MySQL中SQL语句的执行过程详解
1. 客户端连接和请求
客户端连接
在MySQL中,客户端连接和请求过程是执行SQL语句的第一步。该步骤主要涉及客户端如何连接到MySQL服务器,以及如何维护和管理客户端与服务器之间的会话。
-
客户端连接:
-
连接器(Connector): 连接器是MySQL中负责处理客户端连接请求的组件。它处理TCP/IP协议的连接,管理用户的认证和授权。
-
连接过程:
- 建立连接: 客户端通过网络(通常是TCP/IP)向MySQL服务器发送连接请求。
- 用户验证: MySQL服务器会通过连接器验证用户的身份。验证过程涉及检查用户名和密码是否正确。
- 权限检查: 验证通过后,MySQL服务器会检查用户是否具有访问指定数据库和执行特定操作的权限。权限信息存储在MySQL的系统数据库(如
mysql.user表)中。 - 会话维护: 连接器会为每个成功连接的客户端分配一个会话(Session)。会话中包含了该用户的权限信息、当前数据库、连接选项等。会话会一直保持,直到客户端断开连接或发生超时。
-
会话管理:
- 状态信息: 每个会话都会维护客户端连接的状态信息,包括当前正在执行的查询、事务状态等。
- 会话变量: 在会话期间,客户端可以设置一些会话变量,这些变量只在当前会话中有效。例如,可以设置SQL模式(SQL Mode)来影响查询的行为。
-
-
连接池(Connection Pooling):
- 在大型应用中,为了提高连接的效率,通常会使用连接池。连接池是一个连接的缓存池,应用程序可以从中获取已建立的连接,而不是每次都新建一个连接。这大大减少了连接建立和关闭的开销。
SQL语句发送
一旦客户端成功连接到MySQL服务器并通过身份验证,接下来就是发送SQL语句进行数据操作或查询。
-
SQL语句发送:
- SQL语句的形式: 客户端会将SQL语句以文本的形式发送到MySQL服务器。SQL语句可以是查询语句(如
SELECT)、数据操作语句(如INSERT、UPDATE、DELETE)或数据定义语句(如CREATE、ALTER、DROP)。 - 语句传输: SQL语句通过连接器建立的会话传输到MySQL服务器。这通常是通过TCP/IP协议传输的。
- SQL语句的形式: 客户端会将SQL语句以文本的形式发送到MySQL服务器。SQL语句可以是查询语句(如
-
请求处理:
- 接收请求: MySQL服务器接收到SQL语句后,会首先对其进行解析和预处理。服务器会从网络缓冲区中读取完整的SQL语句,并准备进行下一步的解析和执行。
- 并发处理: MySQL服务器通常是多线程的,能够同时处理多个客户端的请求。每个会话都会由一个独立的线程处理,这样可以确保多个客户端请求之间互不干扰。
示例
下面是一个客户端连接到MySQL服务器并发送SQL语句的示例:
1. 客户端连接到MySQL服务器:客户端: 通过TCP/IP发送连接请求到MySQL服务器的3306端口。服务器: 接收到请求后,连接器进行用户身份验证和权限检查。2. 成功建立连接并维护会话:服务器: 连接器为客户端分配一个会话,并维护会话状态。3. 客户端发送SQL语句:客户端: 发送SQL语句 "SELECT * FROM users WHERE id = 1;" 到MySQL服务器。4. 服务器接收并处理SQL语句:服务器: 接收到SQL语句后,准备进行解析、优化和执行。
通过上述过程,客户端和MySQL服务器之间建立了稳定的连接,并能够通过该连接发送SQL语句进行数据操作和查询。
2. 查询解析
查询解析是MySQL执行SQL语句的重要步骤之一。它的主要任务是将SQL语句转换成一种内部表示形式,以便后续步骤(如优化和执行)能够处理。这个过程主要由解析器(Parser)完成。
解析器(Parser)
解析器的主要任务是将SQL语句转换成解析树(Parse Tree)。解析器通常分为两部分:词法分析器(Lexer)和语法分析器(Parser)。
-
词法分析(Lexical Analysis):
-
任务: 词法分析器的任务是将输入的SQL语句分解成一个个单独的标记(tokens)。这些标记是SQL语句的基本组成部分,如关键字、标识符、操作符、字面量等。
-
过程:
- 读取字符: 词法分析器逐字符读取SQL语句。
- 生成标记: 根据SQL的语法规则,将连续的字符序列分组为标记。例如,
SELECT、*、FROM、users都是标记。 - 标记分类: 每个标记都有一个类别,如关键字、标识符、常量等。
-
示例:
SELECT * FROM users WHERE id = 1;词法分析器将其分解为以下标记:
SELECT(关键字)*(操作符)FROM(关键字)users(标识符)WHERE(关键字)id(标识符)=(操作符)1(常量);(分号)
-
-
语法分析(Syntax Analysis):
-
任务: 语法分析器的任务是根据词法分析器生成的标记序列,按照SQL语法规则生成解析树(Parse Tree)。解析树是SQL语句的结构化表示形式,反映了SQL语句的语法结构。
-
过程:
- 验证语法: 语法分析器会检查标记序列是否符合SQL语法规则。如果有语法错误,会返回错误信息。
- 生成解析树: 语法分析器会构建一个解析树,树的节点表示SQL语句的各种元素(如选择列表、表名、条件表达式等)。
-
解析树示例: 对于上面的SQL语句,解析树可能如下:
SELECT_STATEMENT ├── SELECT_LIST │ └── * ├── FROM_CLAUSE │ └── TABLE_NAME │ └── users └── WHERE_CLAUSE└── CONDITION├── COLUMN_NAME│ └── id├── OPERATOR│ └── =└── VALUE└── 1
-
解析过程详解
-
词法分析:
- 词法分析器逐字符读取输入的SQL语句,并根据SQL语言的词法规则生成标记。例如,
SELECT被识别为一个关键字,users被识别为一个标识符。 - 标记是SQL语句的最小语义单元,每个标记都会被赋予一个类型(如关键字、标识符、操作符等)。
- 词法分析器逐字符读取输入的SQL语句,并根据SQL语言的词法规则生成标记。例如,
-
语法分析:
- 语法分析器接收词法分析器生成的标记序列,并根据SQL的语法规则进行解析。
- 语法分析器会生成一个解析树,表示SQL语句的语法结构。解析树的根节点是SQL语句的主要类型(如SELECT语句、INSERT语句等),其子节点表示语句的各个组成部分(如选择列表、表名、条件表达式等)。
-
错误处理:
- 如果在词法分析或语法分析过程中发现错误,解析器会生成错误信息,并返回给客户端。错误信息通常包括错误类型、位置和描述,帮助开发人员定位和修复问题。
总结
解析器是MySQL执行SQL语句的重要组件,通过词法分析和语法分析,将SQL语句转换为解析树。解析树是后续查询优化和执行的基础,确保SQL语句能够被正确理解和处理。
解析过程的具体步骤和示例如下:
