大模型项目落地时,该如何估算模型所需GPU算力资源

近期公司有大模型项目落地。在前期沟通时,对于算力估算和采购方案许多小伙伴不太了解,在此对相关的算力估算和选择进行一些总结。
不喜欢过程的可以直接 跳到HF上提供的模型计算器
要估算大模型的所需的显卡算力,首先要了解大模型的参数基础知识。
大模型的规模、参数的理解
模型参数单位
我们的项目中客户之前测试过Qwen1.5 -110B的模型,效果还比较满意。(Qwen还是国产模型中比较稳定的也是很多项目的首选)
模型中的110B 术语通常指的是大型神经网络模型的参数数量。其中的 “B” 代表 “billion”,也就是十亿。表示模型中的参数量,每个参数用来存储模型的权重和偏差等信息。110B也就是1100亿参数。(大模型的能力涌现基本都是参数要在千亿之上,几十亿几百亿的参数模型虽然也能满足大多数场景,但是谁不想要个更好的呢?『手动狗头』)
比如最新的Qwen2 开源了 5种模型规模,包括0.5B、1.5B、7B、57B-A14B和72B;(57B-A14B模型是570亿参数激活140亿的意思 )
模型参数精度
在深度学习领域内,构建高效率且精确度高的神经网络模型时,选择适当的参数精度至关重要。参数的精度通常指的是其存储和计算方式所采用的数据类型(data type),这直接关系到内存使用、计算性能以及最终模型的准确性。

