【2024】kafka streams的详细使用与案例练习(2)
目录
- 前言
- 使用
- 1、整体结构
- 1.1、序列化
- 2、 Kafka Streams 常用的 API
- 2.1、 StreamsBuilder
- 2.2、 KStream 和 KTable
- 2.3、 filter和 filterNot
- 2.4、 map 和 mapValues
- 2.5、 flatMap 和 flatMapValues
- 2.6、 groupByKey 和 groupBy
- 2.7、 count、reduce 和 aggregate
- 2.8、 join 和 leftJoin
- 2.9、 to 和 toTable
- 2.10、 foreach
- 3、简单案例练习
- 3.1、通过streams实现数据流处理,把字符串装为大写
- 3.2、map 使用,把内容转为key,把value转为内容长度
- 3.3、filter和 filterNot使用过滤消息
- 3.4、通过selectKey配置key
- 4、复杂对象案例练习
- 4.1、自定义序列化
- 4.2、发送消息
- 4.3、通过KafkaStreams接收复杂对象,并且使用split
前言
上一篇文章已经对kafka streams进行了大致的介绍以及简单案例使用,这一片文章主要是对kafka streams常用API的介绍以及使用,如果需要看概念介绍的可以看
Kafka Streams详细介绍与具体使用
下面直接开始进行kafka streams使用操作
使用
1、整体结构
在我们整体处理
streams时,总共就分为三部分
第一部分是创建配置,告诉kafka我们的连接信息,通过StreamsConfig传递,然后创建一个StreamsBuilder类用于构建
kafka streams拓扑的主要类。该类主要用于定义数据流处理的拓扑结构。
还有就是通过Serde进行一个序列化第二部分主要是构建流处理拓扑,通过
StreamsBuilder类得到源Processor处理器也就是KStream类,然后通过KStream的API方法得到不同的Processor处理器(重点)第三部分通过配置流处理拓扑,创建流处理实例,然后通过
kafkaStreams.start()方法启动,结束时再通过kafkaStreams.close()关闭
我们在使用时,1和3基本上都是相同的,一般我们要处理的就是2,根据不同的业务需求,我们得到不同的Processor处理器,然后发送到不同的topic
1.1、序列化
在使用Kafka Streams时,我们需要把从topic接收到的消息进行序列化,然后再把返回topic的消息进行反序列化,
可以和kafka发送一样使用Properties类直接定义全部的,但这样会有很大的局限性,因为我们发送给不同的处理过的topic消息往往都会是不同的类型,所以我们会使用到Serde进行该操作,再每次和topic进行读取或写入消息时通过Serde进行指定key和消息的类型。
基础数据类型都有默认的写好的通过Serdes方法可以获得,如果需要定义复杂的则需要自己定义一个序列化和反序列化的类。
如下:
Serde<String> stringSerde = Serdes.String():String类型Serde<Purchase> propertiesSerde = Serdes.serdeFrom(serializer, deserializer):自定义复杂类型JsonSerializer<Purchase> serializer = new JsonSerializer<>();:自定义的序列化类JsonDeserializer<Purchase> deserializer = new JsonDeserializer<>(Purchase.class);:反序列化类
kafka也有默认的可以直接用的:org.springframework.kafka.support.serializer.JsonSerializer,但一般建议自定义序列化
2、 Kafka Streams 常用的 API
2.1、 StreamsBuilder
StreamsBuilder 是构建 Kafka Streams 拓扑的主要类。它用于定义数据流处理的拓扑结构。
StreamsBuilder builder = new StreamsBuilder();
2.2、 KStream 和 KTable
KStream:表示一个无界的数据流,每个记录都是一个键值对。
KStream<String, String> stream = builder.stream("input-topic");
KTable:表示一个表,每个键对应一个最新的值。
KTable<String, Long> table = builder.table("input-topic");
2.3、 filter和 filterNot
filter:根据条件过滤记录。
KStream<String, String> filteredStream = stream.filter((key, value) -> value.contains("important"));
filterNot:过滤掉不符合条件的记录。
KStream<String, String> filteredStream = stream.filterNot((key, value) -> value.contains("unimportant"));
2.4、 map 和 mapValues
map:对每个记录的键和值进行转换。
KStream<String, Integer> mappedStream = stream.map((key, value) -> new KeyValue<>(key, value.length()));
mapValues:仅对记录的值进行转换。
KStream<String, Integer> mappedStream = stream.mapValues(value -> value.length());
2.5、 flatMap 和 flatMapValues
flatMap:将每个输入记录映射为零个或多个输出记录。
KStream<String, String> flatMappedStream = stream.flatMap((key, value) -> {List<KeyValue<String, String>> result = new ArrayList<>();for (String word : value.split(" ")) {result.add(new KeyValue<>(key, word));}return result;});
flatMapValues:仅将每个输入记录的值映射为零个或多个输出值。
****KStream<String, String> flatMappedStream = stream.flatMapValues(value -> Arrays.asList(value.split(" ")));
2.6、 groupByKey 和 groupBy
groupByKey:根据记录的键进行分组。
KGroupedStream<String, String> groupedStream = stream.groupByKey();
groupBy:根据新的键进行分组。
KGroupedStream<String, String> groupedStream = stream.groupBy((key, value) -> value);
2.7、 count、reduce 和 aggregate
count:计算每个分组中的记录数。
KTable<String, Long> countTable = groupedStream.count();
reduce:对每个分组中的记录进行归约操作。
KTable<String, String> reducedTable = groupedStream.reduce((aggValue, newValue) -> aggValue + newValue);
aggregate:自定义聚合操作。
