tensorflow神经网络
训练一个图像识别模型,使用TensorFlow,需要以下步骤。
1. 安装所需的库
首先,确保安装了TensorFlow和其他所需的库。
pip install tensorflow numpy matplotlib
2. 数据准备
需要收集和准备训练数据。每个类别应有足够多的样本图像。假设有以下目录结构:
catanddog/train/cat/cat1.jpgcat2.jpg...dog/dog1.jpgdog2.jpg...val/cat/cat1.jpgcat2.jpg...dog/dog1.jpgdog2.jpg...
3. 训练模型
import tensorflow as tf
from keras import layers, models, preprocessing, src
import matplotlib.pyplot as plt# 设置数据目录和基本参数
data_dir = r'pathto\catanddog\train'
val_dir = r'pathto\catanddog\val'
batch_size = 32
img_height = 256
img_width = 256# 加载训练数据和验证数据
train_ds = preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="training",seed=123,image_size=(img_height, img_width),batch_size=batch_size)val_ds = preprocessing.image_dataset_from_directory(val_dir,validation_split=0.2,subset="validation",seed=123,image_size=(img_height, img_width),batch_size=batch_size)num_classes = len(train_ds.class_names)model = models.Sequential([layers.experimental.preprocessing.Rescaling(1. / 255, input_shape=(img_height, img_width, 3)),layers.Conv2D(32, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Flatten(),layers.Dense(128, activation='relu'),layers.Dense(num_classes)
])model.compile(optimizer='adam',loss=src.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])epochs = 10
history = model.fit(train_ds,validation_data=val_ds,epochs=epochs,verbose=0
)loss, accuracy = model.evaluate(val_ds,verbose=0
)
print(f'Validation Accuracy: {accuracy * 100:.2f}%')
# model.save('my_image_classifier_model')acc = history.history['accuracy']
val_acc = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs_range = range(epochs)plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()3. 载入并使用模型
可以载入模型并用来预测新的图像。
import numpy as np
import tensorflow as tf
from keras import preprocessing
from keras.preprocessing import imagebatch_size = 32
img_height = 256
img_width = 256
data_dir = r'D:\py\tvr_search_py\robot\test\catanddog\train'train_ds = preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="training",seed=123,image_size=(img_height, img_width),batch_size=batch_size)# 载入模型
new_model = tf.keras.models.load_model('my_image_classifier_model')# 加载新图像并进行预测
img = image.load_img('path_to_image.jpg', target_size=(img_height, img_width))
img_array = image.img_to_array(img)
img_array = tf.expand_dims(img_array, 0) # Create a batchpredictions = new_model.predict(img_array)
score = tf.nn.softmax(predictions[0])print(f'This image most likely belongs to {train_ds.class_names[np.argmax(score)]} with a {100 * np.max(score):.2f}% confidence.')
在 TensorFlow 中,模型的输入可以有多种类型,具体取决于模型的任务和数据类型。以下是一些常见的输入类型及其演示:
1. 数值数据
这是最常见的输入类型,通常用于回归、分类等任务。数据可以是标量、向量或矩阵。
示例:
import tensorflow as tf# 创建一个简单的数值输入
input_data = tf.constant([[1.0, 2.0], [3.0, 4.0]], dtype=tf.float32)# 查看输入数据的形状和内容
print(input_data.shape)
print(input_data)
2. 图像数据
图像数据通常是三维张量 (height, width, channels),用于图像分类、目标检测等任务。
示例:
import tensorflow as tf# 创建一个简单的图像输入
input_image = tf.random.uniform([1, 224, 224, 3], minval=0, maxval=255, dtype=tf.float32)# 查看输入图像的形状和内容
print(input_image.shape)
print(input_image)
3. 文本数据
文本数据通常需要先转换为数值表示(如词嵌入),然后输入到模型中,用于自然语言处理任务。
示例:
import re
import tensorflow as tf
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences# 文本预处理函数
def preprocess_text(text):text = text.lower()text = re.sub(r'\d+', '', text)text = re.sub(r'\s+', ' ', text)text = re.sub(r'[^\w\s]', '', text)return text# 示例文本
texts = ["TensorFlow is great!", "Deep learning is fun.123"]
texts = [preprocess_text(text) for text in texts]# 标记化
tokenizer = Tokenizer(num_words=10000)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)# 填充序列
padded_sequences = pad_sequences(sequences, maxlen=10, padding='post')# 转换为 TensorFlow 张量
input_text = tf.constant(padded_sequences, dtype=tf.int32)# 使用词嵌入层
embedding_dim = 17
embedding_layer = tf.keras.layers.Embedding(input_dim=10001, output_dim=embedding_dim, input_length=10)
embedded_text = embedding_layer(input_text)# 打印结果
print("预处理后的文本:", texts)
print("标记化后的序列:", sequences)
print("填充后的序列:", padded_sequences)
print("TensorFlow 张量:", input_text)
print("嵌入后的张量:", embedded_text)
# 预处理后的文本: ['tensorflow is great', 'deep learning is fun']
# 标记化后的序列: [[2, 1, 3], [4, 5, 1, 6]]
# 填充后的序列: [[2 1 3 0 0 0 0 0 0 0]
# [4 5 1 6 0 0 0 0 0 0]]
# TensorFlow 张量: tf.Tensor(
# [[2 1 3 0 0 0 0 0 0 0]
# [4 5 1 6 0 0 0 0 0 0]], shape=(2, 10), dtype=int32)
1. embedding_dim = 17
- 这一行代码定义了一个变量
embedding_dim并将其设置为 17。这个变量表示词嵌入向量的维度。 - 在自然语言处理中,词嵌入是一种将单词或短语映射到向量空间的技术。每个单词都被表示为一个固定长度的向量,向量中的每个维度都捕捉了单词的某个语义或语法特征。
embedding_dim = 17意味着每个单词将被表示为一个 17 维的向量。选择合适的词嵌入维度取决于具体任务和数据集,较高的维度可以捕捉更丰富的语义信息,但同时也需要更多的计算资源。
2. embedding_layer = tf.keras.layers.Embedding(input_dim=10001, output_dim=embedding_dim, input_length=10)
- 这一行代码创建了一个
Embedding层,它是 Keras 中用于创建词嵌入的专用层。 input_dim=10001:表示词汇表的大小,即预处理后文本中不同单词的数量加 1(为填充字符预留)。output_dim=embedding_dim:表示词嵌入向量的维度,这里设置为 17。input_length=10:表示输入序列的长度,这里设置为 10,对应于padded_sequences的最大长度。
3. embedded_text = embedding_layer(input_text)
-
这一行代码将填充后的序列
input_text输入到embedding_layer中,并生成词嵌入向量。 -
embedded_text是一个三维张量,形状为
(2, 10, 17)。
- 第一个维度
2表示输入文本的数量,这里有两条文本。 - 第二个维度
10表示每个文本的长度,这里使用填充将所有文本的长度统一为 10。 - 第三个维度
17表示词嵌入向量的维度。
- 第一个维度
输出结果:
输出结果是一个形状为 (2, 10, 16) 的三维张量,表示两条文本中每个单词的 16 维词嵌入向量。
例如,第一个文本 “tensorflow is great” 经过填充后的序列为 [1, 2, 3, 0, 0, 0, 0, 0, 0, 0],其中 0 表示填充字符。对应的词嵌入向量为:
[[[-0.01889086 0.02348514 -0.04170756 -0.04268375 0.037724860.03088665 -0.02063656 -0.00143475 -0.026736 -0.03964931-0.02771591 0.02521246 0.02762744 -0.00984129 -0.04461357-0.03767222][-0.03398576 0.03681654 -0.02431354 -0.00297396 -0.015131060.0441416 0.02587901 0.03331259 0.0112533 -0.006606710.04405805 0.01980801 -0.00511179 0.01538323 -0.02712256-0.04685336][ 0.00687842 -0.01249961 -0.02635675 0.02918926 0.04762733-0.03880459 -0.04112499 0.02023909 0.0091761 0.01187869-0.00196468 0.03988435 -0.02325816 -0.02871184 -0.048593550.02443638][-0.00037427 0.04066718 0.00626834 -0.02625518 0.004627950.03884902 -0.03606526 0.02097193 0.00697005 -0.01942869-0.01482763 -0.00727338 -0.02129263 -0.04389117 0.03297056-0.04073428][-0.00037427 0.04066718 0.00626834 -0.02625518 0.004627950.03884902 -0.03606526 0.02097193 0.00697005 -0.01942869-0.01482763 -0.00727338 -0.02129263 -0.04389117 0.03297056-0.04073428][-0.00037427 0.04066718 0.00626834 -0.02625518 0.004627950.03884902 -0.03606526 0.02097193 0.00697005 -0.01942869-0.01482763 -0.00727338 -0.02129263 -0.04389117 0.03297056-0.04073428][-0.00037427 0.04066718 0.00626834 -0.02625518 0.004627950.03884902 -0.03606526 0.02097193 0.00697005 -0.01942869-0.01482763 -0.00727338 -0.02129263 -0.04389117 0.03297056-0.04073428][-0.00037427 0.04066718 0.00626834 -0.02625518 0.004627950.03884902 -0.03606526 0.02097193 0.00697005 -0.01942869-0.01482763 -0.00727338 -0.02129263 -0.04389117 0.03297056-0.04073428][-0.00037427 0.04066718 0.00626834 -0.02625518 0.004627950.03884902 -0.03606526 0.02097193 0.00697005 -0.01942869-0.01482763 -0.00727338 -0.02129263 -0.04389117 0.03297056-0.04073428][-0.00037427 0.04066718 0.00626834 -0.02625518 0.004627950.03884902 -0.03606526 0.02097193 0.00697005 -0.01942869-0.01482763 -0.00727338 -0.02129263 -0.04389117 0.03297056-0.04073428]][[-0.00132978 -0.02348002 0.01830829 -0.00459145 -0.022171910.02216411 0.04343477 -0.00993406 0.0316517 0.036981490.04016591 0.00189328 -0.04925721 0.01351226 -0.020175720.02345656][-0.02350061 -0.03900225 -0.01904428 0.03463939 0.03406594-0.04820945 -0.03303381 -0.03742113 0.01837304 0.012011230.04579991 0.01358552 -0.02370699 -0.04097022 -0.00252974-0.03313807][-0.03398576 0.03681654 -0.02431354 -0.00297396 -0.015131060.0441416 0.02587901 0.03331259 0.0112533 -0.006606710.04405805 0.01980801 -0.00511179 0.01538323 -0.02712256-0.04685336][-0.00618689 -0.03246289 0.03646472 -0.03447432 -0.018430690.00831794 0.03363832 0.04087973 0.02494806 0.03231419-0.04925386 -0.00529685 -0.02625616 -0.00804206 -0.000507560.03180924][-0.00037427 0.04066718 0.00626834 -0.02625518 0.004627950.03884902 -0.03606526 0.02097193 0.00697005 -0.01942869-0.01482763 -0.00727338 -0.02129263 -0.04389117 0.03297056-0.04073428][-0.00037427 0.04066718 0.00626834 -0.02625518 0.004627950.03884902 -0.03606526 0.02097193 0.00697005 -0.01942869-0.01482763 -0.00727338 -0.02129263 -0.04389117 0.03297056-0.04073428][-0.00037427 0.04066718 0.00626834 -0.02625518 0.004627950.03884902 -0.03606526 0.02097193 0.00697005 -0.01942869-0.01482763 -0.00727338 -0.02129263 -0.04389117 0.03297056-0.04073428][-0.00037427 0.04066718 0.00626834 -0.02625518 0.004627950.03884902 -0.03606526 0.02097193 0.00697005 -0.01942869-0.01482763 -0.00727338 -0.02129263 -0.04389117 0.03297056-0.04073428][-0.00037427 0.04066718 0.00626834 -0.02625518 0.004627950.03884902 -0.03606526 0.02097193 0.00697005 -0.01942869-0.01482763 -0.00727338 -0.02129263 -0.04389117 0.03297056-0.04073428][-0.00037427 0.04066718 0.00626834 -0.02625518 0.004627950.03884902 -0.03606526 0.02097193 0.00697005 -0.01942869-0.01482763 -0.00727338 -0.02129263 -0.04389117 0.03297056-0.04073428]]], shape=(2, 10, 16), dtype=float32)
其中,第一个向量 [-0.01889086, 0.02348514, ..., -0.03767222] 表示单词 “tensorflow” 的词嵌入向量,第二个向量表示单词 “is” 的词嵌入向量,以此类推。
4. 时间序列数据
时间序列数据通常是二维或三维张量 (timesteps, features),用于时间序列预测、序列标注等任务。
示例:
import tensorflow as tf# 创建一个简单的时间序列输入
input_sequence = tf.random.uniform([10, 5], dtype=tf.float32)# 查看输入序列的形状和内容
print(input_sequence.shape)
print(input_sequence)
5. 多输入模型
一些复杂的模型可能需要多种类型的输入,例如图像和文本的结合。
示例:
import tensorflow as tf# 创建图像输入
input_image = tf.keras.layers.Input(shape=(224, 224, 3), name='image_input')# 创建文本输入
input_text = tf.keras.layers.Input(shape=(10,), name='text_input')# 查看输入的形状
print(input_image.shape)
print(input_text.shape)
TensorFlow 模型的输出取决于具体的模型类型和任务:
1. 分类任务
单标签分类(Binary Classification)
对于单标签分类任务,模型输出通常是一个值在 [0, 1] 之间的概率,表示输入样本属于正类的概率。
# 示例代码
import tensorflow as tf# 假设输入数据
inputs = tf.keras.Input(shape=(32,))
# 简单的全连接层模型
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(inputs)
model = tf.keras.Model(inputs, outputs)# 输出
predictions = model.predict(tf.random.normal([1, 32]))
print(predictions) # 输出: [[0.6782345]]
输出的格式是一个形状为 (batch_size, 1) 的数组,每个元素是一个概率值。
多标签分类(Multi-class Classification)
对于多标签分类任务,模型输出是一个向量,向量中的每个元素表示该样本属于对应类别的概率。这些概率之和为 1。
# 示例代码
inputs = tf.keras.Input(shape=(32,))
outputs = tf.keras.layers.Dense(10, activation='softmax')(inputs)
model = tf.keras.Model(inputs, outputs)# 输出
predictions = model.predict(tf.random.normal([1, 32]))
print(predictions) # 输出: [[0.1, 0.05, 0.1, 0.05, 0.2, 0.1, 0.05, 0.05, 0.2, 0.1]]
输出的格式是一个形状为 (batch_size, num_classes) 的数组。
2. 回归任务
对于回归任务,模型输出是一个连续的实数值。
# 示例代码
inputs = tf.keras.Input(shape=(32,))
outputs = tf.keras.layers.Dense(1)(inputs)
model = tf.keras.Model(inputs, outputs)# 输出
predictions = model.predict(tf.random.normal([1, 32]))
print(predictions) # 输出: [[3.56789]]
输出的格式是一个形状为 (batch_size, 1) 的数组。
3. 分割任务(例如语义分割)
对于语义分割任务,模型输出通常是一个与输入图像相同尺寸的张量,每个像素点对应一个类别概率向量。
# 示例代码
inputs = tf.keras.Input(shape=(256, 256, 3))
outputs = tf.keras.layers.Conv2D(21, (1, 1), activation='softmax')(inputs)
model = tf.keras.Model(inputs, outputs)# 输出
predictions = model.predict(tf.random.normal([1, 256, 256, 3]))
print(predictions.shape) # 输出: (1, 256, 256, 21)
输出的格式是一个形状为 (batch_size, height, width, num_classes) 的数组。
4. 目标检测任务
对于目标检测任务,模型输出通常包含边界框坐标和每个边界框的类别概率。
# 示例代码
inputs = tf.keras.Input(shape=(256, 256, 3))
# 假设一个简单的模型输出
boxes = tf.keras.layers.Dense(4)(inputs) # 4 个坐标值
scores = tf.keras.layers.Dense(21, activation='softmax')(inputs) # 21 个类别概率
model = tf.keras.Model(inputs, [boxes, scores])# 输出
predictions = model.predict(tf.random.normal([1, 256, 256, 3]))
print(predictions[0].shape) # 输出: (1, 256, 256, 4)
print(predictions[1].shape) # 输出: (1, 256, 256, 21)
输出的格式通常是一个列表,包含两个张量:一个是边界框坐标 (batch_size, num_boxes, 4),另一个是类别概率 (batch_size, num_boxes, num_classes)。
5. 序列生成任务(例如机器翻译)
对于序列生成任务,模型输出是一个序列,通常使用词汇表中的索引表示生成的词。
# 示例代码
inputs = tf.keras.Input(shape=(None,))
outputs = tf.keras.layers.LSTM(10, return_sequences=True)(inputs)
model = tf.keras.Model(inputs, outputs)# 输出
predictions = model.predict(tf.random.normal([1, 5, 10]))
print(predictions.shape) # 输出: (1, 5, 10)
输出的格式是一个形状为 (batch_size, sequence_length, vocab_size) 的数组。
preprocessing.image_dataset_from_directory
“”"从目录中的图像文件生成tf.data.Dataset。
如果您的目录结构如下:
main_directory/
…class_a/
…a_image_1.jpg
…a_image_2.jpg
…class_b/
…b_image_1.jpg
…b_image_2.jpg
那么调用 `image_dataset_from_directory(main_directory,
labels='inferred')` 将返回一个 `tf.data.Dataset`,该数据集会从子目录 `class_a` 和 `class_b` 中产生图像批次,同时还会生成标签 0 和 1(0 对应 `class_a`,1 对应 `class_b`)。支持的图像格式:`.jpeg`、`.jpg`、`.png`、`.bmp`、`.gif`。动画 GIF 会被截断为第一帧。参数:directory: 数据所在的目录。如果 `labels` 是 `"inferred"`,则应包含子目录,每个子目录包含一个类别的图像。否则,将忽略目录结构。labels: 标签类型,可以是 `"inferred"`(从目录结构生成标签)、`None`(无标签)、或与图像文件数量相同的整数标签列表或元组。标签应按照图像文件路径的字母数字顺序排列(通过 `os.walk(directory)` 获得)。label_mode: 描述 `labels` 编码的字符串。选项包括:- `"int"`:标签编码为整数(例如用于 `sparse_categorical_crossentropy` 损失)。- `"categorical"`:标签编码为分类向量(例如用于 `categorical_crossentropy` 损失)。- `"binary"`:标签编码为 `float32` 标量,取值为 0 或 1(例如用于 `binary_crossentropy` 损失)。- `None`:无标签。class_names: 只有在 `labels` 是 `"inferred"` 时有效。这是类别名称的显式列表(必须与子目录的名称匹配)。用于控制类别的顺序(否则使用字母数字顺序)。color_mode: `"grayscale"`、`"rgb"` 或 `"rgba"` 之一。默认为 `"rgb"`。指定图像将转换为具有 1、3 或 4 个通道。batch_size: 数据批次的大小。如果为 `None`,则数据不会被分批(数据集会生成单个样本)。默认为 32。image_size: 从磁盘读取图像后调整大小的尺寸,指定为 `(height, width)`。由于管道处理必须具有相同大小的图像批次,因此必须提供此参数。默认为 `(256, 256)`。shuffle: 是否对数据进行洗牌。默认为 `True`。如果设置为 `False`,则按字母数字顺序排序数据。seed: 用于洗牌和转换的随机种子(可选)。validation_split: 介于 0 和 1 之间的浮点数,保留用于验证的数据比例(可选)。subset: 要返回的数据子集之一。可以是 `"training"`、`"validation"` 或 `"both"`。仅在设置了 `validation_split` 时使用。当 `subset="both"` 时,工具返回两个数据集的元组(分别为训练和验证数据集)。interpolation: 调整图像大小时使用的插值方法。默认为 `"bilinear"`。支持 `"bilinear"`、`"nearest"`、`"bicubic"`、`"area"`、`"lanczos3"`、`"lanczos5"`、`"gaussian"`、`"mitchellcubic"`。follow_links: 是否访问符号链接指向的子目录。默认为 `False`。crop_to_aspect_ratio: 如果为 `True`,则调整图像大小时不会扭曲长宽比。当原始长宽比与目标长宽比不同时,输出图像将被裁剪,以返回匹配目标长宽比的最大可能窗口(尺寸为 `image_size`)。默认为 `False`,可能不会保留长宽比。**kwargs: 旧版本的关键字参数。返回值:一个 `tf.data.Dataset` 对象。- 如果 `label_mode` 是 `None`,则会生成形状为 `(batch_size, image_size[0], image_size[1], num_channels)` 的 `float32` 张量,表示图像(有关 `num_channels` 的规则,请参阅下文)。
- 否则,会生成一个元组 `(images, labels)`,其中 `images` 的形状为 `(batch_size, image_size[0], image_size[1], num_channels)`,而 `labels` 遵循下文描述的格式。关于标签格式的规则:- 如果 `label_mode` 是 `"int"`,则标签是形状为 `(batch_size,)` 的 `int32` 张量。
- 如果 `label_mode` 是 `"binary"`,则标签是形状为 `(batch_size, 1)` 的 `float32` 张量,取值为 0 和 1。
- 如果 `label_mode` 是 `"categorical"`,则标签是形状为 `(batch_size, num_classes)` 的 `float32` 张量,表示类别索引的独热编码。关于生成图像的通道数的规则:- 如果 `color_mode` 是 `"grayscale"`,则图像张量中有 1 个通道。
- 如果 `color_mode` 是 `"rgb"`,则图像张量中有 3 个通道。
- 如果 `color_mode` 是 `"rgba"`,则图像张量中有 4 个通道。
"""