单精度浮点数(float32):
单精度浮点数主要用于表示实数,具有较高的数值精确度,广泛应用于深度学习任务中。它的优点是能提供足够的精度来处理大部分的计算需求,而其32位的数据结构在内存中的占用空间仅为4字节。
半精度浮点数(float16):
相较于单精度浮点数,半精度浮点数具有较低的存储位数(16位),因此可以显著减少所需内存,并加速计算过程。这种数据类型尤其适合在图形处理器(GPU)上进行大量并行处理的应用场景。
BF16,全称为Brain Floating Point Format,是一种16位的半精度浮点数格式,特别为机器学习和人工智能领域的高性能计算优化而设计。BF16是在FP32(单精度浮点数)的基础上进行简化,旨在通过减少存储和计算需求来加速计算密集型任务,同时尽量减少对模型精度的损失。
具体来说,BF16浮点数格式由以下几个部分组成:
- 1位符号位,用来表示数值的正负。
- 8位指数位,相较于FP16的5位指数位,这提供了更宽的数值范围,有助于避免在处理较大或较小数值时的上溢或下溢问题。
- 7位尾数位(也称为小数部分或 mantissa),相比FP16的10位尾数位,这导致BF16在表示小数时的精度略低。
BF16的设计目标是在牺牲一定精度的前提下,提供足够的数值范围来支持深度学习模型的高效运行,尤其是在大规模分布式训练和高性能推理场景中。由于许多深度学习算法对数值的精确度要求不是极高,因此这种折衷在很多情况下是可以接受的,并且能够显著减少内存带宽需求和提高计算效率。
值得注意的是,BF16最初由Google提出,并在一些特定的硬件平台上获得了支持,比如某些CPU(特别是支持ARM NEON指令集的处理器)和NVIDIA的Ampere架构及后续版本的GPU,这些硬件直接支持BF16的加速运算,进一步促进了BF16在AI应用中的普及。
双精度浮点数(float64):
提供更高的数值精确度的是双精度浮点数,通常用于对数值精确度要求较高的任务中,如某些科学研究或金融分析等。虽然提供了额外的准确性保障,但这种数据类型占用内存较大,每单位存储需要8字节。
整数(int32, int64):
在深度学习中,对于处理离散值的情况,例如类别标签,通常会使用整型数据。有符号整数(如int32)能表示正负值,而无符号整数(如uint32)仅用于非负整数。这两种类型分别需要占用4字节和8字节的内存。
参数精度的选择是深度学习实践中的一门艺术,它要求平衡对精度的需求、系统资源限制以及计算效率之间的考量。通常情况下,在不影响模型性能的前提下,倾向于使用较低精度的数据类型以节省内存并提高计算速度。然而,当面对需要更高精度分析的任务时,可能需要权衡增加的内存消耗与提升的准确度。
理解各种参数精度的特点及其在深度学习中的应用是构建高效、优化资源利用和提高模型性能的关键因素之一。在实际应用中,选择适当的参数精度应当基于任务的具体需求、硬件能力以及预期的计算资源限制综合考虑。
大模型的文件体积
大模型除了参数大以外,体积也是相当的大。在了解了参数精度后,我们也就可以一句参数规模推算大模型的体积了。
以Qwen1.5-110B 来说:
全精度模型参数是float32类型, 占用4个字节,粗略计算:1b(10亿)个模型参数,约占用4G存储实际大小计算公式:10^9 * 4 / 1024^3 ~= 3.725 GB
那么Qwen1.5-110B的参数量为110B,那么加载模型参数需要的显存为:3.725 * 110 ~= 409.75GB
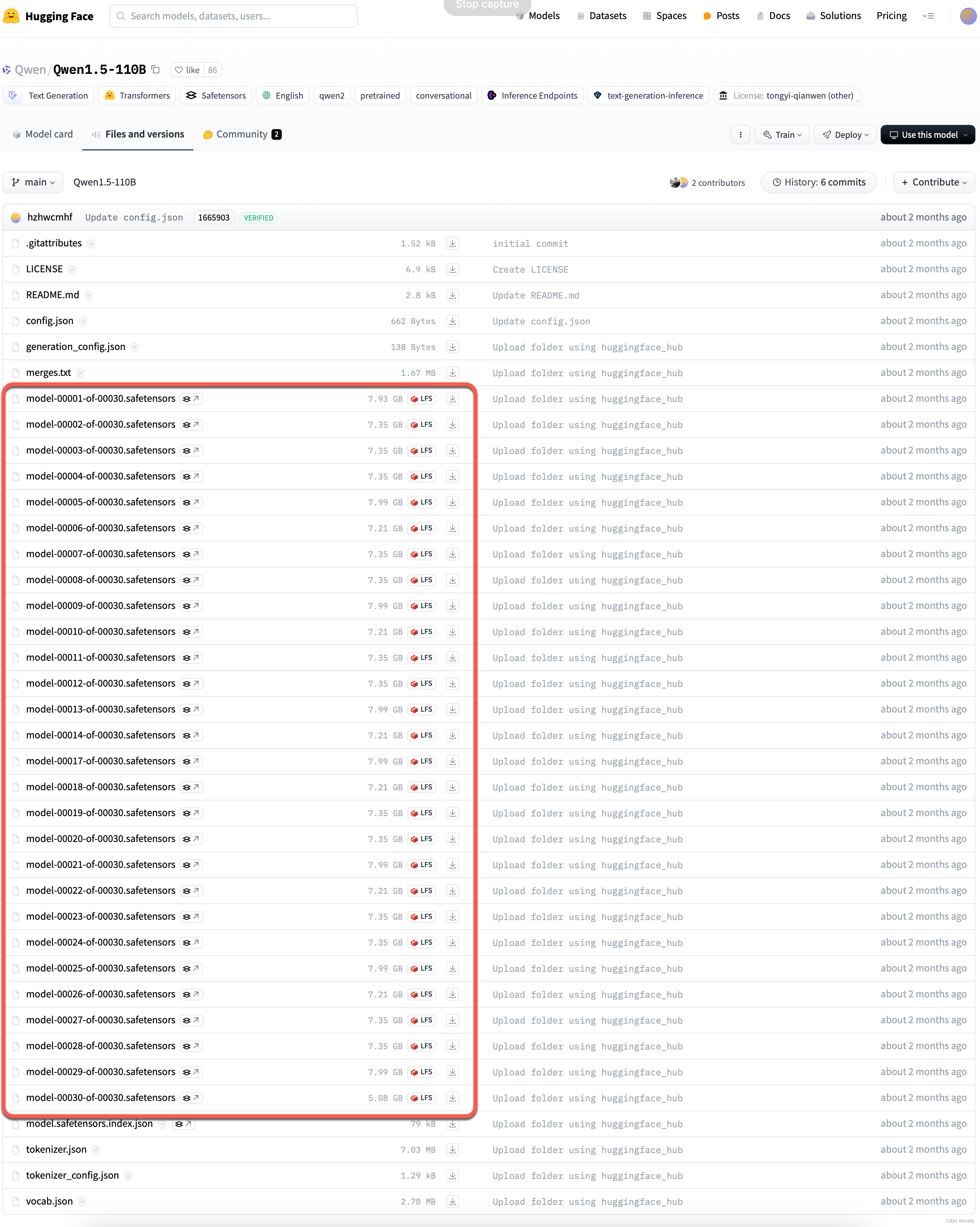
我们可以看下HF上Qwen1.5-110B的开源文件(该开源文件使用的是BF16位数,所以按照计算公式,体积大小为200G左右):
国内在HF上开源的大模型一般都是提供半精度(FP16或BF16)
大模型不光参数大,体积也巨大,要运行这个规模的模型,需要十分高的硬件配置,带来了很大的难度,成为阻碍人工智能发展的障碍,于是很多脑子好使的研究人员就提出了一系列的压缩技术,比如下面说到的常用的量化技术。
大模型量化技术
近年来,在深度学习领域中,研究人员探索使用低比特整数表示模型参数以实现模型的压缩与加速。量化(quantization)技术是其中的关键方法。
量化技术与int4、int8
- 量化技术:通过将浮点数映射到较低位数的整数来减小模型在计算和存储时的需求。
- int4: 使用4位二进制表示一个整数,存储模型参数。量化过程会将浮点数转换为可表示在有限范围内的整数值,并用4个比特记录这些值。
- int8: 类似于int4,但使用8位二进制表示整数,提供更大的表示范围和精确度。
内存占用
- int4:不直接以字节单位描述位数,通常通过位操作存储数据。
- int8:占用1个字节(即8位)空间。
注意事项
量化会导致信息损失,因此需要在压缩效果与模型性能之间进行权衡。根据具体任务需求选择合适的量化精度是关键步骤。通过许多评测综合来看到的结果,通常选择8位(int8)或更低的位宽来表示权重和激活值,但也可根据实际需求选择其他位宽,如BF16。
许多小伙伴在模型本地化尝试中会使用Ollama 来进行本地化部署,有人会觉得本地化部署后,Ollama加载的模型回答质量和能力有些下降。这是因为Ollama 致力于 实现 本地化部署大模型,限于本地化部署用户许多没有足够的算力,在通过
ollama r
相关文章:
大模型项目落地时,该如何估算模型所需GPU算力资源
近期公司有大模型项目落地。在前期沟通时,对于算力估算和采购方案许多小伙伴不太了解,在此对相关的算力估算和选择进行一些总结。 不喜欢过程的可以直接 跳到HF上提供的模型计算器 要估算大模型的所需的显卡算力,首先要了解大模型的参数基础知识。 大模型的规模、参数的理解…...

