【MyBatis】篇三.自定义映射resultMap和动态SQL
= = = =MyBatis整理= = = =
篇一.MyBatis环境搭建与增删改查
篇二.MyBatis查询与特殊SQL
篇三.自定义映射resultMap和动态SQL
篇四.MyBatis缓存和逆向工程
文章目录
- 1、自定义映射
- P1:测试数据准备
- P2:字段和属性的映射关系
- P3:多对一的映射关系
- P4:一对多的映射关系
- 2、动态SQL
- 2.1 IF标签
- 2.2 where标签
- 2.3 trim标签
- 2.4 choose、when、otherwise标签
- 2.5 foreach标签
- 2.6 SQL标签
1、自定义映射
若字段名和实体类的属性名不一致,则需要自定义映射。
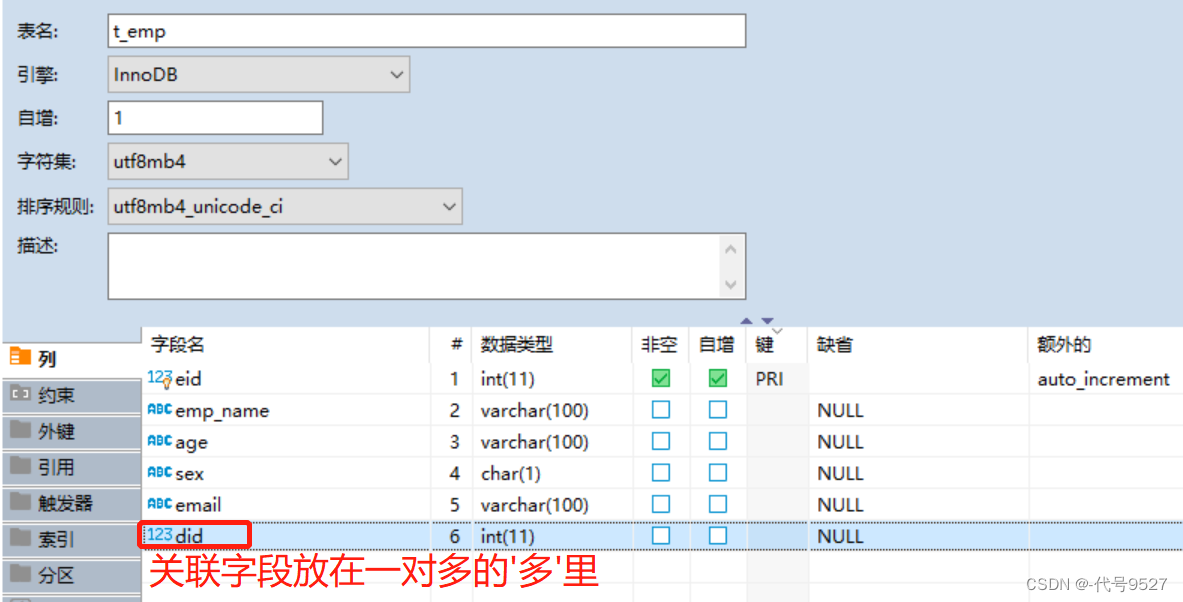
P1:测试数据准备
员工表:
部门表:
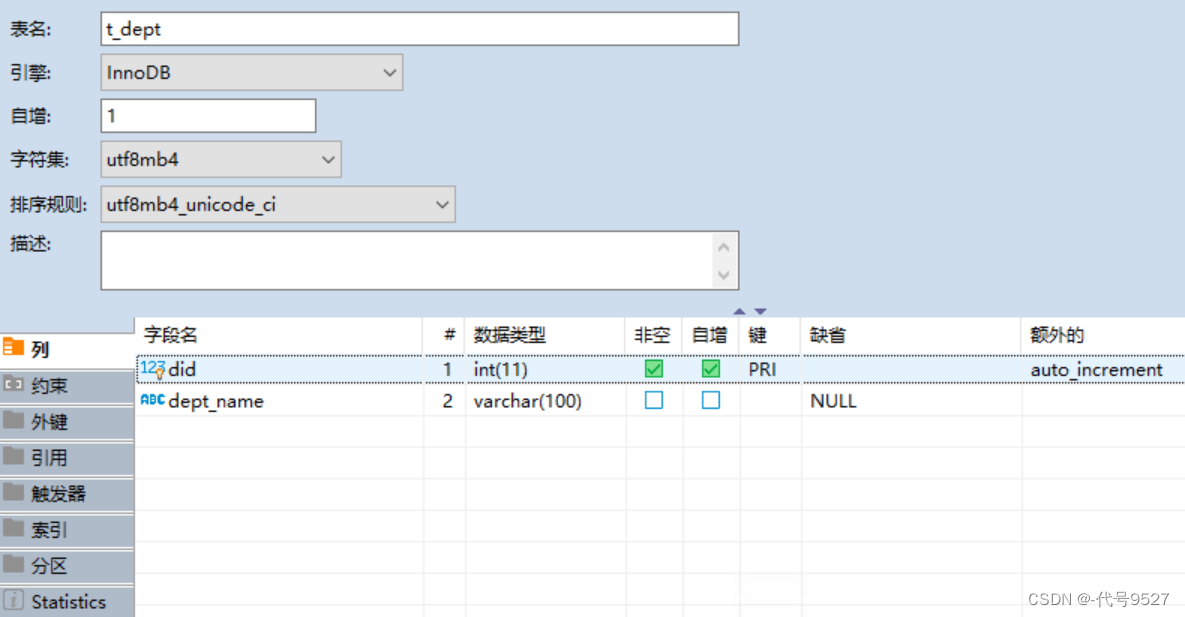
定义对应的实体类:(注意,字段名是下划线命名,属性名是驼峰命名,不再一致了)
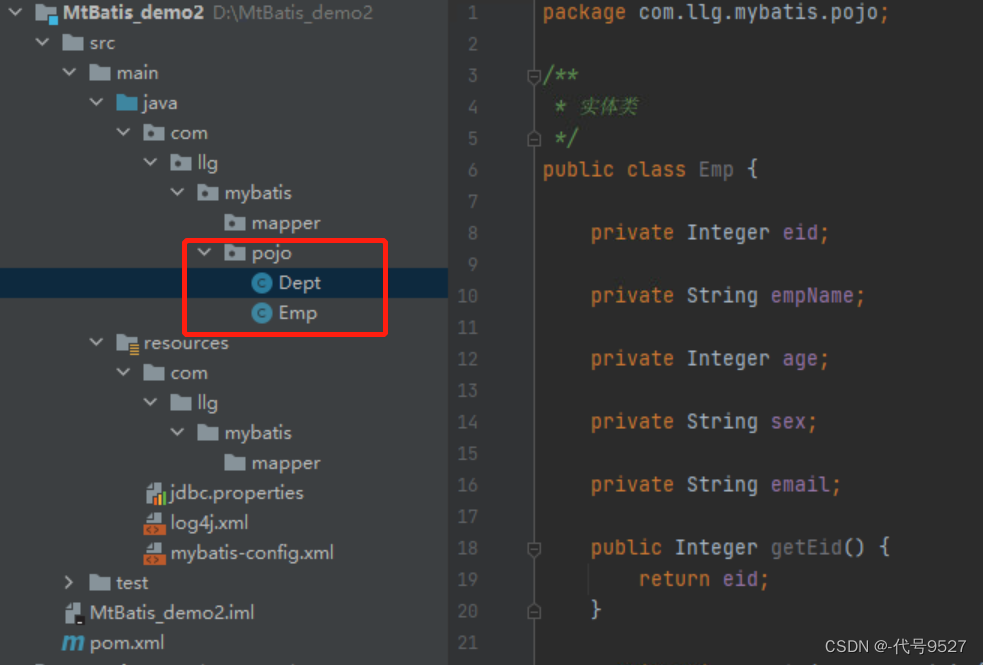
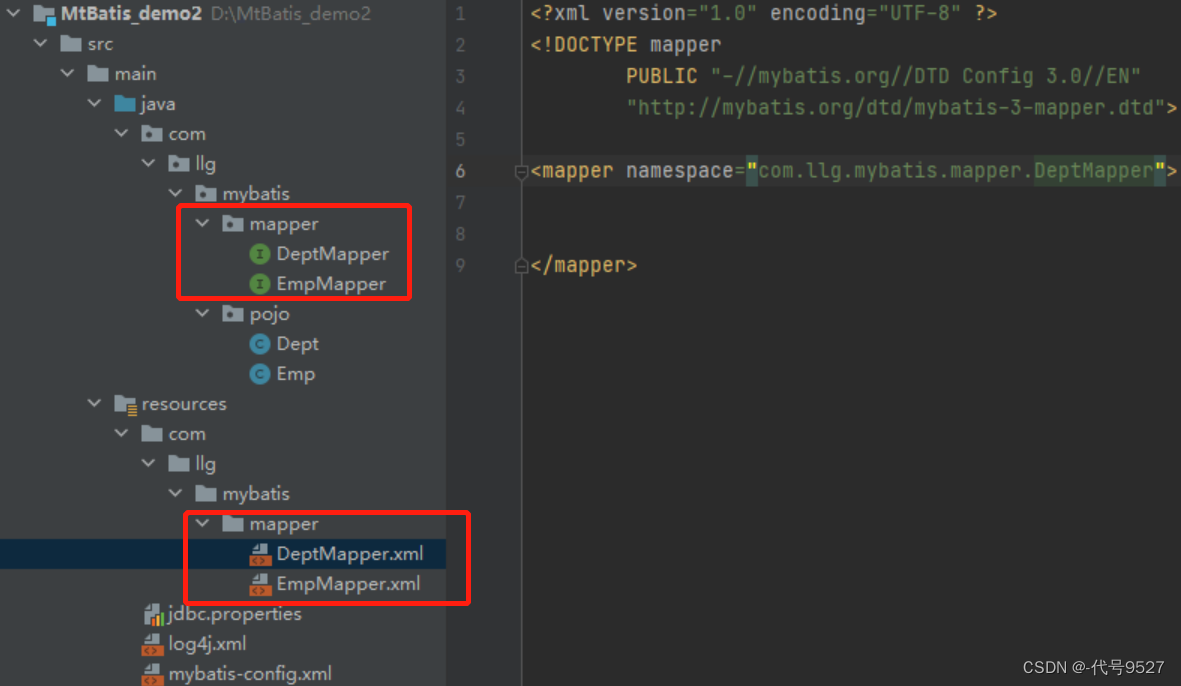
定义Mapper接口和映射文件:
P2:字段和属性的映射关系
当字段名和实体类中的属性名不一致,但是字段名符合数据库的规则(使用_),实体类中的属性名符合Java的规则(使用驼峰),此时使用之前的自动映射resultType,则命名不一致的属性值为null,解决思路有三种:
思路一:给字段名起别名,使其和属性名保持一致
<!--List<Emp> getAllEmp();-->
<select id="getAllEmp" resultType="Emp">select eid,emp_name empName,age,sex,email from t_emp
</select>
思路二:设置全局配置,将下划线_自动映射为驼峰
在核心配置文件mybatis-config.xml中:
<settings><!--将表中字段的下划线自动转换为驼峰--><setting name="mapUnderscoreToCamelCase" value="true"/>
</settings><!--注意这种只能转换规范命名,即emp_name映射为empName-->
此时,SQL语句正常写即可。
思路三:使用resultMap,不再使用之前的resultType做自动映射
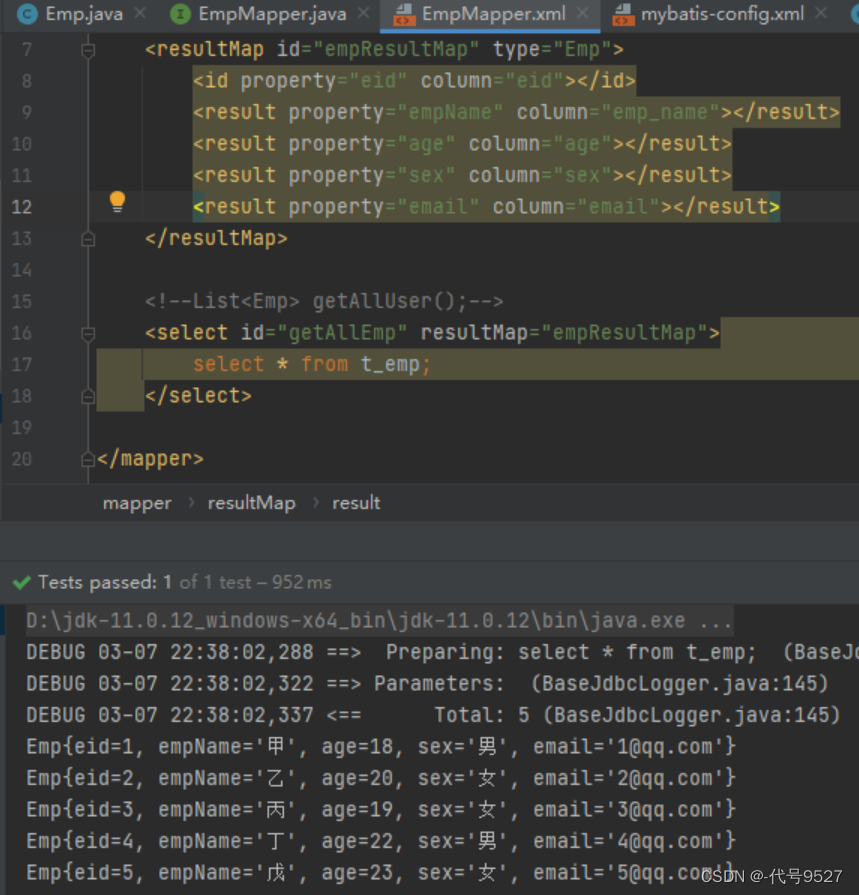
<resultMap id="empResultMap" type="Emp"><id property="eid" column="eid"></id><result property="empName" column="emp_name"></result><result property="age" column="age"></result><result property="sex" column="sex"></result><result property="email" column="email"></result>
</resultMap>
<!--List<Emp> getAllEmp();-->
<select id="getAllEmp" resultMap="empResultMap">select * from t_emp
</select><!--注意别只写不一样的属性,一样的也得写一遍-->
resultMap即设置自定义映射关系:
- 属性:
。 id:我定义的映射的唯一标识,不能重复,给select标签中的resultMap属性用
。 type:查询的数据要映射的实体类的类型 - 子标签:
。 id:设置主键的映射关系
。 result:设置普通字段的映射关系 - 子标签属性:
。 property:设置映射关系中实体类中的属性名
。 column:设置映射关系中表中的字段名
运行结果:
P3:多对一的映射关系
多对一的时候,在’多’的这边设置,设置’一’所对应的对象;在’一’那边,设置’多’的对象集合 。处理多对一的映射关系(如查询企业员工信息及其部门)有三种实现方式:
public class Emp { private Integer eid; private String empName; private Integer age; private String sex; private String email; /*** 这里设置'一'所对应的对象*/private Dept dept;//...构造器、get、set方法等
}
思路一:使用级联属性赋值
<resultMap id="empAndDeptResultMapOne" type="Emp"><id property="eid" column="eid"></id><result property="empName" column="emp_name"></result><result property="age" column="age"></result><result property="sex" column="sex"></result><result property="email" column="email"></result><result property="dept.did" column="did"></result><result property="dept.deptName" column="dept_name"></result>
</resultMap>
<!--Emp getEmpAndDept(@Param("eid")Integer eid);-->
<select id="getEmpAndDept" resultMap="empAndDeptResultMapOne">select * from t_emp left join t_dept on t_emp.did = t_dept.did where t_emp.eid = #{eid}
</select>
思路二:通过association处理多对一的映射
- association:处理多对一映射关系
- property:需要处理多对一映射关系的属性名
- javaType:该属性的类型
<resultMap id="empAndDeptResultMapTwo" type="Emp"><id property="eid" column="eid"></id><result property="empName" column="emp_name"></result><result property="age" column="age"></result><result property="sex" column="sex"></result><result property="email" column="email"></result><association property="dept" javaType="Dept"><id property="did" column="did"></id><result property="deptName" column="dept_name"></result></association>
</resultMap>
<!--Emp getEmpAndDept(@Param("eid")Integer eid);-->
