大数据面试题之Hive(1)
目录
说下为什么要使用Hive?Hive的优缺点?Hive的作用是什么?
说下Hive是什么?跟数据仓库区别?
Hive架构
Hive内部表和外部表的区别?
为什么内部表的删除,就会将数据全部删除,而外部表只删除表结构?为什么用外部表更好?
Hive建表语句?创建表时使用什么分隔符?
Hive删除语句外部表删除的是什么?
Hive数据倾斜以及解决方案
Hive如果不用参数调优,在map和reduce端应该做什么
Hive的用户自定义函数实现步骤与流程
Hive的三种自定义函数是什么?实现步骤与流程?它们之间的区别?作用是什么?
Hive的cluster by、sort bydistribute by、orderby区别?
Hive分区和分桶的区别
Hive的执行流程
Hive SQL转化为MR的过程?
Hive SQL优化处理
Hive的存储引擎和计算引擎
Hive的文件存储格式都有哪些
Hive中如何调整Mapper和Reducer的数目
介绍下知道的Hive窗口函数,举一些例子
Hive的count的用法
Hive的union和unionall的区别
说下为什么要使用Hive?Hive的优缺点?Hive的作用是什么?
使用Hive的原因、Hive的优缺点以及它的作用可以概括如下:简化大数据查询:Hive提供了一种类似SQL的查询语言HiveQL,使得数据分析人员和非编程背景的用户可以轻松
地查询和管理存储在Hadoop分布式文件系统(HDFS)上的大规模数据集,而无需直接编写复杂的MapReduce程
序。降低学习成本:相比直接使用MapReduce,Hive的学习曲线更平缓,因为它抽象了很多底层细节,使得开发人员
可以更快地上手并进行数据处理工作。提高开发效率:Hive避免了手动编写低级别的MapReduce作业,大大提高了数据处理和分析的开发速度。扩展性与容错性:Hive支持集群的动态扩展,能够在不重启服务的情况下增加或减少节点。此外,它具备良好的
容错机制,即使集群中的某些节点发生故障,也能保证SQL查询的完成执行。Hive的优缺点优点:易用性:提供了类SQL的查询语言,使得数据分析更加直观和便捷。
可扩展性:能够轻松扩展集群规模以应对数据增长,且通常不需要重启服务。
元数据管理:提供统一的元数据存储,便于组织和管理数据。
用户自定义函数:支持用户自定义函数(UDF),增强了查询的灵活性和定制化能力。
容错性:即使遇到节点故障,也能确保任务的完成。缺点:延迟较高:由于Hive设计用于批处理和数据分析,它的查询执行延迟相对较高,不适合实时或交互式查询需求。
资源消耗:在处理大量数据时,Hive的查询可能会消耗较多的计算资源。
数据格式限制:虽然支持多种文件格式,但在处理非结构化或半结构化数据时可能不如专门的工具灵活。Hive的作用Hive的主要作用是作为一个数据仓库工具,用于大规模数据集的批处理分析和离线处理。它使得数据分析师、数
据科学家和工程师能够利用熟悉的SQL语法来执行复杂的ETL(提取、转换、加载)任务,数据分析,以及数据汇
总报告等。通过Hive,企业能够更好地管理和分析存储在Hadoop生态系统中的海量数据,支持商业智能、数据挖
掘和其他大数据应用。说下Hive是什么?跟数据仓库区别?
Hive是Apache Hadoop生态系统中的一个数据仓库工具,它最初由Facebook开发,目的是让非程序员(如数据
分析师)能够利用SQL-like语言(称为HiveQL)来查询和管理存储在Hadoop分布式文件系统(HDFS)中的大
规模数据集。Hive简化了大数据处理任务,不需要直接编写复杂的MapReduce程序,而是将HiveQL语句转换为
MapReduce作业来执行,大大降低了大数据分析的门槛。与传统的数据仓库相比,Hive有以下几点主要区别:设计目标与应用场景:Hive 主要是为了支持大数据批处理分析,适用于离线分析场景,比如日志分析、数据挖掘等,对实时性要求不
高。它的设计初衷是处理海量数据的批处理查询和数据分析。数据仓库(如Teradata、Oracle Exadata等)通常用于企业环境,支持复杂的OLAP(联机分析处理)操作,
强调快速响应时间,适用于实时或近实时的业务报告、决策支持系统等。数据仓库往往支持更复杂的事务处理和数
据更新操作。数据处理方式:
Hive 基于Hadoop,使用HDFS存储数据,MapReduce(或Tez、Spark等更现代的执行引擎)作为计算框架,处
理延时相对较高,不适合低延迟查询。
传统数据仓库 可能采用专有的存储和计算技术,如列式存储、索引优化等,以提升查询效率,支持快速的数据检
索和分析。数据模型与灵活性:Hive 侧重于读取大量静态数据,不支持实时数据的修改和更新操作。数据加载通常是批量的,一旦数据被加载进Hive表,就不鼓励对其进行修改。数据仓库 支持更灵活的数据操作,包括INSERT、UPDATE、DELETE等,可以对数据进行实时或定期的更新,支
持更复杂的事务处理。扩展性:Hive 建立在Hadoop之上,理论上可以水平扩展到非常大的数据量,因为HDFS能够存储PB级别的数据。传统数据仓库 虽然也可以扩展,但通常受限于硬件成本和技术架构,扩展能力及成本效益可能不如基于Hadoop的
解决方案。资源消耗与成本:Hive 利用低成本的 commodity hardware 构建,适合处理大规模数据,但处理单个查询的资源消耗可能相对
较高。数据仓库 解决方案可能需要更昂贵的专用硬件和软件许可,但提供更高的处理效率和更低的查询延迟。总的来说,Hive是一种专为大数据分析设计的数据仓库工具,它牺牲了一定程度的实时性和事务处理能力,以换
取对大规模数据集的高效处理和分析能力。而传统数据仓库则更加注重数据的即时访问、事务完整性和复杂的分析
操作。Hive架构
Hive的架构设计围绕着几个核心组件展开,旨在提供一个易于使用的数据仓库系统,以支持大数据分析。以下是
Hive架构的主要组成部分:用户接口(User Interfaces):CLI (Command Line Interface): 允许用户通过命令行输入HiveQL语句进行交互。Beeline: 作为CLI的升级替代,提供更稳定的客户端连接到HiveServer2。JDBC/ODBC: 支持通过Java Database Connectivity (JDBC) 和 Open Database Connectivity
(ODBC) 协议与各种编程语言集成。WebUI: 虽然不是Hive标准安装的一部分,但可以通过第三方工具如Hue来提供图形界面访问Hive。HiveServer2 (HS2):
接收来自客户端的请求,解析HiveQL,管理会话,执行查询,并将结果返回给客户端。它是多线程服务,支持并
发查询。Metastore (元数据存储):
存储关于Hive表结构、列、分区、表的属性等元数据信息。元数据可以存储在内嵌的Derby数据库中,但生产环
境中通常使用MySQL或PostgreSQL等关系型数据库来提高性能和可靠性。Driver (驱动器):
包括解析器(SQL Parser)、编译器(Physical Plan)、优化器(Query Optimizer)和执行器
(Execution Engine)。这个组件负责将HiveQL转换成MapReduce(或Tez、Spark等)任务。Thrift Server:
提供了一种跨语言的服务接口定义,允许不同语言的客户端通过网络调用HiveServer2的服务。Hadoop (HDFS & MapReduce):
Hive依赖Hadoop Distributed File System (HDFS) 存储数据,并使用MapReduce或更现代的计算框架
(如Tez、Spark)来执行查询任务。HCatalog:
虽不是Hive核心组件,但经常与Hive一起使用,提供了一个集中式的元数据管理系统,使得其他Hadoop工具
(如Pig、Spark)可以访问和理解Hive的表结构。ZooKeeper:
在某些部署中,ZooKeeper用于提供分布式协调服务,例如选举HiveServer2的Leader实例,以及维护元数据
锁等。整个架构的设计使得Hive能够以类似SQL的方式处理存储在Hadoop上的大数据集,同时利用Hadoop的可扩展性
和容错性。用户可以通过友好的界面提交查询,而无需关注底层数据的分布式存储和计算细节。Hive内部表和外部表的区别?
Hive内部表和外部表的主要区别体现在数据存储位置、数据管理方式、数据的持久性以及数据的删除行为等方
面。以下是这些区别的详细归纳:数据存储位置:内部表:数据存储在Hive数据仓库目录中,通常位于HDFS(Hadoop Distributed File System)上
的/user/hive/warehouse目录下,由Hive完全管理。外部表:数据存储在用户指定的位置,可以是HDFS上的任意路径,也可以是本地文件系统或其他支持的存储系
统。Hive仅在元数据中维护外部表的结构信息,不对数据的存储位置和文件管理负责。数据管理方式:内部表:Hive完全管理内部表的数据,包括数据的存储、读取和删除。当内部表被删除时,Hive会同时删除表对
应的数据,这意味着删除内部表将导致表数据的彻底丢失。外部表:外部表的数据由用户自行管理,Hive仅维护元数据。如果删除外部表,只会删除元数据而不会影响存储
在外部表位置的数据。这种特性使得外部表适用于对数据有更细粒度控制,希望在删除表时保留数据的情况。数据的持久性:内部表:内部表的数据在被加载到表中后会持久保存,并且只有在显式删除表时才会被删除。在重启Hive或重新
加载元数据后,内部表的数据会保留。外部表:外部表的数据在加载到表中后并不一定被持久保存,因为外部表的数据是由用户管理的。如果数据源是临
时性的,那么在会话结束或Hive重启后,外部表的数据可能会丢失。数据的删除行为:内部表:删除内部表会直接删除元数据及存储数据。
外部表:删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除。数据的导入:内部表:可以使用INSERT语句向内部表中插入数据,Hive会将数据存储在内部表的数据目录中。
外部表:数据可以通过多种方式加载到外部表中,例如通过LOAD DATA语句从本地文件系统或其他数据源加载数
据。在加载数据时,只是将数据的元数据信息添加到外部表中,实际数据保留在外部表的位置。ALTER操作:内部表:对于内部表,可以使用ALTER TABLE语句更改表的属性,例如更改列名、添加/删除分区等。
外部表:对于外部表,ALTER TABLE语句仅允许更改表的一些元数据信息,例如重命名表、更改列的注释等,但
不能更改表的存储位置或数据本身。综上所述,Hive内部表和外部表在数据存储位置、数据管理方式、数据的持久性、数据的删除行为以及数据的导
入和ALTER操作等方面存在显著差异。选择使用内部表还是外部表应根据具体的数据管理需求和使用场景来决定。为什么内部表的删除,就会将数据全部删除,而外部表只删除表结构?为什么用外部表更好?
在 Hive 中,内部表和外部表的删除操作有以下区别:内部表:当删除内部表时,Hive 会同时删除表的元数据和数据。这意味着表的定义以及存储在表中的数据都将被
删除。
外部表:删除外部表只会删除表的元数据,而不会删除实际的数据。数据仍然保留在外部数据源中,例如 HDFS
或其他存储系统。使用外部表的一些优点包括:数据共享:外部表可以方便地与其他工具或系统共享数据,因为数据存储在外部数据源中,其他系统可以直接访问
这些数据。
数据安全:由于删除外部表不会删除实际数据,因此可以更好地保护数据的安全性。即使意外删除了表的定义,数
据仍然存在。灵活性:外部表的数据可以在 Hive 之外进行管理和修改,而不需要通过 Hive 进行加载或删除操作。这提供了
更大的灵活性,尤其是当数据需要与其他系统进行交互或由其他工具进行处理时。然而,是否使用外部表还是内部表取决于具体的需求和场景。以下是一些考虑因素:数据管理需求:如果需要完全由 Hive 管理表的生命周期,包括数据的加载、删除和修改,内部表可能更适合。
数据来源和共享:如果数据已经存在于外部数据源中,并且需要与其他系统共享,或者数据需要在 Hive 之外进行更新,外部表可能是更好的选择。数据安全和备份:如果对数据的安全性要求较高,或者需要进行数据备份和恢复,内部表可能更便于管理。综上所述,外部表在数据共享和灵活性方面具有优势,而内部表在数据管理和控制方面更方便。在实际应用中,可以根据具体情况选择使用内部表或外部表,或者结合使用两者来满足不同的需求。Hive建表语句?创建表时使用什么分隔符?
在Hive中创建表时,你可以使用CREATE TABLE语句。这个语句的基本语法如下:
CREATE TABLE IF NOT EXISTS table_name (column1 data_type,column2 data_type,...columnN data_type
)
[COMMENT table_comment]
[PARTITIONED BY (partition_column1 data_type, partition_column2 data_type, ...)]
[CLUSTERED BY (col_name1, col_name2, ...) INTO num_buckets BUCKETS]
[ROW FORMAT ROW_FORMAT]
[STORED AS FILE_FORMAT]
[LOCATION 'hdfs_path'];这里是一些关键参数的解释:IF NOT EXISTS:可选,如果表已经存在则不会报错。
table_name:你想要创建的表的名称。
column_name data_type:表中列的名称及其对应的数据类型。
COMMENT table_comment:对表的描述或注释。
PARTITIONED BY:可选,用于定义分区列,有助于数据管理和查询优化。
CLUSTERED BY:可选,用于桶表的创建,桶是数据的逻辑分组,有助于提高某些查询的效率。
ROW FORMAT:指定表数据的格式,如DELIMITED, SERDE等。
STORED AS FILE_FORMAT:指定数据的存储格式,如TEXTFILE, ORC, PARQUET等。
LOCATION:可选,指定表数据在HDFS上的存储位置。
关于创建表时使用的分隔符,这通常在ROW FORMAT部分定义。对于文本文件(如CSV),你通常会使用ROW
FORMAT DELIMITED来指定字段分隔符、集合分隔符和行分隔符。例如,使用逗号作为字段分隔符的语句如下:ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n';在这个例子中,FIELDS TERMINATED BY ','指定了字段之间使用逗号作为分隔符。你可以根据实际需求更改这些分隔符。Hive删除语句外部表删除的是什么?
