Python 全栈体系【四阶】(六十一)
第五章 深度学习
十三、自然语言处理(NLP)
5. NLP应用
5.2 文本情感分析
目标:利用训练数据集,对模型训练,从而实现对中文评论语句情感分析。情绪分为正面、负面两种
数据集:中文关于酒店的评论,5265笔用户评论数据,其中2822笔正面评价、其余为负面评价
步骤:同上一案例
模型选择:

代码:
【数据预处理】
# 中文情绪分析:数据预处理部分
import paddle
import paddle.dataset.imdb as imdb
import paddle.fluid as fluid
import numpy as np
import os
import random
from multiprocessing import cpu_count# 数据预处理,将中文文字解析出来,并进行编码转换为数字,每一行文字存入数组
mydict = {} # 存放出现的字及编码,格式: 好,1
code = 1
data_file = "data/hotel_discuss2.csv" # 原始样本路径
dict_file = "data/hotel_dict.txt" # 字典文件路径
encoding_file = "data/hotel_encoding.txt" # 编码后的样本文件路径
puncts = " \n" # 要剔除的标点符号列表with open(data_file, "r", encoding="utf-8-sig") as f:for line in f.readlines():# print(line)trim_line = line.strip()for ch in trim_line:if ch in puncts: # 符号不参与编码continueif ch in mydict: # 已经在编码字典中continueelif len(ch) <= 0:continueelse: # 当前文字没在字典中mydict[ch] = codecode += 1code += 1mydict["<unk>"] = code # 未知字符# 循环结束后,将字典存入字典文件
with open(dict_file, "w", encoding="utf-8-sig") as f:f.write(str(mydict))print("数据字典保存完成!")# 将字典文件中的数据加载到mydict字典中
def load_dict():with open(dict_file, "r", encoding="utf-8-sig") as f:lines = f.readlines()new_dict = eval(lines[0])return new_dict# 对评论数据进行编码
new_dict = load_dict() # 调用函数加载
with open(data_file, "r", encoding="utf-8-sig") as f:with open(encoding_file, "w", encoding="utf-8-sig") as fw:for line in f.readlines():label = line[0] # 标签remark = line[1:-1] # 评论for ch in remark:if ch in puncts: # 符号不参与编码continueelse:fw.write(str(mydict[ch]))fw.write(",")fw.write("\t" + str(label) + "\n") # 写入tab分隔符、标签、换行符print("数据预处理完成")
【模型定义与训练】
# 获取字典的长度
def get_dict_len(dict_path):with open(dict_path, 'r', encoding='utf-8-sig') as f:lines = f.readlines()new_dict = eval(lines[0])return len(new_dict.keys())# 创建数据读取器train_reader和test_reader
# 返回评论列表和标签
def data_mapper(sample):dt, lbl = sampleval = [int(word) for word in dt.split(",") if word.isdigit()]return val, int(lbl)# 随机从训练数据集文件中取出一行数据
def train_reader(train_list_path):def reader():with open(train_list_path, "r", encoding='utf-8-sig') as f:lines = f.readlines()np.random.shuffle(lines) # 打乱数据for line in lines:data, label = line.split("\t")yield data, label# 返回xmap_readers, 能够使用多线程方式读取数据return paddle.reader.xmap_readers(data_mapper, # 映射函数reader, # 读取数据内容cpu_count(), # 线程数量1024) # 读取数据队列大小# 定义LSTM网络
def lstm_net(ipt, input_dim):ipt = fluid.layers.reshape(ipt, [-1, 1],inplace=True) # 是否替换,True则表示输入和返回是同一个对象# 词嵌入层emb = fluid.layers.embedding(input=ipt, size=[input_dim, 128], is_sparse=True)# 第一个全连接层fc1 = fluid.layers.fc(input=emb, size=128)# 第一分支:LSTM分支lstm1, _ = fluid.layers.dynamic_lstm(input=fc1, size=128)lstm2 = fluid.layers.sequence_pool(input=lstm1, pool_type="max")# 第二分支conv = fluid.layers.sequence_pool(input=fc1, pool_type="max")# 输出层:全连接out = fluid.layers.fc([conv, lstm2], size=2, act="softmax")return out# 定义输入数据,lod_level不为0指定输入数据为序列数据
