使用阿里云效API操作流水线
使用阿里云效(Alibaba Cloud DevOps)API操作流水线时,需要注意以下几个方面:
-
认证与授权
确保你已经获取了正确的访问凭证(AccessKey ID 和 AccessKey Secret),并且这些凭证具有足够的权限来执行你需要的操作。可以通过阿里云的RAM(资源访问管理)控制台管理和分配这些权限。 -
API 调用限制
阿里云效API通常有调用频率限制(QPS)。确保在设计你的应用程序时考虑到这些限制,以避免超出配额导致的调用失败。 -
错误处理
在使用API时,要做好错误处理和异常捕获。阿里云效API会返回详细的错误信息,包括错误代码和错误消息。需要根据这些信息来诊断问题并采取适当的措施。 -
API版本
确保你使用的API版本是最新的,并且在代码中指定了正确的版本。如果API有更新或废弃,需及时更新你的代码。 -
参数验证
在调用API前,确保所有必需参数都已正确设置,并且这些参数的值符合API文档中的要求。 -
安全性
在代码中不要硬编码敏感信息如AccessKey ID和AccessKey Secret。可以使用环境变量或其他安全存储方式来管理这些信息。 -
调试和日志
启用详细的日志记录和调试信息,以便在出现问题时能够快速定位和解决问题。 -
资源管理
确保在使用API创建或修改资源时,有相应的清理逻辑,以避免不必要的资源浪费。
注意事项:
- 阿里云子账户需要给策略权限: AliyunRDCFullAccess
- 子账号需要加入云效企业内部,并给足操作权限
文档: 云效API接口 ,云效错误码
示例代码
- 使用python 创建
Pipeline_sample.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import json
import os
import sysfrom typing import Listfrom alibabacloud_devops20210625.client import Client as devops20210625Client
from alibabacloud_tea_openapi import models as open_api_models
from alibabacloud_tea_util import models as util_models
from alibabacloud_tea_util.client import Client as UtilClient
from alibabacloud_devops20210625 import models as devops_20210625_models
from alibabacloud_tea_console.client import Client as ConsoleClientORGANIZATION_ID = [云效企业ID]class Pipeline:def __init__(self):self.organization_id = ORGANIZATION_IDpass@staticmethoddef create_client() -> devops20210625Client:"""使用AK&SK初始化账号Client@return: Client@throws Exception"""# 工程代码泄露可能会导致 AccessKey 泄露,并威胁账号下所有资源的安全性。以下代码示例仅供参考。# 建议使用更安全的 STS 方式,更多鉴权访问方式请参见:https://help.aliyun.com/document_detail/378659.html。config = open_api_models.Config(# 必填,请确保代码运行环境设置了环境变量 ALIBABA_CLOUD_ACCESS_KEY_ID。,access_key_id=os.environ['ALIBABA_CLOUD_ACCESS_KEY_ID'],# 必填,请确保代码运行环境设置了环境变量 ALIBABA_CLOUD_ACCESS_KEY_SECRET。,access_key_secret=os.environ['ALIBABA_CLOUD_ACCESS_KEY_SECRET'])# Endpoint 请参考 https://api.aliyun.com/product/devopsconfig.endpoint = f'devops.cn-hangzhou.aliyuncs.com'return devops20210625Client(config)"""create_pipeline"""@staticmethoddef create_pipeline(name: str, yaml_file_path: str) -> None:# 读取 YAML 文件内容with open(yaml_file_path, 'r') as file:content = file.read()client = Pipeline.create_client()create_pipeline_request = devops_20210625_models.CreatePipelineRequest(name=name,content=content)runtime = util_models.RuntimeOptions()headers = {}try:# 复制代码运行请自行打印 API 的返回值response = client.create_pipeline_with_options(ORGANIZATION_ID, create_pipeline_request, headers,runtime)# 如果API调用成功,这里将处理并打印返回的数据if response:print("Pipeline created successfully.")# 假设返回的数据结构中包含一个status或类似字段来表示操作状态print("Response Data:", response)# print(response.body.__dict__)# 提取并打印 pipelinIdpipelinId = response.body.pipelin_idprint(pipelinId)except Exception as error:# 此处仅做打印展示,请谨慎对待异常处理,在工程项目中切勿直接忽略异常。