Hive中外部表的删除语句(DROP TABLE)主要删除的是该外部表的元数据,而不是存储在HDFS或其他存储系统
中的实际数据。具体来说:元数据删除:当使用DROP TABLE external_table;(或带IF EXISTS的可选参数)命令删除一个外部表时,Hive会从其
元数据存储(通常是Metastore,如Hive Metastore或MySQL等)中删除与该表相关的所有元数据。这些元数
据描述了表的结构、属性、分区等信息。数据保留:
与内部表不同,外部表的数据通常存储在Hive数据仓库之外的HDFS路径或其他支持的文件系统上。因此,当删除
外部表时,Hive不会删除这些存储位置上的实际数据文件。数据完整性:
尽管删除了外部表的元数据,但存储在外部位置的数据文件仍然完整且可访问。这意味着其他Hive表或其他系统
仍然可以访问这些数据,只要它们知道数据的存储位置并具有相应的权限。操作示例:假设有一个名为sample_external_table的外部表,其数据存储在HDFS的/user/data/external_data/路
径下。当执行DROP TABLE IF EXISTS sample_external_table;命令后,Hive将不再识别
sample_external_table这个表,但/user/data/external_data/路径下的数据文件仍然存在且可访问。注意事项:
在删除外部表之前,应确保不再需要该表的元数据,并且了解数据文件的存储位置和访问方式。如果意外删除了包含重要数据的外部表,虽然数据本身没有丢失,但可能会因为元数据丢失而难以重新创建表或访问数据。总结:Hive删除外部表时,主要删除的是与表相关的元数据,而不是实际的数据文件。因此,在删除外部表之
前,应谨慎考虑并确保了解数据的存储位置和访问方式。Hive数据倾斜以及解决方案
Hive 中的数据倾斜指的是在数据处理过程中,某些任务(通常是 Reduce 任务)处理的数据量远远大于其他任
务,从而导致整个作业的执行时间大幅延长。常见的数据倾斜场景及原因包括:大表与小表关联:如果关联键分布不均匀,可能导致某些 Reduce 任务处理的数据量过大。
数据类型不一致:关联键的数据类型在不同表中不一致,可能导致数据分发不均匀。
某些值出现频率过高:例如某些键值在数据集中大量重复。以下是一些常见的解决方案:
增加 Reducer 数量:通过调整相关参数,如 hive.exec.reducers.bytes.per.reducer,增加
Reducer 的数量,从而分散数据处理压力。调整关联方式:
对于大表与小表关联,如果小表足够小,可以将小表广播到所有 Mapper 端进行关联。
对于不同数据类型的关联键,进行类型转换使其一致。对倾斜的键值进行单独处理:
对导致倾斜的键值进行特殊处理,例如将其抽取出来单独处理,然后再与其他结果合并。数据预处理:
在数据加载阶段,对可能导致倾斜的数据进行预处理,例如打散分布不均匀的数据。
使用 MapJoin:如果一张表很小,可以使用 MapJoin,即在 Map 阶段完成关联操作,避免 Reduce 阶段的
倾斜。
加盐(Salting):对可能导致倾斜的键值添加随机前缀,使其分布到不同的 Reducer 上,处理完成后再去掉前
缀。通过以上方法,可以有效地解决或缓解 Hive 中的数据倾斜问题,提高数据处理的效率和性能。Hive如果不用参数调优,在map和reduce端应该做什么
在Hive中,即使不直接调整特定参数,也有一些通用的最佳实践和策略可以在map和reduce端进行,以优化作业
性能。以下是一些建议:Map阶段的优化建议:合理设置Input Split大小:虽然这是通过Hive参数间接控制的,但理解并监控输入数据的分割对于确保map任
务均衡分配很重要。如果输入文件很小,可能导致过多的map任务,降低效率;反之,如果文件太大,单个map任
务可能运行时间过长。
避免数据倾斜:确保数据分布均匀,避免某些map任务处理的数据远多于其他任务,这可能导致整体作业延迟。可
以通过预分区数据或使用Hive的skew join优化来缓解。
使用合适的表连接策略:例如,利用MapJoin在map阶段完成小表的连接,减少到reduce阶段的数据量。
优化数据读取:比如,使用列式存储格式(如ORC或Parquet)可以减少需要读取的数据量,提升I/O效率。Reduce阶段的优化建议:
合理设置reduce任务数:虽然直接调整reduce任务数量通常涉及参数调优,但理解何时需要增加或减少reduce
数量至关重要。太多reduce任务会导致调度开销增大,太少则可能导致reduce任务运行时间过长。可以通过观察
作业执行情况,根据数据量和集群资源动态调整。优化Shuffle过程:尽量减少shuffle数据量,例如通过合理使用分区和排序,或者在可能的情况下避免不必要的shuffle(例如,通过使用Group By而非Distinct操作)。利用Combiner:在reduce之前应用Combiner函数可以局部聚合数据,减少网络传输的数据量。控制输出文件数量:过多的小文件会影响HDFS的性能和未来的查询速度。可以通过设置如
hive.merge.mapfiles和hive.merge.mapredfiles等参数来自动合并小文件。即使不直接调整参数,理解上述原则并根据具体工作负载和集群状况采取相应措施,也能有效提升Hive作业的执行效率。当然,当遇到特定性能瓶颈时,细致地调优Hive参数仍然是必要的。Hive的用户自定义函数实现步骤与流程
Hive的用户自定义函数(UDF, User-Defined Function)实现步骤与流程可以归纳如下:1. 编写自定义函数类
继承类:自定义的UDF类需要继承org.apache.hadoop.hive.ql.exec.UDF或
org.apache.hadoop.hive.ql.udf.generic.GenericUDF(对于更复杂的函数)。实现方法:实现一个或多个evaluate()方法。这个方法名在UDF中是固定的,且可以支持重载。例如,一个简单的UDF实现:package com.hive.test;
import org.apache.hadoop.hive.ql.exec.UDF; public class HiveUdf extends UDF { public String evaluate(int num) { if(num > 1000) { return "very good"; } else if(num > 500) { return "good"; } else { return "bad"; } }
}2. 打包并上传
打包:将包含UDF类的Java代码打包成JAR文件。
上传:将JAR文件上传到Hive可以访问的HDFS目录或Linux服务器的某个目录下。3. 准备测试数据
创建一个Hive表,并导入用于测试UDF的数据。
例如:
create table mytest(id int) row format delimited fields terminated by ' ';
load data local inpath '/test/num.txt' into table mytest;4. 添加JAR到Hive
使用ADD JAR命令将包含UDF的JAR文件添加到Hive的类路径中。
例如:
add jar /test/hiveUdf_jar/hive_test.jar;5. 创建临时或永久函数
临时函数:使用CREATE TEMPORARY FUNCTION命令创建一个指向UDF类的临时函数。
例如:
create temporary function myF as 'com.hive.test.HiveUdf';永久函数(可选):如果需要,可以创建一个永久函数,这需要将JAR文件上传到HDFS并指定JAR的路径。6. 使用自定义函数
使用SELECT语句和自定义函数名来调用UDF。
例如:
select myF(id) from mytest;7. (可选)删除自定义函数
如果不再需要自定义函数,可以使用DROP TEMPORARY FUNCTION或DROP FUNCTION命令删除它。
例如:
drop temporary function myF;注意事项UDF的evaluate()方法是Hive执行UDF时调用的入口点。
Hive UDF可以处理单行数据,并返回单个值或复杂类型(如数组或映射)。
对于更复杂的UDF,可能需要继承GenericUDF类并实现更复杂的逻辑。Hive UDF可以用Java编写,但也可以使用其他支持的语言(如Python、Scala等)通过Hive的SerDe
(Serializer/Deserializer)机制来实现。但这种方式通常比直接使用Java UDF更复杂。Hive的三种自定义函数是什么?实现步骤与流程?它们之间的区别?作用是什么?
Hive 中的三种自定义函数通常是用户自定义函数(UDF)、用户自定义聚合函数(UDAF)和用户自定义表生成函
数(UDTF)。用户自定义函数(UDF):
作用:对传入的单个数据行进行处理,返回一个计算结果。实现步骤与流程:
继承 org.apache.hadoop.hive.ql.exec.UDF 类。实现 evaluate 方法进行具体的计算逻辑。
将编写好的 Java 代码编译成 JAR 包。
在 Hive 中通过 ADD JAR 命令添加 JAR 包。
使用 CREATE TEMPORARY FUNCTION 注册函数。用户自定义聚合函数(UDAF):
作用:对多行数据进行聚合计算,返回一个聚合结果。实现步骤与流程:
继承 org.apache.hadoop.hive.ql.exec.UDAF 类。
实现 init、iterate、terminatePartial、merge 和 terminate 方法。
编译、添加 JAR 包、注册函数的流程与 UDF 类似。用户自定义表生成函数(UDTF):
作用:可以将一行输入数据扩展为多行输出。实现步骤与流程:
继承 org.apache.hadoop.hive.ql.udf.generic.GenericUDTF 类。
实现 initialize、process 和 close 方法。
后续的编译、添加和注册流程与前两者相同。它们之间的区别主要在于:
输入输出行数:UDF 输入一行输出一行;UDAF 输入多行输出一行;UDTF 输入一行输出多行。功能侧重点:UDF 用于对单个值的转换和计算;UDAF 用于聚合计算;UDTF 用于扩展数据行。Hive的cluster by、sort bydistribute by、orderby区别?
在Hive中,CLUSTER BY、SORT BY、DISTRIBUTE BY 和 ORDER BY 都与数据排序和分布有关,但它们各有
不同的用途和行为:ORDER BY:
功能:对整个数据集进行全局排序。这意味着所有数据会被发送到单个Reducer进行排序,确保输出结果是完全有
序的。
适用场景:当你需要全局有序的结果集时使用,但需注意,对于大规模数据集,这可能会导致非常高的延迟,因为
它限制了并行处理的能力。SORT BY:
功能:在每个Reducer内部进行排序,而不是全局排序。因此,数据在多个Reducer之间可能不是全局有序的,
但每个Reducer输出的数据是局部有序的。
适用场景:适用于不需要全局排序,但希望每个Reducer输出是有序的情况,提高了处理大规模数据的效率。DISTRIBUTE BY:
功能:控制数据如何在Reducer间分布。它不涉及排序,仅决定数据应如何分配到各个Reducer,以便后续可能
的排序或聚合操作。
适用场景:常与SORT BY联合使用来模拟CLUSTER BY的行为,或者单独用于控制数据分布以优化后续处理步骤。CLUSTER BY:
功能:实际上是一个结合了DISTRIBUTE BY和SORT BY的简写形式,即数据先按照指定列进行分布(类似于DISTRIBUTE BY),然后在每个Reducer内部按相同的列进行排序(类似于SORT BY)。
适用场景:当你既需要控制数据的分布,又需要在每个分区内部进行排序时使用。注意,CLUSTER BY只能指定一
列进行排序和分布。总结来说,ORDER BY提供全局排序,牺牲了并行处理能力;SORT BY提供局部排序,保持了并行Hive分区和分桶的区别
Hive 中的分区(Partition)和分桶(Bucket)有以下区别:1、划分依据:分区:通常基于表中某一列或多列的值进行划分,例如按照日期、地区等。
分桶:是基于表中指定列的哈希值进行划分,将数据均匀地分布到不同的桶中。2、数据分布:
分区:数据在不同分区之间的分布不一定均匀。
分桶:数据在各个桶中的分布相对均匀。3、目的:
分区:主要用于优化查询性能,通过过滤掉不必要的分区来减少数据扫描量。
分桶:除了优化查询,还常用于数据采样、提高连接操作的效率等。4、数量控制:
分区:分区的数量通常由数据的特点和业务需求决定,可能数量较多。
分桶:桶的数量一般由用户提前指定,相对较少且固定。5、数据管理:
分区:可以方便地动态添加或删除分区。
分桶:一旦创建表时指定了分桶规则,后续难以更改。总之,分区和分桶都是 Hive 中用于优化数据存储和查询的机制,但在划分方式、数据分布、用途和管理方式等
方面存在差异,根据具体的业务场景和需求来选择使用。Hive的执行流程
Hive的执行流程可以清晰地分为以下几个主要步骤:1、接收查询:
用户通过Hive的接口(如CLI、JDBC/ODBC、Web界面等)提交HiveQL查询语句。
Hive Driver接收这些查询语句。2、解析:
Hive Driver将HiveQL查询语句解析为抽象语法树(AST)。
在解析阶段,Hive会对查询进行基本的语法检查和验证。
可以使用Hive的EXPLAIN命令来查看查询的解析结果和执行计划。3、优化:
Hive对解析后的查询进行优化,包括重写查询计划、选择执行引擎等。
优化阶段的目标是提高查询的性能和效率。
Hive提供了一系列的优化规则,如表剪枝、谓词下推等,这些规则可以通过配置文件进行配置。4、编译:
Hive将优化后的查询计划编译成可执行的代码。
Hive支持多种执行引擎,如Apache Tez、Apache Spark和MapReduce等。
编译阶段会将查询计划转换为适合所选执行引擎的格式。5、执行:
Hive将编译后的代码分发到集群中的计算节点上进行并行计算。
使用MapReduce、Tez或Spark等计算框架来执行查询。
在执行阶段,Hive会管理计算资源、处理数据分区和并行化等任务。6、输出:
Hive将计算结果输出到目标文件或表中。
