昇思MindSpore学习总结七——模型训练
1、模型训练
模型训练一般分为四个步骤:
- 构建数据集。
- 定义神经网络模型。
- 定义超参、损失函数及优化器。
- 输入数据集进行训练与评估。
现在我们有了数据集和模型后,可以进行模型的训练与评估。
2、构建数据集
首先从数据集 Dataset加载代码,构建数据集。
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset# Download data from open datasets
from download import downloadurl = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)def datapipe(path, batch_size):image_transforms = [vision.Rescale(1.0 / 255.0, 0),vision.Normalize(mean=(0.1307,), std=(0.3081,)),vision.HWC2CHW()]label_transform = transforms.TypeCast(mindspore.int32)#mindspore.dataset.transforms.TypeCast(data_type)#将输入的Tensor转换为指定的数据类型。dataset = MnistDataset(path)dataset = dataset.map(image_transforms, 'image')dataset = dataset.map(label_transform, 'label')dataset = dataset.batch(batch_size)return datasettrain_dataset = datapipe('MNIST_Data/train', batch_size=64)
test_dataset = datapipe('MNIST_Data/test', batch_size=64)
3、定义神经网络模型
从网络构建中加载代码,构建一个神经网络模型。
class Network(nn.Cell):def __init__(self):super().__init__()self.flatten = nn.Flatten()#将数据从start_dim 到 end_dim 的维度,对输入Tensor进行展平self.dense_relu_sequential = nn.SequentialCell(#构造Cell顺序容器。nn.Dense(28*28, 512),nn.ReLU(),nn.Dense(512, 512),nn.ReLU(),nn.Dense(512, 10))def construct(self, x):x = self.flatten(x)logits = self.dense_relu_sequential(x)return logitsmodel = Network()4、定义超参、损失函数和优化器
4.1 超参
超参(Hyperparameters)是可以调整的参数,可以控制模型训练优化的过程,不同的超参数值可能会影响模型训练和收敛速度。目前深度学习模型多采用批量随机梯度下降算法进行优化,随机梯度下降算法的原理如下:

公式中,𝑛是批量大小(batch size),η是学习率(learning rate)。另外,𝑤𝑡为训练轮次𝑡中的权重参数,∇𝑙为损失函数的导数。除了梯度本身,这两个因子直接决定了模型的权重更新,从优化本身来看,它们是影响模型性能收敛最重要的参数。一般会定义以下超参用于训练:
-
训练轮次(epoch):训练时遍历数据集的次数。
-
批次大小(batch size):数据集进行分批读取训练,设定每个批次数据的大小。batch size过小,花费时间多,同时梯度震荡严重,不利于收敛;batch size过大,不同batch的梯度方向没有任何变化,容易陷入局部极小值,因此需要选择合适的batch size,可以有效提高模型精度、全局收敛。
-
学习率(learning rate):如果学习率偏小,会导致收敛的速度变慢,如果学习率偏大,则可能会导致训练不收敛等不可预测的结果。梯度下降法被广泛应用在最小化模型误差的参数优化算法上。梯度下降法通过多次迭代,并在每一步中最小化损失函数来预估模型的参数。学习率就是在迭代过程中,会控制模型的学习进度。
epochs = 3
batch_size = 64
learning_rate = 1e-24.2 损失函数
损失函数(loss function)用于评估模型的预测值(logits)和目标值(targets)之间的误差。训练模型时,随机初始化的神经网络模型开始时会预测出错误的结果。损失函数会评估预测结果与目标值的相异程度,模型训练的目标即为降低损失函数求得的误差。
常见的损失函数包括用于回归任务的nn.MSELoss(均方误差)和用于分类的nn.NLLLoss(负对数似然)等。 nn.CrossEntropyLoss 结合了nn.LogSoftmax和nn.NLLLoss,可以对logits 进行归一化并计算预测误差。
loss_fn = nn.CrossEntropyLoss()4.3 优化器
模型优化(Optimization)是在每个训练步骤中调整模型参数以减少模型误差的过程。MindSpore提供多种优化算法的实现,称之为优化器(Optimizer)。优化器内部定义了模型的参数优化过程(即梯度如何更新至模型参数),所有优化逻辑都封装在优化器对象中。在这里,我们使用SGD(Stochastic Gradient Descent)优化器。
mindspore.nn.SGD(params, learning_rate=0.1, momentum=0.0, dampening=0.0, weight_decay=0.0, nesterov=False, loss_scale=1.0)
随机梯度下降的实现。动量可选。
【参数】
-
params (Union[list[Parameter], list[dict]]) - 当 params 为会更新的 Parameter 列表时, params 中的元素必须为类 Parameter。当 params 为 dict 列表时,”params”、”lr”、”weight_decay”、”grad_centralization”和”order_params”为可以解析的键。
-
params - 必填。当前组别的权重,该值必须是 Parameter 列表。
-
lr - 可选。如果键中存在”lr”,则使用对应的值作为学习率。如果没有,则使用优化器中的参数 learning_rate 作为学习率。支持固定和动态学习率。
-
weight_decay - 可选。如果键中存在”weight_decay”,则使用对应的值作为权重衰减值。如果没有,则使用优化器中配置的 weight_decay 作为权重衰减值。当前 weight_decay 仅支持float类型,不支持动态变化。
-
grad_centralization - 可选。如果键中存在”grad_centralization”,则使用对应的值,该值必须为布尔类型。如果没有,则认为 grad_centralization 为False。该参数仅适用于卷积层。
-
order_params - 可选。值的顺序是参数更新的顺序。当使用参数分组功能时,通常使用该配置项保持 parameters 的顺序以提升性能。如果键中存在”order_params”,则会忽略该组配置中的其他键。”order_params”中的参数必须在某一组 params 参数中。
-
-
learning_rate (Union[float, int, Tensor, Iterable, LearningRateSchedule]) - 默认值:
0.1。-
float - 固定的学习率。必须大于等于零。
-
int - 固定的学习率。必须大于等于零。整数类型会被转换为浮点数。
-
Tensor - 可以是标量或一维向量。标量是固定的学习率。一维向量是动态的学习率,第i步将取向量中第i个值作为学习率。
-
Iterable - 动态的学习率。第i步将取迭代器第i个值作为学习率。
-
LearningRateSchedule - 动态的学习率。在训练过程中,优化器将使用步数(step)作为输入,调用 LearningRateSchedule 实例来计算当前学习率。
-
-
momentum (float) - 浮点动量,必须大于等于0.0。默认值:
0.0。 -
dampening (float) - 浮点动量阻尼值,必须大于等于0.0。默认值:
0.0。 -
weight_decay (float) - 权重衰减(L2 penalty),必须大于等于0。默认值:
0.0。 -
nesterov (bool) - 启用Nesterov动量。如果使用Nesterov,动量必须为正,阻尼必须等于0.0。默认值:
False。
-
loss_scale (float) - 梯度缩放系数,必须大于0.0。如果 loss_scale 是整数,它将被转换为浮点数。通常使用默认值,仅当训练时使用了 FixedLossScaleManager,且 FixedLossScaleManager 的 drop_overflow_update 属性配置为
False时,此值需要与 FixedLossScaleManager 中的 loss_scale 相同。有关更多详细信息,请参阅 mindspore.amp.FixedLossScaleManager。默认值:1.0。
我们通过model.trainable_params()方法获得模型的可训练参数,并传入学习率超参来初始化优化器。
5、训练与评估
设置了超参、损失函数和优化器后,我们就可以循环输入数据来训练模型。一次数据集的完整迭代循环称为一轮(epoch)。每轮执行训练时包括两个步骤:
- 训练:迭代训练数据集,并尝试收敛到最佳参数。
- 验证/测试:迭代测试数据集,以检查模型性能是否提升。
接下来我们定义用于训练的train_loop函数和用于测试的test_loop函数。
使用函数式自动微分,需先定义正向函数forward_fn,使用value_and_grad获得微分函数grad_fn。然后,我们将微分函数和优化器的执行封装为train_step函数,接下来循环迭代数据集进行训练即可。
mindspore.value_and_grad(fn, grad_position=0, weights=None, has_aux=False, return_ids=False)
生成求导函数,用于计算给定函数的正向计算结果和梯度。
函数求导包含以下三种场景:
-
对输入求导,此时 grad_position 非None,而 weights 是None;
-
对网络变量求导,此时 grad_position 是None,而 weights 非None;
-
同时对输入和网络变量求导,此时 grad_position 和 weights 都非None。
【参数】
-
fn (Union[Cell, Function]) - 待求导的函数或网络。
-
grad_position (Union[NoneType, int, tuple[int]]) - 指定求导输入位置的索引。若为int类型,表示对单个输入求导;若为tuple类型,表示对tuple内索引的位置求导,其中索引从0开始;若是None,表示不对输入求导,这种场景下, weights 非None。默认值:
0。 -
weights (Union[ParameterTuple, Parameter, list[Parameter]]) - 训练网络中需要返回梯度的网络变量。一般可通过 weights = net.trainable_params() 获取。默认值:
None。 -
has_aux (bool) - 是否返回辅助参数的标志。若为
True, fn 输出数量必须超过一个,其中只有 fn 第一个输出参与求导,其他输出值将直接返回。默认值:False。 -
return_ids (bool) - 是否返回由返回的梯度和指定求导输入位置的索引或网络变量组成的tuple。若为
True,其输出中所有的梯度值将被替换为:由该梯度和其输入的位置索引,或者用于计算该梯度的网络变量组成的tuple。默认值:False。
# Define forward function
def forward_fn(data, label):logits = model(data)loss = loss_fn(logits, label)return loss, logits# Get gradient function
grad_fn = mindspore.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)# Define function of one-step training
def train_step(data, label):(loss, _), grads = grad_fn(data, label)optimizer(grads)return lossdef train_loop(model, dataset):size = dataset.get_dataset_size()model.set_train()for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):loss = train_step(data, label)if batch % 100 == 0:loss, current = loss.asnumpy(), batchprint(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")test_loop函数同样需循环遍历数据集,调用模型计算loss和Accuray并返回最终结果。
def test_loop(model, dataset, loss_fn):num_batches = dataset.get_dataset_size()model.set_train(False)total, test_loss, correct = 0, 0, 0for data, label in dataset.create_tuple_iterator():pred = model(data)total += len(data)test_loss += loss_fn(pred, label).asnumpy()correct += (pred.argmax(1) == label).asnumpy().sum()test_loss /= num_batchescorrect /= totalprint(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")

