LongRAG:利用长上下文大语言模型提升检索生成效果
一、前言
前面我们已经介绍了多种检索增强生成 (RAG) 技术,基本上在保证数据质量的前提下,检索增强生成(RAG)技术能够有效提高检索效率和质量,相对于大模型微调技术,其最大的短板还是在于有限的上下文窗口限制。因为传统的 RAG 框架普遍依赖"短检索单元",这一局限性严重制约了模型的性能表现。
传统的短检索单元就像在浩瀚的图书馆中只能借阅残缺的书页,难以获取完整信息。这种局限性给精准高效的答案提取带来了两大挑战:
1)检索器需在海量数据中精确定位包含答案的段落,犹如大海捞针。这不仅加重了检索器的负担,还需要复杂的重排序机制来筛选有用信息,极大地降低了系统效率。
2)受输入长度限制,传统方法只能截取文档部分内容,导致信息丢失和语义不完整。这种"盲人摸象"式的信息获取方式严重影响了答案的准确性和全面性。
幸运的是,长上下文大语言模型(LLM)的蓬勃发展为打破这一瓶颈带来了新的希望。在此背景下,LongRAG 应运而生。它突破了"短检索单元"的限制,赋予阅读器处理超长文本的能力,实现了对"整本书"信息的全面把握。这种创新设计不仅减轻了检索器的负担,还有效避免了信息丢失,从根本上提升了答案的召回率和准确性。
接下来,我们将深入探讨 LongRAG 框架的具体设计和实现细节,并分析其在开放域问答任务中所展现的巨大潜力。通过这种新型框架,我们有望在信息检索和知识生成领域开辟新的前景。
二、LongRAG
为了克服传统 RAG 框架的局限性,最近来自滑铁卢大学的研究团队 Ziyan Jiang、Xueguang Ma 和 Wenhu Chen 在他们的论文《LongRAG: Enhancing Retrieval-Augmented Generation with Long-context LLMs》[1]中提出了一个创新的框架——LongRAG。其核心目标是利用长上下文大语言模型 (LLM) 增强开放域问答任务中的检索增强生成。LongRAG 的设计理念是平衡检索器和“答案生成器”之间的工作量,提高答案召回率,并减轻检索器的负担。
具体来说,LongRAG 主要包含以下几个关键创新点:
- 长检索单元: 不同于传统的短检索单元,LongRAG 将维基百科等知识库处理成更长的语义单元, 比如整篇文章甚至多篇文章, 从而提供更完整的信息, 避免信息片段化带来的理解偏差。
- 长检索器: LongRAG 使用能够处理长文本输入的检索器, 从预处理后的知识库中检索与问题相关的长检索单元, 减轻了传统检索器需要精准定位答案片段的压力。
- 长答案生成器: LongRAG 利用强大的长上下文 LLM 作为“答案生成器”, 使其能够 "阅读" 由长检索单元提供的完整信息, 并生成更准确、 更全面的答案。
为了进一步优化答案提取过程, LongRAG 采用了两轮方法:
- 第一轮: 将长检索上下文和问题连接起来作为输入, 让长“答案生成器”生成一个初步的、 可能比较冗长的答案。
- 第二轮: 使用少量的上下文示例 (例如8个) 来引导长“答案生成器”从第一轮生成的答案中提取最重要的部分, 最终得到简洁准确的答案。
通过长检索单元、 长检索器和长“答案生成器”的协同工作, LongRAG 实现了高效的答案提取, 并在实验中取得了显著的性能提升, 无需依赖复杂的重排序机制。 LongRAG 的提出证明了将 RAG 与长上下文 LLM 相结合的巨大潜力, 为开放域问答系统的发展提供了一种新的思路。

