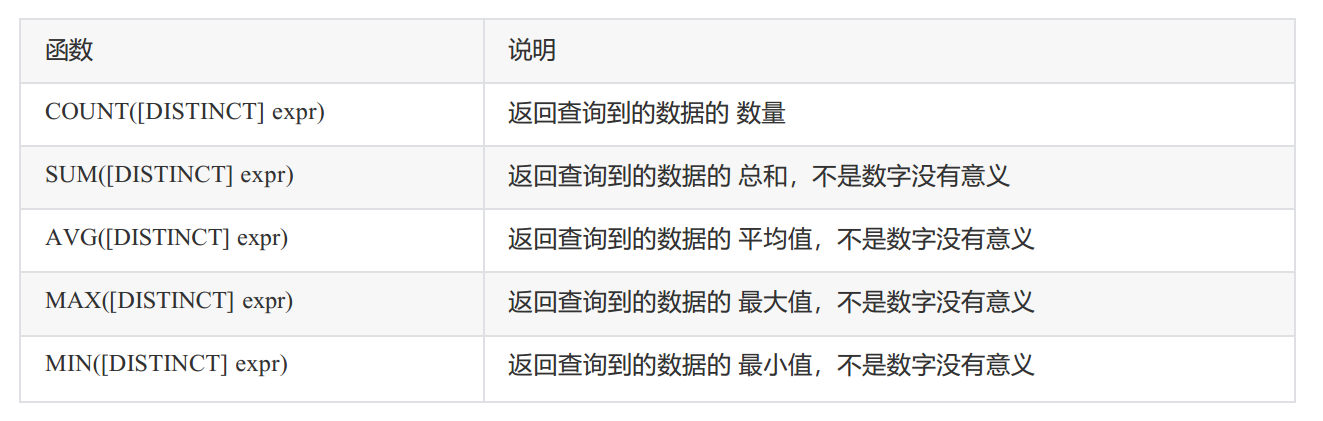
MySQL基本查询
文章目录
- 表的增删查改
- Create(创建)
- 单行数据 + 全列插入
- 多行数据 + 指定列插入
- 插入否则更新
- 替换
- Retrieve(读取)
- SELECT列
- 全列查询
- 指定列查询
- 查询字段为表达式
- 查询结果指定别名
- 结果去重
- WHERE 条件
- 基本比较
- BETWEEN AND 条件连接
- OR 条件连接
- IN 条件连接
- LIKE 条件匹配
- WHERE 条件中使用表达式
- AND 与 NOT 的使用
- 综合性查询
- NULL的查询
- 结果排序
- 升序显示
- 降序排序
- 多字段排序
- ORDER BY 使用表达式
- 结合 WHERE 子句 和 ORDER BY 子句
- 筛选分页结果
- Update(更新)
- 更新单列
- 更新多列
- 更新值为原值基础上变更
- 更新全表
- Delete(删除)
- 删除单条记录
- 删除整表
- 截断表
- 插入查询结果
- 聚合函数
- group by子句的使用
表的增删查改
CRUD : Create(创建), Retrieve(读取), Update(更新), Delete(删除)
Create(创建)
基本语法:
INSERT [INTO] table_name[(column [, column] ...)]VALUES (value_list) [, (value_list)] ...value_list: value, [, value] ...
案例:
mysql> create table students (-> id int unsigned primary key auto_increment,-> sn int not null unique comment '学号',-> name varchar(20) not null,-> email varchar(20)-> )engine=innodb default charset=utf8;
Query OK, 0 rows affected (0.03 sec)mysql> desc students;
+-------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+------------------+------+-----+---------+----------------+
| id | int(10) unsigned | NO | PRI | NULL | auto_increment |
| sn | int(11) | NO | UNI | NULL | |
| name | varchar(20) | NO | | NULL | |
| email | varchar(20) | YES | | NULL | |
+-------+------------------+------+-----+---------+----------------+
4 rows in set (0.00 sec)
单行数据 + 全列插入
插入两条记录,当value_list 数量和定义表的列的数量及顺序一致时,就可以省略value_list。注意,这里在插入的时候,也可以不用指定id,mysql会使用默认的值进行自增。
mysql> insert into students values (100, 1000, 'Curry', NULL);
Query OK, 1 row affected (0.01 sec)mysql> insert into students values (101, 1001, 'Durant', '3306@163.com');
Query OK, 1 row affected (0.00 sec)mysql> select * from students;
+-----+------+--------+--------------+
| id | sn | name | email |
+-----+------+--------+--------------+
| 100 | 1000 | Curry | NULL |
| 101 | 1001 | Durant | 3306@163.com |
+-----+------+--------+--------------+
2 rows in set (0.00 sec)
多行数据 + 指定列插入
插入两条记录,value_list 数量必须和指定列数量及顺序一致
mysql> insert into students (id, sn, name) values (102, 1002, 'Kobe'), (103, 1003, 'Klay');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0mysql> select * from students;
+-----+------+--------+--------------+
| id | sn | name | email |
+-----+------+--------+--------------+
| 100 | 1000 | Curry | NULL |
| 101 | 1001 | Durant | 3306@163.com |
| 102 | 1002 | Kobe | NULL |
| 103 | 1003 | Klay | NULL |
+-----+------+--------+--------------+
4 rows in set (0.00 sec)
插入否则更新
由于 主键 或者 唯一键 对应的值已经存在而导致插入失败
主键冲突:
mysql> insert into students (id, sn, name) values (100, 1004, 'Brown');
ERROR 1062 (23000): Duplicate entry '100' for key 'PRIMARY'
唯一键冲突:
mysql> insert into students (id, sn, name) values (104, 1003, 'Bryant');
ERROR 1062 (23000): Duplicate entry '1003' for key 'sn'
可以选择性的进行同步更新操作 语法:
INSERT ... ON DUPLICATE KEY UPDATEcolumn = value [, column = value] ...
