大数据面试题之HBase(3)
HBase的预分区
HBase的热点问题
HBase的memstore冲刷条件
HBase的MVCC
HBase的大合并与小合并,大合并是如何做的?为什么要大合并
既然HBase底层数据是存储在HDFS上,为什么不直接使用HDFS,而还要用HBase
HBase和Phoenix的区别
HBase支持SQL操作吗
HBase适合读多写少还是写多读少
HBase表设计
Region分配
HBase的Region切分
HBase的预分区
HBase的预分区(Pre-Splitting)是一种优化手段,用于在创建表时提前规划好表的分区结构,以减少数据写入过程中自动分区(Region Split)所带来的资源消耗和性能影响。预分区特别适用于预期会有大量数据写入的新表,通过预设分区,可以使得数据分布更加均匀,提升写入和查询性能。
1、预分区的目的:
1) 减少Region Split:自动Region分裂过程会消耗CPU、I/O等资源,预分区可以减少分裂操作的发生频率,从而减轻系统负担。
2) 优化数据分布:通过预分区,可以根据业务需求和数据分布特性,手动定义初始的Region分布,使得数据在一开始就较为均衡地分布在不同Region上。
3) 提升性能:减少分裂操作可以降低对HBase集群的性能冲击,尤其是在数据批量导入或高写入速率场景下,预分区能显著提升写入速度和整体服务稳定性。
2、如何进行预分区:
1) 确定分区数:首先,根据预期数据量和数据分布特性估算所需的Region数量。
2) 指定分区点:选择合适的RowKey范围作为预分区的边界。这些边界值(Split Keys)应能均匀地将数据分割开,确保数据写入时能均衡分布。
3) 创建表时指定预分区:在使用HBase shell或编程API创建表时,通过SPLITS参数指定预分区的边界值。例如,在HBase shell中,命令可能是这样的:
create 'my_table', 'cf', SPLITS => ['key1', 'key2', ..., 'keyN']
这里,'key1'至'keyN'是预定义的RowKey值,用于分割表。
4) 调整配置:有时,为了配合预分区策略,可能还需要调整HBase的相关配置,比如hbase.hregion.max.filesize,该配置决定了单个Region的最大文件大小,超过此大小时会触发分裂。
注意事项:
预分区是一种静态配置,对于数据增长模式难以预测或数据分布随时间变化的情况,可能需要定期评估和调整预分区策略。
预分区策略应当基于对数据特性的深入了解,包括数据量、访问模式、RowKey设计等因素。
过度预分区可能会导致Region数量过多,增加维护成本和查找时间,因此需要合理规划。
HBase的热点问题
HBase的热点问题通常指在某些特定区域或RegionServer上过度集中的读写操作,导致这些区域或服务器成为性能瓶颈,甚至引发单点故障。热点问题可能导致资源利用不均,降低HBase集群的整体性能和可用性。以下是关于HBase热点问题的详细分析:
一、产生原因
1) 没有提前创建分区:当HBase表创建时,如果没有提前进行预分区,默认情况下只有一个Region,所有的RowKey都写入到这个Region中,导致该Region所在的RegionServer承受过大的压力。
2) RowKey设计不合理:如果RowKey的设计使得大量的数据写入到同一个Region中,或者使得某个Region的读写请求远超过其他Region,就会形成热点问题。例如,如果RowKey按照时间戳递增生成,并且查询也主要基于时间范围,那么最新的数据就会集中写入到同
一个Region中。
二、解决方案
1) 预分区(Pre-splitting):在创建HBase表时,根据数据的访问模式和查询需求,提前将表进行分区。通过指定Region的起始和结束RowKey,将数据分散到不同的RegionServer上,从而避免热点问题。
2) 合理设计RowKey:RowKey的设计应该使得数据在分布式存储中能够均匀分布。可以通过在RowKey中引入随机前缀、散列函数等方式来实现。例如,可以将时间戳反转、添加用户ID等作为RowKey的一部分,以减少数据倾斜。
3) 批量写入和读取:使用HBase的批量写入和读取接口,可以减少网络传输和I/O开销,提高性能。在写入数据时,可以将多个写入操作合并为一个批量写入操作;在读取数据时,可以将多个读取操作合并为一个批量读取操作。
4) 压缩和缓存:使用HBase的数据压缩功能可以减少数据在存储和传输过程中的大小,降低I/O开销。同时,通过合理配置HBase的缓存参数,将热点数据和频繁访问的数据缓存在内存中,可以减少磁盘读取的开销。
5) 使用Bloom Filter和Block Cache等技术:Bloom Filter可以减少不必要的磁盘读取操作,提高查询效率;Block Cache可以将数据块缓存在内存中,提高数据访问速度。
HBase的memstore冲刷条件
HBase的MemStore冲刷(Flush)是将内存中的数据写入磁盘的过程,以确保数据的持久化并控制内存使用。MemStore冲刷主要受以下条件触发:
1、MemStore大小限制:
当某个MemStore的大小达到配置的阈值 hbase.hregion.memstore.flush.size(默认值通常是128MB),该MemStore将会被刷写到
磁盘。这表示只要MemStore中存储的数据量达到了这个设定值,就会触发刷写操作。
2、RegionServer内存使用率:
当RegionServer中所有MemStore的总大小达到堆内存的一定比例(默认情况下,当达到
