【论文精读】ViM: Out-Of-Distribution with Virtual-logit Matching 使用虚拟分对数匹配的分布外检测
文章目录
- 一、文章概览
- (一)问题来源
- (二)文章的主要工作
- (三)相关研究
- 二、动机:Logits 中缺失的信息
- (一)logits
- (三)基于零空间的 OOD 评分
- (四)基于主空间的 OOD 评分
- (五)NuSA 和 Residual的缺点
- 三、虚拟logit匹配
- (一)主子空间和残差
- (二)虚拟logit匹配
- (三)ViM 分数
- (四)与现有方法的连接
- 四、OpenImage-O 数据集
- 五、实验
- (一)实验设置
- (二)BiT实验结果
- (三)ViT实验结果
- (四)更多模型架构的实验结果
- (五)超参数的影响
- (六)分组效果
- (七)ViM的缺点
论文:CVPR 2022 | ViM:使用虚拟分对数匹配的分布外检测
一、文章概览
(一)问题来源
1、OOD检测基本概念
OOD检测问题是检验开放世界识别的一个基准问题。一个直观的例子如下图:一个对于螃蟹和猫的分类网络,可能会把从未见过的拍手(在训练集数据分布之外的测试样本,out-of-distribution sample)错分为螃蟹,把从未见过的狗错分为猫。OOD detection算法是用来判断输入数据是否属于已有训练集分布的方法。由此,深度神经网络不会受到从未学习过的种类的样本的干扰。

2、OOD检测器的核心:得分函数
OOD(Out-of-Distribution)检测器的核心是一个得分函数φ,它将输入特征x映射到R中的一个标量,表示样本有多大可能性是OOD。在测试中,决定一个阈值τ,以确保验证集至少保留一个给定的真阳性率(TPR),例如典型值0.95。如果φ(x) > τ,则将输入样本视为OOD,否则视为ID(即In-Distribution)。在某些情况下,如果需要一个表示ID的分数,我们可以将OOD得分取负作为ID得分。
通过寻找ID样本自然具有而OOD样本容易违反的属性可以设计相当多的得分函数:
- (1)概率,如最大softmax概率、softmax与平均类别条件分布之间的最小KL散度;
- (2)logit,如最大logit、logit的logsumexp函数;
- (3)特征,如特征与其低维嵌入的原像之间的残差范数、特征与类别中心之间的最小马氏距离等。
3、提出问题
大多数现有的分布外 (OOD) 检测算法依赖于单一输入源:特征、logit 或 softmax 概率,这导致其无法应对分布多种多样的OOD样本:有些 OOD 样本在特征空间中很容易识别,但在 Logit 空间中很难区分,反之亦然。
- 仅使用特征可能忽视模型中编码的特定类别相关信息;
- 使用 logit 或 softmax 不仅会错过零空间中的特征变化,该空间携带与类别无关的信息;并且softmax进一步丢弃了logits的范数。

(二)文章的主要工作
1、提出了名为Virtual-logit Matching (ViM) 的新型OOD检测方法
- ViM得分是一种软max得分,但与传统的类别不同,它是为一个构造的虚拟OOD类别计算的。
- 这个虚拟OOD类别的logit(未经过softmax处理的分数)结合了类别无关的特征空间分数和分布内 (ID) 类别相关的logits分数。
特征空间:模型中用来表示输入数据的特征的空间。
logit空间:模型输出层(一般是softmax层之前)的输出。每个logit对应于模型预测的一个类别,因此logit空间反映了模型对不同类别的置信度。
特征空间中的类不可知分数通常指的是从输入样本中提取的特征向量后,计算出的一个分数或者指标。这个分数通常不依赖于具体的类别标签,而是反映了输入样本在特征空间中与训练数据的相似度或者异常度。在OOD检测中,类不可知分数通常用来衡量输入样本与模型在训练时见过的数据分布之间的差异。较高的类不可知分数可能表明输入样本具有与训练数据显著不同的特征,可能是OOD样本的指示。
2、为 ImageNet1K 创建了一个新的 OOD 数据集
- 目前大规模 ID 数据集干净且真实的 OOD 数据集的短缺成为该领域的障碍。
- 以前的 OOD 数据集是根据公共数据集整理的,这些数据集是通过预定义的标签列表收集的,例如 iNaturalist、Texture 和 ImageNet-21k。这可能会导致性能比较出现偏差,特别是小覆盖范围的可破解性
 * 为了避免这种风险,文章根据具有自然类别分布的 OpenImage 数据集为 ImageNet-1K模型构建了一个新的 OOD 基准 OpenImage-O。它包含 17,632 个手动过滤的图像,比最近的 ImageNet-O 数据集大 7.8 倍。
* 为了避免这种风险,文章根据具有自然类别分布的 OpenImage 数据集为 ImageNet-1K模型构建了一个新的 OOD 基准 OpenImage-O。它包含 17,632 个手动过滤的图像,比最近的 ImageNet-O 数据集大 7.8 倍。
3、进行了广泛的实验,包括 CNN 和视觉Transformer,以证明所提出的 ViM 评分的有效性
(三)相关研究
OOD/ID 评分设计:
我们的方法通过虚拟 logit 的新颖机制结合了基于特征的评分和基于 logit 的评分的优点,并得到了实质性的改进。
网络/损失设计:
许多方法通过重新设计训练损失或添加正则化项使网络对OOD更敏感。而我们的方法不需要模型重新进行训练,因此不仅更容易应用,而且还保留了 ID 分类的准确性。
OOD数据暴露:
有些方法利用辅助的OOD数据集(例如Outlier Exposure)来提升OOD检测性能。我们的方法不需要额外的 OOD 数据,从而避免了对引入的 OOD 样本的偏差 。
二、动机:Logits 中缺失的信息
一系列基于logits或softmax概率的OOD检测方法的性能是有限的。
- 基于特征的OOD分数(例如Mahalanobis和Residual)擅长检测ImageNet-O中的OOD,而所有基于logit/概率的方法都落后。
- 最先进的基于概率的方法 KL 匹配的 AUROC 仍然低于纹理数据集特征空间中直接设计的 OOD 分数。

