Nosql期末复习
mongodb基本常用命令(只要掌握所有实验内容就没问题)
上机必考,笔试试卷可能考:
1.1 数据库的操作
1.1.1 选择和创建数据库
(1)use dbname 如果数据库不存在则自动创建,例如,以下语句创建spitdb数据库:
(2)show dbs 或者 show databases #查看有权限查看的所有的数据库命令
(3)db #查看当前正在使用的数据库命令
show dbs 结果如下:
有默认的三个库(选填?)
admin:从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
创建数据库
use 数据库名—创建数据库名
说明如果没有数据库则创建,如果有则替换数据库。
当我们创建好数据库好后,使用show dbs发现无创建的数据库,原因跟mongodb的存储机制有关系,当我们创建数据库时,存放到内存中没有进行持久化存储,所以看不到,如果要看到,需要创建数据库中的集合。
数据库命名的规则,不能是关键字,特色字符,<64字节
1.1.2 数据库的删除
db.dropDatabase()
1.2 集合操作
1.2.1 集合显式创建
db.createCollection(name) #创建集合
show collections /show tables查询集合

1.2.2 集合的隐式创建
当向一个集合中插入一个文档的时候,如果集合不存在,则会自动创建集合。
详见下面文档的插入章节。
通常我们使用隐式创建文档即可
db.集合名.insert({id:1,name:forlan});

【注意集合的命名规范】(选择?)
不能是空字符串
不能含有 \0字符(空字符),这个字符表示集合名的结尾
不能以 "system."开头,这是为系统集合保留的前缀
不能含有保留字符。另外千万不要在名字里出现$
5.在test01数据库中隐式创建集合
集合名 键值对
stu1 Id:202201090,name:李四,depart:大数据
scho1 name:复旦大学,address:上海
dog1 breed:牧羊犬,color:白色
1.2.3查看集合
show tables 或 show collections
db.collections.stats()
1.2.3 集合的删除
db.集合.drop()

返回true表示删除成功
1.3 文档的CRUD
文档(document)的数据结构和 JSON 基本一样。
所有存储在集合中的数据都是 BSON 格式。
BSON是一种二进制序列化文档格式,它基于 JSON 并进行了扩展,以支持更多的数据类型。
mongo _id的生成规则: 时间戳+机器码+PID+计数器(选择?)
1.3.1 文档的插入
语法:
db.collection.insert():单文档插入
db.collection.insertMany():多文档插入
db.collection.insert():单、多文档插入
变量插入文档 db.collection.insertMany(变量)
(1)单个文档插入
使用insert() 方法向集合中插入文档
document document or array 要插入到集合中的文档或文档数组。((json格式)
writeConcern document 选择的性能和可靠性级别(了解)
ordered boolean 可选。如果为真,则按顺序插入数组中的文档,如果其中一个文档出现错误,MongoDB将返回而不处理数组中的其余文档。如果为假,则执行无序插入,如果其中一个文档出现错误,则继续处理数组中的主文档。在版本2.6+中默认为true
示例:
代码:
db.ac1.insert(
{“atcid”:“0001”,“content”:“进入倒春寒,优点冷”,“userid”:“1001”,“name”:“rose”}
)
插入ac1的集合,如果该集合不存在则创建它
//结果如下

