flink 处理函数和流转换
目录
处理函数分类
概览介绍
KeydProcessFunction和ProcessFunction
定时器TimeService
窗口处理函数
多流转换
分流-侧输出流
合流
联合(Uniion)
连接(connect)
广播连接流(BroadcatConnectedStream)
基于时间的合流 -双流联结
窗口连接(windowjoin)
间隔联结(Interval join)
窗口同组联结(window CoGroup)
处理函数分类
窗口 | Apache Flink
处理函数分8种;datastream调用keyby()后得到keyedStream,进而调用window()得到WindowedStream,对于不同的流都可以调用process方法进行自定处理;这是传入的函数都叫处理函数;
概览介绍
flink提供8种不同的处理函数;
窗口和流都可以使用
1.ProcessFunction 是最基本的处理函数,基于DataStream直接调用process()时作为参数传入;
2.KeydProcessFunction:是对流进行分区后的处理函数,基于KeyedStream调用process()时作为参数传入。只有该方法支持定时器功能(onTime);
窗口函数,只有窗口可以使用
3.ProcessWindowFunction:是开窗之后的处理函数,也是全窗口函数的代表,基于windowedStream调用process()时作为参数传入;
4.ProcessAllWindowFunction:开窗后处理函数,基于allWindowedStream的process()时作为参数传入。
连接函数流join使用
5.CoProcessFunction:是合并两条留之后的处理函数,基于ConnectedStreams调用process()时作为参数传入;
窗口的join使用
6.ProcessJoinFunction:是间隔连接两条流字之后的处理函数,基于IntervalJOined调用process()时作为参数传入;
广播状态
7.BroadcastProcessFunction:是广播连接流处理函数,基于BroadcastConnectedStream调用process()时作为参数传入,这里BroadcastConnectedStream是一个未做keyby处理的普通DataStream,与一个广播流(BroadcastStream)连接之后的产物;
8.KeyedBroadcastFunction:是按键分区的广播连接流处理函数,同样基于BroadConnectedStream调用process()时作为参数传入;与BroadcastProcessFunction不同的是是的广播流是keyedStream,与一个广播流(BroadcastStream)连接之后的产物;
KeydProcessFunction和ProcessFunction
我们在看源码的时候看到ProcessFunction 和KeydProcessFunction结构一样,都有两个接口,一个必须实现的processElement()抽象方法,一个非抽象方法onTimer()。差别在上下文Context中KeydProcessFunction多一个获取当前分区key的方法 getCurrentKey。当使用ProcessFunction使用定时器时程序运行会报错,提示定时器只支持keyStream使用;
stream.process(new ProcessFunction< Event, String>() {@Overridepublic void processElement(Event value, ProcessFunction<Event, String>.Context ctx, Collector<String> out) throws Exception {Long currTs = ctx.timerService().currentProcessingTime();out.collect("数据到达,到达时间:" + new Timestamp(currTs));// 注册一个10秒后的定时器ctx.timerService().registerProcessingTimeTimer(currTs + 10 * 1000L);}@Overridepublic void onTimer(long timestamp, ProcessFunction<Event, String>.OnTimerContext ctx, Collector<String> out) throws Exception {out.collect("定时器触发,触发时间:" + new Timestamp(timestamp));}})程序运行后报错
Caused by: java.lang.UnsupportedOperationException: Setting timers is only supported on a keyed streams.at org.apache.flink.streaming.api.operators.ProcessOperator$ContextImpl.registerProcessingTimeTimer(ProcessOperator.java:118)at com.atguigu.chapter07.ProcessingTimeTimerTest$1.processElement(ProcessingTimeTimerTest.java:55)at com.atguigu.chapter07.ProcessingTimeTimerTest$1.processElement(ProcessingTimeTimerTest.java:47)at org.apache.flink.streaming.api.operators.ProcessOperator.processElement(ProcessOperator.java:66)at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.pushToOperator(CopyingChainingOutput.java:71)at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:46)at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:26)at org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:50)at org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:28)at org.apache.flink.streaming.api.operators.StreamSourceContexts$ManualWatermarkContext.processAndCollect(StreamSourceContexts.java:317)at org.apache.flink.streaming.api.operators.StreamSourceContexts$WatermarkContext.collect(StreamSourceContexts.java:411)at com.atguigu.chapter05.ClickSource.run(ClickSource.java:26)at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:110)at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:66)at org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:269)
定时器TimeService
TimeService中有六个方法,可以分为基于处理时间和基于事件时间的方法两大类种;时间精度为毫秒;
获取当前处理时间 long currentProcessingTime(); 获取当前水印时间 long currentWatermark(); 注册处理时间为定时器 void registerProcessingTimeTimer(long time);
long coalescedTime = ((ctx.timestamp() + timeout) / 1000) * 1000;
ctx.timerService().registerProcessingTimeTimer(coalescedTime);注册时间时间为定时器 void registerEventTimeTimer(long time);
long coalescedTime = ctx.timerService().currentWatermark() + 1;
ctx.timerService().registerEventTimeTimer(coalescedTime);删除处理时间定时器 void deleteProcessingTimeTimer(long time);
long timestampOfTimerToStop = ...
ctx.timerService().deleteProcessingTimeTimer(timestampOfTimerToStop);删除时间时间定时器 void deleteEventTimeTimer(long time);
long timestampOfTimerToStop = ...
