【0-1系列】从0-1快速了解搜索引擎Scope以及如何快速安装使用(下)
前言
近日,社区版家族正式发布V2024.5版本,其中,社区开发版系列重磅发布Scope开发版以及StellarDB开发版。
为了可以让大家更进一步了解产品,本系列文章从背景概念开始介绍,深入浅出的为读者介绍Scope的优势以及能力,在上一篇文章中为读者介绍了基础知识、Scope的技术优势以及能力,本篇文章将继续为读者介绍如何安装部署以及使用。
友情链接
- 社区开发版安装部署与使用教程
- 社区版家族V2024.5版本更新说明
安装与部署
企业版(分布式)
- 申请试用
社区订阅版(分布式)
- 订阅流程
社区开发版(单机)
- 安装手册
- 安装视频
安装教程
友情提示:安装前请仔细查看安装手册注意事项章节,下方内容仅供参考
步骤一 将从官网下载下来的产品包解压后上传至安装环境
- 产品包名称:TDH-Scope-Standalone-Community-Transwarp-2024.5-X86_64-final.tar.gz
步骤二 执行下述命令进行解压,解压后将出现一个镜像tar包
tar -zxf TDH-Scope-Standalone-Community-Transwarp-2024.5-X86_64-final.tar.gz
步骤三 执行下述命令加载镜像
docker load -i scope-2024.5.tar
步骤四 执行下方指令启动容器并运行镜像,运行格式为:
docker run -d --network host -v <本地目录路径>:/opt/transwarp --privileged <镜像名>
-v参数配置了TDH挂载的本地磁盘路径。该路径下会保存产品运行过程中产生的配置conf、数据data、日志log。再次提醒请不要随意改动做好备份,以及确保该路径下没有历史版本的数据文件。
操作示例图

步骤五 容器启动后需等待30s至2分钟
步骤六 浏览器访问管理节点8180端口
打开客户端浏览器(推荐使用Google Chrome浏览器),访问http://host:8180,比如http://172.16.3.108:8180/。访问这个地址,您会看到下面的登录页面。

