PostgreSQL逻辑备份-pg_dump
1.pg_dump备份恢复
pg_dump 是一个逻辑备份工具。使用 pg_dump 可以在数据库处于使用状态下进行一致性的备份, 它不会阻塞其他用户对数据库的访问 。一致性备份是 pg_dump 开始运行时,给数据库打了一个快照,且在 pg_dump 运行过程中发生的更新将不会被备份。pg_dump 只备份单个数据库,不能备份数据库公共的全局对象(例如角色和表空间)提示 :将执行 pg_dump/pg_restore 的客户端放在尽可能靠近 源和目标 数据库的位置,以避免因网络延迟不良而导致的性能问题。
-h host,指定数据库主机名,或者 IP
-p port,指定端口号
-U user,指定连接使用的用户名
-W,按提示输入密码
dbname,指定连接的数据库名称,实际上也是要备份的数据库名称。
-f,--file:输出到指定文件中
-F,--format=c|d|t|p: c 为自定义格式,也是二进制格式,压缩存储,只能使用 pg_restore 来还原, 可
以指定还原的表, 编辑 TOC 文件, 定制还原的顺序, 表, 索引等。 d 为目录 t 表示输出为 tar 包 p 为纯文本 SQL,大库不推荐;
-j,--jobs=num:指定并行导出的并行度
-a,--data-only:只导出数据,不导出表结构
-c,--clean:是否生成清理该数据库对象的语句,比如 drop table
-C,--create:是否输出一条创建数据库语句
-n,--schema:只转存匹配 schema 的模式内容
-N,--exclude-scheam:不转存匹配 schema 的模式内容
-O,--no-owner,不设置导出对象的所有权
-s,--schema-only:只导致对象定义模式,不导出数据
-t,--table:只转存匹配到的表,视图,序列,可以使用多个-t 匹配多个表
-T,--exclude-table:不转存匹配到的表。
--inserts:使用 insert 命令形式导出数据,这种方式比默认的 copy 方式慢很多,但是可
用于将数据导入到非 PostgreSQL 数据库。
--column-inserts:导出的数据,有显式列名
3.备份
3.1指定库备份
1.导出sql文件
-- insert 命令形式导出库的数据
pg_dump -h 127.0.0.1 -U postgres -p 5432 -W testdb --inserts > testdb.sql
pg_dump testdb --inserts > testdb.sql
pg_dump testdb --inserts --rows-per-insert=2 > testdb.sql --每次插入 2 行2.导出指定对象
-- 要转储一个数据库到一个自定义格式归档文件:
pg_dump -Fc testdb > testdb.dump
-- 使用 5 个并行任务转储一个数据库到一个目录格式的归档
pg_dump -Fd testdb -j 5 -f dumpdir3.2单表备份
-- 备份单个表
pg_dump -h 127.0.0.1 -U postgres -p 5432 -W testdb -t t1 --inserts > testdb.sql -- 备份多个表
pg_dump -h 127.0.0.1 -U postgres -p 5432 -W testdb -t t1 -t t2 --inserts >
testdb.sql-- 如果只想备份 schema 模式中所有以 t 开头的表,但是不包括 t1 表
pg_dump -t "public.t*" -T public.t1 testdb > testdb.sql -- 转储所有 testdb 的数据库对象,但是不包含以 1 结尾的表
pg_dump -T '*1' testdb > testdb.sql -- 转储 testdb 中 public 和 test 这两个 schema 中的内容
pg_dump -Fc -n public -n test testdb -f testdb.dump -- 转储 testdb 中除了 public schema 中的数据以外的所有数据
pg_dump -Fc -N public testdb -f testdb.dump3.3只备份数据
pg_dump -h 127.0.0.1 -U postgres -p 5432 -W testdb --inserts -a > testdb.sql3.4只备份表结构
pg_dump -h 127.0.0.1 -U postgres -p 5432 -W testdb -s > testdb.sql4.恢复
--恢复一个文本文档
psql newdb < testdb.sql -- 要把一个归档文件重新载入到一个(新创建的)名为 newdb 的数据库:
pg_restore -d newdb testdb.dump -- 把一个归档文件重新装载到同一个数据库(该归档正是从这个数据库中转储得来)中,
丢掉那个数据库中的当前内容
pg_restore -d newdb --clean testdb.dump -- 备份后直接进行恢复,文件不落地
pg_dump testdb| psql newdb -- 并行备份恢复
pg_dump -Fd -j4 testdb -f dumpdir
pg_restore -d newdb -j4 dumpdir4.1利用toc文件选择性恢复
-- 根据二进制备份文件生成 toc 文件
方式一:pg_restore -l testdb.dump > testdb.toc
方式二:pg_restore -l -f testdb.toc testdb.dump -- 修改 toc 文件,用‘;’号注释掉不用还原的内容: -- 以 toc 文件列表做恢复
pg_restore -Fc -L testdb.toc -d newdb testdb.dump
-- 检查发现 t1 表没有被导入。4.2使用unix管道压缩备份恢复
-- 导出并且压缩
pg_dump testdb -f testdb.sql | gzip testdb.sql -- 解压并且导入,压缩文件不变:
gunzip -c testdb.sql.gz | psql testdb -- 分割备份