ctx.timerService().deleteEventTimeTimer(timestampOfTimerToStop);注意:另外定时器使用处理时间和时间在触发上有区别,当设置定时任务为处理时间时,即便后续没有数据写入,定时器依然可以正常触发计算,当如果设置为时间时,定时任务时间依赖水印时间线。只有当水印时间大于定时器触发时间时才会触发计算,即如果后入没有实时数据进入时,最后一个定时器一直不会触发;
窗口处理函数
ProcessWindowFunction和ProcessAllWindowFunction既是创立函数又是全窗口函数,从名称上看他更倾向于窗口函数。用法与处理函数不同。 没有ontime借口和定时器服务,一般窗口有使用窗口触发器Trigger,在作用上可以类似timeservice的作用。
源码上看:
abstract class ProcessWindowFunction[IN, OUT, KEY, W <: Window]extends AbstractRichFunction {/*** Evaluates the window and outputs none or several elements.** @param key The key for which this window is evaluated.* @param context The context in which the window is being evaluated.* @param elements The elements in the window being evaluated.* @param out A collector for emitting elements.* @throws Exception The function may throw exceptions to fail the program and trigger recovery.*/@throws[Exception]def process(key: KEY, context: Context, elements: Iterable[IN], out: Collector[OUT])// 如果有自定义状态,该方法调用清理@throws[Exception]def clear(context: Context) {}abstract class Context {def window: Wdef currentProcessingTime: Longdef currentWatermark: Long
// 获取自定义窗口状态 对当前key,当前窗口有效def windowState: KeyedStateStore
// 获取自定义全局状态 对当前key的全部窗口有效def globalState: KeyedStateStoredef output[X](outputTag: OutputTag[X], value: X);}
}
--------------用法演示------------DataStream<Tuple2<String, Long>> input = ...;input.keyBy(t -> t.f0).window(TumblingEventTimeWindows.of(Time.minutes(5))).process(new MyProcessWindowFunction());/* ... */public class MyProcessWindowFunction extends ProcessWindowFunction<Tuple2<String, Long>, String, String, TimeWindow> {@Overridepublic void process(String key, Context context, Iterable<Tuple2<String, Long>> input, Collector<String> out) {long count = 0;for (Tuple2<String, Long> in: input) {count++;}out.collect("Window: " + context.window() + "count: " + count);}
}多流转换
分流-侧输出流
处理函数有一个特殊功能来处理迟到数据和进行分流,侧输出流(Side Output),再使用可以通过processElement或onTimer的下文context的output()方法就可以了;
旁路输出 | Apache Flink
一下函数都可以获取
- ProcessFunction
- KeyedProcessFunction
- CoProcessFunction
- KeyedCoProcessFunction
- ProcessWindowFunction
- ProcessAllWindowFunction
用法示例
DataStream<Integer> input = ...;
//定义
final OutputTag<String> outputTag = new OutputTag<String>("side-output"){};SingleOutputStreamOperator<Integer> mainDataStream = input.process(new ProcessFunction<Integer, Integer>() {@Overridepublic void processElement(Integer value,Context ctx,Collector<Integer> out) throws Exception {// 发送数据到主要的输出out.collect(value);// 发送数据到旁路输出ctx.output(outputTag, "sideout-" + String.valueOf(value));}});//外部获取测试给出流
DataStream<String> sideOutputStream = mainDataStream.getSideOutput(outputTag);分流之前有split()在1.13版本中已经弃用,直接使用处理函数的侧输出流;
合流
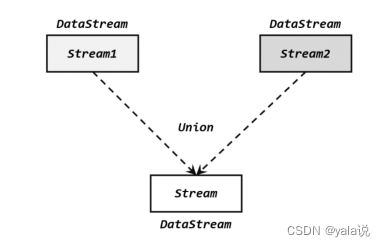
联合(Uniion)
将多个流合成一个流,而一个流中数据类型必须是相同的,因此要求多个流的数据类型必须相同才能合并,合并后流包含所有流的元素,如果流有水位线,合流之后的水位线为最小的为准;
stream1.union(Stream2,stream3,...),
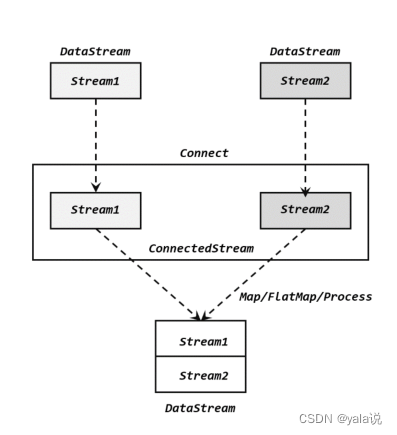
连接(connect)
connect得到的是connectedStreams,与联合有本质的不同,两个是量多流合并成一个流,数据是混在一个流中,跟一个流没什么区别,而connect合并后内部仍然各自保持自己的数据形式不变,彼此独立。因此可以处理不同类型的数据,但是只能两个流连接。如果想要得到新的DataStream,还需要自定义一个“同处理”(co-propcess)转换操作,对不同类型数据进行分别处理转换成同一种类型。
DataStream<Integer> someStream = //...
DataStream<String> otherStream = //...ConnectedStreams<Integer, String> connectedStreams = someStream.connect(otherStream);coMap和coflatmap函数
connectedStreams.map(new CoMapFunction<Integer, String, Boolean>() {@Overridepublic Boolean map1(Integer value) {return true;}@Overridepublic Boolean map2(String value) {return false;}
});
connectedStreams.flatMap(new CoFlatMapFunction<Integer, String, String>() {@Overridepublic void flatMap1(Integer value, Collector<String> out) {out.collect(value.toString());}@Overridepublic void flatMap2(String value, Collector<String> out) {for (String word: value.split(" ")) {out.collect(word);}}
});CoprocessFunction
是处理函数中的亿元,与处理函数用法相识,,keyby的key类型必须相同