<select id="getEmpAndDept" resultMap="empAndDeptResultMapTwo">select * from t_emp left join t_dept on t_emp.did = t_dept.did where t_emp.eid = #{eid}
</select>以上的逻辑是:在association中写要处理多对一关系的属性名dept,再说明该属性的Java类---->知道类型,通过反射拿到该类型的属性did和deptName---->将查询出来的字段赋值给属性---->Dept类的对象有了---->赋值给属性dept
思路三:分步查询处理多对一的映射
先查询员工信息–>拿到部门id–>根据部门id查询部门信息—>将信息赋值给dept属性
引用属性--那个属性的值也是一个对象,丈夫是一个对象:
有姓名属性、年龄属性、妻子属性。妻子属性就是一个引用属性,里面是个对象,有它自己的属性
//EmpMapper里的方法
/*** 通过分步查询,员工及所对应的部门信息* 分步查询第一步:查询员工信息*/
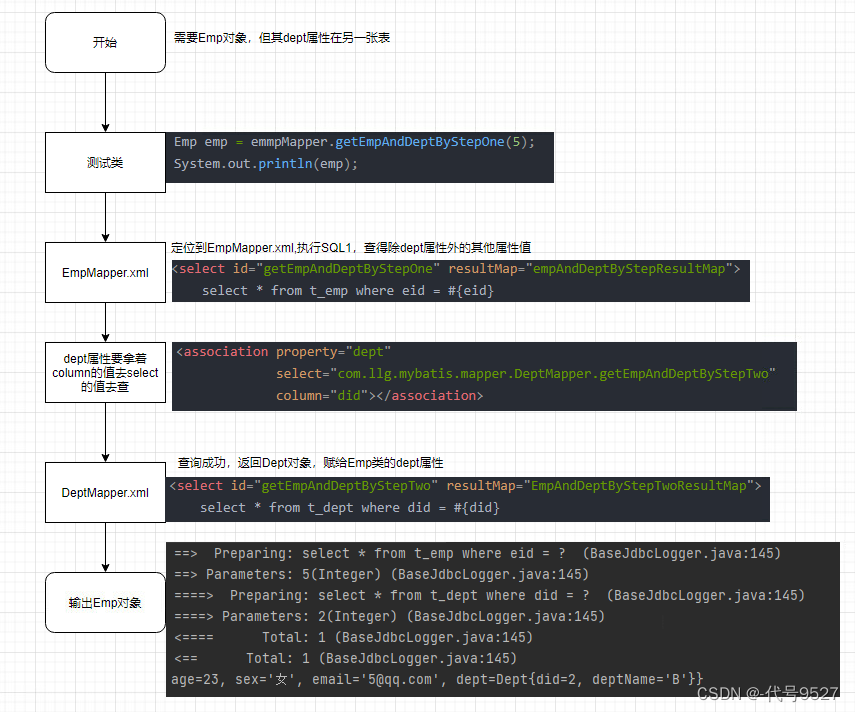
Emp getEmpAndDeptByStepOne(@Param("eid") Integer eid);- property:即要处理多对一映射关系的属性名
select:即设置分布查询的sql的唯一标识(namespace.SQLId或mapper接口的全类名.方法名)column:设置分布查询的条件,要根据员工表的did去查询部门信息,即第二个SQL要根据什么去查
<resultMap id="empAndDeptByStepResultMap" type="Emp"><id property="eid" column="eid"></id><result property="empName" column="emp_name"></result><result property="age" column="age"></result><result property="sex" column="sex"></result><result property="email" column="email"></result><association property="dept"select="com.llg.mybatis.mapper.DeptMapper.getEmpAndDeptByStepTwo"column="did"></association>
</resultMap>
<!--Emp getEmpAndDeptByStepOne(@Param("eid") Integer eid);-->
<select id="getEmpAndDeptByStepOne" resultMap="empAndDeptByStepResultMap">select * from t_emp where eid = #{eid}
</select>第二步:
//DeptMapper里的方法
/*** 通过分步查询,员工及所对应的部门信息* 分步查询第二步:通过did查询员工对应的部门信息* 这里的查询结果要给Emp的dept属性赋值,所以返回类型Dept*/
Dept getEmpAndDeptByStepTwo(@Param("did") Integer did);<!--此处的resultMap仅是处理字段和属性的映射关系,不想写就开启setting后使用resultType-->
<resultMap id="EmpAndDeptByStepTwoResultMap" type="Dept"><id property="did" column="did"></id><result property="deptName" column="dept_name"></result>
</resultMap>
<!--Dept getEmpAndDeptByStepTwo(@Param("did") Integer did);-->
<select id="getEmpAndDeptByStepTwo" resultMap="EmpAndDeptByStepTwoResultMap">select * from t_dept where did = #{did}
</select>测试类:
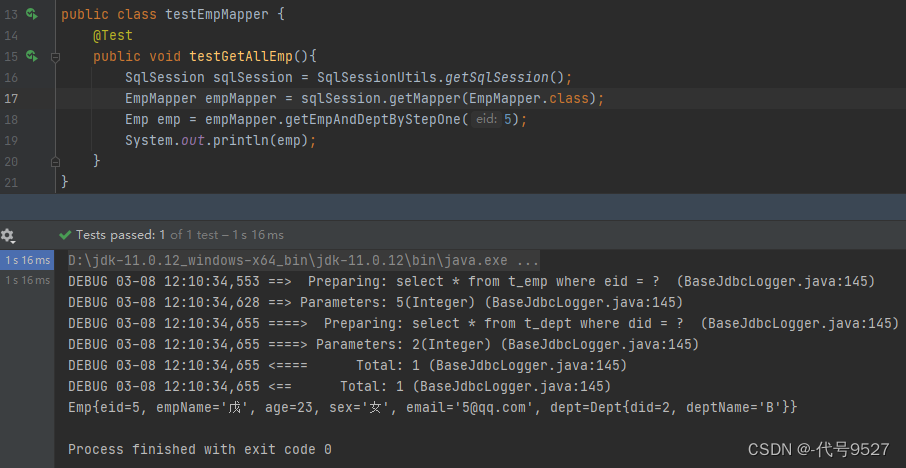
@Test
public void testGetEmpAndDeptByStep() {SqlSession sqlSession = SqlSessionUtils.getSqlSession();EmpMapper empMapper = sqlSession.getMapper(EmpMapper.class);Emp emp = emmpMapper.getEmpAndDeptByStepOne(5);System.out.println(emp);
}运行结果:
梳理下逻辑:
分步查询的好处–延迟加载
分步查询,实现一个功能分了两步,但这两步各自也是一个单独的功能。这就分步查询的好处—实现延迟加载
在核心配置文件中配置全局信息(setting标签):
- lazyLoadingEnabled:延迟加载的全局开关。当开启时,所有关联对象都会延迟加载
- aggressiveLazyLoading:当开启时,任何方法的调用都会加载该对象的所有属性。 否则,每个属性会按需加载
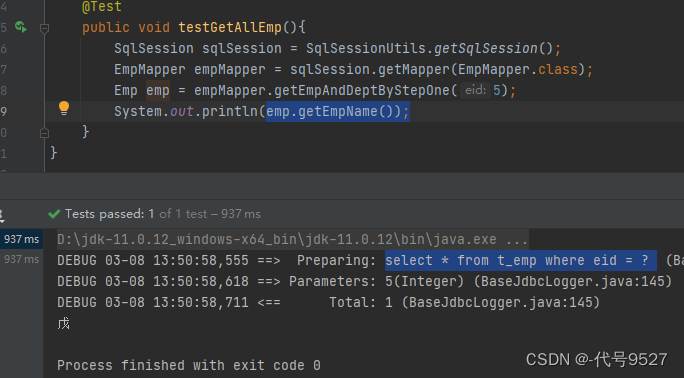
<settings><!--开启延迟加载--><setting name="lazyLoadingEnabled" value="true"/><setting name="aggressiveLazyLoading" value="false"/>
</settings>此时:我只获取员工名称,可以发现第二句SQL并未执行,这就是按需加载,获取的数据是什么,就只会执行相应的sql
而当获取部门信息的时候,两句就都会执行。为了清晰看到效果,先关掉延迟加载,可以看到是两句SQL都执行完了,再拿数据:
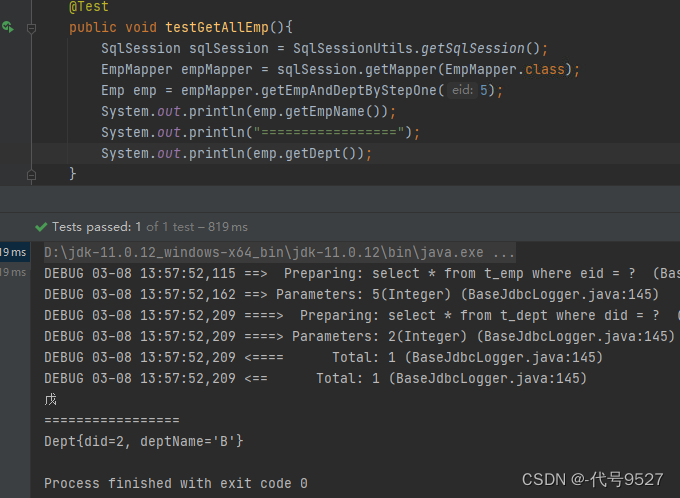
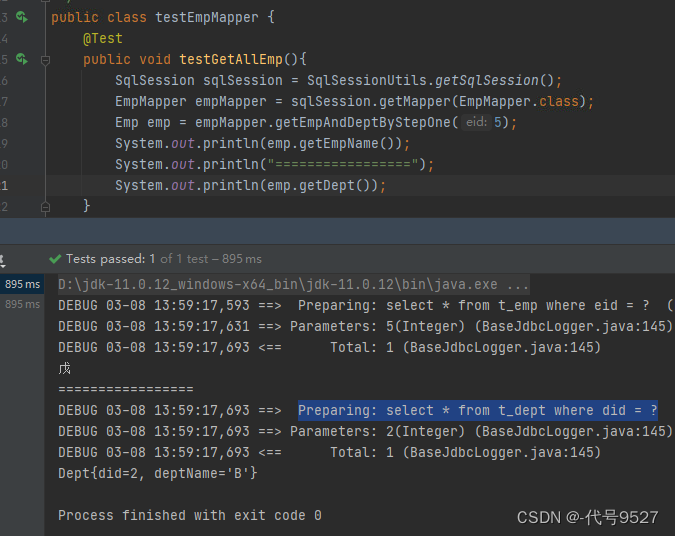
再开启延迟加载,可以看到是先执行了一句SQL,拿到了员工姓名,后面需要部门信息的时候,又执行了第二句SQL,这就是按需加载!!!
更改了全局设置,是否延迟加载则是对所有SQL的。当开启了全局的延迟加载(注意fetchType的前提是开启全局),要想单独控制某一个,可通过association和collection中的fetchType属性设置当前的分步查询是否使用延迟加载:
- fetchType=“lazy(延迟加载)”
- fetchType=“eager(立即加载)”
P4:一对多的映射关系
多对一的时候,在’多’的这边设置,设置’一’所对应的对象;在’一’那边,设置’多’的对象集合 。
public class Dept {private Integer did;private String deptName;//'多'的类型的集合private List<Emp> emps;//...构造器、get、set方法等
}
思路一:使用collection
- collection:处理一对多的映射关系
