的API(安全角度)
目录 API安全概述设计一个安全的API一个基本的API主要代码调用API的一些问题 BasicAuth认证流程主要代码问题 API Key流程主要代码问题 Bearer auth/Token auth流程 Digest Auth流程主要代码问题 JWT Token流程代码问题 Hmac流程主要代码问题 OAuth比较自定义请求签名身份认证&…...
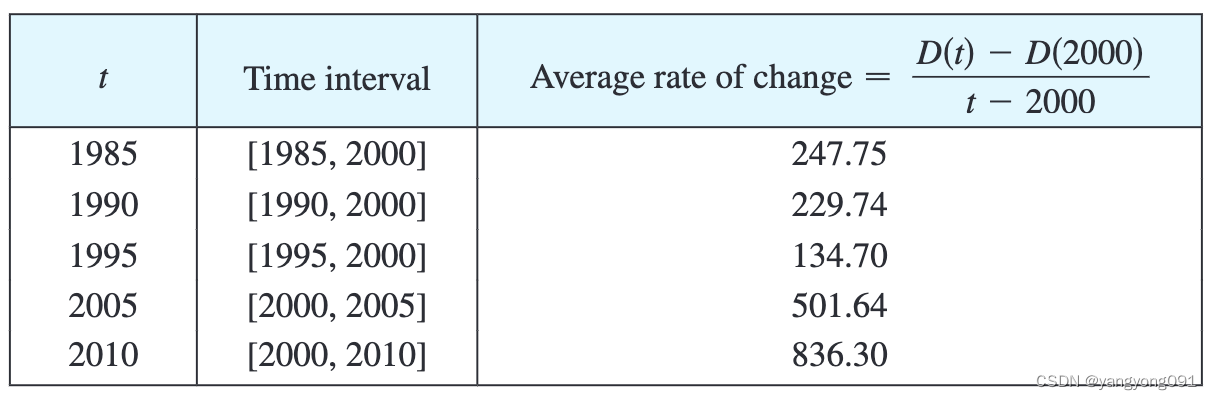
微积分-导数1(导数与变化率)
切线 要求与曲线 C C C相切于 P ( a , f ( a ) ) P(a, f(a)) P(a,f(a))点的切线,我们可以在曲线上找到与之相近的一点 Q ( x , f ( x ) ) Q(x, f(x)) Q(x,f(x)),然后求出割线 P Q PQ PQ的斜率: m P Q f ( x ) − f ( a ) x − a m_{PQ} \…...

最新PHP仿猪八戒任务威客网整站源码/在线接任务网站源码
资源介绍 老规矩,截图为亲测,前后台显示正常,细节功能未测,有兴趣的自己下载。 PHP仿猪八戒整站源码下载,phpmysql环境。威客开源建站系统,其主要交易对象是以用户为主的技能、经验、时间和智慧型商品。经…...
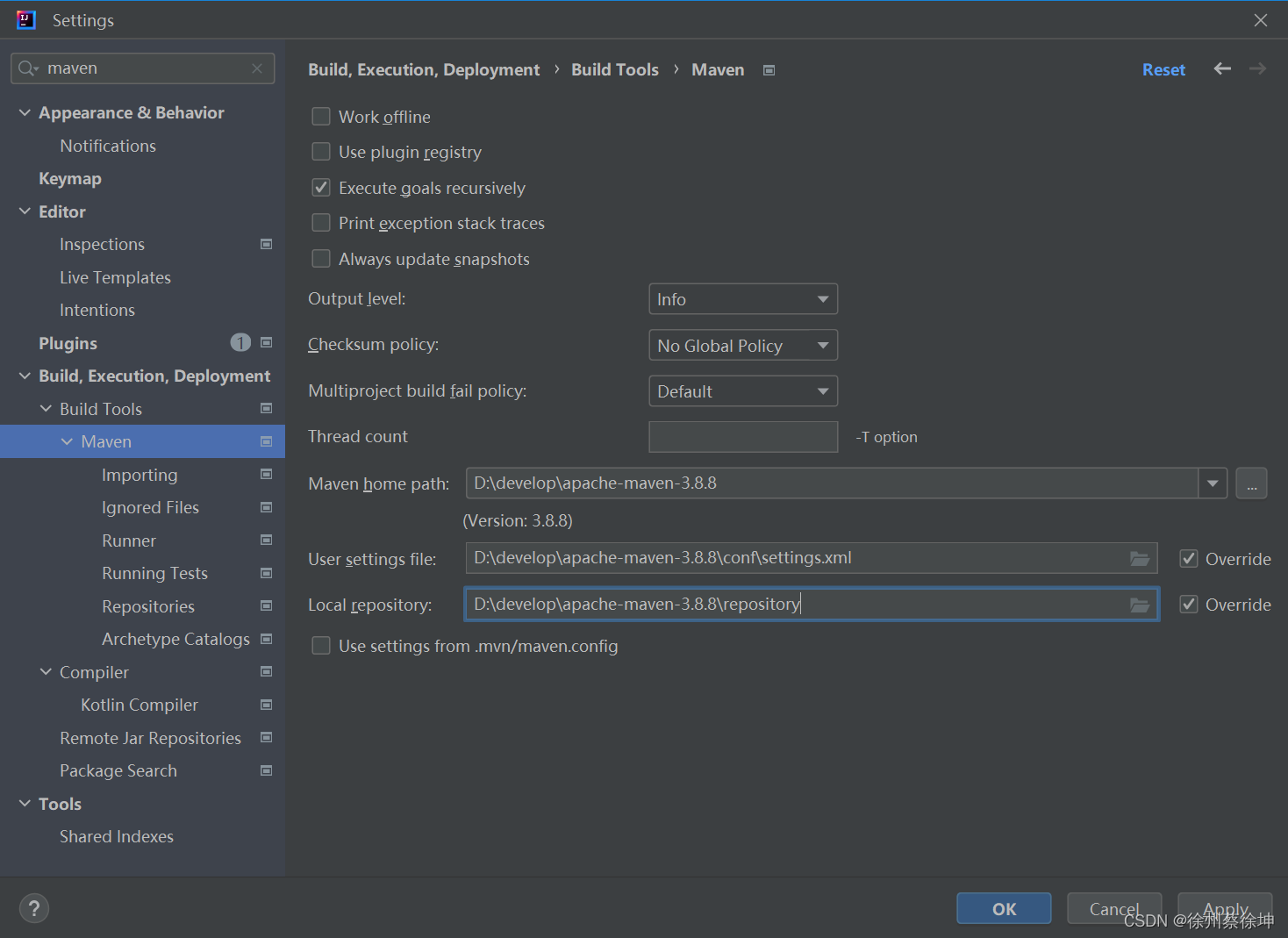
Windows安装配置jdk和maven
他妈的远程连接不上公司电脑,只能在家重新配置一遍,在此记录一下后端环境全部配置 Windows安装配置JDK 1.8一、下载 JDK 1.8二、配置环境变量三、验证安装 Windows安装配置Maven 3.8.8一、下载安装 Maven并配置环境变量二、设置仓库镜像及本地仓库三、测…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