Hive支持将结果输出到HDFS文件系统或其他外部存储系统。
用户可以通过Hive的接口获取查询结果。7、错误处理和日志记录:
在整个执行过程中,Hive会处理可能出现的错误,并记录相应的日志信息。
用户可以根据需要查看这些日志信息,以便进行故障排查和性能调优。归纳起来,Hive的执行流程包括接收查询、解析、优化、编译、执行和输出等主要步骤。每个步骤都有其特定的
功能和目标,以确保Hive能够高效地处理用户的查询请求并返回准确的结果。同时,Hive还提供了丰富的优化规
则和配置选项,以帮助用户提高查询的性能和效率。Hive SQL转化为MR的过程?
Hive SQL转化成MapReduce过程主要包括以下几个步骤:1、解析(Parsing):当用户提交一个Hive SQL查询时,Hive的驱动程序首先会通过解析器(Parser)对SQL
语句进行词法和语法分析,将其转化为抽象语法树(Abstract Syntax Tree, AST)。2、逻辑计划生成(Logical Plan Generation):接下来,Hive使用语义分析器(Semantic Analyzer)
对AST进行进一步处理,检查SQL语句的语义正确性,并将其转换为一个逻辑执行计划。这个逻辑计划是一种更高
级别的、描述查询操作的数据结构,不涉及具体执行细节。3、优化(Optimization):逻辑计划经过优化器(Optimizer)处理,进行一系列规则驱动的优化,如重写查
询、选择最优执行路径等,以提高执行效率。这个阶段可能包括谓词下推(Predicate Pushdown)、列剪枝
(Column Pruning)等优化策略。4、物理计划生成(Physical Plan Generation):优化后的逻辑计划被转换为物理执行计划,这时会确定具
体使用哪些MapReduce作业来执行查询,以及作业的详细配置,如何划分map和reduce阶段、数据如何在各个
阶段间流动等。5、MapReduce作业生成(MapReduce Job Generation):物理计划被进一步转化为一个或多个MapReduce
作业。对于每个MapReduce作业,Hive会生成相应的Java代码(通常是Hadoop的Job对象),这些代码包含了
Mapper、Reducer(如果需要的话)、Partitioner、InputFormat、OutputFormat等组件的配置和实现。6、执行(Execution):最后,生成的MapReduce作业被提交到Hadoop集群上执行。Hadoop的JobTracker和TaskTracker负责作业的调度和任务的执行,数据在Map阶段进行并行处理,然后在Reduce阶段进行聚合或进一步处理,最终输出结果。整个过程中,Hive通过元数据存储来管理表结构、分区等信息,确保查询能够正确地访问和操作数据。此外,随
着Hive的发展,除了MapReduce之外,它也支持其他执行引擎,如Tez、Spark,以提供更灵活和高效的执行选
项。但基本的SQL转化为执行计划的流程大体相似。Hive SQL优化处理
以下是一些 Hive SQL 的优化处理方法:
1、合理使用分区:根据经常用于查询过滤的字段进行分区,减少数据扫描范围。
2、控制数据量:使用 WHERE 子句过滤掉不必要的数据,在连接操作前尽量缩小表的大小。
3、选择合适的连接方式:根据表的大小和数据特点选择 JOIN 类型,如小表和大表连接时可采用 MAPJOIN 。
4、启用并行执行:设置相关参数开启并行任务执行,提高执行效率。
5、避免笛卡尔积:确保连接条件准确,避免无意中产生笛卡尔积导致数据量暴增。
6、合理创建索引:如果适用,为经常用于查询和连接的列创建索引。
7、调整 Reducer 数量:根据数据量和集群资源合理设置 Reducer 的数量。
8、优化表设计:选择合适的数据类型,避免过度使用大字段和复杂数据类型。
9、利用缓存:对于经常使用且不经常变化的数据,可以考虑使用缓存来提高查询速度。
10、分解复杂查询:将复杂的查询分解为多个简单的子查询,便于理解和优化。
11、评估执行计划:通过 EXPLAIN 命令查看查询的执行计划,分析和优化执行流程。Hive的存储引擎和计算引擎
Hive 的存储引擎主要负责数据的存储和检索,它通常与 Hadoop 分布式文件系统(HDFS)或其他兼容的文件系
统集成,以存储 Hive 表中的数据。Hive 支持多种文件格式,包括文本文件、SequenceFile、ORC、
Parquet、Avro 和 JSON 等。Hive 还支持表分区和桶存储,以优化数据的分布和访问。不同的存储格式对性
能有不同的影响,例如列式存储格式(如 ORC 和 Parquet)可以提供更好的压缩和查询性能。Hive 的计算引擎负责执行 HiveQL 语句,处理数据查询和分析任务。Hive 最初使用 MapReduce 作为其主
要的计算引擎,将 HiveQL 语句转换为 MapReduce 作业。后来,Hive 引入了 Tez 和 Spark 作为计算引
擎,它们比 MapReduce 更高效,可以支持更复杂的数据处理任务和更好的性能。Hive 还包含一个查询优化
器,它负责优化查询计划,减少资源消耗和提高查询效率。Hive的文件存储格式都有哪些
1、TextFile:
特点:按行存储,不支持块压缩,是Hive的默认格式。
优点:加载数据的速度最高。
缺点:不支持压缩,磁盘开销大,数据解析开销大。
可结合Gzip、Bzip2等压缩算法使用,但hive不会对数据进行切分,从而无法对数据进行并行操作。2、SequenceFile:
特点:Hadoop API提供的一种二进制文件,以<key, value>的形式序列化到文件中,按行存储。
优点:可压缩和可分割,支持三种压缩选择:NONE, RECORD, BLOCK。Record压缩率低,一般建议使用BLOCK
压缩。
缺点:存储空间消耗较大,但通过压缩可以节省存储空间。3、Avro:
特点:按行存储,带有schema文件格式,一行数据是个map,添加字段方便。
优点:为Hadoop提供数据序列化和数据交换服务,可以在Hadoop生态系统和以任何编程语言编写的程序之间交换
数据。4、RCFile:
特点:数据按行分块,每块按列存储,结合了行存储和列存储的优点。
优点:元组重构的开销很低,能够利用列维度的数据压缩,且能跳过不必要的列读取。5、ORC(Optimized Row Columnar):
特点:数据按行分块,每块按列存储,压缩快,快速列存取。
优点:节省存储空间,查询效率高,压缩快。
Hive从大型表读取、写入和处理数据时,使用ORC文件可以提高性能。6、Parquet:
特点:面向列的二进制文件格式,不能直接进行读取。
优点:压缩效率高,查询效率高,支持Impala查询引擎。
Parquet压缩使用Snappy, gzip等;目前Snappy是默认压缩方式。Hive中如何调整Mapper和Reducer的数目
调整Mapper数量:Hive中的Mapper数量主要由输入数据的分割(split)决定,而分割是由InputFormat类控制的。虽然直接设
置Mapper的具体数量较为困难,但可以通过影响split的大小间接调整Mapper数量。1、控制Input Split大小:Hive使用hive.input.format确定输入格式,通常默认为HiveInputFormat。虽然
直接设置split大小的参数不常见,但可以通过确保数据文件的大小合理分布,间接影响split数量,从而影响
Mapper数量。
2、CombineHiveInputFormat:使用hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat可以合并小文件,
减少split数量,进而减少Mapper数量。但这种方式并不直接增加Mapper数量,而是优化了数据处理的效率。调整Reducer数量:Reducer的数量可以通过直接设置一些配置参数来调整:1、hive.exec.reducers.bytes.per.reducer:这个参数定义了每个Reducer处理的数据量,默认是
256MB(hive.exec.reducers.bytes.per.reducer=256000000)。减小这个值会增加Reducer的数量,
反之则减少。
2、hive.exec.reducers.max:此参数限制了最大的Reducer任务数,默认是1009。设置一个合适的最大值可以防止由于Reducer过多而导致的资源耗尽。
3、mapreduce.job.reduces:在执行查询时,可以直接设置这个参数来指定Reducer的数量。如果设置为-1
(默认值),Hive会根据输入数据量和hive.exec.reducers.bytes.per.reducer自动计算Reducer数量。示例调整命令:
-- 减小每个Reducer处理的数据量,增加Reducer数量
SET hive.exec.reducers.bytes.per.reducer=128000000;
-- 设置Reducer的最大数量
SET hive.exec.reducers.max=500;
-- 直接指定Reducer的数量
SET mapreduce.job.reduces=100;介绍下知道的Hive窗口函数,举一些例子
1、ROW_NUMBER() :为结果集的每一行分配一个唯一的连续整数。SELECT id, name, salary,
ROW_NUMBER() OVER (ORDER BY salary DESC) as row_num
FROM employees;2、RANK() :为相同值的行分配相同的排名,但排名可能不连续。SELECT id, name, salary,
RANK() OVER (ORDER BY salary DESC) as rank
FROM employees;3、DENSE_RANK() :为相同值的行分配相同的排名,排名是连续的。SELECT id, name, salary,
DENSE_RANK() OVER (ORDER BY salary DESC) as dense_rank
FROM employees;4、LAG(col, offset, default_value) :访问当前行之前指定偏移量的行中的值。SELECT id, name, salary,
LAG(salary, 1, 0) OVER (ORDER BY id) as prev_salary
FROM employees;5、LEAD(col, offset, default_value) :访问当前行之后指定偏移量的行中的值。SELECT id, name, salary,
LEAD(salary, 1, 0) OVER (ORDER BY id) as next_salary
FROM employees;6、SUM(col) OVER (PARTITION BY col1 ORDER BY col2) :在指定的分区内,按照指定的排序顺序进
行累计求和。SELECT id, department, salary,
SUM(salary) OVER (PARTITION BY department ORDER BY id) as cumulative_salary
FROM employees;7、AVG(col) OVER (PARTITION BY col1) :在指定的分区内计算平均值。SELECT id, department, salary,
AVG(salary) OVER (PARTITION BY department) as avg_salary
FROM employees;Hive的count的用法
在Hive中,COUNT 函数用于计算行数或特定列的非空值的数量。Hive支持多种COUNT函数的用法,包括:1、COUNT(*)
计算表中的所有行数,包括那些包含NULL值的行。
示例:
SELECT COUNT(*) FROM table_name; 2、COUNT(column_name)
计算指定列的非空值的数量。如果列中的值为NULL,则不会计入总数。
示例:
SELECT COUNT(column_name) FROM table_name;3、COUNT(DISTINCT column_name)
计算指定列的不同非空值的数量。即使列中有多个相同的非空值,也只会计数一次。
示例:
SELECT COUNT(DISTINCT column_name) FROM table_name;4、结合GROUP BY使用
可以与GROUP BY子句结合使用,以计算每个组的行数或非空值的数量。
示例:
SELECT column_group, COUNT(*) FROM table_name GROUP BY column_group;
或者:
SELECT column_group, COUNT(DISTINCT column_name) FROM table_name GROUP BY column_group;5、结合其他函数使用
COUNT函数也可以与其他Hive SQL函数结合使用,以执行更复杂的计算。
请注意,当处理大数据集时,COUNT函数可能会消耗大量资源,并且可能需要一些时间来完成计算。为了提高性
能,可以考虑使用Hive的聚合优化技术,如Bucketing、Skewed Join等。另外,如果你使用的是Hive 0.13或更高版本,并且启用了Hive的严格模式(通过设置
hive.mapred.mode=strict),则当在SELECT语句中使用COUNT(*)但没有与GROUP BY子句结合使用时,需
要使用FROM子句来指定表名。在严格模式下,不允许使用没有FROM子句的SELECT语句。Hive的union和unionall的区别
在 Hive 中,UNION 和 UNION ALL 主要有以下区别:
1、去重处理:
UNION:会对多个查询结果进行去重操作,去除重复的行。
UNION ALL:不会进行去重,直接合并所有的结果集,包括重复的行。2、性能:
由于 UNION 需要进行去重操作,所以其执行的开销通常比 UNION ALL 大。
如果您确定结果集中不会有重复行,或者重复行是可接受的,那么使用 UNION ALL 会有更好的性能。引用:大数据面试题V3.0,约870篇牛客大数据面经480道面试题_牛客网
通义千问、文心一言、豆包
相关文章:
)
大数据面试题之Hive(1)
目录 说下为什么要使用Hive?Hive的优缺点?Hive的作用是什么? 说下Hive是什么?跟数据仓库区别? Hive架构 Hive内部表和外部表的区别? 为什么内部表的删除,就会将数据全部删除,而外部表只删除表结构?为什么用外部表更好? Hive建表语句?创建表…...

