大模型推理知识总结
一、大模型推理概念
大多数流行的only-decode LLM(例如 GPT-3)都是针对因果建模目标进行预训练的,本质上是作为下一个词预测器。这些 LLM 将一系列tokens作为输入,并自回归生成后续tokens,直到满足停止条件(例如,生成tokens数量的限制或遇到停止词)或直到生成特殊的 标记生成结束的tokens。该过程涉及两个阶段:预填充阶段和解码阶段。
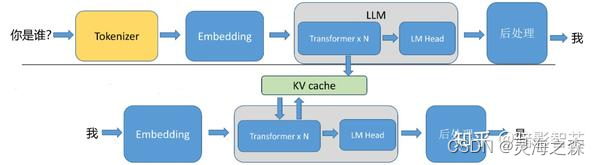
1.预填充阶段
在预填充阶段,LLM处理输入token以计算中间状态(keys和value),用于生成“第一个”token。每个新的token都依赖于所有先前的token,但由于输入的全部已知,因此在运算上,都是高度并行化矩阵运算,可以有效地使用GPU。
prefill:输入编码“你是谁?”,针对输入编码,产生kv cache,然后生成首个token“我”。
2.解码阶段
在解码阶段,LLM一次自回归生成一个输出token,直到满足停止条件。每个输出tokens都需要直到之前迭代的所有输出状态(keys和values)。这与预填充输入处理相比,就像矩阵向量运算未充分利用GPU计算能力。数据(weights, keys, values, activations) 从内存传输到GPU的速度决定了延迟,而不是计算实际时间消耗。即,这是一个内存限制操作。
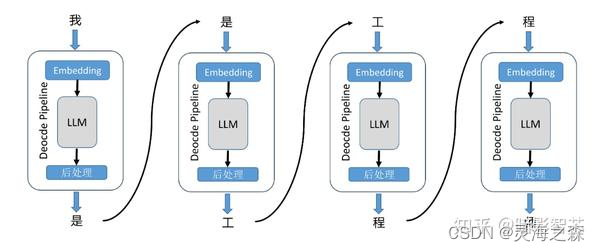
输入一段文本后,生成一段长度为N的输出。单次推理只输出一个token,然后将推理输出的token和输入的tokens拼接在一起,作为下一次推理的输入,不断反复直到遇到终止符。
◈你是谁?–> 我
◈你是谁?我 --> 是
◈你是谁?我是 --> 工
◈你是谁?我是工 --> 程
◈你是谁?我是工程 --> 师
◈你是谁?我是工程师 --> EOS
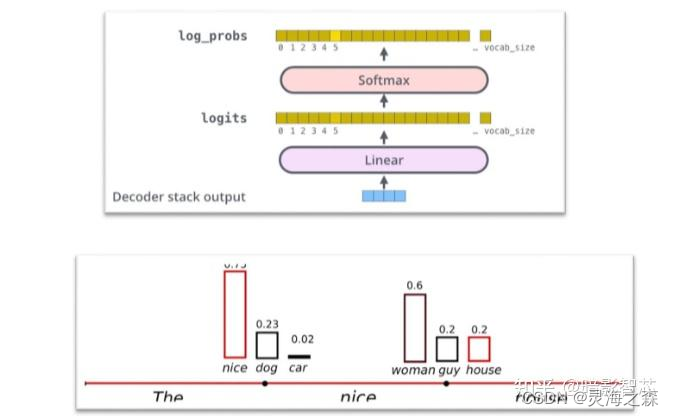
模型是怎么得到next token的
- 经过embedding,位置编码,attention,MLP,softmax等layer的处理,得到最终模型输出的logits。
- logits是一个张量,长度为vocab_size,其元素之和为1,各元素取值代表每个token被选中的概率。
- 基于模型的输出logits,从词表中选出一个token作为当前生成的结果。
怎么选择呢?就是看温度等参数了
http://t.csdnimg.cn/RZDov
这些参数在代码里的实现:
https://zhuanlan.zhihu.com/p/658780653
二、模型推理优化策略
1.模型在推理、训练时所占的显存分析
Transformer模型参数量计算公式:


前向传播计算量:


推理过程
假设模型参数是W.
推理过程包括模型的一次前向传播,显存主要存储模型的参数。
当模型通过Float 16数据类型存储时,每个元素占据2个bytes,因此显存占用量为2W;
当模型通过Float 32数据类型存储时,每个元素占据4个bytes,因此显存占用量为4W。
可以记忆为参数量为WB的模型,以Float 16推理时占用显存为2W个G。
以下是不同精度的数据类型及其对应的大小表格,包括具有70亿个参数的模型的显存占用:
| 数据类型 | 位数 | 字节数 | 具有70亿个参数的模型的显存占用 |
|---|---|---|---|
| FP32 | 32位 | 4字节 | 28 GB = 4*7 |
| FP16 | 16位 | 2字节 | 14 GB =2*7 |
| INT8 | 8位 | 1字节 | 7 GB =1*7 |
| INT4 | 4位 | 0.5字节 | 3.5 GB =0.5*7 |
训练过程
模型训练过程中,显存占用主要包括下面四个部分:模型参数、模型梯度、优化器状态、中间激活值。

以AdamW优化器和混合精度训练进行7B模型训练为例:
AdamW优化器在反向传播时,需要保存一阶梯度及二阶的动量;
混合精度训练指训练过程采用FP16数据格式,反向传播进行参数更新时,采用FP32数据格式。
模型梯度是指在反向传播过程中计算得到的模型参数的导数。这些梯度用于更新模型参数,以最小化损失函数。
优化器状态(Optimizer State)是在模型训练过程中由优化器维护的内部变量。这些变量用于加速和稳定模型参数更新的过程。在反向传播过程中,优化器状态保存并更新这些动量,以实现更高效的参数更新。这些状态变量需要与模型参数一样存储在显存中,因此占用显存资源。
模型参数:和推理时的一样:27 =14G
模型梯度:27 =14G
优化器状态: 47(参数)+ 47(动量)+ 4*7(方差)= 12 * 7 = 84G
中间激活值: batch为1时,模型有28层,隐藏层大小4096,中间隐藏层大小16384,注意力头数32,词表大小130528,上下文长度2048:激活值占大约27G
batch为1时,模型有28层,隐藏层大小4096,中间隐藏层大小16384,注意力头数32,词表大小130528,上下文长度2048:激活值占大约27G
训练时间估计:

参考:
https://www.zhihu.com/collection/951850716
https://zhuanlan.zhihu.com/p/624740065
https://zhuanlan.zhihu.com/p/638199667
https://blog.csdn.net/weixin_43301333/article/details/127237122
2.KV cache的优化

 https://zhuanlan.zhihu.com/p/677660376
https://zhuanlan.zhihu.com/p/677660376
https://zhuanlan.zhihu.com/p/685853516
KV缓存的定义和原理
定义: 键值缓存(KV缓存)是一种优化自回归模型生成速度的方法。它存储先前词元的计算结果,以便在后续生成中重用,避免冗余计算。
原理:
自回归模型生成:
- 自回归模型逐个生成词元,每个新预测依赖于先前生成的词元。
- 例如,生成“Apples are a boring fruit”时,预测“fruit”时需要前面所有词元的信息。
使用KV缓存:
- 存储先前词元的键(Key)和值(Value)对。
- 新的查询(Query)只需与缓存的键值对进行计算,无需重新计算整个序列。
- 提高生成速度和效率。
形象例子: 假设通过decode阶段自回归生成句子“Apples are a boring fruit”。当生成到“fruit”时,如果没有KV缓存,需要将整个句子“Apples are a
boring”作为输入进行attention计算。但是如果有了KV缓存,只需将“boring”作为输入,再从缓存中取出前面的计算结果,即可完成attention计算。这样,生成下一个词时不需要重新计算整个序列的信息,只需利用缓存中的键值对和当前词的查询向量进行计算,大大提高了生成速度和效率。总结
KV缓存通过存储先前词元的计算结果,在自回归生成模型中减少重复计算,优化了生成速度和效率。这种方法在长序列生成任务中尤为重要,可以显著提升模型的性能。
占用显存分析:

动图形象化:

1.Window–窗口

多轮对话场景的 LLMs 有两个难点:1. 解码阶段缓存 KV 需要耗费大量的内存;2. 流行的 LLMs 不能拓展到训练长度之外。

也就是首token非常重要!其实说白了,就是实测发现大部分情况下,前几个Token的注意力占比还是很重的,所以不能去掉,去掉注意力就全乱了。
2.Sparse–稀疏化
H2O、SubGen、LESS三个项目。略过。
https://zhuanlan.zhihu.com/p/685853516
3.Quantization–量化
量化,主要用于降低数值的精度以节省内存。量化时,每个数值都会被舍入或截断以转换至低精度格式。
https://huggingface.co/blog/zh/4bit-transformers-bitsandbytes

