Flink集群运行模式
我们了解了flink的一个集群的一个基础架构,包括里面核心的一些组件,比如说job manager,task manager等一些组件的一些主要的一些组成。本节课程开始我们学习flink的一个集群部署模式。首先我们来看一下flink集群部署模式究竟应该有哪一些种类。我们根据两种条件将flink集群部署模是分成三种类型。两种条件究竟是哪两种条件?第一个就是整个根据集群的一个生命周期和它的一个资源隔离不同,我们整个集群的生命周期的话是在我们对定的这样的一个不同的这样的一个模式里面的话,它生命周期有一定的区别。比如说通过session的这种集群模式的话,它其实是共享我们的job manager和task manager,所有提交的job都是在一个runtime里面去执行。Job的销毁以及job的提交,它是不影响我整个集群的一个它的一个启停。
对于另外一种的话叫做poor job的模式。Poor job的这种模式的话,它是独享照manager和task manager。它会为每一个job单独去启动对应的这样的一个集群的一个run time。它的一个启停作业的一个drop的一个启停,它和我们的一个job manager以及task manager的一个生命周期是相绑定的。也就是说job的如果执行完毕了之后,整个的一个集群也是跟着相应的去进行一个停止。
另外一个的话,我们会根据我们的一个main方法,是否执行在客户端,还是执行在我们的一个集群的管理节点,也就是job manage里面。这个过程其实就是我们在1.1版本里面提出的一个新的一个特性,叫做application model。Application的may方法如果运行在我们的一个cluster上面的话,它就是一种application model的一个模式。也就刚才我们在其实上节课里面已经提到了,我们在客户端里面要进行一些比如说job gravy的一些生成,以及may方法的一些执行。这个过程的话,我们在新的版本里面,通过application model就可以把它放在我们的一个cluster上面去执行。这个时候的话,我们每一个application它其实对应的是一个wrong time。而我们的一个每个application里面的话是可以包含多个drop的。
我们首先来看一下session的一个集群的一个运行模式。30N的集群运行模式其实我们刚才已经介绍。它的job manager和task manager其实是共享一套这样的一个集群的一个runtime的。对于我的一个客户端这边去提交不同的一个top。比如说top 1、top 2、top 3。通过客户端的这种方式去提交我们对应的这样的一个同一个这样的一个job manager里面去接收对应不同的这样的一个job。在我们的一个主管理节点,也就是说我们的master节点的话,它会去管理不同的这样的一个drop,然后再去进行协调的一个操作。然后在不同的这样的一个task manager里面去启动对应的这样的一个task的一些执行的一些slot的一些资源。
整个下来的话,它其实是一种session的一种绘画的这种集群模式。共享我们的一个drop manager。然后通过不同的客户端去提交到同一个job manager,同一个这样的一个集群的master节点。然后在我们的task manager里面去进行相应的一个执行的一个过程。这个时候的话,其实可以发现对于我的一个客户端来讲的话,他首先需要去执行相应的一些生成相应的一些drop gravy的对象,以及把对应的这样的一些价包,以及自己的一些包要传递到我们的一个master的一个节点上面去。然后才能在我们的job manager里面去进行一个调度和生成。
我们总结一下,对于我们三省集群里面的话,它其实另一个比较核心的一点就是我这个job manager的一个生命周期的话。它其实不是受我的一个job的一个影响。不管你在上面去提交多少个job,这个job manager他其实始终是处于一个运行的一个过程。运行的一个阶段,除非你把整个的这样的一个集群停止掉,它才会停止我们对应的这样的一个job manager。
