SpringCloud分布式微服务链路追踪方案:Skywalking
一、引言
随着微服务架构的广泛应用,系统的复杂性也随之增加。在这种复杂的系统中,应用通常由多个相互独立的服务组成,每个服务可能分布在不同的主机上。微服务架构虽然提高了系统的灵活性和可扩展性,但也带来了新的挑战,尤其是在故障排查和性能优化方面。这时,链路追踪(Tracing)成为了一个非常重要的工具。
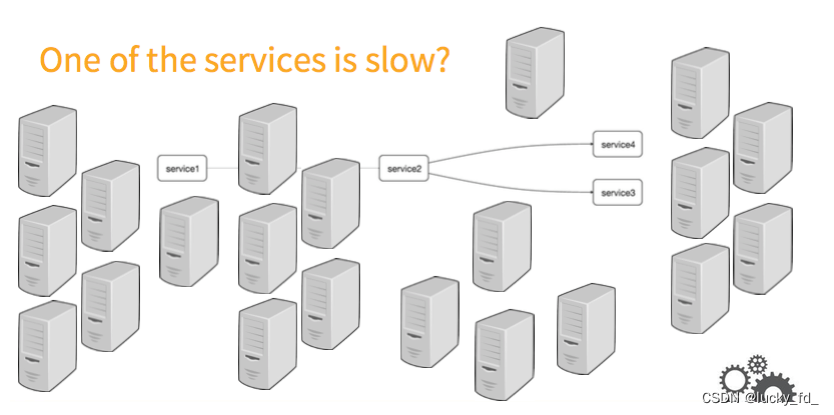
注:图片来自网络
如图,在复杂的调用链路中假设存在一条调用链路响应缓慢,如何定位其中延迟高的服务呢?
- 日志: 通过分析调用链路上的每个服务日志得到结果,这种方式耗时高效率低
- zipkin:Zipkin是Twitter开源的分布式跟踪系统,是开箱即用的产品,主要用来收集系统的时许数据,从而追踪系统的调用问题,使用zipkin的web UI可以一眼看出延迟高的服务。
- Skywalking,中国人吴晟(华为)开源的一款分布式追踪,分析,告警的工具,现在是Apache旗下开源项目,专为微服务、云原生架构和基于容器(Docker、K8s、Mesos)架构而设计。
Zipkin使用方式请参考:SpringCloud分布式微服务链路追踪方案:Zipkin
本文只介绍Skywalking的使用方式。
二、skywalking介绍
skywalking官网:SkyWalking
考虑到部分读者的英语水平可能和博主差不多😂,这里推荐一个中文文档:https://github.com/SkyAPM/document-cn-translation-of-skywalking/blob/master/docs/README.md
架构设计
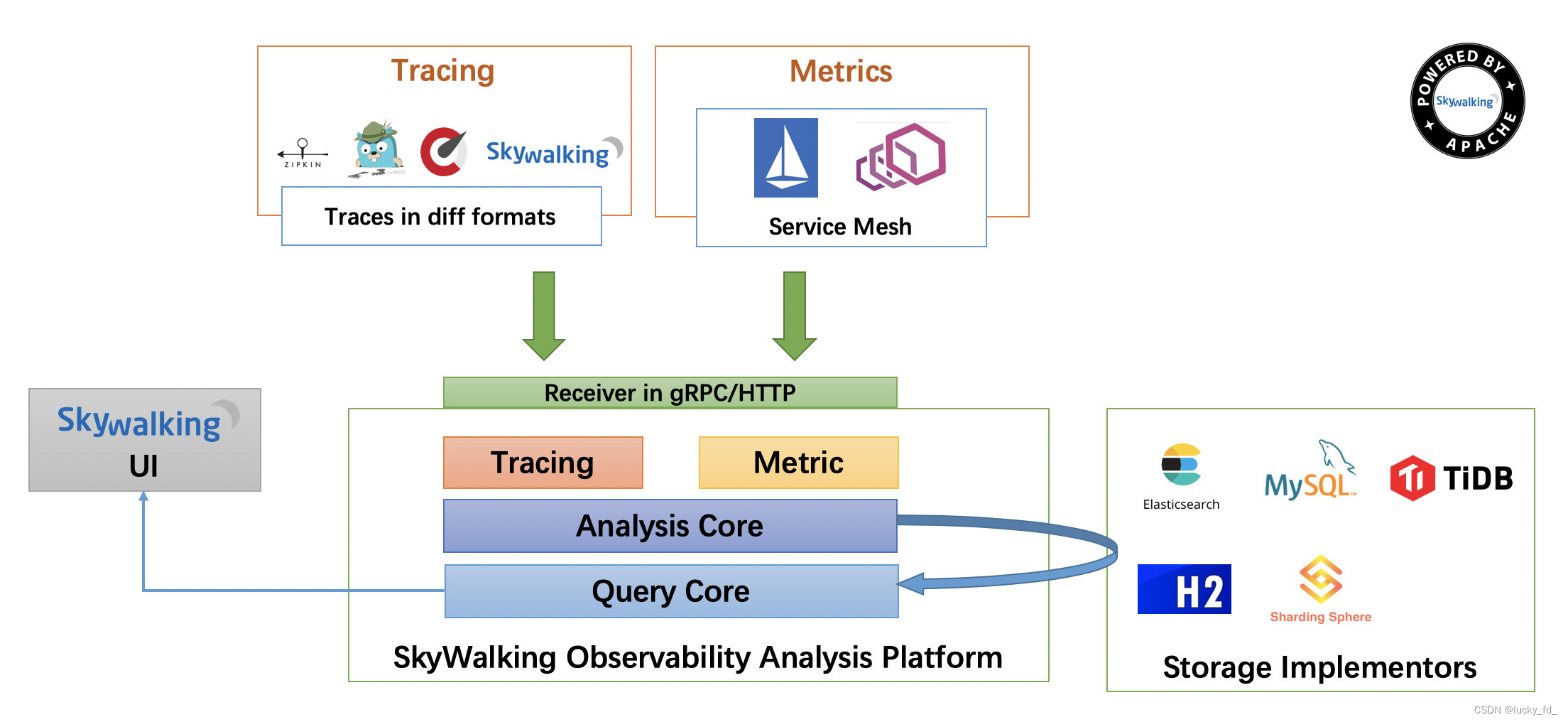
整个架构,分成上、下、左、右四部分:
考虑到让描述更简单,我们舍弃掉 Metric 指标相关,而着重在 Tracing 链路相关功能。
- 上部分 Agent :负责从应用中,收集链路信息,发送给 SkyWalking OAP 服务器。目前支持 SkyWalking、Zikpin、Jaeger 等提供的 Tracing 数据信息。而我们目前采用的是,SkyWalking Agent 收集 SkyWalking Tracing 数据,传递给服务器。
- 下部分 SkyWalking OAP :负责接收 Agent 发送的 Tracing 数据信息,然后进行分析(Analysis Core) ,存储到外部存储器( Storage ),最终提供查询( Query )功能。
- 右部分 Storage :Tracing 数据存储。目前支持 ES、MySQL、Sharding Sphere、TiDB、H2 多种存储器。而我们目前采用的是 ES ,主要考虑是 SkyWalking 开发团队自己的生产环境采用 ES 为主。
- 左部分 SkyWalking UI :负责提供控台,查看链路等等。