- ofType:表示该属性所对应的集合中存储的数据的类型
public interface DeptMapper{/*** 查询部门即其下的所有员工信息*/Dept getDeptAndEmp(@Param("did") Integer did);
}
<resultMap id="DeptAndEmpResultMap" type="Dept"><id property="did" column="did"></id><result property="deptName" column="dept_name"></result><collection property="emps" ofType="Emp"><id property="eid" column="eid"></id><result property="empName" column="emp_name"></result><result property="age" column="age"></result><result property="sex" column="sex"></result><result property="email" column="email"></result></collection>
</resultMap>
<!--Dept getDeptAndEmp(@Param("did") Integer did);-->
<select id="getDeptAndEmp" resultMap="DeptAndEmpResultMap">select * from t_dept left join t_emp on t_dept.did = t_emp.did where t_dept.did = #{did}
</select>
思路二:分步查询
第一步:
public interface DeptMapper{/*** 通过分步查询,查询部门及对应的所有员工信息* 分步查询第一步:查询部门信息*/Dept getDeptAndEmpByStepOne(@Param("did") Integer did);
}<resultMap id="DeptAndEmpByStepOneResultMap" type="Dept"><id property="did" column="did"></id><result property="deptName" column="dept_name"></result><collection property="emps"select="com.llg.mybatis.mapper.EmpMapper.getDeptAndEmpByStepTwo"column="did"></collection>
</resultMap>
<!--Dept getDeptAndEmpByStepOne(@Param("did") Integer did);-->
<select id="getDeptAndEmpByStepOne" resultMap="DeptAndEmpByStepOneResultMap">select * from t_dept where did = #{did}
</select>第二步:
public interface EmpMapper{/*** 通过分步查询,查询部门及对应的所有员工信息* 分步查询第二步:根据部门id查询部门中的所有员工*/List<Emp> getDeptAndEmpByStepTwo(@Param("did") Integer did);
}<!--List<Emp> getDeptAndEmpByStepTwo(@Param("did") Integer did);-->
<select id="getDeptAndEmpByStepTwo" resultType="Emp">select * from t_emp where did = #{did}
</select>结果:
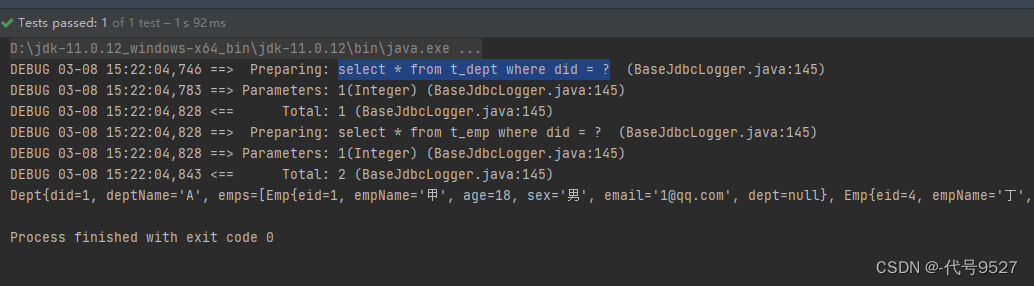
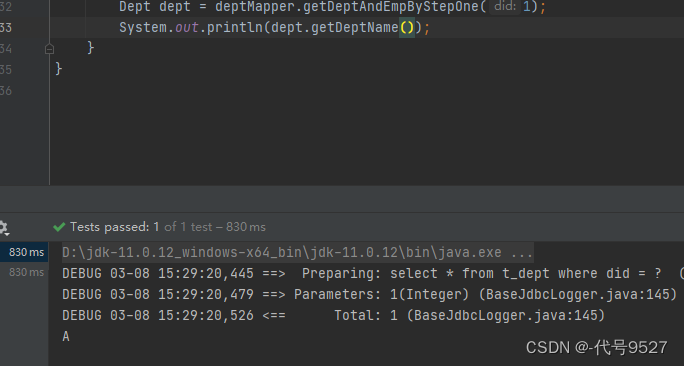
当然,分布查询在这儿也可以得到验证:
2、动态SQL
Mybatis框架的动态SQL技术是一种根据特定条件动态拼装SQL语句的功能,它存在的意义是为了解决拼接SQL语句字符串时的痛点问题
2.1 IF标签
public interface DynamicSQLMapper{/*** 多条件查询*/List<Emp> getEmpByCondition(Emp emp);
}
- if标签可通过
test属性对表达式进行判断,若表达式的结果为true,则标签中的内容会拼接到SQL中,反之标签中的内容不会拼接。 - 在where后面添加一个
恒成立条件1=1,这个条件不会影响查询结果,而又可以很好的拼接后面的SQL:当empName传过来为空,select * from t_emp where and age = ? and sex = ? and email = ?,此时where与and连用,SQL语法错误
<!--List<Emp> getEmpByCondition(Emp emp);-->
<select id="getEmpByCondition" resultType="Emp">select * from t_emp where 1=1<if test="empName != null and empName !=''">and emp_name = #{empName}</if><if test="age != null and age !=''">and age = #{age}</if><if test="sex != null and sex !=''">and sex = #{sex}</if><if test="email != null and email !=''">and email = #{email}</if>
</select>测试:
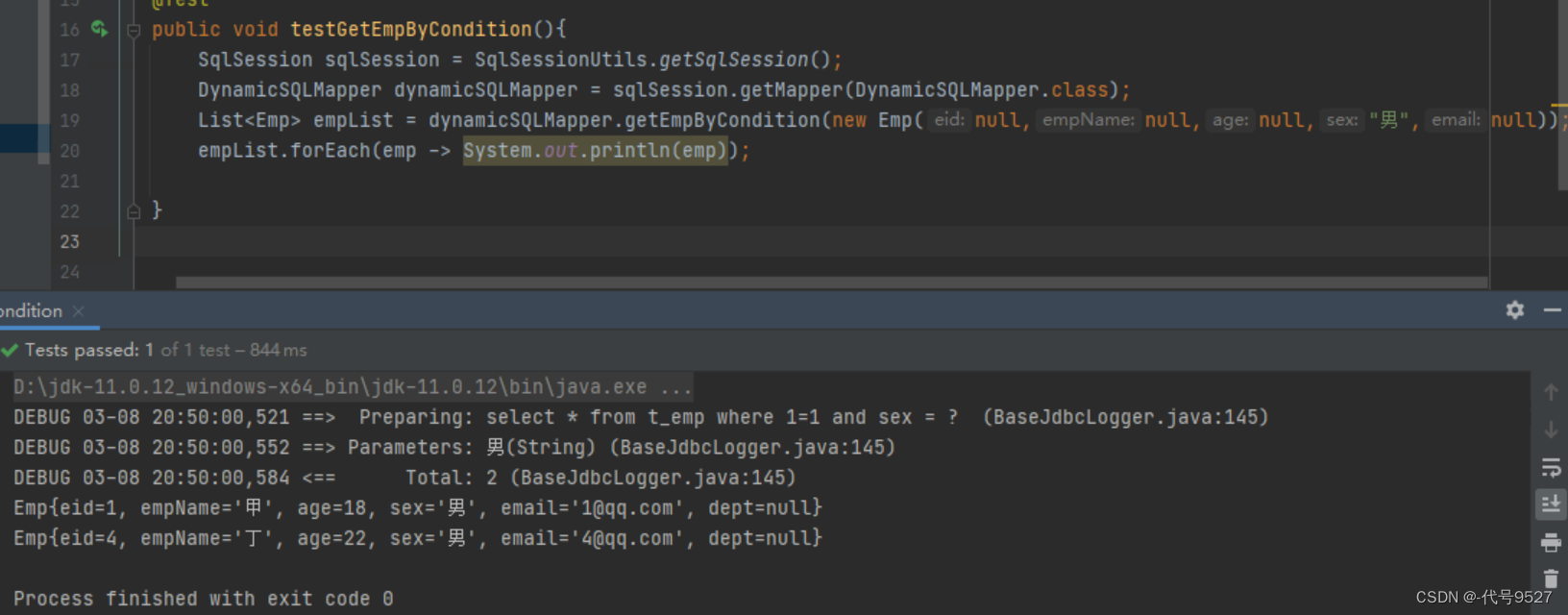
2.2 where标签
当where标签中有内容时,会自动生成where关键字,并将内容前多余的and或者or去掉,而当where标签中没内容时,where关键字也就不再生成。
<!--List<Emp> getEmpByCondition(Emp emp);-->
<select id="getEmpByCondition" resultType="Emp">select * from t_emp<where><if test="empName != null and empName !=''">emp_name = #{empName}</if><if test="age != null and age !=''">and age = #{age}</if><if test="sex != null and sex !=''">and sex = #{sex}</if><if test="email != null and email !=''">and email = #{email}</if></where>
</select>where标签和if标签一般配合使用:
- 若where标签中的if条件都不满足,则where标签没有任何功能,即不会添加where关键字
- 若where标签中的if条件满足,则where标签会自动添加where关键字,并将条件最前方多余的and/or去掉
<!--这种用法是错误的,只能去掉条件前面的and/or,条件后面的不行-->