传统的 RAG 在短检索单元上运行,检索器需要扫描大量的单元才能找到相关的部分。相比之下,LongRAG 在长检索单元(长 30 倍)上运行。检索器的负载要少得多,这显著提高了召回率。LongRAG 充分利用长上下文语言模型(阅读器)的能力来实现强大的性能。
三、实现原理
LongRAG 是一种全新的检索增强生成框架,重点解决传统RAG框架中检索器和阅读器之间工作负载不平衡的问题。传统RAG框架通常使用短文本作为检索单元,例如100字左右的段落,这使得检索器需要在庞大的语料库中寻找“针尖”(即包含答案的确切短文本单元)。相反,阅读器只需从检索到的短文本单元中提取答案,工作量相对较轻。这种“重”检索器和“轻”阅读器的不平衡设计会导致性能欠佳。
为了缓解这种不平衡,LongRAG提出了“长检索器”和“长阅读器”的概念,并围绕着4K词的检索单元进行构建。
3.1、LongRAG 的三大核心组件
- 长检索单元: LongRAG将整个维基百科文档或多个相关文档组合在一起,构建了包含超过4K词的长检索单元。这种设计可以显著减少语料库的大小(语料库中检索单元的数量),从而减轻检索器的负担。例如,在NQ数据集上,LongRAG将语料库大小从2200万个减少到60万个文档单元。此外,长检索单元还提高了信息的完整性,避免了歧义或混淆。
- 长检索器: 长检索器的任务是从所有长检索单元中识别与给定问题相关的粗粒度信息。它首先根据文档之间的关系(例如维基百科中的超链接)将文档分组,形成长检索单元。然后,利用编码器将问题和检索单元映射到向量空间,并通过计算向量之间的相似度来检索最相关的单元。最后,将排名前k位的检索单元拼接成一个长文本作为检索结果。
- 长阅读器: 长阅读器负责从拼接后的长文本中提取答案。LongRAG直接使用现有的长文本语言模型(如Gemini或GPT-4)作为阅读器,并根据文本长度采用不同的提示策略。对于短文本,阅读器直接从检索到的文本中提取答案;对于长文本,则采用两阶段方法:首先让阅读器生成一个较长的答案,然后提示其从长答案中提取最核心的短答案。
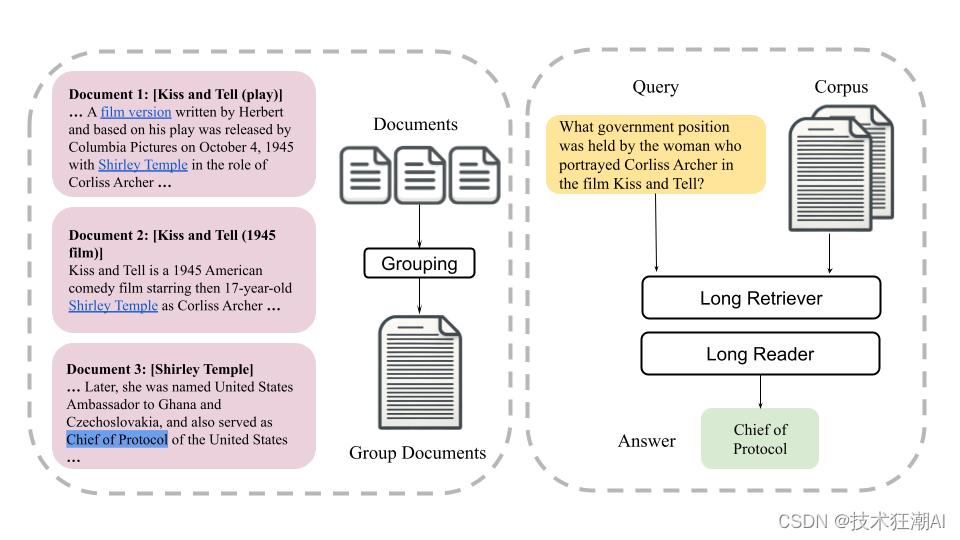
左图展示了长检索单元是如何通过超链接按维基百科文档分组的。每个检索单元平均包含 4K 个 Token,对应于多个相关文档。右图展示了来自 HotpotQA 的多跳问答测试用例。最终结果可以通过仅使用几个检索单元来实现,然后将其输入到长阅读器中。
3.2、Long Retriever: 粗粒度召回,化解检索压力
Long Retriever的核心目标是从海量语料库中高效召回与问题相关的粗粒度信息,而非像传统检索器那样追求精确定位答案。其关键技术创新在于:
- 长检索单元构建: LongRAG巧妙利用维基百科的超链接结构,将相互关联的多个文档聚合为平均长度达4K词的长检索单元。这种设计一方面保证了检索单元的语义完整性,有利于多跳问答等复杂任务;另一方面,显著减少了检索单元总数,例如将NQ数据集语料库压缩了近30倍,极大降低了检索难度。
- 长文本相似度计算: 针对现有Embedding模型难以处理4K词级别长文本的挑战,Long Retriever采用了一种近似计算方法:将长文本切分成多个短文本块,分别计算每个块与问题的相似度,最终取最大值作为整体相似度。这种方法简单有效,但也为更精准高效的长文本Embedding模型研究提出了需求。
- 检索结果聚合: Long Retriever最终返回Top-K个最相关的长检索单元,并将它们拼接成更长的文本传递给Long Reader。K的选择需要根据检索单元粒度和阅读器模型的上下文窗口大小进行调整,论文实验表明最终传递给阅读器的文本长度在30K词左右较为合适。
3.3、Long Reader: 深度理解,精准提取答案