dict_len = get_dict_len(dict_file) # 获取数据字典长度
rmk = fluid.layers.data(name="rmk", shape=[1], dtype="int64", lod_level=1)
label = fluid.layers.data(name="label", shape=[1], dtype="int64")# 定义长短期记忆网络
model = lstm_net(rmk, dict_len)# 定义损失函数,情绪判断实际是一个分类任务,使用交叉熵作为损失函数
cost = fluid.layers.cross_entropy(input=model, label=label)
avg_cost = fluid.layers.mean(cost) # 求损失值平均数
# layers.accuracy接口,用来评估预测准确率
acc = fluid.layers.accuracy(input=model, label=label)# 定义优化方法
# Adagrad(自适应学习率,前期放大梯度调节,后期缩小梯度调节)
optimizer = fluid.optimizer.AdagradOptimizer(learning_rate=0.001)
opt = optimizer.minimize(avg_cost)# 定义网络
# place = fluid.CPUPlace()
place = fluid.CUDAPlace(0)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program()) # 参数初始化# 定义reader
reader = train_reader(encoding_file)
batch_train_reader = paddle.batch(reader, batch_size=128)# 定义输入数据的维度,数据的顺序是一条句子数据对应一个标签
feeder = fluid.DataFeeder(place=place, feed_list=[rmk, label])for pass_id in range(40):for batch_id, data in enumerate(batch_train_reader()):train_cost, train_acc = exe.run(program=fluid.default_main_program(),feed=feeder.feed(data),fetch_list=[avg_cost, acc])if batch_id % 20 == 0:print("pass_id: %d, batch_id: %d, cost: %0.5f, acc:%.5f" %(pass_id, batch_id, train_cost[0], train_acc))print("模型训练完成......")# 保存模型
model_save_dir = "model/chn_emotion_analyses.model"
if not os.path.exists(model_save_dir):print("create model path")os.makedirs(model_save_dir)fluid.io.save_inference_model(model_save_dir, # 保存路径feeded_var_names=[rmk.name],target_vars=[model],executor=exe) # Executorprint("模型保存完成, 保存路径: ", model_save_dir)
【推理预测】
import paddle
import paddle.fluid as fluid
import numpy as np
import os
import random
from multiprocessing import cpu_countdata_file = "data/hotel_discuss2.csv"
dict_file = "data/hotel_dict.txt"
encoding_file = "data/hotel_encoding.txt"
model_save_dir = "model/chn_emotion_analyses.model"def load_dict():with open(dict_file, "r", encoding="utf-8-sig") as f:lines = f.readlines()new_dict = eval(lines[0])return new_dict# 根据字典对字符串进行编码
def encode_by_dict(remark, dict_encoded):remark = remark.strip()if len(remark) <= 0:return []ret = []for ch in remark:if ch in dict_encoded:ret.append(dict_encoded[ch])else:ret.append(dict_encoded["<unk>"])return ret# 编码,预测
lods = []
new_dict = load_dict()
lods.append(encode_by_dict("总体来说房间非常干净,卫浴设施也相当不错,交通也比较便利", new_dict))
lods.append(encode_by_dict("酒店交通方便,环境也不错,正好是我们办事地点的旁边,感觉性价比还可以", new_dict))
lods.append(encode_by_dict("设施还可以,服务人员态度也好,交通还算便利", new_dict))
lods.append(encode_by_dict("酒店服务态度极差,设施很差", new_dict))
lods.append(encode_by_dict("我住过的最不好的酒店,以后决不住了", new_dict))
lods.append(encode_by_dict("说实在的我很失望,我想这家酒店以后无论如何我都不会再去了", new_dict))# 获取每句话的单词数量
base_shape = [[len(c) for c in lods]]# 生成预测数据
place = fluid.CPUPlace()
infer_exe = fluid.Executor(place)