KTable<String, Integer> aggregatedTable = groupedStream.aggregate(() -> 0,(key, value, aggregate) -> aggregate + value.length(),Materialized.<String, Integer, KeyValueStore<Bytes, byte[]>>as("aggregated-store"));
2.8、 join 和 leftJoin
join:对两个流或表进行内连接操作。
KStream<String, String> joinedStream = stream.join(otherStream,(value1, value2) -> value1 + value2,JoinWindows.of(Duration.ofMinutes(5)));
leftJoin:对两个流或表进行左连接操作。
KStream<String, String> leftJoinedStream = stream.leftJoin(otherStream,(value1, value2) -> value1 + (value2 == null ? "" : value2),JoinWindows.of(Duration.ofMinutes(5)));
2.9、 to 和 toTable
to:将流中的记录写入到Kafka主题。
**stream.to("output-topic");**
toTable:将流转换为表。
KTable<String, String> table = stream.toTable();
2.10、 foreach
对每个记录执行一个操作,但不返回新的流。
stream.foreach((key, value) -> System.out.println(key + ": " + value));
上面这些就是KafkaStreams常用到的一些API,通过组合使用这些API,你可以构建复杂的流处理拓扑,以满足各种数据处理需求。
3、简单案例练习
使用脚本
#先进入容器
docker exec -it kafka-server /bin/bash#创建topic(把ip换为自己的)
/opt/kafka/bin/kafka-topics.sh --create --topic sell.purchase.transaction --bootstrap-server localhost:9092 --partitions 2 --replication-factor 1# 进入生产者发消息
/opt/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic input-topic#进入消费者监听
/opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic sell.purchase.transaction
3.1、通过streams实现数据流处理,把字符串装为大写
@Slf4j
public class KafkaStreamsYellingApp {
// appidprivate final static String APPLICATION_ID = "yelling_app_id";private final static String INPUT_TOPIC = "input-topic";private final static String OUTPUT_TOPIC = "out-topic";private final static String BOOTSTRAP_SERVERS = "localhost:9092";public static void main(String[] args) throws InterruptedException {//1、配置客户端和序列化器
// 配置kafka stream属性连接Properties properties = new Properties();properties.put(StreamsConfig.APPLICATION_ID_CONFIG, APPLICATION_ID);properties.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);StreamsConfig streamsConfig = new StreamsConfig(properties);
// 配置键值对的序列化/反序列化Serdes对象Serde<String> stringSerde = Serdes.String();
// 构建流处理拓扑(用于输出)StreamsBuilder builder = new StreamsBuilder();//2、构建流处理拓扑
// 数据源处理器:从指定的topic中取出数据KStream<String, String> inputStream = builder.stream(INPUT_TOPIC, Consumed.with(stringSerde, stringSerde));
//KStream<String, String> upperStream = inputStream.peek((key, value) -> {log.info("[收集]key:{},value:{}", key, value);}).filter((key, value) -> value.length() > 5).mapValues(time -> time.toUpperCase()).peek((key, value) -> log.info("[过滤结束]key:{},value:{}", key, value));
// 日志打印upperStream处理器的数据upperStream.print(Printed.toSysOut());
// 把upperStream处理器的数据输出到指定的topic中upperStream.to(OUTPUT_TOPIC, Produced.with(stringSerde, stringSerde));//3、通过配置流处理拓扑,创建流处理实例KafkaStreams kafkaStreams = new KafkaStreams(builder.build(), streamsConfig);
// jvm关闭时,把流也关闭CountDownLatch downLatch = new CountDownLatch(1);Runtime.getRuntime().addShutdownHook(new Thread(() -> {kafkaStreams.close();downLatch.countDown();log.info("关闭流处理");}));kafkaStreams.start();log.info("启动执行!");}
}
3.2、map 使用,把内容转为key,把value转为内容长度
@Slf4j
public class KafkaStreamsYellingApp2 {private final static String APPLICATION_ID = "yelling_app_id";private final static String INPUT_TOPIC = "input-topic";private final static String OUTPUT_TOPIC = "output-topic";private final static String BOOTSTRAP_SERVERS = "localhost:9092";public static void main(String[] args) throws InterruptedException {// 配置kafka stream属性连接Properties properties = new Properties();properties.put(StreamsConfig.APPLICATION_ID_CONFIG, APPLICATION_ID);properties.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);StreamsConfig streamsConfig = new StreamsConfig(properties);