三、安装skywalking
1. 环境要求
在安装和使用 Skywalking 之前,需要确保以下环境要求:
- JDK 8 或以上版本
- 支持 Docker(可选)
- 操作系统:Windows、Mac OS 或 Linux
- 数据库(如 Elasticsearch、MySQL,用于存储数据)
2. 安装skywalking
下载 SkyWalking
从 Apache SkyWalking 官方网站 下载最新版本的 SkyWalking。下载完成后,解压文件。
下载地址:skywalking安装包
我们这里下载apache-skywalking-apm-es7-8.0.0.tar.gz版本,使用es7作为数据存储。
wget https://archive.apache.org/dist/skywalking/8.0.0/apache-skywalking-apm-es7-8.0.0.tar.gz
tar -xzf apache-skywalking-apm-es7-8.0.0.tar.gz
cd apache-skywalking-apm-bin-es7
配置 SkyWalking
配置文件位于 config 目录下,你可以根据需要修改 application.yml 文件。例如,配置存储为 Elasticsearch7:
vi application.yml
storage:# 配置使用的存储器,默认使用h2selector: ${SW_STORAGE:h2}elasticsearch:nameSpace: ${SW_NAMESPACE:""}clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:localhost:9200}protocol: ${SW_STORAGE_ES_HTTP_PROTOCOL:"http"}trustStorePath: ${SW_STORAGE_ES_SSL_JKS_PATH:""}trustStorePass: ${SW_STORAGE_ES_SSL_JKS_PASS:""}user: ${SW_ES_USER:""}password: ${SW_ES_PASSWORD:""}secretsManagementFile: ${SW_ES_SECRETS_MANAGEMENT_FILE:""} # Secrets management file in the properties format includes the username, password, which are managed by 3rd party tool.dayStep: ${SW_STORAGE_DAY_STEP:1} # Represent the number of days in the one minute/hour/day index.indexShardsNumber: ${SW_STORAGE_ES_INDEX_SHARDS_NUMBER:1} # The index shards number is for store metrics data rather than basic segment recordsuperDatasetIndexShardsFactor: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_SHARDS_FACTOR:5} # Super data set has been defined in the codes, such as trace segments. This factor provides more shards for the super data set, shards number = indexShardsNumber * superDatasetIndexShardsFactor. Also, this factor effects Zipkin and Jaeger traces.indexReplicasNumber: ${SW_STORAGE_ES_INDEX_REPLICAS_NUMBER:0}# Batch process setting, refer to https://www.elastic.co/guide/en/elasticsearch/client/java-api/5.5/java-docs-bulk-processor.htmlbulkActions: ${SW_STORAGE_ES_BULK_ACTIONS:1000} # Execute the bulk every 1000 requestsflushInterval: ${SW_STORAGE_ES_FLUSH_INTERVAL:10} # flush the bulk every 10 seconds whatever the number of requestsconcurrentRequests: ${SW_STORAGE_ES_CONCURRENT_REQUESTS:2} # the number of concurrent requestsresultWindowMaxSize: ${SW_STORAGE_ES_QUERY_MAX_WINDOW_SIZE:10000}metadataQueryMaxSize: ${SW_STORAGE_ES_QUERY_MAX_SIZE:5000}segmentQueryMaxSize: ${SW_STORAGE_ES_QUERY_SEGMENT_SIZE:200}profileTaskQueryMaxSize: ${SW_STORAGE_ES_QUERY_PROFILE_TASK_SIZE:200}advanced: ${SW_STORAGE_ES_ADVANCED:""}elasticsearch7:nameSpace: ${SW_NAMESPACE:""}clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:localhost:9200}protocol: ${SW_STORAGE_ES_HTTP_PROTOCOL:"http"}trustStorePath: ${SW_STORAGE_ES_SSL_JKS_PATH:""}trustStorePass: ${SW_STORAGE_ES_SSL_JKS_PASS:""}dayStep: ${SW_STORAGE_DAY_STEP:1} # Represent the number of days in the one minute/hour/day index.user: ${SW_ES_USER:""}password: ${SW_ES_PASSWORD:""}secretsManagementFile: ${SW_ES_SECRETS_MANAGEMENT_FILE:""} # Secrets management file in the properties format includes the username, password, which are managed by 3rd party tool.indexShardsNumber: ${SW_STORAGE_ES_INDEX_SHARDS_NUMBER:1} # The index shards number is for store metrics data rather than basic segment recordsuperDatasetIndexShardsFactor: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_SHARDS_FACTOR:5} # Super data set has been defined in the codes, such as trace segments. This factor provides more shards for the super data set, shards number = indexShardsNumber * superDatasetIndexShardsFactor. Also, this factor effects Zipkin and Jaeger traces.indexReplicasNumber: ${SW_STORAGE_ES_INDEX_REPLICAS_NUMBER:0}- storage.elasticsearch 配置项,设置使用 Elasticsearch 6.X 版本作为存储器。
- storage.elasticsearch7 配置项,设置使用 Elasticsearch 7.X 版本作为存储器。
- storage.h2 配置项,设置使用 H2 作为存储器。
skywalking默认使用h2存储,这里我们修改为elasticsearch7,并正确配置elasticsearch7的配置信息。
storage:
selector: ${SW_STORAGE:elasticsearch7}
elasticsearch7配置:
- nameSpace: es命名空间
- clusterNodes:es集群节点
- user:es用户
- password: es用户密码
Elasticsearch安装参考:Elasticsearch安装文档
启动Skywalking OAP
$ cd bin/
$ ls
oapService.bat oapServiceInit.sh oapServiceNoInit.sh startup.bat webappService.bat
oapServiceInit.bat oapServiceNoInit.bat oapService.sh startup.sh webappService.sh
$ sh oapService.sh
SkyWalking OAP started successfully!启动成功,我们可以打开 logs/skywalking-oap-server.log 日志文件,查看是否有错误日志。首次启动时,因为 SkyWalking OAP 会创建 Elasticsearch 的索引,所以会“疯狂”的打印日志。最终,我们看到如下日志,基本可以代表 SkyWalking OAP 服务启动成功