# 错误 messageprint(error.message)# 诊断地址print(error.data.get("Recommend"))UtilClient.assert_as_string(error.message)@staticmethoddef delete_pipeline(pipelin_id: str) -> None:client = Pipeline.create_client()runtime = util_models.RuntimeOptions()headers = {}try:# 复制代码运行请自行打印 API 的返回值response = client.delete_pipeline_with_options(ORGANIZATION_ID, pipelin_id, headers, runtime)# 如果API调用成功,这里将处理并打印返回的数据if response:print("Pipeline created successfully.")# 假设返回的数据结构中包含一个status或类似字段来表示操作状态print("Response Data:", response)except Exception as error:# 此处仅做打印展示,请谨慎对待异常处理,在工程项目中切勿直接忽略异常。# 错误 messageprint(error.message)# 诊断地址print(error.data.get("Recommend"))UtilClient.assert_as_string(error.message)@staticmethoddef get_pipelines_list() -> None:client = Pipeline.create_client()list_pipelines_request = devops_20210625_models.ListPipelinesRequest(max_results=10,next_token='123')runtime = util_models.RuntimeOptions()headers = {}try:# 复制代码运行请自行打印 API 的返回值response = client.list_pipelines_with_options(ORGANIZATION_ID, list_pipelines_request, headers, runtime)# 如果API调用成功,这里将处理并打印返回的数据if response:print("Pipeline created successfully.")# 假设返回的数据结构中包含一个status或类似字段来表示操作状态print("Response Data:", response)except Exception as error:# 此处仅做打印展示,请谨慎对待异常处理,在工程项目中切勿直接忽略异常。# 错误 messageprint(error.message)# 诊断地址print(error.data.get("Recommend"))UtilClient.assert_as_string(error.message)@staticmethoddef run_pipeline(json_file_path: str, pipeline_id: str) -> None:with open(json_file_path, 'r') as file:params = json.load(file)client = Pipeline.create_client()start_pipeline_run_request = devops_20210625_models.StartPipelineRunRequest(# params='''{"envs": {# "UPDATE": "ALL",# "IMAGES":"sjdlkfjslkdajf"# }}'''params=params)runtime = util_models.RuntimeOptions()headers = {}try:resp = client.start_pipeline_run_with_options(ORGANIZATION_ID, pipeline_id,start_pipeline_run_request, headers, runtime)ConsoleClient.log(UtilClient.to_jsonstring(resp))except Exception as error:# 此处仅做打印展示,请谨慎对待异常处理,在工程项目中切勿直接忽略异常。# 错误 messageprint(error.message)# 诊断地址print(error.data.get("Recommend"))UtilClient.assert_as_string(error.message)if __name__ == '__main__':# 创建一个测试流水线# Pipeline.create_pipeline( name='测试流水线test4', yaml_file_path='pipeline_content.yaml')# 删除指定的流水线# Pipeline.delete_pipeline('3263926')# 执行指定的流水线Pipeline.run_pipeline("pipeline_params.json","3260926")# 获取流水线列表# Pipeline.get_pipelines_list()传参文件 pipeline_params.json
{"envs": {"UPDATE": "ALL","IMAGES": "sjdlkfjslkdajf"}
}
流水线yaml配置 pipeline_content.yaml
文件可以再流水线使用yaml模式编辑后替换
stages:vm_deploy_stage:name: "部署"jobs:vm_deploy_job:name: "主机部署`测试主机"component: "VMDeploy"with:downloadArtifact: falseuseEncode: falsemachineGroup: "eSa9wUssQfX799kg"run: "/home/test.sh"artifactDownloadPath: ""executeUser: "root"artifact: ""
相关文章:

使用阿里云效API操作流水线
使用阿里云效(Alibaba Cloud DevOps)API操作流水线时,需要注意以下几个方面: 认证与授权 确保你已经获取了正确的访问凭证(AccessKey ID 和 AccessKey Secret),并且这些凭证具有足够的权限来执行…...
使用命令行创建uniapp+TS项目,使用vscode编辑器
一:如果没有pnpm,先安装pnpm 二:使用npx工具和degit工具从 GitHub 上的 dcloudio/uni-preset-vue 仓库克隆一个名为 vite-ts 的分支,到项目中. 执行完上面命令后,去manifest.json添加appid(自己微信小程序的Id),也可不执行直接下一步,执行pnpm install ,再执行pnpm:dev:mp-weix…...

ABC355 Bingo2
分析: 找出其中一行或列或任意对角线被全部标记,即可输出回合数,否则输出-1 如果x%n0,行是x/n,列是n 如果x%n!0,行是x/n1,列是x%n 如果行列或行列n1即为对角线。 标记行列对角线…...
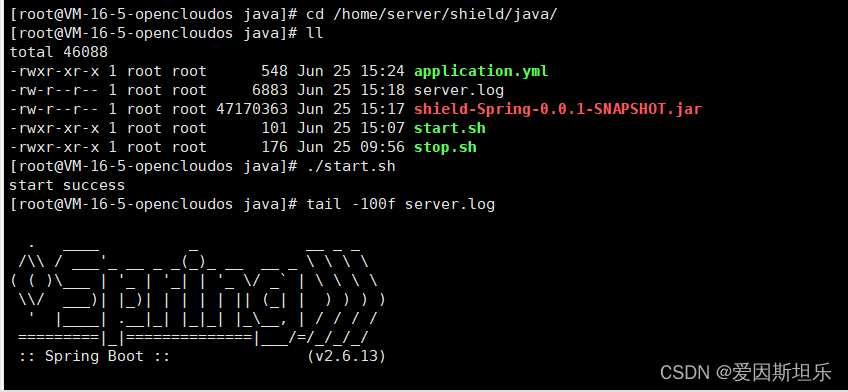
Spring+Vue项目部署
目录 一、需要的资源 二、步骤 1.首先要拥有一个服务器 2.项目准备 vue: 打包: 3.服务器装环境 文件上传 设置application.yml覆盖 添加启动和停止脚本 编辑 安装jdk1.8 安装nginx 安装mysql 报错:「ERR」1273-Unknown collation: utf8m…...