初次登录以admin的身份登录,密码也是admin。
步骤七 按照向导提示进行集群部署与配置即可
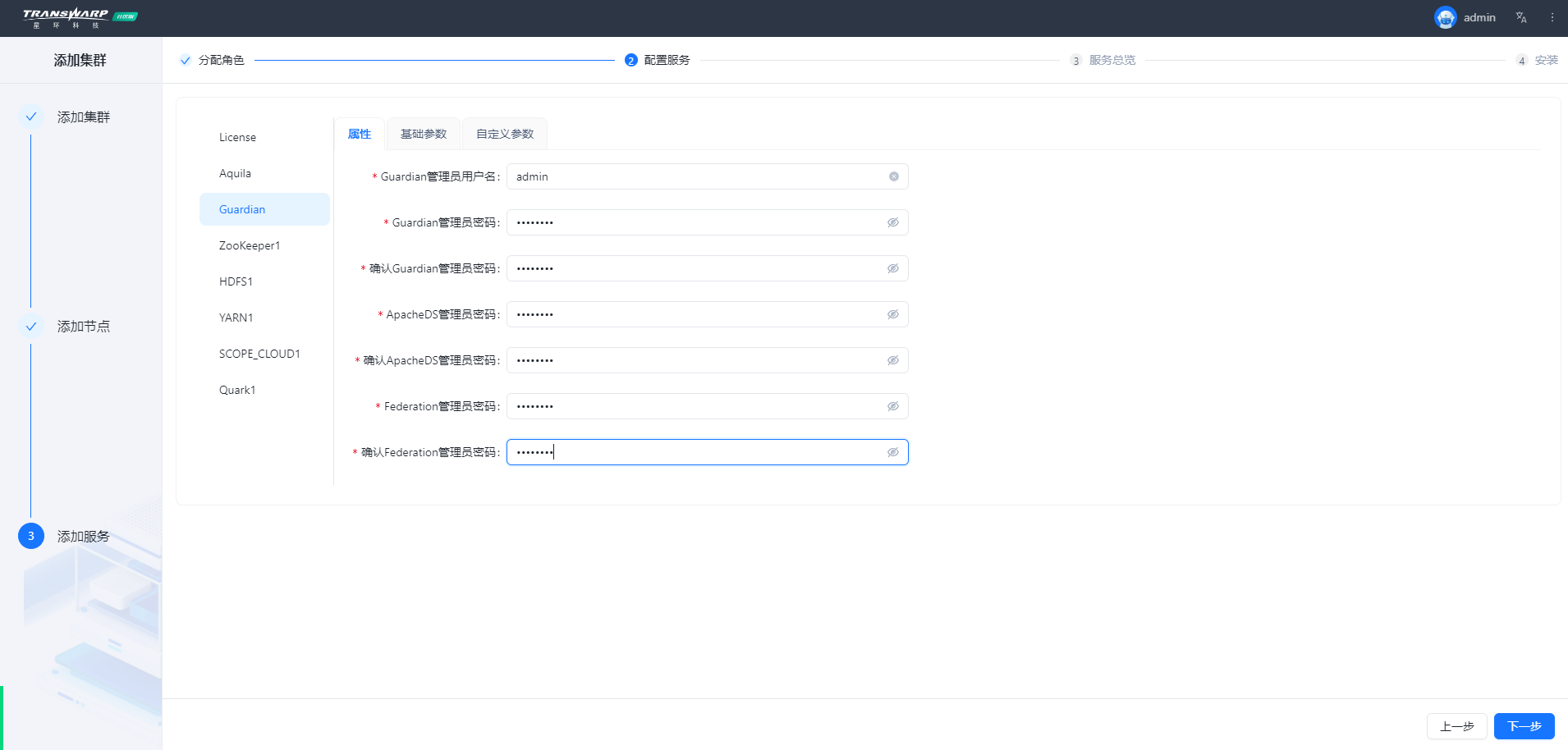
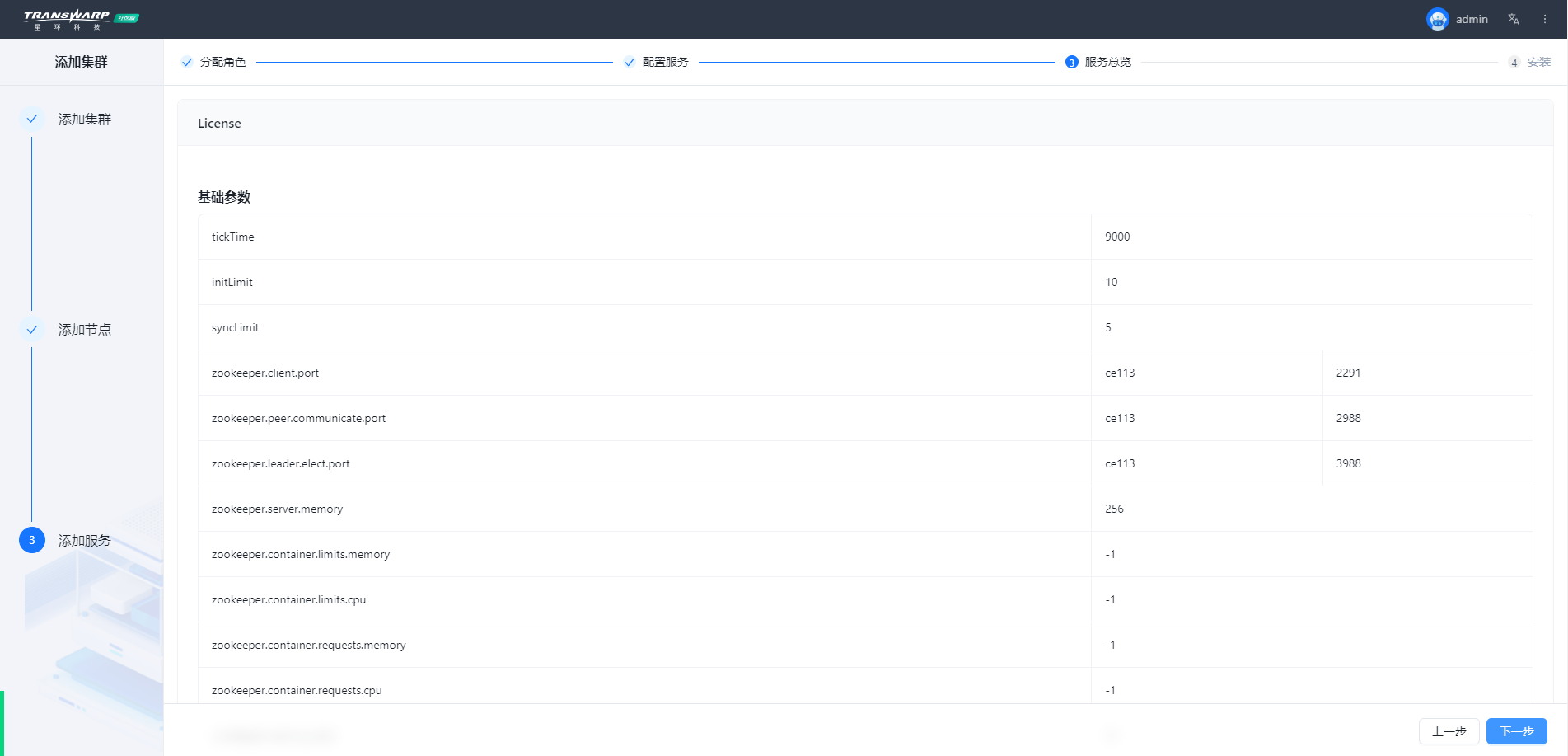
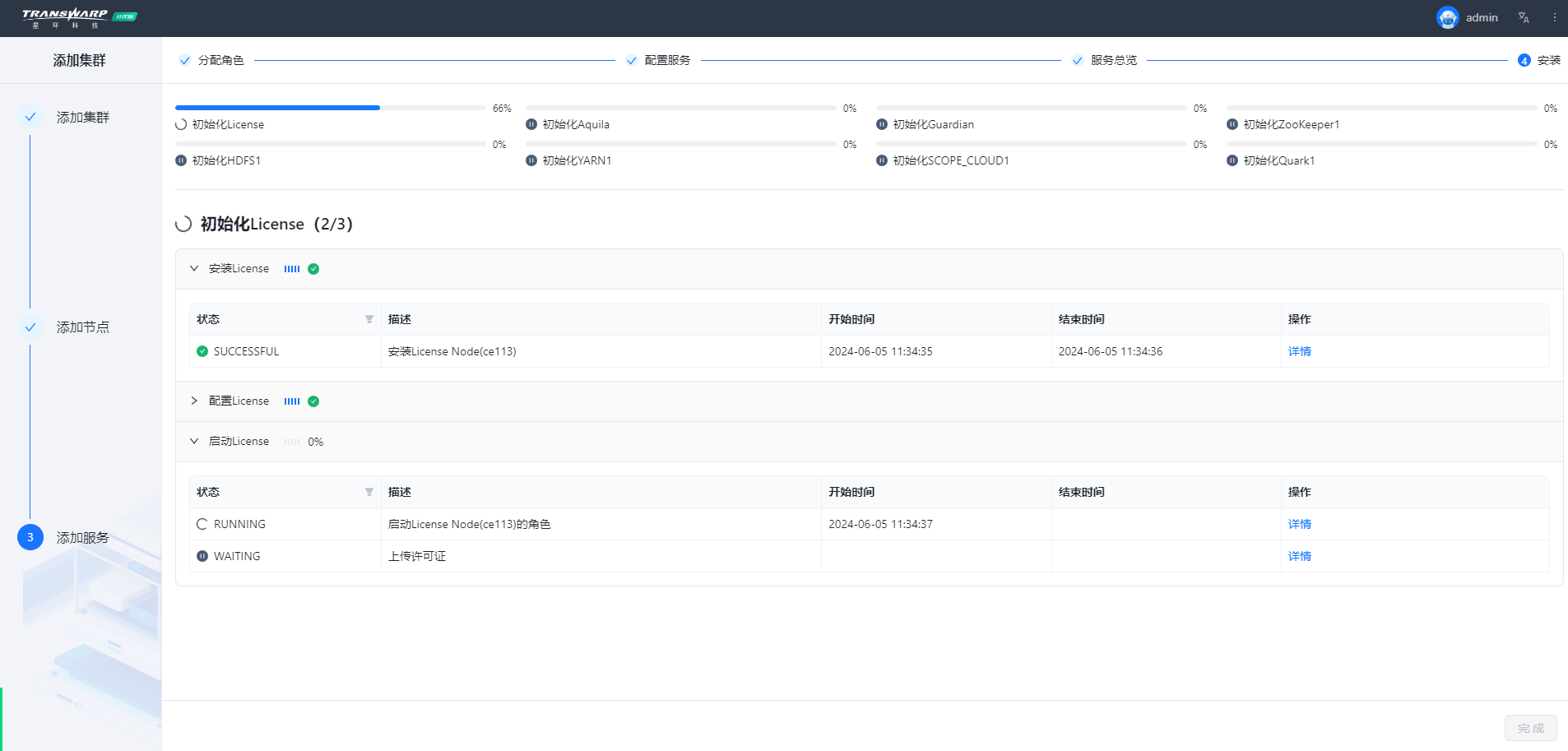
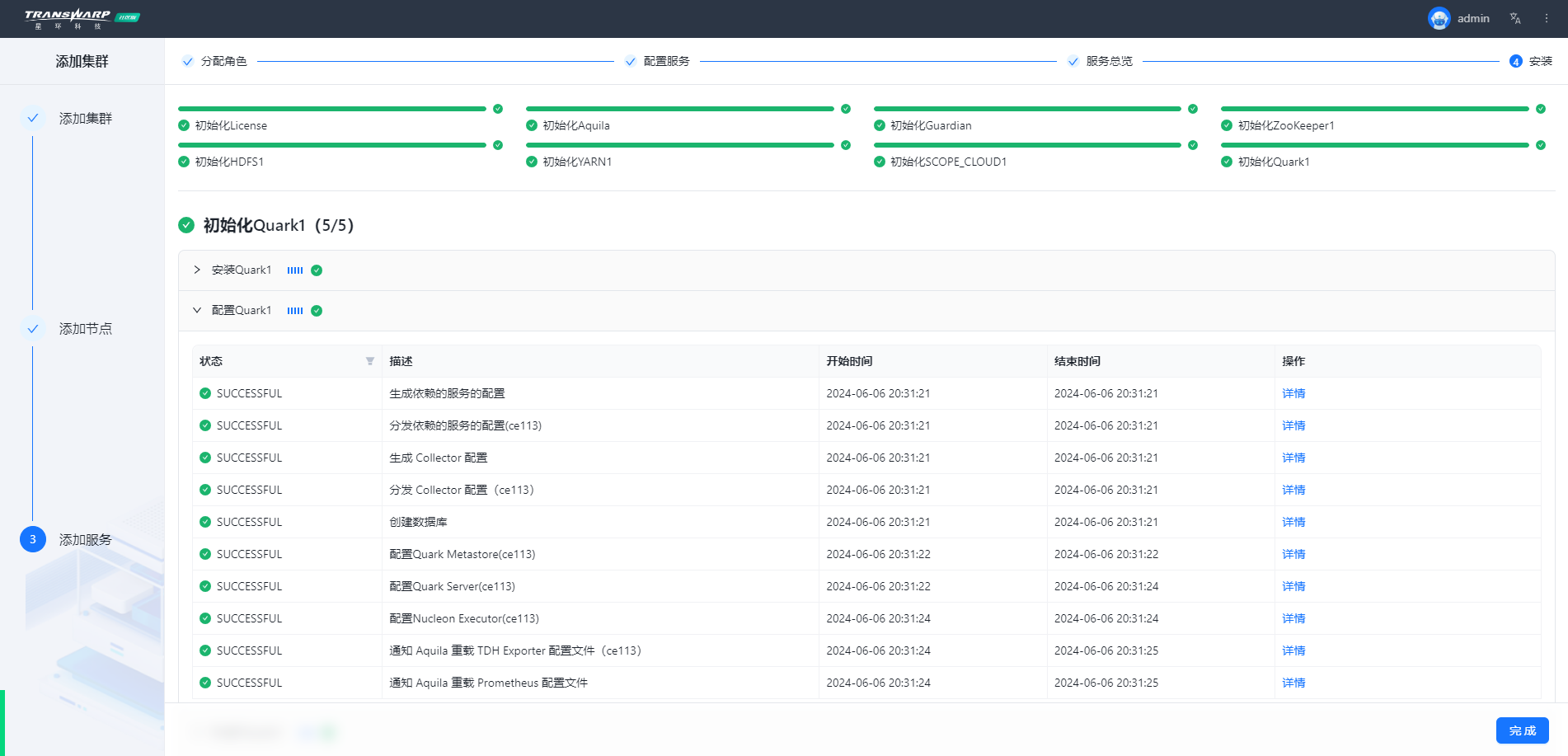
安装完成自助申请许可证即可使用,教程请参考手册
使用示例
产品使用手册
演示示例1. Scope多态语法之rest 语法
创建/删除索引
创建索引
curl -X PUT "localhost:9200/my_index?pretty" -H 'Content-Type: application/json' -d'{"settings": {"number_of_shards": 5,"number_of_replicas": 3},"mappings": {"default_type_": {"properties": {"id": { "type": "integer" },"title": { "type": "text" },"body": { "type": "text" },"date": { "type": "date" },"views": { "type": "integer" },"tags": { "type": "keyword" }}}}
}
';删除索引
curl -X DELETE "localhost:9200/my_index?pretty";数据插入
单条插入
curl -X PUT "localhost:9200/my_index/default_type_/1?pretty" -H 'Content-Type: application/json' -d'
{"id": 1,"title": "Scope for Beginners","body": "Learn how to use Scope to search and analyze your data","date": "2022-05-09","views": 1000,"tags": ["Scope", "search"]
}
';curl -X POST "localhost:9200/my_index/default_type_/?pretty" -H 'Content-Type: application/json' -d'
{"id": 2,"title": "Advanced Scope","body": "Take your Scope skills to the next level","date": "2022-05-10","views": 500,"tags": ["Scope", "advanced"]
}
';批量插入
curl -X POST "localhost:9200/my_index/_bulk?pretty" -H 'Content-Type: application/x-ndjson' --data-binary '
{ "index" : {"_index" : "my_index","_type" : "default_type_", "_id" : "bulk_1" } }
{ "id": 3, "title": "Scope Performance Tuning", "body": "Optimize your Scope cluster for better performance", "date": "2022-05-11","views": 750, "tags": ["Scope", "performance"]}
{ "index" : {"_index" : "my_index","_type" : "default_type_", "_id" : "bulk_2" } }
{ "id": 4, "title": "Scope Security", "body": "Learn how to secure your Scope cluster", "date": "2022-05-12", "views": 250, "tags": ["Scope", "security"]}
{ "index" : {"_index" : "my_index","_type" : "default_type_", "_id" : "bulk_3" } }
{"id": 5, "title": "Scope Monitoring", "body": "Monitor your Scope cluster with the Elastic Stack", "date": "2022-05-13", "views": 100, "tags": ["Scope", "monitoring"]}
';数据查询
Case1
curl -X GET "localhost:9200/my_index/_search?pretty" -H 'Content-Type: application/json' -d'
{"query": {"match": {"body": "Scope"}},"sort": {"date": { "order": "desc" }}
}
';Case2
curl -X GET "localhost:9200/my_index/_search?pretty" -H 'Content-Type: application/json' -d'
{"query": {"range": {"date": {"gte": "2022-05-11"}}},"sort": {"views": { "order": "asc" }}
}
';基础运维指令
查看集群状态
curl -X GET "localhost:9200/_cluster/health?pretty";查看索引状态
curl -X GET "localhost:9200/_cat/indices/my_index?v";查看节点状态
curl -X GET "localhost:9200/_cat/nodes?v";查看分片状态
curl -X GET "localhost:9200/_cat/shards/my_index?v";演示示例2. Scope多态语法之sql语法
创建/删除索引
删除/创建数据库(非必要)
drop database if exists DDL_Scope_DB CASCADE;
create database if not exists DDL_Scope_DB;
use DDL_Scope_DB;删除索引
drop table if exists sql_demo;创建索引
create table sql_demo(id string,title string has analyzer 'standard',author string,price double,description string has analyzer 'mmseg'
)stored as scope
with shard number 5 replication 3
tblproperties('scope.key.column'='id');数据插入
单条插入
insert into sql_demo select '1', '百年孤独', '加西亚·马尔克斯', 39.80, '一部代表魔幻现实主义文学巅峰的经典小说。' from system.dual;