Transformers 中的键值缓存量化很大程度上受启发于 KIVI: A Tuning-Free Asymmetric 2bit Quantization for kv Cache 论文。该论文对大语言模型引入了 2 比特非对称量化,且不会降低质量。KIVI 采用按通道的量化键缓存以及按词元量化值缓存的方法,因为研究表明,就 LLM 而言,键在某些通道上容易出现高幅度的异常值,而值并无此表现。因此,采用按通道量化键和按词元量化值的方法,量化精度和原始精度之间的相对误差要小得多。
4.Allocator–显存分配
主要是Page Attention 。这是VLLM的实现。
PagedAttention的核心是一张表,类似于OS的page table,这里叫block table,记录每个seq的kv分布在哪个physical block上,通过把每个seq的kv cache划分为固定大小的physical block,每个block包含了每个句子某几个tokens的一部分kv,允许连续的kv可以不连续分布。
在attention compute的时候,pagedattention CUDA kernel就通过block table拿到对应的physical block序号,然后CUDA线程ID计算每个seq每个token的offset从而fetch相应的block,拿到kv,继续做attention的计算.

https://www.zhihu.com/question/68482809/answer/3206704509?utm_id=0
https://zhuanlan.zhihu.com/p/638468472
https://blog.csdn.net/buptgshengod/article/details/132783552
https://www.cnblogs.com/wxkang/p/17738945.html
5.Share–KV cache共享
多头注意力 (MHA)、分组查询注意力 (GQA)、多查询注意力 (MQA)、多头潜在注意力 (MLA)
看图就懂。
https://spaces.ac.cn/archives/10091
https://zhuanlan.zhihu.com/p/699970939

3.Flash attention优化
Flash Attention 是一种用于优化 Transformer 模型中自注意力机制的方法,旨在提高计算效率和减少内存使用,尤其在处理长序列时效果显著。其核心思想是通过重新排列注意力计算并利用经典的技术(如块划分和重计算),将内存复杂度从二次方降低到线性级别。
核心技术
块划分(Tiling):
- 将输入序列划分为固定大小的块(blocks),这些块从高带宽内存(HBM)加载到静态随机存取存储器(SRAM)。
- 计算注意力输出时,只需对这些块进行操作,并在计算完成后将结果写回HBM。这样可以减少大量的内存读写操作,从而提高计算效率。
重计算(Recomputation):
- 在前向传播中,不存储中间值,而是在反向传播中重新计算这些值。这种方法避免了存储大量中间矩阵,进一步减少了内存占用。
- 尽管这种方法增加了计算量,但通过减少HBM访问,实际上加快了反向传播的速度。
内核融合(Kernel Fusion):
- 将多个操作融合到一个CUDA内核中执行,减少了多次读写内存的需求。
- 具体步骤包括加载输入数据、执行矩阵乘法、计算softmax、应用掩码和dropout,然后将结果写回HBM。
性能优势
减少内存读写:
- 通过优化数据在HBM和SRAM之间的传输,Flash Attention显著减少了内存读写操作,使得注意力计算更加高效。
加速长序列处理:
- 与标准的注意力机制相比,Flash Attention在处理长序列时效率更高。例如,在处理长度为8K的长序列时,比标准的PyTorch和Megatron-LM实现快2.2到2.7倍。
训练和推理加速:
- Flash Attention不仅在训练阶段显著加速,还能减少推理延迟,特别适合需要长上下文理解的任务,如书籍、高分辨率图像和长视频的处理。
总结
Flash
Attention通过优化注意力机制的计算方式,显著提高了Transformer模型在处理长序列时的效率,减少了内存占用,是一种在大模型训练和推理中非常有用的技术。
推文
https://zhuanlan.zhihu.com/p/672698614
4.模型并行化技术
分布式并行策略有数据并行(Data Parallelism)、模型并行(Model Parallelism)、流水线并行(Pipeline Parallelism)等。
在推理时,主要介绍以下三种:
1.Pipeline并行
Pipeline并行化将模型(垂直)分片为块,其中每个块包含在单独设备上执行的层的子集。

2.Tensor并行
张量并行训练是将一个张量沿特定维度分成 N 块,每个设备只持有整个张量的 1/N,同时不影响计算图的正确性。这需要额外的通信来确保结果的正确性。