(一)logits
1、原始logits
对于一个C类分类器模型,其logit分数为 l = W T x + b l=W^Tx+b l=WTx+b,预测概率为 p ( x ) = s o f t m a x ( l ) p(x)=softmax(l) p(x)=softmax(l)。为推导方便,设置 o : = − ( W T ) + b o:=-(W^T)^+b o:=−(WT)+b,此时logit分数即为:
l = W T x ′ = W T ( x − o ) l=W^Tx'=W^T(x-o) l=WTx′=WT(x−o)
从几何角度来说,每个 logit l i l_i li 是特征 x ′ x′ x′ 和类向量 w i w_i wi ( W W W 的第 i i i 列)之间的内积。
2、虚拟logits
- 虚拟logits推广了普通logits的定义,将原来logits中的 w i w_i wi替换为子空间,从feature与 w w w向量的内积变为feature到某个子空间 S S S的投影长度。
- 为了让虚拟logits可以表示OOD信息,将子空间 S S S设定为所有训练样本特征构成的 D D D维主空间 P P P的正交补空间 P ⊥ P^{\perp} P⊥。这样在 P ⊥ P^{\perp} P⊥上投影越大,样本就越有可能是OOD。
- 为了让虚拟logits的范围与原来的logits尺度匹配,定义了 α \alpha α为匹配系数。
- 在新坐标系中,偏置项被安全地省略。
(三)基于零空间的 OOD 评分
将特征分解为 x = x W ⊥ + x W x=x^{W\perp}+x^W x=xW⊥+xW,其中 x W ⊥ x^{W\perp} xW⊥和 x W x^W xW分别是 x x x在 W ⊥ W^\perp W⊥和 W W W上的投影, W ⊥ W^\perp W⊥是 W T W^T WT的零空间,而 W W W是 W W W的列空间。 x W ⊥ x^{W\perp} xW⊥不影响分类,但是对于OOD检测有重要作用。
N u S A ( x ) = ∣ ∣ x ∣ ∣ 2 − ∣ ∣ x W ⊥ ∣ ∣ 2 ∣ ∣ x ∣ ∣ NuSA(x)=\frac{\sqrt{||x||^2-||x^{W\perp}||^2}}{||x||} NuSA(x)=∣∣x∣∣∣∣x∣∣2−∣∣xW⊥∣∣2
NuSA得分实际上是特征向量在主空间上的能量占总能量的比例。NuSA得分在0到1之间。当特征向量完全在主空间时,NuSA得分为1;当特征向量完全在零空间时,NuSA得分为0。OOD样本在零空间上的能量较大,因此其NuSA得分较低。
(四)基于主空间的 OOD 评分
低维流形 (Low-Dimensional Manifold) 是指数据或特征在高维空间中实际位于一个相对较低维度的子空间上。这一概念广泛应用于机器学习和数据分析中,特别是在降维、特征提取和异常检测等领域。
假设特征向量分布在一个低维流形上,并使用通过原点 O O O的线性子空间作为模型。定义主空间为由矩阵 X T X X^TX XTX的最大 D D D个特征值对应的特征向量所张成的 D D D维子空间 P P P。偏离主空间的特征可能是OOD样本。因此考虑计算特征与主空间的偏差:
R e s i d u a l ( x ) = ∣ ∣ x P ⊥ ∣ ∣ Residual(x)=||x^{P\perp}|| Residual(x)=∣∣xP⊥∣∣
(五)NuSA 和 Residual的缺点
与 logit/概率方法相比,NuSA 和 Residual 都不考虑特定于各个 ID 类的信息,即它们是类不可知的。因此,这些分数忽略了与每个 ID 类别的特征相似性,并且不知道输入最类似于哪个类别。
三、虚拟logit匹配
Logits 包含与类相关的信息,但特征空间中存在无法从 Logits 恢复的与类无关的信息。为了统一 OOD 检测的类不可知和类相关信息,提出了通过 Virtual-logit 匹配(缩写为 ViM)的 OOD 评分。
具体步骤包含三步,分别针对特征、logit和概率进行操作:
- 提取残差:提取输入特征 x x x 相对于主子空间(即主要成分分析得到的低维子空间)的残差 x P ⊥ x^{P\perp} xP⊥。这意味着将输入特征分解为主成分和残差两部分。
- 转换为logit:通过将这些残差的均值匹配到训练样本中的平均最大logit,将残差转换为有效的logit。这一步的目的是使得残差能反映出与现有logit相当的概率信息。
- 计算softmax概率:计算这个虚拟OOD类别的softmax概率,这个概率即为ViM得分。

