自然语言处理中数据增强(Data Augmentation)技术最全盘点
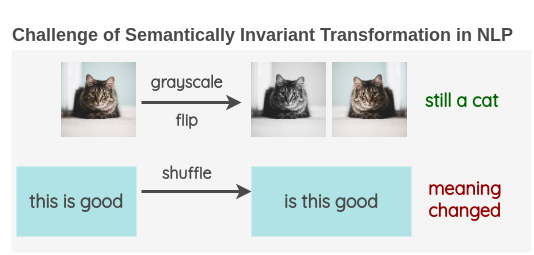
与“计算机视觉”中使用图像数据增强的标准做法不同,在NLP中,文本数据的增强非常少见。这是因为对图像的琐碎操作(例如将图像旋转几度或将其转换为灰度)不会改变其语义。语义上不变的转换的存在是使增强成为Computer Vision研究中必不可少的工具的原因。
是否有尝试为NLP开发增强技术的方法,并探讨了现有文献。在这篇文章中,将基于我的发现概述当前用于文本数据扩充的方法。
本文内容翻译整理自网络。
NLP数据扩充技术
1.词汇替代
此工作尝试在不更改句子含义的情况下替换文本中出现的单词。
基于同义词库的替换
在此技术中,从句子中抽取一个随机单词,然后使用同义词库将其替换为其同义词。例如,可以使用WordNet数据库中的英语查找同义词,然后执行替换。它是一个人工编辑的数据库,描述单词之间的关系。
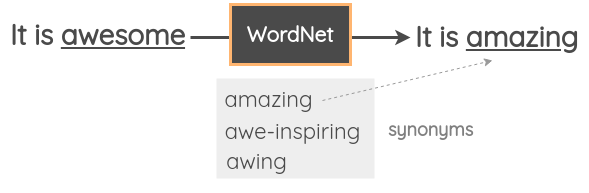
Zhang在他们的2015年论文“Character-level Convolutional Networks for Text Classification”中使用了该技术。Mueller等人使用相似的策略为其句子相似性模型生成额外的10K训练数据。Wei等人也使用了这种技术作为“轻松数据增强”论文中四个随机增强集合中的一种技术。
为了实现,NLTK提供了对WordNet 的编程访问。读者也可以使用TextBlob API。此外,还有一个名为PPDB的数据库,其中包含数百万个可以通过编程方式下载和使用的短语。
词嵌入替换
在这种方法中,采用了经过预训练的词嵌入,例如Word2Vec,GloVe,FastText,Sent2Vec,并使用嵌入空间中最近的相邻词作为句子中某些词的替换。Jiao已在他们的论文“ TinyBert ” 中将这种技术与GloVe嵌入一起使用,以改进其语言模型在下游任务上的通用性。Wang等人用它来增强学习主题模型所需的推文。

例如,读者可以将单词替换为最接近的3个单词,并获得文本的三种变体。
使用诸如Gensim之类的包来访问预先训练的单词向量并获取最近的邻居是很容易的。例如,在这里使用在推特上训练的单词向量找到单词“ awesome”的同义词。
相关好书推荐,京东1万+评论,99%好评:
# pip install gensim
import gensim.downloader as api
model = api.load('glove-twitter-25') model.most_similar('awesome', topn=5)
读者将获得5个最相似的词以及余弦相似度。
[('amazing', 0.9687871932983398),
('best', 0.9600659608840942),
('fun', 0.9331520795822144),
('fantastic', 0.9313924312591553),
('perfect', 0.9243415594100952)]
Masked语言模型
诸如BERT,ROBERTA和ALBERT之类的Transformer模型已使用称为“屏蔽语言模型”的预置任务在大量文本上进行了训练,其中该模型必须根据上下文预测屏蔽词。
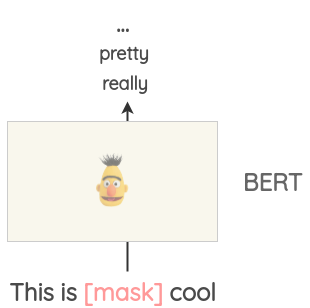
这可以用来扩充一些文本。例如,可以使用预训练的BERT模型,对文本的某些部分进行遮罩,然后要求BERT模型预测被遮罩token。