LLM应用开发-RAG系统评估与优化
前言 Hello,大家好,我是GISer Liu😁,一名热爱AI技术的GIS开发者,在上一篇文章中,我们学习了如何基于LangChain构建RAG应用,并且通过Streamlit将这个RAG应用部署到了阿里云服务器;&am…...
秋招突击——第七弹——Redis快速入门
文章目录 引言Redis是什么 正文对象String字符串面试重点 List面试考点 压缩列表ZipList面试题 Set面试题讲解 Hash面试重点 HASHTABLE底层面试考点 跳表面试重点 ZSET有序链表面试重点 总结 引言 在项目和redis之间,我犹豫了一下,觉得还是了解学习一下…...
软考初级网络管理员__操作系统单选题
1.在Windows资源管理器中,假设已经选定文件,以下关于“复制”操作的叙述中,正确的有()。 按住Ctr键,拖至不同驱动器的图标上 按住AIt键,拖至不同驱动器的图标上 直接拖至不同驱动器的图标上 按住Shift键࿰…...
)
从入门到精通:网络编程套接字(万字详解,小白友好,建议收藏)
一、预备知识 1.1 理解源IP地址和目的IP地址 在网络编程中,IP地址(Internet Protocol Address)是每个连接到互联网的设备的唯一标识符。IP地址可以分为IPv4和IPv6两种类型。IPv4地址是由32位二进制数表示,通常分为四个八位组&am…...