【Git】分布式版本控制工具
一、简介 二、目标 Git分布式版本控制工具 一、简介 Git是一种分布式版本控制系统,用于跟踪和管理源代码的变化。它由林纳斯托瓦兹(Linus Torvalds)于2005年开发,并迅速成为最流行的版本控制工具之一。以下是关于Git的一些关键…...

排序之插入排序----直接插入排序和希尔排序(1)
个人主页:C忠实粉丝 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 C忠实粉丝 原创 排序之插入排序----直接插入排序和希尔排序(1) 收录于专栏【数据结构初阶】 本专栏旨在分享学习数据结构学习的一点学习笔记,欢迎大家在评论区交流讨…...
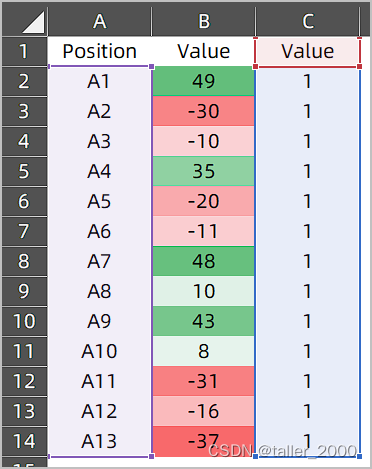
快速创建条形热力图
Excel中的条件格式可以有效的凸显数据特征,如下图中B列所示。 现在需要使用图表展现热力条形图,如下图所示。由于颜色有多个过渡色,因此手工逐个设置数据条的颜色,基本上是不可能完成的任务,使用VBA代码可以快速创建这…...

