MyBatis映射器:一对多关联查询
大家好,我是王有志,一个分享硬核 Java 技术的金融摸鱼侠,欢迎大家加入 Java 人自己的交流群“共同富裕的 Java 人”。
在学习完上一篇文章《MyBatis映射器:一对一关联查询》后,相信你已经掌握了如何在 MyBatis 映射器中实现一对一关联查询。那么今天我们就趁热打铁,来学习如何在 MyBatis 映射器中使用 resultMap 元素实现一对多关联查询。
数据库中的一对多关联查询
实现了查询用户订单及支付订单信息之后,老板提出了新的想法“订单明细也得加进去”。于是你开始在背后蛐蛐老板,它就不能一次性把所有需求都提出来吗?但是蛐蛐归蛐蛐,活还是得干的。
订单信息中添加查询订单明细的需求也很简单,无非是连个表的事情,这有什么难的?说干就干,于是你很快就写完了 SQL 语句:
select uo.order_id,uo.user_id,uo.order_no,uo.order_price,uo.order_status,uo.create_date,uo.pay_date,oi.item_id,oi.order_id,oi.commodity_id,oi.commodity_price,oi.commodity_countfrom user_order uo, order_item oiwhere uo.order_id = oi.order_idand uo.order_no = 'D202405082208045788';
但是执行完 SQL 语句之后你有点懵了,数据库的查询结果给出了 3 条数据,这与我们设想的一条订单信息带 3 条订单明细也不一样啊?