insert into sql_demo values('2', '围城', '钱钟书', 29.80, '一部中国现代文学经典,讽刺了旧中国知识分子的冷嘲热讽和无可奈何。');批量插入
batchinsert into sql_demo batchvalues(values('3', '骆驼祥子', '老舍', 22.80, '一部反映旧中国社会底层生活的文学作品,展现了社会底层人民的生活和奋斗。'),values('4', '茶花女', '小仲马', 18.80, '一部法国浪漫主义文学代表作,描绘了一个上层社会女性的生活和爱情。')
);数据查询
数据查询
select * from sql_demo;
select * from sql_demo order by price;
select * from sql_demo where contains(description,'中国');和 rest 一致性
curl -ushiva:shiva -X GET "localhost:9200/ddl_scope_db.sql_demo/_mapping?pretty";
curl -ushiva:shiva -X GET "local:9200/ddl_scope_db.sql_demo/_settings/?pretty&filter_path=**.number_of_shards,**.number_of_replicas";
curl -ushiva:shiva -X GET "local:9200/ddl_scope_db.sql_demo/_search?pretty";演示示例3. Scope多态语法之JAVA语法
创建索引
CreateIndexRequest request = new CreateIndexRequest("create_index_demo");
request.settings(Settings.builder().put("index.number_of_shards", 1).put("index.number_of_replicas", 1)
);
CreateIndexRequest indexRequest = request.mapping(" {\n" +" \"" + "default_type_" + "\": {\n" +" \"properties\": {\n" +" \"c_text\": {\n" +" \"type\": \"text\"\n" +" },\n" +" \"c_string_mf\": {\n" +" \"type\": \"keyword\"\n" +" }\n" +" }\n" +" }\n" +" }",XContentType.JSON);
CreateIndexResponse createIndexResponse = highLevelClient.indices().create(indexRequest,RequestOptions.DEFAULT);删除索引
DeleteIndexRequest request = new DeleteIndexRequest("create_index_demo");
AcknowledgedResponse deleteIndexResponse = highLevelClient.indices().delete(request,RequestOptions.DEFAULT);数据插入
单条插入
IndexRequest request = new IndexRequest("my_index","default_type_","6");String jsonString = "{\n" +" \"id\": 6,\n" +" \"title\": \"Scope for Beginners\",\n" +" \"body\": \"Learn how to use Scope to search and analyze your data\",\n" +" \"date\": \"2022-05-09\",\n" +" \"views\": 1000,\n" +" \"tags\": [\"Scope\", \"search\"]\n" +"}";
IndexRequest source = request.source(jsonString, XContentType.JSON);
IndexResponse index = highLevelClient.index(source, RequestOptions.DEFAULT);批量插入
String jsonString1 = "{\"id\": 3, \"title\": \"Scope Performance Tuning\", \"body\": \"Optimize your Scope cluster for better performance\", \"date\": \"2022-05-11\",\"views\": 750, \"tags\": [\"Scope\", \"performance\"]}";
String jsonString2 = "{\"id\": 4, \"title\": \"Scope Security\", \"body\": \"Learn how to secure your Scope cluster\", \"date\": \"2022-05-12\", \"views\": 250, \"tags\": [\"Scope\", \"security\"]}";
String jsonString3 = "{\"id\": 5, \"title\": \"Scope Monitoring\", \"body\": \"Monitor your Scope cluster with the Elastic Stack\", \"date\": \"2022-05-13\", \"views\": 100, \"tags\": [\"Scope\", \"monitoring\"]}";
BulkRequest request = new BulkRequest();
request.add(new IndexRequest("my_index", "default_type_", "3").source(jsonString1,XContentType.JSON));
request.add(new IndexRequest("my_index", "default_type_", "4").source(jsonString2,XContentType.JSON));
request.add(new IndexRequest("my_index", "default_type_", "5").source(jsonString3,XContentType.JSON));
BulkResponse bulkResponses = highLevelClient.bulk(request,RequestOptions.DEFAULT);数据查询
term查询
SearchRequest searchRequest = new SearchRequest().indices("my_index").types("default_type_");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.termQuery("body", "how"));