infer_exe.run(fluid.default_startup_program())tensor_words = fluid.create_lod_tensor(lods, base_shape, place)infer_program, feed_target_names, fetch_targets = fluid.io.load_inference_model(dirname=model_save_dir, executor=infer_exe)
# tvar = np.array(fetch_targets, dtype="int64")
results = infer_exe.run(program=infer_program,feed={feed_target_names[0]: tensor_words},fetch_list=fetch_targets)# 打印每句话的正负面预测概率
for i, r in enumerate(results[0]):print("负面: %0.5f, 正面: %0.5f" % (r[0], r[1]))
6. 附录
6.1 附录一:相关数学知识
向量余弦相似度
余弦相似度使用来度量向量相似度的指标,当两个向量夹角越大相似度越低;当两个向量夹角越小,相似度越高。
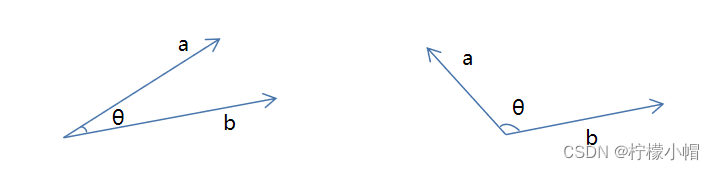
在三角形中,余弦值计算方式为 c o s θ = a 2 + b 2 − c 2 2 a b cos \theta = \frac{a^2 + b^2 - c^2}{2ab} cosθ=2aba2+b2−c2,向量夹角余弦计算公式为:
c o s θ = a b ∣ ∣ a ∣ ∣ × ∣ ∣ b ∣ ∣ cos \theta = \frac{ab}{||a|| \times ||b||} cosθ=∣∣a∣∣×∣∣b∣∣ab
分子为两个向量的内积,分母是两个向量模长的乘积。
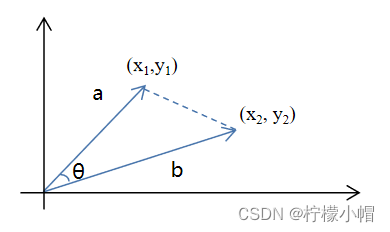
其推导过程如下:
c o s θ = a 2 + b 2 − c 2 2 a b = x 1 2 + y 1 2 + x 2 2 + y 2 2 + ( x 1 − x 2 ) 2 + ( y 1 − y 2 ) 2 2 x 1 2 + y 1 2 x 2 2 + y 2 2 = 2 x 1 x 2 + 2 y 1 y 2 2 x 1 2 + y 1 2 x 2 2 + y 2 2 = a b ∣ ∣ a ∣ ∣ × ∣ ∣ b ∣ ∣ cos \theta = \frac{a^2 + b^2 - c^2}{2ab} \\ = \frac{\sqrt{x_1^2 + y_1^2} + \sqrt{x_2^2 + y_2^2 }+ \sqrt{(x_1 - x_2)^2 + (y_1 - y_2)^2}}{2 \sqrt{x_1^2 + y_1^2} \sqrt{x_2^2 + y_2^2}} \\ = \frac{2 x_1 x_2 + 2 y_1 y_2}{2 \sqrt{x_1^2 + y_1^2} \sqrt{x_2^2 + y_2^2}} = \frac{ab}{||a|| \times ||b||} cosθ=2aba2+b2−c2=2x12+y12x22+y22x12+y12+x22+y22+(x1−x2)2+(y1−y2)2=2x12+y12x22+y222x1x2+2y1y2=∣∣a∣∣×∣∣b∣∣ab
以上是二维向量的计算过程,推广到N维向量,分子部分依然是向量的内积,分母部分依然是两个向量模长的乘积。由此可计算文本的余弦相似度。
6.2 附录二:参考文献
1)《Python自然语言处理实践——核心技术与算法》 ,涂铭、刘祥、刘树春 著 ,机械工业出版社
2)《Tensorflow自然语言处理》,【澳】图珊·加内格达拉,机械工业出版社
3)《深度学习之美》,张玉宏,中国工信出版集团 / 电子工业出版社
4)网络部分资源
6.3 附录三:专业词汇列表
| 英文简写 | 英文全写 | 中文 |
|---|---|---|
| NLP | Nature Language Processing | 自然语言处理 |
| NER | Named Entities Recognition | 命名实体识别 |
| PoS | part-of-speech tagging | 词性标记 |
| MT | Machine Translation | 机器翻译 |
| TF-IDF | Term Frequency-Inverse Document Frequency | 词频-逆文档频率 |
| Text Rank | 文本排名算法 | |
| One-hot | 独热编码 | |
| BOW | Bag-of-Words Model | 词袋模型 |
| N-Gram | N元模型 | |
| word embedding | 词嵌入 | |
| NNLM | Neural Network Language Model | 神经网络语言模型 |
| HMM | Hidden Markov Model | 隐马尔可夫模型 |
| RNN | Recurrent Neural Networks | 循环神经网络 |
| Skip-gram | 跳字模型 | |
| CBOW | Continous Bag of Words | 连续词袋模型 |
| LSTM | Long Short Term Memory | 长短期记忆模型 |
| GRU | Gated Recurrent Unit | 门控环单元 |
| BRNN | Bi-recurrent neural network | 双向循环神经网络 |
| FMM | Forward Maximum Matching | 正向最大匹配 |
| RMM | Reverse Maximum Matching | 逆向最大匹配 |
| Bi-MM | Bi-directional Maximum Matching | 双向最大匹配法 |
相关文章:
Python 全栈体系【四阶】(六十一)
第五章 深度学习 十三、自然语言处理(NLP) 5. NLP应用 5.2 文本情感分析 目标:利用训练数据集,对模型训练,从而实现对中文评论语句情感分析。情绪分为正面、负面两种 数据集:中文关于酒店的评论&#…...
工控必备C#
微软的C# 语言? QT 熟了以后,Qt 更方便些 方法Signal Slot 感觉上一样 现在更推荐PyQt 来构建,底层还是Qt C 的那些库,Qt 的开源协议有点狗...