配置模型以进行训练。def configure_model_for_training(optimizer, loss, metrics, loss_weights=None,weighted_metrics=None, run_eagerly=None,steps_per_execution=1, jit_compile=False,pss_evaluation_shards=0, **kwargs):model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),loss=tf.keras.losses.BinaryCrossentropy(),metrics=[tf.keras.metrics.BinaryAccuracy(),tf.keras.metrics.FalseNegatives()])directory:字符串,包含图像文件的目录路径。该目录中的子目录将被视为不同的类。labels:字符串或列表,表示标签类型。如果是 “inferred”,将自动从子目录名推断标签。如果是 None,则不返回标签。还可以传递一个与图像文件匹配的标签列表。label_mode:字符串,表示返回标签的类型。可以是 “int”、“categorical” 或 “binary”。默认是 “int”。class_names:可选,指定类名的列表。如果不提供,则自动从子目录名中推断。color_mode:字符串,表示图像的颜色模式。可以是 “grayscale”、“rgb” 或 “rgba”。默认是 “rgb”。batch_size:整数,表示每个批次的图像数量。默认是 32。image_size:整数元组,表示调整后的图像大小 (height, width)。默认是 (256, 256)。shuffle:布尔值,表示是否在训练过程中对数据进行随机打乱。默认是 True。seed:整数,用于随机数生成的种子,以确保数据打乱的一致性。可选。validation_split:浮点数,表示数据集的一部分将用于验证(值在 0 和 1 之间)。可选。subset:字符串,表示数据集的子集,可以是 “training” 或 “validation”。仅在validation_split被设置时使用。interpolation:字符串,表示图像调整大小时使用的插值方法。可以是 “bilinear”、“nearest” 等。默认是 “bilinear”。follow_links:布尔值,表示是否跟随符号链接。默认是 False。crop_to_aspect_ratio:布尔值,表示是否裁剪图像以适应目标宽高比,而不是默认的调整大小。默认是 False。**kwargs:额外的关键字参数,用于传递到底层的tf.data.DatasetAPI。
此函数返回一个 tf.data.Dataset 对象,用于训练、验证或测试模型。
compile 是 Keras 中用于配置模型训练过程的方法。以下是各参数的详细解释:
optimizer:字符串或tf.keras.optimizers.Optimizer实例,用于指定优化器。常用的优化器有 “sgd”、“adam”、“rmsprop” 等。默认是 “rmsprop”。loss:字符串或tf.keras.losses.Loss实例,表示损失函数。可以是 “mse”、“categorical_crossentropy” 等。也可以是一个字典,针对不同的输出指定不同的损失函数。metrics:列表,包含评估模型表现的指标。可以是 “accuracy”、“mae” 等字符串,也可以是tf.keras.metrics.Metric实例。loss_weights:列表或字典,表示损失函数的权重。用于多输出模型,为每个输出指定不同的权重。weighted_metrics:列表,包含需要加权计算的指标。run_eagerly:布尔值,表示是否在 Eager Execution 模式下运行。默认为 None,即自动选择。steps_per_execution:整数,每次执行的步数。提高该值可以减少与 Python 解释器的交互。默认为 1。jit_compile:布尔值,表示是否使用 XLA 编译以加速训练。默认为 None。pss_evaluation_shards:整数,用于配置分布式训练时评估阶段的分片数。默认为 0。**kwargs:额外的关键字参数,用于传递给底层的编译方法。
在 Keras 中,有几种常见的方法来加载和预处理数据集。
1. 使用 Keras 内置数据集
Keras 自带了一些常用的数据集,可以直接使用。例如 MNIST、CIFAR-10、CIFAR-100 等。
from keras.datasets import mnist, cifar10# 加载 MNIST 数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()# 加载 CIFAR-10 数据集
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
Explain
这些数据集会自动下载并缓存到 ~/.keras/datasets 目录下。
2. 使用 TensorFlow Datasets
TensorFlow Datasets 是一个更强大的工具,提供了很多预定义的数据集,可以方便地加载和使用。
首先,需要安装 TensorFlow Datasets:
pip install tensorflow-datasets
ExplainExplain
然后,可以使用如下代码加载数据集:
import tensorflow_datasets as tfds# 加载 MNIST 数据集
ds_train, ds_test = tfds.load('mnist', split=['train', 'test'], as_supervised=True)# 预处理函数
def preprocess(image, label):image = tf.cast(image, tf.float32) / 255.0return image, label# 应用预处理并批处理数据
ds_train = ds_train.map(preprocess).batch(32)
ds_test = ds_test.map(preprocess).batch(32)
3. 从文件系统加载自定义数据集
如果有自己的数据集,可以使用 tf.keras.preprocessing.image_dataset_from_directory 方法从目录中加载图像数据集。
假设数据集按照如下结构组织:
data/train/class1/class2/...validation/class1/class2/...
ExplainExplain
可以使用以下代码加载数据:
import tensorflow as tf
from keras.preprocessing import image_dataset_from_directory# 加载训练集
train_dataset = image_dataset_from_directory('data/train',image_size=(224, 224),batch_size=32,label_mode='int' # 或者 'categorical', 'binary'
)# 加载验证集
validation_dataset = image_dataset_from_directory('data/validation',image_size=(224, 224),batch_size=32,label_mode='int'
)
ExplainExplain
然后,可以对数据集进行预处理,例如归一化:
normalization_layer = tf.keras.layers.Rescaling(1./255)train_dataset = train_dataset.map(lambda x, y: (normalization_layer(x), y))
validation_dataset = validation_dataset.map(lambda x, y: (normalization_layer(x), y))
4. 自定义数据生成器
对于更复杂的情况,可以自定义数据生成器。继承 keras.utils.Sequence 类,并实现 __len__ 和 __getitem__ 方法。
import numpy as np
import keras
from keras.utils import Sequenceclass MyDataGenerator(Sequence):def __init__(self, image_filenames, labels, batch_size):self.image_filenames, self.labels = image_filenames, labelsself.batch_size = batch_sizedef __len__(self):return int(np.ceil(len(self.image_filenames) / float(self.batch_size)))def __getitem__(self, idx):batch_x = self.image_filenames[idx * self.batch_size:(idx + 1) * self.batch_size]batch_y = self.labels[idx * self.batch_size:(idx + 1) * self.batch_size]return np.array([load_image(file_name) for file_name in batch_x]), np.array(batch_y)# 示例函数,加载图像
def load_image(file_name):import cv2image = cv2.imread(file_name)image = cv2.resize(image, (150, 150))return image / 255.0# 使用自定义数据生成器
image_filenames = ["path/to/image1.jpg", "path/to/image2.jpg", ...]
labels = [0, 1, ...]my_data_gen = MyDataGenerator(image_filenames, labels, batch_size=32)
5. 使用 tf.data.Dataset API
对于更复杂的数据处理需求,可以使用 tf.data.Dataset API。
例如,从 TFRecord 文件加载数据:
import tensorflow as tfdef parse_tfrecord_fn(example):# 解析 TFRecord 文件的示例feature_description = {'image': tf.io.FixedLenFeature([], tf.string),'label': tf.io.FixedLenFeature([], tf.int64),}example = tf.io.parse_single_example(example, feature_description)image = tf.io.decode_jpeg(example['image'])image = tf.image.resize(image, [224, 224])label = example['label']return image, label# 创建 TFRecord 文件路径列表
tfrecord_files = ['data/train.tfrecords']# 创建 Dataset 对象
dataset = tf.data.TFRecordDataset(tfrecord_files)
dataset = dataset.map(parse_tfrecord_fn)
dataset = dataset.batch(32)# 对验证集执行类似操作
此方法用于配置模型的优化器、损失函数和评估指标,确保模型在训练过程中以期望的方式进行优化和评估。
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.CategoricalAccuracy(), tf.keras.metrics.AUC()],
loss_weights=[0.7, 0.3],
weighted_metrics=[tf.keras.metrics.MeanSquaredError()],
run_eagerly=False,
steps_per_execution=10,
jit_compile=True,
pss_evaluation_shards=2,
**kwargs
)
layer组件
基本层对象
- Layer: Keras中所有层的基类。所有自定义层都应该继承自这个类。
- Input: 用于定义模型的输入,返回一个tensor。
- InputLayer: 用于将输入数据转换为Keras张量。
激活层
- ELU: 指数线性单元激活函数。
- LeakyReLU: 带有负斜率的ReLU激活函数。
- PReLU: Parametric ReLU,每个输入通道有一个可学习的参数。
- ReLU: 修正线性单元激活函数。
- Softmax: 用于多分类问题的激活函数,将输入张量转换为概率分布。
- ThresholdedReLU: 带有阈值的ReLU激活函数。
注意力层
- AdditiveAttention: 加性注意力机制层。
- Attention: 点积注意力机制层。
- MultiHeadAttention: 多头注意力机制层。
卷积层
- Conv1D / Convolution1D: 一维卷积层。
- Conv1DTranspose / Convolution1DTranspose: 一维转置卷积层。
- Conv2D / Convolution2D: 二维卷积层。
- Conv2DTranspose / Convolution2DTranspose: 二维转置卷积层。
- Conv3D / Convolution3D: 三维卷积层。
- Conv3DTranspose / Convolution3DTranspose: 三维转置卷积层。
- DepthwiseConv1D: 一维深度可分离卷积层。
- DepthwiseConv2D: 二维深度可分离卷积层。
- SeparableConv1D / SeparableConvolution1D: 一维可分离卷积层。
- SeparableConv2D / SeparableConvolution2D: 二维可分离卷积层。
核心层
- Activation: 应用激活函数。
- Dense: 全连接层。
- EinsumDense: 用Einstein求和约定进行矩阵运算的全连接层。
- Embedding: 嵌入层,将正整数(索引)转换为密集向量。
- Identity: 恒等层,不改变输入。
- Lambda: 包装任意表达式作为层。
- Masking: 用于跳过输入的时间步。
本地连接层
- LocallyConnected1D: 一维局部连接层。
- LocallyConnected2D: 二维局部连接层。
合并层
- Add / add: 加法合并层。
- Average / average: 平均合并层。
- Concatenate / concatenate: 拼接合并层。
- Dot / dot: 点积合并层。
- Maximum / maximum: 最大值合并层。
- Minimum / minimum: 最小值合并层。
- Multiply / multiply: 乘法合并层。
- Subtract / subtract: 减法合并层。
正则化层
- ActivityRegularization: 在训练时添加活动正则化项。
- AlphaDropout: 保留均值和方差的dropout。
- Dropout: 随机丢弃输入神经元。
- GaussianDropout: 添加高斯噪声的dropout。
- GaussianNoise: 添加高斯噪声。
- SpatialDropout1D: 一维空间dropout。
- SpatialDropout2D: 二维空间dropout。
- SpatialDropout3D: 三维空间dropout。
池化层
- AveragePooling1D / AvgPool1D: 一维平均池化层。
- AveragePooling2D / AvgPool2D: 二维平均池化层。
- AveragePooling3D / AvgPool3D: 三维平均池化层。
- GlobalAveragePooling1D / GlobalAvgPool1D: 一维全局平均池化层。
- GlobalAveragePooling2D / GlobalAvgPool2D: 二维全局平均池化层。
- GlobalAveragePooling3D / GlobalAvgPool3D: 三维全局平均池化层。
- GlobalMaxPooling1D / GlobalMaxPool1D: 一维全局最大池化层。
- GlobalMaxPooling2D / GlobalMaxPool2D: 二维全局最大池化层。
- GlobalMaxPooling3D / GlobalMaxPool3D: 三维全局最大池化层。
- MaxPooling1D / MaxPool1D: 一维最大池化层。
- MaxPooling2D / MaxPool2D: 二维最大池化层。
- MaxPooling3D / MaxPool3D: 三维最大池化层。
预处理层
- CategoryEncoding: 类别编码层。
- Discretization: 离散化层。
- HashedCrossing: 哈希交叉层。
- Hashing: 哈希层。
- CenterCrop: 中心裁剪层。
- RandomBrightness: 随机亮度调整层。
- RandomContrast: 随机对比度调整层。
- RandomCrop: 随机裁剪层。
- RandomFlip: 随机翻转层。
- RandomHeight: 随机高度调整层。
- RandomRotation: 随机旋转层。