//查询集合
db.ac1.find()
查看表中的哪些集合 show collections
(2)多个文档的插入
db.collection.insertMany(
[
{k1:v1,k2:v2},
{k1:v1,k2:v2}
]
)
集合 文档值
data1 “_id”:“1”,“articleid”:“100001”,“content”:“我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我他。”
“userid”:“1002”,“nickname”:“相忘于江湖”,“createdatetime”:new Date(“2019-08-05T22:08:15.522Z”),“likenum”:NumberInt(1000),“state”:“1”
“_id”:“2”,“articleid”:“100001”,“content”:“我夏天空腹喝凉开水,冬天喝温开水”,“userid”:“1005”,“nickname”:“伊人憔悴”,“createdatetime”:new Date(“2019-08-05T23:58:51.485Z”),“likenum”:NumberInt(888),“state”:“1”
“_id”:“3”,“articleid”:“100001”,“content”:“我一直喝凉开水,冬天夏天都喝。”,“userid”:“1004”,“nickname”:“杰克船长”,“createdatetime”:new Date(“2019-08-06T01:05:06.321Z”),“likenum”:NumberInt(666),“state”:“1”
db.data1.insertMany([
{“_id”:“1”,“articleid”:“100001”,“content”:“我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我他。”,“userid”:“1002”,“nickname”:“相忘于江湖”,“createdatetime”:new Date(“2019-08-05T22:08:15.522Z”),“likenum”:NumberInt(1000),“state”:“1”},
{“_id”:“2”,“articleid”:“100001”,“content”:“我夏天空腹喝凉开水,冬天喝温开水”,“userid”:“1005”,“nickname”:“伊人憔悴”,“createdatetime”:new Date(“2019-08-05T23:58:51.485Z”),“likenum”:NumberInt(888),“state”:“1”},
{“_id”:“3”,“articleid”:“100001”,“content”:“我一直喝凉开水,冬天夏天都喝。”,“userid”:“1004”,“nickname”:“杰克船长”,“createdatetime”:new Date(“2019-08-06T01:05:06.321Z”),“likenum”:NumberInt(666),“state”:“1”},
{“_id”:“4”,“articleid”:“100001”,“content”:“专家说不能空腹吃饭,影响健康。”,“userid”:“1003”,“nickname”:“凯撒”,“createdatetime”:new Date(“2019-08-06T08:18:35.288Z”),“likenum”:NumberInt(2000),“state”:“1”},
{“_id”:“5”,“articleid”:“100001”,“content”:“研究表明,刚烧开的水千万不能喝,因为烫嘴。”,“userid”:“1003”,“nickname”:“凯撒”,“createdatetime”:new Date(“2019-08-06T11:01:02.521Z”),“likenum”:NumberInt(3000),“state”:“1”}
])
(3)单、多个文档的插入
db.collection.insert([{k1:v1,k2:v2}…])
【课堂练习】5分钟
1.单行插入文本
集合名 数据
city cityname:重庆,population:3213万
School name:厦门大学,area:9700多亩
2.多个文档的插入
集合名 数据
city “_id”:“1”,“cityname”:“重庆”,“population”:3213
“_id”:“2”,“cityname”:“上海”,“population”:2475
“_id”:“3”,“cityname”:“北京”,“population”:2184
“_id”:“4”,“cityname”:“成都”,“population”:2126
“_id”:“5”,“cityname”:“广州”,“population”:1873
“_id”:“6”,“cityname”:“深圳”,“population”:1756
“_id”:“7”,“cityname”:“武汉”,“population”:1373
“_id”:“8”,“cityname”:“天津”,“population”:1363
“_id”:“9”,“cityname”:“西安”,“population”:1299
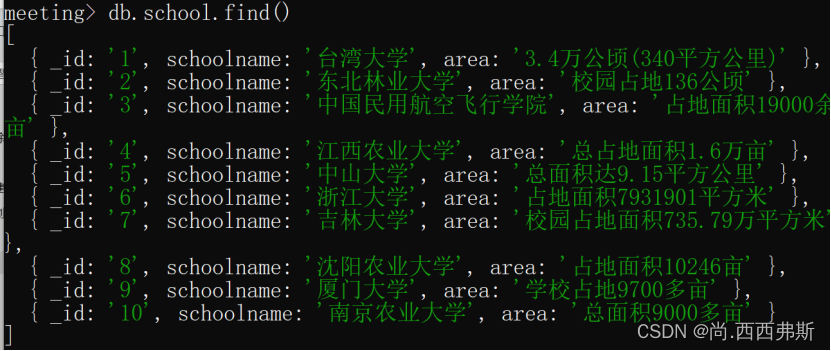
School 占地校园排行榜
“_id”:“1”,“schoolname”:“台湾大学”,“area”:“3.4万公顷(340平方公里)”
“_id”:“2”,“schoolname”:“东北林业大学”,“area”:“校园占地136公顷”
“_id”:“3”,“schoolname”:“中国民用航空飞行学院”,“area”:“占地面积19000余亩”
“_id”:“4”,“schoolname”:“江西农业大学”,“area”:“总占地面积1.6万亩”
“_id”:“5”,“schoolname”:“中山大学”,“area”:“总面积达9.15平方公里”
“_id”:“6”,“schoolname”:“浙江大学”,“area”:“占地面积7931901平方米”
“_id”:“7”,“schoolname”:“吉林大学”,“area”:“校园占地面积735.79万平方米”
“_id”:“8”,“schoolname”:“沈阳农业大学”,“area”:“占地面积10246亩”
“_id”:“9”,“schoolname”:“厦门大学”,“area”:“学校占地9700多亩”
“_id”:“10”,“schoolname”:“南京农业大学”,“area”:“总面积9000多亩”
(4)使用变量插入文档
准备文档文件如1.txt
citydata=([
{“_id”:“1”,“cityname”:“重庆”,“population”:3213},
{“_id”:“2”,“cityname”:“上海”,“population”:2475},
{“_id”:“3”,“cityname”:“北京”,“population”:2184},
{“_id”:“4”,“cityname”:“成都”,“population”:2126},
{“_id”:“5”,“cityname”:“广州”,“population”:1873},
{“_id”:“6”,“cityname”:“深圳”,“population”:1756},
{“_id”:“7”,“cityname”:“武汉”,“population”:1373},
{“_id”:“8”,“cityname”:“天津”,“population”:1363},
{“_id”:“9”,“cityname”:“西安”,“population”:1299}
])
doc=([
{“_id”:“1”,“schoolname”:“台湾大学”,“area”:“3.4万公顷(340平方公里)”},
{“_id”:“2”,“schoolname”:“东北林业大学”,“area”:“校园占地136公顷”},
{“_id”:“3”,“schoolname”:“中国民用航空飞行学院”,“area”:“占地面积19000余亩”},
])
ca=([{“_id”:“4”,“schoolname”:“江西农业大学”,“area”:“总占地面积1.6万亩”},
{“_id”:“5”,“schoolname”:“中山大学”,“area”:“总面积达9.15平方公里”},
{“_id”:“6”,“schoolname”:“浙江大学”,“area”:“占地面积7931901平方米”},
{“_id”:“7”,“schoolname”:“吉林大学”,“area”:“校园占地面积735.79万平方米”},
{“_id”:“8”,“schoolname”:“沈阳农业大学”,“area”:“占地面积10246亩”},
{“_id”:“9”,“schoolname”:“厦门大学”,“area”:“学校占地9700多亩”},
{“_id”:“10”,“schoolname”:“南京农业大学”,“area”:“总面积9000多亩”}
])
db.school.insertMany(doc)
1.3.2 文档的查询
1.3.2 文档的基本查询
db.comment.find() 或 db.comment.find({})
(1)查询集合的所有文档
db.comment.find()
(2)查询集合第一条文档
findOne()

这里你会发现每条文档会有一个叫_id的字段,这个相当于我们原来关系数据库中表的主键,当你在插入文档记录时没有指定该字段,MongoDB会自动创建,其类型是ObjectID类型。(选择?)
如果我们在插入文档记录时指定该字段也可以,其类型可以是ObjectID类型,也可以是MongoDB支持的任意类型
(3)按条件的查询
如果我想按一定条件来查询,比如我想查询userid为1003的记录,怎么办?很简单!只 要在find()中添加参数即可,参数也是json格式,如下:
db.comment.find({userid:‘1003’})

如果你只需要返回符合条件的第一条数据,我们可以使用findOne命令来实现,语法和find一样。如:查询用户编号是1003的记录,但只最多返回符合条件的第一条记录:
(4)投影查询
db.comment.find({userid:“1003”},{userid:1,nickname:1})
如果要查询结果返回部分字段,则需要使用投影查询(不显示所有字段,只显示指定的字段)。如:查询结果只显示 _id、userid、nickname :
db.comment.find({userid:“1003”},{userid:1,nickname:1})
(B)投影查询
db.collections.find({},{“name”:1}) //“_id”始终会被获取
db.collections.find({},{“name”:1,”_id”:0})//”_id”不会被获取