【设计模式之基于特性的动态路由映射模式】
在ASP.NET Core中,路由是核心功能之一,用于将HTTP请求映射到相应的控制器操作。虽然“路由驱动设计模式”是一个我刚杜撰出来的设计模式名称,但我们可以基于ASP.NET Core的路由特性,构建一种以路由为中心的设计模式。 以下是一个…...

GB 16807-2009 防火膨胀密封件
防火膨胀密封件是指在火灾时遇火或高温作用能够膨胀,且能辅助建筑构配件使之具有隔火、隔烟、隔热等防火密封性能的产品。 GB 16807-2009 防火膨胀密封件测试项目 测试要求 测试标准 外观 GB 16807 尺寸允许偏差 GB 16807 膨胀性能 GB 16807 产烟毒性 GB …...
从零开始做题:老照片中的密码
老照片中的密码 1.题目 1.1 给出图片如下 1.2 给出如下提示 这张老照片中的人使用的是莫尔斯电报机,莫尔斯电报机分为莫尔斯人工电报机和莫尔斯自动电报机(简称莫尔斯快机)。莫尔斯人工电报机是一种最简单的电报机,由三个部分组…...
考研数学|张宇和武忠祥,强化能不能同时跟?
可以说你跟武老师学明白了,120完全没问题!如果追求更高,宇哥的怀抱也想你敞开! 学长我21年一战数学83,总分没过线,22年二战143,逆袭上岸211!市面上的老师我基本都听过,最…...