// 配置键值对的序列化/反序列化Serdes对象Serde<String> stringSerde = Serdes.String();Serde<Integer> integerSerde = Serdes.Integer();
// 构建流处理拓扑(用于输出)StreamsBuilder builder = new StreamsBuilder();
// 数据源处理器:从指定的topic中取出数据KStream<String, String> inputStream = builder.stream(INPUT_TOPIC, Consumed.with(stringSerde, stringSerde));
//KStream<String, Integer> k1 = inputStream.map((noKey, value) -> KeyValue.pair(value, value.length()));k1.print(Printed.<String,Integer>toSysOut().withLabel("map"));// k1.to(OUTPUT_TOPIC, Produced.with(stringSerde, integerSerde));KafkaStreams kafkaStreams = new KafkaStreams(builder.build(), streamsConfig);// jvm关闭时,把流也关闭CountDownLatch downLatch = new CountDownLatch(1);Runtime.getRuntime().addShutdownHook(new Thread(() -> {kafkaStreams.close();downLatch.countDown();log.info("关闭流处理");}));kafkaStreams.start();log.info("启动执行!");}}3.3、filter和 filterNot使用过滤消息
/*** filter和 filterNot使用*/
@Slf4j
public class KafkaStreamsYellingApp3 {private final static String APPLICATION_ID = "yelling_app_id";private final static String INPUT_TOPIC = "input-topic";private final static String OUTPUT_TOPIC = "output-topic";private final static String BOOTSTRAP_SERVERS = "localhost:9092";public static void main(String[] args) throws InterruptedException {// 配置kafka stream属性连接Properties properties = new Properties();properties.put(StreamsConfig.APPLICATION_ID_CONFIG, APPLICATION_ID);properties.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);StreamsConfig streamsConfig = new StreamsConfig(properties);
// 配置键值对的序列化/反序列化Serdes对象Serde<String> stringSerde = Serdes.String();Serde<Integer> integerSerde = Serdes.Integer();
// 构建流处理拓扑(用于输出)StreamsBuilder builder = new StreamsBuilder();
// 数据源处理器:从指定的topic中取出数据KStream<String, String> inputStream = builder.stream(INPUT_TOPIC, Consumed.with(stringSerde, stringSerde));
//inputStream.filter((key, value) -> (value.contains("kafka")), Named.as("filtering-processor")).print(Printed.<String,String>toSysOut().withLabel("filtering"));inputStream.filterNot((key, value) -> (value.contains("kafka")), Named.as("filtering-not-processor")).print(Printed.<String,String>toSysOut().withLabel("filtering-not"));KafkaStreams kafkaStreams = new KafkaStreams(builder.build(), streamsConfig);// jvm关闭时,把流也关闭CountDownLatch downLatch = new CountDownLatch(1);Runtime.getRuntime().addShutdownHook(new Thread(() -> {kafkaStreams.close();downLatch.countDown();log.info("关闭流处理");}));kafkaStreams.start();log.info("启动执行!");}
}3.4、通过selectKey配置key
@Slf4j
public class KafkaStreamsYellingApp4 {private final static String APPLICATION_ID = "yelling_app_id";private final static String INPUT_TOPIC = "input-topic";private final static String OUTPUT_TOPIC = "output-topic";private final static String BOOTSTRAP_SERVERS = "localhost:9092";public static void main(String[] args) throws InterruptedException {// 配置kafka stream属性连接Properties properties = new Properties();properties.put(StreamsConfig.APPLICATION_ID_CONFIG, APPLICATION_ID);properties.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);StreamsConfig streamsConfig = new StreamsConfig(properties);
// 配置键值对的序列化/反序列化Serdes对象Serde<String> stringSerde = Serdes.String();Serde<Integer> integerSerde = Serdes.Integer();
// 构建流处理拓扑(用于输出)StreamsBuilder builder = new StreamsBuilder();
// 数据源处理器:从指定的topic中取出数据KStream<String, String> inputStream = builder.stream(INPUT_TOPIC, Consumed.with(stringSerde, stringSerde));