1. 词法分析:输入: SELECT * FROM users WHERE id = 1;输出: 标记序列 [SELECT, *, FROM, users, WHERE, id, =, 1, ;]2. 语法分析:输入: 标记序列 [SELECT, *, FROM, users, WHERE, id, =, 1, ;]输出: 解析树SELECT_STATEMENT├── SELECT_LIST│ └── *├── FROM_CLAUSE│ └── TABLE_NAME│ └── users└── WHERE_CLAUSE└── CONDITION├── COLUMN_NAME│ └── id├── OPERATOR│ └── =└── VALUE└── 1
通过解析器的处理,SQL语句被成功解析为结构化的解析树,为后续的查询优化和执行打下了基础。
3. 查询优化
查询优化是MySQL执行SQL语句的关键步骤之一,旨在生成最优的执行计划以高效地执行SQL查询。这个过程主要由预处理器(Preprocessor)和优化器(Optimizer)完成。
预处理器(Preprocessor)
预处理器的主要任务是对解析树进行进一步处理,包括验证和转换操作,为优化器生成有效的查询块(Query Block)。
-
验证表和列的名称:
- 表名验证: 预处理器检查解析树中的表名是否存在于数据库中。如果表名不存在,则返回错误。
- 列名验证: 预处理器检查每个表的列名是否在相应的表中存在。如果列名不存在,也会返回错误。
-
检查权限:
- 用户权限: 预处理器会检查当前用户是否具有访问所涉及的表和列的权限。如果用户没有足够的权限,将会返回权限错误。
-
查询块转换:
- 生成查询块: 预处理器将解析树转换为查询块(Query Block)。查询块是一个中间表示形式,包含了SQL查询的各个组成部分,如选择列表、表名、连接条件、过滤条件等。
- 查询块分解: 对于复杂查询(如子查询、联合查询),预处理器会将其分解为多个查询块,每个查询块独立处理。
优化器(Optimizer)
优化器是MySQL中的核心组件之一,负责根据查询块生成最优的执行计划(Execution Plan)。执行计划决定了SQL查询的具体执行路径和步骤。
-
选择执行路径:
- 访问路径选择: 优化器会为每个查询块选择最优的访问路径。它会评估各种访问路径(如全表扫描、索引扫描)并选择代价最低的路径。
- 索引选择: 如果查询涉及索引,优化器会评估使用不同索引的代价,并选择最优的索引。
-
连接顺序优化:
- 连接顺序: 对于多表连接查询,优化器会评估不同的连接顺序,并选择最优的顺序。连接顺序的选择对查询性能有重大影响。
- 连接算法选择: 优化器会选择最合适的连接算法(如嵌套循环连接、哈希连接)以最小化连接操作的代价。
-
谓词下推:
- 谓词下推: 优化器会将过滤条件(谓词)尽量下推到最早的步骤执行,以减少中间结果集的大小。这可以显著提高查询性能。
-
代价评估:
- 代价模型: 优化器使用代价模型(Cost Model)来评估不同执行路径的代价。代价通常由I/O操作次数、CPU使用量等因素决定。
- 最优计划选择: 根据代价模型,优化器选择代价最低的执行计划作为最终的执行计划。
执行计划示例
假设有一个查询:
SELECT * FROM users WHERE age > 30 AND city = 'New York';
-
预处理器操作:
- 验证表和列: 确认
users表存在,并且age和city列在users表中存在。 - 检查权限: 检查当前用户是否有权限访问
users表及其列。 - 生成查询块: 创建一个查询块,表示从
users表中选择所有列,并应用两个过滤条件。
- 验证表和列: 确认
-
优化器操作:
- 选择执行路径: 评估使用索引扫描还是全表扫描。假设
city列上有索引,优化器可能选择使用索引扫描。 - 谓词下推: 将过滤条件
age > 30和city = 'New York'下推到索引扫描步骤,以减少扫描的记录数。 - 生成执行计划: 创建执行计划,描述查询的具体执行步骤,如:
- 使用
city列的索引扫描users表,查找city = 'New York'的记录。 - 对索引扫描结果应用
age > 30的过滤条件。 - 返回最终结果集。
- 使用
- 选择执行路径: 评估使用索引扫描还是全表扫描。假设
查询优化过程示意图
SQL查询|V
预处理器(Preprocessor)|V
解析树 -> 查询块|V
优化器(Optimizer)|V
执行计划(Execution Plan)
通过预处理器和优化器的处理,MySQL生成了最优的执行计划,以高效地执行SQL查询,并返回结果集。
4. 查询执行
查询执行是MySQL处理SQL语句的最后一步,主要涉及执行器(Executor)根据优化器生成的执行计划执行SQL查询,并与存储引擎进行交互以获取和操作数据。
执行计划执行
-
执行器(Executor)简介:
- 执行器是MySQL中负责实际执行SQL查询的组件。它根据优化器生成的执行计划,逐步执行各个操作,如表扫描、索引查找、连接操作等。
-
执行具体操作:
- 表扫描: 执行器会根据执行计划选择适当的表扫描方法。如果优化器选择全表扫描,执行器会逐行读取表中的数据。如果选择索引扫描,执行器会使用索引查找所需的数据。
- 索引查找: 执行器会使用索引来加速数据检索。索引查找的效率比全表扫描高,因为索引结构通常是排序和优化的,能够快速定位所需记录。
- 连接操作: 对于多表连接查询,执行器会按照执行计划中的连接顺序和连接算法(如嵌套循环连接、哈希连接)进行表连接操作。
- 过滤条件应用: 执行器会在合适的阶段应用过滤条件(如
WHERE子句中的条件)以减少不必要的数据传输和处理。
-
数据操作:
- 数据读取: 对于查询操作(如
SELECT),执行器会从存储引擎读取数据并将结果返回给客户端。 - 数据修改: 对于数据修改操作(如
INSERT、UPDATE、DELETE),执行器会相应地修改存储引擎中的数据,并在必要时记录操作日志以支持事务和数据恢复。
- 数据读取: 对于查询操作(如
存储引擎交互
-
存储引擎简介:
- MySQL支持多种存储引擎,如InnoDB、MyISAM、Memory等。每种存储引擎负责实际的数据存储和检索,并提供不同的特性和优化。
- InnoDB: 支持事务、外键和行级锁定,是MySQL的默认存储引擎,适用于高可靠性和高并发环境。
- MyISAM: 不支持事务和外键,但具有较高的读取性能,适用于以读取操作为主的应用场景。
- Memory: 数据存储在内存中,速度快,但数据在服务器重启时会丢失,适用于临时数据和快速访问的场景。
-
执行器与存储引擎的交互:
- 请求发送: 执行器会根据执行计划向存储引擎发送数据操作请求,如读取、插入、更新和删除操作。
- 数据读取: 存储引擎会根据请求,从物理存储中读取数据,并返回给执行器。数据读取可能涉及磁盘I/O操作、缓冲区管理等。
- 数据写入: 对于数据写入操作,存储引擎会将数据写入物理存储,并在必要时更新相关索引和记录操作日志。
- 事务管理: 如果使用支持事务的存储引擎(如InnoDB),执行器会管理事务的开始、提交和回滚操作,确保数据的一致性和完整性。
- 锁机制: 执行器与存储引擎会协作管理锁机制,以确保并发访问时的数据一致性。例如,InnoDB支持行级锁定,可以在高并发环境下提供更好的性能和一致性。
执行过程示例
假设有一个查询:
SELECT * FROM users WHERE age > 30 AND city = 'New York';
