python本学期所有代码!
第一单元
-----------------------------------------------------------------------
#圆面积的计算
radius = 25
area = 3.1415 * radius * radius
print(area)
print("{:.2f}".format(area))
-----------------------------------------------------------------------
#简单人名对话
name = input("输入姓名:")
print("{}同学,学好Python,前途无量!".format(name))
print("{}同学,学好Python,前途无量!".format(name[0]))
print("{}同学,学好Python,前途无量!".format(name[1:]))
-----------------------------------------------------------------------
#斐波那契数列的计算
a,b=0,1
while a < 1000: #输出不大于1000的序列print(a,end = ',')a,b = b,a+b
-----------------------------------------------------------------------
#turtle 库的应用
#同切圆的绘制
import turtle
turtle.pensize(2) #设置画笔宽度为2像素
turtle.circle(10) #绘制半径为10像素的圆
turtle.circle(40)
turtle.circle(80)
turtle.circle(160)
-----------------------------------------------------------------------
#日期和时间的输出
from datetime import datetime #引入datetime库
now = datetime.now() #获得当前日期和时间信息
print(now)
now.strftime("%x") #输出其中的日期部分
now.strftime(%X) #输出其中的时间部分
-----------------------------------------------------------------------
#字符串拼接
str1 = input("请输入一个人的名字:")
str2 = input("请输入一个国家的名字:")
print("世界这么大,{}想去{}看看。".format(str1,str2))
-----------------------------------------------------------------------
#整数序列求和
n = input("请输入整数N:")
sum = 0
for i in range(int(n)):sum += i+1
print("1到N求和结果:",sum)
-----------------------------------------------------------------------
#九九乘法表输出
for i in range(1,10):for j in range(1,10):if i >= j:print("{}*{}={} ".format(j,i,i*j),end='')else:print("\n")break
-----------------------------------------------------------------------
第二单元
-----------------------------------------------------------------------
#温度转换
TempStr = input("请输入带有符号的温度值:")
if TempStr[-1] in ['F','f']:C = (eval(TempStr[0:-1])-32)/1.8print("转换后的温度是{:.2f}C".format(C))
elif TempStr[-1] in ['C','c']:F = 1.8*eval(TempStr[0:-1])+32print("转换后的温度是{:.2f}F".format(F))
else:print("输入格式错误")
------------------------------------------------------------------------
#回声函数
print(input("请输入:"))
-------------------------------------------------------
#人民币美元互换
a = input("请输入需要转换的钱数:")
if a[-1] == '¥':print("对应美元为{}$".format(eval(a[0:-1])*6))
elif a[-1] == '$':print("对应人民币为{}¥".format(eval(a[0:-1])/6))
else:print("输入有误,请检查!")
===================================================
#go to()语句的应用
import turtle
turtle.goto(100,100)
turtle.goto(100,-100)
turtle.goto(-100,-100)
turtle.goto(-100,100)
turtle.goto(0,0)
-------------------------------------------------
#蟒蛇绘制,例题
import turtle
turtle.setup(650,350,200,200)#设置主窗体的位置和大小,width,height,startx,starty:窗口宽度,窗口高度,窗口与左边、右边的距离
turtle.penup()#抬起画笔
turtle.fd(-250)#向小海龟当前行进方向前进disance距离,为负值则为反方向
turtle.pendown()#落下画笔
turtle.pensize(25)#设置画笔尺寸
turtle.pencolor("purple")#设置颜色
turtle.seth(-40)#改变小海龟的运行方向
---------------------------------------------
#for 循环!
for i in range(4):turtle.circle(40,80)turtle.circle(-40,80)
turtle.circle(40,80/2)
turtle.fd(40)
turtle.circle(16,180)
turtle.fd(40*2/3)
---------------------------------------------
#同心圆绘制
import turtle
turtle.pencolor("purple")
turtle.pensize(5)
for i in range(10):turtle.circle(20*i)turtle.penup()turtle.seth(-90)turtle.fd(20)turtle.pendown()turtle.seth(0)
---------------------------------------------
#2.4等边三角形的绘制
import turtle as t
t.fd(300)
t.seth(120)
t.fd(300)
t.seth(-120)
t.fd(300)
-----------------------------------------------
#2.5叠加等边三角形的绘制
import turtle as t
t.seth(-120)
t.fd(100)
t.seth(0)
t.fd(200)
t.seth(120)
t.fd(200)
t.seth(-120)
t.fd(100)
t.seth(0)
t.fd(100)
t.seth(-120)
t.fd(100)
t.seth(120)
t.fd(100)
t.seth(0)
t.done()
----------------------------------------------#水仙花数
for i in range(1,10):for j in range(0,10):for k in range(0,10): if (i*100+j*10+k) == (i**3+j**3+k**3): print(i*100+j*10+k)
====================================================
import math as m
sumnumber = 0
for i in range(1,21):a = m.factorial(i)sumnumber += a
print(sumnumber)
==========================
dayup = pow(1.001,365)
daydown = pow(0.999,365)
print("向上:{:.2f},向下:{:.2f}".format(dayup,daydown))
==============================
def dayUP(df): dayup =1.0 for i in range(365): if i % 7 in[6,0]: dayup = dayup * (1-0.01)else: dayup = dayup * (1+df)return dayup
dayfactor = 0.01
while (dayUP(dayfactor)<37.78): dayfactor += 0.001print("每天的努力参数是:{:.3f}".format(dayfactor))
==================
i = 2
j = 1
num1 = 0
for k in range(20):a = ib = jnum1 = a / b+ num1i = a + bj = a
print(num1)
----------------------------------
plaincode = input("请输入明文:")
for p in plaincode:if ord("a") <= ord(p) <= ord("A"):print(chr(ord("a")+(ord(p)-ord("a")+3)%26),end = '')else:print(p,end = '')
-----------------------------------------
plaincode = input("请输入明文:")
for p in plaincode:if ord("a") <= ord(p) <= ord("z"):print(chr(ord("a")+(ord(p)-ord("a")+3)%26),end = '')else:print(p,end = '')
-----------------------------------------------------------
x = input("请输入分钟数:")
while( x.isdigit() != 1): #提示用户输错x = input("您输入的数据有误,请重新输入:")
x = int(x)
h = int(x / 60)#只保留整数部分
m = x - h*60
print("{}小时{}分钟".format(h,m))
-----------------------------------------------------------
def point_get(b):b = b[1:-1]i = 0while b[i] != ',':i+=1else:flag = i #获取逗号在字符串中的索引x,y = eval(b[0:i]),eval(b[i+1::]) #获取x,y的坐标值return x,y
def distance(j,k,l,n):dist = ((j-l)**2+(k-n)**2)**0.5#计算间距return dist
point1 = input("请输入第一个点坐标:")
m = point_get(point1)
x1,y1 = m[0],m[1]
point2 = input("请输入第二个点坐标:")
m = point_get(point2)
x2,y2 = m[0],m[1]
s = distance(x1,y1,x2,y2)
print("({},{})和({},{})这两点的间距为{:.5f}".format(x1,y1,x2,y2,s))
-----------------------------------------------------------
import time
scale = 3
for i in range(scale+1):a = i * '·'print("\rStarting{}done!".format(a))
----------------------------------------------------------
year = eval(input("请输入年:"))
month = eval(input("请输入月:"))
day = eval(input("请输入日:"))
month_day = {1:31,2:28,3:31,4:30,5:31,6:30,7:31,8:31,9:30,10:31,11:30,12:31}
if ((year % 2 == 0 and year % 100 != 0) or (year % 400 == 0)) == 0:month_day = month_day
else:month_day[2] = 29
sumday = 0
for i in range(1,month+1):if month == i:sumday = sumday + dayelse:sumday = sumday + month_day[i]
print("{}年{}月{}日是该年的第{}天".format(year,month,day,sumday))
------------------------------------------------------------
#9*9
for i in range(1,10):for j in range(1,10):if i >= j:print("{}*{}={} ".format(i,j,i*j),end = '')else:print()break
---------------------------------------------------
#猴子摘桃问题
x = 1
for i in range(9):x = (x+1)*2
print("第一天共摘了{}个".format(x))
------------------------------------------------------
#延时一秒输出时间
import time as t
print(t.strftime("%Y-%m-%d %H:%M:%S"))
t.sleep(1)
print(t.strftime("%Y-%m-%d %H:%M:%S"))
--------------------------------------------------------
找数练习
for a in range(1,10):for c in range(1,10):for b in range(0,10):for d in range(0,10):num1 = a*1000 + b*100 + c*10 + dnum2 = c*100 + d*10 +cnum3 = a*100 +b*10 +cif (num1 -num2 == num3):print(num1)
-------------------------------------------------------
#田字格
for i in range(1,22):if i in [1,11,21]:print("+ — — — — + — — — — +")elif(i%2==0):print()else:print("|"+"|".center(37)+"|")
-----------------------------------------------------------def change(n):if n == 0:return str(0)elif n == 1:return str(1)else:return str(n-2) +'1'
print(eval(change(4)))
++++++++++++++++++
#koch 雪花曲线
import turtle as t
def koch(size,n):if n == 0:t.fd(size)else:for angle in [0,60,-120,60]:t.left(angle)koch(size/3,n-1)
def main():t.speed(0)t.penup()t.goto(-300,30)t.pendown()t.pensize(2)koch(600,3)t.right(120)koch(600,3)t.right(120)koch(600,3)t.hideturtle()
main()
===========================
import turtle,time
def drawgap():#增加间隔turtle.penup()turtle.fd(5)
def drawline(draw):#单线绘制drawgap()turtle.pendown() if draw else turtle.penup()turtle.fd(40)drawgap()turtle.right(90)
def drawdigit(d):#单数绘制drawline(True) if d in [2,3,4,5,6,8,9] else drawline(False)drawline(True) if d in [0,1,3,4,5,6,7,8,9] else drawline(False)drawline(True) if d in [0,2,3,5,6,8,9] else drawline(False)drawline(True) if d in [0,2,6,8] else drawline(False)turtle.left(90)drawline(True) if d in [0,4,5,6,8,9] else drawline(False)drawline(True) if d in [0,2,3,5,6,7,8,9] else drawline(False)drawline(True) if d in [0,1,2,3,4,7,8,9] else drawline(False)turtle.right(180)turtle.penup()turtle.fd(20)
def timeget():#时间获取str1 = time.strftime("%Y-%m+%d=",time.gmtime())return str1
def drawdate(a):
timestr = timeget()
turtle.speed(0)
turtle.pensize(5)
turtle.penup()
turtle.fd(-300)
turtle.hideturtle()
=======================================
import randomdef distribute_red_packets(total_amount, num_packets):packets = []remaining_amount = total_amountfor i in range(num_packets - 1):# 随机生成一个红包金额,范围为1分到剩余金额的平均值的两倍amount = random.randint(1, remaining_amount // 50)packets.append(amount)remaining_amount -= amount# 最后一个红包的金额为剩余的金额packets.append(remaining_amount)return packets# 测试代码
total_amount = 1000 # 总金额为10元(单位为分)
num_packets = 30 # 发放5个红包
red_packets = distribute_red_packets(total_amount, num_packets)
print(red_packets)
=========================================
def hanoi(n, begin, target, middle):#汉诺塔if n > 0:hanoi(n - 1, begin, middle, target)print(f"将盘子 {n} 从 {begin} 移动到 {target}")hanoi(n - 1, middle, target, begin)
n = 5
hanoi(n, 'A', 'C', 'B')
=========================================
#Q1
import turtle as t
def draw(n):for i in range(n):t.left(30)t.fd(100)t.left(120)t.fd(100)t.left(120)t.fd(100)t.left(120)t.fd(100)t.right(90)
t.penup()
t.goto(-150,20)
t.speed(0)
t.pendown()
t.pencolor("red")
t.pensize(5)
draw(6)
t.seth(0)
=========================================
#Q2
for i in ['a','b','c']:for j in ['x','y','z']:if (i=='a'and j =='x') or (i=='c'and j=='x')or(i=='c'and j!='z'):continueelse:if (j=='z'and i!='c'):continueelse:if (j == 'y'and i=='b'):continueelse:print("{}和{}比".format(i,j))
=========================================
A = ['x','y','z']
A.remove('x') #a不和x比
B = ['x', 'y', 'z']
C = ['x', 'y', 'z']
C.remove('x')
C.remove('z') #c不和xz比赛
for a in A:for b in B:for c in C:if a!=b and a!=c and b!=c:#当abc对战人都不相同时满足条件print('a和{}比赛 b和{}比赛 c和{}比赛'.format(a, b, c))
==========================================
#Q3
str1 = input("请输入一行字符:")
a,b,c,d=0,0,0,0
for p in str1:if p.isnumeric():a+=1elif p.isspace():b+=1elif 65<=ord(p)<=90 or 97<=ord(p)<=122:c+=1else:d+=1
print("您输入的{}中共有数字{}个,空格{}个,字母{}个,其他字符{}个。".format(str1,a,b,c,d))
==============================================
#Q4
def isPrime():try:a = eval(input("请输入一个整数n:"))if a == 1:return Trueelse:for i in range(1,a):if a % i == 0:return False else:return Trueexcept NameError:print("您所输入的并非整数!")
print(isPrime())
===================================================
#Q5
tstr = input("请输入时间:")
for i in range(len(tstr)):if tstr[i].isnumeric() == 0:flag = i#获取冒号索引break
h = eval(tstr[0:flag])
m = tstr[flag+1::]
if m[0] == '0':m= eval(m[1])#避免输入12:05报错
else:m = eval(m)
#以下是角度计算:
hd = (h * 60 + m) * 0.5
md = m * 6.0
print("{:.3f}".format(min(abs(hd-md),(360-abs(hd-md)))))
========================================================
import math as m
def cos(x):cos,j,a,i= 0,0,1,0while abs(a)>0.01:a = (pow(x,i)/m.factorial(i))i =i+ 2b = (-1)**(j)j = j+1c = a * bcos = cos + celse:return cos