<if test="empName != null and empName !=''">
emp_name = #{empName} and
</if>
<if test="age != null and age !=''">age = #{age}
</if>当empName有值,age为空,则SQL为:
select * from d_emp where emp_name="llg" and
//此处where标签去不掉and了
2.3 trim标签
trim用于去掉或添加标签中的内容,当标签中有内容的时候:
- prefix:在trim标签中的内容的前面添加某些指定内容
- suffix:在trim标签中的内容的后面添加某些指定内容
- prefixOverrides:在trim标签中的内容的前面去掉某些指定内容
- suffixOverrides:在trim标签中的内容的后面去掉某些指定内容
当标签中没有内容的时候,trim标签也没有任何效果
<!--List<Emp> getEmpByCondition(Emp emp);-->
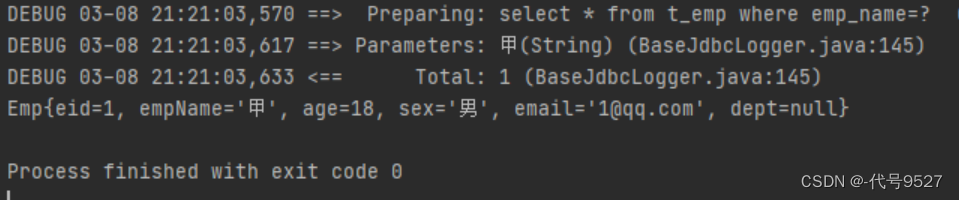
<select id="getEmpByCondition" resultType="Emp">select * from t_emp<trim prefix="where" suffixOverrides="and|or"><if test="empName != null and empName !=''">emp_name = #{empName} and</if><if test="age != null and age !=''">age = #{age} and</if><if test="sex != null and sex !=''">sex = #{sex} or</if><if test="email != null and email !=''">email = #{email}</if></trim>
</select>测试类:
//测试类
@Test
public void getEmpByCondition() {SqlSession sqlSession = SqlSessionUtils.getSqlSession();DynamicSQLMapper mapper = sqlSession.getMapper(DynamicSQLMapper.class);List<Emp> emps= mapper.getEmpByCondition(new Emp(null, "甲", null, null, null, null));System.out.println(emps);
}
2.4 choose、when、otherwise标签
choose…when…otherwise相当于if…else if…else
- when即if或者else if,至少要有一个,when后面的test条件成立,则拼接
- otherwise相当于else,最多只能有一个
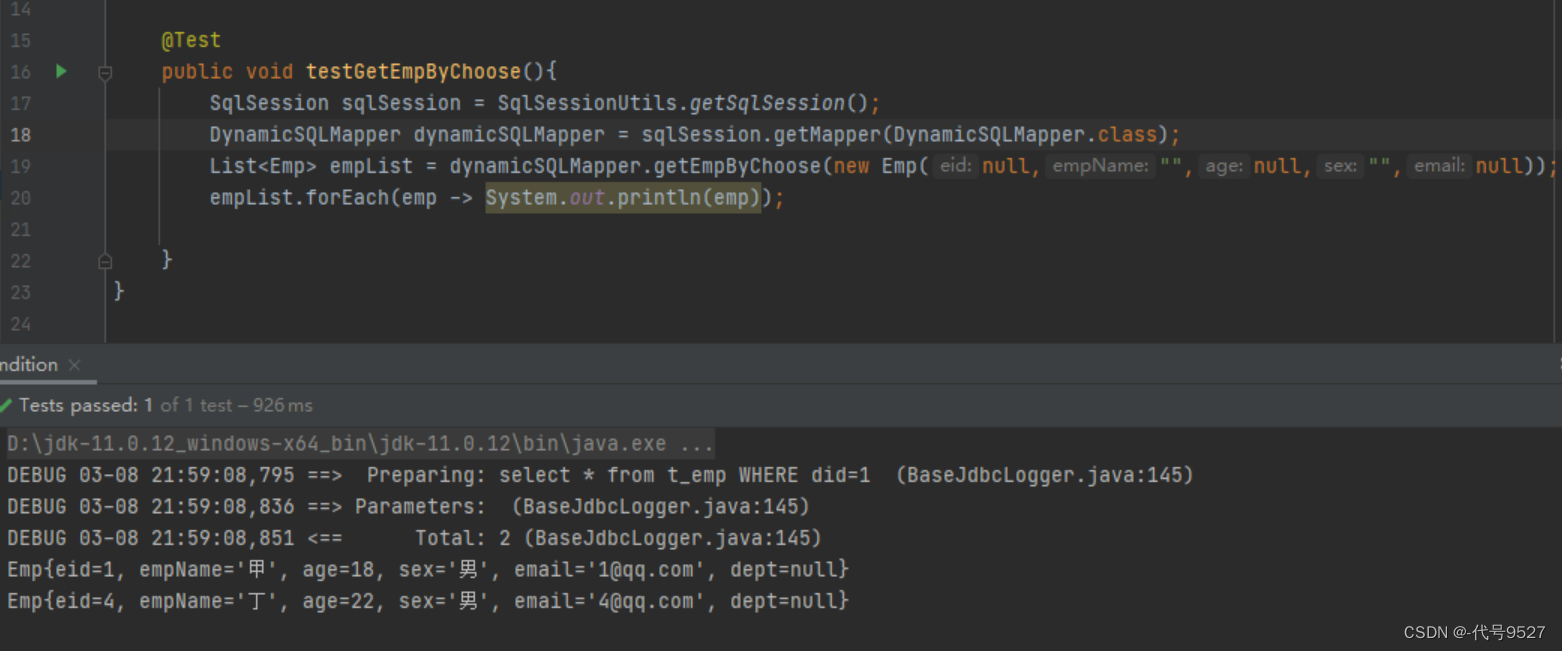
<select id="getEmpByChoose" resultType="Emp">select * from t_emp<where><choose><when test="empName != null and empName != ''">emp_name = #{empName}</when><when test="age != null and age != ''">age = #{age}</when><when test="sex != null and sex != ''">sex = #{sex}</when><when test="email != null and email != ''">email = #{email}</when><otherwise>did = 1</otherwise></choose></where>
</select>
<!--注意这里不用加and或者or了,没意义,if分支中一个就结束了-->
测试程序:
@Test
public void getEmpByChoose() {SqlSession sqlSession = SqlSessionUtils.getSqlSession();DynamicSQLMapper mapper = sqlSession.getMapper(DynamicSQLMapper.class);List<Emp> emps = mapper.getEmpByChoose(new Emp(null, "", null, "", "", null));System.out.println(emps);
}结果:
2.5 foreach标签
foreeach标签的属性有:
- collection:设置要循环的数组或集合
- item:表示集合或数组中的每一个数据
- separator:设置循环体之间的分隔符,分隔符前后默认有一个空格,如,
- open:设置foreach标签中的内容的开始符
- close:设置foreach标签中的内容的结束符
通过数组实现批量删除
public interface DynamicSQLMapper{/*** 通过数组实现批量删除*/int deleteMoreByArray(List<Integer> eids);
}
只论SQL,批量删除的实现可以通过以下两种写法:
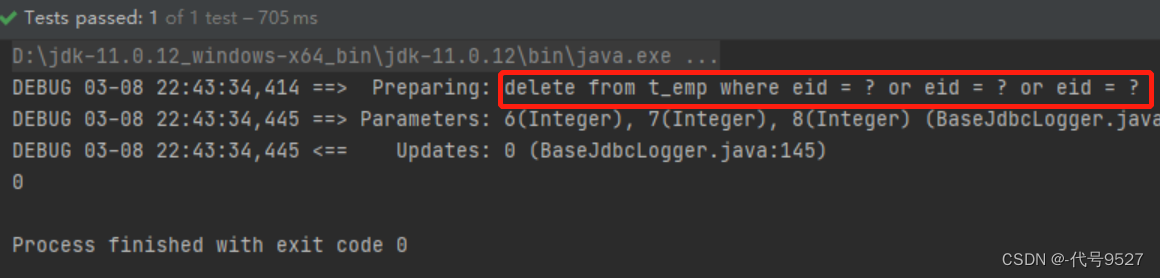
delete from t_emp where eid in (6,7,8);
delte from t_emp where eid=6 or eid=7 or eid=8;
关于第一种SQL的实现:
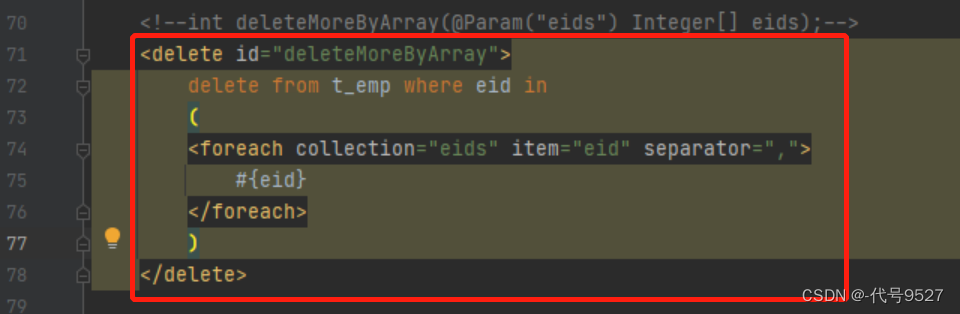
优化一下:
<!--int deleteMoreByArray(Integer[] eids);-->
<delete id="deleteMoreByArray">delete from t_emp where <foreach collection="eids" item="eid" separator="or">eid = #{eid}</foreach>
</delete>关于第二种SQL的实现:
<!--int deleteMoreByArray(Integer[] eids);-->
<delete id="deleteMoreByArray">delete from t_emp where eid in<foreach collection="eids" item="eid" separator="," open="(" close=")">#{eid}</foreach>
</delete>
测试:
@Test
public void deleteMoreByArray() {SqlSession sqlSession = SqlSessionUtils.getSqlSession();DynamicSQLMapper mapper = sqlSession.getMapper(DynamicSQLMapper.class);int result = mapper.deleteMoreByArray(new Integer[]{6, 7, 8});System.out.println(result);
}结果:

通过集合实现批量插入
public interface DynamicSQLMapper{/*** 通过集合实现批量添加*/int insertMoreByList(List<Emp> emps);
}
只说SQL,写法应该是:
insert into t_emp values(a1,a2,a3),(b1,b2,b3),(v1,v2,v3);使用foreach动态实现:
<!--int insertMoreByList(@Param("emps") List<Emp> emps);-->
<insert id="insertMoreByList">insert into t_emp values<foreach collection="emps" item="emp" separator=",">(null,#{emp.empName},#{emp.age},#{emp.sex},#{emp.email},null)</foreach>
</insert>注意,这里不用open和close,批量插入的原SQL是每条数据中有括号,即每次循环有括号,而不是删除SQL中的开头和结尾有括号。
//测试程序
@Test
public void insertMoreByList() {SqlSession sqlSession = SqlSessionUtils.getSqlSession();DynamicSQLMapper mapper = sqlSession.getMapper(DynamicSQLMapper.class);Emp emp1 = new Emp(null,"a",1,"男","123@321.com",null);Emp emp2 = new Emp(null,"b",1,"男","123@321.com",null);List<Emp> emps = Arrays.asList(emp1, emp2);int result = mapper.insertMoreByList(emps);System.out.println(result);
}结果:

2.6 SQL标签
在映射文件中,声明一段SQL片段,把常用的一段SQL进行记录,在要使用的地方使用include标签进行引入。
- 声明
<sql id="empColumns">eid,emp_name,age,sex,email</sql>
- 引用
<!--List<Emp> getEmpByCondition(Emp emp);-->
<select id="getEmpByCondition" resultType="Emp">select <include refid="empColumns"></include> from t_emp
</select>相关文章:
【MyBatis】篇三.自定义映射resultMap和动态SQL
MyBatis整理 篇一.MyBatis环境搭建与增删改查 篇二.MyBatis查询与特殊SQL 篇三.自定义映射resultMap和动态SQL 篇四.MyBatis缓存和逆向工程 文章目录1、自定义映射P1:测试数据准备P2:字段和属性的映射关系P3:多对一的映射关系P4:一对多的映射关系2、动态SQL2.1 IF标签2.2 w…...
什么是API?(详细解说)
编程资料时经常会看到API这个名词,网上各种高大上的解释估计放倒了一批初学者。初学者看到下面这一段话可能就有点头痛了。 API(Application Programming Interface,应用程序编程接口)是一些预先定义的函数,目的是提供应用程序与开…...

