HashMap ConcurrentHashMap介绍
目录
HashMap
数据结构
重要成员变量
Jdk7-扩容死锁分析
单线程扩容
多线程扩容
Jdk8-扩容
ConcurrentHashMap
数据结构
并发安全控制
源码原理分析
重要成员变量
协助扩容helpTransfer
扩容transfer
总结
CopyOnWrite机制
源码原理
HashMap
数据结构
数组+链表+(红黑树jdk>=8)
重要成员变量
- DEFAULT_INITIAL_CAPACITY = 1 << 4; Hash表默认初始容量
- MAXIMUM_CAPACITY = 1 << 30; 最大Hash表容量
- DEFAULT_LOAD_FACTOR = 0.75f;默认加载因子
- TREEIFY_THRESHOLD = 8;链表转红黑树阈值
- UNTREEIFY_THRESHOLD = 6;红黑树转链表阈值
- MIN_TREEIFY_CAPACITY = 64;链表转红黑树时hash表最小容量阈值,达不到优先扩容。
Jdk7-扩容死锁分析
死锁问题核心在于下面代码,多线程扩容导致形成的链表环!
void transfer(Entry[] newTable, boolean rehash) {int newCapacity = newTable.length;for (Entry<K,V> e : table) {while(null != e) {Entry<K,V> next = e.next;//第一行if (rehash) {e.hash = null == e.key ? 0 : hash(e.key);}int i = indexFor(e.hash, newCapacity);//第二行e.next = newTable[i];//第三行newTable[i] = e;//第四行e = next;//第五行}}
}去掉了一些冗余的代码, 层次结构更加清晰了。
- 第一行:记录oldhash表中e.next
- 第二行:rehash计算出数组的位置(hash表中桶的位置)
- 第三行:e要插入链表的头部, 所以要先将e.next指向new hash表中的第一个元素
- 第四行:将e放入到new hash表的头部
- 第五行: 转移e到下一个节点, 继续循环下去
上面源代码的过程就是把原来的数据,有个已经形成链表了,把原来的数据放到新的数组里面,用的头插法进行插入
单线程扩容
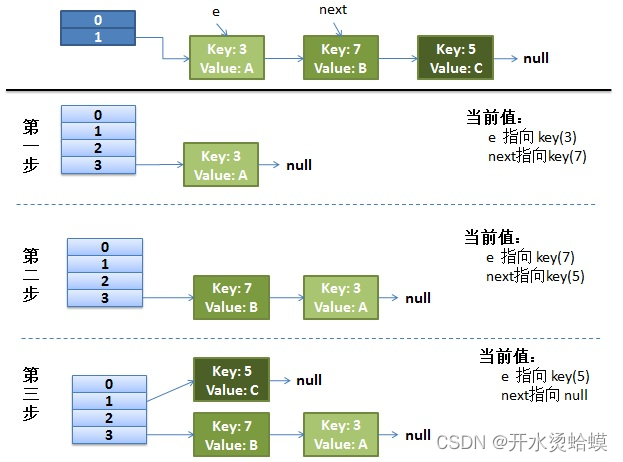
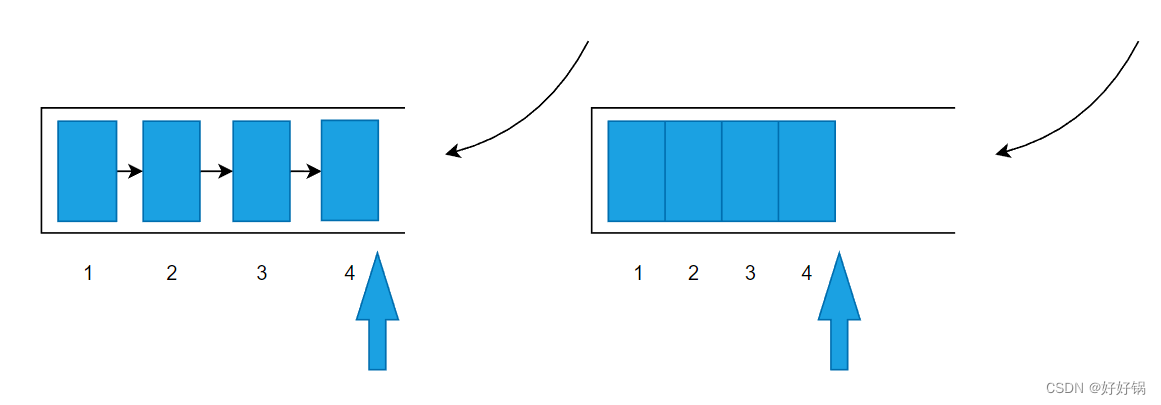
假设:hash算法就是简单的key与length(数组长度)求余。hash表长度为2,如果不扩容, 那么元素key为3,5,7按照计算(key%table.length)的话都应该碰撞到table[1]上。
扩容:hash表长度会扩容为4重新hash,key=3 会落到table[3]上(3%4=3), 当前e.next为key(7), 继续while循环重新hash,key=7 会落到table[3]上(7%4=3), 产生碰撞, 这里采用的是头插入法,所以key=7的Entry会排在key=3前面(这里可以具体看while语句中代码)当前e.next为key(5), 继续while循环重新hash,key=5 会落到table[1]上(5%4=3), 当前e.next为null, 跳出while循环,resize结束。
如下图所示
多线程扩容
下面就是多线程同时put的情况了, 然后同时进入transfer方法中:假设这里有两个线程同时执行了put()操作,并进入了transfer()环节
while(null != e) {Entry<K,V> next = e.next;//第一行,线程1执行到此被调度挂起int i = indexFor(e.hash, newCapacity);//第二行e.next = newTable[i];//第三行newTable[i] = e;//第四行e = next;//第五行
}那么此时状态为:
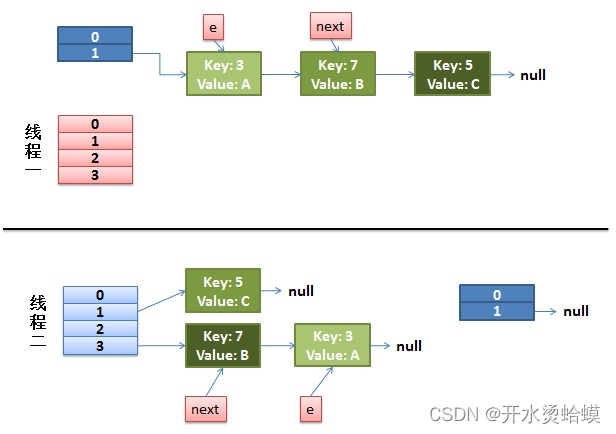
从上面的图我们可以看到,因为线程1的 e 指向了 key(3),而 next 指向了 key(7),在线程2 rehash 后,就指向了线程2 rehash 后的链表。
然后线程1被唤醒了:
- 执行e.next = newTable[i],于是 key(3)的 next 指向了线程1的新 Hash 表,因为新 Hash 表为空,所以e.next = null,
- 执行newTable[i] = e,所以线程1的新 Hash 表第一个元素指向了线程2新 Hash 表的 key(3)。好了,e 处理完毕。
- 执行e = next,将 e 指向 next,所以新的 e 是 key(7)
然后该执行 key(3)的 next 节点 key(7)了:
- 现在的 e 节点是 key(7),首先执行Entry next = e.next,那么 next 就是 key(3)了
- 执行e.next = newTable[i],于是key(7) 的 next 就成了 key(3)
- 执行newTable[i] = e,那么线程1的新 Hash 表第一个元素变成了 key(7)
- 执行e = next,将 e 指向 next,所以新的 e 是 key(3)
此时状态为:

然后又该执行 key(7)的 next 节点 key(3)了:
- 现在的 e 节点是 key(3),首先执行Entry next = e.next,那么 next 就是 null
- 执行e.next = newTable[i],于是key(3) 的 next 就成了 key(7)
- 执行newTable[i] = e,那么线程1的新 Hash 表第一个元素变成了 key(3)
- 执行e = next,将 e 指向 next,所以新的 e 是 key(7)
这时候的状态如图所示:
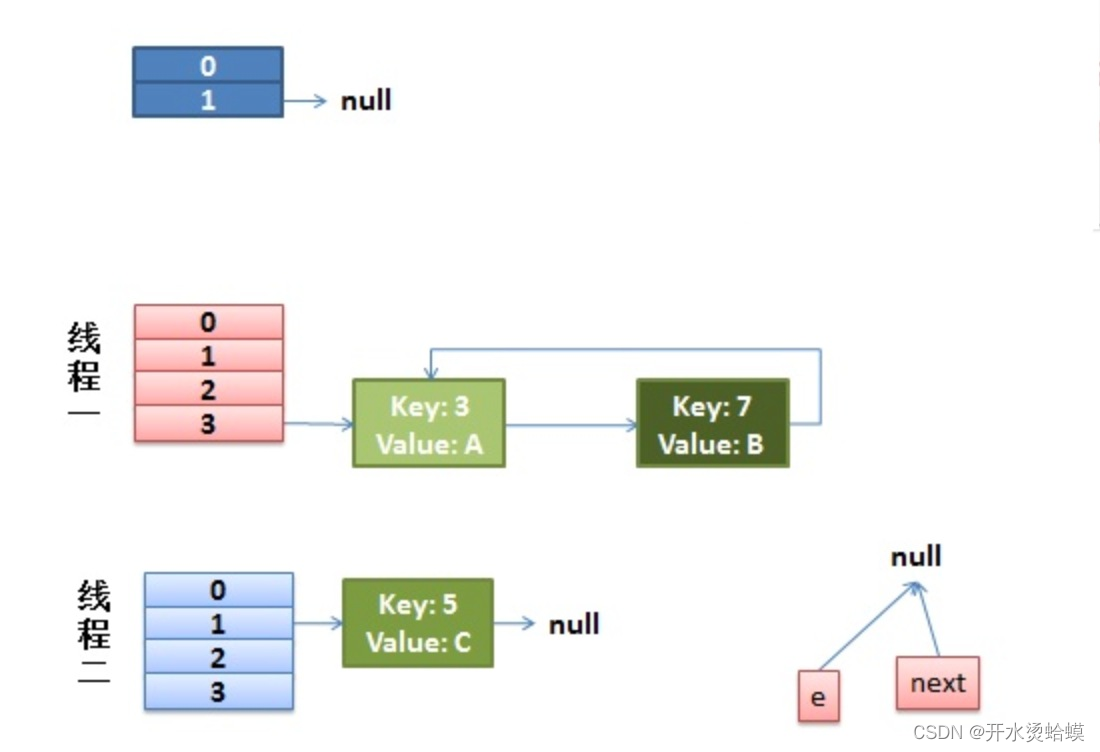
很明显,环形链表出现了。
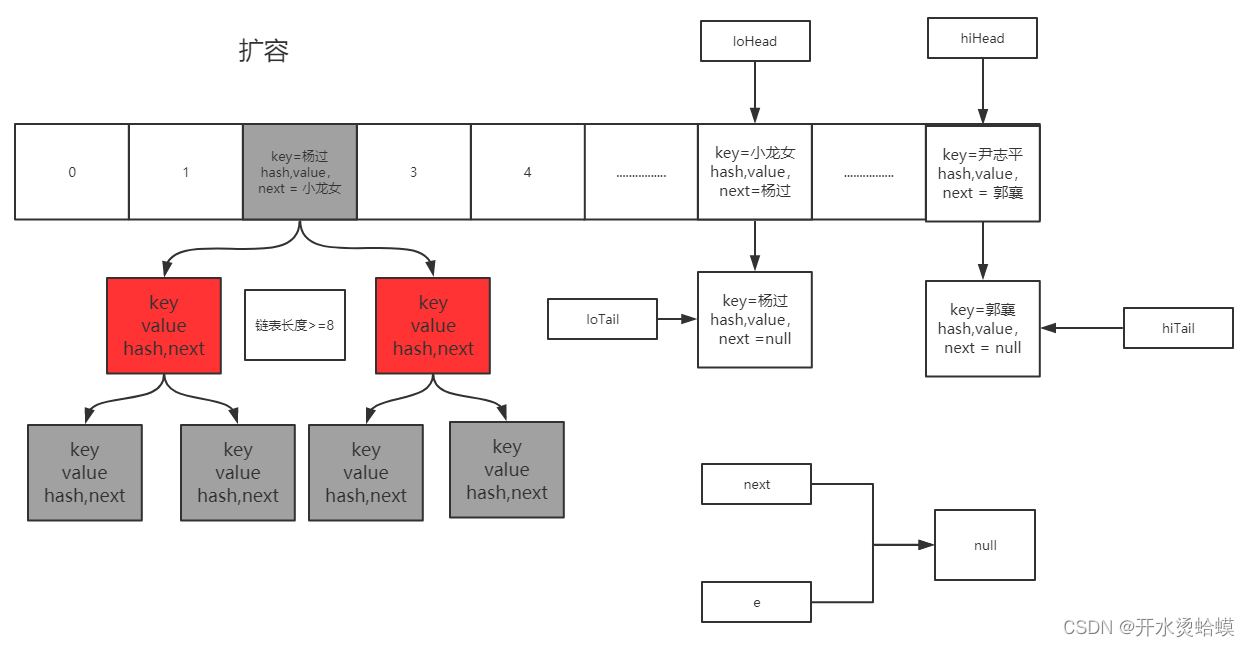
Jdk8-扩容
Java8 HashMap扩容跳过了Jdk7扩容的坑,对源码进行了优化,采用高低位拆分转移方式,避免了链表环的产生。
扩容前:
扩容后:
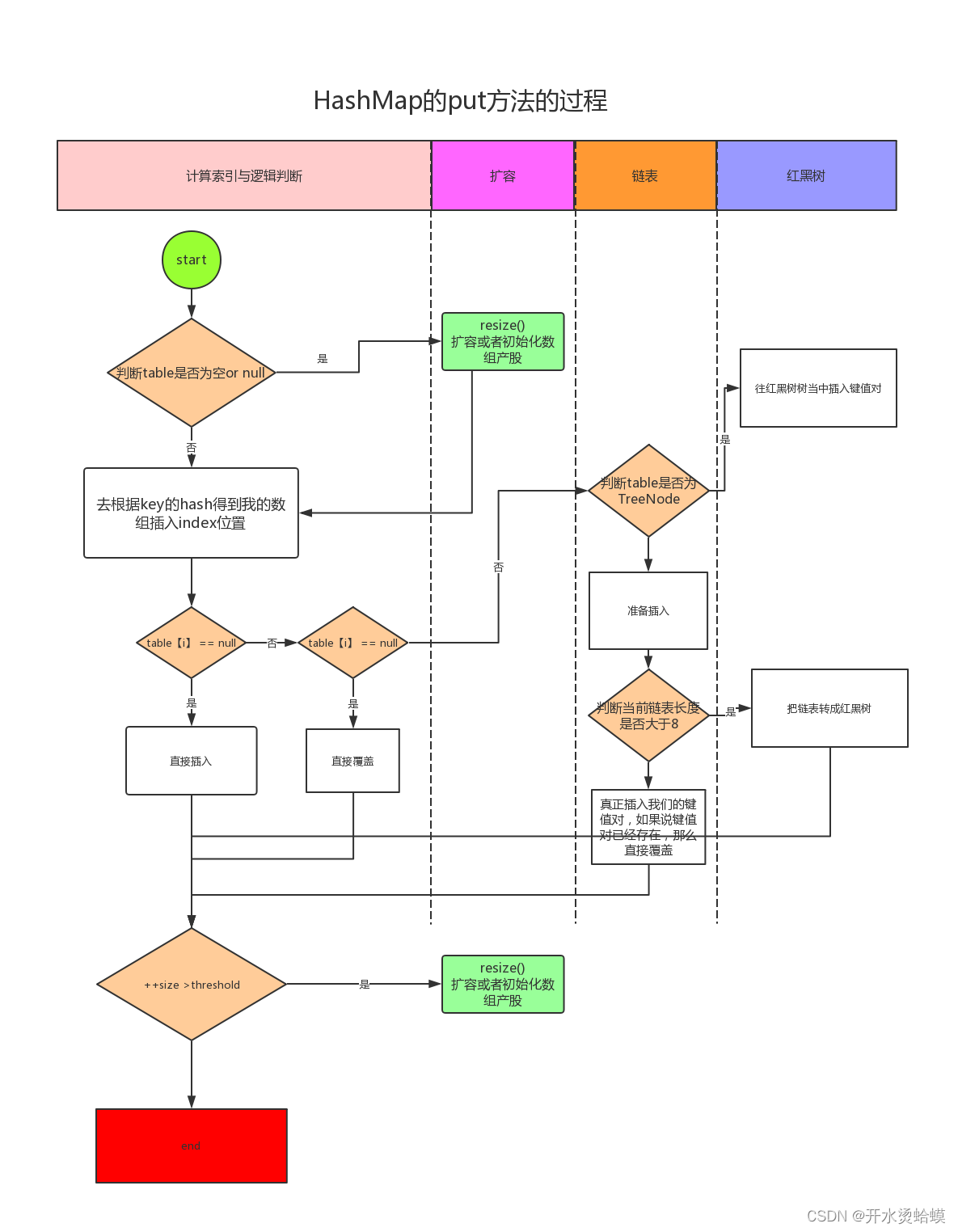
由于Jdk8引入了新的数据结构,所以put方法过程也有了一定改进,其过程如下图所示。
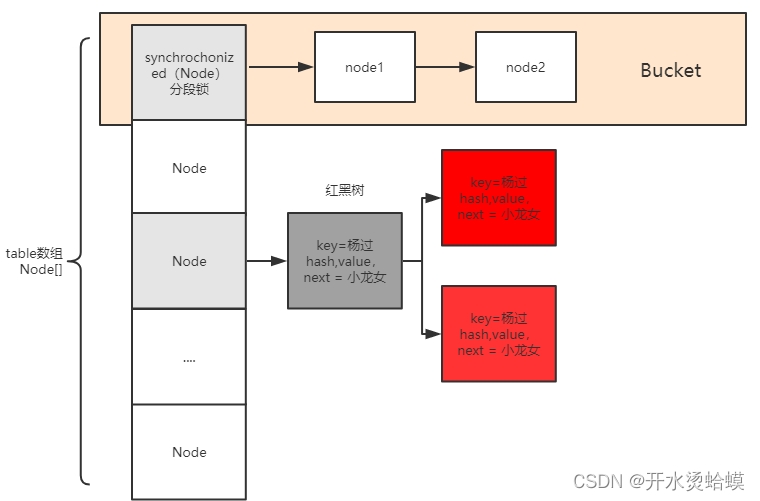
ConcurrentHashMap
数据结构
ConcurrentHashMap的数据结构与HashMap基本类似,区别在于:1、内部在数据写入时加了同步机制(分段锁)保证线程安全,读操作是无锁操作;2、扩容时老数据的转移是并发执行的,这样扩容的效率更高。
并发安全控制
Java7 ConcurrentHashMap基于ReentrantLock实现分段锁