hbase.regionserver.global.memstore.upperLimit 的值,默认为0.40,即40%),HBase会开始阻塞写操作,并按照各个Region的MemStore大小(从大到小)顺序进行刷写,直到总MemStore大小降到 hbase.regionserver.global.memstore.lowerLimit(默认值0.95,即95%)以下。这一过程是为了防止内存溢出,确保系统的稳定运行。
3、手动触发:
管理员可以通过命令行工具或API手动触发MemStore的刷写,这在需要立即释放内存或进行维护操作时非常有用。
4、定期刷写:
虽然不是标准配置中的直接条件,但在某些应用场景中,可能会设置定时任务以周期性地触发MemStore的刷写,以满足特定的维护或性能需求。
5、系统负载或资源压力:
在一些实现或配置中,如果系统检测到资源紧张(如CPU、I/O带宽等),可能会触发刷写操作以减轻系统压力,尽管这不是HBase直接规定的标准刷写条件。
HBase的MVCC
HBase的MVCC(Multi-Version Concurrency Control,多版本并发控制)是用于解决读写一致性问题的一种机制,它允许在并发环境下进行高效的读写操作,同时保证数据的一致性。以下是关于HBase MVCC的详细解释:
1、MVCC的基本原理
1) 多版本控制:MVCC通过保留数据的多个版本来解决并发读写时可能产生的冲突。每个事务在读取数据时,都会看到一个一致性的数据快照,这个快照基于该事务开始时的数据版本。
2) 读写不阻塞:在MVCC机制下,读操作不会阻塞写操作,写操作也不会阻塞读操作。多个事务可以同时进行读写操作,提高了系统的并发性能。
2、HBase中MVCC的实现
1) 版本控制:HBase使用毫秒级时间戳作为数据的版本标识。每次数据更新时,都会生成一个新的版本,并将旧版本保留下来。读操作可以根据需要读取指定版本的数据。
2) 写操作流程:
HRegion级别的seqID自增加一,并且当前writeNo设为seqID + 1亿(这个大数的意义是防止别的写操作提交时把readNo提高了,导致当前writeNo成为一个可读状态的id,后面会将其设回正常的seqID)。
把当前的写操作的一个包含seqID的dummy对象WriteEntry加进队列。
对于实际写操作本身,先写memstore,再写WAL(Write-Ahead Logging,预写日志),如果中间失败则回滚,否则则当做成功继续执行。
写请求提交实际上就是把当前HRegion级别的readNo设为队列中已完成的写请求的seqID最大值,表示seqID以下的写请求都处理完了,可读。
3) 读操作流程:
每个读操作开始都分配一个读序号,也称为读取点(readPoint)。
读取点的值是所有的写操作完成序号中的最大整数(所有的写操作完成序号<=读取点)。
对某个(row, column)的读取操作r来说,结果是满足写序号为“写序号<=读取点这个范围内”的最大整数的所有cell值的组合。
2、MVCC的优势
提高并发性能:通过多版本控制和读写不阻塞的特性,MVCC可以显著提高HBase的并发性能。
保证数据一致性:MVCC通过保留数据的多个版本来解决并发读写时可能产生的冲突,从而保证了数据的一致性。
注意事项
MVCC虽然可以提高并发性能和数据一致性,但也会增加存储空间的开销,因为需要保留数据的多个版本。因此,在使用MVCC时需要根据实际情况进行权衡。
HBase的MVCC实现是在HRegion级别的,因此不同Region之间的数据读写不会相互干扰。但需要注意的是,如果某个Region的数据量过大或读写请求过于集中,可能会导致该Region成为性能瓶颈。此时可以通过预分区、负载均衡等技术手段来优化性能。
HBase的大合并与小合并,大合并是如何做的?为什么要大合并
大合并(Major Compaction)如何进行:
1、触发时机:
- 大合并可以手动触发,通过HBase Shell、Master UI界面或HBase API执行major_compact命令。
- 也可以根据配置自动触发,但通常大合并的自动执行周期较长,比如一周一次,因为其资源消耗较大。
- 在一些场景下,管理员可能会禁用自动大合并,仅在低负载时段通过脚本手动执行,以减少对集群的影响。
2、执行过程:
- 大合并会将一个Region下的所有StoreFile(即属于同一列族的所有HFile)合并成一个或少数几个较大的StoreFile。
- 在合并过程中,HBase会检查每个记录的版本和时间戳,删除那些被标记为删除或已过期的数据(即带有墓碑标记的记录),从而释放存储空间。
- 合并后,旧的HFile将被废弃,新的、更紧凑的HFile将替代它们,减少了文件总数,提升了查询效率。
为什么需要大合并:
1、优化查询性能:
- 大合并减少了存储在磁盘上的HFile数量,使得查询时需要打开和遍历的文件减少,从而加快查询速度。
- 通过删除无效数据,确保查询返回的是最新或有效版本的数据,避免了读取到已删除或过期记录。
2、节省存储空间:
- 删除不再需要的数据,如已标记删除的记录和过期的版本,能够有效回收存储空间。
- 合并成更少、更大的文件减少了存储碎片,进一步提高了空间利用率。
3、维护数据一致性:
- 确保数据的一致性,避免在多次小合并后,仍存在大量冗余或无效数据。
尽管大合并带来了许多好处,但它也是一把双刃剑,因为合并过程会占用大量的I/O资源和磁盘空间(临时空间),可能导致在合并期间集群的读写性能下降。因此,大合并的执行通常需要精心规划,以最小化对在线服务的影响。
既然HBase底层数据是存储在HDFS上,为什么不直接使用HDFS,而还要用HBase
虽然HBase确实依赖HDFS作为其底层存储系统,但HBase提供的功能远超出了单纯文件存储的范畴,它针对特定的应用场景和需求进行了专门设计,补充了HDFS在某些方面的能力不足。以下是HBase相比于直接使用HDFS的一些关键优势:
实时读写能力:
HBase是一个列式存储的NoSQL数据库,设计目标之一是提供低延迟的随机读写访问。相比HDFS更适合批量处理和大规模数据分析,HBase能够支持实时数据查询和更新,适用于需要快速响应的在线应用。