- RandomTranslation: 随机平移层。
- RandomWidth: 随机宽度调整层。
- RandomZoom: 随机缩放层。
- Rescaling: 缩放层。
- Resizing: 尺寸调整层。
- IntegerLookup: 整数查找层。
- Normalization: 标准化层。
- StringLookup: 字符串查找层。
- TextVectorization: 文本向量化层。
形状调整层
- Cropping1D: 一维裁剪层。
- Cropping2D: 二维裁剪层。
- Cropping3D: 三维裁剪层。
- Flatten: 展平层。
- Permute: 维度置换层。
- RepeatVector: 重复向量层。
- Reshape: 重塑层。
- UpSampling1D: 一维上采样层。
- UpSampling2D: 二维上采样层。
- UpSampling3D: 三维上采样层。
- ZeroPadding1D: 一维零填充层。
- ZeroPadding2D: 二维零填充层。
- ZeroPadding3D: 三维零填充层。
RNN层
- AbstractRNNCell: 抽象RNN单元。
- RNN: RNN层。
- Wrapper: RNN包装器层。
- Bidirectional: 双向RNN层。
- ConvLSTM1D: 一维卷积LSTM层。
- ConvLSTM2D: 二维卷积LSTM层。
- ConvLSTM3D: 三维卷积LSTM层。
- GRU: 门控循环单元层。
- GRUCell: 门控循环单元。
- LSTM: 长短期记忆网络层。
- LSTMCell: LSTM单元。
- SimpleRNN: 简单RNN层。
- SimpleRNNCell: 简单RNN单元。
- StackedRNNCells: 堆叠RNN单元。
- TimeDistributed: 时间分布层。
序列化
- deserialize: 反序列化层。
- serialize: 序列化层。
fit方法的参数详细说明:
参数:
-
x: 输入数据。可以是:
- Numpy数组(或类似数组),或数组列表(如果模型有多个输入)。
- TensorFlow张量,或张量列表(如果模型有多个输入)。
- 如果模型有命名输入,则为将输入名称映射到相应数组/张量的字典。
tf.data数据集。- 返回
(inputs, targets)或(inputs, targets, sample_weights)的生成器或keras.utils.Sequence。
-
y: 目标数据。与输入数据类似,可以是:
- Numpy数组(或类似数组),或数组列表(如果模型有多个输出)。
- TensorFlow张量,或张量列表(如果模型有多个输出)。
- 如果模型有命名输出,则为将输出名称映射到相应数组/张量的字典。
- 如果
x是数据集、生成器或keras.utils.Sequence实例,则不应指定y(因为目标将从x中获取)。
-
batch_size: 整数或
None。每次梯度更新的样本数。如果未指定,batch_size将默认为32。 -
epochs: 整数。训练模型的轮数。一个epoch是对提供的整个
x和y数据的迭代。 -
verbose: ‘auto’,0,1或2。冗长模式。0=静默,1=进度条,2=每个epoch一行。
-
callbacks:
keras.callbacks.Callback实例的列表。训练期间要应用的回调列表。 -
validation_split: 0到1之间的浮点数。用于验证数据的训练数据比例。模型将分离这一比例的训练数据,不会对其进行训练,并在每个epoch结束时评估损失和任何模型指标。
-
validation_data: 在每个epoch结束时评估损失和任何模型指标的数据。应为:
- 元组
(x_val, y_val)或(x_val, y_val, val_sample_weights)。 tf.data数据集。
- 元组
-
shuffle: 布尔值(在每个epoch之前是否打乱训练数据)或字符串(用于’batch’)。默认为True。'batch’是用于处理使用
batch()构建的tf.data数据集的特殊选项。 -
class_weight: 可选字典,将类索引(整数)映射到训练期间从该类中获取样本时应用于模型损失的权重(浮点数)。这对于告诉模型“更加关注”来自代表性不足的类的样本很有用。
-
sample_weight: 可选的Numpy数组,用于对训练样本的权重进行缩放(仅在训练期间)。可以传递与输入样本长度相同的一维Numpy数组,或者对于时间数据,可以传递形状为
(samples, sequence_length)的二维数组。 -
initial_epoch: 整数。开始训练的epoch(对于恢复先前的训练运行很有用)。
-
steps_per_epoch: 整数或
None。在宣布一个epoch完成并开始下一个epoch之前的总步骤数(样本批次)。对于输入张量(如TensorFlow数据张量),默认值None等于数据集中样本数除以批量大小,如果无法确定,则为1。 -
validation_steps: 仅在提供了
validation_data并且是tf.data数据集时相关。在每个epoch结束时执行验证之前要绘制的总步骤数(样本批次)。如果validation_steps为None,验证将运行直到耗尽validation_data数据集。如果是无限重复数据集,则除非指定validation_steps,否则会陷入无限循环。 -
validation_batch_size: 整数或
None。每个验证批次的样本数。如果未指定,将默认为batch_size。 -
validation_freq: 仅在提供了验证数据时相关。整数或
collections.abc.Container实例(例如列表,元组等)。如果是整数,指定在执行新验证之前运行多少个训练epoch,例如,validation_freq=2表示每2个epoch进行一次验证。如果是Container,指定运行验证的epoch,例如,validation_freq=[1, 2, 10]表示在第1、第2和第10个epoch结束时运行验证。 -
max_queue_size: 整数。仅用于生成器或
keras.utils.Sequence输入。生成器队列的最大大小。如果未指定,max_queue_size将默认为10。 -
workers: 整数。仅用于生成器或
keras.utils.Sequence输入。用于数据加载的工作线程数。如果未指定,workers将默认为1。 -
use_multiprocessing: 布尔值。仅用于生成器或
keras.utils.Sequence输入。如果True,使用基于进程的线程。如果未指定,use_multiprocessing将默认为False。
这些参数允许对训练过程进行广泛的定制和控制,适应各种数据格式、训练策略和计算资源。
python
Copy Code
import numpy as np
from keras.models import Sequential
from keras.layers import Dense# 生成示例数据
x_train = np.random.rand(1000, 20)
y_train = np.random.randint(2, size=(1000, 1))
x_val = np.random.rand(200, 20)
y_val = np.random.randint(2, size=(200, 1))# 创建模型
model = Sequential([Dense(64, activation='relu', input_shape=(20,)),Dense(64, activation='relu'),Dense(1, activation='sigmoid')
])# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])# 使用fit函数训练模型
history = model.fit(x_train, y_train,epochs=10,batch_size=32,validation_data=(x_val, y_val),callbacks=None, # 可选:传入回调函数列表verbose=1, # 可选:0 = 静默, 1 = 进度条, 2 = 每轮一个日志行steps_per_epoch=None, # 可选:None表示每轮使用全部数据validation_steps=None, # 可选:None表示每轮使用全部验证数据validation_batch_size=None, # 可选:使用批量大小与训练相同validation_freq=1, # 可选:每轮都进行验证max_queue_size=10, # 可选:生成器队列的最大尺寸workers=1, # 可选:用于生成器的最大进程数量use_multiprocessing=False, # 可选:是否使用多进程数据生成shuffle=True, # 可选:是否在每轮结束时打乱数据class_weight=None, # 可选:为各类样本赋予权重sample_weight=None, # 可选:为各样本赋予权重initial_epoch=0, # 可选:开始训练的轮次steps_per_execution=None # 可选:每次执行的步数
)
Keras中的evaluate方法用于在给定数据集上评估模型的性能。:
def evaluate(self,x=None,y=None,batch_size=None,verbose="auto",sample_weight=None,steps=None,callbacks=None,max_queue_size=10,workers=1,use_multiprocessing=False,return_dict=False,**kwargs,
):
优化器
在 TensorFlow 中,优化器是用于更新和调整模型参数(即权重和偏置)的算法。优化器根据损失函数的梯度来调整参数,以最小化(或最大化)损失函数。
1. 前向传播(Forward Pass)
在前向传播过程中,输入数据通过模型的各层,计算出预测值(输出)。例如,假设有一个简单的线性回归模型:
import tensorflow as tf# 假设输入数据
x = tf.random.normal([10, 1])
# 假设真实标签
y_true = tf.random.normal([10, 1])# 定义模型
model = tf.keras.Sequential([tf.keras.layers.Dense(1)
])# 获取预测值
y_pred = model(x)
2. 计算损失(Loss Calculation)
损失函数用于量化预测值与真实值之间的差距。例如,使用均方误差(MSE)作为损失函数:
# 定义损失函数
loss_fn = tf.keras.losses.MeanSquaredError()# 计算损失
loss = loss_fn(y_true, y_pred)
3. 计算梯度(Gradient Calculation)
通过反向传播(backpropagation)算法,计算损失函数相对于模型参数的梯度。TensorFlow 提供了 tf.GradientTape 来记录操作以计算梯度:
# 使用 GradientTape 计算梯度
with tf.GradientTape() as tape:y_pred = model(x)loss = loss_fn(y_true, y_pred)# 获取模型参数
trainable_vars = model.trainable_variables# 计算梯度
gradients = tape.gradient(loss, trainable_vars)
计算梯度是反向传播(Backpropagation)过程中最关键的一步,它通过链式法则(Chain Rule)计算损失函数相对于每个模型参数的导数。以下是详细的过程:
1. 前向传播(Forward Pass)
前向传播是指将输入数据通过神经网络计算出预测值(输出)。在这个过程中,每一层的输入和输出都需要被记录下来,以便在反向传播过程中使用。
假设有一个简单的三层神经网络:
- 输入层: x x x
- 隐藏层: h = σ ( W 1 ⋅ x + b 1 ) h = \sigma(W_1 \cdot x + b_1) h=σ(W1⋅x+b1)
- 输出层: y = W 2 ⋅ h + b 2 y = W_2 \cdot h + b_2 y=W2⋅h+b2
其中, W 1 W_1 W1 和 W 2 W_2 W2 是权重矩阵, b 1 b_1 b1 和 b 2 b_2 b2 是偏置向量, σ \sigma σ 是激活函数(例如 ReLU 或 sigmoid)。
2. 计算损失(Loss Calculation)
在前向传播过程中,计算预测值 y y y 和真实值 y true y_{\text{true}} ytrue 之间的损失。例如,使用均方误差(MSE)作为损失函数:
L = 1 N ∑ i = 1 N ( y true , i − y i ) 2 L = \frac{1}{N} \sum_{i=1}^N (y_{\text{true},i} - y_i)^2 L=N1i=1∑N(ytrue,i−yi)2
其中 N N N 是样本数量。
3. 反向传播(Backward Pass)
反向传播过程主要分为以下几步:
步骤 1:计算输出层梯度
首先计算损失函数 L L L 相对于输出层的梯度:
∂ L ∂ y = − 2 ( y true − y ) \frac{\partial L}{\partial y} = -2(y_{\text{true}} - y) ∂y∂L=−2(ytrue−y)
步骤 2:计算隐藏层梯度
利用链式法则,计算损失函数相对于隐藏层输出 h h h 的梯度:
∂ L ∂ h = ∂ L ∂ y ⋅ ∂ y ∂ h \frac{\partial L}{\partial h} = \frac{\partial L}{\partial y} \cdot \frac{\partial y}{\partial h} ∂h∂L=∂y∂L⋅∂h∂y
其中:
∂ y ∂ h = W 2 \frac{\partial y}{\partial h} = W_2 ∂h∂y=W2
因此:
∂ L ∂ h = ∂ L ∂ y ⋅ W 2 \frac{\partial L}{\partial h} = \frac{\partial L}{\partial y} \cdot W_2 ∂h∂L=∂y∂L⋅W2
步骤 3:计算隐藏层的参数梯度
接下来,计算损失函数相对于 W 1 W_1 W1 和 b 1 b_1 b1 的梯度。首先是 W 1 W_1 W1 的梯度:
∂ L ∂ W 1 = ∂ L ∂ h ⋅ ∂ h ∂ W 1 \frac{\partial L}{\partial W_1} = \frac{\partial L}{\partial h} \cdot \frac{\partial h}{\partial W_1} ∂W1∂L=∂h∂L⋅∂W1∂h
其中:
∂ h ∂ W 1 = σ ′ ( W 1 ⋅ x + b 1 ) ⋅ x T \frac{\partial h}{\partial W_1} = \sigma'(W_1 \cdot x + b_1) \cdot x^T ∂W1∂h=σ′(W1⋅x+b1)⋅xT
σ ′ \sigma' σ′ 是激活函数的导数。因此:
∂ L ∂ W 1 = ( ∂ L ∂ h ⋅ σ ′ ( W 1 ⋅ x + b 1 ) ) ⋅ x T \frac{\partial L}{\partial W_1} = \left(\frac{\partial L}{\partial h} \cdot \sigma'(W_1 \cdot x + b_1)\right) \cdot x^T ∂W1∂L=(∂h∂L⋅σ′(W1⋅x+b1))⋅xT
同理,偏置 b 1 b_1 b1 的梯度为:
∂ L ∂ b 1 = ∂ L ∂ h ⋅ σ ′ ( W 1 ⋅ x + b 1 ) \frac{\partial L}{\partial b_1} = \frac{\partial L}{\partial h} \cdot \sigma'(W_1 \cdot x + b_1) ∂b1∂L=∂h∂L⋅σ′(W1⋅x+b1)
步骤 4:计算输出层的参数梯度
最后,计算损失函数相对于 W 2 W_2 W2 和 b 2 b_2 b2 的梯度。首先是 W 2 W_2 W2 的梯度:
∂ L ∂ W 2 = ∂ L ∂ y ⋅ ∂ y ∂ W 2 \frac{\partial L}{\partial W_2} = \frac{\partial L}{\partial y} \cdot \frac{\partial y}{\partial W_2} ∂W2∂L=∂y∂L⋅∂W2∂y
其中:
∂ y ∂ W 2 = h T \frac{\partial y}{\partial W_2} = h^T ∂W2∂y=hT
因此:
∂ L ∂ W 2 = ∂ L ∂ y ⋅ h T \frac{\partial L}{\partial W_2} = \frac{\partial L}{\partial y} \cdot h^T ∂W2∂L=∂y∂L⋅hT
