关于scrapy模块中setting.py文件的介绍
作用
在Scrapy框架中,settings.py 文件起着非常重要的作用,它用于配置和控制整个Scrapy爬虫项目的行为、性能和功能。
setting.py文件的介绍
# Scrapy settings for haodaifu project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html# 设置爬虫的名称
BOT_NAME = "spidername"# 指定包含的爬虫代码的模块
SPIDER_MODULES = ["spidername.spiders"]
NEWSPIDER_MODULE = "spidername.spiders"# 设置用户代理,用于模拟浏览器或特定的爬虫身份
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"# 配置爬虫是否遵循robots.txt柜子
# Obey robots.txt rules
ROBOTSTXT_OBEY = False# 控制并发请求的数量(默认为16)
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 64# 设置下载延迟,控制请求之间的时间间隔,以避免对目标服务器造成过大负载
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3# 配置每个域名的最大并发请求数
# The download delay setting will honor only one of:
CONCURRENT_REQUESTS_PER_DOMAIN = 16# 设置每个IP地址的最大并发请求数
CONCURRENT_REQUESTS_PER_IP = 16# 启用或禁用cookies
# Disable cookies (enabled by default)
COOKIES_ENABLED = False# 启用或禁用Telnet控制台
# Disable Telnet Console (enabled by default)
TELNETCONSOLE_ENABLED = False# 默认的请求头
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {'Referer': 'https://www.xxx.com/','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36',
}# 启用或禁用爬虫中间件
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
# 爬虫中间件及其顺序
SPIDER_MIDDLEWARES = {"spidername.middlewares.SpidernameSpiderMiddleware": 543,
}# 启用或禁用下载中间件
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# 下载中间件及其顺序
DOWNLOADER_MIDDLEWARES = {"spidername.middlewares.SpidernameDownloaderMiddleware": 543,
}# 启用和配置scrapy扩展
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
EXTENSIONS = {"scrapy.extensions.telnet.TelnetConsole": None,
}# 启用或禁用项目管道
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# 项目管道
ITEM_PIPELINES = {"spidername.pipelines.spidernamePipeline": 300,
}# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
# 是否启用自动限速
AUTOTHROTTLE_ENABLED = True# 初始化下载延迟(秒)
# The initial download delay
AUTOTHROTTLE_START_DELAY = 5# 最大下载延迟(秒)
# The maximum download delay to be set in case of high latencies
AUTOTHROTTLE_MAX_DELAY = 60# The average number of requests Scrapy should be sending in parallel to
# each remote server
# scrapy 的目标并发请求数
AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0# Enable showing throttling stats for every response received:
# 是否启用自动限速调试模式
AUTOTHROTTLE_DEBUG = False# 启用和配置http缓存
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
# 是否启用HTTP缓存
HTTPCACHE_ENABLED = True# 缓存超时时间(秒)
HTTPCACHE_EXPIRATION_SECS = 0# 缓存目录
HTTPCACHE_DIR = "httpcache"# 忽略缓存的HTTP状态码列表
HTTPCACHE_IGNORE_HTTP_CODES = []HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"# Set settings whose default value is deprecated to a future-proof value
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"# 输出feed的编码
FEED_EXPORT_ENCODING = "utf-8"
相关文章:

关于scrapy模块中setting.py文件的介绍
作用 在Scrapy框架中,settings.py 文件起着非常重要的作用,它用于配置和控制整个Scrapy爬虫项目的行为、性能和功能。 setting.py文件的介绍 # Scrapy settings for haodaifu project # # For simplicity, this file contains only settings consider…...

