Linux_应用篇(27) CMake 入门与进阶
在前面章节内容中,我们编写了很多示例程序,但这些示例程序都只有一个.c 源文件,非常简单。 所以,编译这些示例代码其实都非常简单,直接使用 GCC 编译器编译即可,连 Makefile 都不需要。但是,在实际的项目中,并非如此简单, 一个工程中可能包含几十、成百甚至上千个源文件, 这些源文件按照其类型、功能、模块分别放置在不同的目录中; 面对这样的一个工程,通常会使用 make 工具进行管理、编译, make 工具依赖于 Makefile 文件,通过 Makefile 文件来定义整个工程的编译规则,使用 make 工具来解析 Makefile 所定义的编译规则。
Makefile 带来的好处就是——“自动化编译”,一旦写好,只需要一个 make 命令,整个工程完全按照Makefile 文件定义的编译规则进行自动编译,极大的提高了软件开发的效率。 大多数的 IDE 都有这个工具,譬如 Visual C++的 nmake、 linux 下的 GNU make、 Qt 的 qmake 等等, 这些 make 工具遵循着不同的规范和标准, 对应的 Makefile 文件其语法、 格式也不相同, 这样就带来了一个严峻的问题:如果软件想跨平台,必须要保证能够在不同平台下编译, 而如果使用上面的 make 工具,就得为每一种标准写一次 Makefile,这将是一件让人抓狂的工作。
而 cmake 就是针对这个问题所诞生, 允许开发者编写一种与平台无关的 CMakeLists.txt 文件来制定整个工程的编译流程, 再根据具体的编译平台,生成本地化的 Makefile 和工程文件,最后执行 make 编译。因此,对于大多数项目, 我们应当考虑使用更自动化一些的 cmake 或者 autotools 来生成 Makefile,而不是直接动手编写 Makefile。
本章我们便来学习 cmake,本章将会讨论如下主题内容。
⚫ cmake 是什么?
⚫ cmake 和 Makefile 之间的关系
⚫ 如何使用 cmake
cmake 简介
cmake 是一个跨平台的自动构建工具, 前面导语部分也已经给大家介绍了, cmake 的诞生主要是为了解决直接使用 make+Makefile 这种方式无法实现跨平台的问题,所以 cmake 是可以实现跨平台的编译工具,这是它最大的特点,当然除了这个之外, cmake 还包含以下优点:
⚫ 开放源代码。我们可以直接从 cmake 官网 https://cmake.org/下载到它的源代码;
⚫ 跨平台。 cmake 并不直接编译、构建出最终的可执行文件或库文件, 它允许开发者编写一种与平台无关的 CMakeLists.txt 文件来制定整个工程的编译流程, cmake 工具会解析 CMakeLists.txt 文件语法规则,再根据当前的编译平台,生成本地化的 Makefile 和工程文件,最后通过 make 工具来编译整个工程;所以由此可知, cmake 仅仅只是根据不同平台生成对应的 Makefile,最终还是通过 make工具来编译工程源码,但是 cmake 却是跨平台的。
⚫ 语法规则简单。 Makefile 语法规则比较复杂,对于一个初学者来说,通常并不那么友好, 并且Makefile 语法规则在不同平台下往往是不一样的;而 cmake 依赖的是CMakeLists.txt 文件,该文件的语法规则与平台无关,并且语法规则简单、容易理解! cmake 工具通过解析 CMakeLists.txt 自动帮我们生成 Makefile,这样就不需要我们自己手动编写 Makefile 了。
cmake 和 Makefile
直观上理解, cmake 就是用来产生 Makefile 的工具,解析 CMakeLists.txt 自动生成 Makefile: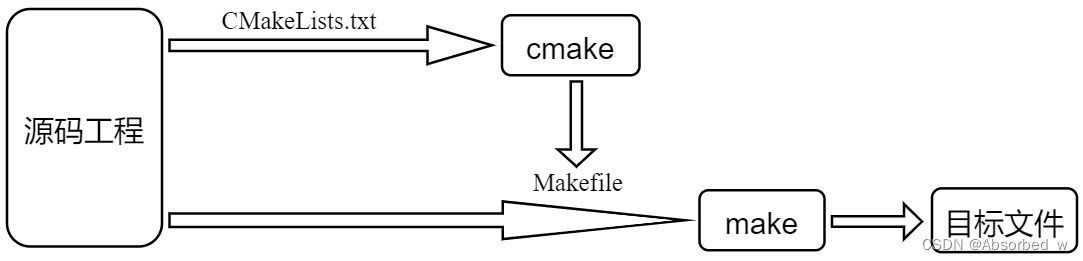
除了 cmake 之外, 还有一些其它的自动构建工具,常用的譬如 automake、 autoconf 等,有兴趣的朋友可以自己了解下。
cmake 的使用方法
cmake 就是一个工具命令,在 Ubuntu 系统下通过 apt-get 命令可以在线安装,如下所示:
sudo apt-get install cmake
笔者的 Ubuntu 系统上已经安装了 cmake 工具, 安装完成之后可以通过 cmake --version 命令查看 cmake的版本号,如下所示:
由上图可知,当前系统安装的 cmake 对应的版本号为 3.5.1, cmake 工具版本更新也是比较快的,从官网 https://cmake.org/可知, cmake 最新版本为 3.22.0,不过这都没关系,其实使用哪个版本都是可以的,差别并不会太大, 所以这个大家不用担心。安装完 cmake 工具之后,接着我们就来学习如何去使用 cmake。 cmake 官方也给大家提供相应教程,链接地址如下所示:
https://cmake.org/documentation/ //文档总链接地址
https://cmake.org/cmake/help/latest/guide/tutorial/index.html //培训教程
如果大家自学能力强,完全可以参考官方提供的培训教程学习 cmake; 对于 cmake 的学习,笔者给大家两个建议:
⚫ 从简单开始、再到复杂!
⚫ 重点是自己动手多练习。
本小节我们将从一个非常简单的示例开始向大家介绍如何使用 cmake,再从这个示例进一步扩展、提出更多需求,来看看 cmake 如何去满足这些需求。
单个源文件
单个源文件的程序通常是最简单的,一个经典的 C 程序“Hello World”,如何用 cmake 来进行构建呢?
#include <stdio.h>int main()
{printf("Hello World!\n");return 0;
}现在我们需要新建一个CMakeLists.txt文件, CMakeLists.txt文件会被cmake工具解析,就好比是Makefile文件会被 make 工具解析一样; CMakeLists.txt 创建完成之后,在文件中写入如下内容:
project(HELLO)
add_executable(hello ./main.c)写入完成之后,保存退出,当前工程目录结构如下所示:
├── CMakeLists.txt
└── main.c在我们的工程目录下有两个文件,源文件 main.c 和 CMakeLists.txt,接着我们在工程目录下直接执行cmake 命令,如下所示:
cmake ./cmake 后面携带的路径指定了 CMakeLists.txt 文件的所在路径,执行结果如下所示: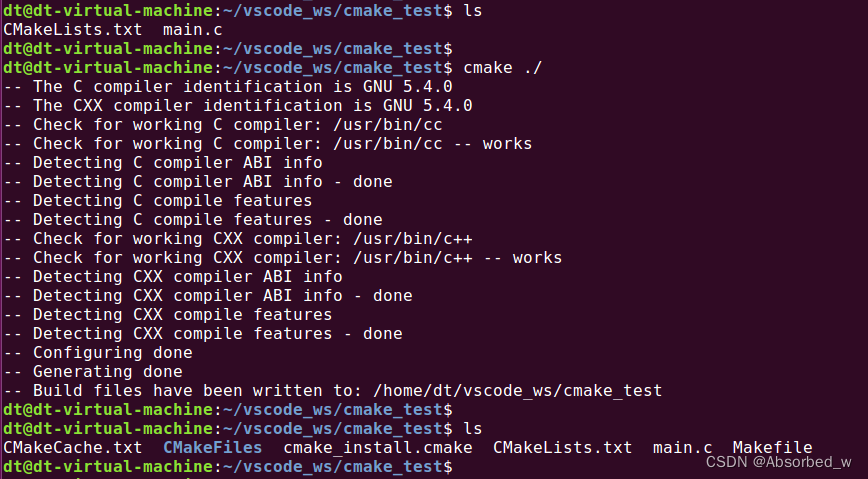
执行完 cmake 之后,除了源文件 main.c 和 CMakeLists.txt 之外,可以看到当前目录下生成了很多其它的文件或文件夹,包括: CMakeCache.txt、 CmakeFiles、 cmake_install.cmake、 Makefile,重点是生成了这个Makefile 文件, 有了 Makefile 之后,接着我们使用 make 工具编译我们的工程,如下所示: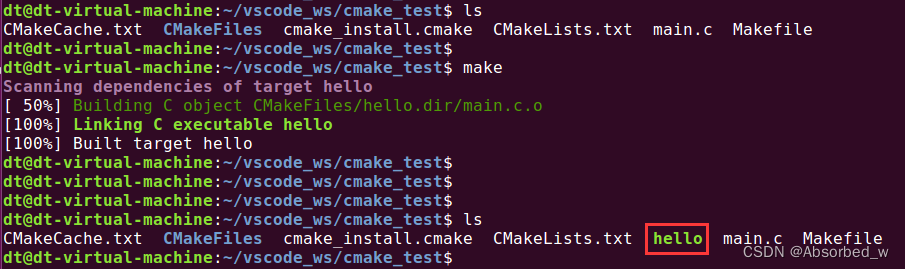
通过 make 编译之后得到了一个可执行文件 hello,这个名字是在 CMakeLists.txt 文件中指定的,稍后向大家介绍。通过 file 命令可以查看到 hello 是一个 x86-64 架构下的可执行文件,所以只能在我们的 UbuntuPC 上运行:
为了验证 hello 可执行文件运行结果是否与源代码相同,我们直接在 Ubuntu 下运行即可,如下所示:
CMakeLists.txt 文件
上面我们通过了一个非常简单例子向大家演示了如何使用 cmake,重点在于去编写一个 CMakeLists.txt文件,现在来看看 CMakeLists.txt 文件中写的都是什么意思。
⚫ 第一行 project(HELLO)
project 是一个命令, 命令的使用方式有点类似于 C 语言中的函数,因为命令后面需要提供一对括号,并且通常需要我们提供参数,多个参数使用空格分隔而不是逗号“,” 。
project 命令用于设置工程的名称, 括号中的参数 HELLO 便是我们要设置的工程名称;设置工程名称并不是强制性的,但是最好加上。
⚫ 第二行 add_executable(hello ./main.c)
add_executable 同样也是一个命令,用于生成一个可执行文件, 在本例中传入了两个参数,第一个参数表示生成的可执行文件对应的文件名,第二个参数表示对应的源文件; 所以 add_executable(hello ./main.c)表示需要生成一个名为 hello 的可执行文件,所需源文件为当前目录下的 main.c。
使用 out-of-source 方式构建
在上面的例子中, cmake 生成的文件以及最终的可执行文件 hello 与工程的源码文件 main.c 混在了一起,这使得工程看起来非常乱,当我们需要清理 cmake 产生的文件时将变得非常麻烦,这不是我们想看到的;我们需要将构建过程生成的文件与源文件分离开来, 不让它们混杂在一起,也就是使用 out-of-source 方式构建。将 cmake 编译生成的文件清理下,然后在工程目录下创建一个 build 目录,如下所示:
├── build
├── CMakeLists.txt
└── main.c然后进入到 build 目录下执行 cmake:
cd build/
cmake ../
make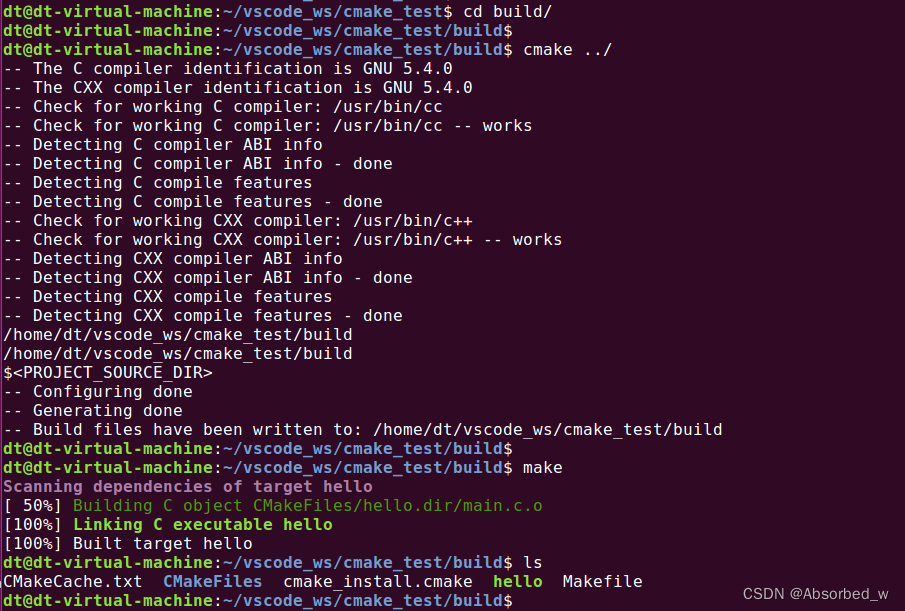
这样 cmake 生成的中间文件以及 make 编译生成的可执行文件就全部在 build 目录下了,如果要清理工程,直接删除 build 目录即可,这样就方便多了。
多个源文件
一个源文件的例子似乎没什么意思,我们再加入一个 hello.h 头文件和 hello.c 源文件。在 hello.c 文件中定义了一个函数 hello,然后在 main.c 源文件中将会调用该函数:
⚫ hello.h 文件内容
#ifndef __TEST_HELLO_
#define __TEST_HELLO_
void hello(const char *name);
#endif //__TEST_HELLO_⚫ hello.c 文件内容
#include <stdio.h>
#include "hello.h"
void hello(const char *name)
{printf("Hello %s!\n", name);
}⚫ main.c 文件内容
#include "hello.h"
int main(void)
{hello("World");return 0;
}⚫ 然后准备好 CMakeLists.txt 文件
project(HELLO)
set(SRC_LIST main.c hello.c)
add_executable(hello ${SRC_LIST})工程目录结构如下所示:
├── build //文件夹
├── CMakeLists.txt
├── hello.c
├── hello.h
└── main.c同样,进入到 build 目录下,执行 cmake、再执行 make 编译工程,最终就会得到可执行文件 hello。在本例子中, CMakeLists.txt 文件中使用到了 set 命令, set 命令用于设置变量,如果变量不存在则创建该变量并设置它;在本例中,我们定义了一个 SRC_LIST 变量, SRC_LIST 变量是一个源文件列表, 记录生成可执行文件 hello 所需的源文件 main.c 和 hello.c,而在 add_executable 命令引用了该变量; 当然我们也可以不去定义 SRC_LIST 变量,直接将源文件列表写在 add_executable 命令中,如下:
add_executable(hello main.c hello.c)生成库文件
在本例中,除了生成可执行文件 hello 之外,我们还需要将 hello.c 编译为静态库文件或者动态库文件,在示例二的基础上对 CMakeLists.txt 文件进行修改,如下所示:
project(HELLO)
add_library(libhello hello.c)
add_executable(hello main.c)
target_link_libraries(hello libhello)进入到 build 目录下,执行 cmake、再执行 make 编译工程,编译完成之后,在 build 目录下就会生成可执行文件 hello 和库文件,如下所示:
├── build
│ ├── hello
│ └── liblibhello.a
├── CMakeLists.txt
├── hello.c
├── hello.h
└── main.cCMakeLists.txt 文件解释
本例中我们使用到了 add_library 命令和 target_link_libraries 命令。add_library 命令用于生成库文件,在本例中我们传入了两个参数,第一个参数表示库文件的名字,需要注意的是,这个名字是不包含前缀和后缀的名字; 在 Linux 系统中,库文件的前缀是 lib,动态库文件的后缀是.so,而静态库文件的后缀是.a; 所以,意味着最终生成的库文件对应的名字会自动添加上前缀和后缀。第二个参数表示库文件对应的源文件。
本例中, add_library 命令生成了一个静态库文件 liblibhello.a,如果要生成动态库文件,可以这样做:
add_library(libhello SHARED hello.c) #生成动态库文件
add_library(libhello STATIC hello.c) #生成静态库文件target_link_libraries 命令为目标指定依赖库,在本例中, hello.c 被编译为库文件, 并将其链接进 hello 程序。
修改生成的库文件名字
本例中有一点非常不爽,生成的库为 liblibhello.a,名字非常不好看;如果想生成 libhello.a 该怎么办?直接修改 add_library 命令的参数,像下面这样可以吗?
add_library(hello hello.c)答案是不行的,因为 hello 这个目标已经存在了(add_executable(hello main.c)),目标名对于整个工程来说是唯一的,不可出现相同名字的目标,所以这种方法肯定是不行的,实际上我们只需要在 CMakeLists.txt文件中添加下面这条命令即可:
set_target_properties(libhello PROPERTIES OUTPUT_NAME "hello")set_target_properties 用于设置目标的属性,这里通过 set_target_properties 命令对 libhello 目标的OUTPUT_NAME 属性进行了设置,将其设置为 hello。我们进行实验,此时 CMakeLists.txt 文件中的内容如下所示:
cmake_minimum_required(VERSION 3.5)
project(HELLO)
add_library(libhello SHARED hello.c)
set_target_properties(libhello PROPERTIES OUTPUT_NAME "hello")
add_executable(hello main.c)
target_link_libraries(hello libhello)除了添加 set_target_properties 命令之外,我们还加入了 cmake_minimum_required 命令,该命令用于设置当前工程的 cmake 最低版本号要求,当然这个并不是强制性的,但是最好还是加上。进入到 build 目录下,使用 cmake+make 编译整个工程, 编译完成之后会发现,生成的库文件为 libhello.a,而不是 liblibhello.a。
├── build
│ ├── hello
│ └── libhello.so
├── CMakeLists.txt
├── hello.c
├── hello.h
└── main.c将源文件组织到不同的目录
上面的示例中,我们已经加入了多个源文件,但是这些源文件都是放在同一个目录下,这样还是不太正规,我们应该将这些源文件按照类型、功能、模块给它们放置到不同的目录下,于是笔者将工程源码进行了整理,当前目录结构如下所示:
├── build #build 目录
├── CMakeLists.txt
├── libhello
│ ├── CMakeLists.txt
│ ├── hello.c
│ └── hello.h
└── src├── CMakeLists.txt└── main.c在工程目录下,我们创建了 src 和 libhello 目录,并将 hello.c 和 hello.h 文件移动到 libhello 目录下,将main.c 文件移动到 src 目录下,并且在顶层目录、 libhello 目录以及 src 目录下都有一个 CMakeLists.txt 文件。CMakeLists.txt 文件的数量从 1 个一下变成了 3 个,顿时感觉到有点触不及防!还好每一个都不复杂!我们来看看每一个 CMakeLists.txt 文件的内容。
⚫ 顶层 CMakeLists.txt
cmake_minimum_required(VERSION 3.5)
project(HELLO)
add_subdirectory(libhello)
add_subdirectory(src)⚫ src 目录下的 CMakeLists.txt
include_directories(${PROJECT_SOURCE_DIR}/libhello)
add_executable(hello main.c)
target_link_libraries(hello libhello)⚫ libhello 目录下的 CMakeLists.txt
add_library(libhello hello.c)
set_target_properties(libhello PROPERTIES OUTPUT_NAME "hello")顶层 CMakeLists.txt 中使用了 add_subdirectory 命令, 该命令告诉 cmake 去子目录中寻找新的CMakeLists.txt 文件并解析它;而在 src 的 CMakeList.txt 文件中,新增加了 include_directories 命令用来指明头文件所在的路径,并且使用到了 PROJECT_SOURCE_DIR 变量,该变量指向了一个路径,从命名上可知,该变量表示工程源码的目录。
和前面一样,进入到 build 目录下进行构建、编译,最终会得到可执行文件 hello(build/src/hello)和库文件 libhello.a(build/libhello/libhello.a):
├── build
│ ├── libhello
│ │ └── libhello.a
│ └── src└── hello
├── CMakeLists.txt
├── libhello
│ ├── CMakeLists.txt
│ ├── hello.c
│ └── hello.h
└── src├── CMakeLists.txt└── main.c将生成的目标文件放置到单独的目录下
前面还有一点不爽, 在默认情况下, make 编译生成的可执行文件和库文件会与 cmake 命令产生的中间文件(CMakeCache.txt、 CmakeFiles、 cmake_install.cmake 以及 Makefile 等)混在一起,也就是它们在同一个目录下; 如果我想让可执行文件单独放置在 bin 目录下,而库文件单独放置在 lib 目录下,就像下面这样:
├── build├── lib│ └── libhello.a└── bin└── hello将库文件存放在 build 目录下的 lib 目录中,而将可执行文件存放在 build 目录下的 bin 目录中,这个时候又该怎么做呢?这个时候我们可以通过两个变量来实现,将 src 目录下的 CMakeList.txt 文件进行修改,如下所示:
include_directories(${PROJECT_SOURCE_DIR}/libhello)
set(EXECUTABLE_OUTPUT_PATH ${PROJECT_BINARY_DIR}/bin)
add_executable(hello main.c)
target_link_libraries(hello libhello)然后再对 libhello 目录下的 CMakeList.txt 文件进行修改,如下所示:
set(LIBRARY_OUTPUT_PATH ${PROJECT_BINARY_DIR}/lib)
add_library(libhello hello.c)
set_target_properties(libhello PROPERTIES OUTPUT_NAME "hello")修改完成之后,再次按照步骤对工程进行构建、编译,此时便会按照我们的要求将生成的可执行文件hello 放置在 build/bin 目录下、库文件 libhello.a 放置在 build/lib 目录下。 最终的目录结构就如下所示:
├── build
│ ├── bin
│ │ └── hello
│ └── lib
│ └── libhello.a
├── CMakeLists.txt
├── libhello
│ ├── CMakeLists.txt
│ ├── hello.c
│ └── hello.h
└── src├── CMakeLists.txt└── main.c其实实现这个需求非常简单,通过对 LIBRARY_OUTPUT_PATH 和 EXECUTABLE_OUTPUT_PATH变 量 进 行 设 置 即 可 完 成 ; EXECUTABLE_OUTPUT_PATH 变 量 控 制 可 执 行 文 件 的 输 出 路 径 , 而LIBRARY_OUTPUT_PATH 变量控制库文件的输出路径。
CMakeLists.txt 语法规则
在上一小节中,笔者通过几个简单地示例向大家演示了 cmake 的使用方法, 由此可知, cmake 的使用方法其实还是非常简单的,重点在于编写 CMakeLists.txt, CMakeLists.txt 的语法规则也简单,并没有 Makefile的语法规则那么复杂难以理解!本小节我们来学习 CMakeLists.txt 的语法规则。
简单语法介绍
⚫ 注释
在 CMakeLists.txt 文件中,使用“#”号进行单行注释,譬如:
#
# 这是注释信息
#
cmake_minimum_required(VERSION 3.5)
project(HELLO)大多数脚本语言都是使用“#”号进行注释。
⚫ 命令(command)
通常在 CMakeLists.txt 文件中,使用最多的是命令,譬如上例中的 cmake_minimum_required、 project 都是命令; 命令的使用方式有点类似于 C 语言中的函数,因为命令后面需要提供一对括号,并且通常需要我们提供参数,多个参数使用空格分隔而不是逗号“,” ,这是与函数不同的地方。命令的语法格式如下所示:
command(参数 1 参数 2 参数 3 ...)不同的命令所需的参数不同,需要注意的是,参数可以分为必要参数和可选参数(通常称为选项),很多命令都提供了这两类参数,必要参数使用<参数>表示,而可选参数使用[参数]表示,譬如 set 命令:
set(<variable> <value>... [PARENT_SCOPE])set 命令用于设置变量,第一个参数<variable>和第二个参数<value>是必要参数,在参数列表(…表示参数个数没有限制) 的最后可以添加一个可选参数 PARENT_SCOPE(PARENT_SCOPE 选项),既然是可选的,那就不是必须的,根据实际使用情况确定是否需要添加。在 CMakeLists.txt 中,命令名不区分大小写,可以使用大写字母或小写字母书写命令名,譬如:
project(HELLO) #小写
PROJECT(HELLO) #大写这俩的效果是相同的,指定的是同一个命令,并没区别; 这个主要看个人喜好, 个人喜欢用小写字母,主要是为了和变量区分开来,因为 cmake 的内置变量其名称都是使用大写字母组成的。
⚫ 变量(variable)
在 CMakeLists.txt 文件中可以使用变量, 使用 set 命令可以对变量进行设置, 譬如:
# 设置变量 MY_VAL
set(MY_VAL "Hello World!")例中,通过 set 命令对变量 MY_VAL 进行设置,将其内容设置为"Hello World!";那如何引用这个变量呢? 这与 Makefile 是相同的,通过${MY_VAL}方式来引用变量,如下所示:
#设置变量 MY_VAL
set(MY_VAL "Hello World!")
#引用变量 MY_VAL
message(${MY_VAL})变量可以分为 cmake 内置变量以及自定义变量,譬如上例中所定义的 MY_VAL 就是一个自定义变量;譬如在前面小节中所使用的 LIBRARY_OUTPUT_PATH 和 EXECUTABLE_OUTPUT_PATH 变量则是cmake 的内置变量,每一个内置变量都有自己的含义,像这样的内置变量还有很多,稍后向大家介绍。
部分常用命令
cmake 提 供 了 很 多 命 令 , 每 一 个 命 令 都 有 它 自 己 的 功 能 、 作 用 , 通 过 这 个 链 接 地 址
https://cmake.org/cmake/help/v3.5/manual/cmake-commands.7.html 可以查询到所有的命令及其相应的介绍、使用方法等等,如下所示:
大家可以把这个链接地址保存起来,可以把它当成字典的形式在有需要的时候进行查询, 由于命令非常多,笔者不可能将所有命令都给大家介绍一遍,这里给大家介绍一些基本的命令, 如下表所示:
| command | 说明 |
| add_executable | 可执行程序目标 |
| add_library | 库文件目标 |
| add_subdirectory | 去指定目录中寻找新的 CMakeLists.txt 文件 |
| aux_source_directory | 收集目录中的文件名并赋值给变量 |
| cmake_minimum_required | 设置 cmake 的最低版本号要求 |
| get_target_property | 获取目标的属性 |
| include_directories | 设置所有目标头文件的搜索路径,相当于 gcc 的-I 选项 |
| link_directories | 设置所有目标库文件的搜索路径,相当于 gcc 的-L 选项 |
| link_libraries | 设置所有目标需要链接的库 |
| list | 列表相关的操作 |
| message | 用于打印、输出信息 |
| project | 设置工程名字 |
| set | 设置变量 |
| set_target_properties | 设置目标属性 |
| target_include_directories | 设置指定目标头文件的搜索路径 |
| target_link_libraries | 设置指定目标库文件的搜索路径 |
| target_sources | 设置指定目标所需的源文件 |
接下来详细地给大家介绍每一个命令。
⚫ add_executable
add_executable 命令用于添加一个可执行程序目标,并设置目标所需的源文件,该命令定义如下所示:
add_executable(<name> [WIN32] [MACOSX_BUNDLE] [EXCLUDE_FROM_ALL] source1 [source2 ...])该命令提供了一些可选参数,这些可选参数的含义笔者就不多说了,通常不需要加入,具体的含义大家可以自己查看 cmake 官方文档(https://cmake.org/cmake/help/v3.5/command/add_executable.html) ;只需传入目标名和对应的源文件即可,譬如:
#生成可执行文件 hello
add_executable(hello 1.c 2.c 3.c)定义了一个可执行程序目标 hello,生成该目标文件所需的源文件为 1.c、 2.c 和 3.c。 需要注意的是,源文件路径既可以使用相对路径、也可以使用绝对路径,相对路径被解释为相对于当前源码路径(注意,这里源码指的是 CMakeLists.txt 文件,因为 CMakeLists.txt 被称为 cmake 的源码,若无特别说明,后续将沿用这个概念! ) 。
⚫ add_library
add_library 命令用于添加一个库文件目标,并设置目标所需的源文件,该命令定义如下所示:
add_library(<name> [STATIC | SHARED | MODULE]
[EXCLUDE_FROM_ALL]
source1 [source2 ...])第一个参数 name 指定目标的名字, 参数 source1…source2 对应源文件列表; add_library 命令默认生成的库文件是静态库文件,通过 SHARED 选项可使其生成动态库文件,具体的使用方法如下:
#生成静态库文件 libmylib.a
add_library(mylib STATIC 1.c 2.c 3.c)
#生成动态库文件 libmylib.so
add_library(mylib SHARED 1.c 2.c 3.c)与 add_executable 命令相同, add_library 命令中源文件既可以使用相对路径指定、也可以使用绝对路径指定,相对路径被解释为相对于当前源码路径。不管是 add_executable、还是 add_library,它们所定义的目标名在整个工程中必须是唯一的,不可出现两个目标名相同的目标。
⚫ add_subdirectory
add_subdirectory 命令告诉 cmake 去指定的目录中寻找源码并执行它, 有点像 Makefile 的 include, 其定义如下所示:
add_subdirectory(source_dir [binary_dir] [EXCLUDE_FROM_ALL])参数 source_dir 指定一个目录, 告诉cmake 去该目录下寻找 CMakeLists.txt文件并执行它;参数binary_dir指定了一个路径,该路径作为子源码(调用 add_subdirectory 命令的源码称为当前源码或父源码,被执行的源码称为子源码)的输出文件(cmake 命令所产生的中间文件) 目录, binary_dir 参数是一个可选参数,如果没有显式指定,则会使用一个默认的输出文件目录;为了后续便于表述,我们将输出文件目录称为BINARY_DIR。
譬如工程目录结构如下所示:
├── build
├── CMakeLists.txt
└── src├── CMakeLists.txt└── main.c顶层 CMakeLists.txt 文件内容如下所示:
# 顶层 CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project("HELLO")
# 告诉 cmake 去 src 目录下寻找 CMakeLists.txt
add_subdirectory(src)
src 目录下的 CMakeLists.txt 文件:
# src 下的 CMakeLists.txt
add_executable(hello main.c) 进入到 build 目录下,执行 cmake、 make 进行构建编译; 在本例中, 顶层源码对应的输出文件会存放在build 目录,也就是执行 cmake 命令所在目录; 子源码(src 目录下的 CMakeLists.txt) 对应的输出文件会存放在 build/src 目录,包括生成的可执行文件默认会与这些中间文件放置在同一个目录,如下所示:
├── build
│ ├── CMakeCache.txt
│ ├── CMakeFiles
│ ├── cmake_install.cmake
│ ├── Makefile
│ └── src
│ ├── CMakeFiles
│ ├── cmake_install.cmake
│ ├── hello
│ └── Makefile
├── CMakeLists.txt
└── src├── CMakeLists.txt└── main.c所以由此可知, 当前源码调用add_subdirectory命令执行子源码时, 若没有为子源码指定BINARY_DIR,默认情况下, 会在当前源码的 BINARY_DIR 中创建与子目录(子源码所在目录) 同名的文件夹,将其作为子源码的 BINARY_DIR。
接下来我们修改顶层 CMakeCache.txt 文件:
# 顶层 CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project("HELLO")
# 告诉 cmake 去 src 目录下寻找 CMakeLists.txt
add_subdirectory(src output)指定子源码的 BINARY_DIR 为 output, 这里使用的是相对路径方式, add_subdirectory 命令对于相对路径的解释为: 相对于当前源码的 BINARY_DIR; 修改完成之后,再次进入到 build 目录下执行 cmake、 make命令进行构建、 编译,此时会在 build 目录下生成一个 output 目录, 这就是子源码的 BINARY_DIR。设置 BINARY_DIR 可以使用相对路径、也可以是绝对路径,相对路径则是相对于当前源码的BINARY_DIR, 并不是当前源码路径, 这个要理解。通过 add_subdirectory 命令加载、执行一个外部文件夹中的源码,既可以是当前源码路径的子目录、也可以是与当前源码路径平级的目录亦或者是当前源码路径上级目录等等;对于当前源码路径的子目录,不强制调用者显式指定子源码的 BINARY_DIR;如果不是当前源码路径的子目录,则需要调用者显式指定BINARY_DIR,否则执行源码时会报错。接下来进行测试,譬如工程目录结构如下所示:
├── build
├── CMakeLists.txt
├── lib
│ └── CMakeLists.txt
└── src├── CMakeLists.txt└── main.c这里一共有 3 个 CMakeLists.txt 文件, lib 目录和 src 目录是平级关系,顶层 CMakeLists.txt 内容如下:
# 顶层 CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project("HELLO")
# 加载 src 目录下的源码
add_subdirectory(src)
src 目录下的 CMakeLists.txt:
# src 目录 CMakeLists.txt
add_executable(hello main.c)
# 加载平级目录 lib 中的源码
add_subdirectory(../lib) 此时调用 add_subdirectory 加载 lib 目录的源码时并未显式指定 BINARY_DIR,我们看看会怎么样,进
入到 build 目录下,执行 cmake 命令,如下所示: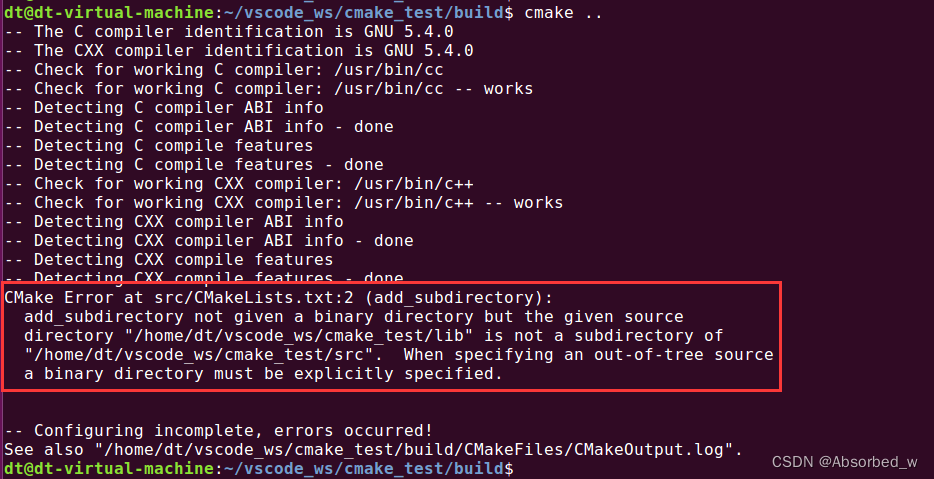
果不其然确实发生了报错,而且提示我们 add_subdirectory 命令必须要指定 BINARY_DIR,那我们将 src目录下的 CMakeLists.txt 进行修改,显式指定 BINARY_DIR,如下所示:
# src 目录 CMakeLists.txt
add_executable(hello main.c)
# 加载平级目录 lib 中的源码
add_subdirectory(../lib output)接着再次执行 cmake(每次执行 cmake 前进行清理,将 build 目录下生成的所有文件全部删除):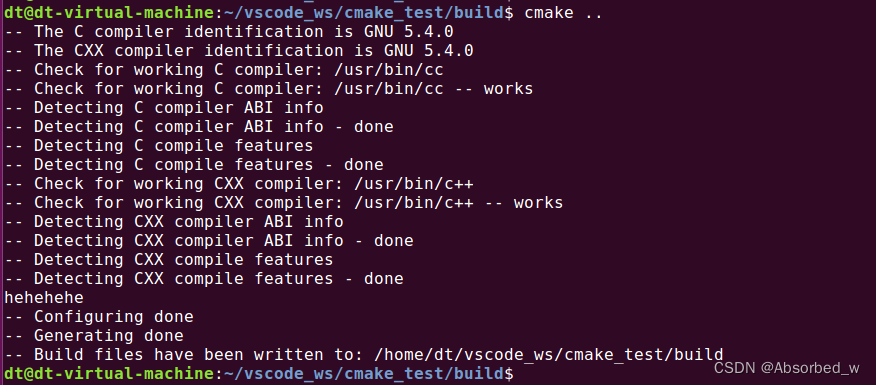
可以看到这次执行 cmake 没有报错打印了。
⚫ aux_source_directory
aux_source_directory 命令会查找目录中的所有源文件,其命令定义如下:
aux_source_directory(<dir> <variable>)从指定的目录中查找所有源文件,并将扫描到的源文件路径信息存放到<variable>变量中,譬如目录结构如下:
├── build
├── CMakeLists.txt
└── src├── 1.c├── 2.c├── 2.cpp└── main.cCMakeCache.txt 内容如下所示:
# 顶层 CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project("HELLO")
# 查找 src 目录下的所有源文件
aux_source_directory(src SRC_LIST)
message("${SRC_LIST}") # 打印 SRC_LIST 变量进入到 build 目录下,执行 cmake ..命令,打印信息如下所示: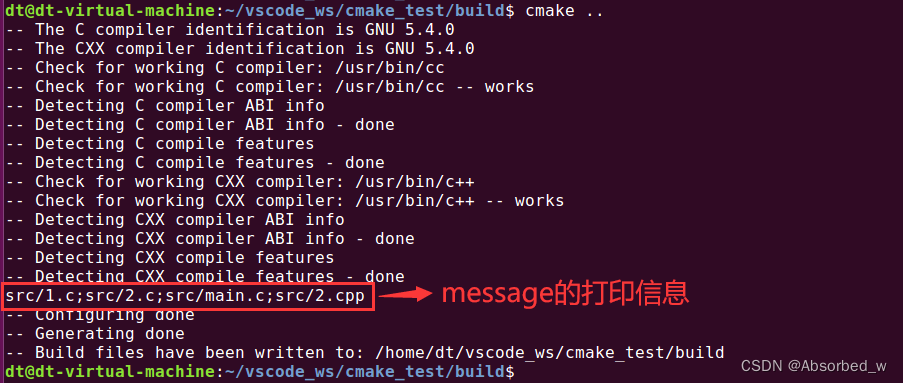
由此可见, aux_source_directory 会将扫描到的每一个源文件添加到 SRC_LIST 变量中,组成一个字符串列表,使用分号“;”分隔。同理, aux_source_directory 既可以使用相对路径,也可以使用绝对路径,相对路径是相对于当前源码路径。
⚫ get_target_property 和 set_target_properties
分别用于获取/设置目标的属性,这个后面再给大家进行专题介绍。
⚫ include_directories
include_directories 命令用于设置头文件的搜索路径,相当于 gcc 的-I 选项,其定义如下所示:
include_directories([AFTER|BEFORE] [SYSTEM] dir1 [dir2 ...])默认情况下会将指定目录添加到头文件搜索列表(可以认为每一个 CMakeLists.txt 源码都有自己的头文件搜索列表) 的最后面, 可以通过设置 CMAKE_INCLUDE_DIRECTORIES_BEFORE 变量为 ON 来改变它默认行为,将目录添加到列表前面。也可以在每次调用 include_directories 命令时使用 AFTER 或 BEFORE
选项来指定是添加到列表的前面或者后面。如果使用 SYSTEM 选项,会把指定目录当成系统的搜索目录。既可以使用绝对路径来指定头文件搜索目录、也可以使用相对路径来指定,相对路径被解释为当前源码路径的相对路径。
譬如工程目录结构如下所示:
├── build
├── CMakeLists.txt
├── include
│ └── hello.h
└── main.c源文件 main.c 中使用了 include 目录下的头文件 hello.h, CMakeLists.txt 内容如下:
# 顶层 CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project("HELLO")
include_directories(include)
add_executable(hello main.c)使用 include_directories 命令将当前目录下的 include 文件夹添加到头文件搜索列表中,进入 build 目录下,执行 cmake、 make 进行构建、编译,编译过程是没有问题的,不会报错提示头文件找不到;但如果去掉 include_directories(include)这条命令,编译肯定会报错,大家可以动手试试!默认情况下, include 目录被添加到头文件搜索列表的最后面,通过 AFTER 或 BEFORE 选项可显式指定添加到列表后面或前面:
# 添加到列表后面
include_directories(AFTER include)
# 添加到列表前面
include_directories(BEFORE include)当调用 add_subdirectory 命令加载子源码时, 会将 include_directories 命令包含的目录列表向下传递给子源码(子源码从父源码中继承过来), 我们测试下,譬如工程目录结构如下所示:
├── build
├── CMakeLists.txt
├── include
│ └── hello.h
└── src├── CMakeLists.txt└── main.csrc 目录下 main.c 源文件中使用了 hello.h 头文件,顶层 CMakeLists.txt 内容如下所示:
# 顶层 CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project("HELLO")
include_directories(include)
add_subdirectory(src)顶层 CMakeLists.txt 源码中调用了 include_directories 将 include 目录添加到当前源码的头文件搜索列表中,接着调用 add_subdirectory 命令加载、执行子源码; src 目录下 CMakeLists.txt 内容如下所示:
# src 目录 CMakeLists.txt
add_executable(hello main.c)进入到 build 目录,进行构建、编译,整个编译过程是没有问题的。
⚫ link_directories 和 link_libraries
link_directories 命令用于设置库文件的搜索路径,相当于 gcc 编译器的-L 选项; link_libraries 命令用于设置需要链接的库文件,相当于 gcc 编译器的-l 选项;命令定义如下所示:
link_directories(directory1 directory2 ...)
link_libraries([item1 [item2 [...]]]
[[debug|optimized|general] <item>] ...)link_directories 会将指定目录添加到库文件搜索列表(可以认为每一个 CMakeLists.txt 源码都有自己的库文件搜索列表) 中;同理, link_libraries 命令会将指定库文件添加到链接库列表。 link_directories 命令可以使用绝对路径或相对路径指定目录,相对路径被解释为当前源码路径的相对路径。譬如工程目录结构如下所示:
├── build
├── CMakeLists.txt
├── include
│ └── hello.h
├── lib
│ └── libhello.so
└── main.c在 lib 目录下有一个动态库文件 libhello.so,编译链接 main.c 源文件时需要链接 libhello.so; CMakeLists.txt文件内容如下所示:
# 顶层 CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project("HELLO")
include_directories(include)
link_directories(lib)
link_libraries(hello)
add_executable(main main.c)库文件名既可以使用简写,也可以库文件名的全称,譬如:
# 简写
link_libraries(hello)
# 全称
link_libraries(libhello.so)link_libraries 命令也可以指定库文件的全路径(绝对路径 /开头),如果不是/开头, link_libraries 会认为调用者传入的是库文件名,而非库文件全路径,譬如上述 CMakeLists.txt 可以修改为下面这种方式:
# 顶层 CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project("HELLO")
include_directories(include)
link_libraries(${PROJECT_SOURCE_DIR}/lib/libhello.so)
add_executable(main main.c)与 include_directories 命令相同,当调用 add_subdirectory 命令加载子源码时, 会将 link_directories 命令包含的目录列表以及 link_libraries 命令包含的链接库列表向下传递给子源码(子源码从父源码中继承过来)。这里不再演示了,大家可以自己测试下。
⚫ list
list 命令是一个关于列表操作的命令,譬如获取列表的长度、从列表中返回由索引值指定的元素、将元素追加到列表中等等。 命令定义如下:
list(LENGTH <list> <output variable>)
list(GET <list> <element index> [<element index> ...] <output variable>)
list(APPEND <list> [<element> ...])
list(FIND <list> <value> <output variable>)
list(INSERT <list> <element_index> <element> [<element> ...])
list(REMOVE_ITEM <list> <value> [<value> ...])
list(REMOVE_AT <list> <index> [<index> ...])
list(REMOVE_DUPLICATES <list>)
list(REVERSE <list>)
list(SORT <list>)列表这个概念还没给大家介绍, 列表其实就是字符串数组(或者叫字符串列表、字符串数组), 稍后再向大家说明。
LENGTH 选项用于返回列表长度;
GET 选项从列表中返回由索引值指定的元素;
APPEND 选项将元素追加到列表后面;
FIND 选项将返回列表中指定元素的索引值,如果未找到,则返回-1。
INSERT 选项将向列表中的指定位置插入元素。
REMOVE_AT 和 REMOVE_ITEM 选项将从列表中删除元素, 不同之处在于 REMOVE_ITEM 将删除给定的元素,而 REMOVE_AT 将删除给定索引值的元素。
REMOVE_DUPLICATES 选项将删除列表中的重复元素。
REVERSE 选项就地反转列表的内容。
SORT 选项按字母顺序对列表进行排序。
⚫ message
message 命令用于打印、输出信息,类似于 Linux 的 echo 命令,命令定义如下所示:
message([<mode>] "message to display" ...)可选的 mode 关键字用于确定消息的类型,如下:
| mode | 说明 |
| none(无) | 重要信息、普通信息 |
| STATUS | 附带信息 |
| WARNING | CMake 警告,继续处理 |
| AUTHOR_WARNING | CMake 警告(开发),继续处理 |
| SEND_ERROR | CMake 错误,继续处理,但跳过生成 |
| FATAL_ERROR | CMake 错误,停止处理和生成 |
| DEPRECATION | 如 果 变 量 CMAKE_ERROR_DEPRECATED 或 CMAKE_WARN_DEPRECATED 分别启用, 则 CMake 弃用错 误或警告,否则没有消息。 |
所以可以使用这个命令作为 CMakeLists.txt 源码中的输出打印语句,譬如:
# 打印"Hello World"
message("Hello World!")⚫ project
project 命令用于设置工程名称:
# 设置工程名称为 HELLO
project(HELLO)执行这个之后会引入两个变量: HELLO_SOURCE_DIR 和 HELLO_BINARY_DIR,注意这两个变量名的前缀就是工程名称, HELLO_SOURCE_DIR 变量指的是 HELLO 工程源码目录、 HELLO_BINARY_DIR 变量指的是 HELLO 工程源码的输出文件目录; 我们可以使用 message 命令打印变量, 譬如 CMakeLists.txt 内容如下所示:
# 顶层 CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project("HELLO")
message(${HELLO_SOURCE_DIR})
message(${HELLO_BINARY_DIR})进入 build 目录下,执行 cmake: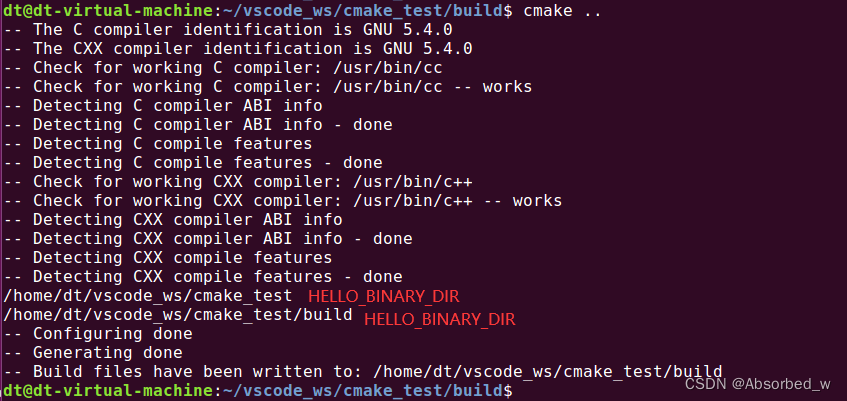
但如果不加入 project(HELLO)命令,这两个变量是不存在的; 工程源码目录指的是顶层源码所在目录,cmake 定义了两个等价的变量 PROJECT_SOURCE_DIR 和 PROJECT_BINARY_DIR,通常在 CMakeLists.txt源码中都会使用这两个等价的变量。通常只需要在顶层 CMakeLists.txt 源码中调用 project 即可!
⚫ set
set 命令用于设置变量,命令定义如下所示:
set(<variable> <value>... [PARENT_SCOPE])设置变量的值, 可选参数 PARENT_SCOPE 影响变量的作用域,这个我们稍后再说。
譬如 CMakeLists.txt 源码内容如下所示:
# 顶层 CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project("HELLO")
# set 命令
set(VAR1 Hello) #设置变量 VAR1=Hello
set(VAR2 World) #设置变量 VAR2=World
# 打印变量
message(${VAR1} " " ${VAR2})对应的打印信息:

