Flink从入门到精通系列(四)
5、DataStream API(基础篇)
Flink 有非常灵活的分层 API 设计,其中的核心层就是 DataStream/DataSet API。由于新版本已经实现了流批一体,DataSet API 将被弃用,官方推荐统一使用 DataStream API 处理流数据和批数据。
DataStream(数据流)本身是 Flink 中一个用来表示数据集合的类(Class),我们编写的Flink 代码其实就是基于这种数据类型的处理,所以这套核心 API 就以 DataStream 命名。对于批处理和流处理,我们都可以用这同一套 API 来实现。
一个 Flink 程序,其实就是对 DataStream 的各种转换。具体来说,代码基本上都由以下几部分构成,如下图所示:

- 获取执行环境(execution environment)
- 读取数据源(source)
- 定义基于数据的转换操作(transformations)
- 定义计算结果的输出位置(sink)
- 触发程序执行(execute)
其中,获取环境和触发执行,都可以认为是针对执行环境的操作。
5.1、执行环境(Execution Environment)
Flink 程序可以在各种上下文环境中运行:我们可以在本地 JVM 中执行程序,也可以提交到远程集群上运行。不同的环境,代码的提交运行的过程会有所不同。这就要求我们在提交作业执行计算时,首先必须获取当前 Flink 的运行环境,从而建立起与 Flink 框架之间的联系。只有获取了环境上下文信息,才能将具体的任务调度到不同的 TaskManager 执行。
5.1.1、创建执行环境
我们要获取的执行环境,是StreamExecutionEnvironment 类的对象,在代码中创建执行环境的方式,就是调用这个类的静态方法,具体有以下三种:
- getExecutionEnvironment
最简单的方式,就是直接调用 getExecutionEnvironment 方法。它会根据当前运行的上下文直接得到正确的结果:如果程序是独立运行的,就返回一个本地执行环境;如果是创建了 jar包,然后从命令行调用它并提交到集群执行,那么就返回集群的执行环境。也就是说,这个方法会根据当前运行的方式,自行决定该返回什么样的运行环境。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
这种“智能”的方式不需要我们额外做判断,用起来简单高效,是最常用的一种创建执行环境的方式。
- createLocalEnvironment
这个方法返回一个本地执行环境。可以在调用时传入一个参数,指定默认的并行度;如果不传入,则默认并行度就是本地的 CPU 核心数。
StreamExecutionEnvironment localEnv = treamExecutionEnvironment.createLocalEnvironment();
- createRemoteEnvironment
这个方法返回集群执行环境。需要在调用时指定 JobManager 的主机名和端口号,并指定要在集群中运行的 Jar 包。
StreamExecutionEnvironment remoteEnv = StreamExecutionEnvironment.createRemoteEnvironment("host", // JobManager 主机名1234, // JobManager 进程端口号"path/to/jarFile.jar" // 提交给 JobManager 的 JAR 包
);
在获取到程序执行环境后,我们还可以对执行环境进行灵活的设置。比如可以全局设置程序的并行度、禁用算子链,还可以定义程序的时间语义、配置容错机制。
5.1.2、执行模式(Execution Mode)
从 1.12.0 版本起,Flink 实现了 API 上的流批统一。DataStream API 新增了一个重要特性:可以支持不同的“执行模式”(execution mode),通过简单的设置就可以让一段 Flink 程序在流处理和批处理之间切换。
- 流执行模式(STREAMING)
这是 DataStream API 最经典的模式,一般用于需要持续实时处理的无界数据流。默认情况下,程序使用的就是 STREAMING 执行模式。 - 批执行模式(BATCH)
专门用于批处理的执行模式, 这种模式下,Flink 处理作业的方式类似于 MapReduce 框架。对于不会持续计算的有界数据,我们用这种模式处理会更方便。 - 自动模式(AUTOMATIC)
在这种模式下,将由程序根据输入数据源是否有界,来自动选择执行模式。
5.1.2.1、BATCH 模式的配置方法
由于 Flink 程序默认是 STREAMING 模式,我们这里重点介绍一下 BATCH 模式的配置。主要有两种方式:
- 通过命令行配置
bin/flink run -Dexecution.runtime-mode=BATCH ...
在提交作业时,增加 execution.runtime-mode 参数,指定值为 BATCH。
- 通过代码配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
在代码中,直接基于执行环境调用 setRuntimeMode 方法,传入 BATCH 模式。
建议: 不要在代码中配置,而是使用命令行。这同设置并行度是类似的:在提交作业时指定参数可以更加灵活,同一段应用程序写好之后,既可以用于批处理也可以用于流处理。
5.1.2.2、什么时候选择 BATCH 模式
用 BATCH 模式处理批量数据,用 STREAMING 模式处理流式数据。因为数据有界的时候,直接输出结果会更加高效;而当数据无界的时候, 我们没得选择——只有 STREAMING 模式才能处理持续的数据流。
5.1.3、触发程序执行
有了执行环境,我们就可以构建程序的处理流程了:基于环境读取数据源,进而进行各种转换操作,最后输出结果到外部系统,写完输出(sink)操作并不代表程序已经结束,因为当 main()方法被调用时,其实只是定义了作业的每个执行操作,然后添加到数据流图中;这时并没有真正处理数据,因为数据可能还没来,Flink 是由事件驱动的,只有等到数据到来,才会触发真正的计算,这也被称为“延迟执行”或“懒执行”(lazy execution)。
所以我们需要显式地调用执行环境的 execute()方法,来触发程序执行。execute()方法将一直等待作业完成,然后返回一个执行结果(JobExecutionResult)。
env.execute();
5.2、源算子(Source)

Flink 可以从各种来源获取数据,然后构建 DataStream 进行转换处理,一般将数据的输入来源称为数据源(data source),而读取数据的算子就是源算子(source operator),所以,source就是我们整个处理程序的输入端。
Flink 代码中通用的添加 source 的方式,是调用执行环境的 addSource()方法:
DataStream<String> stream = env.addSource(...);
方法传入一个对象参数,需要实现 SourceFunction 接口;返回 DataStreamSource。这里的DataStreamSource 类继承自 SingleOutputStreamOperator 类,又进一步继承自 DataStream。所以
很明显,读取数据的 source 操作是一个算子,得到的是一个数据流(DataStream)。
5.2.1、创建event
package com.song.wc.entity;
import java.sql.Timestamp;/*** 创建事件实体*/
public class Event {public String user;public String url;public Long timestamp;public Event() {}public Event(String user, String url, Long timestamp) {this.user = user;this.url = url;this.timestamp = timestamp;}@Overridepublic String toString() {return "Event{" +"user='" + user + '\'' +", url='" + url + '\'' +", timestamp=" + new Timestamp(timestamp) +'}';}
}
这里需要注意,我们定义的 Event,有这样几个特点:
- 类是公有(public)的
- 有一个无参的构造方法
- 所有属性都是公有(public)的
- 所有属性的类型都是可以序列化的
Flink 会把这样的类作为一种特殊的 POJO 数据类型来对待,方便数据的解析和序列化,另外我们在类中还重写了 toString 方法,主要是为了测试输出显示更清晰。
5.2.2、从集合中读取数据
最简单的读取数据的方式,就是在代码中直接创建一个 Java 集合,然后调用执行环境的fromCollection 方法进行读取。这相当于将数据临时存储到内存中,形成特殊的数据结构后,作为数据源使用, 一般用于测试
package com.song.wc;import com.song.wc.entity.Event;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.ArrayList;public class Test {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);ArrayList<Event> clicks = new ArrayList<>();clicks.add(new Event("Mary", "./home", 1000L));clicks.add(new Event("Bob", "./cart", 2000L));DataStream<Event> stream = env.fromCollection(clicks);stream.print();env.execute();}
}也可以不构建集合,直接将元素列举出来,调用 fromElements 方法进行读取数据:
DataStreamSource<Event> stream2 = env.fromElements(new Event("Mary", "./home", 1000L),new Event("Bob", "./cart", 2000L));
5.2.3、从文件读取数据
通常情况下,我们会从存储介质中获取数据,一个比较常见的方式就是读取日志文件。这也是批处理中最常见的读取方式。
DataStream<String> stream = env.readTextFile("clicks.csv");
说明:
- 参数可以是目录,也可以是文件;
- 路径可以是相对路径,也可以是绝对路径;
- 相对路径是从系统属性 user.dir 获取路径: idea 下是 project 的根目录, standalone 模式下是集群节点根目录;
- 也可以从 hdfs 目录下读取, 使用路径 hdfs://…, 由于 Flink 没有提供 hadoop 相关依赖, 需要 pom 中添加相关依赖:
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.5</version><scope>provided</scope>
</dependency>
5.2.4、从 Socket 读取数据
读取 socket 文本流。但是这种方式由于吞吐量小、稳定性较差,一般也是用于测试。
DataStream<String> stream = env.socketTextStream("localhost", 7777);
5.2.5、从 Kafka 读取数据
Kafka 作为分布式消息传输队列,是一个高吞吐、易于扩展的消息系统。而消息队列的传输方式,恰恰和流处理是完全一致的。所以可以说 Kafka 和 Flink 天生一对,是当前处理流式数据的双子星。
在如今的实时流处理应用中,由 Kafka 进行数据的收集和传输,Flink 进行分析计算,这样的架构已经成为众多企业的首选,如下图所示。
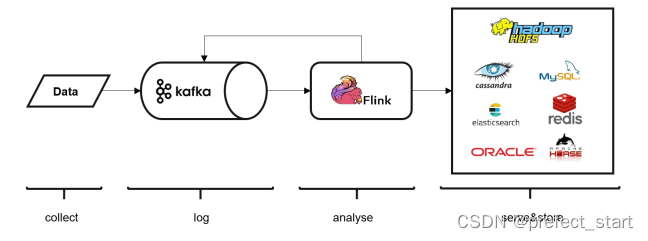
略微遗憾的是,与 Kafka 的连接比较复杂,Flink 内部并没有提供预实现的方法。所以我们只能采用通用的 addSource 方式、实现一个 SourceFunction 了,Flink官方提供了连接工具flink-connector-kafka,直接帮我们实现了一个消费者 FlinkKafkaConsumer,它就是用来读取 Kafka 数据的SourceFunction。
所以想要以 Kafka 作为数据源获取数据,我们只需要引入 Kafka 连接器的依赖。Flink 官方提供的是一个通用的 Kafka 连接器,它会自动跟踪最新版本的 Kafka 客户端。目前最新版本只支持 0.10.0 版本以上的 Kafka,读者使用时可以根据自己安装的 Kafka 版本选定连接器的依赖版本。这里我们需要导入的依赖如下。
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_${scala.binary.version}</artifactId><version>${flink.version}</version>
</dependency>
然后调用 env.addSource(),传入 FlinkKafkaConsumer 的对象实例就可以了。
package com.song.wc;import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import java.util.Properties;public class Test {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);Properties properties = new Properties();properties.setProperty("bootstrap.servers", "hadoop102:9092");properties.setProperty("group.id", "consumer-group");properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");properties.setProperty("auto.offset.reset", "latest");DataStreamSource<String> stream = env.addSource(newFlinkKafkaConsumer<String>("clicks",new SimpleStringSchema(),properties));stream.print("Kafka");env.execute();}
}创建 FlinkKafkaConsumer 时需要传入三个参数:
- 第一个参数 topic,定义了从哪些主题中读取数据。可以是一个 topic,也可以是 topic列表,还可以是匹配所有想要读取的 topic 的正则表达式。当从多个 topic 中读取数据时,Kafka 连接器将会处理所有 topic 的分区,将这些分区的数据放到一条流中去。
- 第二个参数是一个 DeserializationSchema 或者 KeyedDeserializationSchema。Kafka 消息被存储为原始的字节数据,所以需要反序列化成 Java 或者 Scala 对象。上面代码中使用的 SimpleStringSchema,是一个内置的 DeserializationSchema,它只是将字节数组简单地反序列化成字符串。
DeserializationSchema 和 KeyedDeserializationSchema是公共接口,所以我们也可以自定义反序列化逻辑。 - 第三个参数是一个 Properties 对象,设置了 Kafka 客户端的一些属性
5.2.6、自定义 Source
大多数情况下,前面的数据源已经能够满足需要。但是凡事总有例外,如果遇到特殊情况,我们想要读取的数据源来自某个外部系统,而 flink 既没有预实现的方法、也没有提供连接器,那就只好自定义实现 SourceFunction 了。
接下来我们创建一个自定义的数据源,实现 SourceFunction 接口。主要重写两个关键方法:run()和 cancel()
- run()方法:使用运行时上下文对象(SourceContext)向下游发送数据;
- cancel()方法:通过标识位控制退出循环,来达到中断数据源的效果。
package com.song.wc.customersource;import com.song.wc.entity.Event;
import org.apache.flink.streaming.api.functions.source.SourceFunction;import java.util.Calendar;
import java.util.Random;public class ClickSource implements SourceFunction<Event> {// 声明一个布尔变量,作为控制数据生成的标识位private Boolean running = true;@Overridepublic void run(SourceContext<Event> ctx) throws Exception {// 在指定的数据集中随机选取数据Random random = new Random();String[] users = {"Mary", "Alice", "Bob", "Cary"};String[] urls = {"./home", "./cart", "./fav", "./prod?id=1","./prod?id=2"};while (running) {ctx.collect(new Event(users[random.nextInt(users.length)],urls[random.nextInt(urls.length)],Calendar.getInstance().getTimeInMillis()));// 隔 1 秒生成一个点击事件,方便观测Thread.sleep(1000);}}@Overridepublic void cancel() {running = false;}
}
有了自定义的 source function,接下来只要调用 addSource()就可以了:
package com.song.wc.customersource;import com.song.wc.entity.Event;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class SourceCustom {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//有了自定义的 source function,调用 addSource 方法DataStreamSource<Event> stream = env.addSource(new ClickSource());stream.print("SourceCustom");env.execute();}
}
这里要注意的是 SourceFunction 接口定义的数据源,并行度只能设置为 1,如果数据源设置为大于 1 的并行度,则会抛出异常。
package com.song.wc.customersource;import com.song.wc.entity.Event;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class SourceCustom {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
// env.setParallelism(1);//有了自定义的 source function,调用 addSource 方法
// DataStreamSource<Event> stream = env.addSource(new ClickSource());env.addSource(new ClickSource()).setParallelism(2).print();env.execute();}
}