//inputStream.flatMap( //把一个消息的内容通过转为多条消息以map的方式返回,(key, value) -> Arrays.stream(value.split(" ")) //通过使用java的stream把内容转为map.map(e -> KeyValue.pair(e, e.length())).collect(Collectors.toList())).print(Printed.<String,Integer>toSysOut().withLabel("flatMap"));inputStream.flatMapValues( //不改变key,直接转换valuevalue -> Arrays.stream(value.split(" ")).map(String::toUpperCase).toList()).print(Printed.<String,String>toSysOut().withLabel("flatMapValues"));// 配置keyinputStream.selectKey((key, value) -> value).print(Printed.<String,String>toSysOut().withLabel("selectKey"));KafkaStreams kafkaStreams = new KafkaStreams(builder.build(), streamsConfig);// jvm关闭时,把流也关闭CountDownLatch downLatch = new CountDownLatch(1);Runtime.getRuntime().addShutdownHook(new Thread(() -> {kafkaStreams.close();downLatch.countDown();log.info("关闭流处理");}));kafkaStreams.start();log.info("启动执行!");}}
4、复杂对象案例练习
4.1、自定义序列化
对接收topic的消息到拓扑还是发送消息到topic都需要进行序列化和反序列化
- 序列化
public class JsonSerializer<T> implements Serializer<T> {private Gson gson= new Gson();public void configure(Map<String ,?> map, boolean b) {}public byte[] serialize(String topic, T t) {return gson.toJson(t).getBytes();}@Overridepublic void close() {Serializer.super.close();}
}
- 反序列化
/*** 反序列化* @param <T>*/
public class JsonDeserializer<T> implements Deserializer<T> {private Gson gson= new Gson();private Class<T> deserializeClass;public JsonDeserializer(Class<T> deserializeClass){this.deserializeClass=deserializeClass;}public JsonDeserializer(){}@Override@SuppressWarnings("unchecked")public void configure(Map<String,?> map, boolean b){if (deserializeClass == null){deserializeClass = (Class<T>) map.get("serializedClass");}}@Overridepublic T deserialize(String topic, byte[] data) {if (data == null){return null;}return gson.fromJson(new String(data),deserializeClass);}@Overridepublic void close() {}
}
4.2、发送消息
/*** 生产消息到kafka*/
@Slf4j
public class MyProducer {private static final String BOOTSTRAP_SERVERS = "localhost:9092";private final static String TOPIC_NAME = "production-topic";public static void main(String[] args) throws ExecutionException, InterruptedException {Properties props = new Properties();
// 设置参数props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,BOOTSTRAP_SERVERS);
// 设置序列化props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// 连接客户端KafkaProducer<String, String> producer = new KafkaProducer<>(props);for (int i = 0; i < 5; i++) {Purchase purchase = new Purchase();purchase.setId("12431234253");purchase.setDate(new Date().toString());purchase.setName("苹果");purchase.setPrice(100.0+i);String json = new JSONObject(purchase).toString();ProducerRecord<String, String> producerRecord = new ProducerRecord<>(TOPIC_NAME, 0,"my-keyValue3", json);// 同步send(producer,producerRecord);}}/*** @param producer: 客户端对象* @return void* 同步发送* @date 2024/3/22 17:09*/private static void send(KafkaProducer<String, String> producer,ProducerRecord<String, String> producerRecord) throws InterruptedException, ExecutionException {// 等待发送成功的阻塞方法RecordMetadata metadata = producer.send(producerRecord).get();log.info("同步发送消息"+ "topic-"+metadata.topic()+"====partition:"+metadata.partition()+"=====offset:"+metadata.offset());}}
4.3、通过KafkaStreams接收复杂对象,并且使用split
split使用介绍
BranchedKStream<K, V> split(final Named named):split方法一个参数,该参数主要是用来定义分裂后的分支的一个统一前缀。会返回一个BranchedKStream对象。
BranchedKStream:主要用来使用分裂校验的
branch(Predicate<? super K, ? super V> predicate, Branched<K, V> branched):会接收两个参数,前面的是Predicate用做校验判断作为判断条件的,后面的是一个Branched对象,用作处理满足该分支条件拆分出来的消息进行处理defaultBranch(Branched<K, V> branched):作为结尾方法用作对不满足前面的全部branch条件的消息,进行一个最后处理noDefaultBranch():结尾方法,表示对接下来的消息不做处理
