基于堆叠长短期记忆网络 Stacked LSTM 预测A股股票价格走势

前言
系列专栏:【深度学习:算法项目实战】✨︎
涉及医疗健康、财经金融、商业零售、食品饮料、运动健身、交通运输、环境科学、社交媒体以及文本和图像处理等诸多领域,讨论了各种复杂的深度神经网络思想,如卷积神经网络、循环神经网络、生成对抗网络、门控循环单元、长短期记忆、自然语言处理、深度强化学习、大型语言模型和迁移学习。
近来,机器学习得到了长足的发展,并引起了广泛的关注,其中语音和图像识别领域的成果最为显著。本研究论文分析了深度学习方法–长短期记忆神经网络(LSTM)–在A股市中的表现。论文显示,虽然这种技术在语音识别等其他领域取得了不错的成绩,但在应用于金融数据时却表现不佳。事实上,金融数据的特点是噪声信号比高,这使得机器学习模型难以找到模式并预测未来价格。
本文不对LSTM模型过多介绍,只探讨Stacked LSTM在A股中的表现,以及模型调参与性能优化。本研究文章的结构如下。第一节介绍金融时间序列数据。第二部分介绍金融时间数据的特征过程。第三部分是构建模型、定义参数空间、损失函数与优化器。第四部分是模型评估与结果可视化。第五部分是预测下一个时间点的收盘价。
目录
- 1. 金融时间序列数据
- 1.1 获取股票每日价格数据
- 1.2 观察股票收盘价格趋势
- 2. 时间数据特征工程
- 2.1 构造序列数据
- 2.2 特征缩放(归一化)
- 2.3 数据集划分(TimeSeriesSplit)
- 3. 时间序列模型构建(Stacked LSTM)
- 3.1 构建模型
- 3.2 定义参数空间
- 3.3 验证损失与调参循环
- 3.4 最佳模型输出与保存
- 4. 模型评估与可视化
- 4.1 均方误差
- 4.2 反归一化
- 4.3 结果验证(可视化)
- 5. 模型预测
- 5.1 预测下一个时间点的收盘价
1. 金融时间序列数据
金融时间序列数据是指按照时间顺序记录的各种金融指标的数值序列,这些指标包括但不限于股票价格、汇率、利率等。这些数据具有以下几个显著特点:
- 时间连续性:数据按照时间的先后顺序排列,反映了金融市场的动态变化过程。
- 噪声和不确定性:金融市场受到多种复杂因素的影响,因此数据中存在大量噪声和不确定性。
- 非线性和非平稳性:金融时间序列数据通常呈现出明显的非线性和非平稳性特征。
import numpy as np
import pandas as pdfrom pytdx.hq import TdxHq_APIimport plotly.graph_objects as gofrom sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import TimeSeriesSplit
from sklearn.model_selection import ParameterSamplerfrom keras.models import Sequential
from keras.layers import Input, Dense, LSTM, Dropout
from keras.metrics import RootMeanSquaredError
from keras.optimizers import Adam
1.1 获取股票每日价格数据
首先,让我们使用 TdxHq_API() 函数获取股票价格
api = TdxHq_API()
with api.connect('119.147.212.81', 7709):df = api.to_df(api.get_security_bars(9, 1, '600584', 0, 800))print(df)
open close high low vol amount year month day \
0 41.01 39.60 41.29 39.60 432930.0 1.735115e+09 2021 2 25
1 38.63 39.56 39.56 38.51 398273.0 1.553533e+09 2021 2 26
2 39.71 40.47 40.59 39.15 382590.0 1.530225e+09 2021 3 1
3 41.17 40.30 41.26 39.90 334984.0 1.358569e+09 2021 3 2
4 40.20 40.80 40.92 39.38 325774.0 1.306173e+09 2021 3 3
.. ... ... ... ... ... ... ... ... ...
795 29.15 29.05 29.29 28.68 489791.0 1.418345e+09 2024 6 14
796 29.05 31.28 31.90 28.75 980331.0 2.989219e+09 2024 6 17
797 31.20 31.40 31.41 30.81 580956.0 1.811908e+09 2024 6 18
798 31.30 31.75 32.02 31.05 739795.0 2.341768e+09 2024 6 19
799 31.30 31.08 31.88 30.93 530154.0 1.660881e+09 2024 6 20 hour minute datetime
0 15 0 2021-02-25 15:00
1 15 0 2021-02-26 15:00
2 15 0 2021-03-01 15:00
3 15 0 2021-03-02 15:00
4 15 0 2021-03-03 15:00
.. ... ... ...
795 15 0 2024-06-14 15:00
796 15 0 2024-06-17 15:00
797 15 0 2024-06-18 15:00
798 15 0 2024-06-19 15:00
799 15 0 2024-06-20 15:00 [800 rows x 12 columns]
1.2 观察股票收盘价格趋势
接下来,使用 go.Scatter() 函数绘制股票价格趋势
fig = go.Figure([go.Scatter(x=df['datetime'], y=df['close'])])
fig.update_layout(title={'text': 'Close Price History', 'font_size': 24, 'font_family': 'Comic Sans MS', 'font_color': '#454545'},xaxis_title={'text': '', 'font_size': 18, 'font_family': 'Courier New', 'font_color': '#454545'},yaxis_title={'text': 'Close Price CNY', 'font_size': 18, 'font_family': 'Lucida Console', 'font_color': '#454545'},xaxis_tickfont=dict(color='#663300'), yaxis_tickfont=dict(color='#663300'), width=900, height=500,plot_bgcolor='#F2F2F2', paper_bgcolor='#F2F2F2',
)
fig.show()