我们想要自定义并行的数据源的话,需要使用 ParallelSourceFunction,示例程序如下:
package com.song.wc.customersource;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;import java.util.Random;public class ParallelSourceExample {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.addSource(new CustomSource()).setParallelism(2).print();env.execute();}public static class CustomSource implements ParallelSourceFunction<Integer> {private boolean running = true;private Random random = new Random();@Overridepublic void run(SourceContext<Integer> sourceContext) throws Exception {while (running) {sourceContext.collect(random.nextInt());}}@Overridepublic void cancel() {running = false;}}
}
5.2.7、Flink 支持的数据类型
5.2.7.1、Flink 的类型系统
为什么会出现“不支持”的数据类型呢?因为 Flink 作为一个分布式处理框架,处理的是以数据对象作为元素的流,要分布式地处理这些数据,就不可避免地要面对数据的网络传输、状态的落盘和故障恢复等问题,这就需要对数据进行序列化和反序列化。
为了方便地处理数据,Flink 有自己一整套类型系统。 Flink 使用“类型信息”(TypeInformation)来统一表示数据类型。 TypeInformation 类是 Flink 中所有类型描述符的基类。它涵盖了类型的一些基本属性,并为每个数据类型生成特定的序列化器、反序列化器和比较器。
5.2.7.2、Flink 支持的数据类型
简单来说,对于常见的 Java 和 Scala 数据类型,Flink 都是支持的。Flink 在内部,Flink对支持不同的类型进行了划分,这些类型可以在 Types 工具类中找到:
- 基本类型
所有 Java 基本类型及其包装类,再加上 Void、String、Date、BigDecimal 和 BigInteger。 - 数组类型
包括基本类型数组(PRIMITIVE_ARRAY)和对象数组(OBJECT_ARRAY) - 复合数据类型
- Java 元组类型(TUPLE):这是 Flink 内置的元组类型,是 Java API 的一部分。最多25 个字段,也就是从 Tuple0~Tuple25,不支持空字段
- Scala 样例类及 Scala 元组:不支持空字段
- 行类型(ROW):可以认为是具有任意个字段的元组,并支持空字段
- POJO:Flink 自定义的类似于 Java bean 模式的类
- 辅助类型
Option、Either、List、Map 等 - 泛型类型(GENERIC)
- Flink 支持所有的 Java 类和 Scala 类。不过如果没有按照上面 POJO 类型的要求来定义,就会被 Flink 当作泛型类来处理。Flink 会把泛型类型当作黑盒,无法获取它们内部的属性;它们也不是由 Flink 本身序列化的,而是由 Kryo 序列化的。
- 在这些类型中,元组类型和 POJO 类型最为灵活,因为它们支持创建复杂类型。而相比之下,POJO 还支持在键(key)的定义中直接使用字段名,这会让我们的代码可读性大大增加。所以,在项目实践中,往往会将流处理程序中的元素类型定为 Flink 的 POJO 类型。
- Flink 对 POJO 类型的要求如下:
- 类是公共的(public)和独立的(standalone,也就是说没有非静态的内部类);
- 类有一个公共的无参构造方法;
- 类中的所有字段是 public 且非 final 的;或者有一个公共的 getter 和 setter 方法,这些方法需要符合 Java bean 的命名规范。
5.2.7.3、类型提示(Type Hints)
Flink 还具有一个类型提取系统,可以分析函数的输入和返回类型,自动获取类型信息,从而获得对应的序列化器和反序列化器。但是,由于 Java 中泛型擦除的存在,在某些特殊情况下(比如 Lambda 表达式中),自动提取的信息是不够精细的——只告诉 Flink 当前的元素由“船头、船身、船尾”构成,根本无法重建出“大船”的模样;这时就需要显式地提供类型信息,才能使应用程序正常工作或提高其性能。
为了解决这类问题,Java API 提供了专门的“类型提示”(type hints)。之前的 wordCount 流处理程序,我们在将 String 类型的每个词转换成(word,count)二元组后,就明确地用 returns 指定了返回的类型。因为对于 map 里传入的 Lambda 表达式,系统只能推断出返回的是 Tuple2 类型,而无法得到 Tuple2<String, Long>。只有显式地告诉系统当前的返回类型,才能正确地解析出完整数据。
.map(word -> Tuple2.of(word, 1L)).returns(Types.TUPLE(Types.STRING, Types.LONG));
这是一种比较简单的场景,二元组的两个元素都是基本数据类型。那如果元组中的一个元素又有泛型,该怎么处理呢?
Flink 专门提供了 TypeHint 类,它可以捕获泛型的类型信息,并且一直记录下来,为运行时提供足够的信息。我们同样可以通过.returns()方法,明确地指定转换之后的 DataStream 里元素的类型。
returns(new TypeHint<Tuple2<Integer, SomeType>>(){})
5.3、转换算子(Transformation)