Long Reader负责接收Long Retriever返回的长文本,从中精确定位答案并生成最终结果。其性能直接取决于对长文本的理解能力,以及精准的答案提取策略。
- 长文本理解能力: LongRAG选择Gemini-1.5-Pro和GPT-4o这两款具备超长上下文窗口和出色理解能力的LLM作为Reader,充分发挥了长文本LLM的优势,为LongRAG框架的成功奠定了基础。
- 两阶段答案提取: 针对长文本,LongRAG采用了一种“先长后短”的两阶段答案提取策略:
- 首先,将检索到的长文本和问题一起输入LLM,让其生成一个相对完整的长答案,确保答案信息完整性。
- 然后,利用少量样本对LLM进行微调,引导其从长答案中提取最核心的短语或实体作为最终答案,提升答案精准度。
LongRAG框架通过Long Retriever与Long Reader的协同工作,有效解决了传统RAG框架的检索效率与答案精准度难以兼顾的难题。Long Retriever专注于粗粒度信息召回,为Long Reader提供充足的上下文信息;Long Reader则利用强大的长文本理解能力,从容应对长文本,精准提取答案。
四、检索结果
LongRAG 框架中,长上下文检索器的应用对整体性能提升起到了至关重要的作用。相比于传统方法,长上下文检索器在语料库压缩、召回率提升以及对检索单元数量的降低方面展现出显著优势,有效减轻了检索器模型的负担。
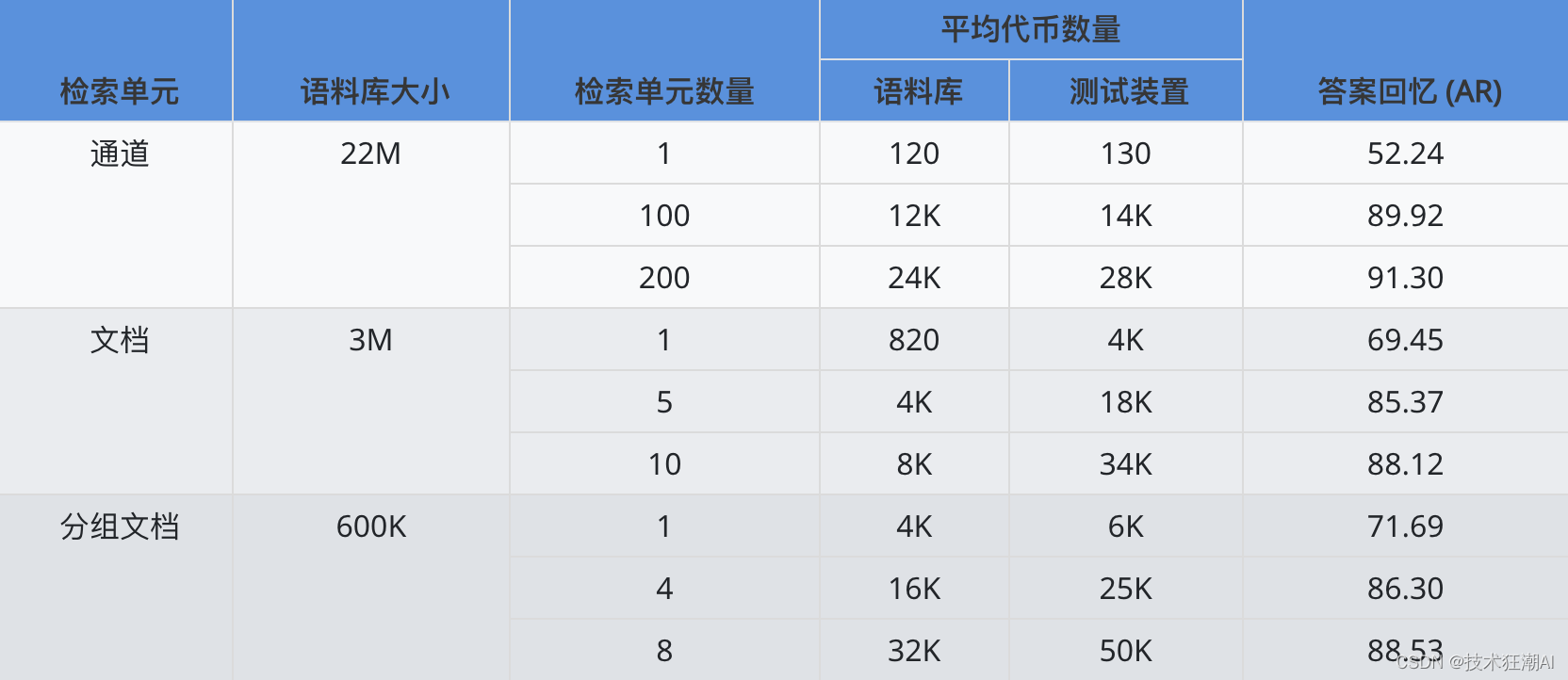
具体来说,论文中采用了平均 Token 数高达 6K 的长检索单元,将 NQ 数据集的语料库大小成功压缩了 30 倍(从 2200 万个减少到 60 万个)。这不仅大幅降低了检索过程中的计算量,更重要的是,长检索单元天然蕴含着更丰富的语义信息,避免了传统短文本检索单元可能导致的信息割裂问题。
实验结果也印证了长上下文检索的有效性:在 NQ 数据集上,top-1 答案召回率提升了约 20 个百分点(从 52.24 提升到 71.69)。这意味着 Long Retriever 能够更精准地定位到与问题相关的文档,为后续 Long Reader 的精准作答提供了更有力的支持。
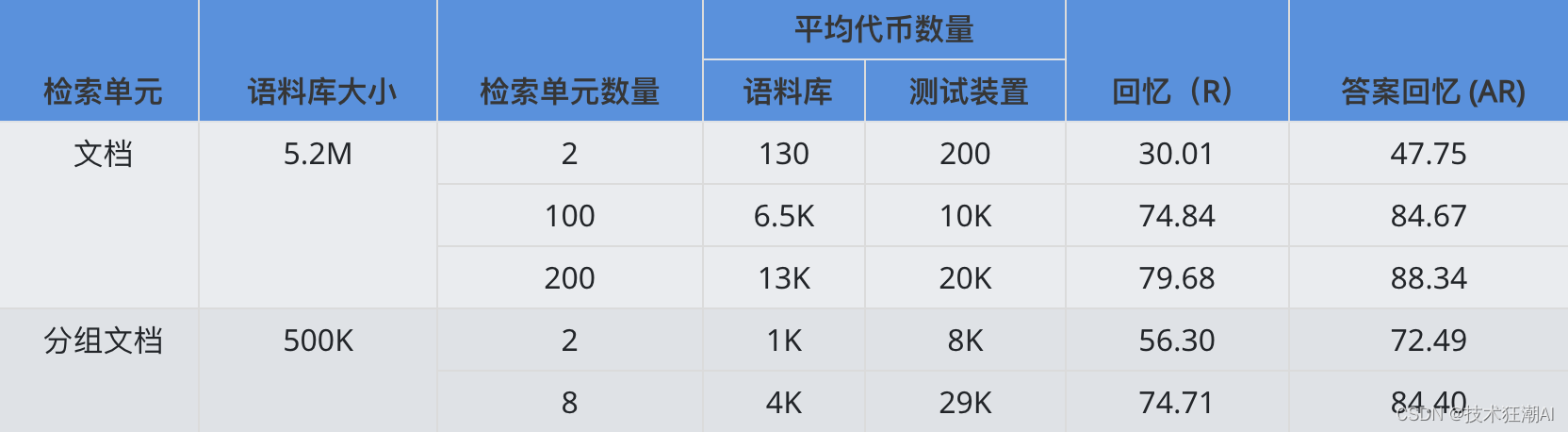
此外,长上下文检索所需的检索单元数量也显著减少。实验表明,仅使用 8 个长检索单元(Grouped Documents)就能达到与 100 个传统短文本检索单元(Passage)相当的召回率。这说明 Long Retriever 能够更有效地利用每个检索单元的信息,避免了冗余检索,进一步降低了计算成本。
长上下文检索通过增加每个检索单元的信息量,在保证甚至提升召回率的同时,显著降低了检索单元的数量和计算量,为 LongRAG 框架的整体性能提升奠定了坚实基础。
五、问答结果
为了验证 LongRAG 框架的有效性,论文中提到在 Natural Questions (NQ) 和 HotpotQA 两个开放域问答数据集上进行了实验,并将 LongRAG 与以下三类问答方法进行了对比:
- 闭卷问答 (Closed-book): 直接使用预训练语言模型进行问答,不依赖任何外部知识库。实验中采用了 GPT-4-Turbo、Gemini-1.5-Pro 和 Claude-3-Opus 等先进的大语言模型,并采用了 16-shot 提示策略。
- 完全监督的 RAG (Fully-supervised RAG): 使用 RAG 框架,并在训练数据上进行完整的监督学习,例如 DPR、FiD、Atlas 等模型。
- 无微调的 RAG (No Fine-tuning RAG): 使用 RAG 框架,但没有进行任何微调,例如 LongRAG (Gemini-1.5-Pro) 和 LongRAG (GPT-4o)。
其中 EM (Exact Match) 指标用于衡量模型预测答案与标准答案完全匹配的比例。