2. 时间数据特征工程
# 设置时间窗口大小
window_size = 180
2.1 构造序列数据
若在收盘之前运行,则最后一个测试price不准确,range中长度最好再减1
# 构造序列数据
def create_dataset(dataset, look_back=1):X, Y = [], []for i in range(len(dataset)-look_back):a = dataset[i:(i+look_back), 0]X.append(a)Y.append(dataset[i + look_back, 0])return np.array(X), np.array(Y)
2.2 特征缩放(归一化)
MinMaxScaler() 函数主要用于将特征数据按比例缩放到指定的范围。默认情况下,它将数据缩放到[0, 1]区间内,但也可以通过参数设置将数据缩放到其他范围。在机器学习中,MinMaxScaler()函数常用于不同尺度特征数据的标准化,以提高模型的泛化能力
# 归一化数据
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(df['close'].values.reshape(-1, 1))
# 创建数据集
X, y = create_dataset(scaled_data, look_back=window_size)
# 重塑输入数据为[samples, time steps, features]
X = np.reshape(X, (X.shape[0], X.shape[1], 1))
2.3 数据集划分(TimeSeriesSplit)
TimeSeriesSplit() 函数与传统的交叉验证方法不同,TimeSeriesSplit 特别适用于需要考虑时间顺序的数据集,因为它确保测试集中的所有数据点都在训练集数据点之后,并且可以分割多个训练集和测试集。
# 使用TimeSeriesSplit划分数据集,根据需要调整n_splits
tscv = TimeSeriesSplit(n_splits=3, test_size=30)
# 遍历所有划分进行交叉验证
for i, (train_index, test_index) in enumerate(tscv.split(X)):X_train, X_test = X[train_index], X[test_index]y_train, y_test = y[train_index], y[test_index]# print(f"Fold {i}:")# print(f" Train: index={train_index}")# print(f" Test: index={test_index}")
这里我们使用最后一个 fold
X_train.shape, X_test.shape, y_train.shape, y_test.shape
((590, 180, 1), (30, 180, 1), (590,), (30,))
3. 时间序列模型构建(Stacked LSTM)
Stacked LSTM,即堆叠长短期记忆网络,是一种深度学习的模型架构,由多个LSTM层堆叠而成。这种架构使得模型能够学习并提取输入序列数据的不同级别的特征,从而提高预测的准确性。
3.1 构建模型
# 定义模型构建函数
def LSTMRegressor(lstm_units, dropout_rate, learning_rate):model = Sequential()model.add(Input(shape=(X_train.shape[1], X_train.shape[2])))model.add(LSTM(lstm_units, return_sequences=True))model.add(Dropout(dropout_rate))model.add(LSTM(lstm_units, return_sequences=True))model.add(Dropout(dropout_rate))model.add(LSTM(lstm_units))model.add(Dropout(dropout_rate))model.add(Dense(60))model.add(Dropout(dropout_rate))model.add(Dense(1)) # 线性回归层opt = Adam(learning_rate=learning_rate)model.compile(optimizer=opt, loss='mean_squared_error')return model
3.2 定义参数空间
使用 ParameterSampler 可以为随机搜索定义参数的分布,却不像网格搜索那样指定所有可能的参数组合。
# 定义参数空间
param_grid = {'lstm_units': [32, 64, 128],'dropout_rate': [0.2, 0.3, 0.4],'learning_rate': [0.001, 0.0001]
}
# 使用ParameterSampler生成参数组合
param_list = list(ParameterSampler(param_grid, n_iter=len(param_grid['lstm_units']) * len(param_grid['dropout_rate']) * len(param_grid['learning_rate']), random_state=42)
)
3.3 验证损失与调参循环
# 初始化最佳验证损失和最佳模型
best_val_loss = float('inf')
best_model = None
# 调参循环
for params in param_list:print(f"Trying parameters: {params}")model = LSTMRegressor(**params)# 训练模型(这里仅使用一部分epoch作为示例)history = model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_test, y_test), verbose=0)# 计算验证集上的损失val_loss = history.history['val_loss'][-1]# 如果当前模型的验证损失比之前的好,则更新最佳模型和最佳验证损失if val_loss < best_val_loss:best_val_loss = val_lossbest_model = modelprint(f"Found better model with validation loss: {best_val_loss}")# 输出最佳模型的参数
print(f"Best model parameters: {param_list[param_list.index(params)]}")
Trying parameters: {'lstm_units': 32, 'learning_rate': 0.001, 'dropout_rate': 0.2}
Found better model with validation loss: 0.007122963201254606
Trying parameters: {'lstm_units': 64, 'learning_rate': 0.001, 'dropout_rate': 0.2}
Found better model with validation loss: 0.006877976469695568
Trying parameters: {'lstm_units': 128, 'learning_rate': 0.001, 'dropout_rate': 0.2}
Found better model with validation loss: 0.003105488372966647
Trying parameters: {'lstm_units': 32, 'learning_rate': 0.0001, 'dropout_rate': 0.2}
Trying parameters: {'lstm_units': 64, 'learning_rate': 0.0001, 'dropout_rate': 0.2}
Trying parameters: {'lstm_units': 128, 'learning_rate': 0.0001, 'dropout_rate': 0.2}
Trying parameters: {'lstm_units': 32, 'learning_rate': 0.001, 'dropout_rate': 0.3}