mysql> insert into students (id, sn, name) values (104, 1003, 'Bryant')-> on duplicate key update id=104, name='Bryant';
Query OK, 2 rows affected (0.01 sec)mysql> select * from students;
+-----+------+--------+--------------+
| id | sn | name | email |
+-----+------+--------+--------------+
| 100 | 1000 | Curry | NULL |
| 101 | 1001 | Durant | 3306@163.com |
| 102 | 1002 | Kobe | NULL |
| 104 | 1003 | Bryant | NULL |
+-----+------+--------+--------------+
4 rows in set (0.00 sec)
- 0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等
- 1 row affected: 表中没有冲突数据,数据被插入
- 2 row affected: 表中有冲突数据,并且数据已经被更新
替换
主键 或者 唯一键 没有冲突,则直接插入;
主键 或者 唯一键 如果冲突,则删除后再插入
mysql> replace into students (sn, name) values (1002, 'Mitchell');
Query OK, 2 rows affected (0.00 sec)mysql> select * from students;
+-----+------+----------+--------------+
| id | sn | name | email |
+-----+------+----------+--------------+
| 100 | 1000 | Curry | NULL |
| 101 | 1001 | Durant | 3306@163.com |
| 104 | 1003 | Bryant | NULL |
| 105 | 1002 | Mitchell | NULL |
+-----+------+----------+--------------+
4 rows in set (0.00 sec)
- 1 row affected: 表中没有冲突数据,数据被插入
- 2 row affected: 表中有冲突数据,删除后重新插入
Retrieve(读取)
基础语法:
SELECT[DISTINCT] {* | {column [, column] ...}[FROM table_name][WHERE ...][ORDER BY column [ASC | DESC], ...]LIMIT ...
案例:
创建表结构:
mysql> create table exam_result (-> id int unsigned primary key auto_increment,-> name varchar(20) not null comment '姓名',-> chinese float default 0.0 comment '语文成绩',-> math float default 0.0 comment '数学成绩',-> english float default 0.0 comment '英语成绩'-> )engine=innodb default charset=utf8;
Query OK, 0 rows affected (0.02 sec)
插入测试数据:
mysql> insert into exam_result (name, chinese, math, english) values-> ('唐三藏', 67, 98, 56),-> ('孙悟空', 87, 78, 77),-> ('猪悟能', 88, 98, 90),-> ('曹孟德', 82, 84, 67),-> ('刘玄德', 55, 85, 45),-> ('孙权', 70, 73, 78),-> ('宋公明', 75, 65, 30);
Query OK, 7 rows affected (0.00 sec)
Records: 7 Duplicates: 0 Warnings: 0
SELECT列
全列查询
通常情况下不建议使用 * 进行全列查询
- 查询的列越多,意味着需要传输的数据量越大;
- 可能会影响到索引的使用;
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 唐三藏 | 67 | 98 | 56 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 5 | 刘玄德 | 55 | 85 | 45 |
| 6 | 孙权 | 70 | 73 | 78 |
| 7 | 宋公明 | 75 | 65 | 30 |
+----+-----------+---------+------+---------+
7 rows in set (0.00 sec)
指定列查询
指定列的顺序不需要按定义表的顺序来
mysql> select id, name, math from exam_result;
+----+-----------+------+
| id | name | math |
+----+-----------+------+
| 1 | 唐三藏 | 98 |
| 2 | 孙悟空 | 78 |
| 3 | 猪悟能 | 98 |
| 4 | 曹孟德 | 84 |
| 5 | 刘玄德 | 85 |
| 6 | 孙权 | 73 |
| 7 | 宋公明 | 65 |
+----+-----------+------+
7 rows in set (0.00 sec)
查询字段为表达式
表达式不包含字段:
mysql> select id, name, 10 from exam_result;
+----+-----------+----+
| id | name | 10 |
+----+-----------+----+
| 1 | 唐三藏 | 10 |
| 2 | 孙悟空 | 10 |
| 3 | 猪悟能 | 10 |
| 4 | 曹孟德 | 10 |
| 5 | 刘玄德 | 10 |
| 6 | 孙权 | 10 |
| 7 | 宋公明 | 10 |
+----+-----------+----+
7 rows in set (0.00 sec)
表达式包含一个字段:
mysql> select id, name, math+10 from exam_result;
+----+-----------+---------+
| id | name | math+10 |
+----+-----------+---------+
| 1 | 唐三藏 | 108 |
| 2 | 孙悟空 | 88 |
| 3 | 猪悟能 | 108 |
| 4 | 曹孟德 | 94 |
| 5 | 刘玄德 | 95 |
| 6 | 孙权 | 83 |
| 7 | 宋公明 | 75 |
+----+-----------+---------+
7 rows in set (0.00 sec)
表达式包含多个字段:
mysql> select id, name, math+chinese+english from exam_result;
+----+-----------+----------------------+
| id | name | math+chinese+english |
+----+-----------+----------------------+
| 1 | 唐三藏 | 221 |
| 2 | 孙悟空 | 242 |
| 3 | 猪悟能 | 276 |
| 4 | 曹孟德 | 233 |
| 5 | 刘玄德 | 185 |
| 6 | 孙权 | 221 |
| 7 | 宋公明 | 170 |
+----+-----------+----------------------+
7 rows in set (0.00 sec)
查询结果指定别名
基础语法:
ELECT column [AS] alias_name [...] FROM table_name;
mysql> select id, name, math+chinese+english total from exam_result;
+----+-----------+-------+
| id | name | total |
+----+-----------+-------+
| 1 | 唐三藏 | 221 |
| 2 | 孙悟空 | 242 |
| 3 | 猪悟能 | 276 |
| 4 | 曹孟德 | 233 |
| 5 | 刘玄德 | 185 |
| 6 | 孙权 | 221 |
| 7 | 宋公明 | 170 |
+----+-----------+-------+
7 rows in set (0.00 sec)
结果去重
查询结果重复:
mysql> select math from exam_result;
+------+
| math |
+------+
| 98 |
| 78 |
| 98 |
| 84 |
| 85 |
| 73 |
| 65 |
+------+
7 rows in set (0.00 sec)
查询结果去重:
mysql> select distinct math from exam_result;
+------+
| math |
+------+
| 98 |
| 78 |
| 84 |
| 85 |
| 73 |
| 65 |
+------+
6 rows in set (0.00 sec)
WHERE 条件
基本比较
英语不及格的同学及英语成绩 ( < 60 ):
mysql> select name, english from exam_result where english<60;
+-----------+---------+
| name | english |
+-----------+---------+
| 唐三藏 | 56 |
| 刘玄德 | 45 |
| 宋公明 | 30 |
+-----------+---------+
3 rows in set (0.00 sec)
BETWEEN AND 条件连接
语文成绩在 [80, 90] 分的同学及语文成绩:
使用 AND 进行条件连接
mysql> select name, chinese from exam_result where chinese>=80 and chinese<=90;