laravel Blade 指令的趣味性
首先,我们通过几个要点来解释 Blade 引擎的工作原理。 您选择一个 Blade 模板进行渲染。引擎使用一系列正则表达式来解析和编译模板。该引擎生成一个普通的 PHP 文件并将其写入磁盘(以便将其缓存以供将来渲染)。包含 PHP 文件并使用输出缓冲…...
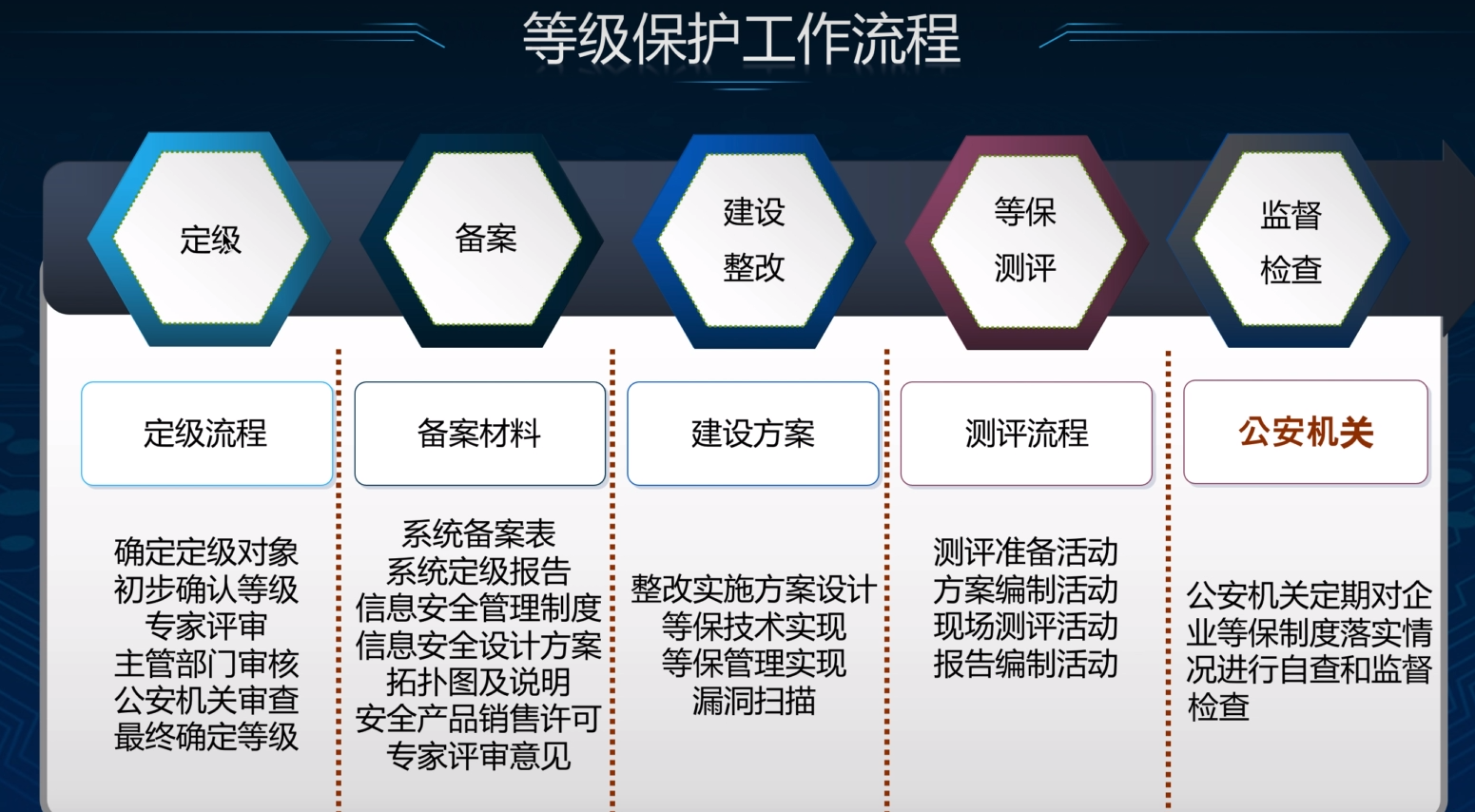
【面试题】等保(等级保护)的工作流程
等保(等级保护)的工作流程主要包括以下几个步骤,以下将详细分点介绍: 系统定级: 确定定级对象:根据《信息系统等级保护管理办法》和《信息系统等级保护定级指南》的要求,确定需要进行等级保护的…...

