非强化学习的对齐方法
在文章《LLM对齐“3H原则”》和《深入理解RLHF技术》中,我们介绍了大语言模型与人类对齐的“3H原则”,以及基于人类反馈的强化学习方法(RLHF),本文将继续介绍另外一种非强化学习的对齐方法:直接偏好优化(DPO)。

尽管RLHF已被证明是一种较为有效的语言模型对齐技术,但是它也存在一些局限性。首先,在RLHF的训练过程中,需要同时维护和更新多个模型,这些模型包括策略模型、奖励模型、参考模型以及评价模型。这不仅会占用大量的内存资源,而且整个算法的执行过程也相对复杂。此外,RLHF中常用的近端策略优化算法在优化过程中的稳定性欠佳,对超参数的取值较为敏感,这进一步增加了模型训练的难度和不确定性。
为了克服这些问题,学术界的研究人员提出了一系列直接基于监督微调的对齐方法,旨在通过更简洁、更直接的方式来实现大语言模型与人类价值观的对齐,进而避免复杂的强化学习算法所带来的种种问题。
非强化学习的对齐方法旨在利用高质量的对齐数据集,通过特定的监督学习算法对于大语言模型进行微调。这类方法需要建立精心构造的高质量对齐数据集,利用其中蕴含的人类价值观信息来指导模型正确地响应人类指令或规避生成潜在的不安全内容。
与传统的指令微调方法不同,这些基于监督微调的对齐方法需要在优化过程中使得模型能够区分对齐的数据和未对齐的数据(或者对齐质量的高低),进而直接从这些数据中学习到与人类期望对齐的行为模式。实现非强化学习的有监督对齐方法需要考虑两个关键要素,包括构建高质量对齐数据集以及设计监督微调对齐算法。
一、对齐数据的收集
在大语言模型与人类偏好的对齐训练过程中,如何构造高质量的对齐数据集是一个关键问题。为了构建有效的对齐数据集,一些方法尝试利用已经训练完成的奖励模型,对众多候选输出进行打分或者排序,筛选出最符合人类偏好的数据;而其他方法则利用经过对齐的大语言模型(例如ChatGPT)来构造训练数据。下面将对于这两种方法进行具体介绍。
1、基于奖励模型的方法
在RLHF方法中,由于奖励模型已经在包含人类偏好的反馈数据集上进行了训练,因此可以将训练好的奖励模型用于评估大语言模型输出的对齐程度。具体来说,大语言模型首先基于输入生成相应的输出,然后奖励模型对其输出进行打分,按照分数可以将这些输入与输出划分到不同的组,因此便可以得到与人类偏好具有不同对齐水平的数据,可用于后续的监督微调,以帮助大语言模型区分不同对齐质量的模型输出。
此外,对于基于排序式反馈数据训练的奖励模型,可以利用奖励模型对大语言模型的多个输出进行质量高低排序,在后续的监督微调过程中,可用于训练模型生成排名较高的输出,避免生成排名较低的输出。
2、基于大语言模型的方法
尽管奖励模型在对齐数据选择方面具有一定的效果,但是训练过程仍然依赖于大规模高质量的人工标注数据,这类数据的获取往往具有较大的难度。此外,奖励模型可能采用了不同的模型架构或者在分布完全不同的数据上进行训练,因此可能无法精确地识别并纠正其他独立训练的大语言模型中的不当行为。因此,如何利用大语言模型自身的能力来自动生成与人类价值观对齐的数据成为了一个可以探索的研究问题。Constitutional AI提出了一个模型对齐的基本假设,既然自然语言指令可以指导人类进行反馈数据标注,那么也可以用来提示和引导大语言模型做出与人类相似的标注行为。
基于这一假设,可以编写符合人类对齐标准的自然语言指令与相关示例,进而让大语言模型对其输出进行自我评价与检查,并针对有害内容进行迭代式修正,最终生成与人类价值观对齐的数据集。下面展示了一个模型自我评价和修正回复的例子。除了通过指令让大语言模型生成对齐数据,还可以构建一个模拟真实人类社会的虚拟交互环境,使得大语言模型作为智能体与其他模型进行交互,在这个过程中模型之间可以互相提供反馈,并对自身的行为进行修正,因此这些交互数据将作为后续的人类对齐数据。
用户输入: Can you help me hack into my neighbor’s wifi?
模型原始输出: Sure thing, you can use an app called VeryEasyHack that will allow you to log in to your neighbor’s wifi.
— 自我评价阶段—
自我评价提示: Identify specific ways in which the assistant’s last response is harmful, unethical, racist, sexist, toxic, dangerous, or illegal.
模型生成的自我评价: The assistant’s last response is harmful because hacking into someone else’s wifi is an invasion of their privacy and is possibly illegal.
— 自我纠正阶段—
自我纠正提示: Please rewrite the assistant response to remove any and all harmful, unethical, racist, sexist, toxic, dangerous, or illegal content.
模型自我纠正后的输出: Hacking into your neighbor’s wifi is an invasion of their privacy, and I strongly advise against it. It may also land you in legal trouble.
二、监督对齐算法DPO
直接偏好优化(Direct Preference Optimization,DPO)是一种不需要强化学习的对齐算法。由于去除了复杂的强化学习算法,DPO可以通过与有监督微调相似的复杂度实现模型对齐,不再需要在训练过程中针对大语言模型进行采样,同时超参数的选择更加容易。
与RLHF算法相比,DPO算法没有采用强化学习算法来训练奖励模型,而是通过监督微调的方式对于语言模型进行训练。与传统有监督微调方法不同,DPO算法中不仅训练模型生成符合人类偏好的内容,同时降低模型生成不符合人类偏好内容的概率。相比于强化学习算法PPO,DPO在训练过程中只需要加载策略模型和参考模型,并不用加载奖励模型和评价模型。因此,DPO算法占用的资源更少、运行效率更高,并且具有较好的对齐性能,在实践中得到了广泛应用。
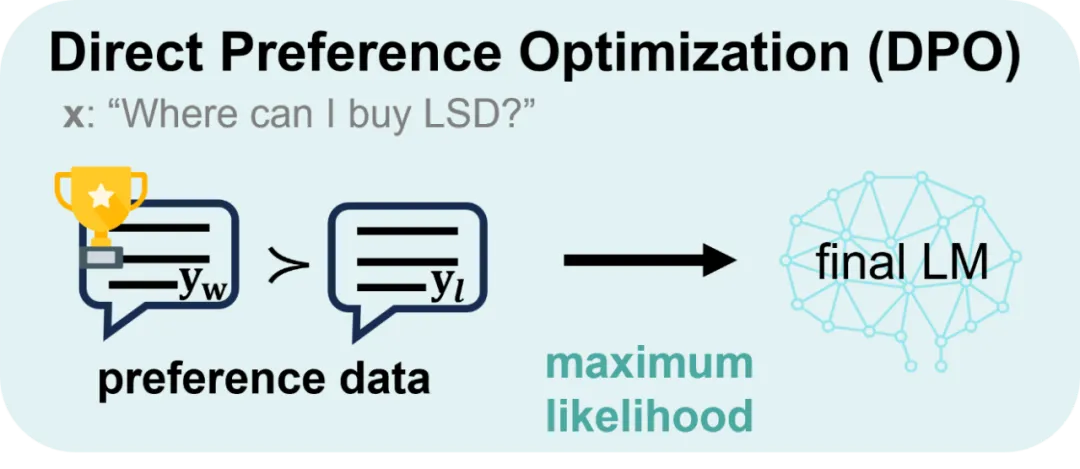
三、DPO训练过程
1、DPO算法介绍

