【课程总结】Day12:YOLO的深入了解
前言
在【课程总结】Day11(下):YOLO的入门使用一节中,我们已经了解YOLO的使用方法,使用过程非常简单,训练时只需要三行代码:引入YOLO,构建模型,训练模型;预测时也同样简单,只需要两行代码:引入YOLO,预测图像即可。以上过程简单主要是ultralytics的代码库已经做了封装,使得使用者集中精力在模型训练和预测上。
为了更加深入了解YOLO的实现原理,本章内容将对YOLO的工程结构、模型构建过程、模型训练过程尝试深入探究。
YOLO项目的工程结构
|- ultralytics/|- assets/ # 存放项目中使用的资源文件,如图像、样本数据等。|- cfg/ # 存放模型配置文件,包括不同模型的配置信息,如网络结构、超参数等。|- data/ # 存放数据集文件和数据处理相关的代码。|- engine/ # 存放训练和推理引擎的代码,包括训练、测试、评估等功能的实现。|- hub/ # 存放模型库相关的代码和模型文件,用于快速调用和使用预训练模型。|- models/ # 存放模型的定义和实现代码,包括不同模型的网络结构和相关函数。|- nn/ # 存放神经网络模块的代码,包括各种层次的定义和实现。|- solutions/ # 存放解决方案相关的代码和实现,用于特定问题或任务的解决方案。|- trackers/ # 存放目标跟踪相关的代码和实现,包括目标追踪算法的实现。|- utils/ # 存放通用的工具函数和辅助函数,用于项目中的各种功能和任务。
进一步查看cfg目录的内容如下:
- ultralytics|- cfg|- datasets # 数据集处理和加载相关文件|- default.yaml # 默认配置信息文件|- models # 包含不同模型结构的配置文件|- yolov8-cls-resnet101.yaml # 定义 YOLOv8 模型结构的配置文件(ResNet-101 版本)|- yolov8-cls-resnet50.yaml # 定义 YOLOv8 模型结构的配置文件(ResNet-50 版本)|- yolov8-cls.yaml # 定义 YOLOv8 模型结构的配置文件|- ... # 其他 YOLOv8 模型版本的配置文件|- trackers # 目标跟踪相关文件
YOLO的yaml文件解析
yaml文件内容
以yolov8.yaml为例,其内容如下:
nc: 80 # 类别数目,nc代表"number of classes",即模型用于检测的对象类别总数。
scales: # 模型复合缩放常数,例如 'model=yolov8n.yaml' 将调用带有 'n' 缩放的 yolov8.yaml# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n概览:225层, 3157200参数, 3157184梯度, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s概览:225层, 11166560参数, 11166544梯度, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m概览:295层, 25902640参数, 25902624梯度, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l概览:365层, 43691520参数, 43691504梯度, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x概览:365层, 68229648参数, 68229632梯度, 258.5 GFLOPs# YOLOv8.0n 骨干层
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 第0层,-1代表将上层的输入作为本层的输入。第0层的输入是640*640*3的图像。Conv代表卷积层,相应的参数:64代表输出通道数,3代表卷积核大小k,2代表stride步长。- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 第1层,本层和上一层是一样的操作(128代表输出通道数,3代表卷积核大小k,2代表stride步长)- [-1, 3, C2f, [128, True]] # 第2层,本层是C2f模块,3代表本层重复3次。128代表输出通道数,True表示Bottleneck有shortcut。- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8 第3层,进行卷积操作(256代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为80*80*256(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样),特征图的长宽已经变成输入图像的1/8。- [-1, 6, C2f, [256, True]] # 第4层,本层是C2f模块,可以参考第2层的讲解。6代表本层重复6次。256代表输出通道数,True表示Bottleneck有shortcut。经过这层之后,特征图尺寸依旧是80*80*256。- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16第5层,进行卷积操作(512代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为40*40*512(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样),特征图的长宽已经变成输入图像的1/16。- [-1, 6, C2f, [512, True]] # 第6层,本层是C2f模块,可以参考第2层的讲解。6代表本层重复6次。512代表输出通道数,True表示Bottleneck有shortcut。经过这层之后,特征图尺寸依旧是40*40*512。- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32第7层,进行卷积操作(1024代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为20*20*1024(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样),特征图的长宽已经变成输入图像的1/32。- [-1, 3, C2f, [1024, True]] # 第8层,本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。1024代表输出通道数,True表示Bottleneck有shortcut。经过这层之后,特征图尺寸依旧是20*20*1024。- [-1, 1, SPPF, [1024, 5]] # 9 第9层,本层是快速空间金字塔池化层(SPPF)。1024代表输出通道数,5代表池化核大小k。结合模块结构图和代码可以看出,最后concat得到的特征图尺寸是20*20*(512*4),经过一次Conv得到20*20*1024。# YOLOv8.0n 头部层
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 第10层,本层是上采样层。-1代表将上层的输出作为本层的输入。None代表上采样的size(输出尺寸)不指定。2代表scale_factor=2,表示输出的尺寸是输入尺寸的2倍。nearest代表使用的上采样算法为最近邻插值算法。经过这层之后,特征图的长和宽变成原来的两倍,通道数不变,所以最终尺寸为40*40*1024。- [[-1, 6], 1, Concat, [1]] # cat backbone P4 第11层,本层是concat层,[-1, 6]代表将上层和第6层的输出作为本层的输入。[1]代表concat拼接的维度是1。从上面的分析可知,上层的输出尺寸是40*40*1024,第6层的输出是40*40*512,最终本层的输出尺寸为40*40*1536。- [-1, 3, C2f, [512]] # 12 第12层,本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。512代表输出通道数。与Backbone中C2f不同的是,此处的C2f的bottleneck模块的shortcut=False。- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 第13层,本层也是上采样层(参考第10层)。经过这层之后,特征图的长和宽变成原来的两倍,通道数不变,所以最终尺寸为80*80*512。- [[-1, 4], 1, Concat, [1]] # cat backbone P3 第14层,本层是concat层,[-1, 4]代表将上层和第4层的输出作为本层的输入。[1]代表concat拼接的维度是1。从上面的分析可知,上层的输出尺寸是80*80*512,第6层的输出是80*80*256,最终本层的输出尺寸为80*80*768。- [-1, 3, C2f, [256]] # 15 (P3/8-small) 第15层,本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。256代表输出通道数。经过这层之后,特征图尺寸变为80*80*256,特征图的长宽已经变成输入图像的1/8。- [-1, 1, Conv, [256, 3, 2]] # 第16层,进行卷积操作(256代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为40*40*256(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样)。- [[-1, 12], 1, Concat, [1]] # cat head P4 第17层,本层是concat层,[-1, 12]代表将上层和第12层的输出作为本层的输入。[1]代表concat拼接的维度是1。从上面的分析可知,上层的输出尺寸是40*40*256,第12层的输出是40*40*512,最终本层的输出尺寸为40*40*768。- [-1, 3, C2f, [512]] # 18 (P4/16-medium) 第18层,本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。512代表输出通道数。经过这层之后,特征图尺寸变为40*40*512,特征图的长宽已经变成输入图像的1/16。- [-1, 1, Conv, [512, 3, 2]] # 第19层,进行卷积操作(512代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为20*20*512(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样)。- [[-1, 9], 1, Concat, [1]] # cat head P5 第20层,本层是concat层,[-1, 9]代表将上层和第9层的输出作为本层的输入。[1]代表concat拼接的维度是1。从上面的分析可知,上层的输出尺寸是20*20*512,第9层的输出是20*20*1024,最终本层的输出尺寸为20*20*1536。- [-1, 3, C2f, [1024]] # 21 (P5/32-large) 第21层,本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。1024代表输出通道数。经过这层之后,特征图尺寸变为20*20*1024,特征图的长宽已经变成输入图像的1/32。- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5) 第20层,本层是Detect层,[15, 18, 21]代表将第15、18、21层的输出(分别是80*80*256、40*40*512、20*20*1024)作为本层的输入。nc是数据集的类别数。yaml文件解析
上述文件包含了 YOLOv8 模型的配置信息,其中包括了模型的类别数目、模型复合缩放常数、主干网络结构和头部网络结构。具体来说:
- nc 表示模型的类别数目为 1000。
- scales 包含了不同缩放常数对应的模型结构参数。
- 子参数:n, s, m, l, x表示不同的模型尺寸,每个尺寸都有对应的depth(深度)、width(宽度)和max_channels(最大通道数)。
depth: 表示深度因子,用来控制一些特定模块的数量的,模块数量多网络深度就深;width: 表示宽度因子,用来控制整个网络结构的通道数量,通道数量越多,网络就看上去更胖更宽;max_channels: 最大通道数,为了动态地调整网络的复杂性。在 YOLO 的早期版本中,网络中的每个层都是固定的,这意味着每个层的通道数也是固定的。但在 YOLOv8 中,为了增加网络的灵活性并使其能够更好地适应不同的任务和数据集,引入了 max_channels 参数。
- backbone 定义了 YOLOv8.0n 模型的主干网络结构,包括了卷积层、C2f 模块等。
from(来自):- 这个字段表示当前层连接到的上一层的索引。通常,-1 表示连接到上一层,0 表示连接到输入数据。
- 例如,[-1, 1, Conv, [64, 3, 2]] 表示当前层连接到上一层,即前一层的输出作为当前层的输入。
repeats(重复次数):- 这个字段表示当前层的模块(module)被重复使用的次数。
- 例如,[-1, 3, C2f, [128, True]] 表示当前层的模块 C2f 会被重复使用 3 次。
module(模块):- 这个字段表示当前层使用的模块类型,如 Conv(卷积层)、C2f 等。
- 例如,[-1, 1, Conv, [64, 3, 2]] 中的 Conv 表示当前层使用的是卷积层。
args(参数):- 这个字段包含了当前层模块的参数,例如卷积层的通道数、卷积核大小、步长等。
- 例如,[-1, 1, Conv, [64, 3, 2]] 中的 [64, 3, 2] 表示卷积层的通道数为 64,卷积核大小为 3,步长为 2。
YOLOv8 模型结构
上述yaml定义的模型结构,使用图示显示如下:

主要组成部分:
- Backbone(主干网络)
主干网络是模型的基础,负责从输入图像中提取特征。这些特征是后续网络层进行目标检测的基础。
- Head(头部网络)
头部网络是目标检测模型的决策部分,负责产生最终的检测结果。
- ConvModule
包含卷积层、BN(批量归一化)和激活函数(如SiLU),用于提取特征。
- DarknetBottleneck:
通过residual connections(残差结构)增加网络深度,同时保持效率。
- CSP Layer:
CSP结构的变体,通过部分连接来提高模型的训练效率。
- Concat:
特征图拼接,用于合并不同层的特征。
- Upsample:
上采样操作,增加特征图的空间分辨率。
主要过程为:
1.多层卷积:图片输入到主干网络,经过P1-P5层卷积后,在第9层通过SPPF模块进行特征提取。
2.上采样和连接:经过SPPF后进行Upsample上采样操作,然后与第6层进行concat操作,再进行C2f模块特征提取。
类似的:
- 在14层与第4层进行concat操作,再进行C2f模块特征提取;
- 在20层与第9层进行concat操作,再进行C2f模块特征提取。
3.目标检测:最后将15层、18层、21层分别经过Detect模块进行目标检测。
YOLO的模型构建过程解析
代码调用时序
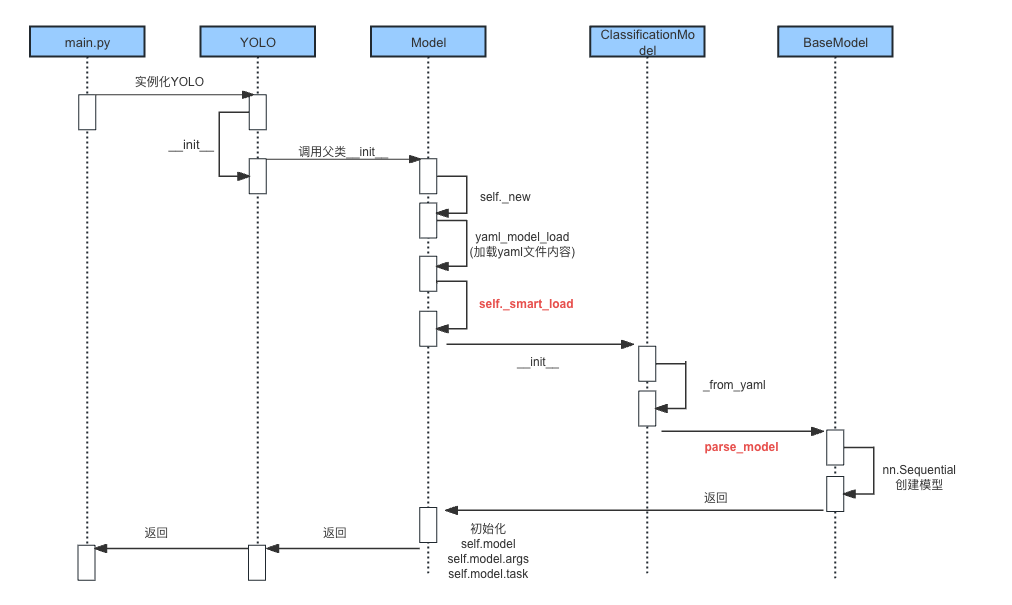
构建模型的核心代码
通过查看上述YOLO构建模型过程,其核心代码主要是以下两处:
核心代码1:self._smart_load()
def _new(self, cfg: str, task=None, model=None, verbose=False) -> None:# 以上部分省略...self.model = (model or self._smart_load("model"))(cfg_dict, verbose=verbose and RANK == -1) # 核心代码self.overrides["model"] = self.cfgself.overrides["task"] = self.taskself.model.args = {**DEFAULT_CFG_DICT, **self.overrides} # 核心代码# 以下部分省略...
代码解析:
self.model = (model or self._smart_load("model"))(cfg_dict, verbose=verbose and RANK == -1)
- 特性:使用 Python 的条件表达式,选择不同的函数或对象进行赋值
- 解释说明:
model or self._smart_load("model")是一个条件表达式,它会根据model变量是否为真值来选择赋值的对象。- 如果
model为真值(非空),则self.model将被赋值为model。 - 如果
model为假值(空),则会调用self._smart_load("model")方法来加载模型,并将返回的对象赋值给self.model。 - 然后与,第二个括号
(cfg_dict, verbose=verbose and RANK == -1)拼接,形成self.model(cfg_dict, verbose=verbose and RANK == -1)
self.model.args = {**DEFAULT_CFG_DICT, **self.overrides}
- 特性:使用 Python 中的字典合并操作符 ** 来将两个字典合并。
- 解释说明:
DEFAULT_CFG_DICT和self.overrides是两个字典。**DEFAULT_CFG_DICT将DEFAULT_CFG_DICT字典中的所有键值对解包并添加到新的字典中。**self.overrides同样将self.overrides字典中的所有键值对解包并添加到同一个新的字典中。- 最终,
{\*\*DEFAULT_CFG_DICT, \*\*self.overrides}表示将这两个字典合并成一个新的字典,其中self.overrides中的键值对将覆盖DEFAULT_CFG_DICT中的同名键值对。
- 举例:
dict1 = {'a': 1, 'b': 2}
dict2 = {'b': 3, 'c': 4}
merged_dict = {**dict1, **dict2}
print(merged_dict)
# 运行结果:
# {'a': 1, 'b': 3, 'c': 4}
核心代码2:self.task_map[self.task][key]
def task_map(self):"""Map head to model, trainer, validator, and predictor classes."""return {"classify": {"model": ClassificationModel,"trainer": yolo.classify.ClassificationTrainer,"validator": yolo.classify.ClassificationValidator,"predictor": yolo.classify.ClassificationPredictor,},"detect": {"model": DetectionModel,"trainer": yolo.detect.DetectionTrainer,"validator": yolo.detect.DetectionValidator,"predictor": yolo.detect.DetectionPredictor,},# 以下部分省略...}
代码解析:
- 以上代码根据传入的self.task类型(例如:classify),来创建对应的模型、训练器、验证器、预测器类。
- 特性:使用了 Python 中的字典,将字符串键与类对象值进行关联,以实现将类对象映射到不同的功能模块
- 字典与类对象映射的举例
class Dog:def __init__(self, name):self.name = name
class Cat:def __init__(self, name):self.name = name