Trying parameters: {'lstm_units': 64, 'learning_rate': 0.001, 'dropout_rate': 0.3}
Trying parameters: {'lstm_units': 128, 'learning_rate': 0.001, 'dropout_rate': 0.3}
Trying parameters: {'lstm_units': 32, 'learning_rate': 0.0001, 'dropout_rate': 0.3}
Trying parameters: {'lstm_units': 64, 'learning_rate': 0.0001, 'dropout_rate': 0.3}
Trying parameters: {'lstm_units': 128, 'learning_rate': 0.0001, 'dropout_rate': 0.3}
Trying parameters: {'lstm_units': 32, 'learning_rate': 0.001, 'dropout_rate': 0.4}
Trying parameters: {'lstm_units': 64, 'learning_rate': 0.001, 'dropout_rate': 0.4}
Trying parameters: {'lstm_units': 128, 'learning_rate': 0.001, 'dropout_rate': 0.4}
Trying parameters: {'lstm_units': 32, 'learning_rate': 0.0001, 'dropout_rate': 0.4}
Trying parameters: {'lstm_units': 64, 'learning_rate': 0.0001, 'dropout_rate': 0.4}
Trying parameters: {'lstm_units': 128, 'learning_rate': 0.0001, 'dropout_rate': 0.4}
Best model parameters: {'lstm_units': 128, 'learning_rate': 0.0001, 'dropout_rate': 0.4}
3.4 最佳模型输出与保存
best_model.summary()
Model: "sequential_2"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ lstm_6 (LSTM) │ (None, 180, 128) │ 66,560 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_8 (Dropout) │ (None, 180, 128) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ lstm_7 (LSTM) │ (None, 180, 128) │ 131,584 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_9 (Dropout) │ (None, 180, 128) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ lstm_8 (LSTM) │ (None, 128) │ 131,584 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_10 (Dropout) │ (None, 128) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_4 (Dense) │ (None, 60) │ 7,740 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_11 (Dropout) │ (None, 60) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_5 (Dense) │ (None, 1) │ 61 │
└──────────────────────────────────────┴─────────────────────────────┴─────────────────┘Total params: 1,012,589 (3.86 MB)Trainable params: 337,529 (1.29 MB)Non-trainable params: 0 (0.00 B)Optimizer params: 675,060 (2.58 MB)
使用 .save() 函数保存最佳模型
# 保存最佳模型
# best_model.save('best_model.h5')
4. 模型评估与可视化
4.1 均方误差
使用均方误差 mean_squared_error() 评估模型性能
from sklearn.metrics import mean_squared_error
# 使用最佳模型进行预测
trainPredict = best_model.predict(X_train)
testPredict = best_model.predict(X_test)
mse = mean_squared_error(y_test, testPredict)
print(f"Test MSE: {mse}")
19/19 ━━━━━━━━━━━━━━━━━━━━ 2s 105ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 94ms/step
Test MSE: 0.0031054877469655923
4.2 反归一化
# 反归一化预测结果
trainPredict = scaler.inverse_transform(trainPredict)
y_train = scaler.inverse_transform([y_train])
testPredict = scaler.inverse_transform(testPredict)
y_test = scaler.inverse_transform([y_test])
4.3 结果验证(可视化)
# 计算绘图数据
train = df[:X_train.shape[0]+X_train.shape[1]]
valid = df[X_train.shape[0]+X_train.shape[1]:]
valid = valid.assign(predictions=testPredict)
# 可视化数据
fig = go.Figure([go.Scatter(x=train['datetime'], y=train['close'],name='Train')])
fig.add_trace(go.Scatter(x=valid['datetime'],y=valid['close'],name='Test'))
fig.add_trace(go.Scatter(x=valid['datetime'],y=valid['predictions'], name='Prediction'))
fig.update_layout(title={'text': 'Close Price Validation', 'font_size': 24, 'font_family': 'Comic Sans MS', 'font_color': '#454545'},xaxis_title={'text': '', 'font_size': 18, 'font_family': 'Courier New', 'font_color': '#454545'},yaxis_title={'text': 'Close Price CNY', 'font_size': 18, 'font_family': 'Lucida Console', 'font_color': '#454545'},xaxis_tickfont=dict(color='#663300'), yaxis_tickfont=dict(color='#663300'), width=900, height=500,plot_bgcolor='#F2F2F2', paper_bgcolor='#F2F2F2',
)
fig.show()

