python系列30:各种爬虫技术总结
1. 使用requests获取网页内容
以巴鲁夫产品为例,可以用get请求获取内容:
https://www.balluff.com.cn/zh-cn/products/BES02YF
对应的网页为:
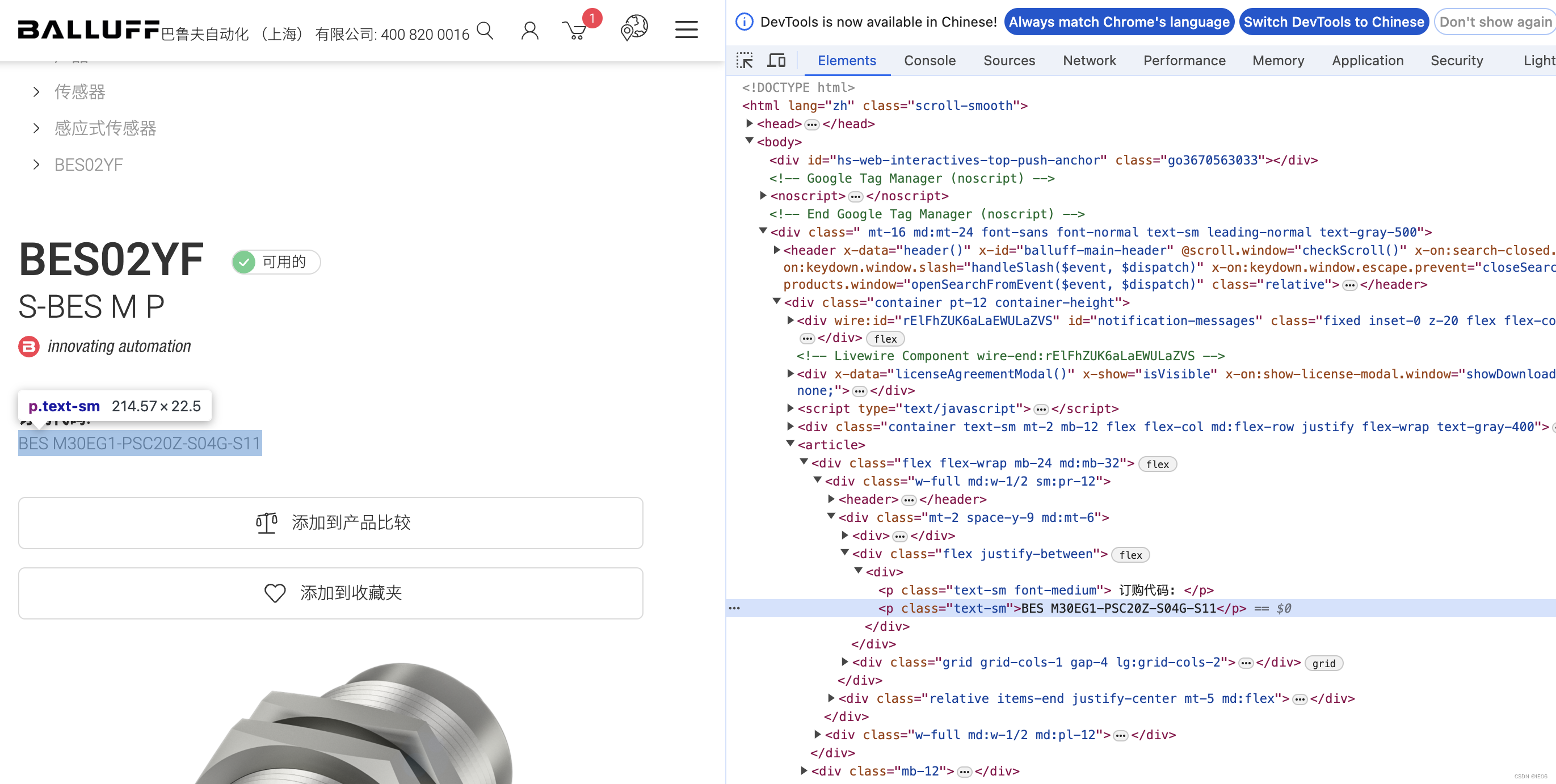
使用简单方法进行解析即可
import requests
r = 'BES02YF'
res = requests.get("https://www.balluff.com.cn/zh-cn/products/%s"%r).text
result = res.split("</title>")[0].split("<title>")[1]
2. 添加多进程
使用multiprocessing进行加速,以上面的balluff为例:
from multiprocessing.dummy import Pool as ThreadPool
from tqdm import tqdm
import numpy as np
import os,json,requests,base64,struct
data = pd.read_excel("balluff.xlsx",sheet_name='all')
valuelist = list(data['Type'])
def getf(type_value):try:res = requests.get("https://www.balluff.com.cn/zh-cn/products/%s"%type_value).textreturn res.split("</title>")[0].split("<title>")[1]except:return None
results = []
with ThreadPool(100) as p:results = list(tqdm(p.imap(getf, valuelist), total=len(valuelist)))
3. 加入header
有一些网站有防爬虫的功能,需要在请求中添加header,例如西门子的网站需要用如下的方法:
def getf(type_value):try:headers = {"user-agent": "Mizilla/5.0"}res = requests.get("""https://mall.industry.siemens.com/mall/zh/CN/Catalog/Product/?mlfb=%s&SiepCountryCode=CN"""%type_value,headers=headers).text.split("""productIdentifier""")[1]return res.split("""</span>""")[0].split('>')[-1]except:return None
4. 使用selenium
以festo为例,会很讨厌的弹出对话框。
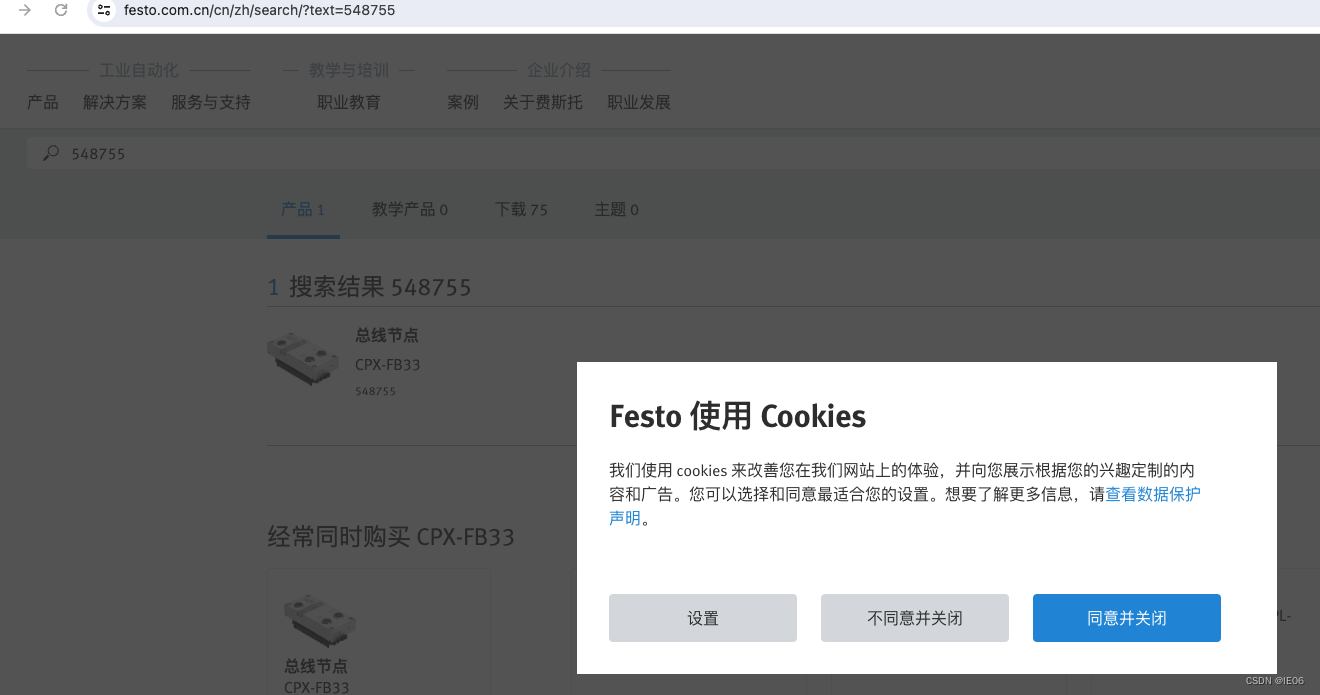
我们使用selenium模拟点击。并且用find_element找到元素:
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://www.festo.com.cn/cn/zh/search/?text=548755')
f1=driver.find_element(By.PARTIAL_LINK_TEXT,'接受')
f1.click()
from tqdm import tqdm
r1 = []
r2 = []
for type_value in tqdm(valuelist):try:driver.get('https://www.festo.com.cn/cn/zh/search/?text=%s'%type_value)time.sleep(1)r1.append(driver.find_element(By.CLASS_NAME,'product-code--NjIDg').text)try:r2.append(driver.find_element(By.CLASS_NAME,'ident-code--qx13c').text)except:r2.append(driver.find_element(By.CLASS_NAME,'product-order-code--TR15s').text)except:r1.append(None)r2.append(None)
