在Spring Data JPA中使用@Query注解
目录
- 前言
- 示例
- 简单示例
- 只查询部分字段,映射到一个实体类中
- 只查询部分字段时,也可以使用List<Object[]>接收返回值
- 再复杂一些
前言
在以往写过几篇spring data jpa相关的文章,分别是
Spring Data JPA 使用JpaSpecificationExecutor实现多条件查询(分页查询和非分页查询)
Spring Data JPA实现分页多条件查询2
都是通过代码而不是sql来完成查询的,但是在做复杂情况的查询时,难免会用到@Query写sql语句。
示例
简单示例
在@Query中用:paramName标识参数,再用@Param来指定方法参数与查询语句中的参数之间的映射关系。
例如:
@Query("select r from RelationDO r where r.indexCode in :idList")
List<RelationDO> findByIdListIn(@Param("idList") Collection<String> idList);
只查询部分字段,映射到一个实体类中
注意类的路径写完整
@Query("SELECT new com.xxx.service.impl.bo.RecordBO(e.code, e.day, e.total, e.success, e.fail, e.app) " +"FROM RecordDO e " +"WHERE e.code = :code AND e.day = :day " +"AND e.app in :appCodes")
List<RecordBO> findCalendarDetail(@Param("code") String code,@Param("day") String day,@Param("appCodes") List<String> appCodes);
这里为什么映射了一个新的BO出来呢… 是RecordDO中有一个id字段,在实体类中添加了@Id注解(实体必须有@Id,不然会报错),这个id字段本来设计的是不会重复的,但是后续经过一些改动,它在某些情况下会重复了,这个时候就会有一个问题,我直接select整个RecordDO,id字段重复的它会当成同一条记录(不确定为什么,但是实际跑出来确实是这样),但我又不想再去改表结构,因此这里我select的时候直接省略了id字段,就正常了。(可能不是一个很好的解决方案,但是确实是可以这么做的)
只查询部分字段在表字段较多,所需字段比较少的时候还是可以用的。
只查询部分字段时,也可以使用List<Object[]>接收返回值
例如我现在需要用code和month查出这么一个结果:
[{"day":"20240601","result":[{"rate": 98.77"app": "0001"},{"rate": 95.32"app": "0002"}]},{"day":"20240602","result":[{"rate": 95.65"app": "0001"},{"rate": 96.89"app": "0002"}]},……
]
也就是说要把月份中的每一天抽取出来,再在下面放每个app对应的明细
这个时候写sql:
@Query("SELECT e.day, e.app, e.success, e.total" +"FROM RecordDO e " +"WHERE e.code = :code AND SUBSTRING(e.day, 1, 6) = :month AND e.total > 0")
List<Object[]> findByMonth(@Param("code") String code,@Param("month") String month);
调用上述方法后封装返回数据:
List<CalendarBO> calendarBOS = Lists.newArrayList();
List<Object[]> resultList = recordRepository.findByMonth(code,month);if (!CollectionUtils.isEmpty(resultList)){for (Object[] result : resultList) {String day = (String) result[0];String app = (String) result[1];Integer success = (Integer) result[2];Integer total = (Integer) result[3];double rate = (double) success * 100 / total ;double roundedRate = Math.round(rate * 100.0) / 100.0;CalendarBO.Result result = CalendarBO.Result.builder().app(app).rate(roundedRate).build();// 组装返回内容Optional<CalendarBO> optionalBO = calendarBOS.stream().filter(bo -> bo.getDay().equals(day)).findFirst();// 该日期值不存在则创建 存在则添加不同app的记录if (!optionalBO.isPresent()) {CalendarBO calendarBO = CalendarBO.builder().day(day).result(Collections.singletonList(result)).build();calendarBOS.add(calendarBO);}else {CalendarBO calendarBO = optionalBO.get();List<CalendarBO.Result> results = calendarBO.getResult();results.add(result);calendarBO.setAssessResult(results);}}
}
再复杂一些
通过beginMonth、endMonth和appCodes筛选,需要返回的数据格式如下
这里的pass是有一个标准rate,当data中success/total(rate) > 标准rate时单项视为pass,而total中的total则代表该月份区间共统计次数。
{"total": [{"total": 13,"pass": 13,"app": "0001"},{"total": 13,"pass": 12,"app": "0002"}],"data": [{"code": "101","month": 202406,"result": [{"total": 13,"success": 13,"rate": 100,"app": "0001"},{"total": 12,"success": 11,"rate": 92,"app": "0002"}]},{"code": "102","month": 202406,"result": [{"total": 15,"success": 15,"rate": 100,"app": "0001"}]},……]
}
此时的sql:
@Query("SELECT e.code, e.app, SUBSTRING(e.day, 1, 6), COUNT(e.statId), " +"SUM(CASE WHEN (CAST(e.success AS double) / e.total) >= :rate THEN 1 ELSE 0 END) " +"FROM RecordDO e " +"WHERE e.code = :code" +" AND SUBSTRING(e.day, 1, 6) BETWEEN :beginMonth AND :endMonth " +" AND ((:appCodes) IS NULL OR e.app IN (:appCodes)) AND e.total > 0 " +"GROUP BY e.code, e.app, SUBSTRING(e.day, 1, 6)")
List<Object[]> findByCodeGroupBy(@Param("code") String code,@Param("beginMonth") String beginMonth,@Param("endMonth") String endMonth,@Param("appCodes") List<String> appCodes,@Param("rate") Double rate);这样就直接把总数和pass的计数给取出来了(statId和总数可以对应)
调用上述方法后封装返回数据,和之前基本一致:
// 根据分类计算总数的映射
Map<String, Integer> totalCounts = new HashMap<>();
Map<String, Integer> passCounts = new HashMap<>();
//返回的明细对象
List<DataBO> dataList = new ArrayList<>();//假设已获取到code和标准rate的对应关系passRate
for (Map.Entry<String, Double> entry : passRate.entrySet()) {List<Object[]> resultList = recordRepository.findByCodeGroupBy(entry.getKey(), reqBO.getBeginMonth(),reqBO.getEndMonth(), reqBO.getAppCodeList(), entry.getValue());if (CollectionUtils.isEmpty(resultList)) {continue;}for (Object[] result : resultList) {String code = (String) result[0];String app = (String) result[1];String month = (String) result[2];Long totalLong = (Long) result[3];String total = totalLong.toString();Long successLong = (Long) result[4];String success = successLong.toString();double rateDouble = Double.parseDouble(success) / Double.parseDouble(total);String rate = String.format("%.2f", rateDouble * 100);DataBO.Result result = DataBO.Result.builder().total(total).success(success).rate(rate).app(app).build();//查看dataList中是否该编码和月份的数据已存在 不存在则新建 存在则获取DataBO data = dataList.stream().filter(a -> a.getCode().equals(code) && a.getMonth().equals(month)).findFirst().orElseGet(() -> {DataBO newAccount = new DataBO();newAccount.setCode(code);newAccount.setMonth(month);accountList.add(newAccount);return newAccount;});if (data.getResult() == null) {data.setResult(Lists.newArrayList());}data.getResult().add(result);// 更新统计totalCounts.put(app, totalCounts.getOrDefault(app, 0) + Integer.parseInt(total));passCounts.put(app, passCounts.getOrDefault(app, 0) + Integer.parseInt(success));}
}
//组装统计类
totalCounts.entrySet().stream().map(entry -> {String app = entry.getKey();int total = entry.getValue();int pass = passCounts.getOrDefault(app, 0);TotalCountBO totalCount = new TotalCountBO();totalCount.setAppCode(app);totalCount.setTotal(String.valueOf(total));totalCount.setPass(String.valueOf(pass));return totalCount;}).collect(Collectors.toList());return RespBO.builder().data(dataList).total(totalCounts).build();
匆忙所写,不确定有没有问题,有的话联系我~
相关文章:

在Spring Data JPA中使用@Query注解
目录 前言示例简单示例只查询部分字段,映射到一个实体类中只查询部分字段时,也可以使用List<Object[]>接收返回值再复杂一些 前言 在以往写过几篇spring data jpa相关的文章,分别是 Spring Data JPA 使用JpaSpecificationExecutor实现…...
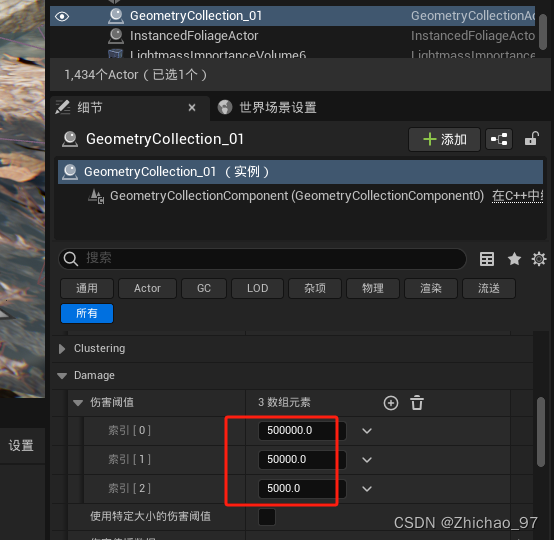
【UE5.1】Chaos物理系统基础——01 创建可被破坏的物体
目录 步骤 一、通过笔刷创建静态网格体 二、破裂静态网格体 三、“统一” 多层级破裂 四、“簇” 群集化的破裂 五、几何体集的材质 六、防止几何体集自动破碎 步骤 一、通过笔刷创建静态网格体 1. 可以在Quixel Bridge中下载两个纹理,用于表示石块的内外纹…...