难道必须要分步查询了吗?
高阶用法:使用 collection 元素实现一对多关联查询
于是你想到是不是还可以使用 resultMap 元素来实现这种一对多的关联查询呢?终于在查阅了相关资料之后,你发现了 reusltMap 元素的子元素 collection 元素似乎可以解决这个问题。
首先我们来修改 UserOrderDO,为其组合上订单明细信息,如下:
public class UserOrderDO {// 省略 UserOrderDO 自身的字段/*** 支付订单信息*/private PayOrderDO payOrder;/*** 用户订单明细*/private List<OrderItemDO> orderItems;
}
接着我们使用 resultMap 元素编写新的映射规则“userOrderContainOrderItemMap”,如下:
<resultMap id="userOrderContainOrderItemMap" type="com.wyz.entity.UserOrderDO" extends="BaseResultMap"><collection property="orderItems" javaType="java.util.ArrayList" ofType="com.wyz.entity.OrderItemDO" columnPrefix="oi_"><id property="itemId" column="item_id" jdbcType="INTEGER"/><result property="orderId" column="order_id" jdbcType="INTEGER"/><result property="commodityId" column="commodity_id" jdbcType="INTEGER"/><result property="commodityPrice" column="commodity_price" jdbcType="DECIMAL"/><result property="commodityCount" column="commodity_count" jdbcType="INTEGER"/></collection>
</resultMap>
这与我们使用 association 元素实现一对一关联查询非常相似,而且 collection 元素中使用的大部分的属性也都在 association 元素中出现过,唯一需要特别关注的是 collection 元素中的 ofType 属性,它与 javaType 属性组合在一起,共同声明了 UserOrderDO 对象中 orderItems 字段的类型,javaType 属性用于声明 orderItems 字段在 UserOrderDO 中的“原始”类型,即该字段为一个集合(ArrayList)类型,而 ofType 属性声明了集合中元素的类型,即该集合中存储的是 OrderItemDO 类型的元素。
接着我们来定义 UserOrderMapper 接口中的方法:
UserOrderDO selectUserOrderAndOrderItemsByOrderNo(@Param("orderNo") String orderNo);
然后我们来编写UserOrderMapper#selectUserOrderAndOrderItemsByOrderNo方法对应的 MyBatis 映射器中的 SQL 语句:
<select id="selectUserOrderAndOrderItemsByOrderNo" resultMap="userOrderContainOrderItemMap">select uo.order_id,uo.user_id,uo.order_no,uo.order_price,uo.order_status,uo.create_date,uo.pay_date,oi.item_id as oi_item_id,oi.order_id as oi_order_id,oi.commodity_id as oi_commodity_id,oi.commodity_price as oi_commodity_price,oi.commodity_count as oi_commodity_countfrom user_order uo, order_item oiwhere uo.order_id = oi.order_idand uo.order_no = #{orderNo,jdbcType=VARCHAR}
</select>
最后我们来写单元测试的代码:
public void selectUserOrderAndOrderItemsByOrderNo() {UserOrderDO userOrder = userOrderMapper.selectUserOrderAndOrderItemsByOrderNo("D202405082208045788");System.out.println("查询结果:");System.out.println(JSON.toJSONString(userOrder, JSONWriter.Feature.PrettyFormat));
}
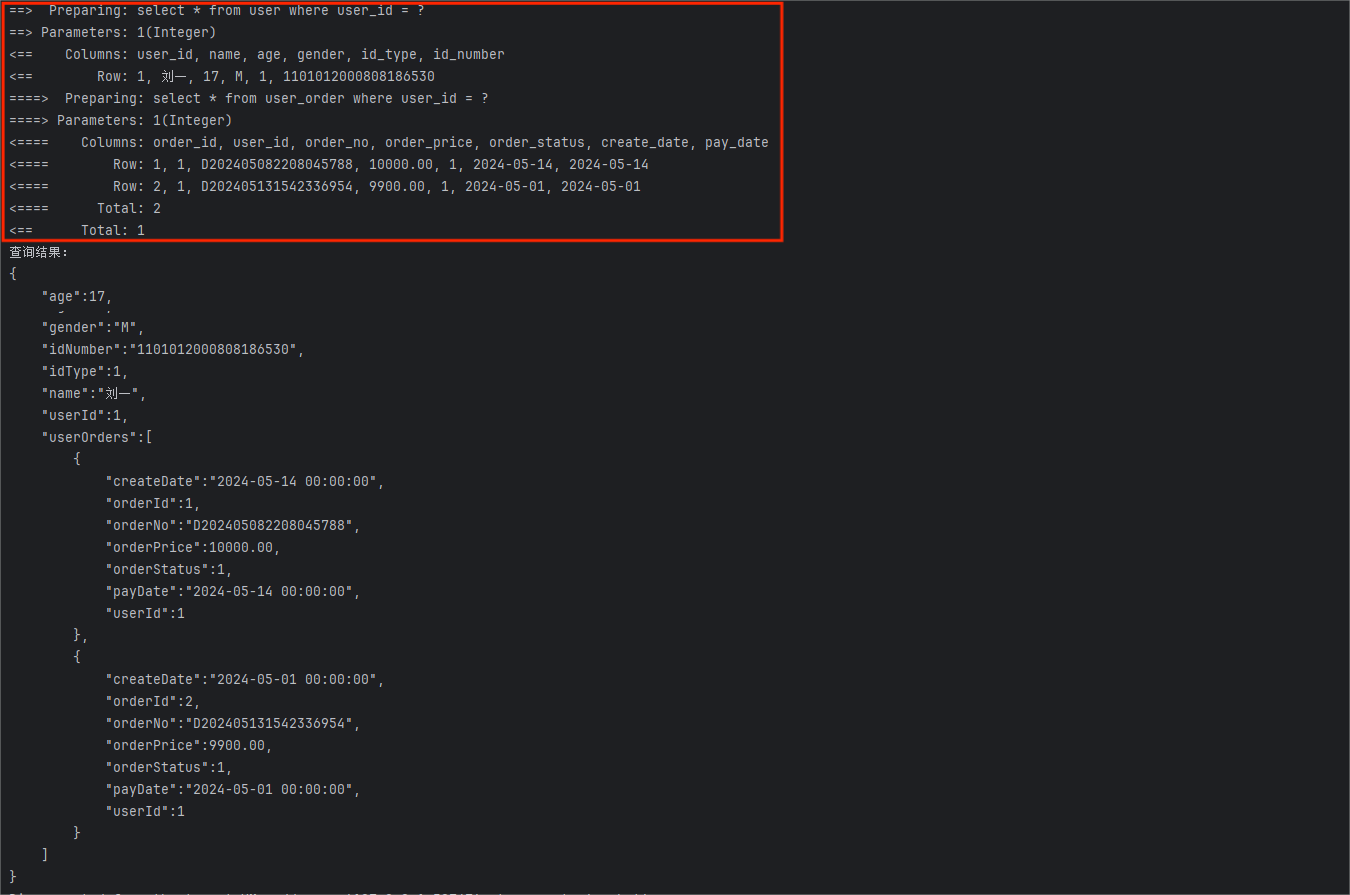
执行单元测试代码,我们来观察控制台输出的结果:
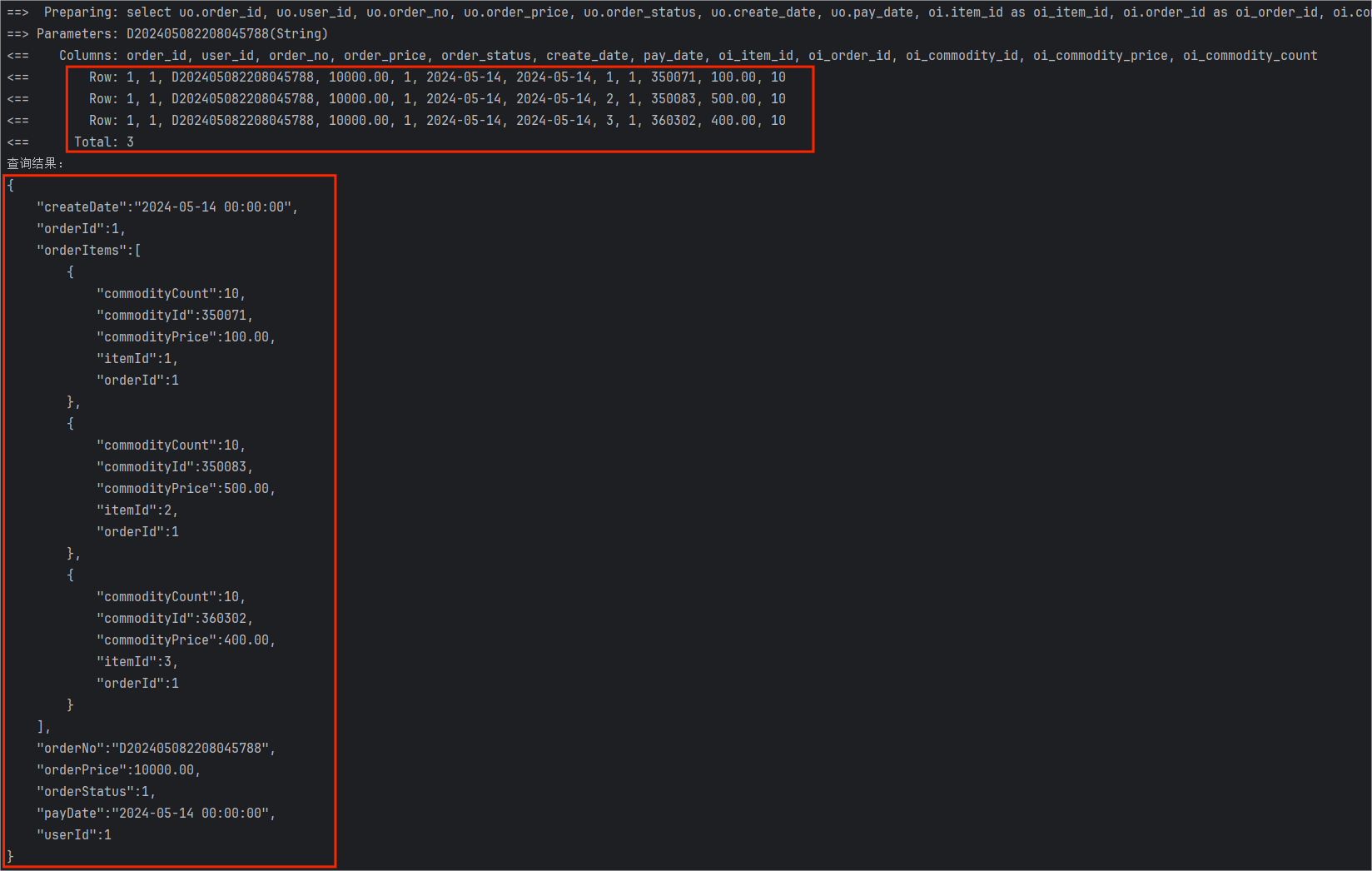
可以看到在 MyBatis 的日志中,SQL 语句查询出的结果是 3 条数据,但是在我们输出的查询结果里只有一条 UserOrderDO 的数据,而 UserOrderDO 对象的 orderItems 字段中却有 3 条数据。
这是因为 MyBatis 在处理结果集时将 3 条数据进行合并,形成一条 UserOrderDO 的数据,合并结果集的主要方法如下:
DefaultResultSetHandler#handleResultSetsDefaultResultSetHandler#handleResultSetDefaultResultSetHandler#handleRowValuesDefaultResultSetHandler#handleRowValuesForNestedResultMapDefaultResultSetHandler#getRowValueDefaultResultSetHandler#applyPropertyMappingsDefaultResultSetHandler#applyNestedResultMappingsDefaultResultSetHandler#linkObjects
因为这是 MyBatis 中结果集处理的核心源码了,在后面源码分析的部分我会和大家一起学习的,所以这里我们先不细说,感兴趣的小伙伴可以自行阅读源码。
高阶用法:使用 collection 元素实现一对多嵌套查询
与 association 元素一样,除了使用关联查询外,还可以通过嵌套查询的方式实现一对多管理。
首先我们来为 OrderItemMapper 接口添加相关的查询方法:
List<OrderItemDO> selectOrderItemByOrderId(@Param("orderId") Integer orderId);
然后为其添加结果集映射规则和编写相应的 SQL 语句:
<resultMap id="BaseResultMap" type="com.wyz.entity.OrderItemDO"><id property="itemId" column="item_id" jdbcType="INTEGER"/><result property="orderId" column="order_id" jdbcType="INTEGER"/><result property="commodityId" column="commodity_id" jdbcType="INTEGER"/><result property="commodityPrice" column="commodity_price" jdbcType="DECIMAL"/><result property="commodityCount" column="commodity_count" jdbcType="INTEGER"/>
</resultMap><select id="selectOrderItemByOrderId" resultMap="BaseResultMap">select * from order_itemwhere order_id = #{orderId, jdbcType=INTEGER}
</select>
下面我们来处理 user_order 表相关的部分,首先是定义 UserOrderMapper 接口中的方法:
UserOrderDO selectUserOrderAndOrderItemsByOrderNoNest(@Param("orderNo") String orderNo);
接着完善映射器中对应的 SQL 语句:
<select id="selectUserOrderAndOrderItemsByOrderNoNest" resultMap="userOrderContainOrderItemNestMap">select *from user_orderwhere order_no = #{orderNo, jdbcType=VARCHAR}
</select>
我们来编写 UserOrderDO 的映射规则“userOrderContainOrderItemNestMap”,如下:
<resultMap id="userOrderContainOrderItemNestMap" type="com.wyz.entity.UserOrderDO" extends="BaseResultMap"><collection property="orderItems"javaType="java.util.ArrayList"ofType="com.wyz.entity.OrderItemDO"select="com.wyz.mapper.OrderItemMapper.selectOrderItemByOrderId"column="{orderId=order_id}"/>
</resultMap>
最后我们编写单元测试代码,如下:
public void selectUserOrderAndOrderItemsByOrderNoNest() {UserOrderDO userOrder = userOrderMapper.selectUserOrderAndOrderItemsByOrderNoNest("D202405082208045788");System.out.println("查询结果:");System.out.println(JSON.toJSONString(userOrder, JSONWriter.Feature.PrettyFormat));
}
执行单元测试可以看到如下结果:
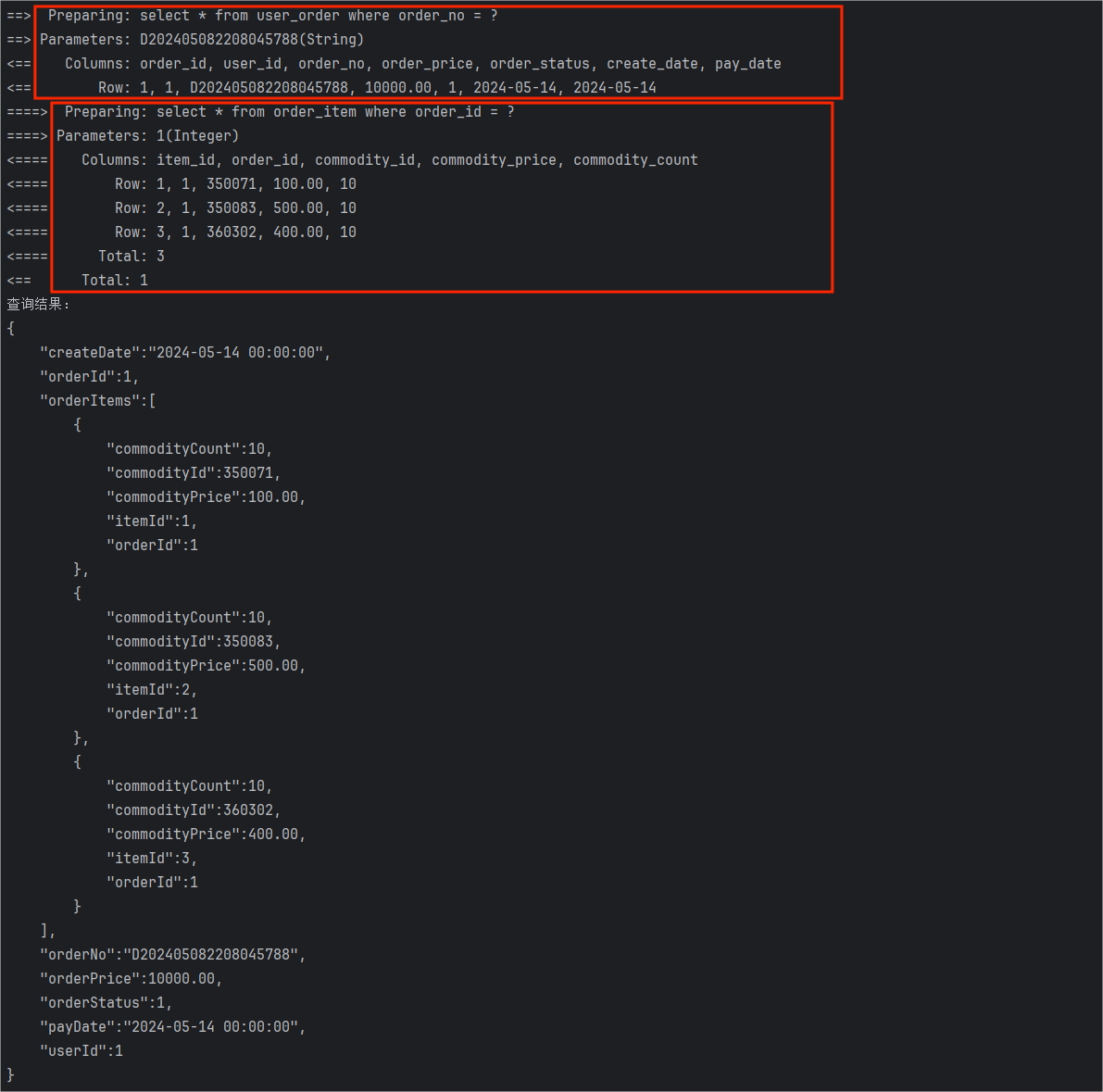
可以看到在控制台输出的执行结果中,执行了两条 SQL 语句,分别用于查询 user_order 表的数据和 order_item 表的数据,而在数据的结果中,MyBatis 也将这些数据进行了合并。
高阶用法:多层级结果集关联查询
实现了上面的所有需求后,你的老板还是不满足,它又提出了新的想法:“为什么不能在查询用户时,把该用户所有的订单,订单明细和支付订单全部查询出来呢?”,于是你再一次在背后蛐蛐了你的老板,并埋头苦干。
有了前面的经验,你很快就想到了 resultMap 元素可以解决,无法就是多套几层罢了。为了更好的进行展示多层映射规则,我们需要补充一些数据,我在附录中提供了补充数据的 SQL 脚本,可以先添加到数据库中,
目前我们的 UserOrderDO 对象中已经组合了 PayOrderDO 和 OrderItemDO,那么我们无非就是把 UserOrderDO 组合到 UserDO 对象中,代码如下:
public class UserDO {// 省略 UserDO 自身的字段/*** 用户订单*/private List<UserOrderDO> userOrders;
}
接着我们为 UserMapper 接口中定义方法:
UserDO selectUserByUserId(@Param("userId") Integer userId);
再来写 SQL 语句,有了前面的经验,很快就能想到联表查询一次数据库交就可以互搞定,代码如下:
<select id="selectUserByUserId" resultMap="userMap">select u.user_id,u.name,u.age,u.gender,u.id_type,u.id_number,uo.order_id as uo_order_id,uo.user_id as uo_user_id,uo.order_no as uo_order_no,uo.order_price as uo_order_price,uo.order_status as uo_order_status,uo.create_date as uo_create_date,uo.pay_date as uo_pay_date,po.pay_order_id as po_pay_order_id,po.order_id as po_order_id,po.pay_order_no as po_pay_order_no,po.pay_amount as po_pay_amount,po.pay_channel as po_pay_channel,po.pay_status as po_pay_status,po.create_date as po_create_date,po.finish_date as po_finish_date,oi.item_id as oi_item_id,oi.order_id as oi_order_id,oi.commodity_id as oi_commodity_id,oi.commodity_price as oi_commodity_price,oi.commodity_count as oi_commodity_countfrom user u, user_order uo, pay_order po, order_item oiwhere u.user_id = #{userId, jdbcType=INTEGER}and u.user_id = uo.user_idand uo.order_id = po.order_idand uo.order_id = oi.order_id