数据源读入数据之后,我们就可以使用各种转换算子,将一个或多个 DataStream 转换为新的 DataStream,如上图 所示。一个 Flink 程序的核心,其实就是所有的转换操作,它们决定了处理的业务逻辑。
5.3.1、基本转换算子
5.3.1.1、映射(map)
map 主要用于将数据流中的数据进行转换,形成新的数据流。简单来说,就是一个“一一映射”,消费一个元素就产出一个元素,如下图所示。
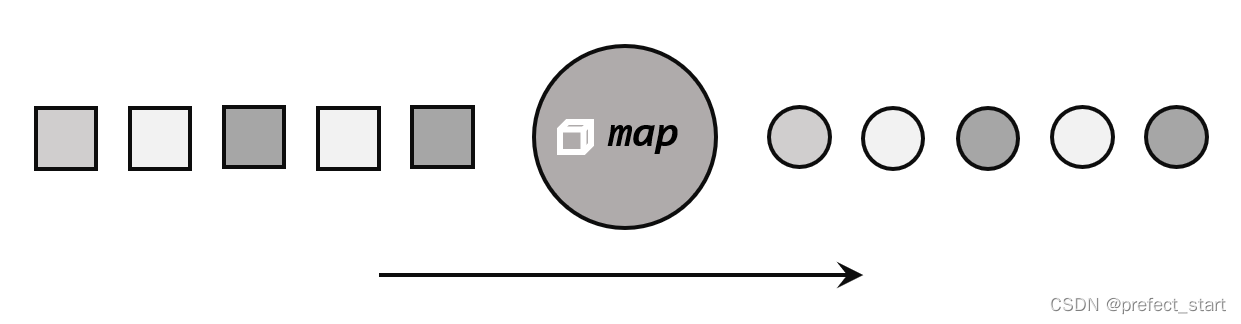
我们只需要基于 DataStrema 调用 map()方法就可以进行转换处理。方法需要传入的参数是接口 MapFunction 的实现;返回值类型还是 DataStream,不过泛型(流中的元素类型)可能改变。
下面的代码用不同的方式,实现了提取 Event 中的 user 字段的功能。
package com.song.wc;
import com.song.wc.entity.Event;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class Test {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Event> stream = env.fromElements(new Event("Mary", "./home", 1000L),new Event("Bob", "./cart", 2000L));// 传入匿名类,实现 MapFunctionstream.map(new MapFunction<Event, String>() {@Overridepublic String map(Event e) throws Exception {return e.user;}});// 传入 MapFunction 的实现类stream.map(new UserExtractor()).print();env.execute();}public static class UserExtractor implements MapFunction<Event, String> {@Overridepublic String map(Event e) throws Exception {return e.user;}}
}上面代码中,MapFunction 实现类的泛型类型,与输入数据类型和输出数据的类型有关。在实现 MapFunction 接口的时候,需要指定两个泛型,分别是输入事件和输出事件的类型,还需要重写一个 map()方法,定义从一个输入事件转换为另一个输出事件的具体逻辑。另外,通过查看 Flink 源码可以发现,基于 DataStream 调用 map 方法,返回的其实是一个 SingleOutputStreamOperator。
public <R> SingleOutputStreamOperator<R> map(MapFunction<T, R> mapper){}
这表示 map 是一个用户可以自定义的转换(transformation)算子,它作用于一条数据流上,转换处理的结果是一个确定的输出类型。当然,SingleOutputStreamOperator 类本身也继承自 DataStream 类,所以说 map 是将一个 DataStream 转换成另一个 DataStream 是完全正确的。
5.3.1.2、过滤(filter)
filter 转换操作,顾名思义是对数据流执行一个过滤,通过一个布尔条件表达式设置过滤条件,对于每一个流内元素进行判断,若为 true 则元素正常输出,若为 false 则元素被过滤掉,如下图所示。
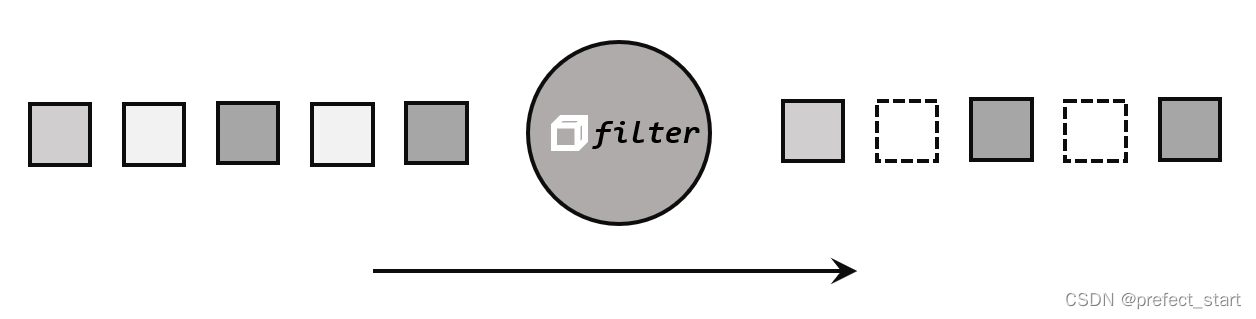
进行 filter 转换之后的新数据流的数据类型与原数据流是相同的。filter 转换需要传入的参数需要实现 FilterFunction 接口,而 FilterFunction 内要实现 filter()方法,就相当于一个返回布尔类型的条件表达式。
下面的代码会将数据流中用户 Mary 的浏览行为过滤出来 。
package com.song.wc;import com.song.wc.entity.Event;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class TransFilterTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Event> stream = env.fromElements(new Event("Mary", "./home", 1000L),new Event("Bob", "./cart", 2000L));// 传入匿名类实现 FilterFunctionstream.filter(new FilterFunction<Event>() {@Overridepublic boolean filter(Event e) throws Exception {return e.user.equals("Mary");}});// 传入 FilterFunction 实现类stream.filter(new UserFilter()).print();env.execute();}public static class UserFilter implements FilterFunction<Event> {@Overridepublic boolean filter(Event e) throws Exception {return e.user.equals("Mary");}}
}
5.3.1.3、扁平映射(flatMap)
flatMap 操作又称为扁平映射,主要是将数据流中的整体(一般是集合类型)拆分成一个一个的个体使用。消费一个元素,可以产生 0 到多个元素。flatMap 可以认为是“扁平化”(flatten)和“映射”(map)两步操作的结合,也就是先按照某种规则对数据进行打散拆分,再对拆分后的元素做转换处理,如下图所示,此前 WordCount 程序的第一步分词操作,就用到了flatMap。
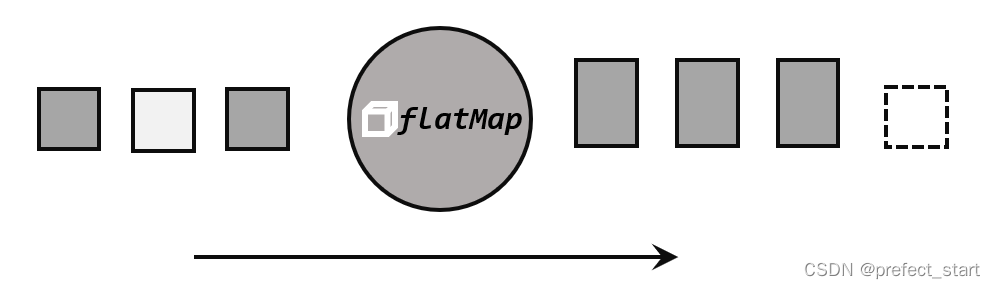
同 map 一样,flatMap 也可以使用 Lambda 表达式或者 FlatMapFunction 接口实现类的方式来进行传参,返回值类型取决于所传参数的具体逻辑,可以与原数据流相同,也可以不同。
flatMap 操作会应用在每一个输入事件上面,FlatMapFunction 接口中定义了 flatMap 方法,用户可以重写这个方法,在这个方法中对输入数据进行处理,并决定是返回 0 个、1 个或多个结果数据。
因此 flatMap 并没有直接定义返回值类型,而是通过一个“收集器”(Collector)来指定输出。希望输出结果时,只要调用收集器.collect()方法就可以了;这个方法可以多次调用,也可以不调用。所以 flatMap 方法也可以实现 map 方法和 filter 方法的功能,当返回结果是 0 个的时候,就相当于对数据进行了过滤,当返回结果是 1 个的时候,相当于对数据进行了简单的转换操作。
package com.song.wc;import com.song.wc.entity.Event;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class TransFilterTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Event> stream = env.fromElements(new Event("Mary", "./home", 1000L),new Event("Bob", "./cart", 2000L));stream.flatMap(new MyFlatMap()).print();env.execute();}public static class MyFlatMap implements FlatMapFunction<Event, String> {@Overridepublic void flatMap(Event value, Collector<String> out) throws Exception {if (value.user.equals("Mary")) {out.collect(value.user);} else if (value.user.equals("Bob")) {out.collect(value.user);out.collect(value.url);}}}
}
5.3.2、聚合算子(Aggregation)
5.3.2.1、按键分区(keyBy)
对于 Flink 而言,DataStream 是没有直接进行聚合的 API 的。因为我们对海量数据做聚合肯定要进行分区并行处理,这样才能提高效率。所以在 Flink 中,要做聚合,需要先进行分区;这个操作就是通过 keyBy 来完成的。
keyBy 是聚合前必须要用到的一个算子,keyBy 通过指定键(key),可以将一条流从逻辑上划分成不同的分区(partitions)。这里所说的分区,其实就是并行处理的子任务,也就对应着任务槽(task slot)。
基于不同的 key,流中的数据将被分配到不同的分区中去,如下图所示;这样一来,所有具有相同的 key 的数据,都将被发往同一个分区,那么下一步算子操作就将会在同一个 slot中进行处理了。
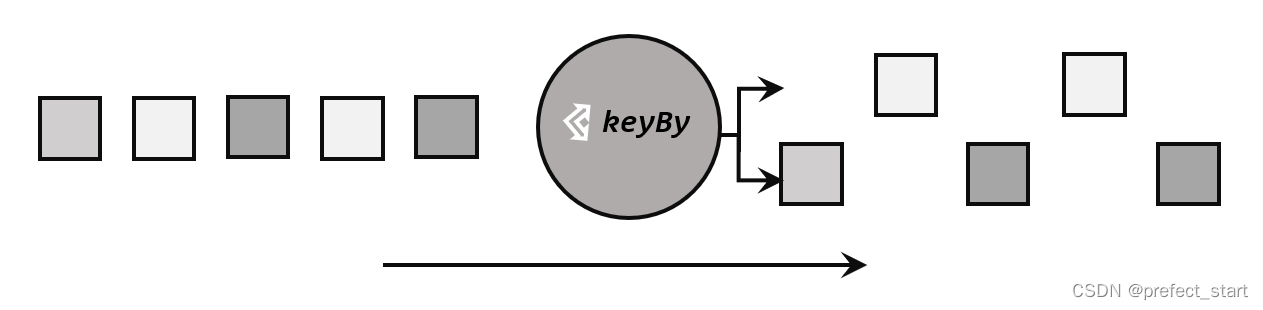
在内部,是通过计算 key 的哈希值(hash code),对分区数进行取模运算来实现的。所以这里 key 如果是 POJO 的话,必须要重写 hashCode()方法。
keyBy()方法需要传入一个参数,这个参数指定了一个或一组 key。有很多不同的方法来指定 key:比如对于 Tuple 数据类型,可以指定字段的位置或者多个位置的组合;对于 POJO 类型,可以指定字段的名称(String);另外,还可以传入 Lambda 表达式或者实现一个键选择器(KeySelector),用于说明从数据中提取 key 的逻辑。
我们可以以 id 作为 key 做一个分区操作,代码实现如下:
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Event> stream = env.fromElements(new Event("Mary", "./home", 1000L),new Event("Bob", "./cart", 2000L));// 使用 Lambda 表达式KeyedStream<Event, String> keyedStream = stream.keyBy(e -> e.user);// 使用匿名类实现 KeySelectorKeyedStream<Event, String> keyedStream1 = stream.keyBy(new KeySelector<Event, String>() {@Overridepublic String getKey(Event e) throws Exception {return e.user;}});env.execute();}
需要注意的是,keyBy 得到的结果将不再是 DataStream,而是会将 DataStream 转换为KeyedStream。
KeyedStream 可以认为是“分区流”或者“键控流”,它是对 DataStream 按照key 的一个逻辑分区,所以泛型有两个类型:除去当前流中的元素类型外,还需要指定 key 的类型。
KeyedStream 也继承自 DataStream,所以基于它的操作也都归属于 DataStream API。但它跟之前的转换操作得到的 SingleOutputStreamOperator 不同,只是一个流的分区操作,并不是一个转换算子。
KeyedStream 是一个非常重要的数据结构,只有基于它才可以做后续的聚合操作(比如 sum,reduce);而且它可以将当前算子任务的状态(state)也按照 key 进行划分、限定为仅对当前 key 有效。
5.3.2.2、简单聚合
Flink 为我们内置实现了一些最基本、最简单的聚合 API,主要有以下几种:
- sum():在输入流上,对指定的字段做叠加求和的操作。
- min():在输入流上,对指定的字段求最小值。
- max():在输入流上,对指定的字段求最大值。
- minBy():与 min()类似,在输入流上针对指定字段求最小值。不同的是,min()只计算指定字段的最小值,其他字段会保留最初第一个数据的值;而 minBy()则会返回包含字段最小值的整条数据。
- maxBy():与 max()类似,在输入流上针对指定字段求最大值。两者区别与min()/minBy()完全一致。
这些聚合方法调用时,也需要传入参数;但并不像基本转换算子那样需要实现自定义函数,只要说明聚合指定的字段就可以了。指定字段的方式有两种:
- 指定位置
- 指定名称
对于元组类型的数据,同样也可以使用这两种方式来指定字段。需要注意的是,元组中字段的名称,是以 f0、f1、f2、…来命名的。
package com.song.wc;import com.song.wc.entity.Event;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class TransFilterTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Tuple2<String, Integer>> stream = env.fromElements(Tuple2.of("a", 1),Tuple2.of("a", 3),Tuple2.of("b", 3),Tuple2.of("b", 4));stream.keyBy(r -> r.f0).sum(1).print();stream.keyBy(r -> r.f0).sum("f1").print();stream.keyBy(r -> r.f0).max(1).print();stream.keyBy(r -> r.f0).max("f1").print();System.out.println("==========");stream.keyBy(r -> r.f0).min(1).print();stream.keyBy(r -> r.f0).min("f1").print();stream.keyBy(r -> r.f0).maxBy(1).print();stream.keyBy(r -> r.f0).maxBy("f1").print();stream.keyBy(r -> r.f0).minBy(1).print();stream.keyBy(r -> r.f0).minBy("f1").print();env.execute();}
