Hadoop权威指南-读书笔记-01-初识Hadoop
Hadoop权威指南-读书笔记
记录一下读这本书的时候觉得有意思或者重要的点~

第一章—初识Hadoop

Tips: 这个引例很有哲理嘻嘻😄,道出了分布式的灵魂。
1.1 数据!数据!
这一小节主要介绍了进入大数据时代,面临数据量飙升的问题,我们该如何管理好自己的数据,或者说如何利用好规模如此庞大的数据。

博主摘录了一些原文:
-
有句话说得好: “大数据胜于好算法。” 意思是说对于某些应用(譬如根据以往的偏好来推荐电影和音乐),不论算法有多牛,基于小数据的推荐效果往往都不如基于大量可用数据的一般算法的推荐效果。(
More Data usually beats better algorithms) -
现在,我们已经有了大量数据,这是个好消息。但不幸的是,我们必须想方设法好好地存储和分析这些数据。
More Data usually beats better algorithms,这个观点博主认为很有意思🤣
1.2 数据的存储与分析
这里博主就直接记录一下原文比较值得思考的片段了哈 ~
- 我们遇到的问题很简单:在硬盘存储容量多年来不断提升的同时,访问速度(硬盘数据读取速度)却没有与时俱进。
Tips:这里并非说多年来硬盘的读取速度没有提升,而是硬盘的读取速度的提升相对于硬盘容量的提升还有差距。
这里文章有一个小例子大家可以看一下:1990年,一个普通硬盘可以存储1370MB数据,传输速度为4.4MB/S,因此只需要5分钟就可以读完整个硬盘中的数据。20年过去了,1TB的硬盘成为主流,但其数据传输速度约为100MB/,读完整个硬盘中的数据至少得花2.5个小时。
-
一个很简单的减少读取时间的办法是同时从多个硬盘上读数据。试想,如果我们有100个硬盘,每个硬盘存储1%的数据,并行读取,那么不到两分钟就可以读完所有数据。
Tips:分布式的思想初见雏形 -
仅使用硬盘容量的1%似乎很浪费。但是我们可以存储100个数据集,每个数据集1TB,并实现共享硬盘的读取。可以想象,用户肯定很乐于通过硬盘共享来缩短数据分析时间;并且,从统计角度来看,用户的分析工作都是在不同时间点进行的,所以彼此之间的干扰并不太大。
-
虽然如此,但要对多个硬盘中的数据并行进行读/写数据,还有更多问题要解决。
-
第一个需要解决的是硬件故障问题。一旦开始使用多个硬件,其中个别硬件就很有可能发生故障。为了避免数据丢失,最常见的做法是复制(replication):系统保存数据的复本(replica),一旦有系统发生故障,就可以使用另外保存的复本。
-
第二个问题是大多数分析任务需要以某种方式结合大部分数据来共同完成分析,即从一个硬盘读取的数据可能需要与从另外99个硬盘中读取的数据结合使用。
-
各种分布式系统允许结合不同来源的数据进行分析,但保证其正确性是一个非常大的挑战。MapReduce提出一个编程模型,该模型抽象出这些硬盘读/写问题并将其转换为对一个数据集(由键-值对组成)的计算。
1.3 查询所有的数据
- MapReduce看似采用了一种蛮力方法。每个查询需要处理整个数据集或至少一个数据集的绝大部分。但反过来想,这也正是它的能力。
- MapReduce是一个批量查询处理器,能够在合理的时间范围内处理针对整个数据集的动态查询。