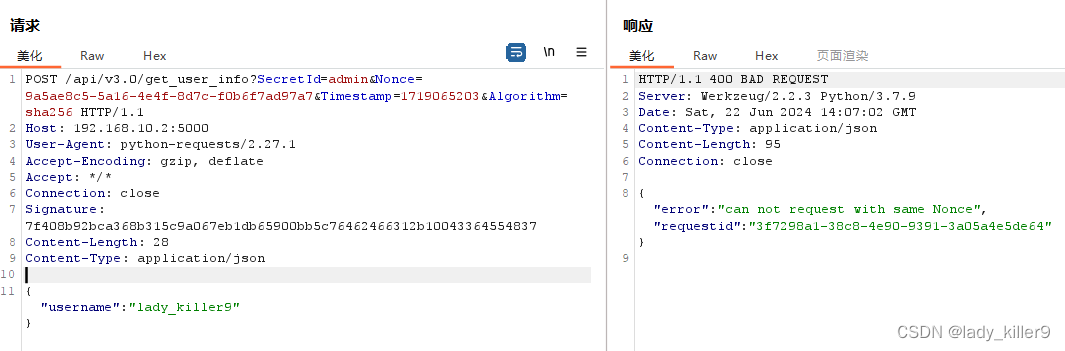
调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

基于服务器使用 apt 安装、配置 Nginx
🧾 一、查看可安装的 Nginx 版本 首先,你可以运行以下命令查看可用版本: apt-cache madison nginx-core输出示例: nginx-core | 1.18.0-6ubuntu14.6 | http://archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages ng…...

【JVM】- 内存结构
引言 JVM:Java Virtual Machine 定义:Java虚拟机,Java二进制字节码的运行环境好处: 一次编写,到处运行自动内存管理,垃圾回收的功能数组下标越界检查(会抛异常,不会覆盖到其他代码…...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...

STM32HAL库USART源代码解析及应用
STM32HAL库USART源代码解析 前言STM32CubeIDE配置串口USART和UART的选择使用模式参数设置GPIO配置DMA配置中断配置硬件流控制使能生成代码解析和使用方法串口初始化__UART_HandleTypeDef结构体浅析HAL库代码实际使用方法使用轮询方式发送使用轮询方式接收使用中断方式发送使用中…...

android13 app的触摸问题定位分析流程
一、知识点 一般来说,触摸问题都是app层面出问题,我们可以在ViewRootImpl.java添加log的方式定位;如果是touchableRegion的计算问题,就会相对比较麻烦了,需要通过adb shell dumpsys input > input.log指令,且通过打印堆栈的方式,逐步定位问题,并找到修改方案。 问题…...

关于uniapp展示PDF的解决方案
在 UniApp 的 H5 环境中使用 pdf-vue3 组件可以实现完整的 PDF 预览功能。以下是详细实现步骤和注意事项: 一、安装依赖 安装 pdf-vue3 和 PDF.js 核心库: npm install pdf-vue3 pdfjs-dist二、基本使用示例 <template><view class"con…...