【机器学习】——【线性回归模型】——详细【学习路线】
目录 1. 引言 2. 线性回归理论基础 2.1 线性模型概述 2.2 最小二乘法 3. 数学基础 3.1 矩阵运算 3.2 微积分 3.3 统计学 4. 实现与应用 4.1 使用Scikit-learn实现线性回归 4.2 模型评估 5. 深入理解 5.1 多元线性回归 5.2 特征选择 5.3 理解模型内部 6. 实战与项…...
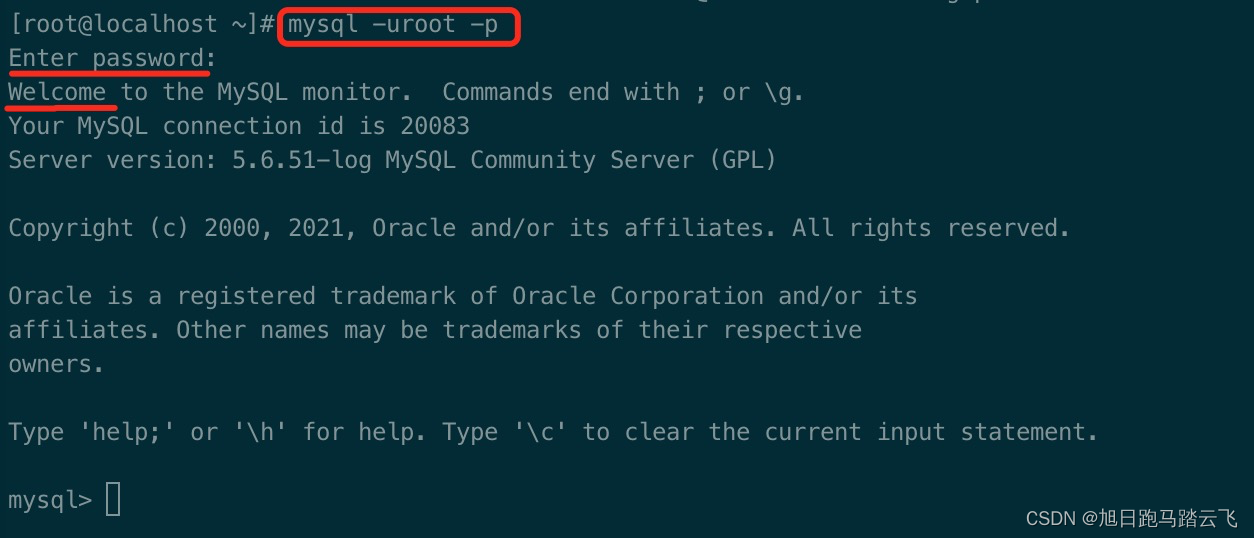
【mysql】常用操作:维护用户/开启远程/忘记密码/常用命令
一、维护用户 1.1 创建用户 -- 语法 > CREATE USER [username][host] IDENTIFIED BY [password];-- 例子: -- 添加用户user007,密码123456,并且只能在本地可以登录 > CREATE USER user007localhost IDENTIFIED BY 123456; -- 添加用户…...

引领AI新时代:深度学习与大模型的关键技术
文章目录 📑前言一、内容概述二、作者简介三、书籍特色四、学习平台与资源 📑前言 在数字化浪潮席卷全球的今天,人工智能(AI)和深度学习技术已经渗透到我们生活的方方面面。从智能手机中的智能语音助手,到…...

STL——常用算法(二)
一、常用拷贝和替换算法 1.copy #include <iostream> #include <vector> #include <algorithm> using namespace std; void printVector(int val) {cout << val << " "; } void test01() {vector<int>v1;for (int i 0; i <…...