}
而如果数据流的类型是 POJO 类,那么就只能通过字段名称来指定,不能通过位置来指定了。
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Event> stream = env.fromElements(new Event("Mary", "./home", 1000L),new Event("Bob", "./cart", 2000L));stream.keyBy(e -> e.user).max("timestamp").print(); // 指定字段名称env.execute();}
简单聚合算子返回的,同样是一个 SingleOutputStreamOperator,也就是从 KeyedStream 又转换成了常规的 DataStream。所以可以这样理解:keyBy 和聚合是成对出现的,先分区、后聚合,得到的依然是一个 DataStream。而且经过简单聚合之后的数据流,元素的数据类型保持不变。
一个聚合算子,会为每一个key保存一个聚合的值,在Flink中我们把它叫作“状态”(state)。所以每当有一个新的数据输入,算子就会更新保存的聚合结果,并发送一个带有更新后聚合值的事件到下游算子。对于无界流来说,这些状态是永远不会被清除的,所以我们使用聚合算子,应该只用在含有有限个 key 的数据流上。
5.3.2.3、归约聚合(reduce)
reduce 算子就是一个一般化的聚合统计操作了,它可以对已有的数据进行归约处理,把每一个新输入的数据和当前已经归约出来的值,再做一个聚合计算。
与简单聚合类似,reduce 操作也会将 KeyedStream 转换为 DataStream。它不会改变流的元素数据类型,所以输出类型和输入类型是一样的。调用 KeyedStream 的 reduce 方法时,需要传入一个参数,实现 ReduceFunction 接口。接口在源码中的定义如下
public interface ReduceFunction<T> extends Function, Serializable {
T reduce(T value1, T value2) throws Exception;
}
ReduceFunction 接口里需要实现 reduce()方法,这个方法接收两个输入事件,经过转换处理之后输出一个相同类型的事件;
所以,对于一组数据,我们可以先取两个进行合并,然后再将合并的结果看作一个数据、再跟后面的数据合并,最终会将它“简化”成唯一的一个数据,这也就是 reduce“归约”的含义。
在流处理的底层实现过程中,实际上是将中间“合并的结果”作为任务的一个状态保存起来的;之后每来一个新的数据,就和之前的聚合状态进一步做归约。其实,reduce 的语义是针对列表进行规约操作,运算规则由 ReduceFunction 中的 reduce方法来定义,而在 ReduceFunction 内部会维护一个初始值为空的累加器,注意累加器的类型和输入元素的类型相同,当第一条元素到来时,累加器的值更新为第一条元素的值,当新的元素到来时,新元素会和累加器进行累加操作,这里的累加操作就是 reduce 函数定义的运算规则。然后将更新以后的累加器的值向下游输出。
我们可以单独定义一个函数类实现 ReduceFunction 接口,也可以直接传入一个匿名类。当然,同样也可以通过传入 Lambda 表达式实现类似的功能。与简单聚合类似,reduce 操作也会将 KeyedStream 转换为 DataStrema。它不会改变流的元素数据类型,所以输出类型和输入类型是一样的。
下面案例:我们将数据流按照用户 id 进行分区,然后用一个 reduce 算子实现 sum 的功能,统计每个
用户访问的频次;进而将所有统计结果分到一组,用另一个 reduce 算子实现 maxBy 的功能,记录所有用户中访问频次最高的那个,也就是当前访问量最大的用户是谁。
package com.song.wc;import com.song.wc.customersource.ClickSource;
import com.song.wc.entity.Event;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class Test {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 这里的 ClickSource()使用了之前自定义数据源小节中的 ClickSource()env.addSource(new ClickSource())// 将 Event 数据类型转换成元组类型.map(new MapFunction<Event, Tuple2<String, Long>>() {@Overridepublic Tuple2<String, Long> map(Event e) throws Exception {return Tuple2.of(e.user, 1L);}}).keyBy(r -> r.f0) // 使用用户名来进行分流.reduce(new ReduceFunction<Tuple2<String, Long>>() {@Overridepublic Tuple2<String, Long> reduce(Tuple2<String, Long> value1,Tuple2<String, Long> value2) throws Exception {// 每到一条数据,用户 pv 的统计值加 1return Tuple2.of(value1.f0, value1.f1 + value2.f1);}}).keyBy(r -> true) // 为每一条数据分配同一个 key,将聚合结果发送到一条流中去.reduce(new ReduceFunction<Tuple2<String, Long>>() {@Overridepublic Tuple2<String, Long> reduce(Tuple2<String, Long> value1,Tuple2<String, Long> value2) throws Exception {// 将累加器更新为当前最大的 pv 统计值,然后向下游发送累加器的值return value1.f1 > value2.f1 ? value1 : value2;}}).print();env.execute();}
}
reduce 同简单聚合算子一样,也要针对每一个 key 保存状态。因为状态不会清空,所以需要将 reduce 算子作用在一个有限 key 的流上。
5.3.3、用户自定义函数(UDF)
5.3.3.1、 函数类(Function Classes)
用户自定义函数(UDF),最简单直接的方式,就是自定义一个函数类,实现对应的接口,来完成处理逻辑的定义。
下面例子实现了 FilterFunction 接口,用来筛选 url 中包含“home”的事件:
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Event> clicks = env.fromElements(new Event("Mary", "./home", 1000L),new Event("Bob", "./cart", 2000L));DataStream<Event> stream = clicks.filter(new FlinkFilter());stream.print();env.execute();}public static class FlinkFilter implements FilterFunction<Event> {@Overridepublic boolean filter(Event value) throws Exception {return value.url.contains("home");}}
当然还可以通过匿名类来实现 FilterFunction 接口:
DataStream<String> stream = clicks.filter(new FilterFunction<Event>() {@Overridepublic boolean filter(Event value) throws Exception {return value.url.contains("home");}
});
为了类可以更加通用,我们还可以将用于过滤的关键字"home"抽象出来作为类的属性,调用构造方法时传进去。
DataStream<Event> stream = clicks.filter(new KeyWordFilter("home"));
public static class KeyWordFilter implements FilterFunction<Event> {private String keyWord;KeyWordFilter(String keyWord) { this.keyWord = keyWord; }@Overridepublic boolean filter(Event value) throws Exception {return value.url.contains(this.keyWord);}
}
5.3.3.2、 匿名函数(Lambda)
Flink 的所有算子都可以使用 Lambda 表达式的方式来进行编码,但是,当 Lambda 表达式使用 Java 的泛型时,我们需要显式的声明类型信息。
下例演示了如何使用 Lambda 表达式来实现一个简单的 map() 函数,我们使用 Lambda 表达式来计算输入的平方。不需要声明 map() 函数的输入 i 和输出参数的数据类型,因为 Java 编译器会对它们做出类型推断。
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Event> clicks = env.fromElements(new Event("Mary", "./home", 1000L),new Event("Bob", "./cart", 2000L));//map 函数使用 Lambda 表达式,返回简单类型,不需要进行类型声明DataStream<String> stream1 = clicks.map(event -> event.url);stream1.print();env.execute();}
由于 OUT 是 String 类型而不是泛型,所以 Flink 可以从函数签名 OUT map(IN value) 的实现中自动提取出结果的类型信息。
但是对于像 flatMap() 这样的函数,它的函数签名 void flatMap(IN value, Collector<OUT> out) 被 Java 编译器编译成了 void flatMap(IN value, Collector out),也就是说将 Collector 的泛型信息擦除掉了。这样 Flink 就无法自动推断输出的类型信息了。
// flatMap 使用 Lambda 表达式,抛出异常
DataStream<String> stream2 = clicks.flatMap((event, out) -> {
out.collect(event.url);
});
stream2.print();
如果执行程序,Flink 会抛出如下异常:
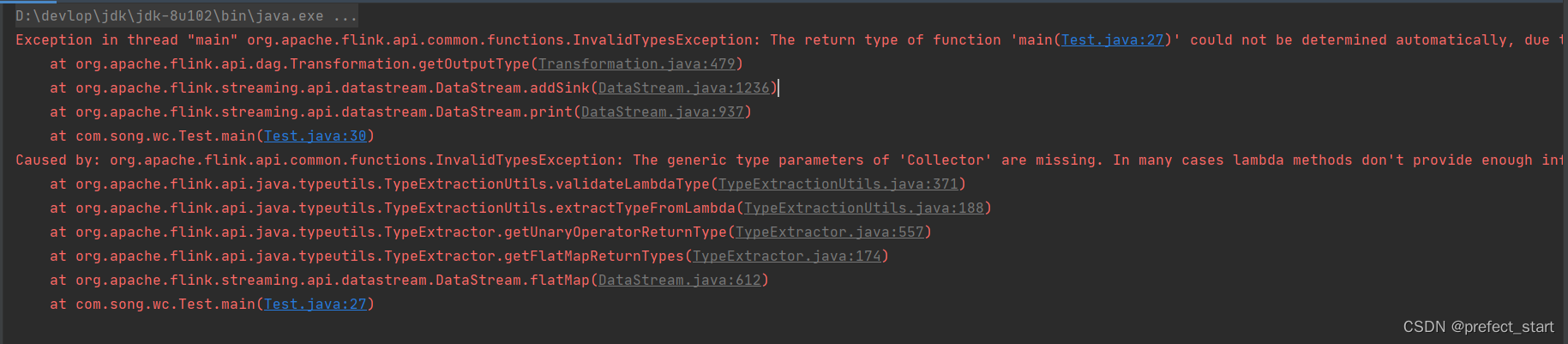
在这种情况下,我们需要显式地指定类型信息,否则输出将被视为 Object 类型,这会导致低效的序列化。
DataStream<String> stream2 = clicks.flatMap((Event event, Collector<String>out) -> {out.collect(event.url);}).returns(Types.STRING);stream2.print();
当使用 map() 函数返回 Flink 自定义的元组类型时也会发生类似的问题。下例中的函数签名 Tuple2<String, Long> map(Event value) 被类型擦除为 Tuple2 map(Event value)。
//使用 map 函数也会出现类似问题,以下代码会报错
DataStream<Tuple2<String, Long>> stream3 = clicks.map( event -> Tuple2.of(event.user, 1L) );
stream3.print();
一般来说,这个问题可以通过多种方式解决:
package com.song.wc;import com.song.wc.customersource.ClickSource;