Java8中 ConcurrentHashMap基于分段锁+CAS保证线程安全,分段锁基于synchronized关键字实现;
源码原理分析
重要成员变量
ConcurrentHashMap拥有出色的性能, 在真正掌握内部结构时, 先要掌握比较重要的成员:
- LOAD_FACTOR: 负载因子, 默认75%, 当table使用率达到75%时, 为减少table的hash碰撞, tabel长度将扩容一倍。负载因子计算: 元素总个数%table.lengh
- TREEIFY_THRESHOLD: 默认8, 当链表长度达到8时, 将结构转变为红黑树。
- UNTREEIFY_THRESHOLD: 默认6, 红黑树转变为链表的阈值。
- MIN_TRANSFER_STRIDE: 默认16, table扩容时, 每个线程最少迁移table的槽位个数。
- MOVED: 值为-1, 当Node.hash为MOVED时, 代表着table正在扩容
- TREEBIN, 置为-2, 代表此元素后接红黑树。
- nextTable: table迁移过程临时变量, 在迁移过程中将元素全部迁移到nextTable上。
- sizeCtl: 用来标志table初始化和扩容的,不同的取值代表着不同的含义:
-
-
- 0: table还没有被初始化
- -1: table正在初始化
- 小于-1: 实际值为resizeStamp(n)
- 大于0: 初始化完成后, 代表table最大存放元素的个数, 默认为0.75*n
-
- transferIndex: table容量从n扩到2n时, 是从索引n->1的元素开始迁移, transferIndex代表当前已经迁移的元素下标
- ForwardingNode: 一个特殊的Node节点, 其hashcode=MOVED, 代表着此时table正在做扩容操作。扩容期间, 若table某个元素为null, 那么该元素设置为ForwardingNode, 当下个线程向这个元素插入数据时, 检查hashcode=MOVED, 就会帮着扩容。
ConcurrentHashMap由三部分构成, table+链表+红黑树, 其中table是一个数组, 既然是数组, 必须要在使用时确定数组的大小, 当table存放的元素过多时, 就需要扩容, 以减少碰撞发生次数, 本文就讲解扩容的过程。扩容检查主要发生在插入元素(putVal())的过程:
- 一个线程插完元素后, 检查table使用率, 若超过阈值, 调用transfer进行扩容
- 一个线程插入数据时, 发现table对应元素的hash=MOVED, 那么调用helpTransfer()协助扩容。
协助扩容helpTransfer
下面是协助扩容的过程
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) { //table扩容Node<K,V>[] nextTab; int sc;if (tab != null && (f instanceof ForwardingNode) &&(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {// 根据 length 得到一个标识符号int rs = resizeStamp(tab.length);while (nextTab == nextTable && table == tab &&(sc = sizeCtl) < 0) {//说明还在扩容//判断是否标志发生了变化|| 扩容结束了if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||//达到最大的帮助线程 || 判断扩容转移下标是否在调整(扩容结束)sc == rs + MAX_RESIZERS || transferIndex <= 0)break;// 将 sizeCtl + 1, (表示增加了一个线程帮助其扩容)if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {transfer(tab, nextTab);break;}}return nextTab;}return table;
}主要做了如下事情:
- 检查是否扩容完成
- 对sizeCtrl = sizeCtrl+1, 然后调用transfer()进行真正的扩容。
扩容transfer
扩容的整体步骤就是新建一个nextTab, size是之前的2倍, 将table上的非空元素迁移到nextTab上面去。
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {int n = tab.length, stride;if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)// subdivide range,每个线程最少迁移16个槽位,大的话,最多stride = MIN_TRANSFER_STRIDE;// initiating 才开始初始化新的nextTabif (nextTab == null) {try {@SuppressWarnings("unchecked")Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1]; //扩容2倍nextTab = nt;} catch (Throwable ex) { // try to cope with OOMEsizeCtl = Integer.MAX_VALUE;return;}nextTable = nextTab;transferIndex = n;//更新的转移下标,}int nextn = nextTab.length;ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);//是否能够向前推进到下一个周期boolean advance = true;// to ensure sweep before committing nextTab,完成状态,如果是,则结束此方法boolean finishing = false;for (int i = 0, bound = 0;;) {Node<K,V> f; int fh;while (advance) { //取下一个周期int