从上图我们可以观察到预测价格存在滞后性,关于如何缓解滞后性请参考连接。1
5. 模型预测
5.1 预测下一个时间点的收盘价
# 使用模型预测下一个时间点的收盘价
# 假设latest_closes是一个包含最新window_size个收盘价的列表或数组
latest_closes = df['close'][-window_size:].values
latest_closes = latest_closes.reshape(-1, 1)
scaled_latest_closes = scaler.fit_transform(latest_closes)
latest_closes_reshape = scaled_latest_closes.reshape(1, window_size, 1)
next_close_pred = best_model.predict(latest_closes_reshape)
next_close_pred = scaler.inverse_transform(next_close_pred)
next_close_pred
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 31ms/step
array([[30.284128]], dtype=float32)
本文仅用于深度学习科学实验和教育目的,并非投资建议
LSTM从理论基础到代码实战 5 关于lstm预测滞后性的讨论 ↩︎
相关文章:
基于堆叠长短期记忆网络 Stacked LSTM 预测A股股票价格走势
前言 系列专栏:【深度学习:算法项目实战】✨︎ 涉及医疗健康、财经金融、商业零售、食品饮料、运动健身、交通运输、环境科学、社交媒体以及文本和图像处理等诸多领域,讨论了各种复杂的深度神经网络思想,如卷积神经网络、循环神经网络、生成对…...
SpringCloud Alibaba Sentinel基础入门与安装
GitHub地址:https://github.com/alibaba/Sentinel 中文文档:https://sentinelguard.io/zh-cn/docs/introduction.html 下载地址:https://github.com/alibaba/Sentinel/releases Spring Cloud Alibaba 官方说明文档:Spring Clou…...
Arduino IDE下载、安装和配置
文章开始先把我自己网盘里的安装包分享给大家,链接:https://pan.baidu.com/s/1cb2_3m0LnuSKLnWP_YoWPw?pwdwwww 提取码:wwww 里面一个是Arduino IDE的安装包,另一个是即将发布的版本。 第一个安装包打开直接按照我的步骤安装就…...
SOBEL图像边缘检测器的设计
本项目使用FPGA设计出SOBEL图像边缘检测器,通过分析项目在使用过程中的工作原理和相关软硬件设计进行分析详细介绍SOBEL图像边缘检测器的设计。 资料获取可联系wechat 号:comprehensivable 边缘可定义为图像中灰度发生急剧变化的区域边界,它是图像最基本…...