- 它改变了我们对数据的传统看法,解放了以前只是保存在磁带和硬盘上的数据。
- 它让我们有机会对数据进行创新。
- 以前需要很长时间处理才能获得结果的问题,到现在变得顷刻之间就迎刃而解,同时还可以引发新的问题和新的见解。
这里文中提到了一个运用MR处理数据的例子:
- Rackspace公司的邮件部门Mailtrust就用Hadoop来处理邮件日志。
- 他们写了一条特别的查询用于帮助找出用户的地理分布。
- 他们是这么描述的:“这些数据非常有用,我们每月运行一次MapReduce任务来帮助我们决定扩容时将新的邮件服务器放在哪些Rackspace数据中心。”
- 通过整合好几百GB的数据,用工具来分析这些数据,Rackspace的工程师能够对以往没有注意到的数据有所理解,甚至还运用这些信息来改善现有的服务。
Tips:挖掘海量数据的信息并服务于业务,使得业务更好的发展。
1.4 不仅仅是批处理
- 从MapReduce的所有长处来看,它基本上是一个批处理系统,并不适合交互式分析。
- 你不可能执行一条查询并在几秒内或更短的时间内得到结果。
- 典型情况下执行查询需要几分钟或更多时间。因此,MapReduce更适合那种没有用户在现场等待查询结果的离线使用场景。
- 然而,从最初的原型出现以来,Hadoop的发展已经超越了批处理本身。
- 实际上,名词“Hadoop”有时被用于指代一个更大的、多个项目组成的生态系统,而不仅仅是HDFS和MapReduce。
- 这些项目都属于分布式计算和大规模数据处理范畴。这些项目中有许多都是由Apache软件基金会管理,该基金会为开源软件项目社区提供支持,其中包括最初的HTTPserver项目(基金会的名称也来源于这个项目)。
- 第一个提供在线访问的组件是HBase,一种使用HDFS做底层存储的键值存储模型。
- HBase不仅提供对单行的在线读/写访问,还提供对数据块读/写的批操作。
- Hadoop2中YARN(
Yet Another Resource Negotiator)的出现意味着 Hadoop 有了新处理模型。 - YARN是一个集群资源管理系统,允许任何一个分布式程序(不仅仅是MapReduce)基于 Hadoop 集群的数据而运行。
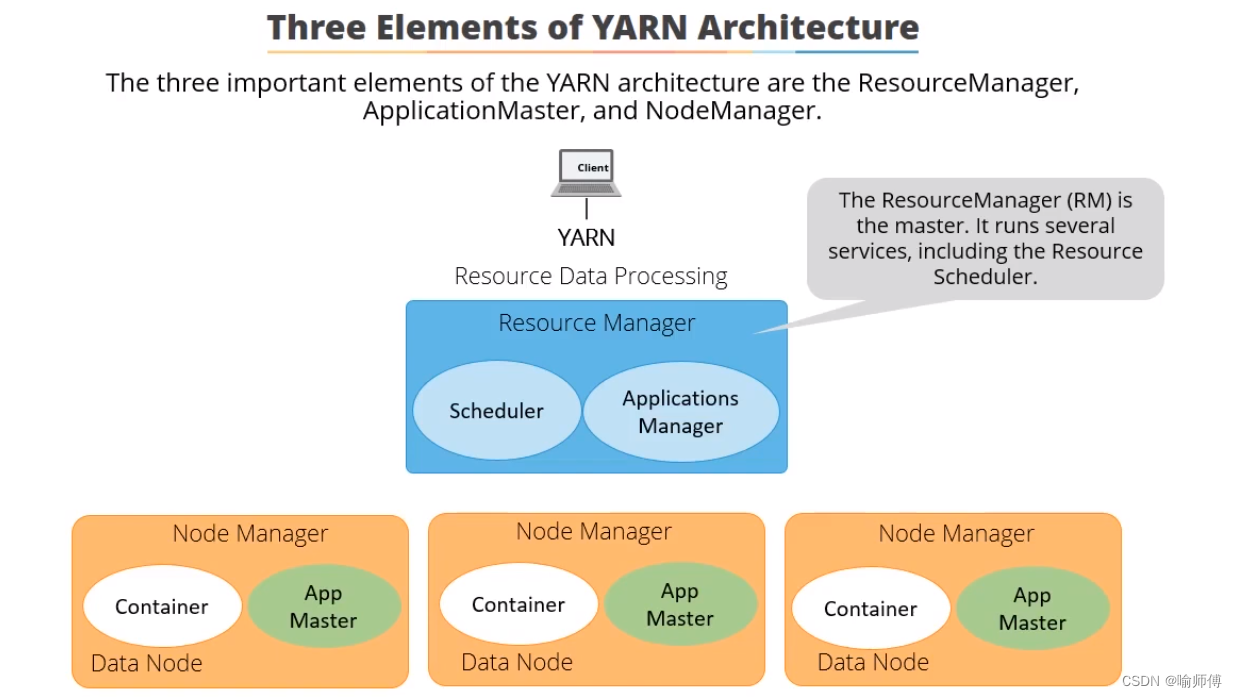
划重点:不只有MR可以使用Yarn,任何一个分布式程序都可。
1.5 相较于其他系统的优势
1.5.1 RDBMS
-
为什么不能用配有大量硬盘的数据库来进行大规模数据分析?我们为什么需要Hadoop?
-
这两个问题的答案来自于计算机硬盘的另一个发展趋势:寻址时间的提升远远不敌于传输速率的提升。
-
寻址是将磁头移动到特定硬盘位置进行读/写操作的过程它是导致硬盘操作延迟的主要原因,而传输速率取决于硬盘的带宽。
-
如果数据访问模式中包含大量的硬盘寻址,那么读取大量数据集就必然会花更长的时间(相较于流数据读取模式,流读取主要取决于传输速率)。
-
另一方面,如果数据库系统只更新一小部分记录,那么传统的B树(关系型数据库中使用的一种数据结构,受限于寻址的速率)就更有优势。
-
但数据库系统如果有大量数据更新时,B树的效率就明显落后于MapReduce,因为需要使用“排序/合并”(sort/merge)来重建数据库。