python调用麦克风和扬声器,并调用阿里云实时语音转文字
import time import queue import sounddevice as sd import numpy as np import nls import sys# 阿里云配置信息 URL "wss://nls-gateway-cn-shanghai.aliyuncs.com/ws/v1" TOKEN "XXXX" # 参考https://help.aliyun.com/document_detail/450255.html获…...
的常见模式。)
描述在React中集成第三方库(如Redux或React Router)的常见模式。
在React中集成第三方库,如状态管理库Redux或路由库React Router,通常遵循一些常见的模式和最佳实践。下面是一些集成这些库的步骤和模式: 集成Redux 安装Redux及相关包: 安装Redux及其中间件(如redux-thunk或redux-saga…...
)
JavaScript语法特性篇-空值合并运算符(??)
1、基本使用 空值合并运算符(??)英文名称为 Nullish coalescing operator,是一个逻辑运算符。 特性:当左侧的操作数为 null 或者 undefined 时,返回其右侧操作数,否则返回左侧操作数。 const foo nul…...
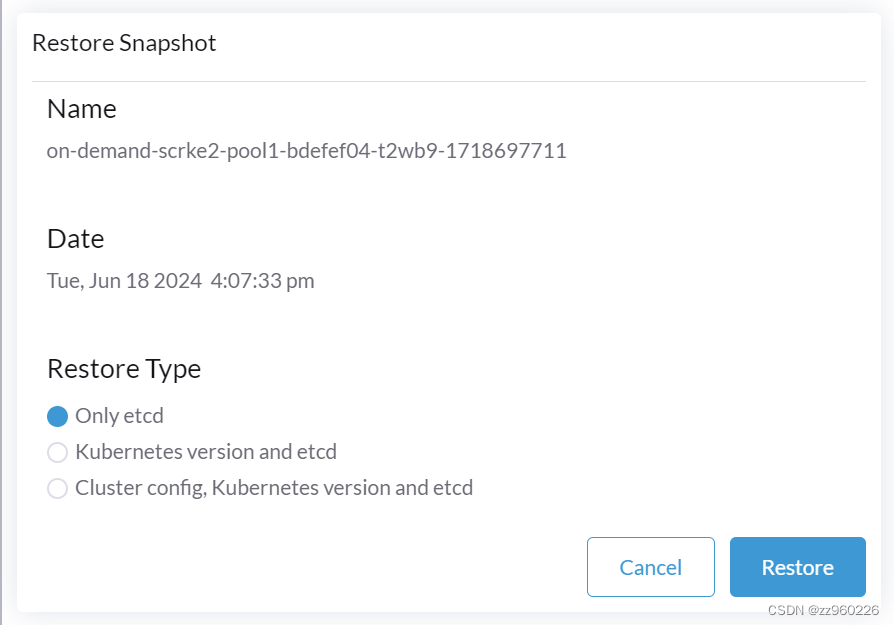
rancher快照备份至S3
巧用rancher的S3快照备份功能,快速实现集群复制、集群转移、完全崩溃后的极限修复 1.进入集群管理,在对应的集群菜单后,点击编辑配置 2.选择ETCD,启用,Backup Snapshots to S3选项 并填入你的minio 3 配置成功后 手…...
ChatGPT API教程在线对接OpenAI APIKey技术教程
一、OpenAI基本库介绍 您可以通过 HTTP 请求与 API 进行交互,这可以通过任何编程语言实现。我们提供官方的 Python 绑定、官方的 Node.js 库,以及由社区维护的库。 要安装官方的 Python 绑定,请运行以下命令: pip install open…...

随心而遇,跟着感觉走
分数限制下,选好专业还是选好学校? 24年高考结束,很多学生犹豫选择专业还是好学校,我的建议是,选择好学校。 本人体验来说,电子,工地,计科,数学,工科相关的…...

LeetCode题练习与总结:只出现一次的数字--136
一、题目描述 给你一个 非空 整数数组 nums ,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。 你必须设计并实现线性时间复杂度的算法来解决此问题,且该算法只使用常量额外空间。 示例 1 : …...

常见的中间件都在解决什么问题?
常见的中间件都在解决什么问题 RocketMQ RocketMQ 是一款功能强大的分布式消息系统。 RocketMQ 源码地址:https://github.com/apache/rocketmq(opens new window) RocketMQ 官方网站:https://rocketmq.apache.org 什么场景下用 RocketMQ?…...