2024-06-27 16:18:42,515 - org.apache.skywalking.oap.server.library.server.jetty.JettyServer - 94 [main] INFO [] - start server, host: 0.0.0.0, port: 12800
2024-06-27 16:18:42,517 - org.eclipse.jetty.server.Server - 359 [main] INFO [] - jetty-9.4.28.v20200408; built: 2020-04-08T17:49:39.557Z; git: ab228fde9e55e9164c738d7fa121f8ac5acd51c9; jvm 1.8.0_144-b01
2024-06-27 16:18:42,546 - org.eclipse.jetty.server.handler.ContextHandler - 843 [main] INFO [] - Started o.e.j.s.ServletContextHandler@1c90029b{/,null,AVAILABLE}
2024-06-27 16:18:42,555 - org.eclipse.jetty.server.AbstractConnector - 331 [main] INFO [] - Started ServerConnector@7e8a46b7{HTTP/1.1, (http/1.1)}{0.0.0.0:12800}
2024-06-27 16:18:42,556 - org.eclipse.jetty.server.Server - 399 [main] INFO [] - Started @14557ms
2024-06-27 16:18:42,557 - org.apache.skywalking.oap.server.core.storage.PersistenceTimer - 56 [main] INFO [] - persistence timer start
2024-06-27 16:18:42,560 - org.apache.skywalking.oap.server.core.cache.CacheUpdateTimer - 46 [main] INFO [] - Cache updateServiceInventory timer start
启动Skywalking UI
$ ./bin/webappService.sh
SkyWalking Web Application started successfully!启动完成,我们到logs/logs/webapp.log查看是否有错误日志。启动成功,会显示以下日志
2024-06-27 15:27:03.937 INFO 180490 — [main] o.s.c.support.DefaultLifecycleProcessor : Starting beans in phase 0
2024-06-27 15:27:03.997 INFO 180490 — [main] o.s.c.support.DefaultLifecycleProcessor : Starting beans in phase 2147483647
2024-06-27 15:27:04.002 INFO 180490 — [main] ration$HystrixMetricsPollerConfiguration : Starting poller
2024-06-27 15:27:04.163 INFO 180490 — [main] s.b.c.e.t.TomcatEmbeddedServletContainer : Tomcat started on port(s): 8080 (http)
2024-06-27 15:27:04.168 INFO 180490 — [main] o.a.s.apm.webapp.ApplicationStartUp : Started ApplicationStartUp in 14.596 seconds (JVM running for 15.68)
如果想要修改 SkyWalking UI 服务的参数,可以编辑 webapp/webapp.yml 配置文件。
server:# skywalking UI访问端口port: 8080collector:path: /graphqlribbon:ReadTimeout: 10000# Point to all backend's restHost:restPort, split by ,# SkyWalking OAP 服务地址数组,SkyWalking UI 界面的数据是通过SkyWalking OAP服务获取listOfServers: 127.0.0.1:12800默认8080端口容易和其他中间件冲突,建议修改。
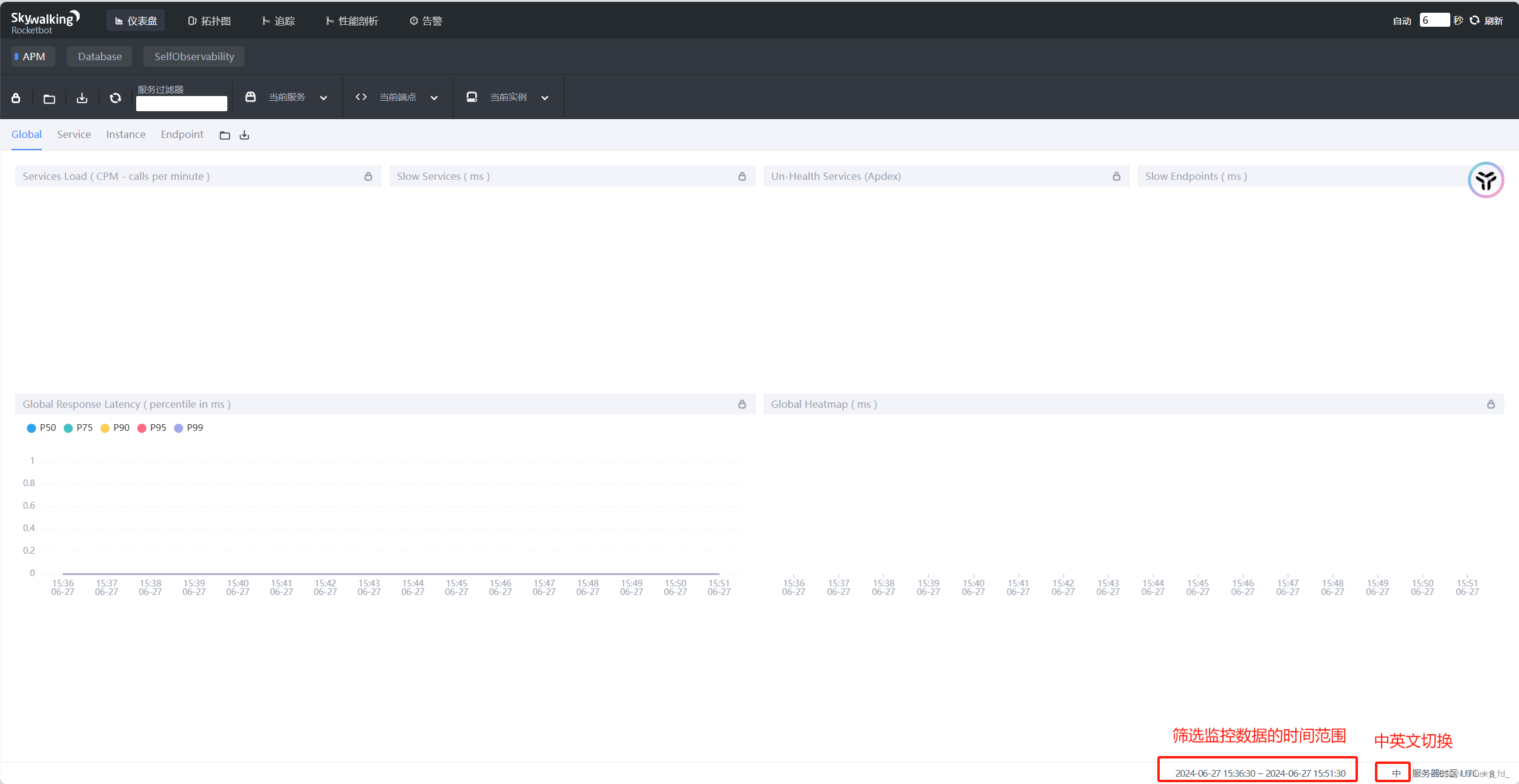
skywalking UI访问:
浏览器打开127.0.0.1:8080,界面如下
四、项目集成skywalking
1. Java应用接入
对于 Java 应用程序,需要添加 SkyWalking Agent。SkyWalking Agent实现数据传输到skywalking OAP服务。
下载并解压 Agent 包,通过-javaagent参数指定SkyWalking Java Agent的路径和配置参数,例如:在启动应用程序时添加以下 JVM 参数:
-javaagent:/path/to/skywalking-agent/skywalking-agent.jar -Dskywalking.agent.service_name=your-service-name -Dskywalking.collector.backend_service=127.0.0.1:11800
- -javaagent:配置agent路径
- -Dskywalking.agent.service_name:设置应用服务名称
- -Dskywalking.collector.backend_service:设置skywalking oap地址
我们需要将apache-skywalking-apm-bin/agent 目录,拷贝到 Java 应用所在的服务器上。这样,Java 应用才可以配置使用该 SkyWalking Agent。
[apache-skywalking-apm-bin-es7]$ ls
agent bin config LICENSE licenses logs NOTICE oap-libs README.txt tools webapp
[apache-skywalking-apm-bin-es7]$ ls ./agent/
activations bootstrap-plugins config logs optional-plugins plugins skywalking-agent.jar首先将apache-skywalking-apm-bin/agent 目录拷贝到java应用服务器,然后在Java启动命令添加JVM参数,例如:
java -jar serviceDemo.jar -javaagent:D:\my_programs\skywalking\agent\skywalking-agent.jar -Dskywalking.collector.backend_service=192.168.253.10:11800
IDEA启动
编辑启动配置,添加JVM参数
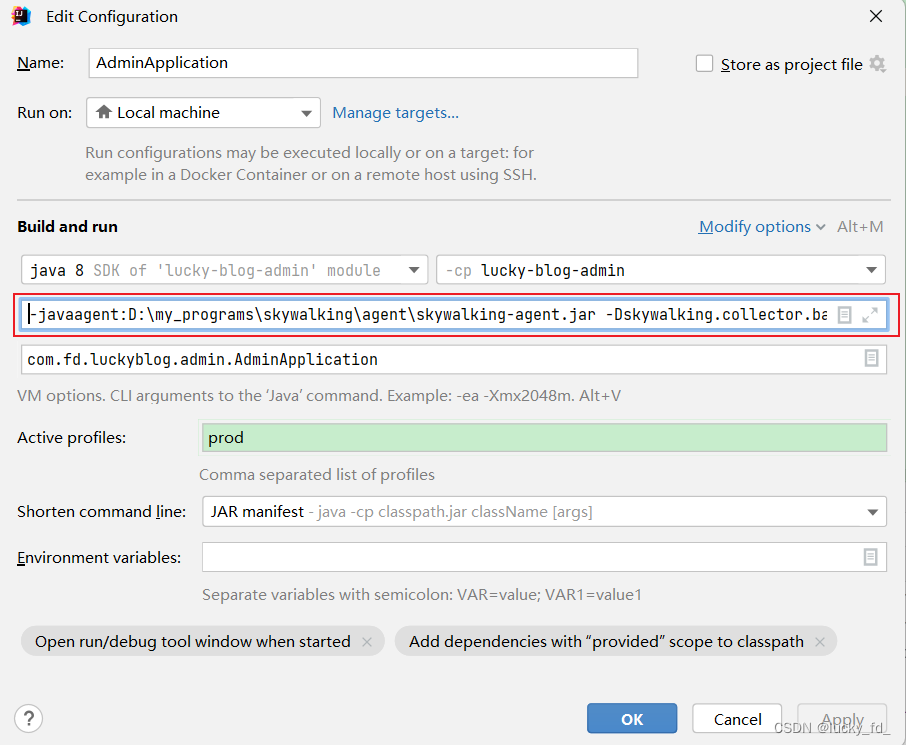
启动 Java 项目。在启动日志中,我们可以看到 SkyWalking Agent 被加载的日志。日志示例如下:
AgentPackagePath : The beacon class location is jar:file:/D:/my_programs/skywalking/agent/skywalking-agent.jar!/org/apache/skywalking/apm/agent/core/boot/AgentPackagePath.class.
SnifferConfigInitializer : Config file found in D:\my_programs\skywalking\agent\config\agent.config.
2. Java Agent配置
可以根据需要编辑agent配置,打开agent/config/agent.config
# The agent namespace 命名空间
# agent.namespace=${SW_AGENT_NAMESPACE:default-namespace}# The service name in UI 当前agent服务名称
agent.service_name=${SW_AGENT_NAME:Your_ApplicationName}# The number of sampled traces per 3 seconds 每3秒采样的记录数