(一)主子空间和残差
首先,通过向量 o = − ( W T ) + b o=-(W^T)^+b o=−(WT)+b 偏移特征空间,以便在 Logits 计算中无偏差: l = W T x ′ = W T ( x − o ) l=W^Tx'=W^T(x-o) l=WTx′=WT(x−o)。主子空间 P 由训练集 X 定义,其中行是原点为 o 的新坐标系中的特征。假设矩阵 X T X X^T X XTX 的特征分解为
X T X = Q Λ Q − 1 X^TX=Q\Lambda Q^{-1} XTX=QΛQ−1
其中 Λ \Lambda Λ 中的特征值按降序排序,则前 D D D 列的跨度是 D D D 维主子空间 P P P 。残差 x P ⊥ x^{P⊥} xP⊥ 是 x x x 在 P ⊥ P^⊥ P⊥ 上的投影,设第 ( D + 1 ) (D + 1) (D+1) 列到方程中 Q Q Q 的最后一列为新矩阵 R ∈ R N × ( N − D ) R ∈ R^{N×(N−D)} R∈RN×(N−D),则 x P ⊥ x^{P⊥} xP⊥ = R R T x RR^T x RRTx。
(二)虚拟logit匹配
虚拟logit是由每个模型常数 α α α 重新调整的残差范数。
l 0 : = α ∣ ∣ x P ⊥ ∣ ∣ = α x T R R T x l_0:=\alpha||x^{P\perp}||=\alpha\sqrt{x^TRR^Tx} l0:=α∣∣xP⊥∣∣=αxTRRTx
范数“ x P ⊥ x^{P⊥} xP⊥ ”不能直接用作新的logit,因为后者的softmax将在logits的指数上进行归一化,因此对logits的尺度非常敏感。如果残差与最大 logit 相比非常小,那么经过 softmax 后,残差将被埋在 logit 的噪声中。所以作者定义 α \alpha α为匹配系数:
α : = ∑ i = 1 K m a x j = 1 , . . , C { l j i } ∑ i = 1 K ∣ ∣ x i P ⊥ ∣ ∣ \alpha:=\frac{\sum_{i=1}^Kmax_{j=1,..,C}\{l_j^i\}}{\sum_{i=1}^K||x_i^{P\perp}||} α:=∑i=1K∣∣xiP⊥∣∣∑i=1Kmaxj=1,..,C{lji}
(三)ViM 分数
将虚拟 logit 附加到原始 logit 并计算 softmax。虚拟logit对应的概率定义为ViM。从数学上讲,设 x x x 的第 i i i 个 logit 为 l i l_i li,则得分为
V i M ( x ) = e α x T R R T x ∑ i = 1 C e l i + e α x T R R T x ViM(x)=\frac{e^{\alpha \sqrt{x^TRR^Tx}}}{\sum_{i=1}^Ce^{l_i}+e^{\alpha \sqrt{x^TRR^Tx}}} ViM(x)=∑i=1Celi+eαxTRRTxeαxTRRTx
(四)与现有方法的连接
对 V i M ViM ViM分数应用一个单调递增函数: t ( x ) = − ln ( 1 x − 1 ) t(x)=-\ln (\frac{1}{x}-1) t(x)=−ln(x1−1),可以得到一个等价的表达式:
α ∣ ∣ x P ⊥ ∣ ∣ − ln ∑ i = 1 C e l i \alpha ||x^{P\perp}||-\ln \sum_{i=1}^Ce^{l_i} α∣∣xP⊥∣∣−lni=1∑Celi
- 第一项是虚拟 logit,第二项是能量得分。
ViM 通过从特征中提供额外的剩余信息来完成能量方法。性能远优于能量和残差。
四、OpenImage-O 数据集
为 ID 数据集 ImageNet-1K 构建了一个名为 OpenImage-O 的新 OOD 数据集:
- 它是手动注释的,具有自然多样化的分布,并且具有17,632张图像的大规模。
- 它的构建是为了克服现有 OOD 基准的几个缺点。
- OpenImage-O 是从 OpenImageV3 的测试集中逐图像选择的,包括从 Flickr 收集的 125,436 张图像,没有预定义的类名称或标签列表,从而实现自然的类统计并避免初始设计偏差。
1、图像级注释的必要性
过去的一些工作仅仅根据类别标签从其他数据集中选择部分数据来进行OOD检测。虽然类别级别的注释成本较低,但生成的数据集可能包含大量不符合预期的噪音。因此,简单地通过查询标签创建OOD数据集是不可靠的,需要对每个图像进行人工检查以确认其有效性。
2、小覆盖范围的可破解性
如果 OOD 数据集有一个中心主题,例如纹理,其分布不太多样化,那么它可能很容易被“黑客攻击”。
3、OpenImage-O 的构建过程
基于 OpenImage-v3 数据集构建 OpenImage-O:
- 对于测试集中的每张图像,我们让人工标注人员确定它是否是 OOD 样本。
- 为了辅助标记,我们将任务简化为将图像与 ImageNet-1K 分类模型预测的前 10 个类别区分开来,即,如果图像不属于这 10 个类别中的任何一个,则该图像为 OOD。
- 提供类别标签以及每个类别中与测试图像最相似的图像(通过特征空间中的余弦相似度来测量)以进行可视化。
为了进一步提高标注质量,我们设计了几种方案:
- (1)如果标注者无法确定图像是否属于10个类别中的任何一个,则可以选择“困难”;
- (2)每张图像由至少两个标注器独立标注,并取两者一致的OOD图像集;
- (3)抽查检验,确保质量。
五、实验
(一)实验设置
模型:使用基于 CNN 和基于 Transformer 的模型对算法进行基准测试
ID数据集:ImageNet-1K
OOD 数据集: 四个 OOD 数据集(表 1)用于对算法进行全面的基准测试。
- OpenImage-O 是我们新收集的大规模 OOD 数据集。
- Texture 由自然纹理图像组成,删除了与 ImageNet 重叠的四个类别(气泡状、蜂窝状、蜘蛛网状、螺旋状)。
- iNaturalist是一个细粒度的物种分类数据集。
- ImageNet-O 中的图像经过对抗性过滤,以便可以欺骗 OOD 检测器。