- 在许多情况下,可以将MapReduce视为关系型数据库管理系统的补充。
- MapReduce比较适合解决需要以批处理方式分析整个数据集的问题,尤其是一些特定目的的分析。
- RDBMS适用于索引后数据集的点查询(
point query)和更新,建立索引的数据库系统能够提供对小规模数据的低延迟数据检索和快速更新。 - MapReduce适合一次写入、多次读取数据的应用,关系型数据库则更适合持续更新的数据集。
- Hadoop和关系型数据库的另一个区别在于它们所操作的数据集的结构化程度。
- 结构化数据(structured data)是具有既定格式的实体化数据,如XML 文档或满足特定预定义格式的数据库表。这是RDBMS包括的内容。
- 另一方面,半结构化数据(semi-structured data)比较松散,虽然可能有格式,但经常被忽略,所以它只能作为对数据结构的一般性指导。例如电子表格,它在结构上是由单元格组成的网格,但是每个单元格内可以保存任何形式的数据。
- 非结构化数据(unstructured data没有什么特别的内部结构,例如纯文本或图像数据。
- Hadoop对非结构化或半结构化数据非常有效,因为它是在处理数据时才对数据进行解释(即所谓的“读时模式”)。这种模式在提供灵活性的同时避免了RDBMS数据加载阶段带来的高开销,因为在Hadoop中仅仅是一个文件拷贝操作。
- 关系型数据往往是规范的(normalized),以保持其数据的完整性且不含几余。规范给Hadoop处理带来了问题,因为它使记录读取成为非本地操作,而Hadoop的核心假设之一偏偏就是可以进行(高速的)流读/写操作。
- MapReduce 以及Hadoop中其他的处理模型是可以随着数据规模线性伸缩的。
- 对数据分区后,函数原语(如map和reduce)能够在各个分区上并行工作。
- 这意味着,如果输入的数据量是原来的两倍,那么作业的运行时间也需要两倍。但如果集群规模扩展为原来的两倍,那么作业的运行速度却仍然与原来一样快。SOL查询一般不具备该特性。
1.5.2 网格计算
-
高性能计算(High Performance Computing,HPC)和网格计算(Grid Computing)组织多年以来一直在研究大规模数据处理,主要使用类似于消息传递接口(
MessagePassing Interface,MPI)的API。 -
从广义上讲,高性能计算采用的方法是将作业分散到集群的各台机器上,这些机器访问存储区域网络(SAN)所组成的共享文件系统。
-
这比较适用于计算密集型的作业,但如果节点需要访问的数据量更庞大(高达几百GB,Hadoop开始施展它的魔法),很多计算节点就会因为网络带宽的瓶颈问题而不得不闲下来等数据。
-
Hadoop尽量在计算节点上存储数据,以实现数据的本地快速访问。"数据本地化(data locality)特性是Hadoop数据处理的核心,并因此而获得良好的性能。
Tips:1998年图灵奖得主JimGray在2003年3月发表的“Distributed ComputingEconomics”(分布式计算经济学)一文中,率先提出这个结论:数据处理应该在离数据本身比较近的地方进行,因为这样有利于降低成本,尤其是网络带宽消费所造成的成本。
- 意识到网络带宽是数据中心环境最珍贵的资源(到处复制数据很容易耗尽网络带宽)之后Hadoop通过显式网络拓扑结构来保留网络带宽。注意,这种排列方式并没有降低Hadoop对计算密集型数据进行分析的能力。
- 虽然MPI赋予程序员很大的控制权,但需要程序员显式处理数据流机制,包括用C语言构造底层的功能模块(例如套接字)和高层的数据分析算法。而Hadoop则在更高层次上执行任务,即程序员仅从数据模型(如MapReduce的键-值对)的角度考虑任务的执行,与此同时,数据流仍然是隐性的。
- 在大规模分布式计算环境下,协调各个进程的执行是一个很大的挑战。最困难的是合理处理系统的部分失效问题(在不知道一个远程进程是否挂了的情况下)同时还需要继续完成整个计算。
- 有了MapReduce这样的分布式处理框架,程序员不必操心系统失效的问题,因为框架能够检测到失败的任务并重新在正常的机器上执行。
- 正因为采用的是无共享(
shared-nothing)框架,MapReduce才能够呈现出这种特性,这意味着各个任务之间是彼此独立的。 - 因此,从程序员的角度来看,任务的执行顺序无关紧要。相比之下,MPI程序必须显式管理自己的检查点和恢复机制,虽然赋予程序员的控制权加大了,但编程的难度也增加了。
1.5.3 志愿计算
- 志愿计算项目将问题分成很多块,每一块称为一个工作单元(workunit),发到世界各地的计算机上进行分析。
- 例如,SETI@home的工作单元是0.35MB无线电望远镜数据,要对这等大小的数据量进行分析,一台普通计算机需要几个小时或几天时间才能完成。完成分析后,结果发送回服务器,客户端随后再获得另一个工作单元。为防止欺骗,每个工作单元要发送到3台不同的机器上执行,而且收到的结果中至少有两个相同才会被接受。
- 从表面上看,SETI@home与MapReduce好像差不多(将问题分解为独立的小块然后并行进行计算),但事实上还是有很多明显的差异。SETI@home问题是CPU高度密集的,比较适合在全球成千上万台计算机上运行。因为计算所花的时间远远超过工作单元数据的传输时间。也就是说,志愿者贡献的是PU周期,而不是网络带宽。
- MapReduce 有三大设计目标:
- (1)为只需要短短几分钟或几个小时就可以完成的作业提供服务;
- (2)运行于同一个内部有高速网络连接的数据中心内;
- (3)数据中心内的计算机都是可靠的、专门的硬件。
- 相比之下,SETI@home则是在接入互联网的不可信的计算机上长时间运行,这些计算机的网络带宽不同,对数据本地化也没有要求。
1.6 Apache Hadoop发展简史
- Hadoop 是 Apache Lucene 创始人道格·卡丁(Doug Cutting)创建的,Lucene 是个应用广泛的文本搜索系统库。
- Hadoop起源于开源网络搜索引擎Apache Nutch后者本身也是Lucene项目的一部分。