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);match查询(对查询条件进行分词)
SearchRequest searchRequest = new SearchRequest().indices("my_index").types("default_type_");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("body","Monitor Optimize"));
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);boolean查询(多条件查询)
SearchRequest searchRequest = new SearchRequest().indices("my_index").types("default_type_");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
SearchSourceBuilder mustQuery = searchSourceBuilder.query(QueryBuilders.boolQuery());
mustQuery.query(QueryBuilders.termQuery("body","cluster"));
mustQuery.query(QueryBuilders.termQuery("date","2022-05-13"));
searchRequest.source(mustQuery);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);演示示例4. 索引与分词机制
在使用搜索引擎的过程中,通常会涉及诸多属于,如segment/doc/term/token/shard/index等等,其中,segment/doc/term/token都是lucene中的概念。理解这些术语有助于更深入的了解和使用搜索引擎。
- document:索引和搜索的主要数据载体,对应写入scope中的一个doc。通常以JSON格式存储;
- field:document中的各个字段,每个字段都有自己的数据类型,使用者可以针对字段内容设置是否对其分词或使用分析器进行分词;
- term词项:搜索时的一个单位,代表文本中的某个词;
- token词条:词项(term)在字段(field)中的一次出现,包括词项的文本、开始和结束的位移、类型等信息;
- index索引:以index为单位组织数据(document),一个index中的数据通常具有相似的特征。需要注意这里的index与宽表数据库中的索引(全局索引)不是一个概念,这里指的是搜索引擎中的数据对象。
lucene内部使用的是倒排索引的数据结构,将词项(term)映射到文档(document)。例如下图的3个document,进行分词后可以搜索引擎可以很快速的返回的下方问题的答案
- 查询document id为 2的document?
- 查询包含choice的document?
- 查询有choice又有is的document?
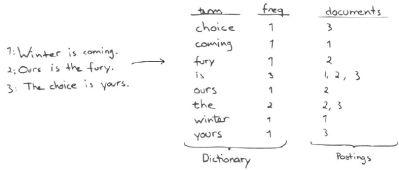
那么是如何实现这一能力的?
分词器介绍
将文档切分成一系列有意义的单词(term/token)的过程称之为分词,其中,分词器则负责这一过程,以建立索引进行高效的搜索和分析。
选择一个合适的分词器可以很大程度上提高检索效率,当前比较常见的分词器有以下几种:
英文分词器
- 标准分词器(Standard Tokenizer)标准分词器类型是standard,用于大多数欧洲语言,使用Unicode文本分割算法对文档进行分词;
- 空格分词器(Whitespace Tokenizer)空格分词类型是whitespace,在空格处分割文本;
- 小写分词器(Lowercase Tokenizer)小写分词器类型是lowercase,在非字母位置上分割文本,并把分词转换为小写形式,功能上是Letter Tokenizer和 Lower Case Token Filter的结合(Combination),但是性能更高,一次性完成两个任务;
- 经典分词器(Classic Tokenizer)经典分词器类型是classic,基于语法规则对文本进行分词,对英语文档分词非常有用,在处理首字母缩写,公司名称,邮件地址和Internet主机名上效果非常好;
- ...
中文分词器
- IK:普及率最广。IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。采用了特有的“正向迭代最细粒度切分算法“,支持细粒度和最大词长两种切分模式;支持英文字母、数字、中文词汇等分词处理。支持用户词典扩展定义。
- Pinyin 分词器:pinyin分词器可以让用户输入拼音,就能查找到相关的关键词。比如在某个商城搜索中,输入yonghui,就能匹配到永辉。这样的体验还是非常好的。
- ...
不同的分词器会产生不同的分词结果,产生不同的索引,所以相同的查询条件会产生不同的结果。
- 更多分词器参考
举例说明生活中全文检索的应用实例:字典。字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。
全文检索就是把文本中的内容拆分成若干个关键词,然后根据关键词创建索引。查询时,根据关键词查询索引,最终找到包含关键词的文章。整个过程类似于查字典的过程。
Scope分词器-Standard
创建索引
curl -X DELETE "localhost:19200/blog_index1?pretty";
curl -X PUT "localhost:19200/blog_index1?pretty" -H 'Content-Type: application/json' -d'{"mappings": {"default_type_": {"properties": {"id": {"type": "integer"},"blog_name": {"type": "text","analyzer": "standard"},"blog_name_english": {"type": "text","analyzer": "standard"}}}}
}
';数据写入
curl -X POST "localhost:19200/blog_index1/_bulk?pretty" -H 'Content-Type: application/x-ndjson' --data-binary '
{ "index" : {"_index" : "blog_index1","_type" : "default_type_", "_id" : "bulk_1" } }
{ "id": 1, "blog_name": "Scope 介绍", "blog_name_english": "Introduction to Scope"}
{ "index" : {"_index" : "blog_index1","_type" : "default_type_", "_id" : "bulk_2" } }
{ "id": 2, "blog_name": "Scope 高级搜索", "blog_name_english": "Advanced Searching in Scope"}