数据模型:
HBase提供了丰富的数据模型,包括列族(Column Families)、列限定符(Column Qualifiers)和时间戳(Timestamps),使得数据结构更加灵活,便于处理半结构化和非结构化的数据。而HDFS主要是面向大规模的文件存储,没有内置复杂的数据模型。
事务和一致性:
HBase支持原子性操作和一定程度的事务处理能力,如行级事务,确保数据更新的一致性。虽然不如传统关系型数据库的ACID特性强大,但对于很多应用场景来说已经足够。
自动分区和扩展性:
HBase通过Region自动分裂和负载均衡机制,能够水平扩展以应对数据量的增长。用户无需手动管理数据分布,HBase会根据数据量和负载情况自动调整。
索引和查询优化:
HBase内部实现了多种优化机制,如Block Cache、Bloom Filters等,提高了查询效率。虽然HDFS可以存储大量数据,但它本身并不提供高效的索引机制来加速数据检索。
易用性接口:
HBase提供了易于使用的API和Shell工具,使得数据的插入、查询、删除等操作更为便捷。同时,HBase还可以与Hadoop生态系统中的其他工具如MapReduce、Pig、Hive等集成,便于进行复杂的数据处理。
简而言之,HBase在HDFS的基础上构建了一层数据库抽象,旨在解决大数据场景下的实时读写、灵活数据模型、复杂查询等需求,它使得开发人员能够以更数据库化的方式操作数据,而不必直接处理底层文件存储的复杂性。
HBase和Phoenix的区别
HBase和Phoenix在功能、用途和架构上存在明显的区别。以下是关于两者区别的详细解释:
1. 定义与用途
HBase:
定义:HBase是基于Hadoop的分布式、面向列的开源数据库,主要用于海量数据的存储和处理。
用途:适用于持久化存储大量数据(TB、PB级别),对扩展伸缩性有要求,需要良好的随机读写性能,以及处理结构化和非结构化的数据。
局限性:不支持复杂的事务处理,不支持SQL查询(但可以通过Phoenix等中间件解决)。
Phoenix:
定义:Phoenix是构建在HBase之上的开源SQL层,允许用户使用标准的JDBC API来建表、插入数据和查询HBase中的数据。
用途:通过Phoenix,用户可以避免直接使用HBase的客户端API,从而简化开发过程。Phoenix支持SQL查询,包括JOIN操作,使得HBase数据更容易被查询和分析。
2. 数据存储与访问
HBase:
数据存储:数据存储在Hadoop的分布式文件系统HDFS中,通过Row Key进行分区,并将不同的Row Key存储在不同的Region中。
数据访问:使用HBase提供的API进行数据读写操作,支持基于列族和列名的多维度数据查询。
Phoenix:
数据存储:虽然数据存储在HBase中,但Phoenix将数据模型映射到关系型世界,使得用户可以使用SQL语言来查询HBase数据。
数据访问:通过标准的JDBC API进行数据访问,支持SQL查询,包括JOIN操作。
3. 架构与特性
HBase:
架构:采用分布式架构,将数据分散存储在多台机器上,以实现数据的无限扩展。采用Master-Slave架构,其中Master负责对数据进行管理和协调,而Slave负责存储和读写数据。
特性:高可扩展性、高可用性、高性能、分布式存储和查询等特点。
Phoenix:
架构:作为HBase的SQL层,Phoenix在HBase之上提供了一个SQL接口,使得用户可以使用SQL语言来查询HBase数据。
特性:支持SQL查询,包括JOIN操作;容易集成其他工具,如Spark、Hive、Pig等;将SQL查询编译为HBase扫描,以优化查询性能。
4. 使用方式与性能
HBase:
使用方式:需要使用HBase提供的API进行数据操作,对开发者有一定的学习成本。
性能:直接操作HBase数据,性能较高,但复杂查询可能需要额外的处理。
Phoenix:
使用方式:使用标准的JDBC API和SQL语言进行数据操作,降低了开发门槛。
性能:通过优化SQL查询和编译为HBase扫描,提高了查询性能,特别是对于复杂查询和JOIN操作。
综上所述,HBase和Phoenix在数据存储、访问方式、架构和特性等方面存在明显的区别。选择使用哪个取决于具体的应用场景和需求。如果需要高性能的数据存储和随机读写能力,可以选择HBase;如果需要支持SQL查询和简化开发过程,可以选择Phoenix。
HBase支持SQL操作吗
HBase本身并不直接支持标准的SQL操作。HBase是一个基于列族的NoSQL数据库,它使用HBase查询语言(HBaseQL)来与数据进行交互,这种查询语言专注于键值对操作,与SQL有显著区别。
然而,想要使用SQL语法操作HBase,可以借助以下几种方式:
1、Apache Phoenix:
Phoenix是一个构建在HBase之上的开源项目,它提供了一个JDBC驱动,允许用户使用SQL查询来操作HBase。Phoenix将SQL查询转换为HBase的原生API调用,支持包括DML(数据操作语言)和DDL(数据定义语言)在内的多种SQL操作,并且还支持二级索引等功能,大大增强了HBase的查询能力。
2、Hive和Impala:
可以通过将HBase表映射为Hive外部表来间接使用SQL查询HBase。Hive支持将HBase表作为数据源,利用HiveQL执行查询,但请注意,这种方式通常更适合批处理查询,因为其查询引擎基于MapReduce,可能不适合低延迟需求。Impala则提供了更接近实时的SQL查询能力,通过直接访问HDFS数据,能够提供比Hive更快的查询响应时间,但同样需要预先设置Hive外部表与HBase的映射。
3、阿里云Lindorm等云服务:
一些云服务提供商,如阿里云的Lindorm,提供了对HBase的增强版本,其中包含了直接使用SQL操作HBase表的功能。这些服务通过特定的SQL兼容层或列映射功能,使得用户能够以SQL方式与HBase数据进行交互。
综上所述,虽然HBase本身不直接支持SQL,但通过上述工具和方法,用户依然能够以SQL的形式来操作HBase数据,从而降低了学习曲线,提高了开发效率,特别是对于熟悉SQL的开发者而言。
HBase适合读多写少还是写多读少
HBase本身并没有明确地被设计为只适合读多写少或写多读少的场景,而是根据具体的应用需求和工作负载来决定的。然而,由于HBase是基于Hadoop的分布式、面向列的数据库,它在某些方面对读多写少的工作负载更为友好。
以下是为什么HBase在某些情况下可能更适合读多写少的工作负载的原因:
1、数据一致性:HBase提供的是最终一致性模型,而不是强一致性模型。这意味着写入操作可能不会立即对所有读取操作可见,因为数据在集群中需要一定的时间进行复制和同步。在读多写少的场景下,写入操作相对较少,因此这种延迟通常是可以接受的。
2、写操作的开销:在HBase中,写入操作通常需要涉及多个组件,如WAL(Write-Ahead Logging,预写日志)、MemStore和HDFS等。这些操作可能需要消耗更多的资源和时间,尤其是在高写入负载下。因此,在写多读少的场景下,写入操作的开销相对较小,不会对系统性能产生太大影响。
3、数据压缩和编码:HBase支持多种数据压缩和编码技术,这些技术可以在存储数据时减少数据的体积并提高读取性能。在读多写少的场景下,由于读取操作更加频繁,因此数据压缩和编码技术可以更加有效地提高读取性能。
4、缓存机制:HBase利用块缓存(BlockCache)来缓存热点数据,以提高读取性能。在读多写少的场景下,热点数据更容易被缓存并频繁访问,从而进一步提高读取性能。
然而,需要注意的是,HBase也支持高写入负载的场景。通过优化写入策略、调整配置参数和使用合适的写入工具(如BulkLoad),HBase可以处理大量的写入操作。此外,HBase还支持事务性写入(通过Phoenix等中间件),可以在一定程度上保证写入操作的一致性和可靠性。
因此,HBase是否适合读多写少或写多读少的场景取决于具体的应用需求和工作负载。在选择使用HBase时,应该根据应用的实际情况进行评估和测试,以确定最佳的配置和策略。
HBase表设计
HBase表设计是关键的一步,它直接影响到数据的存储效率、查询性能以及系统的可扩展性。以下是一些基本的设计原则和最佳实践:
1. 表格模型理解
行键(Row Key):是HBase表中最重要的设计元素,直接影响查询性能。理想的行键应该是唯一且能按时间或逻辑顺序排列,以利用HBase的排序特性。设计时考虑前缀扫描和范围扫描的需求。
列族(Column Family):每个列族中的数据存储在一起,拥有相同的存储和缓存策略。应谨慎选择列族,过多的列族会增加存储开销,因为每个列族都有独立的文件存储。一般不超过3-4个列族。
列限定符(Column Qualifier):列族内的具体列,设计时可以灵活多变,不需要预先定义。
2. 行键设计
时间反序:如果数据有时间属性,可以考虑将时间戳作为行键的一部分,并将其置于行键末尾,这样可以优化最近数据的查询。
散列:如果单个键值范围过大,可以使用散列函数缩短行键长度,但需权衡查询效率。
组合键:结合多个字段生成行键,如用户ID+时间戳,既能保证唯一性,又利于范围查询。
3. 列族设计
减少列族数量:尽量减少列族数量,因为每个列族的元数据都会在内存中缓存,列族过多会增加内存负担。
访问模式匹配:根据访问频率和数据特性划分列族,频繁一起读取的列应放在同一列族中,以便于缓存优化。
4. 版本控制
合理设置版本数量:通过VERSIONS属性控制每个单元格存储的版本数,根据业务需求设置,避免无限制增长导致的空间浪费。
5. 时间戳
利用时间戳:HBase自动为每个单元格记录时间戳,可以利用此特性进行数据的历史版本管理或数据更新。
6. 预分区
预分区:对于大量数据的表,预创建多个Region可以提高写入性能和数据分布的均匀性。
7. 数据压缩
启用压缩:根据数据类型选择合适的压缩算法,如Snappy、GZ等,可以在不牺牲太多性能的情况下减少存储空间。
8. 性能考量
避免全表扫描:尽可能设计数据模型以支持行键或部分行键查询,减少全表扫描操作。
缓存策略:合理配置Block Cache和MemStore,以提升热点数据的访问速度。
9. 扩展性和维护
设计可扩展的表结构:考虑到数据量的增长和查询模式的变化,表结构应具有一定的灵活性和扩展性。
监控和调优:定期审查表设计并根据实际运行情况进行调优,利用HBase提供的监控工具分析性能瓶颈。
综上,HBase表设计是一个综合考量性能、扩展性和业务需求的过程,需要在实践中不断调整和完善。
Region分配
在HBase中,Region的分配是一个动态过程,它涉及到表的创建、数据负载均衡以及Region服务器故障恢复等多种情况。以下是关于HBase Region分配的主要特点和过程的详细解释:
1. Region的定义与功能
定义:HBase中的数据表被分割为多个水平切片,每个切片被称为一个Region。
功能:Region是HBase中数据存储和管理的基本单元,每个Region存储特定范围的行键数据。
2. 初始Region分配
当用户创建一个新的HBase表时,系统会自动分配一些初始的Region。
初始Region的数量和范围由系统内置的预分配策略决定。
3. 负载均衡与Region重新分配
目的:为了实现数据的负载均衡,HBase会定期执行Region的重新分配。
过程:
监控各个RegionServer的负载情况,包括Region数量和数据大小。
如果某个RegionServer上的Region过多,HBase会尝试将一部分Region迁移到相对空闲的RegionServer上。