执行过程可以分为以下几个步骤:
-
执行计划执行:
- 索引扫描: 假设
city列上有索引,执行器会使用该索引扫描users表,查找city = 'New York'的记录。 - 过滤条件应用: 执行器会在索引扫描结果上应用
age > 30的过滤条件,进一步筛选出符合条件的记录。
- 索引扫描: 假设
-
存储引擎交互:
- 索引查找请求: 执行器向存储引擎发送索引查找请求。
- 数据读取: 存储引擎使用索引快速定位并读取符合
city = 'New York'的记录。 - 过滤应用: 存储引擎返回初步结果集后,执行器应用
age > 30的过滤条件,得到最终结果集。 - 结果返回: 执行器将最终结果集返回给客户端。
查询执行过程示意图
SQL查询|V
执行计划|V
执行器(Executor)|V
存储引擎(Storage Engine)|V
数据存储和检索|V
结果集返回
通过执行计划执行和存储引擎交互,MySQL能够高效地执行SQL查询,完成数据的读取和操作,并将结果返回给客户端。
5. 结果返回
查询执行的最后一步是将查询结果集生成并返回给客户端。这一步包括结果集生成和结果集返回客户端两个部分。
结果集生成
-
结果集创建:
- 执行器处理结果: 在执行计划执行完毕后,执行器会将查询过程中获取的各个部分的结果进行汇总。比如,对于一个
SELECT查询,执行器会将满足查询条件的记录逐条汇总到结果集中。 - 临时存储: 为了有效管理和传输,执行器可能会在内部创建一个临时存储结构来保存结果集。这些临时存储结构可以是内存中的数据结构,也可以是磁盘上的临时文件,具体取决于结果集的大小和系统配置。
- 执行器处理结果: 在执行计划执行完毕后,执行器会将查询过程中获取的各个部分的结果进行汇总。比如,对于一个
-
结果集排序和处理:
- 排序: 如果查询中包含排序操作(如
ORDER BY),执行器会对结果集进行排序。排序操作通常在结果集生成的最后阶段进行,以确保返回给客户端的数据是按要求排序的。 - 去重: 如果查询包含去重操作(如
DISTINCT),执行器会在结果集生成过程中去除重复记录。
- 排序: 如果查询中包含排序操作(如
-
结果集优化:
- 分页: 如果查询包含分页操作(如
LIMIT和OFFSET),执行器会根据分页参数生成相应的结果集部分。 - 聚合和计算: 如果查询包含聚合操作(如
SUM、AVG、COUNT等),执行器会在结果集生成过程中进行相应的计算,并将结果包含在最终结果集中。
- 分页: 如果查询包含分页操作(如
结果集返回客户端
-
数据传输:
- 网络传输: 结果集生成后,MySQL服务器会通过网络将结果集发送回客户端。这通常通过TCP/IP协议进行,数据被打包成数据包传输。
- 分批发送: 对于大结果集,MySQL服务器可能会将结果集分批发送,以避免单次传输的数据量过大,导致网络拥堵或客户端无法及时处理。
-
结果集格式:
- 协议格式: 结果集被封装在MySQL协议格式的数据包中。每个数据包包含结果集的一部分,具体格式包括字段名、字段类型、记录值等。
- 数据流: 结果集以数据流的形式发送,客户端接收并逐步解析这些数据包。
-
客户端接收:
- 解析数据包: 客户端接收到数据包后,会根据MySQL协议解析数据包内容,将其转换为客户端能够处理的数据结构(如表格、列表等)。
- 展示结果: 客户端应用程序(如MySQL客户端工具、Web应用等)会将结果集展示给最终用户。展示方式可以是文本、表格、图表等。
-
关闭查询:
- 资源释放: MySQL服务器在将结果集发送完毕后,会释放与该查询相关的资源,包括内存、临时文件、会话状态等。
- 会话管理: 如果客户端没有关闭连接,会话仍然保持活跃,可以继续发送新的查询。如果客户端关闭连接,服务器会终止会话。
示例
假设有一个查询:
SELECT name, age FROM users WHERE city = 'New York' ORDER BY age;
执行过程如下:
-
结果集生成:
- 执行器根据执行计划执行查询,获取满足条件(city = 'New York')的记录。
- 执行器对结果集进行排序(ORDER BY age)。
- 生成最终结果集,包含所有满足条件并按年龄排序的记录。
-
结果集返回客户端:
- 服务器将结果集封装在数据包中,通过网络传输给客户端。
- 客户端接收并解析数据包,将结果集转换为可展示的数据结构。
- 客户端应用展示查询结果,如显示在表格中。
结果返回过程示意图
执行计划执行|V
结果集生成|V
数据包封装|V
网络传输|V
客户端接收|V
结果解析|V
结果展示|V
关闭查询
通过上述步骤,MySQL能够将查询结果高效地返回给客户端,并在完成查询后适当管理资源,确保系统的稳定和高效运行。
6. 日志记录(可选)
在执行写操作(如 INSERT、UPDATE、DELETE)时,MySQL会记录操作日志以支持数据恢复和数据复制。这些日志主要包括二进制日志(binlog)和重做日志(redo log)。它们在不同的场景下发挥不同的作用。
二进制日志(binlog)
-
作用:
- 数据复制: binlog 是 MySQL 复制的基础。在主从复制架构中,主服务器会将数据变更记录在 binlog 中,从服务器则读取 binlog 并重放这些变更以保持数据同步。
- 数据恢复: binlog 可以用于数据恢复。如果出现数据丢失或误操作,可以通过重放 binlog 中的变更记录将数据恢复到特定时间点。
-
记录内容:
- 事件(Event): binlog 以事件的形式记录每个写操作。这些事件包括表结构变更、数据插入、更新、删除等。
- 时间戳和事务信息: 每个事件包含时间戳和事务信息,以确保变更的顺序和一致性。
-
日志格式:
- 基于语句的复制(Statement-Based Replication, SBR): binlog 记录具体的 SQL 语句。这种方式简单,但在某些情况下(如非确定性函数)可能不够准确。
- 基于行的复制(Row-Based Replication, RBR): binlog 记录每行数据的变更。这种方式更精确,但日志量较大。
- 混合模式复制(Mixed-Based Replication, MBR): 结合 SBR 和 RBR,根据具体情况选择合适的记录方式。
重做日志(redo log)
-
作用:
- 事务恢复: redo log 用于事务恢复,确保在数据库崩溃后,未完成的事务可以在数据库重启时继续执行,以保证数据一致性。
- 崩溃恢复: 在数据库意外中断或崩溃后,redo log 可以帮助恢复未写入磁盘的已提交事务,确保数据的持久性。
-
记录内容:
- 物理变更记录: redo log 记录数据页的物理变更,而不仅仅是 SQL 语句。它记录的是数据变更的具体细节,如某个数据页的某个位置发生了何种变更。
-
工作原理:
- 写入时机: 在事务提交之前,MySQL 会先将数据变更记录到 redo log 中,并将其标记为已准备提交(prepare)。当事务真正提交时,MySQL 会将 redo log 标记为已提交(commit)。
- 双写机制: InnoDB 存储引擎使用双写机制(doublewrite)来确保数据的完整性。数据页变更会先写入到 redo log 和内存中的缓冲池,然后再写入到磁盘上的数据文件。