# Negative or zero means off, by default 默认或负数表示关闭,即默认全部采样。
# agent.sample_n_per_3_secs=${SW_AGENT_SAMPLE:-1}# Authentication active is based on backend setting, see application.yml for more details.
# agent.authentication = ${SW_AGENT_AUTHENTICATION:xxxx}# The max amount of spans in a single segment.
# Through this config item, SkyWalking keep your application memory cost estimated.
# agent.span_limit_per_segment=${SW_AGENT_SPAN_LIMIT:150}# Ignore the segments if their operation names end with these suffix.
# agent.ignore_suffix=${SW_AGENT_IGNORE_SUFFIX:.jpg,.jpeg,.js,.css,.png,.bmp,.gif,.ico,.mp3,.mp4,.html,.svg}# If true, SkyWalking agent will save all instrumented classes files in `/debugging` folder.
# SkyWalking team may ask for these files in order to resolve compatible problem.
# agent.is_open_debugging_class = ${SW_AGENT_OPEN_DEBUG:true}# The operationName max length
# Notice, in the current practice, we don't recommend the length over 190.
# agent.operation_name_threshold=${SW_AGENT_OPERATION_NAME_THRESHOLD:150}# If true, skywalking agent will enable profile when user create a new profile task. Otherwise disable profile.
# profile.active=${SW_AGENT_PROFILE_ACTIVE:true}# Parallel monitor segment count
# profile.max_parallel=${SW_AGENT_PROFILE_MAX_PARALLEL:5}# Max monitor segment time(minutes), if current segment monitor time out of limit, then stop it.
# profile.duration=${SW_AGENT_PROFILE_DURATION:10}# Max dump thread stack depth
# profile.dump_max_stack_depth=${SW_AGENT_PROFILE_DUMP_MAX_STACK_DEPTH:500}# Snapshot transport to backend buffer size
# profile.snapshot_transport_buffer_size=${SW_AGENT_PROFILE_SNAPSHOT_TRANSPORT_BUFFER_SIZE:50}# Backend service addresses.
collector.backend_service=${SW_AGENT_COLLECTOR_BACKEND_SERVICES:127.0.0.1:11800}# Logging file_name
logging.file_name=${SW_LOGGING_FILE_NAME:skywalking-api.log}# Logging level
logging.level=${SW_LOGGING_LEVEL:INFO}# Logging dir
# logging.dir=${SW_LOGGING_DIR:""}# Logging max_file_size, default: 300 * 1024 * 1024 = 314572800
# logging.max_file_size=${SW_LOGGING_MAX_FILE_SIZE:314572800}# The max history log files. When rollover happened, if log files exceed this number,
# then the oldest file will be delete. Negative or zero means off, by default.
# logging.max_history_files=${SW_LOGGING_MAX_HISTORY_FILES:-1}# mysql plugin configuration
# plugin.mysql.trace_sql_parameters=${SW_MYSQL_TRACE_SQL_PARAMETERS:false}| 属性名 | 描述 | 默认值 |
|---|---|---|
| agent.namespace | 命名空间,用于隔离跨进程传播的header。如果进行了配置,header将为HeaderName:Namespace. | 未设置 |
| agent.service_name | 在SkyWalking UI中展示的服务名。5.x版本对应Application,6.x版本对应Service。 建议:为每个服务设置个唯一的名字,服务的多个服务实例为同样的服务名 | Your_ApplicationName |
| agent.sample_n_per_3_secs | 负数或0表示关闭,即默认全部采样。生产环境会带来较大开销。SAMPLE_N_PER_3_SECS表示每3秒采样N条。如果设置为100,则每3秒将采样100个链路数据。 | 未设置,建议设置 |
| agent.authentication | 鉴权是否开启取决于后端的配置,可查看application.yml的详细描述。对于大多数的场景,需要后端对鉴权进行扩展。目前仅实现了基本的鉴权功能。 | 未设置 |
| agent.span_limit_per_segment | 单个segment中的span的最大个数。通过这个配置项,Skywalking可评估应用程序内存使用量。 | 300 |
| agent.ignore_suffix | 如果这个集合中包含了第一个span的操作名,这个segment将会被忽略掉。 | 未设置 |
这里列举部分agent环境参数,详细官方文档见:https://github.com/apache/skywalking/blob/v8.0.0/docs/en/setup/service-agent/java-agent/README.md
agent配置有多种姿势,上面修改 agent.config 文件中的值,只是其中一种。还支持以下方式:
系统属性(-D)
使用 -Dskywalking. + agent.config配置文件中的key 即可。例如:
agent.config 文件中有一个属性名为 agent.service_name ,那么如果使用系统属性的方式,则可以写成
java -javaagent:/opt/agent/skywalking-agent.jar -Dskywalking.agent.service_name=你想设置的值 -jar spring-boot.jar
代理选项
在JVM参数中的代理路径之后添加属性即可。格式:
-javaagent:/path/to/skywalking-agent.jar=[option1]=[value1],[option2]=[value2]
例如:
java -javaagent:/opt/agent/skywalking-agent.jar=agent.service_name=你想设置的值 -jar spring-boot.jar
系统环境变量
agent.config 文件中默认的大写值,都可以作为环境变量引用。例如,agent.config 中有如下内容
agent.service_name=${SW_AGENT_NAME:Your_ApplicationName}
这说明Skywalking会读取名为 SW_AGENT_NAME 的环境变量。
优先级:
代理选项 > 系统属性(-D) > 系统环境变量 > 配置文件
3. 测试skywalking
先访问自己的服务,获取agent数据,然后查看skywalking UI显示
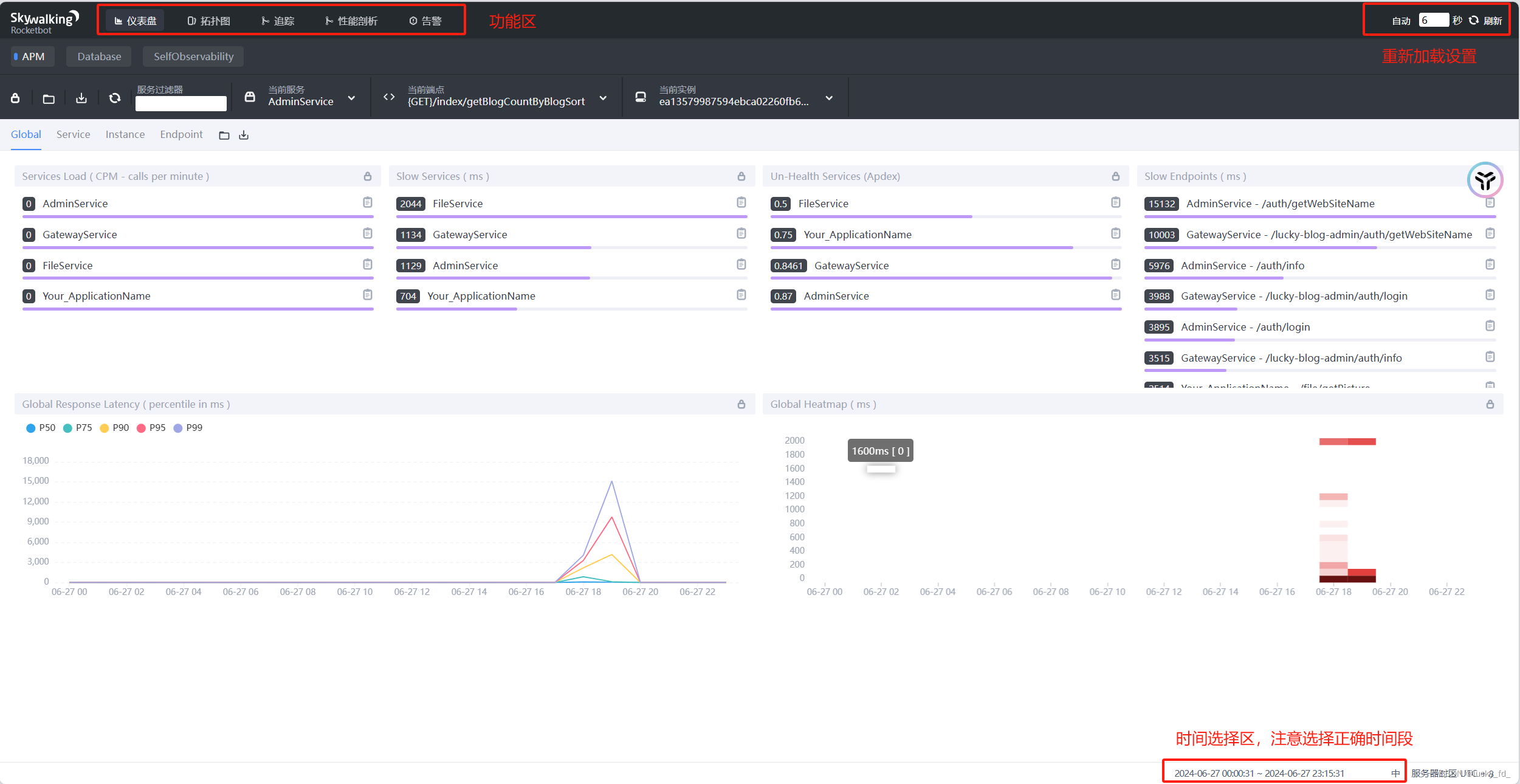
仪表盘:可以查看服务性能,接口总体耗时,数据库sql执行耗时排行等等,分为以下几个功能:
- APM:以全局(Global)、服务(Service)、服务实例(Instance)、端点(Endpoint)的维度展示各项指标。
- Database:展示数据库的各项指标。
- SelfObservability:展示OAP服务端的各项指标。
相关概念解释:
服务(Service):表示对请求提供相同行为的一组工作负载,比如:一个的 Web API系统。
服务实例(Instance):上述的一组工作负载中的每一个工作负载称为一个实例,比如:一个的 Web API 系统集群中的一个实例。
端点(Endpoint):对于特定服务所接收的请求路径,如 HTTP 的 URI 路径和 gRPC 服务的类名 + 方法签名。
更多SkyWalking的UI介绍,请参考:图解 Apache SkyWalking UI 的使用
SkyWalking告警请参考:基于 SkyWalking 的分布式跟踪系统 - 异常告警
常见问题
- Failed to read the config file, skywalking is going to run in default config. org.apache.skywalking.apm.agent.core.conf.ConfigNotFoundException: Failed to load agent.config.
问题原因:未将apache-skywalking-apm-bin/agent 目录,完全拷贝到 Java 应用所在的服务器上
相关文章:
SpringCloud分布式微服务链路追踪方案:Skywalking
一、引言 随着微服务架构的广泛应用,系统的复杂性也随之增加。在这种复杂的系统中,应用通常由多个相互独立的服务组成,每个服务可能分布在不同的主机上。微服务架构虽然提高了系统的灵活性和可扩展性,但也带来了新的挑战…...