因此,可以使用遮罩预测来生成文本的变体。与以前的方法相比,生成的文本在语法上更加连贯,因为模型在进行预测时会考虑上下文。使用诸如Hugging Face开源的tranformer(https://huggingface.co/transformers/)之类的开源库很容易实现。读者可以设置要替换的令牌<mask>并生成预测。
from transformers import pipelinenlp = pipeline('fill-mask')nlp('This is <mask> cool')
[{'score': 0.515411913394928,
'sequence': '<s> This is pretty cool</s>',
'token': 1256},
{'score': 0.1166248694062233,
'sequence': '<s> This is really cool</s>',
'token': 269},
{'score': 0.07387523353099823,
'sequence': '<s> This is super cool</s>',
'token': 2422},
{'score': 0.04272908344864845,
'sequence': '<s> This is kinda cool</s>',
'token': 24282},
{'score': 0.034715913236141205,
'sequence': '<s> This is very cool</s>',
'token': 182}]
但是,此方法的一个需要注意的点是,决定要掩盖文本的哪一部分并非易事。读者将必须使用启发式方法来确定掩码,否则生成的文本可能不会保留原始句子的含义。
基于TF-IDF的单词替换
这种扩展方法是由Xie等人提出的。在无监督数据增强论文中。基本思想是,TF-IDF分数较低的单词是无意义的,因此可以替换而不会影响句子的真实标签。

通过计算整个文档中单词的TF-IDF得分并取最低得分来选择替换原始单词的单词。读者可以在此处的原始文件中参考此代码的实现(https://github.com/google-research/uda/blob/master/text/augmentation/word_level_augment.py)。
2. 回译(Back Translation)
在这种方法中,利用机器翻译来释义文本,同时重新训练其含义。Xie使用此方法来扩充未标记的文本,并仅使用20个标记的示例在IMDB数据集上学习半监督模型。他们的模型优于以前在25,000个带标签的示例上训练的最新模型。
反向翻译过程如下:
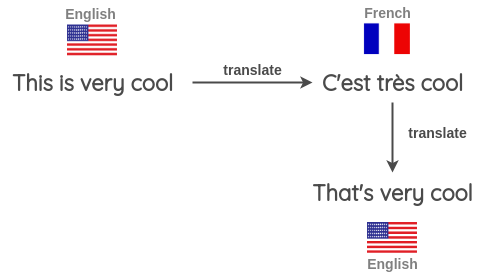
· 用一些句子(例如英语)并翻译成另一种语言,例如法语
· 将法语句子翻译回英语句子
· 检查新句子是否与的原始句子不同。如果是这样,那么将这个新句子用作原始文本的增强版本。
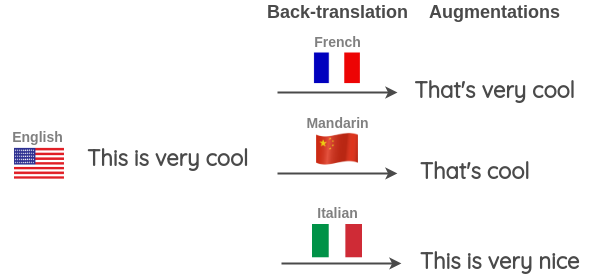
读者还可以一次使用不同的语言进行反向翻译,以产生更多的变化。如下所示,将英语句子翻译成目标语言,然后再将英语翻译成三种目标语言的英语:法语,普通话和意大利语。该技术还被用于Kaggle上的“有毒评论分类挑战” 的第一名解决方案。获胜者将其用于训练数据的增加以及测试期间,将英语句子的预测概率以及使用三种语言(法语,德语,西班牙语)的反向翻译的平均值进行平均,以得出最终预测。
对于实施反向翻译,可以使用TextBlob。另外,读者也可以使用Google表格并按照此处提供的说明免费应用Google翻译(https://amitness.com/2020/02/back-translation-in-google-sheets/)。
3.文字表面转换(Text Surface Transformation)
这些是使用正则表达式应用的简单模式匹配转换,由Claude Coulombe在他的论文中介绍。