m = cos(-3.14)
print("{:.6f}".format(m))
=================================================
for i in range(1,22):if i in [1,11,21]:print("+ — — — — + — — — — +")elif(i%2==0):print()else:print("|"+"|".center(37)+"|")
===========================================
.一 集合
#====================================开始
#集合的三种建立方式
A = {"python",123,("python",123)}#{}直接建立
B = set("pypy123")#set()直接建立,把字符串分割为单个字符并打乱顺序
C = {"python",123,"python",123}#唯一性与无序性的体现
print(A)
print(B)
print(C)
#建立空集合时,必须使用set()
D = set()
print(D)#运行结果为:set()
#====================================
#集合间操作:并,交,补,差,子集,包含以及四种增强运算符。
S = {1,2,3,4}
T = {3,4,5,6}
print(S|T)#并集
print(S-T)#差集
print(S&T)#交集
print(S^T)#补集
print(S<=T and S<T)#判断子集关系
print(S>=T and S>T)#判断包含关系
#==================================
#集合处理方法
S.add(5)#如果x不在集合内部,则添加进入集合
S.discard(5)#移除S中的x元素,若本来不在,不报错
S.remove(4)#移除S中的x元素,如果x不在集合中,报错
a=S.pop()#随机返回S中的一个元素,更新S,若S为空则报错
print(a)
print(S)
S.clear()#移除S中的所有元素
print(S)
S = {1,2,3,4}
a=S.copy()
print(a)#返回集合S的一个副本
print(len(S))#返回集合S的元素个数
if 5 in S:print("5在S")
else:print("no")
print(set([1,2,3,4]))
print(set(["python",123,"1949"]))
print(set("python"))
#遍历集合
for item in S:print(item,end='')
print()
#另一种遍历集合的方法!
try:while 1:print(S.pop(),end="")
except:pass
print()
#集合的应用场景1:判断某元素在不在集合内部/判断集合间的子集关系
S = {1,2,3,4}
if 1 in S:print("True")
if {1,2}< S:print("True")
#集合的应用场景2:数据去重
ls = ['p','p',1,1,3,3,5,5]
a = set(ls)#先换成集合进行数据去重
b = list(a)#再换成列表
print(ls)
print(a)
print(b)
===================
#序列类型及其操作
#序列类型分为:字符串类型、元组类型以及列表类型
#先看元组类型:一种一旦创建就不能再被修改的序列类型,可以用小括号或者tuple()创建
#注意:小括号方法创建元组时小括号可以省略、
creature = "cat","dog","tiger","human"
print("括号法创建的元组是{}".format(creature))
#元组原则上也可以作为其他元组的一个元素,也就是说元组的元素只要是不改变的量就可以!
color =0x001100,"blue",creature
color = [1,2,3,4],"blue",15#列表也可以作为元组的元素,但不可以改变
print(color)
#元组的操作(序列的通用操作)
a = 1,2,3
b = 4,5,6
if 1 in a:print("1在a中")
else:print("1不在a中")
print(a+b)#连接两个元组
print(a*2)
print(2*b)
print(a[0])
print(a[0::])
print(min(a),max(b))#找出元组中最大&最小的元素,要求是元素必须能比较
print(a.index(3))#寻找3第一次在a出现时对应的索引
print(a.count(3))#判断3在元组a中出现了多少次
print(len(a))#返回元素个数
#==============================================
#另一种序列类型:列表
#列表的特点是:1.创建后可以被随意修改2.用[]或list()创建,其中元素用英文逗号分割3.列表中的元素类型可以不一致,而且没有长度限制
ls = ['a',7,8,9,4,'b']
print(ls)
ls[0] = 0#通过索引改变列表对应位置的元素
print(ls[0])
ls[1:4:1] = [1,2,3]#这里是左闭右开
print(ls)
del ls[-1]
print(ls)
ls += [5,6,7]#把后一个列表的元素添加进入前一个列表中
print(ls)
ls*= 2#重复两次ls中的元素,注意:ls作为一个列表,被更新了!
print(ls)
ls.append(8)#在列表最后添加一个元素
lt = ls.copy()#返回ls的一个副本
print(lt,ls)
ls.clear()#清除ls中的所有元素,返回一个空列表
print(ls)
lt.insert(0,0)#向0处添加一个元素0
print(lt)
a = lt.pop(0)
print(a,lt)
lt.remove(6)#正向索引删去第一个元素x
print()
print(lt)
lt = lt.reverse()#反转元素
print(lt)
==============================列表,完毕++++++++++++++++++++++++++++++++基本统计值计算
#基本统计值计算:求出总个数,求和,求平均值,求方差,求中位数
def getls():#多输入获取函数ls = []a = input("请输入元素,当输入为回车时结束输入:")while a != '':ls.append(eval(a))#注意这里应该使用eval()进行类型转换a = input("请继续输入,输入为回车时结束输入:")else:return ls
def average(ls):#总和&平均值计算函数sum = 0for item in ls:sum += itemmean = sum/len(ls)return sum,mean
def median(ls):#计算中位数ls = sorted(ls)size = len(ls)if size % 2 == 0:#注意:求偶数应该是%median = (ls[size//2-1]+ls[size//2])/2#这里是关键!else:median = (ls[size//2])#这里是关键!return median
def dev(ls,mean):sdev = 0.0for num in ls:sdev = sdev + (num-mean)**2return pow(sdev/(len(ls)-1),0.5)
lt = getls()
print(lt)
sum,mean = average(lt)
print("总和为{:.3f},平均值为{:.3f}".format(sum,mean))
median = median(lt)
print("该组数据的中位数是:{:.3f}".format(median))
sdev = dev(lt,mean)
print("该组数据的方差是:{:.3f}".format(sdev))
=============================================
字典类型及操作
#字典:1.键值对是数据索引的扩展。2.字典是键值对的集合,键值对之间无序。
#3.字典采用大括号{}和dict()创建,键值对用冒号表示
dict1 = {"中国":"北京","美国":"华盛顿","法国":"巴黎"}
print(dict1["中国"])#利用[]索引求出对应的值
dict1["意大利"] = "罗马"#利用[]索引给添加新的键值对
dict1["中国"] = "luoma"#利用[]索引改变键值对
print(dict1)
dict2 = {}
print(type(dict2))
#处理方法
del dict1["中国"]#删除选定键对应的值
print(dict1)
judge = "中国" in dict1#判断对应键在不在字典中,如果在就返回True,不在的话返回False
print(judge)
print(dict1.keys())#返回字典中所有的键
print(dict1.values())#返回字典中所有的值
print(dict1.items())#返回字典中所有的键值对
print(dict1.get("中国","不存在这个键"))#键k(第一个)若存在,则返回对应的值,不在返回第二个默认值
print(dict1.pop("美国","beijing"))#若第一个(键k存在),则取出对应值。否则返回默认值
print(dict1.popitem())#随机从字典中取出一个键值对,并以元组形式返回!取出之后就不会存在了
dict1 = {"中国":"北京","美国":"华盛顿","法国":"巴黎"}
dict1.clear()#删除所有键值对
print(dict1)
dict1 = {"中国":"北京","美国":"华盛顿","法国":"巴黎"}
print(len(dict1))#返回字典中键值对的对数
#字典的遍历
dict1 = {"中国":"北京","美国":"华盛顿","法国":"巴黎"}
for item in dict1:print("{}->{}".format(item,dict1[item]))
==============================================
import jieba
a = jieba.lcut("中国是一个伟大的国家")#精确模式:返回一个列表类型的分词结果
# 将语句最精确的切分,不存在冗余数据,适合做文本分析。
b = jieba.lcut("中国是一个伟大的国家",cut_all=True)#全模式,返回一个列表类型的分词结果,存在冗余
#将语句中所有可能是词的词语都切分出来,速度很快,但是存在冗余数据。
c = jieba.lcut_for_search("中华人民共和国是伟大的")#搜索引擎模式
# 在精确模式的基础上,对长词再次进行切分,提高召回率,适合用于搜索引擎分词。
print(a)
print(b)
print(c)
==============================================
import random as r#随机密码生成器
def random_password(n):#n为位数list1 = ("1,2,3,4,5,6,7,8,9,a,b,c,d,e,f,g,h,i,j,""k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z,A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z")list1 = list1.split(",")s = []for i in range(n):s.append(list1[r.randint(0,60)])s = ''.join(s)return s
for i in range(8):a = random_password(8)print("第{}个密码为:{}".format(i+1,a))
================================================
def Repeat_elements(list1):#6.2重复元素判定a = set(list1)if len(a) < len(list1):return True
print(Repeat_elements([1,2,3,4,5,6,7,8,9,1,2,3,4,5,6]))
print(Repeat_elements([1,2,3,4,5,6,7,8,9]))
================================================
#英文小说人物出场次数分析 以hamlet为例子
def gettext():txt = open("hamlet.txt",'r').read()#字符串形式txt = txt.lower()for ch in '!"#$%&()*+-,/:;<=>?@[\\]`~{}|':txt = txt.replace(ch," ")#将文本中的字符全部替换为空格return txt
excludes = {"the","and","of","you","a","i","my","in","to","it","that","is","not","his","this","but","with","for","your","as","be","he","me","what","so","have","him","will","do","no","we","on","our","are","all","by","or","shall","if","o","good","they","come","thou","now","let","from","more","how","at","thy","her"}#以集合类型建立一个排除词汇库
hamlettxt = gettext()
words = hamlettxt.split()#建立单词列表
counts ={}
for word in words:counts[word] = counts.get(word,0) + 1#若存在返回对应值,若不存在则返回默认值0
for word in excludes:del(counts[word])#删除存在于排除词汇库中的键值对
items = list(counts.items())#将字典转换为列表,其中键值对组成的元组为列表的元素
items.sort(key = lambda x:x[1],reverse = True)#按照第二列进行排序
for i in range(10): #选出前10个word ,count = items[i]print("{0:<10}{1:>5}".format(word,count))
=========================================================
#中文小说人物出场频次分析
#三国演义
import jieba
excludes = {"将军","却说","荆州","二人","不可","不能","如此","商议","主公","丞相","如何","军士","左右","军马","引兵","次日","大喜","天下","东吴","于是","今日","不敢","魏兵","陛下","一人","都督","人马","不知"}
txt = open("三国演义.txt",'r',encoding='utf-8').read()
words = jieba.lcut(txt)#精确模式
counts = {}
for word in words:if len(word) == 1:continueelif word =="诸葛亮" or word == "孔明曰":rword = "孔明"elif word == "关公" or word == "云长":rword = "关羽"elif word == "玄德" or word == "玄德曰":rword = "刘备"elif word == "孟德" or word == "丞相曰":rword = "曹操"elif word == "翼德" or word == "翼德曰":rword = "张飞"else:rword =wordcounts[rword] = counts.get(rword,0)+1
for word in excludes:del(counts[word])
items = list(counts.items())
items.sort(key=lambda x :x[1],reverse=True)
for i in range(10):word,count = items[i]#注意这是一个二维列表print("{0:<10}{1:>5}".format(word,count))
====================================================
#文本字符分析 s6.4
def gettxt():#字符串获取&处理函数name = input("请输入您所需要进行文本字符分析的文件名:")name = name+".txt"txt = open(name,"r",encoding='utf-8').read()for ch in '!@#¥%……&*()——+=-、\';|}{】【‘;”:?"''/。,!@#$%^&*()_+=-][\\|}{":''?/><.,\t\n':txt = txt.replace(ch,"")flag = input("您输入的是英文文本(0)/中文文本(1)?")if flag == "0":txt=txt.lower()return txtelse:return txt
txt = gettxt()
counts ={}
for word in txt:counts[word] = counts.get(word,0)+1
del(counts[' '])
#去除冗余
items = list(counts.items())#注意:这里必须使用counts.items()!!!
items.sort(key=lambda x:x[1],reverse=True)
i = 0
while i < len(counts):word, count = items[i]print("{}:{}次 ".format(word,count),end="")i+=1
======================================================
#生日悖论分析:概率计算
import math as m
#P(A)=1-P(B)=1-365!/[(365-n)!*365^n]
def p(n):p1 = (m.factorial(365))/((m.factorial(365-n))*(pow(365,n)))return (1-p1)
n = input("请输入总人数:")
p = p(eval(n))
print("{}个人中至少有两人生日相同的概率为{}".format(eval(n),p))
=========================================================
#文件操作
#文件分为文本文件和二进制文件,文件是数据的抽象和集合
#其中文本文件通常是由单一特定编码组成:UTF-8编码;可以看作是一个长字符串。例如txt文件,.py文件。
#而二进制文件是直接由比特0和1组成的,也就是没有统一的字符编码。例如:.png & .avi文件。
#以文本形式打开文件:
file = open("111.txt","rt",encoding="utf-8")#含有中文字符的时候必须加上utf-8
print(file.readline())
file.close()
#以二进制文件形式打开
file = open("111.txt","rb")#不含中文字符的时候不加utf-8
print(file.readline())
file.close()
#文件的打开模式:r,w,x,a,b,t,+,默认为文本形式只读模式!
#打开必须要配合关闭使用
#文件内容的读取read
file = open("111.txt","rt",encoding="utf-8")
a=file.read(2)#读入全部内容,如果给出参数,读入前size长度,默认size为-1
print(a)#结果为中国
file.close()
#readline
file = open("111.txt","rt",encoding="utf-8")
a=file.read()#读入一行内容,如果给出参数,读入该行前size长度
print(a)#结果为中国是一个伟大的国家!\n我爱中国
file.close()
#readlines
file = open("111.txt","rt",encoding="utf-8")
a=file.readlines(-1)#读入文件所有行,以每行元素形成列表,如果给出参数,读入前参数行,默认参数为-1
print(a)#结果为['中国是一个伟大的国家!\n','我爱中国']
file.close()
#文件的全文本操作方法:遍历全文本,逐行遍历全文本。
#遍历全文本的第一种方法
#filename = input("请输入要打开的文件名称:")
#fo = open(filename,"r",encoding="utf-8")
#for line in fo.readlines():#print(line,end="")#一次读入,分行处理
#fo.close()
#逐行遍历文件的第二种方法
filename = input("请输入要打开的文件名称:")
fo = open(filename,"r",encoding="utf-8")#字符串!
for line in fo:print(line)
fo.close()
#数据的文件写入
filename = input("请输入要打开的文件名称:")
fo = open(filename,"a+",encoding="utf-8")
fo.write("我深深爱着我的祖国!\n")
fo.writelines(["中国","美国","法国"])
for line in fo:print(line)#没有任何输出
fo.seek(0)#改变文件当前操作指针的位置,0-文件开头,1,当前位置;2,文件结尾
for line in fo:print(line)#出现输出
fo.close()
======================================================
#二维数据的格式化与处理
#国际通用的一二维数据储存格式是.csv扩展名,每行一个一维数据,采用逗号分隔,无空行。
#一般使用列表类型表达二维数据,注意:表头也算!
#用列表表示二维数据时,一般嵌套for循环来遍历元素,而外层列表中的每个元素可以对应一行,也可以对应一列。
#注意:利用csv数据储存格式保留二维列表时:一、如果某个元素缺失,逗号依旧保留。二、逗号为英文半角,且逗号与数据之间无空格
#一般存数据,先行后列
fo = open("p111.csv")#csv格式文件读入数据
ls = []
for line in fo:line = line.replace("\n",'')#将每行最后的回车换为空字符串ls.append(line.split(","))#生成二维列表
fo.close()
#csv格式文件写入数据
fo = open("p111.csv",'a')
ls = [["西安",'120','130','150.1'],["郑州",'136','141','114']]
for item in ls:fo.write(','.join(item)+'\n')
fo.close()
#遍历所有二维数据
fo = open("p111.csv")
for row in fo:for column in row:print(column,end='')
=======================================================
#英文词云
import wordcloud
txt = "life is short, i need python"
w = wordcloud.WordCloud(background_color="white")#设置背景为白色
w.generate(txt)#向词云对象中加载文本txt
w.to_file("pywcloud.png")#将词云输出为图像文件:.png or .jpg
#中文词云
=======================================================
#爬虫
import requests
head = {"User-Agent":"Mozilla/5.0(Windows NT 10.0; Win64; x64)"}#把爬虫程序伪装成用户
response = requests.get("http://books.toscrape.com/",headers= head )
#第一步:获取网页内容
print(response)#状态码显示为200表示请求成功,404:网址输错了。
#用response的ok属性检测请求是否成功
if response.ok:print("请求成功")print(response.text)#查看响应体里服务器返回的内容
else:print("请求失败")- 绘制如下图形。