日志记录过程示意图
-
写操作触发日志记录:
- 当执行
INSERT、UPDATE、DELETE等写操作时,MySQL 会触发日志记录机制。
- 当执行
-
binlog 记录:
- 写操作会被记录到 binlog 中,记录内容包括 SQL 语句或具体行的变更。
-
redo log 记录:
- 同时,写操作的物理变更会被记录到 redo log 中,用于事务和崩溃恢复。
-
事务提交:
- 在事务提交时,MySQL 会将 redo log 标记为已提交,并确保 binlog 和 redo log 的一致性。
-
数据持久化:
- 在写操作完成后,数据和日志都会被持久化到磁盘,以确保在数据库崩溃时能够恢复数据。
日志记录示例
假设有一个写操作:
UPDATE users SET age = age + 1 WHERE city = 'New York';
-
触发日志记录:
- MySQL 接收到该写操作请求。
-
binlog 记录:
- 该操作被记录到 binlog 中,具体记录形式取决于日志格式(SBR 或 RBR)。
-
redo log 记录:
- 该操作导致的数据页变更被记录到 redo log 中。
-
事务提交:
- 当事务提交时,MySQL 将 redo log 标记为已提交。
-
数据持久化:
- 数据和日志被写入磁盘,确保在数据库崩溃时可以恢复。
日志记录过程示意图
写操作|V
binlog 记录|V
redo log 记录|V
事务提交|V
数据持久化
通过上述日志记录过程,MySQL 可以确保数据的可靠性和一致性,支持数据恢复和主从复制等关键功能。
执行过程示意图
客户端 -> 连接器 -> 解析器 -> 预处理器 -> 优化器 -> 执行器 -> 存储引擎 -> 执行器 -> 客户端
执行过程图示
+-------------+ +-----------+ +-----------+ +-----------+ +-----------+ +-----------+
| 客户端 | --> | 连接器 | --> | 解析器 | --> | 优化器 | --> | 执行器 | --> | 存储引擎 |
+-------------+ +-----------+ +-----------+ +-----------+ +-----------+ +-----------+^|+-----------+| 执行计划 |+-----------+
MySQL体系结构
MySQL的体系结构是一个分层的架构,主要分为以下几个部分:连接层、服务层、存储引擎层和物理层。每一层负责不同的功能,协同工作以实现高效的数据存储和检索。以下是对MySQL体系结构的详细介绍:
1. 连接层
连接层负责管理客户端连接和权限验证,确保只有合法用户能够访问数据库。
-
连接管理:
- 处理客户端的连接请求。
- 验证用户身份(用户名和密码)。
- 管理客户端的会话,维护连接状态。
-
连接池:
- 连接池可以复用已有的连接,减少连接创建和销毁的开销,提高系统的性能。
2. 服务层
服务层处理MySQL的大部分核心功能,包括查询解析、查询优化、缓存、存储过程等。
-
查询解析:
- 词法和语法解析:将SQL语句解析为解析树。
- 预处理:验证表名和列名,检查权限。
-
查询优化:
- 查询重写:对查询语句进行重写优化。
- 选择执行计划:评估不同的执行计划,选择最优的执行路径。
-
缓存:
- 查询缓存:存储执行过的查询和结果,可以快速返回相同的查询结果(MySQL 8.0已废弃此功能)。
-
存储过程和函数:
- 存储过程:预编译的SQL代码块,可以提高复杂操作的执行效率。
- 触发器:在特定事件发生时自动执行的SQL代码块。
-
事务管理:
- 管理事务的开始、提交和回滚,确保数据一致性。
3. 存储引擎层
存储引擎层是MySQL的核心部分,负责数据的存储和检索。MySQL支持多种存储引擎,用户可以根据需求选择合适的存储引擎。
-
InnoDB:
- 支持事务、行级锁定和外键,是MySQL的默认存储引擎。
-
MyISAM:
- 不支持事务和外键,但具有较高的读取性能,适用于读取密集型应用。
-
Memory:
- 将数据存储在内存中,访问速度快,适用于临时数据和快速访问场景。
-
其他存储引擎:
- 包括CSV、Archive、Federated等,每种存储引擎有不同的特性和应用场景。
4. 物理层
物理层负责实际的数据存储和管理,包括数据文件、日志文件、索引文件等。
-
数据文件:
- 存储表的数据。
-
索引文件:
- 存储表的索引,优化数据检索速度。
-
日志文件:
- 包括二进制日志(binlog)、重做日志(redo log)和撤销日志(undo log),用于数据恢复和复制。
MySQL体系结构图
+---------------------------------------------------+
| 客户端 |
+------------------------|--------------------------+|
+------------------------v--------------------------+
| 连接层 |
| - 连接管理 |
| - 用户身份验证 |
| - 连接池 |
+------------------------|--------------------------+|
+------------------------v--------------------------+
| 服务层 |
| - 查询解析 |
| - 查询优化 |
| - 查询缓存 |
| - 存储过程和函数 |
| - 触发器 |
| - 视图 |
| - 事务管理 |
+------------------------|--------------------------+|
+------------------------v--------------------------+
| 存储引擎层 |
| - InnoDB |
| - MyISAM |
| - Memory |
| - 其他存储引擎 |
+------------------------|--------------------------+|
+------------------------v--------------------------+
| 物理层 |
| - 数据文件 |
| - 索引文件 |
| - 日志文件 |
+---------------------------------------------------+
总结
MySQL的分层体系结构使其具有高度的灵活性和可扩展性。每一层各司其职,共同实现高效的数据管理和操作。通过这种结构,MySQL不仅可以提供高效的查询和数据存储,还能通过不同的存储引擎满足各种应用场景的需求。
注意事项
- 权限管理:在整个过程中,权限检查和管理是至关重要的一环。MySQL会确保用户在执行任何操作前具有相应的权限。
- 事务管理:对于事务性操作(如InnoDB存储引擎),事务的开始、提交和回滚也会在执行过程中处理。
通过上述步骤,MySQL可以高效、准确地执行各种SQL查询,并返回相应的结果。
相关文章:

MySQL中SQL语句的执行过程详解
1. 客户端连接和请求 客户端连接 在MySQL中,客户端连接和请求过程是执行SQL语句的第一步。该步骤主要涉及客户端如何连接到MySQL服务器,以及如何维护和管理客户端与服务器之间的会话。 客户端连接: 连接器(Connector)…...
文心一言4.0免费使用
领取&安装链接:Baidu Comate 领取季卡 视频教程:免费使用文心一言4.0大模型_哔哩哔哩_bilibili 有图有真相 原理:百度comate使用文心一言最新的4.0模型。百度comate目前免费使用,可以借助comate达到免费使用4.0模型目的。 …...
Mongodb安装与配置
Mongodb的下载 这里下载的是MongoDB 7.0.11版本的 首先进入官网:https://www.mongodb.com/ 点击完上面两步后,加载来到该页面,选择自己的版本、系统,是压缩包(zip)还是安装包(msi)。 下载好之后能,来到安装包哪里&a…...

Java校园跑腿小程序校园代买帮忙外卖源码社区外卖源码
🔥校园跑腿与外卖源码揭秘🔥 🚀 引言:为何需要校园跑腿与外卖源码? 在快节奏的校园生活里,学生们对于便捷、高效的服务需求日益增长。校园跑腿和外卖服务成为了解决这一需求的热门选择。然而,…...