相关文章:
昇思MindSpore学习总结七——模型训练
1、模型训练 模型训练一般分为四个步骤: 构建数据集。定义神经网络模型。定义超参、损失函数及优化器。输入数据集进行训练与评估。 现在我们有了数据集和模型后,可以进行模型的训练与评估。 2、构建数据集 首先从数据集 Dataset加载代码࿰…...

AI时代创新潮涌,从探路到引路,萤石云引领千行百业创新
步入AI新时代,AI、云计算、大数据等技术迅速迭代,并日益融入经济社会发展各领域全过程,数字经济成为推动千行百业转型升级的重要驱动力量。 今年的政府工作报告提出,深入推进数字经济创新发展。积极推进数字产业化、产业数字化&a…...

计算机毕业设计Python深度学习美食推荐系统 美食可视化 美食数据分析大屏 美食爬虫 美团爬虫 机器学习 大数据毕业设计 Django Vue.js
Python美食推荐系统开题报告 一、项目背景与意义 随着互联网和移动技术的飞速发展,人们的生活方式发生了巨大变化,尤其是餐饮行业。在线美食平台如雨后春笋般涌现,为用户提供了丰富的美食选择。然而,如何在海量的餐饮信息中快速…...

【鸿蒙学习笔记】鸿蒙ArkTS学习笔记
应用开发导读:https://developer.huawei.com/consumer/cn/doc/harmonyos-guides-V5/application-dev-guide-V5 这里写目录标题 基础组件通用属性容器组件Button 迭代完备 【鸿蒙培训】第1天・环境安装 【鸿蒙培训】第2天・装饰器・组件和页面…...