</select>
下面我们开始定义映射规则“userMap”,如下:
<resultMap id="userMap" type="com.wyz.entity.UserDO"><id property="userId" column="user_id" jdbcType="INTEGER"/><result property="name" column="name" jdbcType="VARCHAR"/><result property="age" column="age" jdbcType="INTEGER"/><result property="gender" column="gender" jdbcType="VARCHAR"/><result property="idType" column="id_type" jdbcType="INTEGER"/><result property="idNumber" column="id_number" jdbcType="VARCHAR"/><collection property="userOrders" javaType="java.util.ArrayList" ofType="com.wyz.entity.UserOrderDO" columnPrefix="uo_"><id property="orderId" column="order_id" jdbcType="INTEGER"/><result property="userId" column="user_id" jdbcType="INTEGER"/><result property="orderNo" column="order_no" jdbcType="VARCHAR"/><result property="orderPrice" column="order_price" jdbcType="DECIMAL"/><result property="orderStatus" column="order_status" jdbcType="INTEGER"/><result property="createDate" column="create_date" jdbcType="DATE"/><result property="payDate" column="pay_date" jdbcType="DATE"/><association property="payOrder" javaType="com.wyz.entity.PayOrderDO" columnPrefix="po_"><id property="payOrderId" column="pay_order_id" jdbcType="INTEGER"/><result property="orderId" column="order_id" jdbcType="INTEGER"/><result property="payOrderNo" column="pay_order_no" jdbcType="VARCHAR"/><result property="payAmount" column="pay_amount" jdbcType="DECIMAL"/><result property="payChannel" column="pay_channel" jdbcType="INTEGER"/><result property="payStatus" column="pay_status" jdbcType="INTEGER"/><result property="createDate" column="create_date" jdbcType="DATE"/><result property="finishDate" column="finish_date" jdbcType="DATE"/></association><collection property="orderItems" javaType="java.util.ArrayList" ofType="com.wyz.entity.OrderItemDO" columnPrefix="oi_"><id property="itemId" column="item_id" jdbcType="INTEGER"/><result property="orderId" column="order_id" jdbcType="INTEGER"/><result property="commodityId" column="commodity_id" jdbcType="INTEGER"/><result property="commodityPrice" column="commodity_price" jdbcType="DECIMAL"/><result property="commodityCount" column="commodity_count" jdbcType="INTEGER"/></collection></collection>
</resultMap>
最后我们来搞定单元测试的代码:
public void selectUserByUserId() {UserDO user = userMapper.selectUserByUserId(1);System.out.println("查询结果:");System.out.println(JSON.toJSONString(user, JSONWriter.Feature.PrettyFormat));
}
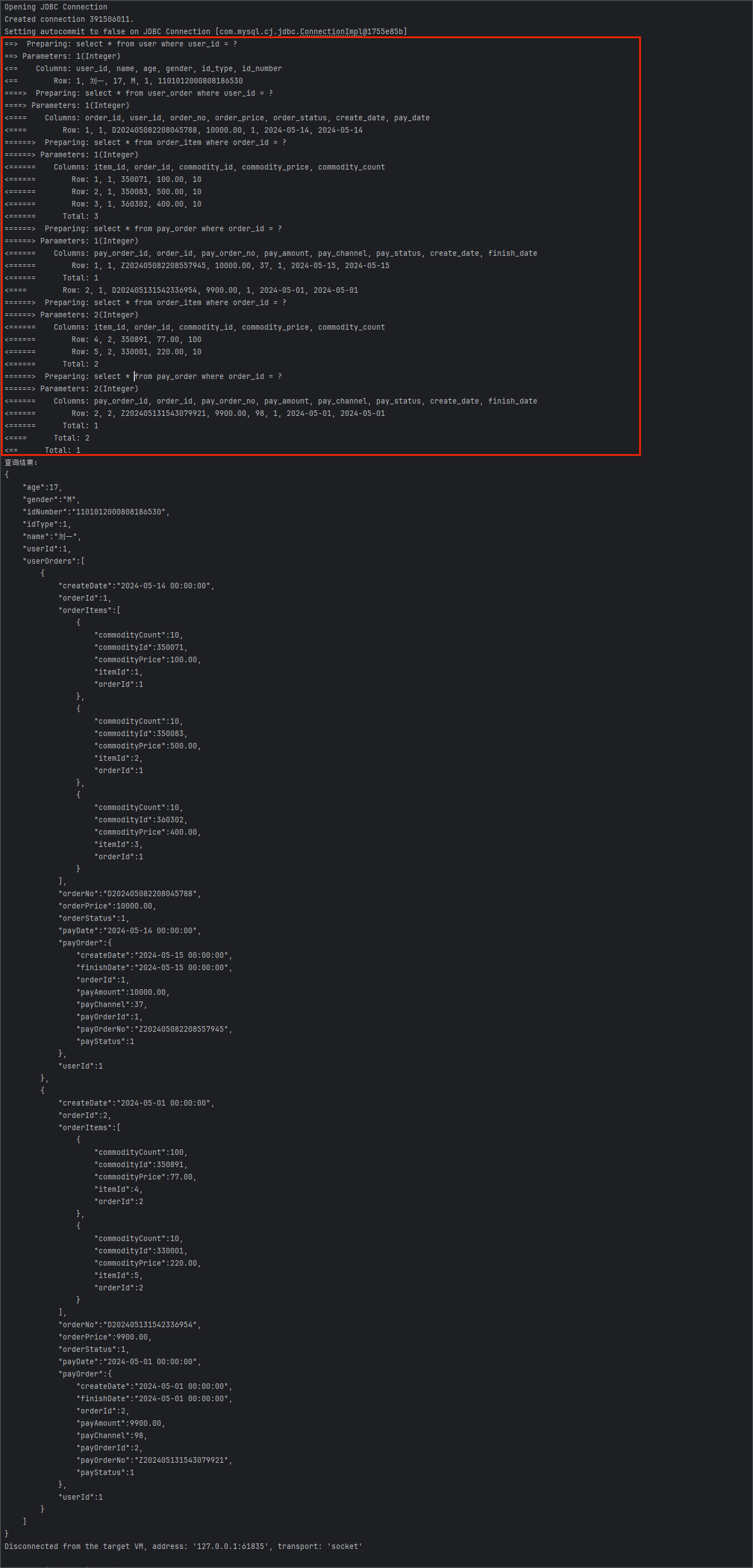
当你自信满满的执行单元测试后,控制台输出的结果却有些出乎意料:
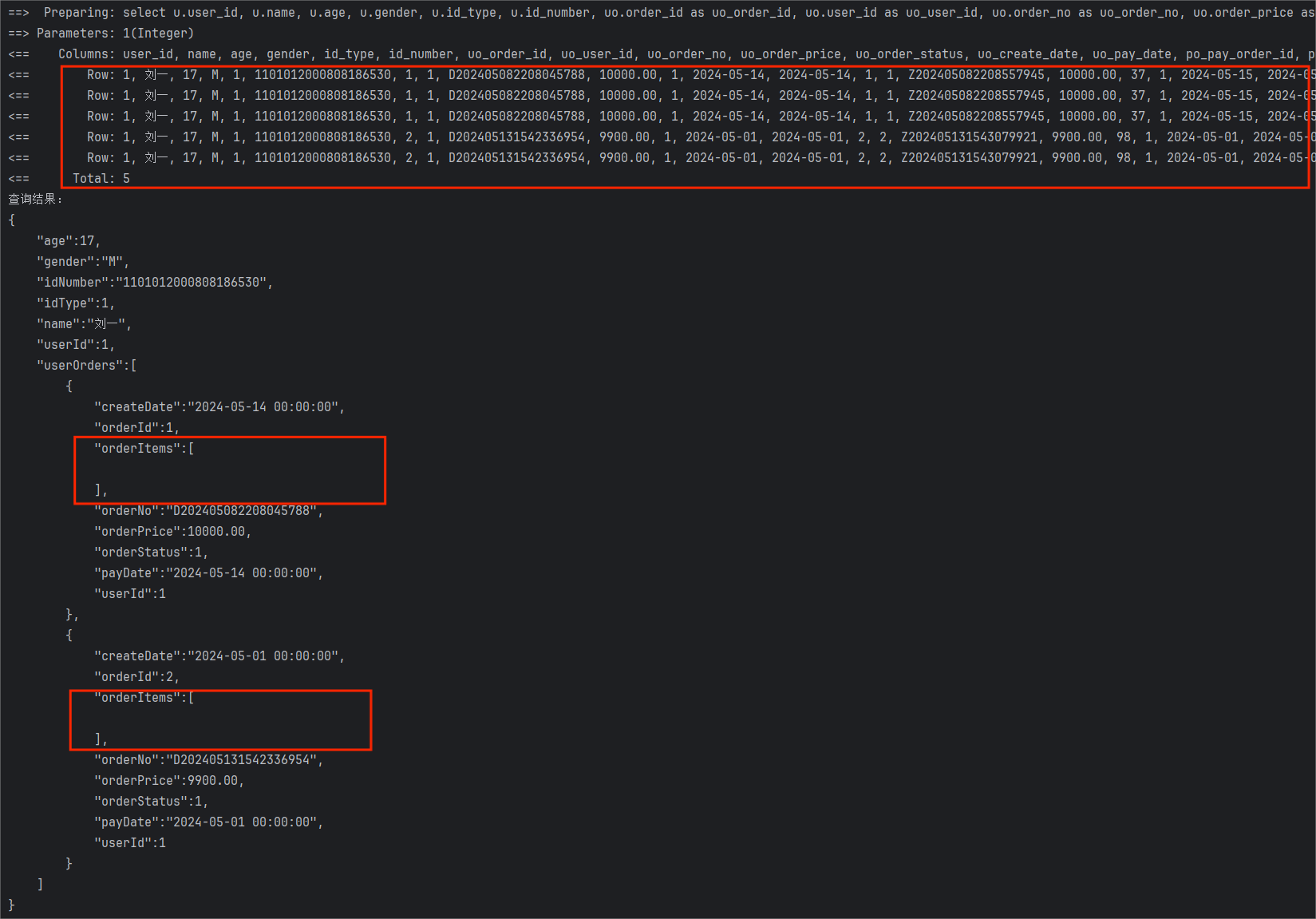
可以看到,MyBatis 执行的 SQL 语句是正常的,输出的查询结果也是正常的,可以在最终的结果集映射上出了问题,PayOrderDO 对象和 OrderItemDO 对象并没有映射成功。
columnPrefix 属性导致的映射失败
是不是 MyBatis 不支持映射规则的多层嵌套呢?
其实不是的,在 MyBatis 中使用多层嵌套规则,且每层嵌套规则都配置了 columnPrefix 属性时,在为下层映射规则的查询字段起别名时,需要将上层的嵌套映射规则配置的 columnPrefix 属性作为前缀,然后再拼接本层的 columnPrefix 属性的配置,而在 resultMap 元素的配置中,每层只需要配置自己的前缀即可。
在上面的多层嵌套映射规则的例子中,映射规则“userMap”不需要改变,SQL 语句需要修改成如下图右侧所示的内容:
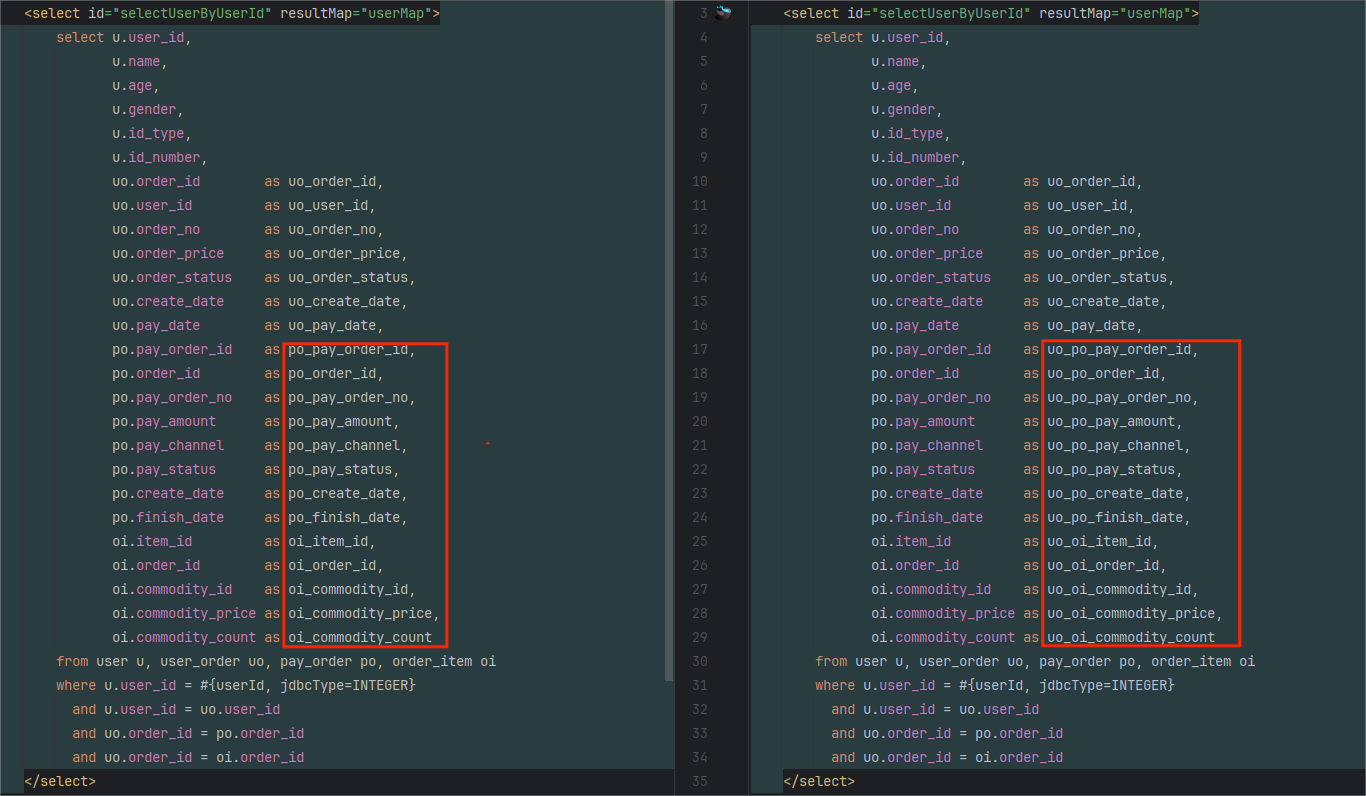
我把图中右侧的 SQL 语句粘到了这里:
<select id="selectUserByUserId" resultMap="userMap">select u.user_id,u.name,u.age,u.gender,u.id_type,u.id_number,uo.order_id as uo_order_id,uo.user_id as uo_user_id,uo.order_no as uo_order_no,uo.order_price as uo_order_price,uo.order_status as uo_order_status,uo.create_date as uo_create_date,uo.pay_date as uo_pay_date,po.pay_order_id as uo_po_pay_order_id,po.order_id as uo_po_order_id,po.pay_order_no as uo_po_pay_order_no,po.pay_amount as uo_po_pay_amount,po.pay_channel as uo_po_pay_channel,po.pay_status as uo_po_pay_status,po.create_date as uo_po_create_date,po.finish_date as uo_po_finish_date,oi.item_id as uo_oi_item_id,oi.order_id as uo_oi_order_id,oi.commodity_id as uo_oi_commodity_id,oi.commodity_price as uo_oi_commodity_price,oi.commodity_count as uo_oi_commodity_countfrom user u, user_order uo, pay_order po, order_item oiwhere u.user_id = #{userId, jdbcType=INTEGER}and u.user_id = uo.user_idand uo.order_id = po.order_idand uo.order_id = oi.order_id
</select>
你可以替换掉 SQL 语句,再执行单元测试看看结果,pay_order 表和 order_item 表的数据是不是已经映射到结果里了呢?
透过源码分析 columnPrefix 属性的逻辑
不感兴趣的可以先跳过这部分内容,因为在后面的源码分析篇中,我们也会涉及到这部分内容。
注意,本文中涉及到源码的部分,我只保留了相关内容的源码,因此删减和改动的部分会非常多,我会尽量保证展示出来的源码能够清晰的解释这段逻辑。
我们先找到DefaultResultSetHandler#handleResultSets方法的源码,部分源码如下:
public List<Object> handleResultSets(Statement stmt) throws SQLException {final List<Object> multipleResults = new ArrayList<>();int resultSetCount = 0;// 获取首行数据ResultSetWrapper rsw = getFirstResultSet(stmt);List<ResultMap> resultMaps = mappedStatement.getResultMaps();while (rsw != null) {ResultMap resultMap = resultMaps.get(resultSetCount);// 处理结果集handleResultSet(rsw, resultMap, multipleResults, null);// 获取下一行数据rsw = getNextResultSet(stmt);resultSetCount++;}
}
DefaultResultSetHandler#handleResultSets方法的主要功能是逐行解析结果集数据,我们接着来看第 10 行中调用的DefaultResultSetHandler#handleResultSet方法:
private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List<Object> multipleResults, ResultMapping parentMapping) throws SQLException {if (parentMapping != null) {handleRowValues(rsw, resultMap, null, RowBounds.DEFAULT, parentMapping);} else if (resultHandler == null) {DefaultResultHandler defaultResultHandler = new DefaultResultHandler(objectFactory);handleRowValues(rsw, resultMap, defaultResultHandler, rowBounds, null);}
}
删减过后DefaultResultSetHandler#handleResultSet方法非常简单(其实原始代码也很简单),我们不需要过多关注这个方法,直接看第 3 行和第 6 行中调用的DefaultResultSetHandler#handleRowValues方法,部分源码如下:
public void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {if (resultMap.hasNestedResultMaps()) {handleRowValuesForNestedResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);} else {handleRowValuesForSimpleResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);}
}
DefaultResultSetHandler#handleRowValues方法的源码也很简。不过需要解释下第 2 行中 if 语句的调用的ResultMap#hasNestedResultMaps方法,该方法返回 ResultMap 中 hasNestedResultMaps 字段的值,该字段的值在解析 MyBatis 映射器中的 resultMap 元素时确定,如果该 resultMap 元素定义的映射规则存在嵌套映射规则,则 hasNestedResultMaps 的值为 true,否则为 false。
对于我们使用的映射规则“userMap”来说,我们嵌套了 3 层,因此在这里的条件语句中会执行第 3 行的DefaultResultSetHandler#handleRowValuesForNestedResultMap方法,部分源码如下:
private void handleRowValuesForNestedResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {final DefaultResultContext<Object> resultContext = new DefaultResultContext<>();Object rowValue = previousRowValue;while (shouldProcessMoreRows(resultContext, rowBounds) && !resultSet.isClosed() && resultSet.next()) {final ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(resultSet, resultMap, null);final CacheKey rowKey = createRowKey(discriminatedResultMap, rsw, null);Object partialObject = nestedResultObjects.get(rowKey);// 获取每行的数据rowValue = getRowValue(rsw, discriminatedResultMap, rowKey, null, partialObject);}
}
DefaultResultSetHandler#handleRowValuesForNestedResultMap方法删减之后就简单很多了,该方法的主要作用是调用DefaultResultSetHandler#getRowValue方法转换结果集数据,不过需要注意下调用DefaultResultSetHandler#getRowValue方法时第 4 个参数,此时为 null。
我们继续向下,来看第 9 行调用的DefaultResultSetHandler#getRowValue方法,部分源码如下:
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap, CacheKey combinedKey, String columnPrefix, Object partialObject) throws SQLException {final String resultMapId = resultMap.getId();Object rowValue = partialObject;rowValue = createResultObject(rsw, resultMap, lazyLoader, columnPrefix);if (rowValue != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {final MetaObject metaObject = configuration.newMetaObject(rowValue);boolean foundValues = this.useConstructorMappings;// 处理当前层级的字段映射规则foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, columnPrefix) || foundValues;// 处理嵌套的字段映射规则foundValues = applyNestedResultMappings(rsw, resultMap, metaObject, columnPrefix, combinedKey, true) || foundValues;}return rowValue;
}
先来看DefaultResultSetHandler#getRowValue方法的声明,第 4 个参数的变量名是“columnPrefix”,即我们在映射规则中配置的 columnPrefix 属性,不过在首次调用DefaultResultSetHandler#getRowValue方法的时候 columnPrefix 参数的值为 null。
接下来我们进入第 11 行中调用的DefaultResultSetHandler#applyNestedResultMappings方法,该方法用于处理嵌套层级的字段映射,部分源码如下:
private boolean applyNestedResultMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, String parentPrefix, CacheKey parentRowKey, boolean newObject) {boolean foundValues = false;for (ResultMapping resultMapping : resultMap.getPropertyResultMappings()) {final String nestedResultMapId = resultMapping.getNestedResultMapId();if (nestedResultMapId != null && resultMapping.getResultSet() == null) {// 获取 columnPrefix final String columnPrefix = getColumnPrefix(parentPrefix, resultMapping);// 获取嵌套规则中的配置final ResultMap nestedResultMap = getNestedResultMap(rsw.getResultSet(), nestedResultMapId, columnPrefix);final CacheKey rowKey = createRowKey(nestedResultMap, rsw, columnPrefix);final CacheKey combinedKey = combineKeys(rowKey, parentRowKey);Object rowValue = nestedResultObjects.get(combinedKey);// 解析嵌套规则中的结果集if (anyNotNullColumnHasValue(resultMapping, columnPrefix, rsw)) {rowValue = getRowValue(rsw, nestedResultMap, combinedKey, columnPrefix, rowValue);if (rowValue != null) {linkObjects(metaObject, resultMapping, rowValue);foundValues = true;}}}}return foundValues;
}
DefaultResultSetHandler#applyNestedResultMappings负责处理嵌套映射规则中的每个字段的映射逻辑。
首先来看第 3 行 for 循环语句,ResultMap 的 propertyResultMappings 字段中存储了 resultMap 元素中每个 id 元素,result 元素,association 元素和 collection 元素的解析结果,因此这里是遍历 resultMap 元素中的每项映射规则的配置。
第 4 行中的 ResultMap 的 nestedResultMapId 字段存储了嵌套映射规则的 ID,这个 ID 是由 MyBatis 自动生成的,其形式如:com.wyz.mapper.UserMapper.mapper_resultMap[userMap]_collection[userOrders],存储了 resuMap 的 ID,嵌套映射规则的类型,以及该嵌套规则对应的字段名。
紧接着是第 5 行的的 if 条件语句,要求 nestedResultMapId 不为空的情况下才会执行 if 条件语句中的逻辑,也就是说只有嵌套映射规则才会执行 if 条件语句中的逻辑。
再来看第 7 行中调用的DefaultResultSetHandler#getColumnPrefix方法,该方法用于获取 columnPrefix 属性中的配置,完成源码如下:
private String getColumnPrefix(String parentPrefix, ResultMapping resultMapping) {final StringBuilder columnPrefixBuilder = new StringBuilder();if (parentPrefix != null) {columnPrefixBuilder.append(parentPrefix);}if (resultMapping.getColumnPrefix() != null) {columnPrefixBuilder.append(resultMapping.getColumnPrefix());}return columnPrefixBuilder.length() == 0 ? null : columnPrefixBuilder.toString().toUpperCase(Locale.ENGLISH);
}
我们来分析这段源码,首先是第一次调用时 parentPrefix 的值为 null,如果此时嵌套映射规则中配置了 columnPrefix 属性,例如在解析映射规则 userMap 时,解析到了下面的配置时:
<collection property="userOrders" javaType="java.util.ArrayList" ofType="com.wyz.entity.UserOrderDO" columnPrefix="uo_">
根据源码中的逻辑,此时返回的值为“uo_”。
我们回到DefaultResultSetHandler#applyNestedResultMappings方法中的第 15 行代码,此时会递归调用DefaultResultSetHandler#getRowValue方法,不过此时传入的是嵌套规则中的配置。
那么后面的就很好理解了,当遍历到嵌套映射规则时,会递归调用DefaultResultSetHandler#getRowValue方法,此时传入的 columnPrefix 参数就有了值,再次执行DefaultResultSetHandler#getColumnPrefix方法时,就是将传入的 columnPrefix 参数与嵌套规则中 columnPrefix 属性的配置组合起来。
那么我们回到最开始的 SQL 语句与映射规则“userMap”中,当遍历到 payOrder 的嵌套映射规则时,此时的前缀应该为“uo_po_”,而遍历到 orderItems 的嵌套映射规则时,此时的前缀应该为“uo_oi_”。
高阶用法:多层级结果集嵌套查询
上面我们实现的通过 user_id 查询用户信息,用户订单信息,订单明细信息以及支付信息的功能中,除了最开始的 pay_order 表和 order_utem 表的数据无法映射外,还存在一个问题,那就是在联表查询的 SQL 语句中,查询结果是笛卡尔积的形式。
不过,由于我们的测试数据非常少,而且表结构非常简单,SQL 语句对性能的影响可以湖绿不急。不过一旦数据量上来,或者联表查询的 SQL 语句设计不合理,那么对整体性能的影响可能是灾难级的,此时与其守着一次数据库交互,倒不如拆分成多个 SQL 语句分别查询了。
说干就干,我们已经知道了如何在 resultMap 元素中嵌套子查询语句,那么改写映射规则“userMap”就非常简单了,代码如下:
<resultMap id="userNestMap" type="com.wyz.entity.UserDO" extends="BaseResultMap"><collection property="userOrders"javaType="java.util.ArrayList"ofType="com.wyz.entity.UserOrderDO"select="com.wyz.mapper.UserOrderMapper.selectUserOrderByUserId"column="{userId=user_id}"><association property="payOrder"javaType="com.wyz.entity.PayOrderDO"select="com.wyz.mapper.PayOrderMapper.selectPayOrderByOrderId"column="{orderId=order_id}"/><collection property="orderItems"javaType="java.util.ArrayList"ofType="com.wyz.entity.OrderItemDO"select="com.wyz.mapper.OrderItemMapper.selectOrderItemByOrderId"column="{orderId=order_id}"/></collection>
</resultMap>
可以看到,新的映射规则“userNestMap”分为 3 层:
- 第 1 层是 user 表与 Java 对象 UserDO 的映射规则,直接继承了 UserMapper 的映射规则集“BaseResultMap”;
- 第 2 层是 usser_order 表与 Java 对象 UserOrderDO 的映射规则,使用了子查询
UserOrderMapper#selectUserOrderByUserId; - 第 3 层 pay_order 表与 Java 对象 PayOrderDO,以及 order_item 表与 Java 对象 OrderItemDO 的映射规则,分别使用了子查询
PayOrderMapper#selectPayOrderByOrderId和OrderItemMapper#selectOrderItemByOrderId。
Tips:这里就不展示 3 个子查询方法了(反正也得改)。
当你做好“万全”的准备之后执行单元测试,控制台的输出再一次让你出乎意料:
明明写了在映射规则中写了 3 个子查询,再加上主查询 SQL 语句,应该执行 4 条 SQL 语句的,可是为什么只执行了两条语句呢?