在本文中,他提供了一个将言语形式从收缩转变为扩张,反之亦然的例子。可以通过应用此生成增强文本。
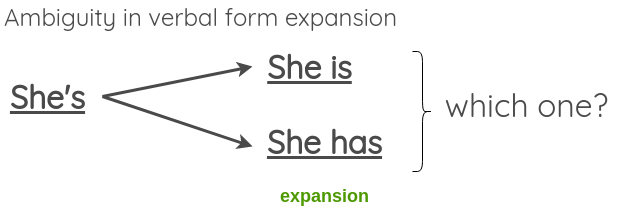
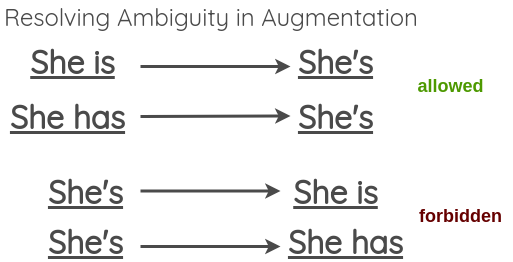
由于转换不应该改变句子的含义,因此可以看到,在展开歧义语言形式的情况下,这样做可能会失败:为解决此问题,本文建议允许歧义收缩,但跳过歧义扩展。
读者可以在此处找到英语的收缩列表。为了扩展,读者可以使用Python中的收缩库(https://en.wikipedia.org/wiki/Wikipedia%3aList_of_English_contractions)。
4.随机噪声注入(Random Noise Injection)
这些方法的思想是在文本中注入噪声,以便训练的模型对扰动具有鲁棒性。
拼写错误注入
在这种方法中,向句子中的某些随机单词添加了拼写错误。这些拼写错误可以通过编程方式添加,也可以使用常见拼写错误的映射(例如英语列表)来添加。

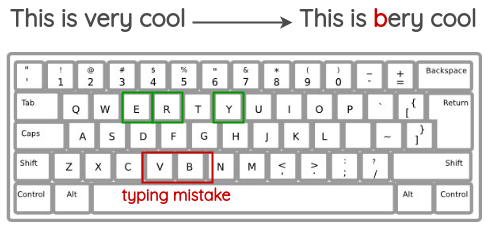
QWERTY键盘错误注入
此方法尝试模拟在QWERTY布局键盘上键入时由于相互之间非常靠近的键而发生的常见错误。根据键盘距离插入错误。
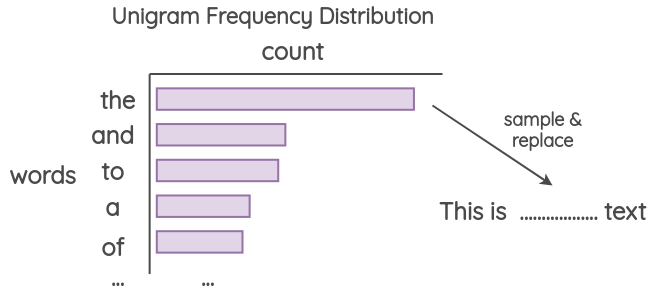
Unigram噪声
Xie等人已使用此方法。这个想法是用从字法频率分布中采样的单词进行替换。该频率基本上是每个单词在训练语料库中出现的次数。
空白噪声
该方法由Xie等人(https://arxiv.org/abs/1703.02573)提出。在他们的论文中。这个想法是用一个占位符标记代替一些随机词。本文使用“ _”作为占位符标记。在本文中,他们将其用作避免在特定上下文上过度拟合的方法以及语言模型的平滑机制。该技术有助于提高困惑度和BLEU分数。