广东行政职业学院数据智能订单班开班暨上进双创工作室签约仪式圆满结束
为响应教育领域数字化与智能化浪潮这一变革,给学生提供更好的教育资源和实践机会,6月27日,“泰迪广东行政职业学院数据智能订单班开班仪式暨上进双创工作室签约授牌”在广东行政职业学院举行。广东行政职业学院智慧政务学院(电子信…...

python与matlab微分切片的区别
python python使用np中的linespace生成等间隔数值, import numpy as np numpy.linspace(start, stop, num50, endpointTrue, retstepFalse, dtypeNone, axis0)start:序列的起始值。stop:序列的结束值。如果 endpoint 为 True,该…...
MSPG3507——蓝牙接收数据显示在OLED,滴答定时器延时500MS
#include "ti_msp_dl_config.h" #include "OLED.h" #include "stdio.h"volatile unsigned int delay_times 0;//搭配滴答定时器实现的精确ms延时 void delay_ms(unsigned int ms) {delay_times ms;while( delay_times ! 0 ); } int a0; …...
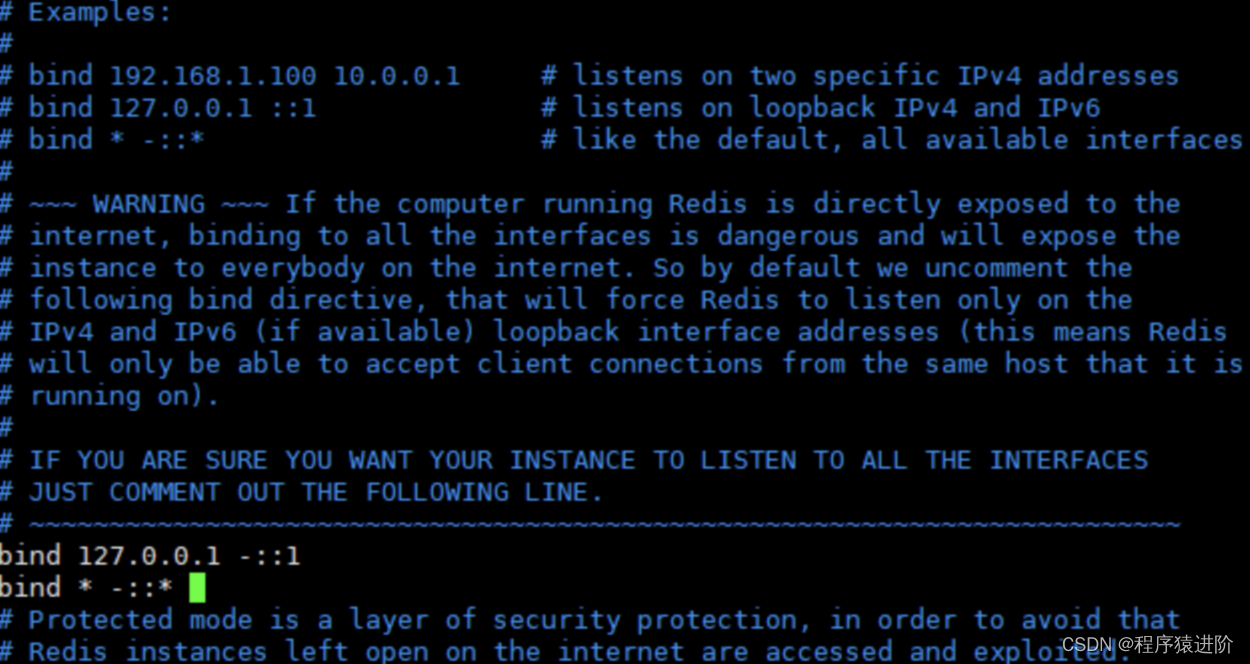
Linux 安装 Redis 教程
优质博文:IT-BLOG-CN 一、准备工作 配置gcc:安装Redis前需要配置gcc: yum install gcc如果配置gcc出现依赖包问题,在安装时提示需要的依赖包版本和本地版本不一致,本地版本过高,出现如下问题:…...