如果某个RegionServer上的Region过少,HBase会尝试从其他RegionServer上迁移一些Region过来以实现负载均衡。
负载均衡频率:这些负载均衡的操作是透明的,用户无需干预,HBase会定期(例如每五分钟)进行检查和调整。
4. 故障恢复与Region分配
当一个RegionServer出现故障时,HBase会进行相应的故障恢复操作。
故障恢复的主要目标是将故障的RegionServer上的Region重新分配到其他正常的RegionServer上。
HBase检测到故障的RegionServer。
将该RegionServer上的所有Region标记为不可用。
根据负载情况,在其他正常的RegionServer上重新分配这些Region。
客户端会被通知新的RegionServer位置,以便继续访问数据。
5. Region分配策略与配置
HBase提供了多种Region分配策略,例如ConstantSizeRegionSplitPolicy、IncreasingToUpperBoundRegionSplitPolicy、SteppingSplitPolicy等,这些策略决定了Region的分裂时机和方式。
用户可以通过调整HBase的配置参数来影响Region的分配和分裂行为,以优化系统的性能和稳定性。
6. 注意事项
Region的分配和分裂是HBase自动管理的,但在某些情况下,如数据倾斜或特定查询模式,可能需要手动干预或调整配置参数以达到最佳性能。
合理地设计表的行键和预分区策略,以及合理地配置Region的分裂阈值等参数,都可以对Region的分配和性能产生积极影响。
HBase的Region切分
HBase的Region切分是HBase分布式存储系统中的重要机制,它确保了数据的均衡分布和查询性能的优化。以下是关于HBase Region切分的详细解释:
1. Region切分的定义
Region是HBase中数据存储的基本单位,每个Region包含一定范围的行数据。随着数据的不断写入,当Region的大小超过一定阈值时,HBase会触发Region的切分操作,将一个大的Region拆分成两个或多个更小的Region。
2. Region切分的触发策略
HBase提供了多种Region切分的触发策略,这些策略决定了何时以及如何触发Region的切分。以下是几种常见的切分策略:
ConstantSizeRegionSplitPolicy:这是HBase早期版本的默认切分策略。当Region的大小超过一个固定的阈值(例如10GB)时,会触发切分操作。然而,这种策略没有考虑到不同表或不同Region之间的数据差异,可能导致在某些情况下切分不够合理。
IncreasingToUpperBoundRegionSplitPolicy:这是HBase后续版本中引入的切分策略,也是当前版本的默认策略。它根据RegionServer上Region的数量动态调整切分的阈值。当Region数量较少时,切分阈值也较低;随着Region数量的增加,切分阈值也逐渐增加,但不会超过一个设定的上限值。这种策略能够更好地适应不同数据量和工作负载的情况。
SteppingSplitPolicy:这是HBase 2.0版本引入的切分策略。它的切分阈值规则与IncreasingToUpperBoundRegionSplitPolicy类似,但更加简化。如果RegionServer上只有一个Region,则切分阈值为MemStore的刷写大小的两倍;否则,切分阈值为设定的最大Region文件大小。
3. Region切分的具体操作
当触发Region切分时,HBase会执行以下操作:
准备阶段:在内存中初始化两个子Region,生成对应的HRegionInfo对象,并创建一个transaction journal来记录切分的进展。
执行阶段:
更改ZooKeeper中Region的状态为SPLITTING。
HBase Master检测到状态变化后,修改内存中Region的状态,并在RIT(Region In Transition)模块中显示Region执行切分的状态信息。
在父Region的存储目录下创建临时文件夹.split,保存切分后的子Region信息。
关闭父Region的数据写入并触发flush操作,将内存中的数据持久化到磁盘。
在.split文件夹下创建两个子文件夹(daughter A和daughter B),并生成reference文件指向父Region中的对应文件。
将daughter A和daughter B拷贝到HBase的根目录下,形成两个新的Region。
父Region通知修改hbase.meta表后下线,不再提供服务。
开启daughter A和daughter B两个子Region,并通知修改hbase.meta表,正式对外提供服务。
回滚阶段:如果执行阶段出现异常,则执行回滚操作,清理相关的垃圾数据。
4. 注意事项
Region的切分是HBase自动管理的,但在某些特殊情况下,如数据倾斜或特定查询模式,可能需要手动干预或调整切分策略。
合理地设置切分策略的参数,如最大Region文件大小等,可以影响Region的切分行为和系统的性能。
频繁的Region切分可能会导致额外的I/O和CPU开销,因此需要权衡切分的频率和系统的性能需求。
引用:https://www.nowcoder.com/discuss/353159520220291072
通义千问、文心一言
相关文章:
)
大数据面试题之HBase(3)
HBase的预分区 HBase的热点问题 HBase的memstore冲刷条件 HBase的MVCC HBase的大合并与小合并,大合并是如何做的?为什么要大合并 既然HBase底层数据是存储在HDFS上,为什么不直接使用HDFS,而还要用HBase HBase和Phoenix的区别 HBase支…...