go switch 与 interface
go switch 与 interface 前言 前言 github.com/google/cel-go/common/types/ref type Val interface {// ConvertToNative converts the Value to a native Go struct according to the// reflected type description, or error if the conversion is not feasible.ConvertTo…...
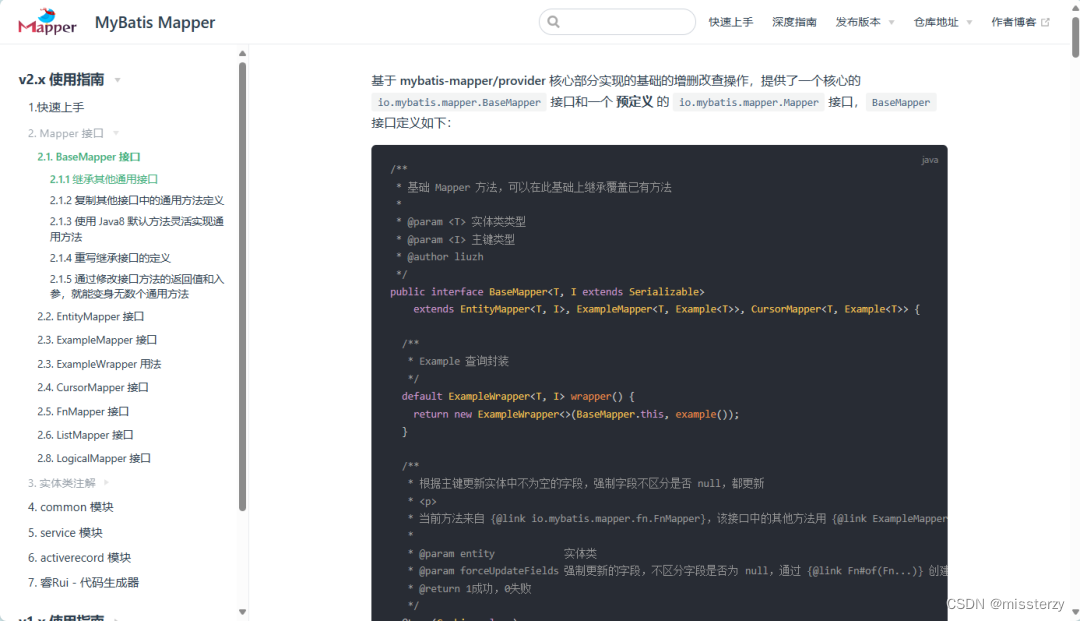
BaseMapper 接口介绍
基于 mybatis-mapper/provider 核心部分实现的基础的增删改查操作,提供了一个核心的 io.mybatis.mapper.BaseMapper 接口和一个 预定义 的 io.mybatis.mapper.Mapper 接口,BaseMapper 接口定义如下: /*** 基础 Mapper 方法,可以在…...

