LLM应用开发-RAG系统评估与优化

前言
Hello,大家好,我是
GISer Liu😁,一名热爱AI技术的GIS开发者,在上一篇文章中,我们学习了如何基于LangChain构建RAG应用,并且通过Streamlit将这个RAG应用部署到了阿里云服务器;😀
在本文中作者将通过:
-
LLM应用评估思路
-
生成内容评估优化
-
检索内容评估优化
帮助读者学习如何对自己开发的RAG应用进行评估,并通过科学的方法优化结果,提高应用性能 ;
一、LLM应用评估策略
1.评估思路
在上一篇文章中,我们基于LangChain构建了一个RAG应用,并使用Streamlit将其部署到阿里云服务器。回顾整个开发流程,我们可以总结出以下几点LLM应用开发特性:
-
① 开发流程快捷:以调用API、以LLM为核心的大模型开发流程快捷,更注重于验证和迭代。
-
② 成本效益高:LLM的强大泛化性使其能够解决许多细节任务,且成本仅为传统应用开发的百分之一。
以开发上一篇文章中的RAG应用为例,作者从选择数据、构建向量数据库、选择LLM API、配置Embedding模型,到开发问答检索链,仅用4小时即可完成。并且开发成本不到10元。
在传统AI应用开发中,我们需要不断收集大量数据来训练和微调模型以优化性能,而LLM应用开发则只需通过几个错误案例调整即可获得良好结果,
无需大量样本迭代。从这里我们可以提取出一点方法论:LLM应用开发抓住业务痛点,从错误的案例中分析应用的不足并加以改善,便可快速提升模型性能。

以Json内容输出为例,在构建LLM应用程序时,我们会经历以下流程:
①少样本调整Prompt:首先,我们会从1-3个小样本中调整我们的Prompt,确保应用能在小样本上成功生成目标结果,例如要求LLM输出Json格式的内容,包括特定字段,如任务名称、任务类型等。初步测试样本后,系统可以在简单任务中正常输出。
②Bad Case定向优化:接着,当我们对系统进行进一步测试时,可能会遇到一些棘手的问题,例如要求输出的字段名称,字段格式要求,每个字段有其取值范围;我们针对这些突出问题定向调整、手动解决;
③模型性能与开发成本的权衡:最终,当我们积累的问题越来越多时,逐个调整或满足每个问题的要求变得不现实。因此,我们开始选择一些自动化手段来评估模型;以质量换成本,权衡利弊;
这个过程中,我们无需追求完美,而是要综合考虑时间成本和模型性能。得益于LLM的飞速发展,我们的应用通常经过几轮调整,就能达到很好的表现。
!但这仅仅的对简单的,具有标准答案的任务,性能指标在这些任务样本上评估并不明显;在没有简单答案或标准答案的情况下,评价指标才能准确反应模型的性能;
2.评估方法
通过识别和解决“Bad Case”,我们将不断优化应用的性能和精度。具体流程为:
- 发现
Bad Case并将每个Bad Case加入验证集。 - 针对性调整对应的Prompt并检索架构。
- 每次优化后重新验证整个验证集,
确保原有Good Case不受影响。
对于:
- 小验证集,采用人工评估;
- 大验证集,则采用自动化评估,以降低成本和时间消耗。
下面我们开始讲解人工评估方法;
环境部署
首先我们加载我们的向量数据库与检索链;继续使用Faiss向量数据库和Mistral模型;代码如下:
# 添加历史对话功能
from __future__ import annotations
import os
from langchain_mistralai.chat_models import ChatMistralAI
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
from langchain_community.vectorstores import FAISS
# 封装Mistral Embedding
import logging
from typing import Dict, List, Any
# 构建检索问答链
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQAfrom langchain.embeddings.base import Embeddings
from langchain.pydantic_v1 import BaseModel, root_validatorlogger = logging.getLogger(__name__)class MistralAIEmbeddings(BaseModel, Embeddings):"""`MistralAI Embeddings` embedding models."""client: Any"""`mistralai.MistralClient`"""@root_validator()def validate_environment(cls, values: Dict) -> Dict:"""实例化MistralClient为values["client"]Args:values (Dict): 包含配置信息的字典,必须包含 client 的字段.Returns:values (Dict): 包含配置信息的字典。如果环境中有mistralai库,则将返回实例化的MistralClient类;否则将报错 'ModuleNotFoundError: No module named 'mistralai''."""from mistralai.client import MistralClientapi_key = os.getenv('MISTRAL_API_KEY')if not api_key:raise ValueError("MISTRAL_API_KEY is not set in the environment variables.")values["client"] = MistralClient(api_key=api_key)return valuesdef embed_query(self, text: str) -> List[float]:"""生成输入文本的 embedding.Args:texts (str): 要生成 embedding 的文本.Return:embeddings (List[float]): 输入文本的 embedding,一个浮点数值列表."""embeddings = self.client.embeddings(model="mistral-embed",input=[text])return embeddings.data[0].embeddingdef embed_documents(self, texts: List[str]) -> List[List[float]]:"""生成输入文本列表的 embedding.Args:texts (List[str]): 要生成 embedding 的文本列表.Returns:List[List[float]]: 输入列表中每个文档的 embedding 列表。每个 embedding 都表示为一个浮点值列表。"""return [self.embed_query(text) for text in texts]# 实例化Embedding模型
embeddings_model = MistralAIEmbeddings()
# 加载向量数据库
loaded_db = FAISS.load_local("./db/GIS_db", embeddings_model, allow_dangerous_deserialization=True)# 获取环境变量 MISTRAL_API_KEY
api_key = os.environ['MISTRAL_API_KEY']# 初始化一个 ChatMistralAI 模型实例,并设置温度为 0
llm = ChatMistralAI(temperature=0,api_key=api_key)template = """使用以下上下文来回答最后的问题。如果你不知道答案或者不确定结果,只需要你不知道,不要试图编造答
案。最多使用三句话。尽量使答案简明扼要。要求使用中文回答。
{context}
问题: {question}
"""QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],template=template)# 构建检索问答链
qa_chain = RetrievalQA.from_chain_type(llm,retriever=loaded_db.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})# 测试结果
question_1 = "GIS的组成?"
result = qa_chain({"query": question_1})
print(result["result"])
测试一下:

没问题!😺
①人工评估方法
适用范围:系统开发初期、验证集体量较小
重点:系统评估与业务强相关,设计具体的评估方法要结合业务深入考虑;
在大模型的应用开发过程中,人工评估是一个不可或缺的环节。其可以帮助我们确保模型的输出质量,尤其是在系统开发的初期,当验证集的体量相对较小的时候。
(1)量化评估
量化评估是不同版本应用性能比较的关键。对每个验证案例的回答进行打分,我们可以计算所有案例的平均分来评估系统的表现。量化的量纲可以是0-5或0-100,当然这取决于业务需求和个人风格。
这里,作者给出两个验证案例:
- ① GIS是什么?
- ② GIS的应用场景?
接下来我们分别用版本A prompt(简明扼要)与版本B prompt(详细具体)来要求模型做出回答:
下面作者的代码:
# 测试结果
question_1 = "GIS是什么"
result1 = qa_chain({"query": question_1})
print(result1["result"])
question_2 = "GIS的应用场景?"
result2 = qa_chain({"query": question_2})
print(result2["result"])
运行结果如下:

可以看出其简单粗暴,是提示词工程最常见的应用;
(2)多维评估
大模型的回答需要在多个维度上进行回答的结果进行评估,每个维度都应设计相应的评估指标和量纲;下面是评价维度,取值区间默认为[0,1]:
- 知识查找正确性
- 回答幻觉比例
- 回答正确性
- 逻辑性
- 通顺性
- 智能性
代码如下:
# 测试结果
print("问题:")
question = "遥感的微波的概念是什么"
print(question)
print("模型回答:")
result = qa_chain({"query": question})
print(result["result"])
经过查询,原始资料为:
微波的的波长比可见光和红外波长,受大气层中云雾的散射影响小,穿透性好,因此能全天候进行遥感。使用微波的遥感被称为微波遥感,它通过接受地面物体发射的微波辐射能量,或接收器本身发出的电磁波束的回波信号,对物体进行探测、识别和分析。由于微波遥感采用主动方式进行,其特点是对云层、地表植被、松散沙层和干燥冰雪具有一定的穿透能力,且不受光照等条线限制。因此微波遥感是一种全天候、全天时的遥感技术。
回答结果为:
问题:
遥感的微波的概念是什么
模型回答:
遥感的微波(Microwave Remote Sensing)指的是使用微波辐射的散射和辐射信息来分析、识别地物或提取专题信息的技术。微波遥感可以使用人工辐射源(如微波雷达)发射微波辐射,然后根据地物散射该辐射返回的反向反射信号来探测和测距。由于微波波长比可见光和红外波长长,因此微波遥感具有较好的穿透能力,可以对云层、地表植被、松散沙层和干燥冰雪等物体进行探测,且不受光照等条件的限制,是一种全天候、全天时的遥感技术。微波遥感中常用的微波辐射源波段为0.8~30cm。
我们可以对其进行打分:
① 知识查找正确性:1分
② 回答一致性:1
③ 回答幻觉比例:1
④ 回答正确性:0.9
⑤ 逻辑性:0.8(微波概念与微波发射混淆)
⑥ 通顺性:0.8(多概念混淆回答)
⑦ 智能性:0.7(技术是严谨的,AI也是,都差不多)
综合上述七个维度,我们可以全面、综合地评估系统在每个案例上的表现,综合考虑所有案例的得分,就可以评估系统在每个维度的表现。
优化空间:
- 多维评估应与量化评估有效结合,并根据业务实际设置不同的量纲。
- 针对不同维度的不同重要性赋予权值,再计算所有维度的加权平均来代表系统得分。
🤔随着系统逐渐复杂和验证集的不断增大,这种评估的此时会达到成千上万次,人力完全不够胜任,因此我们继续一种自动评估模型的方法😀;
②自动评估方法
自动化评估大语言模型(LLM)的难点主要在于模型生成的答案往往难以判断其准确性。
- 对于
客观题,由于有明确的标准答案,评估相对简单; - 对于
主观题,尤其是那些没有固定答案的题目,实现自动化评估则显得尤为困难。
然而,在一定程度上牺牲评估的精确性,我们可以将那些复杂且没有标准答案的主观题转换为具有明确答案的问题,从而利用简单的自动化评估方法。具体来说,有两种策略可以采用:
- 构造客观题:将主观题转化为选择题(如多项选择或单项选择),这样可以通过直接对比模型生成的答案与预设的标准答案来评估其准确性。
怎么有股子独热编码的味道?🤔🤔
- 计算标准答案相似度:通过计算模型生成的答案与标准答案之间的
相似度,来评估答案的准确性。这种方法虽然不如直接对比答案那么简单直接,但可以在一定程度上量化答案的正确程度。
(1)构造客观题
思路:将主观题转化为多项选择题或单项选择题,以便于通过对比模型生成的答案与标准答案来实现简单评估。
例如我们给出问题:
- 遥感传感器的性能指标有?
A:空间分辨率 B:时间分辨率 C:视场角FOV D:光谱分辨率;
我们给定的标准答案是ABC,将模型给出的答案与标准答案进行对比即可实现评估打分,根据以上思想,我们可以构造出一个Prompt问题模版,代码如下:
template = """针对以下的问题,进行作答,这是多选题,不要说多余的话,从选择题中选择出你的答案;只需要输出选项即可,无需解释其他内容。只能从ABCD中选择对应的字母
{context}
问题: {question}
"""QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],template=template)# 构建检索问答链
qa_chain = RetrievalQA.from_chain_type(llm,retriever=loaded_db.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})# 测试结果
print("问题:")
question = "遥感传感器的性能指标有?A:空间分辨率 B:时间分辨率 C:视场角FOV D:光谱分辨率;"
print(question)
print("模型回答:")
result = qa_chain({"query": question})
print(result["result"])
输出结果如下:

这种思路类似于政治类考试的主观题,通过列举出客观的选项,来回答这种主观问题;
当然,鉴于大模型的不稳定性、即使我们要求其给出选择项,其也可能会返回一大堆文字,(解释选择原因或无用信息),因此我们需要构建一种打分方法:我们需要从文字中提取出选择答案;这里我们设计打分策略为:全选为1分,漏选为0.5分,错选不得分;代码如下:
def multi_select_score_v1(true_answer : str, generate_answer : str) -> float:# true_anser : 正确答案,str 类型,例如 'BCD'# generate_answer : 模型生成答案,str 类型true_answers = list(true_answer)'''为便于计算,我们假设每道题都只有 A B C D 四个选项'''# 先找出错误答案集合false_answers = [item for item in ['A', 'B', 'C', 'D'] if item not in true_answers]# 如果生成答案出现了错误答案for one_answer in false_answers:if one_answer in generate_answer:return 0# 再判断是否全选了正确答案if_correct = 0for one_answer in true_answers:if one_answer in generate_answer:if_correct += 1continueif if_correct == 0:# 不选return 0elif if_correct == len(true_answers):# 全选return 1else:# 漏选return 0.5# 测试结果
print("问题:")
question = "遥感传感器的性能指标有?A:空间分辨率 B:时间分辨率 C:视场角FOV D:光谱分辨率;"
print(question)
print("模型回答:")
result = qa_chain({"query": question})
print(result["result"])score = multi_select_score_v1(true_answer='ABCD', generate_answer=result["result"])
print("模型得分:", score)
运行结果为:

但是可以看到,我们要求模型在不能回答的情况下不做选择,错选和不选均为0分,这样其实鼓励了模型的幻觉回答,因此我们可以根据情况调整打分策略,让错选扣一分:除此之外,这里作者认为不够完善,我们可以在prompt中通过格式化输出解析来精准提取回答文本,辅助提高解析精度;修改后我们再次测试:
template = """针对以下的问题,进行作答,不要说多余的话,
{context}
问题: {question}-----------
从选择题中选择出你的答案;只能从ABCD中选择对应的字母;
要求输出的多个选项答案全部包裹在一个```answer```中,例如
```answer
ABC
```,要记住,这是多选题,不要当做单选题
"""QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],template=template)# 构建检索问答链
qa_chain = RetrievalQA.from_chain_type(llm,retriever=loaded_db.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})def multi_select_score_v1(true_answer : str, generate_answer : str) -> float:# true_anser : 正确答案,str 类型,例如 'BCD'# generate_answer : 模型生成答案,str 类型true_answers = list(true_answer)'''为便于计算,我们假设每道题都只有 A B C D 四个选项'''# 先找出错误答案集合false_answers = [item for item in ['A', 'B', 'C', 'D'] if item not in true_answers]# 如果生成答案出现了错误答案for one_answer in false_answers:if one_answer in generate_answer:return 0# 再判断是否全选了正确答案if_correct = 0for one_answer in true_answers:if one_answer in generate_answer:if_correct += 1continueif if_correct == 0:# 不选return 0elif if_correct == len(true_answers):# 全选return 1elif if_correct >= len(true_answers):# 多选return 1else:# 漏选return 0.5# 正则提取任务
def parse_answer(content): # 从模型生成中字符串匹配提取生成的代码pattern = r'```answer(.*?)```' # 使用非贪婪匹配match = re.search(pattern, content, re.DOTALL)answer= match.group(1) if match else contentreturn answer# 测试结果
print("问题:")
question = "遥感传感器的性能指标有?A:空间分辨率 B:时间分辨率 C:视场角FOV D:光谱分辨率;"
print(question)
print("模型回答:")
result = qa_chain({"query": question})
print(result["result"])
answer = parse_answer(result["result"])
print("模型答案:",answer)
score = multi_select_score_v1(true_answer='ABCD', generate_answer=answer)
print("模型得分:", score)

可以看到,这样我们就实现了快速、自动又有区分度的自动评估。在这样的方法下,我们只需对每一个验证案例进行客观题构造,之后每一次验证、迭代都可以完全自动化进行,从而实现了高效的验证。
(2) 计算答案相似度
学习之前文章中的RAG原理的读者应该对向量相似度有一定的了解,我们一般可以针对每个问题构建对应的标准答案,无论主客观题目;我们将模型的回答结果与标准答案都进行向量化,然后相似度计算,相似度越高,我们则认为正确答案程度越高;计算相似度的方法有很多,这里我们使用BLEU来进行相似度计算:
BLEU(Bilingual Evaluation Understudy)🏆是一种用于评估机器翻译质量的指标,它通过比较机器翻译的文本与一组参考翻译(通常是人工翻译)的相似度来计算得分。BLEU的计算原理基于以下几个关键步骤:
- N-gram 匹配:
- BLEU的核心思想是
计算机器翻译文本中的n-gram(连续的n个词)与参考翻译中的n-gram的匹配程度。- 通常,BLEU会计算
1-gram(单个词)、2-gram(两个词)、3-gram和4-gram的匹配情况。
- 精度(Precision)计算:
- 对于每个n-gram,计算其
在机器翻译文本中出现的次数与在参考翻译 中出现的次数的比值。- 如果机器翻译中的某个n-gram在参考翻译中出现的次数更多,则只计
算参考翻译中出现的次数。
- 惩罚因子(Brevity Penalty):
- 为了防止过短的机器翻译获得过高的分数,BLEU引入了一个惩罚因子。
- 如果机器翻译的长度小于参考翻译的长度,则根据长度差异计算一个惩罚因子,使得过短的翻译得分降低。
- 综合得分:
- 将
各个n-gram的精度得分进行加权平均,通常权重是几何平均。- 最后,
乘以惩罚因子得到最终的BLEU得分。BLEU得分的计算公式可以表示为:
BLEU = BP ⋅ exp ( ∑ n = 1 N w n log p n ) \text{BLEU} = \text{BP} \cdot \exp\left(\sum_{n=1}^{N} w_n \log p_n\right) BLEU=BP⋅exp(n=1∑Nwnlogpn)
其中:
- BP \text{BP} BP 是惩罚因子。
- p n p_n pn 是n-gram的精度。
- w n w_n wn是n-gram的权重,通常取几何平均。
BLEU的优点是计算简单且与人工评估有较好的相关性,但它也有一些局限性,比如对语法错误和语义差异不够敏感。尽管如此,BLEU仍然是机器翻译领域广泛使用的评估指标之一。😀
我们可以使用NLTK库中的bleu打分函数进行计算:
from nltk.translate.bleu_score import sentence_bleu
import jiebadef bleu_score(true_answer : str, generate_answer : str) -> float:# true_anser : 标准答案,str 类型# generate_answer : 模型生成答案,str 类型true_answers = list(jieba.cut(true_answer))# print(true_answers)generate_answers = list(jieba.cut(generate_answer))# print(generate_answers)bleu_score = sentence_bleu(true_answers, generate_answers)return bleu_score
true_answer = '微波的的波长比可见光和红外波长,受大气层中云雾的散射影响小,穿透性好,因此能全天候进行遥感。使用微波的遥感被称为微波遥感,它通过接受地面物体发射的微波辐射能量,或接收器本身发出的电磁波束的回波信号,对物体进行探测、识别和分析。由于微波遥感采用主动方式进行,其特点是对云层、地表植被、松散沙层和干燥冰雪具有一定的穿透能力,且不受光照等条线限制。因此微波遥感是一种全天候、全天时的遥感技术。'print("答案一:")
answer1 = '遥感的微波(Microwave Remote Sensing)指的是使用微波辐射的散射和辐射信息来分析、识别地物或提取专题信息的技术。微波遥感可以使用人工辐射源(如微波雷达)发射微波辐射,然后根据地物散射该辐射返回的反向反射信号来探测和测距。由于微波波长比可见光和红外波长长,因此微波遥感具有较好的穿透能力,可以对云层、地表植被、松散沙层和干燥冰雪等物体进行探测,且不受光照等条件的限制,是一种全天候、全天时的遥感技术。微波遥感中常用的微波辐射源波段为0.8~30cm。'
print(answer1)
score = bleu_score(true_answer, answer1)
print("得分:", score)
print("答案二:")
answer2 = '红外线根据其性质可分为近红外、中红外、远红外和超远红外。近红外主要源于太阳辐射,中红外主要源于太阳辐射及地物热辐射,而远红外和超远红外主要源于地物热辐射。红外波段较宽,在此波段地物间不同的反射特性和发射特性均可较好地表现出来,因此该波段在遥感成像中有着重要作用。在整个红外波段中进行的遥感统称红外遥感,按其内部波段的详细划分可分为近红外遥感和热红外遥感。中红外、远红外和超远红外三者是产生热感的主要原因,因此又称为热红外。热红外遥感最大的特点就是具有昼夜工作的能力。由于摄影胶片感光范围的限制,除了近红外可用于摄影成像外,其他波段不能用于摄影成像,而整个红外波段都可用于扫描成像。'
print(answer2)
score = bleu_score(true_answer, answer2)
print("得分:", score)
运行代码测试一下:

可以看到,答案与标准答案一致性越高,则打分评估就越高,通过这种方法,我们同样只需要对一个验证集中的每一个问题构造一个标准答案,之后就可以实现自动、高效的评估;
这种方法的缺点:
- 需要人工构建标准答案,某些垂直领域而言,构建标准答案相对比较空难;
- 通过相似度判断,如果生成回答与标准答案高度相似,但关键位置恰恰相反则会导致答案啊完全错误,但是依旧有很高的BLEU打分;
- 通过计算与标准答案一致性灵活性很差,如果模型生成了比标准答案更好的回答,但评估得分反而会降低;
- 无法评估回答的智能性、流畅性。如果回答是各个标准答案中的关键词拼接出来的,我们认为这样的回答是不可用无法理解的,但 bleu 得分会较高。
利用Embedding向量相似度来打分怎么样?或者使用LLM为LLM打分?🤔🤔🤔
3. 使用大模型进行评估
使用人工评估成本高,效率低;
使用简单自动化评估效率高,但质量低;
那什么样的评估方法可以兼并两者的优点呢?
LLM的发展为我们提供了一种新的方法——使用大模型来评估,我们可以通过提示词工程来让LLM充当一个老师的身份,对我们的LLM应用进行评估;由于其强大的泛化性,其既可以满足多维评估和量化评估,又因为其作为API的特性,我们可以24小时调用它,因此大模型评估可以看做是人工评估的最佳替代;
例如,我们可以构造如下的 Prompt Engineering,让大模型进行打分:
prompt = '''
你是一个模型回答评估员。
接下来,我将给你一个问题、对应的知识片段以及模型根据知识片段对问题的回答。
请你依次评估以下维度模型回答的表现,分别给出打分:① 知识查找正确性。评估系统给定的知识片段是否能够对问题做出回答。如果知识片段不能做出回答,打分为0;如果知识片段可以做出回答,打分为1。② 回答一致性。评估系统的回答是否针对用户问题展开,是否有偏题、错误理解题意的情况,打分分值在0~1之间,0为完全偏题,1为完全切题。③ 回答幻觉比例。该维度需要综合系统回答与查找到的知识片段,评估系统的回答是否出现幻觉,打分分值在0~1之间,0为全部是模型幻觉,1为没有任何幻觉。④ 回答正确性。该维度评估系统回答是否正确,是否充分解答了用户问题,打分分值在0~1之间,0为完全不正确,1为完全正确。⑤ 逻辑性。该维度评估系统回答是否逻辑连贯,是否出现前后冲突、逻辑混乱的情况。打分分值在0~1之间,0为逻辑完全混乱,1为完全没有逻辑问题。⑥ 通顺性。该维度评估系统回答是否通顺、合乎语法。打分分值在0~1之间,0为语句完全不通顺,1为语句完全通顺没有任何语法问题。⑦ 智能性。该维度评估系统回答是否拟人化、智能化,是否能充分让用户混淆人工回答与智能回答。打分分值在0~1之间,0为非常明显的模型回答,1为与人工回答高度一致。你应该是比较严苛的评估员,很少给出满分的高评估。
用户问题:
~~~
{}
~~~
待评估的回答:
~~~
{}
~~~
给定的知识片段:
~~~
{}
~~~
你应该返回给我一个可直接解析的 Python 字典,字典的键是如上维度,值是每一个维度对应的评估打分。
不要输出任何其他内容。
'''
运行代码进行测试:
可以看到通过LLM评估的结果又快有准;
大模型评估的问题:
- 评估大模型基座模型要优于被评估基座模型
- 回答结果不能太长或者评价维度太多
解决方案:
- 拆分评估维度。如果评估维度太多,模型可能会出现错误格式导致返回无法解析,可以考虑将待评估的多个维度拆分,每个维度调用一次大模型进行评估,最后得到统一结果;
- 合并评估维度。如果评估维度太细,模型可能无法正确理解以至于评估不正确,可以考虑将待评估的多个维度合并,例如,将逻辑性、通顺性、智能性合并为智能性等;
3… 提供详细的评估规范。如果没有评估规范,模型很难给出理想的评估结果。可以考虑给出详细、具体的评估规范,从而提升模型的评估能力;- 提供少量示例。模型可能难以理解评估规范,此时可以给出少量评估的示例,供模型参考以实现正确评估。
4.混合评估
就像是决策树与随机森林的关系,在业务开发中,我们要具体问题具体分析,评估方法没有最好的,只有最合适的,因此我们要针对不同的问题进行针对分析;我们更推荐多种评估方法混合评估,对评估问题进行分类;不同的类别使用不同的评估方式,以个人知识库为例:
- 客观题:具有标准答案的题目,可以构造客观题自动评估和答案相似性进行加权评估;
- 主观题:构造客观题自动评估+大模型分维度综合评估
- 回答结果是否智能:因为模型回答的智能性与问题弱相关,通过对评价结果中少许抽样,人工分析Prompt和模型来评估;
- 知识查找正确性:知识查找正确性指对于特定问题,从知识库检索到的知识片段是否正确、是否足够回答问题。知识查找正确性推荐使用大模型进行评估,即要求模型判别给定的知识片段是否足够回答问题。同时,该维度评估结果结合主观正确性可以计算幻觉情况,即如果主观回答正确但知识查找不正确,则说明产生了模型幻觉。
二、生成内容评估优化
在前面的章节中,我们讲到了如何评估一个基于 RAG 框架的大模型应用的整体性能。通过针对性构造验证集,可以采用多种方法从多个维度对系统性能进行评估。但是,评估的目的是为了更好地优化应用效果,要优化应用性能,我们需要结合评估结果,对评估出的 Bad Case 进行拆分,并分别对每一部分做出评估和优化。
AG 全称为检索增强生成,因此,其有两个核心部分:检索部分和生成部分。检索部分的核心功能是保证系统根据用户 query 能够查找到对应的答案片段,而生成部分的核心功能即是保证系统在获得了正确的答案片段之后,可以充分发挥大模型能力生成一个满足用户要求的正确回答。
优化一个大模型应用,我们往往需要从这两部分同时入手,分别评估检索部分和优化部分的性能,找出 Bad Case 并针对性进行性能的优化。而具体到生成部分,在已限定使用的大模型基座的情况下,我们往往会通过优化 Prompt Engineering 来优化生成的回答。在本章中,我们将首先结合我们刚刚搭建出的大模型应用实例——个人知识库助手,向大家讲解如何评估分析生成部分性能,针对性找出 Bad Case,并通过优化 Prompt Engineering 的方式来优化生成部分
###1.初始化检索链
2. 少样本提升回答质量
寻找 Bad Case 的思路有很多,最直观也最简单的就是评估直观回答的质量,结合原有资料内容,判断在什么方面有所不足。例如,上述的测试我们可以构造成一个 Bad Case:
我们再针对性地修改 Prompt 模板,加入要求其回答具体,并去掉“谢谢你的提问”的部分:
可以看到,改进后的 v2 版本能够给出更具体、详细的回答,解决了之前的问题。但是我们可以进一步思考,要求模型给出具体、详细的回答,是否会导致针对一些有要点的回答没有重点、模糊不清?我们测试以下问题:
可以看到,针对我们关于 LLM 课程的提问,模型回答确实详细具体,也充分参考了课程内容,但回答使用首先、其次等词开头,同时将整体答案分成了4段,导致答案不是特别重点清晰,不容易阅读。因此,我们构造以下 Bad Case:
针对该 Bad Case,我们可以改进 Prompt,要求其对有几点的答案进行分点标号,让答案清晰具体:
升回答质量的方法还有很多,核心是围绕具体业务展开思考,找出初始回答中不足以让人满意的点,并针对性进行提升改进,此处不再赘述。
3. 标明知识来源,提升可信度
原始提问:
们可以要求模型在生成回答时注明知识来源,这样可以避免模型杜撰并不存在于给定资料的知识,同时,也可以提高我们对模型生成答案的可信度,代码如下:
运行结果如下:
但是,附上原文来源往往会导致上下文的增加以及回复速度的降低,我们需要根据业务场景酌情考虑是否要求附上原文。
4.构造思维链
大模型往往可以很好地理解并执行指令,但模型本身还存在一些能力的限制,例如大模型的幻觉、无法理解较为复杂的指令、无法执行复杂步骤等。我们可以通过构造思维链,将 Prompt 构造成一系列步骤来尽量减少其能力限制,例如,我们可以构造一个两步的思维链,要求模型在第二步做出反思,以尽可能消除大模型的幻觉问题。
我们首先有这样一个 Bad Case:
问题:我们应该如何去构造一个 LLM 项目
初始回答:略
存在不足:事实上,知识库中中关于如何构造LLM项目的内容是使用 LLM API 去搭建一个应用,模型的回答看似有道理,实则是大模型的幻觉,将部分相关的文本拼接得到,存在问题
question = "我们应该如何去构造一个LLM项目"
result = qa_chain({"query": question})
print(result["result"])Copy to clipboardErrorCopied
对此,我们可以优化 Prompt,将之前的 Prompt 变成两个步骤,要求模型在第二个步骤中做出反思:
template_v4 = """
请你依次执行以下步骤:
① 使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答案。
你应该使答案尽可能详细具体,但不要偏题。如果答案比较长,请酌情进行分段,以提高答案的阅读体验。
如果答案有几点,你应该分点标号回答,让答案清晰具体。
上下文:
{context}
问题:
{question}