字符串列表
通过 set 命令实现字符串列表,如下所示:
# 字符串列表
set(SRC_LIST 1.c 2.c 3.c 4.c 5.c)此时 SRC_LIST 就是一个列表,它包含了 5 个元素(1.c、 2.c、 3.c、 4.c、 5.c), 列表的各个元素使用分号“;”分隔,如下:
SRC_LIST = 1.c;2.c;3.c;4.c;5.c #列表
我们来测试一下,譬如 CMakeLists.txt 源码内容如下所示:
# 顶层 CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project("HELLO")
# set 命令
set(SRC_LIST 1.c 2.c 3.c 4.c 5.c)
# 打印变量
message(${SRC_LIST})执行 cmake 命令打印信息如下:
乍一看这个打印信息你是不是觉得 SRC_LIST 就是一个普通的变量(SRC_LIST=1.c2.c3.c4.c5.c),并不是列表呢?事实并非如此,我们可以修改 message 命令,将${SRC_LIST}放置在双引号中,如下:
# 打印变量
message("${SRC_LIST}")再次执行 cmake,打印信息如下:
可以看到此时打印出来的确实是一个列表,为何加了双引号就会这样呢? 既然是列表,那自然可以使用 list 命令对列表进行相关的操作:
# 顶层 CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project("HELLO")
# 列表
set(SRC_LIST main.c world.c hello.c)
message("SRC_LIST: ${SRC_LIST}")
#列表操作
list(LENGTH SRC_LIST L_LEN)
message("列表长度: ${L_LEN}")
list(GET SRC_LIST 1 VAR1)
message("获取列表中 index=1 的元素: ${VAR1}")
list(APPEND SRC_LIST hello_world.c) #追加元素
message("SRC_LIST: ${SRC_LIST}")
list(SORT SRC_LIST) #排序
message("SRC_LIST: ${SRC_LIST}")cmake 打印信息如下: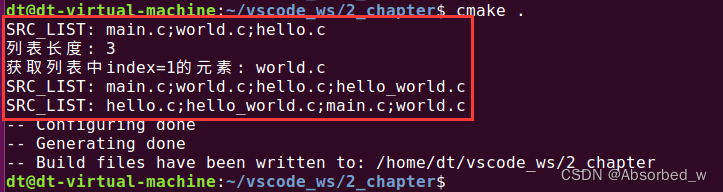
除此之外, 在 cmake 中可以使用循环语句依次读取列表中的各个元素,后续再向大家介绍。
⚫ target_include_directories 和 target_link_libraries
target_include_directories 命令为指定目标设置头文件搜索路径,而 target_link_libraries 命令为指定目标设置链接库文件,这听起来跟 include_directories 和 link_libraries 命令有着相同的作用,确实如此,它们的功能的确相同,但是在一些细节方面却有不同,关于它们之间的区别稍后再给大家进行解释!
target_include_directories 和 target_link_libraries 命令定义如下所示:
target_include_directories(<target> [SYSTEM] [BEFORE]
<INTERFACE|PUBLIC|PRIVATE> [items1...]
[<INTERFACE|PUBLIC|PRIVATE> [items2...] ...])target_link_libraries(<target>
<PRIVATE|PUBLIC|INTERFACE> <item>...
[<PRIVATE|PUBLIC|INTERFACE> <item>...]...)这俩命令都有一个相同的参数<target>目标,这个目标指的就是譬如 add_executable、 add_library 命令所创 建 的 目 标 。 首 先 对 于 target_include_directories 命 令 来 说 , SYSTEM 、 BEFORE 这 两 个 选 项 与include_directories 命令中 SYSTEM、 BEFORE 选项的意义相同,这里不再多说!我们重点关注的是 INTERFACE|PUBLIC|PRIVATE 这三个选项有何不同? 通过一个示例向大家说明,
譬如工程目录结构如下所示:
├── build //build 目录
├── CMakeLists.txt
├── hello_world //生成 libhello_world.so,调用 libhello.so 和 libworld.so
│ ├── CMakeLists.txt
│ ├── hello //生成 libhello.so
│ │ ├── CMakeLists.txt
│ │ ├── hello.c
│ │ └── hello.h //libhello.so 对外头文件
│ ├── hello_world.c
│ ├── hello_world.h //libhello_world.so 对外头文件
│ └── world //生成 libworld.so
│ ├── CMakeLists.txt
│ ├── world.c
│ └── world.h //libworld.so 对外头文件
└── main.c调用关系:
├────libhello.so
可执行文件────libhello_world.so├────libworld.so根据以上工程,我们对 INTERFACE、 PUBLIC、 PRIVATE 三个关键字进行说明:
PRIVATE: 私有的。 main.c 程序调用了 libhello_world.so, 生成 libhello_world.so 时,只在 hello_world.c中包含了 hello.h, libhello_world.so 对外的头文件——hello_world.h 中不包含 hello.h。而且 main.c 不会调用hello.c 中的函数,或者说 main.c 不知道 hello.c 的存在, 它只知道 libhello_world.so 的存在; 那么在hello_world/CMakeLists.txt 中应该写入:
target_link_libraries(hello_world PRIVATE hello)
target_include_directories(hello_world PRIVATE hello)INTERFACE: 接口。 生成 libhello_world.so 时,只在 libhello_world.so 对外的头文件——hello_world.h中包含了 hello.h, hello_world.c 中不包含 hello.h,即 libhello_world.so 不使用 libhello.so 提供的功能,但是main.c 需要使用 libhello.so 中的功能。那么在 hello_world/CMakeLists.txt 中应该写入:
target_link_libraries(hello-world INTERFACE hello)
target_include_directories(hello-world INTERFACE hello)PUBLIC: 公开的。 PUBLIC = PRIVATE + INTERFACE。生成 libhello_world.so 时,在 hello_world.c 和hello_world.h 中 都 包 含 了 hello.h 。 并 且 main.c 中 也 需 要 使 用 libhello.so 提 供 的 功 能 。 那 么 在hello_world/CMakeLists.txt 中应该写入:
target_link_libraries(hello-world PUBLIC hello)
target_include_directories(hello-world PUBLIC hello)不知道大家看懂了没有,其实理解起来很简单, 对于 target_include_directories 来说, 这些关键字用于指示何时需要传递给目标的包含目录列表, 指定了包含目录列表的使用范围(scope):
⚫ 当使用 PRIVATE 关键字修饰时,意味着包含目录列表仅用于当前目标;
⚫ 当使用 INTERFACE 关键字修饰时,意味着包含目录列表不用于当前目标、只能用于依赖该目标的其它目标,也就是说 cmake 会将包含目录列表传递给当前目标的依赖目标;
⚫ 当使用 PUBLIC 关键字修饰时,这就是以上两个的集合, 包含目录列表既用于当前目标、也会传递给当前目标的依赖目标。
对于 target_link_libraries 亦是如此,只不过包含目录列表换成了链接库列表。 譬如:target_link_libraries(hello_world INTERFACE hello):表示目标 hello_world 不需要链接 hello 库,但是对于 hello_world 目标的依赖目标(依赖于 hello_world 的目标)它们需要链接 hello 库。
以上便是笔者对 INTERFACE、 PUBLIC、 PRIVATE 这三个关键字的概括性理解,所以整出这几个关键字主要还是为了控制包含目录列表或链接库列表的使用范围,这就是 target_include_directories、target_link_libraries 命令与 include_directories、 link_libraries 命令的不同之处。 target_include_directories()、target_link_libraries()的功能完全可以使用 include_directories()、 link_libraries()来实现。但是笔者强烈建议大家使用 target_include_directories()和 target_link_libraries()。为什么?保持清晰!
include_directories()、 link_libraries()是针对当前源码中的所有目标, 并且还会向下传递(譬如通过add_subdirectory 加载子源码时,也会将其传递给子源码) 。 在一个大的工程当中,这通常不规范、有时还会编译出现错误、混乱,所以我们应尽量使用 target_include_directories()和 target_link_libraries(),保持整个工程的目录清晰。
总结
本小节内容到此结束了,给大家介绍了一些基本、常用的命令,并进行了详细的解释说明,除此之外,还有很多的命令并未提及,我们会在后面进行专题的介绍,大家要自己多动手、多多练习,这样才能越来越熟练!
部分常用变量
变量也是 cmake 中的一个重头戏, cmake 提供了很多内置变量,每一个变量都有它自己的含义,通过这个链接地址 https://cmake.org/cmake/help/v3.5/manual/cmake-variables.7.html 可以查询到所有的内置变量及其相应的介绍,如下所示:
在这一份文档中,对变量进行分类,分为: 提供信息的变量、改变行为的变量、描述系统的变量、控制编译的变量等等,笔者也按照这个分类给大家介绍一些基本、常用的变量。
⚫ 提供信息的变量
顾名思义,这种变量可以提供某种信息,既然如此,那么我们通常只需要读取变量即可,而不需要对变量进行修改:
| 变量 | 说明 |
| PROJECT_SOURCE_DIR | 工程顶层目录,也就是顶层 CMakeLists.txt 源码所在目录 |
| PROJECT_BINARY_DIR | 工 程 BINARY_DIR , 也 就 是 顶 层 CMakeLists.txt 源 码 的BINARY_DIR |
| CMAKE_SOURCE_DIR | 与 PROJECT_SOURCE_DIR 等价 |
| CMAKE_BINARY_DIR | 与 PROJECT_BINARY_DIR 等价 |
| CMAKE_CURRENT_SOURCE_DIR | 当前源码所在路径 |
| CMAKE_CURRENT_BINARY_DIR | 当前源码的 BINARY_DIR |
| CMAKE_MAJOR_VERSION | cmake 的主版本号 |
| CMAKE_MINOR_VERSION | cmake 的次版本号 |
| CMAKE_VERSION | cmake 的版本号(主+次+修订) |
| PROJECT_VERSION_MAJOR | 工程的主版本号 |
| PROJECT_VERSION_MINOR | 工程的次版本号 |
| PROJECT_VERSION | 工程的版本号 |
| CMAKE_PROJECT_NAME | 工程的名字 |
| PROJECT_NAME | 工程名,与 CMAKE_PROJECT_NAME 等价 |
PROJECT_SOURCE_DIR 和 PROJECT_BINARY_DIR
PROJECT_SOURCE_DIR 变量表示工程的顶级目录,也就是顶层 CMakeLists.txt 文件所在目录;PROJECT_BINARY_DIR 变 量 表示 工程 的 BINARY_DIR ,也 就是 顶 层 CMakeLists.txt 源 码 对 应的BINARY_DIR(输出文件目录) 。
譬如工程目录结构如下所示:
├── build
├── CMakeLists.txt
└── main.cCMakeLists.txt 文件内容如下:
# CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project(HELLO)
message(${PROJECT_SOURCE_DIR})
message(${PROJECT_BINARY_DIR})CMakeLists.txt 中我们打印了 PROJECT_SOURCE_DIR 和 PROJECT_BINARY_DIR 变量,进入到 build目录下,执行 cmake: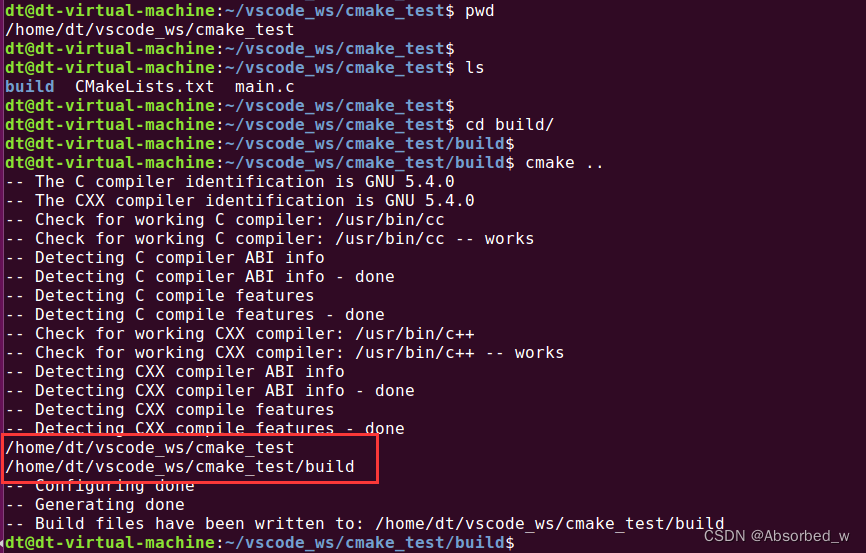
从打印信息可知, PROJECT_SOURCE_DIR 指的就是工程的顶层 CMakeLists.txt 源码所在路径,而PROJECT_BINARY_DIR 指的是我们执行 cmake 命令的所在目录,也是顶层 CMakeLists.txt 源码的BINARY_DIR。
➢ CMAKE_SOURCE_DIR 和 CMAKE_BINARY_DIR
与上面两个等价,大家自己打印出来看看便知!
➢ CMAKE_CURRENT_SOURCE_DIR 和 CMAKE_CURRENT_BINARY_DIR
指的是当前源码的路径以及当前源码的 BINARY_DIR,通过示例来看看,譬如工程目录结构如下所示:
├── build
├── CMakeLists.txt
├── main.c
└── src└── CMakeLists.txt顶层 CMakeLists.txt 文件通过 add_subdirectory 加载子目录 src 下的 CMakeLists.txt, src 目录下CMakeLists.txt 文件内容如下所示:
# src 下的 CMakeLists.txt
message(${PROJECT_SOURCE_DIR})
message(${PROJECT_BINARY_DIR})
message(${CMAKE_CURRENT_SOURCE_DIR})
message(${CMAKE_CURRENT_BINARY_DIR})通过 message 将这些变量打印出来,对比看看,进入到 build 目录下,执行 cmake: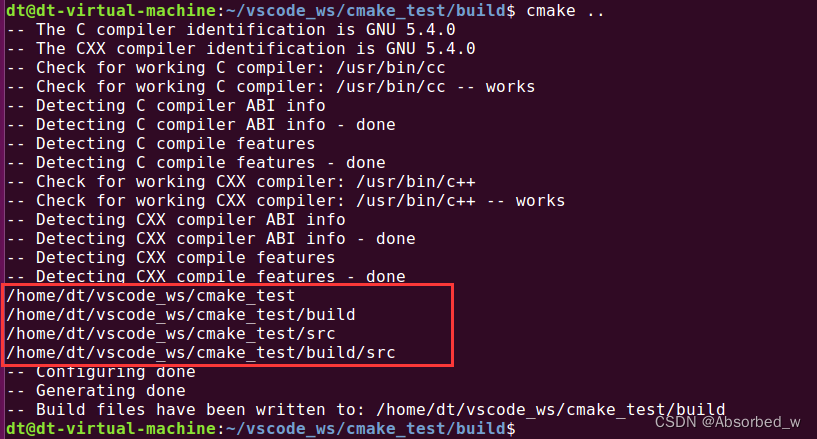
➢ CMAKE_VERSION、 CMAKE_MAJOR_VERSION 和 CMAKE_MINOR_VERSION
记录 cmake 的版本号,如下:
# CMakeLists.txt
message(${CMAKE_VERSION})
message(${CMAKE_MAJOR_VERSION})
message(${CMAKE_MINOR_VERSION})打印信息如下:
➢ PROJECT_VERSION、 PROJECT_VERSION_MAJOR 和 PROJECT_VERSION_MINOR
记录工程的版本号,其实可以给工程设置一个版本号,通过 project()命令进行设置,如下:
# CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project(HELLO VERSION 1.1.0) #设置工程版本号为 1.1.0
# 打印
message(${PROJECT_VERSION})
message(${PROJECT_VERSION_MAJOR})
message(${PROJECT_VERSION_MINOR})打印信息如下:
➢ CMAKE_PROJECT_NAME 和 PROJECT_NAME
这俩是等价的,记录了工程的名字:
# CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project(HELLO VERSION 1.1.0) #设置工程版本号为 1.1.0
# 打印工程名字
message(${CMAKE_PROJECT_NAME})
message(${PROJECT_NAME})打印信息如下:
⚫ 改变行为的变量
顾名思义,意味着这些变量可以改变某些行为,所以我们可以通过对这些变量进行设置以改变行为。
| 变量 | 说明 |
| BUILD_SHARED_LIBS | 控制 cmake 是否生成动态库 |
| CMAKE_BUILD_TYPE | 指定工程的构建类型, release 或 debug |
| CMAKE_SYSROOT | 对应编译器的在--sysroot 选项 |
| CMAKE_IGNORE_PATH | 设置被 find_xxx 命令忽略的目录列表 |
| CMAKE_INCLUDE_PATH | 为 find_file()和 find_path()命令指定搜索路径的目录列表 |
| CMAKE_INCLUDE_DIRECTORIES_BEFORE | 用于控制 include_directories()命令的行为 |
| CMAKE_LIBRARY_PATH | 指定 find_library()命令的搜索路径的目录列表 |
| CMAKE_MODULE_PATH | 指定要由 include()或 find_package()命令加载的 CMake 模块的搜索路径的目录列表 |
| CMAKE_PROGRAM_PATH | 指定 find_program()命令的搜索路径的目录列表 |
➢ BUILD_SHARED_LIB
对于 add_library()命令,当没有显式指定生成动态库时(SHARED 选项),默认生成的是静态库;其实我们可以通过 BUILD_SHARED_LIBS 变量来控制 add_library()命令的行为,当将变量设置为 on 时表示使能动态库,则 add_library()默认生成的便是动态库文件;当变量设置为 off 或未设置时, add_library()默认生成的便是静态库文件。测试如下:
譬如工程目录结构如下所示:
├── build
├── CMakeLists.txt
├── hello
│ └── hello.c
└── world└── world.c顶层 CMakeLists.txt 文件如下所示:
# 顶层 CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project(HELLO VERSION 1.1.0)
set(BUILD_SHARED_LIBS on)
add_library(hello hello/hello.c)
add_library(world world/world.c)进入到 build 目录下,执行 cmake、 make 进行构建、编译,将会生成动态库文件 libhello.so、 libworld.so。
➢ CMAKE_BUILD_TYPE
设置编译类型 Debug 或者 Release。 debug 版会生成相关调试信息,可以使用 GDB 进行调试; release 不会生成调试信息:
# Debug 版本
set(CMAKE_BUILD_TYPE Debug)
# Release 版本
set(CMAKE_BUILD_TYPE Release)关于这个 Debug 或者 Release 版本的问题,后续有机会再给大家进行专题介绍。
➢ CMAKE_SYSROOT
cmake 会将该变量传递给编译器--sysroot 选项,通常我们在设置交叉编译时会使用到,后面再说!
➢ CMAKE_INCLUDE_PATH
为 find_file()和 find_path()命令指定搜索路径的目录列表。 这两个命令前面没给大家介绍,它们分别用于查找文件、路径,我们需要传入一个文件名, find_file()命令会将该文件的全路径返回给我们;而 find_path()命令则会将文件的所在目录返回给我们。
这 两 个 命 令 去 哪 找 文 件 呢 ? 也 就 是 通 过 CMAKE_INCLUDE_PATH 变 量 来 进 行 指 定 ,CMAKE_INCLUDE_PATH 指定了一个目录列表, find_file()、 find_path()会去这个目录列表中查找文件。接下来我们进行测试。
譬如工程目录结构如下所示:
├── build
├── CMakeLists.txt
└── src└── hello.c顶层 CMakeLists.txt 文件内容如下:
# CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project(HELLO VERSION 1.1.0) #设置工程版本号为 1.1.0
find_file(P_VAR hello.c)
message(${P_VAR})通过 find_file 命令查找 hello.c 文件,将路径信息记录在 P_VAR 变量中;现在我们没有设置CMAKE_INCLUDE_PATH 变量,看看能不能找到 hello.c 文件, cmake 打印信息如下:

很明显提示没有找到,现在我们对 CMAKE_INCLUDE_PATH 变量进行设置,如下所示:
# CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project(HELLO VERSION 1.1.0) #设置工程版本号为 1.1.0
# 设置 CMAKE_INCLUDE_PATH 变量
set(CMAKE_INCLUDE_PATH ${PROJECT_SOURCE_DIR}/src)
# 查找文件
find_file(P_VAR hello.c)
message(${P_VAR})此时打印信息为:
这次就成功找到了 hello.c 文件,并将文件的全路径返回给我们。
➢ CMAKE_LIBRARY_PATH
指定 find_library()命令的搜索路径的目录列表。 find_library()命令用于搜索库文件, find_library()将会从CMAKE_LIBRARY_PATH 变量设置的目录列表中进行搜索。
➢ CMAKE_MODULE_PATH
指定要由 include()或 find_package()命令加载的 CMake 模块的搜索路径的目录列表。
➢ CMAKE_INCLUDE_DIRECTORIES_BEFORE
这个变量在前面给大家提到过,它可以改变 include_directories()命令的行为。 include_directories()命令默认情况下会将目录添加到列表的后面, 如果将 CMAKE_INCLUDE_DIRECTORIES_BEFORE 设置为 on, 则include_directories()命令会将目录添加到列表前面; 同理若将 CMAKE_INCLUDE_DIRECTORIES_BEFORE
设置为 off 或未设置该变量, include_directories()会将目录添加到列表后面。
➢ CMAKE_IGNORE_PATH
要被 find_program()、 find_library()、 find_file()和 find_path()命令忽略的目录列表。 表示这些命令不会去CMAKE_IGNORE_PATH 变量指定的目录列表中搜索。
⚫ 描述系统的变量
顾名思义,这些变量描述了系统相关的一些信息:
| 变量 | 说明 |
| CMAKE_HOST_SYSTEM_NAME | 运行 cmake 的操作系统的名称(其实就是 uname -s) |
| CMAKE_HOST_SYSTEM_PROCESSOR | 运行 cmake 的操作系统的处理器名称(uname -p) |
| CMAKE_HOST_SYSTEM | 运行 cmake 的操作系统(复合信息) |
| CMAKE_HOST_SYSTEM_VERSION | 运行 cmake 的操作系统的版本号(uname -r) |
| CMAKE_HOST_UNIX | 如果运行 cmake 的操作系统是 UNIX 和类 UNIX,则 该变量为 true,否则是空值 |
| CMAKE_HOST_WIN32 | 如果运行 cmake 的操作系统是 Windows,则该变量 为 true,否则是空值 |
| CMAKE_SYSTEM_NAME | 目标主机操作系统的名称 |
| CMAKE_SYSTEM_PROCESSOR | 目标主机的处理器名称 |
| CMAKE_SYSTEM | 目标主机的操作系统(复合信息) |
| CMAKE_SYSTEM_VERSION | 目标主机操作系统的版本号 |
| ENV | 用于访问环境变量 |
| UNIX | 与 CMAKE_HOST_UNIX 等价 |
| WIN32 | 与 CMAKE_HOST_WIN32 等价 |
➢ CMAKE_HOST_SYSTEM_NAME 、 CMAKE_HOST_SYSTEM_PROCESSOR 、CMAKE_HOST_SYSTEM 和 CMAKE_HOST_SYSTEM_VERSION
这四个变量描述的是运行 cmake 的主机相关的信息,我们直接打印出来看看即可:
# 打印信息
message(${CMAKE_HOST_SYSTEM_NAME})
message(${CMAKE_HOST_SYSTEM_PROCESSOR})
message(${CMAKE_HOST_SYSTEM})
message(${CMAKE_HOST_SYSTEM_VERSION})对应的打印信息如下: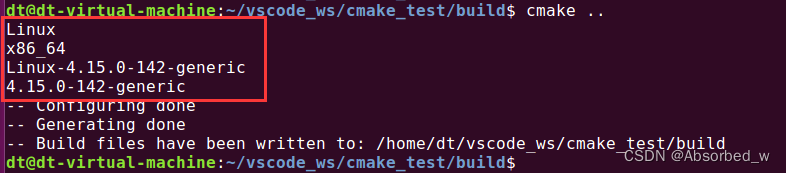
大家自己对照一看就知道了,笔者就不再多说了。
➢ CMAKE_SYSTEM_NAME 、 CMAKE_SYSTEM_PROCESSOR 、 CMAKE_SYSTEM 和CMAKE_SYSTEM_VERSION
这 4 个变量则是用于描述目标主机相关的信息,目标主机指的是可执行文件运行的主机,譬如我们的ARM 开发板。
# 打印信息
message(${CMAKE_SYSTEM_NAME})
message(${CMAKE_SYSTEM_PROCESSOR})
message(${CMAKE_SYSTEM})
message(${CMAKE_SYSTEM_VERSION})cmake 打印信息如下: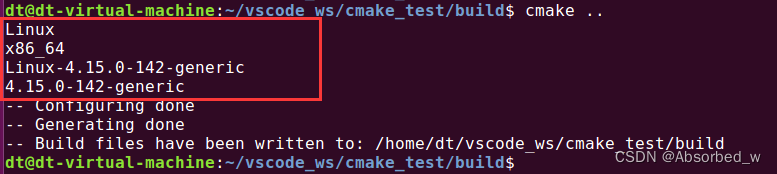
因为我们并没有对 cmake 配置交叉编译,默认会使用 Ubuntu 系统(运行 cmake 的主机)本身的编译工具,所以生成的目标文件(可执行文件或库文件)只能运行在 Ubuntu 系统中,所以这 4 个变量记录的依然是 Ubuntu 主机的信息。
➢ ENV
这个变量可用于访问环境变量,用法很简单$ENV{VAR}
# 访问环境变量
message($ENV{XXX})通过$ENV{XXX}访问 XXX 环境变量,我们来测试一下,首先在 Ubuntu 系统下使用 export 命令导出XXX 环境变量:
export XXX="Hello World!"
cd build/
cmake ..打印信息如下所示:
从打印信息可知, ENV 变量确实可以访问到 Linux 系统的环境变量。
⚫ 控制编译的变量
这些变量可以控制编译过程,具体如下所示:
| 变量 | 说明 |
| EXECUTABLE_OUTPUT_PATH | 可执行程序的输出路径 |
| LIBRARY_OUTPUT_PATH | 库文件的输出路径 |
这两个变量前面我们已经用到过了,分别用来设置可执行文件的输出目录以及库文件的输出目录,接下来我们进行简单地测试。譬如工程目录结构如下所示:
├── build
├── CMakeLists.txt
├── hello
│ ├── hello.c
│ └── hello.h
└── main.chello.c 会被编译成动态库文件 libhello.so,而 main.c 会被编译成可执行程序, main.c 源码中调用了 hello.c提供的函数;顶层 CMakeLists.txt 文件内容如下所示:
# CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project(HELLO VERSION 1.1.0) #设置工程版本号为 1.1.0
# 设置可执行文件和库文件输出路径
set(EXECUTABLE_OUTPUT_PATH ${PROJECT_BINARY_DIR}/bin)
set(LIBRARY_OUTPUT_PATH ${PROJECT_BINARY_DIR}/lib)
# 头文件包含
include_directories(hello)
# 动态库目标
add_library(hello SHARED hello/hello.c)
# 可执行程序目标
add_executable(main main.c)
target_link_libraries(main PRIVATE hello) #链接库进入到build目录下,执行cmake、make进行构建、编译,最终会生成可执行文件main和库文件libhello.so,目录结构如下所示:
├── build
│ ├── bin
│ │ └── main
│ ├── lib
│ └── libhello.so
├── CMakeLists.txt
├── hello
│ ├── hello.c
│ └── hello.h
└── main.c这是因为我们通过设置 EXECUTABLE_OUTPUT_PATH 和 LIBRARY_OUTPUT_PATH 才会使得生成的可执行程序在 build/bin 目录下、生成的库文件在 build/lib 目录下,如果把这两行给注释掉,那么生成的文件在 build 目录中,因为默认情况下,最终的目标文件的输出目录就是源码的 BINARY_DIR。
双引号的作用
CMake 中,双引号的作用我们可以从两个方面进行介绍,命令参数和引用变量。
命令参数
调用命令时,参数可以使用双引号,譬如:
project("HELLO")也可以不使用双引号,譬如:
project(HELLO)那它们有什么区别呢?在本例中是没有区别的, 命令中多个参数之间使用空格进行分隔,而 cmake 会将双引号引起来的内容作为一个整体,当它当成一个参数,假如你的参数中有空格(空格是参数的一部分),那么就可以使用双引号,如下所示:
message(Hello World)
message("Hello World")在这个例子中,第一个 message 命令传入了两个参数,而第二个 message 命令只传入一个参数;在第一个 message 命令中,打印信息时,会将两个独立的字符串 Hello 和 World 都打印出来,而且 World 会紧跟在Hello 之后, 如下:
HelloWorld
而第二个 message 命令只有一个参数,所以打印信息如下:
Hello World
这就是双引号在参数中的一个作用。
引用变量
我们先来看个例子,如下所示:
# CMakeLists.txt
set(MY_LIST Hello World China)
message(${MY_LIST})这个例子的打印信息如下:
HelloWorldChina
在这个例子中, MY_LIST 是一个列表,该列表包含了 3 个元素,分别是 Hello、 World、 China。但这个message 命令打印时却将这三个元素全部打印出来,并且各个元素之间没有任何分隔。此时我们可以在引用变量(${MY_LIST}) 时加上双引号,如下所示:
# CMakeLists.txt
set(MY_LIST Hello World China)
message("${MY_LIST}")此时 message 打印信息如下:
Hello;World;China
因为此时${MY_LIST}是一个列表,我们用"${MY_LIST}"这种形式的时候,表示要让 CMake 把这个数组的所有元素当成一个整体,而不是分散的个体。于是,为了保持数组的含义,又提供一个整体的表达方式,CMake 就会用分号“;” 把这数组的多个元素连接起来。而如果不加双引号时, CMake 不会数组当成一个整体看待,而是会将数组中的各个元素提取出进行打印输出。
条件判断
在 cmake 中可以使用条件判断, 条件判断形式如下:
if(expression)
# then section.
command1(args ...)
command2(args ...)
...
elseif(expression2)
# elseif section.
command1(args ...)
command2(args ...)
...
else(expression)
# else section.
command1(args ...)
command2(args ...)
...
endif(expression)else 和 endif 括号中的<expression>可写可不写,如果写了,就必须和 if 中的<expression>一致。expression 就是一个进行判断的表达式,表达式对照表如下:
| 表达式 | true | false | 说明 |
| <constant> | 如果constant为1、ON、 YES、 TRUE、 Y 或非零 数,则为真 | 如果constant为0、 OFF 、 NO 、 FALSE 、 N 、 IGNORE 、 NOTFOUND、空 字符串或以后缀- NOTFOUND 结 尾,则为 False。 | 布尔值大小 写不敏感;如 果与这些常 量都不匹配, 则将其视为 变量或字符 串 |
| <variable|string> | 已 经 定 义 并 且 不 是 false 的变量 | 未 定 义 或 者 是 false 的变量 | 变量就是字 符串 |
| NOT <expression> | expression 为 false | expression 为 true | |
| <expr1> AND <expr2> | expr1 和 expr2 同时为 true | expr1 和 expr2 至 少有一个为 false | |
| <expr1> OR <expr2> | expr1 和 expr2 至少有 一个为 true | expr1 和 expr2 都 是 false | |
| COMMAND name | name 是一个已经定义 的命令、宏或者函数 | name 未定义 | |
| TARGET name | name 是 add_executable() 、 add_library() 或 add_custom_target() 定 义的目标 | name 未定义 | |
| TEST name | name 是由 add_test()命 令创建的现有测试名 称 | name 未创建 | |
| EXISTS path | path 指定的文件或目 录存在 | path 指定的文件 或目录不存在 | 仅适用于完 整路径 |
| IS_DIRECTORY path | path 指定的路径为目 录 | path 指定的路径 不为目录 | 仅适用于完 整路径 |
| IS_SYMLINK path | path 为符号链接 | path 不是符号链 接 | 仅适用于完 整路径 |
| IS_ABSOLUTE path | path 为绝对路径 | path 不是绝对路 径 | |
| <variable|string> MATCHES regex | variable 与正则表达式 regex 匹配成功 | variable 与正则表 达式 regex 匹配失 败 | |
| <variable|string> IN_LIST <variable> | 右边列表中包含左边 的元素 | 右边列表中不含 左边的元素 | |
| DEFINED <variable> | 如果给定的变量已定 义,则为真。 | 如果给定的变量 未定义 | 只要变量已 经被设置,它 是真还是假 并不重要。 ( 注意宏不 是变量。) |
| <variable|string> LESS <variable|string> | 如果给定的字符串或 变量的值是有效数字 且小于右侧的数字,则 为真。 | 左侧的数字大于 或等于右侧的数 字 | |
| <variable|string> GREATER <variable|string> | 如果给定的字符串或 变量的值是有效数字且大于右侧的数字,则 为真。 | 左侧的数字小于 或等于右侧的数 字 | |
| <variable|string> EQUAL <variable|string> | 如果给定的字符串或 变量的值是有效数字 并且等于右侧的值,则 为真 | 左侧的数字不等 于右侧的数字 |
上 表 中 只是 列 出其 中一 部 分 表达 式 ,还 有其 它 一 些表 达 式这 里并 未 列 出 , 大 家可 以通 过
https://cmake.org/cmake/help/v3.5/command/if.html 这个链接地址进行查看,现在我们对上表中的表达式进行详解。
⚫ <constant>
在 if(constant)条件判断中,如果 constant 是 1、 ON、 YES、 TRUE、 Y 或非零数字,那么这个 if 条件就是 true;如果 constant 是 0、 OFF、 NO、 FALSE、 N、 IGNORE、 NOTFOUND、空字符串或以后缀-NOTFOUND结尾,那么这个条件判断的结果就是 false。在 cmake 中,可以把 1、 ON、 YES、 TRUE、 Y 或非零数字以及 0、 OFF、 NO、 FALSE、 N、 IGNORE、NOTFOUND、空字符串或以后缀-NOTFOUND 结尾这些理解为常量,类似于布尔值,而且它们不区分大小写; 如果参数不是这些特定常量之一,则将其视为变量或字符串,并使用除<constant>之外的表达式。
if(ON)
message(true)
else()
message(false)
endif()
输出为: true
if(YES)
message(true)
else()
message(false)
endif()
输出为: true
if(true)
message(true)
else()
message(false)
endif()
输出为: true
if(100)
message(true)
else()
message(false)
endif()
输出为: true
if(0)
message(true)
else()
message(false)
endif()
输出为: false
if(N)
message(true)
else()
message(false)
endif()
输出为: false
if(NO)
message(true)
else()
message(false)
endif()
输出为: false⚫ <variable/string>
在 if(<variable/string>)条件判断中,如果变量已经定义,并且它的值是一个非假常量,则条件为真;否则为假,注意宏参数不是变量(在 cmake 中也可以使用宏,这个后面再给大家介绍)。
set(GG Hello)
if(GG)
message(true)
else()
message(false)
endif()
输出为: true
set(GG NO)
if(GG)
message(true)
else()
message(false)
endif()
输出为: false
if(GG)
message(true)
else()
message(false)
endif()
输出为: false⚫ NOT <expression>
NOT 其实就类似于 C 语言中的取反,在 if(NOT <expression>)条件判断中,如果表达式 expression 为真,则条件判断为假;如果表达式 expression 为假,则条件判断为真。
if(NOT GG)
message(true)
else()
message(false)
endif()
输出为: true
因为 GG 变量没有定义,所以 GG 表达式为假,但因为前面有 NOT 关键字,进行取反操作,整个 if 条件判断为真。
if(NOT YES)
message(true)
else()
message(false)
endif()
输出为: false
if(NOT 0)
message(true)
else()
message(false)
endif()
输出为: true⚫ <expr1> AND <expr2>
这个就类似于 C 语言中的逻辑与(&&) ,只有 expr1 和 expr2 同时为真时,条件判断才为真;否则条件判断为假。
if(yes AND on)
message(true)
else()
message(false)
endif()
输出为: true
if(yes AND no)
message(true)
else()
message(false)
endif()
输出为: false
if(false AND no)
message(true)
else()
message(false)
endif()
输出为: false⚫ <expr1> OR <expr2>
类似于 C 语言中的逻辑或(||),当 expr1 或 expr2 至少有一个为真时,条件判断为真;否则为假。
if(false OR no)
message(true)
else()
message(false)
endif()
输出为: false
if(yes OR no)
message(true)
else()
message(false)
endif()
输出为: true
if(ON OR yes)
message(true)
else()
message(false)
endif()
输出为: true⚫ COMMAND command-name
如果 command-name 是一个已经定义的命令、宏或函数时,条件判断为真;否则为假。除了宏之外,在 cmake 中还可以定义函数,这个我们也会在后面向大家介绍。
if(COMMAND yyds)
message(true)
else()
message(false)
endif()
输出为: false
if(COMMAND project)
message(true)
else()
message(false)
endif()
输出为: true⚫ TARGET target-name
如果 target-name 是 add_executable()、 add_library()或 add_custom_target()定义的目标(这些目标在整个工程中必须是唯一的,不可出现两个名字相同的目标) ,则条件判断为真;否则为假。
if(TARGET hello)
message(true)
else()
message(false)
endif()
输出为: false
add_library(hello hello.c)
if(TARGET hello)
message(true)
else()
message(false)
endif()
输出为: true⚫ EXISTS path
如果 path 指定的文件或目录存在,则条件判断为真;否则为假。需要注意的是, path 必须是文件或目录的全路径,也就是绝对路径。
譬如工程目录结构如下所示:
├── build
├── CMakeLists.txt
├── hello
│ ├── hello.c
│ └── hello.h
└── main.c在顶层 CMakeLists.txt 文件中使用 if(EXISTS path)进行判断:
if(EXISTS ${PROJECT_BINARY_DIR})
message(true)
else()
message(false)
endif()
输出为: true
if(EXISTS ${PROJECT_BINARY_DIR}/hello)
message(true)
else()
message(false)
endif()
输出为: true
if(EXISTS ${PROJECT_BINARY_DIR}/world)
message(true)
else()
message(false)
endif()
输出为: false
if(EXISTS ${PROJECT_BINARY_DIR}/hello/hello.c)
message(true)
else()
message(false)
endif()
输出为: true ⚫ IS_DIRECTORY path
如果 path 指定的路径是一个目录,则条件判断为真;否则为假,同样, path 也必须是一个绝对路径。还是以上例中的工程目录结构为例:
if(IS_DIRECTORY ${PROJECT_BINARY_DIR}/hello)
message(true)
else()
message(false)
endif()
输出为: true
if(IS_DIRECTORY ${PROJECT_BINARY_DIR}/hello/hello.c)
message(true)
else()
message(false)
endif()
输出为: true⚫ IS_ABSOLUTE path
如果给定的路径 path 是一个绝对路径,则条件判断为真;否则为假。
if(IS_ABSOLUTE ${PROJECT_BINARY_DIR})
message(true)
else()
message(false)
endif()
输出为: true
if(IS_ABSOLUTE ./hello)
message(true)
else()
message(false)
endif()
输出为: false⚫ <variable|string> MATCHES regex
这个表达式用的比较多,可以用来匹配字符串,可以使用正则表达式进行匹配。如果给定的字符串或变量的值与给定的正则表达式匹配,则为真, 否则为假。
set(MY_STR "Hello World")
if(MY_STR MATCHES "Hello World")
message(true)
else()
message(false)
endif()
输出为: true其实也可以引用变量:
set(MY_STR "Hello World")
if(${MY_STR} MATCHES "Hello World")
message(true)
else()
message(false)
endif()
输出为: true
set(MY_STR "Hello World")
if("Hello World" MATCHES "Hello World")
message(true)
else()
message(false)
endif()
输出为: true⚫ <variable|string> IN_LIST <variable>
如果左边给定的变量或字符串是右边列表中的某个元素相同,则条件判断为真;否则为假。
set(MY_LIST Hello World China)
if(Hello IN_LIST MY_LIST)
message(true)
else()
message(false)
endif()
输出为: true
set(MY_LIST Hello World China)
set(Hello China)
if(Hello IN_LIST MY_LIST)
message(true)
else()
message(false)
endif()
输出为: true⚫ DEFINED <variable>
如果给定的变量已经定义,则条件判断为真,否则为假; 只要变量已经被设置(定义) , if 条件判断就是真,至于变量的值是真还是假并不重要。
if(DEFINED yyds)
message(true)
else()
message(false)
endif()
输出为: false
set(yyds "YYDS")
if(DEFINED yyds)
message(true)
else()
message(false)
endif()
输出为: true⚫ <variable|string> LESS <variable|string>
如果左边给定的字符串或变量的值是有效数字并且小于右侧的值,则为真。 否则为假。测试如下:
if(100 LESS 20)
message(true)
else()
message(false)
endif()
输出为: false
if(20 LESS 100)
message(true)
else()
message(false)
endif()
输出为: true⚫ <variable|string> GREATER <variable|string>
如果左边给定的字符串或变量的值是有效数字并且大于右侧的值,则为真。 否则为假。测试如下:
if(20 GREATER 100)
message(true)
else()
message(false)
endif()
输出为: false
if(100 GREATER 20)
message(true)
else()
message(false)
endif()
输出为: true⚫ <variable|string> EQUAL <variable|string>
如果左边给定的字符串或变量的值是有效数字并且等于右侧的值,则为真。 否则为假。测试如下:
if(100 EQUAL 20)
message(true)
else()
message(false)
endif()
输出为: false
if(100 EQUAL 100)
message(true)
else()
message(false)
endif()
输出为: true⚫ elseif 分支
可以使用 elseif 组成多个不同的分支:
set(MY_LIST Hello World China)
if(Hello IN_LIST MY_LIST)
message(Hello)
elseif(World IN_LIST MY_LIST)
message(World)
elseif(China IN_LIST MY_LIST)
message(China)
else()
message(false)
endif()循环语句
cmake 中除了 if 条件判断之外,还支持循环语句,包括 foreach()循环、 while()循环。
一、 foreach 循环
①、 foreach 基本用法
foreach 循环的基本用法如下所示:
foreach(loop_var arg1 arg2 ...)
command1(args ...)
command2(args ...)
...
endforeach(loop_var)endforeach 括号中的<loop_var>可写可不写,如果写了,就必须和 foreach 中的<loop_var>一致。参数 loop_var 是一个循环变量,循环过程中会将参数列表中的变量依次赋值给他,类似于 C 语言 for 循环中经常使用的变量 i。
# foreach 循环测试
foreach(loop_var A B C D)
message("${loop_var}")
endforeach()打印信息为:
A B C D
使用 foreach 可以遍历一个列表中的所有元素,如下所示:
# foreach 循环测试
set(my_list hello world china)
foreach(loop_var ${my_list})
message("${loop_var}")
endforeach()打印信息如下:
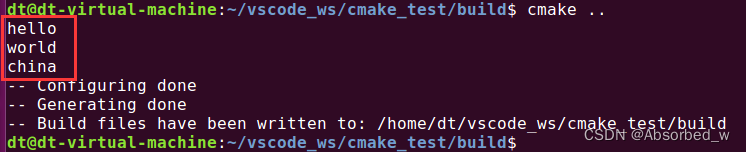
②、 foreach 循环之 RANGE 关键字
用法如下所示:
foreach(loop_var RANGE stop)
foreach(loop_var RANGE start stop [step])对于第一种方式,循环会从 0 到指定的数字 stop,包含 stop, stop 不能为负数。
而对于第二种,循环从指定的数字 start 开始到 stop 结束,步长为 step,不过 step 参数是一个可选参数,如果不指定,默认 step=1;三个参数都不能为负数,而且 stop 不能比 start 小。接下来我们进行测试,测试一:
# foreach 循环测试
foreach(loop_var RANGE 4)
message("${loop_var}")
endforeach()打印信息如下: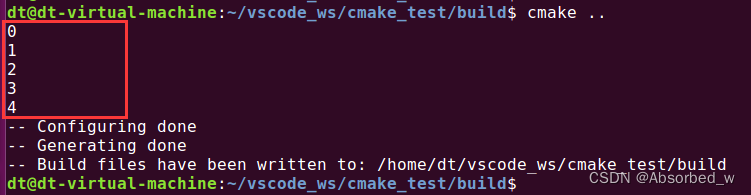
测试二:
# foreach 循环测试
foreach(loop_var RANGE 1 4 1)
message("${loop_var}")
endforeach()打印信息如下: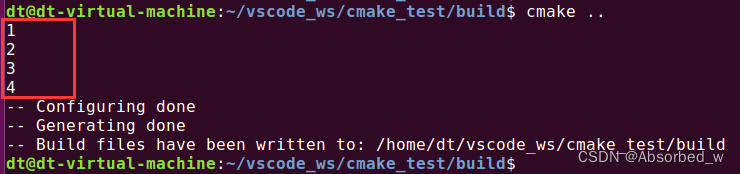
③、 foreach 循环之 IN 关键字
用法如下:
foreach(loop_var IN [LISTS [list1 [...]]] [ITEMS [item1 [...]]])循环列表中的每一个元素,或者直接指定元素。
接下来进行测试,测试一:
# foreach 循环测试
set(my_list A B C D)
foreach(loop_var IN LISTS my_list)
message("${loop_var}")
endforeach()打印信息如下: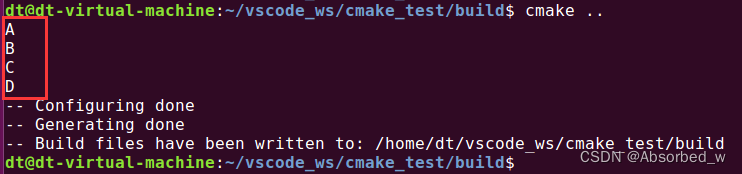
测试二:
# foreach 循环测试
foreach(loop_var IN ITEMS A B C D)
message("${loop_var}")
endforeach()打印信息同上。
二、 while 循环
while 循环用法如下:
while(condition)
command1(args ...)
command1(args ...)
...
endwhile(condition)endwhile 括号中的 condition 可写可不写,如果写了,就必须和 while 中的 condition 一致。cmake 中 while 循环的含义与 C 语言中 while 循环的含义相同,但条件 condition 为真时,执行循环体中的命令,而条件 condition 的语法形式与 if 条件判断中的语法形式相同。
# while 循环测试
set(loop_var 4)
while(loop_var GREATER 0)
message("${loop_var}")
math(EXPR loop_var "${loop_var} - 1")
endwhile()输出结果如下: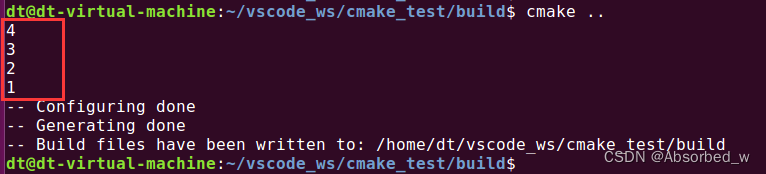
上例中, while 循环的条件是(loop_var GREATER 0),等价于(loop_var > 0),当 loop_var 变量的有效数值大于 0 时,执行 while 循环体;在 while 循环体中使用到了 cmake 中的数学运算命令 math(),关于数学运算下小节会向大家介绍。在 while 循环体中,打印 loop_var,之后将 loop_var 减一。
三、 break、 continue
cmake 中,也可以在循环体中使用类似于 C 语言中的 break 和 continue 语句。
①、 break
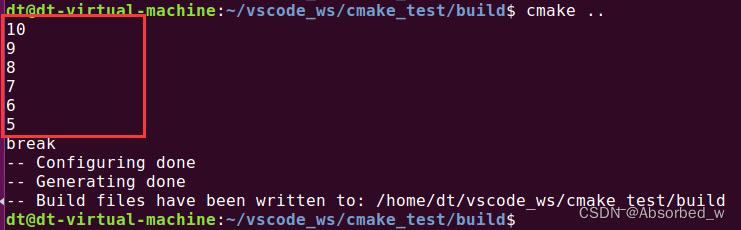
break()命令用于跳出循环,和在 C 语言中的作用是一样的,测试如下:
# while...break 测试
set(loop_var 10)
while(loop_var GREATER 0) #loop_var>0 时 执行循环体
message("${loop_var}")
if(loop_var LESS 6) #当 loop_var 小于 6 时
message("break")
break() #跳出循环
endif()
math(EXPR loop_var "${loop_var} - 1")#loop_var--
endwhile()打印信息如下:
②、 continue
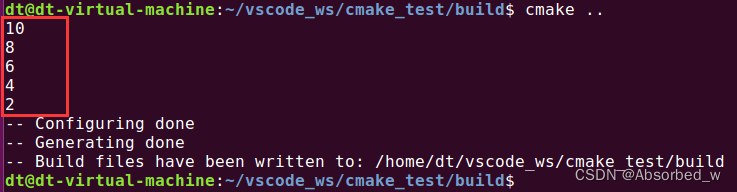
continue()命令用于结束本次循环,执行下一次循环,测试如下:
# while...continue 测试
# 打印所有偶数
set(loop_var 10)
while(loop_var GREATER 0) #loop_var>0 时 执行循环体
math(EXPR var "${loop_var} % 2") #求余
if(var EQUAL 0) #如果 var=0,表示它是偶数
message("${loop_var}") #打印这个偶数
math(EXPR loop_var "${loop_var} - 1")#loop_var--
continue() # 执行下一次循环
endif()
math(EXPR loop_var "${loop_var} - 1")#loop_var--
endwhile()这段 cmake 代码是求 0 到 10 之间的偶数(左闭右开),并将偶数打印出来,使用到了 continue()命令,代码不再解释,注释已经写得很清楚了。打印结果如下:
关于 break()和 continue()命令的使用就介绍到这里了。
数学运算 math
在 cmake 中如何使用数学运算呢?其实, cmake 提供了一个命令用于实现数学运算功能,这个命令就是 math(),如下所示:
math(EXPR <output variable> <math expression>)math 命令中,第一个参数是一个固定的关键字 EXPR,第二个参数是一个返回参数,将数学运算结果存放在这个变量中;而第三个参数则是一个数学运算表达式, 支持的运算符包括: +(加)、 -(减)、 *(乘)、/(除)、 %(求余)、 |(按位或)、 &(按位与)、 ^(按位异或)、 ~(按位取反)、 <<(左移)、 >>(右移)以及这些运算符的组合运算, 它们的含义与 C 语言中相同。
譬如:
math(EXPR out_var "1+1") #计算 1+1
math(EXPR out_var "100 * 2") ##计算 100x2
math(EXPR out_var "10 & 20") #计算 10 & 20我们进行测试:
# math()命令测试
math(EXPR out_var "100 + 100")
message("${out_var}")
math(EXPR out_var "100 - 50")
message("${out_var}")
math(EXPR out_var "100 * 100")
message("${out_var}")
math(EXPR out_var "100 / 50")
message("${out_var}")
math(EXPR out_var "(100 & 100) * 50 - 2")
message("${out_var}")测试结果如下: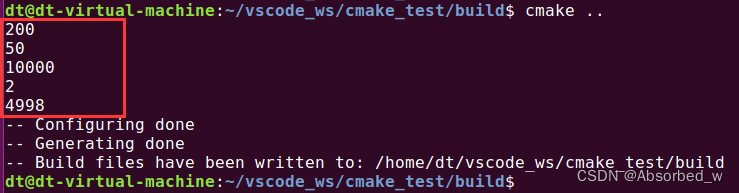
cmake 进阶
上小节,已经将 cmake 中常用的命令 command、变量 variable 都给大家进行了详细介绍,通过上小节的学习,相信大家已经掌握了 cmake 工具的基本使用方法; 本小节我们在进一步学习 cmake,看看 cmake 还有哪些东西。
定义函数
在 cmake 中我们也可以定义函数, cmake 提供了 function()命令用于定义一个函数,使用方法如下所示:
function(<name> [arg1 [arg2 [arg3 ...]]])
command1(args ...)
command2(args ...)
...
endfunction(<name>)endfunction 括号中的<name>可写可不写,如果写了,就必须和 function 括号中的<name>一致。
①、基本使用方法
第一个参数 name 表示函数的名字, arg1、 arg2…表示传递给函数的参数。 调用函数的方法其实就跟使用命令一样,一个简单地示例如下所示:
# function 函数测试
# 函数名: xyz
function(xyz arg1 arg2)
message("${arg1} ${arg2}")
endfunction()
# 调用函数
xyz(Hello World)打印信息如下:
②、使用 return()命令
在 function()函数中也可以使用 C 语言中的 return 语句退出函数, 如下所示:
# function 函数测试
# 函数名: xyz
function(xyz)
message(Hello)
return() # 退出函数
message(World)
endfunction()
# 调用函数
xyz()执行结果如下:
只打印了 Hello,并没有打印 World,说明 return()命令是生效的,执行 return()命令之后就已经退出当前函数了,所以并不会打印 World。 但是需要注意的是, return 并不可以用于返回参数,那函数中如何返回参数给调用者呢?关于这个问题,后续再给大家讲解,因为这里涉及到其它一些问题,本小节暂时先不去理会这个问题。
③、可变参函数
在 cmake 中,调用函数时实际传入的参数个数不需要等于函数定义的参数个数(甚至函数定义时,参数个数为 0) ,但是实际传入的参数个数必须大于或等于函数定义的参数个数,如下所示:
# function 函数测试
# 函数名: xyz
function(xyz arg1)
message(${arg1})
endfunction()
# 调用函数
xyz(Hello World China)函数 xyz 定义时只有一个参数,但是实际调用时我们传入了 3 个参数,注意这并不会报错,是符合function()语法规则的,会正常执行,打印信息如下:
从打印信息可知, message()命令打印出了调用者传入的第一个参数,也就是 Hello。这种设计有什么用途呢?正如我们的标题所言,这种设计可用于实现可变参函数(与 C 语言中的可变参数函数概念相同) ; 但是有个问题, 就如上例中所示,用户传入了 3 个参数,但是函数定义时并没有定义这些形参,函数中如何引用到第二个参数 World 以及第三个参数 China 呢?其实 cmake 早就为大家考虑到了,并给出了相应的解决方案,就是接下来向大家介绍的内部变量。
④、函数的内部变量
function()函数中可以使用内部变量, 所谓函数的内部变量,指的就是在函数内部使用的内置变量, 这些内部变量如下所示:
| 函数中的内部变量 | 说明 |
| ARGVX | X 是一个数字,譬如 ARGV0、 ARGV1、 ARGV2、 ARGV3…,这些变量表 示函数的参数, ARGV0 为第一个参数、 ARGV1 位第二个参数,依次类推! |
| ARGV | 实际调用时传入的参数会存放在 ARGV 变量中(如果是多个参数,那它就 是一个参数列表) |
| ARGN | 假如定义函数时参数为 2 个,实际调用时传入了 4 个,则 ARGN 存放了剩 下的 2 个参数(如果是多个参数,那它也是一个参数列表) |
| ARGC | 调用函数时, 实际传入的参数个数 |
我们可以进行测试:
# function 函数测试
# 函数名: xyz
function(xyz arg1 arg2)
message("ARGC: ${ARGC}")
message("ARGV: ${ARGV}")
message("ARGN: ${ARGN}")
message("ARGV0: ${ARGV0}")
message("ARGV1: ${ARGV1}")
# 循环打印出各个参数
set(i 0)
foreach(loop ${ARGV})
message("arg${i}: " ${loop})
math(EXPR i "${i} + 1")
endforeach()
endfunction()
# 调用函数
xyz(A B C D E F G)源码执行结果如下: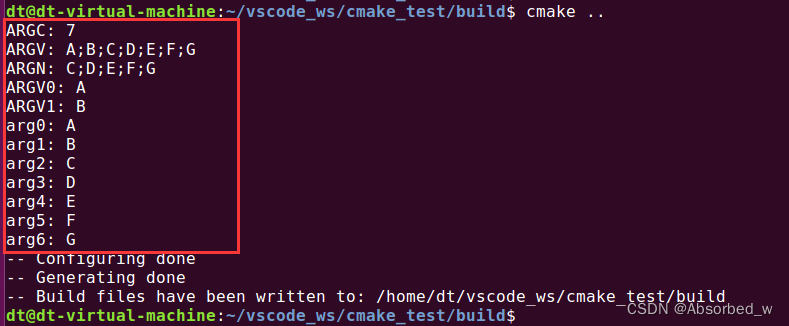
⑤、函数的作用域
在 cmake 中,通过 function()命令定义的函数类似于一个自定义命令(实际上并不是) ,当然,事实上,cmake 提供了自定义命令的方式,譬如通过 add_custom_command()来实现,如果大家有兴趣,可以自己去学习下,笔者便不再进行介绍了。
使用 function()定义的函数,我们需要对它的使用范围进行一个简单地了解,譬如有如下工程目录结构:
├── build
├── CMakeLists.txt
├── hello
├── CMakeLists.txt我们在顶层目录下定义了一个函数 xyz,顶层 CMakeLists.txt 源码内容如下:
# CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project(HELLO VERSION 1.1.0)
# 函数名: xyz
function(xyz)
message("Hello World!")
endfunction()
# 加载子源码
add_subdirectory(hello)接着我们在子源码中调用 xyz()函数, hello 目录下的 CMakeLists.txt 如下所示:
# hello 目录下的 CMakeLists.txt
message("这是子源码")
xyz() # 调用 xyz()函数大家觉得这样子可以调用成功吗?事实上,这是没问题的,父源码中定义的函数、在子源码中是可以调用的,打印信息如下:
那反过来,子源码中定义的函数,在父源码中可以使用吗?我们来进行测试,顶层 CMakeLists.txt 源码内容如下:
# CMakeLists.txt
cmake_minimum_required("VERSION" "3.5")
project(HELLO VERSION 1.1.0) #设置工程版本号为 1.1.0
# 加载子源码
add_subdirectory(hello)
message("这是父源码")
xyz()
在父源码中调用 xyz()函数,在子源码中定义 xyz()函数,如下所示:
message("这是子源码")
# 函数名: xyz
function(xyz)
message("Hello World!")
endfunction()进入到 build 目录执行 cmake,如下所示: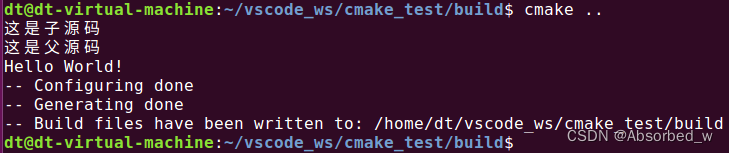
事实证明,这样也是可以的,说明通过 function()定义的函数它的使用范围是全局的,并不局限于当前源码、可以在其子源码或者父源码中被使用。
宏定义
cmake 提供了定义宏的方法, cmake 中函数 function 和宏定义 macro 在某种程度上来说是一样的,都是创建一段有名字的代码可以在后面被调用,还可以传参数。通过 macro()命令定义宏,如下所示:
macro(<name> [arg1 [arg2 [arg3 ...]]])
COMMAND1(ARGS ...)
COMMAND2(ARGS ...)
...
endmacro(<name>)endmacro 括号中的<name>可写可不写,如果写了,就必须和 macro 括号中的<name>一致。 参数 name表示宏定义的名字,在宏定义中也可以使用前面给大家介绍的 ARGVX(X 是一个数字)、 ARGC、 ARGV、ARGN 这些变量,所以这些也是宏定义的内部变量,如下所示:
# macro 宏定义测试
macro(XYZ arg1 arg2)
message("ARGC: ${ARGC}")
message("ARGV: ${ARGV}")
message("ARGN: ${ARGN}")
message("ARGV0: ${ARGV0}")
message("ARGV1: ${ARGV1}")
# 循环打印出各个参数
set(i 0)
foreach(loop ${ARGV})
message("arg${i}: " ${loop})
math(EXPR i "${i} + 1")
endforeach()
endmacro()
# 使用宏
XYZ(A B C D E)源码打印信息如下: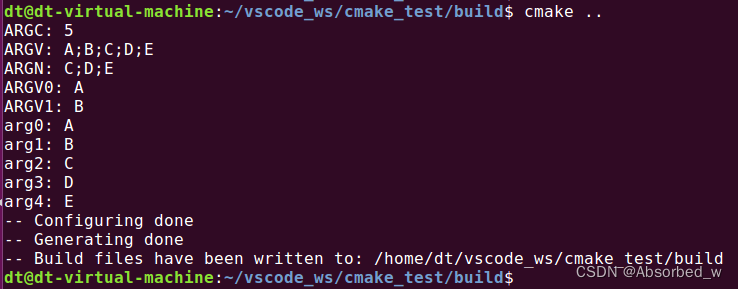
从定义上看他们貌似一模一样,宏和函数确实差不多, 但还是有区别的, 譬如, 宏的参数和诸如 ARGV、ARGC、 ARGN 之类的值不是通常 CMake 意义上的变量, 它们是字符串替换,就像 C 语言预处理器对宏所做的一样, 因此,您将无法使用以下命令:
if(ARGV1) # ARGV1 is not a variable
if(DEFINED ARGV2) # ARGV2 is not a variable
if(ARGC GREATER 2) # ARGC is not a variable
foreach(loop_var IN LISTS ARGN) # ARGN is not a variable因为在宏定义中,宏的参数和诸如 ARGC、 ARGV、 ARGN 等这些值并不是变量,它们是字符串替换,也就是说,当 cmake 执行宏定义时,会先将宏的参数和 ARGC、 ARGV、 ARGN 等这些值进行字符串替换,然后再去执行这段宏,其实就像是 C 语言中的预处理步骤,这是与函数不同的地方。
我们来进行测试:
# macro 宏
macro(abc arg1 arg2)
if(DEFINED ARGC)
message(true)
else()
message(false)
endif()
endmacro()
# function 函数
function(xyz arg1 arg2)
if(DEFINED ARGC)
message(true)
else()
message(false)
endif()
endfunction()
# 调用宏
abc(A B C D)
# 调用函数
xyz(A B C D)
上面的代码中,我们定义了一个宏 abc 和一个函数 xyz,它们俩的代码是一样的,都是在内部使用 if()判断 ARGC 是不是一个变量,如果是打印 true,如果不是打印 false;下面会分别调用宏 abc 和函数 xyz,打印信息如下所示:
所以从打印信息可知,在宏定义中, ARGC 确实不是变量,其实在执行宏之前,会将 ARGC 进行替换,如下所示:
if(DEFINED 4)
message(true)
else()
message(false)
endif()把 ARGC 替换为 4(因为我们实际传入了 4 个参数)。
当然,除此之外, cmake 中函数和宏定义还有其它的区别,譬如函数有自己的作用域、而宏定义是没有作用域的概念。
文件操作
cmake 提供了 file()命令可对文件进行一系列操作,譬如读写文件、删除文件、文件重命名、拷贝文件、创建目录等等,本小节我们一起来学习这个功能强大的 file()命令。
①、写文件:写、追加内容
使用 file()命令写文件,使用方式如下所示:
file(WRITE <filename> <content>...)
file(APPEND <filename> <content>...)将<content>写入名为<filename>的文件中。 如果文件不存在,它将被创建; 如果文件已经存在, WRITE模式将覆盖它, APPEND 模式将内容追加到文件末尾。
测试代码如下:
# file()写文件测试
file(WRITE wtest.txt "Hello World!") #给定内容生成 wtest.txt 文件
file(APPEND wtest.txt " China") #给定内容追加到 wtest.txt 文件末尾注意文件可以使用绝对路径或相对路径指定,相对路径被解释为相对于当前源码路径。
执行 CMakeLists.txt 代码之后,会在当前源码目录下生成一个名为 wtest.txt 的文件,如下所示:
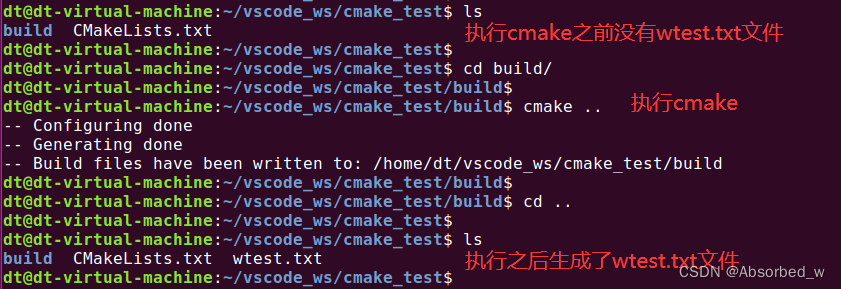
接着查看 wtest.txt 文件中内容,如下所示: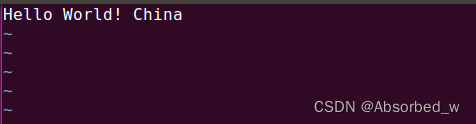
②、写文件:由内容生成文件
由内容生成文件的命令为:
file(GENERATE OUTPUT output-file
<INPUT input-file|CONTENT content>
[CONDITION expression])output-file:指定输出文件名,可以带路径(绝对路径或相对路径);
INPUT input-file:指定输入文件,通过输入文件的内容来生成输出文件;
CONTENT content:指定内容,直接指定内容来生成输出文件;
CONDITION expression:如果表达式 expression 条件判断为真,则生成文件、否则不生成文件。
同样,指定文件既可以使用相对路径、也可使用绝对路径,不过在这里,相对路径被解释为相对于当前源码的 BINARY_DIR 路径,而不是当前源码路径。
测试代码如下:
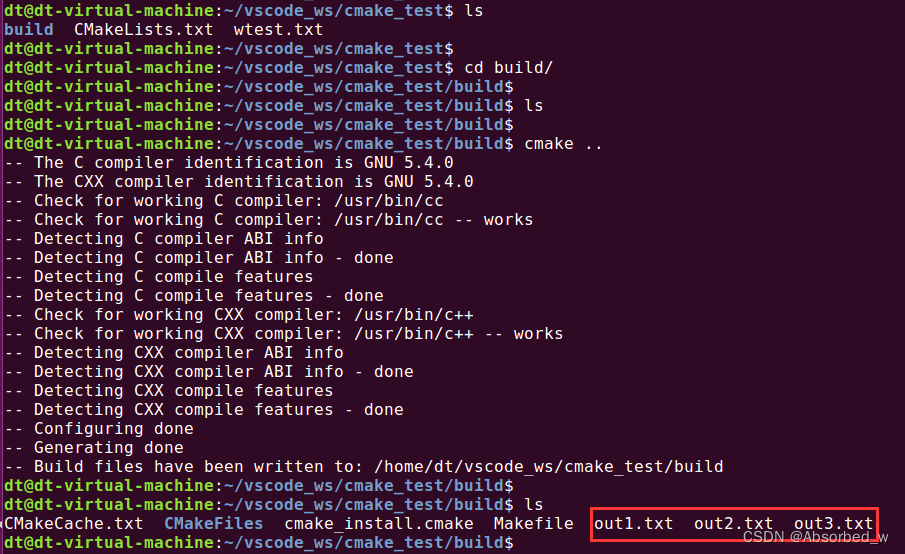
# 由前面生成的 wtest.txt 中的内容去生成 out1.txt 文件
file(GENERATE OUTPUT out1.txt INPUT "${PROJECT_SOURCE_DIR}/wtest.txt")
# 由指定的内容生成 out2.txt
file(GENERATE OUTPUT out2.txt CONTENT "This is the out2.txt file")
# 由指定的内容生成 out3.txt,加上条件控制,用户可根据实际情况
# 用表达式判断是否需要生成文件,这里只是演示,直接是 1
file(GENERATE OUTPUT out3.txt CONTENT "This is the out3.txt file" CONDITION 1)进入到 build 目录下执行 cmake:
执行完 cmake 之后会在 build 目录(也就是顶层源码的 BINARY_DIR)下生成了 out1.txt、 out2.txt 和
out3.txt 三个文件,内容如下: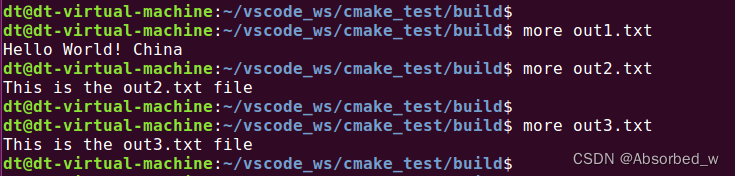
③、读文件:字节读取
file()读文件命令格式如下:
file(READ <filename> <variable>
[OFFSET <offset>] [LIMIT <max-in>] [HEX])从名为<filename>的文件中读取内容并将其存储在<variable>中。可选择从给定的<offset>开始,最多读取<max-in>字节。 HEX 选项使数据转换为十六进制表示(对二进制数据有用)。同样,指定文件既可以使用相对路径、也可使用绝对路径,相对路径被解释为相对于当前源码路径。
测试代码如下:
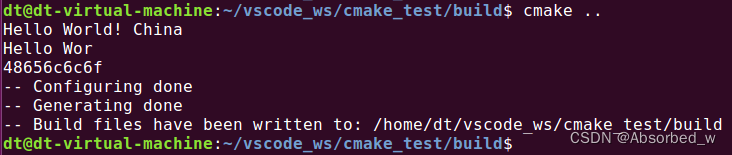
# file()读文件测试
file(READ "${PROJECT_SOURCE_DIR}/wtest.txt" out_var) #读取前面生成的 wtest.txt
message(${out_var}) # 打印输出
# 读取 wtest.txt 文件:限定起始字节和大小
file(READ "${PROJECT_SOURCE_DIR}/wtest.txt" out_var OFFSET 0 LIMIT 10)
message(${out_var})
# 读取 wtest.txt 文件:以二进制形式读取,限定起始字节和大小,
file(READ "${PROJECT_SOURCE_DIR}/wtest.txt" out_var OFFSET 0 LIMIT 5 HEX)
message(${out_var})打印信息如下所示:
④、 以字符串形式读取
命令格式如下所示:
file(STRINGS <filename> <variable> [<options>...])从<filename>文件中解析 ASCII 字符串列表并将其存储在<variable>中。 这个命令专用于读取字符串,会将文件中的二进制数据将被忽略, 回车符(\r, CR)字符被忽略。
filename: 指定需要读取的文件,可使用绝对路径、也可使用相对路径,相对路径被解释为相对于当前源码路径。
variable:存放字符串的变量。
options:可选的参数,可选择 0 个、 1 个或多个选项,这些选项包括:
➢ LENGTH_MAXIMUM <max-len>: 读取的字符串的最大长度;
➢ LENGTH_MINIMUM <min-len>: 读取的字符串的最小长度;
➢ LIMIT_COUNT <max-num>: 读取的行数;
➢ LIMIT_INPUT <max-in>: 读取的字节数;
➢ LIMIT_OUTPUT <max-out>: 存储到变量的限制字节数;
➢ NEWLINE_CONSUME: 把换行符也考虑进去;
➢ NO_HEX_CONVERSION: 除非提供此选项,否则 Intel Hex 和 Motorola S-record 文件在读取时会自动转换为二进制文件。
➢ REGEX <regex>: 只读取符合正则表达式的行;
➢ ENCODING <encoding-type>: 指定输入文件的编码格式, 目前支持的编码有: UTF-8、 UTF-16LE、UTF-16BE、 UTF-32LE、 UTF-32BE。如果未提供 ENCODING 选项并且文件具有字节顺序标记,
则 ENCODING 选项将默认为尊重字节顺序标记。
测试代码如下:
# 从 input.txt 文件读取字符串
file(STRINGS "${PROJECT_SOURCE_DIR}/input.txt" out_var)
message("${out_var}")
# 限定读取字符串的最大长度
file(STRINGS "${PROJECT_SOURCE_DIR}/input.txt" out_var LENGTH_MAXIMUM 5)
message("${out_var}")
# 限定读取字符串的最小长度
file(STRINGS "${PROJECT_SOURCE_DIR}/input.txt" out_var LENGTH_MINIMUM 4)
message("${out_var}")
# 限定读取行数
file(STRINGS "${PROJECT_SOURCE_DIR}/input.txt" out_var LIMIT_COUNT 3)
message("${out_var}")从 input.txt 文件读取字符串, input.txt 文件的内容如下所示: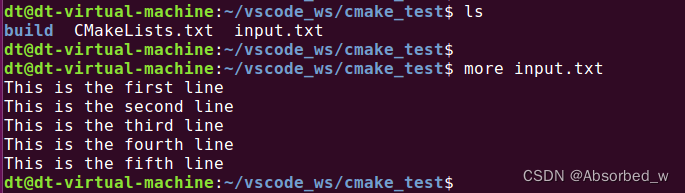
上述代码执行的结果如下所示:
大家自己去对比就知道这些选项具体是什么意思了,这里便不再多说!
⑤、 计算文件的 hash 值
file()命令可以计算指定文件内容的加密散列(hash 值) 并将其存储在变量中。 命令格式如下所示:
file(<MD5|SHA1|SHA224|SHA256|SHA384|SHA512> <filename> <variable>)MD5|SHA1|SHA224|SHA256|SHA384|SHA512 表示不同的计算 hash 的算法,必须要指定其中之一,filename 指定文件(可使用绝对路径、也可使用相对路径,相对路径被解释为相对于当前源码的 BINARY_DIR) ,将计算结果存储在 variable 变量中。
测试代码如下:
# 计算文件的 hash 值
file(SHA256 "${PROJECT_SOURCE_DIR}/input.txt" out_var)
message("${out_var}")这里我们还是用上面创建的 input.txt 文件,使用 SHA256 算法进行计算,结果如下:
⑥、文件重命名
使用 file()命令可以对文件进行重命名操作,命令格式如下:
file(RENAME <oldname> <newname>)oldname 指的是原文件, newname 指的是重命名后的新文件,文件既可以使用绝对路径指定,也可以使用相对路径指定,相对路径被解释为相对于当前源码路径。
测试代码:
# 文件重命名
file(RENAME "${PROJECT_SOURCE_DIR}/input.txt" "${PROJECT_SOURCE_DIR}/output.txt")测试结果如下: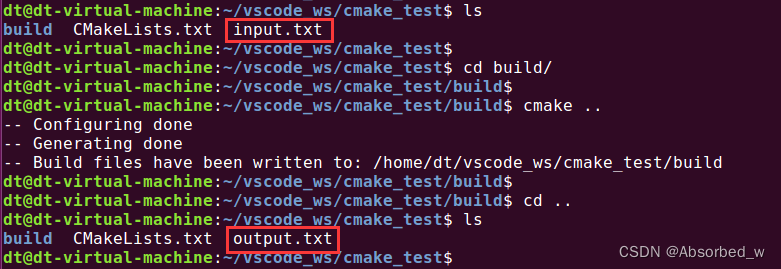
⑦、删除文件
使用 file()命令可以删除文件,命令格式如下:
file(REMOVE [<files>...])
file(REMOVE_RECURSE [<files>...])REMOVE 选项将删除给定的文件,但不可以删除目录;而 REMOVE_RECURSE 选项将删除给定的文件或目录、 以及非空目录。 指定文件或目录既可以使用绝对路径、也可以使用相对路径,相对路径被解释为相对于当前源码路径。
测试代码:
# file 删除文件或目录测试
file(REMOVE "${PROJECT_SOURCE_DIR}/out1.txt")
file(REMOVE_RECURSE "${PROJECT_SOURCE_DIR}/out2.txt" "${PROJECT_SOURCE_DIR}/empty-dir"
"${PROJECT_SOURCE_DIR}/Non_empty-dir")out1.txt 和 out2.txt 是普通文件, empty-dir 是一个空目录,而 Non_empty-dir 是一个非空目录,如下所示: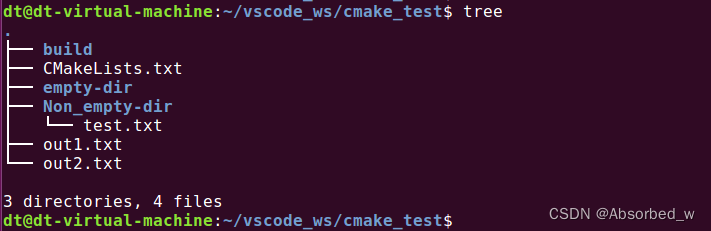
进入到 build 目录下,执行 cmake:
执行完 cmake 命令之后,这些文件以及文件夹都被删除了。
关于 file()命令就给大家介绍这么多了,其实 file()命令的功能很强大,除了以上给大家介绍的基本功能外,还支持文件下载、文件锁等功能,大家有兴趣可以自己去了解。
设置交叉编译
前面笔者一直没给大家提过如何去设置交叉编译,因为如果不设置交叉编译,默认情况下, cmake 会使用主机系统(运行 cmake 命令的操作系统)的编译器来编译我们的工程,那么得到的可执行文件或库文件只能在 Ubuntu 系统运行,如果我们需要使得编译得到的可执行文件或库文件能够在我们的开发板(ARM 平台) 上运行,则需要配置交叉编译,本小节将进行介绍。
我们使用的交叉编译器如下:
arm-poky-linux-gnueabi-gcc #C 编译器
arm-poky-linux-gnueabi-g++ #C++编译器
其实配置交叉编译非常简单,只需要设置几个变量即可,如下所示:
# 配置 ARM 交叉编译
set(CMAKE_SYSTEM_NAME Linux) #设置目标系统名字
set(CMAKE_SYSTEM_PROCESSOR arm) #设置目标处理器架构# 指定编译器的 sysroot 路径
set(TOOLCHAIN_DIR /opt/fsl-imx-x11/4.1.15-2.1.0/sysroots)
set(CMAKE_SYSROOT ${TOOLCHAIN_DIR}/cortexa7hf-neon-poky-linux-gnueabi)# 指定交叉编译器 arm-gcc 和 arm-g++
set(CMAKE_C_COMPILER ${TOOLCHAIN_DIR}/x86_64-pokysdk-linux/usr/bin/arm-poky-linux-gnueabi/armpoky-linux-gnueabi-gcc)
set(CMAKE_CXX_COMPILER ${TOOLCHAIN_DIR}/x86_64-pokysdk-linux/usr/bin/arm-poky-linuxgnueabi/arm-poky-linux-gnueabi-g++)# 为编译器添加编译选项
set(CMAKE_C_FLAGS "-march=armv7ve -mfpu=neon -mfloat-abi=hard -mcpu=cortex-a7")
set(CMAKE_CXX_FLAGS "-march=armv7ve -mfpu=neon -mfloat-abi=hard -mcpu=cortex-a7")
set(CMAKE_FIND_ROOT_PATH_MODE_PROGRAM NEVER)
set(CMAKE_FIND_ROOT_PATH_MODE_LIBRARY ONLY)
set(CMAKE_FIND_ROOT_PATH_MODE_INCLUDE ONLY)CMAKE_SYSTEM_NAME 变量在前面给大家介绍过,表示目标主机(譬如 ARM 开发板)的操作系统名称,这里将其设置为 Linux,表示目标操作系统是 Linux 系统。
CMAKE_SYSTEM_PROCESSOR 变量表示目标架构名称。CMAKE_SYSROOT 变量前面也给大家介绍过,该变量的值会传递给 gcc 编译器的--sysroot 选项,也就
是--sysroot=${CMAKE_SYSROOT}, --sysroot 选项指定了编译器的 sysroot 目录,也就是编译器的系统根目录, 编译过程中需要链接的库、 头文件等, 就会去该目录下寻找,譬如标准 C 库、标准 C 头文件这些。CMAKE_C_COMPILER 变量指定了 C 语言编译器 gcc,由于是交叉编译,所以应该指定为 arm-gcc。CMAKE_CXX_COMPILER 变量指定了 C++语言编译器 g++,由于是交叉编译,所以应该指定为 armg++。CMAKE_C_FLAGS 变量为 gcc 编译器添加编译选项, CMAKE_CXX_FLAGS 变量为 g++编译器添加编
译选项。
CMAKE_FIND_ROOT_PATH_MODE_LIBRARY 和 CMAKE_FIND_ROOT_PATH_MODE_INCLUDE被设置为 ONLY; CMAKE_FIND_ROOT_PATH_MODE_INCLUDE 变量控制 CMAKE_SYSROOT 中的路径是否被 find_file()和 find_path()使用。如果设置为 ONLY,则只会搜索 CMAKE_SYSROOT 中的路径, 如果设置为 NEVER,则 CMAKE_SYSROOT 中的路径将被忽略并且仅使用主机系统路径。如果设置为 BOTH,则将搜索主机系统路径和 CMAKE_SYSROOT 中的路径。同理, CMAKE_FIND_ROOT_PATH_MODE_LIBRARY 变量控制 CMAKE_SYSROOT 中的路径是否被find_library()使用, 如果设置为 ONLY,则只会搜索 CMAKE_SYSROOT 中的路径, 如果设置为 NEVER,则 CMAKE_SYSROOT 中的路径将被忽略并且仅使用主机系统路径。如果设置为 BOTH,则将搜索主机系统路径和 CMAKE_SYSROOT 中的路径。
CMAKE_SYSROOT、 CMAKE_C_COMPILER、 CMAKE_CXX_COMPILER 这些变量涉及到交叉编译工具的安装路径,需要根据自己的实际安装路径来确定。
接着我们进行测试, 譬如工程目录结构如下所示:
├── build
├── CMakeLists.txt
└── main.c
main.c 源文件中调用了 printf()函数打印了“Hello World!”字符串, CMakeLists.txt 文件内容如下:
# CMakeLists.txt
cmake_minimum_required(VERSION 3.5)
##################################
# 配置 ARM 交叉编译
#################################
set(CMAKE_SYSTEM_NAME Linux) #设置目标系统名字
set(CMAKE_SYSTEM_PROCESSOR arm) #设置目标处理器架构
# 指定编译器的 sysroot 路径
set(TOOLCHAIN_DIR /opt/fsl-imx-x11/4.1.15-2.1.0/sysroots)
set(CMAKE_SYSROOT ${TOOLCHAIN_DIR}/cortexa7hf-neon-poky-linux-gnueabi)
# 指定交叉编译器 arm-linux-gcc 和 arm-linux-g++
set(CMAKE_C_COMPILER ${TOOLCHAIN_DIR}/x86_64-pokysdk-linux/usr/bin/arm-poky-linux-gnueabi/armpoky-linux-gnueabi-gcc)
set(CMAKE_CXX_COMPILER ${TOOLCHAIN_DIR}/x86_64-pokysdk-linux/usr/bin/arm-poky-linuxgnueabi/arm-poky-linux-gnueabi-g++)
# 为编译器添加编译选项
set(CMAKE_C_FLAGS "-march=armv7ve -mfpu=neon -mfloat-abi=hard -mcpu=cortex-a7")
set(CMAKE_CXX_FLAGS "-march=armv7ve -mfpu=neon -mfloat-abi=hard -mcpu=cortex-a7")
set(CMAKE_FIND_ROOT_PATH_MODE_PROGRAM NEVER)
set(CMAKE_FIND_ROOT_PATH_MODE_LIBRARY ONLY)
set(CMAKE_FIND_ROOT_PATH_MODE_INCLUDE ONLY)
#################################
# end
##################################
project(HELLO) #设置工程名称
add_executable(main main.c)这里要注意,配置 ARM 交叉编译的这些代码需要放置在 project()命令之前,否则不会生效!接着进入到 build 目录下,然后执行 cmake,此时笔者发现,执行 cmake 会报错!如下所示:

一开始笔者也是死活想不明白, CMakeLists.txt 代码没问题呀,咋会报错?后来笔者实在没办法,尝试换一个高版本的 cmake 来运行,果然就没问题了;因为笔者用的是 Ubuntu 系统自带的 cmake 工具,前面也给大家看了,它的版本是 3.5.1,当前最新 cmake 版本已经更新到了 3.22 了,所以 3.5.1 这个版本可能确实是太旧了,导致这里出错,所以笔者建议大家去下载一个高版本的 cmake,然后使用这个高版本的 cmake 工具,不然会报错。那怎么去下载高版本的 cmake,其实非常简单,我们首先进入到 cmake 的 GitHub 链接地址https://github.com/Kitware/CMake/releases,笔者并没有使用最新的 cmake,而是使用了 3.16.0,为了保持一致,也建议大家下载这个版本,往后翻页找到这个版本,如下所示:
这里我们下载 cmake-3.16.0-Linux-x86_64.tar.gz 压缩包文件,这个不是 cmake 的源码工程,而是可以在x86-64 的 Linux 系统下运行的可执行程序,其中就包括了 cmake 工具,所以我们下载这个即可,非常方便,都不用自己编译!下载成功之后将其拷贝到 Ubuntu 系统的用户家目录下, 并将其解压到某个目录, 解压之后生成 cmake-
3.16.0-Linux-x86_64 文件夹, 这里笔者选择将其解压到家目录下的 tools 目录中,如下所示:
cmake 工具就在 cmake-3.16.0-Linux-x86_64/bin 目录下。
现在重新进入到我们的工程目录下,进入到 build 目录执行 cmake,如下所示: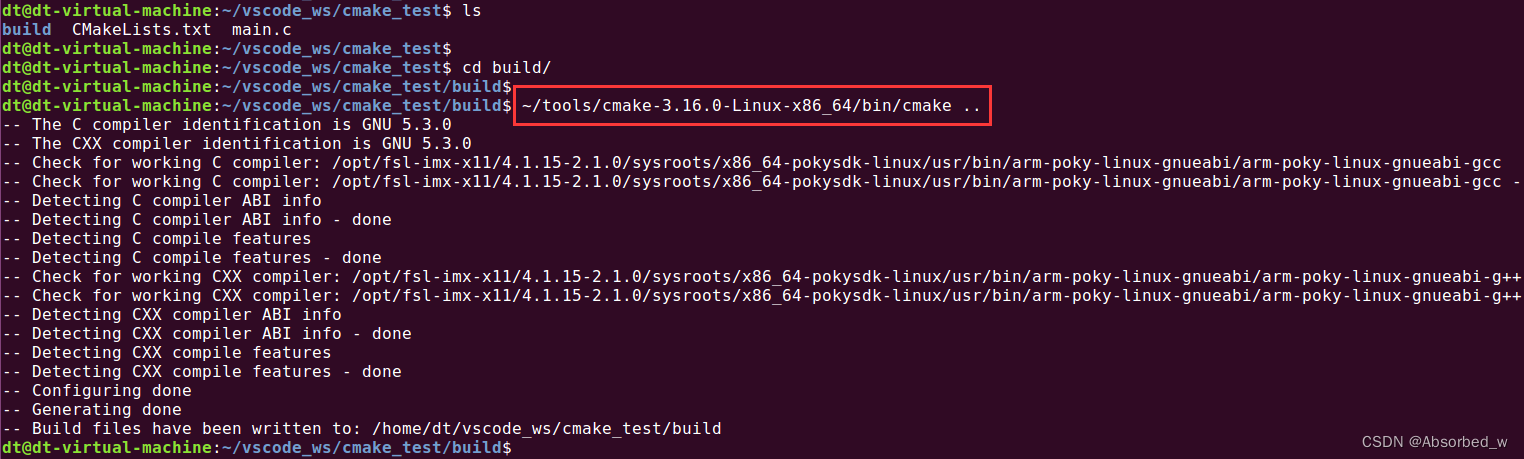
接着执行 make 命令编译:
编译生成的 main 可执行文件,通过 file 命令查看可知,它是一个 ARM 架构的可执行程序,可以把它拷贝到开发板上去运行,肯定是没有问题的,这里就不再演示了。
上例中的这种交叉编译配置方式自然是没有问题的,但是不规范,通常的做法是,将这些配置项(也就是变量的设置)单独拿出来写在一个单独的配置文件中,而不直接写入到 CMakeLists.txt 源码中,然后在执行 cmake 命令时,指定配置文件给 cmake,让它去配置交叉编译环境。如何指定配置文件呢?通过如下方式:
cmake -DCMAKE_TOOLCHAIN_FILE=cfg_file_path ..通过-DCMAKE_TOOLCHAIN_FILE 选项指定配置文件, -D 是 cmake 命令提供的一个选项,通过该选项可以创建一个缓存变量(缓存变量就是全局变量,在整个工程中都是生效的,会覆盖 CMakeLists.txt 源码中 定 义 的 同 名 变 量 ) , 所 以 -DCMAKE_TOOLCHAIN_FILE 其 实 就 是 设 置 了 缓 存 变 量CMAKE_TOOLCHAIN_FILE,它的值就是“=”号后面的内容, cmake 会执行 CMAKE_TOOLCHAIN_FILE变量所指定的源文件,对交叉编译进行设置; 现在我们进行测试,在工程源码目录下创建一个配置文件 armlinux-setup.cmake,内容如下:
##################################
# 配置 ARM 交叉编译
#################################
set(CMAKE_SYSTEM_NAME Linux) #设置目标系统名字
set(CMAKE_SYSTEM_PROCESSOR arm) #设置目标处理器架构
# 指定编译器的 sysroot 路径
set(TOOLCHAIN_DIR /opt/fsl-imx-x11/4.1.15-2.1.0/sysroots)
set(CMAKE_SYSROOT ${TOOLCHAIN_DIR}/cortexa7hf-neon-poky-linux-gnueabi)
# 指定交叉编译器 arm-linux-gcc 和 arm-linux-g++
set(CMAKE_C_COMPILER ${TOOLCHAIN_DIR}/x86_64-pokysdk-linux/usr/bin/arm-poky-linux-gnueabi/armpoky-linux-gnueabi-gcc)
set(CMAKE_CXX_COMPILER ${TOOLCHAIN_DIR}/x86_64-pokysdk-linux/usr/bin/arm-poky-linuxgnueabi/arm-poky-linux-gnueabi-g++)
# 为编译器添加编译选项
set(CMAKE_C_FLAGS "-march=armv7ve -mfpu=neon -mfloat-abi=hard -mcpu=cortex-a7")
set(CMAKE_CXX_FLAGS "-march=armv7ve -mfpu=neon -mfloat-abi=hard -mcpu=cortex-a7")
set(CMAKE_FIND_ROOT_PATH_MODE_PROGRAM NEVER)
set(CMAKE_FIND_ROOT_PATH_MODE_LIBRARY ONLY)
set(CMAKE_FIND_ROOT_PATH_MODE_INCLUDE ONLY)
#################################
# end
##################################此时 CMakeLists.txt 文件内容需要剔除交叉编译的配置项
工程目录结构如下所示:
├── arm-linux-setup.cmake
├── build
├── CMakeLists.txt
└── main.c
进入到 build 目录下,执行 cmake:
接着执行 make 编译:
所以这种方式也是没有问题的,推荐使用这种方式配置交叉编译,而不是直接写入到 CMakeLists.txt 源码中。
变量的作用域
如同 C 语言一样,在 cmake 中,变量也有作用域的概念,本小节我们就来聊一聊关于 cmake 中变量作用域的问题。本小节从三个方面进行介绍:函数作用域、目录作用域以及全局作用域。
一、函数作用域(function scope)
我把这个作用域叫做函数作用域, 当在函数内通过 set 将变量 var 与当前函数作用域绑定时,变量 var仅在函数作用域内有效,出了这个作用域,如果这个作用域外也有同名的变量 var,那么使用的将是域外同名变量 var; func1()内部调用 func2(),嵌套调用的函数 func2()内部如果也引用变量 var,那么该变量 var 应该是 func1()内部定义的变量,如果有的话; 如果 func1()内部没有绑定变量 var,那么就会使用 func1()作用域外定义的变量 var,依次向外搜索。
以上这段话大家可能不好理解,我们通过几个示例来看看函数作用域。
①、函数内部引用函数外部定义的变量
示例代码如下所示:
# 函数 xyz
function(xyz)
message(${ABC}) #引用变量 ABC
endfunction()
set(ABC "Hello World") #定义变量 ABC
xyz() # 调用函数ABC 是函数外部定义的一个变量,在函数 xyz 中引用了该变量,打印信息如下:
所以可知,函数内可以引用函数外部定义的变量。
②、函数内定义的变量是否可以被外部引用
示例代码如下所示:
# 函数 xyz
function(xyz)
set(ABC "Hello World")#定义变量 ABC
endfunction()
xyz() # 调用函数
if(DEFINED ABC)
message("true")
message("${ABC}") #引用函数内定义的变量 ABC
else()
message("false")
endif()函数内定义了变量 ABC,外部调用函数之后,通过 if(DEFINED ABC)来判断变量 ABC 是否有定义,如果定义了该变量打印 true 并将变量打印出来,如果没有定义该变量则打印 false。测试结果如下:

所以可知,函数内部定义的变量仅在函数内部可使用,出了函数之后便无效了,这其实跟 C 语言中差不多,函数中定义的变量可以认为是局部变量,外部自然是无法去引用的。
③、函数内定义与外部同名的变量
测试代码如下所示:
# 函数 xyz
function(xyz)
message("函数内部")
message("${ABC}")
set(ABC "Hello China!")#设置变量 ABC
message("${ABC}")
endfunction()
set(ABC "Hello World!")#定义变量 ABC
xyz() # 调用函数
message("函数外部")
message("${ABC}")在这段代码中,我们在函数外定义了变量 ABC="Hello World!",在函数内去设置变量 ABC="Hello China!",函数执行完之后,在外部调用 message()打印变量 ABC。如果按照 C 语言中的理解,那么函数外部打印 ABC 变量的值应该等于"Hello China!"(大家不要去关注变量的定义是否需要放在函数定义之前,这种解释性脚本语言是没有类似于 C 语言中申明这种概念的, 函数虽然定义了,但是调用函数是在定义变量之后的), 但事实是不是这样呢,我们来看看打印信息: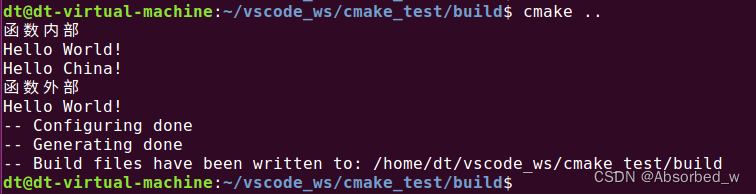
从打印信息可知,事实并非我们上面所假设那样,函数内调用 set 去设置变量 ABC,并不是设置了外部变量 ABC 的值,而是在函数新创建了一个变量 ABC,这个与 C 语言是不一样的,跟 Python 很像,如果大家学过 Python 的话应该就知道。所以函数内部的代码中,调用 set 之前,引用了变量 ABC,此时它会搜索函数内是否定义了该变量,如果没有,它会向外搜索,结果就找到了外部定义的变量 ABC,所以函数内部的第一条打印信息是"Hello World!";调用 set 之后,函数内也创建了一个变量 ABC,此时再次引用 ABC 将使用函数内定义的变量,而非是外部定义的变量,所以第二条打印信息是"Hello China!"。
④、 函数内如何设置外部定义的变量
那如果需要在函数内修改外部定义的变量,该如何做呢?譬如下面这段代码:
# 函数 xyz
function(xyz)
set(ABC "Hello China!")
endfunction()
set(ABC "Hello World!")
xyz() # 调用函数
message("${ABC}")通过前面的介绍可知, xyz()函数内通过 set 只是创建了一个在函数内部使用的变量 ABC,而并非是去修改外部定义的变量 ABC,那如何能使得函数内可以去修改外部定义的变量呢?其实也非常简单, set 命令提供了一个可选选项 PARENT_SCOPE,只需在调用 set 命令时在参数列表末尾加上 PARENT_SCOPE 关键字即可,如下所示:
# 函数 xyz
function(xyz)
set(ABC "Hello China!" PARENT_SCOPE) #加上 PARENT_SCOPE
endfunction()
set(ABC "Hello World!")
xyz() # 调用函数
message("${ABC}")再来看看打印信息:

打印信息证明,加上 PARENT_SCOPE 之后确实可以,那 PARENT_SCOPE 选项究竟是什么?官方给出的解释是这样的: 如果添加了 PARENT_SCOPE 选项,则变量将设置在当前作用域范围之上的作用域范围内, 每个目录(在这里“目录” 指的是包含了 CMakeLists.txt 的目录) 或函数都会创建一个新作用域, 此命令会将变量的值设置到父目录或上层调用函数中(函数嵌套的情况下)。这是什么意思呢?其实就是说,如果 set 命令添加了 PARENT_SCOPE 选项,那就意味着并不是在当前作用域(set 命令所在作用域)内设置这个变量,而是在当前作用域的上一层作用域(父作用域) 中设置该变量;当前作用域的上一层作用域该怎么理解呢?这个根据具体的情况而定, 下面举几个例子进行说明。
示例代码 1:
# 函数 xyz
function(xyz)
set(ABC "Hello China!" PARENT_SCOPE) #加上 PARENT_SCOPE
endfunction()
set(ABC "Hello World!")
xyz() # 调用函数
message("${ABC}")在这个例子中,函数 xyz 中调用 set 时添加了 PARENT_SCOPE 选项,意味着会在函数 xyz 的上一层作用域中设置 ABC 变量,函数的上一层作用域也就是调用 xyz()函数时所在的作用域,也就是当前源码对应的作用域(当前目录作用域)。
示例代码 2:
# 函数 func2
function(func2)
set(ABC "Hello People!" PARENT_SCOPE)
endfunction()
# 函数 func1
function(func1)
set(ABC "Hello China!")
func2()
endfunction()
set(ABC "Hello World!")
func1()
message("${ABC}")在这个示例中,函数 func1 中调用了 func2,那么函数 func2 的上一层作用域就是 func1 函数对应的作用域。
示例代码 3:
有如下工程目录结构:
├── build
├── CMakeLists.txt
└── src└── CMakeLists.txt顶层 CMakeLists.txt 文件内容如下:
# CMakeLists.txt
cmake_minimum_required(VERSION 3.5)
project(TEST)
add_subdirectory(src)
xyz()
message("${ABC}")顶层源码调用 src 目录下的子源码,子源码下定义了一个函数 xyz,如下所示:
# src 下的 CMakeLists.txt
function(xyz)
set(ABC "Hello World!" PARENT_SCOPE)
endfunction()在这种情况下,函数 xyz 的上一层作用域便是顶层目录作用域(顶层源码作用域) ,关键是看“谁”调用该函数。
同理下面这种情况也是如此:
顶层 CMakeLists.txt 文件:
# CMakeLists.txt
cmake_minimum_required(VERSION 3.5)
project(TEST)
add_subdirectory(src)
message("${ABC}")
src 目录下的 CMakeLists.txt 文件:
# src 下的 CMakeLists.txt
set(ABC "Hello World!" PARENT_SCOPE)变量 ABC 会在顶层源码中被设置,而不是 set 命令所在的作用域中。
⑤、函数的返回值如何实现?
前面给大家介绍函数的时候提到过, cmake 中函数也可以有返回值,但是不能通过 return()命令来实现,由于当时没介绍 PARENT_SCOPE,所以没法给大家讲解如何去实返回值,现在我们已经知道了PARENT_SCOPE 选项的作用,其实就是通过这个选项来实现函数的返回值功能。
先来看个示例:
# 顶层 CMakeLists.txt
cmake_minimum_required(VERSION 3.5)
project(TEST)
# 定义一个函数 xyz
# 实现两个数相加,并将结果通过 out 参数返回给调用者
function(xyz out var1 var2)
math(EXPR temp "${var1} + ${var2}")
set(${out} ${temp} PARENT_SCOPE)
endfunction()
xyz(out_var 5 10)
message("${out_var}")打印结果如下:

看到这里不知道大家明白了没,其实很简单,调用 xyz()函数时,传入的 out_var 是作为一个参数传入进去的,而不是变量名,但现在需要将其变成一个变量名,怎么做呢?那就是在函数中获取参数 out 的值,将参数 out 的值作为变量名,然后用 set 创建该变量,并添加了 PARENT_SCOPE 选项。所以通过 message 便可以打印出该变量,因为这个变量在源码中定义了。
二、目录作用域(Directory Scope)
我把这个作用域叫做目录作用域。子目录会将父目录的所有变量拷贝到当前 CMakeLists.txt 源码中,当前 CMakeLists.txt 中的变量的作用域仅在当前目录有效。目录作用域有两个特点:向下有效(上层作用域中定义的变量在下层作用域中是有效的) ,值拷贝。 举个栗子来进一步阐述!
譬如目录结构如下所示:
├── CMakeLists.txt
└── sub_dir└── CMakeLists.txt父目录 CMakeLists.txt 文件内容如下:
# 父源码
cmake_minimum_required(VERSION 3.5)
project(TEST)
set(parent_var "Hello parent")
message("parent-<parent_var>: ${parent_var}")
add_subdirectory(sub_dir)
message("parent-<parent_var>: ${parent_var}")在父源码中,我们定义了一个变量 parent_var,并将其设置为"Hello parent"。
子源码 CMakeLists.txt 内容:
message("subdir-<parent_var>: ${parent_var}")
set(parent_var "Hello child")
message("变量修改之后")
message("subdir-<parent_var>: ${parent_var}")在子源码中,第 1 行打印了 parent_var 变量, 这个变量是由父源码所创建的, 由于变量向下有效, 所以在子源码中也可以使用;第 2 行,我们去修改 parent_var 变量,将其设置为"Hello child",但这是子源码新建的一个变量,并没改变父源码中的 parent_var 变量,也就是说这里的 set 并不影响父源码中的 parent_var变量, 仅仅只是改变了子源码中的 parent_var 变量, 这就是值拷贝的含义(子源码从父源码中拷贝了一份变量,副本)。
执行结果如下:
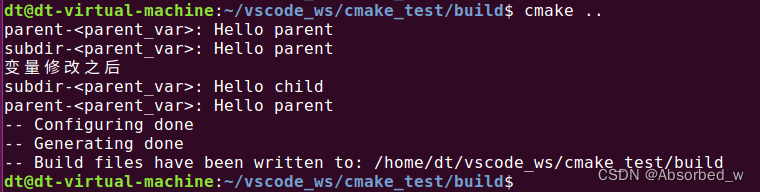
三、全局作用域(Persistent Cache 持久缓存、缓存变量)
缓存变量在整个 cmake 工程的编译生命周期内都有效, 所以这些变量的作用域是全局范围的, 工程内的其他任意目录都可以访问缓存变量, 注意 cmake 是从上到下来解析 CMakeLists.txt 文件的。缓存变量可以通过 set 命令来定义,使用 set 命令时添加 CACHE 选项来实现;除此之外,还有其它多种方式可以定义缓存变量,譬如前面给大家介绍的 cmake -D 选项是经常用来定义缓存变量的方法, cmake -DXXX,就表示创建了一个名为 XXX 的全局变量; 关于缓存变量笔者就不过多的介绍了,有兴趣的读者可以自己去研究下。
属性
本小节简单地向大家介绍一下 cmake 中的属性相关的概念。属性大概可以分为多种:全局属性、目录属性(源码属性)、目标属性以及其它一些分类。 在
https://cmake.org/cmake/help/v3.5/manual/cmake-properties.7.html 中有详细介绍。如下:
属性会影响到一些行为, 这里重点给大家介绍下目录属性和目标属性,其它的大家自己去看。
一、目录属性
目录属性其实就是 CMakeLists.txt 源码的属性,来看看有哪些:
这里我们随便挑几个来讲解:
CACHE_VARIABLES
当前目录中可用的缓存变量列表。
CLEAN_NO_CUSTOM
如果设置为 true 以告诉 Makefile Generators 在 make clean 操作期间不要删除此目录的自定义命令的输出文件。 如何获取或设置属性稍后再给大家介绍。
INCLUDE_DIRECTORIES
此 属 性 是 目 录 的 头 文 件 搜 索 路 径 列 表 , 其 实 就 是 include_directories() 命 令 所 添 加 的 目 录 ,include_directories() 命 令 会 将 指 定 的 目 录 添 加 到 INCLUDE_DIRECTORIES 属 性 中 , 所 以INCLUDE_DIRECTORIES 属性其实就是一个头文件搜索路径列表。
测试代码如下:
# 父源码
cmake_minimum_required(VERSION 3.5)
project(TEST)
#获取目录的 INCLUDE_DIRECTORIES 属性
get_directory_property(out_var INCLUDE_DIRECTORIES)
message("${out_var}")
#调用 include_directories 添加头文件搜索目录
include_directories(include)
#再次获取 INCLUDE_DIRECTORIES 属性
get_directory_property(out_var INCLUDE_DIRECTORIES)
message("${out_var}")
#再次调用 include_directories,将目录放在列表前面
include_directories(BEFORE hello)
#再次获取 INCLUDE_DIRECTORIES 属性
get_directory_property(out_var INCLUDE_DIRECTORIES)
message("${out_var}")本例中,使用了 get_directory_property()命令,该命令用于获取目录的属性,使用方法如下:
get_directory_property(<variable> [DIRECTORY <dir>] <prop-name>)将属性的值存储在 variable 变量中;第二个参数是一个可选参数,可指定一个目录,如果不指定,则默认是当前源码所在目录;第三个参数 prop-name 表示对应的属性名称。
上述代码的打印信息如下所示:
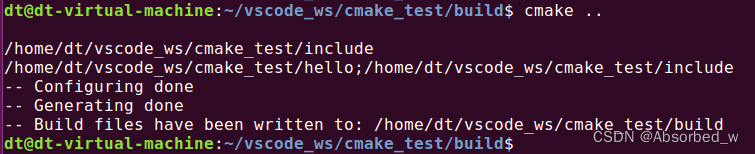
第一个 message 打印的是空信息,说明此时 INCLUDE_DIRECTORIES 是空的,没有添加任何目录。include_directories()命令默认将目录添加到 INCLUDE_DIRECTORIES 列表的末尾,可显式指定 BEFORE 或AFTER 将目录添加到列表的前面或后面,在前面给大家介绍过。既然如此,那是不是可以直接去设置 INCLUDE_DIRECTORIES 属性来添加头文件搜索目录,而不使用include_directories()命令来添加?这样当然是可以的,可以使用 set_directory_properties()命令设置目录属性,
如下所示:
set_directory_properties(PROPERTIES prop1 value1 prop2 value2)接下来进行测试,假设工程目录结构如下所示:
├── build
├── CMakeLists.txt
├── include
│ └── hello.h
└── main.c源文件 main.c 中包含了 hello.h 头文件, hello.h 头文件在 include 目录下, CMakeLists.txt 如下:
# 父源码
cmake_minimum_required(VERSION 3.5)
project(TEST)
set_directory_properties(PROPERTIES INCLUDE_DIRECTORIES /home/dt/vscode_ws/cmake_test/include)
get_directory_property(out_var INCLUDE_DIRECTORIES)
message("${out_var}")
add_executable(main main.c)进入到 build 目录下,执行 cmake、 make 构建、编译: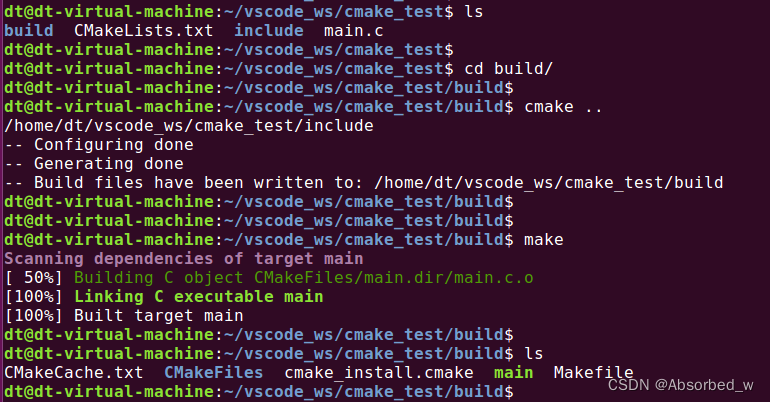
编译成功,说明这种做法是没有问题的,需要注意的是,调用 set_directory_properties()命令设置属性时,需要使用绝对路径。父目录的 INCLUDE_DIRECTORIES 属性可以初始化、填充子目录的 INCLUDE_DIRECTORIES 属性,测试如下:
譬如工程目录结构如下:
├── CMakeLists.txt
└── subdir└── CMakeLists.txt父源码内容如下所示:
# 父源码
cmake_minimum_required(VERSION 3.5)
project(TEST)
#调用 include_directories 添加 2 个目录
include_directories(include hello)
get_directory_property(p_list INCLUDE_DIRECTORIES)
message("${p_list}")
#调用子源码
add_subdirectory(subdir)
子源码内容:
#子源码
get_directory_property(c_list INCLUDE_DIRECTORIES)
message("${c_list}")打印信息如下:

LINK_DIRECTORIES
此属性是目录的库文件搜索路径列表,其实就是 link_directories()命令所添加的目录, link_directories 命令会将指定的目录添加到 LINK_DIRECTORIES 属性中,所以 LINK_DIRECTORIES 属性其实就是一个库文件搜索路径列表。
测试如下:
# 父源码
cmake_minimum_required(VERSION 3.5)
project(TEST)
#获取目录的 LINK_DIRECTORIES 属性
get_directory_property(out_var LINK_DIRECTORIES)
message("${out_var}")
#添加库文件搜索目录
link_directories(include hello)
get_directory_property(out_var LINK_DIRECTORIES)
message("${out_var}")打印信息如下:
同样,父目录的 LINK_DIRECTORIES 属性可以初始化、填充子目录的 LINK_DIRECTORIES 属性。也直接去设置 LINK_DIRECTORIES 属性来添加库文件搜索目录,而不使用 link_directories()命令来添加,大家可以去测试一下,这里不再演示了!
MACROS
当期目录中可用的宏命令列表。
PARENT_DIRECTORY
加载当前子目录的源目录,其实就是说,当前源码的父源码所在路径,对于顶级目录,该值为空字符串。此属性只读、不可修改。
VARIABLES
当前目录中定义的变量列表。只读属性、不可修改!
二、目标属性
目标属性,顾名思义就是目标对应的属性,如下:
目标属性可通过 get_target_property、 set_target_property 命令获取或设置。目标属性比较多,这里挑几个给大家介绍下:
BINARY_DIR
只读属性, 定义目标的目录中 CMAKE_CURRENT_BINARY_DIR 变量的值。
SOURCE_DIR
只读属性, 定义目标的目录中 CMAKE_CURRENT_SOURCE_DIR 变量的值。
INCLUDE_DIRECTORIES
目标的头文件搜索路径列表, target_include_directories()命令会将目录添加到 INCLUDE_DIRECTORIES列表中, INCLUDE_DIRECTORIES 会拷贝目录属性中的
INCLUDE_DIRECTORIES 属性作为初始值。
INTERFACE_INCLUDE_DIRECTORIES
target_include_directories()命令使用 PUBLIC 和 INTERFACE 关键字的值填充此属性。
INTERFACE_LINK_LIBRARIES
target_link_libraries()命令使用 PUBLIC 和 INTERFACE 关键字的值填充此属性。
LIBRARY_OUTPUT_DIRECTORY
LIBRARY_OUTPUT_NAME
LINK_LIBRARIES
目标的链接依赖库列表。
OUTPUT_NAME
目标文件的输出名称。
TYPE
目 标 的 类 型 , 它 将 是 STATIC_LIBRARY 、 MODULE_LIBRARY 、 SHARED_LIBRARY 、INTERFACE_LIBRARY、 EXECUTABLE 之一或内部目标类型之一。
相关文章:
Linux_应用篇(27) CMake 入门与进阶
在前面章节内容中,我们编写了很多示例程序,但这些示例程序都只有一个.c 源文件,非常简单。 所以,编译这些示例代码其实都非常简单,直接使用 GCC 编译器编译即可,连 Makefile 都不需要。但是,在实…...
51单片机STC89C52RC——8.1 8*8 LED点阵模块(点亮一个LED)
目录 目的/效果 一,STC单片机模块 二,8*8 LED点阵模块 2.1 电路图 2.1.1 8*8 点阵模块电路图 2.1.2 74HC595(串转并)模块 电路图 2.1.3 芯片引脚 2.2 引脚电平分析 2.3 74HC595 串转并模块 2.3.1 装弹(移位…...

2024最新免费版轻量级Navicat Premium Lite 下载和安装教程
2024最新免费版轻量级Navicat Premium Lite 下载和安装教程 关于猫头虎 大家好,我是猫头虎,别名猫头虎博主,擅长的技术领域包括云原生、前端、后端、运维和AI。我的博客主要分享技术教程、bug解决思路、开发工具教程、前沿科技资讯、产品评…...

PHP+laravel 生成word
此功能较为繁琐我会从源头讲起 首先是数据库设置,下面是我的数据库结构 合同模版表 CREATE TABLE contract_tpl (id bigint unsigned NOT NULL AUTO_INCREMENT,name varchar(191) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT 合同名称,file varchar(191) COLL…...

redis集群简单介绍及其搭建过程
Redis集群 1、哨兵模式 哨兵可以有多个,从服务器也可以有多个,从服务器也可以有多个,在Redis3.0以前的版本要实现集群一般是借助哨兵sentinel工具来监控master节点的状态,如果master节点异常,则会实现主从切换&#x…...

linux桌面运维----第五天
1、创建用户命令useradd: 作用:创建用户 语法:useradd [选项名] 用户名 选项: -d<登入目录> 指定用户登入时的起始目录。 【掌握】 -g<群组> 指定用户所属的群组(基本组)。【掌握】…...
【SQL Server数据库】简单查询
目录 用SQL语句完成下列查询。使用数据库为SCHOOL数据库 1. 查询学生的姓名、性别、班级名称,并把结果存储在一张新表中。 2. 查询男生的资料。 3. 查询所有计算机系的班级信息。 4.查询艾老师所教的课程号。 5. 查询年龄小于30岁的女同学的学号和姓名。…...

Docker 从入门到精通(大全)
一、概述 1.1 基本概念 Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源。 Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。…...
基于JSP的在线教育资源管理系统
开头语: 你好呀,我是计算机学长猫哥!如果你对在线教育资源管理系统感兴趣或者有相关需求,欢迎在文末找到我的联系方式。 开发语言:Java 数据库:MySQL 技术:JSP技术 工具:IDE、N…...

在java中代理http请求,如何避免陷入循环?
在 Java 中,代理 HTTP 请求时,如果不小心配置不当,可能会导致循环请求。循环请求通常发生在代理服务器将请求再次发送回自己,形成一个死循环。为了避免这种情况,可以采取以下几种方法: 将域名设置为指定的…...

国内镜像源网址
腾讯:腾讯软件源 (tencent.com) 阿里:阿里巴巴开源镜像站-OPSX镜像站-阿里云开发者社区 (aliyun.com) 清华:清华大学开源软件镜像站 | Tsinghua Open Source Mirror...
合适的智能猫砂盆到底怎么挑?开放式封闭式一次说清!
想当初我也是在网上看了各种测评,纠结了好久才下定决心入手了智能猫砂盆。封闭式和开放式都用过,各有各的利与弊,不过最后的我还是选择了开放式的智能猫砂盆,因为开放式的设计结构会更加方便我观察小猫,哪个铲屎官不喜…...

阿里云开启ssl证书过程记录 NGINX
🤞作者简介:大家好,我是思无邪,2024 毕业生,某厂 Go 开发工程师.。 🐂我的网站:https://www.yishanicode.top/ ,持续更新,希望对你有帮助。 🐞如果文章或网站…...
C语言程序设计 9.37 调用随机函数为5x4的矩阵置 100以内的整数,输出该矩阵,求出每行元素之和,并把和的最大的那一行与第一行的元素对调
void count_sum(int sum[]) {int i;printf("每行相加的情况如下\n");for (i 0;i < 5; i){printf("%d ", sum[i]);}printf("\n"); } void test(int arr[5][4]) {int i, j;srand((unsigned)time(NULL));//添加这个可以每次不同的随机数&#x…...
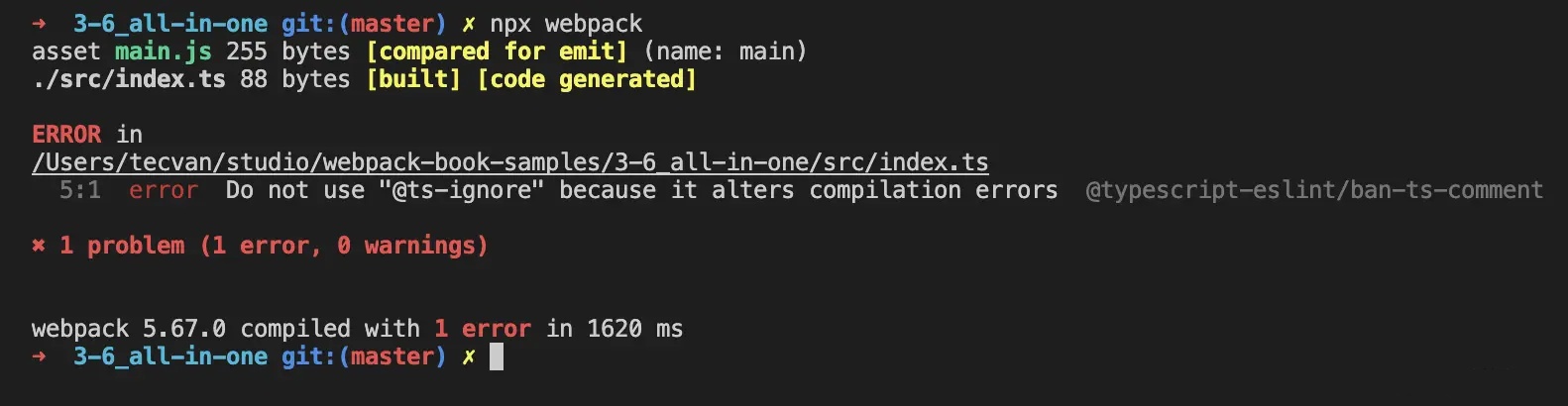
Webpack: 借助 Babel+TS+ESLint 构建现代 JS 工程环境
概述 Webpack 场景下处理 JavaScript 的三种常用工具:Babel、TypeScript、ESLint 的历史背景、功能以及接入 Webpack 的步骤借助这些工具,我们能构建出更健壮、优雅的 JavaScript 应用 使用 Babel ECMAScript 6.0(简称 ES6) 版本补充了大量提升 JavaSc…...

孩子不想上学,父母应如何教育?“强迫教育”会激起孩子反抗心理
上周末朋友聚会,都是家有上学娃的年纪,闲聊中,话题自然少不了孩子的上学问题。其中,不少朋友都有抱怨过同一个问题:孩子不想上学,即使人到了学校,心也不在学校。 事实上,孩子出现…...

Python深度学习技术
原文链接:Python深度学习技术 近年来,伴随着以卷积神经网络(CNN)为代表的深度学习的快速发展,人工智能迈入了第三次发展浪潮,AI技术在各个领域中的应用越来越广泛。Transformer模型(BERT、GPT-…...

ECharts 雷达图案例002 - 诈骗性质分析
ECharts 雷达图案例002 - 诈骗性质分析 📊 ECharts 雷达图案例002 - 诈骗性质分析 深入挖掘数据背后的故事,用可视化手段揭示诈骗行为的模式和趋势。 🔍 案例亮点 创新的数据展示方式,让复杂的诈骗数据一目了然。定制化的雷达图…...

想远程控制手机,用哪个软件好?
很多人都想知道安卓系统或iOS系统要如何实现手机远程控制手机、电脑远程控制手机,分别需要用到什么软件,这篇文章一次说清楚。 注意,安卓系统需要是7.0及以上版本,iOS系统需要是11及以上版本。具体使用步骤请点击关注,…...

数字内容“遍地开花”,AI技术如何创新“造梦”?
文 | 智能相对论 作者 | 陈泊丞 这是春晚舞台西安分会场《山河诗长安》的一幕:“李白”现世,带领观众齐颂《将进酒》,将中国人骨子里的豪情与浪漫演绎得淋漓尽致。 这又是浙江义乌商品市场里的另一幕:只会说几个英文单词的女老板…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

零基础在实践中学习网络安全-皮卡丘靶场(第九期-Unsafe Fileupload模块)(yakit方式)
本期内容并不是很难,相信大家会学的很愉快,当然对于有后端基础的朋友来说,本期内容更加容易了解,当然没有基础的也别担心,本期内容会详细解释有关内容 本期用到的软件:yakit(因为经过之前好多期…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的“no matching...“系列算法协商失败问题
【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的"no matching..."系列算法协商失败问题 摘要: 近期,在使用较新版本的OpenSSH客户端连接老旧SSH服务器时,会遇到 "no matching key exchange method found", "n…...