HAL-Cubemax定时器使用记录
title: HAL-Cubemax定时器使用记录 tags: STM32HalCubemax 文章目录 HAL-Cubemax定时器使用记录分享一种思路1.创建一个ms(毫秒)级延时中断2.创建计数的变量3.在需要延时的函数中对变量阈值进行判断4.验证实例--完整使用记录代码 问题往期内容基础库HAL cubemax VSCODE GCC …...

同时使用磁吸充电器和Lightning时,iPhone充电速度会变快吗?
在智能手机的世界里,续航能力一直是用户关注的焦点。苹果公司以其创新的MagSafe技术和传统的Lightning接口,为iPhone用户提供了多样化的充电解决方案。 然而,当这两种技术同时使用时,它们能否带来更快的充电速度?本文…...
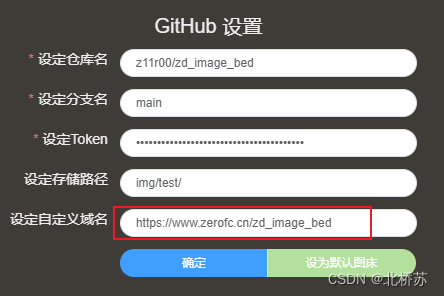
零成本搭建个人图床服务器
前言 图床服务器是一种用于存储和管理图片的服务器,可以给我们提供将图片上传后能外部访问浏览的服务。这样我们在写文章时插入的说明图片,就可以集中放到图床里,既方便多平台文章发布,又能统一管理和备份。 当然下面通过在 Git…...