pg_dump testdb | split -b 1m -- 恢复
cat filename* | psql dbname5.迁移大表
5.1如果需要迁移多个大表怎么办?
可以使用 -j 选项来指定执行 pg_dump 和 pg_restore 时要使用的线程数。可以使用目录格式 (-Fd),它会提供压缩转储(使用 gzip)。使用 -Fd 选项可以提供超过5 倍的压缩。对于较大的数据库(例如超过 1 TB),压缩转储可以减少磁盘 IOPS。
示例:
pg_dump -Fd testdb -j 5 -f dump_dir
pg_restore -d newdb -j 5 dump_dir5.2 如果大多数表都很小,但有一张表非常大,如何迁移?
可以将 pg_dump 的输出通过管道传输到 pg_restore,这样就无需等待转储完成后再开始
恢复; 两者可以同时运行。 这避免了将转储存储在客户端,可以显着减少将转储写入磁盘所需的 IOPS 开销。在这种情况下,-j 选项没有用,因为 pg_dump/pg_restore 每个表只运行一个线程,它们在转储和恢复大表时受到限制。 此外,当使用 -j 标志时,无法将 pg_dump 的输出通过管道传输到 pg_restore。示例:pg_dump -Fc testdb | pg_restore -d newdb
5.3 如何使用多个线程迁移单个大表?
可以利用多个线程来迁移单个大表,方法是在逻辑上将 Postgres 表分为多个部分,然后使用一对线程——一个从源读取,一个写入目标。可以根据 主键(例如,id 列)或时间字段(例如,created_time、updated_time 等)对表进行拆分。GitHub 上有一个 Parallel Loader 的 Python 脚本,它实现了拆分迁移。下载地址:https://github.com/microsoft/OrcasNinjaTeam/tree/master/azurepostgresql/data_migration
#suppose the filename is parallel_migrate.py
import os
import sys
#source info
source_url = sys.argv[1]
source_table = sys.argv[2] #dest info
dest_url = sys.argv[3]
dest_table = sys.argv[4]
#others
total_threads=int(sys.argv[5]);
size=int(sys.argv[6]);
interval=size/total_threads;
start=0;
end=start+interval;
for i in range(0,total_threads): if(i!=total_threads-1): select_query = '\"\COPY (SELECT * from ' + source_table + ' WHERE
id>='+str(start)+' AND id<'+str(end)+") TO STDOUT\""; read_query = "psql \"" + source_url + "\" -c " + select_query write_query = "psql \"" + dest_url + "\" -c \"\COPY " + dest_table +"
FROM STDIN\"" os.system(read_query+'|'+write_query + ' &') else: select_query = '\"\COPY (SELECT * from '+ source_table +' WHERE
id>='+str(start)+") TO STDOUT\""; read_query = "psql \"" + source_url + "\" -c " + select_query write_query = "psql \"" + dest_url + "\" -c \"\COPY " + dest_table +"
FROM STDIN\"" os.system(read_query+'|'+write_query) start=end; end=start+interval;5.3.1如何调用并进行加载程序脚本
python parallel_migrate.py "source_connection_string" source_table "destination_connection_string" destination_table number_of_threadscount_of_table
示例:
python parallel_migrate.py "host=192.168.1.102 port=5432 dbname=postgres
user=postgres password=postgres sslmode=prefer" t1 "host=192.168.1.102
port=5432 dbname=newdb user=postgres password=postgres sslmode=prefer"
t1 4 1000000使用 Parallel Loader 脚本,可以控制用于迁移大表的线程数。 在上述调用中,number_of_threads 参数控制并行度因子。上述实现使用表的单调递增的 id 列将其拆分并使用并行线程将数据从源表流式传输到目标表。
5.3.2对比 Parallel Loader 与 pg_dump/pg_restore 迁移大表的性能
| parallel loader | pg_dump&pg_restore |
| 7 小时 45 分钟 | 超过一天 |
可以将 pg_dump/pg_restore 与 Parallel Loader 结合使用,以实现更快的数据迁移pg_dump/pg_restore 是可以将数据从一个数据库迁移到另一个数据库。但是,当数据库中有非常大的表时,会大大减慢迁移速度。为了解决这个问题,可以使用 Parallel Loader脚本将单个大表进行迁移,而 pg_dump/pg_restore 可用于迁移其余的表。
相关文章:

PostgreSQL逻辑备份-pg_dump
1.pg_dump备份恢复 pg_dump 是一个逻辑备份工具。使用 pg_dump 可以在数据库处于使用状态下进行一致 性的备份, 它不会阻塞其他用户对数据库的访问 。 一致性备份是 pg_dump 开始运行时,给数据库打了一个快照,且在 pg_dump 运行过程 中发生…...

UG_NX11.0之Windows11中安装出错及解决方法
UG_NX11.0之Windows11中安装出错及解决方法 文章目录 UG_NX11.0之Windows11中安装出错及解决方法1. 安装出错2. 解决方法1. 设置以兼容性模式运行2. 配置环境变量 3. 再次安装问题解决4. 安装后可删除配置的环境变量(可选) 1. 安装出错 以管理员身份运行Launch.exe,如下 点击D…...

android view 设置过 transalationY/X 后 marginTop/marginStart/Left 不变
在 Android 开发中,当你对一个视图(View)设置了 translationY 属性后,这个视图的 marginTop 属性实际上并不会改变。这是因为 translationY 只会影响视图的绘制位置,而不会改变视图的布局参数。换句话说,translationY 是一个运行时…...

解释在Android中如何实现本地存储,包括SQLite数据库和SharedPreferences。
在Android开发中,本地存储是不可或缺的一部分,它允许应用程序在用户的设备上保存和检索数据。两种常见的本地存储方式是SQLite数据库和SharedPreferences。下面我将从技术难点、面试官关注点、回答吸引力和代码举例四个方面来详细解释如何在Android中实现…...
鸿蒙开发 之 健康App案例
1.项目介绍 该项目是记录用户日常饮食情况,以及针对不同食物摄入营养不同会有对应的营养摄入情况和日常运动消耗情况,用户可以自己添加食品以及对应的热量。 1.1登陆页 1.2饮食统计页 1.3 食物列表页 2.登陆页 2.1自定义弹框 import preferences from oh…...

umi3项目axios 请求参数序列化参数
由于get 请求中有一个日期参数 dates 是一个数组类型。 未处理参数时请求地址是这样的:/api/list?page1&pageSize10&keyWord&dates[]2024-06-10&dates[]2024-06-24 会发现dates后面有中括号,所以前端需要将参数格式处理变成如下:/api…...

js实现数据去重合并
应用场景,一个list,包含已经选择的数据和未选择的数据,新增数据到已选择的数据中。 要考虑到二次选择的数据和已经选择的数据有重复的可能,所以,第一步先从二次选择的数据中进行去重,然后再将两个list进行数…...