import com.song.wc.entity.Event;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class Test {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Event> clicks = env.fromElements(new Event("Mary", "./home", 1000L),new Event("Bob", "./cart", 2000L));// 想要转换成二元组类型,需要进行以下处理// 1) 使用显式的 ".returns(...)"DataStream<Tuple2<String, Long>> stream3 = clicks.map(event -> Tuple2.of(event.user, 1L)).returns(Types.TUPLE(Types.STRING, Types.LONG));stream3.print();// 2) 使用类来替代 Lambda 表达式clicks.map(new MyTuple2Mapper()).print();// 3) 使用匿名类来代替 Lambda 表达式clicks.map(new MapFunction<Event, Tuple2<String, Long>>() {@Overridepublic Tuple2<String, Long> map(Event value) throws Exception {return Tuple2.of(value.user, 1L);}}).print();env.execute();}// 自定义 MapFunction 的实现类public static class MyTuple2Mapper implements MapFunction<Event, Tuple2<String,Long>> {@Overridepublic Tuple2<String, Long> map(Event value) throws Exception {return Tuple2.of(value.user, 1L);}}
}
这些方法对于其它泛型擦除的场景同样适用。
5.3.3.3、 富函数类(Rich Function Classes)
“富函数类”也是 DataStream API 提供的一个函数类的接口,所有的 Flink 函数类都有其Rich 版本。富函数类一般是以抽象类的形式出现的。例如:RichMapFunction、RichFilterFunction、RichReduceFunction 等。
既然“富”,那么它一定会比常规的函数类提供更多、更丰富的功能。与常规函数类的不同主要在于,富函数类可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能。
Rich Function 有生命周期的概念。典型的生命周期方法有:
- open()方法,是 Rich Function 的初始化方法,也就是会开启一个算子的生命周期。当一个算子的实际工作方法例如 map()或者 filter()方法被调用之前,open()会首先被调用。所以像文件 IO 的创建,数据库连接的创建,配置文件的读取等等这样一次性的工作,都适合在 open()方法中完成。
- close()方法,是生命周期中的最后一个调用的方法,类似于解构方法。一般用来做一些清理工作。需要注意的是,这里的生命周期方法,对于一个并行子任务来说只会调用一次;而对应的,实际工作方法,例如 RichMapFunction 中的 map(),在每条数据到来后都会触发一次调用。
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(2);DataStreamSource<Event> clicks = env.fromElements(new Event("Mary", "./home", 1000L),new Event("Bob", "./cart", 2000L),new Event("Alice", "./prod?id=1", 5 * 1000L),new Event("Cary", "./home", 60 * 1000L));// 将点击事件转换成长整型的时间戳输出clicks.map(new RichMapFunction<Event, Long>() {@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);System.out.println(" 索 引 为 " + getRuntimeContext().getIndexOfThisSubtask() + " 的任务开始");}@Overridepublic Long map(Event value) throws Exception {return value.timestamp;}@Overridepublic void close() throws Exception {super.close();System.out.println(" 索 引 为 " + getRuntimeContext().getIndexOfThisSubtask() + " 的任务结束");}}).print();env.execute();}
输出结果是:
索引为 0 的任务开始
索引为 1 的任务开始
1> 1000
2> 2000
2> 60000
1> 5000
索引为 0 的任务结束
索引为 1 的任务结束
另外,富函数类提供了 getRuntimeContext()方法,可以获取到运行时上下文的一些信息,例如程序执行的并行度,任务名称,以及状态(state)。这使得我们可以大大扩展程序的功能,特别是对于状态的操作,使得 Flink 中的算子具备了处理复杂业务的能力。
5.3.4、物理分区(Physical Partitioning)
“分区”(partitioning)操作就是要将数据进行重新分布,传递到不同的流分区去进行下一步处理。
keyBy,它就是一种按照键的哈希值来进行重新分区的操作。只不过这种分区操作只能保证把数据按key“分开”,至于分得均不均匀、每个 key 的数据具体会分到哪一区去,这些是完全无从控制的——所以我们有时也说,keyBy 是一种逻辑分区(logical partitioning)操作。
如果说 keyBy 这种逻辑分区是一种“软分区”,那真正硬核的分区就应该是所谓的“物理分区”(physical partitioning)。也就是我们要真正控制分区策略,精准地调配数据,告诉每个数据到底去哪里。
其实这种分区方式在一些情况下已经在发生了:例如我们编写的程序可能对多个处理任务设置了不同的并行度,那么当数据执行的上下游任务并行度变化时,数据就不应该还在当前分区以直通(forward)方式传输了——因为如果并行度变小,当前分区可能没有下游任务了;而如果并行度变大,所有数据还在原先的分区处理就会导致资源的浪费。所以这种情况下,系统会自动地将数据均匀地发往下游所有的并行任务,保证各个分区的负载均衡。
有些时候,我们还需要手动控制数据分区分配策略。比如当发生数据倾斜的时候,系统无法自动调整,这时就需要我们重新进行负载均衡,将数据流较为平均地发送到下游任务操作分区中去。
Flink 对于经过转换操作之后的 DataStream,提供了一系列的底层操作接口,能够帮我们实现数据流的手动重分区。为了同 keyBy 相区别,我们把这些操作统称为“物理分区”操作。物理分区与 keyBy 另一大区别在于,keyBy 之后得到的是一个 KeyedStream,而物理分区之后结果仍是 DataStream,且流中元素数据类型保持不变。从这一点也可以看出,分区算子并不对数据进行转换处理,只是定义了数据的传输方式。
常见的物理分区策略有
- 随机分配(Random)
- 轮询分配(Round-Robin)
- 重缩放(Rescale)
- 广播(Broadcast)
5.3.4.1、随机分区(shuffle)
最简单的重分区方式就是直接“洗牌”。通过调用 DataStream 的.shuffle()方法,将数据随机地分配到下游算子的并行任务中去。
随机分区服从均匀分布(uniform distribution),所以可以把流中的数据随机打乱,均匀地传递到下游任务分区,如下图所示。因为是完全随机的,所以对于同样的输入数据, 每次执行得到的结果也不会相同。
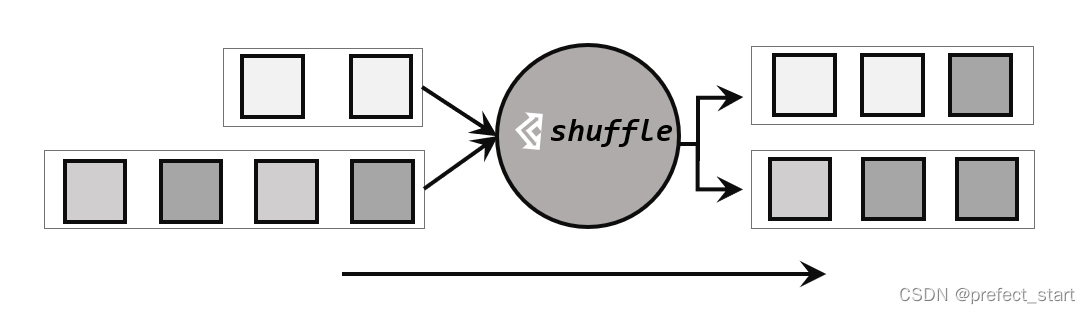
经过随机分区之后,得到的依然是一个 DataStream。
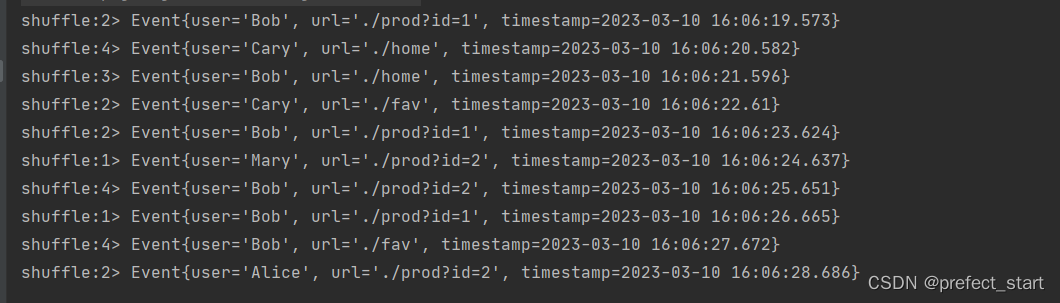
我们可以做个简单测试:将数据读入之后直接打印到控制台,将输出的并行度设置为 4,中间经历一次 shuffle。执行多次,观察结果是否相同。
public static void main(String[] args) throws Exception {// 创建执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 读取数据源,并行度为 1DataStreamSource<Event> stream = env.addSource(new ClickSource());// 经洗牌后打印输出,并行度为 4stream.shuffle().print("shuffle").setParallelism(4);env.execute();}
5.3.4.2、轮询分区(Round-Robin)
轮询也是一种常见的重分区方式。简单来说就是“发牌”,按照先后顺序将数据做依次分发,如下图所示。通过调用 DataStream 的.rebalance()方法,就可以实现轮询重分区。
rebalance使用的是 Round-Robin 负载均衡算法,可以将输入流数据平均分配到下游的并行任务中去。
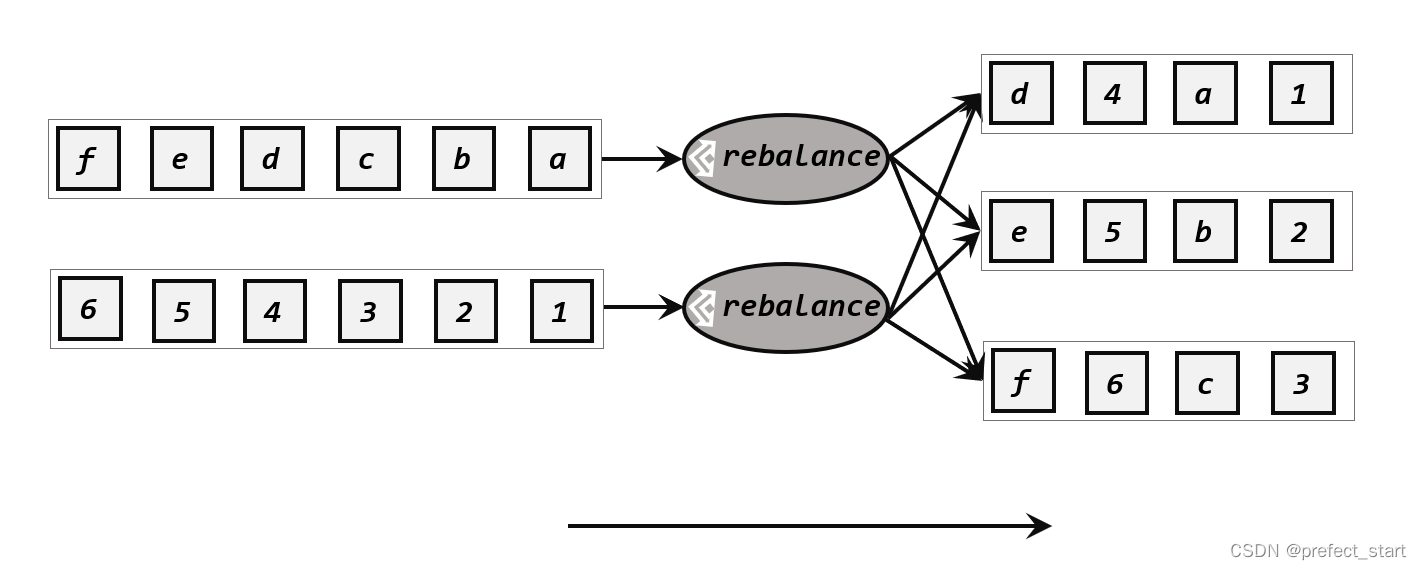
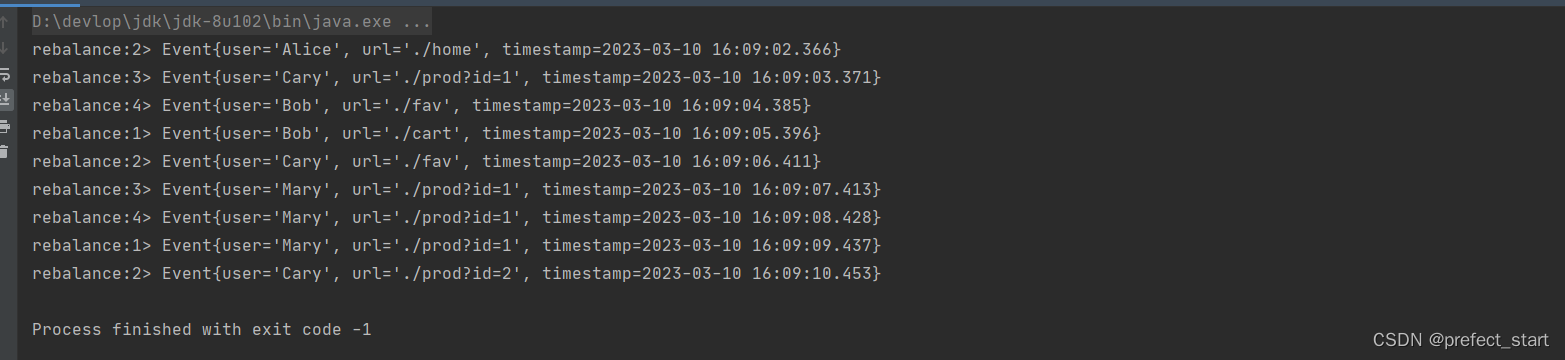
public static void main(String[] args) throws Exception {// 创建执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 读取数据源,并行度为 1DataStreamSource<Event> stream = env.addSource(new ClickSource());// 经轮询重分区后打印输出,并行度为 4stream.rebalance().print("rebalance").setParallelism(4);env.execute();}
输出结果的形式如下所示,可以看到,数据被平均分配到所有并行任务中去了。
5.3.4.3、重缩放分区(rescale)
重缩放分区和轮询分区非常相似。当调用 rescale()方法时,其实底层也是使用 Round-Robin算法进行轮询,但是只会将数据轮询发送到下游并行任务的一部分中,如下图所示。也就是说,“发牌人”如果有多个,那么 rebalance 的方式是每个发牌人都面向所有人发牌;而 rescale的做法是分成小团体,发牌人只给自己团体内的所有人轮流发牌。
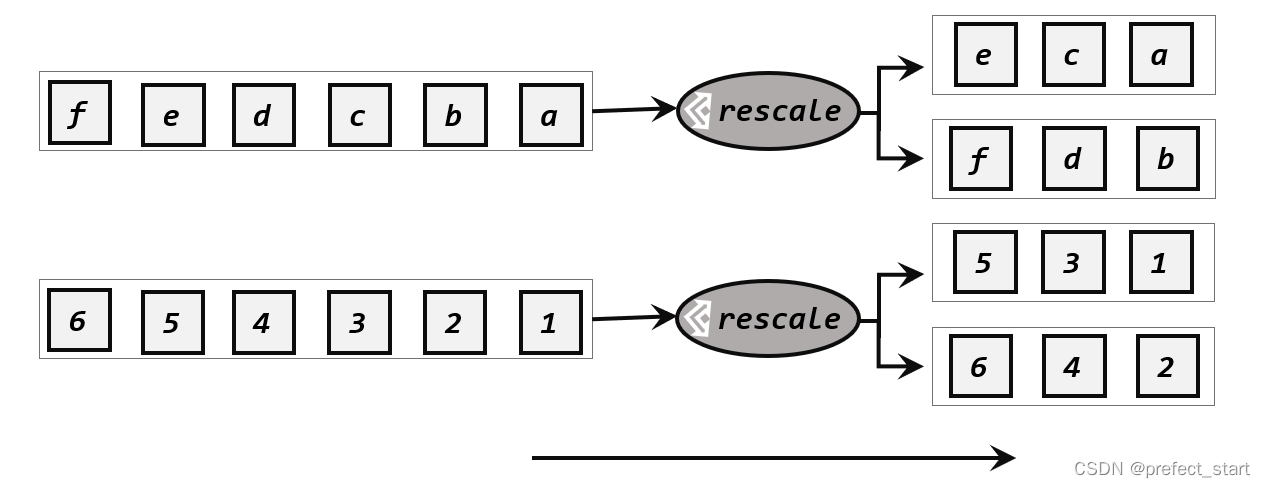
当下游任务(数据接收方)的数量是上游任务(数据发送方)数量的整数倍时,rescale的效率明显会更高。比如当上游任务数量是 2,下游任务数量是 6 时,上游任务其中一个分区的数据就将会平均分配到下游任务的 3 个分区中。
由于 rebalance 是所有分区数据的“重新平衡”,当 TaskManager 数据量较多时,这种跨节点的网络传输必然影响效率;而如果我们配置的 task slot 数量合适,用 rescale 的方式进行“局部重缩放”,就可以让数据只在当前 TaskManager 的多个 slot 之间重新分配,从而避免了网络传输带来的损耗。
从底层实现上看,rebalance 和 rescale 的根本区别在于任务之间的连接机制不同。rebalance将会针对所有上游任务(发送数据方)和所有下游任务(接收数据方)之间建立通信通道,这是一个笛卡尔积的关系;而 rescale 仅仅针对每一个任务和下游对应的部分任务之间建立通信通道,节省了很多资源。
5.3.4.4、 广播(broadcast)
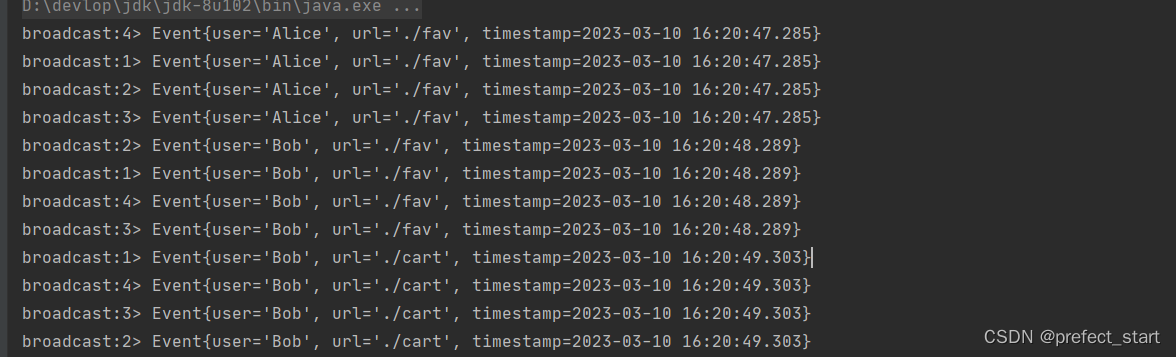
这种方式其实不应该叫做“重分区”,因为经过广播之后,数据会在不同的分区都保留一份,可能进行重复处理。可以通过调用 DataStream 的 broadcast()方法,将输入数据复制并发送到下游算子的所有并行任务中去。
public static void main(String[] args) throws Exception {// 创建执行环境StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 读取数据源,并行度为 1DataStreamSource<Event> stream = env.addSource(new ClickSource());// 经广播后打印输出,并行度为 4stream.broadcast().print("broadcast").setParallelism(4);env.execute();}
5.3.4.5、 自定义分区(Custom)
当Flink提供的所有分区策略都不能满足用户的需求时,我们可以通过使用partitionCustom()方法来自定义分区策略。
在调用时,方法需要传入两个参数,第一个是自定义分区器(Partitioner)对象,第二个是应用分区器的字段,它的指定方式与 keyBy 指定 key 基本一样:可以通过字段名称指定,也可以通过字段位置索引来指定,还可以实现一个 KeySelector。
例如,我们可以对一组自然数按照奇偶性进行重分区。代码如下:
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 将自然数按照奇偶分区env.fromElements(1, 2, 3, 4, 5, 6, 7, 8).partitionCustom(new Partitioner<Integer>() {@Overridepublic int partition(Integer key, int numPartitions) {return key % 2;}}, new KeySelector<Integer, Integer>() {@Overridepublic Integer getKey(Integer value) throws Exception {return value;}}).print().setParallelism(2);env.execute();}
5.4、输出算子(Sink)