Predicate:判断验证条件,满足该条件的消息会被拆分出来到当前分支
Branched:对分裂到当前分支的消息进行处理
as(final String name):给该分支添加一个名字,不做处理。withFunction():对该分支的消息进行处理,然后会把处理后的消息返回到结果的map中去withConsumer():对该分支的消息进行处理,不会把消息返回回去

- 具体代码
在测试使用前需要把几个topic先创建出来
@Slf4j
public class ZMartKafkaStreamsApp {private final static String APPLICATION_ID = "ZMart_app_id";private static final String BOOTSTRAP_SERVERS = "localhost:9092";private final static String TOPIC_NAME = "production-topic";private final static String APPLE_TOPIC_NAME = "apple-topic";private final static String WATERMELON_TOPIC_NAME = "watermelon-topic";private final static String OUT_TOPIC_NAME = "out-topic";public static void main(String[] args) throws InterruptedException {StreamsConfig streamsConfig = new StreamsConfig(getProperties());JsonSerializer<Purchase> serializer = new JsonSerializer<>();JsonDeserializer<Purchase> deserializer = new JsonDeserializer<>(Purchase.class);Serde<Purchase> propertiesSerde = Serdes.serdeFrom(serializer, deserializer);Serde<String> stringSerde = Serdes.String();StreamsBuilder builder = new StreamsBuilder();KStream<String, Purchase> inputStream = builder.stream(TOPIC_NAME, Consumed.with(stringSerde, propertiesSerde));// 谓词条件 判断把流输送到哪个分支上Predicate<String, Purchase> isWatermelon = (key, value) -> {String name = value.getName();return name.equals("西瓜");};// split:分裂流Map<String, KStream<String, Purchase>> stringKStreamMap = inputStream.peek((k,v)-> log.info("[分裂消息===>] k:{},value:{}" ,k,v)).split(Named.as("split-"))//拼接的key前缀.branch(isWatermelon, Branched.withFunction(ks -> { //对满足isWatermelon条件的分支的消息进行处理的处理器
// ks.print(Printed.<String, Purchase>toSysOut().withLabel("西瓜分支"));return ks.mapValues(v -> {String modifiedNumber = v.getId().replaceAll("(?<=\\d)\\d(?=\\d)", "*");v.setId( modifiedNumber);return v;});},"watermelon")) //这个地方需要指定name,用作为返回的map的key 如该分支存放到返回的map的key为:split-watermelon.branch((key, value) -> value.getName().equals("苹果"),Branched.withConsumer( //不满足上面的条件的会继续向下匹配,满足条件直接发送ks -> ks.peek((k, v) -> log.info("[苹果分支] value:{}" ,v)).to(APPLE_TOPIC_NAME, Produced.with(stringSerde, propertiesSerde)),"apple")).defaultBranch(Branched.withConsumer( //把不满足前面所以branch条件的消息发送到默认主题ks -> ks.to(OUT_TOPIC_NAME, Produced.with(stringSerde, propertiesSerde)),"defaultBranch"));// 把上面的消息打印出来stringKStreamMap.forEach((s, kStream) ->kStream.print(Printed.<String, Purchase>toSysOut().withLabel(s)));KafkaStreams kafkaStreams = new KafkaStreams(builder.build(), streamsConfig);
// jvm关闭时,把流也关闭CountDownLatch latch = new CountDownLatch(1);Runtime.getRuntime().addShutdownHook(new Thread(() -> {kafkaStreams.close();latch.countDown();log.info("The Kafka Streams 执行关闭!");}));kafkaStreams.start();log.info("kafka streams 启动成功!>>>>");latch.await();}@NotNullprivate static Properties getProperties() {Properties properties = new Properties();properties.put(StreamsConfig.APPLICATION_ID_CONFIG, APPLICATION_ID);properties.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,BOOTSTRAP_SERVERS);return properties;}
}
相关文章:
【2024】kafka streams的详细使用与案例练习(2)
目录 前言使用1、整体结构1.1、序列化 2、 Kafka Streams 常用的 API2.1、 StreamsBuilder2.2、 KStream 和 KTable2.3、 filter和 filterNot2.4、 map 和 mapValues2.5、 flatMap 和 flatMapValues2.6、 groupByKey 和 groupBy2.7、 count、reduce 和 aggregate2.8、 join 和 …...
qt 简单实验 读取json格式的配置文件
1.概要 2.代码 //#include "mainwindow.h"#include <QApplication> #include <QFile> #include <QJsonDocument> #include <QJsonObject> #include <QDebug> //读取json数据的配置文件QJsonObject readJsonConfigFile(const QString …...