+-----------+---------+
| name | chinese |
+-----------+---------+
| 孙悟空 | 87 |
| 猪悟能 | 88 |
| 曹孟德 | 82 |
+-----------+---------+
3 rows in set (0.00 sec)
使用 BETWEEN AND 条件连接
mysql> select name, chinese from exam_result where chinese between 80 and 90;
+-----------+---------+
| name | chinese |
+-----------+---------+
| 孙悟空 | 87 |
| 猪悟能 | 88 |
| 曹孟德 | 82 |
+-----------+---------+
3 rows in set (0.00 sec)
OR 条件连接
数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩:
mysql> select name, math from exam_result where math=58 or math=59 or math=98 or math=99;
+-----------+------+
| name | math |
+-----------+------+
| 唐三藏 | 98 |
| 猪悟能 | 98 |
+-----------+------+
2 rows in set (0.00 sec)
IN 条件连接
数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩:
mysql> select name, math from exam_result where math in (58,59,98,99);
+-----------+------+
| name | math |
+-----------+------+
| 唐三藏 | 98 |
| 猪悟能 | 98 |
+-----------+------+
2 rows in set (0.00 sec)
LIKE 条件匹配
查找姓孙的同学:% 匹配任意多个(包括 0 个)任意字符
mysql> select name from exam_result where name like '孙%';
+-----------+
| name |
+-----------+
| 孙悟空 |
| 孙权 |
+-----------+
2 rows in set (0.00 sec)
查找孙某同学: _ 匹配严格的一个任意字符
mysql> select name from exam_result where name like '孙_';
+--------+
| name |
+--------+
| 孙权 |
+--------+
1 row in set (0.00 sec)
WHERE 条件中使用表达式
总分在 200 分以下的同学:
mysql> select name, chinese+math+english total from exam_result where total<200;
ERROR 1054 (42S22): Unknown column 'total' in 'where clause'
这里我们发现一个问题,where条件查询中不能使用指定别名,这是因为chinese+math+english这个字句比where total<200字句先执行,所以MySQL并不认识total这个别名,就会报错。
正确写法:
mysql> select name, chinese+math+english total from exam_result where chinese+math+english<200;
+-----------+-------+
| name | total |
+-----------+-------+
| 刘玄德 | 185 |
| 宋公明 | 170 |
+-----------+-------+
2 rows in set (0.00 sec)
AND 与 NOT 的使用
语文成绩 > 80 并且不姓孙的同学:
mysql> select name,chinese from exam_result where chinese>80 and name not like '孙%';
+-----------+---------+
| name | chinese |
+-----------+---------+
| 猪悟能 | 88 |
| 曹孟德 | 82 |
+-----------+---------+
2 rows in set (0.00 sec)
综合性查询
查询孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80:
mysql> select name,chinese,math,english,chinese+math+english total from exam_result-> where (name like '孙_') or (chinese+math+english>200 and chinese<math and english>80);
+-----------+---------+------+---------+-------+
| name | chinese | math | english | total |
+-----------+---------+------+---------+-------+
| 猪悟能 | 88 | 98 | 90 | 276 |
| 孙权 | 70 | 73 | 78 | 221 |
+-----------+---------+------+---------+-------+
2 rows in set (0.00 sec)
NULL的查询
查询 email 号已知的同学姓名:
mysql> select name from students where email is not null;
+--------+
| name |
+--------+
| Durant |
+--------+
1 row in set (0.00 sec)
NULL 和 NULL 的比较,= 和 <=> 的区别:
mysql> select NULL=NULL, NULL=1, NULL=0;
+-----------+--------+--------+
| NULL=NULL | NULL=1 | NULL=0 |
+-----------+--------+--------+
| NULL | NULL | NULL |
+-----------+--------+--------+
1 row in set (0.00 sec)mysql> select NULL<=>NULL, NULL<=>1, NULL<=>0;
+-------------+----------+----------+
| NULL<=>NULL | NULL<=>1 | NULL<=>0 |
+-------------+----------+----------+
| 1 | 0 | 0 |
+-------------+----------+----------+
1 row in set (0.00 sec)
结果排序
基本语法:
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
SELECT ... FROM table_name [WHERE ...]ORDER BY column [ASC|DESC], [...];
升序显示
查询姓名及数学成绩,按数学成绩升序显示:
mysql> select name,math from exam_result order by math;
+-----------+------+
| name | math |
+-----------+------+
| 宋公明 | 65 |
| 孙权 | 73 |
| 孙悟空 | 78 |
| 曹孟德 | 84 |
| 刘玄德 | 85 |
| 唐三藏 | 98 |
| 猪悟能 | 98 |
+-----------+------+
7 rows in set (0.00 sec)
降序排序
查询姓名 及 eamil,按 eamil排序显示:
mysql> select name,email from students order by email;
+----------+--------------+
| name | email |
+----------+--------------+
| Curry | NULL |
| Bryant | NULL |
| Mitchell | NULL |
| Durant | 3306@163.com |
+----------+--------------+
4 rows in set (0.00 sec)
NULL 视为比任何值都小,升序出现在最上面
多字段排序
查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示:
mysql> select name,chinese,math,english from exam_result order by math desc, english asc, chinese asc;
+-----------+---------+------+---------+
| name | chinese | math | english |
+-----------+---------+------+---------+
| 唐三藏 | 67 | 98 | 56 |
| 猪悟能 | 88 | 98 | 90 |
| 刘玄德 | 55 | 85 | 45 |
| 曹孟德 | 82 | 84 | 67 |
| 孙悟空 | 87 | 78 | 77 |
| 孙权 | 70 | 73 | 78 |
| 宋公明 | 75 | 65 | 30 |
+-----------+---------+------+---------+
7 rows in set (0.00 sec)
多字段排序,排序优先级随书写顺序
ORDER BY 使用表达式
查询同学及总分,由高到低:
mysql> select name, chinese+math+english from exam_result order by chinese+math+english desc;
+-----------+----------------------+
| name | chinese+math+english |