评估指标:AUROC、FPR95
(二)BiT实验结果
- 在 OpenImage-O、Texture 和 ImageNet-O 三个数据集上,ViM 实现了最大的 AUROC 和最小的 FPR95。 ViM 平均 AUROC 为 90.91%,比第二名高出 4.29%。平均FPR95也是其中最低的。
- 结果表明ViM在所有数据集上都明显优于Residual Score和Energy Score两种方法。这表明 ViM 非常规地结合了 Residual 和 Energy 中的 OOD 信息。
- 在 iNaturalist 上,ViM 仅排名第三。我们假设它在 iNaturalist 上的中等性能与残差中包含多少信息有关,因为 iNaturalist 在四个 OOD 数据集(iNaturalist 4.65、OpenImage-O 5.04、ImageNet-O 5.16 和 Texture 8.16)中具有最小的平均残差范数。

表中显示了有关信息源的有趣模式:
- 如果零空间中不存在特征变化,例如在依赖 logits 和 softmax 的方法中,Texture 和 ImageNetO 的性能就会受到限制。例如,在Texture数据集上,依赖logit和softmax的性能最好的方法是KL Matching,其AUROC为86.92%,远远落后于在特征空间上操作的ViM、Mahalanobis和Residual。相反,如果丢弃类相关信息(例如在 Residual 方法中),iNaturalist 和 OpenImage-O 中的性能也会受到限制。然而,无论数据集类型如何,建议的 ViM 评分都是合格的。
(三)ViT实验结果
ViT 模型的两种性能最好的方法是 ViM 和 Mahalanobis。他们的 AU-ROC 在所有四个数据集上都很接近。然而,马氏距离需要计算类的马氏距离,这使得其计算成本很高。相比之下,ViM方法轻量且快速。 ReAct、Energy、MaxLogit 和 ODIN 四种方法排名第二,其余三种方法的 AUROC 相对较低。