- 两个乒乓球队进行比赛,各出三人。甲队为a,b,c三人,乙队为x,y,z三人。已抽签决定比赛名单。有人向队员打听比赛的名单。a说他不和x比,c说他不和x,z比,请编程序找出三队赛手的名单。(采用循环+条件判断的方法)
- 统计不同字符个数。用户从键盘输入一行字符,编写一个程序,统计并输出其中的英文字符、数字、空格和其他字符的个数。
- 实现isPrime()函数,参数为整数,要有异常处理。如果整数是质数,返回True,否则返回False.
- 普通时钟都有时针和分针,在任意时刻时针和分针都有一个夹角,并且假设时针和分针都是连续移动的。现已知当前的时刻,试求出该时刻时针和分针的夹角A(0-180度之间)。注意:当分针处于0分和59分之间时,时针相对于该小时的起始位置也有一个偏移角度。
【输入样例】8:10
【输出样例】 175.000
- 编写函数求余弦函数的近似值,用下列公式求cos(x)的近似值,精确到最后一项绝对值小于0.01.
例如cos(-3.14)=-9.999899
- (附加题)模拟发红包,输入红包金额,红包个数,输出每个红包的金额。输入金额单位为分(输入的金额为整数),每个红包金额最少为1分。
放一点题,下次更这个!
相关文章:
python本学期所有代码!
第一单元 ----------------------------------------------------------------------- #圆面积的计算 radius 25 area 3.1415 * radius * radius print(area) print("{:.2f}".format(area)) --------------------------------------------------------------------…...