3.Sequence并行
介绍Megatron-LM的实现。
Tensor并行化是有局限性,它需要将层划分为独立的、可管理的块,不适用于 LayerNorm 和 Dropout 等操作,而是在tensor并行中复制。虽然 LayerNorm 和 Dropout 的计算成本较低,但它们确实需要大量内存来存储(冗余)激活。
是针对上述局限性做的改进

https://zhuanlan.zhihu.com/p/659792351
三、推理服务技术
在大语言模型(LLM)的推理过程中,以下四个关键指标用于衡量和优化其性能:

具体到服务技术上,可以采取:
1.静态批处理 static batching:
输出长度不一致,将多个input组合成一个batch,执行一次推理过程,直到输出最长的推理完成,才完成一个完整的batch推理过程。一般不用。
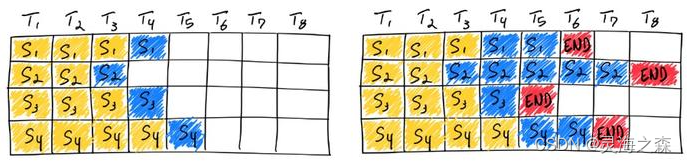
2.连续批处理(VLLM)
LLMs的整个文本生成过程可以分解为模型上的多次执行迭代。
采用了迭代级调度,其中批大小根据每次迭代确定。结果是,一旦批中的一个序列完成生成,就可以在其位置插入一个新的序列,从而实现比静态批处理更高的GPU利用率。
 如上图所示,使用连续批处理完成七条序列。左图显示了单个迭代后的批,右图显示了多次迭代后的批。一旦一个序列产生结束序列标记,我们在其位置插入新的序列(即序列S5、S6和S7)。这实现了更高的 GPU 利用率,因为 GPU 不需要等待所有序列完成才开始新的一个。
如上图所示,使用连续批处理完成七条序列。左图显示了单个迭代后的批,右图显示了多次迭代后的批。一旦一个序列产生结束序列标记,我们在其位置插入新的序列(即序列S5、S6和S7)。这实现了更高的 GPU 利用率,因为 GPU 不需要等待所有序列完成才开始新的一个。
3.预测推理(Speculative inference)
预测推理也称为推测采样、辅助生成或分块并行解码,是并行执行 LLM 的另一种方式。
 这种方法的基本思想是使用一些“更便宜”的过程来生成几个token长的临时序列。然后,并行执行多个步骤的主要“验证”模型,使用廉价临时序列作为需要的执行步骤的“预测”上下文。
这种方法的基本思想是使用一些“更便宜”的过程来生成几个token长的临时序列。然后,并行执行多个步骤的主要“验证”模型,使用廉价临时序列作为需要的执行步骤的“预测”上下文。
如果验证模型生成与临时序列相同的token,那么就知道接受这些token作为输出。否则,可以丢弃第一个不匹配标记之后的所有内容,并使用新的临时序列重复该过程。
https://zhuanlan.zhihu.com/p/657586838
总参考:
GitHub链接
总结起来也很费时间
相关文章:
大模型推理知识总结
一、大模型推理概念 大多数流行的only-decode LLM(例如 GPT-3)都是针对因果建模目标进行预训练的,本质上是作为下一个词预测器。这些 LLM 将一系列tokens作为输入,并自回归生成后续tokens,直到满足停止条件࿰…...

[笔记] keytool 导入服务器证书和证书私钥
背景 我当前手头已有一个服务器证书和对应的私钥,现在需要转换为 Java KeyStore 格式使用,找了一大圈才发现 keytool 无法直接导入服务器证书和私钥,当然证书可以直接导入,但是私钥是无法直接导入。找了一大圈发现可以先将服务器…...
【2024-热-办公软件】ONLYOFFICE8.1版本桌面编辑器测评
在今日快速发展的数字化办公环境中,选择一个功能全面且高效的办公软件是至关重要的。最近,我有幸体验了ONLYOFFICE 8.1版本的桌面编辑器,这款软件不仅提供了强大的编辑功能,还拥有众多改进,让办公更加流畅和高效。在本…...
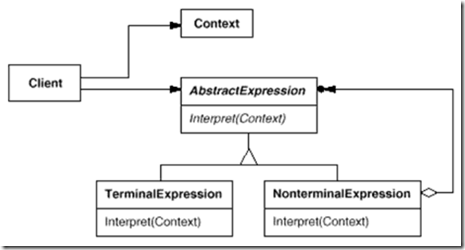
C# 23设计模式备忘
创建型模式:单例(Singleton)模式:某个类只能生成一个实例,该类提供了一个全局访问点供外部获取该实例,其拓展是有限多例模式。 原型(Prototype)模式:将一个对象作为原型&…...