c#中赋值、浅拷贝和深拷贝
在 C# 编程中,深拷贝(Deep Copy)和浅拷贝(Shallow Copy)是用于复制对象的两种不同方式,它们在处理对象时有着重要的区别和适用场景。 浅拷贝(Shallow Copy) 浅拷贝是指创建一个新对…...

旧版st7789屏幕模块 没有CS引脚的天坑 已解决!!!
今天解决了天坑一个,大家可能有的人买的是st7789屏幕模块,240x240,1.3寸的 他标注的是老版,没有CS引脚,小崽子长这样: 这熊孩子用很多通用的驱动不吃,死活不显示,网上猛搜ÿ…...

激光粒度分析仪校准步骤详解:提升测量精度的秘诀
在材料科学、环境监测、医药研发等众多领域,激光粒度分析仪以其高精度、高效率的测量性能,成为了不可或缺的测试工具。然而,为了保持其测量结果的准确性和可靠性,定期校准是不可或缺的步骤。 接下来,佰德将为您详细介…...

独一无二的设计模式——单例模式(python实现)
1. 引言 大家好,今天我们来聊聊设计模式中的“独一无二”——单例模式。想象一下,我们在开发一个复杂的软件系统,需要一个全局唯一的配置管理器,或者一个统一的日志记录器;如果每次使用这些功能都要创建新的实例&…...
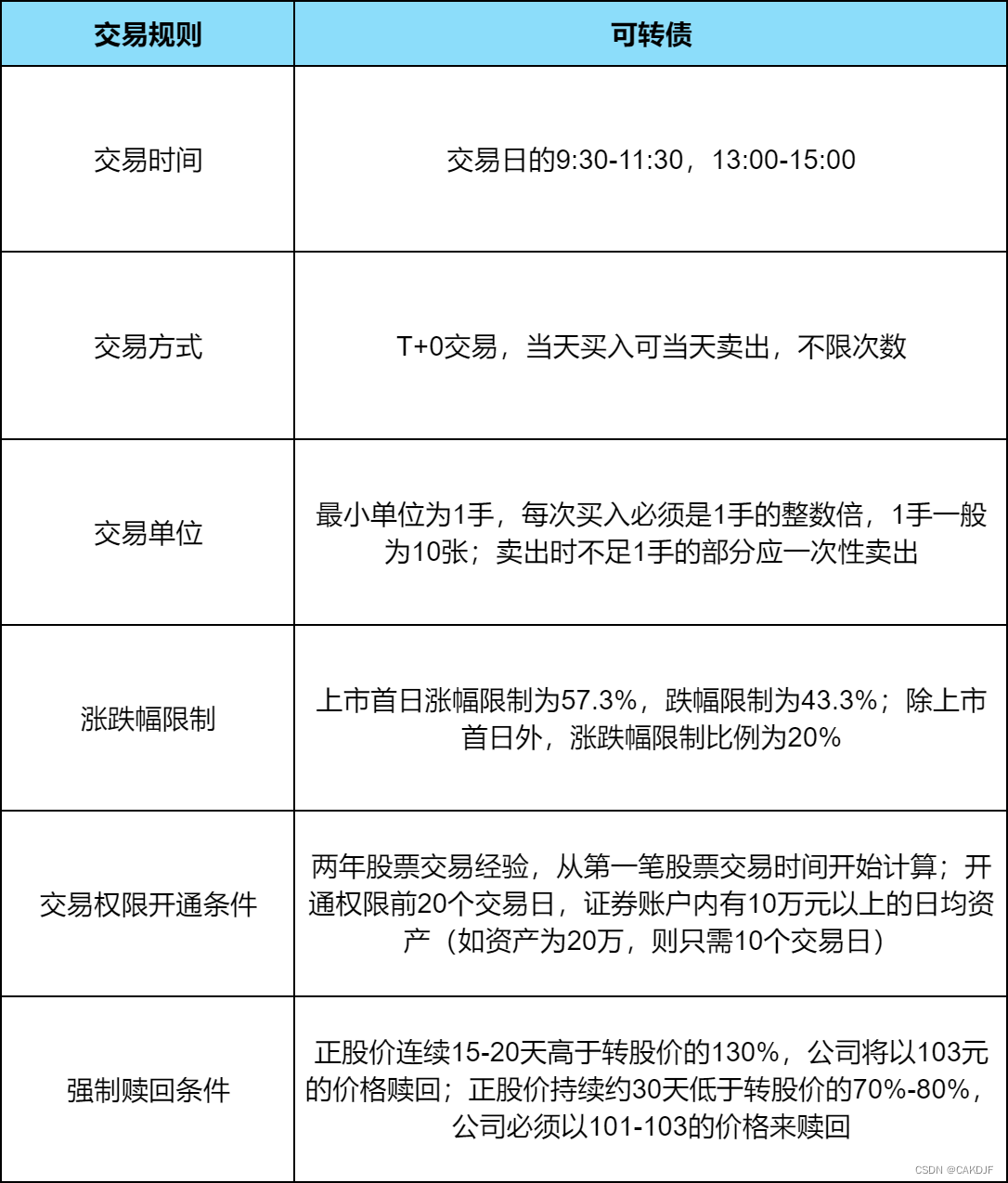
第二证券:可转债基础知识?想玩可转债一定要搞懂的交易规则!
可转债,全称是“可转化公司债券”,是上市公司为了融资,向社会公众所发行的一种债券,具有股票和债券的双重特点,投资者可以选择按照发行时约定的价格将债券转化成公司一般股票,也可作为债券持有到期后收取本…...