另外一个的话,我们来去对比我们的这样的一个session集群的一个模式的一个优点。三省模式的优点的话,它其实可以达到一个集群的一个资源的一个充分共享的一个作用。提升我们整个集群的一个资源利用率。当我作业执行完成了之后,我无需去把我的这样的一个job manager去停掉。另外这个的话,对于我的一个job manager执行过程中的话,它其实也本身也会消耗相应的这样的一个计算资源。我们无需去为每一个job都要去生成一套新的一套集群。所以说这样的模式的话,像相对去对资源利用率的一个提升上面有非常大的一个帮助。
另外一个的话,对于我用户去提交不同的这样的一个作业来讲的话。它在flink session的一个集群里面进行一个管理和运维,相对来说比较简单一点。如果是不借助于这样的一个session的一种模式的话,将对应的每一个job去依托于我们的一个class manager进行管理的话,我们整个的一个运维的一个过程和它的一个成本会有相对比较高的一个提升。
另外一个三个模式它的一个运行的一个缺点是什么?第一个就是我们的一个集群的一个资源隔离相对较弱一点。对于我照不去提交,比如说我们如果top 1赵P2提交上来,集群的整个的一个资源用完了,那么job 3可能就是无法去提交到。即使我们外围的这样的一个集群的一个资源管理器,比如说ER或K8S还有额外的一些资源。但是这种情况下可能也会导致我的一个作业无法去执行的这样的一种情况。
另外一种的话就是刚才其实提到如果就是非negative部署的这种模式。Negative部署的话后面我们会有单独的章节进行讲解。它的一个特点就是我们的task manager是在我们启动的时候,它已经固定了。比如说我启动三个task manager,会在事先启动我对应的集群的时候,他已经把对应的这样的一个task manager启动起来,然后再去申请对应的slot资源。对于我这种情况的话,session模式的话,它这样的一个TM不易扩展的话,那我们的整个集群的一个计算资源的一个伸缩性就会相对来说比较弱一点。但是如果集群是negative这种模式的话,那么集群的一个资源的一个伸缩性的话,这一块的问题倒可以去解决。
另外一个的话其实就是叫做poor job的模式。Poor job的模式从名称上面其实就知道,就是我们每个job的话相当于说自己有一套自己的session的一个集群。也就是自己有一套这样的一个wrong time的一个集群。
每个job单独去共享我们的一个job manager。比如说提当一个drop上来了之后,它有单独的这样的一个job manager去启动,然后再去启动对应的task manager。Task manager的话也是跟我的每个job之间相互绑定,它也不会形成对应的共享的一个机制。比如说另外一个drop去提上来了之后,它也会去启动一个新的job manager,然后再去启动对应的task manager,在和job manager之间进行相互的一个通信和调度。同理其中第三个的话,我们还会启动第三个的task manager。整个下来的话,我们在一套集群资源管理器上面看到就会启动很多个这样的一个套job manager的一个管理节点,以及很多个这样的一个task manager节点。
这个里面的话,其实我们可以看得到,对于我提交的不同job申请的资源的会指定它的一个task manager里面的一些slot的一些数量。这个可以根据每个job的的不同申请的不同,它会选择启动不同的这样的一个task slot,这样的一个资源的一个卡槽。所以这个其实也是一个特点。
对于pull job的这种模式的话,它的一个另外一个比较大的一个特点就是我们的一个job的一个生成和提交的这个过程的话,它是跟整个top的一个生命周期是绑定的。我们比如说如果top 1执行完毕了之后,那么top 1对应的这样的一个job manager以及它的一个task manager的一些节点的话,全部都会进行一个释放和回收。然后当你再去提交一个,再再去启动对应的这样的一个资源,这个的过程的话,其实是我们的一个生命周期,会跟我们的一个job进行绑定。