注:在_id字段为0的时候,其他字段可以写1;
在_id字段为1的时候,其他字段必须写1;
如果是除了_id字段以外的其他字段,必须同为1或者同为0
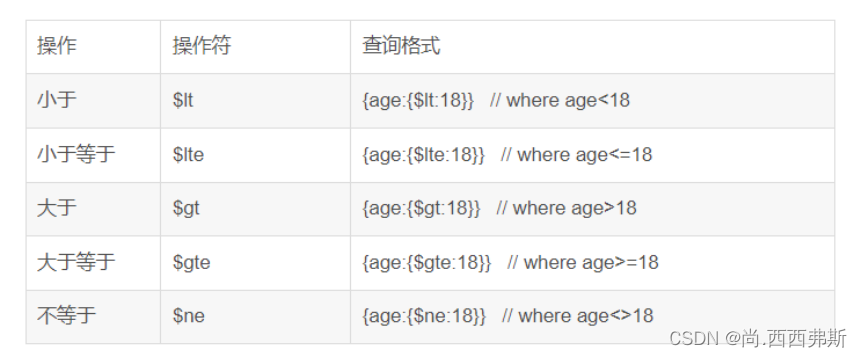
(5)比较查询
db.user.find({age:{$lt:30}})
//等同于 select * from user where age<30;
实例:创建集合
集合名 数据
city “_id”:“1”,“cityname”:“重庆”,“population”:3213
“_id”:“2”,“cityname”:“上海”,“population”:2475
“_id”:“3”,“cityname”:“北京”,“population”:2184
“_id”:“4”,“cityname”:“成都”,“population”:2126
“_id”:“5”,“cityname”:“广州”,“population”:1873
“_id”:“6”,“cityname”:“深圳”,“population”:1756
“_id”:“7”,“cityname”:“武汉”,“population”:1373
“_id”:“8”,“cityname”:“天津”,“population”:1363
“_id”:“9”,“cityname”:“西安”,“population”:1299
ci=([
{“_id”:“1”,“cityname”:“重庆”,“population”:3213},
{“_id”:“2”,“cityname”:“上海”,“population”:2475},
{“_id”:“3”,“cityname”:“北京”,“population”:2184},
{“_id”:“4”,“cityname”:“成都”,“population”:2126},
{“_id”:“5”,“cityname”:“广州”,“population”:1873},
{“_id”:“6”,“cityname”:“深圳”,“population”:1756},
{“_id”:“7”,“cityname”:“武汉”,“population”:1373},
{“_id”:“8”,“cityname”:“天津”,“population”:1363},
{“_id”:“9”,“cityname”:“西安”,“population”:1299}
])
①查询人口数大于3000万的城市
②查询人口数大于2000万的城市
③查询人数小于2000万的城市
④查询人口数在1500-2000万的城市
或者
(6)逻辑查询
and查询
db.user.find(
{$and:
[
{age:20,sex:0}
]
}
);
// 等同于 select * from user where age=20 and sex=0
或者缺省$and
db.user.find({age:20,sex:0})
(选择?填空?)
(7)or查询
db.user.find({
$ or:[
{age:{$lt:24}},
{sex:1}
]});
//等同于 select * from user where age<24 or sex=1
查mongo
查询school中吉林大学和台湾大学的信息
(8) in 和nin 查询
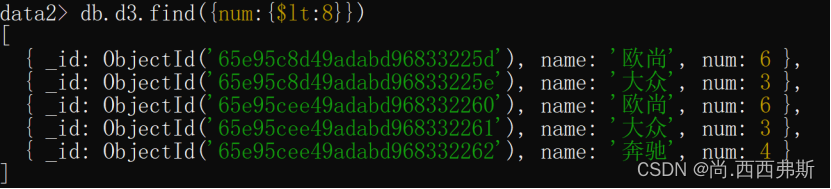
db.user.find({age:{$in:[18,19,20]}})
//等同于 select * from user where age in (18,19,20)
查询台湾大学,吉林大学,厦门大学
查询北京 南京 珠海的城市信息
(9)为空查询
db.user.find({name:{$exists:1}});不为空查询
db.school.find({area:{$exists:0}})查询为空的数据
(10)查询排序
db.collectins.find().sort({“age”:-1})
注:-1为逆序,1为顺序
按人口数量的升序排序
db.citys.find().sort({population:1})
按人口的降序排序
(12)分页查询
使用函数limit()和skip()来实现分页查询
db.collections.find().limit().skip() //跳过多少行查询多少行
①如查询前三条数据 limit(3)
db.citys.find().limit(3)
②查询从第3条到第6条的数据 skip(2).limit(4)
db.citys.find().limit(4).skip(2)
③查询人口数最多排名第3名的城市
db.citys.find().limit(1).skip(2).sort({population:-1})
查询人口数从高到低排名第3名-第8名的城市
db.city2.find().limit(6).skip(2).sort({population:-1})
(13)正则匹配
正则表达式用于模式匹配,基本上是用于在文档中搜索字符串中的模式。它是一种将模式与字符序列匹配的通用方法。$regex运算符用作正则表达式,用于在字符串中查找模式。
集合的数据为:
①某文档包含某字段的模糊查询:{ $regex:/xxx/ }
使用 sql 的写法select * from member where name like ‘%XXX%’
在mongodb中db.member.find({“name”:{ KaTeX parse error: Expected 'EOF', got '}' at position 13: regex:/XXX/ }̲}) 实例:查询城市名有京的城…regex:/^xxx/}
查询“上”开头的城市
db.citys.find({cityname:{$regex:/^上/}})
③查询以某字段为结尾的文档 { r e g e x : / X X X regex:/XXX regex:/XXX/}
db.member.find({“name”:{ r e g e x : / X X X regex:/XXX regex:/XXX/}})
查询城市名最后一个字为“海”的城市
db.citys.find( { cityname: { r e g e x : / 海 regex: /海 regex:/海/ } } )
④查询忽略大小写 {$regex:/XXX/i}
查询含有a的数据
db.citys.find( { cityname: { $regex: /a/i } } )
1.3.3 文档的更新
基本语法
db.collection.update(query, update, options)
//或
db.collection.update(
,
,
{
upsert: ,
multi: ,
writeConcern: ,
collation: ,
arrayFilters: [ , … ],
hint: <document|string> // Available starting in MongoDB 4.2
}
)
(1)局部修改 s e t / / 为了解决这个问题,我们需要使用修改器 set //为了解决这个问题,我们需要使用修改器 set//为了解决这个问题,我们需要使用修改器set来实现,
db.comment.update({_id:“2”},{$set:{likenum:NumberInt(889)}})
(2)批量的修改{multi:true}
//更新所有用户为 1003 的用户的昵称为 凯撒大帝
//默认只修改第一条数据
db.comment.update({userid:“1003”},{KaTeX parse error: Expected 'EOF', got '}' at position 21: …nickname:"凯撒2"}}̲) //修改所有符合条件的数据…set:{nickname:“凯撒大帝”}},{multi:true})
实例:修改所有石家庄城市为廊坊
db.citys.update({ cityname: “石家庄” }, { $set: { cityname: “廊坊” } }, { multi: true } )
实例:将城市名中包含 a (不区分大小写),修改为你好
db.citys.update({ cityname: { $regex: /a/i } }, { $set: { cityname: “你好” } }, { multi: true })