【高考志愿】建筑学
目录 一、专业介绍 1.1 专业定义 1.2 专业培养目标 1.3 核心课程 二、就业方向和前景 2.1 就业方向 2.2 专业前景 三、报考注意 四、行业趋势与未来展望 五、建筑学专业排名 一、专业介绍 1.1 专业定义 建筑学,这一充满艺术与科技魅力的学科,…...

Kubernetes的发展历程:从Google内部项目到云原生计算的基石
目录 一、起源与背景 1.1 Google的内部项目 1.2 Omega的出现 二、Kubernetes的诞生 2.1 开源的决策 2.2 初期发布 三、Kubernetes的发展历程 3.1 社区的成长 3.2 生态系统的壮大 3.3 重大版本和功能 3.4 多云和混合云的支持 四、Kubernetes的核心概念 4.1 Pod 4.…...

/proc/config.gz
前言 有时候,我们想知道一个运行着的内核都打开了哪些编译选项,当然,查看编译环境的 .config 文件是一个不错的选择,除此之外,还有没有别的办法呢?当然有,那就是 /proc/config.gz。 一睹风采 …...
论坛万能粘贴手(可将任意文件转为文本)
该软件可将任意文件转为文本。 还原为原文件的方法:将得到的文本粘贴到记事本,另存为UUE格式,再用压缩软件如winrar解压即可得到原文件。建议用于小软件。 下载地址:https://download.csdn.net/download/wgxds/89505015 使用演示…...
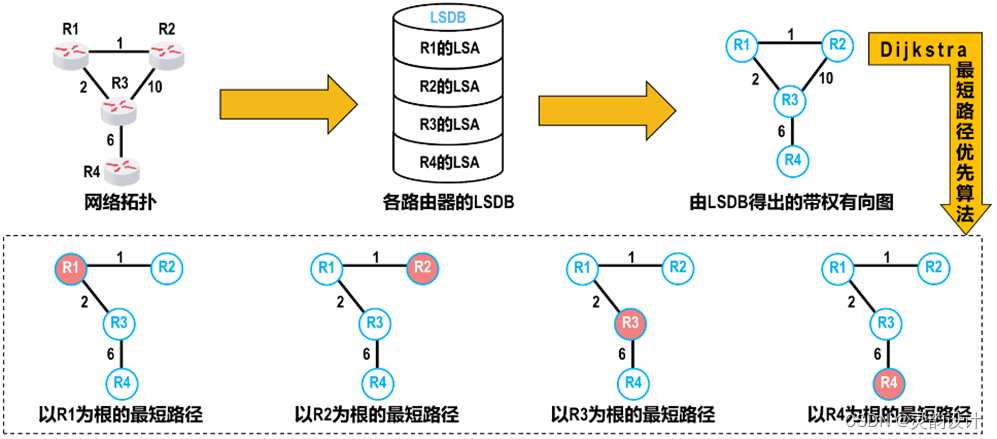
学习笔记——动态路由——OSPF(OSPF协议的工作原理)
八、OSPF协议的工作原理 1、原理概要 (1)相邻路由器之间周期性发送HELLO报文,以便建立和维护邻居关系 (2)建立邻居关系后,给邻居路由器发送数据库描述报文(DBD),也就是将自己链路状态数据库中的所有链路状态项目的摘要信息发送给邻居路由器…...

Mybatis1(JDBC编程和ORM模型 MyBatis简介 实现增删改查 MyBatis生命周期)
目录 一、JDBC编程和ORM模型 1. JDBC回顾 2. JDBC的弊端 3. ORM模型 Mybatis和hibernate 区别: 4. mybatis 解决了jdbc 的问题 二、MyBatis简介 1. MyBatis快速开始 1.1 导入jar包 1.2 引入 mybatis-config.xml 配置文件 1.3 引入 Mapper 映射文件 1.3 测试 …...

论文阅读YOLO-World: Real-Time Open-Vocabulary Object Detection
核心: 开放词汇的实时的yolo检测器。重参数化的视觉语言聚合路径模块Re-parameterizable VisionLanguage Path Aggregation Network (RepVL-PAN)实时核心:轻量化的检测器离线词汇推理过程重参数化 方法 预训练方案:将实例注释重新定义为区域…...