比cat更好用的命令!
大家好,我是良许。 作为程序员,大家一定对 cat 这个命令不陌生。它主要的功能就是用来显示文本文件的具体内容。 但 cat 命令两个很重大的缺陷:1. 不能语法高亮输出;2. 文本太长的话无法翻页输出。正是这两个不足,使…...
MySQL、HBase、ElasticSearch三者对比
1、概念介绍 MySQL:关系型数据库,主要面向OLTP,支持事务,支持二级索引,支持sql,支持主从、Group Replication架构模型(本文全部以Innodb为例,不涉及别的存储引擎)。 HBas…...

Vue+ElementUI+Vuex购物车
最完整最能理解的Vuex版本的购物车购物车是最经典的小案例。Vuex代码:import Vue from vue import Vuex from vuex import $http from ../request/http Vue.use(Vuex)const store new Vuex.Store({state:{shopList:[],},mutations:{setShopCarList(state,payload)…...

Android 录屏 实现
https://lixiaogang03.github.io/2021/11/02/Android-%E5%BD%95%E5%B1%8F/ https://xie.infoq.cn/article/dd40cd5d753c896225063f696 视频地址: https://time.geekbang.org/dailylesson/detail/100056832 概述 在视频会议、线上课堂、游戏直播等场景下&#x…...