(四)更多模型架构的实验结果
我们展示了各种模型架构的更多结果。结果表明,ViM 对模型架构变化具有鲁棒性。

(五)超参数的影响
1、主空间的维度D

2、匹配参数 α :控制不同 OOD 特征之间权衡的相对重要性

(六)分组效果
与利用了大规模语义空间中的分组结构的 MOS 进行比较: (1) MaxGroup是MSP的分组版本,它首先通过对组成类求和来获得分组概率,然后将最大分组概率作为ID分数。 (2) ViM+Group 也将最大组概率作为 ID 分数,只不过概率取自 (C + 1) 维向量,并额外有一个 ViM 虚拟类参与 softmax 归一化。 MaxGroup和ViM+Group是在BiT的预训练权重上进行评估的,而MOS需要使用基于组的学习来微调模型。结果显示:
- (1)MaxGroup 的平均 AUROC 比普通 MSP 提高了从 77.25% 到 79.23%,显示了组信息的有用性;
- (2) 我们的原始 ViM 和 ViM 的团体版本在四个数据集中的三个上都明显优于 MOS。

(七)ViM的缺点
- ViM 在残差较小的 OOD 数据集(例如 iNaturalist)上表现出较小的性能提升。
- ViM不需要训练的特性是一把双刃剑。这意味着ViM受到原始网络特征质量的限制。
相关文章:
【论文精读】ViM: Out-Of-Distribution with Virtual-logit Matching 使用虚拟分对数匹配的分布外检测
文章目录 一、文章概览(一)问题来源(二)文章的主要工作(三)相关研究 二、动机:Logits 中缺失的信息(一)logits(三)基于零空间的 OOD 评分…...

【面试题】前端 移动端自适应?_前端移动端适配面试题
设备像素比 设备像素比 (DevicePixelRatio) 指的是设备物理像素和逻辑像素的比例 。比如 iPhone6 的 DPR 是2。 设备像素比 物理像素 / 逻辑像素。可通过 window.devicePixelRatio 获取,CSS 媒体查询代码如下 media (-webkit-min-device-pixel-ratio: 3), (min-…...
在Maven工程中手动配置并测试SpringBoot(巨详)
本篇博客承继自博客: 在IDEA 2024.1.3 (Community Edition)中创建Maven项目_idea2024.1.3如何创建maven项目-CSDN博客 配置POM文件 打开工程中的pom.xml文件,先向其中写入 <parent><groupId>org.springframework.boot</groupId><…...

c# 去掉字符串首尾的 特殊符号
如果首尾的 - 数量不确定,可以使用以下方法来去掉字符串两端的 - 字符: 使用正则表达式: using System.Text.RegularExpressions;string input "---Hello, World!---"; string trimmed Regex.Replace(input, "^-*|-*$", ""); // trimmed 为 …...

在容器中共享本地文件
在容器中共享本地文件 目录 卷与绑定挂载的对比在主机和容器之间共享文件Docker 访问主机文件的文件权限试一试 运行一个容器使用绑定挂载在 Docker Dashboard 中访问文件停止容器 额外资源下一步 每个容器都有一切需要运行的资源,而不依赖于主机机器上预先安装的…...