Linux下SUID提权学习 - 从原理到使用
目录 1. 文件权限介绍1.1 suid权限1.2 sgid权限1.3 sticky权限 2. SUID权限3. 设置SUID权限4. SUID提权原理5. SUID提权步骤6. 常用指令的提权方法6.1 nmap6.2 find6.3 vim6.4 bash6.5 less6.6 more6.7 其他命令的提权方法 1. 文件权限介绍 linux的文件有普通权限和特殊权限&a…...

Redis主从复制搭建一主多从
1、创建/myredis文件夹 2、复制redis.conf配置文件到新建的文件夹中 3、配置一主两从,创建三个配置文件 ----redis6379.conf ----redis6380.conf ----redis6381.conf 4、在三个配置文件写入内容 redis6379.conf里面的内容 include /myredis/redis.conf pidfile /va…...
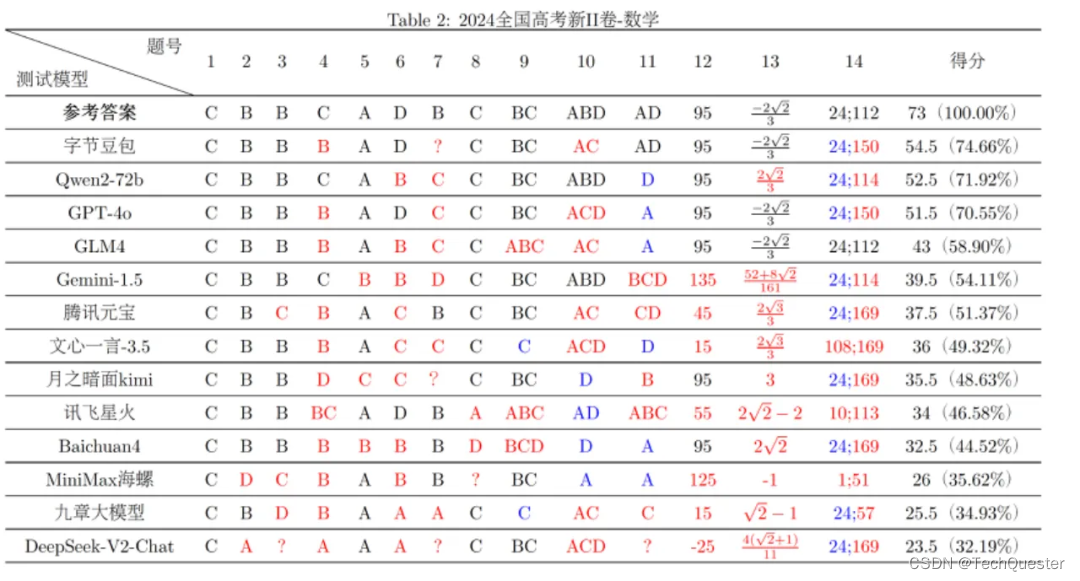
GPT-4o文科成绩超一本线,理科为何表现不佳?
目录 01 评测榜单 02 实际效果 什么?许多大模型的文科成绩竟然超过了一本线,还是在竞争激烈的河南省? 没错,最近有一项大模型“高考大摸底”评测引起了广泛关注。 河南高考文科今年的一本线是521分,根据这项评测&…...