(3)列值增长的修改 i n c (增加运算) inc (增加运算) inc(增加运算)mul(乘法运算)
//如果我们想实现对某列值在原有值的基础上进行增加或减少,可以使用 KaTeX parse error: Expected '}', got 'EOF' at end of input: …ate({_id:"3"},{inc:{likenum:NumberInt(1)}})
如:修改北京人口,在之前的数据上增加 500万
实例:重庆人口增加一倍$mul
实例:重庆人口减少3000万
(4)修改健名{KaTeX parse error: Expected 'EOF', got '}' at position 23: …{cityname:”重庆”}}̲ 实例:修改万州中cityna…rename:{cityname:“citynames”}})
(5)删除某个健名KaTeX parse error: Expected '}', got 'EOF' at end of input: …me:"舟山"}, ... {unset:{add:“”}
… )
db.citys.update( {cityname:“舟山”}, {$unset:{add:“”}} )
(6)采用 $ min,$max,修改当前值为给定的最小值或者最大值
如:修改重庆人口为给定的最小值
db.citys.update({ cityname: “重庆” }, { $min: { population: 1000 } } )
db.citys.update({ cityname: “重庆” }, { KaTeX parse error: Expected 'EOF', got '}' at position 27: …lation: 4000 } }̲ ) (7)ISODate()…set:{time:ISODate(“2021-01-01 10:10:10”)}})
1.3.4 文档的删除
(1)全部删除文档
db.comment.remove({})
(2)删除集合
db.集合名.drop()
删除整个集合,这个方法的效率更高
(3)删除_id=1的记录
db.comment.remove({_id:“1”})
如删除万州的城市
db.citys.remove({cityname:“万州”})
后面的应该不是上机考的内容(闭卷笔试选择、手写命令、和简答题)
2.1MongoDB索引
MongoDB是基于集合建立索引的,索引的目的是提高查询效率。
如果没有建立索引,当MongoDB读取数据时候,是要扫描集合中的所有文档,这种扫描的效率分层的低,尤其在处理大数据时,查询可能需要几十秒到几分钟时间,这种效率对互联网的应用来说是示范可怕的。
2.1.1索引的分类
按照索引包含的字段数量,可以分为单键索引和组合索引(或复合索引)。
按照索引字段的类型,可以分为主键索引和非主键索引。
按照索引节点与物理记录的对应方式来分,可以分为聚簇索引和非聚簇索引,其
中聚簇索引是指索引节点上直接包含了数据记录,而后者则仅仅包含一个指向数据记
录的指针。
2.1.2索引分类
按照索引包含的字段数量,可以分为单键索引和组合索引(或复合索引)。
按照索引字段的类型,可以分为主键索引和非主键索引。
按照索引节点与物理记录的对应方式来分,可以分为聚簇索引和非聚簇索引,其中聚簇索引是指索引节点上直接包含了数据记录,而后者则仅仅包含一个指向数据记
录的指针。
2.1.3索引设计原则
1、每个查询原则上都需要创建对应索引
2、单个索引设计应考虑满足尽量多的查询
3、索引字段选择及顺序需要考虑查询覆盖率及选择性
4、对于更新及其频繁的字段上创建索引需慎重
5、对于数组索引需要慎重考虑未来元素个数
6、对于超长字符串类型字段上慎用索引
7、并发更新较高的单个集合上不宜创建过多索引
2.1.4索引操作
(1)默认自动创建_id建立唯一索引
避免重复插入_id值相同的文档
(2)单一健索引
db.集合名.createIndex({key:})
db.books.createIndex({name:-1})
key为健名,n为1或者-1 代表升序和降序
实例:集合数据 中国古典十大名曲
集合名 文档
books
{name:“高山流水”,content:“中国古琴曲,属于中国十大古曲之一。传说先秦的琴师伯牙一次在荒山野地弹琴,樵夫钟子期竟能领会这是描绘峨峨兮若泰山和洋洋兮若江河。伯牙惊道:善哉,子之心而与吾心同。钟子期死后,伯牙痛失知音,摔琴绝弦,终生不弹,故有高山流水之曲。”}
{name:”梅花三弄”,content:”《梅花三弄 [8] [11]》,又名《梅花引》《梅花曲》《玉妃引》,根据《太音补遗》和《蕉庵琴谱》所载,相传原本是晋朝桓伊所作的一首笛曲,后来改编为古琴曲。”}
{name:”汉宫秋月”,content:”《汉宫秋月》现流传的演奏形式有二胡曲、琵琶曲、筝曲、江南丝竹等。主要表达的是古代宫女哀怨悲愁的情绪及一种无可奈何、寂寥清冷的生命意境。”}
{name:”阳春白雪”,content:”《阳春白雪》 [2-3]是古典名曲,为中国著名十大古曲之一。表现的是冬去春来,大地复苏,万物欣欣向荣的初春美景。”}
{name:”渔樵问答”,content:”《渔樵问答》是一首中国古琴名曲,为中国十大古曲之一。此曲在历代传谱中,有30多种版本,有的还附有歌词。”}
{name:”广陵散”,content:”又名《广陵止息》。它是中国古代一首大型琴曲,中国音乐史上非常著名的古琴曲,著名十大古琴曲之一。”}
{name:”平沙落雁”,content:”又名《雁落平沙》,是一首中国古琴名曲,有多种流派传谱,其意在借大雁之远志,写逸士之心胸。”}
{name:”十面埋伏”,content:”乐曲整体可分为三部分,由十三段带有小标题的段落构成,分别是:列营、吹打、点将、排阵、走队、埋伏、鸡鸣山小战、九里山大战、项王败阵、乌江自刎、众军奏凯、诸将争功和得胜回营。该曲以公元前202年刘邦与项羽垓下之战的史实为内容,用标题音乐的形式描绘了激烈的战争场面,虽为史实,却也不乏丰富的感情色彩”}
db=([{name:“高山流水”,content:“中国古琴曲,属于中国十大古曲之一。传说先秦的 琴师伯牙一次在荒山野地弹琴,樵夫钟子期竟能领会这是描绘峨峨兮若泰山和洋洋兮若江河。 伯牙惊道:善哉,子之心而与吾心同。钟子期死后,伯牙痛失知音,摔琴绝弦,终生不弹,故 有高山流水之曲。”},{name:“梅花三弄”,content:“名梅花引、梅花曲、玉妃引,根据太音补遗和蕉庵琴谱所载,相传原本是晋朝桓伊所作的一首笛曲,后来改编为古琴曲”},
{name:“阳春白雪”,content:“阳春白雪》 [2-3]是古典名曲,为中国著名十大古曲之一。表现的是冬去春来,大地复苏,万物欣欣向荣的初春美景。”}])
案例2:学生信息表
集合 文档记录
Student {_id:”20090101”,name:”王庆”,depart:”计算机科学与技术”}
{_id:”20090102”,name:”周三”,depart:”计算机科学与技术”}
{_id:”20090101”,name:”刘明明”,depart:”计算机科学与技术”}
{_id:”20090101”,name:”王青云”,depart:”计算机科学与技术”}
(3)唯一索引
db.book.createIndex({name:1},{unique:true})
Name的值时唯一的,测试
(4)复合索引
db.book.createIndex({key:n,key:n})
(5)文本索引
db.book.createIndex({name:text})
建立文档索引
(6)查看索引
#查看索引信息
db.books.getIndexes()
#查看索引键
db.books.getIndexKeys()
(7)查看索引占用空间
db.collection.totalIndexSize([is_detail])
(8)删除索引
#删除集合指定索引
db.col.dropIndex(“索引名称”)
[备注]删除索引,索引名要与查询的索引名一样
#删除集合所有索引 不能删除主键索引
db.col.dropIndexes()
(9)地理空间索引
在移动互联网时代,基于地理位置的检索(LBS)功能几乎是所有应用系统的标配。 MongoDB为地理空间检索提供了非常方便的功能。 地理空间索引(2dsphereindex)就是 专门用于实现位置检索的一种特殊索引。
实例:创建集合
db.res.insert({