{ "index" : {"_index" : "blog_index1","_type" : "default_type_", "_id" : "bulk_3" } }
{ "id": 3, "blog_name": "全文检索技术比较", "blog_name_english": "Comparison of Full-Text Search Technologies"}
{ "index" : {"_index" : "blog_index1","_type" : "default_type_", "_id" : "bulk_4" } }
{ "id": 4, "blog_name": "Scope 数据聚合", "blog_name_english": "Scope Data Aggregation"}
{ "index" : {"_index" : "blog_index1","_type" : "default_type_", "_id" : "bulk_4" } }
{ "id": 5, "blog_name": "分布式数据库架构", "blog_name_english": "Introduction to NoSQL Databases"}
';英文检索
curl -XGET "localhost:19200/blog_index1/_search?pretty" -H 'Content-Type: application/json' -d'{"query": {"term": {"blog_name_english": "search"}}
}';中文检索
curl -XGET "localhost:19200/blog_index1/_search?pretty" -H 'Content-Type: application/json' -d'{"query": {"term": {"blog_name": "搜索"}}
}';Scope分词器-ik_max_word
创建索引
curl -X DELETE "localhost:9200/blog_index2?pretty";
curl -X PUT "localhost:9200/blog_index2?pretty" -H 'Content-Type: application/json' -d'{"mappings": {"default_type_": {"properties": {"id": {"type": "integer"},"blog_name": {"type": "text","analyzer": "ik_max_word"},"blog_name_english": {"type": "text","analyzer": "standard"},"blog_summary": {"type": "text","analyzer": "ik_max_word"}}}}
}
';数据写入
curl -X POST "localhost:9200/blog_index2/_bulk?pretty" -H 'Content-Type: application/x-ndjson' --data-binary '
{ "index" : {"_index" : "blog_index2","_type" : "default_type_", "_id" : "bulk_1" } }
{ "id": 1, "blog_name": "Scope 介绍", "blog_name_english": "Introduction to Scope", "blog_summary": "Scope 是一个分布式搜索引擎,用于快速和可扩展地搜索和分析大量数据。"}
{ "index" : {"_index" : "blog_index2","_type" : "default_type_", "_id" : "bulk_2" } }
{ "id": 2, "blog_name": "Scope 高级搜索", "blog_name_english": "Advanced Searching in Scope", "blog_summary": "学习如何使用 Scope 进行高级搜索和优化查询性能的技巧。"}
{ "index" : {"_index" : "blog_index2","_type" : "default_type_", "_id" : "bulk_3" } }
{ "id": 3, "blog_name": "全文检索技术比较", "blog_name_english": "Comparison of Full-Text Search Technologies", "blog_summary": "比较不同全文检索技术之间的性能和功能,了解它们在搜索算法和评估方面的优缺点。"}
{ "index" : {"_index" : "blog_index2","_type" : "default_type_", "_id" : "bulk_4" } }
{ "id": 4, "blog_name": "Scope 数据聚合", "blog_name_english": "Scope Data Aggregation", "blog_summary": "使用 Scope 进行数据聚合和分析,了解如何从大量数据中提取有价值的信息。"}
{ "index" : {"_index" : "blog_index2","_type" : "default_type_", "_id" : "bulk_4" } }
{ "id": 5, "blog_name": "分布式数据库架构", "blog_name_english": "Introduction to NoSQL Databases", "blog_summary": "探索分布式数据库架构的原理和设计,了解如何在分布式环境中实现数据一致性和高可用性。"}
';英文检索
curl -XGET "localhost:9200/blog_index2/_search?pretty" -H 'Content-Type: application/json' -d'{"query": {"term": {"blog_name_english": "search"}}
}';中文检索
curl -XGET "localhost:9200/blog_index2/_search?pretty" -H 'Content-Type: application/json' -d'{"query": {"term": {"blog_name": "搜索"}}
}';curl -XGET "localhost:9200/blog_index2/_search?pretty" -H 'Content-Type: application/json' -d'{"query": {"term": {"blog_summary": "搜索"}}
}';更多使用教程可以参考 Scope使用手册 ,欢迎体验开发版Scope。
相关文章:
【0-1系列】从0-1快速了解搜索引擎Scope以及如何快速安装使用(下)
前言 近日,社区版家族正式发布V2024.5版本,其中,社区开发版系列重磅发布Scope开发版以及StellarDB开发版。 为了可以让大家更进一步了解产品,本系列文章从背景概念开始介绍,深入浅出的为读者介绍Scope的优势以及能力…...