Day35:2734. 执行字串操作后的字典序最小字符串
Leetcode 2734. 执行字串操作后的字典序最小字符串 给你一个仅由小写英文字母组成的字符串 s 。在一步操作中,你可以完成以下行为: 选择 s 的任一非空子字符串,可能是整个字符串,接着将字符串中的每一个字符替换为英文字母表中的前…...

【高考志愿】机械工程
目录 一、专业概述 二、学科特点 三、就业前景 四、机械工程学科排名 五、专业选择建议 高考志愿选择机械工程,这是一个需要深思熟虑的决定,因为它不仅关乎未来的学习和职业发展,更是对自我兴趣和潜能的一次重要考量。 一、专业概述 机…...

ffmpeg将mp4转换为swf
文章目录 ffmpeg安装、配置java运行报错 Cannot run program "ffmpeg" ffmpeg命令mp4转为swf示例 ### ffmpeg -i input.mkv -b:v 600 -c:v libx264 -vf scale1920:1080 -crf 10 -ar 48000 -r 24 output.swfmkv转为swf示例 其他文档命令参数简介 需要将mp4转换为swf&a…...

论文学习 --- RL Regret-based Defense in Adversarial Reinforcement Learning
前言 个人拙见,如果我的理解有问题欢迎讨论 (●′ω`●) 原文链接:https://www.ifaamas.org/Proceedings/aamas2024/pdfs/p2633.pdf 研究背景 深度强化学习(Deep Reinforcement Learning, DRL)在复杂和安全关键任务中取得了显著成果,例如自动驾驶。然而,DRL策略容易受…...

【Linux小命令】一文讲清ldd命令及使用场景
一文讲清ldd命令及使用场景 前言下面进入正题:ldd命令 前言 博主今天ubuntu编译go项目出来的一个可执行文件,放centos运行发现居然依赖于XXlib库。然后我一下就想到两个系统库版本不一致,重编。换系统,导项目,配环境……...

自费5K,测评安德迈、小米、希喂三款宠物空气净化器谁才是高性价比之王
最近,家里的猫咪掉毛严重,简直成了一个活生生的蒲公英,家中、空气中各处都弥漫着猫浮毛甚至所有衣物都覆盖着一层厚厚的猫毛。令人难以置信的是,有时我甚至在抠出的眼屎中都能发现夹杂着几根猫毛。真的超级困扰了。但其实最空气中…...