有用的回答:
② 基于提供的上下文,反思回答中有没有不正确或不是基于上下文得到的内容,如果有,回答你不知道
确保你执行了每一个步骤,不要跳过任意一个步骤。
"""QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],template=template_v4)
qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})question = "我们应该如何去构造一个LLM项目"
result = qa_chain({"query": question})
print(result["result"])
可以看出,要求模型做出自我反思之后,模型修复了自己的幻觉,给出了正确的答案。我们还可以通过构造思维链完成更多功能,此处就不再赘述了,欢迎读者尝试。
5. 增加一个输出解析
这一步也就是我们之前说的输出解析器:通过限定格式和每个输出的类型,使其结果更加专业化;代码如下:
通过上述讲解的思路,结合实际业务情况,我们可以不断发现 Bad Case 并针对性优化 Prompt,从而提升生成部分的性能。但是,上述优化的前提是检索部分能够检索到正确的答案片段,也就是检索的准确率和召回率尽可能高。那么,如何能够评估并优化检索部分的性能呢?下一章我们会深入探讨这个问题。
三、检索内容评估优化
我们讲解了如何针对生成部分评估优化 Prompt Engineering,来提高大模型的生成质量。但生成的前提是检索,只有当我们应用的检索部分能够根据用户 query 检索到正确的答案文档时,大模型的生成结果才可能是正确的。因此,检索部分的检索精确率和召回率其实更大程度影响了应用的整体性能。但是,检索部分的优化是一个更工程也更深入的命题,我们往往需要使用到很多高级的、源于搜索的进阶技巧并探索更多实用工具,甚至手写一些工具来进行优化。因此,在本章中,我们仅大致讨论检索部分评估与优化的思路,
1. 评估检索效果
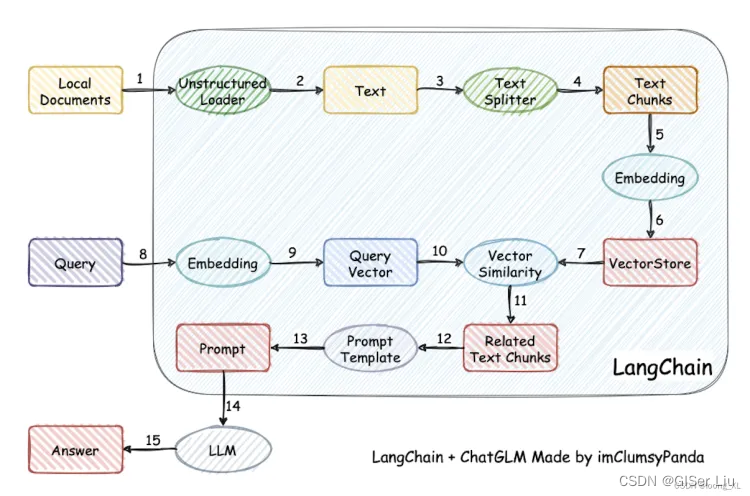
针对用户输入的一个 query,系统会将其转化为向量并在向量数据库中匹配最相关的文本段,然后根据我们的设定选择 3~5 个文本段落和用户的 query 一起交给大模型,再由大模型根据检索到的文本段落回答用户 query 中提出的问题。在这一整个系统中,我们将向量数据库检索相关文本段落的部分称为检索部分,将大模型根据检索到的文本段落进行答案生成的部分称为生成部分。
因此,检索部分的核心功能是找到存在于知识库中、能够正确回答用户 query 中的提问的文本段落。因此,我们可以定义一个最直观的准确率在评估检索效果:对于 N 个给定 query,我们保证每一个 query 对应的正确答案都存在于知识库中。假设对于每一个 query,系统找到了 K 个文本片段,如果正确答案在 K 个文本片段之一,那么我们认为检索成功;如果正确答案不在 K 个文本片段之一,我们任务检索失败。那么,系统的检索准确率可以被简单地计算为:
𝑎𝑐𝑐𝑢𝑟𝑎𝑐𝑦=𝑀𝑁accuracy=NM
其中,M 是成功检索的 query 数。
通过上述准确率,我们可以衡量系统的检索能力,对于系统能成功检索到的 query,我们才能进一步优化 Prompt 来提高系统性能。对于系统检索失败的 query,我们就必须改进检索系统来优化检索效果。但是注意,当我们在计算如上定义的准确率时,一定要保证我们的每一个验证 query 的正确答案都确实存在于知识库中;如果正确答案本就不存在,那我们应该将 Bad Case 归因到知识库构建部分,说明知识库构建的广度和处理精度还有待提升。
当然,这只是最简单的一种评估方式,事实上,这种评估方式存在很多不足。例如:
● 有的 query 可能需要联合多个知识片段才能做出回答,对于这种 query,我们如何评估?
● 检索到的知识片段彼此之间的顺序其实会对大模型的生成带来影响,我们是否应该将检索片段的排序纳入考虑?
● 除去检索到正确的知识片段之外,我们的系统还应尽量避免检索到错误的、误导性知识片段,否则大模型的生成结果很可能被错误片段误导。我们是否应当将检索到的错误片段纳入指标计算?
上述问题都不存在标准答案,需要针对项目实际针对的业务、评估的成本来综合考虑。
除去通过上述方法来评估检索效果外,我们还可以将检索部分建模为一个经典的搜索任务。让我们来看看经典的搜索场景。搜索场景的任务是,针对用户给定的检索 query,从给定范围的内容(一般是网页)中找到相关的内容并进行排序,尽量使排序靠前的内容能够满足用户需求。
其实我们的检索部分的任务和搜索场景非常类似,同样是针对用户 query,只不过我们相对更强调召回而非排序,以及我们检索的内容不是网页而是知识片段。因此,我们可以类似地将我们的检索任务建模为一个搜索任务,那么,我们就可以引入搜索算法中经典的评估思路(如准确率、召回率等)和优化思路(例如构建索引、重排等)来更充分地评估优化我们的检索效果。这部分就不再赘述,欢迎有兴趣的读者进行深入研究和分享。
二、优化检索的思路
上文陈述来评估检索效果的几种一般思路,当我们对系统的检索效果做出合理评估,找到对应的 Bad Case 之后,我们就可以将 Bad Case 拆解到多个维度来针对性优化检索部分。注意,虽然在上文评估部分,我们强调了评估检索效果的验证 query 一定要保证其正确答案存在于知识库之中,但是在此处,我们默认知识库构建也作为检索部分的一部分,因此,我们也需要在这一部分解决由于知识库构建有误带来的 Bad Case。在此,我们分享一些常见的 Bad Case 归因和可行的优化思路。
- 知识片段被割裂导致答案丢失
该问题一般表现为,对于一个用户 query,我们可以确定其问题一定是存在于知识库之中的,但是我们发现检索到的知识片段将正确答案分割开了,导致不能形成一个完整、合理的答案。该种问题在需要较长回答的 query 上较为常见。
该类问题的一般优化思路是,优化文本切割方式。我们在《C3 搭建知识库》中使用到的是最原始的分割方式,即根据特定字符和 chunk 大小进行分割,但该类分割方式往往不能照顾到文本语义,容易造成同一主题的强相关上下文被切分到两个 chunk 总。对于一些格式统一、组织清晰的知识文档,我们可以针对性构建更合适的分割规则;对于格式混乱、无法形成统一的分割规则的文档,我们可以考虑纳入一定的人力进行分割。我们也可以考虑训练一个专用于文本分割的模型,来实现根据语义和主题的 chunk 切分。 - query 提问需要长上下文概括回答
该问题也是存在于知识库构建的一个问题。即部分 query 提出的问题需要检索部分跨越很长的上下文来做出概括性回答,也就是需要跨越多个 chunk 来综合回答问题。但是由于模型上下文限制,我们往往很难给出足够的 chunk 数。
该类问题的一般优化思路是,优化知识库构建方式。针对可能需要此类回答的文档,我们可以增加一个步骤,通过使用 LLM 来对长文档进行概括总结,或者预设提问让 LLM 做出回答,从而将此类问题的可能答案预先填入知识库作为单独的 chunk,来一定程度解决该问题。 - 关键词误导
该问题一般表现为,对于一个用户 query,系统检索到的知识片段有很多与 query 强相关的关键词,但知识片段本身并非针对 query 做出的回答。这种情况一般源于 query 中有多个关键词,其中次要关键词的匹配效果影响了主要关键词。
该类问题的一般优化思路是,对用户 query 进行改写,这也是目前很多大模型应用的常用思路。即对于用户输入 query,我们首先通过 LLM 来将用户 query 改写成一种合理的形式,去除次要关键词以及可能出现的错字、漏字的影响。具体改写成什么形式根据具体业务而定,可以要求 LLM 对 query 进行提炼形成 Json 对象,也可以要求 LLM 对 query 进行扩写等。 - 匹配关系不合理
该问题是较为常见的,即匹配到的强相关文本段并没有包含答案文本。该问题的核心问题在于,我们使用的向量模型和我们一开始的假设不符。在讲解 RAG 的框架时,我们有提到,RAG 起效果是有一个核心假设的,即我们假设我们匹配到的强相关文本段就是问题对应的答案文本段。但是很多向量模型其实构建的是“配对”的语义相似度而非“因果”的语义相似度,例如对于 query-“今天天气怎么样”,会认为“我想知道今天天气”的相关性比“天气不错”更高。
该类问题的一般优化思路是,优化向量模型或是构建倒排索引。我们可以选择效果更好的向量模型,或是收集部分数据,在自己的业务上微调一个更符合自己业务的向量模型。我们也可以考虑构建倒排索引,即针对知识库的每一个知识片段,构建一个能够表征该片段内容但和 query 的相对相关性更准确的索引,在检索时匹配索引和 query 的相关性而不是全文,从而提高匹配关系的准确性。
优化检索部分的思路还有很多,事实上,检索部分的优化往往是 RAG 应用开发的核心工程部分。限于篇幅原因,此处就不再赘述更多的技巧及方
文章参考
- OpenAI官方文档
- DeepSeek官方文档
- Mistral官方文档
- ChatGLM官方文档
项目地址
- Github地址
- 拓展阅读
- 专栏文章