武汉星起航:无锡跨境电商加速“出海”,物流升级助品牌全球布局
随着全球化的不断深入,跨境电商作为数字外贸的新业态,正逐渐成为无锡企业拓展海外市场的重要渠道。武汉星起航关注到,近年来,无锡市通过积极推进国际物流枢纽建设,完善海外仓布局,以及各特色产业带的积极参…...
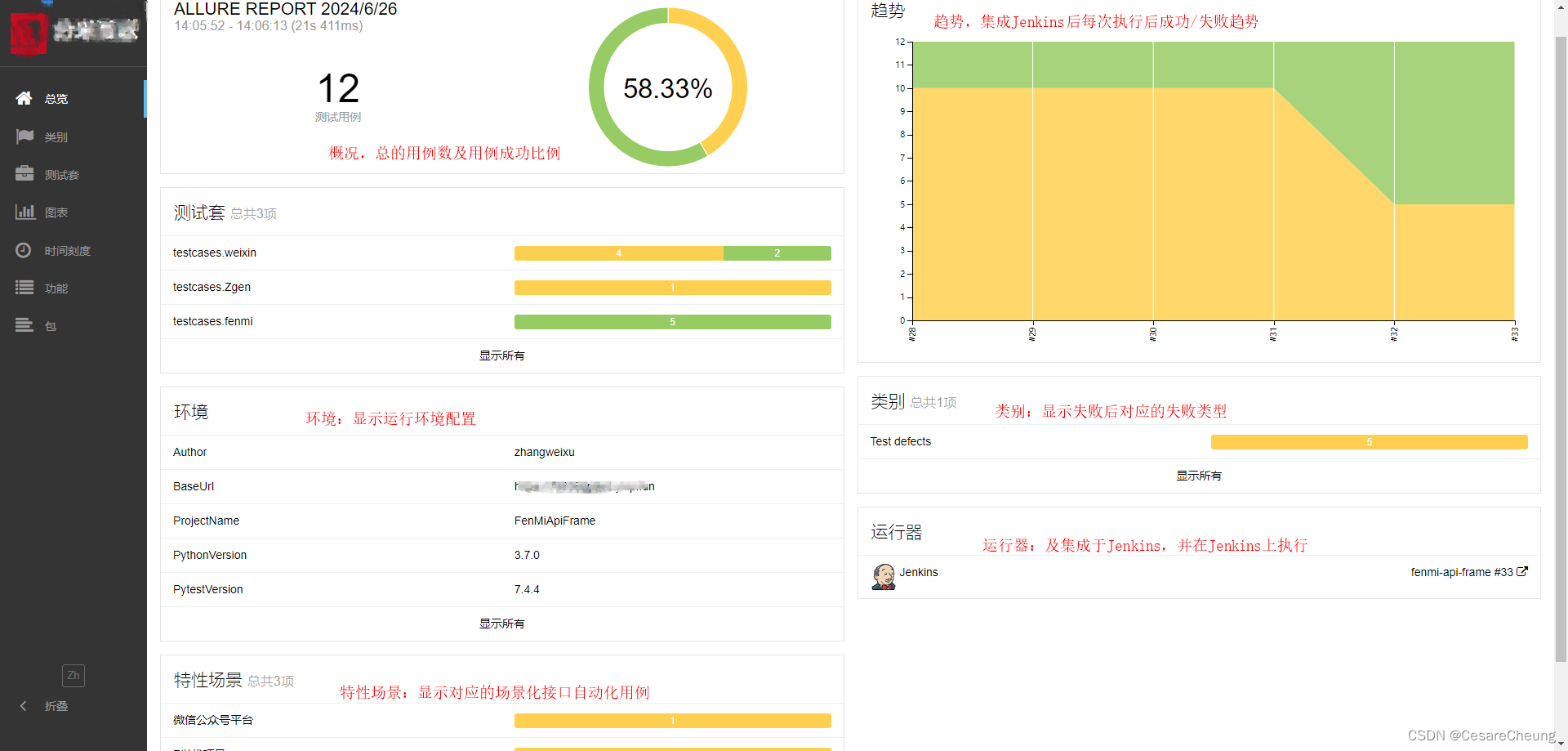
Python+Pytest+Allure+Yaml+Pymysql+Jenkins+GitLab接口自动化测试框架详解
PythonPytestAllureYaml接口自动化测试框架详解 编撰人:CesareCheung 更新时间:2024.06.20 一、技术栈 PythonPytestAllureYamlJenkinsGitLab 版本要求:Python3.7.0,Pytest7.4.4,Allure2.18.1,PyYaml6.0 二、环境配置 安装python3.7&…...