前端核心框架Vue指令详解
目录 ▐ 关于Vue指令的介绍 ▐ v-text与v-html ▐ v-on ▐ v-model ▐ v-show与v-if ▐ v-bind ▐ v-for ▐ 前言:在学习Vue框架过程中,大家一定要多参考官方API ! Vue2官方网址https://v2.cn.vuejs.org/v2/guide/ ▐ 关于Vue指令的…...

SD卡无法读取?原因分析与数据恢复策略
一、SD卡无法读取的困境 SD卡作为便携式的存储介质,广泛应用于手机、相机、平板等多种电子设备中。然而,在使用过程中,我们可能会遭遇SD卡无法读取的困扰。当我们将SD卡插入设备时,设备无法识别SD卡,或者虽然识别了SD…...

线程池的工作原理
线程池可以减少创建和销毁线程的次数,从而减少系统资源的消耗。当一个任务(Runnable或Callable对象)(Runnable无返回值,Callable有返回值)被提交到线程池时: 一、首先判断核心线程池中的线程是…...

Nikto一键扫描Web服务器(KALI工具系列三十)
目录 1、KALI LINUX 简介 2、Nikto工具简介 3、信息收集 3.1 目标IP(服务器) 3.2kali的IP 4、操作实例 4.1 基本扫描 4.2 扫描特定端口 4.3 保存扫描结果 4.4 指定保存格式 4.5 连接尝试 4.6 仅扫描文件上传 5、总结 1、KALI LINUX 简介 Kali Linux 是一…...