[ios逆向]查看ios安装包ipa签名证书embedded.mobileprovision解密 附带解密环境openssl
openssl smime -inform der -verify -noverify -in embedded.mobileprovision 解密embedded.mobileprovision文件 链接:https://pan.baidu.com/s/1UwNOWONKV1SNj5aX_ZZCzQ?pwdglco 提取码:glco –来自百度网盘超级会员V8的分享 可以使用everything 查看…...

tr、cut、split、grep -E
目录 tr命令:替换和删除 cut命令:快速裁剪 split命令:文件拆分 文件合并 面试题 1.现在有一个日志文件,有5个G,能不能快速的打开 2.cat合并和paste合并之间的区别? 3.统计当前主机的连接状态&#…...
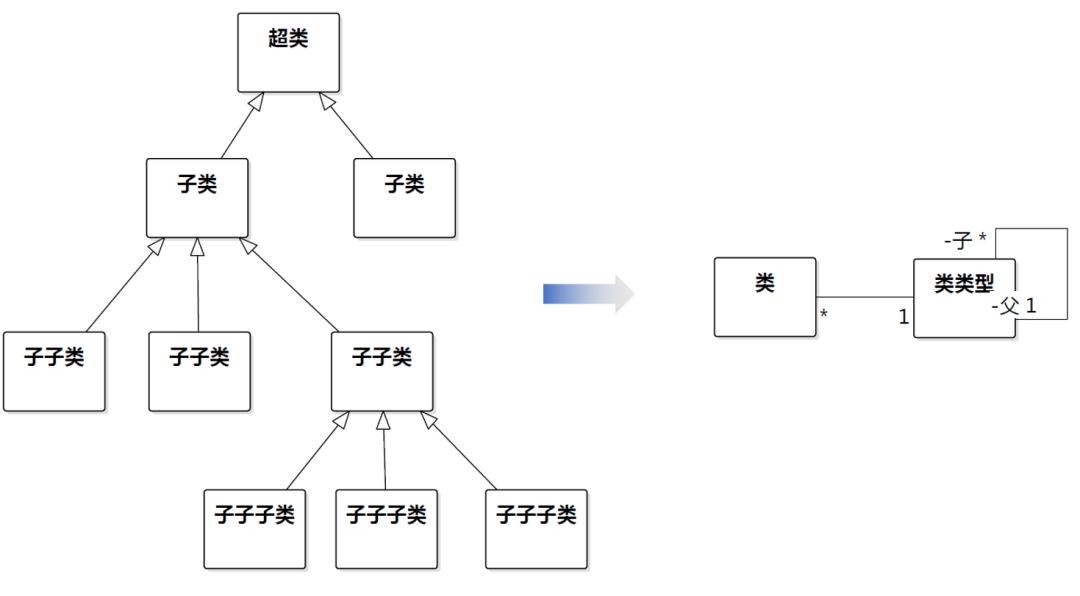
《分析模式》漫谈08-单继承不是“唯一继承”
DDD领域驱动设计批评文集 做强化自测题获得“软件方法建模师”称号 《软件方法》各章合集 《分析模式》第2章这一段: 划线处的single inheritance,2004中译本的翻译: 翻译为“单继承”,是正确的。 2020中译本的翻译:…...