5. 获取真实的requests地址
以keyence为例,查看网页源代码是无法获得产品清单的,需要在chrome的开发者工具中点击Network,选择Fetch/XHR,然后刷新页面,找到Type为fetch的链接:
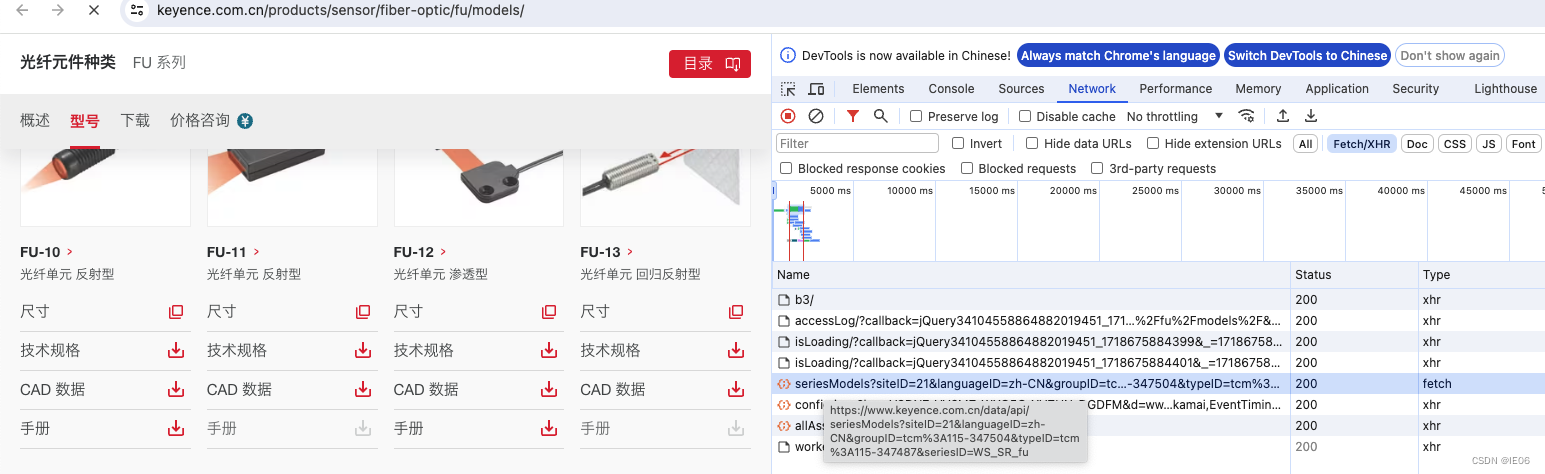
链接为/data/api/seriesModels?siteID=21&languageID=zh-CN&groupID=tcm%3A115-347504&typeID=tcm%3A115-347487&seriesID=WS_SR_fu,其中groupID开始的部分,可以从源代码中获得。具体代码为:
import json
from tqdm import tqdm
result = []
for r2i in tqdm(r2):result += json.loads(requests.get('https://www.keyence.com.cn/data/api/seriesModels?siteID=21&languageID=zh-CN&'+\list(filter(lambda x:'prd-seriesFooter-navLink of-support' in x,requests.get(r2i)\.text.split('\n')))[0].split('?')[1].split('&modelId')[0].replace('Id','ID')).text)['models']
如果找到的链接过于难处理(比如post请求带着一堆请求体),那可以直接右键,选择copy->copy curl,然后替换其中的关键字,用命令行执行即可。
相关文章:
python系列30:各种爬虫技术总结
1. 使用requests获取网页内容 以巴鲁夫产品为例,可以用get请求获取内容: https://www.balluff.com.cn/zh-cn/products/BES02YF 对应的网页为: 使用简单方法进行解析即可 import requests r BES02YF res requests.get("https://www.…...

