Python酷库之旅-第三方库openpyxl(15)
目录
一、 openpyxl库的由来
1、背景
2、起源
3、发展
4、特点
4-1、支持.xlsx格式
4-2、读写Excel文件
4-3、操作单元格
4-4、创建和修改工作表
4-5、样式设置
4-6、图表和公式
4-7、支持数字和日期格式
二、openpyxl库的优缺点
1、优点
1-1、支持现代Excel格式
1-2、功能丰富
1-3、易于使用
1-4、与Excel兼容性
1-5、性能良好
1-6、社区支持
1-7、跨平台
2、缺点
2-1、不支持旧版格式
2-2、某些特性支持有限
2-3、内存占用
2-4、文档和示例可能不足
2-5.、依赖关系
2-6、学习曲线
三、openpyxl库的用途
1、读取Excel文件
2、写入Excel文件
3、修改Excel文件
4、自动化
5、与Excel交互
6、数据迁移和转换
7、创建模板化的报告
四、如何学好openpyxl库?
1、获取openpyxl库的属性和方法
2、获取xlwt库的帮助信息
3、实战案例
3-141、引用输入了文本的全部单元格
3-142、引用输入了逻辑值的全部单元格
3-143、引用输入了批注的全部单元格
3-144、引用没有输入任何数据和公式的空单元格
3-145、引用所有可见的单元格
3-146、引用输入了日期的单元格
3-147、引用含有相同计算公式的所有单元格
3-148、引用合并单元格区域
3-149、引用定义名称所指定的单元格区域
3-150、引用输入了任何内容的最后一行单元格
3-151、引用多个非连续单元格区域集合(类似Union方法)
3-152、引用多个非连续单元格区域集合(循环处理)
3-153、引用多个单元格区域的交叉区域
3-154、获取计算公式的所有引用单元格
3-155、获取计算公式中引用的其他工作表单元格
3-156、获取某个单元格的从属单元格
3-157、引用某个单元格所在的整个行
3-158、引用某个单元格所在的整个列
3-159、引用单元格区域所在的行范围
3-160、引用单元格区域所在的列范围
五、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、博客个人主页