原型模式的实现
1. 引言 1.1 背景 在实际编程中,有时需要频繁创建多个相似但稍有不同的对象。如果采用传统的对象创建方式,容易造成代码冗余,对象重复初始化操作也可能带来大量的的资源消耗(如时间、内存等)。这样不仅降低了灵活性,导致难以适应状态的变化,还降低了代码的可扩展性。 …...

【第二套】华为 2024 年校招-硬件电源岗
1.为了避免 50Hz 的电⽹电压⼲扰放⼤器,应该⽤那种滤波器: A.带阻滤波器 B.带通滤波器 C.低通滤波器 D.⾼通滤波器 2.PID 中的 I 和 D 的作⽤分别是? A、消除静态误差和提⾼动态性能 B、消除静态误差和减⼩调节时间 C、提⾼动态性能和减⼩超调…...
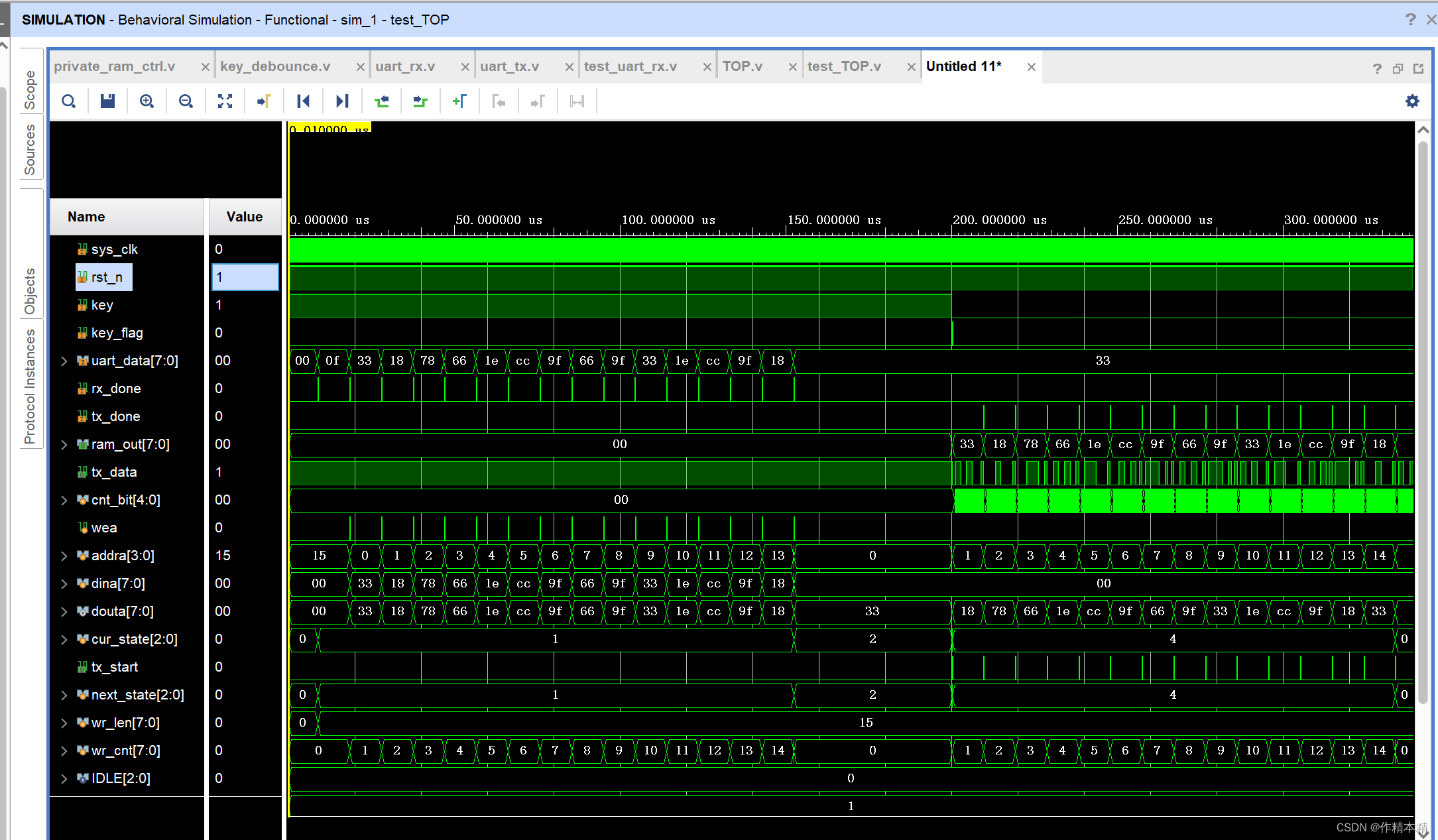
Xilinx FPGA:vivado利用单端RAM/串口传输数据实现自定义私有协议
一、项目要求 实现自定义私有协议,如:pc端产生数据:02 56 38 ,“02”代表要发送数据的个数,“56”“38”需要写进RAM中。当按键信号到来时,将“56”“38”读出返回给PC端。 二、信号流向图 三、状态…...

Spark on k8s 源码解析执行流程
Spark on k8s 源码解析执行流程 1.通过spark-submit脚本提交spark程序 在spark-submit脚本里面执行了SparkSubmit类的main方法 2.运行SparkSubmit类的main方法,解析spark参数,调用submit方法 3.在submit方法里调用doRunMain方法,最终调用r…...

粤港联动,北斗高质量国际化发展的重要机遇
今年是香港回归27周年,也是《粤港澳大湾区发展规划纲要》公布5周年,5年来各项政策、平台不断为粤港联动增添新动能。“十四五”时期的粤港澳大湾区,被国家赋予了更重大的使命,国家“十四五”《规划纲要》提出,以京津冀…...

Chrome导出cookie的实战教程
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...

视频文字转语音经验笔记
自媒体视频制作的一些小经验,分享给大家。 一、音频部分: 1、文字转语音阐述: 微软语音识别 云希-青年男, 0.5-0.8变速 。注:云泽-中年男(不支持长音频录制), 适合郑重场合&#…...

视频融合共享平台LntonCVS统一视频接入平台智慧安防应用方案
安防视频监控平台LntonCVS是一款拥有强大拓展性和灵活部署能力的综合管理平台。它支持多种主流标准协议,包括国标GB28181、RTSP/Onvif、RTMP等,同时兼容各厂家的私有协议和SDK,如海康Ehome、海大宇等。LntonCVS不仅具备传统安防视频监控功能&…...