首次线下联合亮相!灵途科技携手AEye、ATI亮相2024 EAC 易贸汽车产业大会
6月22日,2024 EAC 易贸汽车产业大会在苏州国际博览中心圆满落幕,泛自动驾驶领域光电感知专家灵途科技携手自适应高性能激光雷达解决方案全球领导者AEye公司(NASDAQ:LIDR)及光电器件规模化量产巨头Accelight Technologiesÿ…...
一文入门CMake
我们前几篇文章已经入门了gcc和Makefile,现在可以来玩玩CMake了。 CMake和Makefile是差不多的,基本上是可以相互替换使用的。CMAke可以生成Makefile,所以本质上我们还是用的Makefile,只不过用了CMake就不用再写Makefile了&#x…...

【LeetCode面试经典150题】117. 填充每个节点的下一个右侧节点指针 II
一、题目 117. 填充每个节点的下一个右侧节点指针 II - 力扣(LeetCode) 给定一个二叉树: struct Node {int val;Node *left;Node *right;Node *next; } 填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个…...
RTDETR更换优化器——Lion
RTDETR更换Lion优化器 论文:https://arxiv.org/abs/2302.06675 代码:https://github.com/google/automl/blob/master/lion/lion_pytorch.py 简介: Lion优化器是一种基于梯度的优化算法,旨在提高梯度下降法在深度学习中的优化效果…...