一、 openpyxl库的由来
openpyxl库的由来可以总结为以下几点:
1、背景
在openpyxl库诞生之前,Python中缺乏一个专门用于读取和编写Office Open XML格式(如Excel 2010及更高版本的.xlsx文件)的库。
2、起源
openpyxl库的创建是为了解决上述提到的Python在处理Excel文件时的不足,它的开发受到了PHPExcel团队的启发,因为openpyxl最初是基于PHPExcel的。
3、发展
随着时间的推移,openpyxl逐渐发展成为一个功能强大的Python库,专门用于处理Excel文件。它支持Excel 2010及更高版本的文件格式,并提供了丰富的API,用于读取、写入、修改Excel文件。
4、特点
4-1、支持.xlsx格式
openpyxl主要用于处理Excel 2010及更新版本的.xlsx文件。
4-2、读写Excel文件
使用openpyxl可以读取现有的Excel文件,获取数据,修改数据,并保存到新的文件中。
4-3、操作单元格
openpyxl允许用户按行、列或具体的单元格进行数据的读取和写入。
4-4、创建和修改工作表
用户可以创建新的工作表,复制和删除现有的工作表,设置工作表的属性等。
4-5、样式设置
openpyxl支持设置单元格的字体、颜色、边框等样式。
4-6、图表和公式
用户可以通过openpyxl创建图表、添加公式等。
4-7、支持数字和日期格式
openpyxl能够正确处理数字和日期格式,确保在Excel中显示正确的格式。
综上所述,openpyxl库的出现填补了Python在处理Excel文件时的空白,经过不断的发展和完善,成为了一个功能丰富、易于使用的Python库。
二、openpyxl库的优缺点
openpyxl库是一个用于读写Excel 2010 xlsx/xlsm/xltx/xltm文件的Python库,它基于Python,并且对于处理Excel文件提供了很多便利的功能,其主要优缺点有:
1、优点
1-1、支持现代Excel格式
openpyxl支持.xlsx格式的Excel文件,这是Excel 2010及更高版本使用的格式,也是目前广泛使用的格式。
1-2、功能丰富
openpyxl提供了创建、修改和保存Excel工作簿、工作表、单元格、图表、公式、图像等功能。
1-3、易于使用
openpyxl的API设计得相对直观,使得Python开发者能够很容易地掌握和使用。
1-4、与Excel兼容性
openpyxl能够处理Excel文件中的很多复杂特性,如公式、样式、条件格式等,这确保了与Excel的良好兼容性。
1-5、性能良好
在处理大型Excel文件时,openpyxl通常能够保持较好的性能。
1-6、社区支持
openpyxl是一个开源项目,拥有活跃的社区支持和维护,这意味着开发者可以获得帮助和修复错误的快速响应。
1-7、跨平台
openpyxl可以在不同的操作系统上运行,包括Windows、Linux和macOS等。
2、缺点
2-1、不支持旧版格式
openpyxl不支持较旧的.xls格式(Excel 97-2003)。如果需要处理这种格式的文件,需要使用其他库如xlrd和xlwt(尽管这些库也面临一些兼容性和维护问题)。
2-2、某些特性支持有限
虽然openpyxl支持许多Excel特性,但可能对于某些高级或特定的Excel功能支持有限或不支持。
2-3、内存占用
在处理大型Excel文件时,openpyxl可能会占用较多的内存。这是因为openpyxl会将整个工作簿加载到内存中。
2-4、文档和示例可能不足
尽管openpyxl的文档相对完整,但对于某些高级功能或特定用例,可能缺乏足够的示例或详细解释。
2-5.、依赖关系
openpyxl依赖于lxml和et_xmlfile这两个Python库来处理XML和Excel文件,在某些环境中,可能需要额外安装这些依赖项。
2-6、学习曲线
虽然openpyxl的API设计得相对直观,但对于初学者来说,可能需要一些时间来熟悉和掌握其用法。
三、openpyxl库的用途
openpyxl是一个用于读写Excel 2010 xlsx/xlsm/xltx/xltm文件的Python库。它是用Python编写的,不需要Microsoft Excel,并且支持多种Excel数据类型,包括图表、图像、公式等,其主要用途有:
1、读取Excel文件
你可以使用openpyxl来读取 Excel 文件中的数据,如单元格值、工作表名称、公式等,它支持多种数据类型,如字符串、数字、日期等。
2、写入Excel文件
使用openpyxl,你可以创建新的Excel文件或向现有文件添加数据,你可以设置单元格的字体、颜色、边框等样式,你还可以添加图表、图像和其他复杂的Excel功能。
3、修改Excel文件
你可以使用openpyxl来修改现有的Excel文件,如更改单元格值、添加或删除工作表等,这对于自动化数据处理和报告生成非常有用。
4、自动化
openpyxl可以与其他Python库和框架(如 pandas、numpy、matplotlib 等)结合使用,以自动化数据处理和分析任务。你可以编写脚本来从多个数据源收集数据,将数据整合到 Excel 文件中,并执行各种数据分析任务。
5、与Excel交互
如果你正在开发需要与Excel交互的应用程序或工具,openpyxl可以提供一个强大的API来处理Excel文件,它允许你读取和写入Excel文件,而无需依赖Microsoft Excel或其他第三方库。
6、数据迁移和转换
使用openpyxl,你可以轻松地将数据从Excel文件迁移到其他数据库或文件格式,或将其他数据源的数据导入到Excel文件中。
7、创建模板化的报告
你可以使用openpyxl来创建模板化的Excel报告,并在需要时填充数据,这对于需要定期生成具有一致格式和布局的报告的场景非常有用。
总之,openpyxl是一个功能强大的库,可用于在Python中处理Excel文件,它提供了灵活的API来读取、写入、修改和自动化Excel文件的各个方面。
四、如何学好openpyxl库?
1、获取openpyxl库的属性和方法
用print()和dir()两个函数获取openpyxl库所有属性和方法的列表
# ['DEBUG', 'DEFUSEDXML', 'LXML', 'NUMPY', 'Workbook', '__author__', '__author_email__', '__builtins__', '__cached__',
# '__doc__', '__file__', '__license__', '__loader__', '__maintainer_email__', '__name__', '__package__', '__path__',
# '__spec__', '__url__', '__version__', '_constants', 'cell', 'chart', 'chartsheet', 'comments', 'compat', 'constants',
# 'descriptors', 'drawing', 'formatting', 'formula', 'load_workbook', 'open', 'packaging', 'pivot', 'reader', 'styles',
# 'utils', 'workbook', 'worksheet', 'writer', 'xml']2、获取xlwt库的帮助信息
用help()函数获取openpyxl库的帮助信息
Help on package openpyxl:NAMEopenpyxl - # Copyright (c) 2010-2024 openpyxlPACKAGE CONTENTS_constantscell (package)chart (package)chartsheet (package)comments (package)compat (package)descriptors (package)drawing (package)formatting (package)formula (package)packaging (package)pivot (package)reader (package)styles (package)utils (package)workbook (package)worksheet (package)writer (package)xml (package)SUBMODULESconstantsDATADEBUG = FalseDEFUSEDXML = FalseLXML = TrueNUMPY = True__author_email__ = 'charlie.clark@clark-consulting.eu'__license__ = 'MIT'__maintainer_email__ = 'openpyxl-users@googlegroups.com'__url__ = 'https://openpyxl.readthedocs.io'VERSION3.1.3AUTHORSee AUTHORSFILEe:\python_workspace\pythonproject\lib\site-packages\openpyxl\__init__.py3、实战案例
3-141、引用输入了文本的全部单元格
# 3-141、引用输入了文本的全部单元格
import openpyxl
# 打开 Excel 文件
workbook = openpyxl.load_workbook('example.xlsx')
# 获取所有工作表的名称
sheet_names = workbook.sheetnames
# 遍历每个工作表
for sheet_name in sheet_names:sheet = workbook[sheet_name]print(f"Processing sheet: {sheet_name}")# 遍历每一行和每一列for row in sheet.iter_rows():for cell in row:# 检查单元格是否包含文本if cell.data_type == 's': # 's' 表示单元格包含字符串print(f"Cell {cell.coordinate} contains text: {cell.value}")3-142、引用输入了逻辑值的全部单元格
略,openpyxl库暂不支持此功能,需要借助其他库实现3-143、引用输入了批注的全部单元格
# 3-143、引用输入了批注的全部单元格
import openpyxl
# 打开 Excel 文件
workbook = openpyxl.load_workbook('example.xlsx')
# 假设我们只对第一个工作表感兴趣
sheet = workbook.active # 或者使用 workbook['Sheet1'] 来指定工作表名称
# 遍历工作表中的每一行和每一列
for row in sheet.iter_rows(min_row=sheet.min_row, max_row=sheet.max_row, min_col=sheet.min_column,max_col=sheet.max_column):for cell in row:# 检查单元格是否包含批注if cell.comment is not None:# 打印单元格的引用和批注的内容print(f"Cell {cell.coordinate} contains a comment: {cell.comment.text}")3-144、引用没有输入任何数据和公式的空单元格