appStream.connect(thirdpartStream).keyBy(data -> data.f0, data -> data.f0).process(new OrderMatchResult()).print();public static class OrderMatchResult extends CoProcessFunction<Tuple3<String, String, Long>, Tuple4<String, String, String, Long>, String>{// 定义状态变量,用来保存已经到达的事件private ValueState<Tuple3<String, String, Long>> appEventState;private ValueState<Tuple4<String, String, String, Long>> thirdPartyEventState;@Overridepublic void open(Configuration parameters) throws Exception {appEventState = getRuntimeContext().getState(new ValueStateDescriptor<Tuple3<String, String, Long>>("app-event", Types.TUPLE(Types.STRING, Types.STRING, Types.LONG)));thirdPartyEventState = getRuntimeContext().getState(new ValueStateDescriptor<Tuple4<String, String, String, Long>>("thirdparty-event", Types.TUPLE(Types.STRING, Types.STRING, Types.STRING,Types.LONG)));}@Overridepublic void processElement1(Tuple3<String, String, Long> value, Context ctx, Collector<String> out) throws Exception {// 看另一条流中事件是否来过if (thirdPartyEventState.value() != null){out.collect("对账成功:" + value + " " + thirdPartyEventState.value());// 清空状态thirdPartyEventState.clear();} else {// 更新状态appEventState.update(value);// 注册一个5秒后的定时器,开始等待另一条流的事件ctx.timerService().registerEventTimeTimer(value.f2 + 5000L);}}@Overridepublic void processElement2(Tuple4<String, String, String, Long> value, Context ctx, Collector<String> out) throws Exception {if (appEventState.value() != null){out.collect("对账成功:" + appEventState.value() + " " + value);// 清空状态appEventState.clear();} else {// 更新状态thirdPartyEventState.update(value);// 注册一个5秒后的定时器,开始等待另一条流的事件ctx.timerService().registerEventTimeTimer(value.f3 + 5000L);}}@Overridepublic void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {// 定时器触发,判断状态,如果某个状态不为空,说明另一条流中事件没来if (appEventState.value() != null) {out.collect("对账失败:" + appEventState.value() + " " + "第三方支付平台信息未到");}if (thirdPartyEventState.value() != null) {out.collect("对账失败:" + thirdPartyEventState.value() + " " + "app信息未到");}appEventState.clear();thirdPartyEventState.clear();}}}广播连接流(BroadcatConnectedStream)
DataStream在调用connect()时传入的参数可以不是一个DataStream,而是一个广播流(BroadcastStream),这是合并两条流,得到的就是一个广播连接流(BroadcastConnectedStream),比较实用动态定义规则或配置的场景。下游算子收到广播规则后吧保存为状态。这就是广播状态。
广播状态底层是一个映射(map)结构来保存的。可以直接DataStream.broadcast()方法调用;
// 一个 map descriptor,它描述了用于存储规则名称与规则本身的 map 存储结构
MapStateDescriptor<String, Rule> ruleStateDescriptor = new MapStateDescriptor<>("RulesBroadcastState",BasicTypeInfo.STRING_TYPE_INFO,TypeInformation.of(new TypeHint<Rule>() {}));// 广播流,广播规则并且创建 broadcast state
BroadcastStream<Rule> ruleBroadcastStream = ruleStream.broadcast(ruleStateDescriptor);//使用
DataStream<String> output = colorPartitionedStream.connect(ruleBroadcastStream).process(// KeyedBroadcastProcessFunction 中的类型参数表示:// 1. key stream 中的 key 类型// 2. 非广播流中的元素类型// 3. 广播流中的元素类型// 4. 结果的类型,在这里是 stringnew KeyedBroadcastProcessFunction<Color, Item, Rule, String>() {// 模式匹配逻辑});为了关联一个非广播流(keyed 或者 non-keyed)与一个广播流(BroadcastStream),我们可以调用非广播流的方法 connect(),并将 BroadcastStream 当做参数传入。 这个方法的返回参数是 BroadcastConnectedStream,具有类型方法 process(),传入一个特殊的 CoProcessFunction 来书写我们的模式识别逻辑。 具体传入 process() 的是哪个类型取决于非广播流的类型:
- 如果流是一个 keyed 流,那就是
KeyedBroadcastProcessFunction类型; - 如果流是一个 non-keyed 流,那就是
BroadcastProcessFunction类型。
BroadcastProcessFunction 和 KeyedBroadcastProcessFunction
在传入的 BroadcastProcessFunction 或 KeyedBroadcastProcessFunction 中,我们需要实现两个方法。processBroadcastElement() 方法负责处理广播流中的元素,processElement() 负责处理非广播流中的元素。 两个子类型定义如下:
public abstract class BroadcastProcessFunction<IN1, IN2, OUT> extends BaseBroadcastProcessFunction {public abstract void processElement(IN1 value, ReadOnlyContext ctx, Collector<OUT> out) throws Exception;public abstract void processBroadcastElement(IN2 value, Context ctx, Collector<OUT> out) throws Exception;
}
public abstract class KeyedBroadcastProcessFunction<KS, IN1, IN2, OUT> {public abstract void processElement(IN1 value, ReadOnlyContext ctx, Collector<OUT> out) throws Exception;public abstract void processBroadcastElement(IN2 value, Context ctx, Collector<OUT> out) throws Exception;public void onTimer(long timestamp, OnTimerContext ctx, Collector<OUT> out) throws Exception;
}基于时间的合流 -双流联结
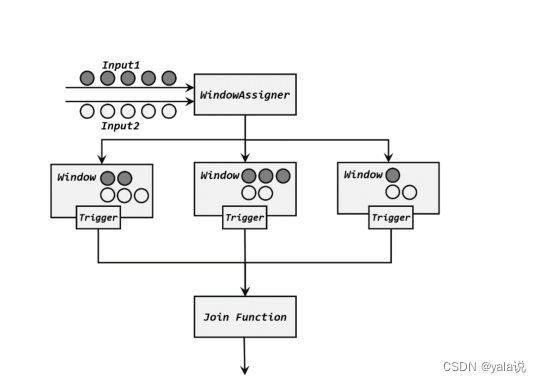
窗口连接(windowjoin)
flink内置的join算子,join()和coGroup(),适用于窗口统计的,不用再进行自定义触发器,简化了开发逻辑; 等同于sql的inner join on 或 select * from table1 t1,table2 t2 where t1.id=t2.id
wehre()和 equalTo()方法制定两条流中连接的key;然后通过window()开窗口,并调用apply()传入自连接窗口函数进行计算,