- Nutch项目开始于2002年,一个可以运行的网页爬取工具和搜索引擎系统很快面世。
- 但后来,它的创造者认为这一架构的灵活性不够,不足以解决数十亿网页的搜索问题。
划重点:
- 一篇发表于2003年的论文为此提供了帮助,文中描述的是谷歌产品架构,该架构称为“谷歌分布式文件系统”(GFS)。"GFS或类似的架构可以解决他们在网页爬取和索引过程中产生的超大文件的存储需求。
- 特别关键的是,GFS能够节省系统管理(如管理存储节点)所花的大量时间。
- 在2004年,Nutch的开发者开始着手做开源版本的实现,即Nutch分布式文件系统(NDFS)。
- 2004年,谷歌发表论文向全世界介绍他们的MapReduce系统。
- 2005年初,Nutch的开发人员在Nutch上实现了一个MapReduce 系统,到年中,Nutch的所有主要算法均完成移植,用MapReduce和NDFS来运行。
- Nutch的NDFS和MapReduce实现不只适用于搜索领域。
- 在2006年2月,开发人员将NDFS和MapReduce移出utch形成ucene的个子项目,命名为Hadoop。
- 大约在同一时间,DougCutting加入雅虎,雅虎为此组织了专门的团队和资源,将Hadoop发展成能够以Web网络规模运行的系统(参见随后的补充材料)。
- 在2008年2月,雅虎宣布,雅虎搜索引警使用的索引是在一个拥有1万个内核的 Hadoop 集群上构建的。
- 2008年1月,Hadoop已成为Apache的顶级项目,证明了它的成功、多样化和生命力。
仅供学习使用~
相关文章:
Hadoop权威指南-读书笔记-01-初识Hadoop
Hadoop权威指南-读书笔记 记录一下读这本书的时候觉得有意思或者重要的点~ 第一章—初识Hadoop Tips: 这个引例很有哲理嘻嘻😄,道出了分布式的灵魂。 1.1 数据!数据! 这一小节主要介绍了进入大数据时代,面…...
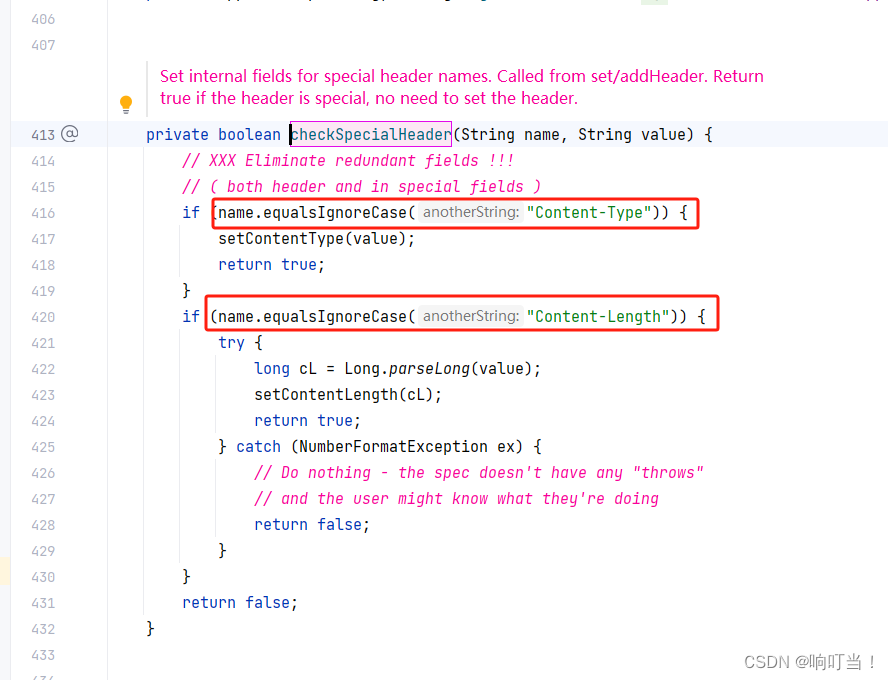
HttpServletResponse设置headers返回,发现headers中缺少“Content-Length“和“Content-Type“两个参数。
业务中需要将用httpUtils请求返回的headers全部返回,塞到HttpServletResponse中,代码如下: HttpServletResponse response;// 返回headers Arrays.stream(httpResponse.getHeaders()).forEach(header -> response.setHeader(header.getNa…...