MySQL高级-MVCC-基本概念(当前读、快照读)
文章目录 1、MVCC基本概念1.1、当前读1.1.1、创建表 stu1.1.2、测试 1.2、快照读 1、MVCC基本概念 全称Multi-Version Concurrency Control,多版本并发控制。指维护一个数据的多个版本,使得读写操作没有冲突,快照读为MySQL实现MVCC提供了一个…...
kubernetes给指定用户分配调用k8s的api权限
文章目录 概要利用RBAC添加角色权限使用shell命令创建角色权限使用配置文件创建角色权限 调用k8s的api获取k8s账户的token 小结 概要 使用kubernetes部署项目时,有些特殊场景,我们需要在自己创建的pod里面调用k8s的api来管理k8s,但是需要使用…...

无人机的弱点和限制
1.电池和续航能力: 续航时间短:大多数无人机依赖锂电池供电,续航时间通常在30分钟至1小时之间,限制了其长时间任务的执行能力。 能量密度低:现有电池技术的能量密度无法满足长时间飞行需求,需要突破性的发…...

ElementUI的基本搭建
目录 1,首先在控制终端中输入下面代码:npm i element-ui -S 安装element UI 2,构架登录页面,login.vue编辑 3,在官网获取对应所需的代码直接复制粘贴到对应位置 4,在继续完善,从官网添加…...
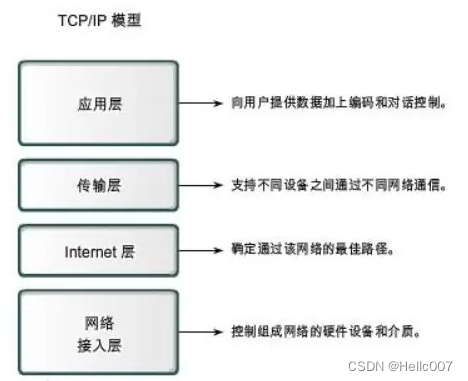
Modbus TCP与TCP/IP协议间的差异与应用场景
Modbus TCP概述 Modbus协议简介 Modbus是一种专为工业自动化系统设计的通信协议,采用主从模式,即一个主设备(通常是计算机或可编程逻辑控制器)与多个从设备(如传感器、执行器等)进行通信。Modbus协议具有…...
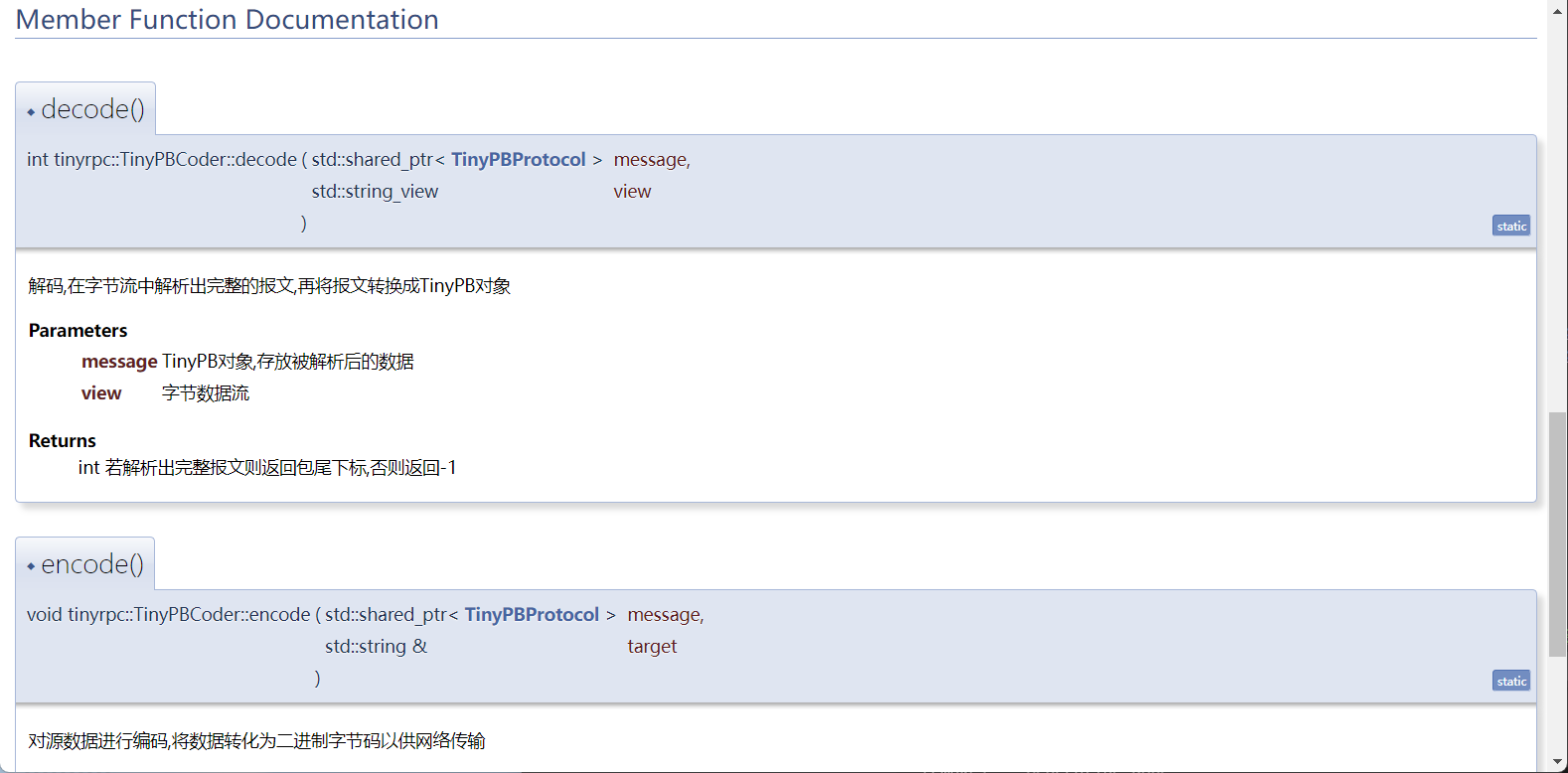
Linux Doxygen快速生成文档
此前写过一篇编写Doxygen格式的注释以用于生成文档,点击以查阅, Doxygen常用语法与字段记录,但是当时用的windows桌面版的doxygen,最近使用ubuntu编写代码想直接使用doxygen生成,故写下此博客 Doxygen Doxygen是一个用于生成软件文档的工具,它可以从代码中提取注释…...

MobPush REST API的推送 API之批量推送
调用验证 详情参见 REST API 概述的 鉴权方式 说明。 频率控制 详情参见推送限制策略的 接口限制 说明。 调用地址 POST http://api.push.mob.com/v3/push/createMulti 推送对象 以 JSON 格式表达,表示一条推送相关的所有信息 字段类型必须说明pushWorkobje…...

Arthas快速入门
简介 Arthas 是一款线上监控诊断产品,通过全局视角实时查看应用 load、内存、gc、线程的状态信息,并能在不修改应用代码的情况下,对业务问题进行诊断,包括查看方法调用的出入参、异常,监测方法执行耗时,类…...
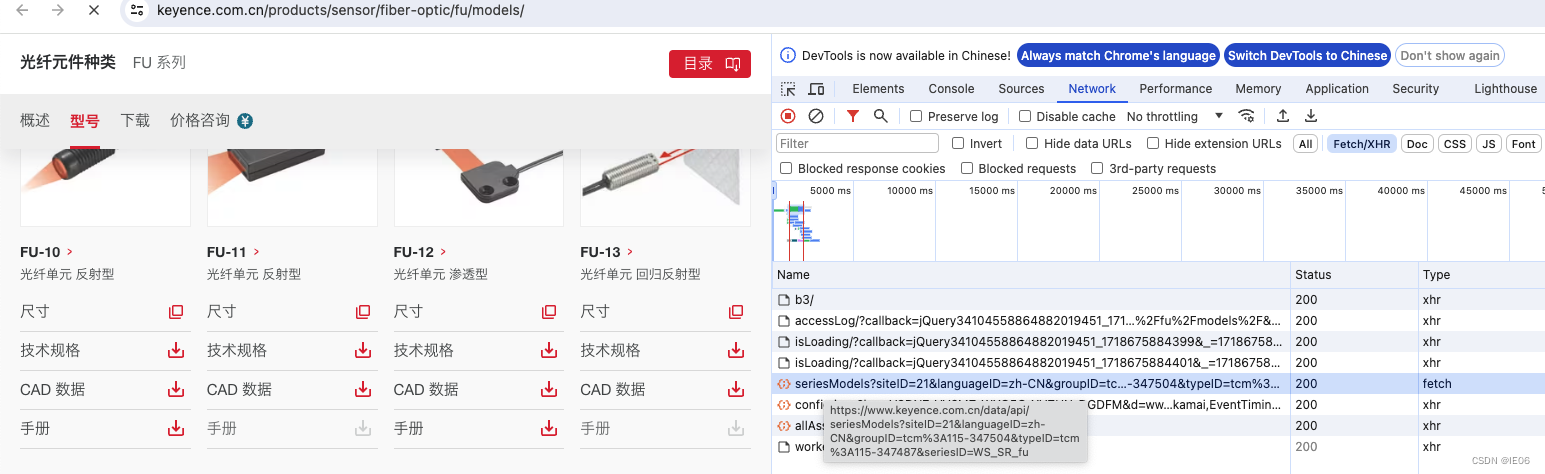
python系列30:各种爬虫技术总结
1. 使用requests获取网页内容 以巴鲁夫产品为例,可以用get请求获取内容: https://www.balluff.com.cn/zh-cn/products/BES02YF 对应的网页为: 使用简单方法进行解析即可 import requests r BES02YF res requests.get("https://www.…...