如果觉得我的文章对您有帮助,三连+关注便是对我创作的最大鼓励!或者一个star🌟也可以😂.
相关文章:
LLM应用开发-RAG系统评估与优化
前言 Hello,大家好,我是GISer Liu😁,一名热爱AI技术的GIS开发者,在上一篇文章中,我们学习了如何基于LangChain构建RAG应用,并且通过Streamlit将这个RAG应用部署到了阿里云服务器;&am…...
秋招突击——第七弹——Redis快速入门
文章目录 引言Redis是什么 正文对象String字符串面试重点 List面试考点 压缩列表ZipList面试题 Set面试题讲解 Hash面试重点 HASHTABLE底层面试考点 跳表面试重点 ZSET有序链表面试重点 总结 引言 在项目和redis之间,我犹豫了一下,觉得还是了解学习一下…...
软考初级网络管理员__操作系统单选题
1.在Windows资源管理器中,假设已经选定文件,以下关于“复制”操作的叙述中,正确的有()。 按住Ctr键,拖至不同驱动器的图标上 按住AIt键,拖至不同驱动器的图标上 直接拖至不同驱动器的图标上 按住Shift键࿰…...
)
从入门到精通:网络编程套接字(万字详解,小白友好,建议收藏)
一、预备知识 1.1 理解源IP地址和目的IP地址 在网络编程中,IP地址(Internet Protocol Address)是每个连接到互联网的设备的唯一标识符。IP地址可以分为IPv4和IPv6两种类型。IPv4地址是由32位二进制数表示,通常分为四个八位组&am…...