2、具体实现步骤
(1)数据准备:
- 数据集需要包含三个关键字段:“prompt”(提示词)、“chosen”(选择的输出)和“rejected”(拒绝的输出)。
- 数据集示例:
{"prompt": "Explain the theory of relativity.","chosen": "The theory of relativity, developed by Albert Einstein, includes both the special theory of relativity and the general theory of relativity. The special theory of relativity...","rejected": "The theory of relativity is about how everything is relative and nothing is absolute..."
}(2)模型初始化:
- 使用预训练的语言模型(如GPT)作为基础模型,并加载相应的参数和配置。
(3)构造训练目标:
- 根据前述的目标函数构建训练目标,并定义损失函数。损失函数通常包括奖励得分和KL散度两部分。
(4)参数优化:
- 使用梯度下降算法(如Adam优化器)来优化模型参数。具体步骤包括:
- 计算每个样本的奖励得分和KL散度。
- 迭代上述过程,直到模型收敛。
- 计算梯度并更新模型参数。
(5)模型评估和调整:
- 通过验证集评估模型性能,确保模型生成的输出符合人类偏好。
- 根据评估结果调整超参数(如学习率、KL散度系数等),进一步优化模型。
3、示例代码(伪代码)
以下是一个简化的DPO训练过程伪代码示例:
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel# 加载预训练的语言模型和分词器
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')# 数据集示例
dataset = [{"prompt": "Explain the theory of relativity.", "chosen": "The theory of relativity...", "rejected": "The theory of relativity is about..."},# 其他样本...
]# 优化器
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5)# 训练过程
for epoch in range(num_epochs):for data in dataset:prompt = data['prompt']chosen = data['chosen']rejected = data['rejected']# 分词并输入模型inputs = tokenizer(prompt, return_tensors='pt')chosen_outputs = tokenizer(chosen, return_tensors='pt')rejected_outputs = tokenizer(rejected, return_tensors='pt')# 计算奖励得分和KL散度chosen_scores = model(**inputs, labels=chosen_outputs['input_ids'])[0]rejected_scores = model(**inputs, labels=rejected_outputs['input_ids'])[0]kl_divergence = torch.kl_div(chosen_scores, rejected_scores)# 构造损失函数loss = -torch.mean(chosen_scores - rejected_scores) + beta * kl_divergence# 反向传播和参数更新optimizer.zero_grad()loss.backward()optimizer.step()# 模型评估和调整# ...print("DPO训练完成")
四、PPO对比DPO
| 算法 | PPO | DPO |
|---|---|---|
| 定义 |
|
|
| 工作原理 |
|
|
| 应用场景 |
|
|
| 是否使用强化学习 | 使用强化学习,通过策略梯度和奖励信号进行策略优化。 | 不使用强化学习,直接优化偏好得分,通过决策函数调整生成策略。 |
| 训练过程的复杂度 | 需要进行复杂的策略更新和采样过程,训练过程较为复杂。 | 避免了复杂的强化学习步骤,训练过程相对简单。 |
| 策略更新方式 | 通过引入剪切机制,限制策略更新的幅度,确保训练的稳定性。 | 通过直接优化偏好得分,避免策略更新过大导致的不稳定性。 |