微信小程序-scroll-view实现上拉加载和下拉刷新
一.scroll-view实现上拉加载 scroll-view组件通过自身一些属性实现上拉加载的功能。 lower-threshold“100"属性表示距离底部多少px就会实现触发下拉加载的事件。 类似于在.json文件里面配置"onReachBottomDistance”: 100 bindscrolltolower"getMore"属…...

TS中interface和type的区别
在 TypeScript 中,interface 和 type 都可以用来定义对象的类型,但它们之间存在一些差异。 以下是 interface 和 type 的主要区别: 扩展(Extending): interface 可以通过 extends 关键字来扩展其他 interface。interfa…...
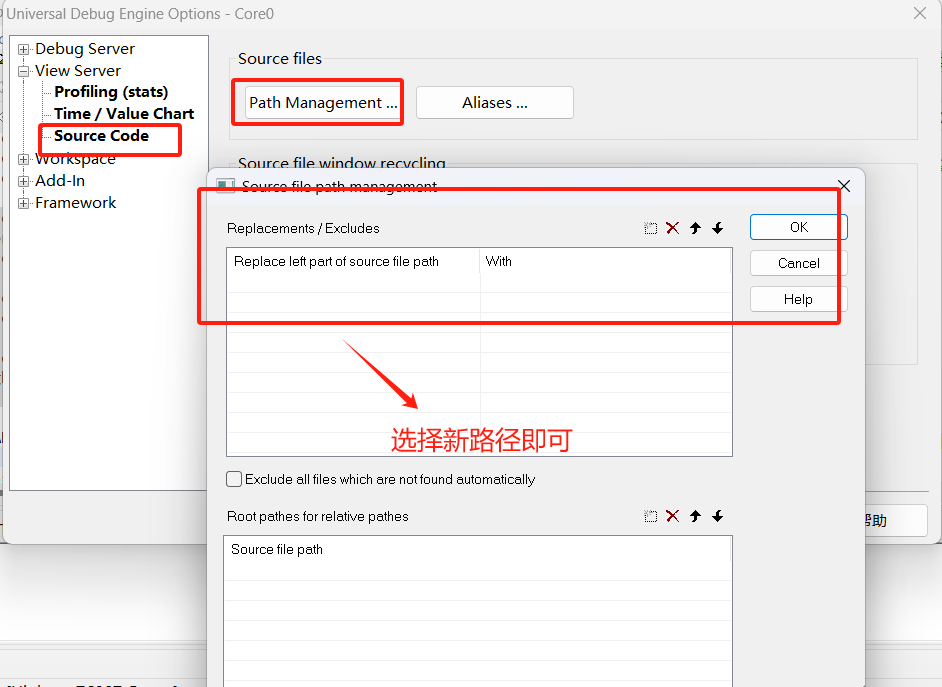
Hightec编译器系列之高级调试技巧精华总结
Hightec编译器系列之高级调试技巧精华总结 小T为了便于大家理解,本文的思维导图大纲如下: 之前可能很多小伙伴没有使用过Hightec编译器,大家可以参考小T之前的文章《Hightec编译器系列之白嫖就是爽》可以下载一年试用版本。 小T使用过适配英…...

【论文笔记】LoRA LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
题目:LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS 来源: ICLR 2022 模型名称: LoRA 论文链接: https://arxiv.org/abs/2106.09685 项目链接: https://github.com/microsoft/LoRA 文章目录 摘要引言问题定义现有方法的问题方法将 LORA 应用于 Transformer 实…...

【Sa-Token|4】Sa-Token微服务项目应用
若微服务数量多,如果每个服务都改动,工作量大,则可以只在网关和用户中心进行改动,也是可以实现服务之间的跳转。 这种方式可以通过在网关服务中生成和验证 Sa-Token,并将其与现有的 Token关联存储在 Redis 中。用户中心…...
】)
鸿蒙开发系统基础能力:【@ohos.hilog (日志打印)】
日志打印 hilog日志系统,使应用/服务可以按照指定级别、标识和格式字符串输出日志内容,帮助开发者了解应用/服务的运行状态,更好地调试程序。 说明: 本模块首批接口从API version 7开始支持。后续版本的新增接口,采用…...