# 3-144、引用没有输入任何数据和公式的空单元格
import openpyxl
# 加载 Excel 文件
workbook = openpyxl.load_workbook('example.xlsx')
sheet = workbook.active # 或者使用 workbook[sheetname] 指定具体的工作表
# 存储空单元格的列表
empty_cells = []
# 遍历工作表中的每个单元格
for row in sheet.iter_rows():for cell in row:if cell.value is None and cell.data_type != 'f': # 检查单元格是否为空且没有公式empty_cells.append(cell.coordinate) # 存储空单元格的坐标
# 输出所有空单元格的坐标
print("以下单元格为空且没有输入公式:")
for coord in empty_cells:print(coord)3-145、引用所有可见的单元格
# 3-145、引用所有可见的单元格
import openpyxl
# 加载 Excel 文件
workbook = openpyxl.load_workbook('example.xlsx')
sheet = workbook.active # 或者使用 workbook[sheetname] 指定具体的工作表
# 存储可见单元格的列表
visible_cells = []
# 遍历工作表中的每个单元格
for row in sheet.iter_rows():for cell in row:if not cell.column_letter in sheet.column_dimensions or not sheet.column_dimensions[cell.column_letter].hidden:if not cell.row in sheet.row_dimensions or not sheet.row_dimensions[cell.row].hidden:visible_cells.append(cell.coordinate)
# 输出所有可见单元格的坐标
print("以下单元格是可见的:")
for coord in visible_cells:print(coord)3-146、引用输入了日期的单元格
# 3-146、引用输入了日期的单元格
import openpyxl
# 注意:这里没有从openpyxl.utils导入datetime,因为我们直接使用内置的datetime模块
from datetime import datetime
# 加载Excel文件
workbook = openpyxl.load_workbook('example.xlsx')
# 如果需要检查所有工作表,可以使用workbook.sheetnames来迭代
sheet = workbook.active # 或者使用workbook[sheetname]指定具体的工作表
# 存储包含日期的单元格的列表
date_cells = []
# 遍历工作表中的每个单元格
for row in sheet.iter_rows():for cell in row:# 检查单元格的值是否是datetime类型if isinstance(cell.value, datetime):date_cells.append(cell.coordinate)
# 输出所有包含日期的单元格的坐标
print("以下单元格包含日期:")
for coord in date_cells:print(coord)3-147、引用含有相同计算公式的所有单元格
# 3-147、引用含有相同计算公式的所有单元格
import openpyxl
# 加载Excel文件
workbook = openpyxl.load_workbook('example.xlsx', data_only=False)
sheet = workbook.active # 或者使用 workbook[sheetname] 指定具体的工作表
# 特定的公式
target_formula = '=SUM(C1:C2)' # 例如 '=SUM(C1:C2)'
# 存储包含相同公式的单元格的列表
formula_cells = []
# 遍历工作表中的每个单元格
for row in sheet.iter_rows():for cell in row:if cell.value and isinstance(cell.value, str) and cell.value.startswith('='):if cell.value.strip().upper() == target_formula.strip().upper():formula_cells.append(cell.coordinate)
# 输出所有包含相同公式的单元格的坐标
print("以下单元格包含相同公式:")
for coord in formula_cells:print(coord)3-148、引用合并单元格区域
# 3-148、引用合并单元格区域
import openpyxl
# 加载Excel文件
workbook = openpyxl.load_workbook('example.xlsx')
sheet = workbook.active # 或者使用 workbook[sheetname] 指定具体的工作表
# 获取所有合并单元格的区域
merged_cells_ranges = sheet.merged_cells.ranges
# 遍历并输出所有合并单元格区域
print("以下是所有合并单元格的区域:")
for merged_range in merged_cells_ranges:print(merged_range)# 例如,可以获取合并单元格的起始单元格和结束单元格start_cell = sheet[merged_range.coord.split(":")[0]]end_cell = sheet[merged_range.coord.split(":")[1]]print(f"起始单元格: {start_cell.coordinate}, 结束单元格: {end_cell.coordinate}")# 示例:修改合并单元格的值start_cell.value = "新值"
# 保存修改后的工作簿
workbook.save('修改后的文件.xlsx')3-149、引用定义名称所指定的单元格区域
略,openpyxl库暂不支持此功能,需要借助其他库实现3-150、引用输入了任何内容的最后一行单元格
# 3-150、引用输入了任何内容的最后一行单元格
import openpyxl
def find_last_filled_row(sheet):# 初始化最后一行索引last_row = 0# 遍历每一行for row in sheet.iter_rows():for cell in row:if cell.value is not None:# 更新最后一行索引last_row = max(last_row, cell.row)return last_row
# 加载 Excel 文件
workbook = openpyxl.load_workbook('example.xlsx')
sheet = workbook.active # 或者使用 workbook[sheetname] 指定具体的工作表
# 找到最后一行有内容的单元格的行号
last_filled_row = find_last_filled_row(sheet)
# 输出最后一行有内容的单元格的行号
print(f"最后一行有内容的单元格的行号是: {last_filled_row}")
# 示例:引用最后一行的单元格
if last_filled_row > 0:last_row_cells = sheet[last_filled_row]for cell in last_row_cells:print(f"单元格 {cell.coordinate} 的值: {cell.value}")
# 你可以在此处进行进一步的操作,例如修改最后一行的单元格的值
# 保存修改后的工作簿
workbook.save('修改后的文件.xlsx')3-151、引用多个非连续单元格区域集合(类似Union方法)
# 3-151、引用多个非连续单元格区域集合(类似Union方法)
import openpyxl
# 加载 Excel 文件
workbook = openpyxl.load_workbook('example.xlsx')
sheet = workbook.active # 或者使用 workbook[sheetname] 指定具体的工作表
# 定义多个非连续单元格区域
regions = ['A1:B2', 'D4:E5', 'G7:H8']
# 初始化一个字典来存储各区域的单元格
cells = {}
for region in regions:cells[region] = sheet[region]
# 示例:遍历并打印各区域的单元格的值
for region, cell_range in cells.items():print(f"Region: {region}")for row in cell_range:for cell in row:print(f"单元格 {cell.coordinate} 的值: {cell.value}")
# 示例:修改各区域的单元格的值
for cell_range in cells.values():for row in cell_range:for cell in row:cell.value = "修改后的值"
# 保存修改后的工作簿
workbook.save('修改后的文件.xlsx')3-152、引用多个非连续单元格区域集合(循环处理)
# 3-152、引用多个非连续单元格区域集合(循环处理)
import openpyxl
# 加载 Excel 文件
workbook = openpyxl.load_workbook('example.xlsx')
sheet = workbook.active # 或者使用 workbook[sheetname] 指定具体的工作表
# 定义多个非连续单元格区域
regions = ['A1:B2', 'D4:E5', 'G7:H8']
# 循环处理每个区域
for region in regions:cell_range = sheet[region]for row in cell_range:for cell in row:# 处理单元格的逻辑,例如打印单元格值print(f"单元格 {cell.coordinate} 的值: {cell.value}")# 示例:修改单元格的值cell.value = "新的值"
# 保存修改后的工作簿
workbook.save('修改后的文件.xlsx')3-153、引用多个单元格区域的交叉区域
# 3-153、引用多个单元格区域的交叉区域
import openpyxl
def get_cells_from_range(sheet, cell_range):"""Helper function to get all cells from a given range."""cells = set()for row in sheet[cell_range]:for cell in row:cells.add(cell.coordinate)return cells
# 加载Excel文件
workbook = openpyxl.load_workbook('example.xlsx')