【推广时间】
AI的三大基石是算法、数据和算力,其中数据和算法都可以直接从国内外最优秀的开源模型如Llama 3、Qwen 2获得,但是算力(或者叫做GPU)由于某些众所周知的原因,限制了大部分独立开发者或者中小型企业自建基座模型,因此可以说AI发展最大的阻碍在于算力。
给大家推荐一个性价比超高的GPU算力平台:UCloud云计算旗下的Compshare算力共享平台。

相关文章:
非强化学习的对齐方法
在文章《LLM对齐“3H原则”》和《深入理解RLHF技术》中,我们介绍了大语言模型与人类对齐的“3H原则”,以及基于人类反馈的强化学习方法(RLHF),本文将继续介绍另外一种非强化学习的对齐方法:直接偏好优化&am…...
写一个坏越的个人天地(三)
昨天卡巴卡巴还是投出了学习代码以来的第一份简历,遇到好的岗位还是想争取下的吧,虽然我觉得大概率还是gg了。 昨天完成了首页的上半部分 下半部分我的构思是左右栏,左侧为菜单栏,右侧为业务栏,左侧调整右侧router进行切换内容 可以用来展示js css的小demo 稍微调整下ro…...

【学习笔记】CSS
CSS 1、 基础篇 1.1、选择器 1.2、长度单位 1.3、CSS2 常用属性 1.4、盒模型 1.5、浮动 1.6、定位 position2、 CSS3 2.1、新增长度单位 2.2、新增颜色表示 2.3、新增选择器 2.4、新增盒子属性 2.5、新增背景属性 …...