+-----------+----------------------+
| 猪悟能 | 276 |
| 孙悟空 | 242 |
| 曹孟德 | 233 |
| 唐三藏 | 221 |
| 孙权 | 221 |
| 刘玄德 | 185 |
| 宋公明 | 170 |
+-----------+----------------------+
7 rows in set (0.00 sec)
ORDER BY 子句中可以使用列别名:
mysql> select name, chinese+math+english total from exam_result order by total desc;
+-----------+-------+
| name | total |
+-----------+-------+
| 猪悟能 | 276 |
| 孙悟空 | 242 |
| 曹孟德 | 233 |
| 唐三藏 | 221 |
| 孙权 | 221 |
| 刘玄德 | 185 |
| 宋公明 | 170 |
+-----------+-------+
7 rows in set (0.00 sec)
结合 WHERE 子句 和 ORDER BY 子句
查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示:
mysql> select name,math from exam_result where name like '孙%' or name like '曹%' order by math desc;
+-----------+------+
| name | math |
+-----------+------+
| 曹孟德 | 84 |
| 孙悟空 | 78 |
| 孙权 | 73 |
+-----------+------+
3 rows in set (0.00 sec)
筛选分页结果
基础语法:
-- 起始下标为 0
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
建议:对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死按 id 进行分页,每页 3 条记录,分别显示 第 1、2、3 页。
案例:第 1 页:
mysql> select id, name, chinese, math, english from exam_result order by id limit 3 offset 0;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 唐三藏 | 67 | 98 | 56 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
+----+-----------+---------+------+---------+
3 rows in set (0.00 sec)
第 2 页:
mysql> select id, name, chinese, math, english from exam_result order by id limit 3 offset 3;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 4 | 曹孟德 | 82 | 84 | 67 |
| 5 | 刘玄德 | 55 | 85 | 45 |
| 6 | 孙权 | 70 | 73 | 78 |
+----+-----------+---------+------+---------+
3 rows in set (0.00 sec)
第 3 页,如果结果不足 3 个,不会有影响:
mysql> select id, name, chinese, math, english from exam_result order by id limit 3 offset 6;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 7 | 宋公明 | 75 | 65 | 30 |
+----+-----------+---------+------+---------+
1 row in set (0.00 sec)
Update(更新)
基本语法:
UPDATE table_name SET column = expr [, column = expr ...][WHERE ...] [ORDER BY ...] [LIMIT ...]
更新单列
将孙悟空同学的数学成绩变更为 80 分:
mysql> select name, math from exam_result where name='孙悟空';
+-----------+------+
| name | math |
+-----------+------+
| 孙悟空 | 78 |
+-----------+------+
1 row in set (0.00 sec)mysql> update exam_result set math=80 where name='孙悟空';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> select name, math from exam_result where name='孙悟空';
+-----------+------+
| name | math |
+-----------+------+
| 孙悟空 | 80 |
+-----------+------+
1 row in set (0.00 sec)
更新多列
将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分:
mysql> select name, math, chinese from exam_result where name='曹孟德';
+-----------+------+---------+
| name | math | chinese |
+-----------+------+---------+
| 曹孟德 | 84 | 82 |
+-----------+------+---------+
1 row in set (0.00 sec)mysql> update exam_result set math=60, chinese=70 where name='曹孟德';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> select name, math, chinese from exam_result where name='曹孟德';
+-----------+------+---------+
| name | math | chinese |
+-----------+------+---------+
| 曹孟德 | 60 | 70 |
+-----------+------+---------+
1 row in set (0.00 sec)
更新值为原值基础上变更
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分:
mysql> update exam_result set math=math+30 order by chinese+math+english limit 3;
Query OK, 3 rows affected (0.00 sec)
Rows matched: 3 Changed: 3 Warnings: 0mysql> select name, math from exam_result;
+-----------+------+
| name | math |
+-----------+------+
| 唐三藏 | 98 |
| 孙悟空 | 80 |
| 猪悟能 | 98 |
| 曹孟德 | 90 |
| 刘玄德 | 115 |
| 孙权 | 73 |
| 宋公明 | 95 |
+-----------+------+
7 rows in set (0.00 sec)
更新全表
将所有同学的语文成绩更新为原来的 2 倍:
mysql> select name, chinese from exam_result;
+-----------+---------+
| name | chinese |
+-----------+---------+
| 唐三藏 | 67 |
| 孙悟空 | 87 |
| 猪悟能 | 88 |
| 曹孟德 | 70 |
| 刘玄德 | 55 |
| 孙权 | 70 |
| 宋公明 | 75 |
+-----------+---------+
7 rows in set (0.00 sec)mysql> update exam_result set chinese=chinese*2;
Query OK, 7 rows affected (0.00 sec)
Rows matched: 7 Changed: 7 Warnings: 0mysql> select name, chinese from exam_result;
+-----------+---------+
| name | chinese |
+-----------+---------+
| 唐三藏 | 134 |
| 孙悟空 | 174 |
| 猪悟能 | 176 |
| 曹孟德 | 140 |
| 刘玄德 | 110 |
| 孙权 | 140 |
| 宋公明 | 150 |
+-----------+---------+
7 rows in set (0.00 sec)
Delete(删除)
基础语法:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
删除单条记录
删除孙悟空同学的考试成绩:
mysql> select * from exam_result where name='孙悟空';
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 2 | 孙悟空 | 174 | 80 | 77 |
+----+-----------+---------+------+---------+
1 row in set (0.00 sec)mysql> delete from exam_result where name='孙悟空';
Query OK, 1 row affected (0.00 sec)mysql> select * from exam_result where name='孙悟空';
Empty set (0.00 sec)
删除整表
注意:删除整表操作要慎用!