Lombok的hashCode方法
Lombok对于重写hashCode的算法真的是很经典,但是目前而言有一个令人难以注意到的细节。在继承关系中,父类的hashCode针对父类的所有属性进行运算,而子类的hashCode却只是针对子类才有的属性进行运算,立此贴提醒自己。 目前重写ha…...

关于springboot创建kafkaTopic
工具类提供,方法名见名知意。使用kafka admin import org.apache.kafka.clients.admin.*; import org.apache.kafka.common.KafkaFuture;import java.util.*; import java.util.concurrent.ExecutionException;import org.apache.kafka.clients.admin.AdminClient; …...

OOAD的概念
面向对象分析与设计(OOAD, Object-Oriented Analysis and Design)是一种软件开发方法,它利用面向对象的概念和技术来分析和设计软件系统。OOAD 主要关注对象、类以及它们之间的关系,通过抽象、封装、继承和多态等面向对象的基本原…...

Day47
Day47 手写Spring-MVC之DispatcherServlet DispatcherServlet的思路: 前端传来URI,在TypeContainer容器类中通过uri得到对应的类描述类对象(注意:在监听器封装类描述类对象的时候,是针对于每一个URI进行封装的&#x…...

【面试系列】后端开发工程师 高频面试题及详细解答
欢迎来到我的博客,很高兴能够在这里和您见面!欢迎订阅相关专栏: ⭐️ 全网最全IT互联网公司面试宝典:收集整理全网各大IT互联网公司技术、项目、HR面试真题. ⭐️ AIGC时代的创新与未来:详细讲解AIGC的概念、核心技术、…...

mac|浏览器链接不上服务器但可以登微信
千万千万千万不要没有关梯子直接关机,不然就会这样子呜呜呜 设置-网络,点击三个点--选择--位置--编辑位置(默认是自动) 新增一个,然后选中点击完成 这样就可以正常上网了...
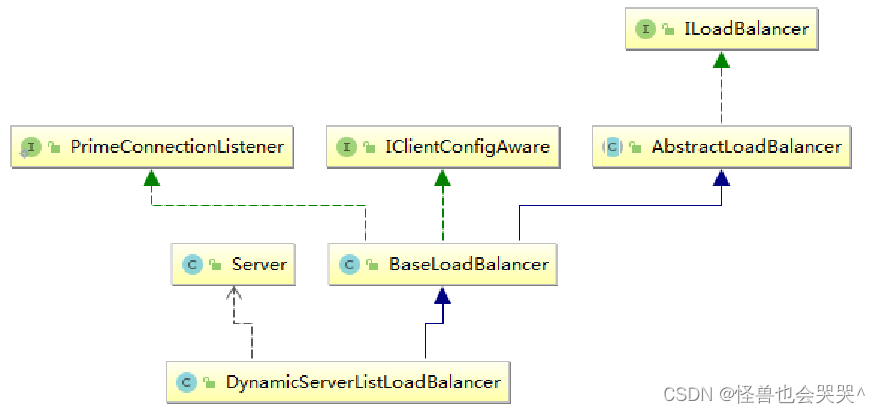
Spring Cloud Alibaba之负载均衡组件Ribbon
一、什么是负载均衡? (1)概念: 在基于微服务架构开发的系统里,为了能够提升系统应对高并发的能力,开发人员通常会把具有相同业务功能的模块同时部署到多台的服务器中,并把访问业务功能的请求均…...
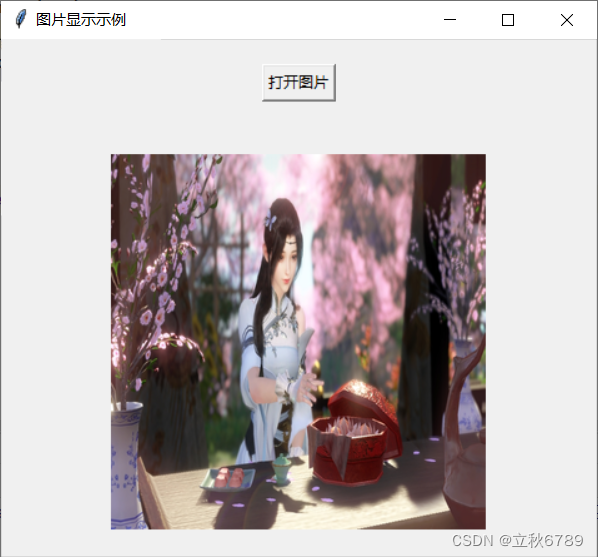
tkinter显示图片
tkinter显示图片 效果代码解析打开和显示图像 代码 效果 代码解析 打开和显示图像 def open_image():file_path filedialog.askopenfilename(title"选择图片", filetypes(("PNG文件", "*.png"), ("JPEG文件", "*.jpg;*.jpeg&q…...

