实战:基于Java的大数据处理与分析平台
实战:基于Java的大数据处理与分析平台
大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将探讨如何利用Java构建高效的大数据处理与分析平台。随着数据量的快速增长和复杂性的提升,有效处理和分析数据成为了企业发展的关键。
为什么选择Java构建大数据处理平台?
Java作为一种广泛应用于企业级应用开发的语言,具有良好的跨平台性、稳定性和可扩展性,非常适合构建大规模数据处理和分析平台。
核心组件与技术栈选择
1. Apache Hadoop
Apache Hadoop是开源的分布式计算框架,支持大数据的存储和处理。它的核心是分布式文件系统HDFS和分布式计算框架MapReduce。
import cn.juwatech.hadoop.*;
// 示例代码:使用Apache Hadoop进行数据处理
public class HadoopExample {public static void main(String[] args) {// 初始化Hadoop配置Configuration conf = new Configuration();conf.set("fs.defaultFS", "hdfs://localhost:9000");// 创建Job对象Job job = Job.getInstance(conf, "WordCount");// 设置Mapper和Reducer类job.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);// 设置输入输出路径FileInputFormat.addInputPath(job, new Path("input"));FileOutputFormat.setOutputPath(job, new Path("output"));// 提交作业job.waitForCompletion(true);}
}
2. Apache Spark
Apache Spark是一种快速、通用的大数据处理引擎,支持内存计算和数据流处理。它通过RDD(Resilient Distributed Dataset)实现高效的数据并行处理。
import cn.juwatech.spark.*;
// 示例代码:使用Apache Spark进行数据分析
public class SparkExample {public static void main(String[] args) {SparkConf conf = new SparkConf().setAppName("WordCount").setMaster("local");JavaSparkContext sc = new JavaSparkContext(conf);// 读取数据文件JavaRDD<String> lines = sc.textFile("input");// 执行WordCount操作JavaPairRDD<String, Integer> wordCounts = lines.flatMapToPair(line -> Arrays.asList(line.split(" ")).stream().map(word -> new Tuple2<>(word, 1)).iterator()).reduceByKey((a, b) -> a + b);// 将结果保存到文件wordCounts.saveAsTextFile("output");// 关闭SparkContextsc.close();}
}
3. Spring Batch
Spring Batch是Spring框架提供的一个批处理框架,用于处理大量的数据操作。它提供了事务管理、作业调度、日志记录等功能,适合处理数据ETL(Extract-Transform-Load)流程。
import cn.juwatech.springbatch.*;
// 示例代码:使用Spring Batch进行数据批处理
@Configuration
@EnableBatchProcessing
public class BatchProcessingJob {@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Beanpublic Job job() {return jobBuilderFactory.get("job").start(step1()).build();}@Beanpublic Step step1() {return stepBuilderFactory.get("step1").tasklet((contribution, chunkContext) -> {// 执行批处理任务System.out.println("Batch job executed!");return RepeatStatus.FINISHED;}).build();}
}
实战案例:构建一个简单的大数据处理平台
我们以一个简单的WordCount示例来说明如何结合上述技术栈构建一个Java的大数据处理平台。
- 准备数据:准备一个文本文件作为输入数据。
- 使用Apache Hadoop进行处理:通过MapReduce模型计算文本中单词的频率。
- 使用Apache Spark进行分析:使用Spark计算单词的总数,并将结果保存到文件。
- 使用Spring Batch进行批处理:创建一个简单的作业来执行上述步骤。
优化策略与挑战
构建大数据处理平台面临性能优化、并发处理、数据一致性等挑战。可以通过优化算法、增加集群规模、引入缓存和调度等手段来提高系统的性能和稳定性。
结语
通过本文的介绍,我们深入理解了如何利用Java构建高效的大数据处理与分析平台,涵盖了Apache Hadoop、Apache Spark和Spring Batch等关键技术。希望本文能为您在实践中构建和优化大数据处理平台提供一些启发和帮助。
相关文章:

实战:基于Java的大数据处理与分析平台
实战:基于Java的大数据处理与分析平台 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将探讨如何利用Java构建高效的大数据处理与分析平台。…...

构建安全稳定的应用:Spring Security 实用指南
前言 在现代 Web 应用程序中,安全性是至关重要的一个方面。Spring Security 作为一个功能强大且广泛使用的安全框架,为 Java 应用程序提供了全面的安全解决方案。本文将深入介绍 Spring Security 的基本概念、核心功能以及如何在应用程序中使用它来实现…...