准备测试表:
mysql> create table for_delete (-> id int unsigned primary key auto_increment,-> name varchar(20)-> )engine=innodb default charset=utf8;
Query OK, 0 rows affected (0.02 sec)
插入测试数据:
mysql> insert into for_delete (name) values ('a'), ('b'), ('c');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0mysql> select * from for_delete;
+----+------+
| id | name |
+----+------+
| 1 | a |
| 2 | b |
| 3 | c |
+----+------+
3 rows in set (0.00 sec)
删除整表数据:
mysql> delete from for_delete;
Query OK, 3 rows affected (0.00 sec)mysql> select * from for_delete;
Empty set (0.00 sec)
再插入一条数据,自增 id 在原值上增长:
mysql> insert into for_delete (name) values ('d');
Query OK, 1 row affected (0.00 sec)mysql> select * from for_delete;
+----+------+
| id | name |
+----+------+
| 4 | d |
+----+------+
1 row in set (0.00 sec)
查看表结构,会有 AUTO_INCREMENT=n 项:
mysql> show create table for_delete \G
*************************** 1. row ***************************Table: for_delete
Create Table: CREATE TABLE `for_delete` (`id` int(10) unsigned NOT NULL AUTO_INCREMENT,`name` varchar(20) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
说明:虽然delete语句删除了整表,但是再向删除后的表插入时,表中的自增值会在之前的原数据的基础之上增加。
截断表
基础语法:
TRUNCATE [TABLE] table_name
- TRUNCATE 只能对整表操作,不能像 DELETE 一样针对部分数据操作;
- 实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事物,所以无法回滚
- 会重置 AUTO_INCREMENT 项
准备测试表:
mysql> create table for_truncate (-> id int unsigned primary key auto_increment,-> name varchar(20)-> )engine=innodb default charset=utf8;
Query OK, 0 rows affected (0.02 sec)
插入测试数据:
mysql> insert into for_truncate (name) values ('a'), ('b'), ('c');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0mysql> select * from for_truncate;
+----+------+
| id | name |
+----+------+
| 1 | a |
| 2 | b |
| 3 | c |
+----+------+
3 rows in set (0.00 sec)
截断整表数据,注意影响行数是 0,所以实际上没有对数据真正操作:
mysql> truncate for_truncate;
Query OK, 0 rows affected (0.02 sec)mysql> select * from for_truncate;
Empty set (0.00 sec)
再插入一条数据,自增 id 在重新增长:
mysql> insert into for_truncate (name) values ('d');
Query OK, 1 row affected (0.00 sec)mysql> select * from for_truncate;
+----+------+
| id | name |
+----+------+
| 1 | d |
+----+------+
1 row in set (0.00 sec)
查看表结构,会有 AUTO_INCREMENT=2 项:
mysql> show create table for_truncate \G
*************************** 1. row ***************************Table: for_truncate
Create Table: CREATE TABLE `for_truncate` (`id` int(10) unsigned NOT NULL AUTO_INCREMENT,`name` varchar(20) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
插入查询结果
基础语法:
INSERT INTO table_name [(column [, column ...])] SELECT ...
案例:删除表中的的重复记录,重复的数据只能有一份
创建原数据表,插入测试数据:
mysql> create table duplicate_table (-> id int,-> name varchar(20)-> );
Query OK, 0 rows affected (0.04 sec)mysql> insert into duplicate_table values-> (100, 'aaa'),-> (100, 'aaa'),-> (200, 'bbb'),-> (200, 'bbb'),-> (200, 'bbb'),-> (300, 'ccc');
Query OK, 6 rows affected (0.00 sec)
Records: 6 Duplicates: 0 Warnings: 0
创建一张空表 no_duplicate_table结构和 duplicate_table结构一样:
mysql> create table no_duplicate_table like duplicate_table;
Query OK, 0 rows affected (0.01 sec)mysql> desc no_duplicate_table;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
将 duplicate_table 的去重数据插入到 no_duplicate_table:
mysql> insert into no_duplicate_table select distinct * from duplicate_table;
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0mysql> select * from no_duplicate_table;
+------+------+
| id | name |
+------+------+
| 100 | aaa |
| 200 | bbb |