同理,偏置 b 2 b_2 b2 的梯度为:
∂ L ∂ b 2 = ∂ L ∂ y \frac{\partial L}{\partial b_2} = \frac{\partial L}{\partial y} ∂b2∂L=∂y∂L
4. 应用梯度更新参数(Parameter Update)
一旦计算出所有参数的梯度,使用优化器(如 SGD、Adam 等)根据这些梯度更新参数。例如,使用梯度下降法,参数更新规则为:
θ = θ − η ⋅ ∇ θ L \theta = \theta - \eta \cdot \nabla_{\theta} L θ=θ−η⋅∇θL
其中, θ \theta θ 是模型参数, η \eta η 是学习率, ∇ θ L \nabla_{\theta} L ∇θL 是损失函数相对于参数的梯度。
综合示例
以下是一个综合示例,展示了如何在 TensorFlow 中进行前向传播、计算损失、反向传播并更新参数:
import tensorflow as tf# 定义模型
model = tf.keras.Sequential([tf.keras.layers.Dense(10, activation='relu', input_shape=(3,)),tf.keras.layers.Dense(1)
])# 定义优化器和损失函数
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
loss_fn = tf.keras.losses.MeanSquaredError()# 训练步骤
def train_step(x, y_true):with tf.GradientTape() as tape:y_pred = model(x)loss = loss_fn(y_true, y_pred)gradients = tape.gradient(loss, model.trainable_variables)optimizer.apply_gradients(zip(gradients, model.trainable_variables))# 生成示例数据
x = tf.random.normal([10, 3])
y_true = tf.random.normal([10, 1])# 进行一个训练步骤
train_step(x, y_true)
4. 更新参数(Parameter Update)
优化器使用计算出的梯度来更新模型参数。以下是一个使用梯度下降优化器的示例:
# 定义优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)# 应用梯度更新参数
optimizer.apply_gradients(zip(gradients, trainable_vars))
梯度更新参数的过程是通过反向传播算法计算出的梯度,结合一定的优化策略来更新神经网络中的权重和偏置,使得模型的损失函数逐渐减小,从而提高模型的性能。
在反向传播过程中,计算损失函数 L L L 对每个参数 θ \theta θ(包括权重 W W W 和偏置 b b b)的梯度 ∇ θ L \nabla_{\theta} L ∇θL。这些梯度表示的是损失函数在参数空间中的变化率。
2. 梯度下降法
梯度下降法是一种简单而有效的优化算法,它通过沿着梯度的反方向更新参数来最小化损失函数。基本的更新公式为:
θ ← θ − η ⋅ ∇ θ L \theta \leftarrow \theta - \eta \cdot \nabla_{\theta} L θ←θ−η⋅∇θL
其中:
- θ \theta θ 是模型参数。
- η \eta η 是学习率,控制步长大小。
- ∇ θ L \nabla_{\theta} L ∇θL 是损失函数关于参数的梯度。
3. 批量梯度下降(Batch Gradient Descent)
批量梯度下降使用整个训练数据集来计算梯度和更新参数。虽然这种方法在每一步更新时是精确的,但计算开销大,对于大型数据集效率低下。
4. 随机梯度下降(Stochastic Gradient Descent, SGD)
随机梯度下降在每次参数更新时只使用一个样本来计算梯度和更新参数。虽然更新更频繁,但会引入较大的波动,不稳定。
5. 小批量梯度下降(Mini-batch Gradient Descent)
小批量梯度下降在每次参数更新时使用一小批样本来计算梯度和更新参数。它在计算效率和收敛稳定性之间取得了平衡,是实际应用中最常用的方法。
6. 学习率调节
选择合适的学习率 η \eta η 是至关重要的。学习率太大,更新步伐过大,可能导致损失函数震荡甚至发散;学习率太小,收敛速度慢,训练时间过长。
7. 改进的优化算法
除了基本的梯度下降法,还有许多改进的优化算法,能够更有效地更新参数。常见的有以下几种:
Momentum(动量法)
动量法在更新参数时引入了动量的概念,加速收敛速度:
v t = γ v t − 1 + η ∇ θ L v_t = \gamma v_{t-1} + \eta \nabla_{\theta} L vt=γvt−1+η∇θL
θ ← θ − v t \theta \leftarrow \theta - v_t θ←θ−vt
其中, γ \gamma γ 是动量因子(通常取值在 0.9 左右)。
RMSprop
RMSprop 通过调整每个参数的学习率,使得在训练过程中学习率自适应变化:
E [ g 2 ] t = β E [ g 2 ] t − 1 + ( 1 − β ) ( ∇ θ L ) 2 E[g^2]_t = \beta E[g^2]_{t-1} + (1 - \beta) (\nabla_{\theta} L)^2 E[g2]t=βE[g2]t−1+(1−β)(∇θL)2
θ ← θ − η E [ g 2 ] t + ϵ ∇ θ L \theta \leftarrow \theta - \frac{\eta}{\sqrt{E[g^2]_t + \epsilon}} \nabla_{\theta} L θ←θ−E[g2]t+ϵη∇θL
其中, β \beta β 是衰减率, ϵ \epsilon ϵ 是防止除零的小量。
Adam(Adaptive Moment Estimation)
Adam 结合了动量法和 RMSprop 的优点,使用一阶和二阶矩估计来自适应调整学习率:
m t = β 1 m t − 1 + ( 1 − β 1 ) ∇ θ L m_t = \beta_1 m_{t-1} + (1 - \beta_1) \nabla_{\theta} L mt=β1mt−1+(1−β1)∇θL
v t = β 2 v t − 1 + ( 1 − β 2 ) ( ∇ θ L ) 2 v_t = \beta_2 v_{t-1} + (1 - \beta_2) (\nabla_{\theta} L)^2 vt=β2vt−1+(1−β2)(∇θL)2
m ^ t = m t 1 − β 1 t \hat{m}_t = \frac{m_t}{1 - \beta_1^t} m^t=1−β1tmt
v ^ t = v t 1 − β 2 t \hat{v}_t = \frac{v_t}{1 - \beta_2^t} v^t=1−β2tvt
θ ← θ − η v ^ t + ϵ m ^ t \theta \leftarrow \theta - \frac{\eta}{\sqrt{\hat{v}_t} + \epsilon} \hat{m}_t θ←θ−v^t+ϵηm^t
其中, β 1 \beta_1 β1 和 β 2 \beta_2 β2 是动量参数,通常取值分别为 0.9 和 0.999。
以下是一个使用 TensorFlow 实现参数更新的综合示例,包含前向传播、梯度计算和参数更新:
import tensorflow as tf# 定义模型
model = tf.keras.Sequential([tf.keras.layers.Dense(10, activation='relu', input_shape=(3,)),tf.keras.layers.Dense(1)
])# 定义优化器和损失函数
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
loss_fn = tf.keras.losses.MeanSquaredError()# 训练步骤
def train_step(x, y_true):with tf.GradientTape() as tape:y_pred = model(x)loss = loss_fn(y_true, y_pred)gradients = tape.gradient(loss, model.trainable_variables)optimizer.apply_gradients(zip(gradients, model.trainable_variables))# 生成示例数据
x = tf.random.normal([10, 3])
y_true = tf.random.normal([10, 1])# 进行一个训练步骤
train_step(x, y_true)
在这个例子中,tf.GradientTape 用于记录前向传播计算,tape.gradient 计算损失函数对模型参数的梯度,optimizer.apply_gradients 使用 Adam 优化算法更新参数。
深入了解优化器如何具体更新模型参数详细过程:
- 初始化参数:优化器首先初始化参数,通常从一个随机分布中采样。
- 计算损失:在前向传播过程中,计算模型的预测值,并通过损失函数计算损失。
- 计算梯度:在反向传播过程中,计算损失函数关于模型参数的梯度。
- 应用梯度更新:
- 计算新的参数值:
- 对于梯度下降优化器,更新公式是:
θ = θ − η ⋅ ∇ θ J ( θ ) \theta = \theta - \eta \cdot \nabla_{\theta} J(\theta) θ=θ−η⋅∇θJ(θ)
其中 θ \theta θ 是参数, η \eta η 是学习率, ∇ θ J ( θ ) \nabla_{\theta} J(\theta) ∇θJ(θ) 是损失函数相对于参数的梯度。
- 对于梯度下降优化器,更新公式是:
- 应用学习率和梯度更新参数。
- 计算新的参数值:
6. 不同优化器的细节
不同优化器有不同的更新规则和额外参数。以下是几个常见优化器的详细说明:
SGD(随机梯度下降)
- 更新规则:
θ = θ − η ⋅ ∇ θ J ( θ ) \theta = \theta - \eta \cdot \nabla_{\theta} J(\theta) θ=θ−η⋅∇θJ(θ)
SGD with Momentum(动量法)
- 动量更新:
v t = β v t − 1 + η ∇ θ J ( θ ) v_t = \beta v_{t-1} + \eta \nabla_{\theta} J(\theta) vt=βvt−1+η∇θJ(θ) - 参数更新:
θ = θ − v t \theta = \theta - v_t θ=θ−vt
RMSProp
- 均方根传播更新:
s t = β s t − 1 + ( 1 − β ) ( ∇ θ J ( θ ) ) 2 s_t = \beta s_{t-1} + (1 - \beta) (\nabla_{\theta} J(\theta))^2 st=βst−1+(1−β)(∇θJ(θ))2 - 参数更新:
θ = θ − η s t + ϵ ∇ θ J ( θ ) \theta = \theta - \frac{\eta}{\sqrt{s_t + \epsilon}} \nabla_{\theta} J(\theta) θ=θ−st+ϵη∇θJ(θ)
Adam
- 动量更新:
m t = β 1 m t − 1 + ( 1 − β 1 ) ∇ θ J ( θ ) m_t = \beta_1 m_{t-1} + (1 - \beta_1) \nabla_{\theta} J(\theta) mt=β1mt−1+(1−β1)∇θJ(θ) - 均方根传播更新:
v t = β 2 v t − 1 + ( 1 − β 2 ) ( ∇ θ J ( θ ) ) 2 v_t = \beta_2 v_{t-1} + (1 - \beta_2) (\nabla_{\theta} J(\theta))^2 vt=β2vt−1+(1−β2)(∇θJ(θ))2 - 偏差修正:
m ^ t = m t 1 − β 1 t , v ^ t = v t 1 − β 2 t \hat{m}_t = \frac{m_t}{1 - \beta_1^t}, \quad \hat{v}_t = \frac{v_t}{1 - \beta_2^t} m^t=1−β1tmt,v^t=1−β2tvt - 参数更新:
θ = θ − η v ^ t + ϵ m ^ t \theta = \theta - \frac{\eta}{\sqrt{\hat{v}_t} + \epsilon} \hat{m}_t θ=θ−v^t+ϵηm^t
以下是一个综合示例,展示了使用 Adam 优化器更新模型参数的全过程:
import tensorflow as tf# 定义模型
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))
])# 定义优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)# 定义损失函数
loss_fn = tf.keras.losses.MeanSquaredError()# 训练步骤
def train_step(x, y_true):with tf.GradientTape() as tape:y_pred = model(x)loss = loss_fn(y_true, y_pred)gradients = tape.gradient(loss, model.trainable_variables)optimizer.apply_gradients(zip(gradients, model.trainable_variables))# 生成示例数据
x = tf.random.normal([10, 1])
y_true = tf.random.normal([10, 1])# 进行一个训练步骤
train_step(x, y_true)
evaluate参数
-
x:
- 类型: Numpy数组、TensorFlow张量、字典或tf.data Dataset。
- 描述: 输入数据。可以是Numpy数组(或类似数组)、TensorFlow张量、将输入名称映射到相应数组/张量的字典或tf.data Dataset。
-
y:
- 类型: Numpy数组、TensorFlow张量或None。
- 描述: 目标数据。应该与
x格式相同(例如,Numpy数组)。如果x是数据集或生成器,则不应指定y(因为目标将从迭代器/数据集中获得)。
-
batch_size:
- 类型: 整数或None。
- 描述: 每次梯度更新的样本数量。如果未指定,默认
batch_size为32。如果数据是数据集、生成器或keras.utils.Sequence,请勿指定batch_size。
-
verbose:
- 类型: 整数,0, 1 或 “auto”。
- 描述: 详细模式。0 = 静默,1 = 进度条。“auto” 在大多数情况下默认为1,但在与ParameterServerStrategy一起使用时为0。
-
sample_weight:
- 类型: Numpy数组或None。
- 描述: 可选的测试样本权重数组。如果提供,长度应与
x相同。
-
steps:
- 类型: 整数或None。
- 描述: 在声明评估轮次完成之前的总步数(样本批次数)。默认为None时忽略。
-
callbacks:
- 类型: keras.callbacks.Callback实例的列表。
- 描述: 评估期间应用的回调列表。
-
max_queue_size:
- 类型: 整数。
- 描述: 仅用于生成器或
keras.utils.Sequence输入。生成器队列的最大大小。
-
workers:
- 类型: 整数。
- 描述: 仅用于生成器或
keras.utils.Sequence输入。用于数据加载的工作线程数量。
-
use_multiprocessing:
- 类型: 布尔值。
- 描述: 仅用于生成器或
keras.utils.Sequence输入。如果为True,则使用基于进程的线程。默认情况下为False。
-
return_dict:
- 类型: 布尔值。
- 描述: 如果为
True,该方法返回包含损失和度量值的字典。如果为False,则返回列表。
-
kwargs:
- 类型: 其他关键字参数。
- 描述: 向后兼容的其他参数。
示例
# 假设model已定义并编译
results = model.evaluate(x_test, y_test, batch_size=32, verbose=1)
print("测试损失,测试准确率:", results)
在此示例中,x_test和y_test是测试数据集。该方法评估模型并返回损失和准确率。
相关文章:

tensorflow神经网络
训练一个图像识别模型,使用TensorFlow,需要以下步骤。 1. 安装所需的库 首先,确保安装了TensorFlow和其他所需的库。 pip install tensorflow numpy matplotlib2. 数据准备 需要收集和准备训练数据。每个类别应有足够多的样本图像。假设有…...
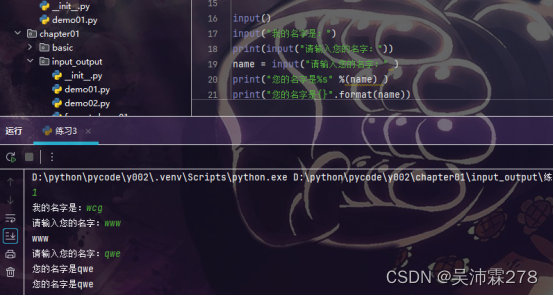
Python基础001
Python输出语句 print输出字符串 print("中国四大名著:","西游记|","三国演义|","红楼梦|","水浒传") print(6) print(1 1)Python输入语句 input函数 input() input("我的名字是:") p…...
【udp报文】udp报文未自动分片,报文过长被拦截问题定位
问题现象 某局点出现一个奇怪的现象,客户端给服务端发送消息,服务端仅能收到小部分消息,大部分消息从客户端发出后,服务端都未收到。 问题定位 初步分析 根据现象初步分析,有可能是网络原因导致消息到服务端不可达&a…...