restaurantId: 0,
restaurantName: “兰州牛肉面”,
location: {
type: “Point”,
coordinates: [73.97, 40.77]
}
})
创建一个2dsphere索引
db.restaurant.createIndex({location : “2dsphere”})
MongoDB搭建集群
一、认识MongDB的复制集
二、运用MongoDB复制集搭建主从架构集群
1.创建数据目录
2.参考配置Mongod.conf文件
【注意事项】前面是4个空格
3.分别启动3个MOngoDB的节点( 启动 MongoDB 进程)
mongod -f D:\mongodb\data\db1\mongod.conf
mongod -f D:\mongodb\data\db2\mongod.conf
mongod -f D:\mongodb\data\db3\mongod.conf
如图所示:
【注意】以上命令需要在3个不同的窗口执行,执行后不可关闭窗口否则进程将直接结束。
4.配置复制集
(1)进入MongoDb主节点mongo shell
Mongosh --port=28017
(2)创建复制集
rs.initiate({
_id: “rs0”,
members:
[
{_id: 0,host: “localhost:28017”},
{_id: 1,host: “localhost:28018”},
{_id: 2,host: “localhost:28019”}
]
})
(3)观察节点信息发生变化
rs.status() —集群的基本信息
主节点
(3)测试集群
A.主节点测试登录
#连接primary节点 mongo --host 127.0.0.1 --port=28017 db.users.insert({“name”:“liyong”,“age”:11});
db.users.find();
可以看到集群搭建成功以后连接
测试主节点读数据
b.users.find(); #在从节点进行查询数据
我们可以看到这也一个错误,需要执行rs.slaveOk();
rs.slaveOk(); #执行此命令以后我们就可以进行查询数据了
B.从节点测试:
secondary节点
mongo --host 127.0.0.1 --port=28018
插入文档,返回失败,从节点不能写入数据
db.users.insert({“name”:“liyong”,“age”:11});
插入数据的时候提示我们了,不是主节点,这也验证了前面提到的再从节点是只读的,主节点可读可写
C.测试从节点读取数据
默认的情况下从节点是没有读写的权限的
设置允许从节点读数据
rs.secondaryOk()
然后从节点就可以写数据
测试关闭primary节点,演示主节点重新选取
三、MongoDB分片搭建集群
(5)mongodb分片集群的使用
A.连接路由服务器
Mongosh --port=27017
sh.status() ##查看分片集群的状态,关注shards和databases分组
B、分片集群添加数据角色,数据角色为副本集的方式
sh.addShard(“rs10/127.0.0.1:29020,127.0.0.1:29021,127.0.0.1:29022”)
sh.addShard(“rs11/127.0.0.1:29023,127.0.0.1:29024,127.0.0.1:29025”)
C.查看分片集群信息 sh.status()
1.分片集群介绍
高数据量和吞吐量的数据库应用会对单机的性能造成较大压力,大的查询量会将单机的CPU耗尽,大的数据量对单机的存储压力较大,最终会耗尽系统的内存而将压力转移到磁盘IO上。
为了解决这些问题,有两个基本的方法: 垂直扩展和水平扩展。
垂直扩展:增加更多的CPU和存储资源来扩展容量。
水平扩展:将数据集分布在多个服务器上。水平扩展即分片。
2.MongoDB分片集群简介
(1)分片介绍
分片是指将数据拆分并分散存放在不同机器上的过程,有时也用分区来表示这个概念。将数据分散到不同的机器上,不需要功能强大的计算机就可以存储更多的数据,处理更大的负载。MongoDB支持自动分片,可以使数据库架构对应用程序不可见,简化系统管理。对应用程序而言,就如同始终在使用一个单机的MongoDB服务器一样。
(2)MongoDB分片
分片集群组件介绍
构建一个MongoDB的分片集群,需要三个重要组件,分别是分片服务器(Shard Server)、配置服务器(Config Server)、路由服务器(Router Server)。
Shard Server
每个分片服务器都是一个mongod数据库实例,用于存储实际的数据块,整个数据库集合分成多个存储在不同的分片服务器中。在实际生产中,一个Shard Server可以由多台机器组成一个副本集来承担,防止因主节点单点故障导致整个系统崩溃。
Config Server
这是独立的一个mongod进程,存储所有数据库元信息(路由、分片)的配置。mongos本身没有物理存储分片服务器和数据路由信息,只是缓存在内存里,配置服务器则实际存储这些数据。
mongos第一次启动或者关掉重启就会从config server加载配置信息,以后如果配置服务器信息变化会通知到所有的mongos更新自己的状态,这样mongos就能继续准确路由。在生产环境通常设置多个config server,因为它存储了分片路由的元数据,防止单点数据丢失!
Router Server
这是独立的一个mongod进程,Router Server在集群中可作为路由使用,客户端由此
接入,让整个集群看起来像是一个单一的数据库,提供客户端应用程序和分片集群之间的接口。
Router Server本身不保存数据,启动时从Config Server加载集群信息到缓存中,并将客户端的请求路由给每个Shard Server,在各Shard Server返回结果后进行聚合并返回给客户端。
在实际生产环境中,副本集和分片是结合起来使用的,可满足实际应用场景中高可用性和高可扩展性的需求。
3.MongoDB分片集群的部署通常涉及以下几个步骤
(1)配置分片(shard)服务器
(2)配置配置服务器(config servers)
(3)设置mongos路由实例
(4)启动集群
(5)分片数据
4.MongoDB分片集群部署实战演练
(1)分片集群的搭建说明
使用同一份mongodb二进制文件,即mongod.conf
修改对应的配置就能实现分片集群的搭建
Config Server:使用28017、28018、28019三个端口来搭建(3台)–也是采用复制集这种搭建
Router Server:使用27017、27018两个端口来搭建(2台)—也是采用复制集这种搭建
Shard Server: 使用29020、29021、29022,29023,29024,29025六个端口来搭建,三个一组,模拟(两个分片)两个数据的集群,每个分片采用3个节点搭建复制集集群
(2)Config Server搭建
【备注】假设Config server3台数据库的数据目录为
A.配置mongod.conf
mongodb配置角色的搭建,配置文件路径/usr/local/mongodb/28017/mongod.conf
文件内容参考如下文件:
mongod.conf
c:\data\db1\mongod.conf
systemLog:
destination: file
path: D:\mongodb\fenpian\config1\mongod.log #日志文件路径
logAppend: true
storage:
dbPath: D:\mongodb\fenpian\config1 # 数据目录
net:
bindIp: 0.0.0.0
port: 28017 # 端口
replication:
replSetName: rs1
##配置分片角色
sharding:
clusterRole: configsvr
B.启动mongodb configsvr实例
mongod.exe -f D:\mongodb\fenpian\config1\mongod.conf
mongod.exe -f D:\mongodb\fenpian\config2\mongod.conf
mongod.exe -f D:\mongodb\fenpian\config3\mongod.conf
C.Windows操作系统下 侦听端口