nextIndex, nextBound;//本线程处理的区间范围为[bound, i),范围还没有处理完成,那么就继续处理if (--i >= bound || finishing)advance = false;//目前处理到了这里(从大到小, 下线),开始找新的一轮的区间else if ((nextIndex = transferIndex) <= 0) {i = -1;advance = false;}//这个条件改变的是transferIndex的值,从16变成了1else if (U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex,//nextBound 是这次迁移任务的边界,注意,是从后往前nextBound = (nextIndex > stride ?nextIndex - stride : 0))) {bound = nextBound; //一块区间最小桶的下标i = nextIndex - 1; //能够处理的最大桶的下标advance = false;}}if (i < 0 || i >= n || i + n >= nextn) { //每个迁移线程都能达到这里int sc;if (finishing) { //迁移完成nextTable = null;//直接把以前的table丢弃了,上面的MOVE等标志全部丢弃,使用新的table = nextTab;sizeCtl = (n << 1) - (n >>> 1); //扩大2n-0.5n = 1.50n, 更新新的容量阈值return;}//表示当前线程迁移完成了if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {//注意此时sc的值并不等于sizeCtl,上一步,sizeCtl=sizeCtl-1了。这两个对象还是分割的if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)return;finishing = advance = true;i = n; // recheck before commit}}//如果对应位置为null, 则将ForwardingNode放在对应的地方else if ((f = tabAt(tab, i)) == null)advance = casTabAt(tab, i, null, fwd);else if ((fh = f.hash) == MOVED) //别的线程已经在处理了,再推进一个下标advance = true; // already processed,推动到下一个周期,仍然会检查i与bound是否结束else { //说明位置上有值了,//需要加锁,防止再向里面放值,在放数据时,也会锁住。比如整个table正在迁移,还没有迁移到这个元素,另外一个线程向这个节点插入数据,此时迁移到这里了,会被阻塞住synchronized (f) {if (tabAt(tab, i) == f) {//判断i下标和f是否相同Node<K,V> ln, hn; //高位桶, 地位桶if (fh >= 0) {int runBit = fh & n;//n为2^n, 取余后只能是2^nNode<K,V> lastRun = f;///找到最后一个不和fn相同的节点for (Node<K,V> p = f.next; p != null; p = p.next) {int b = p.hash & n;//只要找到这,之后的取值都是一样的,下次循环时,就不用再循环后面的if (b != runBit) {runBit = b;lastRun = p;}}if (runBit == 0) {ln = lastRun;hn = null;}else { //比如1,16,32,如果低位%16,那么肯定是0。hn = lastRun;ln = null;}for (Node<K,V> p = f; p != lastRun; p = p.next) {int ph = p.hash; K pk = p.key; V pv = p.val;if ((ph & n) == 0)//这样就把相同串的给串起来了ln = new Node<K,V>(ph, pk, pv, ln);else//这样就把相同串的给串起来了,注意这里ln用法,第一个next为null,烦着串起来了。hn = new Node<K,V>(ph, pk, pv, hn);}setTabAt(nextTab, i, ln); //反着给串起来了setTabAt(nextTab, i + n, hn);setTabAt(tab, i, fwd);advance = true;}else if (f instanceof TreeBin) {// 如果是红黑树TreeBin<K,V> t = (TreeBin<K,V>)f;TreeNode<K,V> lo = null, loTail = null; //也是高低节点TreeNode<K,V> hi = null, hiTail = null;//也是高低节点int lc = 0, hc = 0;for (Node<K,V> e = t.first; e != null; e = e.next) { //中序遍历红黑树int h = e.hash;TreeNode<K,V> p = new TreeNode<K,V>(h, e.key, e.val, null, null);if ((h & n) == 0) { //0的放低位//注意这里p.prev = loTail,每一个p都是下一个的previf ((p.prev = loTail) == null)lo = p; //把头记住elseloTail.next = p; //上一次的p的next是这次的ploTail = p; //把上次p给记住++lc;}else { //高位if ((p.prev = hiTail) == null)hi = p; //把尾记住elsehiTail.next = p;hiTail = p;++hc;}}ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :// //判断是否需要转化为树(hc != 0) ? new TreeBin<K,V>(lo) : t; //如果没有高低的话,则部分为两个树hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :(lc != 0) ? new TreeBin<K,V>(hi) : t;setTabAt(nextTab, i, ln);setTabAt(nextTab, i + n, hn);setTabAt(tab, i, fwd);advance = true;}}}}}