对于poor job的这种部署模式,它的一个优势是什么?Job和job之间的话,资源大家其实可以看得到,其实是一个相互隔离的一个过程。对于我的一个每一个job之间,它其实都是独享对应的这样的一些计算资源。而像这样的话,资源可以进行相互这样的一个充分的一个隔离。另外一个的话是我们刚才也提到了这个task里面task manager slot一个资源的数量的话,可以根据我不同的job进行指定。
另外一个的话对于我们pull job模式的话,它也有自己的一些劣势。比如说我们那个资源浪费就会比较严重。对于我每提交一个job上来的话,它就会有对应的这样的一个集群的一个wrong time的一个生成。这种的话对于我job manager也会需要消耗相应的这样的一个计算资源。
另外一个的话,我们的一个job提交的方式的话,完全去提交到我们的class management上面去。可能在我们比如说在一二的队列里面的话,会有很多个job的一些对应的一些job manager的一些管理。对于这种管理的模式的话,可能会完全去依托于我们的一个cluster management进行一个管理。这种的话其实会带来一些管理上面的一些复杂度的一些提升。
另外一种的话其实。是我们会发现在我们整个session和poor job类型的这样的一个集群部署的时候,它都会面临一个这样的一个问题。比如说我们都会有这样的一个模式,比如说我们用户要去提交一个自己的作业的话,它首先需要去下载对应的这样的一个application的一些dependency。比如说首先你必须得去下载相应的这样的一些依赖包括自己的一些本地的一些客户端的一些安装,以及我们的一个application的一些价包的一些上传,传递完毕了之后,下面一步的话是在我们客户端去执行相应的main方法,去生成对应的job graf的一个对象。这个过程的话,其实会相对来说比较消耗我们本地客户端的一些进程的一些资源,就是包括一些CPU的一些资源。
另外一个的话,我们会把对应的一些相应的一些用户的一些包,每次都要去通过summe的方式去提交到我们的一个集群上面去运行。如果这个用沪提交的这样的一个架包会非常大,比如说十几二十兆或几百兆的这样的一个包。每次如果进行这样的一个作业的一个提交的话,它就会占用我们这样的一个带宽。也就是说clients会跟我们这个照manager之间这样的一个网络上面会进行非常大的一个网络消耗,带宽的一个消耗。
另外一个的话,生成job graph的话,它其实本身也会消耗本机的一些CPU的一些资源。另外一个的话就是说当我如果是在通过同一个客户端去提交不同的这样的一个job到我们的集群上面运行的时候。这种任务多的情况下,它会势必会导致我的这样的一个客户端的压力会非常大。这样的话其实会造成我们的这样的一个运行的一个过程。它其实会有一个非常大的一个稳定性的一个不足。
另外一个的话,其实我们每次需要去提交这样的一个价包的话。其实如果是提交了多了的话,它其实我们每一次提交的这样的一个任务,它其实是一个blocking的。也就是说我们是一个阻塞的。它其实后面的这样的一个用户再去提交的话,它其实是一个需要进行相应的这样的一个排队等待的一个过程。对于我们如果是一种,比如说是一个流式的这样的一个流平台的这样类似于这样的一个项目的话。比如说不同的一些用户如果去提交对应的这样的一个作业的话,它就会造成了这样的一个大量的大面积的一个排队和等待的一个过程。
对于这种情况有没有一个更好的这种方式去解觉?我们其实社区里面就提出了一个方式,就是说为什么我们不能把这样的一个在客户端里面进行执行的一个过程去转嫁到我们的一个集群的一个job manager里面去执行。这样的话,我们可以去释放我们一个本地客户端的一个压力。最终在我们的一个客户端里面,只需要去简单的负责一个命令的一个提交,以及作业的一个命令的一个下发,然后同时在等待我们的一个job运行的一个结果。其实就可以这样的话就可以减轻我们整个client的一个压力。我们这个地方的话,其实就是讲到了另外一种新的在1.1版本提出来的一种另外一种集群的一个运行的一个模式,叫做application model。