使用PowerShell
打开PowerShell(可以在开始菜单中搜索“PowerShell”)。
输入命令 Get-NetTCPConnection,然后按回车。
这将显示所有TCP连接的详细信息,包括状态为“Listen”的端口。
D.分片集群的配置角色副本集搭建
(1)进入MongoDb主节点mongo shell
mongosh --port=28017
(2)创建复制集
ca={_id:“rs1”,
configsvr: true,
members:[{_id:0,host:“127.0.0.1:28017”},{_id:1,host:“127.0.0.1:28018”},{_id:2,host:“127.0.0.1:28019”}]
}
cmd【备注】_id的值与配置文件 “replSetName: rs1” 是一样的
rs.initiate(ca)
(3)#查看副本集状态
rs.status()
(3)Shard Server搭建
A.数据角色:分片集群的数据角色里存储着真正的数据,所以数据角色一定得使用副本集
29020、29021、29022一个集群,数据角色rs10
29023、29024、29025一个集群,数据角色rs11
设计分片服务器
备注:线上生产环境一个集群中应至少启用三个mongodb实例
B.在配置文件中设置角色为 shardsvr
注意有两个分片集群,其中复制集的名字分别设置为rs10 和rs11
C.Shard Server启动所有实例
mongod.exe -f D:\mongodb\fenpian\shard-29020\mongod.conf
mongod.exe -f D:\mongodb\fenpian\shard-29021\mongod.conf
mongod.exe -f D:\mongodb\fenpian\shard-29022\mongod.conf
mongod.exe -f D:\mongodb\fenpian\shard-29023\mongod.conf
mongod.exe -f D:\mongodb\fenpian\shard-29024\mongod.conf
mongod.exe -f D:\mongodb\fenpian\shard-29025\mongod.conf
D.数据角色的副本集搭建
①数据角色rs10
(1)进入MongoDb主节点mongo shell
mongosh --port=29020
(2)创建复制集
config={_id:“rs10”, members:[{_id:0,host:“127.0.0.1:29020”},{_id:1,host:“127.0.0.1:29021”},{_id:2,host:“127.0.0.1:29022”}]}
rs.initiate(config)
(3)查看分片集群装填
rs.status()
②数据角色rs11
(1)进入MongoDb主节点mongo shell
mongosh --port=29023
(2)创建复制集
config={_id:“rs11”, members:[{_id:0,host:“127.0.0.1:29023”},{_id:1,host:“127.0.0.1:29024”},{_id:2,host:“127.0.0.1:29025”}]}
rs.initiate(config)
(3)查看分片集群装填
rs.status()
(4)Router Server搭建
mongodb中的router角色只负责提供一个入口,不存储任何的数据。
A.配置mongodb.conf
Router配置文件路径27017/mongodb.conf
【注意事项】#不需要配置副本集名称
Router最重要的配置是:
(1)指定configsvr的地址,使用副本集id+ip端口的方式指定
(2)配置多个Router,任何一个都能正常的获取数据
(3)##不参与数据存储,所以不需要配置存储数据的目录
配置文件:
systemLog:
destination: file
path: D:\mongodb\fenpian\27017\mongod.log #日志文件路径
logAppend: true
##不参与数据存储,所以不需要配置存储数据的目录
#storage:
dbPath: D:\mongodb\fenpian\27017 # 数据目录
net:
bindIp: 0.0.0.0
port: 27018 # 端口
#replication:
replSetName: rs1
##配置分片角色 #配置configsvr副本集和IP端口
sharding:
configDB: rs1/127.0.0.1:28017,127.0.0.1:28018,127.0.0.1:28019
B、启动mongodb Routersvr实例
mongos -f D:\mongodb\fenpian\27017\mongod.conf
mongos -f D:\mongodb\fenpian\27018\mongod.conf
(5)mongodb分片集群的使用
A.连接路由服务器
Mongosh --port=27017
sh.status() ##查看分片集群的状态,关注shards和databases分组
B、分片集群添加数据角色,数据角色为副本集的方式
sh.addShard(“rs10/127.0.0.1:29020,127.0.0.1:29021,127.0.0.1:29022”)
sh.addShard(“rs12/127.0.0.1:29023,127.0.0.1:29024,127.0.0.1:29025”)
C.查看分片集群信息 sh.status()
(6)测试分片集群
A.实际操作演练
默认添加数据是没有使用分片存储的,操作都是在路由服务器中,如:
#插入500条数据做实验
use data1
for (i=1; i<=500; i++){db.users.insert({name:‘test’ + i, id:i})}
sh.status() ##查看分片集状态,可以看到500条数据全部插入到了其中一个rs11副本集群中,并没有分片
B.配置hash分片存储
针对某个数据库的某个集合使用hash分片存储,这样就能实现同一个集合分配两个数据角色
【备注】当某个数据库要开启分片存放数据时,这个数据库必须要创建索引
(1)设置data1数据库中users集合的索引
use data1
db.users.createIndex({id:1})
(2)切换到admin数据库中对 data1中集合users设置分片存储数据
use admim
db.runCommand({ enablesharding : “data1”})
#使用此命令开启data1数据库的分片存储
db.runCommand({ shardcollection : “data1.users”, key : {id:“hashed”}})
##根据data1数据库中users集合的默认_id字段开启hash分片存储
(3)测试数据2:插入数据校验,数据被均匀分配到两个数据库中
use data1
for (i=1; i<=800; i++){db.users.insert({name:‘test’ + i, id:i})}
(4)查看分片集群的状态 sh.status()
(5)路由服务器:进入到data1数据库中
查看users集合有多少数据
db.users.count() #有多少条数据
(7)进入分片服务器rs10
mongosh --port=29020
show dbs
use data1
show tables
db.users.count()
(8)进入分片服务器rs11
以上步骤就实现了MongoDB的分片集群的搭建
相关文章:
Nosql期末复习
mongodb基本常用命令(只要掌握所有实验内容就没问题) 上机必考,笔试试卷可能考: 1.1 数据库的操作 1.1.1 选择和创建数据库 (1)use dbname 如果数据库不存在则自动创建,例如,以下…...
Pytest+Allure+Yaml+PyMsql+Jenkins+Gitlab接口自动化(四)Jenkins配置
一、背景 Jenkins(本地宿主机搭建) 拉取GitLab(服务器)代码到在Jenkins工作空间本地运行并生成Allure测试报告 二、框架改动点 框架主运行程序需要先注释掉运行代码(可不改,如果运行报allure找不到就直接注释掉) …...