PHP和phpSpider:如何应对反爬虫机制的封锁?
php和phpspider:如何应对反爬虫机制的封锁? 引言: 随着互联网的快速发展,对于大数据的需求也越来越大。爬虫作为一种抓取数据的工具,可以自动化地从网页中提取所需的信息。然而,由于爬虫的存在,…...
学生宿舍管理系统
摘 要 随着高校规模的不断扩大和学生人数的增加,学生宿舍管理成为高校日常管理工作中的重要组成部分。传统的学生宿舍管理方式往往依赖于纸质记录和人工管理,这种方式不仅效率低下,而且容易出错,无法满足现代高校管理的需求。因此…...

一分钟彻底掌握Java迭代器Iterator
Iterator Iterator 是 Java 的 java.util 包中的一个接口 iterator() 是 Java 集合框架中的一个方法,它返回一个 Iterator 对象,该对象可以用来遍历集合中的元素。 Iterator确实是一个接口,你不能直接实例化一个接口。但是,你可以…...

第三十七篇——麦克斯韦的妖:为什么要保持系统的开放性?
目录 一、背景介绍二、思路&方案三、过程1.思维导图2.文章中经典的句子理解3.学习之后对于投资市场的理解4.通过这篇文章结合我知道的东西我能想到什么? 四、总结五、升华 一、背景介绍 如果没有详细的学习这篇文章,我觉得我就是被麦克斯韦妖摆弄的…...

青岛网站建设一般多少钱
青岛网站建设的价格一般会根据网站的规模、功能、设计风格等因素来定,价格会存在着一定的差异。一般来说,一个简单的网站建设可能在数千元到一万元之间,而一个复杂的大型网站建设可能会需要数万元到数十万元不等。所以在选择网站建设服务时&a…...

Linux 进程状态:TASK_INTERRUPTIBLE 和 TASK_UNINTERRUPTIBLE
文章目录 1. 前言2. TASK_INTERRUPTIBLE 和 TASK_UNINTERRUPTIBLE2.1 语义2.2 实现2.2.1 TASK_INTERRUPTIBLE 实现2.2.1.1 等待的条件成立时 唤醒2.2.1.2 信号 唤醒2.2.1.3 中断 唤醒2.2.1.3.1 内核态的处理过程2.2.1.3.2 用户态的处理过程 2.2.2 TASK_UNINTERRUPTIBLE 实现 2.…...

vue3使用vant4的列表vant-list点击进入详情自动滚动到对应位置,踩坑日记(一天半的踩坑经历)
1.路由添加keepAlive <!-- Vue3缓存组件,写法和Vue2不一样--><router-view v-slot"{ Component }"><keep-alive><component :is"Component" v-if"$route.meta.keepAlive"/></keep-alive><component…...
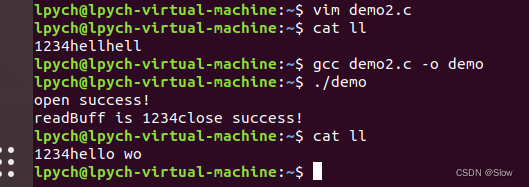
Linux的fwrite函数
函数原型: 向文件fp中写入writeBuff里面的内容 int fwrite(void*buffer,intsize,intcount,FILE*fp) /* * description : 对已打开的流进行写入数据块 * param ‐ ptr :指向 数据块的指针 * param ‐ size :指定…...