# 创建一个字典,将字符串键映射到不同的类对象
animal_map = {"dog": Dog,"cat": Cat,
}
# 根据键来实例化不同的类对象
my_dog = animal_map["dog"]("Buddy")
my_cat = animaljson_map["cat"]("Whiskers")
print(my_dog.name) # 输出: Buddy
print(my_cat.name) # 输出: Whiskers核心代码3:parse_model()函数
def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)"""Parse a YOLO model.yaml dictionary into a PyTorch model."""import ast# Argsmax_channels = float("inf")nc, act, scales = (d.get(x) for x in ("nc", "activation", "scales"))depth, width, kpt_shape = (d.get(x, 1.0) for x in ("depth_multiple", "width_multiple", "kpt_shape"))if scales:scale = d.get("scale")if not scale:scale = tuple(scales.keys())[0]LOGGER.warning(f"WARNING ⚠️ no model scale passed. Assuming scale='{scale}'.")depth, width, max_channels = scales[scale]if act:Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()if verbose:LOGGER.info(f"{colorstr('activation:')} {act}") # printch = [ch]layers, save, c2 = [], [], ch[-1] # layers, savelist, ch outfor i, (f, n, m, args) in enumerate(d["backbone"] + d["head"]): # from, number, module, argsm = getattr(torch.nn, m[3:]) if "nn." in m else globals()[m] # get modulefor j, a in enumerate(args):if isinstance(a, str):with contextlib.suppress(ValueError):args[j] = locals()[a] if a in locals() else ast.literal_eval(a)n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gainif m in {Classify,Conv,ConvTranspose,GhostConv,Bottleneck,GhostBottleneck,SPP,SPPF,DWConv,Focus,BottleneckCSP,C1,C2,C2f,RepNCSPELAN4,ELAN1,ADown,AConv,SPPELAN,C2fAttn,C3,C3TR,C3Ghost,nn.ConvTranspose2d,DWConvTranspose2d,C3x,RepC3,PSA,SCDown,C2fCIB,}:c1, c2 = ch[f], args[0]if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)c2 = make_divisible(min(c2, max_channels) * width, 8)if m is C2fAttn:args[1] = make_divisible(min(args[1], max_channels // 2) * width, 8) # embed channelsargs[2] = int(max(round(min(args[2], max_channels // 2 // 32)) * width, 1) if args[2] > 1 else args[2]) # num headsargs = [c1, c2, *args[1:]]# ...((篇幅原因,代码已做省略))m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # modulet = str(m)[8:-2].replace("__main__.", "") # module typem.np = sum(x.numel() for x in m_.parameters()) # number paramsm_.i, m_.f, m_.type = i, f, t # attach index, 'from' index, typeif verbose:LOGGER.info(f"{i:>3}{str(f):>20}{n_:>3}{m.np:10.0f} {t:<45}{str(args):<30}") # printsave.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelistlayers.append(m_)if i == 0:ch = []ch.append(c2)return nn.Sequential(*layers), sorted(save)
代码解析:
- 参数设置:
- 以上代码定义了一些初始参数,如 max_channels、nc(类别数)、act(激活函数类型)、scales(模型尺度)、depth(深度倍数)、width(宽度倍数)等。
- 根据配置文件中的 scales 参数设置模型的深度、宽度和最大通道数。
- 激活函数设置:
- 如果配置文件中指定了激活函数类型 act,则重新定义默认激活函数为指定的激活函数(如 nn.SiLU())。