dledger原理源码分析系列(一)架构,核心组件和rpc组件
简介 dledger是openmessaging的一个组件, raft算法实现,用于分布式日志,本系列分析dledger如何实现raft概念,以及dledger在rocketmq的应用 本系列使用dledger v0.40 本文分析dledger的架构,核心组件;rpc组…...

第七节:如何浅显易懂地理解Spring Boot中的依赖注入(自学Spring boot 3.x的第二天)
大家好,我是网创有方,今天我开始学习spring boot的第一天,一口气写了这么多。 这节通过一个非常浅显易懂的列子来讲解依赖注入。 在Spring Boot 3.x中,依赖注入(Dependency Injection, DI)是一个核心概念…...

Postman自动化测试实战:使用脚本提升测试效率
在软件开发过程中,接口测试是确保后端服务稳定性和可靠性的关键步骤。Postman作为一个流行的API开发工具,提供了强大的脚本功能来实现自动化测试。通过在Postman中使用脚本,测试人员可以编写测试逻辑,实现测试用例的自动化执行&am…...

CSMA/CA并不是“公平”的
CSMA/CA会造成过于公平,对于最需要流量的节点,是最不友好的,而对于最不需要流量的节点,则是最友好的。 CSMA/CA是优先公平来工作的。 CSMA/CA首先各节点使用DIFS界定air idle,在此期间大家都等待 其次,为了同时发送引起碰撞,在DIFS之后随机从CWmin和CWmax之间选择一个时…...

【漏洞复现】I doc view——任意文件读取
声明:本文档或演示材料仅供教育和教学目的使用,任何个人或组织使用本文档中的信息进行非法活动,均与本文档的作者或发布者无关。 文章目录 漏洞描述漏洞复现测试工具 漏洞描述 I doc view 在线文档预览是一个用于查看、编辑、管理文档的工具…...
图数据库 vs 向量数据库
最近大模型出来之后,向量数据库重新翻红,业界和市场上有不少声音认为向量数据库会极大的影响图数据库,图数据库市场会萎缩甚至消失,今天就从技术原理角度来讨论下图数据库和向量数据库到底差别在哪里,适合什么场景&…...

企业品牌出海第一站 维基百科词条创建
维基百科是一部内容开放、自由的网络百科全书,旨在创造一个涵盖所有领域知识,服务所有互联网用户的知识性百科全书。其在国外应用非常广泛且认可度很高,国内品牌出海或国际品牌都很有必要创建企业自己的维基百科页面,以及企业高管的个人维基百科页面。 如…...
Windows下activemq集群配置(broker-network)
1.activemq版本信息 activemq:apache-activemq-5.18.4 2.activemq架构 3.activemq集群配置 activemq集群配置基于Networks of Brokers 这种HA方案的优点:是占用的节点数更少(只需要2个节点),而且2个broker都可以响应消息的接收与发送。不足ÿ…...
心理辅导平台系统
摘 要 中文本论文基于Java Web技术设计与实现了一个心理辅导平台。通过对国内外心理辅导平台发展现状的调研,本文分析了心理辅导平台的背景与意义,并提出了论文研究内容与创新点。在相关技术介绍部分,对Java Web、SpringBoot、B/S架构、MVC模…...