嵌入式STM32F103项目实例可以按照以下步骤进行构建和实现
嵌入式STM32F103项目实例可以按照以下步骤进行构建和实现: 1. 项目概述 目标:演示STM32F103开发板的基本功能,通过LED闪烁来实现。硬件需求:STM32F103开发板、LED灯、杜邦线、USB转串口模块(可选,用于调试…...

2024最新Stable Diffusion【插件篇】:SD提示词智能生成插件教程!
前言 今天我们介绍几款可以自动生成提示词的插件。所谓智能生成提示词,就是我们只需要输入非常少量的关键字,插件就会根据关键词提示信息帮助我们生成一系列关键字或者句子作为提示词。下面来和我一起看看吧。 一. SD智能提示词工具 之前的文章中和大…...

彻底学会Gradle插件版本和Gradle版本及对应关系
看完这篇,保你彻底学会Gradle插件版本和Gradle版本及对应关系,超详细超全的对应关系表 需要知道Gradle插件版本和Gradle版本的对应关系,其实就是需要知道Gradle插件版本对应所需的gradle最低版本,详细对应关系如下表格࿰…...

p2p、分布式,区块链笔记: 通过libp2p的Kademlia网络协议实现kv-store
Kademlia 网络协议 Kademlia 是一种分布式哈希表协议和算法,用于构建去中心化的对等网络,核心思想是通过分布式的网络结构来实现高效的数据查找和存储。在这个学习项目里,Kademlia 作为 libp2p 中的 NetworkBehaviour的组成。 以下这些函数或…...
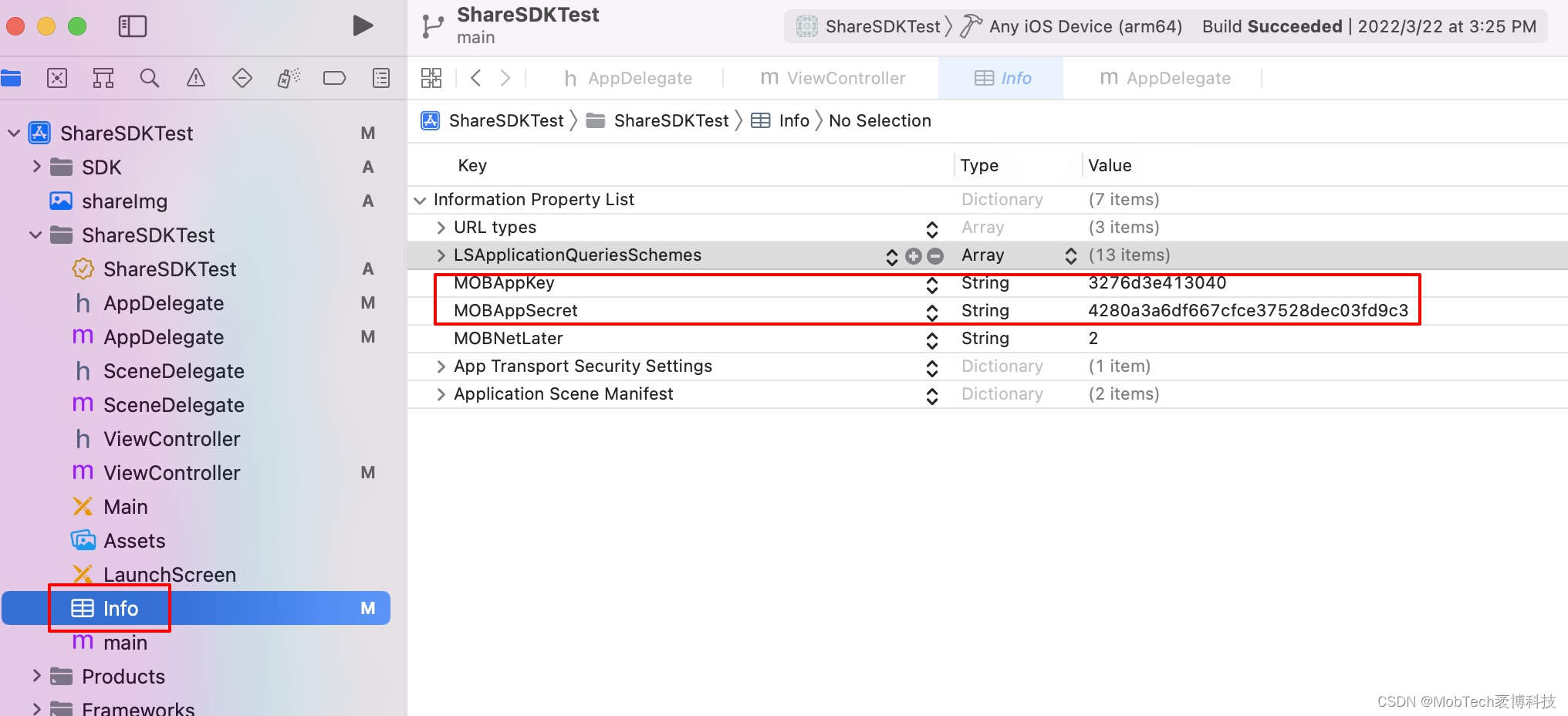
ShareSDK iOS端如何实现小红书分享
下载SDK 请登陆官网 ,找到SDK下载,勾选需要的平台下载 导入SDK (1)离线导入将上述下载到的SDK,直接将整个SDK资源文件拖进项目里,如下图: 并且勾选以下3个选项 在点击Finish,…...