- 模型解析:
- 遍历配置文件中的 backbone 和 head 部分,解析每个层的信息。
- 根据模块类型 m(如 Conv、Bottleneck 等)选择相应的处理逻辑,设置输入通道 c1、输出通道 c2 以及其他参数。
- 创建模块:
- 根据解析得到的参数和模块类型,通过
nn.Sequential(*layers)创建相应的层,最终返回解析后的模型。
- 根据解析得到的参数和模块类型,通过
YOLO的模型训练过程解析
代码调用时序
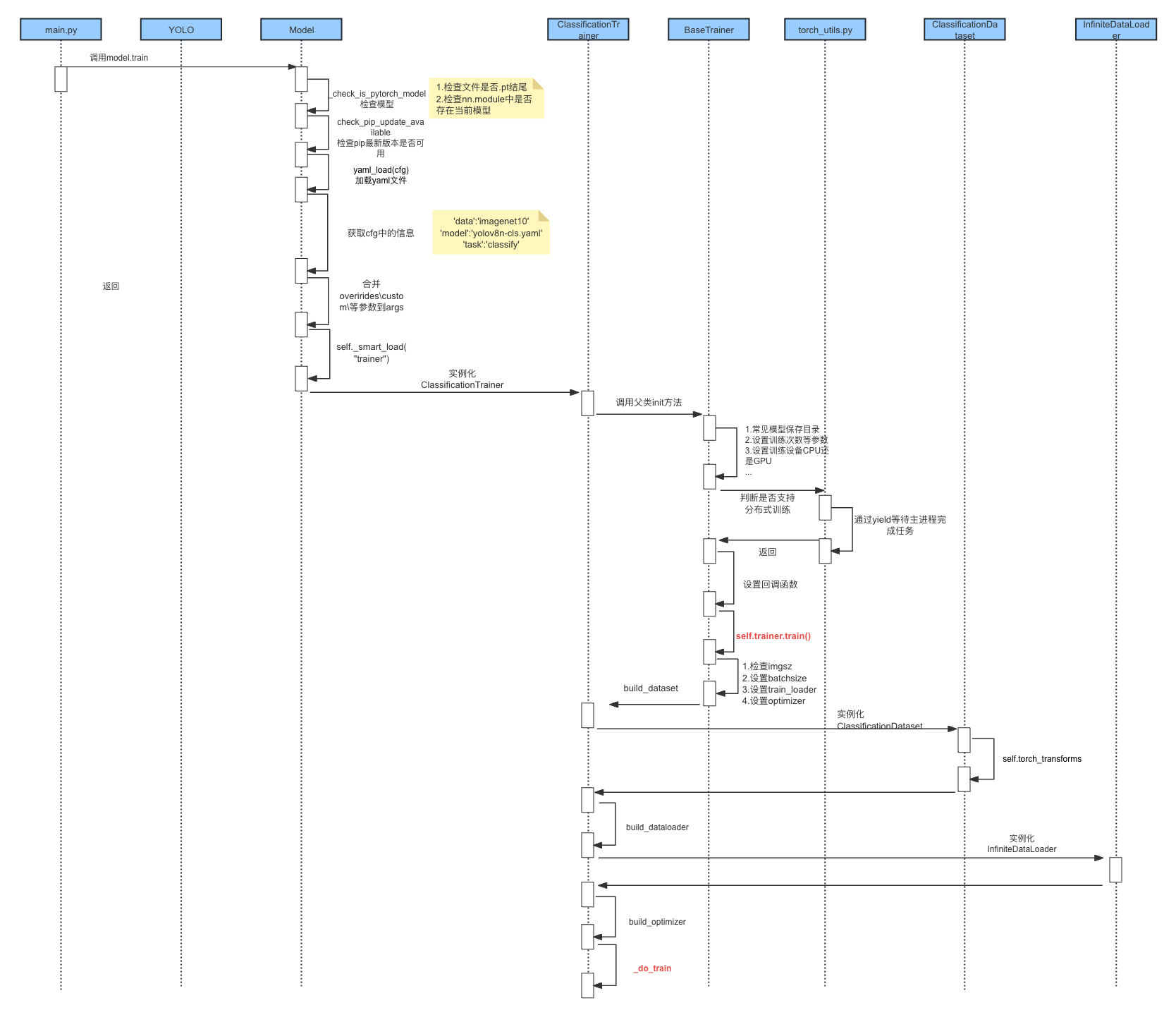
构建模型的核心代码
核心代码1:ClassificationDataset数据集
def __init__(self, root, args, augment=False, prefix=""):# 以上内容省略self.torch_transforms = (classify_augmentations(size=args.imgsz,scale=scale,hflip=args.fliplr,vflip=args.flipud,erasing=args.erasing,auto_augment=args.auto_augment,hsv_h=args.hsv_h,hsv_s=args.hsv_s,hsv_v=args.hsv_v,)if augmentelse classify_transforms(size=args.imgsz, crop_fraction=args.crop_fraction))
代码解析:
- 以上代码是ClassificationDataset数据集的初始化函数
- self.torch_transforms = …:
- 根据条件选择不同的数据增强方法:
- 如果 augment 为 True,则调用 classify_augmentations() 方法进行数据增强。
- 否则,调用 classify_transforms() 方法进行数据转换。
- 除此之外,该数据集按照标准规范,实现了__getitem__(),len()等回调函数。
核心代码2:筹备训练
def _setup_train(self, world_size):"""Builds dataloaders and optimizer on correct rank process."""# Modelself.run_callbacks("on_pretrain_routine_start")ckpt = self.setup_model()self.model = self.model.to(self.device)self.set_model_attributes()# Freeze layers# 篇幅原因,代码已省略# Check AMP# 篇幅原因,代码已省略# Check imgszgs = max(int(self.model.stride.max() if hasattr(self.model, "stride") else 32), 32) # grid size (max stride)self.args.imgsz = check_imgsz(self.args.imgsz, stride=gs, floor=gs, max_dim=1)self.stride = gs # for multiscale training# Batch size# 篇幅原因,代码已省略# Dataloadersbatch_size = self.batch_size // max(world_size, 1)self.train_loader = self.get_dataloader(self.trainset, batch_size=batch_size, rank=RANK, mode="train")# 代码已省略# Optimizerself.accumulate = max(round(self.args.nbs / self.batch_size), 1) # accumulate loss before optimizingweight_decay = self.args.weight_decay * self.batch_size * self.accumulate / self.args.nbs # scale weight_decayiterations = math.ceil(len(self.train_loader.dataset) / max(self.batch_size, self.args.nbs)) * self.epochsself.optimizer = self.build_optimizer(model=self.model,name=self.args.optimizer,lr=self.args.lr0,momentum=self.args.momentum,decay=weight_decay,iterations=iterations,)# Scheduler# 篇幅原因,代码已省略
核心代码3:开始训练
def _do_train(self, world_size=1):"""Train completed, evaluate and plot if specified by arguments."""if world_size > 1:self._setup_ddp(world_size)self._setup_train(world_size)nb = len(self.train_loader) # number of batchesnw = max(round(self.args.warmup_epochs * nb), 100) if self.args.warmup_epochs > 0 else -1 # warmup iterationslast_opt_step = -1self.epoch_time = Noneself.epoch_time_start = time.time()self.train_time_start = time.time()# 篇幅原因,代码已省略epoch = self.start_epochself.optimizer.zero_grad() # zero any resumed gradients to ensure stability on train startwhile True:self.epoch = epochself.run_callbacks("on_train_epoch_start")# 篇幅原因,代码已省略self.model.train()if RANK != -1:self.train_loader.sampler.set_epoch(epoch)pbar = enumerate(self.train_loader)# Update dataloader attributes (optional)if epoch == (self.epochs - self.args.close_mosaic):self._close_dataloader_mosaic()self.train_loader.reset()# 篇幅原因,代码已省略self.tloss = Nonefor i, batch in pbar:self.run_callbacks("on_train_batch_start")# Warmup# 篇幅原因,代码已省略# Forward 正向传播with torch.cuda.amp.autocast(self.amp):batch = self.preprocess_batch(batch)self.loss, self.loss_items = self.model(batch) # 损失计算if RANK != -1:self.loss *= world_sizeself.tloss = ((self.tloss * i + self.loss_items) / (i + 1) if self.tloss is not None else self.loss_items)# Backward 反向传播self.scaler.scale(self.loss).backward()# Optimize 优化一步if ni - last_opt_step >= self.accumulate:self.optimizer_step()last_opt_step = ni# Timed stopping# 篇幅原因,代码已省略# Logmem = f"{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G" # (GB)loss_len = self.tloss.shape[0] if len(self.tloss.shape) else 1losses = self.tloss if loss_len > 1 else torch.unsqueeze(self.tloss, 0)# 篇幅原因,代码已省略self.lr = {f"lr/pg{ir}": x["lr"] for ir, x in enumerate(self.optimizer.param_groups)} # for loggersself.run_callbacks("on_train_epoch_end")if RANK in {-1, 0}:final_epoch = epoch + 1 >= self.epochsself.ema.update_attr(self.model, include=["yaml", "nc", "args", "names", "stride", "class_weights"])# Validation# 篇幅原因,代码已省略# Save model 保存模型if self.args.save or final_epoch:self.save_model()self.run_callbacks("on_model_save")# Scheduler# 篇幅原因,代码已省略# Early Stoppingif RANK != -1: # if DDP trainingbroadcast_list = [self.stop if RANK == 0 else None]dist.broadcast_object_list(broadcast_list, 0) # broadcast 'stop' to all ranksself.stop = broadcast_list[0]if self.stop:break # must break all DDP ranksepoch += 1# 篇幅原因,代码已省略
代码解析:
在_do_train函数中,可以看到深度学习基本的步骤,即:
- 正向传播
- 损失计算
- 反向传播
- 优化一步
- 清空梯度
- 保存模型
备注:清空梯度封装在optimizer_step函数中了。
内容小结
- YOLOv8的网络结构
- 主要有主干网络和Head网络组成
- 主干网络中进行P1-P5层卷积,经过SPPF后进行Upsample上采样操作后,与P3、P4、P5进行concat操作
- 最后通过15层、18层、21层分别经过Detect模块进行目标检测。
- YOLOv8的代码解析
- 构建模型的核心函数是:self._smart_load()、self.task_map[self.task][key]和parse_model函数
- self.task_map使用了字符串键与类对象值进行关联,由此达到根据关键字选择对应的模型类
- parse_model函数中通过读取参数、设置激活函数后,使用nn.Sequential创建对应的模型
- 训练模型的核心函数为ClassificationDataset的封装、_setup_train()函数和_do_train()函数
- _do_train()函数中包含深度学习的基本步骤,即:正向传播→损失计算→反向传播→优化一步→清空梯度→保存模型
参考资料
B站:YoloV8Ultralytics模型结构详细讲解
YOLOv8模型yaml结构图理解(逐层分析)
相关文章:
【课程总结】Day12:YOLO的深入了解
前言 在【课程总结】Day11(下):YOLO的入门使用一节中,我们已经了解YOLO的使用方法,使用过程非常简单,训练时只需要三行代码:引入YOLO,构建模型,训练模型;预测…...