Spring Boot中最佳实践:数据源配置详解
Spring Boot中最佳实践:数据源配置详解 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将深入探讨在Spring Boot中如何进行最佳实践的数据源…...
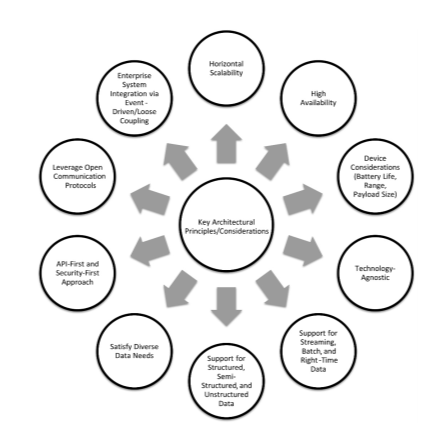
第1章 物联网模式简介---独特要求和体系结构原则
物联网用例的独特要求 物联网用例往往在功耗、带宽、分析等方面具有非常独特的要求。此外,物联网实施的固有复杂性(一端的现场设备在计算上受到挑战,另一端的云容量几乎无限)迫使架构师做出艰难的架构决策和实施选择。可用实现技…...
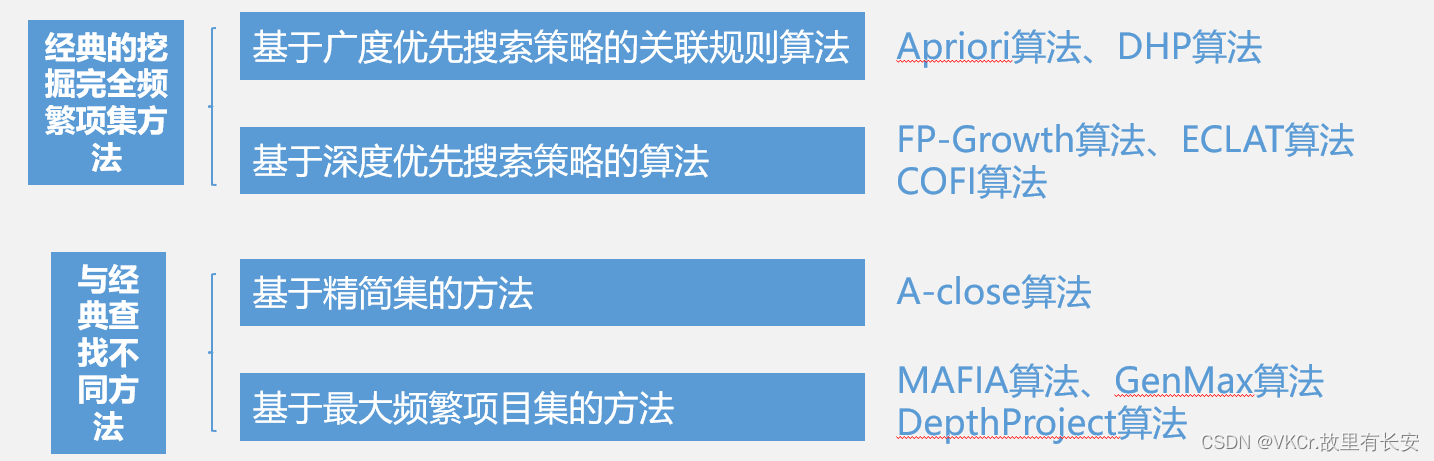
数据挖掘概览
数据挖掘(Data Mining)就是从大量的,不完全的,有噪声的,模糊的,随机的实际应用数据中,提取隐含在其中的,人们事先不知道的,但又是潜在有用的信息和知识的过程. 预测性数据挖掘 分类 定义:分类就是把一些新的数据项映射到给定类别中的某一个类别 分类流程&#x…...