GraphPad Prism生物医学数据分析软件下载安装 GraphPad Prism轻松绘制各种图表
Prism软件作为一款功能强大的生物医学数据分析与可视化工具,其绘图功能尤为突出。该软件不仅支持绘制基础的图表类型,如直观明了的柱状图、展示数据分布的散点图,以及描绘变化趋势的曲线图,更能应对复杂的数据呈现需求,…...

7/1 uart
uart4.c #include "uart4.h"//UART4_RX > PB2 //UART4_TX > PG11char rebuf[51] {0}; //rcc/gpio/uart4初始化 void hal_uart4_init() {/********RCC章节初始化*******///1.使能GPIOB组控制器 MP_AHB4ENSETR[1] 1RCC->MP_AHB4ENSETR | (0x1 << 1)…...
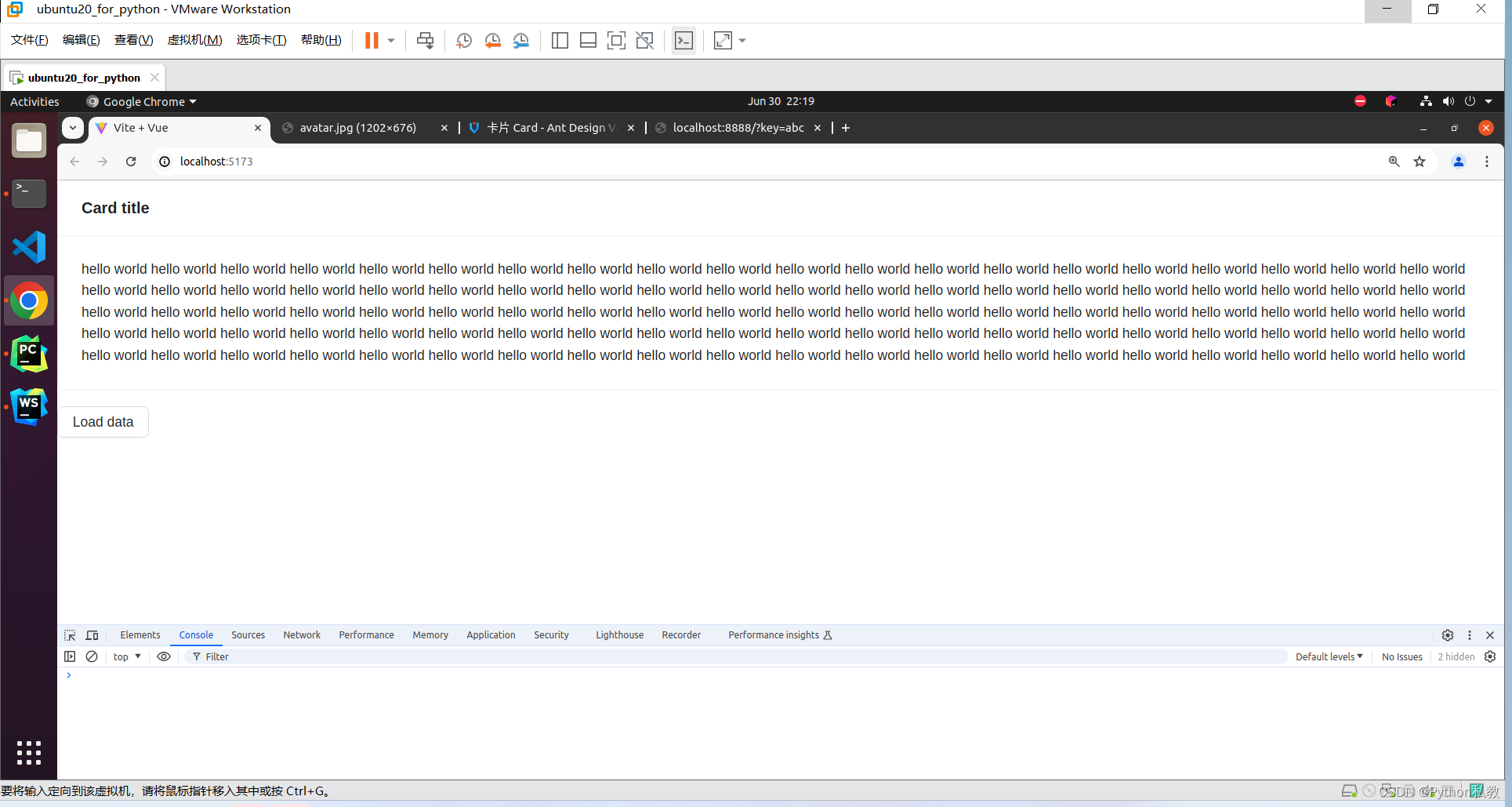
zdppy_api+vue3+antd开发前后端分离的预加载卡片实战案例
后端代码 import api import upload import timesave_dir "uploads"async def rand_content(request):key api.req.get_query(request, "key")time.sleep(0.3)return api.resp.success(f"{key} " * 100)app api.Api(routes[api.resp.get(&qu…...
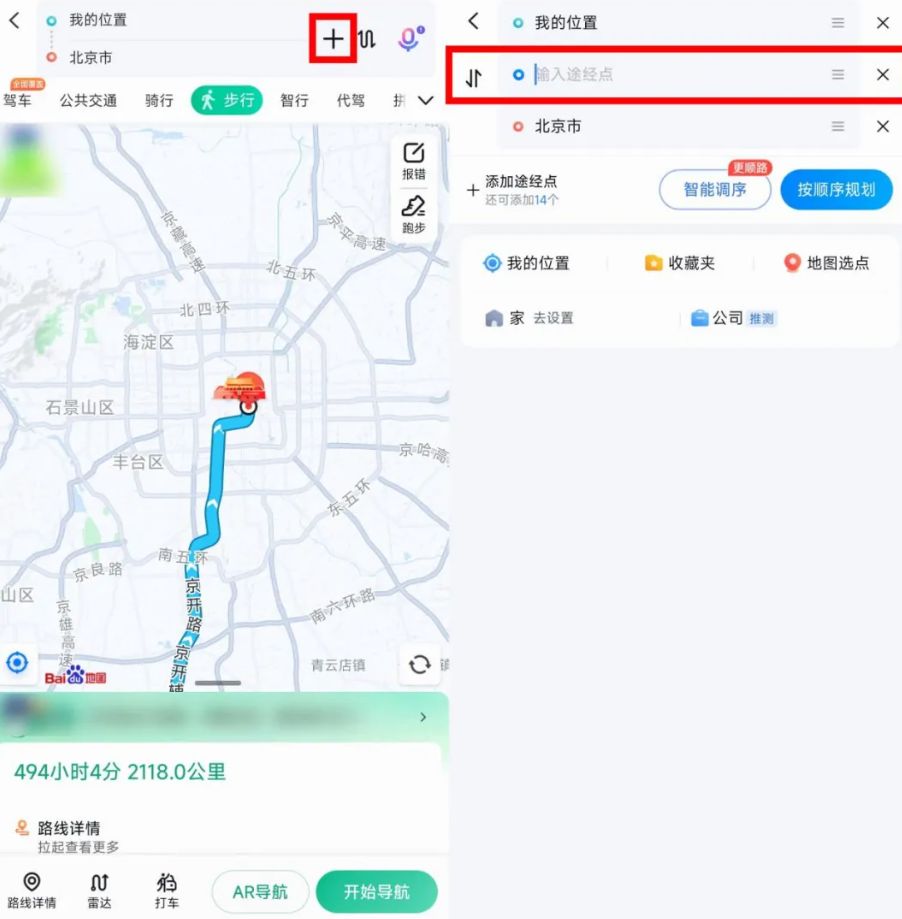
别小看手机导航,这些隐藏功能大部分人可能都不知道
在科技日新月异的今天,手机导航已经成为我们日常生活中不可或缺的一部分。它不仅仅是指引我们前往目的地的工具,更隐藏着许多黑科技功能,极大地丰富了我们的出行体验。 今天,让我们一起探索手机导航中那些鲜为人知却大有用处的隐…...
)
Lua实现链表(面向对象应用)
Lua实现面向对象 面向对象核心三要素Lua面向对象大致原理面向对象示例继承与多态示例 面向对象核心三要素 1.封装:对一个事物的抽象为一些属性和行为动作的集合,封装将属性和行为动作(操作数据的方法)绑定在一起,并隐藏…...