SpringBoot 搭建sftp服务 实现远程上传和下载文件
maven依赖: <dependency><groupId>com.jcraft</groupId><artifactId>jsch</artifactId><version>0.1.55</version> </dependency>application.yml sftp:protocol: sftphost: port: 22username: rootpassword: sp…...
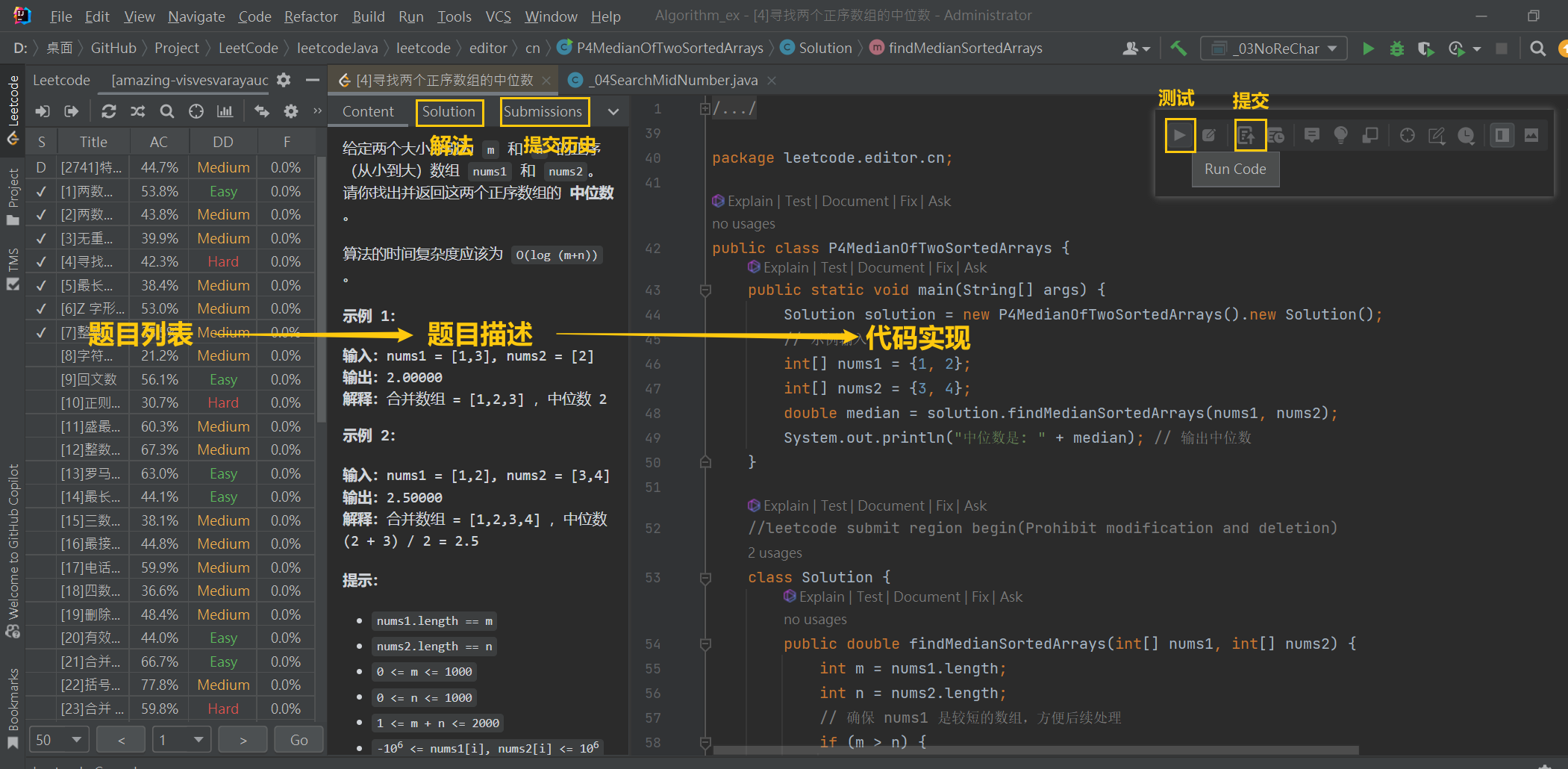
IDEA中使用leetcode 刷题
目录 1.IDEA下载leetcode插件 2.侧边点开插件 3.打开网页版登录找到cookie复制 4.回到IDEA登录 5.刷题 6.共勉 1.IDEA下载leetcode插件 2.侧边点开插件 3.打开网页版登录找到cookie复制 4.回到IDEA登录 5.刷题 6.共勉 算法题来了不畏惧, 挑战前行是成长的舞台…...