c++字典
在C中,“字典”通常指的是std::map或std::unordered_map,它们是标准库中提供的关联容器,用于存储键值对。以下是一些常见的操作示例,包括插入、访问、删除和遍历元素。 使用 std::map std::map 是一种有序的关联容器,键…...

rga_mm: RGA_MMU unsupported Memory larger than 4G!解决
目录 报错完整log如下:解决方案:报错完整log如下: [ 3668.824164] rga_mm: RGA_MMU unsupported Memory larger than 4G! [ 3668.824305] rga_mm: scheduler core[4] unsupported mm_flag[0x0]! [ 3668.824320] rga_mm: rga_mm_map_buffer map dma_buf err...
构建个人文件上传服务:Python Flask实现上传和下载完整指南
介绍 在本教程中,我们将学习如何使用Python Flask框架将文件上传到服务器,并使用SQLite数据库来跟踪上传的文件。我们将提供后端代码和一个示例项目的Git链接,以便您可以轻松地跟随本教程。 准备工作 首先,您需要安装Python和F…...
瓦罗兰特新赛季更新资讯 瓦罗兰特新赛季免费加速器
瓦罗兰特新赛季来喽,这是一款由拳头开发的免费第一人称射击游戏,游戏凭借其独特的玩法和丰富的英雄选择吸引了大量玩家。 我们可以在游戏中选择自己喜欢的角色出场与敌人进行对战,而且每一个角色都有自己独特的道具以及技能,使用好…...
希尔排序的实现
引言 排序在我们生活中十分常见,无论是购物软件中的商品推荐还是名次、排名都与排序算法息息相关。希尔排序是排序中较快的一种,而希尔排序实现的基础是插入排序。 排序的实现 插入排序(以升序为例) 插入排序的原理是从第二个数…...

使用Python selenium爬虫领英数据,并进行AI岗位数据挖掘
随着OpenAI大火,从事AI开发的人趋之若鹜,这次使用Python selenium抓取了领英上几万条岗位薪资数据,并使用Pandas、matplotlib、seaborn等库进行可视化探索分析。 但领英设置了一些反爬措施,对IP进行限制封禁,因此会用到…...

如何在Android应用程序中实现高效的图片加载和缓存机制。
在Android应用程序中实现高效的图片加载和缓存机制 一、技术难点 在Android应用程序中实现高效的图片加载和缓存机制,主要面临以下几个技术难点: 内存管理:Android设备的内存资源有限,如果加载大量高清图片而不进行适当的内存管…...

【机器学习项目实战(二)】基于朴素贝叶斯的中文垃圾短信分类
完整代码、数据集和相应的报告 链接已经放在了正文最下方, 供大家参考学习 摘要 本文探讨了中文垃圾短信分类的问题,通过收集实际数据集,运用多种机器学习算法进行分类,并对比了不同算法在垃圾短信分类任务上的性能。本研究旨在提高中文垃圾短信的识别准确率,为构建更…...

当用户需求不详细时,如何有效应对
在项目沟通时,用户对需求说明不详细,可能是由于多种原因。以下是一些可能的原因及如何应对这些问题的建议: 1. 用户不完全理解自己的需求 原因: 用户对技术细节不了解,不知道如何具体描述需求。 用户对项目的全局和…...
最新AI智能聊天对话问答系统源码(图文搭建部署教程)+AI绘画,文生图,TTS语音识别输入,文档分析
一、人工智能语言模型和AI绘画在多个领域广泛应用 人工智能语言模型和AI绘画在多个领域都有广泛的应用。以下是一些它们的主要用处: 人工智能语言模型 内容生成 写作辅助:帮助撰写文章、博客、报告、剧本等。 代码生成:自动生成或补全代码&…...

综述不会写?全网爆红的AI论文平台 —— 千笔写作工具
你是否也经历过这样的时刻:面对论文写作无从下手,选题纠结、框架混乱、文献检索困难、查重率居高不下?很多专科生在写论文时常常感到力不从心,甚至因此影响毕业进度。而如今,一款被全网爆红的AI论文平台——千笔AI&…...