1373. 二叉搜索子树的最大键值和
Problem: 1373. 二叉搜索子树的最大键值和 文章目录 思路解题方法复杂度Code 思路 解决这个问题的关键在于采用深度优先搜索(DFS)策略,并结合树形动态规划的思想。我们需要设计一个递归函数,它不仅能够遍历整棵树,还能…...
基于java + Springboot 的二手物品交易平台实现
目录 📚 前言 📑摘要 📑系统架构 📚 数据库设计 📚 系统功能的具体实现 💬 登录模块 首页模块 二手商品轮播图添加 💬 后台功能模块 二手商品商品列表 添加二手商品商品 添加购物车 &a…...
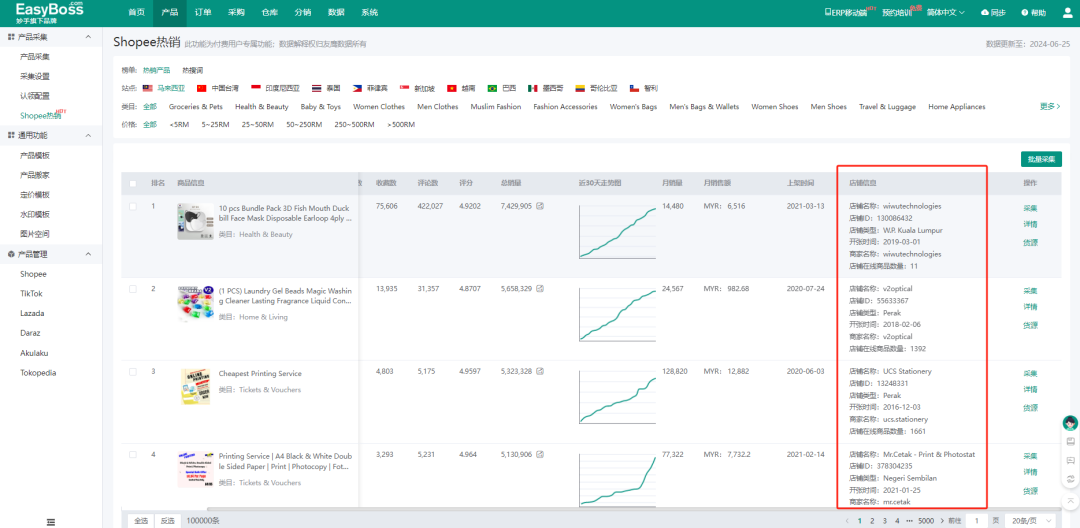
Shopee本土店选品有什么技巧?EasyBoss ERP为你整理了6个高效选品的方法!
电商圈有句话叫:七分靠选品,三分靠运营,选品对了,事半功倍,选品错了,功亏一篑! 很多卖家都会为选品发愁,特别对于Shopee本土店卖家来说,要囤货到海外仓,如果…...
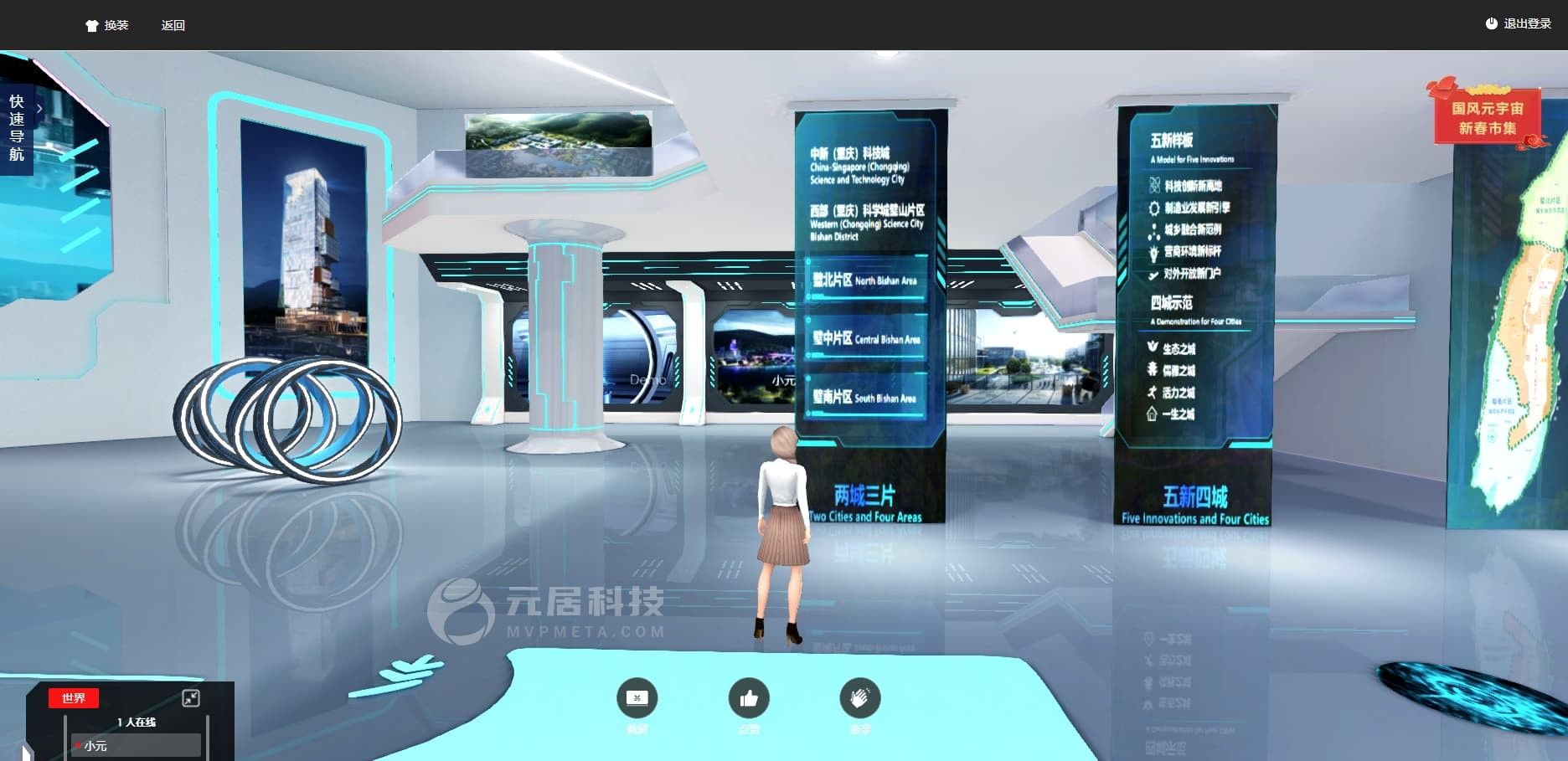
3D在线展览馆的独特魅力,技术如何重塑展览业的未来?
在数字化和虚拟现实技术迅猛发展的今天,3D在线展览馆已经成为一种颇具前景的创新形式。搭建3D在线展览馆不仅能够突破传统展览的时空限制,还能为参观者提供身临其境的体验,极大地提升展示效果和用户互动。 一、3D在线展览馆的意义 1、突破时空…...