保护隐私,释放智能:使用LangChain和Presidio构建安全的AI问答系统
保护隐私,释放智能:使用LangChain和Presidio构建安全的AI问答系统 在人工智能(AI)飞速发展的今天,AI问答系统已经成为企业与客户互动的重要工具。然而,随之而来的个人数据隐私问题也日益凸显。如何在不泄露…...

【高考志愿】自动化
目录 一、专业概述 二、课程设计 三、就业前景与方向 四、志愿填报 五、自动化专业排名 一、专业概述 高考志愿自动化专业选择,无疑是迈向现代化工业与科技发展的一把金钥匙。自动化专业,作为现代工程领域的重要支柱,融合了计算机、电子…...

技巧类题目
目录 技巧类题目 136 只出现一次的数字 191 位1的个数 231. 2 的幂 169 多数元素 75 颜色分类 (双指针) 287. 寻找重复数 136 只出现一次的数字 给你一个 非空 整数数组 nums ,除了某个元素只出现一次以外,其余每个元素均…...
)
Vue3自定义指令参数修饰符值(3)
自定义指令参数修饰符值 在vue3中我们如何获取自定义的参数的内容,并根据业务来修改展示的内容呢,需要依靠mounted方法中的bindings参数来获取。 参考实例 directives/unit.js文件 export default function directiveUnit(app){app.directive("unit",{…...