【CSAPP】家庭作业2.55~2.76
文章目录2.55*2.56*2.57*2.58**2.59**2.60**位级整数编码规则2.61**2.62***2.63***2.64*2.65****2.66***2.67**2.68**2.69***2.70**2.71*2.72**2.73**2.74**2.75***2.76*2.55* 问:在你能访问的不同的机器上,编译show_bytes.c并运行代码,确定…...

Python操作MySQL数据库详细案例
Python操作MySQL数据库详细案例一、前言二、数据准备三、建立数据库四、处理和上传数据五、下载数据六、完整项目数据和代码一、前言 本文通过案例讲解如何使用Python操作MySQL数据库。具体任务为:假设你已经了解MySQL和知识图谱标注工具Brat,将Brat标注…...
:AXI_CAN的使用)
MicroBlaze系列教程(8):AXI_CAN的使用
文章目录 @[toc]CAN总线概述AXI_CAN简介MicroBlaze硬件配置常用函数使用示例波形实测参考资料工程下载本文是Xilinx MicroBlaze系列教程的第8篇文章。 CAN总线概述 **CAN(Controller Area Network)**是 ISO 国际标准化的串行通信协议,是由德国博世(BOSCH)公司在20世纪80年代…...

网络安全领域中八大类CISP证书
CISP注册信息安全专业人员 注册信息安全专业人员(Certified Information Security Professional),是经中国信息安全产品测评认证中心实施的国家认证,对信息安全人员执业资质的认可。该证书是面向信息安全企业、信息安全咨询服务…...
stm32学习笔记-5EXIT外部中断
5 EXIT外部中断 [toc] 注:笔记主要参考B站 江科大自化协 教学视频“STM32入门教程-2023持续更新中”。 注:工程及代码文件放在了本人的Github仓库。 5.1 STM32中断系统 图5-1 中断及中断嵌套示意图 中断 是指在主程序运行过程中,出现了特定…...

MySQL Workbench 图形化界面工具
Workbench 介绍 MySQL官方提供了一款免费的图形工具——MySQL Workbench,它是一款功能强大且易于使用的数据库设计、管理和开发工具,总之,MySQL Workbench是一款非常好用的MySQL图形工具,可以满足大多数MySQL用户的需求。 目录 W…...
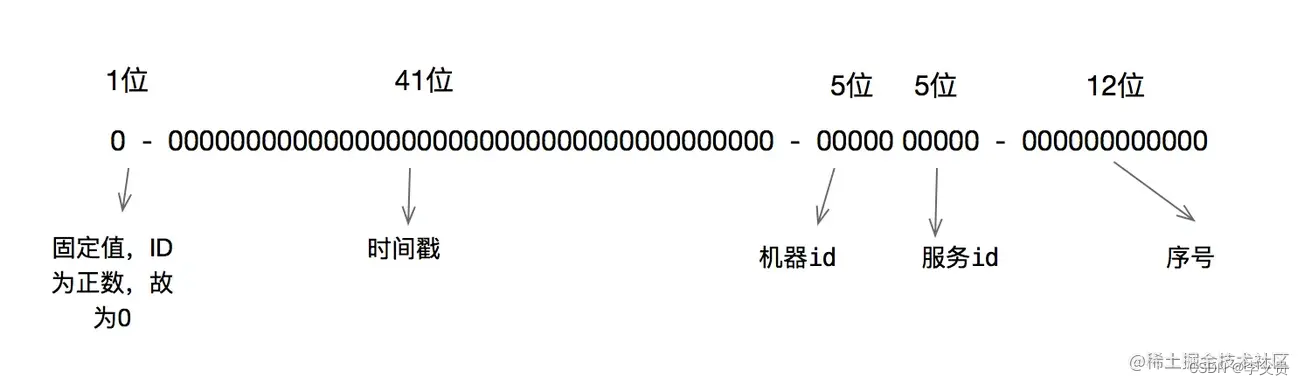
雪花算法(SnowFlake)
简介现在的服务基本是分布式、微服务形式的,而且大数据量也导致分库分表的产生,对于水平分表就需要保证表中 id 的全局唯一性。对于 MySQL 而言,一个表中的主键 id 一般使用自增的方式,但是如果进行水平分表之后,多个表…...

Linux防火墙
一、Linux防火墙Linux的防火墙体系主要在网络层,针对TCP/IP数据包实施过滤和限制,属于典型的包过滤防火墙(或称为网络层防火墙)。Linux系统的防火墙体系基于内核编码实现,具有非常稳定的性能和极高的效率,因…...

网络安全系列-四十七: IP协议号大全
IP协议号列表 这是用在IPv4头部和IPv6头部的下一首部域的IP协议号列表。 十进制十六进制关键字协议引用00x00HOPOPTIPv6逐跳选项RFC 246010x01ICMP互联网控制消息协议(ICMP)RFC 79220x02IGMP...
HTTP协议格式以及Fiddler用法
目录 今日良言:焦虑和恐惧改变不了明天,唯一能做的就是把握今天 一、HTTP协议的基本格式 二、Fiddler的用法 1.Fidder的下载 2.Fidder的使用 今日良言:焦虑和恐惧改变不了明天,唯一能做的就是把握今天 一、HTTP协议的基本格式 先来介绍一下http协议: http 协议(全称为 &q…...