再仔细观察控制台输出的 SQL 执行记录,你发现了最外层查询 user 表的 SQL 语句和第 2 层查询 user_order 表的 SQL 语句都执行了,只有第 3 层查询 pay_order 表和查询 order_item 表的两条 SQL 语句没有执行,难道是 MyBatis 不支持 3 层嵌套子查询?
还真是这样的,MyBatis 最多只能在一个映射规则中支持两层嵌套子查询,即只允许主查询语句“拥有”子查询语句,而子查询不能再“拥有”子查询语句。
透过源码分析多层嵌套子查询
造成这种现象的原因是因为 MyBatis 在解析 resultMap 元素时,只会解析一层嵌套的子查询语句。
来看 MyBatis 解析 resultMap 元素的源码,我们直接从XMLMapperBuilder#resultMapElements方法入手,部分源码如下:
private void resultMapElements(List<XNode> list) {for (XNode resultMapNode : list) {resultMapElement(resultMapNode);}
}
该方法用于遍历映射器文件中的所有 resultMap 元素定义的映射规则,并逐个进行解析。
接下来看第 3 行调用的XMLMapperBuilder# resultMapElement方法:
private ResultMap resultMapElement(XNode resultMapNode, List<ResultMapping> additionalResultMappings, Class<?> enclosingType) {Class<?> typeClass = resolveClass(type);List<ResultMapping> resultMappings = new ArrayList<>(additionalResultMappings);List<XNode> resultChildren = resultMapNode.getChildren();for (XNode resultChild : resultChildren) {resultMappings.add(buildResultMappingFromContext(resultChild, typeClass, flags));}
}
XMLMapperBuilder# resultMapElement方法用于遍历 resultMap 元素的所有子元素,并根据子元素类型的不同执行不同的处理逻辑(这里省略了其它类型子元素的判断逻辑和处理逻辑),如果是 id 元素,result 元素,association 元素和 collection 元素等,会调用第 6 行中的XMLMapperBuilder#buildResultMappingFromContext方法,源码如下:
private ResultMapping buildResultMappingFromContext(XNode context, Class<?> resultType, List<ResultFlag> flags) {String property;if (flags.contains(ResultFlag.CONSTRUCTOR)) {property = context.getStringAttribute("name");} else {property = context.getStringAttribute("property");}String column = context.getStringAttribute("column");String javaType = context.getStringAttribute("javaType");String jdbcType = context.getStringAttribute("jdbcType");String nestedSelect = context.getStringAttribute("select");String nestedResultMap = context.getStringAttribute("resultMap", () -> processNestedResultMappings(context, Collections.emptyList(), resultType));String notNullColumn = context.getStringAttribute("notNullColumn");String columnPrefix = context.getStringAttribute("columnPrefix");String typeHandler = context.getStringAttribute("typeHandler");String resultSet = context.getStringAttribute("resultSet");String foreignColumn = context.getStringAttribute("foreignColumn");boolean lazy = "lazy".equals(context.getStringAttribute("fetchType", configuration.isLazyLoadingEnabled() ? "lazy" : "eager"));Class<?> javaTypeClass = resolveClass(javaType);Class<? extends TypeHandler<?>> typeHandlerClass = resolveClass(typeHandler);JdbcType jdbcTypeEnum = resolveJdbcType(jdbcType);return builderAssistant.buildResultMapping(resultType, property, column, javaTypeClass, jdbcTypeEnum, nestedSelect, nestedResultMap, notNullColumn, columnPrefix, typeHandlerClass, flags, resultSet, foreignColumn, lazy);
}
这是XMLMapperBuilder#buildResultMappingFromContext方法的全部源码了,先来看第 11 行中,获取了子元素中 select 属性的配置,即我们的子查询语句。
接着来看第 12 行中调用的XMLMapperBuilder#processNestedResultMappings方法,源码如下:
private String processNestedResultMappings(XNode context, List<ResultMapping> resultMappings, Class<?> enclosingType) {if (Arrays.asList("association", "collection", "case").contains(context.getName()) && context.getStringAttribute("select") == null) {validateCollection(context, enclosingType);ResultMap resultMap = resultMapElement(context, resultMappings, enclosingType);return resultMap.getId();}return null;
}
在XMLMapperBuilder#processNestedResultMappings方法中,第 2 行的 if 条件语句中,判断了子元素的类型属于
association 元素,collection 元素或 case 元素中的一种,并且没有配置 select 属性时进入条件语句中递归调用XMLMapperBuilder#resultMapElement方法解析映射规则。
这也就是说,当 resultMap 中配置了多层级的嵌套规则时,MyBatis 会将每层规则单独解析,如果是嵌套的子查询,就不会继续向下解析了,这也就是为什么在我们的多层级嵌套子查询的映射规则“userNestMap”中,无法解析到第 3 层的嵌套子查询语句。
Tips:前面的“透过源码分析 columnPrefix 属性的逻辑”中,我们提到到嵌套映射规则,就是在这里生成的。
改写多层嵌套子查询
那么我们来改写多层嵌套子查询映射规则“userNestMap”,首先我们要做的是将 3 层嵌套子查询改成两层,那么我们需要将查询 pay_order 表的子查询与查询 order_item 表的子查询移动到查询 user_order 表的数据的映射规则中。
前面我们已经写了映射规则“userOrderContainOrderItemNestMap”并且集成了 order_item 表的子查询,并且上一篇文章《MyBatis映射器:一对一关联查询》中的映射规则“userOrderContainPayOrderNestMap”集成了 pay_order 表的子查询,那么我们将两者结合一下,不就包含了两个子查询了吗?代码如下:
<resultMap id="userOrderContainOrderItemNestMap" type="com.wyz.entity.UserOrderDO" extends="userOrderContainPayOrderNestMap"><collection property="orderItems"javaType="java.util.ArrayList"ofType="com.wyz.entity.OrderItemDO"select="com.wyz.mapper.OrderItemMapper.selectOrderItemByOrderId"column="{orderId=order_id}"/>
</resultMap>
改写完映射规则之后,我们还要为 UserOrderMapper 接口添加一个新的接口方法,因为 user 表与 user_order 表是通过 user_id 字段进行关联的,如下:
List<UserOrderDO> selectUserOrderByUserIdNest(@Param("userId")Integer userId);
接着是 UserMapper 接口对应的映射器中的 SQL 语句,如下:
<select id="selectUserOrderByUserIdNest" resultMap="userOrderContainOrderItemNestMap">select * from user_order where user_id = #{userId,jdbcType=INTEGER}
</select>
做完这些准备工作之后,我们就来改写映射规则“userMap”,如下:
<resultMap id="userNestMap" type="com.wyz.entity.UserDO" extends="BaseResultMap"><collection property="userOrders"javaType="java.util.ArrayList"ofType="com.wyz.entity.UserOrderDO"select="com.wyz.mapper.UserOrderMapper.selectUserOrderByUserIdNest"column="{userId=user_id}"></collection>
</resultMap>
最后我们执行单元测试,来观察控制台的输出:
可以看到在输出的查询语句中,比我们想象中的要多,这是因为该用户有两个订单,而我们嵌套的子查询语句只允许传入单个订单 ID,因此需要根据订单 ID 查询多次支付订单信息和订单明细信息。
当然了,你可以修改这个映射规则,允许部分简单的联表查询,以减少执行 SQL 语句的次数,减少与数据库的交互。不过我是累了,就留给大家自行实现吧~~
最后,我再补充一点 association 元素和 collection 元素中是有一个属性叫做 resultMap 的,你可以用它来引入其它的映射规则,来减少配置,这个也留给大家自行探索吧。
附录:数据补充
补充数据,用于测试多层嵌套关联查询,SQL 脚本如下:
-- 用户信息
INSERT INTO user (user_id, name, age, gender, id_type, id_number) VALUES (2, '陈二', 18, 'M', 1, '1101012000808186531');-- 用户订单信息
INSERT INTO user_order (order_id, user_id, order_no, order_price, order_status, create_date, pay_date) VALUES (3, 2, 'D202405202033475889', 100.00, 1, '2024-05-20', '2024-05-21');-- 支付订单信息
INSERT INTO pay_order (pay_order_id, order_id, pay_order_no, pay_amount, pay_channel, pay_status, create_date, finish_date) VALUES (3, 3, 'Z202405202033475889', 100.00, 755, 1, '2024-05-21', '2024-05-21');-- 订单明细
INSERT INTO order_item (item_id, order_id, commodity_id, commodity_price, commodity_count) VALUES (4, 2, 350891, 77.00, 100);
INSERT INTO order_item (item_id, order_id, commodity_id, commodity_price, commodity_count) VALUES (5, 2, 330001, 220.00, 10);
INSERT INTO order_item (item_id, order_id, commodity_id, commodity_price, commodity_count) VALUES (6, 3, 330002, 100.00, 1);