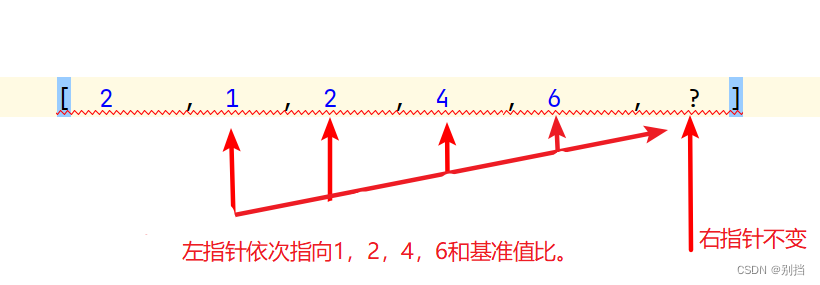
算法day1 两数之和 两数相加 冒泡排序 快速排序
两数之和 最简单的思维方式肯定是去凑两个数,两个数的和是目标值就ok。这里两遍for循环解决。 两数相加 敲了一晚上哈哈,结果超过int范围捏,难受捏。 public class Test2 {public static void main(String[] args) { // ListNode l1 …...
Rust监控可观测性
可观测性 在监控章节的引言中,我们提到了老板、前端、后端眼中的监控是各不相同的,那么有没有办法将监控模型进行抽象、统一呢? 来简单分析一下: 业务指标实时展示,这是一个指标型的数据( metric )手机 APP 上传的数…...
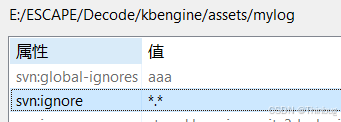
SVN 的忽略(Ignore)和递归(Recursively)以及忽略部分
SVN中忽略大家经常用到,但总是似懂非懂,下面就详细展开说明一下忽略如何设置。 两个忽略 通常设置忽略都是文件夹和里面的文件都忽略。 设置忽略我们通常只需要鼠标右键点击忽略就可以了,如图: 第一个忽略用的最多,…...
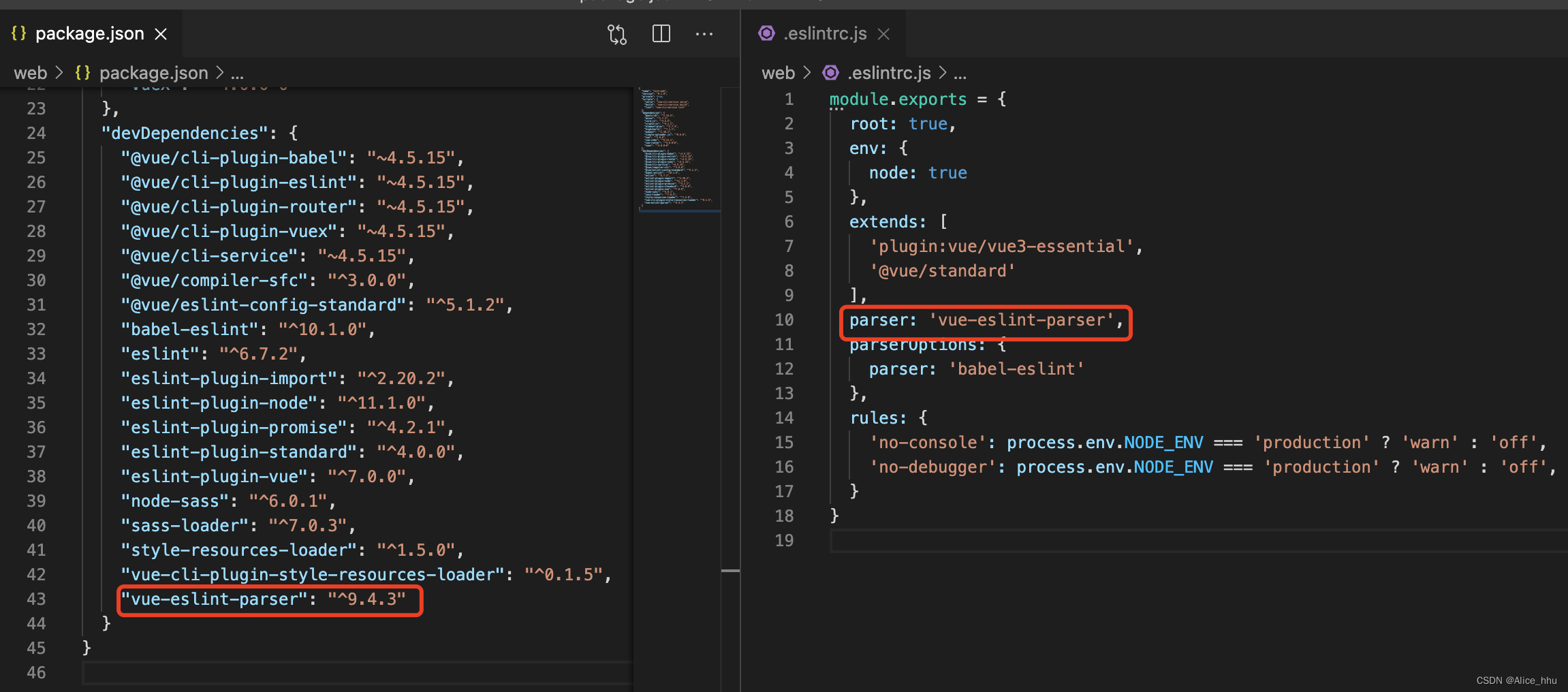
vue3开发过程中遇到的一些问题记录
问题: vue3在使用 defineProps、defineEmits、defineExpose 时不需要import,但是 eslint会报错error defineProps is not defined no-undef 解决方法: 安装 vue-eslint-parser 插件,在 .eslintrc.js 文件中添加配置 parser: vue-e…...