| 300 | ccc |
+------+------+
3 rows in set (0.00 sec)
通过重命名表,实现原子的去重操作:
mysql> alter table duplicate_table rename to duplicate_table_bak;
Query OK, 0 rows affected (0.00 sec)mysql> alter table no_duplicate_table rename to duplicate_table;
Query OK, 0 rows affected (0.01 sec)
聚合函数
案例:
统计班级共有多少同学:
mysql> select count(*) from students;
+----------+
| count(*) |
+----------+
| 4 |
+----------+
1 row in set (0.00 sec)
统计班级收集的 email 有多少:
mysql> select count(email) from students;
+--------------+
| count(email) |
+--------------+
| 1 |
+--------------+
1 row in set (0.00 sec)
统计本次考试的数学成绩分数个数:
统计全部成绩:
mysql> select count(math) from exam_result;
+-------------+
| count(math) |
+-------------+
| 6 |
+-------------+
1 row in set (0.00 sec)
统计去重成绩数量:
mysql> select count(distinct math) from exam_result;
+----------------------+
| count(distinct math) |
+----------------------+
| 5 |
+----------------------+
1 row in set (0.00 sec)
统计数学成绩总分:
mysql> select sum(math) from exam_result;
+-----------+
| sum(math) |
+-----------+
| 569 |
+-----------+
1 row in set (0.00 sec)
统计平均总分:
mysql> select avg(chinese+math+english) from exam_result;
+---------------------------+
| avg(chinese+math+english) |
+---------------------------+
| 297.5 |
+---------------------------+
1 row in set (0.00 sec)
返回英语最高分:
mysql> select max(english) from exam_result;
+--------------+
| max(english) |
+--------------+
| 90 |
+--------------+
1 row in set (0.00 sec)
返回 > 70 分以上的数学最低分:
mysql> select min(math) from exam_result where math>70;
+-----------+
| min(math) |
+-----------+
| 73 |
+-----------+
1 row in set (0.00 sec)
group by子句的使用
在select中使用group by 子句可以对指定列进行分组查询
基本语法:
select column1, column2, .. from table group by column;
案例:
准备工作,创建一个雇员信息表
- EMP员工表
- DEPT部门表
- SALGRADE工资等级表
mysql> desc dept;
+--------+--------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+--------------------------+------+-----+---------+-------+
| deptno | int(2) unsigned zerofill | NO | | NULL | |
| dname | varchar(14) | YES | | NULL | |
| loc | varchar(13) | YES | | NULL | |
+--------+--------------------------+------+-----+---------+-------+
3 rows in set (0.00 sec)mysql> desc emp;
+----------+--------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+--------------------------+------+-----+---------+-------+
| empno | int(6) unsigned zerofill | NO | | NULL | |
| ename | varchar(10) | YES | | NULL | |
| job | varchar(9) | YES | | NULL | |
| mgr | int(4) unsigned zerofill | YES | | NULL | |
| hiredate | datetime | YES | | NULL | |
| sal | decimal(7,2) | YES | | NULL | |
| comm | decimal(7,2) | YES | | NULL | |
| deptno | int(2) unsigned zerofill | YES | | NULL | |
+----------+--------------------------+------+-----+---------+-------+
8 rows in set (0.00 sec)mysql> desc salgrade;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| grade | int(11) | YES | | NULL | |
| losal | int(11) | YES | | NULL | |
| hisal | int(11) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
3 rows in set (0.00 sec)
显示每个部门的平均工资和最高工资:
mysql> select deptno, avg(sal) avg, max(sal) max from emp group by deptno;
+--------+-------------+---------+
| deptno | avg | max |
+--------+-------------+---------+
| 10 | 2916.666667 | 5000.00 |
| 20 | 2175.000000 | 3000.00 |
| 30 | 1566.666667 | 2850.00 |
+--------+-------------+---------+
3 rows in set (0.00 sec)
每个部门的每种岗位的平均工资和最低工资:
mysql> select deptno, job, avg(sal) avg, min(sal) min from emp group by deptno, job;