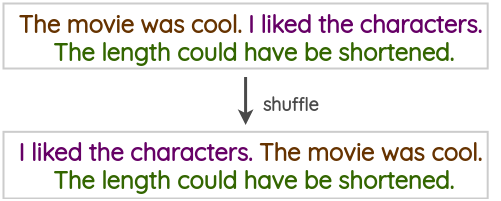
句子改组
这是一种幼稚的技术,可以对训练文本中存在的句子进行改组以创建增强版本。
随机插入
该技术由Wei等人(https://arxiv.org/abs/1901.11196)提出。在他们的论文“Easy Data Augmentation”中。在这种技术中,首先从不是停用词的句子中选择一个随机词。然后,找到其同义词并将其插入句子中的随机位置。

随机交换
此技术也由Wei等人提出。在他们的论文“Easy Data Augmentation”中。想法是随机交换句子中的任何两个单词。

相关好书推荐,京东1万+评论,99%好评:
随机删除
该技术也是由Wei等人提出的。在他们的论文“Easy Data Augmentation”中。在这种情况下,以一定概率p随机删除句子中的每个单词。

5.实例交叉扩展(Instance Crossover Augmentation)
这项技术是Luque(https://arxiv.org/abs/1909.11241)在他对TASS 2019的情感分析的论文中引入的。它受到遗传学中染色体交叉操作的启发。
在该方法中,一条推文被分为两半,并且两个极性相同(即正/负)的随机推文被互换。假设是,即使结果是不合语法且语义上不合理的,新文本仍将保留情感。

该技术对准确性没有影响,但有助于提高F1分数,表明该技术可帮助减少诸如Tweet的中性类别等少数群体。

6.语法树(Syntax-tree)操作
此技术已在Coulombe(https://arxiv.org/abs/1812.04718)的论文中使用。想法是解析并生成原始句子的依存关系树,使用规则对其进行转换并生成释义的句子。
例如,一种不改变句子含义的转换就是从主动语态到被动语态的转换,反之亦然。
7.文字混合(Mixup for Text)
混合是张等人(https://arxiv.org/abs/1710.09412)介绍的一种简单而有效的图像增强技术。这是在2017年提出的。想法是将两个随机图像按一定比例组合在一个小批量中,以生成用于训练的合成示例。对于图像,这意味着将两个不同类别的图像像素组合在一起。它是训练过程中的一种正规化形式。

郭等人(https://arxiv.org/abs/1905.08941)将这个想法带给了自然语言处理。修改了Mixup以处理文本。他们提出了两种新颖的方法将Mixup应用于文本:
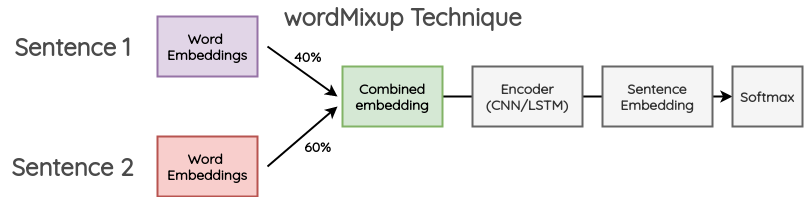
· wordMixup:
在此方法中,在一个小批量中获取两个随机句子,并将它们零填充为相同的长度。然后,将它们的词嵌入按一定比例组合。生成的单词嵌入将传递到常规流程以进行文本分类。对于给定比例的原始文本的两个标签,计算交叉熵损失。
sentMixup:
在此方法中,采用两个句子并将它们零填充为相同的长度。然后,它们的词嵌入通过LSTM / CNN编码器传递,将最后的隐藏状态作为句子嵌入。这些嵌入按一定比例组合,然后传递到最终分类层。基于给定比例的原始句子的两个标签计算交叉熵损失。