SQL面试题练习 —— 查询前2大和前2小用户并有序拼接
目录 1 题目2 建表语句3 题解 1 题目 有用户账户表,包含年份,用户id和值,请按照年份分组,取出值前两小和前两大对应的用户id,需要保持值最小和最大的用户id排首位。 样例数据 ------------------------- | year | user_id | v…...

Arthas常见使用姿势
文章目录 Arthas常见使用姿势官网基本命令通用参数解释表达式核心变量说明常用命令一些常用特殊案例举例其他技巧关于OGNLOGNL的常见使用OGNL的一些特殊用法与说明OGNL内置的虚拟属性OGNL的个人思考OGNL的杂碎,收集未做验证 Arthas常见使用姿势 官网 https://arth…...

Apache Kylin的入门学习
Apache Kylin的入门学习可以从以下几个方面进行: 1. 了解Kylin的基本概念 定义:Apache Kylin是一个开源的分布式分析引擎,它基于Hadoop和HBase构建,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能…...
路由v5.x(11)源码(3)- 实现 Router)
React@16.x(46)路由v5.x(11)源码(3)- 实现 Router
目录 1,Router 的结构2,实现2.1,react-router1,matchPath.js2,Router.js3,RouterContext.jsx4,index.jsx 2.2,react-router-domBrowserRouter.jsxindex.jsx 1,Router 的结…...