dledger原理源码分析系列(一)架构,核心组件和rpc组件
简介 dledger是openmessaging的一个组件, raft算法实现,用于分布式日志,本系列分析dledger如何实现raft概念,以及dledger在rocketmq的应用 本系列使用dledger v0.40 本文分析dledger的架构,核心组件;rpc组…...

第七节:如何浅显易懂地理解Spring Boot中的依赖注入(自学Spring boot 3.x的第二天)
大家好,我是网创有方,今天我开始学习spring boot的第一天,一口气写了这么多。 这节通过一个非常浅显易懂的列子来讲解依赖注入。 在Spring Boot 3.x中,依赖注入(Dependency Injection, DI)是一个核心概念…...

Postman自动化测试实战:使用脚本提升测试效率
在软件开发过程中,接口测试是确保后端服务稳定性和可靠性的关键步骤。Postman作为一个流行的API开发工具,提供了强大的脚本功能来实现自动化测试。通过在Postman中使用脚本,测试人员可以编写测试逻辑,实现测试用例的自动化执行&am…...

CSMA/CA并不是“公平”的
CSMA/CA会造成过于公平,对于最需要流量的节点,是最不友好的,而对于最不需要流量的节点,则是最友好的。 CSMA/CA是优先公平来工作的。 CSMA/CA首先各节点使用DIFS界定air idle,在此期间大家都等待 其次,为了同时发送引起碰撞,在DIFS之后随机从CWmin和CWmax之间选择一个时…...

【漏洞复现】I doc view——任意文件读取
声明:本文档或演示材料仅供教育和教学目的使用,任何个人或组织使用本文档中的信息进行非法活动,均与本文档的作者或发布者无关。 文章目录 漏洞描述漏洞复现测试工具 漏洞描述 I doc view 在线文档预览是一个用于查看、编辑、管理文档的工具…...
图数据库 vs 向量数据库
最近大模型出来之后,向量数据库重新翻红,业界和市场上有不少声音认为向量数据库会极大的影响图数据库,图数据库市场会萎缩甚至消失,今天就从技术原理角度来讨论下图数据库和向量数据库到底差别在哪里,适合什么场景&…...

企业品牌出海第一站 维基百科词条创建
维基百科是一部内容开放、自由的网络百科全书,旨在创造一个涵盖所有领域知识,服务所有互联网用户的知识性百科全书。其在国外应用非常广泛且认可度很高,国内品牌出海或国际品牌都很有必要创建企业自己的维基百科页面,以及企业高管的个人维基百科页面。 如…...
Windows下activemq集群配置(broker-network)
1.activemq版本信息 activemq:apache-activemq-5.18.4 2.activemq架构 3.activemq集群配置 activemq集群配置基于Networks of Brokers 这种HA方案的优点:是占用的节点数更少(只需要2个节点),而且2个broker都可以响应消息的接收与发送。不足ÿ…...
心理辅导平台系统
摘 要 中文本论文基于Java Web技术设计与实现了一个心理辅导平台。通过对国内外心理辅导平台发展现状的调研,本文分析了心理辅导平台的背景与意义,并提出了论文研究内容与创新点。在相关技术介绍部分,对Java Web、SpringBoot、B/S架构、MVC模…...

代理IP对SEO影响分析:提升网站排名的关键策略
你是否曾经为网站排名难以提升而苦恼?代理服务器或许就是你忽略的关键因素。在竞争激烈的互联网环境中,了解代理服务器对SEO的影响,有助于你采取更有效的策略,提高网站的搜索引擎排名。本文将为你详细分析代理服务器在SEO优化中的…...

【leetcode--三数之和】
这道题记得之前做过,但是想不起来了。。总结一下: 函数的主要步骤和关键点: 排序:对输入的整数数组nums进行排序。这是非常重要的,因为它允许我们使用双指针技巧来高效地找到满足条件的三元组。初始化:定…...

解决Java中的ClassCastException问题
解决Java中的ClassCastException问题 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在Java编程中,ClassCastException是一个常见的运行时异常&am…...

【TensorFlow深度学习】混合生成模型:结合AR与AE的创新尝试
混合生成模型:结合AR与AE的创新尝试 引言自回归模型与自动编码器的简述混合模型的创新尝试组合AR与AE:MADE混合模型在图学习中的应用 结论与展望 在自我监督学习的广阔天地里,混合生成模型以其独特的魅力,跨越了自回归(…...

Spring:Spring中分布式事务解决方案
一、前言 在Spring中,分布式事务是指涉及多个数据库或系统的事务处理,其中事务的参与者、支持事务的服务器、资源管理器以及事务管理器位于分布式系统的不同节点上。这样的架构使得两个或多个网络计算机上的数据能够被访问并更新,同时将这些操…...
音视频开发32 FFmpeg 编码- 视频编码 h264 参数相关
1. ffmpeg -h 这个命令总不会忘记,用这个先将ffmpeg所有的help信息都list出来 C:\Users\Administrator>ffmpeg -h ffmpeg version 6.0-full_build-www.gyan.dev Copyright (c) 2000-2023 the FFmpeg developersbuilt with gcc 12.2.0 (Rev10, Built by MSYS2 pro…...
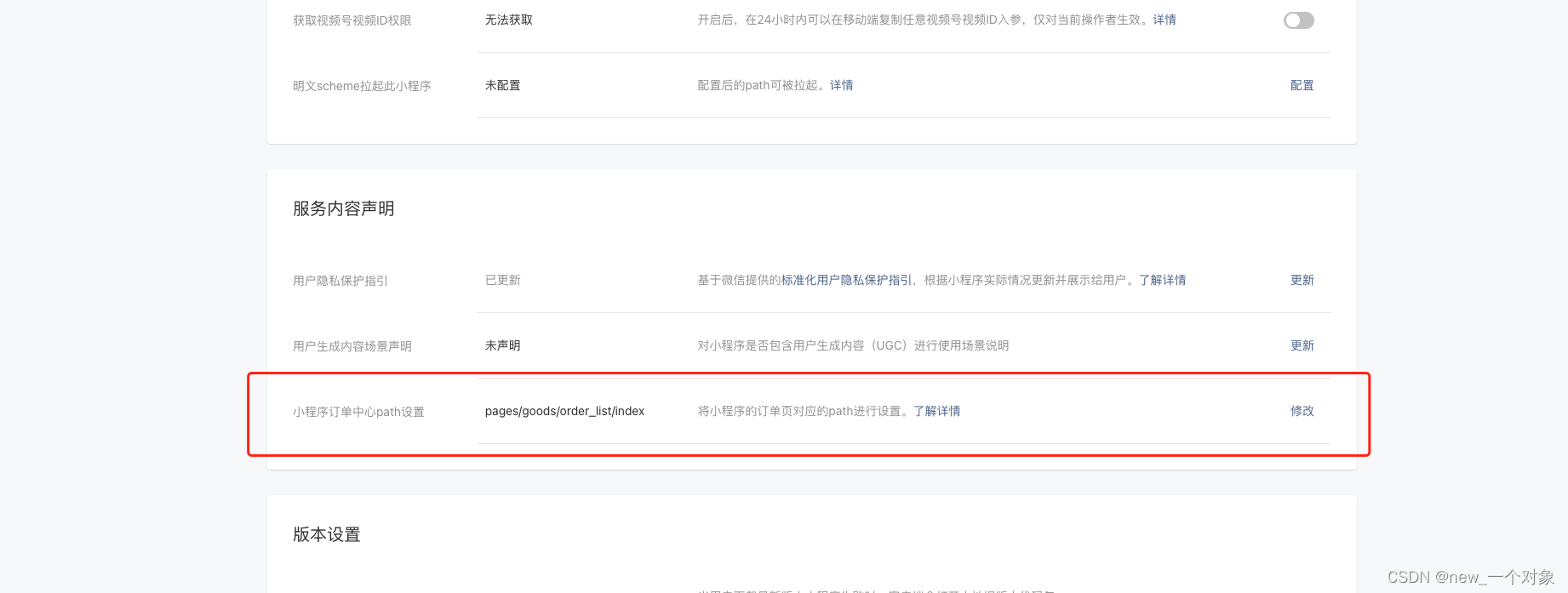
标准版小程序订单中心path审核不通过处理教程
首先看自己小程序是不是已经审核通过并上线状态才在站内信里面提醒的? 如果没有提交过审核,请在提交的时候填写。path地址为:pages/goods/order_list/index 如果是已经上线的小程序,当时没要求填这个,但新的政策要求填…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...