8.生成方法(Generative Methods)
此工作尝试在保留标签类别的同时生成其他训练数据。
条件预训练语言模型
这项技术由Anaby-Tavor等人首先提出。在他们的论文Not Enough Data? Deep Learning to the Rescue!。Kumar等人的(https://arxiv.org/abs/2003.02245)最新论文。在多个基于Transformer的预训练模型中评估了这个想法。问题表述如下:
将类别标签附加到训练数据中的每个文本
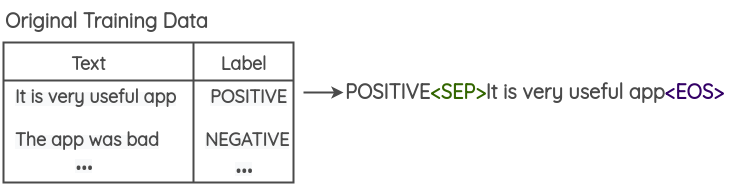
在修改后的训练数据上微调一个大型的预训练语言模型(BERT / GPT2 / BART)。对于GPT2,微调任务是生成,而对于BERT,目标将是屏蔽token预测。

使用微调的语言模型,可以通过使用类标签和少量的初始单词作为模型提示来生成新样本。本文使用每个训练文本的3个初始单词,并为训练数据中的每个点生成一个综合示例。

实现
诸如nlpaug(https://github.com/makcedward/nlpaug)和textattack(https://github.com/QData/TextAttack)之类的库提供了简单而一致的API,以在Python中应用上述NLP数据增强方法。它们与框架无关,可以轻松集成到读者的管道中。
结论
我从文献回顾中得出的结论是,许多这些NLP增强方法都是非常特定于任务的,并且仅在某些特定用例中研究了它们对性能的影响。系统地比较这些方法并分析它们对许多任务的性能的影响将是一个有趣的研究。
相关文章:
自然语言处理中数据增强(Data Augmentation)技术最全盘点
与“计算机视觉”中使用图像数据增强的标准做法不同,在NLP中,文本数据的增强非常少见。这是因为对图像的琐碎操作(例如将图像旋转几度或将其转换为灰度)不会改变其语义。语义上不变的转换的存在是使增强成为Computer Vision研究中…...
PINN解偏微分方程实例1
PINN解偏微分方程实例11. PINN简介2. 偏微分方程实例3. 基于pytorch实现代码4. 数值解参考资料1. PINN简介 PINN是一种利用神经网络求解偏微分方程的方法,其计算流程图如下图所示,这里以偏微分方程(1)为例。 ∂u∂tu∂u∂xv∂2u∂x2\begin{align} \frac{…...

【python 基础篇 十二】python的函数-------函数生成器
目录1.生成器基本概念2.生成器的创建方式3.生成器的输出方式4.send()方法5.关闭生成器6.注意事项1.生成器基本概念 是一个特色的迭代器(迭代器的抽象层级更高)所以拥有迭代器的特性 惰性计算数据 节省内存 ----就是不是立马生成所有数据,而是…...
elasticsearch全解 (待续)
目录elasticsearchELK技术栈Lucene与Elasticsearch关系为什么不是其他搜索技术?Elasticsearch核心概念Cluster:集群Node:节点Shard:分片Replia:副本全文检索倒排索引正向和倒排es的一些概念文档和字段索引和映射mysql与…...

springboot2集成knife4j
springboot2集成knife4j springboot2集成knife4j 环境说明集成knife4j 第一步:引入依赖第二步:编写配置类第三步:测试一下 第一小步:编写controller第二小步:启动项目,访问api文档 相关资料 环境说明 …...

Qt 性能优化:CPU占有率高的现象和解决办法
一、前言 在最近的项目中,发现执行 Qt 程序时,有些情况下的 CPU 占用率奇高,最高高达 100%。项目跑在嵌入式板子上,最开始使用 EGLFS 插件,但是由于板子没有单独的鼠标层,导致鼠标移动起来卡顿,…...