实验结果表明:
(1)在 NQ 数据集上,LongRAG 表现出色: 无论使用 Gemini-1.5-Pro 还是 GPT-4o 作为阅读器,LongRAG 都取得了优于所有基线模型的 EM 分数,其中 LongRAG (GPT-4o) 更是达到了 62.7% 的 EM,与目前最先进的完全监督 RAG 模型 Atlas (64.0 EM) 相当。这充分说明了 LongRAG 框架能够有效地利用长文本检索和阅读能力来提高问答性能,即使在没有进行任何微调的情况下也能取得优异表现。
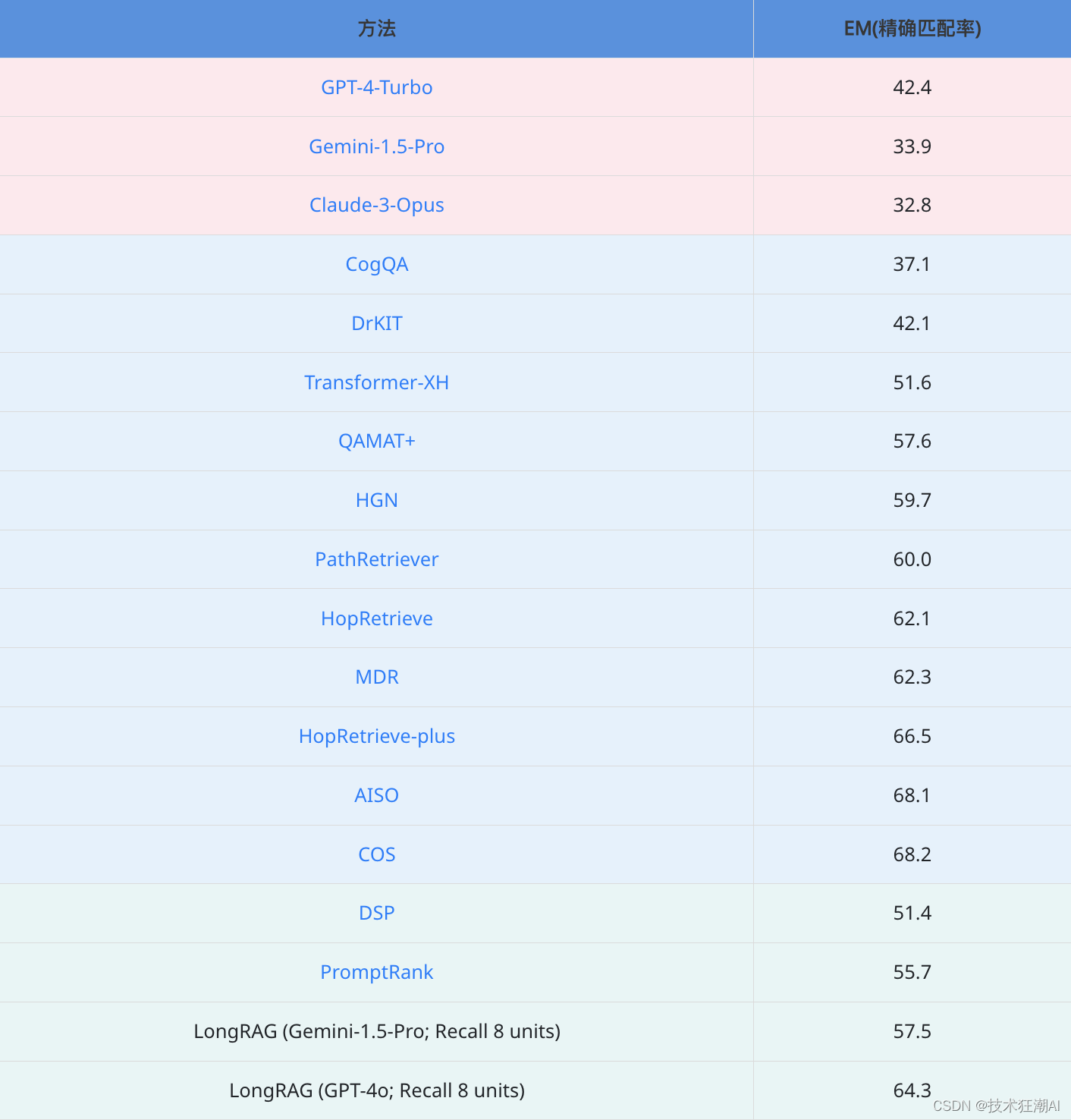
(2)在 HotpotQA 数据集上,LongRAG 也展现出强大的竞争力: LongRAG (GPT-4o) 再次取得了接近 SoTA 水平的 64.3% EM 分数,超越了绝大多数传统 RAG 方法,仅略低于 AISO (68.1 EM) 和 COS (68.2 EM)。需要指出的是,AISO 和 COS 均为针对 HotpotQA 数据集专门设计和训练的模型,而 LongRAG 并没有针对特定数据集进行任何优化。这说明 LongRAG 框架具有很强的泛化能力,能够在不同类型的问答数据集上都取得不错的效果。
从实验结果进一步分析可以发现:
- 长上下文信息至关重要: LongRAG 的成功得益于其对长上下文信息的有效利用。相比之下,传统的短文本 RAG 模型难以捕捉到复杂问题和答案之间的多跳推理关系,因此在性能上存在明显差距。
- 更强大的 LLM 可以进一步提升 LongRAG 性能: 实验结果显示,使用 GPT-4o 作为阅读器的 LongRAG 模型比使用 Gemini-1.5-Pro 的模型性能更优。这说明更强大的 LLM 能够更好地理解长文本信息,并更准确地提取答案。
总而言之,LongRAG 框架通过引入长上下文检索和阅读机制,为开放域问答任务提供了一种高效且强大的解决方案。 虽然 LongRAG 目前在某些数据集上的性能略低于专门训练的 SoTA 模型,但其无需微调、易于部署的优势,以及未来通过更强大的 LLM 进一步提升性能的潜力,都使其成为 RAG 领域一个极具前景的研究方向。
六、未来展望
LongRAG 提出了一种新颖的检索增强生成框架,通过长检索单元和长阅读器的协同工作,有效提升了开放域问答的性能。LongRAG 巧妙利用长文本信息来提升问答效果的思路很不错,但在以下几方面也存在一定的局限性:
1)对长文本 Embedding 模型的依赖: LongRAG 的高效运行依赖于高质量的长文本 Embedding 模型。现有的长文本 Embedding 技术尚不成熟,难以兼顾效率和精度。如果无法突破这个瓶颈,LongRAG 的性能提升将受到限制。
2)长检索单元构建方法的普适性: 论文中使用的基于超链接的构建方法仅适用于维基百科等结构化知识库。如何将 LongRAG 框架推广到其他类型的文本数据,例如新闻、小说等,需要探索更通用的长检索单元构建方法。
3)计算资源消耗: 长文本的处理和长文本 LLM 的调用都需要消耗大量的计算资源,这限制了 LongRAG 在资源受限场景下的应用。未来需要探索更高效的模型压缩、剪枝和量化技术,降低 LongRAG 的计算成本。
4)对长文本 LLM 理解能力的依赖: LongRAG 的性能很大程度上取决于 Long Reader,也就是长文本 LLM 的理解和推理能力。现有的长文本 LLM 在处理长距离依赖、逻辑推理等方面仍有不足,这也会影响 LongRAG 的最终效果。