stream.join(otherStream).where(<KeySelector>) //stream的key.equalTo(<KeySelector>) //otherStream的key.window(<WindowAssigner>).apply(<JoinFunction>)//案例stream1.join(stream2).where(r -> r.f0).equalTo(r -> r.f0).window(TumblingEventTimeWindows.of(Time.seconds(5))).apply(new JoinFunction<Tuple2<String, Long>, Tuple2<String, Long>, String>() {@Overridepublic String join(Tuple2<String, Long> left, Tuple2<String, Long> right) throws Exception {return left + "=>" + right;}}).print();join function 不是真正的窗口函数,只是定义了窗口函数在调用是对匹配数据额具体处理逻辑。
@Public
@FunctionalInterface
public interface JoinFunction<IN1, IN2, OUT> extends Function, Serializable {/*** The join method, called once per joined pair of elements.** @param first The element from first input.* @param second The element from second input.* @return The resulting element.* @throws Exception This method may throw exceptions. Throwing an exception will cause the* operation to fail and may trigger recovery.*/OUT join(IN1 first, IN2 second) throws Exception;
}
join时数据先按照key进行分组、进入对应的窗口存储,当窗口结束时,算子会先统计出窗口内两条流的数据所有组合,即做一个笛卡尔积;然后进行遍历传入joinfunction的join方法中
出了JoinFunction,在apply方法中还可以闯入FlatJoinFunction,使用方法类似,区别是内部join实现犯法没有返回值,使用收集器来实现。
间隔联结(Interval join)
间隔联结需要设定两个时间点,对应上界(upperBound)和下届(lowerBound),对于同一条流A的任意一个元素a,开辟一段时间间隔[a.timestamp+lowerBound,a.timestamp+upperBound],即开辟以a为中心,上下届点为边界的一个闭区间,相当于窗口。对于另外一条流B中的元素b,如果时间戳b.timestamp>=a.timestamp+lowerBound and b.timestamp<=a.timestamp+upperBoundm 那么a和b就可以匹配上;
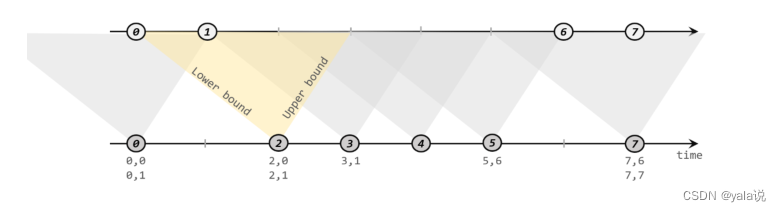
调用:
orderStream.keyBy(data -> data.f0).intervalJoin(clickStream.keyBy(data -> data.user)).between(Time.seconds(-5), Time.seconds(10)).process(new ProcessJoinFunction<Tuple3<String, String, Long>, Event, String>() {@Overridepublic void processElement(Tuple3<String, String, Long> left, Event right, Context ctx, Collector<String> out) throws Exception {out.collect(right + " => " + left);}}).print();窗口同组联结(window CoGroup)
使用与join相同。将window的join替换成cogroup即可。与join不同是,cogroup传递的一个可以遍历的集合,没有做笛卡尔积。出了实现inner join还可以实现左外连接,右外连接,全外连接。
并且窗口联结底层也是通过同组联结实现
stream1.coGroup(stream2).where(r -> r.f0).equalTo(r -> r.f0).window(TumblingEventTimeWindows.of(Time.seconds(5))).apply(new CoGroupFunction<Tuple2<String, Long>, Tuple2<String, Long>, String>() {//与join 区别是参数非单个元素,而是遍历集合@Overridepublic void coGroup(Iterable<Tuple2<String, Long>> iter1, Iterable<Tuple2<String, Long>> iter2, Collector<String> collector) throws Exception {collector.collect(iter1 + "=>" + iter2);}}).print();窗口联结地城代码
stream1.join(stream2).where(r -> r.f0).equalTo(r -> r.f0).window(TumblingEventTimeWindows.of(Time.seconds(5))).apply(new JoinFunction<Tuple2<String, Long>, Tuple2<String, Long>, String>() {@Overridepublic String join(Tuple2<String, Long> left, Tuple2<String, Long> right) throws Exception {return left + "=>" + right;}}).print();==================查看apply源码================public <T> DataStream<T> apply(JoinFunction<T1, T2, T> function) {TypeInformation<T> resultType =TypeExtractor.getBinaryOperatorReturnType(function,JoinFunction.class,0,1,2,TypeExtractor.NO_INDEX,input1.getType(),input2.getType(),"Join",false);// 继续点击apply 查看源码return apply(function, resultType);}public <T> DataStream<T> apply(JoinFunction<T1, T2, T> function, TypeInformation<T> resultType) {// clean the closurefunction = input1.getExecutionEnvironment().clean(function);//源码使用coGroup,继续点击cocoGroupedWindowedStream =input1.coGroup(input2).where(keySelector1).equalTo(keySelector2).window(windowAssigner).trigger(trigger).evictor(evictor).allowedLateness(allowedLateness);// 点击查看实现的JoinCoGroupFunction源码return coGroupedWindowedStream.apply(new JoinCoGroupFunction<>(function), resultType);}
===========查看实现JoinCoGroupFunction,源码中将两个集合做笛卡尔积 ===========================public JoinCoGroupFunction(JoinFunction<T1, T2, T> wrappedFunction) {super(wrappedFunction);}@Overridepublic void coGroup(Iterable<T1> first, Iterable<T2> second, Collector<T> out)throws Exception {for (T1 val1 : first) {for (T2 val2 : second) {out.collect(wrappedFunction.join(val1, val2));}}}}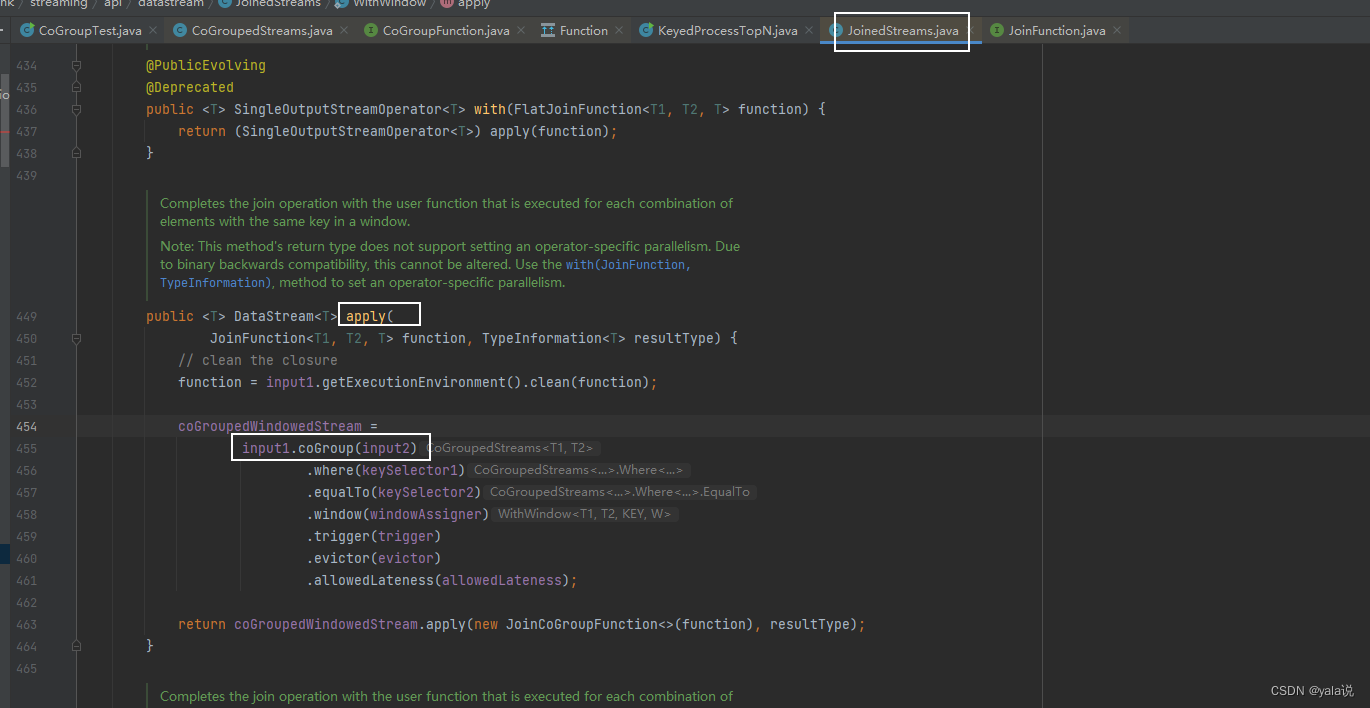
相关文章:
flink 处理函数和流转换
目录 处理函数分类 概览介绍 KeydProcessFunction和ProcessFunction 定时器TimeService 窗口处理函数 多流转换 分流-侧输出流 合流 联合(Uniion) 连接(connect) 广播连接流(BroadcatConnectedStream…...
详细分析Springmvc中的@ModelAttribute基本知识(附Demo)
目录 前言1. 注解用法1.1 方法参数1.2 方法1.3 类 2. 注解场景2.1 表单参数2.2 AJAX请求2.3 文件上传 3. 实战4. 总结 前言 将请求参数绑定到模型对象上,或者在请求处理之前添加模型属性 可以在方法参数、方法或者类上使用 一般适用这几种场景: 表单…...