MySQL专题(学会就毕业)
MySQL专题0.准备sql设计一张员工信息表,要求如下:编号(纯数字)员工工号 (字符串类型,长度不超过10位)员工姓名(字符串类型,长度不超过10位)性别(男/女,存储一…...

Java高级技术:单元测试、反射、注解
目录 单元测试 单元测试概述 单元测试快速入门 单元测试常用注解 反射 反射概述 反射获取类对象 反射获取构造器对象 反射获取成员变量对象 反射获取方法对象 反射的作用-绕过编译阶段为集合添加数据 反射的作用-通用框架的底层原理 注解 注解概述 自定义注解 …...

C语言初识
#include <stdio.h>//这种写法是过时的写法 void main() {}//int是整型的意思 //main前面的int表示main函数调用后返回一个整型值 int main() {return 0; }int main() { //主函数--程序的入口--main函数有且仅有一个//在这里完成任务//在屏幕伤输出hello world//函数-pri…...

Cadence Allegro 导出Etch Length by Layer Report报告详解
⏪《上一篇》 🏡《上级目录》 ⏩《下一篇》 目录 1,概述2,Etch Length by Layer Report作用3,Etch Length by Layer Report示例4,Etch Length by Layer Report导出方法4.2,方法14.2,方法2B站关注“硬小二”浏览更多演示视频...
无监督对比学习(CL)最新必读经典论文整理分享
对比自监督学习技术是一种很有前途的方法,它通过学习对使两种事物相似或不同的东西进行编码来构建表示。Contrastive learning有很多文章介绍,区别于生成式的自监督方法,如AutoEncoder通过重建输入信号获取中间表示,Contrastive M…...

最长回文子串【Java实现】
题目描述 现有一个字符串s,求s的最长回文子串的长度 输入描述 一个字符串s,仅由小写字母组成,长度不超过100 输出描述 输出一个整数,表示最长回文子串的长度 样例 输入 lozjujzve输出 // 最长公共子串为zjujz,长度为…...