【uml期末复习】统一建模语言大纲
前言: 关于uml的期末复习的常考知识点,可能对你们有帮助😉 目录 第一部分 概念与基础 第一章 面向对象技术 第二章 统一软件过程 第三章 UML概述 第四章 用例图 第五章 类图 第六章 对象图 第七章 顺序图 第八章 协作图 第九章 状态…...
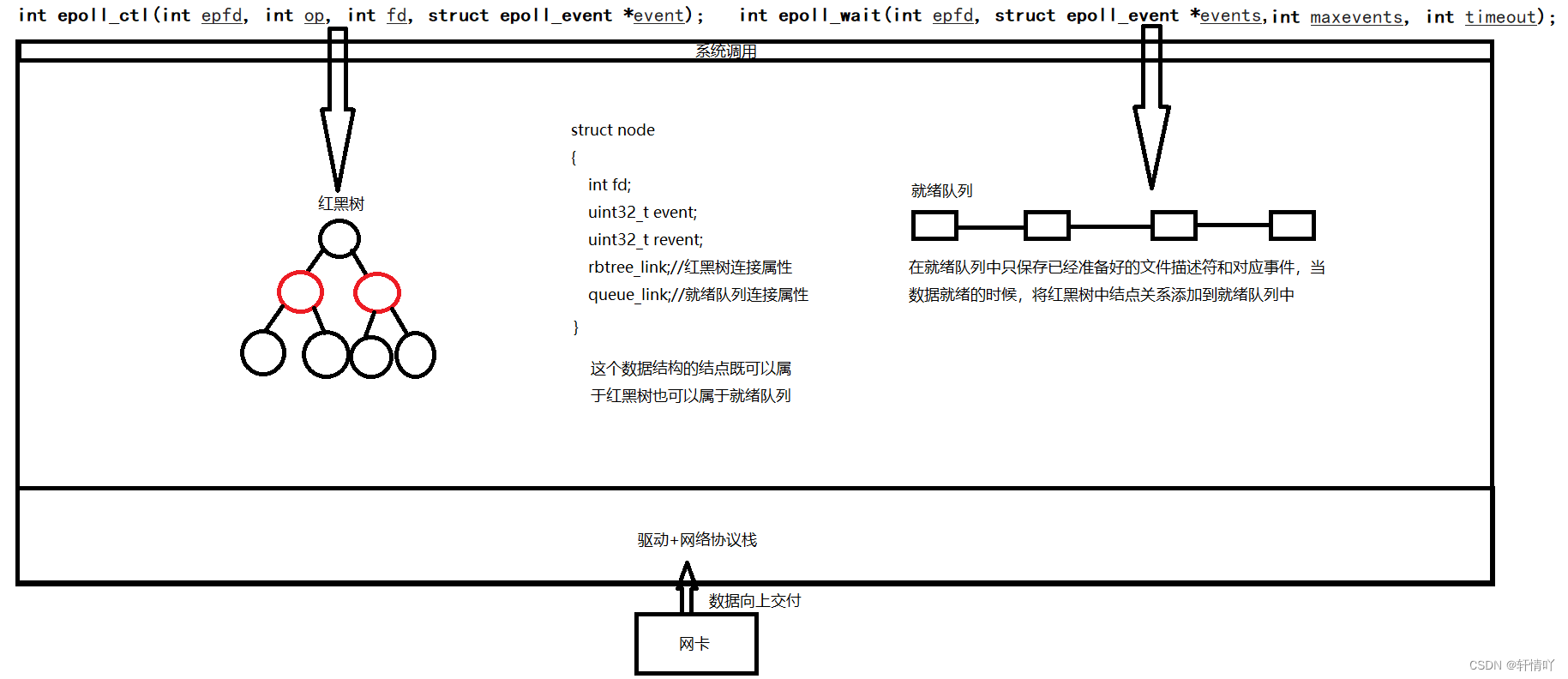
Linux高级IO
高级IO 1.五种IO模型1.1 阻塞IO1.2 非阻塞IO1.3 信号驱动IO1.4 多路复用/多路转接IO1.5 异步IO1.6 小结 2.高级IO重要概念3.非阻塞IO3.1 实现函数NoBlock3.2 轮询方式读取标准输入 4.I/O多路转接之select4.1 理解select执行过程4.2 select的特点4.3 select缺点4.4 实现 5.I/O多…...
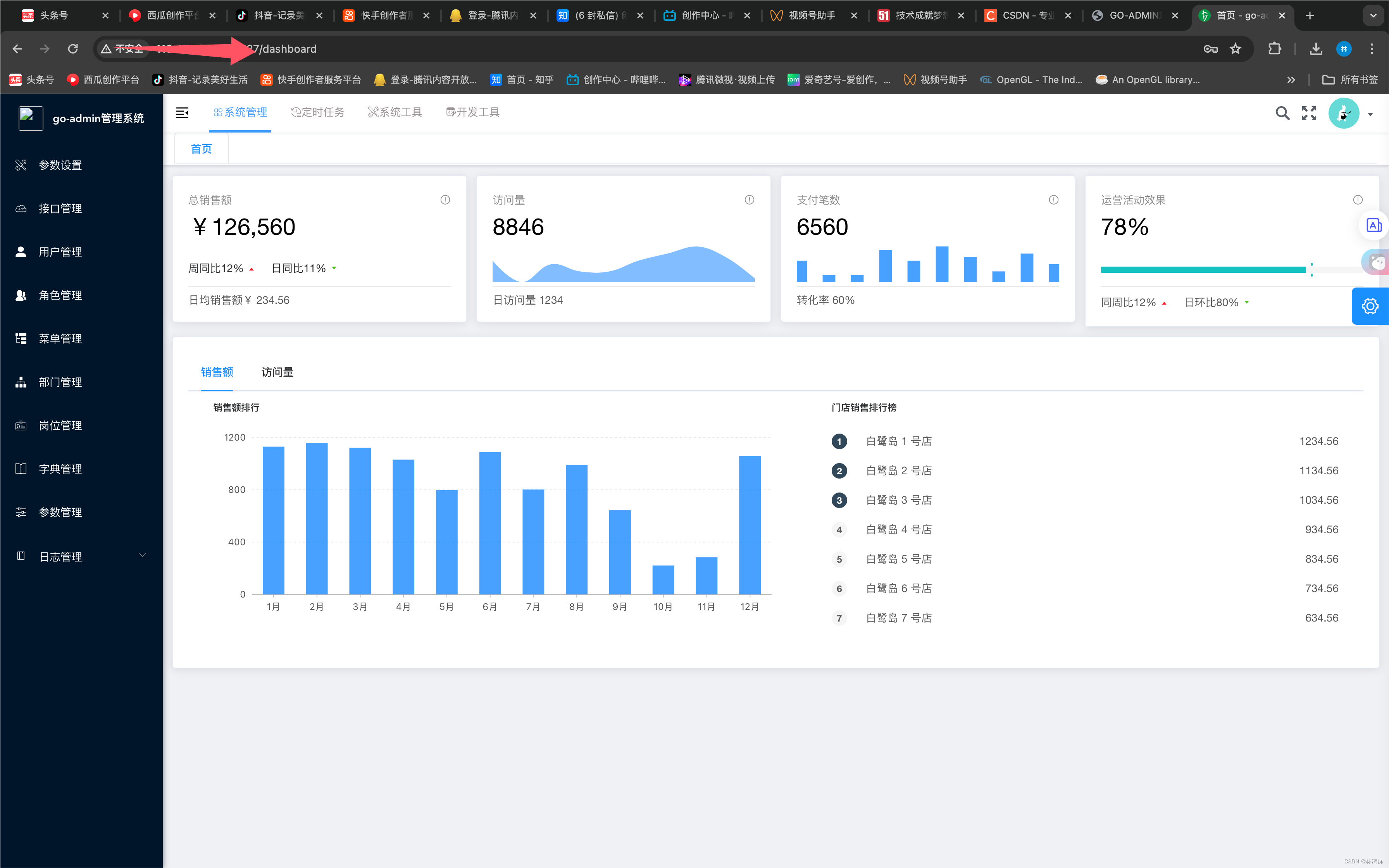
go-admin-ui开源后台管理系统华为云部署
1.华为云开通8000与9527端口 2.编译 编译成功 3.发布到远程服务器 4.登陆华为云终端 5.安装Nginx 6.查看服务启动状态 7.添加网站 添加与修改配置www-data 改为 www 自定义日志输出格式 添加网站配置文件go_admin_ui.conf 添加如下内容: location 下的root指向网站文件夹 修…...