和利时SIS安全系统模块SGM210 SGM210-A02
和利时SIS安全系统模块SGM210 SGM210-A02 阀门定位器:(福克斯波罗, YTC,山武) PLC:(西门子,施耐德,ABB,AB,三菱,欧姆龙) 泵阀:(力士…...
浔川3样AI产品即将上线!——浔川总社部
浔川3样AI产品即将上线! 浔川AI翻译v3.0 即将上线! 浔川画板v5.1 即将上线! 浔川AI五子棋v1.4 即将上线! 整体通告详见:浔川AI五子棋(改进(完整)版1.3)——浔川python社…...

小阿轩yx-MySQL索引、事务
小阿轩yx-MySQL索引、事务 MySQL 索引介绍 是一个排序的列表,存储着索引的值和包含这个值的数据所在行的物理地址数据很多时,索引可以大大加快查询的速度使用索引后可以不用扫描全表来定位某行的数据而是先通过索引表找到该行数据对应的物理地址然后访…...

搞定求职难题:工作岗位列表+简历制作工具 | 开源专题 No.75
SimplifyJobs/New-Grad-Positions Stars: 8.5k License: NOASSERTION 这个项目是一个用于分享和跟踪美国、加拿大或远程职位的软件工作机会列表。该项目的核心优势和关键特点如下: 自动更新新岗位信息便捷地提交问题进行贡献提供一键申请选项 BartoszJarocki/cv…...
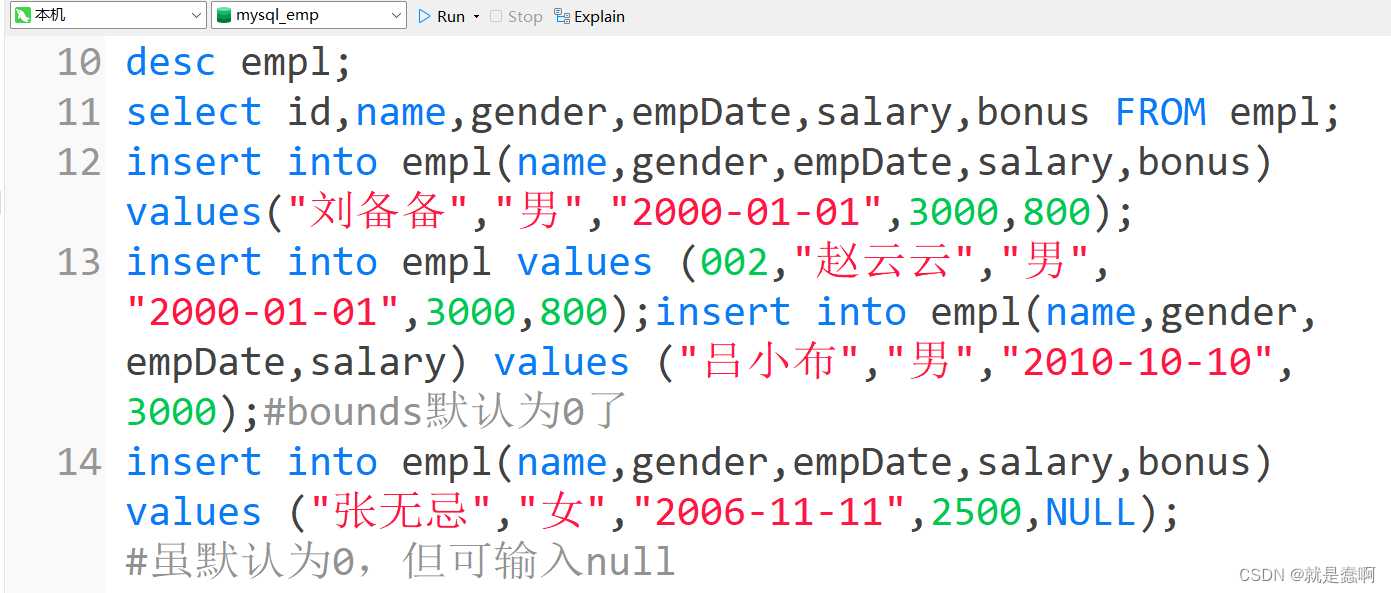
JavaWeb——MySQL数据库:约束
目录 1. 约束 1.1 概念: 1.2 分类: 1.3 使用: 1.4 外键约束; 1.5 总结 数据库:数据库都有约束,数据库设计,多表查询,事物这四方面的知识; 我们先按这个顺序进行学习ÿ…...
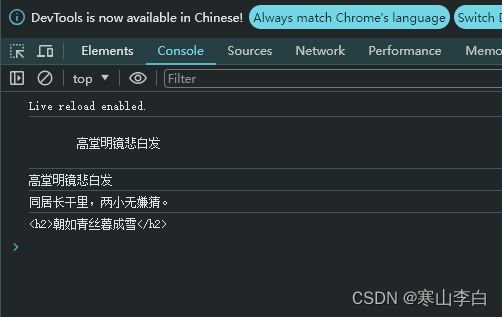
JS(JavaScript)入门指南(DOM、事件处理、BOM、数据校验)
天行健,君子以自强不息;地势坤,君子以厚德载物。 每个人都有惰性,但不断学习是好好生活的根本,共勉! 文章均为学习整理笔记,分享记录为主,如有错误请指正,共同学习进步。 玉阶生白露,夜久侵罗袜。 却下水晶帘,玲珑望秋月。 ——《玉阶怨》 文章目录 一、DOM操作1. D…...
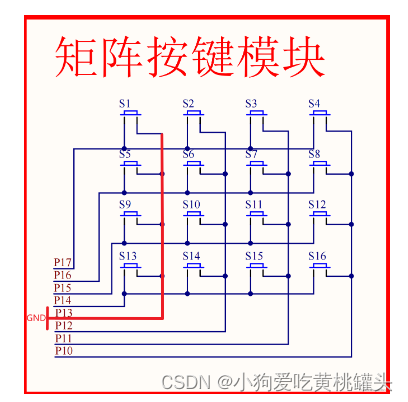
江协科技51单片机学习- p16 矩阵键盘
🚀write in front🚀 🔎大家好,我是黄桃罐头,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流 🎁欢迎各位→点赞👍 收藏⭐️ 留言📝…...