【学习】软件测试中常见的文档类型及其作用
在软件开发的生命周期中,软件测试是确保产品质量的关键步骤。为了系统地进行测试活动,并保证测试结果的有效性和可追溯性,产生了一系列标准化的测试文档。这些文档不仅为测试人员提供了执行指南,而且为项目管理者和利益相关者提供…...

electron的托盘Tray
1.在主进程文件background.js中引入需要的文件 import { Tray, Menu } from "electron"; const path require("path");2.获取托盘图标 const baseSRC process.cwd(); //这里不能使用__dirname,使用dirname会直接获取dist_electron中的文件,…...

Harmony OS UI框架探索笔记
本文探讨了如何将现有的常用架构理论与Arkts和ArkUI结合起来,使代码更有条理,并利用Previewer快速调整布局,同时在不改变代码的情况下运行显示真实数据。 开发环境 Windows 11DevEco Studio 4.0 ReleaseBuild Version: 4.0.0.600, built on…...
transformers evaluate
☆ Evaluate https://huggingface.co/docs/evaluate/main/en/installation ★ 解决方案 常用代码 # 查看支持的评估函数 evaluate.list_evaluation_modules(include_communityTrue)# 加载评估函数 accuracy evaluate.load("accuracy")# load function descripti…...
【ONLYOFFICE深度探索】:ONLYOFFICE桌面编辑器8.1震撼发布,打造高效办公新境界
文章目录 一、功能完善的PDF编辑器:解锁文档处理新维度二、幻灯片版式设计:释放创意,打造专业演示三、改进从右至左显示:尊重多元文化,优化阅读体验四、新增本地化选项:连接全球用户,跨越语言障…...
架构类型)
C++系统相关操作4 - 获取CPU(指令集)架构类型
1. 关键词2. sysutil.h3. sysutil.cpp4. 测试代码5. 运行结果6. 源码地址 1. 关键词 关键词: C 系统调用 CPU架构 指令集 跨平台 实现原理: Unix-like 系统: 可以通过 uname -m 命令获取 CPU 架构类型。Windows 系统: 可以通过环境变量 PROCESSOR_A…...

whisper 实现语音转文字
准备需要转码的音频 https://support.huaweicloud.com/sdkreference-sis/sis_05_0039.html 编码转吗的代码 import whisperif __name__ "__main__":file_path "16k16bit.wav"model whisper.load_model("small")result model.transcribe(f…...

使用VLLM部署llama3量化版
1.首先去魔塔社区下载量化后的llama3模型 git clone https://www.modelscope.cn/huangjintao/Meta-Llama-3-8B-Instruct-AWQ.git 2.跑起来模型 1)python -m vllm.entrypoints.openai.api_server --model /home/cxh/Meta-Llama-3-8B-Instruct-AWQ --dtype auto --…...