虽然存在以上挑战,但 LongRAG 为 RAG 领域的应用发展指明了方向提供了新的思路。未来研究可以着重解决 LongRAG 现存的瓶颈,并进一步释放长文本理解的潜力:
1)更强大的长文本 Embedding 模型: 这是 Long Retriever 性能进一步提升的关键。目前的近似计算方法效率虽高,但牺牲了一定的精度。未来可以探索更精准高效的长文本 Embedding 模型,例如结合 Transformer 结构和稀疏注意力机制,或采用分段编码、局部聚合等策略,在保证效率的同时提升长文本表示的准确性。
2)更通用的长检索单元构建方法: 目前的超链接方法仅适用于维基百科等结构化知识库,限制了 LongRAG 的应用范围。未来可以探索更通用的长检索单元构建方法,例如基于语义聚类、主题模型或图神经网络等技术,将来自不同来源、不同模态的信息整合到长检索单元中,以处理更复杂的问答场景。
3)更高效的 Long Reader 架构: 现有的 Long Reader 主要依赖于通用的长文本 LLM,未来可以探索更适合长文本理解和答案提取的模型架构。例如,可以设计基于稀疏注意力机制的阅读器,重点关注检索文本中的关键信息,或采用动态上下文窗口机制,根据问题和答案的复杂程度自适应地调整阅读范围,以提升效率和精准度。
4)探索 LongRAG 在其他 NLP 任务中的应用: LongRAG 框架的长文本理解能力具有广泛的应用价值,未来可以探索其在其他 NLP 任务中的应用,例如长文本摘要、多文档问答、对话系统等,进一步拓展 LongRAG 的应用场景。
七、总结
LongRAG 框架创新性地解决了传统检索增强生成(RAG)框架中检索器负担过重的问题,通过引入“长检索单元”、“长检索器”和“长阅读器”,将完整的维基百科文章处理成 4K Token 的单元,将语料库大小缩减了 97% 以上,从而显著提升了检索效率和整体性能。
LongRAG 的优势主要体现在:
- 大幅提升检索效率: 在 NQ 和 HotpotQA 数据集上,LongRAG 无需复杂排序机制即可分别实现 71% 的 Recall@1 和 72% 的 Recall@2,远超传统的短文本检索方法。这体现了长检索单元在信息完整性和检索效率方面的优势。
- 零样本问答性能卓越: 在零样本问答任务中,LongRAG 在 NQ 和 HotpotQA 数据集上分别取得了 62.7% 和 64.3% 的 EM,与最先进模型相当,甚至超越了许多完全监督训练的 RAG 模型。这充分说明了 LongRAG 框架的有效性和长文本理解能力的强大潜力。
LongRAG 为 RAG 与长上下文语言模型的结合提供了新的思路,未来有望通过更强大的长嵌入模型和更通用的长单元公式进一步提升性能。
参考资料:
[1]. Paper:https://arxiv.org/abs/2406.15319
[2]. Code:https://github.com/TIGER-AI-Lab/LongRAG/
[3]. Dataset:https://huggingface.co/datasets/TIGER-Lab/LongRAG
相关文章:
LongRAG:利用长上下文大语言模型提升检索生成效果
一、前言 前面我们已经介绍了多种检索增强生成 (RAG) 技术,基本上在保证数据质量的前提下,检索增强生成(RAG)技术能够有效提高检索效率和质量,相对于大模型微调技术,其最大的短板还是在于有限的上下文窗口…...