基于SpringBoot的藏区特产销售平台
你好呀,我是计算机学姐码农小野!如果有相关需求,可以私信联系我。 开发语言: Java 数据库: MySQL 技术: SpringBoot框架 工具: MyEclipse 系统展示 首页 个人中心 特产信息管理 订单管…...
)
hudi系列-schema evolution(一)
hudi+flink在非schema on read模式下也表现出了支持一部分的schema evolution功能,本篇中测试一下在非schema on read模式下,发生各种列变更情况时数据写入与读取情况。 flink 1.14.5hudi 0.13.1mor表思路: 选择mor表是因为它的数据文件有avro和parquet两种格式,能覆盖得更…...
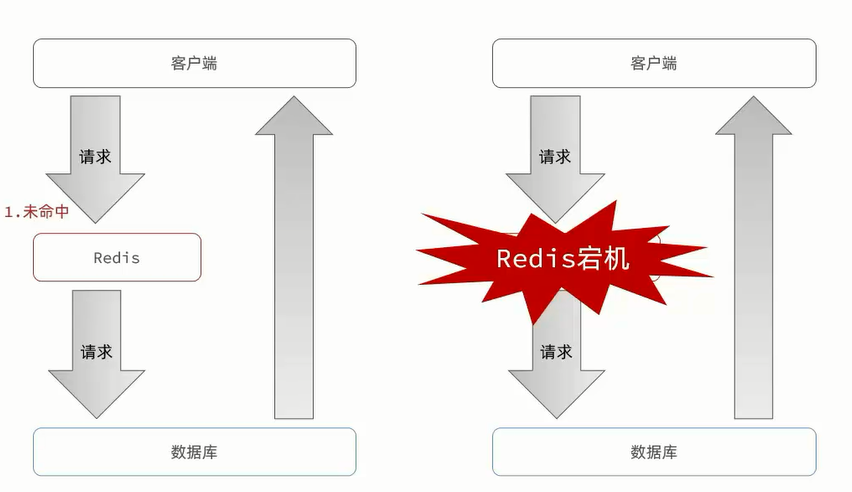
Redis-实战篇-缓存雪崩
文章目录 1、缓存雪崩2、解决方案: 1、缓存雪崩 缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。 2、解决方案: 给不同的key的TTL添加随机值利用Redis集群提高服务的可用性…...