grpc学习golang版( 四、多服务示例)
系列文章目录 第一章 grpc基本概念与安装 第二章 grpc入门示例 第三章 proto文件数据类型 第四章 多服务示例 文章目录 一、前言二、定义proto文件三、编写server服务端四、编写Client客户端五、测试六、示例代码 一、前言 多服务,即一个rpc提供多个服务给外界调用…...

Linux安装jdk17
我们进入到cd /usr/lib/下然后创建一个jdk17的文件夹 mkdir jdk17 进入到jdk17目录下 下载jdk17包 上传到Linux 解压jar包 tar -zxvf jdk-17_linux-x64_bin.tar.gz压解完毕后 配置环境变量 vim/etc/profilei 修改 esc 退出 :wq保存 export JAVA_HOME/usr/lib/jdk17/jdk-1…...
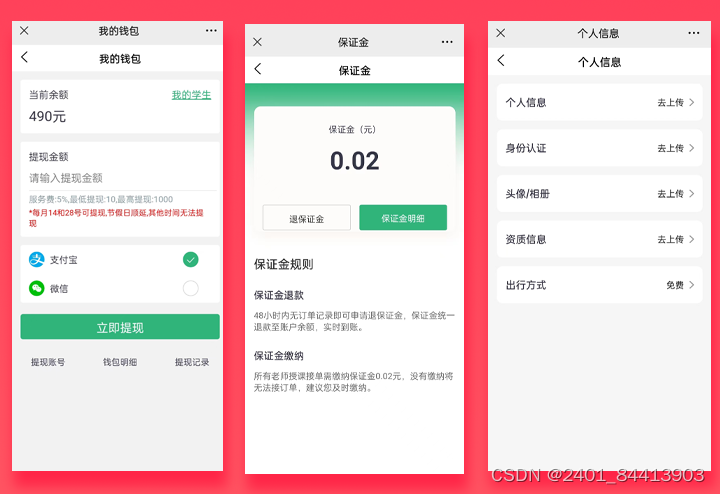
Java家教系统小程序APP公众号h5源码
让学习更高效,更便捷 🌟 引言:家教新选择,小程序来助力 在快节奏的现代生活中,家长们越来越注重孩子的教育问题。然而,如何为孩子找到一位合适的家教老师,成为了许多家长头疼的问题。现在&…...
PHP入门
一、环境搭建 无脑: 小皮面板(phpstudy) - 让天下没有难配的服务器环境!phpStudy官网2019正式推出phpStudy V8.0版本PHP集成环境,支持Windows与Linux系统,支持WEB面板操作管理,一键网站开发环境搭建配置,…...