SM2的签名值byte数组与ASN.1互转
ASN.1抽象语言标记(Abstract Syntax Notation One) ASN.1是一种 ISO/ITU-T 标准,描述了一种对数据进行表示、编码、传输和解码的数据格式,它提供了一整套正规的格式用于描述对象的结构。 一、该结构的应用场景 例如在做待签名的数字信封时,数字信封使用ASN.1封装,这个时…...

云计算与生成式AI的技术盛宴!亚马逊云科技深圳 Community Day 社区活动流程抢先知道!
小李哥最近要给大家分享7月7日在深圳的即将举办的亚马逊云科技生成式AI社区活动Community Day ,干货很多内容非常硬核,不仅有技术分享学习前沿AI技术,大家在现场还可以动手实践沉浸式体验大模型,另外参与现场活动还可以领取诸多精…...

【鸿蒙学习笔记】基础组件Progress:进度条组件
官方文档:Progress 目录标题 作用最全属性迭代追加进度赋值风格样式 作用 进度条组件 最全属性迭代追加 Progress({ value: 20, total: 100, type: ProgressType.Linear }).color(Color.Green)// 颜色.width(200)// 大小.height(50)// 高度.value(50)// 进度可更…...
前程无忧滑块
声明(lianxi a15018601872) 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 前言(lianxi …...

一站式uniapp优质源码项目模版交易平台的崛起与影响
一、引言 随着信息技术的飞速发展,软件源码已成为推动行业进步的重要力量。源码的获取、交易和流通,对于开发者、企业以及项目团队而言,具有极其重要的意义。为满足市场对高质量源码资源的迫切需求,一站式uniapp优质源码项目模版…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...
)
rknn优化教程(二)
文章目录 1. 前述2. 三方库的封装2.1 xrepo中的库2.2 xrepo之外的库2.2.1 opencv2.2.2 rknnrt2.2.3 spdlog 3. rknn_engine库 1. 前述 OK,开始写第二篇的内容了。这篇博客主要能写一下: 如何给一些三方库按照xmake方式进行封装,供调用如何按…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

Golang——9、反射和文件操作
反射和文件操作 1、反射1.1、reflect.TypeOf()获取任意值的类型对象1.2、reflect.ValueOf()1.3、结构体反射 2、文件操作2.1、os.Open()打开文件2.2、方式一:使用Read()读取文件2.3、方式二:bufio读取文件2.4、方式三:os.ReadFile读取2.5、写…...

WPF八大法则:告别模态窗口卡顿
⚙️ 核心问题:阻塞式模态窗口的缺陷 原始代码中ShowDialog()会阻塞UI线程,导致后续逻辑无法执行: var result modalWindow.ShowDialog(); // 线程阻塞 ProcessResult(result); // 必须等待窗口关闭根本问题:…...

在RK3588上搭建ROS1环境:创建节点与数据可视化实战指南
在RK3588上搭建ROS1环境:创建节点与数据可视化实战指南 背景介绍完整操作步骤1. 创建Docker容器环境2. 验证GUI显示功能3. 安装ROS Noetic4. 配置环境变量5. 创建ROS节点(小球运动模拟)6. 配置RVIZ默认视图7. 创建启动脚本8. 运行可视化系统效果展示与交互技术解析ROS节点通…...

从实验室到产业:IndexTTS 在六大核心场景的落地实践
一、内容创作:重构数字内容生产范式 在短视频创作领域,IndexTTS 的语音克隆技术彻底改变了配音流程。B 站 UP 主通过 5 秒参考音频即可克隆出郭老师音色,生成的 “各位吴彦祖们大家好” 语音相似度达 97%,单条视频播放量突破百万…...

基于Uniapp的HarmonyOS 5.0体育应用开发攻略
一、技术架构设计 1.混合开发框架选型 (1)使用Uniapp 3.8版本支持ArkTS编译 (2)通过uni-harmony插件调用原生能力 (3)分层架构设计: graph TDA[UI层] -->|Vue语法| B(Uniapp框架)B --&g…...