点云入门知识
点云的处理任务 场景语义分割 物体的三维表达方法(3D representations): 点云:是由物体表面上许多点数据来表征这个物体。最接近原始传感器数据,且具有丰富的几何信息。 Mesh:用三角形面片和正方形面片拼…...

HTML静态网页成品作业(HTML+CSS+JS)——家乡莆田介绍网页(5个页面)
🎉不定期分享源码,关注不丢失哦 文章目录 一、作品介绍二、作品演示三、代码目录四、网站代码HTML部分代码 五、源码获取 一、作品介绍 🏷️本套采用HTMLCSS,使用Javacsript代码实现图片轮播,共有5个页面。 二、作品…...

#### grpc比http性能高的原因 ####
grpc比http性能高的原因 二进制消息格式:gRPC使用Protobuf(一种有效的二进制消息格式)进行序列化,这种格式在服务器和客户端上的序列化速度非常快,且序列化后的消息体积小,适合带宽有限的场景。 HTTP/2协…...

微软Edge浏览器搜索引擎切换全攻略
微软Edge浏览器作为Windows 10的默认浏览器,提供了丰富的功能和良好的用户体验。其中,搜索引擎的切换功能允许用户根据个人喜好和需求,快速更换搜索引擎,从而获得更加个性化的搜索服务。本文将详细介绍如何在Edge浏览器中进行搜索…...

<Linux> 实现命名管道多进程任务派发
实现命名管道多进程任务派发 common文件 #ifndef _COMMON_H_ #define _COMMON_H_#pragma once #include <iostream> #include <unistd.h> #include <string> #include <sys/types.h> #include <sys/stat.h> #include <wait.h> #include &…...

BigInteger 和 BigDecimal(java)
文章目录 BigInteger(大整数)常用构造方法常用方法 BigDecimal(大浮点数)常用构造方法常用方法 DecimalFormat(数字格式化) BigInteger(大整数) java.math.BigInteger。 父类:Number 常用构造方法 构造方法:BigIntege…...

Linux 进程间通讯
Linux IPC 方式 在Linux系统中,进程间通信(IPC)是多个运行中的程序或进程之间交换数据和信息的关键机制。Linux提供了多种IPC机制,每种机制都有其特定的用途和优势。以下是Linux上主要的IPC通信方式: 管道(…...

数据分析三剑客-Matplotlib
数据分析三剑客 数据分析三剑客通常指的是在Python数据分析领域中,三个非常重要的工具和库:Pandas、NumPy和Matplotlib。Pandas主要负责数据处理和分析,NumPy专注于数值计算和数学运算,而Matplotlib则负责数据可视化。这三个库相…...