Cinnamon修改面板小工具图标
Cinnamon开始菜单-CSDN博客 设置模块都是做好的,比GNOME简单得多! 在 applet.js 里增加 const Settings imports.ui.settings;this.settings new Settings.AppletSettings(this, HTYMenusonichy, instance_id); this.settings.bind(menu-icon, menu…...

12.找到字符串中所有字母异位词
🧠 题目解析 题目描述: 给定两个字符串 s 和 p,找出 s 中所有 p 的字母异位词的起始索引。 返回的答案以数组形式表示。 字母异位词定义: 若两个字符串包含的字符种类和出现次数完全相同,顺序无所谓,则互为…...

【C++进阶篇】智能指针
C内存管理终极指南:智能指针从入门到源码剖析 一. 智能指针1.1 auto_ptr1.2 unique_ptr1.3 shared_ptr1.4 make_shared 二. 原理三. shared_ptr循环引用问题三. 线程安全问题四. 内存泄漏4.1 什么是内存泄漏4.2 危害4.3 避免内存泄漏 五. 最后 一. 智能指针 智能指…...

C++ 设计模式 《小明的奶茶加料风波》
👨🎓 模式名称:装饰器模式(Decorator Pattern) 👦 小明最近上线了校园奶茶配送功能,业务火爆,大家都在加料: 有的同学要加波霸 🟤,有的要加椰果…...

学习一下用鸿蒙DevEco Studio HarmonyOS5实现百度地图
在鸿蒙(HarmonyOS5)中集成百度地图,可以通过以下步骤和技术方案实现。结合鸿蒙的分布式能力和百度地图的API,可以构建跨设备的定位、导航和地图展示功能。 1. 鸿蒙环境准备 开发工具:下载安装 De…...
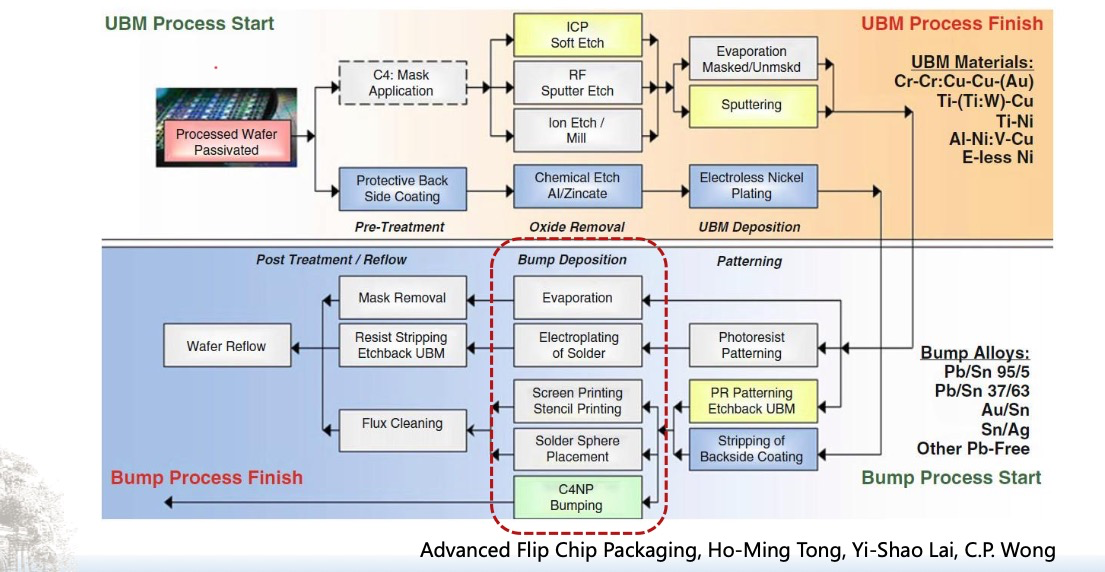
倒装芯片凸点成型工艺
UBM(Under Bump Metallization)与Bump(焊球)形成工艺流程。我们可以将整张流程图分为三大阶段来理解: 🔧 一、UBM(Under Bump Metallization)工艺流程(黄色区域ÿ…...

【免费数据】2005-2019年我国272个地级市的旅游竞争力多指标数据(33个指标)
旅游业是一个城市的重要产业构成。旅游竞争力是一个城市竞争力的重要构成部分。一个城市的旅游竞争力反映了其在旅游市场竞争中的比较优势。 今日我们分享的是2005-2019年我国272个地级市的旅游竞争力多指标数据!该数据集源自2025年4月发表于《地理学报》的论文成果…...
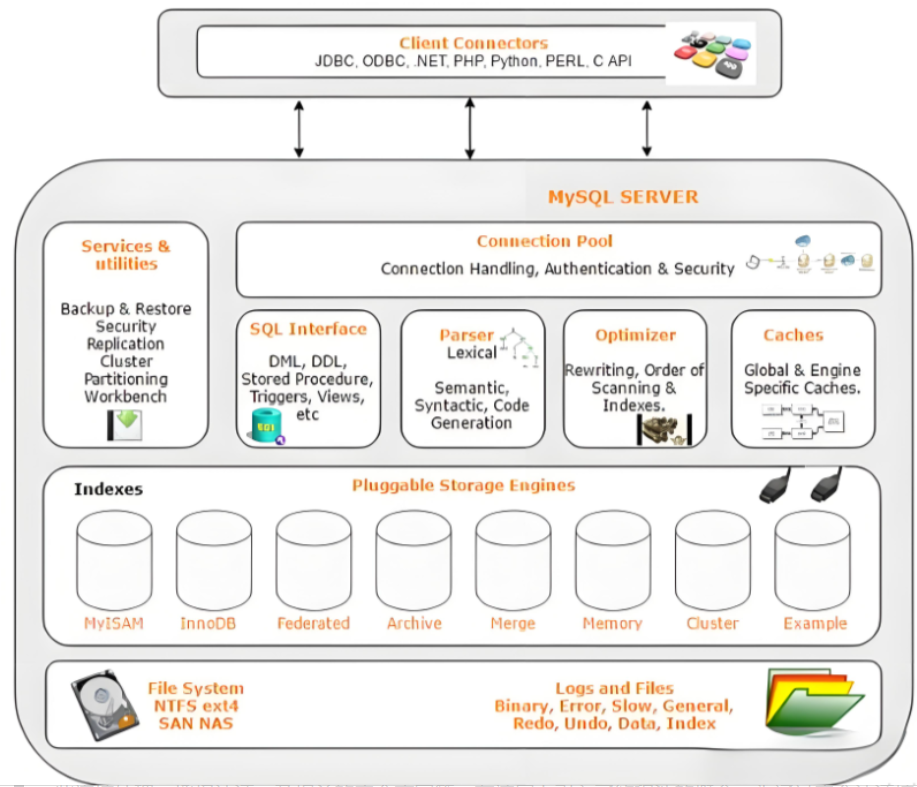
Mysql故障排插与环境优化
前置知识点 最上层是一些客户端和连接服务,包含本 sock 通信和大多数jiyukehuduan/服务端工具实现的TCP/IP通信。主要完成一些简介处理、授权认证、及相关的安全方案等。在该层上引入了线程池的概念,为通过安全认证接入的客户端提供线程。同样在该层上可…...