Java Matcher类方法深度剖析:查找和匹配、索引方法
1. 引言 在Java中,正则表达式是处理字符串的强大工具,而java.util.regex包中的Matcher类则是实现这一功能的核心。对于Java工程师而言,熟练掌握Matcher类的使用方法,无疑能够极大地提升字符串处理的效率和准确性。本文将对Matcher类的方法进行深度讲解,并按照查找和匹配方…...
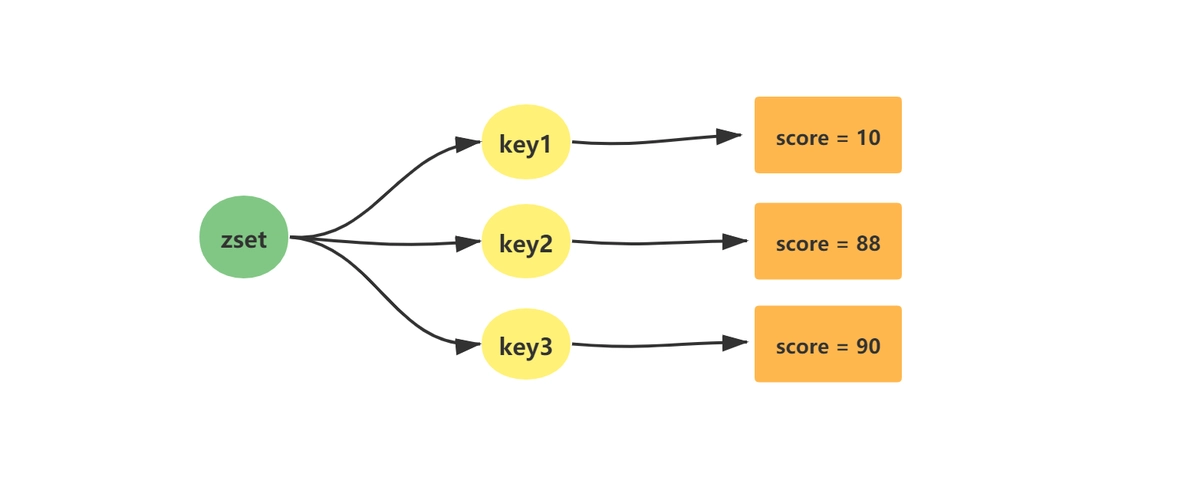
Redis-数据类型-zset
文章目录 1、查看redis是否启动2、通过客户端连接redis3、切换到db4数据库4、将一个或多个member元素及其score值加入到有序集key当中5、升序返回有序集key6、升序返回有序集key,让分数一起和值返回的结果集7、降序返回有序集key,让分数一起和值返回到结…...
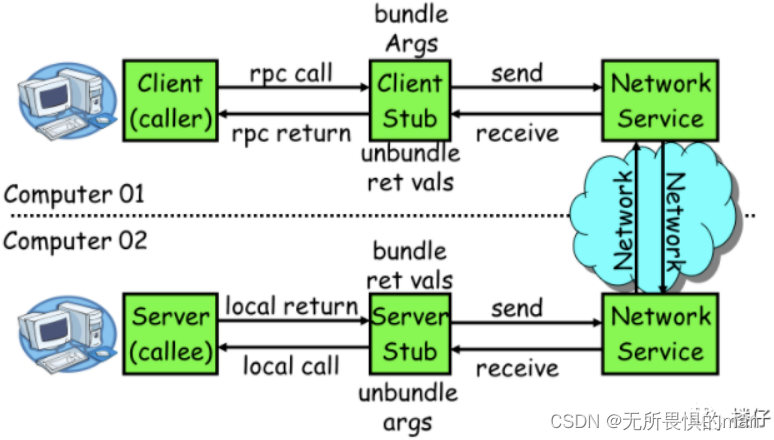
手撕RPC——前言
手撕RPC——前言 一、RPC是什么?二、为什么会出现RPC三、RPC的原理3.1 RPC是如何做到透明化远程服务调用?3.2 如何实现传输消息的编解码? 一、RPC是什么? RPC(Remote Procedure Call,远程过程调用ÿ…...
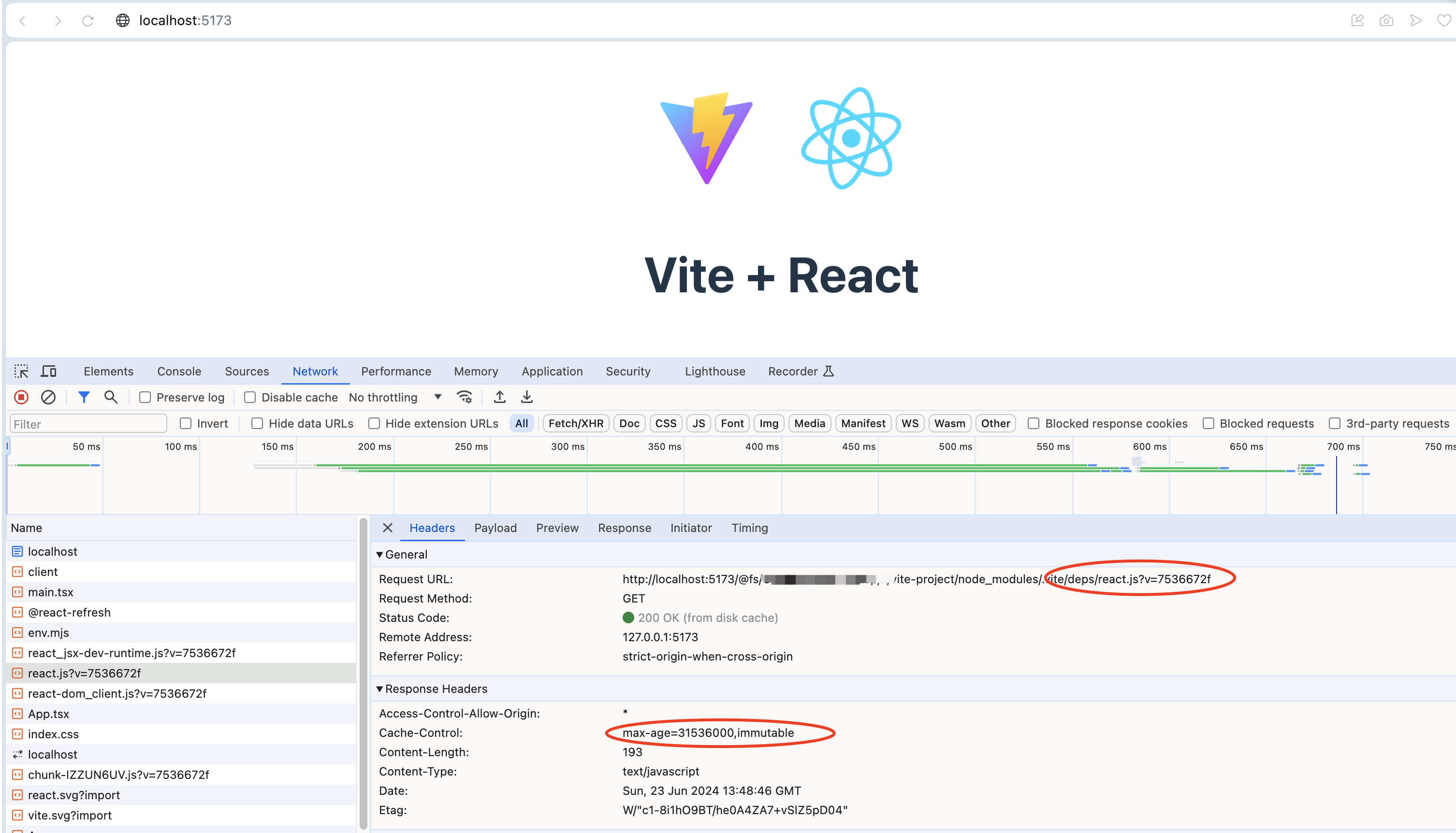
Vite: 关于预构建的毫秒级响应
概述 在我们的项目代码中,我们所说的模块代码其实分为两部分 一部分是源代码,也就是业务代码另一部分是第三方依赖的代码,即 node_modules 中的代码 Vite 是一个提倡 no-bundle 的构建工具,相比于传统的 Webpack能做到开发时的模…...
)
Docker 中 MySQL 迁移策略(单节点)
目录 一、 简介二、操作流程2.1 进入mysql容器2.2 导出 MySQL 数据2.3. 将导出的文件复制到宿主机2.4 创建 Docker Compose 配置2.5 启动新的 Docker 容器2.6 导入数据到新的容器2.7 验证数据2.8 删除旧的容器(删除操作需慎重) 三、推荐配置四、写在后面…...