Flink 作为数据处理框架,最终还是要把计算处理的结果写入外部存储,为外部应用提供支持,如上图 所示。
5.4.1、连接到外部系统
Flink 的 DataStream API 专门提供了向外部写入数据的方法:addSink。与 addSource 类似,addSink 方法对应着一个“Sink”算子,主要就是用来实现与外部系统连接、并将数据提交写入的;Flink 程序中所有对外的输出操作,一般都是利用 Sink 算子完成的。
与 Source 算子非常类似,除去一些 Flink 预实现的 Sink,一般情况下 Sink 算子的创建是通过调用 DataStream 的.addSink()方法实现的。
stream.addSink(new SinkFunction(…));
addSource 的参数需要实现一个 SourceFunction 接口;类似地,addSink 方法同样需要传入一个参数,实现的是 SinkFunction 接口。在这个接口中只需要重写一个方法 invoke(),用来将指定的值写入到外部系统中。这个方法在每条数据记录到来时都会调用:
default void invoke(IN value, Context context) throws Exception
当然,SinkFuntion 多数情况下同样并不需要我们自己实现。Flink 官方提供了一部分的框架的 Sink 连接器。如下图所示,列出了 Flink 官方目前支持的第三方系统连接器:

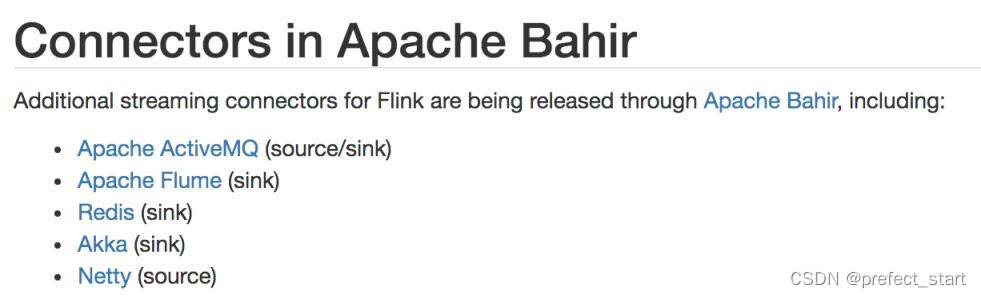
除 Flink 官方之外,Apache Bahir 作为给 Spark 和 Flink 提供扩展支持的项目,也实现了一些其他第三方系统与 Flink 的连接器,初次之外,还可以自定义sink 连接器。
5.4.2、输出到文件
Flink 也有一些非常简单粗暴的输出到文件的预实现方法:如 writeAsText()、writeAsCsv(),可以直接将输出结果保存到文本文件或 Csv 文件。但是这种方式是不支持同时写入一份文件的;所以我们往往会将最后的 Sink 操作并行度设为 1,这就大大拖慢了系统效率;而且对于故障恢复后的状态一致性,也没有任何保证。所以目前这些简单的方法已经要被弃用。
Flink 为此专门提供了一个流式文件系统的连接器:StreamingFileSink,它继承自抽象类
RichSinkFunction,而且集成了 Flink 的检查点(checkpoint)机制,用来保证精确一次(exactly
once)的一致性语义。
StreamingFileSink 为批处理和流处理提供了一个统一的 Sink,它可以将分区文件写入 Flink支持的文件系统。它可以保证精确一次的状态一致性,大大改进了之前流式文件 Sink 的方式。它的主要操作是将数据写入桶(buckets),每个桶中的数据都可以分割成一个个大小有限的分区文件,这样一来就实现真正意义上的分布式文件存储。我们可以通过各种配置来控制“分桶”的操作;默认的分桶方式是基于时间的,我们每小时写入一个新的桶。换句话说,每个桶内保存的文件,记录的都是 1 小时的输出数据。
StreamingFileSink 支持行编码(Row-encoded)和批量编码(Bulk-encoded,比如 Parquet)格式。这两种不同的方式都有各自的构建器(builder),调用方法也非常简单,可以直接调用StreamingFileSink 的静态方法:
- 行编码:StreamingFileSink.forRowFormat(basePath,rowEncoder)。
- 批量编码:StreamingFileSink.forBulkFormat(basePath,bulkWriterFactory)。
在创建行或批量编码 Sink 时,我们需要传入两个参数,用来指定存储桶的基本路径(basePath)和数据的编码逻辑(rowEncoder 或 bulkWriterFactory)。
下面我们就以行编码为例,将一些测试数据直接写入文件:
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(4);DataStreamSource<Event> stream = env.fromElements(new Event("Mary","./home", 1000L),new Event("Bob", "./cart", 2000L),new Event("Alice", "./prod?id=100", 3000L),new Event("Alice", "./prod?id=200", 3500L),new Event("Bob", "./prod?id=2", 2500L),new Event("Alice", "./prod?id=300", 3600L),new Event("Bob", "./home", 3000L),new Event("Bob", "./prod?id=1", 2300L),new Event("Bob", "./prod?id=3", 3300L));StreamingFileSink<String> fileSink = StreamingFileSink.<String>forRowFormat(new Path("./output"),new SimpleStringEncoder<>("UTF-8")).withRollingPolicy(DefaultRollingPolicy.builder().withRolloverInterval(TimeUnit.MINUTES.toMillis(15)).withInactivityInterval(TimeUnit.MINUTES.toMillis(5)).withMaxPartSize(1024 * 1024 * 1024).build()).build();// 将 Event 转换成 String 写入文件stream.map(Event::toString).addSink(fileSink);env.execute();}
这里我们创建了一个简单的文件 Sink,通过.withRollingPolicy()方法指定了一个“滚动策略”。“滚动”的概念在日志文件的写入中经常遇到:因为文件会有内容持续不断地写入,所以我们应该给一个标准,到什么时候就开启新的文件,将之前的内容归档保存。也就是说,上面的代码设置了在以下 3 种情况下,我们就会滚动分区文件:
- 至少包含 15 分钟的数据
- 最近 5 分钟没有收到新的数据
- 文件大小已达到 1 GB
5.4.3、输出到 Kafka
Kafka 是一个分布式的基于发布/订阅的消息系统,本身处理的也是流式数据,所以经常会作为 Flink 的输入数据源和输出系统。Flink 官方为 Kafka 提供了 Source和 Sink 的连接器,我们可以用它方便地从 Kafka 读写数据。
现在我们要将数据输出到 Kafka,整个数据处理的闭环已经形成,所以可以完整测试如下:
- 添加 Kafka 连接器依赖
- 启动 Kafka 集群
- 编写输出到 Kafka 的示例代码
我们可以直接将用户行为数据保存为文件 clicks.csv,读取后不做转换直接写入 Kafka,主题(topic)命名为“clicks”。
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);Properties properties = new Properties();properties.put("bootstrap.servers", "hadoop102:9092");DataStreamSource<String> stream = env.readTextFile("input/clicks.csv");stream.addSink(new FlinkKafkaProducer<String>("clicks",new SimpleStringSchema(),properties));env.execute();}
addSink 传入的参数是一个 FlinkKafkaProducer。因为需要向 Kafka 写入数据,自然应该创建一个生产者。FlinkKafkaProducer 继承了抽象类TwoPhaseCommitSinkFunction,这是一个实现了“两阶段提交”的 RichSinkFunction。两阶段提交提供了 Flink 向 Kafka 写入数据的事务性保证,能够真正做到精确一次(exactly once)的状态一致性。
Linux 主机启动一个消费者, 查看是否收到数据
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic clicks
5.4.4、输出到 Redis
Redis 是一个开源的内存式的数据存储,提供了像字符串(string)、哈希表(hash)、列表(list)、集合(set)、排序集合(sorted set)、位图(bitmap)、地理索引和流(stream)等一系列常用的数据结构。因为它运行速度快、支持的数据类型丰富,在实际项目中已经成为了架构优化必不可少的一员,一般用作数据库、缓存,也可以作为消息代理。
Flink 没有直接提供官方的 Redis 连接器,不过 Bahir 项目提供了 Flink-Redis 的连接工具。
具体测试步骤如下:
- 导入的 Redis 连接器依赖
<dependency><groupId>org.apache.bahir</groupId><artifactId>flink-connector-redis_2.11</artifactId><version>1.0</version>
</dependency>
- 启动 Redis 集群
- 输出到 Redis 的示例代码
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 创建一个到 redis 连接的配置FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("hadoop102").build();env.addSource(new ClickSource()).addSink(new RedisSink<Event>(conf, new MyRedisMapper()));env.execute();}public static class MyRedisMapper implements RedisMapper<Event> {@Overridepublic String getKeyFromData(Event e) {return e.user;}@Overridepublic String getValueFromData(Event e) {return e.url;}@Overridepublic RedisCommandDescription getCommandDescription() {return new RedisCommandDescription(RedisCommand.HSET, "clicks");}}
保存到 Redis 时调用的命令是 HSET,所以是保存为哈希表(hash),表名为“clicks”;保存的数据以 user 为 key,以 url 为 value,每来一条数据就会做一次转换。
- 运行代码,Redis 查看是否收到数据
$ redis-cli
hadoop102:6379>hgetall clicks
1) “Mary”
2) “./home”
3) “Bob”
4) “./cart”
5.4.5、输出到 Elasticsearch
ElasticSearch 是一个分布式的开源搜索和分析引擎,适用于所有类型的数据。ElasticSearch有着简洁的 REST 风格的 API,以良好的分布式特性、速度和可扩展性而闻名,在大数据领域应用非常广泛。
Flink 为 ElasticSearch 专门提供了官方的 Sink 连接器,Flink 1.13 支持当前最新版本的ElasticSearch。
写入数据的 ElasticSearch 的测试步骤如下。
- 添加 Elasticsearch 连接器依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-elasticsearch7_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency>
- 启动 Elasticsearch 集群
- 编写输出到 Elasticsearch 的示例代码
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Event> stream = env.fromElements(new Event("Mary", "./home", 1000L),new Event("Bob", "./cart", 2000L),new Event("Alice", "./prod?id=100", 3000L),new Event("Alice", "./prod?id=200", 3500L),new Event("Bob", "./prod?id=2", 2500L),new Event("Alice", "./prod?id=300", 3600L),new Event("Bob", "./home", 3000L),new Event("Bob", "./prod?id=1", 2300L),new Event("Bob", "./prod?id=3", 3300L));ArrayList<HttpHost> httpHosts = new ArrayList<>();httpHosts.add(new HttpHost("hadoop102", 9200, "http"));// 创建一个 ElasticsearchSinkFunctionElasticsearchSinkFunction<Event> elasticsearchSinkFunction = new ElasticsearchSinkFunction<Event>() {@Overridepublic void process(Event element, RuntimeContext ctx, RequestIndexer indexer) {HashMap<String, String> data = new HashMap<>();data.put(element.user, element.url);IndexRequest request = Requests.indexRequest().index("clicks").type("type") // Es 6 必须定义 type.source(data);indexer.add(request);}};stream.addSink(new ElasticsearchSink.Builder<Event>(httpHosts,elasticsearchSinkFunction).build());
// stream.addSink(esBuilder.build());env.execute();}
与 RedisSink 类 似 , 连 接 器 也 为 我 们 实 现 了 写 入 到 Elasticsearch 的SinkFunction——ElasticsearchSink。区别在于,这个类的构造方法是私有(private)的,我们需要使用elasticsearchSink 的 Builder 内部静态类,调用它的 build()方法才能创建出真正的SinkFunction。而 Builder 的构造方法中又有两个参数:
- httpHosts:连接到的 Elasticsearch 集群主机列表
- elasticsearchSinkFunction:这并不是我们所说的 SinkFunction,而是用来说明具体处理逻辑、准备数据向 Elasticsearch 发送请求的函数
具体的操作需要重写中 elasticsearchSinkFunction 中的 process 方法,我们可以将要发送的数据放在一个 HashMap 中,包装成 IndexRequest 向外部发送 HTTP 请求。
- 运行代码,访问 Elasticsearch 查看是否收到数据,查询结果如下所示。
{"took" : 5,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : "total" : {"value" : 9,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "clicks","_type" : "_doc","_id" : "dAxBYHoB7eAyu-y5suyU","_score" : 1.0,"_source" : {"Mary" : "./home"}}...]}
}
5.4.6、输出到 MySQL(JDBC)
写入数据的 MySQL 的测试步骤如下。
- 添加依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId><version>${flink.version}</version>
</dependency>
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.47</version>
</dependency>
- 启动 MySQL,在 database 库下建表 clicks
mysql> create table clicks(-> user varchar(20) not null,-> url varchar(100) not null);
- 编写输出到 MySQL 的示例代码
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Event> stream = env.fromElements(new Event("Mary", "./home", 1000L),new Event("Bob", "./cart", 2000L),new Event("Alice", "./prod?id=100", 3000L),new Event("Alice", "./prod?id=200", 3500L),new Event("Bob", "./prod?id=2", 2500L),new Event("Alice", "./prod?id=300", 3600L),new Event("Bob", "./home", 3000L),116new Event("Bob", "./prod?id=1", 2300L),new Event("Bob", "./prod?id=3", 3300L));stream.addSink(JdbcSink.sink("INSERT INTO clicks (user, url) VALUES (?, ?)",(statement, r) -> {statement.setString(1, r.user);statement.setString(2, r.url);},JdbcExecutionOptions.builder().withBatchSize(1000).withBatchIntervalMs(200).withMaxRetries(5).build(),new JdbcConnectionOptions.JdbcConnectionOptionsBuilder().withUrl("jdbc:mysql://localhost:3306/userbehavior")// 对于 MySQL 5.7,用"com.mysql.jdbc.Driver".withDriverName("com.mysql.cj.jdbc.Driver").withUsername("username").withPassword("password").build()));env.execute();}
- 运行代码,用客户端连接 MySQL,查看是否成功写入数据
mysql> select * from clicks;
+------+--------------+
| user | url |
+------+--------------+
| Mary | ./home |
| Alice| ./prod?id=300 |
| Bob | ./prod?id=3 |
+------+---------------+
3 rows in set (0.00 sec)
5.4.7、自定义 Sink 输出
与 Source 类似,Flink 为我们提供了通用的 SinkFunction 接口和对应的 RichSinkDunction抽象类,只要实现它,通过简单地调用 DataStream 的.addSink()方法就可以自定义写入任何外部存储。
例如,Flink 并没有提供 HBase 的连接器,在实现 SinkFunction 的时候,需要重写的一个关键方法 invoke(),在这个方法中我们就可以实现将流里的数据发送出去的逻辑。我们这里使用了 SinkFunction 的富函数版本,因为这里我们又使用到了生命周期的概念,创建 HBase 的连接以及关闭 HBase 的连接需要分别放在 open()方法和 close()方法中。
- 导入依赖
<dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>${hbase.version}</version>
</dependency>
- 编写输出到 HBase 的示例代码
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.fromElements("hello", "world").addSink(new RichSinkFunction<String>() {public org.apache.hadoop.conf.Configuration configuration; // 管理 Hbase 的配置信息,这里因为 Configuration 的重名问题,将类以完整路径导入public Connection connection; // 管理 Hbase 连接@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);configuration = HBaseConfiguration.create();configuration.set("hbase.zookeeper.quorum", "hadoop102:2181");connection = ConnectionFactory.createConnection(configuration);}@Overridepublic void invoke(String value, Context context) throws Exception {Table table = connection.getTable(TableName.valueOf("test")); // 表名为 testPut put = new Put("rowkey".getBytes(StandardCharsets.UTF_8)); // 指定 rowkeyput.addColumn("info".getBytes(StandardCharsets.UTF_8) // 指定列名, value.getBytes(StandardCharsets.UTF_8) // 写入的数据, "1".getBytes(StandardCharsets.UTF_8)); // 写入的数据table.put(put); // 执行 put 操作table.close(); // 将表关闭}@Overridepublic void close() throws Exception {super.close();connection.close(); // 关闭连接}});env.execute();}
SSS
相关文章:
Flink从入门到精通系列(四)
5、DataStream API(基础篇) Flink 有非常灵活的分层 API 设计,其中的核心层就是 DataStream/DataSet API。由于新版本已经实现了流批一体,DataSet API 将被弃用,官方推荐统一使用 DataStream API 处理流数据和批数据。…...
Nginx 配置实例-反向代理案例一
实现效果:使用nginx反向代理,访问 www.suke.com 直接跳转到本机地址127.0.0.1:8080 一、准备工作 Centos7 安装 Nginxhttps://liush.blog.csdn.net/article/details/125027693 1. 启动一个 tomcat Centos7安装JDK1.8https://liush.blog.csdn.net/arti…...