}其中有两个变量需要了解下:
- advance: 表示是否可以向下一个轮元素进行迁移。
- finishing: table所有元素是否迁移完成。
大致做了如下事情:
- 确定线程每轮迁移元素的个数stride, 比如进来一个线程, 确定扩容table下标为(a,b]之间元素, 下一个线程扩容(b,c]。这里对b-a或者c-b也是由最小值16限制的。 也就是说每个线程最少扩容连续16个table的元素。而标志当前迁移的下标保存在transferIndex里面。
- 检查nextTab是否完成初始化, 若没有的话, 说明是第一个迁移的线程, 先初始化nextTab, size是之前table的2倍。
- 进入while循环查找本轮迁移的table下标元素区间, 保存在(bound, i]中, 注意这里是半开半闭区间。
- 从i -> bound开始遍历table中每个元素, 这里是从大到小遍历的:
- 若该元素为空, 则向该元素标写入ForwardingNode, 然后检查下一个元素。 当别的线程向这个元素插入数据时, 根据这个标志符知道了table正在被别的线程迁移, 在putVal中就会调用helpTransfer帮着迁移。
- 若该元素的hash=MOVED, 代表次table正在处于迁移之中, 跳过。 按道理不会跑着这里的。
- 否则说明该元素跟着的是一个链表或者是个红黑树结构, 若hash>0, 则说明是个链表, 若f instanceof TreeBin, 则说明是个红黑树结构。
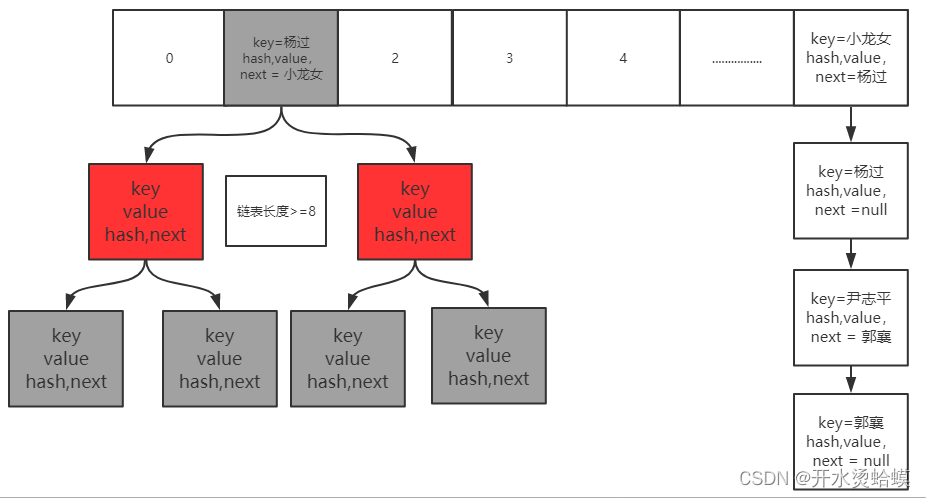
- 链表迁移原理如下: 遍历链表每个节点。 若节点的f.hash&n==0成立, 则将节点放在i, 否则, 则将节点放在n+i上面。
迁移前, 对该元素进行加锁。 遍历链表时, 这里使用lastRun变量, 保留的是上次hash的值, 假如整个链表全部节点f.hash&n==0, 那么第二次遍历, 只要找到lastRun的值, 那么认为之后的节点都是相同值, 减少了不必要的f.hash&n取值。遍历完所有的节点后, 此时形成了两条链表, ln存放的是f.hash&n=0的节点, hn存放的是非0的节点, 然后将ln存放在nextTable第i元素的位置, n+i存放在n+i的位置。
蓝色节点代表:f.hash&n==0, 绿色节点代表f.hash&n!=0。 最终蓝色的节点仍在存放在(0, n)范围里, 绿的节点存放在(n, 2n-1)的范围之内。
- 迁移链表和红黑树的原理是一样的, 在红黑树中, 我们记录了每个红黑树的first(这个节点不是hash最小的节点)和每个节点的next, 根据这两个元素, 我们可以访问红黑树所有的元素, 红黑树此时也是一个链表, 红黑树和链表迁移的过程一样。红黑树根据迁移后拆分成了hn和ln, 根据链表长度确定链表是红黑树结构还是退化为了链表。
4.如何确定table所有元素迁移完成:
//表示当前线程迁移完成了
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {//注意此时sc的值并不等于sizeCtl,上一步,sizeCtl=sizeCtl-1了。这两个对象还是分割的if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)return;finishing = advance = true;i = n; // recheck before commit
}第一个线程开始迁移时, 设置了sizeCtl= resizeStamp(n) resizeStamp(n)
总结
table扩容过程就是将table元素迁移到新的table上, 在元素迁移时, 可以并发完成, 加快了迁移速度, 同时不至于阻塞线程。所有元素迁移完成后, 旧的table直接丢失, 直接使用新的table。
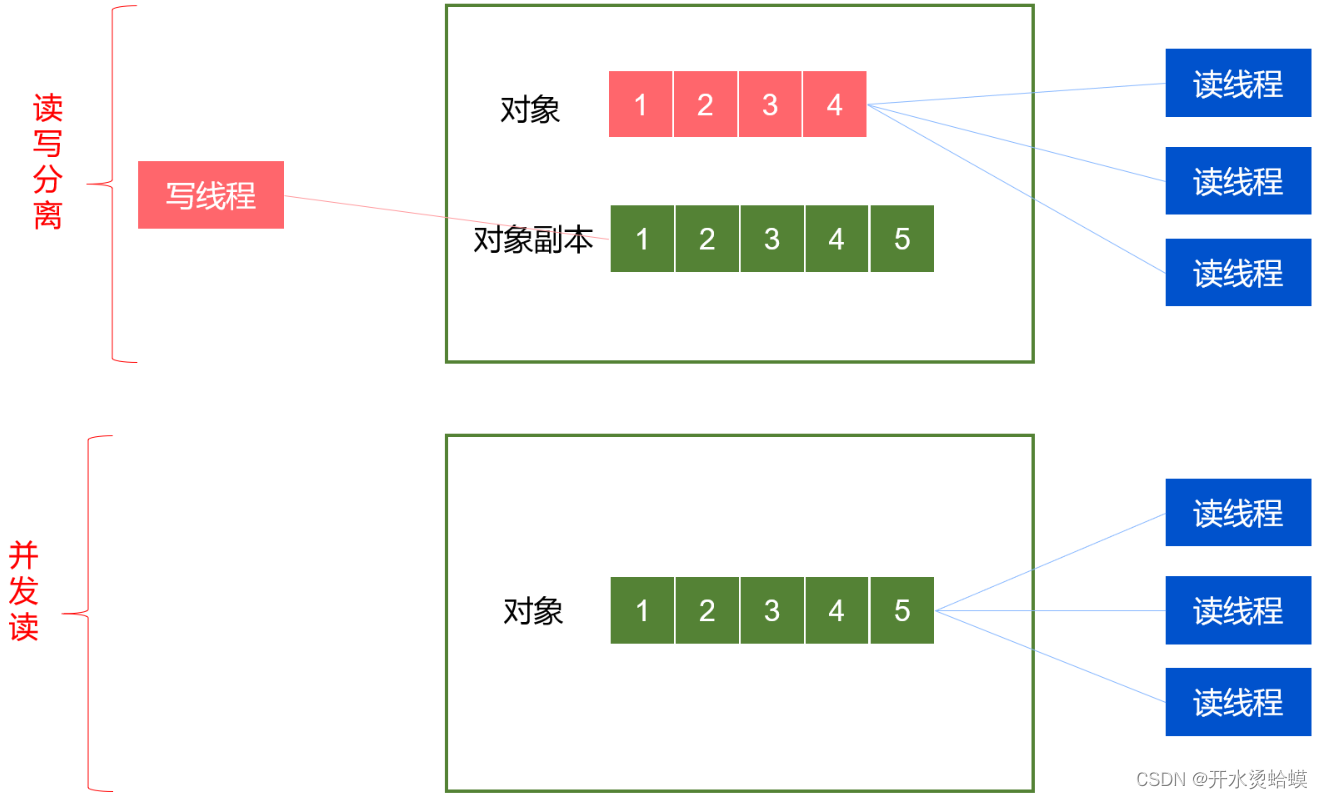
CopyOnWrite机制
核心思想:读写分离,空间换时间,避免为保证并发安全导致的激烈的锁竞争。
划关键点:
- CopyOnWrite适用于读多写少的情况,最大程度的提高读的效率;
- CopyOnWrite是最终一致性,在写的过程中,原有的读的数据是不会发生更新的,只有新的读才能读到最新数据;
- 如何使其他线程能够及时读到新的数据,需要使用volatile变量;
- 写的时候不能并发写,需要对写操作进行加锁;
源码原理
写时复制
/** 添加元素api*/
public boolean add(E e) {final ReentrantLock lock = this.lock;lock.lock();try {Object[] elements = getArray();int len = elements.length;Object[] newElements = Arrays.copyOf(elements, len + 1); //复制一个array副本newElements[len] = e; //往副本里写入setArray(newElements); //副本替换原本,成为新的原本return true;} finally {lock.unlock();}
}
//读api
public E get(int index) {return get(getArray(), index); //无锁
}相关文章:
HashMap ConcurrentHashMap介绍
目录 HashMap 数据结构 重要成员变量 Jdk7-扩容死锁分析 单线程扩容 多线程扩容 Jdk8-扩容 ConcurrentHashMap 数据结构 并发安全控制 源码原理分析 重要成员变量 协助扩容helpTransfer 扩容transfer 总结 CopyOnWrite机制 源码原理 HashMap 数据结构 数组…...