全局变量和局部变量
全局变量未初始化,则它的值为0; 局部变量未初始化,则它的值为随机值; 局部变量的作用域是变量所在的局部范围; 全局变量的作用域是整个工程; 生命周期: 变量的生命周期指的是变量从创建到销毁的整个阶段。 局部变量的生…...
[机器学习算法]支持向量机
支持向量机(SVM)是一种用于分类和回归分析的监督学习模型。SVM通过找到一个超平面来将数据点分开,从而实现分类。 1. 理解基本概念和理论: 超平面(Hyperplane):在高维空间中,将数据…...
Springboot应用的信创适配
CentOS7在2024.6.30停止维护后,可替代的Linux操作系统-CSDN博客 全面国产化之路-信创-CSDN博客 信创适配评测-CSDN博客 Springboot应用的信创适配 Springboot应用的信创适配,如上图所示需要适配的很多,从硬件、操作系统、中间件(…...
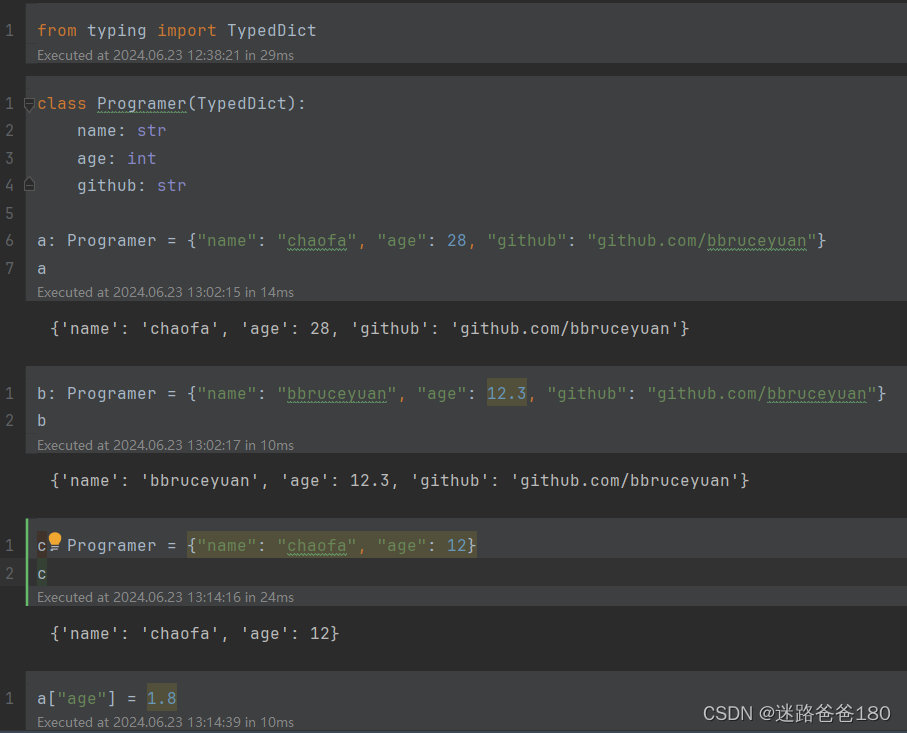
TypedDict 解析
TypedDict 解析 文章目录 TypedDict 解析1. 类型安全性2. 可读性3. 可维护性TypedDict 的解决方案没有 TypedDict 会发生什么?使用 TypedDict 的优势 TypedDict 应用场景1. 配置文件解析2. API 数据解析3. 数据库记录表示4. 表单数据验证5. 大型团队协作6. 静态类型…...
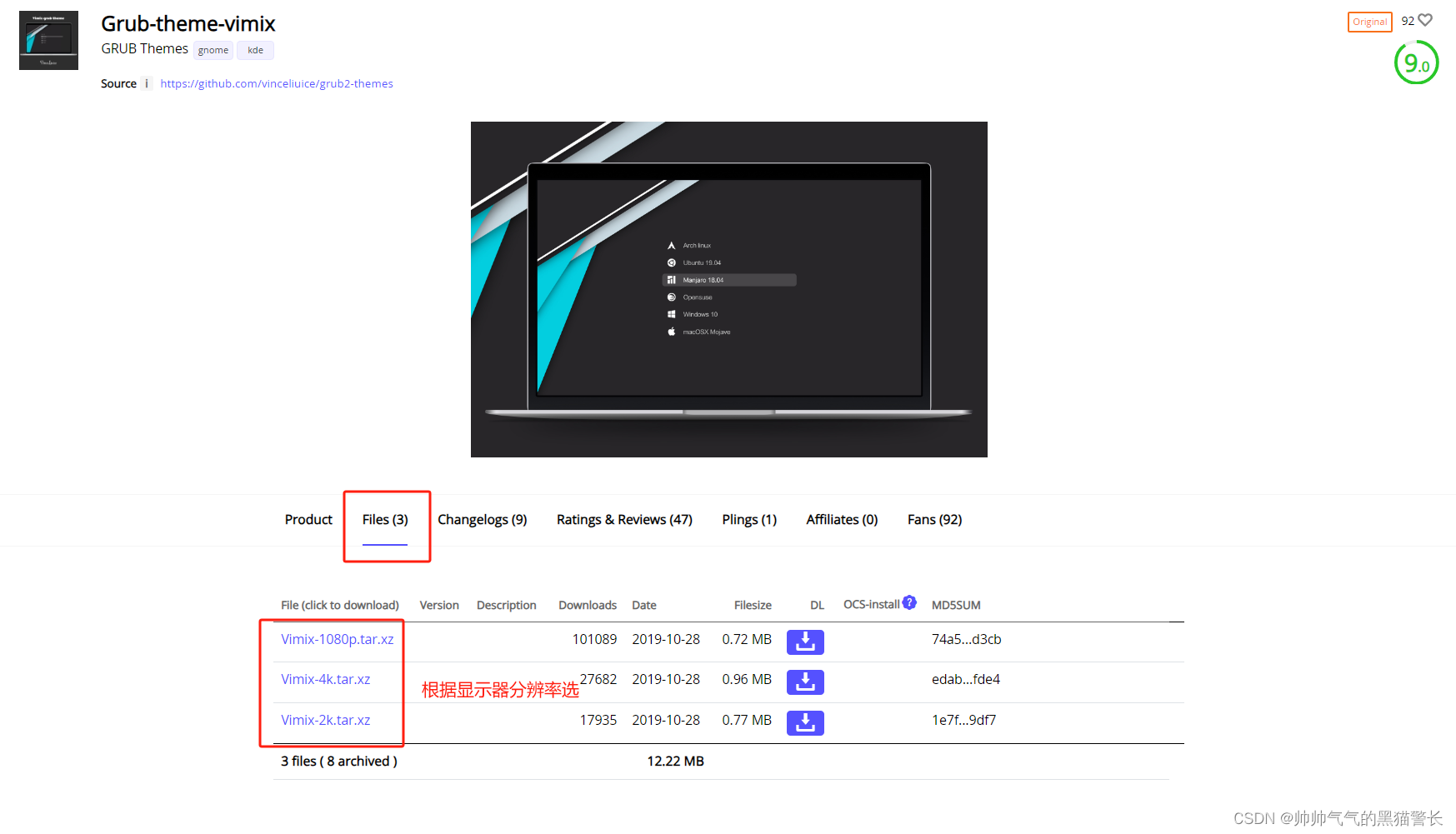
Windows11和Ubuntu22双系统安装指南
一、需求描述 台式机电脑,已有Windows11操作系统,想要安装Ubuntu22系统(版本任意)。其中Windows安装在Nvme固态上,Ubuntu安装在Sata固态上,双盘双系统。开机时使用Grub控制进入哪个系统,效果图…...

Dockerfile-php7.4.33
# 使用一个包含基本编译工具的基础镜像 FROM ubuntu:latestRUN ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \echo "Asia/Shanghai" > /etc/timezone# 更新包列表并安装必要的编译工具和库 RUN apt-get update && apt-get i…...