LeetCode 438. Find All Anagrams in a String
LeetCode 438. Find All Anagrams in a String 题目描述 Given two strings s and p, return an array of all the start indices of p’s anagrams in s. You may return the answer in any order. An Anagram is a word or phrase formed by rearranging the letters of a…...
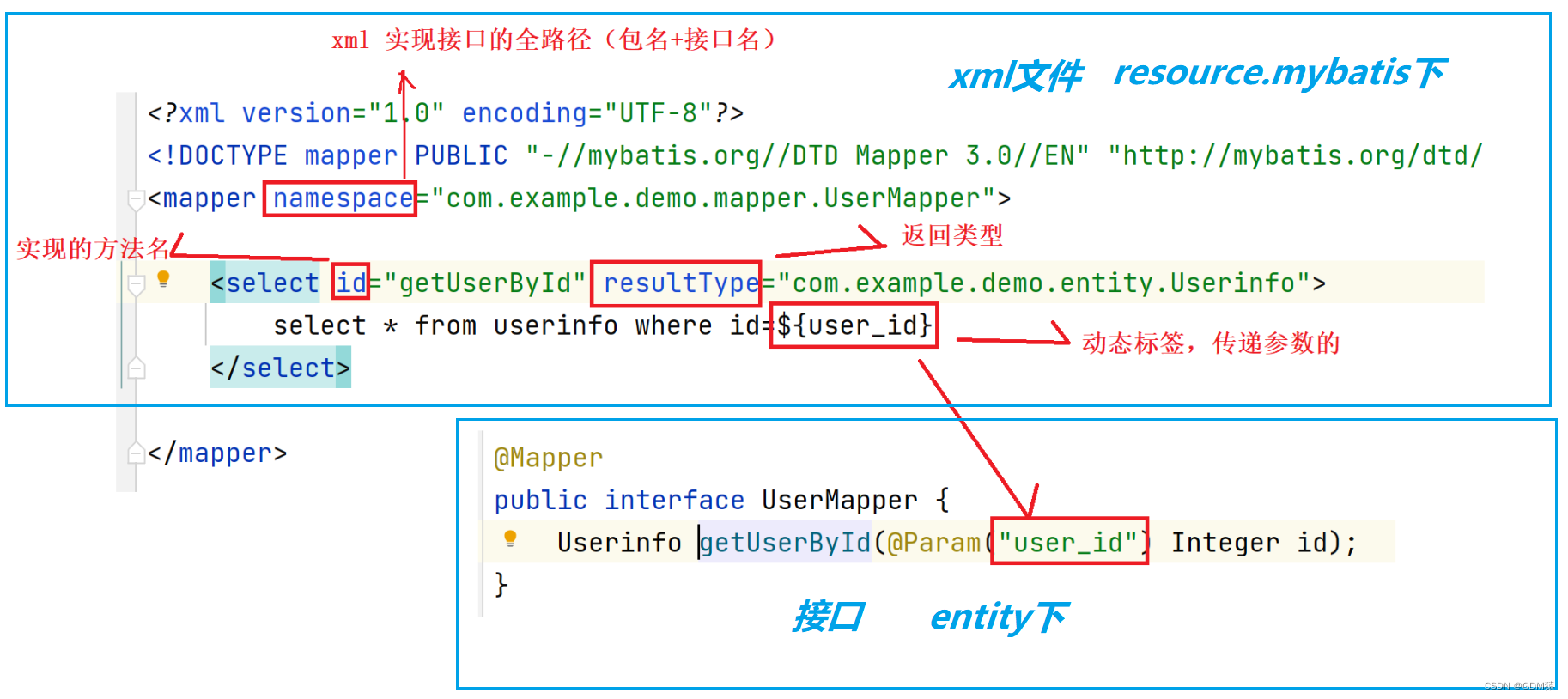
MyBatis-1:基础概念+环境配置
什么是MyBatis?MyBatis是一款优秀的持久层框架,支持自定义sql,存储过程以及高级映射。MyBatis就是可以让我们更加简单的实现程序和数据库之间进行交互的一个工具。可以让我们更加简单的操作和读取数据库的内容。MyBatis的官网:htt…...

R语言基础(五):流程控制语句
R语言基础(一):注释、变量 R语言基础(二):常用函数 R语言基础(三):运算 R语言基础(四):数据类型 6.流程控制语句 和大多数编程语言一样,R语言支持选择结构和循环结构。 6.1 选择语句 选择语句是当条件满足的时候才执行…...

【Java开发】设计模式 02:工厂模式
1 工厂模式介绍工厂模式(Factory Pattern)是 Java 中最常用的设计模式之一。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使…...
合并两个链表(自定义位置合并与有序合并)LeetCode--OJ题详解
图片: csdn 自定义位置合并 问题: 给两个链表 list1 和 list2 ,它们包含的元素分别为 n 个和 m 个。 请你将 list1 中 下标从 a 到 b 的全部节点都删除,并将list2 接在被删除节点 的位置。 比如: 输入:list1 [1…...

Java编程问题总结
Java编程问题总结 整理自 https://github.com/giantray/stackoverflow-java-top-qa 基础语法 将InputStream转换为String apache commons-io String content IOUtils.toString(new FileInputStream(file), StandardCharsets.UTF_8); //String value FileUtils.readFileT…...

binutils工具集——objcopy的用法
以下内容源于网络资源的学习与整理,如有侵权请告知删除。 一、工具简介 objcopy主要用来转换目标文件的格式。 在实际开发中,我们会用该工具进行格式转换与内容删除。 (1)在链接完成后,将elf格式的.out文件转化为bi…...
Windows使用Stable Diffusion时遇到的各种问题和知识点整理(更新中...)
Stable Diffusion安装完成后,在使用过程中会出现卡死、文件不存在等问题,在本文中将把遇到的问题陆续记录下来,有兴趣的朋友可以参考。 如果要了解如何安装sd,则参考本文《Windows安装Stable Diffusion WebUI及问题解决记录》。如…...