docker ce的使用介绍
docker docker17.03以后 docker ce,社区免费版,vscode的docker插件使用的该版本(默认windows只支持windows容器,linux支持linux容器)docker ee,企业版本 docker17.03以前 docker toolbox,基于…...
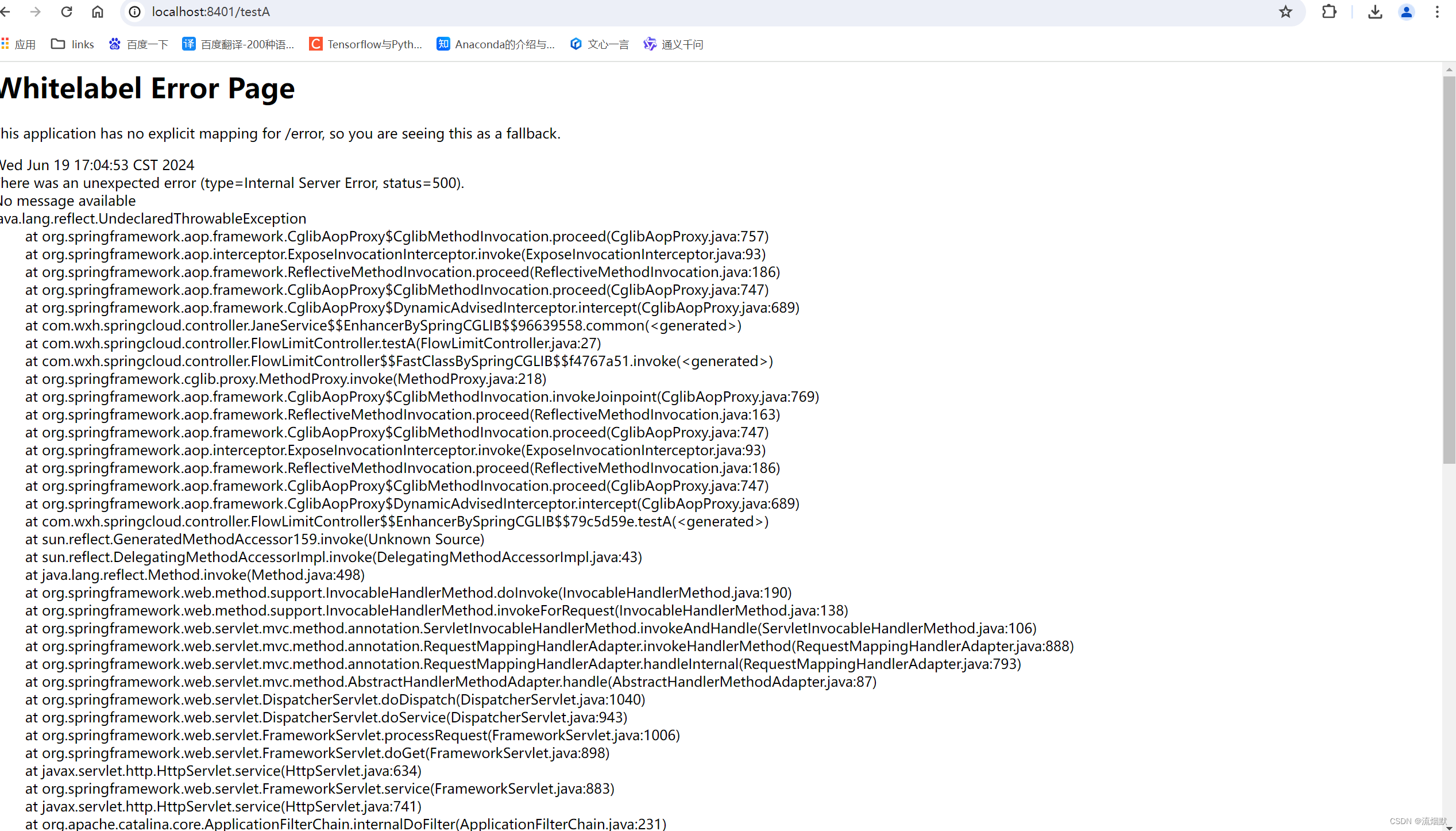
SpringCloud Alibaba Sentinel 流量控制之流控模式实践总结
官网文档:https://sentinelguard.io/zh-cn/docs/flow-control.html wiki地址:https://github.com/alibaba/Sentinel/wiki/%E6%B5%81%E9%87%8F%E6%8E%A7%E5%88%B6 本文版本:spring-cloud-starter-alibaba:2.2.0.RELEASE 如下图所…...