go中的方法 func-----数据类型
本文是java学习者学go种产生的容易记混点的笔记,所以有其他编译语言的基础更好 go的方法有点像js 基础 func main() {fmt.Println("Starting")var p *string new(string)*p "hello world"demo : "demo"fmt.Println(*&demo) //这样既然也…...

408计算机网络--物理层
一、物理层概述 物理层是干嘛使得? 物理层解决如何在连接各种计算机的传输媒体上传输数据比特流,而不是指具体的传输媒体。 物理层主要任务是确定与传输媒体接口有关的一些特性。定义标准可以理解为插排上的两孔三孔 机械特性:定义物理连接…...

十年,亚马逊云科技合作伙伴网络开启AI新征程
“十年之前,你不认识我,我不认识你,因为云计算我们携手并肩;十年之后,我们仍是伙伴,更是朋友,因为人工智能再次起程。”这就是今天的亚马逊云科技与其合作伙伴的真实写照。 2024年是亚马逊云科技…...
基于Spring Boot的在线医疗咨询平台的设计与实现【附源码】
基于Spring Boot的在线医疗咨询平台的设计与实现 Design and implementation of the computer hardware mall based on Spring Boot Candidate: Supervisor: April 20th, 2024 学位论文原创性声明 本人郑重声明:所呈交的论文是本人在导师…...

星坤Type-A连接器:创新快充技术,引领电子连接!
快速发展的电子时代,消费者对电子设备的性能和便利性有着更高的要求。特别是在充电和数据传输方面,快充技术和高速传输已成为市场的新宠。中国星坤公司推出的Type-A连接器系列,以其卓越的性能和创新的设计,满足了市场对高效、稳定…...
入门JavaWeb之 Response 下载文件
web 服务器接收到客户端的 http 请求 针对这个请求,分别创建一个代表请求的 HttpServletRequest 对象,代表响应的 HttpServletResponse 对象 获取客户端请求过来的参数:HttpServletRequest 给客户端响应一些信息:HttpServletRe…...

Java自定义注解校验token并直接返回给前端状态
自定义注解 CheckToken import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target;Target(ElementType.METHOD) Retention(RetentionPolicy.RUNTIME) public int…...

C++ | Leetcode C++题解之第200题岛屿数量
题目: 题解: class Solution { private:void dfs(vector<vector<char>>& grid, int r, int c) {int nr grid.size();int nc grid[0].size();grid[r][c] 0;if (r - 1 > 0 && grid[r-1][c] 1) dfs(grid, r - 1, c);if (r …...