每隔一个小时gc一次的问题
原文地址https://www.cnblogs.com/jiangxinlingdu/p/7581064.html 设置一下这个 -XX:ExplicitGCInvokesConcurrent 或 -XXExplicitGCInvokesConcurrentAndUnloadsClasses 并且检查一下,并下面的值设置变大 java.rmi.dgc.leaseValue sun.rmi.dgc.client.gcInterv…...
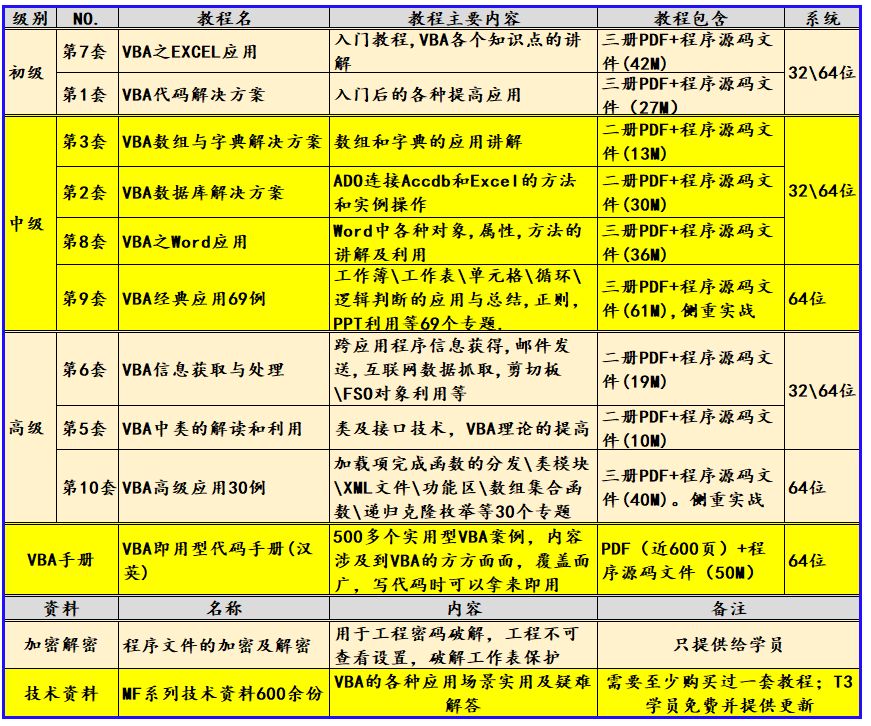
VBA数据库解决方案第十二讲:如何判断数据库中数据表是否存在
《VBA数据库解决方案》教程(版权10090845)是我推出的第二套教程,目前已经是第二版修订了。这套教程定位于中级,是学完字典后的另一个专题讲解。数据库是数据处理的利器,教程中详细介绍了利用ADO连接ACCDB和EXCEL的方法…...
五、Spring IoCDI ★ ✔
5. Spring IoC&DI 1. IoC & DI ⼊⻔1.1 Spring 是什么?★ (Spring 是包含了众多⼯具⽅法的 IoC 容器)1.1.1 什么是容器?1.1.2 什么是 IoC?★ (IoC: Inversion of Control (控制反转))总…...

计算机网络八股文
计算机网络体系架构? OSI结构:理论上的 7应用层:定义了应用进程间通信和交互的规则,常见协议有HTTP、SFTP、DNS、WebSocket6表示层:数据的表示、安全、压缩。确保一个系统的应用层所发消息能被另一个系统的应用层读取…...
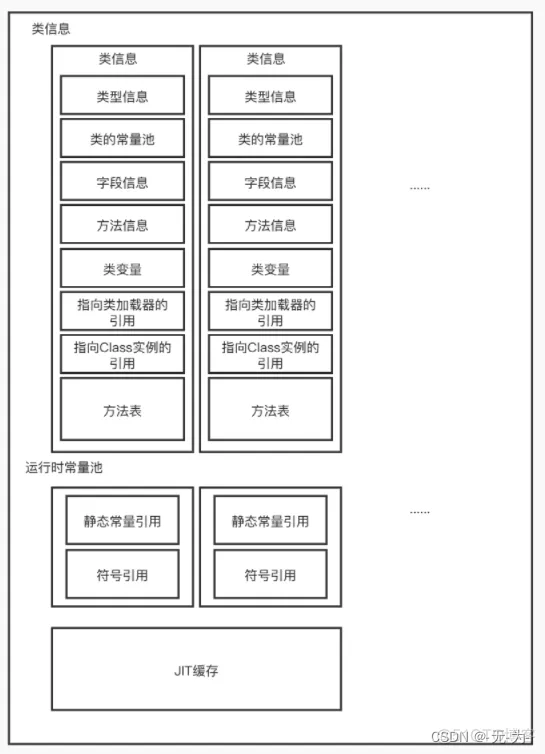
科普文:一文搞懂jvm原理(四)运行时数据区
概叙 科普文:一文搞懂jvm(一)jvm概叙-CSDN博客 科普文:一文搞懂jvm原理(二)类加载器-CSDN博客 科普文:一文搞懂jvm原理(三)执行引擎-CSDN博客 前面我们介绍了jvm,jvm主要包括两个子系统和两个组件: Class loader(类…...
《昇思25天学习打卡营第5天|数据变换 Transforms》
文章目录 前言:今日所学:1. Common Transforms2. Vision Transforms3. Text Transforms 前言: 我们知道在进行神经网络训练的时候,通常要将原始数据进行一系列的数据预处理操作才会进行训练,所以MindSpore提供了不同类…...