为什么北欧的顶级程序员数量远超中国?
说起北欧,很多人会想到寒冷的冬天,漫长的极夜,童话王国和圣诞老人,但是如果我罗列下诞生于北欧的计算机技术,恐怕你会惊掉下巴。Linux:世界上最流行的开源操作系统,最早的内核由Linus Torvalds开…...
vuex getters的作用和使用(求平均年龄),以及辅助函数mapGetters
getters作用:派生状态数据mapGetters作用:映射getters中的数据使用:方法名自定义,系统自动注入参数:state,每一个方法中必须有return,其return的结果被该方法名所接收。在state中声明数据listst…...
20230311给Ubuntu18.04下的GTX1080M安装驱动
20230311给Ubuntu18.04下的GTX1080M安装驱动 2023/3/11 12:50 2. 安装GTX1080驱动 安装 Nvidia 驱动 367.27 sudo add-apt-repository ppa:graphics-drivers/ppa 第一次运行出现如下的警告: Fresh drivers from upstream, currently shipping Nvidia. ## Curren…...

2023腾讯面试真题:
【腾讯】面试真题: 1、Kafka 是什么?主要应用场景有哪些? Kafka 是一个分布式流式处理平台。这到底是什么意思呢? 流平台具有三个关键功能: 消息队列:发布和订阅消息流,这个功能类似于消息…...
)
23种设计模式-建造者模式(Android应用场景介绍)
什么是建造者模式 建造者模式是一种创建型设计模式,它允许您使用相同的创建过程来生成不同类型和表示的对象。在本文中,我们将深入探讨建造者模式的Java实现,并通过一个例子来解释其工作原理。我们还将探讨如何在Android应用程序中使用建造者…...

English Learning - L2 语音作业打卡 双元音 [ʊə] [eə] Day17 2023.3.9 周四
English Learning - L2 语音作业打卡 双元音 [ʊə] [eə] Day17 2023.3.9 周四💌发音小贴士:💌当日目标音发音规则/技巧:🍭 Part 1【热身练习】🍭 Part2【练习内容】🍭【练习感受】🍓元音 [ʊə…...