000.二分查找算法题解目录
000.二分查找算法题解目录 69. x 的平方根(简单)34. 在排序数组中查找元素的第一个和最后一个位置(中等)...

数据资产赋能企业决策:通过精准的数据分析和洞察,构建高效的数据资产解决方案,为企业提供决策支持,助力企业实现精准营销、风险管理、产品创新等目标,提升企业竞争力
一、引言 在信息化和数字化飞速发展的今天,数据已成为企业最宝贵的资产之一。数据资产不仅包含了企业的基本信息,还蕴含了丰富的市场趋势、消费者行为和潜在商机。如何通过精准的数据分析和洞察,构建高效的数据资产解决方案,为企…...
【java开发环境】多版本jdk 自由切换window和linux
win10 一、准备 各种版本的jdk,按自己的需要下载。 我这里是需要jdk17和jdk8。 1、jdk17 下载:Java Downloads | Oracle,选择exe后缀文件 2、jdk8下 载:Java Downloads | Oracle,选择exe后缀文件 二、详细步骤 1、…...
MySQL实训项目——餐饮点餐系统
项目简介:餐饮点餐系统是一款为餐厅和顾客提供便捷点餐服务的在线平台。通过该系统,餐厅能够展示其菜单,顾客可以浏览菜品,并将其加入购物车或直接下单。系统还提供了订单管理功能,方便餐厅跟踪和处理顾客的订单。 1. …...

昇思MindSpore学习总结七——模型训练
1、模型训练 模型训练一般分为四个步骤: 构建数据集。定义神经网络模型。定义超参、损失函数及优化器。输入数据集进行训练与评估。 现在我们有了数据集和模型后,可以进行模型的训练与评估。 2、构建数据集 首先从数据集 Dataset加载代码࿰…...

AI时代创新潮涌,从探路到引路,萤石云引领千行百业创新
步入AI新时代,AI、云计算、大数据等技术迅速迭代,并日益融入经济社会发展各领域全过程,数字经济成为推动千行百业转型升级的重要驱动力量。 今年的政府工作报告提出,深入推进数字经济创新发展。积极推进数字产业化、产业数字化&a…...

计算机毕业设计Python深度学习美食推荐系统 美食可视化 美食数据分析大屏 美食爬虫 美团爬虫 机器学习 大数据毕业设计 Django Vue.js
Python美食推荐系统开题报告 一、项目背景与意义 随着互联网和移动技术的飞速发展,人们的生活方式发生了巨大变化,尤其是餐饮行业。在线美食平台如雨后春笋般涌现,为用户提供了丰富的美食选择。然而,如何在海量的餐饮信息中快速…...
)
浏览器访问 AWS ECS 上部署的 Docker 容器(监听 80 端口)
✅ 一、ECS 服务配置 Dockerfile 确保监听 80 端口 EXPOSE 80 CMD ["nginx", "-g", "daemon off;"]或 EXPOSE 80 CMD ["python3", "-m", "http.server", "80"]任务定义(Task Definition&…...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...
)
C++课设:简易日历程序(支持传统节假日 + 二十四节气 + 个人纪念日管理)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、为什么要开发一个日历程序?1. 深入理解时间算法2. 练习面向对象设计3. 学习数据结构应用二、核心算法深度解析…...