Linux安全配置
Linux系统审计信息有:系统启动日志(boot.log)、记录用户执行命令日志(acct/pacct)、记录使用su命令的使用(sulog)、记录当前登录的用户信息(utmp)、用户每次登陆和退出信…...

vue实现不预览PDF的情况下打印pdf文件
前景:默认情况,实现打印需要根据预览的内容进行打印。 但是当只有打印按钮存在,不预览文件内容的情况下,实现打印的话,可以通过后端接口返回服务器上PDF的地址,前端通过隐藏的iframe标签中src可实现预览功能 主要是根据…...
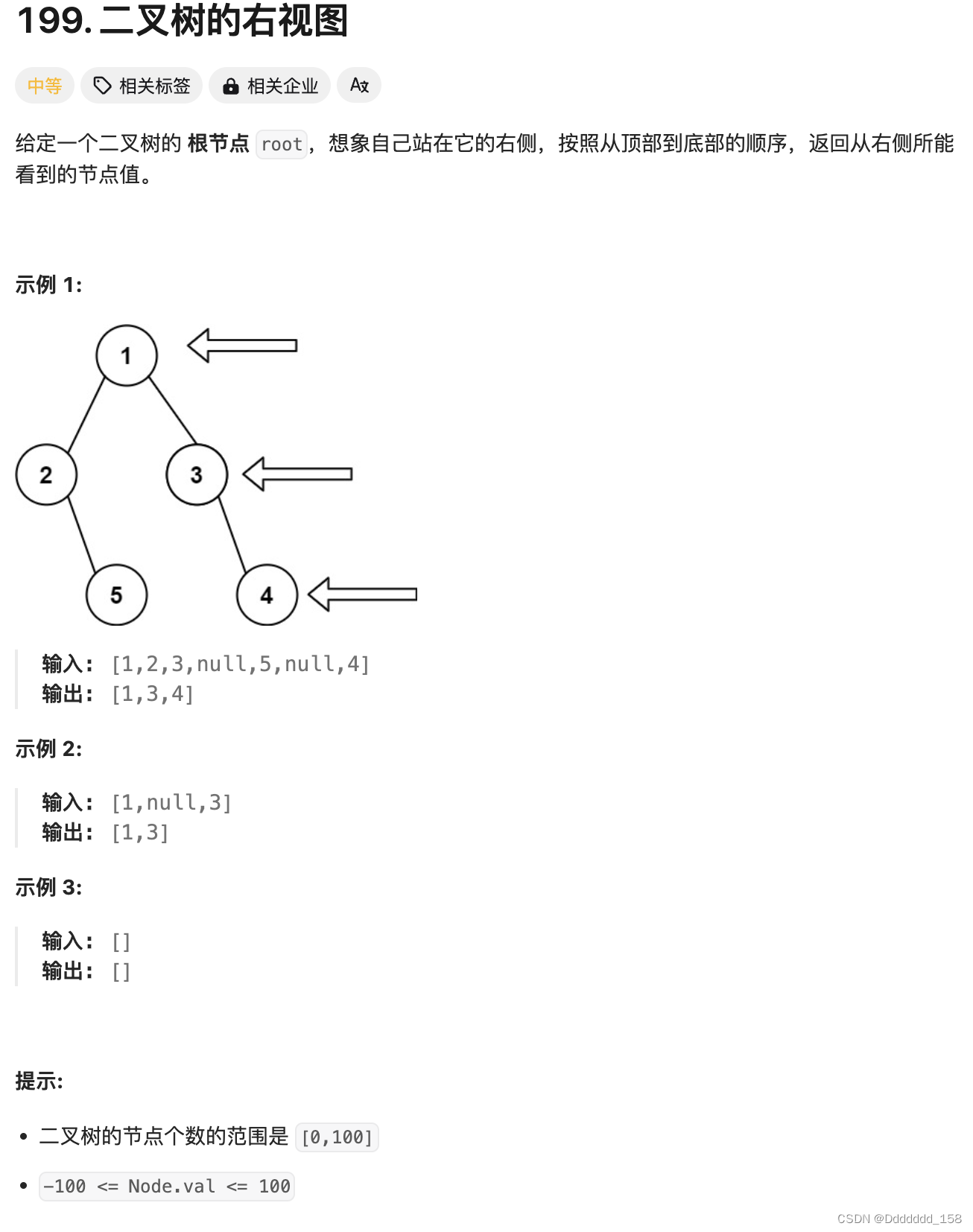
C++ | Leetcode C++题解之第199题二叉树的右视图
题目: 题解: class Solution { public:vector<int> rightSideView(TreeNode* root) {unordered_map<int, int> rightmostValueAtDepth;int max_depth -1;stack<TreeNode*> nodeStack;stack<int> depthStack;nodeStack.push(ro…...
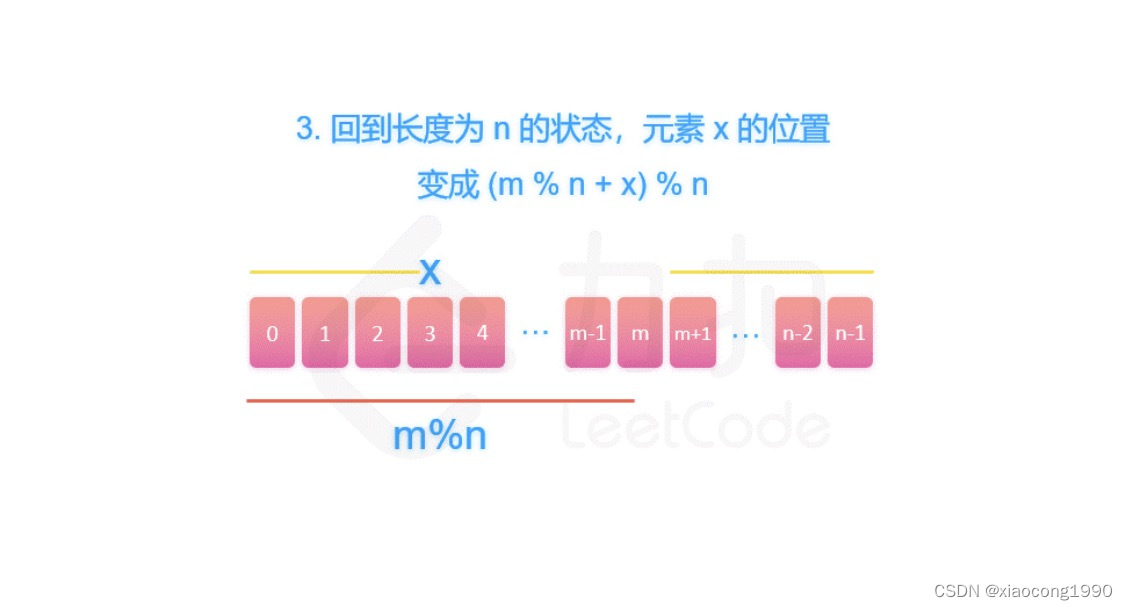
[leetcode]圆圈中最后剩下的数字/ 破冰游戏
. - 力扣(LeetCode) class Solution {int f(int num, int target) {if (num 1) {return 0;}int x f(num - 1, target);return (target x) % num;} public:int iceBreakingGame(int num, int target) {return f(num, target);} };...
mysql数据库的管理
目录 一、常用的数据类型 二、MySQ数据库基础操作 1、登录数据库 2、查看当前的 MySQL 版本信息及连接用户名 3、查看当前服务器中的数据库 4.查看数据库中包含的表 5.查看表的结构(字段) 6、MySQL的6大约束属性 三、SQL…...
)
Java项目分层(持续更新中)
第一次更新时间2024.6.26 分包 实体类 功能类 工具类 分层 实体类层 我们要操作的对象,Book,Student... 控制层 控制请求转发 业务层 处理业务 数据层 连接数据库 处理数据 工具类层 JDBC等工具类 测试层 最终启动项目 明确我们所要做的业务之后&a…...