HTML(23)——垂直对齐方式
垂直对齐方式 属性名:vertical-align 属性值效果baseline基线对齐(默认)top顶部对齐middle居中对齐bottom底部对齐 默认情况下浏览器对行内块,行内标签都按文字处理,默认基线对齐 导致图片看起来会偏上,文字偏下。 示例&#…...

linux查看二进制文件
在Linux中,查看二进制文件可以使用hexdump或xxd命令。 例如,要查看一个名为example.bin的二进制文件的内容,可以使用以下命令之一: 使用hexdump: bash hexdump -C example.bin使用xxd: bash xxd exam…...

营销翻车,杜国楹出面道歉,小罐茶的“大师作”故事仓皇结尾
“小罐茶,大师作”,这句slogan曾一度在央视平台长时间、高密度播放,成为家喻户晓的广告词,也打响了小罐茶品牌的名号。但同时,市场上关于“大师作”真实性的质疑也从未停息。 就在6月25日小罐茶十二周年发布会上&#…...

linux server下人脸检测与识别服务程序的系统架构设计
一、绪论 1.1 定义 1.2 研究背景及意义 1.3 相关技术综述 二、人脸检测与识别技术概述 2.1 人脸检测原理与算法 2.2 人脸识别技术及方法 2.3 人脸识别过程简介 三、人脸检测与识别服务程序的系统架构 3.1 系统架构设计 3.2 技术实现流程 四、后续设计及经验瞎谈 4.…...
安装CLion配置opencv和torch环境
配置操作如图,源码见底部附录部分 安装CLion 官网下载 创建项目 设置环境 调整类型为release 配置opencv和项目 编译环境 编译后 重启CLion 测试opencv环境 测试代码 运行main.cpp显示图片 测试torch环境 没标红表示配置成功 附件 CMakeList.txt cmake_mi…...

[leetcode]number-of-longest-increasing-subsequence
. - 力扣(LeetCode) class Solution { public:int findNumberOfLIS(vector<int> &nums) {int n nums.size(), maxLen 0, ans 0;vector<int> dp(n), cnt(n);for (int i 0; i < n; i) {dp[i] 1;cnt[i] 1;for (int j 0; j < i…...

[MYSQL] MYSQL库的操作
前言 本文主要介绍MYSQL里 库 的操作 请注意 : 在MYSQL中,命令行是不区分大小写的 1.创建库 create database [if not exists] database_name [charsetutf8 collateutf8_general_ci] ...] create database 是命名语法,不可省略[if not exists] 如果不存在创建,如果存在跳过…...