猫头虎 分享已解决Error || API Rate Limits: HTTP 429 Too Many Requests
猫头虎 分享已解决Error || API Rate Limits: HTTP 429 Too Many Requests 🐯 摘要 📄 大家好,我是猫头虎,一名专注于人工智能领域的博主。在AI开发中,我们经常会遇到各种各样的错误,其中API Rate Limits…...

开发一个python工具,pdf转图片,并且截成单个图片,然后修整没用的白边及循环遍历文件夹全量压缩图片
今天推荐一键款本人开发的pdf转单张图片并截取没有用的白边工具 一、开发背景: 业务需要将一个pdf文件展示在前端显示,但是基于各种原因,放弃了h5使用插件展示 原因有多个,文件资源太大加载太慢、pdf展示兼容性问题、pdf展示效果…...
【数据结构与算法 经典例题】使用栈实现队列(图文详解)
💓 博客主页:倔强的石头的CSDN主页 📝Gitee主页:倔强的石头的gitee主页 ⏩ 文章专栏:《数据结构与算法 经典例题》C语言 期待您的关注 目录 一、问题描述 二、前置知识 三、解题思路 原理: 图解&…...

不知大家信不信,竟有这么巧的事,我领导的老婆,竟然是我老婆的下属,我在想要不要利用下这层关系,改善下领导对我的态度,领导怕老婆
职场如战场,每个人都身不由己。每天上班,除了要面对堆积如山的工作,还要小心应对来自领导的“狂风暴雨”。最近,我无意间发现领导一个秘密,这个秘密让我对职场关系和人性都产生了新的思考。 故事要从那天晚上说起。我…...

使用pkg -r 命令选项向jail虚拟子系统里安装软件@FreeBSD
刷FreeBSD 论坛的时候,看到这样一招:使用pkg -r选项,往jail等虚拟机子系统里安装软件。jails - How to install a pkg offline into a jail? | The FreeBSD Forums rootfbhost:~ # pkg pkg: not enough arguments Usage: pkg [-v] [-d] [-l…...
Go语言开发框架GoFly已集成数据可视化大屏开发功能,让开发者只专注业务开发,本文指导大家如何使用
前言 框架提供数据大屏开发基础,是考虑当前市场软件应用有一大部分是需要把业务数据做出大屏,很多政府项目对大屏需求特别高,还有生产企业项目也对大屏有需求,没有提供基础规范的后台框架,在开发大屏需要很多时间去基…...