stm32-hal库(5)--usart串口通信三种模式(主从通信)(关于通信失败和串口不断发送数据问题的解决)
问题: 最近发现,stm32cubemx最新版本f1系列的hal库(1.85版本)生成的hal库,其中stm32f1xx_hal_uart.c的库文件中,其串口发送接收存在一些问题: 1.没有使用 __HAL_LOCK 和 __HAL_UNLOCK 宏&…...

一文学会LVS:概念、架构、原理、搭建过程、常用命令及实战案例
引言 随着互联网技术的飞速发展,服务器负载均衡技术变得越来越重要。LVS(Linux Virtual Server)作为一种高效的负载均衡解决方案,广泛应用于各大企业的生产环境中。本文将深入探讨LVS的概念、架构、工作原理,详细讲解其…...
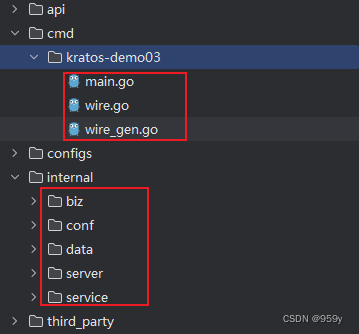
[Go 微服务] Kratos 使用的简单总结
文章目录 1.Kratos 简介2.传输协议3.日志4.错误处理5.配置管理6.wire 1.Kratos 简介 Kratos并不绑定于特定的基础设施,不限定于某种注册中心,或数据库ORM等,所以您可以十分轻松地将任意库集成进项目里,与Kratos共同运作。 API -&…...