MyCAT 2 底层原理
MyCAT 2 底层原理 1. MyCAT 2 架构概述 MyCAT 2 是一款开源的数据库中间件,它通过分库分表、读写分离、动态路由等机制提升数据库系统的性能和扩展性。MyCAT 2 的架构设计灵活,适用于多种数据库类型,包括 MySQL、PostgreSQL 和 SQL Server …...
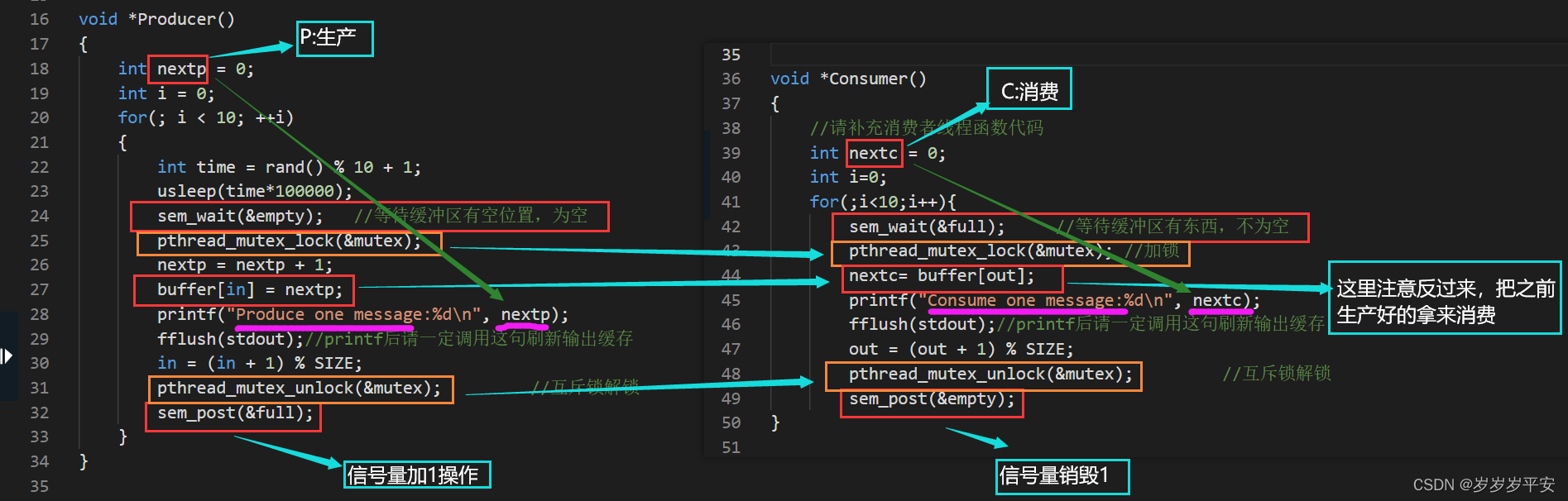
操作系统实训复习笔记(第7关:生产者消费者问题实践)
目录 第7关:生产者消费者问题实践 第1关:生产者消费者问题实践 1、在主线程中初始化锁为解锁状态 2、访问对象时的加锁操作与解锁操作 3、(生产和消费进程操作后)信号量操作实现进程同步 4、先等待(生产还是消费…...

通过物联网管理多台MQTT设备-基于全志T527开发板
一、系统概述 基于米尔-全志 T527设计一个简易的物联网网关,该网关能够管理多台MQTT设备,通过MQTT协议对设备进行读写操作,同时提供HTTP接口,允许用户通过HTTP协议与网关进行交互,并对设备进行读写操作。 二、系统架…...

Python学习前简介
1.python简介 2.python特点 3.python解释器 4.pyCharm简介 一、python简介 Python是一种高级编程语言,用于多种应用,包括网站开发、数据科学、人工智能、机器学习、桌面应用、网络应用、软件开发、网络爬虫等。它由Guido van Rossum于1991年首次发布&am…...