自动写代码?别闹了!
大家好,我是良许。 这几天,GitHub 上有个很火的插件在抖音刷屏了——Copilot。 这个神器有啥用呢?简单来讲,它就是一款由人工智能打造的编程辅助工具。 我们来看看它有啥用。 首先就是代码补全功能,你只要给出函数…...
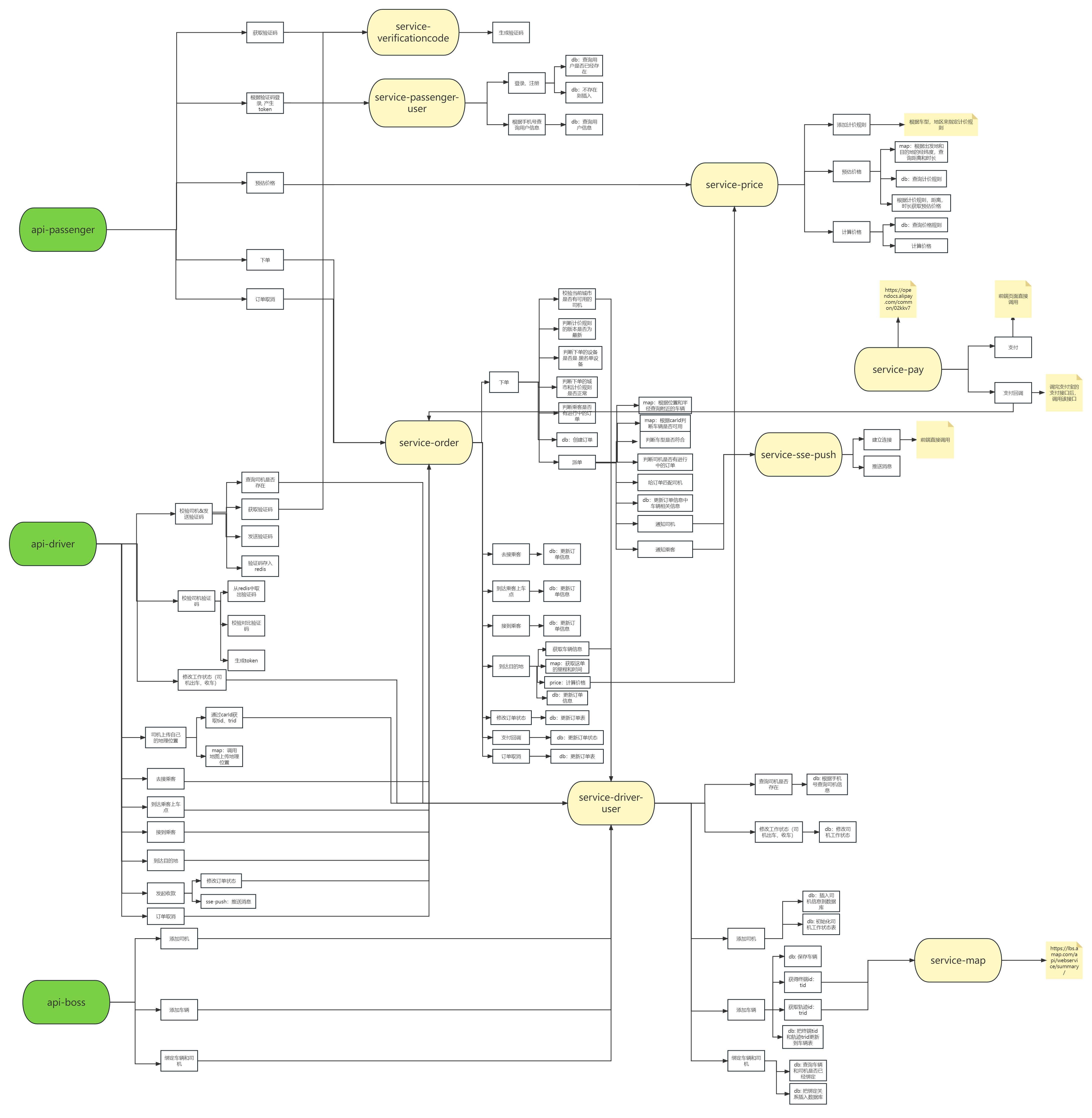
项目心得--网约车
一、RESTFULPost:新增Put:全量修改Patch:修改某个值Delete: 删除Get:查询删除接口也可以用POST请求url注意:url中不要带有敏感词(用户id等)url中的名词用复数形式url设计:api.xxx.co…...

【二叉树广度优先遍历和深度优先遍历】
文章目录一、二叉树的深度优先遍历0.建立一棵树1. 前序遍历2.中序遍历3. 后序遍历二、二叉树的广度优先遍历层序遍历三、有关二叉树练习一、二叉树的深度优先遍历 学习二叉树结构,最简单的方式就是遍历。 所谓二叉树遍历(Traversal)是按照某种特定的规则ÿ…...
Spring Cloud微服务架构必备技术
单体架构 单体架构,也叫单体应用架构,是一个传统的软件架构模式。单体架构是指将应用程序的所有组件部署到一个单一的应用程序中,并统一进行部署、维护和扩展。在单体架构中,应用程序的所有功能都在同一个进程中运行,…...

罗技鼠标宏终极指南:绝地求生压枪自动化解决方案
罗技鼠标宏终极指南:绝地求生压枪自动化解决方案 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 在《绝地求生》这款竞技射击游戏中&…...

Docker运行AI代码总被入侵?揭秘3层隔离失效链及5分钟应急熔断方案
更多请点击: https://intelliparadigm.com 第一章:Docker Sandbox 运行 AI 代码隔离技术 面试题汇总 Docker Sandbox 是当前 AI 工程化部署中保障安全执行的关键实践,尤其适用于模型推理服务、用户提交代码沙箱(如在线编程平台、…...

CitySim交通数据集:构建自动驾驶安全研究的终极数字孪生平台
CitySim交通数据集:构建自动驾驶安全研究的终极数字孪生平台 【免费下载链接】UCF-SST-CitySim1-Dataset Official github page of UCF SST CitySim Dataset 项目地址: https://gitcode.com/gh_mirrors/ucf/UCF-SST-CitySim-Dataset CitySim是一个基于无人机…...

基于LangGraph与Gemini构建具备规划-执行-反思能力的智能研究助手
1. 项目概述:一个能“思考”的智能研究助手如果你正在寻找一个能帮你自动完成复杂网络研究、并给出有据可查答案的智能应用,那么这个基于 Google Gemini 和 LangGraph 构建的全栈项目,绝对值得你花时间深入探索。它不仅仅是一个简单的聊天机器…...

Mistral Vibe:基于CLI的智能编码助手,赋能自然语言编程与项目感知
1. 项目概述:Mistral Vibe,一个能“听懂”你项目的命令行伙伴 如果你和我一样,每天大部分时间都泡在终端里,和代码、配置文件、版本控制系统打交道,那你肯定也幻想过:要是能直接用自然语言告诉电脑“帮我重…...

Snap.Hutao原神工具箱终极指南:从基础使用到高级技巧的完整教程
Snap.Hutao原神工具箱终极指南:从基础使用到高级技巧的完整教程 【免费下载链接】Snap.Hutao 实用的开源多功能原神工具箱 🧰 / Multifunctional Open-Source Genshin Impact Toolkit 🧰 项目地址: https://gitcode.com/GitHub_Trending/sn…...

PostgreSQL 13/14远程连接配置全攻略:从listen_addresses到pg_hba.conf,避开scram-sha-256认证坑
PostgreSQL远程连接配置深度解析:从基础配置到安全实践 PostgreSQL作为企业级开源数据库的代表,其安全性和灵活性一直备受开发者推崇。但随着版本迭代,特别是13/14版本引入的scram-sha-256认证方式,让不少开发者在配置远程连接时频…...

WindowResizer终极指南:免费工具强制调整任意窗口尺寸的完整教程
WindowResizer终极指南:免费工具强制调整任意窗口尺寸的完整教程 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 还在为那些固执的应用程序窗口烦恼吗?有些…...
)
STM32CubeMX新手避坑指南:从零配置STM32F407ZGT6的GPIO点灯(含Reset and Run设置)
STM32CubeMX实战避坑手册:从GPIO配置到稳定运行的完整解决方案 第一次打开STM32CubeMX时,那个五彩缤纷的引脚分配图确实让人眼前一亮——直到你按照教程生成了代码,编译通过,点击下载,然后...开发板毫无反应。这种挫败…...

Krita AI Diffusion:数字创作工作流中的AI集成解决方案
Krita AI Diffusion:数字创作工作流中的AI集成解决方案 【免费下载链接】krita-ai-diffusion Streamlined interface for generating images with AI in Krita. Inpaint and outpaint with optional text prompt, no tweaking required. 项目地址: https://gitcod…...