开源大模型落地实践:SenseVoice-Small ONNX在中小企业会议转录中的应用
开源大模型落地实践:SenseVoice-Small ONNX在中小企业会议转录中的应用 1. 项目简介:让语音识别变得简单高效 如果你在中小企业工作,肯定遇到过这样的场景:开完会后需要整理会议记录,要么自己边听录音边打字…...

Qwen3-ASR安全防护指南:防止语音识别系统被恶意利用
Qwen3-ASR安全防护指南:防止语音识别系统被恶意利用 1. 引言 语音识别技术正在改变我们与设备交互的方式,从智能助手到客服系统,Qwen3-ASR这样的先进模型让机器"听懂"人类语言变得前所未有的简单。但强大的能力也伴随着安全风险—…...
: QLineEdit)
QT编程(10): QLineEdit
一、QLineEdit核心定义与继承关系 QLineEdit是Qt Widgets模块中最基础、最常用的单行文本输入与显示控件,专门用于处理短文本内容的交互,仅支持单行纯文本输入,不支持换行和富文本格式,是Qt界面开发中短文本交互的核心组件&#x…...

数字化转型浪潮下,海量数据如何高效管理?
对于企业和个人用户而言,如何有效管理和存储知识、数据与信息,成为了关键挑战之一。在这个时代,云存储作为现代企业数据管理的重要工具,逐渐在办公环境中占据了极其重要的位置。而企业网盘,作为云存储的一部分…...

如何快速搭建Ruby on Rails管理后台:Trestle现代化框架的完整指南
如何快速搭建Ruby on Rails管理后台:Trestle现代化框架的完整指南 【免费下载链接】trestle A modern, responsive admin framework for Ruby on Rails 项目地址: https://gitcode.com/gh_mirrors/tr/trestle Trestle是一个为Ruby on Rails设计的现代化响应式…...
PyCaret特征工程:轻松构建专业级特征缩放与选择Pipeline
PyCaret特征工程:轻松构建专业级特征缩放与选择Pipeline 【免费下载链接】pycaret An open-source, low-code machine learning library in Python 项目地址: https://gitcode.com/gh_mirrors/py/pycaret PyCaret是一款开源的低代码机器学习库,它…...

基于代价的连接条件下推,金仓数据库让我们不在焦虑
你是否遇到过这样的场景:一个看似复杂的SQL,在测试环境运行飞快,一到生产环境就"卡死",一查执行计划,发现子查询生成了一个巨大的中间结果集,导致后续操作全部陷入性能泥潭? 如果你正…...

OpenInTerminal终极指南:10个高级脚本生成器和自定义命令配置技巧
OpenInTerminal终极指南:10个高级脚本生成器和自定义命令配置技巧 【免费下载链接】OpenInTerminal ✨ Finder Toolbar app for macOS to open the current directory in Terminal, iTerm, Hyper or Alacritty. 项目地址: https://gitcode.com/gh_mirrors/op/Open…...

Qiskit性能调优终极指南:10个技巧解决量子计算瓶颈
Qiskit性能调优终极指南:10个技巧解决量子计算瓶颈 【免费下载链接】qiskit Qiskit is an open-source SDK for working with quantum computers at the level of extended quantum circuits, operators, and primitives. 项目地址: https://gitcode.com/gh_mirro…...

00——计算机操作系统
操作系统是管理计算机硬件与软件资源的计算机程序,会对计算机管理硬件、驱动硬件;管理软件;资源分配与回收,操作系统也提供一个让用户与系统交互的操作界面。操作系统是一个计算机程序,是人类和计算机硬件沟通的一个桥…...