+--------+-----------+-------------+---------+
| deptno | job | avg | min |
+--------+-----------+-------------+---------+
| 10 | CLERK | 1300.000000 | 1300.00 |
| 10 | MANAGER | 2450.000000 | 2450.00 |
| 10 | PRESIDENT | 5000.000000 | 5000.00 |
| 20 | ANALYST | 3000.000000 | 3000.00 |
| 20 | CLERK | 950.000000 | 800.00 |
| 20 | MANAGER | 2975.000000 | 2975.00 |
| 30 | CLERK | 950.000000 | 950.00 |
| 30 | MANAGER | 2850.000000 | 2850.00 |
| 30 | SALESMAN | 1400.000000 | 1250.00 |
+--------+-----------+-------------+---------+
9 rows in set (0.00 sec)
平均工资低于2000的部门和它的平均工资:
mysql> select deptno, avg(sal) avg from emp group by deptno having avg < 2000;
+--------+-------------+
| deptno | avg |
+--------+-------------+
| 30 | 1566.666667 |
+--------+-------------+
1 row in set (0.00 sec)
having经常和group by搭配使用,作用是对分组进行筛选,作用有些像where,但是having通常在数据where选择完,group by进行分组,再执行having筛选。
相关文章:
MySQL基本查询
文章目录表的增删查改Create(创建)单行数据 全列插入多行数据 指定列插入插入否则更新替换Retrieve(读取)SELECT列全列查询指定列查询查询字段为表达式查询结果指定别名结果去重WHERE 条件基本比较BETWEEN AND 条件连接OR 条件连…...

你需要知道的 7 个 Vue3 技巧
VNode 钩子在每个组件或html标签上,我们可以使用一些特殊的(文档没写的)钩子作为事件监听器。这些钩子有:onVnodeBeforeMountonVnodeMountedonVnodeBeforeUpdateonVnodeUpdatedonVnodeBeforeUnmountonVnodeUnmounted我主要是在组件…...

行政区划获取
行政区划获取一、导入jar包二、代码展示背景:公司的行政区划代码有问题,有的没有街道信息,有的关联信息有误,然后找到了国家的网站国家统计局-行政区划,这个里面是包含了所有的行政信息,但是全是html页面&a…...

让ChatGPT介绍一下ChatGPT
申请新必应内测通过了,我在New Bing中使用下ChatGPT,让ChatGPT介绍一下ChatGPT 问题1:帮我生成一篇介绍chatGPT的文章,不少于2000字 回答: chatGPT是什么?它有什么特点和用途? chatGPT是一种…...
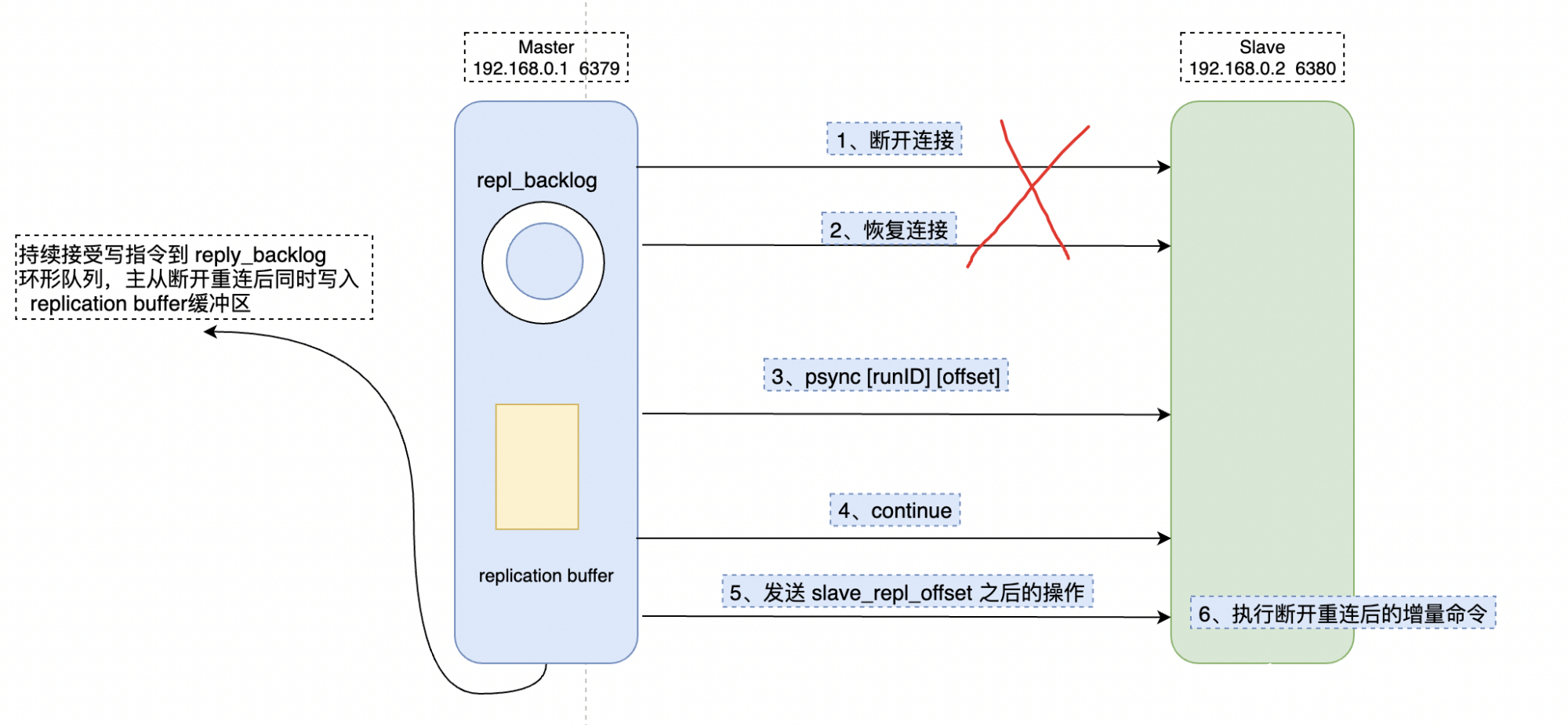
【Redis】Redis 主从复制 + 读写分离
Redis 主从复制 读写分离1. Redis 主从复制 读写分离介绍1.1 从数据持久化到服务高可用1.2 主从复制1.3 如何保证主从数据一致性?1.4 为何采用读写分离模式?2. 一主两从环境准备2.1 配置文件2.2 启动 Redis3. 主从复制原理3.1 全量同步3.1.1 建立连接3…...

2023届秋招,鬼知道我经历了什么
仅记录个人经历,充满主观感受,甚至纯属虚构,仅供参考,杠就是你对 本想毕业再写,但是考虑到等毕业了,24秋招的提前批就快开始了,大概就来不及了,正好现在有点时间,陆陆续…...
ChatGPT助力校招----面试问题分享(一)
1 ChatGPT每日一题:期望薪资是多少 问题:面试官问期望薪资是多少,如何回答 ChatGPT:当面试官问及期望薪资时,以下是一些建议的回答方法: 1、调查市场行情:在回答之前,可以先调查一…...

CSS媒体查询@media (prefers-color-scheme:dark)判断系统白天黑夜模式
前言 在最近学习中突然看到了在媒体查询中prefers-color-scheme:dark监听的使用,然后就模仿里边写了个简单例子,代码如下: body {background-color: #f5f5f5;}media (prefers-color-scheme: dark) {body {background-color: #666;}}然后通过…...
运行YOLOv8实现识别
https://github.com/ultralytics/ultralyticshttps://docs.ultralytics.com/环境配置官方环境要求Python>3.7(我是python3.8也是可以用的) environment with PyTorch>1.7.这是ultralyticsCommand Line Interface命令行接口运行输入参数的格式yolo …...
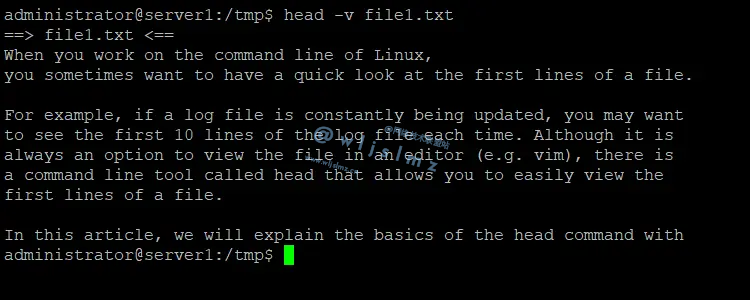
如何在Linux中优雅的使用 head 命令,用来看日志简直溜的不行
当您在 Linux 的命令行上工作时,有时希望快速查看文件的第一行,例如,有个日志文件不断更新,希望每次都查看日志文件的前 10 行。很多朋友使用文本编辑的命令是vim,但还有个命令head也可以让轻松查看文件的第一行。 在…...

Nginx.conf 配置详解
#安全问题,建议用nobody,不要用root. #user nobody; #worker数和服务器的cpu数相等是最为适宜 worker_processes 2; #work绑定cpu(4 work绑定4cpu) worker_cpu_affinity 0001 0010 0100 1000 #error_log path(存放路径) level(日志等级) path表示日志路径&…...

剖析NLP历史,看chatGPT的发展
1、NLP历史演进 1.1 NLP有监督范式 NLP里的有监督任务的范式,可以归纳成如下的样子。 输入是字词序列,中间一步关键的是语义表征,有了语义表征之后,然后交给下游的模型学习。所以预训练技术的发展,都是在围绕怎么…...

20个Python使用小技巧,建议收藏~
1、易混淆操作 本节对一些 Python 易混淆的操作进行对比。 1.1 有放回随机采样和无放回随机采样 import random random.choices(seq, k1) # 长度为k的list,有放回采样 random.sample(seq, k) # 长度为k的list,无放回采样1.2 lambda 函数的参数 …...

Kafka 主题管理
Kafka 主题管理创建主题查看主题修改主题内部主题异常主题删除失败创建主题 创建 Kafka 主题 create : 创建主题partitions : 主题的分区数replication-factor : 每个分区下的副本数 bin/kafka-topics.sh \ --bootstrap-server broker_host:port \ --create --topic my_topi…...
【深度学习】GPT系列模型:语言理解能力的革新
GPT-1🏡 自然语言理解包括一系列不同的任务,例如文本蕴涵、问答、语义相似度评估和文档分类。尽管大量的未标记文本语料库很充足,但用于学习这些特定任务的标记数据却很稀缺,使得判别式训练模型难以达到良好的表现。我们证明&…...