sheet = workbook.active # 或者使用 workbook[sheetname] 指定具体的工作表
# 定义多个单元格区域
regions = ['A1:C3', 'B2:D4']
# 获取每个区域的单元格集合
sets_of_cells = [get_cells_from_range(sheet, region) for region in regions]
# 找出交叉区域的单元格
intersection = set.intersection(*sets_of_cells)
# 循环处理交叉区域的每个单元格
for cell_coord in intersection:cell = sheet[cell_coord]print(f"单元格 {cell.coordinate} 的值: {cell.value}")# 示例:修改单元格的值cell.value = "交叉区域"
# 保存修改后的工作簿
workbook.save('修改后的文件.xlsx')3-154、获取计算公式的所有引用单元格
# 3-154、获取计算公式的所有引用单元格
import openpyxl
import re
def get_referenced_cells(formula):"""Helper function to extract referenced cells from a formula."""# Regular expression to match cell references like A1, B2, etc.cell_ref_pattern = re.compile(r'(\$?[A-Z]+\$?\d+)')return cell_ref_pattern.findall(formula)
# 加载 Excel 文件
workbook = openpyxl.load_workbook('example.xlsx')
sheet = workbook.active # 或者使用 workbook[sheetname] 指定具体的工作表
# 选择包含公式的单元格
cell_with_formula = sheet['C7'] # 假设C7单元格包含公式
# 获取单元格的公式
formula = cell_with_formula.value
if formula and formula.startswith('='):# 提取公式中的所有引用单元格referenced_cells = get_referenced_cells(formula)print(f"公式 '{formula}' 引用了以下单元格: {referenced_cells}")# 示例:遍历并打印每个引用单元格的值for cell_ref in referenced_cells:cell = sheet[cell_ref]print(f"单元格 {cell.coordinate} 的值: {cell.value}")
else:print(f"单元格 {cell_with_formula.coordinate} 不包含公式或公式无效")
# 如果需要,可以保存修改后的工作簿
# workbook.save('修改后的文件.xlsx')3-155、获取计算公式中引用的其他工作表单元格
略,openpyxl库暂不支持此功能,需要借助其他库实现3-156、获取某个单元格的从属单元格
# 3-156、获取某个单元格的从属单元格
from openpyxl import load_workbook
import re
def find_dependent_cells(file_path, target_sheet, target_cell):wb = load_workbook(file_path, data_only=False)dependent_cells = []target_ref = f'{target_sheet}!{target_cell}'# 正则表达式匹配单元格引用,例如:A1pattern = re.compile(r"([A-Z]+[0-9]+)")for sheet in wb.sheetnames:ws = wb[sheet]for row in ws.iter_rows():for cell in row:if cell.data_type == 'f': # 仅处理包含公式的单元格formula = cell.valuematches = pattern.findall(formula)cell_references = [f'{sheet}!{match}' for match in matches]if target_ref in cell_references:dependent_cells.append(f'{sheet}!{cell.coordinate}')return dependent_cells
if __name__ == '__main__':file_path = 'example.xlsx' # 替换为你的Excel文件路径target_sheet = 'Sheet' # 替换为目标单元格所在的工作表target_cell = 'A1' # 替换为目标单元格dependent_cells = find_dependent_cells(file_path, target_sheet, target_cell)print(f'单元格 {target_sheet}!{target_cell} 的从属单元格: {dependent_cells}')3-157、引用某个单元格所在的整个行
# 3-157、引用某个单元格所在的整个行
from openpyxl import load_workbook
import re
def find_dependent_rows(file_path, target_sheet, target_cell):wb = load_workbook(file_path, data_only=False)ws = wb[target_sheet]# 获取目标单元格所在的行号target_row = ws[target_cell].row# 构建目标行的单元格引用列表target_row_cells = [f'{target_sheet}!{ws.cell(row=target_row, column=col).coordinate}'for col in range(1, ws.max_column + 1)]# 正则表达式匹配单元格引用,例如:A1pattern = re.compile(r"([A-Z]+[0-9]+)")dependent_cells = []for sheet in wb.sheetnames:ws = wb[sheet]for row in ws.iter_rows():for cell in row:if cell.data_type == 'f': # 仅处理包含公式的单元格formula = cell.valuematches = pattern.findall(formula)cell_references = [f'{sheet}!{match}' for match in matches]if any(ref in cell_references for ref in target_row_cells):dependent_cells.append(f'{sheet}!{cell.coordinate}')return dependent_cells
if __name__ == '__main__':file_path = 'example.xlsx' # 替换为你的Excel文件路径target_sheet = 'Sheet' # 替换为目标单元格所在的工作表target_cell = 'A1' # 替换为目标单元格dependent_cells = find_dependent_rows(file_path, target_sheet, target_cell)print(f'单元格 {target_sheet}!{target_cell} 所在行的从属单元格: {dependent_cells}')3-158、引用某个单元格所在的整个列
# 3-158、引用某个单元格所在的整个列
from openpyxl import load_workbook
import re
def find_dependent_columns(file_path, target_sheet, target_cell):wb = load_workbook(file_path, data_only=False)ws = wb[target_sheet]# 获取目标单元格所在的列号target_col = ws[target_cell].column# 构建目标列的单元格引用列表target_col_cells = [f'{target_sheet}!{ws.cell(row=row, column=target_col).coordinate}'for row in range(1, ws.max_row + 1)]# 正则表达式匹配单元格引用,例如:A1pattern = re.compile(r"([A-Z]+[0-9]+)")dependent_cells = []for sheet in wb.sheetnames:ws = wb[sheet]for row in ws.iter_rows():for cell in row:if cell.data_type == 'f': # 仅处理包含公式的单元格formula = cell.valuematches = pattern.findall(formula)cell_references = [f'{sheet}!{match}' for match in matches]if any(ref in cell_references for ref in target_col_cells):dependent_cells.append(f'{sheet}!{cell.coordinate}')return dependent_cells
if __name__ == '__main__':file_path = 'example.xlsx' # 替换为你的Excel文件路径target_sheet = 'Sheet' # 替换为目标单元格所在的工作表target_cell = 'D10' # 替换为目标单元格dependent_cells = find_dependent_columns(file_path, target_sheet, target_cell)print(f'单元格 {target_sheet}!{target_cell} 所在列的从属单元格: {dependent_cells}')3-159、引用单元格区域所在的行范围
略,openpyxl库暂不支持此功能,需要借助其他库实现3-160、引用单元格区域所在的列范围
略,openpyxl库暂不支持此功能,需要借助其他库实现五、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、博客个人主页
相关文章:
Python酷库之旅-第三方库openpyxl(15)
目录 一、 openpyxl库的由来 1、背景 2、起源 3、发展 4、特点 4-1、支持.xlsx格式 4-2、读写Excel文件 4-3、操作单元格 4-4、创建和修改工作表 4-5、样式设置 4-6、图表和公式 4-7、支持数字和日期格式 二、openpyxl库的优缺点 1、优点 1-1、支持现代Excel格式…...