相关文章:
MyBatis映射器:一对多关联查询
大家好,我是王有志,一个分享硬核 Java 技术的金融摸鱼侠,欢迎大家加入 Java 人自己的交流群“共同富裕的 Java 人”。 在学习完上一篇文章《MyBatis映射器:一对一关联查询》后,相信你已经掌握了如何在 MyBatis 映射器…...

100多个ChatGPT指令提示词分享
当前,ChatGPT几乎已经占领了整个互联网。全球范围内成千上万的用户正使用这款人工智能驱动的聊天机器人来满足各种需求。然而,并不是每个人都知道如何充分有效地利用ChatGPT的潜力。其实有许多令人惊叹的ChatGPT指令提示词,可以提升您与ChatG…...

vue2和vue3数据代理的区别
前言: vue2 的双向数据绑定是利⽤ES5的⼀个 API ,Object.defineProperty( )对数据进行劫持结合发布订阅模式的方式来实现的。 vue3 中使⽤了 ES6的Proxy代理对象,通过 reactive() 函数给每⼀个对象都包⼀层Proxy,通过 Proxy监听属…...
已解决ApplicationException异常的正确解决方法,亲测有效!!!
已解决ApplicationException异常的正确解决方法,亲测有效!!! 目录 问题分析 出现问题的场景 报错原因 解决思路 解决方法 分析错误日志 检查业务逻辑 验证输入数据 确认服务器端资源的可用性 增加对特殊业务情况的处理…...