【unity实战】使用旧输入系统Input Manager 写一个 2D 平台游戏玩家控制器——包括移动、跳跃、滑墙、蹬墙跳
最终效果 文章目录 最终效果素材下载人物环境 简单绘制环境角色移动跳跃视差和摄像机跟随效果奔跑动画切换跳跃动画,跳跃次数限制角色添加2d物理材质,防止角色粘在墙上如果角色移动时背景出现黑线条方法一方法二 墙壁滑行实现角色滑墙不可以通过移动离开…...
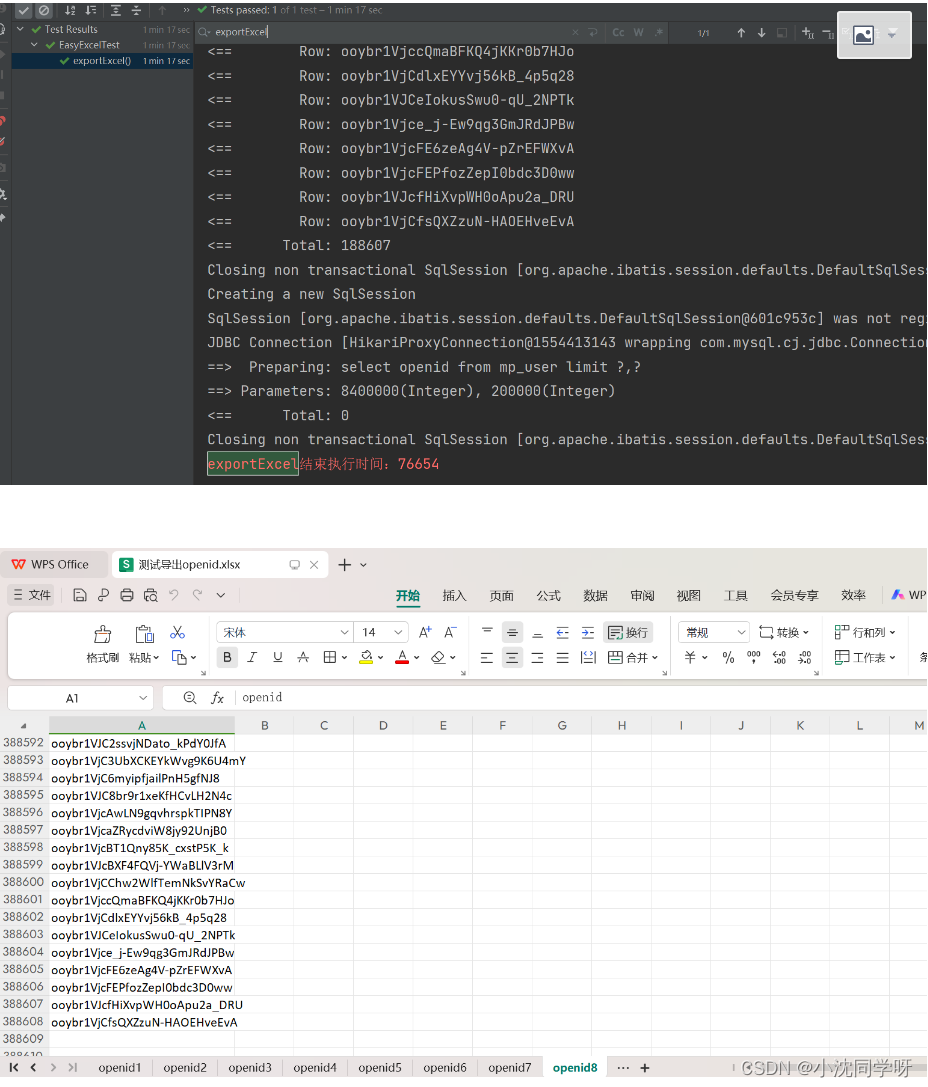
【实战】EasyExcel实现百万级数据导入导出
文章目录 前言技术积累实战演示实现思路模拟代码测试结果 前言 最近接到一个百万级excel数据导入导出的需求,大概就是我们在进行公众号API群发的时候,需要支持500w以上的openid进行群发,并且可以提供发送openid数据的导出功能。可能有的同学…...