Jedis、Lettuce、RedisTemplate连接中间件
jedis就像jdbc一样,用于两个端直接的连接。 1.创建Spring项目 这里不过多赘述... 2.导入连接工具jedis 在pom文件中导入jedis的依赖。 <dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version&…...
【C++】继承(详解)
前言:今天我们正式的步入C进阶内容的学习了,当然了既然是进阶意味着学习难度的不断提升,各位一起努力呐。 💖 博主CSDN主页:卫卫卫的个人主页 💞 👉 专栏分类:高质量C学习 👈 &#…...
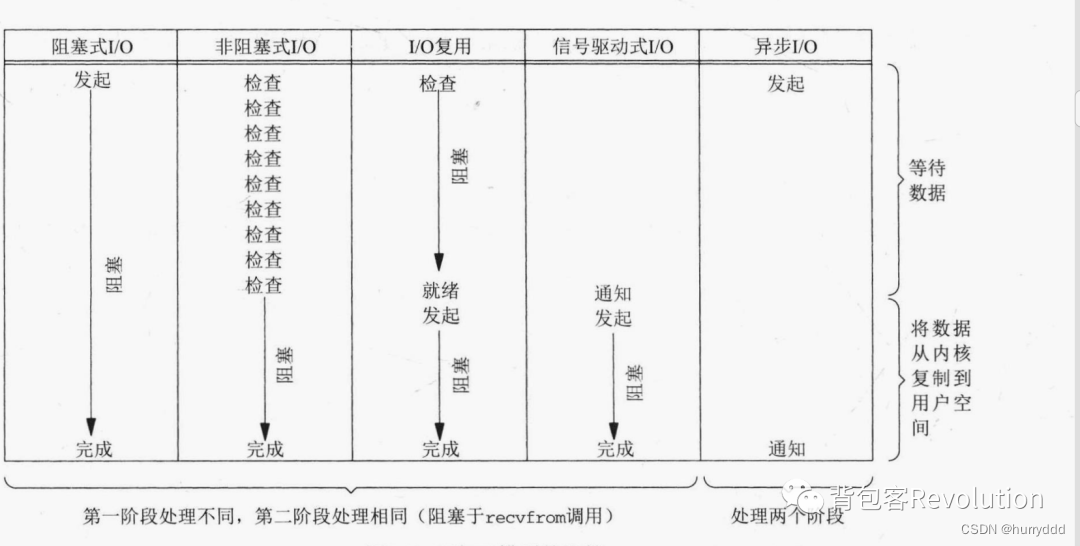
网络io与select,poll,epoll
前言 网络 IO,会涉及到两个系统对象,一个是用户空间调用 IO 的进程或者线程,另一个是内核空间的内核系统,比如发生 IO 操作 read 时,它会经历两个阶段: 1. 等待数据准备就绪 2. 将数据从内核拷贝到进程或…...