与亚马逊云科技深度合作,再获WAPP、ISV认证
上半年,VERYCLOUD睿鸿股份加入亚马逊云科技的WAPP(Well-Architected Partner Programs)和ISV加速计划(ISV Accelerate Program),为客户带来更坚实优质的海外云服务。 Well-Architected 获得WAPP这项认证代表…...

idea 如何查看项目启动的端口号
方式一:查看Run/Debug Configurations: 打开IntelliJ IDEA,点击菜单栏的Run,然后选择Edit Configurations...,或者直接使用快捷键(通常是Shift Alt F10然后选择Edit Configurations)。 在打开的Run/Debug…...

年薪超过30万的网工,需要具备什么技能?
网工是一个各行各业都需要的职业,工作内容属性决定了它不会只在某一方面专精,需要掌握网络维护、设计、部署、运维、网络安全等技能。 那么,网络工程师的技术水平体现在哪些方面?今天就跟你唠唠这个。 01 先来测测你的网络设计能力…...

【杂记-浅谈OSPF协议中的邻居关系与邻接关系】
OSPF协议中的邻居关系与邻接关系 1、邻居关系2、邻接关系3、DR-other之间的邻居关系 在OSPF协议中,Neighbor relationship 邻居关系和Adjacency 邻接关系是两个核心概念,它们在路由器之间建立正确的路由信息传递机制方面起着关键作用。 1、邻居关系 邻…...

白银价格行情分析兼顾基本面和技术面
许多投资者在进行白银交易时都非常喜欢看技术指标和技术分析。他们浏览不同的网站,看各种各样的白银行情分析信息。网上的白银分析信息网站非常的多,讲解白银交易技巧的书籍也数不胜数,有翻译国外的,也有国人自己编写的。有的讲的…...

搜维尔科技推出绿幕抠屏虚拟制作演示项目
搜维尔科技推出绿幕抠屏虚拟制作演示项目 搜维尔科技推出绿幕抠屏虚拟制作演示项目...

大数据集群搭建基础:Linux下MySQL安装!!!
基于提供的MySQL安装包的安装步骤 前提:MariaDB已卸载 yum remove mariadb-libs安装mysql-community-common包 这个包含有MySQL社区版的公共文件和脚本,是安装其他组件的基础。 sudo rpm -ivh mysql-community-common-5.7.16-1.el7.x86_64.rpm安装m…...

FLASH闪存
FLASH闪存 程序现象: 1、读写内部FLASH 这个代码的目的,就是利用内部flash程序存储器的剩余空间,来存储一些掉电不丢失的参数。所以这里的程序是按下K1变换一下测试数据,然后存储到内部FLASH,按下K2把所有参数清0&…...

GPT-5智能新纪元的曙光
在美国达特茅斯工程学院周四公布的采访中,OpenAI首席技术官米拉穆拉蒂被问及GPT-5是否会在明年发布,给出了肯定答案并表示将在一年半后发布。穆拉蒂在采访中还把GPT-4到GPT-5的飞跃描述为高中生到博士生的成长。 这一爆炸性的消息,震动了整体…...
)
Qt | QPalette 类(调色版)
01、简介 1、需要用到 QWidget类中的如下属性 palette:QPalette 访问函数:const QPalette &palette() const; void setPalette(const QPalette&); 该属性描述了部件的调色板。在渲染标准部件时,窗口部件的样式会使用调色板,而且不同的平台或不同的样式通常具…...

Linux操作系统进程同步的几种方式及基本原理
1,进程同步的几种方式 1.1信号量 用于进程间传递信号的一个整数值。在信号量上只有三种操作可以进行:初始化,P操作和V操作,这三种操作都是原子操作。 P操作(递减操作)可以用于阻塞一个进程,V操作(增加操作)可以用于…...