「前端+鸿蒙」鸿蒙应用开发-常用UI组件-图片-参数
在鸿蒙应用开发中,图片组件是展示图像的关键UI元素。以下是详细介绍图片组件的三个主要参数:图片尺寸、图片缩放和图片插值,并提供相应的示例代码。 图片尺寸 图片尺寸指的是图片组件在界面上显示的宽度和高度。你可以使用像素(px)或其他单位来指定尺寸。 width: 设置图片…...
Tobii Pro Lab 1.232是全球领先的眼动追踪研究实验软件
Tobii Pro Lab是全球领先的眼动追踪研究实验软件。软件功能强大且拥有友好的用户界面,使眼动追踪研究变得更加简单、高效。该软件提供了很高的灵活性,可运行高级实验,深入了解注意力和认知过程。 获取软件安装包以及永久授权联系邮箱:289535…...

【flink实战】flink-connector-mysql-cdc导致mysql连接器报类型转换错误
文章目录 一. 报错现象二. 方案二:重新编译打包flink-connector-cdc1. 排查脚本2. 重新编译打包flink-sql-connector-mysql-cdc-2.4.0.jar3. 测试flink环境 三. 方案一:改造flink连接器 一. 报错现象 flink sql任务是:mysql到hdfs的离线任务&…...
【Linux】系统文件IO·文件描述符fd
前言 C语言文件接口 C 语言读写文件 1.C语言写入文件 2.C语言读取文件 stdin/stdout/stderr 系统文件IO 文件描述符fd: 文件描述符分配规则: 文件描述符fd: 前言 我们早在C语言中学习关于如何用代码来管理文件,比如文件的…...