STL中的迭代器模式:将算法与数据结构分离
目录 1.概述 2.容器类 2.1.序列容器 2.2.关联容器 2.3.容器适配器 2.4.数组 3.迭代器 4.重用标准迭代器 5.总结 1.概述 在之前,我们讲了迭代器设计模式,分析了它的结构、角色以及优缺点: 设计模式之迭代器模式-CSDN博客 在 STL 中&a…...

TCP、UDP详解
目录 1.区别 1.1 概括 1.2 详解 2.TCP 2.1 内容 2.2 可靠传输 2.2.1 确认应答 2.2.2 超时重传 2.2.3 连接管理 三次握手 四次挥手 2.2.4 滑动窗口 2.2.5 流量控制 2.2.6 拥塞控制 2.2.7 延时应答 2.2.8 捎带应答 2.2.9 面向字节流 2.2.10 异常情况的处理 1.…...
)
【脚本工具库】批量下采样图像(附源码)
在图像处理领域,我们经常需要对大批量图像进行下采样操作,以便减小图像的尺寸和文件大小,这对于节省存储空间和提高处理速度非常有帮助。手动操作不仅耗时,而且容易出错。为了解决这个问题,我们可以编写一个Python脚本…...

Web渗透:文件包含漏洞
Ⅱ.远程文件包含 远程文件包含漏洞(Remote File Inclusion, RFI)是一种Web应用程序漏洞,允许攻击者通过URL从远程服务器包含并执行文件;RFI漏洞通常出现在动态包含文件的功能中,且用户输入未经适当验证和过滤。接着我…...
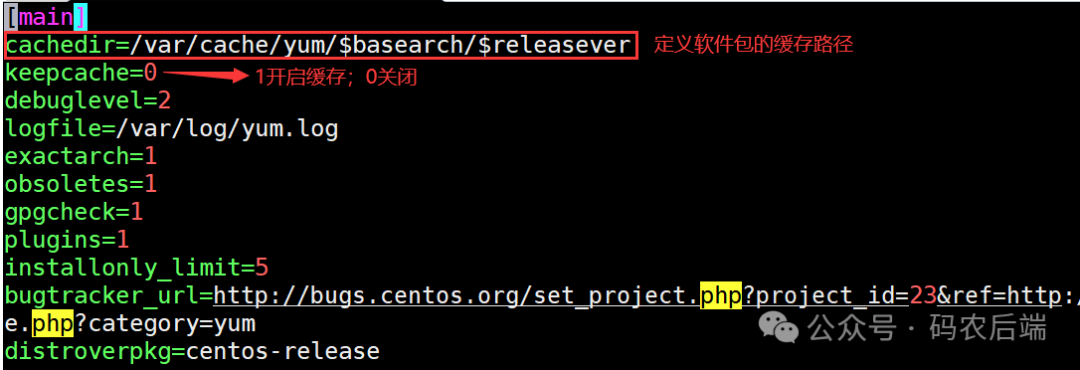
什么是yum源?如何对其进行配置?
哈喽,大家好呀!这里是码农后端。今天来聊一聊Linux下的yum源及其配置相关的内容。简单来说,yum源就相当于一个管理软件的工具,可以想象成一个很大的仓库,里面存放着各种我们所需要的软件包及其依赖。 一、Linux下软件包…...
Node.js全栈指南:认识MIME和HTTP
MIME,全称 “多用途互联网邮件扩展类型”。 这名称相当学术,用人话来说就是: 我们浏览一个网页的时候,之所以能看到 html 文件展示成网页,图片可以正常显示,css 样式能正常影响网页效果,js 脚…...
基于weixin小程序智慧物业系统的设计
管理员账户功能包括:系统首页,个人中心,管理员管理,用户管理,员工管理,房屋管理,缴费管理,车位管理,报修管理 工作人员账号功能包括:系统首页,维…...

成功解决TypeError: __call__() got an unexpected keyword argument ‘first_int‘
成功解决TypeError: __call__() got an unexpected keyword argument first_int 目录 解决问题 解决思路 解决方法 T1、直接调用原始函数 T2、检查装饰器实现 T3、使用不同的调用方式 解决问题 result = multiply(**arguments) File "D:\ProgramData\Anaconda3\Li…...

vue3用自定义指令实现按钮权限
1,编写permission.ts文件 在src/utils/permission.ts import type { Directive } from "vue"; export const permission:Directive{// 在绑定元素的父组件被挂载后调用mounted(el,binding){// el:指令所绑定的元素,可以用来直接操…...