Docker常用命令与实战示例
docker 1. 安装2. 常用命令3. 存储4. 网络5. redis主从复制示例6. wordpress示例7. DockerFile8. 一键安装超多中间件(compose) 1. 安装 以centOS系统为例 # 移除旧版本docker sudo yum remove docker \docker-client \docker-client-latest \docker-c…...
)
数据结构(基础知识)
基础概念: 数据:数据是信息的载体,是描述客观事物属性的数,字符及所有能输入到计算机中并被计算机程序识别和处理的符号的集合 数据元素:是数据的基本单位,在程序中常作为一个整体来考虑 数据对象&#…...
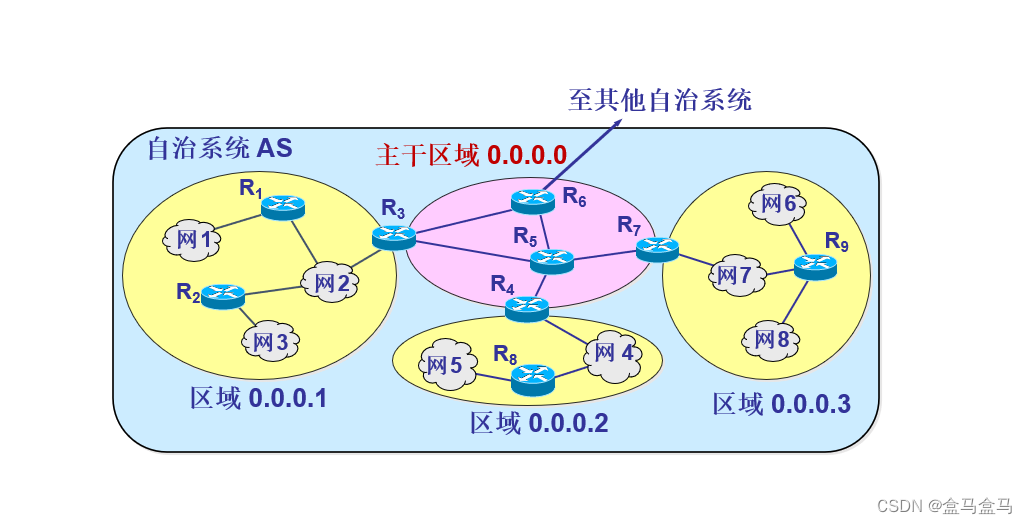
计算机网络:网络层 - 路由选择协议
计算机网络:网络层 - 路由选择协议 路由器的结构路由选择协议概述自治系统 AS内部网关协议路由信息协议 RIP距离向量算法RIP报文格式收敛问题 开放最短路径优先 OSPF基本工作原理自治系统分区 外部网关协议BGP-4 路由器的结构 如图所示,路由器被分为路由…...
JupyterLab使用指南(六):JupyterLab的 Widget 控件
1. 什么是 Widget 控件 JupyterLab 中的 Widget 控件是一种交互式的小部件,可以用于创建动态的、响应用户输入的界面。通过使用 ipywidgets 库,用户可以在 Jupyter notebook 中创建滑块、按钮、文本框、选择器等控件,从而实现数据的交互式展…...
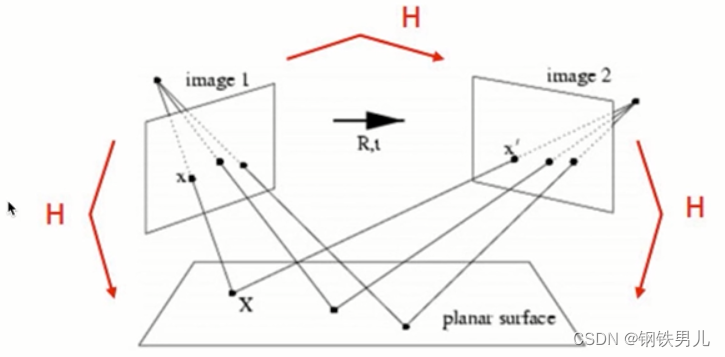
OpenCV 特征点检测与匹配
一 OpenCV特征场景 ①图像搜索,如以图搜图; ②拼图游戏; ③图像拼接,将两长有关联得图拼接到一起; 1 拼图方法 寻找特征 特征是唯一的 可追踪的 能比较的 二 角点 在特征中最重要的是角点 灰度剃度的最大值对应的…...

css布局之flex应用
/*父 100*/.parent-div {/* 这里添加你想要的属性 */display: flex;flex-direction: row; //行justify-content: space-between; //左右对齐align-items: center;flex-wrap: wrap; //换行}/*中 90 10 */.middle-div {/* 这里添加你想要的属性 */display: flex;flex-direction:…...