python udsoncan 详解
python udsoncan 详解 udsoncan 是一个Python库,用于实现汽车统一诊断服务(Unified Diagnostic Services,UDS)协议。UDS是一种用于汽车诊断的标准化通信协议,它定义了一系列的服务和流程,用于ECUÿ…...
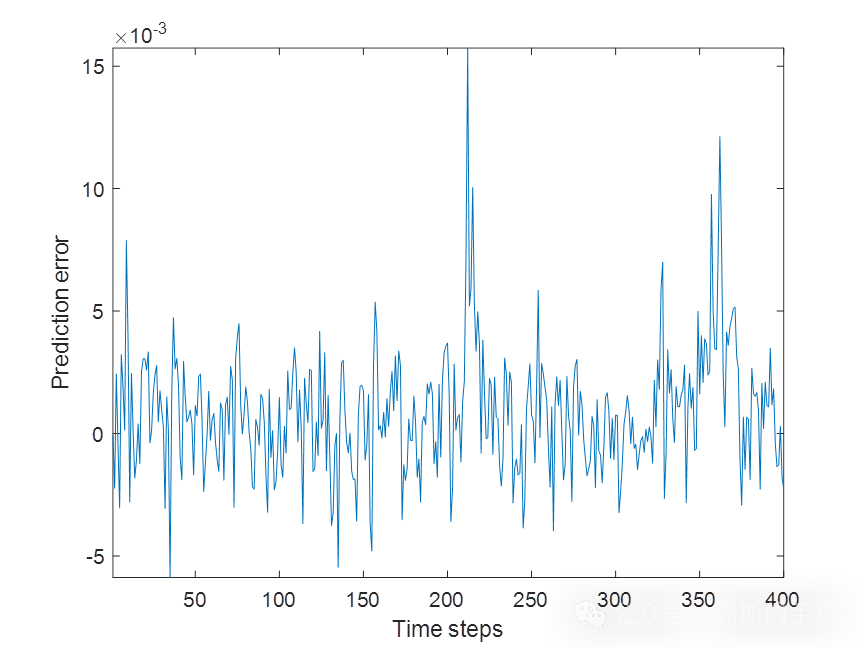
基于自组织长短期记忆神经网络的时间序列预测(MATLAB)
LSTM是为了解决RNN 的梯度消失问题而诞生的特殊循环神经网络。该网络开发了一种异于普通神经元的节点结构,引入了3 个控制门的概念。该节点称为LSTM 单元。LSTM 神经网络避免了梯度消失的情况,能够记忆更长久的历史信息,更能有效地拟合长期时…...
240629_昇思学习打卡-Day11-Vision Transformer中的self-Attention
240629_昇思学习打卡-Day11-Transformer中的self-Attention 根据昇思课程顺序来看呢,今儿应该看Vision Transformer图像分类这里了,但是大概看了一下官方api,发现我还是太笨了,看不太明白。正巧昨天学SSD的时候不是参考了太阳花的…...

代码随想录-Day43
52. 携带研究材料(第七期模拟笔试) 小明是一位科学家,他需要参加一场重要的国际科学大会,以展示自己的最新研究成果。他需要带一些研究材料,但是他的行李箱空间有限。这些研究材料包括实验设备、文献资料和实验样本等…...
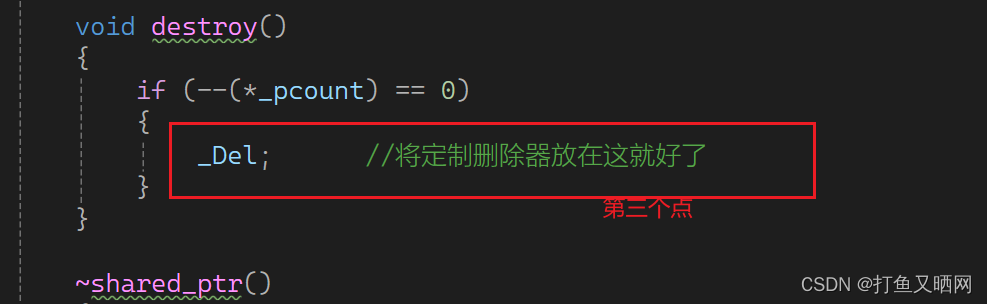
C++——探索智能指针的设计原理
前言: RAII是资源获得即初始化, 是一种利用对象生命周期来控制程序资源地手段。 智能指针是在对象构造时获取资源, 并且在对象的声明周期内控制资源, 最后在对象析构的时候释放资源。注意, 本篇文章参考——C 智能指针 - 全部用法…...