Nuxt3:当前页面滚动到指定位置
在Nuxt 3中,如果你想让当前页面跳转到指定位置,可以使用scrollIntoView方法。你需要给目标位置的元素添加一个ref引用,然后通过程序调用该ref来执行滚动。 以下是一个简单的例子: <template><div><!-- 其他内容 …...
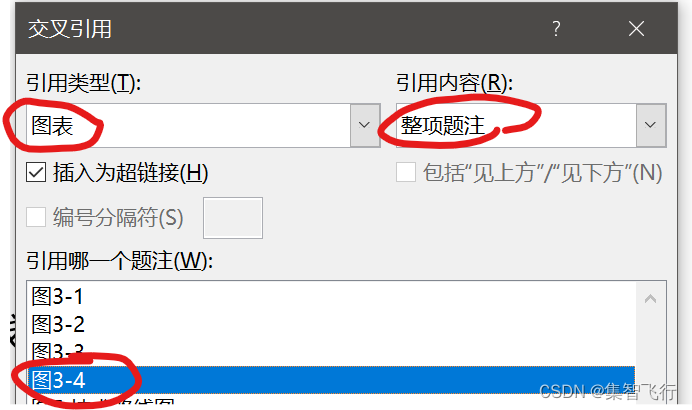
word图题表题公式按照章节编号(不用题注)
预期效果: 其中3表示第三章,4表示第3章里的第4个图。标题、公式编号也是类似的。 为了达到这种按照章节编号的效果,原本可以用插入题注里的“包含章节编号” 但实际情况是,这不仅需要一级标题的序号是用“开始->多级列表”自动…...

最小生成树模型
文章目录 题单最小生成树模型1.[最短网络(prim)](https://www.acwing.com/problem/content/1142/)2. [局域网(kruskul)](https://www.acwing.com/problem/content/1143/)3. [繁忙的都市](https://www.acwing.com/problem/content/1144/)4. [ 联络员 ](https://www.acwing.com/p…...

基于盲信号处理的声音分离-基于改进的信息最大化的ICA算法
基于信息最大化的ICA算法的主要依据是使输入端与输出端的互信息达到最大,且输出各个分量之间的相关性最小化,即输出各个分量之间互信息量最小化,其算法的系统框图如图所示。 基于信息最大化的ICA算法的主要依据是使输入端与输出端的互信息达到…...

如何在Qt Designer中管理QSplitter
问题描述 当按下按钮时,我希望弹出一个对话框,用户可以在其中选择内容并最终按下 ‘Ok’ 按钮。我想在这个对话框中放置一个 QSplitter,左侧面板将显示树状结构,右侧将显示其他内容。如何正确实现这一点? 从 Qt 的示…...

关于新零售的一些思考
本文作为2024上半年大量输入之后的核心思考之一。工作到一定阶段之后,思考的重要性越来越高,后续会把自己的个人思考记录在这个新系列《施展爱思考》。背景是上半年面临业务转型从电商到新零售,本文是相关大量输入之后的思考,对新…...

C++初学者指南-2.输入和输出---从输入流错误中恢复
C初学者指南-2.输入和输出—从输入流错误中恢复 文章目录 C初学者指南-2.输入和输出---从输入流错误中恢复怎么了?解决方案:出错后重置输入流 怎么了? 示例:连续输入 int main () {cout << "i? ";int i 0;cin…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

反向工程与模型迁移:打造未来商品详情API的可持续创新体系
在电商行业蓬勃发展的当下,商品详情API作为连接电商平台与开发者、商家及用户的关键纽带,其重要性日益凸显。传统商品详情API主要聚焦于商品基本信息(如名称、价格、库存等)的获取与展示,已难以满足市场对个性化、智能…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

centos 7 部署awstats 网站访问检测
一、基础环境准备(两种安装方式都要做) bash # 安装必要依赖 yum install -y httpd perl mod_perl perl-Time-HiRes perl-DateTime systemctl enable httpd # 设置 Apache 开机自启 systemctl start httpd # 启动 Apache二、安装 AWStats࿰…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...

Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信
文章目录 Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信前言一、网络通信基础概念二、服务端与客户端的完整流程图解三、每一步的详细讲解和代码示例1. 创建Socket(服务端和客户端都要)2. 绑定本地地址和端口&#x…...