详细分析Oracle修改默认的时间格式(四种方式)
目录 前言1. 会话级别2. 系统级别3. 环境配置4. 函数格式化5. 总结 前言 默认的日期和时间格式由参数NLS_DATE_FORMAT控制 如果需要修改默认的时间格式,可以通过修改会话级别或系统级别的参数来实现 1. 会话级别 在当前会话中设置日期格式,这只会影响…...

以 Vue 3 项目为例,你是否经常遇到 import 语句顺序混乱的问题?要想解决它其实很容易!
大家好,我是CodeQi! 在项目开发过程中,我们经常会遇到项目中的 import 语句顺序混乱的问题。 这不仅会影响代码的可读性,还可能使我们代码在提交的时候产生不必要的冲突。 面对这种情况,要想解决它其实很容易。 通过合理的规范和自动化工具,我们可以确保 import 语句…...

mysql数据库ibdata文件被误删后恢复数据的方法
使用mysql数据库的时候不小心误删除了ibdata和ib_logfile文件,但是幸好.ibd文件还在。这种情况下其实数据还在并未丢失,丢失的是表结构。查询表数据时会报错:ERROR 1146 (42S02): Table ‘testdb.test’ doesn’t exist,其实是说表…...
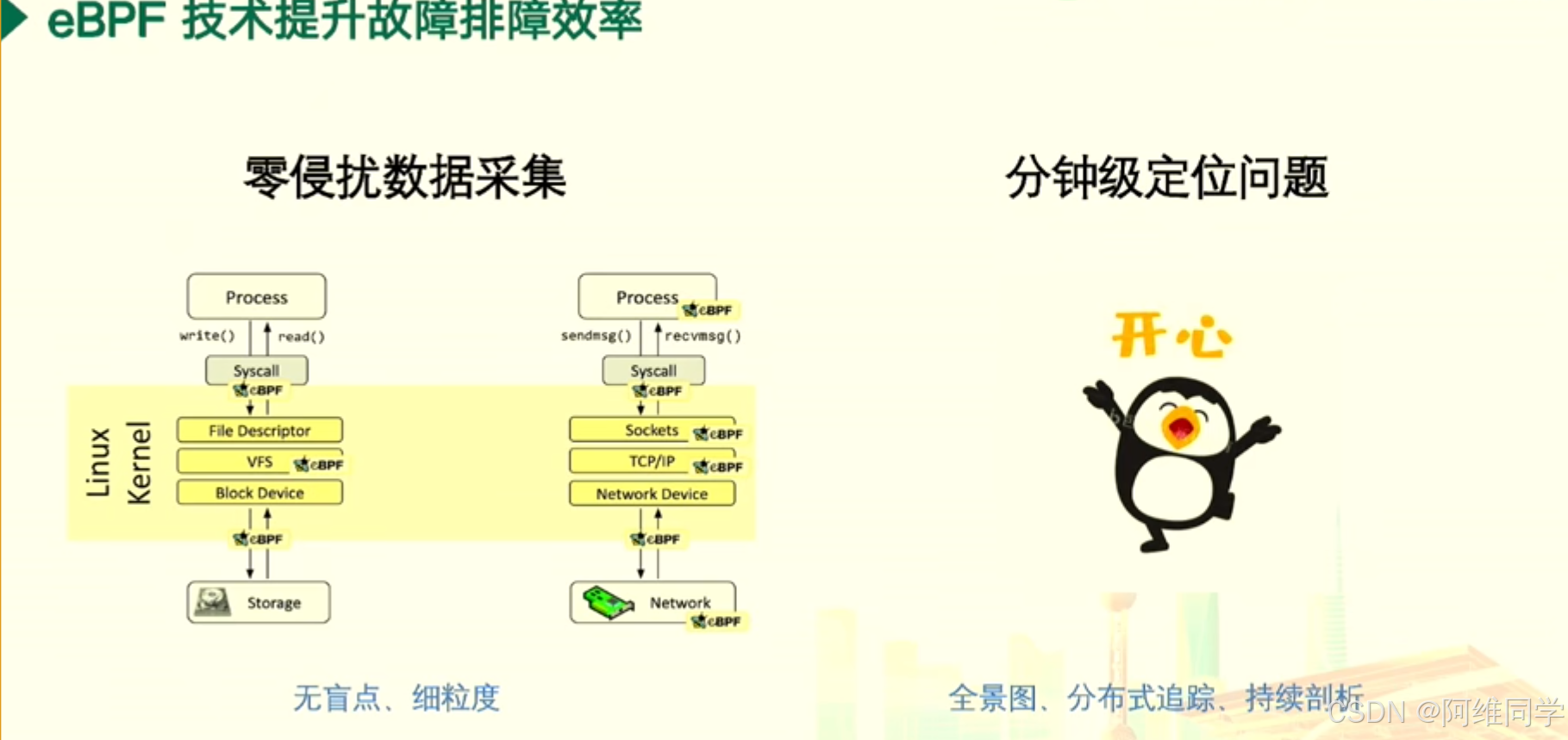
eBPF技术揭秘:DeepFlow如何引领故障排查,提升运维效率
DeepFlow 实战:eBPF 技术如何提升故障排查效率 目录 DeepFlow 实战:eBPF 技术如何提升故障排查效率 微服务架构系统中各个服务、组件及其相互关系的全景 零侵扰分布式追踪(Distributed Tracing)的架构和工作流程 关于零侵扰持…...