【计算机网络篇】数据链路层(6)共享式以太网_网络适配器_MAC地址
文章目录 🍔网络适配器🍔MAC地址🗒️IEEE 802局域网的MAC地址格式📒IEEE 802局域网的MAC地址发送顺序🥚单播MAC地址🥚广播MAC地址🥚多播MAC地址🔎小结 🍔网络适配器 要将…...

导入别人的net文件报红问题sdk
1. 使用cmd命令 dotnet --info 查看自己使用的SDK版本 2.直接找到项目中的 global.json 文件,右键打开,直接修改版本为本机的SDK版本,就可以用了...

LangChain 介绍
In recent times, you would probably have heard of many AI applications, one of them being chatpdf.com. 在最近,你可能听说过很多的AI应用,chatpdf.com就是其中的一个。 On this website, you can upload your own PDF. After uploading, you ca…...
【区分vue2和vue3下的element UI Avatar 头像组件,分别详细介绍属性,事件,方法如何使用,并举例】
在 Vue 2 的 Element UI 和 Vue 3 的 Element Plus 中,Avatar 头像组件可能并没有直接作为官方组件库的一部分。然而,为了回答你的问题,我将假设 Element UI 和 Element Plus 在未来的版本中可能添加了 Avatar 组件,或者我们将使用…...

数据分析必备:一步步教你如何用matplotlib做数据可视化(10)
1、Matplotlib 二维箭头图 箭头图将速度矢量显示为箭头,其中分量(u,v)位于点(x,y)。 quiver(x,y,u,v)上述命令将矢量绘制为在x和y中每个对应元素对中指定的坐标处的箭头。 参数 下表列出了quiver()函数的参数 - x - 1D或2D阵列,…...
Stable Diffusion部署教程,开启你的AI绘图之路
本文环境 系统:Ubuntu 20.04 64位 内存:32G 环境安装 2.1 安装GPU驱动 在英伟达官网根据显卡型号、操作系统、CUDA等查询驱动版本。官网查询链接https://www.nvidia.com/Download/index.aspx?langen-us 注意这里的CUDA版本,如未安装CUD…...

三生随记——诡异的牙线
在小镇的角落,坐落着一间古老的牙医诊所。这所诊所早已荒废多年,窗户上爬满了藤蔓,门板上的油漆斑驳脱落,仿佛诉说着无尽的沉寂与孤独。然而,在午夜时分,偶尔会有低沉的呻吟声从紧闭的诊所里传出࿰…...
批量重命名神器揭秘:一键实现文件夹随机命名,自定义长度轻松搞定!
在数字化时代,我们经常需要管理大量的文件夹,尤其是对于那些需要频繁更改或整理的文件来说,给它们进行批量重命名可以大大提高工作效率。然而,传统的重命名方法既繁琐又耗时,无法满足高效工作的需求。今天,…...
学习笔记——路由网络基础——路由转发
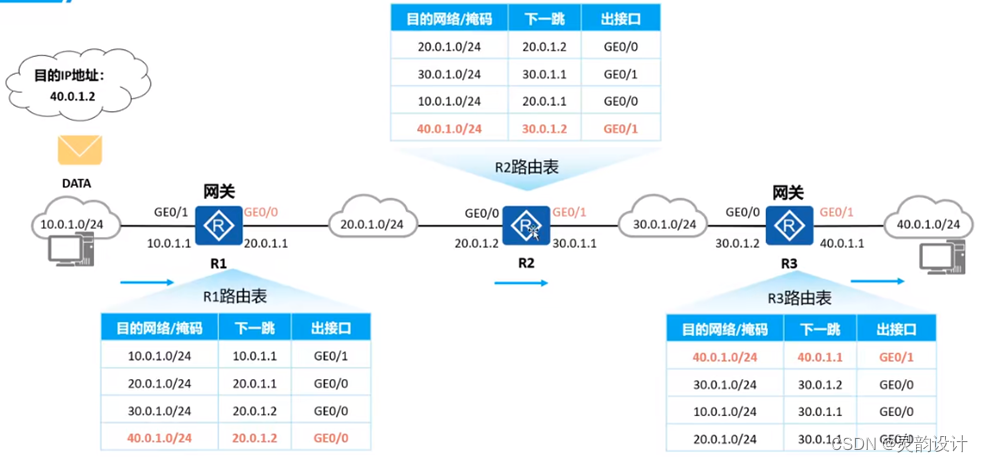
六、路由转发 1、最长匹配原则 最长匹配原则 是支持IP路由的设备默认的路由查找方式(事实上几乎所有支持IP路由的设备都是这种查找方式)。当路由器收到一个IP数据包时,会将数据包的目的IP地址与自己本地路由表中的表项进行逐位(Bit-By-Bit)的逐位查找,…...

Python网络安全项目开发实战,如何防命令注入
注意:本文的下载教程,与以下文章的思路有相同点,也有不同点,最终目标只是让读者从多维度去熟练掌握本知识点。 下载教程: Python网络安全项目开发实战_防命令注入_编程案例解析实例详解课程教程.pdf 在Python网络安全项目开发中,防止命令注入(Command Injection)是一项…...

程序员如何高效读代码?
程序员高效读代码的技巧包括以下几点: 明确阅读目的:在开始阅读代码之前,先明确你的阅读目的。是为了理解整个系统的架构?还是为了修复一个具体的bug?或者是为了了解某个功能是如何实现的?明确目的可以帮助…...

全面分析一下前端框架Angular的来龙去脉,分析angular的技术要点和难点,以及详细的语法和使用规则,底层原理-小白进阶之路
Angular 前端框架全面分析 Angular 是一个由 Google 维护的开源前端框架。它最早在 2010 年发布,最初版本称为 AngularJS。2016 年,团队发布了一个完全重写的版本,称为 Angular 2,之后的版本(如 Angular 4、Angular 5…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

React19源码系列之 事件插件系统
事件类别 事件类型 定义 文档 Event Event 接口表示在 EventTarget 上出现的事件。 Event - Web API | MDN UIEvent UIEvent 接口表示简单的用户界面事件。 UIEvent - Web API | MDN KeyboardEvent KeyboardEvent 对象描述了用户与键盘的交互。 KeyboardEvent - Web…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...

08. C#入门系列【类的基本概念】:开启编程世界的奇妙冒险
C#入门系列【类的基本概念】:开启编程世界的奇妙冒险 嘿,各位编程小白探险家!欢迎来到 C# 的奇幻大陆!今天咱们要深入探索这片大陆上至关重要的 “建筑”—— 类!别害怕,跟着我,保准让你轻松搞…...
淘宝扭蛋机小程序系统开发:打造互动性强的购物平台
淘宝扭蛋机小程序系统的开发,旨在打造一个互动性强的购物平台,让用户在购物的同时,能够享受到更多的乐趣和惊喜。 淘宝扭蛋机小程序系统拥有丰富的互动功能。用户可以通过虚拟摇杆操作扭蛋机,实现旋转、抽拉等动作,增…...

springboot 日志类切面,接口成功记录日志,失败不记录
springboot 日志类切面,接口成功记录日志,失败不记录 自定义一个注解方法 import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target;/***…...

绕过 Xcode?使用 Appuploader和主流工具实现 iOS 上架自动化
iOS 应用的发布流程一直是开发链路中最“苹果味”的环节:强依赖 Xcode、必须使用 macOS、各种证书和描述文件配置……对很多跨平台开发者来说,这一套流程并不友好。 特别是当你的项目主要在 Windows 或 Linux 下开发(例如 Flutter、React Na…...

CppCon 2015 学习:Time Programming Fundamentals
Civil Time 公历时间 特点: 共 6 个字段: Year(年)Month(月)Day(日)Hour(小时)Minute(分钟)Second(秒) 表示…...