【Linux】多线程(一万六千字)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 文章目录 前言 线程的概念 线程的理解(Linux系统为例) 在Linux系统里如何保证让正文部分的代码可以并发的去跑呢? 为什么要有多进程呢? 为…...

sh脚本笔记2
test条件测试 语法 条件测试语法说明语法1:test <测试表达式>这是利用test命令进行条件测试表达式的方法。test命令和“<测试表达式>”之间至少有一个空格语法2:[ <测试表达式> ]这是通过[](单中括号)进行条件…...

js替换对象里面的对象名称
data为数组,val为修改前的名称,name为修改后的名称 JSON.parse(JSON.stringify(data).replace(/val/g, name)) ; 1.替换data里面的对象tenantInfoRespVO名称替换成tenantInfoUpdateReqVO 2.替换语句: 代码可复制 let tenantInf…...

鸿蒙开发设备管理:【@ohos.settings (设置数据项名称)】
设置数据项名称 说明: 本模块首批接口从API version 8开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。 本模块提供设置数据项的访问功能相关接口的说明及示例。 导入模块 import settings from ohos.settings;settings.getUri…...

STM32之五:TIM定时器(2-通用定时器)
目录 通用定时器(TIM2~5)框图 1、 输入时钟源选择 2、 时基单元 3 、输入捕获:(IC—Input Capture) 3.1 输入捕获通道框图(TI1为例) 3.1.1 滤波器: 3.1.2 边沿检测器…...
【分布式系统】监控平台Zabbix对接grafana
以前两篇博客为基础 【分布式系统】监控平台Zabbix介绍与部署(命令截图版)-CSDN博客 【分布式系统】监控平台Zabbix自定义模版配置-CSDN博客 一.安装grafana并启动 添加一台服务器192.168.80.104 初始化操作 systemctl disable --now firewalld set…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...
 + 力扣解决)
LRU 缓存机制详解与实现(Java版) + 力扣解决
📌 LRU 缓存机制详解与实现(Java版) 一、📖 问题背景 在日常开发中,我们经常会使用 缓存(Cache) 来提升性能。但由于内存有限,缓存不可能无限增长,于是需要策略决定&am…...

【 java 虚拟机知识 第一篇 】
目录 1.内存模型 1.1.JVM内存模型的介绍 1.2.堆和栈的区别 1.3.栈的存储细节 1.4.堆的部分 1.5.程序计数器的作用 1.6.方法区的内容 1.7.字符串池 1.8.引用类型 1.9.内存泄漏与内存溢出 1.10.会出现内存溢出的结构 1.内存模型 1.1.JVM内存模型的介绍 内存模型主要分…...

LangFlow技术架构分析
🔧 LangFlow 的可视化技术栈 前端节点编辑器 底层框架:基于 (一个现代化的 React 节点绘图库) 功能: 拖拽式构建 LangGraph 状态机 实时连线定义节点依赖关系 可视化调试循环和分支逻辑 与 LangGraph 的深…...

WEB3全栈开发——面试专业技能点P7前端与链上集成
一、Next.js技术栈 ✅ 概念介绍 Next.js 是一个基于 React 的 服务端渲染(SSR)与静态网站生成(SSG) 框架,由 Vercel 开发。它简化了构建生产级 React 应用的过程,并内置了很多特性: ✅ 文件系…...