【Text2SQL 论文】MAGIC:为 Text2SQL 任务自动生成 self-correction guideline
论文:MAGIC: Generating Self-Correction Guideline for In-Context Text-to-SQL ⭐⭐⭐ 莱顿大学 & Microsoft, arXiv:2406.12692 一、论文速读 DIN-SQL 模型中使用了一个 self-correction 模块,他把 LLM 直接生成的 SQL 带上一些 guidelines 的 p…...
2024 年 8 款最佳建筑 3D 渲染软件
你现在使用的3D 渲染软件真得适合你吗? 在建筑和室内渲染当中,市面上有许多3D渲染软件可供选择。然而,并不是每款软件都适合你的需求。本指南将重点介绍2024年精选的8款最佳建筑3D渲染软件,帮助你了解不同的选项,并选…...
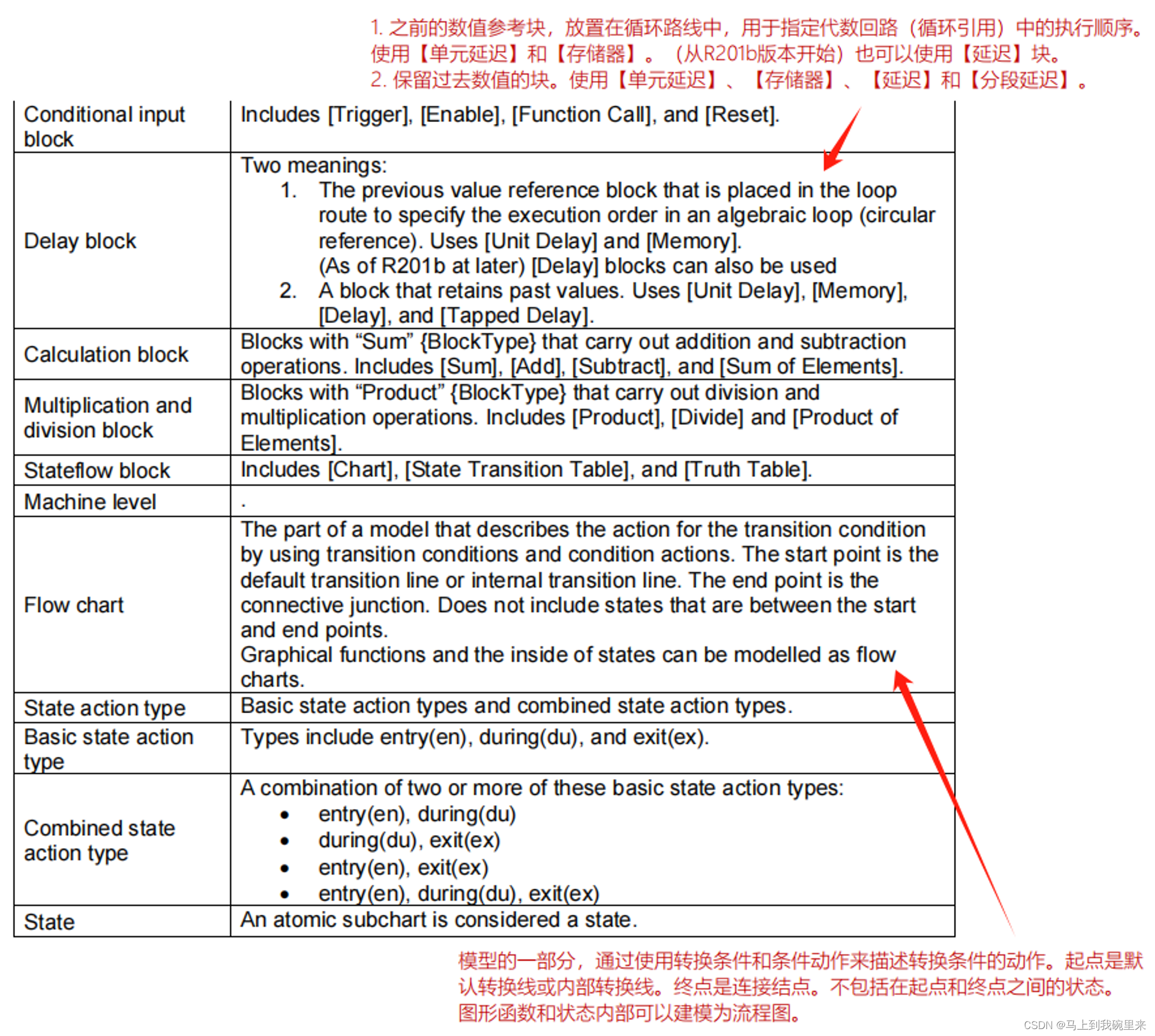
MAB规范(3):Chapter6 Glossary 术语表
第6章 - 术语表 此章不做过多的批注,都是些简单的术语解释。...