如何降低MCU系统功耗?
大家在做MCU系统开发的时候,是否也碰到过降低MCU系统功耗的需求? MCU系统整板功耗是个综合的数据,包括MCU功耗以及外部器件功耗,在此我们主要介绍如何降低MCU的功耗: 可以在满足应用的前提下,降低MCU的运…...
移动端 UI 风格,诠释精致
移动端 UI 风格,诠释精致...

【408考点之数据结构】数组和特殊矩阵的压缩存储
数组和特殊矩阵的压缩存储 在数据结构中,数组是一种基础的数据结构,用于存储相同类型的元素的集合。矩阵则是一个二维数组,常用于表示图像、图形以及数学运算中的系数。随着矩阵的广泛应用,一些特殊类型的矩阵也被引入并得到了有…...
函数)
26、matlab多项式曲线拟合:polyfit ()函数
1、前言 在 MATLAB 中,可以使用 polyfit() 函数进行多项式曲线拟合。polyfit() 函数可以拟合一个多项式模型到给定的数据点,从而找到最符合这些数据点的多项式曲线。以下是关于 polyfit() 函数的一些基本说明和示例用法: 语法 p = polyfit(x, y, n) x 和 y 是数据点的横纵…...

VMR,支持30+种编程语言的SDK版本管理器,支持Windows/MacOS/Linux。
官方文档地址:https://docs.vmr.us.kg/ 欢迎安装使用,分享转发,前往github star。 跨平台,支持Windows,Linux,MacOS支持多种语言和工具,省心受到lazygit的启发,拥有更友好的TUI&…...

模板初阶【C++】
文章目录 模板的作用模板的原理模板分为两大类——函数模板和类模板函数模板语法函数模板实例化模板函数的方式模板函数的类型转换既有函数模板又有已经实现的函数,会优先调用哪一个? 类模板语法模板类实例化对象模板类的模板参数可以有缺省值类模板中的…...
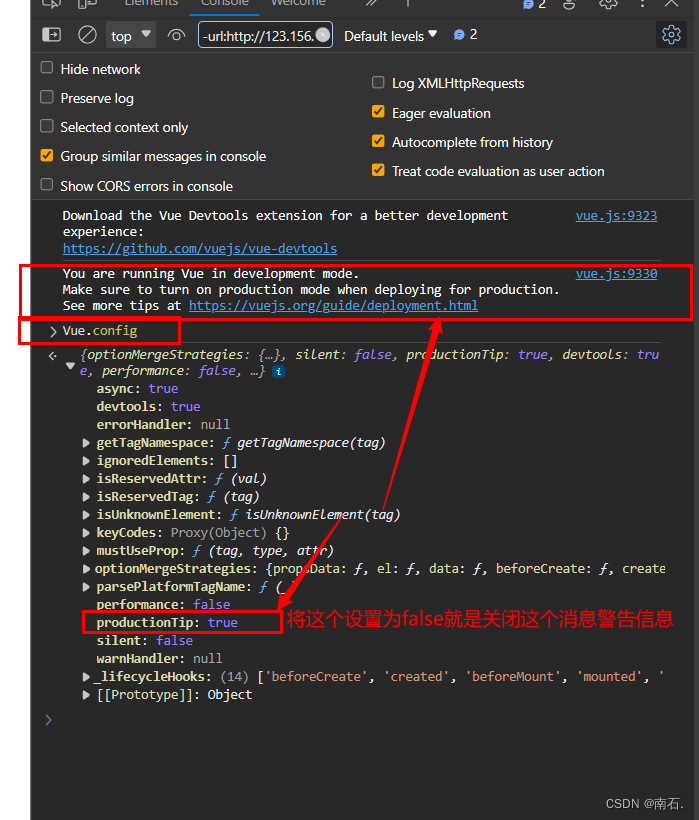
搭建Vue的环境
目录 # 开篇 步骤一,准备Vue 的环境 步骤二,下载Vue.js的包 步骤三,创建并打开写前端代码的文件夹 步骤四,在VSCode中引入Vue.js的包 步骤五,创建第一个vue.html Vue其他知识 Vue.config命令 # 开篇 介绍&…...

[学习笔记]-MyBatis-Plus简介
简介 Mybatis-Plus(简称 MP)是一个 MyBatis (opens new window)的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。 简言之就是对单表的增删改查有了很好的封装。基本不用再单独写sql语句了。目前此类…...

2024.6.23 刷题总结
2024.6.23 **每日一题** 520.检测大写字母,本题是简单模拟题,考察了ASCLL码相关的知识,根据题意,本题对于字符串有三种正确的用法,所以我们分三类来讨论,先根据首字母的大小写来分类,如果首字母…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

拉力测试cuda pytorch 把 4070显卡拉满
import torch import timedef stress_test_gpu(matrix_size16384, duration300):"""对GPU进行压力测试,通过持续的矩阵乘法来最大化GPU利用率参数:matrix_size: 矩阵维度大小,增大可提高计算复杂度duration: 测试持续时间(秒&…...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...

保姆级教程:在无网络无显卡的Windows电脑的vscode本地部署deepseek
文章目录 1 前言2 部署流程2.1 准备工作2.2 Ollama2.2.1 使用有网络的电脑下载Ollama2.2.2 安装Ollama(有网络的电脑)2.2.3 安装Ollama(无网络的电脑)2.2.4 安装验证2.2.5 修改大模型安装位置2.2.6 下载Deepseek模型 2.3 将deepse…...

腾讯云V3签名
想要接入腾讯云的Api,必然先按其文档计算出所要求的签名。 之前也调用过腾讯云的接口,但总是卡在签名这一步,最后放弃选择SDK,这次终于自己代码实现。 可能腾讯云翻新了接口文档,现在阅读起来,清晰了很多&…...

并发编程 - go版
1.并发编程基础概念 进程和线程 A. 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。B. 线程是进程的一个执行实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。C.一个进程可以创建和撤销多个线程;同一个进程中…...
详细解析)
Caliper 负载(Workload)详细解析
Caliper 负载(Workload)详细解析 负载(Workload)是 Caliper 性能测试的核心部分,它定义了测试期间要执行的具体合约调用行为和交易模式。下面我将全面深入地讲解负载的各个方面。 一、负载模块基本结构 一个典型的负载模块(如 workload.js)包含以下基本结构: use strict;/…...