计算机缺失OpenCL.dll怎么办,OpenCL.dll丢失的多种解决方法
在使用电脑的过程中,我们经常会遇到一些开机弹窗问题。其中,开机弹窗找不到OpenCL.dll是一种常见的情况。本文将详细介绍开机弹窗找不到OpenCL.dll的原因分析、解决方法以及预防措辞,帮助大家更好地解决这一问题。 一,了解OpenCL.…...

git 本地代码管理
简介 git 能实现本地代码多个更改版本的管理和导出。 首先复制好项目(参考 git clone 别人项目后正确的修改和同步操作 中的前三步) 实操 克隆原始项目 首先,从远程仓库克隆项目到本地: git clone https://github.com/libo-huan…...
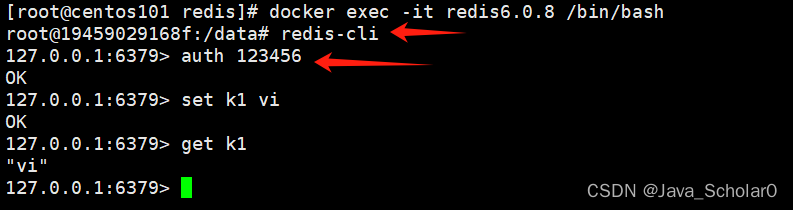
Docker(九)-Docker运行redis6.0.8容器实例
1.宿主机新建目录存放redis.conf文件 目的:运行redis容器实例时使用自己的配置文件2.运行redis容器实例 docker run -d -p 6379:6379 --privilegedtrue -v 【宿主机配置文件目录】:/etc/redis/redis.conf -v 【宿主机数据目录】:/data --nameredis6.0.8 redis:6.0…...
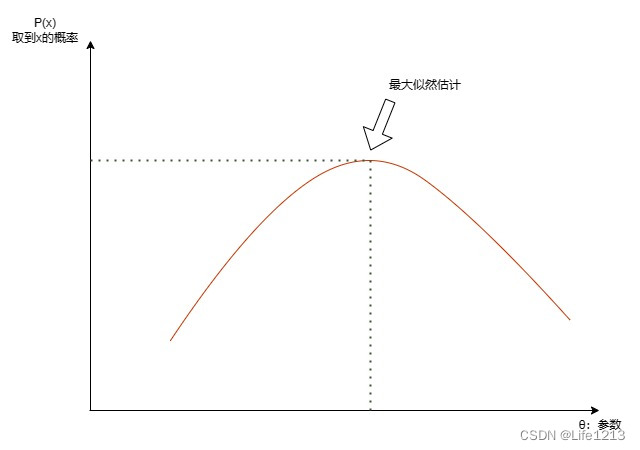
似然 与 概率
概率似然概率函数与似然函数的关系似然与机器学习的关系最大似然估计 似然与概率分别是针对不同内容的估计和近似 概率 概率:概率表达给定参数 θ \theta θ下样本随机向量 X x \textbf{X} {x} Xx的可能性。 概率密度函数的定义形式是 f ( x ∣ θ ) f(x|\t…...

从仿真到实战:如何用VPI+Matlab复现一篇光通信顶会论文的DSP算法?
从仿真到实战:如何用VPIMatlab复现光通信顶会论文的DSP算法? 在光通信领域,学术论文中提出的数字信号处理(DSP)算法往往需要经过严格的仿真验证才能应用于实际工程。本文将带你深入探索如何利用VPI和Matlab联合仿真环境…...

阿里云 AgentRun 能力升级:支持 Skills 安全托管,千种技能一键直达!
引言:当 Skill 成为 Agent 时代的硬通货万万没想到,如今 Skill 正在成为 AI Agent 时代的硬通货。最近,GitHub 上一个叫"同事.skill"的项目,5 天拿下超 6600 个 star,直接冲上全网热搜。随后,&qu…...
)
RestSharp实战:5分钟搞定微信支付/天气API接口调用(C#保姆级教程)
RestSharp实战:5分钟搞定微信支付与天气API调用(C#保姆级教程) 当我们需要快速集成第三方API时,一个高效、简洁的HTTP客户端库能大幅提升开发效率。RestSharp作为.NET生态中广受欢迎的轻量级解决方案,以其直观的API设计…...
)
OAK-D-Pro上手实测:用Python+DepthAI SDK跑通第一个SLAM Demo(保姆级避坑指南)
OAK-D-Pro实战指南:从零搭建SLAM开发环境的完整避坑手册 当你第一次拆开OAK-D-Pro相机的包装时,那种兴奋感我至今记忆犹新——但随之而来的是一连串的困惑:驱动装不上、环境冲突、示例代码跑不通...这正是我写下这篇指南的原因。不同于市面上…...

探索ComfyUI-FramePackWrapper:基于FP8优化的高效视频生成架构
探索ComfyUI-FramePackWrapper:基于FP8优化的高效视频生成架构 【免费下载链接】ComfyUI-FramePackWrapper 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-FramePackWrapper 在AI视频生成领域,ComfyUI-FramePackWrapper作为lllyasviel F…...

django python多进程 多线程传递变量数据
数据库(MySQL)和 Redis 在共享变量这件事上到底差在哪,你一看就知道该用哪个。一句话核心区别MySQL 数据库:硬盘为主,慢,持久,能存大量数据Redis:内存为主,极快ÿ…...

Citra模拟器完整教程:在PC上高效运行3DS游戏的实用指南
Citra模拟器完整教程:在PC上高效运行3DS游戏的实用指南 【免费下载链接】citra A Nintendo 3DS Emulator 项目地址: https://gitcode.com/gh_mirrors/cit/citra 想要在电脑上重温任天堂3DS的经典游戏吗?Citra模拟器为您提供了完美的解决方案&…...

自动ping值脚本
import subprocess import time import json import reTARGET_IP "改成设备ip" PING_COUNT 1000 TIMEOUT 1000 # ms STUTTER_THRESHOLD 100 # mslatencies [] packet_loss 0 stutter_count 0def ping_once(ip):try:result subprocess.run(["ping"…...

PDown下载器:百度网盘高速下载的终极免费解决方案
PDown下载器:百度网盘高速下载的终极免费解决方案 【免费下载链接】pdown 百度网盘下载器,2020百度网盘高速下载 项目地址: https://gitcode.com/gh_mirrors/pd/pdown 你是否厌倦了百度网盘那令人抓狂的下载速度?面对几个GB的学习资料…...
彻底搞懂Verilog的always、case和assign)
别再死记硬背了!用这3个真实小项目(呼吸灯、按键消抖、数码管)彻底搞懂Verilog的always、case和assign
用三个实战项目解锁Verilog核心语法:从呼吸灯到数码管显示 第一次接触Verilog时,我被各种语法规则搞得晕头转向——always块的触发方式、case语句的匹配规则、assign连线的使用场景,每个概念单独看都明白,但一到实际项目中就手足无…...