PR模板 | RGB特效视频标题模板Titles | MOGRT
RGB特效视频标题模板mogrt免费下载 4K分辨率(38402160) 支持任何语言 友好的界面 输入和输出动画 快速渲染 视频教程 免费下载:https://prmuban.com/39055.html 更多pr模板视频素材下载地址:https://prmuban.com...

python替换文件内容
# 打开文件with open(name, r) as file:content file.read()# 替换内容old_string binarynew_string cc_library_sharedcontent content.replace(old_string, new_string)# 写回文件with open(name, w) as file:file.write(content)...

SD-WAN是什么?它有哪些应用领域?
随着企业业务的不断扩展和数字化转型的加速,传统网络架构已无法满足企业对高效、灵活和安全网络连接的需求。在此背景下,SD-WAN(软件定义广域网)应运而生,为企业带来了全新的网络连接体验。本文将详细介绍SD-WAN网络及…...
PHP-CGI的漏洞(CVE-2024-4577)
通过前两篇文章的铺垫,现在我们可以了解 CVE-2024-4577这个漏洞的原理 漏洞原理 CVE-2024-4577是CVE-2012-1823这个老漏洞的绕过,php cgi的老漏洞至今已经12年,具体可以参考我的另一个文档 简单来说,就是使用cgi模式运行的PHP&…...

基于服务器使用 apt 安装、配置 Nginx
🧾 一、查看可安装的 Nginx 版本 首先,你可以运行以下命令查看可用版本: apt-cache madison nginx-core输出示例: nginx-core | 1.18.0-6ubuntu14.6 | http://archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages ng…...

C/C++ 中附加包含目录、附加库目录与附加依赖项详解
在 C/C 编程的编译和链接过程中,附加包含目录、附加库目录和附加依赖项是三个至关重要的设置,它们相互配合,确保程序能够正确引用外部资源并顺利构建。虽然在学习过程中,这些概念容易让人混淆,但深入理解它们的作用和联…...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...

Rust 开发环境搭建
环境搭建 1、开发工具RustRover 或者vs code 2、Cygwin64 安装 https://cygwin.com/install.html 在工具终端执行: rustup toolchain install stable-x86_64-pc-windows-gnu rustup default stable-x86_64-pc-windows-gnu 2、Hello World fn main() { println…...

日常一水C
多态 言简意赅:就是一个对象面对同一事件时做出的不同反应 而之前的继承中说过,当子类和父类的函数名相同时,会隐藏父类的同名函数转而调用子类的同名函数,如果要调用父类的同名函数,那么就需要对父类进行引用&#…...

SpringAI实战:ChatModel智能对话全解
一、引言:Spring AI 与 Chat Model 的核心价值 🚀 在 Java 生态中集成大模型能力,Spring AI 提供了高效的解决方案 🤖。其中 Chat Model 作为核心交互组件,通过标准化接口简化了与大语言模型(LLM࿰…...

Python网页自动化Selenium中文文档
1. 安装 1.1. 安装 Selenium Python bindings 提供了一个简单的API,让你使用Selenium WebDriver来编写功能/校验测试。 通过Selenium Python的API,你可以非常直观的使用Selenium WebDriver的所有功能。 Selenium Python bindings 使用非常简洁方便的A…...

加密通信 + 行为分析:运营商行业安全防御体系重构
在数字经济蓬勃发展的时代,运营商作为信息通信网络的核心枢纽,承载着海量用户数据与关键业务传输,其安全防御体系的可靠性直接关乎国家安全、社会稳定与企业发展。随着网络攻击手段的不断升级,传统安全防护体系逐渐暴露出局限性&a…...
基于单片机的宠物屋智能系统设计与实现(论文+源码)
本设计基于单片机的宠物屋智能系统核心是实现对宠物生活环境及状态的智能管理。系统以单片机为中枢,连接红外测温传感器,可实时精准捕捉宠物体温变化,以便及时发现健康异常;水位检测传感器时刻监测饮用水余量,防止宠物…...

自定义线程池1.2
自定义线程池 1.2 1. 简介 上次我们实现了 1.1 版本,将线程池中的线程数量交给使用者决定,并且将线程的创建延迟到任务提交的时候,在本文中我们将对这个版本进行如下的优化: 在新建线程时交给线程一个任务。让线程在某种情况下…...