40python数据分析numpy基础之diag处理矩阵对角线元素
1 python数据分析numpy基础之diag处理矩阵对角线元素 python的numpy库的diag(v,k0)函数,以一维数组的形式返回方阵的对角线元素,或将一维数组转换为方阵(非对角线元素为0)。 方阵:方形矩阵,行数和列数相等…...
ffmpeg+nginx+video实现rtsp流转hls流,web页面播放
项目场景: 最近调试海康摄像头需要将rtsp流在html页面播放,因为不想去折腾推拉流,所以我选择ffmpeg转hls流,nginx转发,html直接访问就好了 1.首先要下载nginx和ffmpeg 附上下载地址: nginx nginx news ffmpeg htt…...

1、Redis系列-Redis高性能原理详解
Redis高性能原理详解 Redis是一款高性能的内存数据库,广泛应用于需要快速读写访问的数据密集型应用中。它的高性能得益于多方面的设计和优化。以下是Redis高性能实现的详细解释: 1. 单线程架构 Redis采用单线程架构来处理客户端请求,这与传…...

【2025年】解决Burpsuite抓不到https包的问题
环境:windows11 burpsuite:2025.5 在抓取https网站时,burpsuite抓取不到https数据包,只显示: 解决该问题只需如下三个步骤: 1、浏览器中访问 http://burp 2、下载 CA certificate 证书 3、在设置--隐私与安全--…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...

成都鼎讯硬核科技!雷达目标与干扰模拟器,以卓越性能制胜电磁频谱战
在现代战争中,电磁频谱已成为继陆、海、空、天之后的 “第五维战场”,雷达作为电磁频谱领域的关键装备,其干扰与抗干扰能力的较量,直接影响着战争的胜负走向。由成都鼎讯科技匠心打造的雷达目标与干扰模拟器,凭借数字射…...

dify打造数据可视化图表
一、概述 在日常工作和学习中,我们经常需要和数据打交道。无论是分析报告、项目展示,还是简单的数据洞察,一个清晰直观的图表,往往能胜过千言万语。 一款能让数据可视化变得超级简单的 MCP Server,由蚂蚁集团 AntV 团队…...

使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台
🎯 使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台 📌 项目背景 随着大语言模型(LLM)的广泛应用,开发者常面临多个挑战: 各大模型(OpenAI、Claude、Gemini、Ollama)接口风格不统一;缺乏一个统一平台进行模型调用与测试;本地模型 Ollama 的集成与前…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...

DingDing机器人群消息推送
文章目录 1 新建机器人2 API文档说明3 代码编写 1 新建机器人 点击群设置 下滑到群管理的机器人,点击进入 添加机器人 选择自定义Webhook服务 点击添加 设置安全设置,详见说明文档 成功后,记录Webhook 2 API文档说明 点击设置说明 查看自…...

NPOI操作EXCEL文件 ——CAD C# 二次开发
缺点:dll.版本容易加载错误。CAD加载插件时,没有加载所有类库。插件运行过程中用到某个类库,会从CAD的安装目录找,找不到就报错了。 【方案2】让CAD在加载过程中把类库加载到内存 【方案3】是发现缺少了哪个库,就用插件程序加载进…...

论文阅读:LLM4Drive: A Survey of Large Language Models for Autonomous Driving
地址:LLM4Drive: A Survey of Large Language Models for Autonomous Driving 摘要翻译 自动驾驶技术作为推动交通和城市出行变革的催化剂,正从基于规则的系统向数据驱动策略转变。传统的模块化系统受限于级联模块间的累积误差和缺乏灵活性的预设规则。…...

规则与人性的天平——由高考迟到事件引发的思考
当那位身着校服的考生在考场关闭1分钟后狂奔而至,他涨红的脸上写满绝望。铁门内秒针划过的弧度,成为改变人生的残酷抛物线。家长声嘶力竭的哀求与考务人员机械的"这是规定",构成当代中国教育最尖锐的隐喻。 一、刚性规则的必要性 …...