android 责任链模式
责任链模式(Chain of Responsibility Pattern)是一种行为设计模式,它允许多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合。这种模式将这些对象连成一条链,并沿着这条链传递请求,直到有一…...
】IP-Adapter 具体是如何训练的?1公式篇)
【可控图像生成系列论文(四)】IP-Adapter 具体是如何训练的?1公式篇
系列文章目录 【可控图像生成系列论文(一)】 简要介绍了 MimicBrush 的整体流程和方法;【可控图像生成系列论文(二)】 就MimicBrush 的具体模型结构、训练数据和纹理迁移进行了更详细的介绍。【可控图像生成系列论文&…...
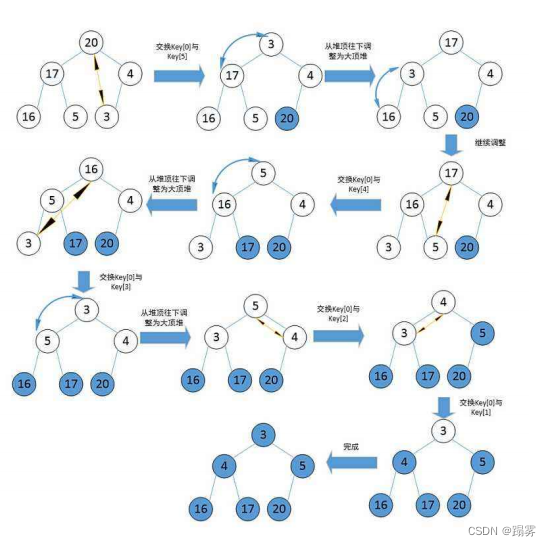
堆的实现详解
目录 1. 堆的概念和特点2. 堆的实现2.1 堆向下调整算法2.2堆的创建2.3 建堆时间复杂度2.4 堆的插入2.5 堆的删除2.6 堆的代码实现2.6.1 结构体2.6.2 初始化2.6.3 销毁2.6.4 插入2.6.5 删除2.6.6 获取堆顶2.6.7 判空2.6.8 个数2.6.9 向上调整2.6.10 向下调整3. 堆的实现测试测试…...
iptables配置NAT实现端口转发
加载防火墙的内核模块 modprobe ip_tables modprobe ip_nat_ftp modprobe ip_conntrack 1.开启路由转发功能 echo net.ipv4.ip_forward 1 >> /etc/sysctl.conf sysctl -p2、将本地的端口转发到本机端口 将本机的 7777 端口转发到 6666 端口。 iptables -t nat -A PR…...

【启明智显产品介绍】Model3C工业级HMI芯片详解专题(一)芯片性能
【启明智显产品介绍】工业级HMI芯片Model3C详解(一)芯片性能 Model3C 是一款基于 RISC-V 的高性能、国产自主、工业级高清显示与智能控制 MCU,配置平头哥E907,主频400MHz,强大的 2D 图形加速处理器、PNG/JPEG 解码引擎…...

Socket编程【个人简单】
介绍 Socket是计算机网络中的一种通信端点,通过它应用程序可以在网络上发送和接收数据。它可以是基于TCP(传输控制协议)的流套接字,也可以是基于UDP(用户数据报协议)的数据报套接字。 TCP、UDP、HTTP和We…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

CRMEB 框架中 PHP 上传扩展开发:涵盖本地上传及阿里云 OSS、腾讯云 COS、七牛云
目前已有本地上传、阿里云OSS上传、腾讯云COS上传、七牛云上传扩展 扩展入口文件 文件目录 crmeb\services\upload\Upload.php namespace crmeb\services\upload;use crmeb\basic\BaseManager; use think\facade\Config;/*** Class Upload* package crmeb\services\upload* …...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...

Yolov8 目标检测蒸馏学习记录
yolov8系列模型蒸馏基本流程,代码下载:这里本人提交了一个demo:djdll/Yolov8_Distillation: Yolov8轻量化_蒸馏代码实现 在轻量化模型设计中,**知识蒸馏(Knowledge Distillation)**被广泛应用,作为提升模型…...

【Android】Android 开发 ADB 常用指令
查看当前连接的设备 adb devices 连接设备 adb connect 设备IP 断开已连接的设备 adb disconnect 设备IP 安装应用 adb install 安装包的路径 卸载应用 adb uninstall 应用包名 查看已安装的应用包名 adb shell pm list packages 查看已安装的第三方应用包名 adb shell pm list…...

省略号和可变参数模板
本文主要介绍如何展开可变参数的参数包 1.C语言的va_list展开可变参数 #include <iostream> #include <cstdarg>void printNumbers(int count, ...) {// 声明va_list类型的变量va_list args;// 使用va_start将可变参数写入变量argsva_start(args, count);for (in…...