2024年软件测试面试题大全【答案+文档】
🍅 视频学习:文末有免费的配套视频可观看 🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 一、面试基础题 简述测试流程: 1、阅读相关技术文档(如产品PRD、UI设计…...
——体系:数据转换——概述、关注焦点)
数据赋能(131)——体系:数据转换——概述、关注焦点
概述 数据转换是指将数据从一种格式、结构或类型转换为另一种格式、结构或类型的过程。 数据转换操作属于数据整理过程。 它通常涉及数据清洗、数据映射、数据合并、数据拆分等操作,以确保数据的正确性和一致性。 数据转换的目的在于将原始数据转换为更易于处理…...

【自然语言处理系列】掌握jieba分词器:从基础到实战,深入文本分析与词云图展示
本文旨在全面介绍jieba分词器的功能与应用,从分词器的基本情况入手,逐步解析全模式与精确模式的不同应用场景。文章进一步指导读者如何通过添加自定义词典优化分词效果,以及如何利用jieba分词器进行关键词抽取和词性标注,为后续的…...

TikTok短视频矩阵系统
随着数字化时代的到来,短视频已成为人们获取信息、娱乐消遣的重要渠道。TikTok,作为全球最受欢迎的短视频平台之一,其背后的短视频矩阵系统是支撑其成功的关键因素。本文将深入探讨TikTok短视频矩阵系统的构成、功能以及它在新媒体时代中的影…...

码题杯:我会修改图
原题链接:码题集OJ-我会修改图 题目大意:给你一张n个点(编号为1∼n),m条边(编号为1∼m)的无向图,图上每个点都有一个点权,权值分别为a1,a2,…,an&…...

Linux应用开发之网络套接字编程(实例篇)
服务端与客户端单连接 服务端代码 #include <sys/socket.h> #include <sys/types.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <arpa/inet.h> #include <pthread.h> …...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

最新SpringBoot+SpringCloud+Nacos微服务框架分享
文章目录 前言一、服务规划二、架构核心1.cloud的pom2.gateway的异常handler3.gateway的filter4、admin的pom5、admin的登录核心 三、code-helper分享总结 前言 最近有个活蛮赶的,根据Excel列的需求预估的工时直接打骨折,不要问我为什么,主要…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...

土地利用/土地覆盖遥感解译与基于CLUE模型未来变化情景预测;从基础到高级,涵盖ArcGIS数据处理、ENVI遥感解译与CLUE模型情景模拟等
🔍 土地利用/土地覆盖数据是生态、环境和气象等诸多领域模型的关键输入参数。通过遥感影像解译技术,可以精准获取历史或当前任何一个区域的土地利用/土地覆盖情况。这些数据不仅能够用于评估区域生态环境的变化趋势,还能有效评价重大生态工程…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...