葡萄串目标检测YoloV8——从Pytorch模型训练到C++部署
文章目录 软硬件准备数据准备数据处理脚本模型训练模型部署数据分享软硬件准备 训练端 PytorchultralyticsNvidia 3080Ti部署端 fastdeployonnxruntime数据准备 用labelimg进行数据标注 数据处理脚本 xml2yolo import os import glob import xml.etree.ElementTree as ETxm…...
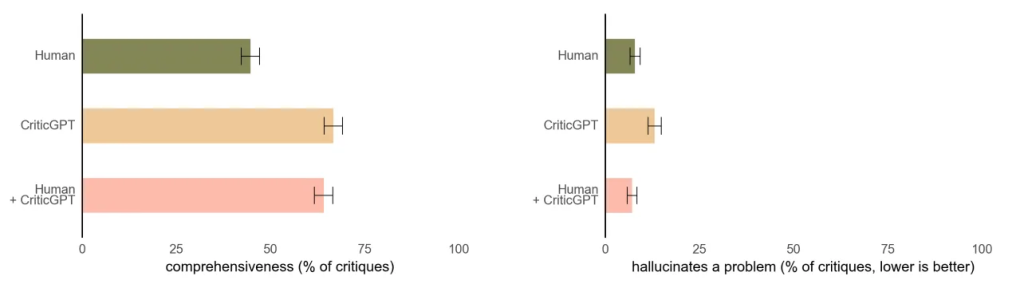
OpenAI推出自我改进AI- CriticGPT
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
springboot系列七: Lombok注解,Spring Initializr,yaml语法
老韩学生 LombokLombok介绍Lombok常用注解Lombok应用实例代码实现idea安装lombok插件 Spring InitializrSpring Initializr介绍Spring Initializr使用演示需求说明方式1: IDEA创建方式2: start.spring.io创建 注意事项和说明 yaml语法yaml介绍使用文档yaml基本语法数据类型字面…...