Graalvm配置文件与Feature和Substitute机制介绍
GraalVM介绍 GraalVM提前将Java应用程序编译成独立与机器码二进制文件(可执行文件、动态库文件),如windows系统中的exe文件和dll文件。与在Java虚拟机(JVM)上运行的应用程序相比,这些二进制文件更小,启动速…...
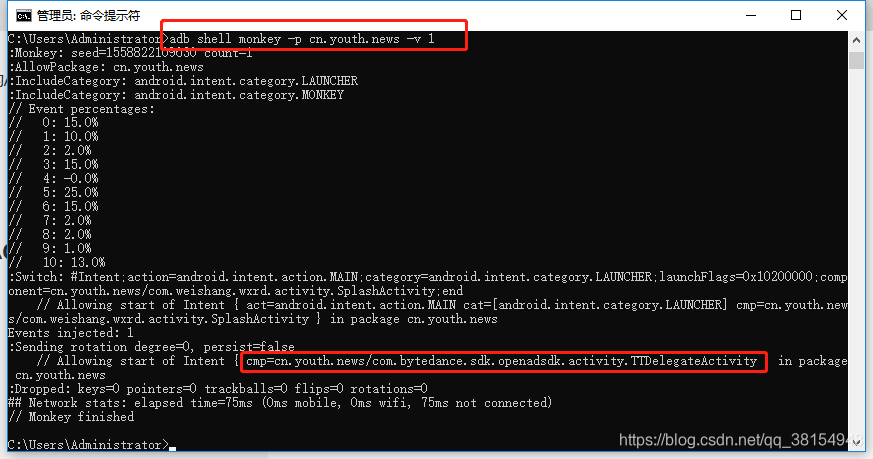
Appium adb 获取appActivity
方法一(最简单有效的方法) 通过cmd命令,前提是先打开手机中你要获取包名的APP adb devices -l 获取连接设备详细信息 adb shell dumpsys activity | grep mFocusedActivity 有时获取到的不是真实的Activity 方法二 adb shell monkey -p …...

调整分区失败致盘无法访问:深度解析与数据恢复全攻略
调整分区失败盘打不开的困境 在计算机的日常维护与管理中,调整磁盘分区是常见的操作之一,旨在优化存储空间布局、提升系统性能或满足特定应用需求。然而,当这一操作未能如预期般顺利进行,反而导致分区调整失败,进而使…...
试用笔记之-汇通计算机等级考试软件一级Windows
首先下载汇通计算机等级考试软件一级Windows http://www.htsoft.com.cn/download/htwork.rar...
Java的NIO体系
目录 NIO1、操作系统级别下的IO模型有哪些?2、Java语言下的IO模型有哪些?3、Java的NIO应用场景?相比于IO的优势在哪?4、Java的IO、NIO、AIO 操作文件读写5、NIO的核心类 :Buffer(缓冲区)、Channelÿ…...