C++语法规则3(C++面向对象)
多态 C多态意味着调用成员函数时,会根据调用函数的对象的类型来执行不同的函数; 形成多态必须具备三个条件: 必须存在继承关系;继承关系必须有同名虚函数(其中虚函数是在基类中使用关键字 virtual 声明的函数&#…...
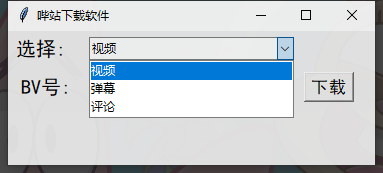
Python tkinter 如何实现网站下载工具?将所有数据一键获取
前言 铁汁们有没有想过,如何把几个代码的功能结合到一起呢? 有想过的话,有没有实现过呢? 其实很简单的啊,咱就写一个界面就好了,想要哪个代码运行,鼠标轻轻一点就行 开发环境 python 3.8: 解…...
第六章:C语言数据结构与算法初阶之栈
系列文章目录 文章目录系列文章目录前言一、栈二、栈的实现三、接口函数的实现1、初始化2、销毁栈3、压栈与出栈4、判空5、元素个数6、返回栈顶元素四、栈中元素的访问总结前言 栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。 一、…...

Android学习之WebView
什么是WebView WebView是Android中UI组件的一种,WebView基于webkit内核,不过由于兼容性的原因在Android5.0后改为了Chromium内核。 WebView可以用来展示网页,常用于我们不想打开浏览器但又想浏览网页的情况。 WebView的使用 WebVeiw的常用…...