专访ATFX首席战略官Drew Niv:以科技创新引领企业高速发展
在金融科技创新的浪潮中,人才是推动企业高速发展的核心驱动力,优质服务是引领企业急速前行的灯塔。作为差价合约领域的知名品牌,ATFX高度重视人才引进工作,秉持“聚天下英才而用之”的理念,在全球范围内广揽科技精英&a…...
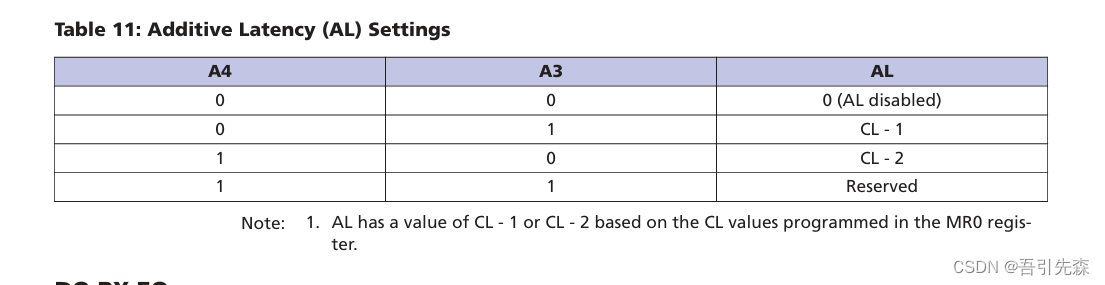
关于FPGA对 DDR4 (MT40A256M16)的读写控制 4
关于FPGA对 DDR4 (MT40A256M16)的读写控制 4 语言 :Verilg HDL 、VHDL EDA工具:ISE、Vivado、Quartus II 关于FPGA对 DDR4 (MT40A256M16)的读写控制 4一、引言二、DDR4 SDRAM设备中模式寄存器重要的模式寄存…...