华为海思CPU解读
安全可靠CPU测评结果(华为海思篇) 中国信息安全测评中心于2024年5月20日发布安全可靠测评结果公告(2024年第1号),公布依据《安全可靠测评工作指南(试行)》的测评结果,自发布起有效期…...

中介子方程三十三
XXFXXuXXWXXuXXdXXrXXαXXuXpXXdXXpXuXXαXXrXXdXXuXWXπXXWXeXyXeXbXπXpXXNXXqXeXXrXXαXXuXpXXdXXpXuXXαXXrXXeXqXXNXXpXπXbXeXyXeXWXXπXWXuXXdXXrXXαXXuXpXXdXXpXuXXαXXrXXdXXuXXWXXuXXFXXEXXyXXEXXrXXαXXuXpXXdXXpXuXXαXXrXXEXXyXXαXiXXαXiXrXkXtXyXXpXVXXdXuXWX…...

今年哪两个行业可能有贝塔?
银行和综合板块存在比较明显的行业贝塔,背后原因是:银行板块中,最小的几家银行市值也不小;综合板块中,最大的几家市值也不大。 一、今年哪两个行业可能有贝塔? 我们一直强调今年市场呈现出【行业弱beta、风…...
嵌入式软件开发工具使用介绍
软件开发工具 辅助开发工具 硬件工具与仪器设备 逻辑分析仪使用 串口数据解码分析 示波器使用 1.示波器简介 TBS 1052B(Tektronix)系列数字存储示波器在紧凑的设计中提供了经济的性能。 由于多种标配功能, 包括 USB 连接、34 种自动测量、…...

【TB作品】MSP430G2553,单片机,口袋板, 交通灯控制系统
题8 交通灯控制系统 十字路口交通灯由红、绿两色LED显示器(两位8段LED显示器)组成,LED显示器显示切换倒计时,以秒为单位,每秒更新一次;为确保安全,绿LED计数到0转红,经5秒延时&#…...

windows 安装 Kubernetes(k8s)
windows 安装 docker 详情见: https://blog.csdn.net/sinat_32502451/article/details/133026301 minikube Minikube 是一种轻量级的Kubernetes 实现,可在本地计算机上创建VM 并部署仅包含一个节点的简单集群。 下载地址:https://github.…...

C语言 | Leetcode C语言题解之第189题轮转数组
题目: 题解: void swap(int* a, int* b) {int t *a;*a *b, *b t; }void reverse(int* nums, int start, int end) {while (start < end) {swap(&nums[start], &nums[end]);start 1;end - 1;} }void rotate(int* nums, int numsSize, int…...

【安全审核】音视频审核开通以及计费相关
融云控制台音视频审核入口:音视频审核 1 音视频审核文档:融云开发者文档 1 提示: 开发环境: 免费体验 7 天(含 21 万分钟音频流和 420 万张视频审核用量),免费额度用尽后,将关停服务…...
【实战】Spring Cloud Stream 3.1+整合Kafka
文章目录 前言新版版本优势实战演示增加maven依赖增加applicaiton.yaml配置新增Kafka通道消费者新增发送消息的接口 实战测试postman发送一个正常的消息postman发送异常消息 前言 之前我们已经整合过Spring Cloud Stream 3.0版本与Kafka、RabbitMQ中间件,简直不要太…...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

从深圳崛起的“机器之眼”:赴港乐动机器人的万亿赛道赶考路
进入2025年以来,尽管围绕人形机器人、具身智能等机器人赛道的质疑声不断,但全球市场热度依然高涨,入局者持续增加。 以国内市场为例,天眼查专业版数据显示,截至5月底,我国现存在业、存续状态的机器人相关企…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...

均衡后的SNRSINR
本文主要摘自参考文献中的前两篇,相关文献中经常会出现MIMO检测后的SINR不过一直没有找到相关数学推到过程,其中文献[1]中给出了相关原理在此仅做记录。 1. 系统模型 复信道模型 n t n_t nt 根发送天线, n r n_r nr 根接收天线的 MIMO 系…...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...

视频行为标注工具BehaviLabel(源码+使用介绍+Windows.Exe版本)
前言: 最近在做行为检测相关的模型,用的是时空图卷积网络(STGCN),但原有kinetic-400数据集数据质量较低,需要进行细粒度的标注,同时粗略搜了下已有开源工具基本都集中于图像分割这块,…...

初探Service服务发现机制
1.Service简介 Service是将运行在一组Pod上的应用程序发布为网络服务的抽象方法。 主要功能:服务发现和负载均衡。 Service类型的包括ClusterIP类型、NodePort类型、LoadBalancer类型、ExternalName类型 2.Endpoints简介 Endpoints是一种Kubernetes资源…...
混合(Blending))
C++.OpenGL (20/64)混合(Blending)
混合(Blending) 透明效果核心原理 #mermaid-svg-SWG0UzVfJms7Sm3e {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-icon{fill:#552222;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-text{fill…...

tomcat入门
1 tomcat 是什么 apache开发的web服务器可以为java web程序提供运行环境tomcat是一款高效,稳定,易于使用的web服务器tomcathttp服务器Servlet服务器 2 tomcat 目录介绍 -bin #存放tomcat的脚本 -conf #存放tomcat的配置文件 ---catalina.policy #to…...