【动态规划】多重背包问题,分组背包问题
Halo,这里是Ppeua。平时主要更新C语言,C,数据结构算法......感兴趣就关注我吧!你定不会失望。 🌈个人主页:主页链接 🌈算法专栏:专栏链接 我会一直往里填充内容哒! &…...

JAVA面向对象特征之——封装
4.封装 private关键字 是一个权限修饰符 可以修饰成员(成员变量和成员方法) 作用是保护成员不被别的类使用,被private修饰的成员只在本类中才能访问 针对private修饰的成员变量,如果需要被其他类使用,提供相应的操作 提供 “get变量名()…...

【数据结构】二叉树相关OJ题
文章目录一、单值二叉树二、检查两颗树是否相同三、判断一棵树是否为另一颗树的子树四、对称二叉树五、二叉树的前序遍历六、二叉树中序遍历七、二叉树的后序遍历八、二叉树的构建及遍历一、单值二叉树 单值二叉树 题目描述 如果二叉树每个节点都具有相同的值,那…...
Windows安装Hadoop
当初搭建Hadoop、Hive、HBase、Flink等这些没有截图写文,今为分享特重装。下载Hadoop下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/以管理员身份运行cmd切换到所在目录执行start winrar x -y hadoop-3.3.4.tar.gz,解压。配置…...
ICG-Hydrazide,吲哚菁绿-酰肼,ICG-HZ结构式,溶于二氯甲烷等部分有机溶剂,
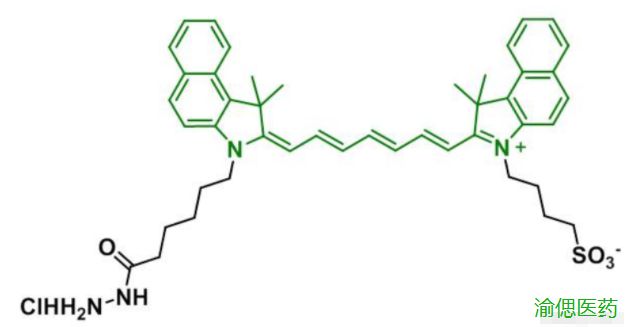
ICG-Hydrazide,吲哚菁绿-酰肼 中文名称:吲哚菁绿-酰肼 英文名称:ICG-Hydrazide 英文别名:ICG-HZ 性状:粉末或固体 溶剂:溶于二氯甲烷等部分有机溶剂 稳定性:-20℃密封保存、置阴凉干燥处、防潮 分子…...
【论文阅读】浏览器扩展危害-Helping or Hindering? How Browser Extensions Undermine Security
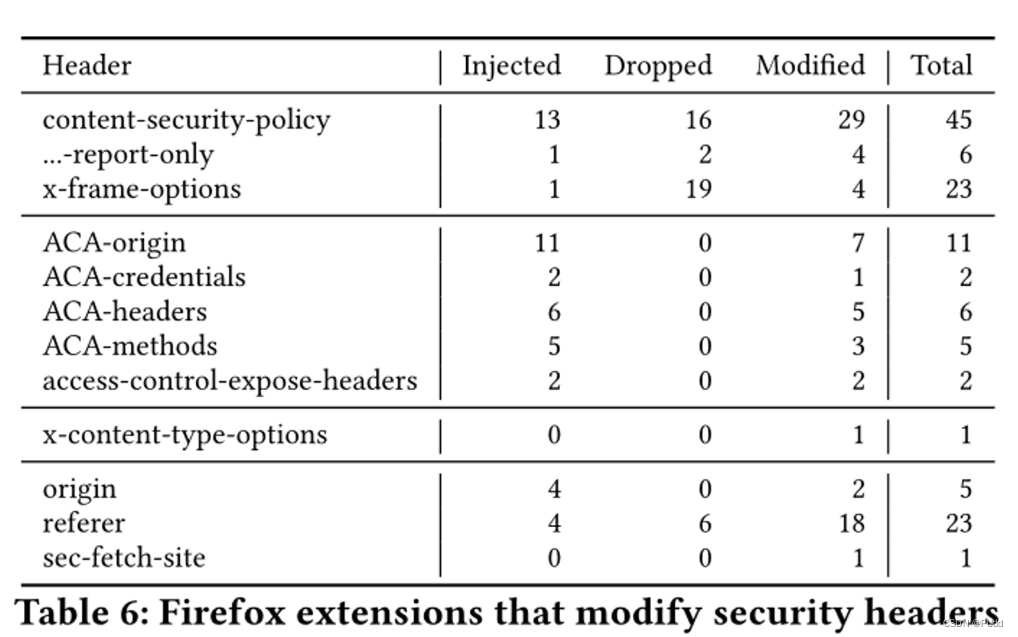
本文来源于ACM CCS 2022; https://dl.acm.org/doi/10.1145/3548606.3560685 摘要 “浏览器扩展”是轻量级的浏览器附加组件,使用各个浏览器特定的功能丰富的JavaScript api,为用户提供了额外的Web客户端功能,如改进网站外观和与…...
线性和非线性最小二乘问题的常见解法总结
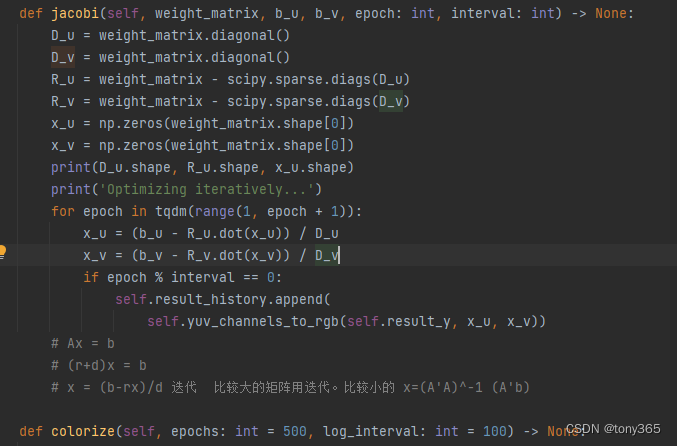
线性和非线性最小二乘问题的各种解法 先看这篇博客,非常好:线性和非线性最小二乘问题的各种解法 1. 线性最小二乘问题有最优解 但是面对大型稀疏矩阵的时候使用迭代法效率更好。 迭代法 有Jacobi迭代法、 Seidel迭代法及Sor法 【数值分析】Jacobi、Se…...

数据库知识点
数据库是指按照一定规则存储、组织和管理数据的系统。在现代化的信息化社会中,数据库已经成为了各种应用系统中不可或缺的一部分。因此,对于数据库的知识掌握不仅是计算机专业人员必备的技能,也是各个行业从业者必须具备的基本素质之一。 数…...

Maven打包构建Docker镜像并推送到仓库
Maven打包构建Docker镜像并推送到仓库 文章目录Maven打包构建Docker镜像并推送到仓库一,服务器Docker配置二,本地项目maven配置2.1 pom.xml2.2 dockerfile2.3 验证2.4 统一dockerfile对于开发完成的服务要发布至服务器Docker时,我刚学习了解D…...

TypeScript 基础学习之泛型和 extends 关键字
越来越多的团队开始使用 TS 写工程项目, TS 的优缺点也不在此赘述,相信大家都听的很多了。平时对 TS 说了解,仔细思考了解的也不深,借机重新看了 TS 文档,边学习边分享,提升对 TS 的认知的同时,…...
《数据分析-JiMuReport04》JiMuReport报表设计入门介绍-页面优化
报表设计 2 页面优化 如上图所示的报表,仅仅是展示数据,不过这样看起来似乎太草率了,所以再优化一下吧 保存报表后,在积木报表中就可以看到对应的报表文件 此时我们如果还需要编辑报表,就点击这个报表即可 2.1 居中…...
带头双向循环链表及链表总结
1、链表种类大全 1、链表严格来说可能用2*2*28种结构,从是否带头,是否循环,是否双向三个角度区分。 2、无头单向循环链表一般不会在实际运用中直接存储数据,而会作为某些更复杂结构的一个子结构,毕竟它只在头插、头删…...
)
CSS3文字闪烁效果实战:3种方法让你的网页标题更吸睛(附完整代码)
CSS3文字闪烁效果实战:3种方法让你的网页标题更吸睛 在电商促销页面或活动公告栏中,一个醒目的标题往往能瞬间抓住用户的注意力。文字闪烁效果作为一种经典的视觉设计手法,通过动态变化的光影和色彩,能够有效提升关键信息的传达效…...

第16篇:卡尔曼滤波器之递归算法与数据融合
你是否遇到过? 做机器人定位解算、自动驾驶姿态融合、工业现场传感器数据采集时,是不是总被随机噪声卡住进度?单一传感器精度不足、数据跳变严重,多传感器读数互相矛盾没法直接复用,想做数据降噪融合,却被复…...

STM32F4 ADC初始化避坑指南:从GPIO配置到数据采集的完整流程
STM32F4 ADC开发实战:从硬件设计到软件优化的全流程解析 第一次接触STM32F4的ADC功能时,我对着开发板连续调试了三个通宵——采样值总是莫名其妙地跳动,时钟配置怎么调都不对劲。直到发现参考电压引脚没接电容,那一刻才真正理解数…...
)
室内照明系统(有完整资料)
资料查找方式:特纳斯电子(电子校园网):搜索下面编号即可编号:T1902205M设计简介:本设计是基于单片机的室内照明系统,主要实现以下功能:1.采集光照数据和是否有人,实时显示…...
)
Xenon 1900扫码枪USB键盘模式配置全攻略(附C语言解析代码)
Xenon 1900扫码枪USB键盘模式配置与数据解析实战 在工业自动化、零售仓储等场景中,扫码枪作为高效的数据采集工具,其配置灵活性直接影响开发效率。Xenon 1900系列以其卓越的成像性能和可编程特性成为工程师首选,但如何正确配置USB键盘模式并解…...

Qwen2.5-VL-7B-Instruct开源可部署优势:完全离线运行,无外网依赖保障安全
Qwen2.5-VL-7B-Instruct开源可部署优势:完全离线运行,无外网依赖保障安全 1. 项目概述 Qwen2.5-VL-7B-Instruct是一款强大的多模态视觉-语言模型,能够同时处理图像和文本输入,生成高质量的文本输出。这个开源模型最突出的特点是…...

GradNorm:多任务学习中的自适应梯度平衡策略
1. GradNorm是什么?为什么我们需要它 第一次接触多任务学习时,我遇到了一个头疼的问题:明明给模型设计了完美的共享层结构,训练时却总是发现某个任务"霸占"了整个模型。比如同时做图像分类和物体检测时,分类…...

如何快速实现Flutter持续集成:GitHub Actions自动化部署完整指南
如何快速实现Flutter持续集成:GitHub Actions自动化部署完整指南 【免费下载链接】Flutter-Notebook FlutterDemo合集,今天你fu了吗 项目地址: https://gitcode.com/gh_mirrors/fl/Flutter-Notebook Flutter-Notebook是一个包含丰富Flutter Demo的…...

2026年就业寒冬下,有个行业327万人才缺口,IT行业薪资断层领先,小白如何抓住红利?
IT行业,尤其是网络安全领域,成为2026年就业市场的"超级引擎",拥有10万亿市场规模和12%年复合增长率。网络安全人才缺口达327万,平均年薪21.28万元,远超传统行业。IT行业具备五大优势:高增长红利、…...

3月23日GitHub热门项目推荐|看腻了龙虾?来看看这3款新星!
1. spec-kit - GitHub官方规格驱动开发工具包📈 项目状态:刚刚发布 (2026年3月23日)🔧 关键技术:Python、AI代码生成、规格解析📅 最新更新:2026年3月23日🔗 项目链接:https://githu…...