【Vue.js】全局状态管理模式插件vuex
文章目录全局状态管理模式Vuexvuex是什么?什么是“状态管理模式”?vuex的应用场景Vuex安装开始核心概念一、State1、单一状态树2、在 Vue 组件中获得 Vuex 状态3、mapState辅助函数二、Getter三、Mutation1、提交载荷(Payload)2、…...

JPA 之 Hibernate EntityManager 使用指南
Hibernate EntityManager 专题 参考: JPA – EntityManager常用API详解EntityManager基本概念 基本概念及获得 EntityManager 对象 基本概念 在使用持久化工具的时候,一般都有一个对象来操作数据库,在原生的Hibernate中叫做Session&…...
)
英语作文提示(持续更新)
星期(介词on)Monday星期一Tuesday星期二Wednesday星期三Thursday星期四Friday星期五Saturday星期六Sunday星期日月份(介词in)lunar calendar农历on the second day of the second lunar农历初二January1月February2月March3月Apri…...
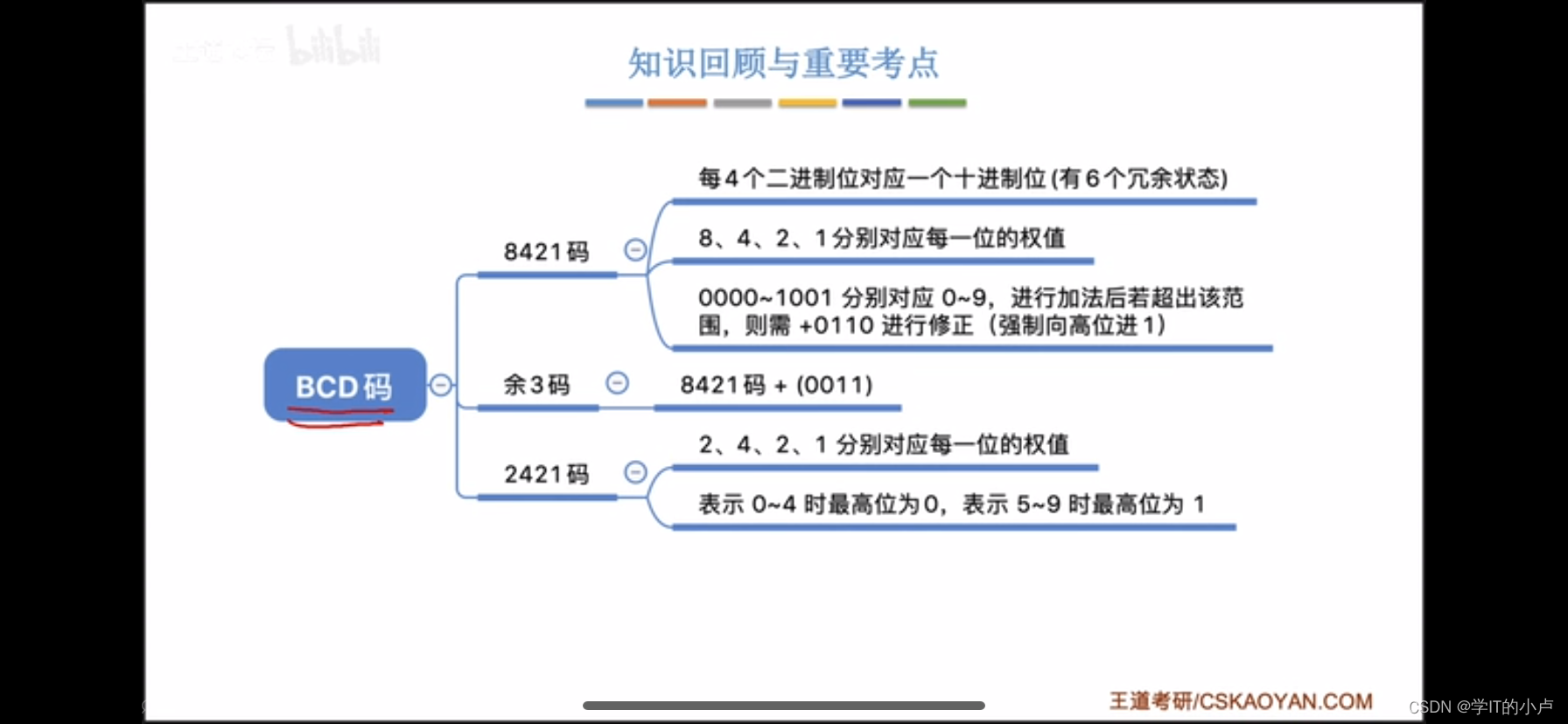
【计算机组成原理】计算机的性能指标、数据的表示和运算、BCD码和余3码
计算机组成原理(二) 计算机的性能指标: 存储器的性能指标: 存储器中,MAR为存储单元的个数 MDR为机械字长也就是存储单元的长度 存储器的大小MAR*MDR n为二进制位能表示出几种不同的状态呢? 2的n次方种不同的状态 CPU的性能指标…...
三天吃透MySQL八股文(2023最新整理)
本文已经收录到Github仓库,该仓库包含计算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享等核心知识点,欢迎star~ Github地址:https://github.com/…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...

解决本地部署 SmolVLM2 大语言模型运行 flash-attn 报错
出现的问题 安装 flash-attn 会一直卡在 build 那一步或者运行报错 解决办法 是因为你安装的 flash-attn 版本没有对应上,所以报错,到 https://github.com/Dao-AILab/flash-attention/releases 下载对应版本,cu、torch、cp 的版本一定要对…...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

算法笔记2
1.字符串拼接最好用StringBuilder,不用String 2.创建List<>类型的数组并创建内存 List arr[] new ArrayList[26]; Arrays.setAll(arr, i -> new ArrayList<>()); 3.去掉首尾空格...

JVM 内存结构 详解
内存结构 运行时数据区: Java虚拟机在运行Java程序过程中管理的内存区域。 程序计数器: 线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。 每个线程都有一个程序计数…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...