PHP和phpSpider:如何应对反爬虫机制的封锁?
php和phpspider:如何应对反爬虫机制的封锁? 引言: 随着互联网的快速发展,对于大数据的需求也越来越大。爬虫作为一种抓取数据的工具,可以自动化地从网页中提取所需的信息。然而,由于爬虫的存在,…...
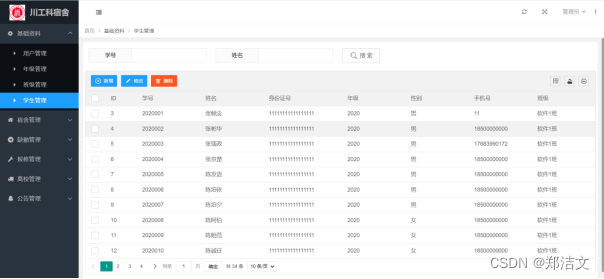
学生宿舍管理系统
摘 要 随着高校规模的不断扩大和学生人数的增加,学生宿舍管理成为高校日常管理工作中的重要组成部分。传统的学生宿舍管理方式往往依赖于纸质记录和人工管理,这种方式不仅效率低下,而且容易出错,无法满足现代高校管理的需求。因此…...

一分钟彻底掌握Java迭代器Iterator
Iterator Iterator 是 Java 的 java.util 包中的一个接口 iterator() 是 Java 集合框架中的一个方法,它返回一个 Iterator 对象,该对象可以用来遍历集合中的元素。 Iterator确实是一个接口,你不能直接实例化一个接口。但是,你可以…...

第三十七篇——麦克斯韦的妖:为什么要保持系统的开放性?
目录 一、背景介绍二、思路&方案三、过程1.思维导图2.文章中经典的句子理解3.学习之后对于投资市场的理解4.通过这篇文章结合我知道的东西我能想到什么? 四、总结五、升华 一、背景介绍 如果没有详细的学习这篇文章,我觉得我就是被麦克斯韦妖摆弄的…...

青岛网站建设一般多少钱
青岛网站建设的价格一般会根据网站的规模、功能、设计风格等因素来定,价格会存在着一定的差异。一般来说,一个简单的网站建设可能在数千元到一万元之间,而一个复杂的大型网站建设可能会需要数万元到数十万元不等。所以在选择网站建设服务时&a…...

Linux 进程状态:TASK_INTERRUPTIBLE 和 TASK_UNINTERRUPTIBLE
文章目录 1. 前言2. TASK_INTERRUPTIBLE 和 TASK_UNINTERRUPTIBLE2.1 语义2.2 实现2.2.1 TASK_INTERRUPTIBLE 实现2.2.1.1 等待的条件成立时 唤醒2.2.1.2 信号 唤醒2.2.1.3 中断 唤醒2.2.1.3.1 内核态的处理过程2.2.1.3.2 用户态的处理过程 2.2.2 TASK_UNINTERRUPTIBLE 实现 2.…...

vue3使用vant4的列表vant-list点击进入详情自动滚动到对应位置,踩坑日记(一天半的踩坑经历)
1.路由添加keepAlive <!-- Vue3缓存组件,写法和Vue2不一样--><router-view v-slot"{ Component }"><keep-alive><component :is"Component" v-if"$route.meta.keepAlive"/></keep-alive><component…...

【Java学习笔记】Arrays类
Arrays 类 1. 导入包:import java.util.Arrays 2. 常用方法一览表 方法描述Arrays.toString()返回数组的字符串形式Arrays.sort()排序(自然排序和定制排序)Arrays.binarySearch()通过二分搜索法进行查找(前提:数组是…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...

vue3 定时器-定义全局方法 vue+ts
1.创建ts文件 路径:src/utils/timer.ts 完整代码: import { onUnmounted } from vuetype TimerCallback (...args: any[]) > voidexport function useGlobalTimer() {const timers: Map<number, NodeJS.Timeout> new Map()// 创建定时器con…...

Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析
Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析 一、第一轮提问(基础概念问题) 1. 请解释Spring框架的核心容器是什么?它在Spring中起到什么作用? Spring框架的核心容器是IoC容器&#…...

LLMs 系列实操科普(1)
写在前面: 本期内容我们继续 Andrej Karpathy 的《How I use LLMs》讲座内容,原视频时长 ~130 分钟,以实操演示主流的一些 LLMs 的使用,由于涉及到实操,实际上并不适合以文字整理,但还是决定尽量整理一份笔…...

「全栈技术解析」推客小程序系统开发:从架构设计到裂变增长的完整解决方案
在移动互联网营销竞争白热化的当下,推客小程序系统凭借其裂变传播、精准营销等特性,成为企业抢占市场的利器。本文将深度解析推客小程序系统开发的核心技术与实现路径,助力开发者打造具有市场竞争力的营销工具。 一、系统核心功能架构&…...

前端中slice和splic的区别
1. slice slice 用于从数组中提取一部分元素,返回一个新的数组。 特点: 不修改原数组:slice 不会改变原数组,而是返回一个新的数组。提取数组的部分:slice 会根据指定的开始索引和结束索引提取数组的一部分。不包含…...