代理IP对SEO影响分析:提升网站排名的关键策略
你是否曾经为网站排名难以提升而苦恼?代理服务器或许就是你忽略的关键因素。在竞争激烈的互联网环境中,了解代理服务器对SEO的影响,有助于你采取更有效的策略,提高网站的搜索引擎排名。本文将为你详细分析代理服务器在SEO优化中的…...

【leetcode--三数之和】
这道题记得之前做过,但是想不起来了。。总结一下: 函数的主要步骤和关键点: 排序:对输入的整数数组nums进行排序。这是非常重要的,因为它允许我们使用双指针技巧来高效地找到满足条件的三元组。初始化:定…...

解决Java中的ClassCastException问题
解决Java中的ClassCastException问题 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在Java编程中,ClassCastException是一个常见的运行时异常&am…...

【TensorFlow深度学习】混合生成模型:结合AR与AE的创新尝试
混合生成模型:结合AR与AE的创新尝试 引言自回归模型与自动编码器的简述混合模型的创新尝试组合AR与AE:MADE混合模型在图学习中的应用 结论与展望 在自我监督学习的广阔天地里,混合生成模型以其独特的魅力,跨越了自回归(…...

Spring:Spring中分布式事务解决方案
一、前言 在Spring中,分布式事务是指涉及多个数据库或系统的事务处理,其中事务的参与者、支持事务的服务器、资源管理器以及事务管理器位于分布式系统的不同节点上。这样的架构使得两个或多个网络计算机上的数据能够被访问并更新,同时将这些操…...
音视频开发32 FFmpeg 编码- 视频编码 h264 参数相关
1. ffmpeg -h 这个命令总不会忘记,用这个先将ffmpeg所有的help信息都list出来 C:\Users\Administrator>ffmpeg -h ffmpeg version 6.0-full_build-www.gyan.dev Copyright (c) 2000-2023 the FFmpeg developersbuilt with gcc 12.2.0 (Rev10, Built by MSYS2 pro…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

练习(含atoi的模拟实现,自定义类型等练习)
一、结构体大小的计算及位段 (结构体大小计算及位段 详解请看:自定义类型:结构体进阶-CSDN博客) 1.在32位系统环境,编译选项为4字节对齐,那么sizeof(A)和sizeof(B)是多少? #pragma pack(4)st…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

对WWDC 2025 Keynote 内容的预测
借助我们以往对苹果公司发展路径的深入研究经验,以及大语言模型的分析能力,我们系统梳理了多年来苹果 WWDC 主题演讲的规律。在 WWDC 2025 即将揭幕之际,我们让 ChatGPT 对今年的 Keynote 内容进行了一个初步预测,聊作存档。等到明…...

Spring是如何解决Bean的循环依赖:三级缓存机制
1、什么是 Bean 的循环依赖 在 Spring框架中,Bean 的循环依赖是指多个 Bean 之间互相持有对方引用,形成闭环依赖关系的现象。 多个 Bean 的依赖关系构成环形链路,例如: 双向依赖:Bean A 依赖 Bean B,同时 Bean B 也依赖 Bean A(A↔B)。链条循环: Bean A → Bean…...

推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材)
推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材) 这个项目能干嘛? 使用 gemini 2.0 的 api 和 google 其他的 api 来做衍生处理 简化和优化了文生图和图生图的行为(我的最主要) 并且有一些目标检测和切割(我用不到) 视频和 imagefx 因为没 a…...
: 一刀斩断视频片头广告)
快刀集(1): 一刀斩断视频片头广告
一刀流:用一个简单脚本,秒杀视频片头广告,还你清爽观影体验。 1. 引子 作为一个爱生活、爱学习、爱收藏高清资源的老码农,平时写代码之余看看电影、补补片,是再正常不过的事。 电影嘛,要沉浸,…...

4. TypeScript 类型推断与类型组合
一、类型推断 (一) 什么是类型推断 TypeScript 的类型推断会根据变量、函数返回值、对象和数组的赋值和使用方式,自动确定它们的类型。 这一特性减少了显式类型注解的需要,在保持类型安全的同时简化了代码。通过分析上下文和初始值,TypeSc…...