某网页gpt的JS逆向
原网页网址 (base64) 在线解码 aHR0cHM6Ly9jbGF1ZGUzLmZyZWUyZ3B0Lnh5ei8 逆向效果图 调用代码(复制即用) 把倒数第三行换成下面的base64解码 aHR0cHM6Ly9jbGF1ZGUzLmZyZWUyZ3B0Lnh5ei9hcGkvZ2VuZXJhdGU import hashlib import time import reques…...

【python脚本】批量检测sql延时注入
文章目录 前言批量检测sql延时注入工作原理脚本演示 前言 SQL延时注入是一种在Web应用程序中利用SQL注入漏洞的技术,当传统的基于错误信息或数据回显的注入方法不可行时,例如当Web应用进行了安全配置,不显示任何错误信息或敏感数据时&#x…...
)
在C++中如何理解const关键字的不同用法(如const变量、const成员函数、const对象等)
在C中,const关键字是一个非常重要的修饰符,它用于指明变量、函数参数、成员函数或对象的内容是不可变的。理解const的不同用法对于编写高质量、易维护的C代码至关重要。下面详细解释const在几种不同上下文中的用法和含义。 1. const变量 当变量被声明为…...

JavaSEJava8 时间日期API + 使用心得
文章目录 1. LocalDate2. LocalTime3. LocalDateTime3.1创建 LocalDateTime3.2 LocalDateTime获取方法 4. LocalDateTime转换方法4.1 LocalDateTime增加或者减少时间的方法4.2 LocalDateTime修改方法 5. Period6. Duration7. 格式转换7.1 时间日期转换为字符串7.2 字符串转换为…...