SpringMVC系列十: 中文乱码处理与JSON处理
文章目录 中文乱码处理自定义中文乱码过滤器Spring提供的过滤器处理中文 处理json和HttpMessageConverter<T>处理JSON-ResponseBody处理JSON-RequestBody处理JSON-注意事项和细节HttpMessageConverter<T\>文件下载-ResponseEntity<T\>作业布置 上一讲, 我们学…...
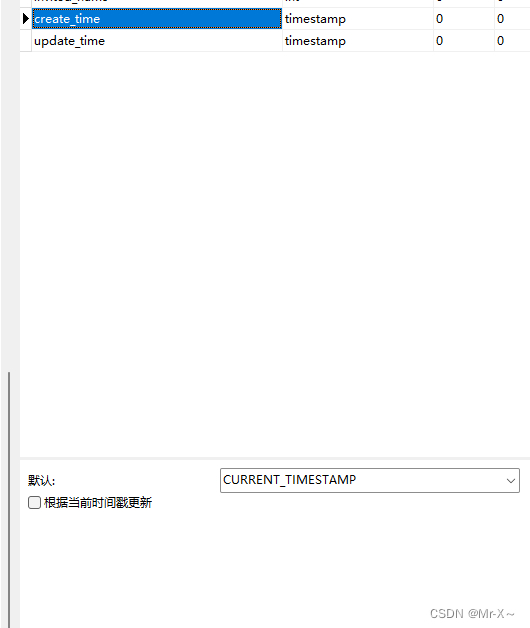
使用MyBatisPlus进行字段的自动填充
使用MyBatisPlus进行字段的自动填充 需求场景 当我们往数据库里面插入一条数据,或者是更新一条数据时,一般都需要标记创建时间create_time和更新时间update_time的值,但是如果我们每张表的每个请求,在执行sql语句的时候我们都手…...

python爬虫之aiohttp多任务异步爬虫
python爬虫之aiohttp多任务异步爬虫 爬取的flash服务如下: from flask import Flask import timeapp Flask(__name__)app.route(/bobo) def index_bobo():time.sleep(2)return Hello boboapp.route(/jay) def index_jay():time.sleep(2)return Hello jayapp.rout…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

相机从app启动流程
一、流程框架图 二、具体流程分析 1、得到cameralist和对应的静态信息 目录如下: 重点代码分析: 启动相机前,先要通过getCameraIdList获取camera的个数以及id,然后可以通过getCameraCharacteristics获取对应id camera的capabilities(静态信息)进行一些openCamera前的…...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...

SpringTask-03.入门案例
一.入门案例 启动类: package com.sky;import lombok.extern.slf4j.Slf4j; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cache.annotation.EnableCach…...

学习STC51单片机32(芯片为STC89C52RCRC)OLED显示屏2
每日一言 今天的每一份坚持,都是在为未来积攒底气。 案例:OLED显示一个A 这边观察到一个点,怎么雪花了就是都是乱七八糟的占满了屏幕。。 解释 : 如果代码里信号切换太快(比如 SDA 刚变,SCL 立刻变&#…...

dify打造数据可视化图表
一、概述 在日常工作和学习中,我们经常需要和数据打交道。无论是分析报告、项目展示,还是简单的数据洞察,一个清晰直观的图表,往往能胜过千言万语。 一款能让数据可视化变得超级简单的 MCP Server,由蚂蚁集团 AntV 团队…...
: 一刀斩断视频片头广告)
快刀集(1): 一刀斩断视频片头广告
一刀流:用一个简单脚本,秒杀视频片头广告,还你清爽观影体验。 1. 引子 作为一个爱生活、爱学习、爱收藏高清资源的老码农,平时写代码之余看看电影、补补片,是再正常不过的事。 电影嘛,要沉浸,…...
[ACTF2020 新生赛]Include 1(php://filter伪协议)
题目 做法 启动靶机,点进去 点进去 查看URL,有 ?fileflag.php说明存在文件包含,原理是php://filter 协议 当它与包含函数结合时,php://filter流会被当作php文件执行。 用php://filter加编码,能让PHP把文件内容…...