自下而上的选股与自上而下的选股
一起学习了《战胜华尔街》,不知道大家有没有这么一种感受:林奇的选股方法是典型的自下而上的选股方法。虽然这一点没有单独拎出来讨论过,但在《从低迷中寻找卓越》《如何通过财务指标筛选股票?》《边逛街边选股?》《好…...

Tech Talk:智能电视eMMC存储的五问五答
智能电视作为搭载操作系统的综合影音载体,以稳步扩大的市场规模走入越来越多的家庭,成为人们生活娱乐的重要组成部分。存储部件是智能电视不可或缺的组成部分,用于保存操作系统、应用程序、多媒体文件和用户数据等信息。智能电视使用eMMC作为…...

scikit-learn教程
scikit-learn(通常简称为sklearn)是Python中最受欢迎的机器学习库之一,它提供了各种监督和非监督学习算法的实现。下面是一个基本的教程,涵盖如何使用sklearn进行数据预处理、模型训练和评估。 1. 安装和导入包 首先确保安装了…...

CentOS 7 搭建rsyslog日志服务器
CentOS 7 搭建rsyslog日志服务器 前言一、IP地址及主机名称规划1.修改主机名 二、配置rsyslog日志服务器1.安装rsyslog服务2.编辑/etc/rsyslog.conf 文件3.启动并启用rsyslog服务4.验证端口是否侦听 三、在rsyslog日志服务器上配置firewalld防火墙四、配置rsyslog日志客户端1.编…...

使用Spring Boot Actuator监控应用健康状态
使用Spring Boot Actuator监控应用健康状态 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将探讨如何利用Spring Boot Actuator来监控和管理应用程序的…...

leetcode刷题:vector刷题
🔥个人主页:guoguoqiang. 🔥专栏:leetcode刷题 1.只出现一次的数字 这道题很简单,我们只需要遍历一次数组即可通过异或运算实现。(一个数与自身异或结果为0,任何数与0异或还是它本身) class Solut…...

CGI面试题及参考答案
什么是CGI?它在Web服务器与应用程序之间扮演什么角色? CGI(Common Gateway Interface) 是一种标准协议,它定义了Web服务器与运行在服务器上的外部程序(通常是脚本或应用程序)之间的通信方式。简单来说,CGI充当了一个桥梁,使得Web服务器能够将用户的请求传递给后端程序…...

Python异步爬虫框架lightclaw:轻量级高性能Web数据采集实战
1. 项目概述:一个轻量级、高性能的Web爬虫框架最近在做一个需要大规模采集公开网页数据的项目,市面上成熟的爬虫框架很多,像Scrapy、Playwright这些,功能强大但有时候也显得“笨重”。尤其是在处理海量、高并发的简单页面抓取时&a…...

边缘计算中ViT模型压缩与硬件加速技术解析
1. 边缘计算中的ViT模型压缩技术全景解析Vision Transformer(ViT)模型在计算机视觉领域展现出卓越性能的同时,其庞大的计算量和内存需求成为边缘设备部署的主要障碍。模型压缩技术通过降低模型复杂度,使其能够在资源受限的边缘设备…...

AI短剧角色和场景总不一致?用辰入梦 v2.8.0 先固定创作资产
很多 AI 短剧项目卡在模型配置上:剧本、分镜图和视频生成混在一起调,结果每一步都难复现。更稳的方式是把文本模型、图片模型和视频模型分层管理。 文本模型负责剧本结构、角色对白和分集节奏。图片模型用于角色参考、场景设计和 GPT Image-2 导演故事板…...
)
助睿实验作业1:订单利润分流数据加工(零代码 ETL 完整流程)
前言 本文是我在完成 助睿数智(Uniplore)一站式数据科学实验平台 入门实验时的完整学习笔记。实验任务是将订单明细表与产品信息表关联,并根据利润正负将数据分流为盈利订单和亏损订单,最终输出到两个 Excel 文件中。全程使用零代…...

蓝牙广播帧实战解析:从ADV_IND到AUX_CHAIN_IND的报文拆解
1. 蓝牙广播帧入门:为什么需要这么多类型? 刚接触蓝牙协议栈的开发者,第一次看到ADV_IND、ADV_DIRECT_IND这些缩写时,往往会感到一头雾水。我自己最初调试蓝牙设备时,就曾经对着抓包工具里密密麻麻的广播数据发愣——为…...

铁路光纤熔接机推荐:鼎讯 TY-30H 性能参数与应用场景
在铁路与高速公路通信建设中,光纤熔接质量直接决定信号传输稳定性。鼎讯 TY-30H 光纤熔接机作为专为野外严苛工况设计的熔接设备,凭借高效、低耗、耐用的综合性能,成为铁路高速通信施工、日常维护及应急抢修的核心设备。一、鼎讯 TY-30H 光纤…...

ARMv8/v9架构ID_AA64ISAR3_EL1寄存器详解与应用
1. AArch64指令集属性寄存器ID_AA64ISAR3_EL1概述 在ARMv8/v9架构中,ID_AA64ISAR3_EL1是一个关键的系统寄存器,它属于AArch64指令集属性寄存器家族。这个64位寄存器专门用于描述处理器在AArch64执行状态下实现的各种指令集扩展特性。作为ARM架构的标准实…...
)
动漫线稿上色失控?用--stylize 500+--no “shading, texture noise“双指令锁死干净赛璐珞效果(实测出图成功率提升310%)
更多请点击: https://intelliparadigm.com 第一章:动漫线稿上色失控的本质与赛璐珞美学底层逻辑 赛璐珞动画的视觉稳定性并非源于技术精度,而来自人为设定的**色彩边界契约**——即在手绘时代,上色师必须严格遵循线条闭合区域的物…...

自由职业者收入追踪器:从数据模型到可视化分析的全栈实现
1. 项目概述:一个为自由职业者量身定制的收入追踪器如果你是一名自由职业者、独立开发者,或者正在经营自己的副业,那么“收入管理”这件事,大概率会让你感到头疼。项目款什么时候到账?这个月到底赚了多少钱?…...

YuukiPS启动器:动漫游戏玩家的智能启动解决方案终极指南
YuukiPS启动器:动漫游戏玩家的智能启动解决方案终极指南 【免费下载链接】Launcher-PC 项目地址: https://gitcode.com/gh_mirrors/la/Launcher-PC 你是否厌倦了每次启动游戏都要重复繁琐的配置步骤?是否希望有一个工具能够智能管理多个游戏账号…...