树莓派4B设置AP热点步骤
树莓派4B设置AP热点步骤:先进入root模式 预先进行apt-get update 第1步:安装network-manager sudo apt-get install network-manager第2步:安装git apt-get install git apt-get install util-linux procps hostapd iproute2 iw haveged …...
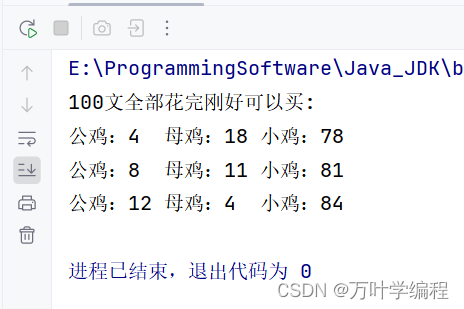
Java程序之百鸡百钱问题
题目: 百钱买百鸡的问题算是一套非常经典的不定方程的问题,题目很简单:公鸡5文钱一只,母鸡3文钱一只,小鸡3只一文钱,用100文钱买一百只鸡,其中公鸡,母鸡,小鸡都必须要有,…...

Mybatis——动态sql
if标签 用于判断条件是否成立。使用test属性进行条件判断,如果条件为true,则拼接sql。 <where>标签用于识别语句是否需要连接词and,识别sql语句。 package com.t0.maybatisc.mapper;import com.t0.maybatisc.pojo.Emp; import org.a…...

可视化大屏开发系列——页面布局
页面布局是可视化大屏的基础,想要拥有一个基本美观的大屏,就得考虑页面整体模块的宽高自适应,我们自然就会想到具有强大灵活性flex布局,再借助百分比布局来辅助。至此,大屏页面布局问题即可得到解决。 可视化大屏开发系…...

Python statistics 模块
Python 的 statistics 模块提供了一组用于执行各种统计计算的函数,包括平均值、中位数、标准差、方差以及其他统计量。让我来简单介绍一下。 首先,你可以使用以下方式导入 statistics 模块: python import statistics 接下来,…...

wireshark常见使用表达式
目录 1. 捕获过滤器 (Capture Filters)基本捕获过滤器组合捕获过滤器 2. 显示过滤器 (Display Filters)基本显示过滤器复杂显示过滤器协议特定显示过滤器 3. 进阶显示过滤器技巧使用函数和操作符逻辑操作符 4. 常见网络协议过滤表达式示例HTTP 协议HTTPS 协议DNS 协议DHCP 协议…...

用Java获取键盘输入数的个十百位数
这段Java代码是一个简单的程序,用于接收用户输入的一个三位数,并将其分解为个位、十位和百位数字,然后分别打印出来。下面是代码的详细解释: 导入所需类库: import java.util.Scanner;:导入Scanner类,用于从…...

第10章 启动过程组 (制定项目章程)
第10章 启动过程组 9.1制定项目章程,在第三版教材第356~360页; 文字图片音频方式 视频12 第一个知识点:主要输出 1、项目章程(重要知识点) 项目目的 为了稳定与发展公司的客户群(抽象,非具体) 可测量的项目…...
html侧导航栏客服栏
ico 替换 ICO <html xmlns"http://www.w3.org/1999/xhtml"><head><meta http-equiv"Content-Type" content"text/html; charsetutf-8"><title>返回顶部</title><script src"js/jquery-2.0.3.min.js"…...