Newtonsoft.Json 高级玩法:用 JsonSerializerSettings 定制你的 JSON 序列化规则
Newtonsoft.Json 高级玩法:用 JsonSerializerSettings 定制你的 JSON 序列化规则 在数据交换和存储的场景中,JSON 格式因其轻量和易读性而广受欢迎。对于 C# 开发者来说,Newtonsoft.Json(现称 Json.NET)无疑是处理 JSO…...
)
别再手动装Oracle了!用Docker 5分钟搞定Oracle 11g开发环境(附阿里云镜像地址)
5分钟极速部署Oracle 11g:Docker化开发环境实战指南 每次新项目需要Oracle数据库支持时,传统安装方式总让人望而却步——动辄数小时的安装过程、复杂的系统配置、难以清理的残留文件。作为经历过十几次Oracle安装的老手,我深刻理解这种痛苦。…...

nlp_gte_sentence-embedding_chinese-large在教育资源检索中的应用
nlp_gte_sentence-embedding_chinese-large在教育资源检索中的应用 1. 引言 教育资源检索一直是教育工作者和学习者面临的重要挑战。传统的检索方式往往依赖关键词匹配,当用户搜索"数学解题技巧"时,系统可能只能找到包含这些确切词汇的资源&…...
字典管理实战:如何在Thymeleaf中高效使用下拉框与单选框)
若依(ruoyi)字典管理实战:如何在Thymeleaf中高效使用下拉框与单选框
若依(ruoyi)字典管理实战:Thymeleaf下拉框与单选框高效应用指南 在Java企业级开发领域,若依框架(ruoyi)凭借其完善的权限体系和丰富的功能组件,已成为众多开发团队的首选技术栈。其中,字典管理模块作为基础数据标准化的重要工具&a…...
)
密码学开发实战:如何在Windows上快速搭建PBC+GMP开发环境(含VS2019适配方案)
密码学开发实战:Windows下PBC与GMP开发环境高效配置指南 1. 环境搭建前的准备工作 在开始配置PBC和GMP开发环境之前,我们需要先了解这两个库的基本情况。PBC(Pairing-Based Cryptography)库是一个专门用于双线性对密码学运算的开源…...

WuliArt Qwen-Image Turbo显存优化部署:VAE分块编码+CPU卸载实测报告
WuliArt Qwen-Image Turbo显存优化部署:VAE分块编码CPU卸载实测报告 1. 引言:当高清文生图遇上个人显卡 如果你尝试过在个人电脑上运行最新的文生图模型,大概率会遇到一个头疼的问题:显存爆炸。动辄需要40G、80G显存的模型&…...

TeslaMate低功耗优化终极指南:树莓派部署的节能设置与性能平衡
TeslaMate低功耗优化终极指南:树莓派部署的节能设置与性能平衡 【免费下载链接】teslamate 项目地址: https://gitcode.com/gh_mirrors/tes/teslamate TeslaMate是一款强大的开源Tesla车辆数据监控工具,通过树莓派部署可实现24/7不间断数据采集。…...

金仓数据库KingbaseES高可用集群搭建:从零到主备切换的完整避坑手册
金仓数据库KingbaseES高可用集群搭建:从零到主备切换的完整避坑手册 在企业级数据库运维中,高可用性设计如同给业务系统装上"安全气囊"。金仓数据库KingbaseES凭借其成熟的流复制机制和repmgr管理工具,已成为国产数据库高可用方案的…...

探索 L4 无人车自动驾驶系统方案:无代码的蓝图魅力
L4无人车自动驾驶系统方案 系统方案设计,150多页系统方案 方案文档,没有配套代码最近深入研究了一份足足 150 多页的 L4 无人车自动驾驶系统方案文档,虽然没有配套代码,但这并不影响它本身蕴含的巨大价值,就像一座建筑…...