如何在Windows本机安装Python并确保与Python.NET兼容
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
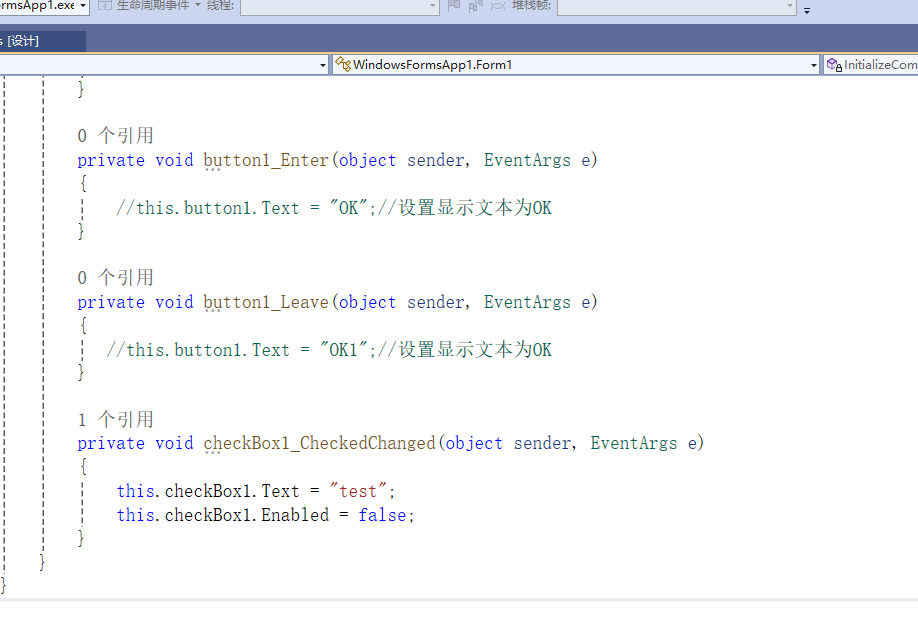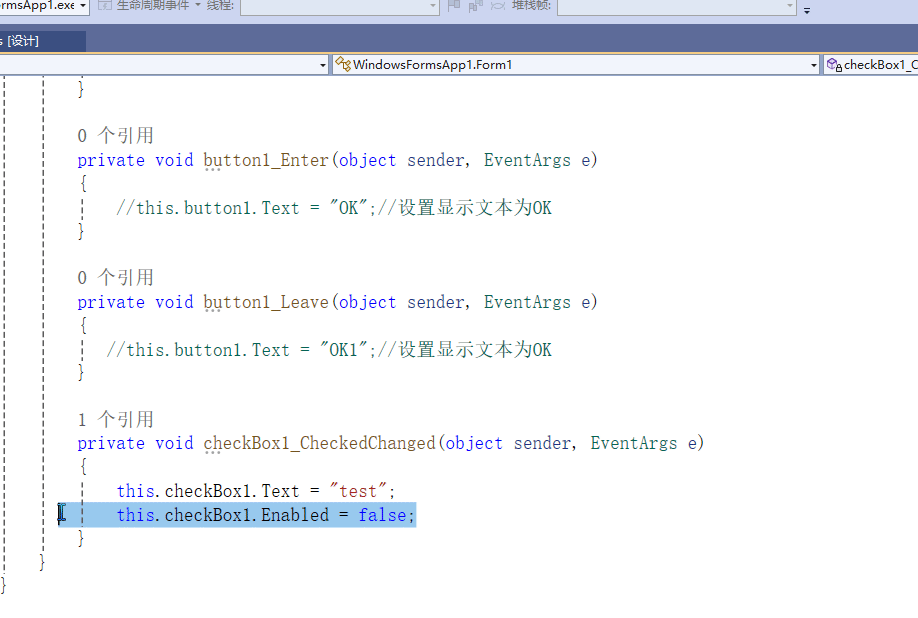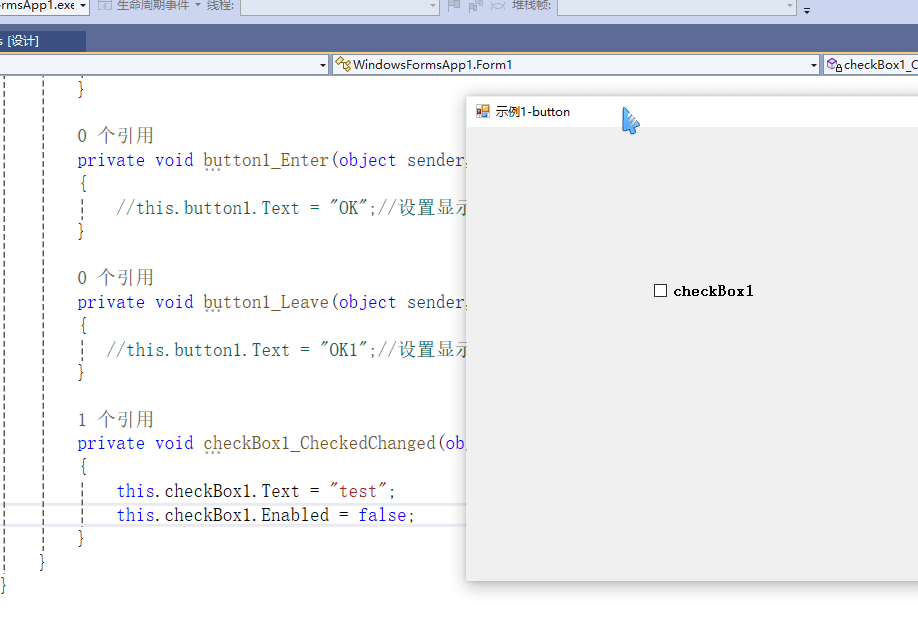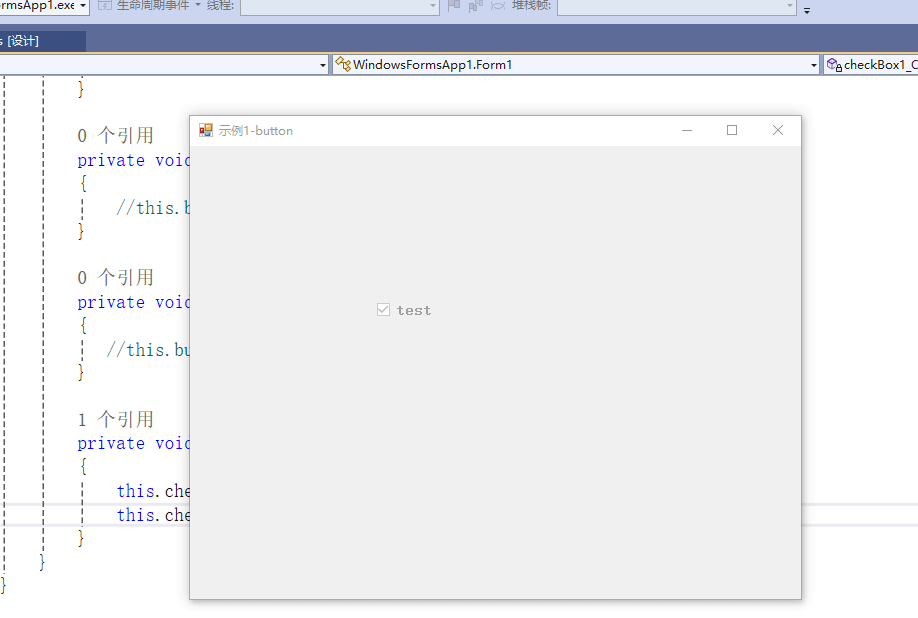
C# winform教程(二)----checkbox
一、作用 提供一个用户选择或者不选的状态,这是一个可以多选的控件。 二、属性 其实功能大差不差,除了特殊的几个外,与button基本相同,所有说几个独有的 checkbox属性 名称内容含义appearance控件外观可以变成按钮形状checkali…...