3/11 考试总结
时间安排 7:30–7:50 读题,T1 是个利用随机性的题目,T2 dp,T3 不知道是啥。 7:50–8:30 T1,对于随机有个结论时最值突变不超过 log ,于是可以处理出所有 log 个区间然后统计答案,但这暴力做是个 3log 铁定过不去。 8:30–8:50 T2…...

Leetcode 141.环形链表 142环形链表II
141环形链表 文章目录快慢指针快慢指针 代码思路: slow 和fast 指向 head slow走一步,fast走两步 没有环: fast每次走2步 ,如果 fast 最终遇到NULL(链表中的元素是 偶数)或者fast->next(链表中的元素是 奇数)遇到NULL…...
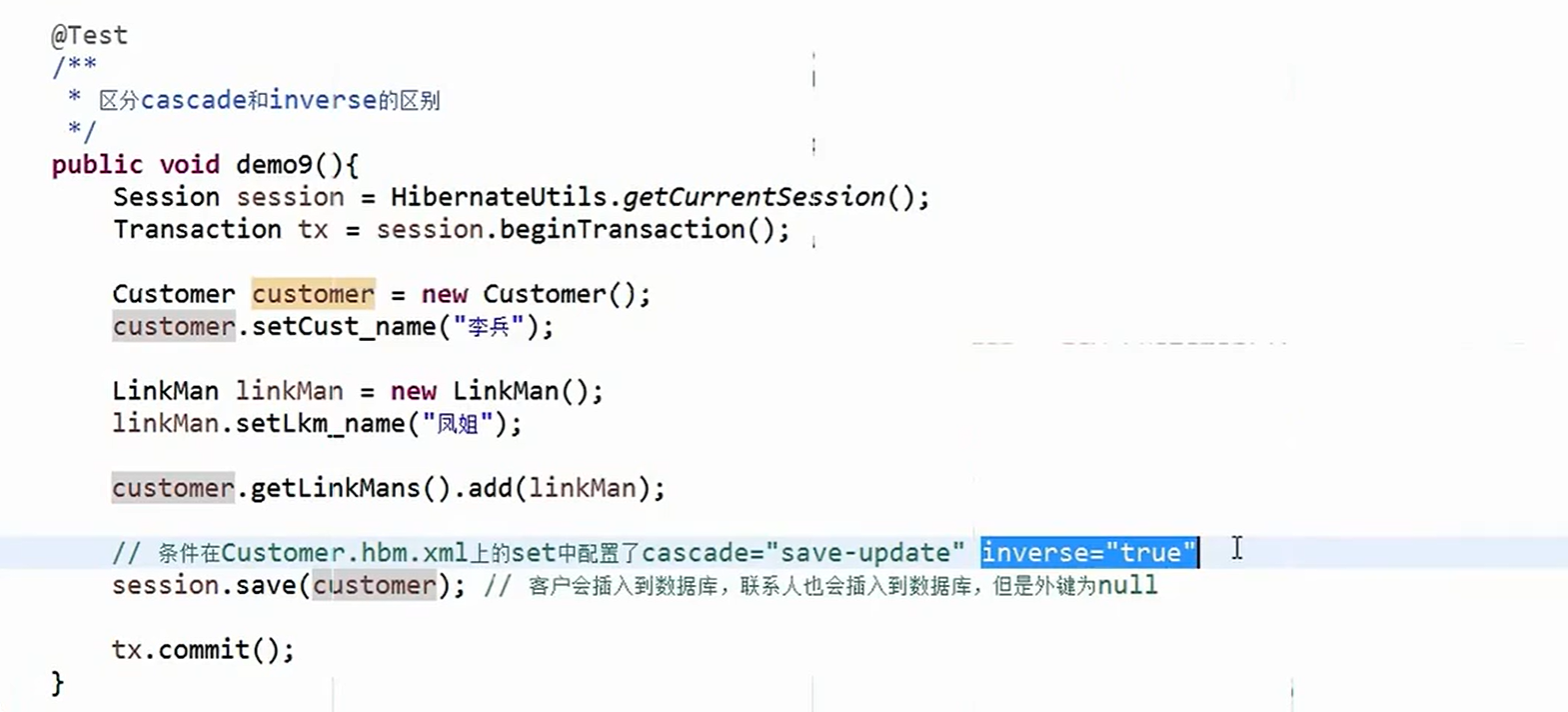
hibernate学习(五)
hibernate学习(五) hibernate的一对多关联映射: 一、数据库表与表之间关系 一对多建表原则: 多对多的建表原则: 一对一建表原则: (1)唯一外键对应: (…...

STM32CubeIDE 快速开发入门指南
描述 STM32CubeIDE是一体式多操作系统开发工具,是STM32Cube软件生态系统的一部分。 STM32CubeIDE是一种高级C/C开发平台,具有STM32微控制器和微处理器的外设配置、代码生成、代码编译和调试功能。它基于Eclipse/CDT™框架和用于开发的GCC工具链…...
【独家】)
华为OD机试 - 火星文计算(C 语言解题)【独家】
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 使用说明本期题目:火星文计…...

超超超超保姆式详解——字符函数和字符串函数(学不会打我)上
目录 长度不受限制的字符串函数 strlen部分 strlen函数的易错小知识 strlen函数的实现 strcpy部分 strcat部分 自己实现strcat strstr函数部分 简单例子: 分析 strcmp部分 长度受限制的字符串函数 strncpy 简单例子 strncat strncmp 简单例子 &…...

Data mesh 笔记
有用的网站 https://www.datamesh-architecture.com/ https://www.agilelab.it/data-mesh-in-action https://learn.microsoft.com/en-us/azure/cloud-adoption-framework/scenarios/cloud-scale-analytics/well-architected-framework https://www.datamesh-architecture.com…...
大白话透彻研究通过explain命令得到的SQL执行计划(2))
(八十三)大白话透彻研究通过explain命令得到的SQL执行计划(2)
今天我们就一步一步的来讲解不同的SQL语句的执行计划长什么样子,先来看第一条SQL语句,特别的简单,就是: explain select * from t1 就这么一个简单的SQL语句,那么假设他这个里面有大概几千条数据,此时执行计…...