android——Livedata、StateFlow、ShareFlow和Channel的介绍和使用
目录 一、LiveData介绍 二、StateFlow介绍 三、ShareFlow介绍 四、Channel介绍 小结 一、LiveData介绍 LiveData是一种在Android开发中用于观察数据变化的组件。它可以被观察者注册并在数据变化时通知观察者,从而实现数据的实时更新。LiveData具有生命周期感知能力&…...

Debezium 同步 MySQL 实时数据并解决数据重复消费问题
我们使用 Debezium 实时同步一个 MySQL 的数据到另一个 MySQL,代码网上基本都有,都是在引入 debezium-api,debezium-embedded 后写 Java 代码,做好了基本配置后启动程序,Debezium 会自动读取 MySQL 的实时 binlog&…...

【图像处理】1、使用OpenCV库图像轮廓的检测和绘制
OpenCV (Open Source Computer Vision Library) 是一个用于计算机视觉和图像处理的开源库。它提供了数百种用于图像和视频分析的算法,并被广泛应用于研究和商业领域。OpenCV 支持多种编程语言,包括 C、Python、Java 等,具有跨平台的特性&…...
【AI编译器】triton学习:矩阵乘优化
Matrix Multiplication 主要内容: 块级矩阵乘法 多维指针算术 重新编排程序以提升L2缓存命 自动性能调整 Motivations 矩阵乘法是当今高性能计算系统的一个关键组件,在大多数情况下被用于构建硬件。由于该操作特别复杂,因此通常由软件提…...