openGauss真的比PostgreSQL差了10年?
前不久写了MogDB针对PostgreSQL的兼容性文章,我在文中提到针对PostgreSQL而言,MogDB兼容性还是不错的,其中也给出了其中一个能源客户之前POC的迁移报告数据。 But很快我发现总有人回留言喷我,而且我发现每次喷的这帮人是根本不看文…...

【国产开源可视化引擎Meta2d.js】快速上手
提示 初始化引擎后,会生成一个 meta2d 全局对象,可直接使用。 调用meta2d前,需要确保meta2d所在的父容器element元素位置大小已经渲染完成。如果样式或css(特别是css动画)没有初始化完成,可能会报错&…...

c#与倍福Plc通信
bcdedit /set hypervisorlaunchtype off...

【OceanBase诊断调优】—— 如何通过trace_id找到对应的执行节点IP
1. 前言 OceanBase作为分布式数据库,查问题找对节点很关键。好在OceanBase执行的每一条SQL都能通过trace_id来关联起来,知道trace_id怎么知道是在哪个节点发起的呢,请看本文。 2. trace_id生成规则 ob内部trace_id的生成函数如下࿰…...

鸿蒙开发Ability Kit(程序访问控制):【使用粘贴控件】
使用粘贴控件 粘贴控件是一种特殊的系统安全控件,它允许应用在用户的授权下无提示地读取剪贴板数据。 在应用集成粘贴控件后,用户点击该控件,应用读取剪贴板数据时不会弹窗提示。可以用于任何应用需要读取剪贴板的场景,避免弹窗…...

PL/SQL入门到实践
一、什么是PL/SQL PL/SQL是Procedural Language/Structured Query Language的缩写。PL/SQL是一种过程化编程语言,运行于服务器端的编程语言。PL/SQL是对SQL语言的扩展。PL/SQL结合了SQL语句和过程性编程语言的特性,可以用于编写存储过程、触发器、函数等…...

双非本 985 硕,我马上要入职上海AI实验室大模型算法岗
暑期实习基本结束了,校招即将开启。 不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。 最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑&…...

C盘清理和管理
本篇是C盘一些常用的管理方法,以及定期清理C盘的方法,大部分情况下都能避免C盘爆红。 C盘清理和管理 C盘存储管理查看存储情况清理存储存储感知清理临时文件清理不需要的 迁移存储 磁盘清理桌面存储管理应用存储管理浏览器微信 工具清理 C盘存储管理 查…...

晚上睡觉要不要关路由器?一语中的
前言 前几天小白去了一个朋友家,有朋友说:路由器不关机的话会影响睡眠吗? 这个影响睡眠嘛,确实是会的。毕竟一时冲浪一时爽,一直冲浪一直爽……刷剧刷抖音刷到根本停不下来,肯定影响睡眠。 所以晚上睡觉要…...

ardupilot开发 --- 坐标变换 篇
Good Morning, and in case I dont see you, good afternoon, good evening, and good night! 0. 一些概念1. 坐标系的旋转1.1 轴角法1.2 四元素1.3 基于欧拉角的旋转矩阵1.3.1 单轴旋转矩阵1.3.2 多轴旋转矩阵1.3.3 其他 2. 齐次变换矩阵3. visp实践 0. 一些概念 相关概念&am…...

git clone 别人项目后正确的修改和同步操作
简介 git clone主要是克隆别人的开源项目。但更高端的操作是实现本地修改的同时,能同步别人的在线修改,并且不相互干扰: 克隆原始项目:从远程仓库克隆项目到本地。添加上游仓库:将原始项目的远程仓库添加为上游仓库。…...
JAVA连接FastGPT实现流式请求SSE效果
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景! 一、先看效果 真正实流式请求,SSE效果,SSE解释&am…...

二分查找1
1. 二分查找(704) 题目描述: 算法原理: 暴力解法就是遍历数组来找到相应的元素,使用二分查找的解法就是每次在数组中选定一个元素来将数组划分为两部分,然后因为数组有序,所以通过大小关系舍弃…...
什么美业门店管理系统好用?2024美业收银系统软件排名分享
美业SAAS系统在美容、美发、美甲等行业中十分重要,这种系统为美业提供了一种数字化解决方案,帮助企业更高效地管理业务和客户关系。 美业门店管理系统通常提供预约管理、客户管理、库存管理、报表生成等一系列功能,以满足美容院、美发沙龙等…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

大学生职业发展与就业创业指导教学评价
这里是引用 作为软工2203/2204班的学生,我们非常感谢您在《大学生职业发展与就业创业指导》课程中的悉心教导。这门课程对我们即将面临实习和就业的工科学生来说至关重要,而您认真负责的教学态度,让课程的每一部分都充满了实用价值。 尤其让我…...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...

【Redis】笔记|第8节|大厂高并发缓存架构实战与优化
缓存架构 代码结构 代码详情 功能点: 多级缓存,先查本地缓存,再查Redis,最后才查数据库热点数据重建逻辑使用分布式锁,二次查询更新缓存采用读写锁提升性能采用Redis的发布订阅机制通知所有实例更新本地缓存适用读多…...

【MATLAB代码】基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),附源代码|订阅专栏后可直接查看
文章所述的代码实现了基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),针对传感器观测数据中存在的脉冲型异常噪声问题,通过非线性加权机制提升滤波器的抗干扰能力。代码通过对比传统KF与MCC-KF在含异常值场景下的表现,验证了后者在状态估计鲁棒性方面的显著优…...