办公效率新高度:利用办公软件实现文件夹编号批量复制与移动,轻松管理文件
在数字化时代,我们的工作和生活都围绕着海量的数据和文件展开。然而,随着数据量的不断增加,如何高效地管理这些数字资产成为了摆在我们面前的一大难题。今天,我要向您介绍一种革命性的方法——利用办公软件实现文件夹编号批量复制…...
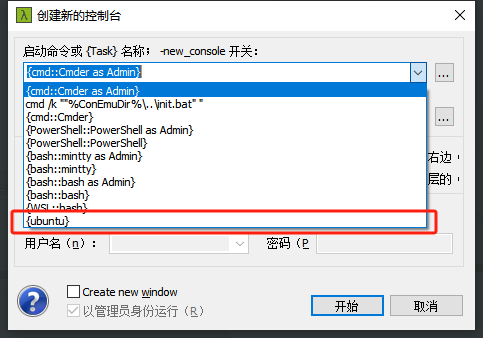
Windows kubectl终端日志聚合(wsl+ubuntu+cmder+kubetail)
Windows kubectl终端日志聚合 一、kubectl终端日志聚合二、windows安装ubuntu子系统1. 启用wsl支持2. 安装所选的 Linux 分发版 三、ubuntu安装kubetail四、配置cmder五、使用 一、kubectl终端日志聚合 k8s在实际部署时,一般都会采用多pod方式,这种情况下…...

【MySQL】数据库——事务
一.事务概念 事务是一种机制、一个操作序列,包含了一组数据库操作命令,并且把所有的命令作为一个整体一起向系统提交或撤销操作请求,即这一组数据库命令要么都执行,要么都不执行事务是一个不可分割的工作逻辑单元,在数…...
)
python代码缩进规范(2空格或4空格)
C、C、Java、C#、Rust、Go、JavaScript 等常见语言都是用"{“和”}"来标记一个块作用域的开始和结束,而Python 程序则是用缩进来表示块作用域的开始和结束: 作用域是编程语言里的一个重要的概念,特别是块作用域,编程语言…...

前后端分离的后台管理系统开发模板(带你从零开发一套自己的若依框架)上
前言: 目前,前后端分离开发已经成为当前web开发的主流。目前最流行的技术选型是前端vue3后端的spring boot3,本次。就基于这两个市面上主流的框架来开发出一套基本的后台管理系统的模板,以便于我们今后的开发。 前端使用vue3ele…...

【C++ | 委托构造函数】委托构造函数 详解 及 例子源码
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 🤣本文内容🤣&a…...

java_网络服务相关_gateway_nacos_feign区别联系
1. spring-cloud-starter-gateway 作用:作为微服务架构的网关,统一入口,处理所有外部请求。 核心能力: 路由转发(基于路径、服务名等)过滤器(鉴权、限流、日志、Header 处理)支持负…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...
基础光照(Basic Lighting))
C++.OpenGL (10/64)基础光照(Basic Lighting)
基础光照(Basic Lighting) 冯氏光照模型(Phong Lighting Model) #mermaid-svg-GLdskXwWINxNGHso {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-GLdskXwWINxNGHso .error-icon{fill:#552222;}#mermaid-svg-GLd…...

QT: `long long` 类型转换为 `QString` 2025.6.5
在 Qt 中,将 long long 类型转换为 QString 可以通过以下两种常用方法实现: 方法 1:使用 QString::number() 直接调用 QString 的静态方法 number(),将数值转换为字符串: long long value 1234567890123456789LL; …...

什么是Ansible Jinja2
理解 Ansible Jinja2 模板 Ansible 是一款功能强大的开源自动化工具,可让您无缝地管理和配置系统。Ansible 的一大亮点是它使用 Jinja2 模板,允许您根据变量数据动态生成文件、配置设置和脚本。本文将向您介绍 Ansible 中的 Jinja2 模板,并通…...
Mobile ALOHA全身模仿学习
一、题目 Mobile ALOHA:通过低成本全身远程操作学习双手移动操作 传统模仿学习(Imitation Learning)缺点:聚焦与桌面操作,缺乏通用任务所需的移动性和灵活性 本论文优点:(1)在ALOHA…...