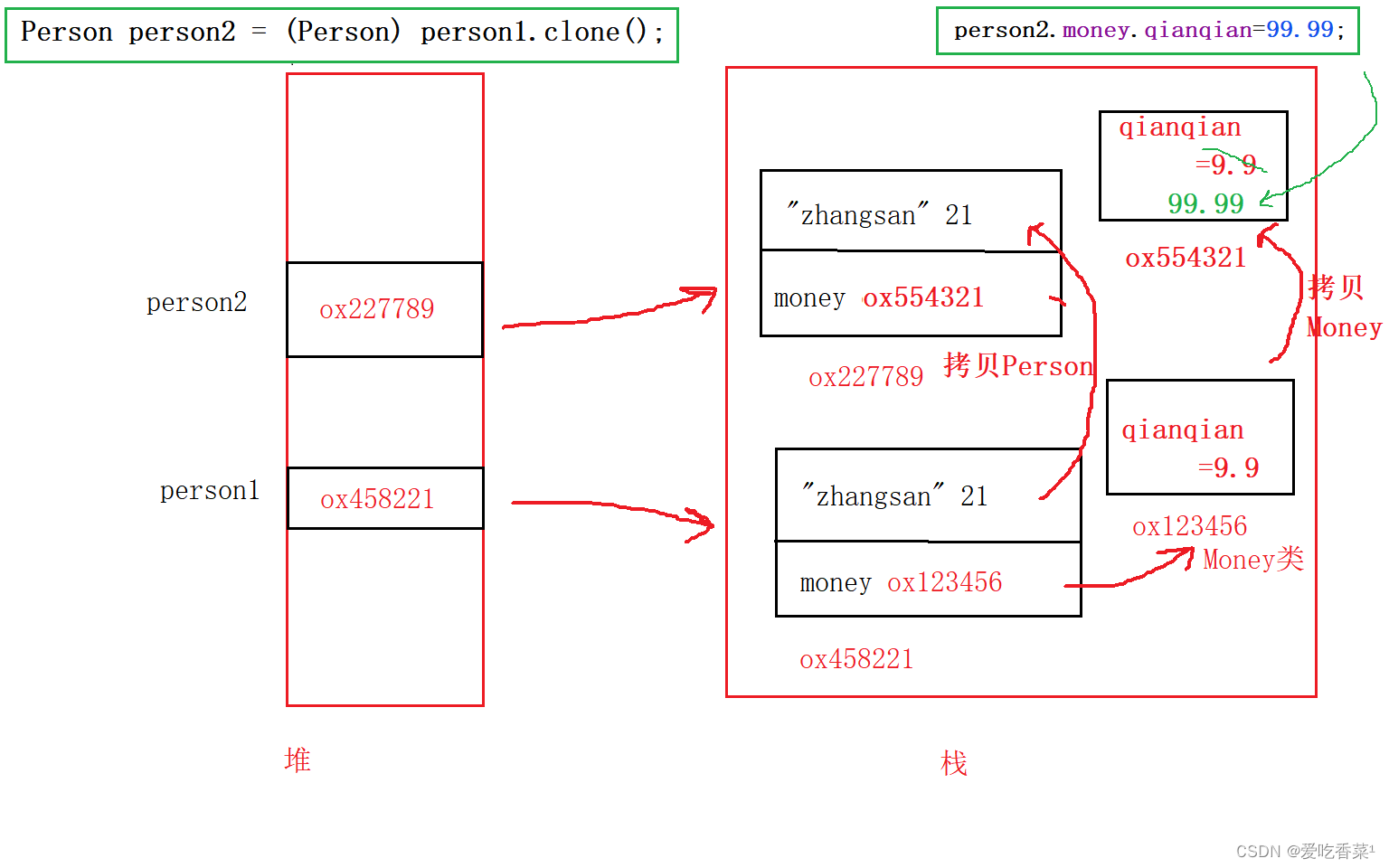
Clonable接口和拷贝
Hello~小伙伴们!本篇学习Clonable接口与深拷贝,一起往下看吧~(画图水平有限,两张图,,我真的画了巨久,求路过的朋友来个3连~阿阿阿~~~) 目录 1、Clonable接口概念 2、拷贝 2、1浅拷贝 2、2深拷贝 1、Clon…...

关于小蛋の编程和小蛋编程为同一作者的说明
小蛋の编程和小蛋编程的作品为同一人制作,因前者为父母的手机号进行注册,现用本人手机号注册了新账号小蛋编程,后续文章将在新账号小蛋编程上进行刊登,同时在小蛋编程上对原账号文章进行转载。此账号不再发布帖子,请大…...

大数据平台之Spark
Apache Spark 是一个开源的分布式计算系统,主要用于大规模数据处理和分析。它由UC Berkeley AMPLab开发,并由Apache Software Foundation维护。Spark旨在提供比Hadoop MapReduce更快的处理速度和更丰富的功能,特别是在处理迭代算法和交互式数…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

Java如何权衡是使用无序的数组还是有序的数组
在 Java 中,选择有序数组还是无序数组取决于具体场景的性能需求与操作特点。以下是关键权衡因素及决策指南: ⚖️ 核心权衡维度 维度有序数组无序数组查询性能二分查找 O(log n) ✅线性扫描 O(n) ❌插入/删除需移位维护顺序 O(n) ❌直接操作尾部 O(1) ✅内存开销与无序数组相…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

企业如何增强终端安全?
在数字化转型加速的今天,企业的业务运行越来越依赖于终端设备。从员工的笔记本电脑、智能手机,到工厂里的物联网设备、智能传感器,这些终端构成了企业与外部世界连接的 “神经末梢”。然而,随着远程办公的常态化和设备接入的爆炸式…...