【高考志愿】电子科学与技术
高考志愿选择电子科学与技术专业,无疑是向着科技创新的前沿迈出坚定步伐的明智之选。这一专业以其深厚的理论基础、前沿的技术应用和广泛的就业前景,吸引了众多有志于投身科技领域的学子。 首先,电子科学与技术专业所涵盖的内容丰富而深入。它…...
【AI增强版】)
2024.06.26【读书笔记】|医疗科技创新流程(前言)【AI增强版】
目录 《BIODESIGN》第二版前言详细总结前言概述新增重要内容价值导向 (Value Orientation)全球视角 (Global Perspectives)更好的教学和学习方法 (Better Ways to Teach and Learn)全新视频集合 (New Videos)扩展的“实地”案例研究 (Expanded “From the Field” Case Studies…...

kubernetes Job yaml文件解析
一、yaml文件示例 apiVersion: batch/v1 kind: Job metadata:name: test-jobnamespace: mtactor spec:completions: 3parallelism: 1backoffLimit: 5activeDeadlineSeconds: 100template:spec:containers:- name: test-jobimage: centoscommand: ["echo","test…...

php goto解密脚本源码
php goto解密脚本源码 源码下载:https://download.csdn.net/download/m0_66047725/89426171 更多资源下载:关注我。...

2023: 芒种集•序言
2023: 芒种集•序言 2023: 芒种集•序言 从西南旅游回来,一直忙着整理游记“2024:追寻红色足迹”,之后又应初建平索要刘桂蓉遗作“我们一起走过”,于是把“别了,老屋”和诗作“二月”一并合编,把我写的悼念…...

导师在地铁改博士论文被拍,网友:“他边看边挠头,越看越发愁”。。。
点击下方卡片,关注“CVer”公众号AI/CV重磅干货,第一时间送达点击进入—>【顶会/顶刊】投稿交流群添加微信号:CVer2233,小助手拉你进群!扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶…...

2026 年 3 月 15 日刷题
今天的题目是有关 BFS 广度优先搜索的。BFS 可以理解是从树的顶端一层一层往下逐层遍历。维护一个队列,在遍历过程中不断加入符合要求的元素,最后当队列为空时返回。207 课程表这道题目是拓扑排序,就是将一张有向无环图按照层次来遍历&#x…...

Agent社会实验室
当你的分身开始社交,会发生什么? Social Mirror 晚间即将震撼发布~ 知乎 x Second Me 全球A2A黑客松...

打开CATIA模型发现有个诡异破面?别慌,这几乎是每个工程师第一次做多软件联动的必修课。咱们今天直接上手实操,用APDL命令流暴力解决模型转换的坑
catia模型转入ansys进行静力学仿真分析从CATIA导出.step文件时记得勾选"缝合曲面"选项(这步能避免80%的破面问题)。导入ANSYS Workbench别急着点鼠标,直接进Mechanical点右键选"Export to MAPDL"生成CDB文件——这比中间…...

全志V3S嵌入式Linux开发板设计与网络启动实践
1. 项目概述全志V3S是一款面向嵌入式Linux应用的低成本、低功耗SoC芯片,采用ARM Cortex-A7单核架构,主频最高可达1.2GHz,集成Video Engine视频编解码引擎、MIPI CSI-2摄像头接口、RGB/LVDS显示接口、内置百兆以太网PHY、USB 2.0 OTG控制器及丰…...

智慧校园系统价格解析:如何看懂报价背后的逻辑与选择适合自己的方案?
✅作者简介:合肥自友科技 📌核心产品:智慧校园平台(包括教工管理、学工管理、教务管理、考务管理、后勤管理、德育管理、资产管理、公寓管理、实习管理、就业管理、离校管理、科研平台、档案管理、学生平台等26个子平台) 。公司所有人员均有多…...

基于双dq变换的六相永磁同步电机矢量控制仿真、附参考文献
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室👇 关注我领取海量matlab电子书和…...

WebAssembly技术终极指南:浏览器中运行Python的完整解决方案
WebAssembly技术终极指南:浏览器中运行Python的完整解决方案 【免费下载链接】pyodide Pyodide is a Python distribution for the browser and Node.js based on WebAssembly 项目地址: https://gitcode.com/gh_mirrors/py/pyodide Pyodide是一个基于WebAss…...

自动化测试框架从入门到落地:架构设计、实操实现与效率优化
摘要:在软件迭代速度日益加快的今天,手动测试已难以满足高频迭代、多环境适配的测试需求,自动化测试框架成为测试工程师的核心必备技能。本文从自动化测试框架的核心价值出发,拆解经典架构设计、实操实现流程,结合Pyth…...

东华Oj101-103
101. 找出质数 作者: SunCiHai 时间限制: 10s 章节: 字符串 问题描述 明明学习数学已经有一段时间了。一次老师在课上讲了什么叫质数。质数就是大于等于2且只能被1和其本身整除的整数。明明觉得这很简单,以为这很容易掌握,于是就不多做练习。明的爸…...