案例18-面向对象之开门小例子
目录 一:背景介绍 二:思路&方案 1.面向过程 2.面向对象 3.面向对象(反射) 三:过程 1.面向过程:原本何老师的作用交给我了米老师来完成。 2.面向对象:把开门的方法完全交个何老师,米老师不需要有…...
【碎片化知识总结】三月第一周
目录 前言 1、开发中常用的 IDEA 编辑器,如何做到不用每次都重新配置? 2、如何使用 Python 获取视频文件信息? 3、使用 Java 的 try-with-resources 优化代码 4、使用 shell 脚本批量修改服务器某一目录下的文件后缀名称 5、MySQL优化&…...
:启程)
从零开始的JSON库(1):启程
1. JSON 是什么 JSON(JavaScript Object Notation)是一个用于数据交换的文本格式,现时的标准为ECMA-404 。 虽然 JSON 源自于 JavaScript 语言,但它只是一种数据格式,可用于任何编程语言。现时具有类似功能的格式有X…...
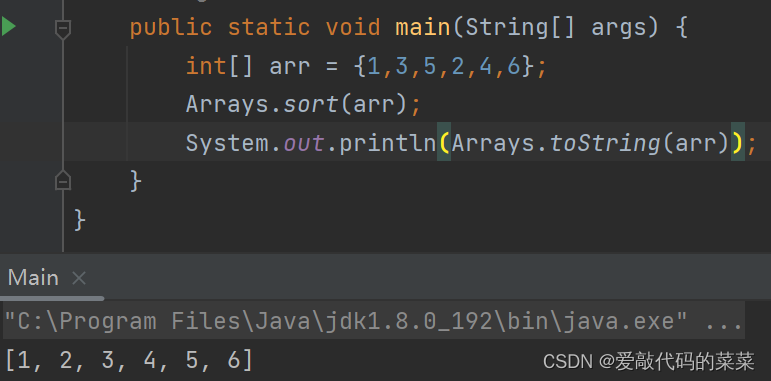
【Java】数组
目录 1.数组的定义与初始化 2.遍历数组 3.认识null 4.引用变量 5.返回多个值 6.数组拷贝 7.数组逆序 8.数组填充 9.小练习 //将整形数组转化为字符串 //二分查找优化 //冒泡排序优化 10.二维数组 //遍历二维数组 //不规则的二维数组 1.数组的定义与初始化 int…...
【C++】非类型的模板参数,特化
目录 1.类型模板参数和非类型模板参数 2.特化 3. 模板的分离编译 4.模板的优缺点 1.类型模板参数和非类型模板参数 之前写模板传的都是类型——类型模板参数 现在想定义两个静态数组,数组长度不同,就可以用模板参数传数值而不是传类型 非类型模板…...
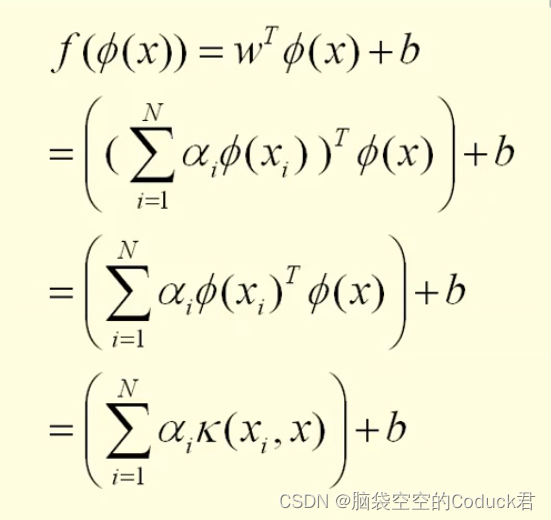
核方法(kernel Method)
核方法 核方法定义 一种能够将在原始数据空间中的非线性数据映射到高维线性可分的方法。 核方法的用处 1、低维数据非线性,当其映射到高维空间(feature space)时,可以用线性方法对数据进行处理。 2、线性学习器相对于非线性学…...
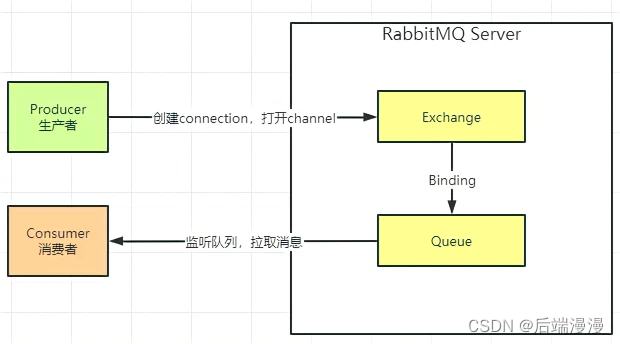
消息队列MQ用来做什么的,市场上主流的四大MQ如何选择?RabbitMQ带你HelloWorld!
文章目录MQ用来做什么的MQ会有什么样的麻烦MQ消息队列模式分类MQ消息队列常用协议市场主流四大MQRabbitMQ项目开发RabbitMQ中的组成部分MQ用来做什么的 省流 :系统解耦、异步调用、流量削峰 系统解耦 首先举例下面这个场景,现有ABCDE五个系统ÿ…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...

涂鸦T5AI手搓语音、emoji、otto机器人从入门到实战
“🤖手搓TuyaAI语音指令 😍秒变表情包大师,让萌系Otto机器人🔥玩出智能新花样!开整!” 🤖 Otto机器人 → 直接点明主体 手搓TuyaAI语音 → 强调 自主编程/自定义 语音控制(TuyaAI…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...

使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台
🎯 使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台 📌 项目背景 随着大语言模型(LLM)的广泛应用,开发者常面临多个挑战: 各大模型(OpenAI、Claude、Gemini、Ollama)接口风格不统一;缺乏一个统一平台进行模型调用与测试;本地模型 Ollama 的集成与前…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...

Rust 开发环境搭建
环境搭建 1、开发工具RustRover 或者vs code 2、Cygwin64 安装 https://cygwin.com/install.html 在工具终端执行: rustup toolchain install stable-x86_64-pc-windows-gnu rustup default stable-x86_64-pc-windows-gnu 2、Hello World fn main() { println…...

区块链技术概述
区块链技术是一种去中心化、分布式账本技术,通过密码学、共识机制和智能合约等核心组件,实现数据不可篡改、透明可追溯的系统。 一、核心技术 1. 去中心化 特点:数据存储在网络中的多个节点(计算机),而非…...

使用SSE解决获取状态不一致问题
使用SSE解决获取状态不一致问题 1. 问题描述2. SSE介绍2.1 SSE 的工作原理2.2 SSE 的事件格式规范2.3 SSE与其他技术对比2.4 SSE 的优缺点 3. 实战代码 1. 问题描述 目前做的一个功能是上传多个文件,这个上传文件是整体功能的一部分,文件在上传的过程中…...

基于stm32F10x 系列微控制器的智能电子琴(附完整项目源码、详细接线及讲解视频)
注:文章末尾网盘链接中自取成品使用演示视频、项目源码、项目文档 所用硬件:STM32F103C8T6、无源蜂鸣器、44矩阵键盘、flash存储模块、OLED显示屏、RGB三色灯、面包板、杜邦线、usb转ttl串口 stm32f103c8t6 面包板 …...