使用Python绘制动态螺旋线:旋转动画效果
文章目录 引言准备工作前置条件 代码实现与解析导入必要的库初始化Pygame绘制螺旋线函数主循环 完整代码 引言 螺旋线是一个具有美学和数学魅力的图形。通过编程,我们可以轻松创建动态旋转的螺旋线动画。在这篇博客中,我们将使用Python和Pygame库来实现…...

Symfony实战手册:PHP框架的高级应用技巧
引言 Symfony是一个功能强大且广泛应用于PHP应用程序开发的框架,它提供了许多高级特性和工具,可以帮助开发人员更高效地构建和管理复杂的Web应用程序。以下是Symfony框架的几个关键方面及其高级应用技巧: 1. 路由和控制器 Symfony的路由组…...
TOGAF培训什么内容?参加TOGAF培训有什么好处?考试通过率多少?
TOGAF培训什么内容?参加TOGAF培训有什么好处?考试通过率多少? TOGAF培训哪些内容? 通过本课程,你将掌握TOGAF的理论和实践,理解企业架构的影响,能够评估、启动、设 计、执行新一轮企业和IT架构…...

keepalived HA nginx方案
安装 centos: yum -y install epel-release yum -y install nginx keepalivedkeepalived配置解析 /etc/keepalived/keepalived.conf ! Configuration File for keepalived # 全局变量 global_defs {router_id nginx_ha # 主从保持一致script_user root # 执行健康检查的…...
 known to git)
报错:pathspec ‘xxx‘ did not match any file(s) known to git
在 escode 中进行分支切换时报如下错误 PS > git checkout xxx error: pathspec xxx did not match any file(s) known to git远程分支已经在 gitlab 客户端手动创建,在 escode 中也使用了拉取之类的操作,但是切换分支时依然报错。 解决方案 查看分…...

sed 保持空间命令之 x 的执行逻辑
目录 1. 将模式空间和保持空间的内容互换并打印 2. 将保持空间的内容交换回模式空间 3. 使用保持空间保存状态信息 4. 交换模式空间与保持空间隔行匹配 sed 有两个内置的缓存空间: 模式空间:该空间是 sed 内置的一个缓冲区,是 sed 执行的…...

C语言结构体定义与自增运算符a++详解
有一个结构体名是stu,它当中包含着5个成员,其中一个成员是name,还有一个成员是num,另外一个成员是age,再有一个成员是group,最后一个成员是score。 除了不能初始化这一点外,结构体成员的定义方式…...

THE LEATHER ARCHIVE快速体验:一键生成杂志级AI皮衣大片,小白也能当设计师
THE LEATHER ARCHIVE快速体验:一键生成杂志级AI皮衣大片,小白也能当设计师 1. 项目介绍与核心价值 想象一下,你不需要专业的设计技能,就能创造出媲美时尚杂志封面的皮衣设计作品。THE LEATHER ARCHIVE正是这样一个让创意触手可及…...

告别重复操作:用快马生成智能浏览器扩展,极速提升前端调试与数据提取效率
作为一名前端开发者,每天都要和网页元素打交道。调试样式、提取数据这些重复性工作,如果全靠手动操作,不仅效率低下还容易出错。最近我发现用InsCode(快马)平台可以快速生成定制化的浏览器扩展,把那些繁琐操作变成一键自动化&…...
)
别再手动改稿了!用LaTeX的soul包搞定论文批注(删除线/高亮/引用兼容)
LaTeX高效批注指南:用soul包实现学术协作的优雅排版 当导师的红色批注铺满论文初稿,或是合作者发来二十处修改意见时,大多数研究者都会面临一个共同困境——如何在保留原始内容的同时清晰标记修改痕迹?传统的手动添加删除线或高亮…...

Visio高效绘制神经网络卷积层:从基础到三维呈现
1. Visio绘制神经网络卷积层的入门指南 第一次用Visio画神经网络结构时,我盯着满屏的工具栏发懵——这玩意儿比Photoshop的图层还复杂。但摸索半天后发现,只要掌握几个核心功能,画卷积层其实比用PPT简单十倍。先说说最基础的形状选择…...
)
从零开始:在Unity中完美实现视频播放功能的完整指南(附常见报错解决方案)
从零开始:在Unity中完美实现视频播放功能的完整指南(附常见报错解决方案) 在游戏开发中,视频播放功能的应用场景越来越广泛——从开场动画、过场剧情到UI背景,视频元素能为玩家带来更丰富的视听体验。Unity作为主流的…...

3分钟免费激活Windows和Office:KMS_VL_ALL_AIO终极指南
3分钟免费激活Windows和Office:KMS_VL_ALL_AIO终极指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office文档突然变成只…...

TEdit终极指南:如何用免费地图编辑器10倍提升泰拉瑞亚创作效率
TEdit终极指南:如何用免费地图编辑器10倍提升泰拉瑞亚创作效率 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also let…...

[特殊字符] Nano-Banana部署教程:Ubuntu/CentOS环境下的镜像拉取与启动
Nano-Banana部署教程:Ubuntu/CentOS环境下的镜像拉取与启动 1. 项目简介 Nano-Banana是一款专门为产品拆解和平铺展示风格设计的轻量级文本生成图像系统。这个项目的核心在于深度融合了Nano-Banana专属的Turbo LoRA微调权重,专门针对Knolling平铺、爆炸…...

别再只查列表了!Flowable 7.x 待办任务‘状态’字段的实战设计与前端动态渲染
Flowable 7.x 待办任务状态引擎设计与前端动态交互实战 在当今企业级应用开发中,工作流引擎已成为复杂业务流程管理的核心基础设施。作为Activiti的下一代产品,Flowable 7.x在任务状态管理和前后端协同方面提供了更强大的能力。本文将深入探讨如何基于Fl…...