FastAPI-Body、Field
参考:模式的额外信息 - 例子 - FastAPI 在FastAPI中,Body和Field是两个常用的注解,它们用于定义请求体中的数据或路径参数、查询参数等的处理方式。这两个注解都来自于Pydantic库,用于数据验证和解析,但它们的应用场景…...
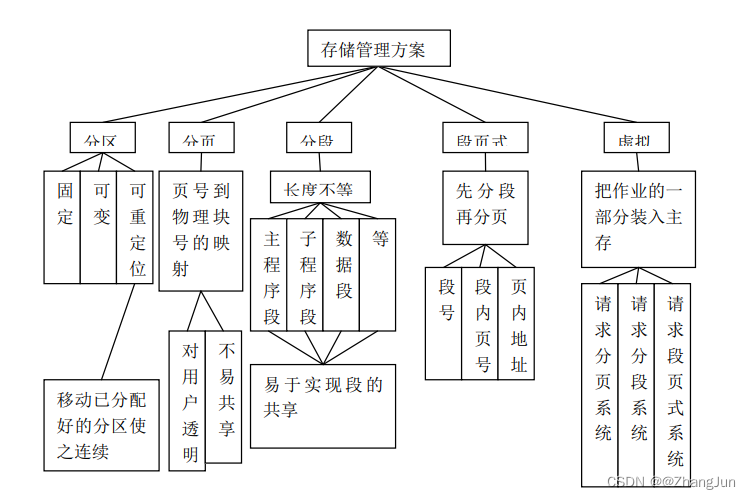
软件设计师笔记-操作系统知识(二)
线程 以下是关于线程的一些关键点: 线程是进程中的一个实体:进程是操作系统分配资源(如内存空间、文件句柄等)的基本单位,而线程是进程中的一个执行单元。多个线程可以共享同一个进程的地址空间和其他资源。线程是CP…...

鸿蒙UI开发快速入门 —— part12: 渲染控制
如果你对鸿蒙开发感兴趣,加入Harmony自习室吧~👇🏻👇🏻👇🏻👇🏻 扫描下面的二维码关注公众号。 1、前言 在声明式描述语句中开发者除了使用系统组件外,还可…...
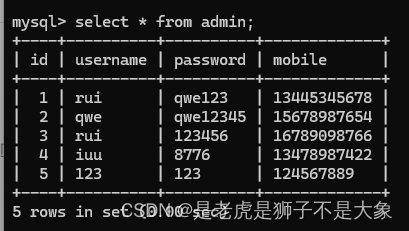
添加用户页面(Flask+前端+MySQL整合)
首先导入Flask库和pymysql库。Flask用于创建Web应用程序,pymysql用于连接和操作MySQL数据库。 from flask import Flask, render_template, request import pymysql创建一个Flask应用实例。__name__参数告诉Flask使用当前模块作为应用的名称。 app Flask(__name_…...
)
素数筛(算法篇)
算法之素数筛 素数筛 引言: 素数(质数):除了1和自己本身之外,没有任何因子的数叫做素数(质数) 朴素筛法(优化版) 概念: 朴素筛法:是直接暴力枚举2到当前判断的数x(不包括),然后看在这范围内是否存在因…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...
)
【位运算】消失的两个数字(hard)
消失的两个数字(hard) 题⽬描述:解法(位运算):Java 算法代码:更简便代码 题⽬链接:⾯试题 17.19. 消失的两个数字 题⽬描述: 给定⼀个数组,包含从 1 到 N 所有…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

企业如何增强终端安全?
在数字化转型加速的今天,企业的业务运行越来越依赖于终端设备。从员工的笔记本电脑、智能手机,到工厂里的物联网设备、智能传感器,这些终端构成了企业与外部世界连接的 “神经末梢”。然而,随着远程办公的常态化和设备接入的爆炸式…...

HarmonyOS运动开发:如何用mpchart绘制运动配速图表
##鸿蒙核心技术##运动开发##Sensor Service Kit(传感器服务)# 前言 在运动类应用中,运动数据的可视化是提升用户体验的重要环节。通过直观的图表展示运动过程中的关键数据,如配速、距离、卡路里消耗等,用户可以更清晰…...

R语言速释制剂QBD解决方案之三
本文是《Quality by Design for ANDAs: An Example for Immediate-Release Dosage Forms》第一个处方的R语言解决方案。 第一个处方研究评估原料药粒径分布、MCC/Lactose比例、崩解剂用量对制剂CQAs的影响。 第二处方研究用于理解颗粒外加硬脂酸镁和滑石粉对片剂质量和可生产…...