刚才已经提到了,在我们客户端这边的话,只需要去负责相应的一些命令的一些提交即可。对应的这样的一些job的一些job graph的生成,以及架包的一些下载和上传。这些工作的话完全就交给我们整个集群进行一个操作。比如说对于drop py的一个生成的话,也是在我们job manager里面执行相应的一些魅方法。然后把妹方法里面去抽取对应的这样的一个drop graph的一个对象。对于我的这样的一个作业所依赖的一些价包的话,都可以通过类似于分布式的HDFS的这种分布式的这样的一种存储,直接去获取对应的这样的一个dependency的一些包。然后去拉到我们的这样的一个集集群里面去运行相应的这样的一个作业。
对于我招manager里面的话,首先会去到我们的HDFS去获取这些依赖的一些包。然后去把整个的一个作业进行一个生成job graph。然后到他的一个执行,然后到他的一个调度,都是在我们的这样的一个job manager的管理节点里面进行相应的这样的一个操做。
对于我们的客户端来讲的话,它其实并没有太大的这样的一些负载。客户端的负载的话,全部都转嫁到我们的这样的一个集群的job manager里面去。这样带来的一个好处是什么?第一个就是我用户这边的话,无需去每次事先需要把我的这样的一些依赖的一些价包去需要去传到我的运营的这样的一个集群。它可以去避免我们在客户端和我们的一个集群之间的这样的一个网络的一个带宽的上面进的一个大量的一个消耗。对于我的一个客户端来讲的话,它可以去有效去降低我的一个带宽消耗以及客户端的一个负载。
在我们这样的一个application model里面的话,它可以去实现一个application的级别的一个资源隔离。也就是说我们每次提交的话,它会再切分成一个这样的一个application的一个级别出来。Application的话,它里面可以去提交不同的一个drop。每个application的这样的一个过程的话,其实跟我们的一个poor job的一个集群的这样的一个运行模式是一样的。它也有自己的相应的启动对应的这样的一些task manager。另外一个application的话,可能也是去启动一个这样的一个runtime,一个集群。在我们的一个application里面的话,可以去提交多个这样的一个drop的一个资源。
另外一个的话,我们可以看到application model它其实也有相应的一些缺点。比如说这个功能太轻,可能还没有经过一些生产的一些验证。另外一个的话,他可能仅支持亚和carbonate这样两套class management的上面的一个提交。对于像R上面的话,可以通过HDFS上面直接去获取我们的一些依赖的一些包。但对于carbonate的话,我们需要去事先去构建相应的一个镜像。把对应的这样的一个user jar application jar去达到我们的一个镜像里面了之后,再去通过application model去进行一个运行。整个的话其实会有相应的这样的一个编译和镜像构建的一个过程。所以说这一块的话对于后面社区的一个不断的跟进的话,这一块的功能点的话会进行相应的一个优化和一些提升。
通过本节的学习的话,我们了解了flink的不同的集群的一个运行模式。比如说session or job以及application model。我们通过对比不同的这样的一个运行模式,了解每种运行模式的一个优点和一些它的一些缺点。下一节课程的话,我们会讲到flink能够去支持哪一些cluster management。也就是说我们的集群管理器上面去运行我们的flink的不同的这样的一个session或者说per job,以及我们的一个application model的一些这样的一些flink集群。
相关文章:

Flink集群运行模式
我们了解了flink的一个集群的一个基础架构,包括里面核心的一些组件,比如说job manager,task manager等一些组件的一些主要的一些组成。本节课程开始我们学习flink的一个集群部署模式。首先我们来看一下flink集群部署模式究竟应该有哪一些种类…...

XSS 安全漏洞介绍及修复方案
简介 XSS(Cross Site Scripting)是一种常见的 Web 安全漏洞,攻击者通过在网页中注入恶意脚本代码,使得网页在用户端执行这些脚本,从而窃取用户信息或者进行其他恶意操作。为了防止 XSS 攻击,可以使用正则表…...
基于STM32的智能仓库管理系统
目录 引言环境准备智能仓库管理系统基础代码实现:实现智能仓库管理系统 4.1 数据采集模块4.2 数据处理与分析4.3 通信模块实现4.4 用户界面与数据可视化应用场景:仓库管理与优化问题解决方案与优化收尾与总结 1. 引言 智能仓库管理系统通过使用STM32嵌…...

LeetCode —— 只出现一次的数字
只出现一次的数字 I 本题依靠异或运算符的特性,两个相同数据异或等于0,数字与0异或为本身即可解答。代码如下: class Solution { public:int singleNumber(vector<int>& nums) {int ret 0;for (auto e : nums){ret ^ e;}return ret;} };只出…...
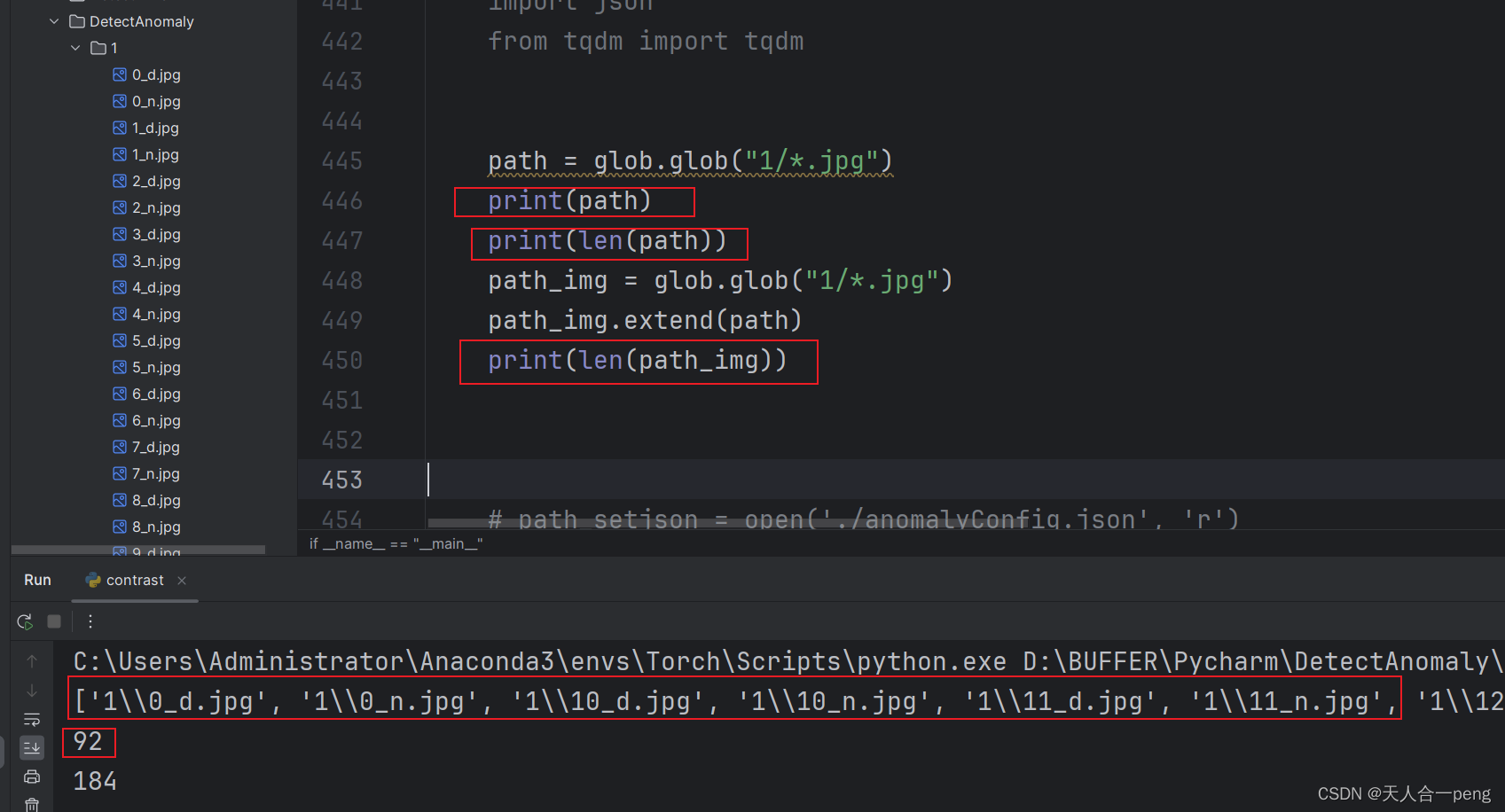
python遍历文件夹中所有图片
python遍历文件夹中的图片-CSDN博客 这个是之前的版本,现在这个版本会更好,直接进来就在列表中 path glob.glob("1/*.jpg")print(path)print(len(path))path_img glob.glob("1/*.jpg")path_img.extend(path)print(len(path_img))…...