线性代数|机器学习-P18快速下降奇异值
文章目录 1. 为什么要低秩矩阵1.1 矩阵A的秩定义1.2 矩阵压缩PCA 2. 低秩矩阵图像处理3. 秩的相关性质3.1 秩的公差轴表示3.2 Eckart-Young 定理 4. 低秩矩阵4.1 低秩矩阵描述4.2 函数低秩矩阵形式4.3通项小结4.4 函数采样拟合 5. 西尔维斯特方程5.1 希尔伯特矩阵举例5.2 范德蒙…...
本地离线模型搭建指南-中文大语言模型底座选择依据
搭建一个本地中文大语言模型(LLM)涉及多个关键步骤,从选择模型底座,到运行机器和框架,再到具体的架构实现和训练方式。以下是一个详细的指南,帮助你从零开始构建和运行一个中文大语言模型。 本地离线模型搭…...

【代码随想录】【算法训练营】【第51天】 [115]不同的子序列 [583]两个字符串的删除操作 [72]编辑距离
前言 思路及算法思维,指路 代码随想录。 题目来自 LeetCode。 day 51,周四,又是不能坚持的一天~ 题目详情 [115] 不同的子序列 题目描述 115 不同的子序列 解题思路 前提: 思路: 重点: 代码实现 …...
)
Win10下Excel数据源配置全攻略:ODBC连接保姆级教程(含常见问题解决)
Win10下Excel数据源配置全攻略:ODBC连接保姆级教程(含常见问题解决) 在数据分析与报表自动化领域,Excel作为最普及的工具之一,经常需要与其他系统进行数据交互。ODBC(开放数据库互连)技术就像一…...

洛阳万达商场美团快闪店设计,凭什么成为商圈流量密码?肆墨设计
在商业美陈从 “装饰载体” 向 “生活场景容器” 转型的当下,洛阳万达商场美团 “美事发生” 美好生活集市快闪店,以品牌 IP 为核心锚点,融合女性消费心理与地域商业特质,构建了一场兼具视觉冲击力、情感共鸣与商业转化的沉浸式空…...

弹性伸缩与高可用:重力科技智能投放平台的云原生架构实践
一、 出海营销平台:流量洪峰与全球化部署的挑战 重力科技的AI智能投放平台,作为全球出海品牌的营销利器,面临着严峻的架构挑战: 流量洪峰: 面对全球不同时区的营销活动、节假日促销、突发热点等,请求量可能…...

『NAS』老破小也能玩 AI?飞牛 NAS 部署 LocalAI
点赞 关注 收藏 学会了 💡整理了一个 NAS 专属玩法专栏,感兴趣的工友可以戳这里关注 👉 《NAS邪修》 LocalAI 是一个开源的"AI壳",它能让你在自己的硬件上(比如 NAS)离线运行各种大模型&#…...
)
图解Uboot FIT Image:its文件里的load、entry地址到底怎么填?(以i.MX8MP为例)
深入解析Uboot FIT Image:i.MX8MP平台its文件地址配置实战指南 当你在i.MX8MP平台上第一次看到FIT Image的its文件时,那些神秘的load和entry地址值是否让你感到困惑?这些看似随意的十六进制数字背后,其实隐藏着嵌入式系统启动过程…...

LTspice DC Sweep双变量扫描实操:三极管输出特性曲线与厄利电压的仿真观测指南
LTspice DC Sweep双变量扫描实操:三极管输出特性曲线与厄利电压的仿真观测指南 在电子工程领域,三极管作为基础却关键的半导体器件,其特性曲线的准确获取对电路设计至关重要。传统实验室测量方法不仅耗时耗力,还受限于设备精度和环…...

ebs-modbus:传输层无关的嵌入式Modbus状态机库
1. 项目概述ebs-modbus是一个面向嵌入式系统的、传输层无关(Transport-Agnostic)的 Modbus 协议状态机实现库。其核心设计目标并非封装特定硬件接口(如 UART、TCP/IP 或 RTU over RS-485),而是聚焦于 Modbus 协议栈的协…...

三相PWM储能变流器PCS设计与仿真:双向DCDC与三相PWM变流器的协调控制策略研究
三相PWM储能变流器PCS仿真设计 【双向DCDC三相PWM变流器】 [1]储能Buck-Boost采用电流PID控制实现双向DC/DC功能,对电池进行恒功率充电或恒功率放电;实现能量由电网与直流母线的双向流动。 [2]三相PWM变流器采用电压外环、电流内环双闭环PI控制ÿ…...
)
告别漏检!用YOLOv10+NWD搞定工业质检中的微小缺陷检测(避坑指南)
工业质检中的微小缺陷检测:YOLOv10与NWD损失函数的实战指南 在精密制造和电子元件生产线上,一个仅占几个像素的微小缺陷可能导致整批产品报废。传统检测方法面对这种挑战往往力不从心——漏检率居高不下,误检频发,产线工程师们不得…...
)
STM32F103实战:用AD9833打造可调波形信号发生器(附完整代码)
STM32F103与AD9833联袂打造高精度可编程信号发生器实战指南 在电子设计与嵌入式开发领域,信号发生器作为基础测试设备的重要性不言而喻。本文将深入探讨如何利用STM32F103微控制器与AD9833 DDS模块构建一款功能全面、操作灵活的可编程信号发生器,涵盖从硬…...