动静分离网络
动静分离网络的主要目的是分别处理视频帧中的静止区域和运动区域,以便对不同区域采用不同的去噪策略。这里提供一个实现思路,通过两个分支网络分别处理静止区域和运动区域,然后将两者的输出融合起来。 实现步骤 帧差图生成:计算…...
——Python数据分析的应用①Matplotlib数据可视化基础)
Python商务数据分析知识专栏(三)——Python数据分析的应用①Matplotlib数据可视化基础
Python商务数据分析知识专栏(三)——Python数据分析的应用①Matplotlib数据可视化基础 Matplotlib数据可视化基础1.掌握绘图基本语法与常用绘图2.分析特征间关系3.分析特征内部数据分布与分散情况 Matplotlib数据可视化基础 1.掌握绘图基本语法与常用绘…...
DataV大屏组件库
DataV官方文档 DataV组件库基于Vue (React版 (opens new window)) ,主要用于构建大屏(全屏)数据展示页面即数据可视化,具有多种类型组件可供使用: 源码下载...

paraview跨节点并行渲染
参考: https://cloud.tencent.com/developer/ask/sof/101483588 ParaView 支持使用其内置的网络拓扑来进行跨节点的并行渲染。以下是一个简单的步骤来设置和运行跨节点的并行渲染: 确保你的计算环境支持多节点计算,比如通过SSH、MPI或其他集…...

Java中相等比较详解
本文对Java中的相等判断进行详细解释,包括,equals和compareTo等。 一、 运算符 1. 用途 基本数据类型:用于比较两个基本数据类型的值是否相等。 引用类型:用于比较两个对象引用是否指向同一个对象。 2. 示例 // 基本数据类型比…...

HBuilder X 小白日记01
1.创建项目 2.右击项目,可创建html文件 3.保存CtrlS,运行一下 我们写的内容,一般是写在body里面 注释的快捷键:Ctrl/ h标签 <h1> 定义重要等级最高的(最大)的标题。<h6> 定义最小的标题。 H标签起侧重、强调的作用…...

使用Protocol Buffers优化数据传输
使用Protocol Buffers优化数据传输 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 什么是Protocol Buffers? Protocol Buffers(简称P…...
如何把mkv转成mp4?介绍一下将mkv转成MP4的几种方法
如何把mkv转成mp4?如果你有一个MKV格式的视频文件,但是需要将其转换为MP4格式以便更广泛地在各种设备和平台上播放和共享,你可以通过进行简单的文件格式转换来实现。转换MKV到MP4格式可以提供更好的兼容性,并确保你的视频文件能够…...
PHP语言学习02
好久不见,学如逆水行舟,不进则退,真是这样。。。突然感觉自己有点废。。。 <?php phpinfo(); ?> 新生第一个代码。 要想看到运行结果,打开浏览器(127.0.0.1/start/demo01.php) 其中,…...

PX2资料及问题记录
PX2的一些资料 官方论坛:https://devtalk.nvidia.com/default/board/182/drive-px2/ 官方网站:https://www.nvidia.com/en-us/self-driving-cars/ap2x/ 开发网站:https://developer.nvidia.com/drive/downloads docker docker run --devic…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

html css js网页制作成品——HTML+CSS榴莲商城网页设计(4页)附源码
目录 一、👨🎓网站题目 二、✍️网站描述 三、📚网站介绍 四、🌐网站效果 五、🪓 代码实现 🧱HTML 六、🥇 如何让学习不再盲目 七、🎁更多干货 一、👨…...

人机融合智能 | “人智交互”跨学科新领域
本文系统地提出基于“以人为中心AI(HCAI)”理念的人-人工智能交互(人智交互)这一跨学科新领域及框架,定义人智交互领域的理念、基本理论和关键问题、方法、开发流程和参与团队等,阐述提出人智交互新领域的意义。然后,提出人智交互研究的三种新范式取向以及它们的意义。最后,总结…...
)
C++课设:简易日历程序(支持传统节假日 + 二十四节气 + 个人纪念日管理)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、为什么要开发一个日历程序?1. 深入理解时间算法2. 练习面向对象设计3. 学习数据结构应用二、核心算法深度解析…...

使用SSE解决获取状态不一致问题
使用SSE解决获取状态不一致问题 1. 问题描述2. SSE介绍2.1 SSE 的工作原理2.2 SSE 的事件格式规范2.3 SSE与其他技术对比2.4 SSE 的优缺点 3. 实战代码 1. 问题描述 目前做的一个功能是上传多个文件,这个上传文件是整体功能的一部分,文件在上传的过程中…...