速盾:DDOS能打死高防ip吗?
DDoS攻击是一种利用大量计算机或设备发起的分布式拒绝服务攻击。它的目标是通过发送大量流量或请求,使目标服务器或网络资源无法正常工作。高防IP是一种具有强大防御能力的网络服务,能够抵御各种形式的网络攻击,包括DDoS攻击。然而࿰…...

3dsMax怎样让渲染效果更逼真出色?三套低中高参数设置
渲染是将精心构建的3D模型转化为逼真图像的关键步骤。但要获得令人惊叹的渲染效果,仅仅依赖默认设置是不够的。 实现在追求极致画面效果的同时,兼顾渲染速度和时间还需要进行一些调节设置,如何让渲染效果更加逼真? 一、全局照明与…...

Android的OverlayFS原理与作用
标签: OverlayFS; Android;Overlay Filesystem; Android的OverlayFS原理与作用 概述 OverlayFS(Overlay Filesystem)是一种联合文件系统,允许将一个或多个文件系统叠加在一起,使它们表现为一个单一的文件系统。Android系统利用OverlayFS来实现动态文件系统的叠加和管…...

奇点临近:人类与智能时代的未来
在信息爆炸的时代,我们每天都被海量的信息所淹没,如何才能在这个嘈杂的世界中找到真正有价值的信息?如何才能利用信息的力量,提升我们的认知水平,重塑我们的未来? 这些问题的答案,或许都能在雷…...
NAS教程丨铁威马如何登录 SSH终端?
适用型号: 所有TNAS 型号 如您有特殊操作需要通过 SSH 终端登录 TNAS,请参照以下指引: (注意: 关于以下操作步骤中的"cd /"的指令,其作用是使当前 SSH/Telnet 连接的位置切换到根目录,以免造成对卷的占用.请不要遗漏它.) Windows…...

2024-06-24 百度地图的使用及gps定位坐标获取
1.百度地图的使用教程 2. 定位功能的实现 第一种:通过h5自带定位获取当前gps坐标 var options {enableHighAccuracy: true,timeout: 5000,maximumAge: 0};function success(pos) {var crd pos.coords;alert(crd.latitude---crd.longitude---crd.accuracy);conso…...

Python二级考试试题②
1. 以下关于程序设计语言的描述,错误的选项是: A Python语言是一种脚本编程语言 B 汇编语言是直接操作计算机硬件的编程语言 C 程序设计语言经历了机器语言、汇编语言、脚本语言三个阶段 D 编译和解释的区别是一次性翻译程序还是每次执行时都要翻…...

安装和使用nvm安装Nodejs
文章目录 安装和使用 nvm1. 安装 nvm2. 重新加载终端配置3. 安装所需的 Node.js 版本4. 使用安装的 Node.js 版本 nvm 常用命令 安装和使用 nvm 以下是安装 nvm 并使用它来安装 Node.js 的步骤: 1. 安装 nvm 首先,您需要安装 nvm。您可以使用 curl 或…...
)
非遗!四川省21市非遗大师工作室申报认定条件程序和认定补贴经费支持(管理办法)
第一章总则 第一条贯彻落实中共中央办公厅、国务院办公厅《关于进一步加强非物质文化遗产保护工作的意见》(厅字〔2021〕31号)、四川省文化和旅游厅等12部门《关于进一步加强非物质文化遗产保护工作的实施意见》(川文旅发〔2022〕25号&#…...

uni-app系列:uni.navigateTo传值跳转
文章目录 1. 使用URL参数2. 使用页面栈注意事项:uni.navigateTo API 参数详细说明回调函数参数 在uni-app中,如果想要通过uni.navigateTo方法跳转到另一个页面并传递参数,可以使用页面路由的URL参数或者页面栈的方式来传递。但是,…...

6.3万美刀BTC的车还能上吗?
原创 | 刘教链 隔夜BTC接连下挫,一度击穿63k(6.3万美刀)。[昨夜6.23内参说到了几个导致近期行情低迷的原因,比如,仅6月份以来,BTC矿工们就以一年来最快的速度,向市场倾泻了几十亿美刀的现货]。 其实,矿工慌…...

在 Vue 3 中设置 `@` 指向根目录的方法汇总
在 Vue 3 项目开发中,为了方便管理和引用文件路径,设置 指向根目录是一项常见的需求。以下为您总结了几种常见的实现方式。 方法一:使用 Vite 配置(适用于 Vite 构建的项目) 在项目根目录创建 vite.config.js 文件&a…...

基于 NXP LS1046 +FPGA系列 CPCI 架构轨道交通专用板卡
基于 NXP LS1046 系列 CPCI 架构轨道板卡 该产品是一款 CPCI 无风扇架构的高可靠性板卡,CPU 选用 NXP LS1046A 系统平台,支持嵌入式 Linux 或者标准 Ubuntu Linux 、凝思等操作系统,轨道交通 EMC 及宽温级别设计,板载多路 M12 高速…...