C++视觉开发 三.缺陷检测
一.距离变换 1.概念和功能 距离变换是一种图像处理技术,用于计算图像中每个像素到最近的零像素(背景像素)的距离。它常用于图像分割、形态学操作和形状分析等领域。它计算图像中每个像素到最近的零像素(背景像素)的距…...

使用 Amazon Bedrock Converse API 简化大语言模型交互
本文将介绍如何使用 Amazon Bedrock 最新推出的 Converse API,来简化与各种大型语言模型的交互。该 API 提供了一致的接口,可以无缝调用各种大型模型,从而消除了需要自己编写复杂辅助功能函数的重复性工作。文中示例将展示它相比于以前针对每…...
)
第二十一章 函数(Python)
文章目录 前言一、定义函数二、函数参数三、参数类型四、函数返回值五、函数类型1、无参数,无返回值2、无参数,有返回值3、有参数,无返回值4、有参数,有返回值 六、函数的嵌套七、全局变量和局部变量1、局部变量2、全局变量 前言 …...

基于AI浏览器架构缺陷的钓鱼攻击机理与防御重构
摘要:随着人工智能技术与Web浏览器的深度融合,新一代AI原生浏览器(如Comet AI Browser)在提升用户信息获取效率的同时,也引入了前所未有的安全挑战。近期披露的新型攻击技术表明,攻击者能够利用AI浏览器特有…...

UG NX 曲率梳分析精要
UG NX 曲率梳分析精要 曲率梳通过梳状图形直观显示曲线上的曲率变化(方向与半径),是分析曲线连续性的核心工具。用户可单选或多选曲线进行分析。 通过曲率梳可判定曲线的四种连续类型: 1. G0(位置连续) 定义…...

PHP的SAAS版跨境电商ERP实战的庖丁解牛
PHP 构建 SaaS 版跨境电商 ERP 是软件工程与国际贸易规则的深度结合。 这不仅仅是写代码,而是构建一个多租户、多平台、多币种、多时区的复杂分布式系统。它要求数据绝对一致(库存、资金),接口高度稳定(平台 API 限制&…...

Qwen3-0.6B-FP8极速对话工具:Dify平台集成与自动化部署
Qwen3-0.6B-FP8极速对话工具:Dify平台集成与自动化部署 如何在可视化开发平台上快速搭建一个高性能、可维护的对话应用 1. 为什么选择 Dify 部署对话模型 如果你尝试过从零开始部署一个对话模型,大概率会遇到环境配置复杂、依赖冲突、服务稳定性差这些问…...

yz-bijini-cosplay作品展示:支持‘COS角色+现实场景’如‘漫展现场+地铁车厢’混合生成
yz-bijini-cosplay作品展示:支持‘COS角色现实场景’如‘漫展现场地铁车厢’混合生成 想象一下,你想创作一张“初音未来在地铁车厢里”的Cosplay作品。传统方法可能需要先找模特、租服装、找场地、拍摄,再后期修图,耗时耗力。现在…...

基于SpringBoot+Vue的Spring Boot阳光音乐厅订票系统管理系统设计与实现【Java+MySQL+MyBatis完整源码】
💡实话实说:C有自己的项目库存,不需要找别人拿货再加价。摘要 随着互联网技术的快速发展和人们生活水平的不断提高,线上娱乐消费需求日益增长,音乐演出市场呈现出蓬勃发展的态势。传统的线下购票方式存在排队时间长、信…...

从数据到农田:基于YOLOv8的番茄叶片病害实时检测系统全流程实战
1. 番茄病害检测的农业痛点与技术选型 在传统农业生产中,番茄种植户通常需要每天巡视大棚或田间,用肉眼观察叶片状态来判断病害情况。这种方法存在三个致命缺陷:一是人工检查效率低下,一个标准大棚需要30-40分钟才能完成全面检查&…...
——五步代码实现自适应线性神经元对死区效应的精准补偿)
永磁同步电机谐波抑制实战(1)——五步代码实现自适应线性神经元对死区效应的精准补偿
1. 死区效应与谐波问题的工程困扰 永磁同步电机控制系统中,逆变器死区时间是导致电流谐波的关键因素之一。我在调试一款工业伺服电机时,发现即使采用最优的SVPWM算法,电机相电流依然存在明显的5次、7次谐波分量。用示波器观察电流波形时&…...

Windows系统苹果设备驱动安装完全指南:从问题诊断到高效应用
Windows系统苹果设备驱动安装完全指南:从问题诊断到高效应用 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/…...

LiuJuan20260223Zimage快速部署:3步完成Xinference服务启动+Gradio WebUI访问
LiuJuan20260223Zimage快速部署:3步完成Xinference服务启动Gradio WebUI访问 想快速体验一个专门生成LiuJuan风格图片的AI模型吗?今天介绍的LiuJuan20260223Zimage镜像,让你在几分钟内就能启动一个完整的文生图服务。这个镜像基于强大的Z-Im…...