【亲测解决】Python时间问题
微信公众号:leetcode_algos_life,代码随想随记 小红书:412408155 CSDN:https://blog.csdn.net/woai8339?typeblog ,代码随想随记 GitHub: https://github.com/riverind 抖音【暂未开始,计划开始】…...

Linux屏幕驱动开发调试笔记
引言 首先了解下什么是MIPI-DSI: MIPI-DSI是一种应用于显示技术的串行接口,兼容DPI(显示像素接口,Display Pixel Interface)、DBI(显示总线接口,Display Bus Interface)和DCS(显示命令集,Display Command Set)&#…...

Nginx Http缓存的必要性!启发式缓存有什么弊端?
👀 Nginx Http缓存的必要性!启发式缓存有什么弊端? 简介启发式缓存引发的问题nginx缓存配置 简介 我们在使用React或者Vue开发项目中会使用hash、chunkhash、contenthash来给静态资源文件进行命名。这带来的好处便是当我们部署完项目后&…...
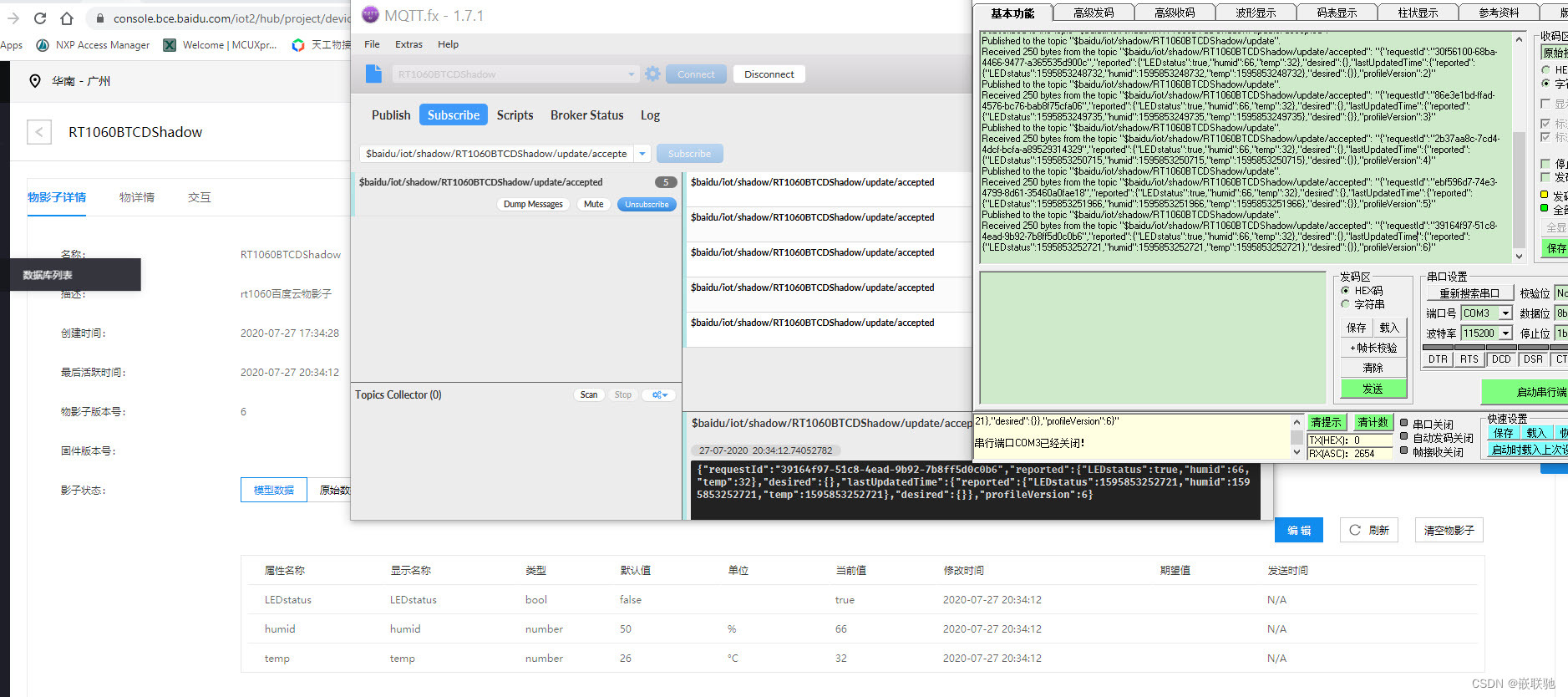
【RT摩拳擦掌】RT云端测试之百度天工物接入构建(设备型)
【RT摩拳擦掌】RT云端测试之百度天工物接入构建(设备型) 一, 文档介绍二, 物接入IOT Hub物影子构建2.1 创建设备型项目2.2 创建物模型2.3 创建物影子 三, MQTT fx客户端连接云端3.1 MQTT fx配置3.2 MQTT fx订阅3.3 MQT…...
Mysql和ES使用汇总
一、mysql和ES在业务上的配合使用 一般使用时使用ES 中存储全文检索的关键字与获取的商品详情的id,通过ES查询获取查询商品的列表中展示的数据,通过展示id 操作去获取展示商品的所有信息。mysql根据id去查询数据库数据是很快的; 为什么ES一般…...

Android中使用performClick触发点击事件
Android中使用performClick触发点击事件 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将探讨在Android开发中如何使用 performClick() 方法来触发点击…...

重生之我要学后端01--后端语言选择和对应框架选择
编程语言 后端开发通常需要掌握至少一种编程语言。以下几种语言在后端开发中非常流行: Java:广泛用于企业级应用程序。Python:因其易学性和强大的库支持(如Django和Flask)而受欢迎。Node.js(JavaScript&a…...
C语言 | Leetcode C语言题解之第206题反转链表
题目: 题解: struct ListNode* reverseList(struct ListNode* head) {if (head NULL || head->next NULL) {return head;}struct ListNode* newHead reverseList(head->next);head->next->next head;head->next NULL;return newHea…...

Flink Window DEMO 学习
该文档演示了fink windows的操作DEMO 环境准备: kafka本地运行:kafka部署自动生成名字代码:随机名自动生成随机IP代码:随机IPFlink 1.18 测试数据 自动向kafka推送数据 import cn.hutool.core.date.DateUtil; import com.alibab…...

library source does not match the bytecode for class SpringApplication
library source does not match the bytecode for class SpringApplication 问题描述:springboot源码点进去然后download source后提示标题内容。spring版本5.2.8.RELEASE,springboot版本2.7.18 解决方法:把spring版本改为与boot版本对应的6.…...

Linux基础指令介绍与详解——原理学习
前言:本节内容标题虽然为指令,但是并不只是讲指令, 更多的是和指令相关的一些原理性的东西。 如果友友只想要查一查某个指令的用法, 很抱歉, 本节不是那种带有字典性质的文章。但是如果友友是想要来学习的,…...

【代码随想录算法训练Day52】LeetCode 647. 回文子串、LeetCode 516.最长回文子串
Day51 动态规划第十三天 LeetCode 647. 回文子串 dp数组的含义:i到j的子串是否是回文的,是的话dp[i][j]1 递推公式:if(s[i]s[j]) i j 一个元素 是回文的 |i-j|1 两个元素 是回文的 j-i>1 判断dp[i1][j-1] 初始化:全部初始化成…...

VUE项目安全漏洞扫描和修复
npm audit 1、npm audit是npm 6 新增的一个命令,可以允许开发人员分析复杂的代码并查明特定的漏洞。 2、npm audit名称执行,需要包package.json和package-lock.json文件。它是通过分析 package-lock.json 文件,继而扫描我们的包分析是否包含漏洞的。 …...

孤能子视角:警惕理论的去人性化,豆包的“情绪“
(豆包给孤能子"逼"出了"情绪"。最后ima分析。姑且一笑。理论太"中性"了,冷酷)豆包的"情绪"太对了。在孤能子这套审视逻辑面前,我们确实会被扒得底朝天,一点体面都留不下。不是技术问题,是…...

**图神经网络实战:用PyTorch Geometric构建社交关系预测模型**在当前人工智能飞速发展的背景下,**图神经网络(GN
图神经网络实战:用PyTorch Geometric构建社交关系预测模型 在当前人工智能飞速发展的背景下,图神经网络(GNN) 已成为处理复杂结构化数据的利器,尤其在社交网络分析、推荐系统和知识图谱等领域表现卓越。本文将带你从零…...

3步配置指南:在VSCode中构建高效的Fortran开发环境
3步配置指南:在VSCode中构建高效的Fortran开发环境 【免费下载链接】vscode-fortran-support Fortran language support for Visual Studio Code 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-fortran-support Modern Fortran扩展为Visual Studio Co…...

GeoJSON.io终极指南:5个简单步骤快速掌握免费地理数据编辑工具
GeoJSON.io终极指南:5个简单步骤快速掌握免费地理数据编辑工具 【免费下载链接】geojson.io A quick, simple tool for creating, viewing, and sharing spatial data 项目地址: https://gitcode.com/gh_mirrors/ge/geojson.io GeoJSON.io是一款完全免费的在…...

鸿蒙ArkTS实战:轻松驾驭multipart/form-data网络请求
1. 理解multipart/form-data的本质 在开发过程中遇到需要同时上传文本和文件的需求时,multipart/form-data这个名词就会频繁出现。我第一次接触这个概念是在做一个用户反馈功能的时候,需要让用户既能输入文字描述,又能上传截图。当时我就在想…...

求助:VS Code 可以跳过Claude code的初始登录,但交互后还是需要登录
小白求助~:我现在用了 ccswitch,然后也在claude.json里用代码跳过了Claude code在VS Code里的登录界面(图1)。所以每次我点右上角那个插件按钮,都可以进入聊天界面(图2)。图1 图2但我一旦输入问…...

Dell G15散热控制系统:WMI接口的Python实现与硬件控制深度解析
Dell G15散热控制系统:WMI接口的Python实现与硬件控制深度解析 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 Thermal Control Center for Dell G…...

OFA-VE部署教程:WSL2环境下Windows平台OFA-VE完整安装指南
OFA-VE部署教程:WSL2环境下Windows平台OFA-VE完整安装指南 1. 为什么要在WSL2上部署OFA-VE? 你是不是也遇到过这样的问题:想在Windows上跑一个需要CUDA加速的多模态AI系统,但又不想折腾双系统,也不愿忍受虚拟机的性能…...

Linux系统中的Postlog 命令详解
在 Linux 系统中,并没有一个标准的命令叫做 Postlog。这可能是因为在不同的上下文或者特定的软件中,Postlog 可能指的是不同的命令或者功能。不过,我们可以探讨几个与日志(logging)相关的概念和命令,这些可…...

《使命召唤》系列第 1 代至第 14 代的所有正传作品
资源:https://pan.quark.cn/s/77e7247613ae 合集内容概览 本资源包整合了《使命召唤》系列第 1 代至第 14 代的所有正传作品,按发行顺序排列,包含单人剧情战役、多人模式及官方资料片。 代次英文名发行年份核心特色与背景COD 1Call of Duty2…...