快速上手 Spring Boot:基础使用详解
快速上手 Spring Boot:基础使用详解 文章目录 快速上手 Spring Boot:基础使用详解1、什么是SpringBoot2、Springboot快速入门搭建3、SpringBoot起步依赖4、SpringBoot自动配置:以tomcat启动为例5、SpringBoot基础配置6、yaml7、多环境开发配置…...
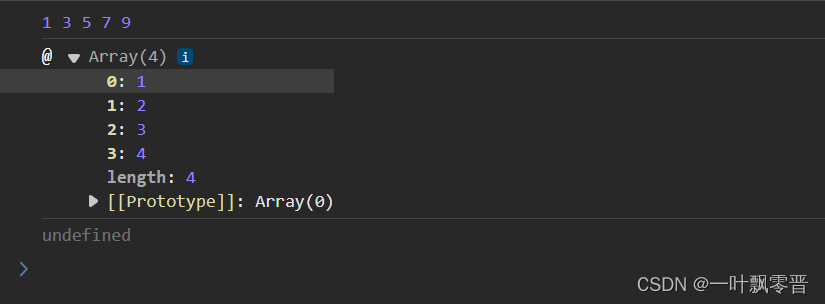
react学习——08三点运算符
1、代码 let arr1[1,3,5,7,9]let arr2[2,4,6,8,10]console.log(...arr1);//展开一个数组let arr3[...arr1,...arr2]//连续数组//在函数中使用function sum (...numbers){console.log(,numbers)numbers.reduce((previousValue,currentValue)>{return previousValuecurrentVa…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

Vue3 + Element Plus + TypeScript中el-transfer穿梭框组件使用详解及示例
使用详解 Element Plus 的 el-transfer 组件是一个强大的穿梭框组件,常用于在两个集合之间进行数据转移,如权限分配、数据选择等场景。下面我将详细介绍其用法并提供一个完整示例。 核心特性与用法 基本属性 v-model:绑定右侧列表的值&…...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

Maven 概述、安装、配置、仓库、私服详解
目录 1、Maven 概述 1.1 Maven 的定义 1.2 Maven 解决的问题 1.3 Maven 的核心特性与优势 2、Maven 安装 2.1 下载 Maven 2.2 安装配置 Maven 2.3 测试安装 2.4 修改 Maven 本地仓库的默认路径 3、Maven 配置 3.1 配置本地仓库 3.2 配置 JDK 3.3 IDEA 配置本地 Ma…...

探索Selenium:自动化测试的神奇钥匙
目录 一、Selenium 是什么1.1 定义与概念1.2 发展历程1.3 功能概述 二、Selenium 工作原理剖析2.1 架构组成2.2 工作流程2.3 通信机制 三、Selenium 的优势3.1 跨浏览器与平台支持3.2 丰富的语言支持3.3 强大的社区支持 四、Selenium 的应用场景4.1 Web 应用自动化测试4.2 数据…...
)
安卓基础(Java 和 Gradle 版本)
1. 设置项目的 JDK 版本 方法1:通过 Project Structure File → Project Structure... (或按 CtrlAltShiftS) 左侧选择 SDK Location 在 Gradle Settings 部分,设置 Gradle JDK 方法2:通过 Settings File → Settings... (或 CtrlAltS)…...

嵌入式常见 CPU 架构
架构类型架构厂商芯片厂商典型芯片特点与应用场景PICRISC (8/16 位)MicrochipMicrochipPIC16F877A、PIC18F4550简化指令集,单周期执行;低功耗、CIP 独立外设;用于家电、小电机控制、安防面板等嵌入式场景8051CISC (8 位)Intel(原始…...

基于江科大stm32屏幕驱动,实现OLED多级菜单(动画效果),结构体链表实现(独创源码)
引言 在嵌入式系统中,用户界面的设计往往直接影响到用户体验。本文将以STM32微控制器和OLED显示屏为例,介绍如何实现一个多级菜单系统。该系统支持用户通过按键导航菜单,执行相应操作,并提供平滑的滚动动画效果。 本文设计了一个…...

Python常用模块:time、os、shutil与flask初探
一、Flask初探 & PyCharm终端配置 目的: 快速搭建小型Web服务器以提供数据。 工具: 第三方Web框架 Flask (需 pip install flask 安装)。 安装 Flask: 建议: 使用 PyCharm 内置的 Terminal (模拟命令行) 进行安装,避免频繁切换。 PyCharm Terminal 配置建议: 打开 Py…...