数字黄金 vs 全球计算机:比特币与以太坊现货 ETF 对比
撰文:Andrew Kang 编译:J1N,Techub News 本文来源香港Web3媒体:Techub News 比特币现货 ETF 的通过为许多新买家打开了进入加密货币市场的大门,让他们可以在投资组合中配置比特币。但以太坊现货 ETF 的通过…...

互联网直播/点播技术与平台创新应用:视频推拉流EasyDSS案例分析
随着互联网技术的快速发展,直播/点播平台已成为信息传播和娱乐的重要载体。特别是在电视购物领域,互联网直播/点播平台与技术的应用,不仅为用户带来了全新的购物体验,也为商家提供了更广阔的营销渠道。传统媒体再一次切实感受到了…...

怎么在线电脑上做图片二维码?在线3步图片转活码的制作方法
图片怎么才能做成二维码展示呢?图片生成二维码的方式能够在手机上查看图片,有利于图片的快速分享,通过这种方法能够减少对内存的占用,也提高了用户获取图片的便利性。通过生成图片活码能够不断提供最新的图片给用户展示࿰…...

lighttpd安装和配置https
apt install lighttpd apt-get install php-cgi lighttpd-enable-mod fastcgi fastcgi-php service lighttpd force-reload lighttpd配置https sudo nano /etc/lighttpd/lighttpd.conf加入: server.modules ("mod_openssl") $SERVER["socket&quo…...

淘客返利平台的API设计与安全
淘客返利平台的API设计与安全 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在构建淘客返利平台时,API设计和安全是两个至关重要的方面。API设计…...
)
SQL面试真题解答 SQL求连续五天上升 (SQL窗口函数使用)
SQL面试真题解答 SQL求连续五天上升 (SQL窗口函数使用) sql进阶:求某个日期的连续上涨天数 求解连续区间是数据分析、数据仓库笔试面试中常考的SQL题目,今天分享笔试面试题,期待各位拿到心仪的offer或有所收获! 一…...

39 - 安全技术与防火墙
39、安全技术和防火墙 一、安全技术 入侵检测系统:特点是不阻断网络访问,主要是提供报警和事后监督。不主动介入,默默看着你(监控)。 入侵防御系统:透明模式工作,数据包,网络监控…...
Python学习笔记26:进阶篇(十五)常见标准库使用之性能测试cProfile模块学习使用
前言 本文是根据python官方教程中标准库模块的介绍,自己查询资料并整理,编写代码示例做出的学习笔记。 根据模块知识,一次讲解单个或者多个模块的内容。 教程链接:https://docs.python.org/zh-cn/3/tutorial/index.html 本文主要…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

Python 包管理器 uv 介绍
Python 包管理器 uv 全面介绍 uv 是由 Astral(热门工具 Ruff 的开发者)推出的下一代高性能 Python 包管理器和构建工具,用 Rust 编写。它旨在解决传统工具(如 pip、virtualenv、pip-tools)的性能瓶颈,同时…...

HashMap中的put方法执行流程(流程图)
1 put操作整体流程 HashMap 的 put 操作是其最核心的功能之一。在 JDK 1.8 及以后版本中,其主要逻辑封装在 putVal 这个内部方法中。整个过程大致如下: 初始判断与哈希计算: 首先,putVal 方法会检查当前的 table(也就…...
淘宝扭蛋机小程序系统开发:打造互动性强的购物平台
淘宝扭蛋机小程序系统的开发,旨在打造一个互动性强的购物平台,让用户在购物的同时,能够享受到更多的乐趣和惊喜。 淘宝扭蛋机小程序系统拥有丰富的互动功能。用户可以通过虚拟摇杆操作扭蛋机,实现旋转、抽拉等动作,增…...

libfmt: 现代C++的格式化工具库介绍与酷炫功能
libfmt: 现代C的格式化工具库介绍与酷炫功能 libfmt 是一个开源的C格式化库,提供了高效、安全的文本格式化功能,是C20中引入的std::format的基础实现。它比传统的printf和iostream更安全、更灵活、性能更好。 基本介绍 主要特点 类型安全:…...

springboot 日志类切面,接口成功记录日志,失败不记录
springboot 日志类切面,接口成功记录日志,失败不记录 自定义一个注解方法 import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target;/***…...

【堆垛策略】设计方法
堆垛策略的设计是积木堆叠系统的核心,直接影响堆叠的稳定性、效率和容错能力。以下是分层次的堆垛策略设计方法,涵盖基础规则、优化算法和容错机制: 1. 基础堆垛规则 (1) 物理稳定性优先 重心原则: 大尺寸/重量积木在下…...

DiscuzX3.5发帖json api
参考文章:PHP实现独立Discuz站外发帖(直连操作数据库)_discuz 发帖api-CSDN博客 简单改造了一下,适配我自己的需求 有一个站点存在多个采集站,我想通过主站拿标题,采集站拿内容 使用到的sql如下 CREATE TABLE pre_forum_post_…...